1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据:
地区人均GDP/元人均消费水平/元
北京辽宁上海江西河南贵州陕西 22460
11226
34547
4851
5444
2662
4549
7326
4490
11546
2396
2208
1608
2035
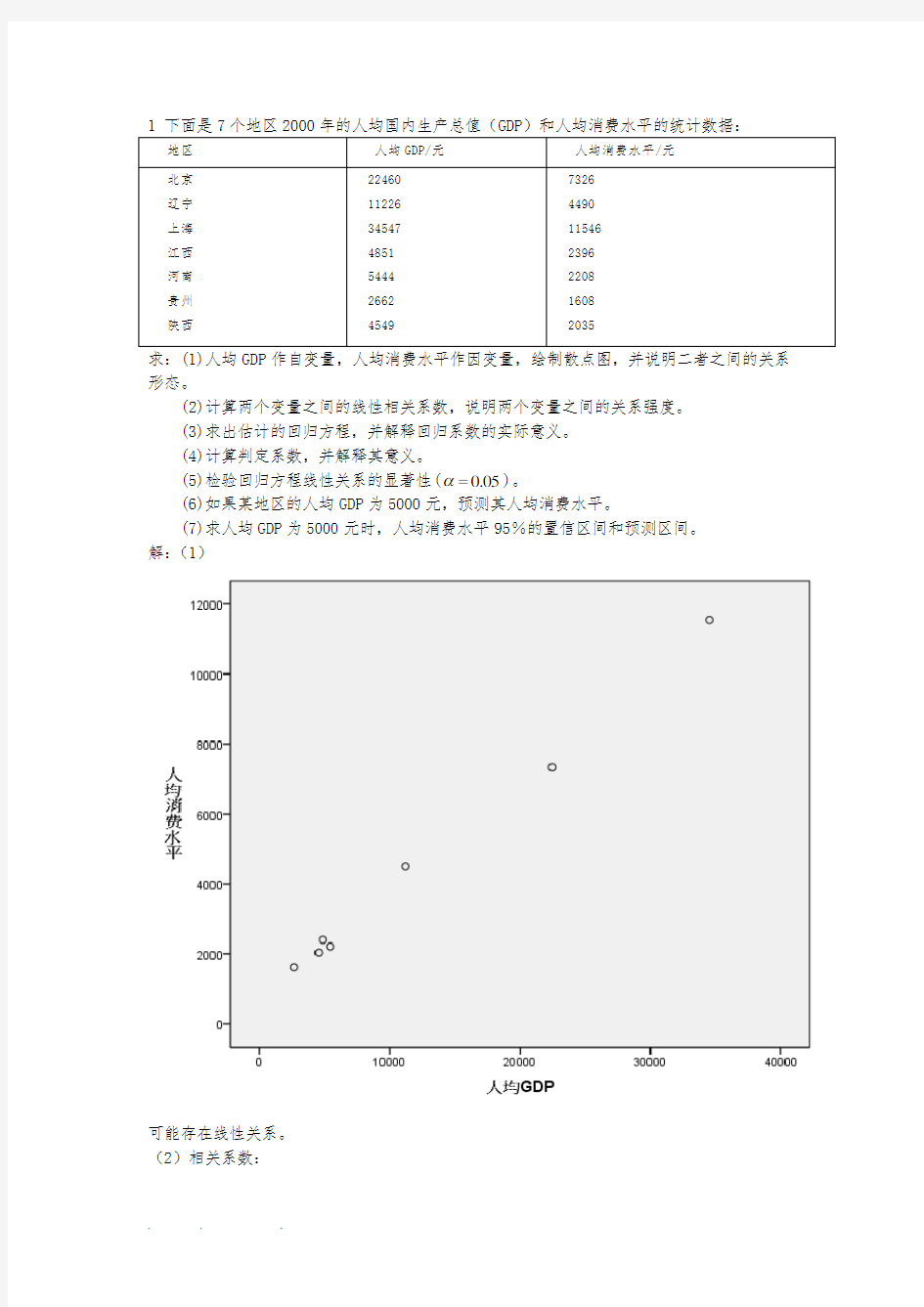
求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。
(2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。
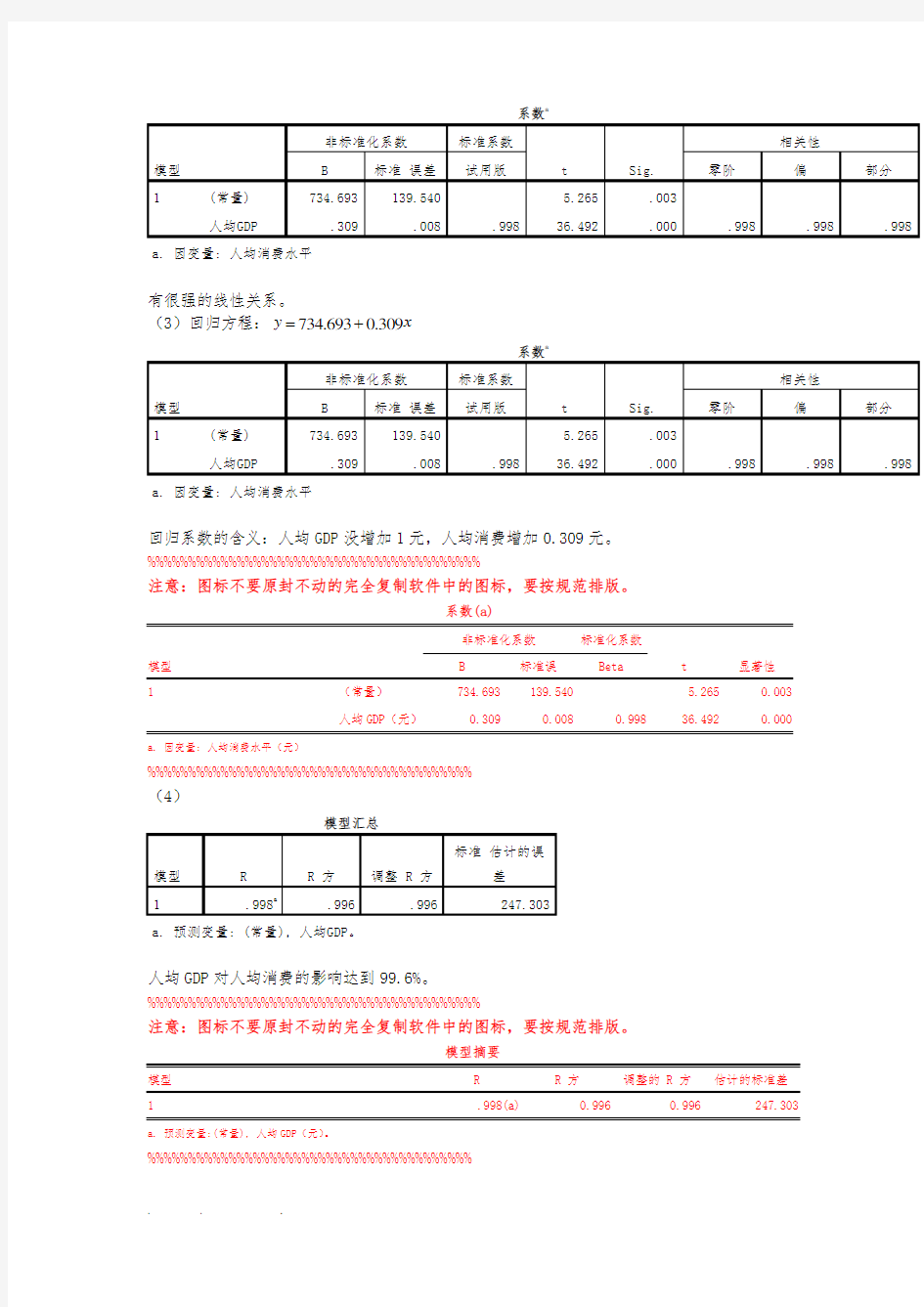
(3)求出估计的回归方程,并解释回归系数的实际意义。
(4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(0.05
α=)。
(6)如果某地区的人均GDP为5000元,预测其人均消费水平。
(7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。
解:(1)
可能存在线性关系。
(2)相关系数:
(3)回归方程:734.6930.309
y x
=+
回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)
模型非标准化系数标准化系数
t 显著性B 标准误Beta
1 (常量)734.693 139.540 5.265 0.003
人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
(4)
模型汇总
模型R R 方调整 R 方标准估计的误
差
1 .998a.996 .996 247.303
a. 预测变量: (常量), 人均GDP。
人均GDP对人均消费的影响达到99.6%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
模型摘要
模型R R 方调整的 R 方估计的标准差
1 .998(a) 0.996 0.996 247.303
a. 预测变量:(常量), 人均GDP(元)。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
(5)F 检验:
Anova b
模型 平方和 df
均方 F Sig. 1
回归 81444968.680 1 81444968.680 1331.692
.000a
残差 305795.034 5 61159.007
总计
81750763.714
6
a. 预测变量: (常量), 人均GDP 。
b. 因变量: 人均消费水平
回归系数的检验:t 检验
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。
系数(a)
模型 非标准化系数
标准化系数 t 显著性
B 标准误 Beta
1
(常量) 734.693 139.540 5.265
0.003 人均GDP (元)
0.309
0.008
0.998
36.492
0.000
a. 因变量: 人均消费水平(元)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
(6)
某地区的人均GDP 为5000元,预测其人均消费水平为 734.6930.30950002278.693y =+?=(元)。
(7)
人均GDP 为5000元时,人均消费水平95%的置信区间为[1990.74915,2565.46399],预测区间为[1580.46315,2975.74999]。
2 从n =20的样本中得到的有关回归结果是:SSR (回归平方和)=60,SSE (误差平方和)=40。要检验x 与y 之间的线性关系是否显著,即检验假设:01:0H β=。 (1)线性关系检验的统计量F 值是多少? (2)给定显著性水平0.05α=,F α是多少? (3)是拒绝原假设还是不拒绝原假设?
(4)假定x 与y 之间是负相关,计算相关系数r 。 (5)检验x 与y 之间的线性关系是否显著?
解:(1)SSR 的自由度为k=1;SSE 的自由度为n-k-1=18;
因此:F=1SSR k SSE n k --=60
14018
=27 (2)()1,18F α=()0.051,18F =4.41 (3)拒绝原假设,线性关系显著。 (4)
=0.7746,由于是负相关,因此r=-0.7746
(5)从F 检验看线性关系显著。
(1)用广告费支出作自变量x ,销售额作因变量y ,求出估计的回归方程。 (2)检验广告费支出与销售额之间的线性关系是否显著(0.05α=)。 (3)绘制关于x 的残差图,你觉得关于误差项ε的假定被满足了吗? (4)你是选用这个模型,还是另寻找一个更好的模型? 解:(1)
系数(a)
模型 非标准化系数
标准化系数 t 显著性
B 标准误
Beta
1
(常量)
29.399 4.807 6.116
0.002 广告费支出(万元)
1.547
0.463
0.831
3.339
0.021
a. 因变量: 销售额(万元)
(2)回归直线的F 检验:
ANOVA(b)
模型 平方和 df
均方 F 显著性 1
回归 691.723 1 691.723 11.147
.021(a)
残差
310.277
5
62.055
合计1,002.000 6
a. 预测变量:(常量), 广告费支出(万元)。
b. 因变量: 销售额(万元)
显著。
回归系数的t检验:
系数(a)
模型非标准化系数标准化系数
t 显著性B 标准误Beta
1 (常量)29.399 4.807 6.116 0.002
广告费支出(万元) 1.547 0.463 0.831 3.339 0.021 a. 因变量: 销售额(万元)
显著。
(3)未标准化残差图:
标准化残差图:
第5 章自变量选择与逐步回归 思考与练习参考答案 自变量选择对回归参数的估计有何影响? 答:回归自变量的选择是建立回归模型得一个极为重要的问题。如果模型中丢 掉了重要的自变量, 出现模型的设定偏误,这样模型容易出现异方差或自相关 性,影响回归的效果;如果模型中增加了不必要的自变量, 或者数据质量很差的自变量, 不仅使得建模计算量增大, 自变量之间信息有重叠,而且得到的模型稳定性较差,影响回归模型的应用。 自变量选择对回归预测有何影响? 答:当全模型(m元)正确采用选模型(p 元)时,我们舍弃了m-p 个自变量,回归系数的最小二乘估计是全模型相应参数的有偏估计,使得用选模型的预测是有偏的,但由于选模型的参数估计、预测残差和预测均方误差具有较小的方差, 所以全模型正确而误用选模型有利有弊。当选模型(p 元)正确采用全模型(m 元)时,全模型回归系数的最小二乘估计是相应参数的有偏估计,使得用模型的预测是有偏的,并且全模型的参数估计、预测残差和预测均方误差的方差都比选 模型的大,所以回归自变量的选择应少而精。 如果所建模型主要用于预测,应该用哪个准则来衡量回归方程的优劣? 答:如果所建模型主要用于预测,则应使用C p 统计量达到最小的准则来衡量回 归方程的优劣。 试述前进法的思想方法。 答:前进法的基本思想方法是:首先因变量Y对全部的自变量x1,x2,...,xm 建立m个一元线性回归方程, 并计算 F 检验值,选择偏回归平方和显著的变量(F 值最大且大于临界值)进入回归方程。每一步只引入一个变量,同时建立m-1个二元线性回归方程,计算它们的 F 检验值,选择偏回归平方和显著的两变量变 量(F 值最大且大于临界值)进入回归方程。在确定引入的两个自变量以后,再 引入一个变量,建立m-2 个三元线性回归方程,计算它们的 F 检验值,选择偏
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
中级经济师基础知识 第 1题:单选题(本题1分) 某公司产品当产量为1000单位时,其总成本为4000元;当产量为2000单位时,其总成本为5000,则设产量为x,总成本为y,正确的一元回归方程表达式应该是( )。 A、y = 3000 + x B、y = 4000 + 4x C、y = 4000 + x D、y = 3000 + 4x 【正确答案】:A 【答案解析】: 本题可列方程组:设该方程为y = a + bx,则由题意可得:4000 = a + 1000b5000 = a + 2000b 解该方程,得b=1,a=3000,所以方程为y = 3000 + x 第 2题:单选题(本题1分) 在回归分析中,估计回归系数的最小二乘法的原理是( )。 A、使得因变量观测值与均值之间的离差平方和最小 B、使得因变量估计值与均值之间的离差平方和最小 C、使得观测值与估计值之间的乘积和最小 D、使得因变量观测值与估计值之间的离差平方和最小 【正确答案】:D 【答案解析】: 较偏较难的一道题目。最小二乘法就是使得因变量的观测值与估计值之间的离差平方和最小来估计参数的一种方法 第 3题:多选题(本题2分) 关于相关分析和回归分析的说法,正确的的有() A、相关分析可以从一个变量的变化来推测另一个变量的变化 B、相关分析研究变量间相关的方向和相关的程度 C、相关分析中需要明确自变量和因变量 D、回归分析研究变量间相互关系的具体形式 E、相关分析和回归分析在研究方法和研究目的有明显区别 【正确答案】:BDE 【答案解析】: 相关分析与回归分析在研究目的和方法上具有明显的区别。 (1)、相关分析研究变量之间相关的方向和相关的程度,无法从一个变量的变化来推测另一变量的变化情况。 (2)、回归分析是研究变量之间相关关系的具体形式
第6章 6.1 试举一个产生多重共线性的经济实例。 答:例如有人建立某地区粮食产量回归模型,以粮食产量为因变量Y,化肥用量为X1,水浇地面积为X2,农业投入资金为X3。由于农业投入资金X3与化肥用量X1,水浇地面积X2有很强的相关性,所以回归方程效果会很差。再例如根据某行业企业数据资料拟合此行业的生产函数时,资本投入、劳动力投入、资金投入与能源供应都与企业的生产规模有关,往往出现高度相关情况,大企业二者都大,小企业都小。 6.2多重共线性对回归参数的估计有何影响? 答:1、完全共线性下参数估计量不存在; 2、参数估计量经济含义不合理; 3、变量的显著性检验失去意义; 4、模型的预测功能失效。 6.3 具有严重多重共线性的回归方程能不能用来做经济预测? 答:虽然参数估计值方差的变大容易使区间预测的“区间”变大,使预测失去意义。但如果利用模型去做经济预测,只要保证自变量的相关类型在未来期中一直保持不变,即使回归模型中包含严重多重共线性的变量,也可以得到较好预测结果;否则会对经济预测产生严重的影响。 6.4多重共线性的产生于样本容量的个数n、自变量的个数p有无关系? 答:有关系,增加样本容量不能消除模型中的多重共线性,但能适当消除多重共线性造成的后果。当自变量的个数p较大时,一般多重共线性容易发生,所以自变量应选择少而精。 6.6对第5章习题9财政收入的数据分析多重共线性,并根据多重共线性剔除变量。将所得结果与逐步回归法所得的选元结果相比较。 5.9 在研究国家财政收入时,我们把财政收入按收入形式分为:各项税收收入、企业收入、债务收入、国家能源交通重点建设收入、基本建设贷款归还收入、国家预算调节基金收入、其他收入等。为了建立国家财政收入回归模型,我们以财政收入y(亿元)为因变量,自变量如下:x1为农业增加值(亿元),x2为工业增加值(亿元),x3为建筑业增加值(亿元),x4为人口数(万人),x5为社
第8章 非线性回归 思考与练习参考答案 8.1 在非线性回归线性化时,对因变量作变换应注意什么问题? 答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。如: (1) 乘性误差项,模型形式为 e y AK L αβε =, (2) 加性误差项,模型形式为y AK L αβ ε = + 对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。 一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。 8.2为了研究生产率与废料率之间的关系,记录了如表8.15所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。 表8.15 生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%) 5.2 6.5 6.8 8.1 10.2 10.3 13.0 解:先画出散点图如下图: 5000.00 4000.003000.002000.001000.00x 12.00 10.00 8.006.00 y
从散点图大致可以判断出x 和y 之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。 (1)二次曲线 SPSS 输出结果如下: Model Summ ary .981 .962 .942 .651 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x. ANOVA 42.571221.28650.160.001 1.6974.424 44.269 6 Regression Residual Total Sum of Squares df Mean Square F Sig.The independent variable is x. Coe fficients -.001.001-.449-.891.4234.47E -007.000 1.417 2.812.0485.843 1.324 4.414.012 x x ** 2 (Constant) B Std. E rror Unstandardized Coefficients Beta Standardized Coefficients t Sig. 从上表可以得到回归方程为:72? 5.8430.087 4.4710y x x -=-+? 由x 的系数检验P 值大于0.05,得到x 的系数未通过显著性检验。 由x 2的系数检验P 值小于0.05,得到x 2的系数通过了显著性检验。 (2)指数曲线 Model Summ ary .970 .941 .929 .085 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x.
1 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数据: 求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。 α=)。 (5)检验回归方程线性关系的显著性(0.05 (6)如果某地区的人均GDP为5000元,预测其人均消费水平。 (7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 解:(1)
可能存在线性关系。 (2)相关系数: 系数a 模型非标准化系数标准系数 t Sig. 相关性 B标准误差试用版零阶偏部分 1(常量).003 人均GDP.309.008.998.000.998.998.998 a. 因变量: 人均消费水平 有很强的线性关系。 (3)回归方程:734.6930.309 y x =+ 系数a 模型非标准化系数标准系数t Sig.相关性
回归系数的含义:人均GDP没增加1元,人均消费增加元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 系数(a) 模型非标准化系数标准化系数 t显著性B标准误Beta 1(常量) 人均GDP(元) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%(4) 模型汇总 模型R R 方调整 R 方标准估计的误 差 1.998a.996.996 a. 预测变量: (常量), 人均GDP。 人均GDP对人均消费的影响达到%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 模型摘要 模型R R 方调整的 R 方估计的标准差
地区人均GDP/元人均消费水平/元 22460 11226 34547 4851 5444 2662 4549 7326 4490 11546 2396 2208 1608 2035 求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。 (5)检验回归方程线性关系的显著性(0.05 α=)。 (6)如果某地区的人均GDP为5000元,预测其人均消费水平。 (7)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 解:(1) 可能存在线性关系。 (2)相关系数:
有很强的线性关系。 (3)回归方程:734.6930.309 y x =+ 回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 系数(a) 模型非标准化系数标准化系数 t 显著性B 标准误Beta 1 (常量)734.693 139.540 5.265 0.003 人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% (4) 模型汇总 模型R R 方调整R 方标准估计的误 差 1 .998a.996 .996 247.303 a. 预测变量: (常量), 人均GDP。 人均GDP对人均消费的影响达到99.6%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规范排版。 模型摘要 模型R R 方调整的R 方估计的标准差 1 .998(a) 0.996 0.996 247.303
多元线性回归模型 一、单项选择题 1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定 系数为,则调整后的多重决定系数为( D ) A. B. C. 下列样本模型中,哪一个模型通常是无效 的(B ) A. i C (消费)=500+i I (收入) B. d i Q (商品需求)=10+i I (收入)+i P (价格) C. s i Q (商品供给)=20+i P (价格) D. i Y (产出量)=0.6i L (劳动)0.4i K (资本) 3.用一组有30个观测值的样本估计模型01122t t t t y b b x b x u =+++后,在的显著性水平上对 1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C ) A. )30(05.0t B. )28(025.0t C. )27(025.0t D. )28,1(025.0F 4.模型 t t t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B ) A.x 关于y 的弹性 B. y 关于x 的弹性 C. x 关于y 的边际倾向 D. y 关于x 的边际倾向 5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明 模型中存在( C ) A.异方差性 B.序列相关 C.多重共线性 D.高拟合优度 6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...) t H b i k ==时,所用的统计量 服从( C ) (n-k+1) (n-k-2) (n-k-1) (n-k+2) 7. 调整的判定系数 与多重判定系数 之间有如下关系( D ) A.2 211n R R n k -=-- B. 22111 n R R n k -=--- C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=---- 8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。 A.只有随机因素 B.只有系统因素 C.既有随机因素,又有系统因素 、B 、C 都不对 9.在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):( C ) A n ≥k+1 B n 实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日 一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1) 图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏 5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。 1.1回归分析的基本思想及其初步应用 一、选择题 1. 某同学由x 与y 之间的一组数据求得两个变量间的线性回归方程为y bx a =+,已知:数据x 的平 均值为2,数据 y 的平均值为3,则 ( ) A .回归直线必过点(2,3) B .回归直线一定不过点(2,3) C .点(2,3)在回归直线上方 D .点(2,3)在回归直线下方 2. 在一次试验中,测得(x,y)的四组值分别是A(1,2),B(2,3),C(3,4),D(4,5),则Y 与X 之间的回归直线方程为( )A . y x 1=+ B . y x 2=+ C . y 2x 1=+ D. y x 1=-3. 在对两个变量x ,y 进行线性回归分析时,有下列步骤: ①对所求出的回归直线方程作出解释; ②收集数据(i x 、i y ) ,1,2i =,…,n ; ③求线性回归方程; ④求未知参数; ⑤根据所搜集的数据绘制散点图 如果根据可行性要求能够作出变量,x y 具有线性相关结论,则在下列操作中正确的是( ) A .①②⑤③④ B .③②④⑤① C .②④③①⑤ D .②⑤④③① 4. 下列说法中正确的是( ) A .任何两个变量都具有相关关系 B .人的知识与其年龄具有相关关系 C .散点图中的各点是分散的没有规律 D .根据散点图求得的回归直线方程都是有意义的 5. 给出下列结论: (1)在回归分析中,可用指数系数2 R 的值判断模型的拟合效果,2 R 越大,模型的拟合效果越好; (2)在回归分析中,可用残差平方和判断模型的拟合效果,残差平方和越大,模型的拟合效果越好; (3)在回归分析中,可用相关系数r 的值判断模型的拟合效果,r 越小,模型的拟合效果越好; (4)在回归分析中,可用残差图判断模型的拟合效果,残差点比较均匀地落在水平的带状区域中,说明这样的模型比较合适.带状区域的宽度越窄,说明模型的拟合精度越高. 以上结论中,正确的有( )个. A .1 B .2 C .3 D .4 6. 已知直线回归方程为2 1.5y x =-,则变量x 增加一个单位时( ) A.y 平均增加1.5个单位 B.y 平均增加2个单位 C.y 平均减少1.5个单位 D. y 平均减少2个单位 7. 下面的各图中,散点图与相关系数r 不符合的是( ) 应用回归分析课后习题 参考答案 Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】 第二章一元线性回归分析 思考与练习参考答案 一元线性回归有哪些基本假定 答:假设1、解释变量X是确定性变量,Y是随机变量; 假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(ε i )=0 i=1,2, …,n Var (ε i )=2i=1,2, …,n Cov(ε i, ε j )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X之间不相关: Cov(X i , ε i )=0 i=1,2, …,n 假设4、ε服从零均值、同方差、零协方差的正态分布 ε i ~N(0, 2) i=1,2, …,n 考虑过原点的线性回归模型 Y i =β 1 X i +ε i i=1,2, …,n 误差εi(i=1,2, …,n)仍满足基本假定。求β1的最小二乘估计解: 得: 证明(式),e i =0 ,e i X i=0 。 证明: ∑ ∑+ - = - = n i i i n i X Y Y Y Q 1 2 1 2 1 )) ? ?( ( )? (β β 其中: 即:e i =0 ,e i X i=0 2 1 1 1 2) ? ( )? ( i n i i n i i i e X Y Y Y Qβ ∑ ∑ = = - = - = ) ? ( 2 ?1 1 1 = - - = ? ?∑ = i i n i i e X X Y Q β β ) ( ) ( ? 1 2 1 1 ∑ ∑ = = = n i i n i i i X Y X β 01 ?? ?? i i i i i Y X e Y Y ββ =+=- 01 00 ?? Q Q ββ ?? == ?? 第九章spss的回归分析 1、利用习题二第4题的数据,任意选择两门课程成绩作为解释变量和被解释变量,利用SPSS 提供的绘制散点图功能进行一元线性回归分析。请绘制全部样本以及不同性别下两门课程成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二和第三条分别针对男生样本和女生样本,并对各回归直线的拟和效果进行评价。 选择fore和phy两门成绩做散点图 步骤:图形→旧对话框→散点图→简单散点图→定义→将phy导入X轴、将fore导入Y 轴,将sex导入设置标记→确定 图标剪辑器内点击元素菜单→选择总计拟合线→选择线性→确定→再次选择元素菜单→点击子组拟合线→选择线性→确定 分析:如上图所示,通过散点图,被解释变量y与fore有一定的线性相关关系。 2、线性回归分析与相关性回归分析的关系是怎样的? 线性回归分析是相关性回归分析的一种,研究的是一个变量的增加或减少会不会引起另一个变量的增加或者减少。 3、为什么需要对线性回归方程进行统计检验?一般需要对哪些方面进行检验? 线性回归方程能够较好地反映被解释变量和解释变量之间的统计关系的前提是被解释变量和解释变量之间确实存在显著的线性关系。 回归方程的显著性检验正是要检验被解释变量和解释变量之间的线性关系是否显著,用线性模型来描述他们之间的关系是否恰当。一般包括回归系数的检验,残差分析等。 4、SPSS多元线性回归分析中提供了哪几种解释变量筛选策略? 包括向前筛选策略、向后筛选策略和逐步筛选策略。 5、先收集到若干年粮食总产量以及播种面积、使用化肥量、农业劳动人数等数据,请利用建立多元线性回归方程,分析影响粮食总产量的主要因素。数据文件名为“粮食总产量.sav”。 步骤:分析→回归→线性→粮食总产量导入因变量、其余变量导入自变量→确定 结果如图: Variables Entered/Removed b Model Variables Entered Variables Removed Method 1 农业劳动者人数(百万人), 总播种面积(万公顷), 风灾 面积比例(%), 粮食播种面 积(万公顷), 施用化肥量 (kg/公顷), 年份a . Enter a. All requested variables entered. b. Dependent Variable: 粮食总产量(y万吨) ANOVA b Model Sum of Squares df Mean Square F Sig. 1 Regression 2.025E9 6 3.375E8 414.944 .000a Residual 2.278E7 28 813478.405 Total 2.048E9 34 a. Predictors: (Constant), 农业劳动者人数(百万人), 总播种面积(万公顷), 风灾面积比例(%), 粮食播种面积(万公顷), 施用化肥量(kg/公顷), 年份 b. Dependent Variable: 粮食总产量(y万吨) Coefficients a Model Unstandardized Coefficients Standardized Coefficients t Sig. B Std. Error Beta 1 下面是7个地区2000年的人均国生产总值(GDP)与人均消费水平的统计数据:地区人均GDP/元人均消费水平/元 北京上海 22460 11226 34547 4851 5444 2662 4549 7326 4490 11546 2396 2208 1608 2035 求:(1)人均GDP作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。 (5)检验回归方程线性关系的显著性(0.05 α=)。 (6)如果某地区的人均GDP为5000元,预测其人均消费水平。 (7)求人均GDP为5000元时,人均消费水平95%的置信区间与预测区间。 解:(1) 可能存在线性关系。 (2)相关系数: (3)回归方程:734.6930.309 y x =+ 回归系数的含义:人均GDP没增加1元,人均消费增加0.309元。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规排版。 系数(a) 模型非标准化系数标准化系数 t 显著性B 标准误Beta 1 (常量)734.693 .540 5.265 0.003 人均GDP(元)0.309 0.008 0.998 36.492 0.000 a. 因变量: 人均消费水平(元)%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% (4) 模型汇总 模型R R 方调整 R 方标准估计的误 差 1 .998a.996 .996 247.303 a. 预测变量: (常量), 人均GDP。 人均GDP对人均消费的影响达到99.6%。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规排版。 模型摘要 模型R R 方调整的 R 方估计的标准差 1 .998(a) 0.996 0.996 247.303 a. 预测变量:(常量), 人均GDP(元)。%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 一、问题描述 2016年1月12日 13:04 学习并使用SPSS软件进行相关分析和回归分析,具体包括: (1) 皮尔逊pearson简单相关系数的计算与分析 (2) 学会在SPSS上实现一元及多元回归模型的计算与检验。 (3) 学会回归模型的散点图与样本方程图形。 (4) 学会对所计算结果进行统计分析说明。 二、实验原理 2016年1月12日 13:13 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。 线性回归数学模型如下: 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量和解释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。回归模型的检验包括一级检验和二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟和优度评价和显著性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。 三、数据录入 2016年1月13日 20:05 有“连续变量简单相关系数的计算与分析_时间与成绩”数据文件,以此录入做相关分析: 相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS软件进行相关分析与回归分析,具体包括: (1)皮尔逊pearson简单相关系数的计算与分析 (2)学会在SPSS上实现一元及多元回归模型的计算与检验。 (3)学会回归模型的散点图与样本方程图形。 (4)学会对所计算结果进行统计分析说明。 (5)要求试验前,了解回归分析的如下内容。 参数α、β的估计 回归模型的检验方法:回归系数β的显着性检验(t-检验); 回归方程显着性检验(F-检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数与模型进行检验与判断,并进行预测等。 线性回归数学模型如下: 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量与解释变量及其函数形式,或者对数据进行加工整理之后再 次估计参数。回归模型的检验包括一级检验与二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟与优度评价与显着性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。 三、试验演示内容与步骤 1.连续变量简单相关系数的计算与分析 在上市公司财务分析中,常常利用资产收益率、净资产收益率、每股净收益与托宾Q值4个指标来衡量公司经营绩效。本试验利用SPSS对这4个指标的相关性进行检验。操作步骤与过程: 打开数据文件“上市公司财务数据(连续变量相关分析).sav”,依次选择“【分析】→【相关】→【双变量】”打开对话框如图,将待分析的4个指标移入右边的变量列表框内。其他均可选择默认项,单击ok提交系统运行。 图5.1 Bivariate Correlations对话框 结果分析: 表给出了Pearson简单相关系数,相关检验t统计量对应的p值。相关系数右上角有两个星号表示相关系数在0.01的显着性水平下显着。从表中可以看出,每股收益、净资产收益率与总资产收益率3个指标之间的相关系数都在0.8以上,对应的p值都接近0,表示3个指标具有较强的正相关关系,而托宾Q值与其他3个变量之间的相关性较弱。 表5.1 Pearson简单相关分析 Correlations 每股收益 率净资产 收益率 资产收益 率 托宾Q 值 每股收益率Pearson Correlation 1 .877(* *) .824(**)-.073 Sig. ..000.000.199 求:(1)人均GDP 乍自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系 形态。 (2) 计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3) 求出估计的回归方程,并解释回归系数的实际意义。 (4) 计算判定系数,并解释其意义。 (5) 检验回归方程线性关系的显著性 ( 0.05)。 (6) 如果某地区的人均 GDP 为5000元,预测其人均消费水平。 (7) 求人均GDP 为5000元时,人均消费水平 95%的置信区间与预测区间。 解: (1) 可能存在线性关系。 12000- 1DOOQ - 6000- 6000- 4QD0- 2000- 0- D 10000 20000 人均GDP 30000 4MOO (2) 相关系数: a.因变量人均消费水平 有很强的线性关系。 (3)回归方程: y 734.693 0.309x a.因变量人均消费水平 回归系数的含义:人均 GDP 没增加1元,人均消费增加 0.309元。 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规排版。 系数(a ) a.因变量人均消费水平(元) %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% (4) 模型汇总 a.预测变量常量),人均GDP 人均GDP 寸人均消费的影响达到 99.6%。 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 注意:图标不要原封不动的完全复制软件中的图标,要按规排版。 a.预测变量:(常量人均GDP (元)。 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% 第4章违背基本假设的情况 思考与练习参考答案 4.1 试举例说明产生异方差的原因。 答:例4.1:截面资料下研究居民家庭的储蓄行为 Y i=β0+β1X i+εi 其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。 由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以εi的方差呈现单调递增型变化。 例4.2:以某一行业的企业为样本建立企业生产函数模型 Y i=A iβ1K iβ2L iβ3eεi 被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。 4.2 异方差带来的后果有哪些? 答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果: 1、参数估计量非有效 2、变量的显著性检验失去意义 3、回归方程的应用效果极不理想 总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。 4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。 答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差 的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。 加权最小二乘法的方法: 4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。 答:运用加权最小二乘法消除多元线性回归中异方差性的思想与一元线性回归的类似。多元线性回归加权最小二乘法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为: ∑=----=n i ip p i i i p w x x y w Q 1211010)( ),,,(ββββββ (2) 加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差平方和w Q 达极小。所得加权最小二乘经验回归方程记做 22011 1 ???()()N N w i i i i i i i i Q w y y w y x ββ===-=--∑∑22 __ 1 _ 2 _ _ 02 222 ()() ?()?1 11 1 ,i i N w i i i w i w i w w w w w kx i i i i m i i i m i w x x y y x x y x w kx x kx w x σβββσσ==---=-= = ===∑∑1N i =1 1表示=或 实验课程案例数据1 香烟消费数据:一个国家保险组织想要研究在美国所有50个州和哥伦比亚特区的香烟消费模式,表1给出了研究中所选的变量,表2给出了1970年的数据。讨论下列问题: 表1. 香烟消费数据的变量 表2. 香烟消费数据(1970年) 州年龄HS 收入黑人比例女性比例价格销量 AL2741.3294826.251.742.789.8 AK22.966.74644345.741.8121.3 AZ26.358.13665350.838.5115.2 AR29.139.9287818.351.538.8100.3 CA28.162.64493750.839.7123 CO26.263.93855350.731.1124.8 CT29.1564917651.545.5120 DE26.854.6452414.351.341.3155 DC28.455.2507971.153.532.6200.4 FL32.352.6373815.351.843.8123.6 GA25.940.6335425.951.435.8109.9 HI2561.9462314836.782.1 ID26.459.532900.350.133.6102.4 IL28.652.6450712.851.541.4124.8 IN27.252.93772 6.951.332.2134.6 IO28.8593751 1.251.438.5108.5 KA28.759.93853 4.85138.9114 KY27.538.531127.250.930.1155.8 LA24.842.2309029.851.439.3115.9 ME2854.733020.351.338.8128.5 MD27.152.3430917.851.134.2123.5 MA2958.54340 3.152.241124.3 MI26.352.8418011.25139.2128.6 第9章 含定性变量的回归模型 思考与练习参考答案 9.1 一个学生使用含有季节定性自变量的回归模型,对春夏秋冬四个季节引入4个0-1型自变量,用SPSS 软件计算的结果中总是自动删除了其中的一个自变量,他为此感到困惑不解。出现这种情况的原因是什么? 答:假如这个含有季节定性自变量的回归模型为: t t t t kt k t t D D D X X Y μαααβββ++++++=332211110 其中含有k 个定量变量,记为x i 。对春夏秋冬四个季节引入4个0-1型自变量,记为D i ,只取了6个观测值,其中春季与夏季取了两次,秋、冬各取到一次观测值,则样本设计矩阵为: ????? ? ?? ?? ? ?=00011001011000101001 0010100011 )(6 165154143 132121 11k k k k k k X X X X X X X X X X X X D X, 显然,(X,D)中的第1列可表示成后4列的线性组合,从而(X,D)不满秩,参数无法唯一求出。这就是所谓的“虚拟变量陷井”,应避免。 当某自变量x j 对其余p-1个自变量的复判定系数2j R 超过一定界限时,SPSS 软件将拒绝这个自变量x j 进入回归模型。称Tol j =1-2 j R 为自变量x j 的容忍度(Tolerance ),SPSS 软件的默认容忍度为0.0001。也就是说,当2j R >0.9999时,自变量x j 将被自动拒绝在回归方程之外,除非我们修改容忍度的默认值。 ??? ??? ? ??=k βββ 10β??? ??? ? ??=4321ααααα回归分析实验报告
回归分析练习题(有答案)
应用回归分析课后习题参考答案
第九章---spss的回归分析
回归分析练习题与参考答案
实验五相关分析与回归分析
相关分析和回归分析SPSS实现
回归分析练习题与参考答案
应用回归分析,第4章课后习题参考答案.
回归分析实验案例数据1
应用回归分析-第9章课后习题答案
相关主题
文本预览