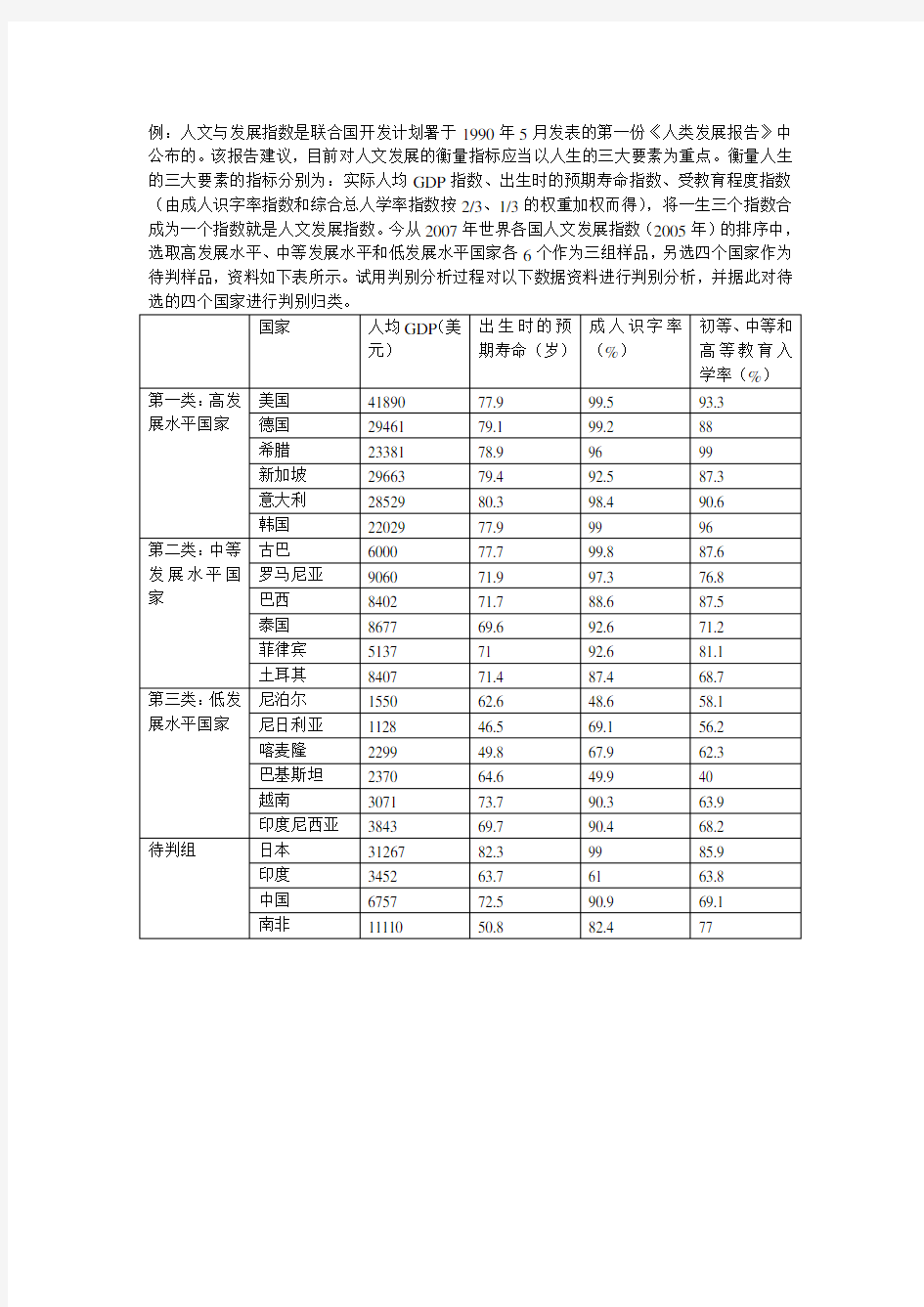

例:人文与发展指数是联合国开发计划署于1990年5月发表的第一份《人类发展报告》中公布的。该报告建议,目前对人文发展的衡量指标应当以人生的三大要素为重点。衡量人生的三大要素的指标分别为:实际人均GDP指数、出生时的预期寿命指数、受教育程度指数(由成人识字率指数和综合总人学率指数按2/3、1/3的权重加权而得),将一生三个指数合成为一个指数就是人文发展指数。今从2007年世界各国人文发展指数(2005年)的排序中,选取高发展水平、中等发展水平和低发展水平国家各6个作为三组样品,另选四个国家作为待判样品,资料如下表所示。试用判别分析过程对以下数据资料进行判别分析,并据此对待
data develop;
input type gdp life rate zhrate@@;
cards;
1 41890 77.9 99.5 93.3
1 29461 79.1 99.
2 88
1 23381 78.9 96 99
1 29663 79.4 92.5 87.3
1 28529 80.3 98.4 90.6
1 22029 77.9 99 96
2 6000 77.7 99.8 87.6
2 9060 71.9 97.
3 76.8
2 8402 71.7 88.6 87.5
2 8677 69.6 92.6 71.2
2 5137 71 92.6 81.1
2 8407 71.4 87.4 68.7
3 1550 62.6 48.6 58.1
3 1128 46.5 69.1 56.2
3 2299 49.8 67.9 62.3
3 2370 64.6 49.9 40
3 3071 73.7 90.3 63.9
3 3843 69.7 90.
4 68.2
. 31267 82.3 99 85.9
. 3452 63.7 61 63.8
. 6757 72.5 90.9 69.1
. 11110 50.8 82.4 77
;
proc discrim simple wcov distance list;/*simple:要求技术各类样品的简单描述统计量;选项WCOV要求计算类内协方差阵;选项DISTANCE要求计算马氏距离;选项LIST要求输出重复替换归类结果。由于没有给出方法选项,所以系统按缺省时的正态分布进行有关参数的估计和归类。*/
class type;
var gdp life rate zhrate;
run;
proc discrim pool=test slpool=0.05list; /*simple: */
class type;
priors'1'=0.3'2'=0.4'3'=0.3 ;
run;
proc discrim method=npar k=2list; /*simple: */
class type;
run;
proc candisc out=result ncan=2; /*simple: */
class type;
var gdp life rate zhrate;
run;
proc gplot data=reult;
plot can1*can2=type;
run;
proc discrim data=result distance list;
class type;
var can1 can2;
run;
表1 已知样本分类水平信息
表2 样本统计量信息
表3 类间距离及三类总体均值差异的显著性检验
表3给出了类1与类2之间的马氏距离为37.58288,类1与类3之间的马氏距离为75.97603,类2与类3之间的马氏距离为10.91428.类与类之间总体均值的F检验统计量值分布为22.54978,45.58562,22.54973,对应的检验概率分别为<0.0001, <0.0001,<0.0001, 说明三类总体均值两辆之间的差异是显著的,因此判别分析有意义。
表4 线形判别函数
由表4可写出线形判别函数如下:
高发展水平:y1=-157.18932+0.00204gdp+1.66582life-0.37085rate+1.72851zhrate
中等发展水平Y2=-99.12840+0.0006250gdp+1.49389life-0.09262rate+1.19559zhrate
低发展水平:Y3=-62.22473+0.0002576gdp+1.31631life-0.08940rate+0.85253zhrate
表5:用距离判别法判别分析结果
由表5得,最后四个观测的归类结果为19号(日本)观测为高发展水平国家,第20号(印度)为第3类,即低发展水平国家,21号(中国)和22号(南非)归为中等发展水平国家。
表6 距离判别法判别分析结果小结
表6给出了分类错误信息,由输出结果可知分类错误的比率为0,即正确的比率为100%。
本程序中第二个判别分析过程的选项“pool=test”,要求进行类内协方差阵一致性检验,检验的显著性水平由选项”slpool=0.05”给出为0.05. priors语句给出了各发展水平国家的先验概率。
表7 分类信息及类内协方差阵一致性检验结果
表7表明3个类的先验概率分别为0.3,0.4,0.3,类内协方差阵行列式的自然对数不相等,表明类内协方差阵不相等,而卡方统计量值为46.068898,对应的概率是0.0008,在0.05的显著性水平下是显著的,即类内协方差阵存在显著差异。由于类内协方差阵不等,所以判别函数应是二次函数。
表8 类间配对广义马氏距离
由表8可知,类内广义马氏距离不再为0,而且类间的广义马氏距离也不再相等,因而类内协方差和先验概率对后验概率的计算是起作用的。
表9 用Bayes判别法得到的判别分析部分结果
由表9可知,用BAYES判别法对待判样品的判别结果与距离判别法结果一致。
本程序中的第三个过程要求进行非参数分析,即对类密度函数进行非参数估计。选项K=2要求用最近邻的两个样品进行密度函数估计,选项list要求输出重复替换归类结果。该过程运行结果如下:
表10 用NPAR方法得到的判别分析部分结果
由表10可知,4个待判的样品中19号和21号归类结果与BAYES判别归类结果是一致的,但20号和22号所属类别则不能确定,这是与前面2中判别方法结果不一致的地方。
第四种FISHER判别:第一个过程执行典型判别分析。第二个过程要求绘制第一个典型变量CAN1和第二个典型变量CAN2的散点图,以便更加直观了解分类情况。第一、二个过程输出结果如下:
表11 典型相关的多变量检验结果
由上表对相关阵的显著性检验结果可知,至少有
表12 典型相关与特征值
上表可知,第一典型相关为0.969875,而第二典型相关为0.653396。第一个特征值为15.8514,所占比例为95.51%,第二个特征值为0.7450,所占比例仅有4.49%,说明只需用第一个典型变量即可。
表13 原始变量的典型相关系数
由表12可得两个典型变量分别为:
CAN1=0.0002096544gdp+0.0382960552life-0.0346472260rate+0.0988009134zhrate
Can2=-0.0001135485gdp+0.0394378902life+0.0500655661rate+0.0390500134zhrate
表14 类间马氏距离及各类总体均值的显著性检验
由上表的显著性概率可知,在0.05的显著性水平下,三个类的总体均值两两显著不等。
表15 线性判别函数
由表15得3个类的线形判别函数分别为:
第一类:Y1=-12.01131+4.88922can1-0.34378can2
第二类:Y2=-1.16768-1.07130can1+1.08981can2
第三类:y3=-7.56654-3.81792can1-0.74604can2
表16 由DISCRIM利用两个典型变量进行判别部分样品归类结果
上表分类结果与前几种分类方法结果一样,总错判率为0.
为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 5
贝叶斯判别的SPSS操作方法: 1. 建立数据文件 2.单击Analyze→ Classify→ Discriminant,打开Discriminant Analysis 判别分析对话框如图1所示: 图1 Discriminant Analysis判别分析对话框 3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。 从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。 选择后点击Continue按钮返回Discriminant Analysis主对话框。 图2 Define Range对话框 4、选择分析方法 Enter independent together 所有变量全部参与判别分析(系统默 认)。本例选择此项。 Use stepwise method 采用逐步判别法自动筛选变量。
距离判别法及其应用 一、什么是距离判别 (一)定义 距离判别分析方法是判别样品所属类别的一应用性很强的多因素决策方法,根据已掌握的、历史上每个类别的若干样本数据信息,总结出客观事物分类的规律性,建立判别准则,当遇到新的样本点,只需根据总结得出的判别公式和判别准则,就能判别该样本点所属的类别。 距离判别分析的基本思想是:样本和哪个总体的距离最近,就判它属于哪个总体。 (二)作用 判别个体所属类型。例如在经济学中,可根据各国的人均国人民收入、人均工农业产值和人均消费水平等多种指标来判定一个国家经济发展程度的怕属类型医学上根据口才的体温、白血球数目以及其他病理指标来判断患者所患何病等。 二、距离判别分析原理 (一)欧氏距离 欧氏距离(Euclidean distance )是一个通常采用的距离定义,最多的应用是对距离的测度。大多情况下,人们谈到距离的时候,都会很自然的想到欧氏距离。从数学的角度来讲,它是在m 维空间中两个点之间的真实距离。 在二维空间中其公式为: 2 21221)()(y y x x d -+-=
推广到n 维空间其公式为: 2 1) (1 i n i i y x d -=∑= (二)马氏距离 在判别分析中,考虑到欧氏距离没有考虑总体分布的分散性信息,印度统计学家马哈诺必斯(Mahalanobis )于1936年提出了马氏距离的概念。 设总体T m X X X G },...,,{21=为m 维总体(考察m 个指标),样本 T m i x x x X },...,,{21=。令μ=E(i X )(i=1,2, …,m),则总体均值向量为 T m },,{21μμμμ???=。总体G 的协方差矩阵为: ]))([()(T G G E G COV μμ--==∑。 设X ,Y 是从总体G 中抽取的两个样本,则X 与Y 之间的平方马氏距离为: )()(),(12Y X Y X Y X d T -∑-=- 样本X 与总体G 的马氏距离的平方定义为: )()(),(12μμ-∑-=-X X G X d T 1.两总体距离判别。设有两总体1G 和2G 的均值分别为1μ和2μ,协方差矩阵分别为1∑和2∑(1∑,2∑>0),1?m X 是一个新样本,判断其属于哪个总体。定义1?m X 到1G 和2G 的距离为),(12 G X d 和),(22 G X d , 则按如下判别规则进行判断: 1G X ∈,若),(12G X d ≤),(22G X d 2G X ∈,若),(22G X d ﹤),(12G X d (1)当1∑=2∑时,该判别式可进行如下简化: ),(12G X d -),(22G X d =)()(111μμ-∑--X X T -)()(212μμ-∑--X X T
第六章 判别分析 §6.1 什么是判别分析 判别分析是判别样品所属类型的一种统计方法,其应用之广可与回归分析媲美。 在生产、科研和日常生活中经常需要根据观测到的数据资料,对所研究的对象进行分类。例如在经济学中,根据人均国民收入、人均工农业产值、人均消费水平等多种指标来判定一个国家的经济发展程度所属类型;在市场预测中,根据以往调查所得的种种指标,判别下季度产品是畅销、平常或滞销;在地质勘探中,根据岩石标本的多种特性来判别地层的地质年代,由采样分析出的多种成份来判别此地是有矿或无矿,是铜矿或铁矿等;在油田开发中,根据钻井的电测或化验数据,判别是否遇到油层、水层、干层或油水混合层;在农林害虫预报中,根据以往的虫情、多种气象因子来判别一个月后的虫情是大发生、中发生或正常; 在体育运动中,判别某游泳运动员的“苗子”是适合练蛙泳、仰泳、还是自由泳等;在医疗诊断中,根据某人多种体验指标(如体温、血压、白血球等)来判别此人是有病还是无病。总之,在实际问题中需要判别的问题几乎到处可见。 判别分析与聚类分析不同。判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。对于聚类分析来说,一批给定样品要划分的类型事先并不知道,正需要通过聚类分析来给以确定类型的。 正因为如此,判别分析和聚类分析往往联合起来使用,例如判别分析是要求先知道各类总体情况才能判断新样品的归类,当总体分类不清楚时,可先用聚类分析对原来的一批样品进行分类,然后再用判别分析建立判别式以对新样品进行判别。 判别分析内容很丰富,方法很多。判别分析按判别的组数来区分,有两组判别分析和多组判别分析;按区分不同总体的所用的数学模型来分,有线性判别和非线性判别;按判别时所处理的变量方法不同,有逐步判别和序贯判别等。判别分析可以从不同角度提出的问题,因此有不同的判别准则,如马氏距离最小准则、Fisher 准则、平均损失最小准则、最小平方准则、最大似然准则、最大概率准则等等,按判别准则的不同又提出多种判别方法。本章仅介绍四种常用的判别方法即距离判别法、Fisher 判别法、Bayes 判别法和逐步判别法。 §6.2 距离判别法 基本思想:首先根据已知分类的数据,分别计算各类的重心即分组(类)的均值,判别准则是对任给的一次观测,若它与第i 类的重心距离最近,就认为它来自第i 类。 距离判别法,对各类(或总体)的分布,并无特定的要求。 1 两个总体的距离判别法 设有两个总体(或称两类)G 1、G 2,从第一个总体中抽取n 1个样品,从第二个总体中抽取n 2个样品,每个样品测量p 个指标如下页表。 今任取一个样品,实测指标值为),,(1'=p x x X ,问X 应判归为哪一类? 首先计算X 到G 1、G 2总体的距离,分别记为),(1G X D 和),(2G X D ,按距离最近准则
多个总体距离判别法 及其应用 课程名: 年级: 专业: 姓名: 学号:
目录 一、摘要 (1) 二、引言 (1) 三、原理 (1) 3.1定义 (1) 3.2思想 (1) 3.3判别分析过程 (1) 四、具体应用 (3) 4.1判别分析在医学上的应用 (3) 4.2距离判别法在居民生活水平方面的应用 (9) 4.3判别分析软件的使用 (12) 五、参考文献 (14) 六、附录 (15)
一、 摘要 近年来随着信息化社会的进行,数据分析对我们来说日趋重要,为了对数据的分类进行判别,本文介绍了数据分类判别的一种方法:距离判别法。本文从多个总体距离判别法理论出发并结合例题详细介绍了多个总体距离判别法的在医学领域以及居民生活水平方面的应用,同时也简单介绍了spss 软件一般判别法的具体操作。 关键词: 距离判别法 判别分析 一般判别分析 二、 引言 随着科技的发展,判别分析在经济,医学等很多领域以及气候分类,农业区划,土地类型划分等有着重要的应用, 本文从多个总体距离判别分析理论出发,介绍了多个总体距离判别法在医学以及人民生活方面的应用,并介绍了spss 一般判别分析的应用。 三、 原理 3.1 定义 距离判别法:距离判别分析方法是判别样品所属类别的一应用性很强的多因素决方法,其中包括两个样本总体距离判别法,多个样本距离判别法。 多个总体距离判别法:多个总体距离判别法是距离判别法的一种,是两个总体距离判别法的推广,具有多个总体,将待测样本归为多个样本中的一类。 3.2 思想 计算待测样本与各总体之间的距离,将待测样本归为与其距离最进的一类。 3.3 判别分析过程 对于k 个总体k 21G G G ?, ,,假设其均值分别为:k 21u u u ,,,?,协方差阵
实验指导之二 判别分析的SPSS软件的基本操作 [实验例题]为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 x5:人均集体所有制职工标准工资
贝叶斯判别的SPSS操作方法: 1. 建立数据文件 2.单击Analyze→Classify→Discriminant,打开Discriminant Analysis判别分析对话框如图1所示: 图1 Discriminant Analysis判别分析对话框 3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。 从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range 对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。 选择后点击Continue按钮返回Discriminant Analysis主对话框。 图2 Define Range对话框 4、选择分析方法
判别分析的基本原理
判别分析的基本原理和模型 一、判别分析概述 (一)什么是判别分析 判别分析是多元统计中用于判别样品所属类型的一种统计分析方法,是一种在已知研究对象用某种方法已经分成若干类的情况下,确定新的样品属于哪一类的多元统计分析方法。 判别分析方法处理问题时,通常要给出用来衡量新样品与各已知组别的接近程度的指标,即判别函数,同时也指定一种判别准则,借以判定新样品的归属。所谓判别准则是用于衡量新样品与各已知组别接近程度的理论依据和方法准则。常用的有,距离准则、Fisher 准则、贝叶斯准则等。判别准则可以是统计性的,如决定新样品所属类别时用到数理统计的显著性检验,也可以是确定性的,如决定样品归属时,只考虑判别函数值的大小。判别函数是指基于一定的判别准则计算出的用于衡量新样品与各已知组别接近程度的函数式或描述指标。 (二)判别分析的种类 按照判别组数划分有两组判别分析和多组判别分析;按照区分不同总体的所用数学模型来分有线性判别分析和非线性判别分析;按照处理变量的方法不同有逐步判别、序贯判别等;按照判别准则来分有距离准则、费舍准则与贝叶斯判别准则。 二、判别分析方法 (一)距离判别法 1.基本思想:首先根据已知分类的数据,分别计算各类的重心,即分组(类)均值,距离判别准则是对于任给一新样品的观测值,若它与第i 类的重心距离最近,就认为它来自第i 类。因此,距离判别法又称为最邻近方法(nearest neighbor method )。距离判别法对各类总体的分布没有特定的要求,适用于任意分布的资料。 2.两组距离判别 两组距离判别的基本原理。设有两组总体B A G G 和,相应抽出样品个数为21,n n , n n n =+)(21,每个样品观测p 个指标得观测数据如下,
学生实验报告书 实验课程名称多元统计分析 开课学院经济学院 指导教师姓名唐湘晋 学生姓名朱天国 学生专业班级金融sy1201 20014-- 20015学年第一学期
实验教学管理基本规范 实验是培养学生动手能力、分析解决问题能力的重要环节;实验报告是反映实验教学水平与质量的重要依据。为加强实验过程管理,改革实验成绩考核方法,改善实验教学效果,提高学生质量,特制定实验教学管理基本规范。 1、本规范适用于理工科类专业实验课程,文、经、管、计算机类实验课程可根据具体情况参 照执行或暂不执行。 2、每门实验课程一般会包括许多实验项目,除非常简单的验证演示性实验项目可以不写实验 报告外,其他实验项目均应按本格式完成实验报告。 3、实验报告应由实验预习、实验过程、结果分析三大部分组成。每部分均在实验成绩中占一 定比例。各部分成绩的观测点、考核目标、所占比例可参考附表执行。各专业也可以根据具体情况,调整考核内容和评分标准。 4、实验预习、实验过程、结果分析三部分按优、良、中、及格和不及格五级评定,折合计算 实验成绩(百分制)标准为:优95,良85,中75,及格60,不及格50。 5、学生必须在完成实验预习内容的前提下进行实验。教师要在实验过程中抽查学生预习情况, 在学生离开实验室前,检查学生实验操作和记录情况,并在实验报告第二部分教师签字栏签名,以确保实验记录的真实性。 6、学生应在做完实验后三天内完成实验报告,交指导教师评阅。 7、教师应及时评阅学生的实验报告并给出各实验项目成绩,完整保存实验报告。在完成所有 实验项目后,教师应按学生姓名将批改好的各实验项目实验报告装订成册,构成该实验课程总报告,按班级交课程承担单位(实验中心或实验室)保管存档。
作业一: 为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为两种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 x5:人均集体所有制职工标准工资
一、距离判别法 解:变量个数p=9,两类总体各有11个样品,即n1=n2=11 ,有2个待判样品,假定两总体协差阵相等。由spss可计算出:协方差和平均值
合计x1 123.2881 23.27817 22 22.000 x2 80.4895 22.04796 22 22.000 x3 50.8709 6.14867 22 22.000 x4 10.1450 3.11887 22 22.000 x5 6.0659 2.72297 22 22.000 x6 14.6060 6.73264 22 22.000 x7 15.7215 6.64603 22 22.000 x8 8.7895 3.02700 22 22.000 x9 1.5291 1.31496 22 22.000 知道了均值和协方差可利用matlab计算线性判别函数W(x)的判别系数a和判别常数。程序如下: v=[1.000,0.217,0.299,0.045,-0.054,0.688,0.212,0.121,-0.245;.217,1,.102,-.234,-.211,. 136,-.052,.116,.154;.299,.102,1,-.296,-.062,.091,-.017,-.607,-.034;.045,-.234,-.296,1,. 762,-.172,-.297,.103,-.554;-.054,-.211,-.062,.762,1,-.156,-.342,.022,-.654;.688,.136,.0 91,-.172,-.156,1,.235,.384,-.098;.212,-.052,-.017,-.297,-.342,.235,1,-.040,.424;.121,.1 16,-.607,.103,.022,.384,-.040,1,-.071;-.245,.154,-.034,-.554,-.654,-.098,.424,-.071,1]; >> m1=[139.2664;93.0918;53.9882;11.2073;6.7645;17.9345;17,8327;11.0018;1.6736];m 2=[107.3099;67.8873;47.7536;9.0827;5.3673;11.2775;13.6102;6.5773;1.3845]; >> m=(m1+m2)/2; >> arfa=inv(v)*(m1-m2);
第六章 判别分析 § 什么是判别分析 判别分析是判别样品所属类型的一种统计方法,其应用之广可与回归分析媲美。 在生产、科研和日常生活中经常需要根据观测到的数据资料,对所研究的对象进行分类。例如在经济学中,根据人均国民收入、人均工农业产值、人均消费水平等多种指标来判定一个国家的经济发展程度所属类型;在市场预测中,根据以往调查所得的种种指标,判别下季度产品是畅销、平常或滞销;在地质勘探中,根据岩石标本的多种特性来判别地层的地质年代,由采样分析出的多种成份来判别此地是有矿或无矿,是铜矿或铁矿等;在油田开发中,根据钻井的电测或化验数据,判别是否遇到油层、水层、干层或油水混合层;在农林害虫预报中,根据以往的虫情、多种气象因子来判别一个月后的虫情是大发生、中发生或正常; 在体育运动中,判别某游泳运动员的“苗子”是适合练蛙泳、仰泳、还是自由泳等;在医疗诊断中,根据某人多种体验指标(如体温、血压、白血球等)来判别此人是有病还是无病。总之,在实际问题中需要判别的问题几乎到处可见。 判别分析与聚类分析不同。判别分析是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品进行判别分类。对于聚类分析来说,一批给定样品要划分的类型事先并不知道,正需要通过聚类分析来给以确定类型的。 正因为如此,判别分析和聚类分析往往联合起来使用,例如判别分析是要求先知道各类总体情况才能判断新样品的归类,当总体分类不清楚时,可先用聚类分析对原来的一批样品进行分类,然后再用判别分析建立判别式以对新样品进行判别。 判别分析内容很丰富,方法很多。判别分析按判别的组数来区分,有两组判别分析和多组判别分析;按区分不同总体的所用的数学模型来分,有线性判别和非线性判别;按判别时所处理的变量方法不同,有逐步判别和序贯判别等。判别分析可以从不同角度提出的问题,因此有不同的判别准则,如马氏距离最小准则、Fisher 准则、平均损失最小准则、最小平方准则、最大似然准则、最大概率准则等等,按判别准则的不同又提出多种判别方法。本章仅介绍四种常用的判别方法即距离判别法、Fisher 判别法、Bayes 判别法和逐步判别法。 § 距离判别法 基本思想:首先根据已知分类的数据,分别计算各类的重心即分组(类)的均值,判别准则是对任给的一次观测,若它与第i 类的重心距离最近,就认为它来自第i 类。 距离判别法,对各类(或总体)的分布,并无特定的要求。 1 两个总体的距离判别法 设有两个总体(或称两类)G 1、G 2,从第一个总体中抽取n 1个样品,从第二个总体中抽取n 2个样品,每个样品测量p 个指标如下页表。 今任取一个样品,实测指标值为),,(1'=p x x X ,问X 应判归为哪一类 首先计算X 到G 1、G 2总体的距离,分别记为),(1G X D 和),(2G X D ,按距离最近准则
1 绪论 1.1课题背景 随着社会经济不断发展,科学技术的不断进步,人们已经进入了信息时代,要在大量的信息中获得有科学价值的结果,从而统计方法越来越成为人们必不可少的工具和手段。多元统计分析是近年来发展迅速的统计分析方法之一,应用于自然科学和社会各个领域,成为探索多元世界强有力的工具。 判别分析是统计分析中的典型代表,判别分析的主要目的是识别一个个体所属类别的情况下有着广泛的应用。潜在的应用包括预测一个公司是否成功;决定一个学生是否录取;在医疗诊断中,根据病人的多种检查指标判断此病人是否有某种疾病等等。它是在已知观测对象的分类结果和若干表明观测对象特征的变量值的情况下,建立一定的判别准则,使得利用判别准则对新的观测对象的类别进行判断时,出错的概率很小。而Fisher判别方法是多元统计分析中判别分析方法的常用方法之一,能在各领域得到应用。通常用来判别某观测量是属于哪种类型。在方法的具体实现上,采用国内广泛使用的统计软件SPSS (Statistical Product and Service Solutions),它也是美国SPSS公司在20世纪80年代初开发的国际上最流行的视窗统计软件包之一 1.2 Fisher判别法的概述 根据判别标准不同,可以分为距离判别、Fisher判别、Bayes判别法等。Fisher 判别法是判别分析中的一种,其思想是投影,Fisher判别的基本思路就是投影,针对P维空间中的某点x=(x1,x2,x3,…,xp)寻找一个能使它降为一维数值的线性函数y(x):()j j x y = x∑ C 然后应用这个线性函数把P维空间中的已知类别总体以及求知类别归属的样本都变换为一维数据,再根据其间的亲疏程度把未知归属的样本点判定其归属。这个线性函数应该能够在把P维空间中的所有点转化为一维数值之后,既能最大限度地缩小同类中各个样本点之间的差异,又能最大限度地扩大不同类别中各个样本点之间的差异,这样才可能获得较高的判别效率。在这里借用了一元方差分析的思想,即依据组间均方差与组内均方差之比最大的原则来进行判别。 1.3 算法优缺点分析
距离判别法及其应用 一、什么是距离判别 (一)定义 距离判别分析方法是判别样品所属类别的一应用性很强的多因素决策方法,根据已掌握的、历史上每个类别的若干样本数据信息,总结出客观事物分类的规律性,建立判别准则,当遇到新的样本点,只需根据总结得出的判别公式和判别准则,就能判别该样本点所属的类别。 距离判别分析的基本思想是:样本和哪个总体的距离最近,就判它属于哪个总体。 (二)作用 判别个体所属类型。例如在经济学中,可根据各国的人均国人民收入、人均工农业产值和人均消费水平等多种指标来判定一个国家经济发展程度的怕属类型医学上根据口才的体温、白血球数目以及其他病理指标来判断患者所患何病等。 二、距离判别分析原理 (一)欧氏距离 欧氏距离(Euclidean distance )是一个通常采用的距离定义,最多的应用是对距离的测度。大多情况下,人们谈到距离的时候,都会很自然的想到欧氏距离。从数学的角度来讲,它是在m 维空间中两个点之间的真实距离。 在二维空间中其公式为: 2 21221)()(y y x x d -+-=
推广到n 维空间其公式为: 21) (1i n i i y x d -=∑= (二)马氏距离 在判别分析中,考虑到欧氏距离没有考虑总体分布的分散性信息,印度统计学家马哈诺必斯(Mahalanobis )于1936年提出了马氏距离的概念。 设总体T m X X X G },...,,{21=为m 维总体(考察m 个指标),样本 T m i x x x X },...,,{21=。令μ=E(i X )(i=1,2, …,m),则总体均值向量为 T m },,{21μμμμ???=。总体G 的协方差矩阵为: ]))([()(T G G E G COV μμ--==∑。 设X ,Y 是从总体G 中抽取的两个样本,则X 与Y 之间的平方马氏距离为: )()(),(12Y X Y X Y X d T -∑-=- 样本X 与总体G 的马氏距离的平方定义为: )()(),(12μμ-∑-=-X X G X d T 1.两总体距离判别。设有两总体1G 和2G 的均值分别为1μ和2μ,协方差矩阵分别为1∑和2∑(1∑,2∑>0),1?m X 是一个新样本,判断其 属于哪个总体。定义1?m X 到1G 和2G 的距离为),(12G X d 和 ),(22G X d ,则按如下判别规则进行判断: 1G X ∈,若),(12G X d ≤),(22G X d 2G X ∈,若),(22G X d ﹤),(12G X d (1)当1∑=2∑时,该判别式可进行如下简化:
实验二判别分析 姓名:张杨 学号: 2014962001 年级: 2014级 专业:统计学 课程名称:多元统计分析 指导教师:范英兵 完成日期: 2016-09-30
表1-6 Wilks' Lambda (λ) 函數的檢定Wilks' Lambda (λ) 卡方df 顯著性 1 至 2 .02 3 546.115 8 .000 2 .778 36.530 3 .000 输出结果表1-5,表1-6分析的是典型判别函数。表1-5反映判别函数的特征值、解释方差的比例和典型相关系数。第一判别函数解释了99.1%的方差,第二判别函数解释了0.9%的方差,两个判别函数解释了全部方差。第2张表是对两个判别函数的显著性检验。由Wilks’Lambda 检验,认为两个判别函数在0.05的显著性水平上是显著的。 表1-7 標準化典型區別函數係數 函數 1 2 萼片长-.427 .012 萼片宽-.521 .735 花瓣长.947 -.401 花瓣宽.575 .581 表-8 結構矩陣 函數 1 2 花瓣长.706*.168 萼片宽-.119 .864* 花瓣宽.633 .737* 萼片长.223 .311* 區別變數與標準化典型區別函數之 間的聯合組內相關性 依函數內相關性絕對大小排序的 變數。 *. 每一個變數與任何區別函數之 間最大的絕對相關性
表1-9 典型區別函數係數 函數 1 2 萼片长 -.829 .024 萼片宽 -1.534 2.165 花瓣长 2.201 -.932 花瓣宽 2.810 2.839 (常數) -2.105 -6.661 非標準化係數 表1-10 群組重心的函數 被解释变量 函數 1 2 Setosa 鸢尾花 -7.608 .215 Versico-lor 鸢尾花 1.825 -.728 Virginica 鸢尾花 5.783 .513 以群組平均值求值的非標準化典型區別函數 输出结果表1-7,1-8,1-9,1-10显示的是判别函数、判别载荷和各组的重心。表1-7是标准化的判别函数,表示为: ****1****20.427.0.521.0.947.0.575.0.012.0.735.0.401.0.581.y Sepal Length Sepal Width Petal Length Petal Width y Sepal Length Sepal Width Petal Length Petal Width =--++=+-+ 这里* 表示标准化变量,标准化变量的系数也就是前面讲的判别权重。表1-8是结构矩阵,即判别载荷。由判别权重和判别载荷可以看出两个解释变量对判别函数的贡献较大。 表1-9是非标准化的判别函数,表示为 12 2.1050.829. 1.534. 2.201. 2.810.6.6610.024. 2.165.0.932. 2.839.y Sepal Length Sepal Width Petal Length Petal Width y Sepal Length Sepal Width Petal Length Petal Width =---++=-++-+ 我们可以根据这个判别函数计算每个观测的判别Z 得分。表1-10是反映判别函数在各组的重心。根据结果,判别函数在1y =这一组的重心为(-7.608,0.215),在2y =这一组的重心为(1.825,-0.728),在3y =这一组的重心为(5.783,0.513)。这样,我们就可以根据每个观测
一、实验目的及要求: 1、目的 用SPSS软件实现判别分析及其应用。 2、内容及要求 用SPSS对实验数据利用Fisher判别法和贝叶斯判别法,建立判别函数并判定宿州、广安等13个地级市分别属于哪个管理水平类型。 二、仪器用具: 三、实验方法与步骤: 准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS 数据文件中,同时,由于只有当被解释变量是属性变量而解释变量是度量变量时,判别分析才适用,所以将城市管理的7个效率指数变量的变量类型改为“数值(N)”,度量标准改为“度量(S)”,以备接下来的分析。 四、实验结果与数据处理: 表1是对各组均值是否相等的检验,由该表可以看出,在0.05的显著性水平上我们不能拒绝结构效率标准指数和环境效率标准指数在三组的均值相等的假设,即认为除了结构效率标准指数和环境效率标准指数外,其余五个标准指数在三组的均值是有显著差异的。
表2 对数行列式 group 秩对数行列式 1 6 -33.410 2 6 -33.177 3 6 -40.584 汇聚的组内 6 -32.308 打印的行列式的秩和自然对数是组协方差矩阵的秩和自然对数。 表3 检验结果 箱的 M 140.196 F 近似。 2.498 df1 42 df2 1990.001 Sig. .000 对相等总体协方差矩阵的零假设进行检验。 以上是对各组协方差矩阵是否相等的Box’M检验,表2反映协方差矩阵的秩和行列式的对数值。由行列式的值可以看出,协方差矩阵不是病态矩阵。表3是对各总体协方差阵是否相等的统计检验,由F值及其显著水平,在0.05的显著性水平下拒绝原假设,认为各总体协方差阵不相等。 1)Fisher判别法: 图一
第四章判别分析 习题4.8 (1)根据数据建立贝叶斯判别函数,并根据此判别函数对原样本进行回判。(2)现有一新品牌的饮料在该超市试销,其销售价格为3.0,顾客对其口味评分为8,信任度评分平均为5,试预测该饮料的销售情况。 将数据导入SPSS,分析得到以下结果: 1.典型判别函数的特征函数的特征值表 表1-1 特征值表 表1-1所示是典型判别函数的特征值表,只有两个判别函数,所以特征值只有2个。函数1的特征值为17.791,函数2的特征值为0.720,判别函数的特征值越大,说明函数越具有区别判断力。函数1方差的累积贡献率高达96.1%,且典型相关系数为0.973,而函数2方差的贡献率仅为3.9%,典型相关系数为0.647。由此,说明函数1的区别判断力比函数2的强,函数1更具有区别判断力。 2.Wilks检验结果 表1-2 Wilks 的Lambda 上表中判别函数1和判别函数2的Wilks’Lambda值为0.031,判别函数2的Wilks’Lambda值为0.581。“1到2”表示两个判别函数的平均数在三个类间的差异情况,P值=0.002<0.05表示差异达到显著水平“2”表示在排除了第一个判别函数后,第二个判别函数在三个组别间的差异情况,P值=0.197>0.05表示判别函数2未达到显著水平。 3.建立贝叶斯判别函数
表1-3 贝叶斯判别法函数系数 上表为贝叶斯判别函数的系数矩阵,用数学表达式表示各类的贝叶斯判别函数为: 第一组: F1=-81.843-11.689X1+12.97X2+16.761X3 第二组: F2=-94.536-10.707X1+13.361X2+17.086X3 第三组: F3=-17.499-2.194X1+4.960X2+6.447X3 将新品牌饮料样品的自变量值分别代入上述三个贝叶斯判别函数,得到三个函数值为: F1=65.271,F2=65.661,F3=47.884 比较三个值,可以看出F2=65.661最大,据此得出新品牌饮料样品应该属于第二组,即该饮料的销售情况为平销。 4.个案观察结果表 表1-4 个案观察结果表