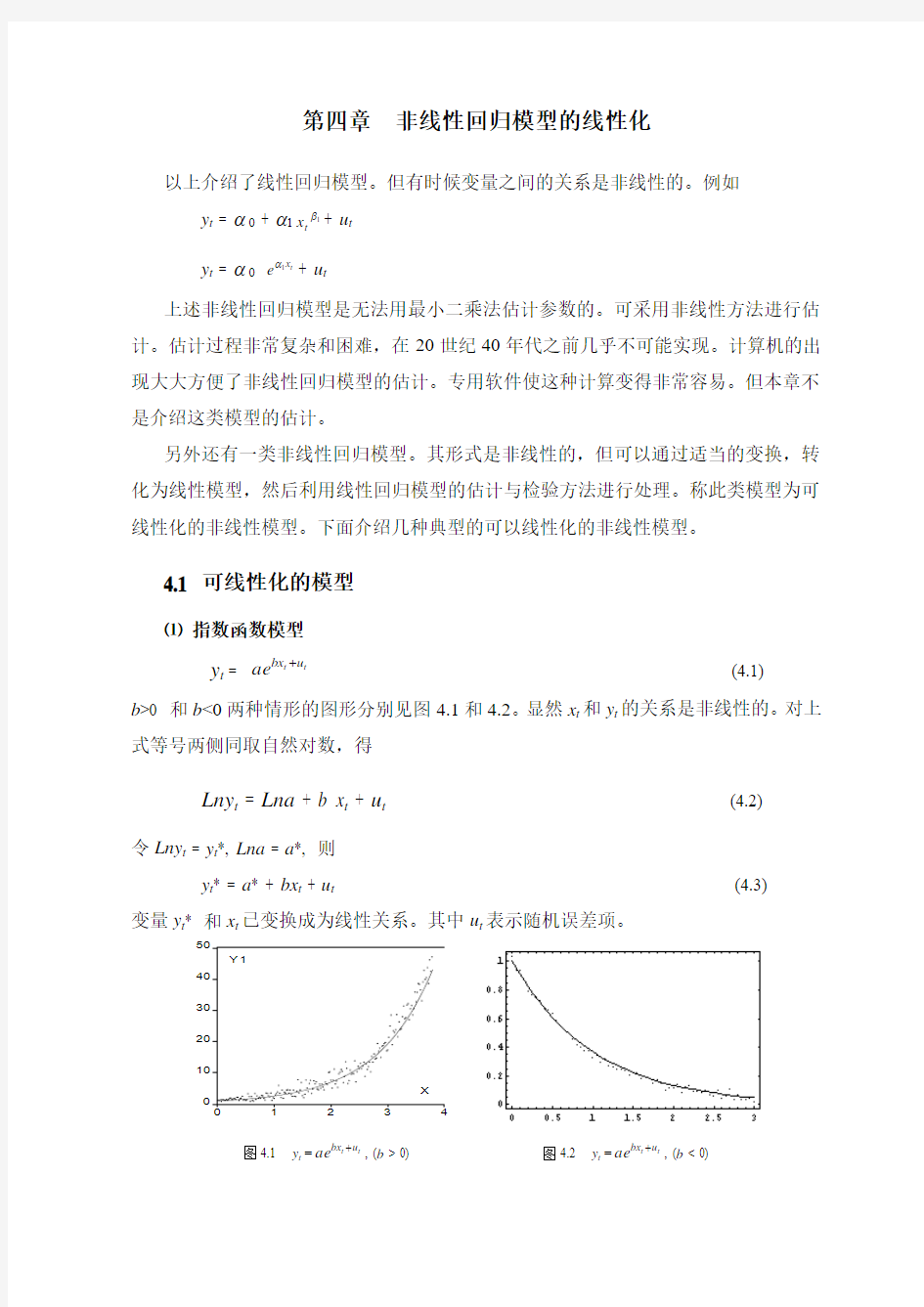

第四章 非线性回归模型的线性化
以上介绍了线性回归模型。但有时候变量之间的关系是非线性的。例如 y t = α 0 + α11βt x + u t y t = α 0 t x e 1α+ u t
上述非线性回归模型是无法用最小二乘法估计参数的。可采用非线性方法进行估计。估计过程非常复杂和困难,在20世纪40年代之前几乎不可能实现。计算机的出现大大方便了非线性回归模型的估计。专用软件使这种计算变得非常容易。但本章不是介绍这类模型的估计。
另外还有一类非线性回归模型。其形式是非线性的,但可以通过适当的变换,转化为线性模型,然后利用线性回归模型的估计与检验方法进行处理。称此类模型为可线性化的非线性模型。下面介绍几种典型的可以线性化的非线性模型。
4.1 可线性化的模型
⑴ 指数函数模型
y t = t t u
bx ae + (4.1)
b >0 和b <0两种情形的图形分别见图4.1和4.2。显然x t 和y t 的关系是非线性的。对上式等号两侧同取自然对数,得
Lny t = Lna + b x t + u t (4.2)
令Lny t = y t *, Lna = a *, 则
y t * = a * + bx t + u t (4.3) 变量y t * 和x t 已变换成为线性关系。其中u t 表示随机误差项。
010
20
30
40
50
1
2
3
4
X
Y 1
图4.1 y t =t
t u bx ae
+, (b > 0) 图4.2 y t =t
t u bx ae
+, (b < 0)
⑵对数函数模型
y t = a + b Ln x t+ u t(4.4)
b>0和b<0两种情形的图形分别见图4.3和4.4。x t和y t的关系是非线性的。令x t* = Lnx t, 则
y t = a + b x t* + u t(4.5)
变量y t和x t* 已变换成为线性关系。
图4.3 y t = a + b Lnx t + u t , (b > 0) 图4.4 y t = a + b Lnx t + u t , (b < 0)
⑶幂函数模型
y t= a x t b t u e(4.6) b取不同值的图形分别见图4.5和4.6。x t和y t的关系是非线性的。对上式等号两侧同取对数,得
Lny t = Lna + b Lnx t + u t(4.7)
令y t* = Lny t, a* = Lna, x t* = Lnx t, 则上式表示为
y t* = a* + b x t* + u t(4.8)
变量y t* 和x t* 之间已成线性关系。其中u t表示随机误差项。(4.7) 式也称作全对数模型。
图4.5 y t = a x t b t u e图4.6 y t = a x t b t u e
⑷双曲线函数模型
1/y t = a + b/x t+ u t(4.9)
也可写成,
y t = 1/ (a + b/x t+ u t) (4.10)
b>0情形的图形见图4.7。x t和y t的关系是非线性的。令y t* = 1/y t, x t* = 1/x t,得
y t* = a + b x t* + u t
已变换为线性回归模型。其中u t表示随机误差项。
图4.7 y t = 1/ (a + b/x t ), (b > 0) 图4.8 y t = a + b/x t , (b > 0) 双曲线函数还有另一种表达方式,
y t = a + b/x t + u t(4.11)
b>0情形的图形见图4.8。x t和y t的关系是非线性的。令x t* = 1/x t,得
y t = a + b x t* + u t
上式已变换成线性回归模型。
例 4.2(P139,例3.5
⑸多项式方程模型
一种多项式方程的表达形式是
y t = b0 +b1 x t + b2 x t2 + b3 x t3 + u t(4.12)
其中b1>0, b2>0, b3>0和b1<0, b2>0, b3<0情形的图形分别见图4.9和4.10。令x t 1 = x t,x t 2 = x t2,x t 3 = x t3,上式变为
y t = b0 +b1 x t 1 + b2 x t 2 + b3 x t 3 + u t(4.13)
这是一个三元线性回归模型。如经济学中的总成本曲线与图4.9相似。
图4.9 y t = b 0 +b 1 x t + b 2 x t 2 + b 3 x t 3 + u t 图4.10 y t = b 0 + b 1 x t + b 2 x t 2 + b 3 x t 3 + u t
另一种多项式方程的表达形式是
y t = b 0 + b 1 x t + b 2 x t 2 + u t (4.14)
其中b 1>0, b 2>0和b 1<0, b 2<0情形的图形分别见图4.11和4.12。令x t 1 = x t ,x t 2 = x t 2,上式线性化为,
y t = b 0 + b 1 x t 1 + b 2 x t 2 + u t (4.15)
如经济学中的边际成本曲线、平均成本曲线与图4.11相似。
图4.11 y t = b 0 +b 1x t + b 2x t 2 + u t 图4.12 y t = b 0 + b 1x t + b 2x t 2 + u t
例4.3(P141例3.6)
⑹ 生长曲线 (logistic) 模型
y t =
t
u t f e
k ++)(1 (4.16)
一般f (t ) = a 0 + a 1 t + a 2 t 2 + … + a n t n ,常见形式为f (t ) = a 0 - a t
y t =
u
u at a e
k +-+)(01=
t
u at be
k +-+1 (4.17)
其中b = 0a e 。a > 0情形的图形分别见图4.13和4.14。美国人口统计学家Pearl 和Reed 广泛研究了有机体的生长,得到了上述数学模型。生长模型(或逻辑斯谛曲线,Pearl-Reed 曲线)常用于描述有机体生长发育过程。其中k 和0分别为y t 的生长上限
和下限。∞
→t t Limy = k , -∞
→t t Limy = 0。a , b 为待估参数。曲线有拐点,坐标为(
a Ln
b ,2
k
),曲线的上下两部分对称于拐点。
图4.13 y t = k / (1 +t
u at be
+-) 图4.14 y t = k / (1 +t
u at be +)
为能运用最小二乘法估计参数a , b ,必须事先估计出生曲线长上极限值k 。线性化过程如下。当k 给出时,作如下变换,
k /y t = 1 + t
u at be
+-
移项, k /y t - 1 = t u at be +-
取自然对数,Ln ( k /y t - 1) = Lnb - a t + u t (4.18) 令y t * = Ln ( k /y t - 1), b * = Lnb , 则
y t * = b * - a t + u t (4.19) 此时可用最小二乘法估计b *和a 。
图4.15 内地5月1日至28日每天非典数据一览
⑺ 龚伯斯(Gompertz )曲线
英国统计学家和数学家最初提出把该曲线作为控制人口增长的一种数学模型,此模型可用来描述一项新技术,一种新产品的发展过程。曲线的数学形式是,
y t =
at be ke
--
图4.15 y t =at be ke
--
曲线的上限和下限分别为k 和0,∞
→t t Limy = k , -∞
→t t Limy = 0。a , b 为待估参数。曲线有拐点,
坐标为(
a Ln
b ,e
k ),但曲线不对称于拐点。一般情形,上限值k 可事先估计,有了k 值,龚伯斯曲线才可以用最小二乘法估计参数。线性化过程如下:当k 给定时,
y t / k =
at be e
--,
k /y t =
at be e
-
Ln (k /y t ) = at be -, Ln [Ln (k /y t )] = Lnb - a t
令y *= Ln [Ln (k /y t )], b * = Lnb ,则
y * = b * - a t
上式可用最小二乘法估计b * 和 a 。 ⑻ Cobb-Douglas 生产函数
下面介绍柯布?道格拉斯(Cobb-Douglas )生产函数。其形式是
Q = k L α C 1- α (4.24)
其中Q 表示产量;L 表示劳动力投入量;C 表示资本投入量;k 是常数;0 < α < 1。这种生产函数是美国经济学家柯布和道格拉斯根据1899-1922年美国关于生产方面的数据研究得出的。α的估计值是0.75,β的估计值是0.25。更习惯的表达形式是
y t =t u
t t e x x 21210β
ββ (4.25)
这是一个非线性模型,无法用OLS 法直接估计,但可先作线性化处理。上式两边同取对数,得:
Lny t = Ln β0 + β1 Lnx t 1 + β2 Lnx t 2 + u t (4.26)
取 y t * = Lny t , β0* = Ln β0, x t 1* = Ln x t 1, x t 2* = Ln x t 2,有
y t *= β0* +β1 x t 1* + β2 x t 2* + u t (4.27)
上式为线性模型。用OLS 法估计后,再返回到原模型。若回归参数 β1 + β2 = 1,称模型为规模报酬不变型(新古典增长理论); β1 + β2 > 1,称模型为规模报酬递增型; β1 + β2 < 1,称模型为规模报酬递减型。
对于对数线性模型,Lny = Ln β0 + β1 Lnx t 1 + β2 Lnx t 2 + u t ,β1和β2称作弹性系数。以β1为例,
β1 =
1
t t
Lnx Lny ??=
1
111t t t t x x y y ??--=
1
1//t t t t x x y y ??=
1
1t t t t x y y x ?? (4.28)
可见弹性系数是两个变量的变化率的比。注意,弹性系数是一个无量纲参数,所以便于在不同变量之间比较相应弹性系数的大小。
对于线性模型,y t = α0 + α1 x t 1 + α2 x t 2 + u t ,α1和 α2称作边际系数。以α1为例,
α1 =
1
t t x y ?? (4.29)
通过比较(4.28)和(4.29)式,可知线性模型中的回归系数(边际系数)是对数线性回归模型中弹性系数的一个分量。 例4.1 (136P 例3.4)略
4.2非线性化模型的处理方法
模型:12
01122
b b y a a x a x =++无论通过什么变换都不可能实现线性化,对于这种模型称为非线性化模型。可采用高斯—牛顿迭代法进行估计,即将其展开泰勒级数后,再进行迭代估计方法进行估计。
1、迭代估计法
思想是:通过泰勒级数展开,先使非线性方程在某组初始参数估计值附近线性化,然后对这一线性方程应用OLS 法,得出一组新的参数估计值。下一步是使非线性方程在新参数估计值附近线性化,对新的线性方程再应用OLS 法,又得出一组新的参数估计值。不断重复上述过程,直至参数估计值收敛时为止。其步骤如下。
1)对模型:1212(,,
,,,,
,)k p y f x x x b b b u =+在给定的参数初始值b 10,b 20…b p0展
开泰勒级数:
12102012011(,,
,,,,
,)()
1
()()2io
io j p
k po i io i i b p
p
i io j j i j i j
b b f y f x x x b b b b b b f b b b b u b b ===??
?=+- ??????
?+--+ ? ?????∑∑∑取前两项,便有线性近似:
12102012
0111(,,
,,,,
,)1
()()2io
io
io j p
k po io i i b p
p
p
i i io j j i i j i i j b b b f y f x x x b b b b b f f b b b b b u b b b ====??
?-+ ?
?????
????=+--+ ? ? ????????∑∑∑∑
2)将上式左端看成组新的因变量,将右端io
i b
f b ??
? ????看成一组新的自变量,这就已
经成为标准线性模型,再对其就用OLS 法,得出一组估计值11211
???,,
,p b b b 。 3)重复第一、二步,在参数估计值11211
???,,
,p b b b 附近再做一次泰勒级数展开,得到新的线性模型,应用OLS 法,又得出一组参数估计值:12222
???,,
,p b b b 。 4)如此反复,得出一组点序列12???,,,(1,2,)j j pj
b b b j =直到其收敛为止。 2、迭代估计法的EViews 实现过程 1)设定代估参数的初始值,方法有两种: A 、使用Param 命令设定,
例如,Param 1 0.5 2 0 3 0 则将待估的三个参数的初始值设成了0.5,0,0. B 、在工作文件窗口中双击序列C ,并在序列窗口直接输入参数的初始值。 2)估计参数 A 、命令方式
在命令窗口可以直接键入非线性模型的迭代估计命令NLS 。格式为: NLS 被解释变量,=非线性函数表达式 例如,对于非线性回归模型x b
y a u x c
-=++估计命令为 NLS y=c(1)*(x-c(2))/(x-c(3)) B 、菜单方式。
在数组窗口“proc s →make epuation ;
在弹出的方程描述对话框中输入非线性回归模型的具体形式;
y=c(1)*(x-c(2))/(x-c(3))
选择估计方法为最小二乘法后单击(OK)
例(P146例3.7) 略
4.3回归模型的比较
当经济变量呈现非线性关系时,经常可以采用多个不同数学形式的非线性模型。如何选择?
1、图开观察分析
1)观察被解释变量和解释变量的趋势图。
2)观察被解释变量和解释变量的相关图
2、模型估计结果分析
1)回归系数符号和大小是否符合经济意义,
2)改变模型后,是否使决定系数的值明显提高。
3)T检验与F检验。
3、残差分析
残差反映了模型未能解释部分的变化情况。
1)残差分布表中,各期残差是否大都落在σ±的虚线内。
2)残差分布是否具有某种规律性。
3)近期的残差分析情况。
例1:此模型用来评价台湾农业生产效率。用台湾1958-1972年农业生产总值(y t),劳动力(x t1),资本投入(x t2)数据(见表4.1)为样本得估计模型,
∧
L n y= -3.4 + 1.50 Lnx t1 + 0.49 Lnx t2(4.30)
t
(2.78) (4.80) R2 = 0.89, F = 48.45
还原后得,
y?= 0.713 x t11.50x t20.49(4.31)
t
因为1.50 + 0.49 = 1.99,所以,此生产函数属规模报酬递增函数。当劳动力和资本投入都增加1%时,产出增加近2%。
例2:用天津市工业生产总值(Y t),职工人数(L t),固定资产净值与流动资产平均余额(K t)数据(1949-1997) 为样本得估计模型如下:
Ln Y t = 0.7272 + 0.2587Ln L t + 0.6986 LnK t
(3.12) (3.08) (18.75)
R2 = 0.98, s.e. = 0.17, DW = 0.42, F = 1381.4
因为0.2587 + 0.6986 = 0.9573,所以此生产函数基本属于规模报酬不变函数。
例3:硫酸透明度与铁杂质含量的关系(摘自《数理统计与管理》1988.4, p.16)某硫酸厂生产的硫酸的透明度一直达不到优质指标。经分析透明度低与硫酸中金属杂质的含量太高有关。影响透明度的主要金属杂质是铁、钙、铅、镁等。通过正交试验的方法发现铁是影响硫酸透明度的最主要原因。测量了47个样本,得硫酸透明度(y)与铁杂质含量(x)的散点图如下(file:nonli01):
(1)y = 121.59 - 0.91 x
(10.1) (-5.7)
R2 = 0.42, s.e. = 36.6, F= 32 (2)1/y = 0.069 - 2.37 (1/x)
(18.6) (-11.9)
R2
= 0.76, s.e. = 0.009, F= 142
(3)y = -54.40 + 6524.83 (1/x)
(-7.2) (16.3)
R2 = 0.86, s.e. = 18.2, F= 266
(4)Lny = 1.99 + 104.5 (1/x)
(22.0) (21.6)
R2 = 0.91, s.e. = 0.22, F= 468
还原,Lny = Ln(7.33) + 104.5 (1/x)
y = 7.33 )
1
(5.
104
x
e
(5)非线性估计结果是y = 8.2965
)
1
(1.
100
x
e
R2 = 0.96,
EViews命令Y=C(1)*EXP(C(2)*(1/X))
例4 中国铅笔需求预测模型(非线性模型案例,file:nonli6)
中国从上个世纪30年代开始生产铅笔。1985年全国有22个厂家生产铅笔。产量居世界首位(33.9亿支),占世界总产量的1/3。改革开放以后,铅笔生产增长极为迅速。1979-1983年平均年增长率为8.5%。铅笔销售量时间序列见图 4.21。1961-1964年的销售量平稳状态是受到了经济收缩的影响。文革期间销售量出现两次下降,是受到了当时政治因素的影响。1969-1972年的增长是由于一度中断了的中小学教育逐步恢复的结果。1977-1978年的增长是由于高考正式恢复的结果。1981年中国开始生产自动铅笔,对传统铅笔市场冲击很大。1979-1985年的缓慢增长是受到了自动铅笔上市的影响。
初始确定的影响铅笔销量的因素有全国人口、各类在校人数、设计人员数、居民消费水平、社会总产值、自动铅笔产量、价格因素、原材料供给量、政策因素等。经过多次筛选、组合和逐步回归分析,最后确定的被解释变量是y t(铅笔年销售量,千万支);解释变量分别是x t1(自动铅笔年产量,百万支);x t2(全国人口数,百万人);x t3(居民年均消费水平,元);x t4(政策变量)。因政策因素影响铅笔销量出现大幅下降时,政策变量取负值。例如1967、1968年的x t4值取-2,1966、1969-1971、1974-1977年的x t4值取-1)。
由图4.22知中国自生产自动铅笔起,自动铅笔产量与铅笔销量存在线性关系。由图4.23知全国人口与铅笔销量存在线性关系。说明人口越多,对铅笔的需求就越大。由图4.24知居民年均消费水平与铅笔销量存在近似对数的关系。散点图说明居民年均消费水平越高,则铅笔销量就越大。但这种增加随着居民消费水平的增加变得越来越缓慢。图4.25显示政策变量与铅笔销量也呈线性关系。
50
10015020025030035062
64
66
68
70
72
74
76
78
80
82
84
Y
铅笔销售量时间序列(1961-1985)(文件名nonli6)
100200300
400
10
20
30
40
X 1
Y
100
200
300400
600
700
800
900
1000
1100
X 2
Y
Y , X1散点图 Y , X2散点图
100
200300
400
100200
300
400
500
X 3
Y
100
200
300400
-2.5
-2.0
-1.5
-1.0
-0.5
0.0
X 4
Y
Y , X3散点图 Y , X4散点图
基于上述分析建立的模型形式是
y t = β0 + β1 x t 1 + β2 x t 2 + β3 Ln (x t 3) + β4 x t 4 + u t (4.40)
y t 与x t 3呈非线性关系。估计结果如下。
t y
?= -907.94 - 2.95 x t 1 + 0.31 x t 2 + 170.19 Ln x t 3 + 45.51 x t 4 (4.41) (-6.4) (-3.7) (4.8) (4.4) (12.6) R 2 = 0.9885, DW = 2.09, F = 429, s.e. = 10.34
上式说明,在上述期间自动铅笔年产量每增加1百万支,平均使铅笔的年销售量减少2950万支。全国人口数每增加1百万人,平均使铅笔的年销售量增加310万支。对数的居民年均消费水平每增加1个单位,平均使铅笔的年销售量增加17亿支。一般性政策负面变动使铅笔的年销售量减少4.551亿支。当政策出现大的负面变动时,铅笔的
年销量会减少9.102亿支。
当y t 对所有变量都进行线性回归时(见下式),显然估计结果不如(4.41)式好。
t y
?= -254.26 - 3.29 x t 1 + 0.42 x t 2 + 0.66 x t 3 + 40.74 x t 4 (4.42) (-12.0) (-3.0) (8.6) (3.5) (11.7) R 2 = 0.9857, DW = 1.77, F = 346, s.e. = 11.5
案例5:厦门市贷款总额与GDP 的关系分析(1990~2003,file:bank08) 数据和散点图如下。从散点图看,用多项式方程拟合比较合理。
200
400
600
800
1000
200
400
600
800
G D P
L O A N
Loan t = β0 +β1 GDP t + β2 GDP t 2 + β3 x t 3 + u t
∧
loan t = -24.5932 +1.6354 GDP t - 0.0026GDP t 2 + 0. GDP t 3
(-2.0) (11.3) (-6.3) (7.9)
R 2=0.9986, DW=2.6
200
400
600
800
1000
200
400
600
800
GDP
LOANHAT LOAN
例6钉螺存活率曲线(file:nonli3)(生长曲线模型)
在冬季土埋钉螺的研究中,先把一批钉螺埋入土中,以后每隔一个月取出部分钉螺,检测存活个数,计算存活率。数据见表4.3。散点图见图4.20。
y t ,存活率(%)
t ,土埋月数
050
100
5
10
15
T
Y
100.0 0 93.0 1 92.3 2 88.0 3 84.7 4 82.0 5 48.4 6 41.0 7 15.0 8 5.2 9 3.5 10 1.3 11 0.5
12
设定y t 的上渐近极限值k =101(因为已有观测值y t =100,所以令k =101更好些。),得估计结果如下:
估计式是:
)1101
(
log -∧
t
y = -4.3108 + 0.7653 t (4.38)
(-14.8) (18.5) R 2 = 0.97
因为log (0.013) = -4.3108,所以b = 0.013。则逻辑函数的估计结果是
t y
?= t
e 7653.0013.01101+ (4.39)
当t =10.5时,
t y
?= 5
.107653.0013.01101
?+e
= 2.38
Y YF
020
40
60
80
100
5
10
T
Y Y F
100.0 99.66 93.0 98.17 92.3 95.10 88.0 89.12 84.7 78.50 82.0 62.50 48.4 43.45 41.0 26.26 15.0 14.19 5.20 7.14 3.50 3.45 1.30 1.63 0.50
0.77
非线性回归模型的线性化 以上介绍了线性回归模型。但有时候变量之间的关系是非线性的。例如 y t = α 0 + α11βt x + u t y t = α 0 t x e 1α+ u t 上述非线性回归模型是无法用最小二乘法估计参数的。可采用非线性方法进行估计。估计过程非常复杂和困难,在20世纪40年代之前几乎不可能实现。计算机的出现大大方便了非线性回归模型的估计。专用软件使这种计算变得非常容易。但本章不是介绍这类模型的估计。 另外还有一类非线性回归模型。其形式是非线性的,但可以通过适当的变换,转化为线性模型,然后利用线性回归模型的估计与检验方法进行处理。称此类模型为可线性化的非线性模型。下面介绍几种典型的可以做线性化处理的非线性模型。 ⑴ 指数函数模型 y t = t t u bx ae + (4.1) b >0 和b <0两种情形的图形分别见图4.1和4.2。显然x t 和y t 的关系是非线性的。对上式等号两侧同取自然对数,得 Lny t = Lna + b x t + u t (4.2) 令Lny t = y t *, Lna = a *, 则 y t * = a * + bx t + u t (4.3) 变量y t * 和x t 已变换成为线性关系。其中u t 表示随机误差项。 图4.1 y t =t t u bx ae +, (b > 0) 图4.2 y t =t t u bx ae +, (b < 0) ⑵ 对数函数模型 y t = a + b Ln x t + u t (4.4) b >0和b <0两种情形的图形分别见图4.3和4.4。x t 和y t 的关系是非线性的。令x t * = Lnx t , 则 y t = a + b x t * + u t (4.5) 变量y t 和x t * 已变换成为线性关系。
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S" 两个模型,点击确定,得到如下结果: 通过“二次”和“S “ 两个模型的对比,可以看出S 模型的拟合度明显高于
常见非线性回归模型 1.简非线性模型简介 非线性回归模型在经济学研究中有着广泛的应用。有一些非线性回归模型可以通 过直接代换或间接代换转化为线性回归模型,但也有一些非线性回归模型却无 法通过代换转化为线性回归模型。 柯布—道格拉斯生产函数模型 y AKL 其中L和K分别是劳力投入和资金投入, y是产出。由于误差项是可加的, 从而也不能通过代换转化为线性回归模型。 对于联立方程模型,只要其中有一个方程是不能通过代换转化为线性,那么这个联立方程模型就是非线性的。 单方程非线性回归模型的一般形式为 y f(x1,x2, ,xk; 1, 2, , p) 2.可化为线性回归的曲线回归 在实际问题当中,有许多回归模型的被解释变量y与解释变量x之间的关系都不是线性的,其中一些回归模型通过对自变量或因变量的函数变换可以转化为
线性关系,利用线性回归求解未知参数,并作回归诊断。如下列模型。 (1)y 0 1e x (2)y 0 1x2x2p x p (3)y ae bx (4)y=alnx+b 对于(1)式,只需令x e x即可化为y对x是线性的形式y01x,需要指出的是,新引进的自变量只能依赖于原始变量,而不能与未知参数有关。 对于(2)式,可以令x1=x,x2=x2,?,x p=x p,于是得到y关于x1,x2,?, x p 的线性表达式y 0 1x12x2 pxp 对与(3)式,对等式两边同时去自然数对数,得lnylnabx ,令 y lny, 0 lna, 1 b,于是得到y关于x的一元线性回归模型: y 0 1x。 乘性误差项模型和加性误差项模型所得的结果有一定差异,其中乘性误差项模型认为yt本身是异方差的,而lnyt是等方差的。加性误差项模型认为yt是等 方差的。从统计性质看两者的差异,前者淡化了y t值大的项(近期数据)的作用, 强化了y t值小的项(早期数据)的作用,对早起数据拟合得效果较好,而后者则 对近期数据拟合得效果较好。 影响模型拟合效果的统计性质主要是异方差、自相关和共线性这三个方面。 异方差可以同构选择乘性误差项模型和加性误差项模型解决,必要时还可以使用 加权最小二乘。
上课材料之二: 第二章 数学基础 (Mathematics) 第一节 矩阵(Matrix)及其二次型(Quadratic Forms) 第二节 分布函数(Distribution Function),数学期望(Expectation)及方差(Variance) 第三节 数理统计(Mathematical Statistics ) 第一节 矩阵及其二次型(Matrix and its Quadratic Forms) 2.1 矩阵的基本概念与运算 一个m ×n 矩阵可表示为: 矩阵的加法较为简单,若C=A +B ,c ij =a ij +b ij 但矩阵的乘法的定义比较特殊,若A 是一个m ×n 1的矩阵,B 是一个n 1×n 的矩阵,则C =AB 是一个m ×n 的矩阵,而且∑== n k kj ik ij b a c 1,一般来讲,AB ≠BA ,但如下运算是成立 的: ● 结合律(Associative Law ) (AB )C =A (BC ) ● 分配律(Distributive Law ) A (B +C )=AB +AC 问题:(A+B)2=A 2+2AB+B 2是否成立? 向量(Vector )是一个有序的数组,既可以按行,也可以按列排列。 行向量(row ve ctor)是只有一行的向量,列向量(column vector)只有一列的向量。 如果α是一个标量,则αA =[αa ij ]。 矩阵A 的转置矩阵(transpose matrix)记为A ',是通过把A 的行向量变成相应的列向量而得到。 显然(A ')′=A ,而且(A +B )′=A '+B ', ● 乘积的转置(Transpose of a production ) A B AB ''=')(,A B C ABC '''=')(。 ● 可逆矩阵(inverse matrix ),如果n 级方阵(square matrix)A 和B ,满足AB=BA=I 。 则称A 、B 是可逆矩阵,显然1-=B A ,1-=A B 。如下结果是成立的: 1111111)()()()(-------='='=A B AB A A A A 。 2.2 特殊矩阵 1)恒等矩阵(identity matrix)
第四节 非线形回归模型 一、 可线性化模型 在非线性回归模型中,有一些模型经过适当的变量变换或函数变换就可以转化成线性回归模型,从而将非线性回归模型的参数估计问题转化成线性回归模型的参数估计,称这类模型为可线性化模型。在计量经济分析中经常使用的可线性化模型有对数线性模型、半对数线性模型、倒数线性模型、多项式线性模型、成长曲线模型等。 1.倒数模型 我们把形如: u x b b y ++=110;u x b b y ++=1110 (3.4.1) 的模型称为倒数(又称为双曲线函数)模型。 设:x x 1*=,y y 1*=,即进行变量的倒数变换,就可以将其转化成线性回归模型。 倒数变换模型有一个明显的特征:随着x 的无限扩大,y 将趋于极限值0b (或0/1b ),即有一个渐进下限或上限。有些经济现象(如平均固定成本曲线、商品的成长曲线、恩格尔曲线、菲利普斯曲线等)恰好有类似的变动规律,因此可以由倒数变换模型进行描述。 2.对数模型 模型形式: u x b b y ++=ln ln 10 (3.4.2) (该模型是将u b e Ax y 1=两边取对数,做恒等变换的另一种形式,其中A b ln 0=)。 上式lny 对参数0b 和1b 是线性的,而且变量的对数形式也是线性的。因此,我们将以上模型称为双对数(double-log)模型或称为对数一线性(log-liner)模型。 令:x x y y ln ,ln **==代入模型将其转化为线性回归模型: u x b b y ++=*10* (3.4.3) 变换后的模型不仅参数是线性的,而且通过变换后的变量间也是线性的。 模型特点:斜率1b 度量了y 关于x 的弹性:
非线性回归问题, 知识目标:通过典型案例的探究,进一步学习非线性回归模型的回归分析。 能力目标:会将非线性回归模型通过降次和换元的方法转化成线性化回归模型。 情感目标:体会数学知识变化无穷的魅力。 教学要求:通过典型案例的探究,进一步了解回归分析的基本思想、方法及初步应用. 教学重点:通过探究使学生体会有些非线性模型通过变换可以转化为线性回归模型,了解在解决实际问题的 过程中寻找更好的模型的方法. 教学难点:了解常用函数的图象特点,选择不同的模型建模,并通过比较相关指数对不同的模型进行比较. 教学方式:合作探究 教学过程: 一、复习准备: 对于非线性回归问题,并且没有给出经验公式,这时我们可以画出已知数据的散点图,把它与必修模块《数学1》中学过的各种函数(幂函数、指数函数、对数函数等)的图象作比较,挑选一种跟这些散点拟合得最好的函数,然后采用适当的变量代换,把问题转化为线性回归问题,使其得到解决. 二、讲授新课: 1. 探究非线性回归方程的确定: 1. 给出例1:一只红铃虫的产卵数y 和温度x 有关,现收集了7组观测数据列于下表中,试建立y 与x 之间 2. 讨论:观察右图中的散点图,发现样本点并没有分布在某个带状区域内,即两个变量不呈线性相关关系,所以不能直接用线性回归方程来建立两个变量之间的关系. ① 如果散点图中的点分布在一个直线状带形区域,可以选线性回归模型来建模;如果散点图中的点分布在一个曲线状带形区域,就需选择非线性回归模型来建模. ② 根据已有的函数知识,可以发现样本点分布在某一条指数函数曲线y =2C 1e x C 的周围(其中12,c c 是待定的参数),故可用指数函数模型来拟合这两个变量. ③ 在上式两边取对数,得21ln ln y c x c =+ ,再令ln z y =,则21ln z c x c =+, 可以用线性回归方程来拟合. ④ 利用计算器算得 3.843,0.272a b =-=,z 与x 间的线性回归方程为0.272 3.843z x =-$,因此红铃虫的产卵数对温度的非线性回归方程为$0.272 3.843x y e -=. ⑤ 利用回归方程探究非线性回归问题,可按“作散点图→建模→确定方程”这三个步骤进行. 其关键在于如何通过适当的变换,将非线性回归问题转化成线性回归问题. 三、合作探究 例 2.:炼钢厂出钢时所用的盛钢水的钢包,在使用过程中,由于钢液及炉渣对包衬耐火材料的侵蚀,使其容积不断增大,请根据表格中的数据找出使用次数x 与增大的容积y 之间的关系.
1. 总离差平方和可分解为回归平方和与残差平方和。( 对 ) 2. 整个多元回归模型在统计上是显着的意味着模型中任何一个单独的解释变量均是统计显着的。( 错 ) 3. 多重共线性只有在多元线性回归中才可能发生。( 对 ) 4. 通过作解释变量对时间的散点图可大致判断是否存在自相关。( 错 ) 5. 在计量回归中,如果估计量的方差有偏,则可推断模型应该存在异方差( 错 ) 6. 存在异方差时,可以用广义差分法来进行补救。( 错 ) 7. 当经典假设不满足时,普通最小二乘估计一定不是最优线性无偏估计量。( 错 ) 8. 判定系数检验中,回归平方和占的比重越大,判定系数也越大。( 对 ) 9. 可以作残差对某个解释变量的散点图来大致判断是否存在自相关。( 错 )做残差 ) n 5、经典线性回归模型(CLRM )中的干扰项不服从正态分布的,OLS 估计量将有偏的。错,,即使经典线性回归模型(CLRM )中的干扰项不服从正态分布的,OLS 估计量仍然是无偏的。 因为222)()?(βμββ=+=∑i i K E E ,该表达式成立与否与正态性无关。 1、在简单线性回归中可决系数2R 与斜率系数的t 检验的没有关系。错误,在简单线性回归 中,由于解释变量只有一个,当t 检验显示解释变量的影响显着时,必然会有该回归模型的可决系数大,拟合优度高。 2、异方差性、自相关性都是随机误差现象,但两者是有区别的。正确,异方差的出现总是与模型中某个解释变量的变化有关。自相关性是各回归模型的随机误差项之间具有相关关
系。3、通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与模型有无截距项无关。错误,模型有截距项时,如果被考察的定性因素有m个相互排斥属性,则模型中引入m-1个虚拟变量,否则会陷入“虚拟变量陷阱”;模型无截距项时,若被考察的定性因素有m个相互排斥属性,可以引入m个虚拟变量,这时不会出现多重共线性。 4、满足阶条件的方程一定可以识别。错误,阶条件只是一个必要条件,即满足阶条件的的方程也可能是不可识别的。 5、库依克模型、自适应预期模型与局部调整模型的最终形式是不同的。错误,库依克模型、自适应预期模型与局部调整模型的最终形式是相同的,其最终形式都是一阶自回归模型。2、多重共线性问题是随机扰动项违背古典假定引起的。错误,应该是解释变量之间高度相关引起的. (3) 线性回归模型意味着因变量是自变量的线性函数。(错) (4) 在线性回归模型中,解释变量是原因,被解释变量是结果。(对) 1、虚拟变量的取值只能取0或1(对) 2、通过引入虚拟变量,可以对模型的参数变化进行检验(对) 1、简单线性回归模型与多元线性回归模型的基本假定是相同的。错 在多元线性回归模型里除了对随机误差项提出假定外,还对解释变量之间提 出无多重共线性的假定。 2、在模型中引入解释变量的多个滞后项容易产生多重共线性。对 在分布滞后模型里多引进解释变量的滞后项,由于变量的经济意义一样,只
浅谈非线性回归模型的线性化 广东省惠州市惠阳区崇雅中学高中部 卢瑞勤(516213) 回归分析在各个领域中都有十分重要的作用,比如:在财务中可以用回归分析进行财务预测;在医疗检验中可以用回归分析进行病理预报等等。高中新课标教材就在《必修3》和《选修2-3》中分别增加了《线性回归》和《回归分析》的内容,介绍了求线性回归方程的方法。但在实际问题中,变量间的关系并非总是线性关系,本文结合本人的教学实践,对教材中的这两部分内容进行适当延伸,谈谈对一些可线性化的非线性回归模型的线性化问题,供各位同行在教学时参考。 一、什么是可线性化的非线性回归模型 线性回归模型的基本特征是预报变量可以表示成解释变量和一个系数相乘的和,即预报变量y 可以表示成解释变量i x (i =1,2,3,……)的如下形式:0112233y a a x a x a x =++++ ,其中变量i x 是以其原型(而不是以n i x 或其它)的形式出现,变量y 是各变量i x 的线性函数。而有些回归模型不具备这个特点,但是可以通过适当的代数变换转化成这种形式,我们称这类回归模型为可线性化的回归模型。 在本文中,我们只讨论只有一个解释变量可线性化的非线性回归模型的线性化。 二、非线性回归模型的线性化的基本思路 非线性回归模线性化的基本思路是:由已知数据,确定解释变量和预报变量,作出散点图,根据经验,确定回归曲线的类型,然后作适当的代数变换,若变换后散点图体现较好的线性关系,即可将其化成线性形式求解,最后还原到原来的回归曲线。如果回归曲线可用多种形式表示,可以各自将其线性化后求解,再用相关系数2 R 进行拟合效果分析,2 R 越大,拟合效果越好,所求的回归方程也就越精确。 三、非线性回归模型的线性化的常用方法 可线性化的非线性回归模型有以下几种常见类型: (1)双曲线型,其形式为 1a b y x =+,其变换为1y y '=, 1 x x '=,变换后的形式为y b ax ''=+ (2)幂函数型,其形式为b y ax = ,可以变形为ln ln ln y a b x =+,作变换ln y y '= ,ln x x '= ,变换后的形式为y a bx ''=+ (3)指数函数型,其形式为bx y ae = ,以变形为ln ln y a bx =+,作变换ln y y '=,ln a a '= ,变换后的形式为y a bx ''=+ (4)对数函数型,其形式为ln y a b x =+,作变换ln x x '=,变换后的形式为y a bx '=+ 下面以高中新课标数学教材《选修2-3》一道习题为例加以说明 【例】在某地区的一段时间内观察到的不小于某震级x 的地震个数y 数据如下表,试建立回归方程表述二者之间的关系。
1.3非线性回归问题, 知识目标:通过典型案例的探究,进一步学习非线性回归模型的回归分析。 能力目标:会将非线性回归模型通过降次和换元的方法转化成线性化回归模型。 情感目标:体会数学知识变化无穷的魅力。 教学要求:通过典型案例的探究,进一步了解回归分析的基本思想、方法及初步应用. 教学重点:通过探究使学生体会有些非线性模型通过变换可以转化为线性回归模型,了解在解决实际问题的 过程中寻找更好的模型的方法. 教学难点:了解常用函数的图象特点,选择不同的模型建模,并通过比较相关指数对不同的模型进行比较. 教学方式:合作探究 教学过程: 一、复习准备: 对于非线性回归问题,并且没有给出经验公式,这时我们可以画出已知数据的散点图,把它与必修模块《数学1》中学过的各种函数(幂函数、指数函数、对数函数等)的图象作比较,挑选一种跟这些散点拟合得最好的函数,然后采用适当的变量代换,把问题转化为线性回归问题,使其得到解决. 二、讲授新课: 1. 探究非线性回归方程的确定: 1. 给出例1:一只红铃虫的产卵数y 和温度x 有关,现收集了7组观测数据列于下表中,试建立y 与x 之间的/y 个 2. 讨论:观察右图中的散点图,发现样本点并没有分布在某个带状区域内,即两个变量不呈线性相关关系,所以不能直接用线性回归方程来建立两个变量之间的关系. ① 如果散点图中的点分布在一个直线状带形区域,可以选线性回归模型来建模;如果散点图中的点分布在一个曲线状带形区域,就需选择非线性回归模型来建模. ② 根据已有的函数知识,可以发现样本点分布在某一条指数函数曲线y =2C 1e x C 的周围(其中12,c c 是待定的参数),故可用指数函数模型来拟合这两个变量. ③ 在上式两边取对数,得21ln ln y c x c =+,再令ln z y =,则21ln z c x c =+,可以用线性回归方程来拟合. ④ 利用计算器算得 3.843,0.272a b =-=,z 与x 间的线性回归方程为 0.272 3.843z x =-,因此红铃虫的产卵数对温度的非线性回归方程为0.272 3.843x y e -=. ⑤ 利用回归方程探究非线性回归问题,可按“作散点图→建模→确定方程”这三个步骤进行. 其关键在于如何通过适当的变换,将非线性回归问题转化成线性回归问题. 三、合作探究 例 2.:炼钢厂出钢时所用的盛钢水的钢包,在使用过程中,由于钢液及炉渣对包衬耐火材料的侵蚀,使其容积不断增大,请根据表格中的数据找出使用次数 x 与增大的容积y 之间的关系.
计量经济学试题一 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。() 2.多元回归模型统计显著是指模型中每个变量都是统计显著的。() 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。()4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。() 5.线性回归是指解释变量和被解释变量之间呈现线性关系。() 6.判定系数的大小不受到回归模型中所包含的解释变量个数的影响。()7.多重共线性是一种随机误差现象。() 8.当存在自相关时,OLS估计量是有偏的并且也是无效的。() 9.在异方差的情况下,OLS估计量误差放大的原因是从属回归的变大。()10.任何两个计量经济模型的都是可以比较的。() 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 三.下面是我国1990-2003年GDP对M1之间回归的结果。(5分) 1.求出空白处的数值,填在括号内。(2分) 2.系数是否显著,给出理由。(3分) 四.试述异方差的后果及其补救措施。(10分)
五.多重共线性的后果及修正措施。(10分) 六.试述D-W检验的适用条件及其检验步骤?(10分) 七.(15分)下面是宏观经济模型 变量分别为货币供给、投资、价格指数和产出。 1.指出模型中哪些是内是变量,哪些是外生变量。(5分) 2.对模型进行识别。(4分) 3.指出恰好识别方程和过度识别方程的估计方法。(6分) 八、(20分)应用题 为了研究我国经济增长和国债之间的关系,建立回归模型。得到的结果如下:Dependent Variable: LOG(GDP) Method: Least Squares Date: 06/04/05 Time: 18:58 Sample: 1985 2003 Included observations: 19 Variable Coefficient Std. Error t-Statistic Prob. LOG(DEBT) 0.65 0.02 32.8 0 Adjusted R-squared 0.983 S.D. dependent var 0.86 S.E. of regression 0.11 Akaike info criterion -1.46 Sum squared resid 0.21 Schwarz criterion -1.36 Log likelihood 15.8 F-statistic 1075.5 Durbin-Watson stat 0.81 Prob(F-statistic) 0 其中,GDP表示国内生产总值,DEBT表示国债发行量。 (1)写出回归方程。(2分) (2)解释系数的经济学含义?(4分) (3)模型可能存在什么问题?如何检验?(7分)
多元线性回归模型 一.概述 当今农村农民人均纯收入与多个因素存在着紧密的联系,例如人均工资收入,人均农林牧渔产值人均生产费用支出,人均转移性和财产性收入等。本次将以安徽1995-2009年农村居民纯收入与人均工资收入,人均生产费用支出,人均转移性和财产性收入等因素的数据,通过建立计量经济模型来分析上述变量之间的关系,强调农村居民生活的重要性,从而促进全国经济的发展。 二、模型构建过程 ⒈变量的定义 被解释变量:农民人均纯收入y 解释变量:人均工资收入x1, 人均农林牧渔产值x2 人均生产费用支出x3 人均转移性和财产性收入x4。 建立计量经济模型:解释农民人均纯收入与人均工资收入,人均生产费用支出,人均转移性和财产性收入的关系 ⒉模型的数学形式 设定农民人均纯收入与五个解释变量相关关系模型,样本回归模型为: ∧Y i=∧ β + ∧ β 1 X i1+∧β 2 X i2+∧β 3 X i3+∧β 4 X i4+e i ⒊数据的收集 该模型的构建过程中共有四个变量,分别是中国从1995-2009年人均工资收入,人均农林牧渔产值人均生产费用支出,人均转移性和财产性收入,因此为时间序列数据,最后一个即2009年的数据作为预测对比数据,收集的数据如下所示: ⒋用OLS法估计模型 回归结果,散点图分别如下:
Y?=33.632+0.659X1+0.59X2-0.274X3+0.152X4 i d.f.=10 ,R2=0.997116 , Se=(186.261) (0.1815 (0.1245) (0.2037) (0.5699) t=(0.1805) (3.632) (4.741) (-1.347) (2.674) 三、模型的检验及结果的解释、评价
第四章 非线性回归模型的线性化 以上介绍了线性回归模型。但有时候变量之间的关系是非线性的。例如 y t = α 0 + α11βt x + u t y t = α 0 t x e 1α+ u t 上述非线性回归模型是无法用最小二乘法估计参数的。可采用非线性方法进行估计。估计过程非常复杂和困难,在20世纪40年代之前几乎不可能实现。计算机的出现大大方便了非线性回归模型的估计。专用软件使这种计算变得非常容易。但本章不是介绍这类模型的估计。 另外还有一类非线性回归模型。其形式是非线性的,但可以通过适当的变换,转化为线性模型,然后利用线性回归模型的估计与检验方法进行处理。称此类模型为可线性化的非线性模型。下面介绍几种典型的可以线性化的非线性模型。 4.1 可线性化的模型 ⑴ 指数函数模型 y t = t t u bx ae + (4.1) b >0 和b <0两种情形的图形分别见图4.1和4.2。显然x t 和y t 的关系是非线性的。对上式等号两侧同取自然对数,得 Lny t = Lna + b x t + u t (4.2) 令Lny t = y t *, Lna = a *, 则 y t * = a * + bx t + u t (4.3) 变量y t * 和x t 已变换成为线性关系。其中u t 表示随机误差项。 010 20 30 40 50 1 2 3 4 X Y 1 图4.1 y t =t t u bx ae +, (b > 0) 图4.2 y t =t t u bx ae +, (b < 0)
⑵对数函数模型 y t = a + b Ln x t+ u t(4.4) b>0和b<0两种情形的图形分别见图4.3和4.4。x t和y t的关系是非线性的。令x t* = Lnx t, 则 y t = a + b x t* + u t(4.5) 变量y t和x t* 已变换成为线性关系。 图4.3 y t = a + b Lnx t + u t , (b > 0) 图4.4 y t = a + b Lnx t + u t , (b < 0) ⑶幂函数模型 y t= a x t b t u e(4.6) b取不同值的图形分别见图4.5和4.6。x t和y t的关系是非线性的。对上式等号两侧同取对数,得 Lny t = Lna + b Lnx t + u t(4.7) 令y t* = Lny t, a* = Lna, x t* = Lnx t, 则上式表示为 y t* = a* + b x t* + u t(4.8) 变量y t* 和x t* 之间已成线性关系。其中u t表示随机误差项。(4.7) 式也称作全对数模型。 图4.5 y t = a x t b t u e图4.6 y t = a x t b t u e
第4章非线性回归模型的线性化(1)多项式函数模型 (2)双曲线函数模型 (3)对数函数模型 (4)生长曲线(logistic) 模型 (比教材中的模型复杂些) (5)指数函数模型 (6)幂函数模型 (7)不可线性化的非线性回归模型估计方法(不要求掌握)
第4章非线性回归模型的线性化 有时候变量之间的关系是非线性的。虽然其形式是非线性的,但可以通过适当的变换,转化为线性模型,然后利用线性回归模型的估计与检验方法进行处理。称此类模型为可线性化的非线性模型。 以下非线性回归模型是无法用最小二乘法估计参数的。可采用非线性方法进行估计。估计过程非常复杂和困难,计算机的出现大大方便了非线性回归模型的估计。专用软件使这种计算变得非常容易。但本章不是介绍这类模型的估计。 y t = α0 + α11β x+ u t t y t = α0t x e1α+ u t 下面介绍几种典型的可以做线性化处理的非线性模型。
(1)多项式函数模型(1) (第2版教材第111页)(第3版教材第90页) 一种多项式方程的表达形式是 y t = b 0+b 1 x t + b 2 x t 2+ b 3 x t 3+ u t 令x t 1 = x t ,x t 2 = x t 2,x t 3 = x t 3,上式变为 y t = b 0+b 1 x t 1+ b 2 x t 2+ b 3 x t 3+ u t 这是一个三元线性回归模型。如经济学中的 总成本与产品产量曲线与左图相似。 (b 1>0, b 2>0, b 3>0) (b 1<0, b 2>0, b 3<0)
(1)多项式函数模型(1) 例4.1:总成本与产品产量的关系(课本91页) y t= b0+b1 x t+ b2 x t2+ b3 x t3+ u t (第2版教材第112页) (第3版教材第91页)
回归模型分析报告 背景意义: 教育是立国之本,强国之基。随着改革开放的进行、经济的快速发展和人们生活水平的逐步提高,“教育”越来越受到人们的重视。一方面,人均国内生产总值的增加与教育经费收入的增加有着某种联系,而人口的增长也必定会对教育经费收入产生影响。本报告将从这两个方面进行分析。 我国1991年~2013年的教育经费收入、人均国内生产总值指数、年末城镇人口数的统计资料如下表所示。试建立教育经费收入Y关于人均国内生产总值指数X1和年末城镇人口数X2的回归模型,并进行回归分析。 年份教育经费收入 Y(亿元) 人均国内生产总值指数 X1(1978年=100) 年末城镇人口数 X2(万人) 199131203 199232175 199333173 199434169 199535174 199637304 199739449 199841608 199943748 200045906 200148064 200250212 200352376 200454283 200556212 200658288 200760633 200862403 200964512 201066978 201169079 201271182 201373111 资料来源:中经网统计数据库。 根据经济理论和对实际情况的分析可以知道,教育经费收入Y依赖于人均国内生产总值指数X1和年末城镇人口数X2的变化,因此我们设定回归模型为 Y Y=Y0+Y1Y1Y+Y2Y2Y+Y Y 应用EViews的最小二乘法程序,输出结果如下表 Y?Y=5058.835+28.7491Y1Y?0.3982Y2Y
R2= Y???2= F= 异方差的检验 1.Goldfeld-Quandt检验 X1和X2的样本观测值均已按照升序排列,去掉中间X1和X2各5个观测值,用第一个子样本回归: Y?Y=?3510.668+5.9096Y1Y+0.0839Y2Y SSE1= 用第二个子样本回归: Y?Y=178636.6+107.5861Y1Y?4.7488Y2Y SSE2=6602898 H0=u t具有同方差, H1=u t具有递增型异方差 构造F统计量。F=SSE2 SSE1=6602898 45633.64 =>(9,9) = 所以拒绝原假设,计量模型的随机误差项存在异方差 2.White检验 因为模型中含有两个解释变量,辅助回归式一般形式如下 Y?Y2=Y0+Y1Y Y1+Y2Y Y2+Y3Y Y12+Y4Y Y22+Y5Y Y1Y Y2+Y Y 辅助回归式估计结果如下 Y?Y2=??40478.23Y Y1+1067.432Y Y2?18.9196Y Y12?0.0202Y Y22 +1.3633Y Y1Y Y2 因为TR2=>Y0.12 (5)= 该回归模型中存在异方差 3.克服异方差 以1/X1做加权最小二乘估计,
非线性回归分析 回归分析中,当研究的因果关系只涉及因变量和一个自变量时,叫做一元回归分析;当研究的因果关系涉及因变量和两个或两个以上自变量时,叫做多元回归分析。此外,回归分析中,又依据描述自变量与因变量之间因果关系的函数表达式是线性的还是非线性的,分为线性回归分析和非线性回归分析。通常线性回归分析法是最基本的分析方法,遇到非线性回归问题可以借助数学手段化为线性回归问题处理 两个现象变量之间的相关关系并非线性关系,而呈现某种非线性的曲线关系,如:双曲线、二次曲线、三次曲线、幂函数曲线、指数函数曲线(Gompertz)、S 型曲线(Logistic) 对数曲线、指数曲线等,以这些变量之间的曲线相关关系,拟合相应的 回归曲线,建立非线性回归方程,进行回归分析称为非线性回归分析 常见非线性规划曲线 1. 双曲线1b a y x =+ 2. 二次曲线 3. 三次曲线 4. 幂函数曲线 5. 指数函数曲线(Gompertz) 6. 倒指数曲线y=a /e b x 其中a>0, 7. S 型曲线(Logistic) 1e x y a b -=+ 8. 对数曲线 y=a+b log x,x >0 9. 指数曲线y =a e bx 其中参数a >0 1.回归: (1)确定回归系数的命令 [beta ,r ,J]=nlinfit (x,y,’model’,beta0) (2)非线性回归命令:nlintool (x ,y ,’model’, beta0,alpha ) 2.预测和预测误差估计: [Y ,DELTA]=nlpredci (’model’, x,beta ,r ,J ) 求nlinfit 或lintool 所得的回归函数在x 处的预测值Y 及预测值的显著性水平为1-alpha 的置信区间Y ,DELTA. 例2 观测物体降落的距离s 与时间t 的关系,得到数据如下表,求s 关于t 的回归方程2?ct bt a s ++=. 解: 1. 对将要拟合的非线性模型y=a /e b x ,建立M 文件volum.m 如下: function yhat=volum(beta,x) yhat=beta(1)*exp(beta(2)./x); 2.输入数据: x=2:16; y=[6.42 8.20 9.58 9.5 9.7 10 9.93 9.99 10.49 10.59 10.60 10.80 10.60 10.90 10.76];
1.3可线性化的回归分析 [学习目标] 1.进一步体会回归分析的基本思想. 2.通过非线性回归分析,判断几种不同模型的拟合程度. [知识链接] 1.有些变量间的关系并不是线性相关,怎样确定回归模型? 答首先要作出散点图,如果散点图中的样本点并没有分布在某个带状区域内,则两个变量不呈现线性相关关系,不能直接利用线性回归方程来建立两个变量之间的关系,这时可以根据已有函数知识,观察样本点是否呈指数函数关系或二次函数关系,选定适当的回归模型. 2.如果两个变量呈现非线性相关关系,怎样求出回归方程? 答可以通过对解释变量进行变换,如对数变换或平方变换,先得到另外两个变量间的回归方程,再得到所求两个变量的回归方程. [预习导引] 1.非线性回归分析 对不具有线性相关关系的两个变量做统计分析,通过变量代换,转化为线性回归模型. 2.非线性回归方程
要点一 线性回归分析 例1 某产品的广告费用x 与销售额y 的统计数据如下表: (1)由数据易知y 与x 具有线性相关关系,若b =9.4,求线性回归方程y =a +bx ; (2)据此模型预报广告费用为4万元时的销售额. 解 (1)x -=4+2+3+54=3.5,y - =49+26+39+54 4 =42, ∴a =y - -b x - =42-9.4×3.5=9.1 ∴回归直线方程为y =9.1+9.4x . (2)当x =4时,y =9.1+9.4×4=46.7, 故广告费用为6万元时销售额为46.7万元. 跟踪演练1 为了研究3月下旬的平均气温(x )与4月20日前棉花害虫化蛹高峰日(y )的关系,某地区观察了2006年2011年的情况,得到了下面的数据: (1)对变量x ,y 进行相关性检验; (2)据气象预测,该地区在2012年3月下旬平均气温为27 ℃,试估计2012年4月化蛹高峰日为哪天.
第一章绪论 一、单项选择题 1、变量之间的关系可以分为两大类,它们是【】 A 函数关系和相关关系 B 线性相关关系和非线性相关关系 C 正相关关系和负相关关系 D 简单相关关系和复杂相关关系 2、相关关系是指【】 A 变量间的依存关系 B 变量间的因果关系 C 变量间的函数关系 D 变量间表现出来的随机数学关系 3、进行相关分析时,假定相关的两个变量【】 A 都是随机变量 B 都不是随机变量 C 一个是随机变量,一个不是随机变量 D 随机或非随机都可以 4、计量经济研究中的数据主要有两类:一类是时间序列数据,另一类是【】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 5、下面属于截面数据的是【】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 6、同一统计指标按时间顺序记录的数据列称为【】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 7、经济计量分析的基本步骤是【】 A 设定理论模型→收集样本资料→估计模型参数→检验模型 B 设定模型→估计参数→检验模型→应用模型 C 个体设计→总体设计→估计模型→应用模型 D 确定模型导向→确定变量及方程式→估计模型→应用模型 8、计量经济模型的基本应用领域有【】 A 结构分析、经济预测、政策评价 B 弹性分析、乘数分析、政策模拟 C 消费需求分析、生产技术分析、市场均衡分析 D 季度分析、年度分析、中长期分析 9、计量经济模型是指【】 A 投入产出模型 B 数学规划模型 C 包含随机方程的经济数学模型 D 模糊数学模型 10、回归分析中定义【】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 11、下列选项中,哪一项是统计检验基础上的再检验(亦称二级检验)准则【】 A. 计量经济学准则 B 经济理论准则 C 统计准则 D 统计准则和经济理论准则
第一节 两变量线性回归模型 一.模型的建立 1.数理模型的基本形式 y x αβ=+ (2.1) 这里y 称为被解释变量(dependent variable),x 称为解释变量(independent variable) 注意:(1)x 、y 选择的方法:主要是从所研究的问题的经济关系出发,根据已有的经济理论进行合理选择。 (2)变量之间是否是线性关系可先通过散点图来观察。 2.例 如果在研究上海消费规律时,已经得到上海城市居民1981-1998年期间的人均可支配收入和人均消费性支出数据(见表1),能否用两变量线性函数进行分析? 表1.上海居民收入消费情况 年份 可支配收入 消费性支出 年份 可支配收入 消费性支出 1981 636.82 585 1990 2181.65 1936 1982 659.25 576 1991 2485.46 2167 1983 685.92 615 1992 3008.97 2509 1984 834.15 726 1993 4277.38 3530 1985 1075.26 992 1994 5868.48 4669 1986 1293.24 1170 1995 7171.91 5868
19871437.09128219968158.746763 19881723.44164819978438.896820 19891975.64181219988773.16866 2.一些非线性模型向线性模型的转化 一些双变量之间虽然不存在线性关系,但通过变量代换可化为线性形式,这些双变量关系包括对数关系、双曲线关系等。 例3-2 如果认为一个国家或地区总产出具有规模报酬不变的特征,那么采用人均产出y与人均资本k的形式,该国家或者说地区的总产出规律可以表示为下列C-D生产函数形式 y Akα = (2.2)
计量经济学实验 报告 ——简单线性回归的模型 专业班级:物流管理20102班 姓名:孙善祥 学号: 2010517453
案例分析 案例: 全国居民消费水平(CT)与国民总收入(GNI)数量关系的分析 一、提出问题:随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也在不断增长。研究全国居民消费水平(CT)与国民总收入(GNI)的数量关系,对于探寻居民消费增长的规律性,预测居民消费的发展趋势有重要意义。 二、理论分析:影响居民人均消费水平的因素有多种,但从理论和经验分析,最主要的影响因素应是经济发展水平。从理论上说经济发展水平越高,居民消费越多。 变量选择:被解释变量选择“全体居民人均年消费水平” 解释变量选择表现经济增长水平的“国民总收入(GNI)” 研究范围:1979年至2008年中国“全体居民人均年消费水平”与“国民总收入(GNI)”的时间序列数据。 数据: 为分析“全体居民人均年消费水平”(Y)与“国民总收入(GNI)”(X)的关系,作散点图:
从散点图可以看出“全体居民人均年消费水平” (Y)与“国民总收入(GNI )”大体呈现为线性关系。为分析数量规律性,可以建立如下简单线性回归模型: 三、估计参数 假定模型中随机扰动满足基本假定,可用OLS 法。具体操作:使用EViews 软件,估计结果是: 用规范的形式将参数估计和检验的结果写为: (77.71158)(0.000721) n =30 12t t t Y X u ββ=++
四、模型检验 1、经济意义检验 估计的解释变量的系数为 说明国民总收入每增加一个单位,可导致全体居民人均年消费水平增 2、可决系数: 模型整体上拟合好。 3、系数显著性检验:给定 ,查 t 分布表, 在自由度为 时临界值为 因为 应拒绝 应拒绝 表明,人均GDP 对居民消费水平确有显著影响。 五、 点预测: 如果2009年国民总收入将比2008年增长15.56%将达到350000,利用所估计的模型可预测2009年全体居民人均年消费水平。 =10147.3504 为了做区间估计,取 ,Y 的平均置信度95%的预测区间为 已知: 10147.3504,,n =30 由X 和Y 的描述统计结果 0.05α=282302=-=-n 048.2)28(025.0=t 02:0H β=01:0H β=??F F α21Y =Y t σ+n