
计算机学院研究生《并行计算》课程
考试试题
(2010级研究生,2011.1)
1.(12分)定义图中节点u 和v 之间的距离为从u 到v 最短路径的长度。已知一个d 维的超立方体,1)指定其中的一个源节点s ,问有多少个节点与s 的距离为i ,其中0≤i ≤d 。证明你的结论。2)证明如果在一个超立方体中节点u 与节点v 的距离为i ,则存在i !条从u 到v 的长度为i 的路径。 1)有i
d C 个节点与s 的距离为i 。 证明:由超立方体的性质知:
一个d 维的超立方体的每个节点都可由d 位二进制来表示,则与某个节
点的距离为i 的节点必定在这d 位二进制中有i 位与之不同,那么随机从d 位中选择i 位就有i
d C 种选择方式,即与s 的距离为i 得节点就有i
d C 个。 2)
证明:由1)所述可知:
节点u 与节点v 的距离为i 则分别表示u 、v 节点的二进制位数中有i 位是不同的。设节点u 表示为:121D .........j j i j i d D D D D D +-+,节点v 表示为:
''121D .........j j i j i d
D D D D D +-+,则现在就是要求得从
121D .........j j i j i d D D D D D +-+变换到''121D .........j j i j i d D D D D D +-+ 的途径有多
少种。那么利用组合理论知识可知共有*(1)*(2)*...*2*1i i i --即!i 中途径。所以存在i !条从u 到v 的长度为i 的路径。
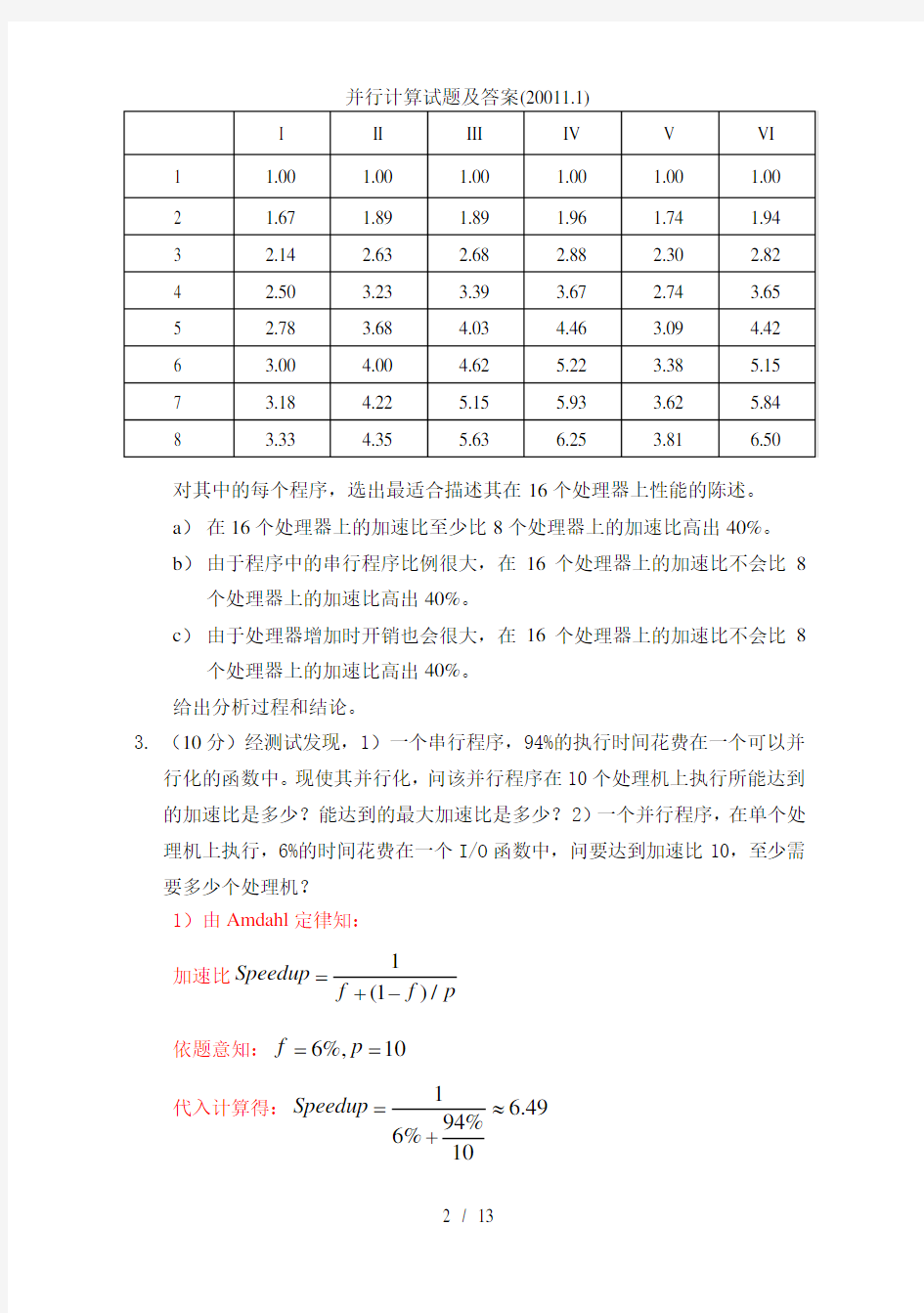
2.(18分)6个并行程序的执行时间,用I-VI 表示,在1-8个处理器上执行了测试。下表表示了各程序达到的加速比。
对其中的每个程序,选出最适合描述其在16个处理器上性能的陈述。 a ) 在16个处理器上的加速比至少比8个处理器上的加速比高出40%。 b ) 由于程序中的串行程序比例很大,在16个处理器上的加速比不会比8
个处理器上的加速比高出40%。
c ) 由于处理器增加时开销也会很大,在16个处理器上的加速比不会比8
个处理器上的加速比高出40%。 给出分析过程和结论。
3. (10分)经测试发现,1)一个串行程序,94%的执行时间花费在一个可以并行化的函数中。现使其并行化,问该并行程序在10个处理机上执行所能达到的加速比是多少?能达到的最大加速比是多少?2)一个并行程序,在单个处理机上执行,6%的时间花费在一个I/O 函数中,问要达到加速比10,至少需要多少个处理机? 1)由Amdahl 定律知:
加速比1
(1)/Speedup f f p
=
+-
依题意知:6%,10f p ==
代入计算得:1
6.4994%6%10
Speedup =
≈+
最大加速比为:
111
lim lim16.7
(1)/6%
p p
Speedup
f f p f
→∞→∞
===≈
+-
2)由题意知:此时的串行时间比例为6%则:
由式子
11
10
94%
(1)/6%
f f p
p
≤=
+-+
得:23.5
p≥
故至少需要24台处理机。
4.(12分)将一个由256个节点组成的环以dilation-1的方式嵌入到一个8维超立方体里,环中的节点编号为0~255,1)问环节点31,127,255分别映射到超立方体的哪个节点上?2)若超立方体中的结点10110011和进行通讯,如果按照环网拓扑结构,从出发,在超立方体中依次经过哪些节点才能把一条消息传递到?如果按照超立方体拓扑结构,又是如何实现从传递一条消息到的?
5.(16分)已知12个具有单位执行时间的任务,任务图如下。现在3个处理机上处理该任务集,请用Coffman-Graham算法求该任务集的调度优先表L,并用Graham表调度算法调度L,给出任务调度的Gantt图表示。
6.(10分)采用与前序遍历二元树的PRAM算法相同的数据结构,设计一个后序遍历二元树的PRAM算法。
7.(10分)下面是一个串行程序段,用OpenMP最大限度地开发其并行性。这里假设a、b均为正实值数组,有合法的定义。
float rowterm[m]
float colterm[q];
int i, j;
#pragma omp parallel {
#pragma omp sections{
#pragma omp parallel for private(j)
for ( i=0; i rowterm[i] = 0.0; #pragma omp parallel for reduction(+:rowterm[i]) for (j=0; j rowterm[i] += a[i][2*j] * a[i][2*j+1]; #pragma omp parallel for for (j=0; j a[i][2*j] /= rowterm[i]; a[i][2*j+1] /= rowterm[i]; } } } #pragma omp sections{ #pragma omp parallel for private(j) for ( i=0; i colterm[i] = 0.0; #pragma omp parallel for reduce(+:colterm [i]) for ( j=0; j colterm[i] += b [2*j][i] * b [2*j+1] [i]; #pragma omp parallel for for ( j=0; j b [2*j][i] /= colterm[i]; b [2*j+1] [i] /= colterm[i]; } } } } 8.(12分)查阅文献并结合自己的体会,列举1-2个你的研究领域里存在的典型并行计算应用,讨论一下它们适合的并行计算模式(不少于500字)。 答案 1. 证明:(1)由超立方体的性质知: 一个d 维的超立方体的每个节点都可由d 位二进制来表示,则与某个节点的距离为i 的节点必定在这d 位二进制中有i 位与之不同,那么随机从d 位中选择i 位就有i d C 种选择方式,即与s 的距离为i 得节点就有i d C 个。 (2)由(1)所述可知: 节点u 与节点v 的距离为i 则分别表示u 、v 节点的二进制位数中有i 位是不同的。设节点u 表示为:121D .........j j i j i d D D D D D +-+,节点v 表示为: ''121D .........j j i j i d D D D D D +-+,则现在就是要求得从 121D .........j j i j i d D D D D D +-+变换到''121D .........j j i j i d D D D D D +-+ 的途径有多 少种。那么利用组合理论知识可知共有*(1)*(2)*...*2*1i i i --即!i 中途径。所以存在i !条从u 到v 的长度为i 的路径。 2. 解: 由题可知计算规模是固定的,所以在并行环境下,根据Amdahl 定律可知: 加速比S=1/(1/p+f(1-1/p)),其中p 为处理器数,f 为串行分量的比例,则,f=(p/s-1)/(p-1),同时对于固定规模的问题,并行系统所能达到的加速上限为1/f ,即受到串行分量的比例的限制。 在2个处理器的环境下,根据上图数据计算各并行程序的串行分量的 比: 并行程序I :f 1=0.20; 并行程序II :f 2=0.06; 并行程序III :f 3=0.06; 并行程序IV :f 4=0.02; 并行程序V :f 5=0.15; 并行程序VI :f 6=0.03; 在16个处理器的环境下,根据上图数据计算各并行程序的加速比如下: 并行程序I :S 1=4.00 并行程序II :S 2=5.72; 并行程序III :S 3=8.41; 并行程序IV :S 4=10.00; 并行程序V :S 5=4.77; 并行程序VI :S 6=10.67; 则个并行程序在16个处理器的环境下与8个处理器的环境下的加速比提高了: 并行程序I :d 1=20%; 并行程序II :d 2=31%; 并行程序III :d 3=49%; 并行程序IV :d 4=60%; 并行程序V :d 5=25%; 并行程序VI :d 6=64%; 根据并行程序I 、V 的串行分量的比和16个处理器的环境下的加速比可知,对并行程序I 、V 在16个处理器上性能的陈述都选(b); 根据并行程序II 和III 的串行分量的比和16个处理器的环境下的加速比可知,对并行程序II 在16个处理器上性能的陈述选(c); 根据并行程序III 、IV 、VI 在16个处理器的环境下的加速比可知,对并行程序III 、IV 、VI 在16个处理器上性能的陈述都选(a); 3. 1)由Amdahl 定律知: 加速比1 (1)/Speedup f f p = +- 依题意知:6%,10f p == 代入计算得: 1 6.49 94% 6% 10 Speedup=≈ + 最大加速比为: 111 lim lim16.7 (1)/6% p p Speedup f f p f →∞→∞ ===≈ +- 2)由题意知:此时的串行时间比例为6%则: 由式子 11 10 94% (1)/6% f f p p ≤= +-+ 得:23.5 p≥ 故至少需要24台处理机。 4.(12分)将一个由256个节点组成的环以dilation-1的方式嵌入到一个8维超立方体里,环中的节点编号为0~255, 1)问环节点31,127,255分别映射到超立方体的哪个节点上? 31:00010000;127:01000000;255:10000000 若超立方体中的结点和进行通讯,如果按照环网拓扑结构,从出发,在超立方体中依次经过哪些节点才能把一条消息传递到?如果按照超立方体拓扑结构,又是如何实现从传递一条消息到0101 1001的? 1011 0011: 221 0101 1001:110 1011 0011(221)->1011 0001(222)->1011 0000(223)->1001 0000(224)->1001 0001->……-> 1000 0000(255)->0000 0000(0)->0000 0001->…..->0101 1100(104)->0101 1101(105)-> 0101 1111(106)->0101 1110(107)->0101 1010(108)->0101 1011(109)->0101 1001(110) 1011 0011->1011 0001->1011 1001->1001 1001->1101 1001->0101 1001(第一种方法) 1011 0011->0011 0011->0111 0011->0101 0011->0101 1011->0101 1001(第二种方法) 1101 0011->1001 0011->1101 0011->0101 0011->0101 0001->0101 1001(第三种方法) 5.Step1: R={T11,T12}是无直接后继的任务,任取,选T12,有a(T12)<-1; Step2: i从2到12循环,完成对a(Tj)(j=1,2…12)赋值 i=2;R={T11,T10},N(T10)={1},N(T10)={0},选T11,则a(T11)<-2; i=3; R={T9,T6,T10},N(T9)=2,N(T6)={2,1},N(T10)=1,选T10则a(T10)<-3; i=4;R={T9,T6,T7,T8},N(T9)=2,N(T6)={2,1},N(T7)=3,N(T8)=3,T9,T6任选,选T6,a(T6)<-4; i=5;R={T9,T7,T8},N(T9)=2,N(T7)=3,N(T8)=3,选T9,则a(T9)<-5; i=6;R={T4,T5,T7,T8},N(T4)=5,N(T5)=5,N(T7)=3,N(T8)=3,任选T7,T8,选T7,则a(T7)<-6; i=7;R={T4,T5,T8},N(T4)=5,N(T5)=5,N(T8)=3,选T8,则a(T8)<-7; i=8;R={T4,T5,T3},N(T4)=5,N(T5)=5,N(T3)={7,6},T4,T5任选,选T4,则a(T4)<-8 i=9,R={T5,T3},N(T5)=5,N(T3)={7,6},选T5,则a(T5)<-9; i=10,R={T2,T3},N(T2)={9,8,4},N{T3}={7,6},选T3,a(T3)<-10; i=11,R={T2},N(T2)={9,8,4},选T2,a(T2)<-11; i=12,a(T1)<-12; Step3: 构造L表:L={T1,T2,T3,T5,T4,T8,T7,T9,T6,T10,T11,T12}; Step4: 6. 策略如下: 在执行后序遍历时,我们系统地访问树中所有的边,而且每条边要通过两次:一次从父节点到子节点,而另一次从子节点到父节点。 现将每条边“分成”两条,一条用于从上往下的遍历(向下边),而另一条用于从下往上的回溯(向上边)。这样,后序遍历树问题就可转换为单链表问题。 基于这种面向边的树遍历观点可以设计出一个快速的并行算法求结点编号。该算法由四步完成。具体如下: Step1. 构造一个单链表(singly-linked List),单链表的每个顶点对应于遍历树时向下边或向上边。 Step2. 给新创建的单链表中的每个结点赋权值。 与向下边相应的顶点赋予权值0,表示当这个边被遍历时,该结点不被计数;与向上边相应的顶点赋予权值1,表示该结点要被计数。 如图3.3所示。 A C B E D F H G A C B E D F H G (a) (b) 图3.3 树的后序遍历。 说明:(a)树 (b)增加向上边(虚线边) (c)对树的边建立联结表,向下边赋权值0,向上边赋权值1 (d)计算各结点到表尾的位置序号(权值的后缀和)。 (e)后序遍历的结点编号 结点的后序遍历数=n-结点的位置序数 Step3 计算节点的位置序号(rank)。 使用与“求单链表中元素位置序号”类似的方法求 singly-Linked List表中每一元素的位置序号。Step4 与向上边相关联的处理机使用计算出的位置序号计算结点的后序遍历数并赋给与之相联的树的结点 ——该结点是向上边起始点所对应的结点。 7. float rowterm[m]; float colterm[q]; int i, j; #pragma omp parallel for private(i) if(j>5000) for (j=0; j { for(i=0;i { rowterm[i] = 0.0; rowterm[i] += a[i][2*j] * a[i][2*j+1]; } for(i=0;i { a[i][2*j] /= rowterm[i]; a[i][2*j+1] /= rowterm[i]; } } #pragma omp parallel for private(i) if(j>5000) for (j=0; j { for(i=0;i { rowterm[i] = 0.0; colterm[i] += b[2*j][i] * b[2*j+1] [i]; } for(i=0;i { b[2*j][i] /= colterm[i]; b[2*j+1] [i] /= colterm[i]; } } 8. 我研究生阶段的主要研究方向就是做信息检索。随着计算机的普及和网络的日益发展,数字化信息爆炸式增长。这些海量信息包含了大量宝贵的资源,虽然单台计算机的处理能力不断提高,但是在如此大规模的条件下,要对这样海量的信息进行检索,单台计算机的处理能力毕竟有限,需要多台计算机进行“团队作战”。而并行计算能够利用多台计算机或者多个处理器的计算或存储资源来解决大规模问题。因此,很自然地会想到将并行处理技术引入到信息检索当中,产生了相应的并行信息检索。 要实现并行检索,首先让我们考察信息检索的一般过程: 图1 一般信息检索的过程 如图1所示,用户提交一条查询,代理程序(broker)对原始查询进行处理(如查询的分析转换或格式化处理等等),然后将处理后的查询发给搜索程序,搜索程序找到结果并进行处理(如排序)后返回给代理,代理经过必要的处理(如结果的归整、合并等)将结果返回给用户。 从以上可以看出,信息检索有并行处理的潜力可以充分挖掘。根据对象的不同,并行检索总体上可通过以下两种方式实现并行: 1. 多条查询之间的并行处理 一个最自然的想法就是利用MIMD结构对多条查询的处理并行化,即每个处理器处理不同的查询,每个查询的处理之间相互独立,最多只对共享内存内的部分代码或者公有数据实行共享。这种方法也称为任务级的并行检索。它可以同时处理多个查询请求,从而提高检索的吞吐量。图2显示了3条不同查询在3个处理器上的并行处理过程。每条查询通过代理(也可同时运行多个代理程序,每个代理分别处理一条查询)发送到不同搜索程序(每个处理器上运行一个搜索程序)上去执行,每个搜索程序的结果通过代理返回到不同查询的发起者。 图2 查询间的并行处理过程 如果MIMD由多台具有自身处理器和磁盘的计算机组成,每台机器执行自己的搜索程序,并且只访问本地的磁盘,则没有硬件资源访问冲突问题。但如果多个搜索程序访问的是相同的磁盘资源,则可能存在磁盘存取冲突问题。这时可以通过增加磁盘或采用类似Raid磁盘阵列的方法来减少冲突,但同时不免加大硬件设备的开销。另外一些可能的方法包括复制访问频繁的数据到不同磁盘以降低访问冲突、将数据分割到多个磁盘等等。 查询间并行化策略是从一般检索升级到并行检索的最简单方法。简单地说,就是将检索系统复制多份(数据可以复制也可以不复制),每份分别处理不同的查询请求。当然,这种升级硬件资源消耗比较高。而且,简单地堆积硬件资源并不一定就可以提高信息检索的效率,必须考虑硬件资源的访问冲突,设计合理的软件结构和访问策略,才能提高信息检索的总体性能。 2. 单条查询内部的并行处理 即对单条查询的计算量进行分割,分成多个子任务,并分配到多个处理器上的搜索进程上去执行。这种检索也称为进程级并行检索。将单条查询分成多个子任务的方法通常有两种:一种称为数据集分割,它是事先将数据集分割成多个子集合,对同一条查询分别查询多个子集合数据,然后将每个子集合上的结果合并成最终结果;另一种称为查询项分割,它是将查询分解成多个子查询(如将一个多关键词查询分成多个单关键词查询),对每个子查询分别查询数据集,得到部分结果,并将部分结果合并成最终结果。图3给出了一个单条查询内部并行处理的示意图:查询发送给代理程序,代理程序将一条查询划分成多条子查询,每条子查询分别发送给一个搜索进程进行处理,各进程返回的子结果在代理上进行综合,得到最后的总结果返回给用户。 图3 查询内部的并行处理过程 多核编程与并行计算实验报告 姓名: 日期:2014年 4月20日 实验一 // exa1.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 实验二 // exa2.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 特征值:一矩阵A作用与一向量a,结果只相当与该向量乘以一常数λ。即A*a=λa,则a 为该矩阵A的特征向量,λ为该矩阵A的特征值。 奇异值:设A为m*n阶矩阵,A H A的n个特征值的非负平方根叫作A的奇异值。记 (A) 为σ i 上一次写了关于PCA与LDA的文章,PCA的实现一般有两种,一种是用特征值分解去实现的,一种是用奇异值分解去实现的。在上篇文章中便是基于特征值分解的一种解释。特征值和奇异值在大部分人的印象中,往往是停留在纯粹的数学计算中。而且线性代数或者矩阵论里面,也很少讲任何跟特征值与奇异值有关的应用背景。奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。就像是描述一个人一样,给别人描述说这个人长得浓眉大眼,方脸,络腮胡,而且带个黑框的眼镜,这样寥寥的几个特征,就让别人脑海里面就有一个较为清楚的认识,实际上,人脸上的特征是有着无数种的,之所以能这么描述,是因为人天生就有着非常好的抽取重要特征的能力,让机器学会抽取重要的特征,SVD是一个重要的方法。 在机器学习领域,有相当多的应用与奇异值都可以扯上关系,比如做feature reduction的PCA,做数据压缩(以图像压缩为代表)的算法,还有做搜索引擎语义层次检索的LSI(Latent Semantic Indexing) 另外在这里抱怨一下,之前在百度里面搜索过SVD,出来的结果都是俄罗斯的一种狙击枪(AK47同时代的),是因为穿越火线这个游戏里面有一把狙击枪叫做 SVD,而在Google上面搜索的时候,出来的都是奇异值分解(英文资料为主)。想玩玩战争游戏,玩玩COD不是非常好吗,玩山寨的CS有神马意思啊。国内的网页中的话语权也被这些没有太多营养的帖子所占据。真心希望国内的气氛能够更浓一点,搞游戏的人真正是喜欢制作游戏,搞Data Mining的人是真正喜欢挖数据的,都不是仅仅为了混口饭吃,这样谈超越别人才有意义,中文文章中,能踏踏实实谈谈技术的太少了,改变这个状况,从我自己做起吧。 前面说了这么多,本文主要关注奇异值的一些特性,另外还会稍稍提及奇异值的计算,不过本文不准备在如何计算奇异值上展开太多。另外,本文里面有部分不算太深的线性代数的知识,如果完全忘记了线性代数,看本文可能会有些困难。 一、奇异值与特征值基础知识: 特征值分解和奇异值分解在机器学习领域都是属于满地可见的方法。两者有着很紧密的关系,我在接下来会谈到,特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。先谈谈特征值分解吧: 计算方法实验报告1 【课题名称】 用列主元高斯消去法和列主元三角分解法解线性方程 【目的和意义】 高斯消去法是一个古老的求解线性方程组的方法,但由它改进得到的选主元的高斯消去法则是目前计算机上常用的解低阶稠密矩阵方程组的有效方法。 用高斯消去法解线性方程组的基本思想时用矩阵行的初等变换将系数矩阵A 约化为具有简单形式的矩阵(上三角矩阵、单位矩阵等),而三角形方程组则可以直接回带求解 用高斯消去法解线性方程组b Ax =(其中A ∈Rn ×n )的计算量为:乘除法运算步骤为 32(1)(1)(21)(1)(1)262233n n n n n n n n n n n MD n ----+= +++=+-,加减运算步骤为 (1)(21)(1)(1)(1)(25) 6226 n n n n n n n n n n AS -----+= ++= 。相比之下,传统的克莱姆 法则则较为繁琐,如求解20阶线性方程组,克莱姆法则大约要19 510?次乘法,而用高斯消去法只需要3060次乘除法。 在高斯消去法运算的过程中,如果出现abs(A(i,i))等于零或过小的情况,则会导致矩阵元素数量级严重增长和舍入误差的扩散,使得最后的计算结果不可靠,所以目前计算机上常用的解低阶稠密矩阵方程的快速有效的方法时列主元高斯消去法,从而使计算结果更加精确。 2、列主元三角分解法 高斯消去法的消去过程,实质上是将A 分解为两个三角矩阵的乘积A=LU ,并求解Ly=b 的过程。回带过程就是求解上三角方程组Ux=y 。所以在实际的运算中,矩阵L 和U 可以直接计算出,而不需要任何中间步骤,从而在计算过程中将高斯消去法的步骤进行了进一步的简略,大大提高了运算速度,这就是三角分解法 采用选主元的方式与列主元高斯消去法一样,也是为了避免除数过小,从而保证了计算的精确度 【计算公式】 1、 列主元高斯消去法 设有线性方程组Ax=b ,其中设A 为非奇异矩阵。方程组的增广矩阵为 第1步(k=1):首先在A 的第一列中选取绝对值最大的元素 1l a ,作为第一步的主元素: 111211212222112[,]n n n l n nn n a a a a b a a a b a a a b ?? ???? ?? =?????? ?? ????a b 2014年《并行计算系统》复习题 1.(15分)给出五种并行计算机体系结构的名称,并分别画出其典型结构。 ①并行向量处理机(PVP) ②对称多机系统(SMP) ③大规模并行处理机(MPP) ④分布式共享存储器多机系统(DSM) ⑤工作站机群(COW) 2.(10分)给出五种典型的访存模型,并分别简要描述其特点。 ①均匀访存模型(UMA): 物理存储器被所有处理机均匀共享 所有处理机访存时间相同 适于通用的或分时的应用程序类型 ②非均匀访存模型(NUMA): 是所有处理机的本地存储器的集合 访问本地LM的访存时间较短 访问远程LM的访存时间较长 ③Cache一致性非均匀访存模型(CC-NUMA): DSM结构 ④全局Cache访存模型(COMA): 是NUMA的一种特例,是采用各处理机的Cache组成的全局地址空间 远程Cache的访问是由Cache目录支持的 ⑤非远程访存模型(NORMA): 在分布式存储器多机系统中,如果所有存储器都是专用的,而且只能被本地存储机访问,则这种访问模型称为NORAM 绝大多数的NUMA支持NORAM 在DSM中,NORAM的特性被隐匿的 3. (15分)对于如下的静态互连网络,给出其网络直径、节点的度数、对剖宽度,说明该网络是否是一个对称网络。 网络直径:8 节点的度数:2 对剖宽度:2 该网络是一个对称网络 4. (15分)设一个计算任务,在一个处理机上执行需10个小时完成,其中可并行化的部分为9个小时,不可并行化的部分为1个小时。问: (1)该程序的串行比例因子是多少,并行比例因子是多少? 串行比例因子:1/10 并行比例因子:9/10 (2)如果有10个处理机并行执行该程序,可达到的加速比是多少?10/(9/10 + 1) = 5.263 (3)如果有20个处理机并行执行该程序,可达到的加速比是多少?10/(9/20 + 1)= 6.897 5.(15分)什么是并行计算系统的可扩放性?可放性包括哪些方面?可扩放性研究的目的是什么? 一个计算机系统(硬件、软件、算法、程序等)被称为可扩放的,是指其性能随处理机数目的增加而按比例提高。例如,工作负载能力和加速比都可随处理机的数目的增加而增加。 可扩放性包括: 1.机器规模的可扩放性 并行计算 实 验 报 告 学院名称计算机科学与技术学院专业计算机科学与技术 学生姓名 学号 年班级 2016年5 月20 日 一、实验内容 本次试验的主要内容为采用多线程的方法计算pi的值,熟悉linux下pthread 形式的多线程编程,对实验结果进行统计并分析以及加速比曲线分析,从而对并行计算有初步了解。 二、实验原理 本次实验利用中值积分定理计算pi的值 图1 中值定理计算pi 其中公式可以变换如下: 图2 积分计算pi公式的变形 当N足够大时,可以足够逼近pi,多线程的计算方法主要通过将for循环的计算过程分到几个线程中去,每次计算都要更新sum的值,为避免一个线程更新sum 值后,另一个线程仍读到旧的值,所以每个线程计算自己的部分,最后相加。三、程序流程图 程序主体部分流程图如下: 多线程执行函数流程图如下: 四、实验结果及分析 令线程数分别为1、2、5、10、20、30、40、50和100,并且对于每次实验重复十次求平均值。结果如下: 图5 时间随线程的变化 实验加速比曲线的计算公式类似于 结果如下: 图5 加速比曲线 实验结果与预期类似,当线程总数较少时,线程数的增多会对程序计算速度带来明显的提升,当线程总数增大到足够大时,由于物理节点的核心数是有限的,因此会给cpu带来较多的调度,线程的切换和最后结果的汇总带来的时间开销较大,所以线程数较大时,增加线程数不会带来明显的速度提升,甚至可能下降。 五、实验总结 本次试验的主要内容是多线程计算pi的实现,通过这次实验,我对并行计算有了进一步的理解。上学期的操作系统课程中,已经做过相似的题目,因此程序主体部分相似。不同的地方在于,首先本程序按照老师要求应在命令行提供参数,而非将数值写定在程序里,其次是程序不是在自己的电脑上运行,而是通过ssh和批处理脚本等登录到远程服务器提交任务执行。 在运行方面,因为对批处理任务不够熟悉,出现了提交任务无结果的情况,原因在于windows系统要采用换行的方式来表明结束。在实验过程中也遇到了其他问题,大多还是来自于经验的缺乏。 在分析实验结果方面,因为自己是第一次分析多线程程序的加速比,因此比较生疏,参考网上资料和ppt后分析得出结果。 从自己遇到的问题来看,自己对批处理的理解和认识还比较有限,经过本次实验,我对并行计算的理解有了进一步的提高,也意识到了自己存在的一些问题。 六、程序代码及部署 程序源代码见cpp文件 部署说明: 使用gcc编译即可,编译时加上-pthread参数,运行时任务提交到服务器上。 编译命令如下: gcc -pthread PI_3013216011.cpp -o pi pbs脚本(runPI.pbs)如下: #!/bin/bash #PBS -N pi #PBS -l nodes=1:ppn=8 #PBS -q AM016_queue #PBS -j oe cd $PBS_O_WORKDIR for ((i=1;i<=10;i++)) do ./pi num_threads N >> runPI.log 奇异值分解定理:设,则存在m 阶正交矩阵U 和n 阶正交矩阵V ,使得 ,其中为矩阵A 的全部非零奇 异值,满足0r 21>≥≥?≥≥,σσσ,前几个值比较大,它们包含了矩阵A 的大部分信息。U 的列向量(左奇异向量)是 的特征向量,V 的列向量(右奇异向量)是的特征 向量。 奇异值分解的性质: 1. 奇异值的稳定性 定理1:假设, A 和 B 的SVD 分别为和 ,其中p =min ( m , n) ,则有。 定理1表明当矩阵A 有微小扰动时,扰动前后矩阵奇异值的变化不会大于扰动矩阵的-2范数。这个性质表明,对于存在灰度变化、噪声干扰等情况的图像,通过SVD 后,图像的特征向量不会出现大的变化。这一性质放宽了对图像预处理的要求, 并使匹配结果的准确性得到了保证。 2. 奇异值的比例不变性 因此,为了消除幅度大小对特征提取的影响,所进行的归一化处理不会从本质改变奇异值的相对大小。 3. 奇异值的旋转不变性 图像奇异值特征向量不但具有正交变换、旋转、位移、镜像映射等代数和几何上的不变性,而且具有良好的稳定性和抗噪性,广泛应用于模式识别与图像分析中。对图像进行奇异值分解的目的是:得到唯一、稳定的特征描述;降低特征空间的维数;提高抵抗干扰和噪声的能力。 欧氏距离(Euclidean distance ) 欧氏距离定义:欧氏距离(Euclidean distance)是一个通常采用的距离定义,它是在m维空间中两个点之间的真实距离。欧氏距离看作信号的相似程度,距离越近就越相似。 设x,y是M× N 维的两幅图像,那么其在图像空间中可以表示为: 式中为图像x,y的第(k,l)个像素点。则图像的欧氏距离定义为 根据上述定义,一幅M×N 的图像可以看作M×N 维欧氏空间中的一点,每个坐标对应于一个像素的灰度值。 特征匹配算法 采用遍历搜索法,计算特征向量两两间的欧氏距离,确定向量之间的最近邻距离(MD)第二近邻距离(SMD),并计算二者的比值:MD/ SMD。设定阈值s,当MD/ SMD §4 直接三角分解法 一、教学设计 1.教学内容:Doolittle 分解法、Crout 分解法,紧凑格式的Doolittle 分解法、部分选主元的Doolittle 分解法。 2.重点难点:紧凑格式的Doolittle 分解法、部分选主元的Doolittle 分解法。 3.教学目标:了解直接三角分解法的基本思想,掌握基本三角分解法及其各种变形。 4.教学方法:讲授与讨论。 二、教学过程 在上节中我们用矩阵初等变换来分析Gauss 消去法,得到了重要的矩阵LU 分解定理(定理 3.1,3.2)。由此我们将得到Gauss 消去法的变形:直接三角分解法。直接三角分解法的基本想法是,一旦实现了矩阵A 的LU 分解,那么求解方程组b x =A 的问题就等价于求解两个三角形方程组 (1)b y =L ,求y ; (2)y x =U ,求x 。 而这两个三角形方程组的求解是容易的。下面我们先给出这两个三角形方程组的求解公式;然后研究在LU A =或LU PA =时,U L ,的元素与A 的元素之间的直接关系。 4-0 三角形线性方程组的解法 设 ????? ???????= nn n n l l l l l l L 21222111, 11121222n n nn u u u u u U u ??????=???????? 则b y =L 为下三角形方程组,它的第i 个方程为 ),2,1(11,22111 n i b y l y l y l y l y l i i ii i i i i i i j j ij ==++++=--=∑ 假定0≠ii l ,按n y y y ,,,21 的顺序解得: ??? ?? ? ?=+-==∑-=) ,,3,2(/1111 11n i l b y l y l b y ii i i j j ij i 上三角形方程组y x =U 的第i 个方程为 Reviews on parallel programming并行计算英文班复习考试范围及题型:(1—10章) 1 基本概念解释;Translation (Chinese) 2 问答题。Questions and answer 3 算法的画图描述。Graphical description on algorithms 4 编程。Algorithms Reviews on parallel programming并行计算 1 基本概念解释;Translation (Chinese) SMP MPP Cluster of Workstation Parallelism, pipelining, Network topology, diameter of a network, Bisection width, data decomposition, task dependency graphs granularity concurrency process processor, linear array, mesh, hypercube, reduction, prefix-sum, gather, scatter, thread s, mutual exclusion shared address space, synchronization, the degree of concurrency, Dual of a communication operation, 2 问答题。Questions and answer Chapter 1 第1章 1) Why we need parallel computing? 1)为什么我们需要并行计算? 答: 2) Please explain what are the main difference between parallel computing and sequential computing 2)解释并行计算与串行计算在算法设计中的主要不同点在那里? 答: Chapter 2 第2章 1) What are SIMD, SPMD and MIMD denote? 1)解释SIMD, SPMD 和 MIMD是什么含义。 答: 2) Please draw a typical architecture of SIMD and a typical architecture of MIMD to explan. 2)请绘制一个典型的SIMD的体系结构和MIMD的架构。 答: 并行计算 一、并行计算概述 1.并行计算定义: 并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程。为执行并行计算,计算资源应包括一台配有多处理机(并行处理)的计算机、一个与网络相连的计算机专有编号,或者两者结合使用。并行计算的主要目的是快速解决大型且复杂的计算问题。此外还包括:利用非本地资源,节约成本―使用多个“廉价”计算资源取代大型计算机,同时克服单个计算机上存在的存储器限制。 为利用并行计算,通常计算问题表现为以下特征: (1)将工作分离成离散部分,有助于同时解决; (2)随时并及时地执行多个程序指令; (3)多计算资源下解决问题的耗时要少于单个计算资源下的耗时。 并行计算是相对于串行计算来说的,所谓并行计算分为时间上的并行和空间上的并行。时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计算。2.并行化方法 1)域分解 首先,确定数据如何划分到各个处理器 然后,确定每个处理器所需要做的事情 示例:求数组中的最大值 2)任务(功能)分解 首先,将任务划分到各个处理器 然后,确定各个处理器需要处理的数据 Example: Event-handler for GUI 二、并行计算硬件环境 1.并行计算机系统结构 1)Flynn分类 a. MIMD 多指令流多数据流(Multiple Instruction Stream Multiple Data Stream,简称MIMD),它使用多个控制器来异步的控制多个处理器,从而实现空间上的并行性。 对于大多数并行计算机而言,多个处理单元都是根据不同的控制流程执行不同的操作,处理不同的数据,因此,它们被称作是多指令流多数据流计算机 b. SIMD 单指令流多数据流(Single Instruction Multiple Data)能够复制多个操作数,并把它们打包在大型寄存器的一组指令集,以同步方式,在同一时间内执行同一条指令。 以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。 2)并行计算及结构模型 a. SMP SMP (Symmetric Multiprocessor) 采用商品化的处理器,这些处理器通过总线或交叉开关连接到共享存储器。每个处理器可等同地访问共享存储器、I/O设备和操作系统服务。 扩展性有限。 《计算方法》上机实验报告 班级:XXXXXX 小组成员:XXXXXXX XXXXXXX XXXXXXX XXXXXXX 任课教师:XXX 二〇一八年五月二十五日 前言 通过进行多次的上机实验,我们结合课本上的内容以及老师对我们的指导,能够较为熟练地掌握Newton 迭代法、Jacobi 迭代法、Gauss-Seidel 迭代法、Newton 插值法、Lagrange 插值法和Gauss 求积公式等六种算法的原理和使用方法,并参考课本例题进行了MATLAB 程序的编写。 以下为本次上机实验报告,按照实验内容共分为六部分。 实验一: 一、实验名称及题目: Newton 迭代法 例2.7(P38):应用Newton 迭代法求 在 附近的数值解 ,并使其满足 . 二、解题思路: 设'x 是0)(=x f 的根,选取0x 作为'x 初始近似值,过点())(,00x f x 做曲线)(x f y =的切线L ,L 的方程为))((')(000x x x f x f y -+=,求出L 与x 轴交点的横坐标) (') (0001x f x f x x - =,称1x 为'x 的一次近似值,过点))(,(11x f x 做曲线)(x f y =的切线,求该切线与x 轴的横坐标) (') (1112x f x f x x - =称2x 为'x 的二次近似值,重复以上过程,得'x 的近似值序列{}n x ,把 ) (') (1n n n n x f x f x x - =+称为'x 的1+n 次近似值,这种求解方法就是牛顿迭代法。 三、Matlab 程序代码: function newton_iteration(x0,tol) syms z %定义自变量 format long %定义精度 f=z*z*z-z-1; f1=diff(f);%求导 y=subs(f,z,x0); y1=subs(f1,z,x0);%向函数中代值 x1=x0-y/y1; k=1; while abs(x1-x0)>=tol x0=x1; y=subs(f,z,x0); y1=subs(f1,z,x0); x1=x0-y/y1;k=k+1; end x=double(x1) K 四、运行结果: 实验二: 第一部分:预备知识 1.1 矩阵的F-范数与矩阵迹的关系 引理:设m n A R ?∈,令()ij m n A a ?=,则2211 ||||||()()m n T T F ij i j A a tr AA tr A A === ==∑∑;其中,()tr ?定义如下: 令方阵11 12121 22212r r r r rr m m m m m m M m m m ?? ??? ?=???? ?? ,则11221 ()r rr ii i tr M m m m m ==+++=∑ ,即矩阵M 的迹。注意,()tr ?只能作用于方阵。 那么,下面来看下为什么有2211 ||||||()()m n T T F ij i j A a tr AA tr A A === ==∑∑? 首先,22 11 ||||||m n F ij i j A a === ∑∑这个等式是矩阵F-范数的定义,即一个矩阵的F-范数等于矩阵中每个元素的平方和。 其次,因11121212221 2 ()n n ij m n m m mn a a a a a a A a a a a ???????==?? ???? ,则11 2111222212m m T n n mn a a a a a a A a a a ?? ????=?? ? ? ?? ,易得2211 ()()||||||m n T T ij F i j tr AA tr A A a A ==== =∑∑。(T AA 或T A A 的第r 个对角元素等于第r 行或列元素的平方和,所有对角元素之和就是矩阵每个元素的平方和,即有上式成立。)此过程如图1和图2所示。 列主元三角分解法在matlab中的实现 摘要:介绍了M atlab语言并给出用M atlab语言实现线性方程组的列主元三角分解法,其有效性已在计算机实现中得到了验证。 关键词:M atlab语言;高斯消去法;列主元三角分解法 0前言 M atlab是M atrix Laboratory(矩阵实验室)的缩写,它是由美国M athwork公司于1967年推出的软件包,现已发展成为一种功能强大的计算机语言。它编程简单,使用方便,在M a tlab环境下数组的操作与数的操作一样简单,进行数学运算可以像草稿纸一样随心所欲,使计算机兼备高级计算器的优点。M atlab语言具有强大的矩阵和向量的操作功能,是Fo rtran和C语言无法比拟的;M a tlab语言的函数库可任意扩充;语句简单,内涵丰富;还具有二维和三维绘图功能且使用方便,特别适用于科学和工程计算。 在科学和工程计算中,应用最广泛的是求解线性方程组的解,一般可用高斯消去法求解,如果系数矩阵不满足高斯消去法在计算机上可行的条件,那么消元过程中可能会出现零主元或小主元,消元或不可行或数值不稳定,解决办法就是对方程组进行行交换或列交换来消除零主元或小主元,这就是选主元的思想。 1 定义 列主元三角分解:如果A为非奇异矩阵,则存在排列矩阵P,使PA=LU,其中L为单位下三角矩阵,U为上三角阵。列主元三角分角法是对直接三角分解法的一种改进,主要目的和列主元高斯消元法一样, 就是避免小数作为分母项. 2 算法概述 列主元三角分解法和普通三角分解法基本上类似,所不同的是在构造Gauss 变换前,先在对应列中选择绝对值最大的元素(称为列主元),然后实施初等行交换将该元素调整到矩阵对角线上。 例如第)1,,2,1(-=n k 步变换叙述如下: 选主元:确定p 使{}1)1( max -≤≤-=k ik n i k k pk a a ; 行交换:将矩阵的第k 行和第p 行上的元素互换位置,即 . 实施Gauss 变换:通过初行变换,将列主对角线以下的元素消为零.即 3 列主元三角分解在matlab 中的实现 《并行算法设计与分析》考题与答案 一、1.3,处理器PI的编号是: 解:对于n ×n 网孔结构,令位于第j行,第k 列(0≤j,k≤n-1)的处理器为P i(0≤i≤n2-1)。以16处理器网孔为例,n=4(假设j、k由0开始): 由p0=p(j,k)=p(0,0) P8=p(j,k)=p(2,0) P1=p(j,k)=p(0,1) P9=p(j,k)=p(2,1) P2=p(j,k)=p(0,2) P10=p(j,k)=p(2,2) P3=p(j,k)=p(0,3) P11=p(j,k)=p(2,3) P4=p(j,k)=p(1,0) P12=p(j,k)=p(3,0) P5=p(j,k)=p(1,1) P13=p(j,k)=p(3,1) P6=p(j,k)=p(1,2) P14=p(j,k)=p(3,2) P7=p(j,k)=p(1,3) P15=p(j,k)=p(3,3) 同时观察i和j、k之间的关系,可以得出i的表达式为:i= j * n+k 一、1.6矩阵相乘(心动算法) a)相乘过程 设 A 矩阵= 121221122121 4321 B 矩阵=1 23443212121121 2 【注】矩阵元素中A(i,l)表示自左向右移动的矩阵,B(l,j)表示自上向下移动的矩阵,黑色倾斜加粗标记表示已经计算出的矩阵元素,如12, C(i,j)= C(i,j)+ A(i,l)* B(l,j) 1 2、 4、 6、 8、 10 计算完毕 b)可以在10步后完成,移动矩阵长L=7,4*4矩阵N=4,所以需要L+N-1=10 江苏科技大学 计算机科学与工程学院 实验报告 实验名称:Java多线程编程 学号:姓名:班级: 完成日期:2014年04月22日 1.1 实验目的 (1) 掌握多线程编程的特点; (2) 了解线程的调度和执行过程; (3)掌握资源共享访问的实现方法。 1.2 知识要点 1.2.1线程的概念 (1)线程是程序中的一个执行流,多线程则指多个执行流; (2)线程是比进程更小的执行单位,一个进程包括多个线程; (3)Java语言中线程包括3部分:虚拟CPU、该CPU执行的代码及代码所操作的数据。 (4)Java代码可以为不同线程共享,数据也可以为不同线程共享; 1.2.2 线程的创建 (1) 方式1:实现Runnable接口 Thread类使用一个实现Runnable接口的实例对象作为其构造方法的参数,该对象提供了run方法,启动Thread将执行该run方法; (2)方式2:继承Thread类 重写Thread类的run方法; 1.2.3 线程的调度 (1) 线程的优先级 ●取值范围1~10,在Thread类提供了3个常量,MIN_PRIORITY=1、MAX_ PRIORITY=10、NORM_PRIORITY=5; ●用setPriority()设置线程优先级,用getPriority()获取线程优先级; ●子线程继承父线程的优先级,主线程具有正常优先级。 (2) 线程的调度:采用抢占式调度策略,高优先级的线程优先执行,在Java中,系统按照优先级的级别设置不同的等待队列。 1.2.4 线程的状态与生命周期 说明:新创建的线程处于“新建状态”,必须通过执行start()方法,让其进入到“就绪状态”,处于就绪状态的线程才有机会得到调度执行。线程在运行时也可能因资源等待或主动睡眠而放弃运行,进入“阻塞状态”,线程执行完毕,或主动执行stop方法将进入“终止状态”。 1.2.5 线程的同步--解决资源访问冲突问题 (1) 对象的加锁 所有被共享访问的数据及访问代码必须作为临界区,用synchronized加锁。对象的同步代码的执行过程如图14-2所示。 synchronized关键字的使用方法有两种: ●用在对象前面限制一段代码的执行,表示执行该段代码必须取得对象锁。 ●在方法前面,表示该方法为同步方法,执行该方法必须取得对象锁。 (2) wait()和notify()方法 用于解决多线程中对资源的访问控制问题。 ●wait()方法:释放对象锁,将线程进入等待唤醒队列; ●notify()方法:唤醒等待资源锁的线程,让其进入对象锁的获取等待队列。 (3)避免死锁 指多个线程相互等待对方释放持有的锁,并且在得到对方锁之前不会释放自己的锁。 1.3 上机测试下列程序 样例1:利用多线程编程编写一个龟兔赛跑程序。 乌龟:速度慢,休息时间短; 第十二章 并行程序设计基础 习题例题: 1、假定有n 个进程P(0),P(1),…,P(n -1),数组元素][i a 开始时被分配给进程P(i )。试写出求归约和]1[]1[]0[-+++n a a a 的代码段,并以8=n 示例之。 2、假定某公司在银行中有三个账户X 、Y 和Z ,它们可以由公司的任何雇员随意访问。雇员们对银行的存、取和转帐等事务处理的代码段可描述如下: /*从账户X 支取¥100元*/ atomic { if (balance[X] > 100) balance[X] = balance[X]-100; } /*从账户Y 存入¥100元*/ atomic {balance[Y] = balance[Y]-100;} /*从账户X 中转¥100元到帐号Z*/ atomic { if (balance[X] > 100){ balance[X] = balance[X]-100; balance[Z] = balance[Z]+100; } } 其中,atomic {}为子原子操作。试解释为什么雇员们在任何时候(同时)支、取、转帐时,这些事务操作总是安全有效的。 3、考虑如下使用lock 和unlock 的并行代码: parfor (i = 0;i < n ;i++){ noncritical section lock(S); critical section unlock(S); } 假定非临界区操作取T ncs时间,临界区操作取T cs时间,加锁取t lock时间,而去锁时间可忽略。则相应的串行程序需n( T ncs + T cs )时间。试问: ①总的并行执行时间是多少? ②使用n个处理器时加速多大? ③你能忽略开销吗? 4、计算两整数数组之内积的串行代码如下: Sum = 0; for(i = 0;i < N;i++) Sum = Sum + A[i]*B[i]; 试用①相并行;②分治并行;③流水线并行;④主-从行并行;⑤工作池并行等五种并行编程风范,写出如上计算内积的并行代码段。 5、图12.15示出了点到点和各种集合通信操作。试根据该图解式点倒点、播送、散步、收集、全交换、移位、归约与前缀和等通信操作的含义。 图12.15点到点和集合通信操作 (此文档为word格式,下载后您可任意编辑修改!) 多核编程与并行计算实验报告 姓名: 日期:2014年 4月20日 实验一 // exa1.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include 实验二 // exa2.cpp : Defines the entry point for the console application. // #include"stdafx.h" #include %直接三角分解法(1) function [x,y,L,U]=nalu(a,b) n=length(a); x=zeros(n,1);y=zeros(n,1); U=zeros(n,n);L=eye(n,n); U(1,:)=a(1,:); L(2:n,1)=a(2:n,1)/U(1,1); for k=2:n U(k,k:n)=a(k,k:n)-L(k,1:k-1)*U(1:k-1,k: n); L(k+1:n,k)=(a(k+1:n,k)-L(k+1:n,1:k-1)*U (1:k-1,k))/U(k,k); end for i=2:n y(1,1)=b(1,1); y(i,1)=b(i,1)-L(i,1:i-1)*y(1:i-1,1); end y(:,1); for i=n-1:-1:1 x(n,1)=y(n,1)/U(n,n); x(i,1)=(y(i,1)-U(i,i+1:n)*x(i+1:n,1))/U (i,i); end x(:,1); clear all; clc; A=[1,2,3;2,5,2;3,1,5]; b=[14;18;20]; [x,y,L,U]=nalu(A,b); function [x,y,L,U]=sanjiao(a,b) n=length(a); x=zeros(n,1); y=zeros(n,1); L=eye(n,n); U=zeros(n,n); %L,U·??a U(1,:)=a(1,:); L(2:n,1)=a(2:n,1)/U(1,1); for j=2:n U(j,j:n)=a(j,j:n)-L(j,1:j-1)*U(1:j-1,j: n); L(j+1:n,j)=(a(j+1:n,j)-L(j+1:n,1:j-1)*U (1:j-1,j))/U(j,j); end %?ó?a£?áíUx=y,Ly=b y(1,1)=b(1,1); for i=2:n y(i,1)=b(i,1)-L(i,1:i-1)*y(1:i-1,1); end 第二章习题(P69-70) 一、复习题 1.简述冯?诺依曼原理,冯?诺依曼结构计算机包含哪几部分部件,其结构以何部件为中心? 答:冯?诺依曼理论的要点包括:指令像数据那样存放在存储器中,并可以像数据那样进行处理;指令格式使用二进制机器码表示;用程序存储控制方式工作。这3条合称冯?诺依曼原理 冯?诺依曼计算机由五大部分组成:运算器、控制器、存储器、输入设备、输出设备,整个结构一般以运算器为中心,也可以以控制器为中心。 (P51-P54) 2.简述计算机体系结构与组成、实现之间的关系。 答:计算机体系结构通常是指程序设计人员所见到的计算机系统的属性,是硬件子系统的结构概念及其功能特性。计算机组成(computer organization)是依据计算机体系结构确定并且分配了硬件系统的概念结构和功能特性的基础上,设计计算机各部件的具体组成,它们之间的连接关系,实现机器指令级的各种功能和特性。同时,为实现指令的控制功能,还需要设计相应的软件系统来构成一个完整的运算系统。计算机实现,是计算机组成的物理实现, 就是把完成逻辑设计的计算机组成方案转换为真实的计算机。计算机体系结构、计算机组成和计算机实现是三个不同的概念,各自有不同的含义,但是又有着密切的联系,而且随着时间和技术的进步,这些含意也会有所改变。在某些情况下,有时也无须特意地去区分计算机体系结构和计算机组成的不同含义。 (P47-P48) 3.根据指令系统结构划分,现代计算机包含哪两种主要的体系结构? 答:根据指令系统结构划分,现代计算机主要包含:CISC和RISC两种结构。 (P55) 4.简述RISC技术的特点? 答:从指令系统结构上看,RISC 体系结构一般具有如下特点: (1) 精简指令系统。可以通过对过去大量的机器语言程序进行指令使用频度的统计,来选取其中常用的基本指令,并根据对操作系统、高级语言和应用环境等的支持增设一些最常用的指令; (2) 减少指令系统可采用的寻址方式种类,一般限制在2或3种; (3) 在指令的功能、格式和编码设计上尽可能地简化和规整,让所有指令尽可能等长; (4) 单机器周期指令,即大多数的指令都可以在一个机器周期内完成,并且允许处理器在同一时间内执行一系列的指令。 (P57-58) 5.有人认为,RISC技术将全面替代CISC,这种观点是否正确,说明理由? 答:不正确。与CISC 架构相比较,RISC计算机具备结构简单、易于设计和程序执行效率高的特点,但并不能认为RISC 架构就可以取代CISC 架构。事实上,RISC 和CISC 各有优势,CISC计算机功能丰富,指令执行更加灵活,这些时RISC计算机无法比拟的,当今时代,两者正在逐步融合,成为CPU设计的新趋势。 (P55-59) 6.什么是流水线技术? 答:流水线技术,指的是允许一个机器周期内的计算机各处理步骤重叠进行。特别是,当执行一条指令时,可以读取下一条指令,也就意味着,在任何一个时刻可以有不止一条指令在“流水线”上,每条指令处在不同的执行阶段。这样,即便读取和执行每条指令的时间保持不变,而计算机的总的吞吐量提高了。 (P60-62) 7.多处理器结构包含哪几种主要的体系结构,分别有什么特点? 答:多处理器系统:主要通过资源共享,让共享输入/输出子系统、数据库资源及共享或不共享存储的一组处理机在统一的操作系统全盘控制下,实现软件和硬件各级上相互作用,达到时间和空间上的异步并行。 SIMD计算机有多个处理单元,由单一的指令部件控制,按照同一指令流的要求为他们多核编程与并行计算实验报告 (1)
特征值分解与奇异值分解
列主元高斯消去法和列主元三角分解法解线性方程
并行计算 - 练习题
并行计算1
奇异值分解定理
2.4直接三角分解法
并行计算-期末考试模拟题原题
并行计算(天津大学软件学院)
计算方法上机实验报告
奇异值分解的一些特性以及应用小案例
列主元三角分解法在matlab中的实现
并行算法设计与分析考题与答案
并行计算实验报告一
并行计算-习题及答案-第12章 并行程序设计基础
多核编程与并行计算实验报告 (1)
数值分析中直接三角分解法matlab程序
计算机体系结构 习题与答案
相关主题
文本预览