
数据仓库和LOAP应用技术
传统数据库以及OLTP(On-Line Transaction Processing联机事务处理)在日常的管理事务处理中获得了巨大的成功,但是对管理人员的决策分析要求却无法满足。
因为,管理人员常常希望能够通过对组织中的大量数据进行分析,了解业务的发展趋势。而传统数据库只保留了当前的业务处理信息,缺乏决策分析所需要的大量的历史信息。
为满足管理人员的决策分析需要,就需要在数据库的基础上产生适应决策分析的数据环境——数据仓库(Data Warehouse)。
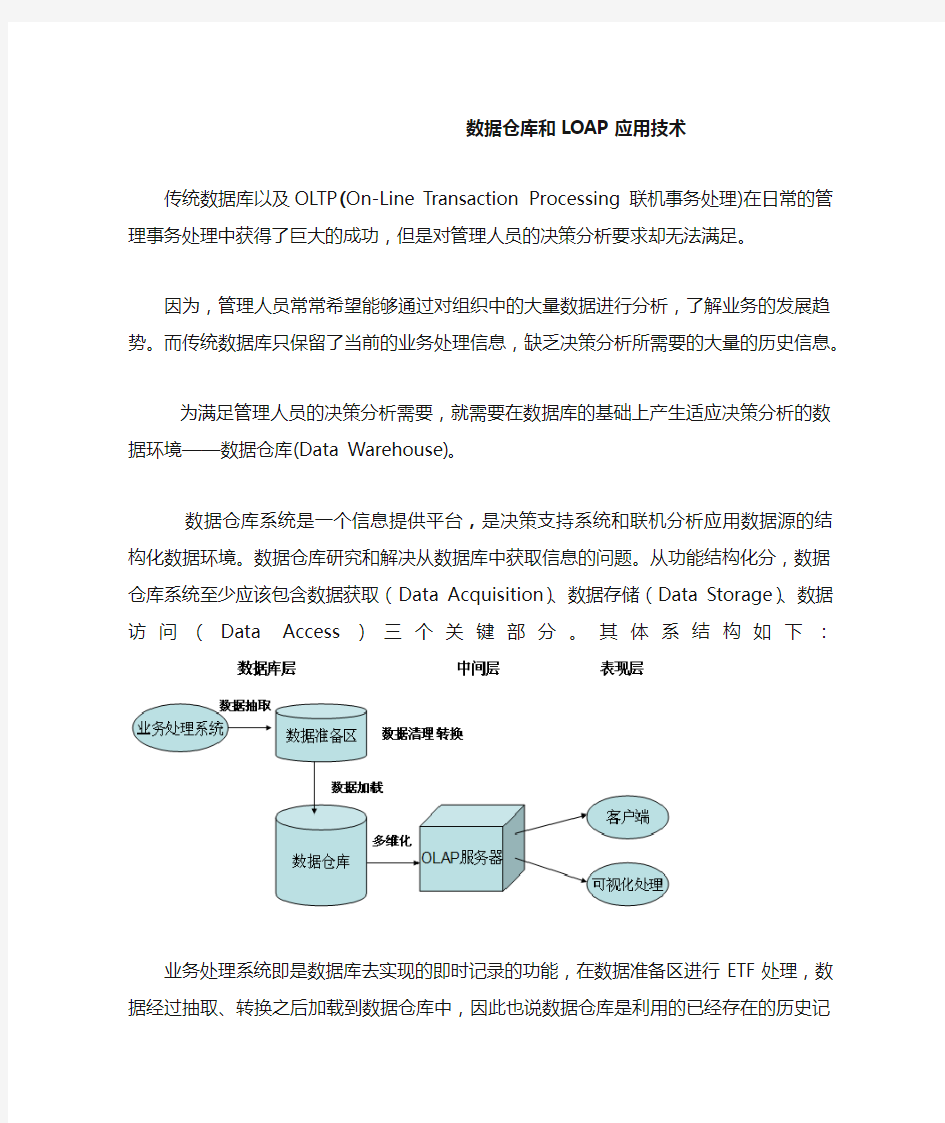
数据仓库系统是一个信息提供平台,是决策支持系统和联机分析应用数据源的结构化数据环境。数据仓库研究和解决从数据库中获取信息的问题。从功能结构化分,数据仓库系统至少应该包含数据获取(Data Acquisition)、数据存储(Data Storage)、数据访问(Data Access)三个关键部分。其体系结构如下:
业务处理系统即是数据库去实现的即时记录的功能,在数据准备区进行ETF处理,数据经过抽取、转换之后加载到数据仓库中,因此也说数据仓库是利用的已经存在的历史记录去整合,是利用原有数据分析下一步行动的决策,是有风险的。分析完主题和数据元后建立数据模型(概念模型、逻辑模型、物理模型)并形成事实表和纬度表,然后通过粒度分析将历史记录先抽取整合,然后再根据决策者可能用到的数据集合分解成若干记录,以备不同决策者使用;再利用OLAP工具技术进行数据的分析导出。当然,这些都在了解了管理者即客户的需求之后进行的,或者是由企业的管理者自己进行的技术应用或分析。
模型设计的过程如下:
数据仓库是管理决策分析的基础,要有效地利用数据仓库的信息资源,必须要有强大的工具对数据仓库的信息进行分析决策。
On-line Analytical Processing(在线分析处理或联机分析处理)就是一个应用广泛的数据仓库使用技术。它可以根据分析人员的要求,迅速灵活地对当量的数据进行复杂的查询处理,并以直观的容易理解的形式将查询结果提供给各种决策人员,使他们能够迅速准确地掌握企业的运营情况,了解市场的需求。具体的说,OLAP(联机分析处理)是使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业维特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。(OLAP委员会的定义) OLAP的目标是满足决策支持或多维环境特定的查询和报表需求,它的技术核心是“维”这个概念,因此OLAP也可以说是多维数据分析工具的集合。OLAP是连接数据仓库和用户的桥梁,通过OLAP服务器用户可以很方便的浏览信息,进行决策!按照数据的存储方式进行分类,OLAP分为MOLAP,ROLAP,HOLAP三类。
OLAP支持最终用户进行动态多维分析、预测分析;切片和切块并在屏幕上显示,从宏观到微观,对数据进行深入分析;可查询底层的细节数据,在观察区域中选转,进行不同维之间的比较,在OLAP中有变量、维、维的层次、维成员、多维数组、数据单元等基本概念降,变量是从现实系统中抽象出来的,用于描述数据的实际含义;维是观察者观察数据的特定角度;维的层次是数据的某个维还可以存在细节程度不同的多个描述方面,称为维的层次;维成员是维的一个取值。如果一个维是多层次的,那么维成员就是不同维层次取值的组合。例如时间维具有年、月、日这三个层次,分别在年、月、目上各取一个值组合起来,就得到了时间维的一个维成员,如:2005年6月6日;多维数据集是决策支持的支柱,也是OLAP的核心,有时也称为立方体或超立方体。
0LAP使用三层的体系结构:数据库服务器、0LAP服务器和客户端工具。
第一层是数据仓库服务器,它实现与基层运营的数据库系统的连接,完成企业级数据一致和数据共享的工作。
第二层是OLAP服务器,它根据最终客户的请求实现分解成OLAP分析的各种动作,并使用数据仓库中的数据完成这些动作。
第三层是前端的展现工具,用于将OLA卫服务器处理得到的结果用直观的方式,如多维报表、饼图、柱状图、三维图形等展现给最终用户。
这种三层体系结构使数据、应用逻辑和客户应用分离开,有利于系统维护和升级。系统需要修改或者增加功能时,只修改其中的某些部分,而不用像两层的客户/HI务器体系做整体的改动。
数据仓库中的数据是不能用于联机事务处理(0TLP')的,而OLAP技术则利用数据仓库中的数据进行联机分析,将复杂的分析查询结果快速地返回给用户。OLAP利用多维数据集和数据聚集技术对数据仓库中的数据进行组织和汇总,用联机分析和可视化工具对这些数据迅速进行评价。OLAP用多维结构表示数据仓库中的数据,创建组织和汇总数据的立方体,这样才能有效地提高用户复杂查询的要求。因此数据仓库结合OLAP分析技术使管理决策更加高效有据!
北京甲骨文软件有限公司咨询经理鲁百年博士 一、国内信息化的现状 1、信息化建设的发展历史:在国内信息化建设过程中,基本上是按照当时业务系统的需求进行建设,例如:在一个企业中,财务部门为了减少工资发放的差错,提高发放的效率,先建设一个工资发放和管理程序;为了报账和核对的需求,建设一个财务管理程序;在银行首先为了业务处理的方便,将最基本的手工记帐和处理的业务建成一个系统,过一段时间,如果有新的业务推出,就再建设一个新的系统,或在原系统的基础上增加新的业务处理。这样的结果使每个系统和系统之间缺少真正的信息沟通和信息交换。 2、为何要建立数据仓库:前面我们讲过,业务系统各自为政,相互独立。当很多业务系统建立后,由于领导的要求和决策的需求,需要一些指标的分析,在相应的业务系统基础上再增加分析和相应的报表功能,这样每个系统就增加了报表和分析功能。但是,由于数据源不统一导致了对同一个指标分析的结果不相同。为了解决该问题,Bell Inman提出了数据仓库的概念,其目的是为了分析和决策的需要,将相互分离的业务系统的数据源整合在一起,可以为领导和决策层提供分析和辅助决策。 3、国内企业对数据仓库建设认识的误区: 大家对数据仓库的认识是将业务系统的数据进行数据抽取、迁移和加载(ETL),将这些数据进行整合存放在一起,统一管理,需要什么样的分析就可提供什么样的分析,这就是数据仓库。这样做的结果是花了一年到两年的时间都无法将整个企业业务系统的数据整合在一起,花钱多、见效慢、风险大。一年后领导问起数据仓库项目时,回答往往是资金不足,人力不够,再投入一些资源、或者再延长半年的时间就会见到效果,但是往往半年过后还是仅仅可以看到十几张或者几十张报表。领导不满意,项目负责人压力也很大,无法交待。这时,项目经理或者项目负责人才意识到,项目有问题,但是谁也不敢说项目有问题,因为这样显然是自己当时的决策失误。怎么办?寻找咨询公司或者一些大的厂商,答案往往是数据仓库缺乏数据模型,应该考虑数据模型。如果建设时考虑到整个企业的数据模型,就可以建设成企业级的数据仓库(EDW。什么是数据模型,就是满足整 个企业分析要求的所有数据源。结果会如何,我个人认为:这样做企业级数据仓
浅谈煤矿安全管理数据仓库的构建与应用(通用版) Safety is the prerequisite for enterprise production, and production is the guarantee of efficiency. Pay attention to safety at all times. ( 安全论文) 单位:_______________________ 部门:_______________________ 日期:_______________________ 本文档文字可以自由修改
浅谈煤矿安全管理数据仓库的构建与应用 (通用版) 摘要:改革开放以来,随着我国煤矿企业的发展以及计算机信息时代的到来,煤矿安全信息计算机管理越来越受到人们的重视。本文从加强煤矿信息管理建设的角度出发,在借鉴前人研究的基础上,结合当下煤矿安全生产的特点,通过对煤矿安全信息进行分析,提出了基于数据仓库模型的煤矿信息安全管理,同时还就数据仓库在企业中的应用进行了探讨。 关键词:煤矿安全信息管理;数据仓库;应用 一、数据仓库 1.1数据仓库的概念 数据仓库,英文名称为DataWarehouse,可简写为DW或
DWH。数据仓库是一种数据的战略集合,其目的是为企业所有级别的决策制定过程提供支持。应用数据仓库的最终目的是为企业提供需要业务智能来指导业务流程改进。 1.2数据仓库的特点 数据仓库并不是一般意义上的“大型数据库”,它是在数据库已经大量存在的前提下,为进一步挖掘数据资源、做出更好的而建立的。由于以有的数据库中的数据有较大的冗余,所以需要的存储也较大,为了更方便的为前端查询和分析,因而便想到数据仓库方案的建设。为了更好地为前端应用服务,数据仓库的特点一般具有以下几点: (1)效率高 对于大多数情况来说,利用数据仓库分析的数据一般分为日、周、月、季、年等。而其中以日为周期的数据所要求的效率最高,其要求24小时或者12小时内,客户能看到前一天的数据分析。由于有的企业每日的数据量很大,如果数据仓库的设计不好,数据仓库经常出问题,从而导致数据分析需要延迟1-3
数据仓库技术在医院信息系统中的应用 本文介绍了数据仓库技术的发展历程及特点,对数据仓库技术在医院信息管理平台的应用进行了分析,并对医院信息平台使用数据仓库技术提出了建议,为数据仓库技术在医院的建设及使用提供了一定有价值的参考。 标签:数据仓库;医院信息;应用 数据仓库可为所有类型的数据起到支持与集合作用,也是企业发展过程中对决策定制必须要用到的。数据仓库作为独立的数据存储,对企业业务报告进行分析以及作出决策等提供一定支持,对业务流程、所花费成本以及质量等进行控制的一种系统。 1 数据仓库技术 数据仓库由数据仓库之父比尔·恩门(Bill Inmon)于1990年提出,主要功能是将组织透过资讯系统之联机事务处理(OLTP)经年累月所累積的大量资料,透过数据仓库理论所特有的资料储存架构,有系统的进行分析整理,以利于各种分析方法如联机分析处理(OLAP)、数据挖掘(Data Mining)的进行,并进而支持如决策支持系统(DSS)、主管资讯系统(EIS)的创建,帮助决策者能快速有效的从大量资料中,分析出有价值的资讯,有利于决策拟定及快速回应外在环境变动,帮助建构商业智能(BI)[1]。数据仓库技术主要对数据库中获得的信息进行研究和分析,以找出解决方法,因此,数据仓库最大的特点就是具有集成性、稳定性和实时性。 2 数据仓库的特点 数据仓库最大的特点就是可以在数据库存储大量数据的情况下,还可以对数据进行深度挖掘,以对企业在决策问题上提供支持。数据仓库同其他系统大型数据库不同,数据仓库存在的最主要目的就是为企业所得数据进行分析与查询,以为企业提供数据依靠,所以在所用的存储量上较多。数据仓库为了能为企业提供更多前端应用服务,在其实际应用过程中还存在以下几点特点: 2.1对数据仓库要求效率过高数据库对数据进行分析也是有其规律的,分别按照年、季、月、周、日为周期对数据进行分析。以日周期为例,对数据仓库的要求上尤其高,要求其分析数据的频率能够在客户所要求的时间内得出结果。但对于大型企业来说,每天企业所涉及的数据量非常多,如果数据仓库使用不恰当则会延误客户的需求,进而给企业造成影响。 2.2对数据质量要求严格数据仓库所收集到的各种信息必须保证准确,如果在某一数据或者某一代码中出现错误,那么往往就会造成部分数据失真。在数据仓库实际使用过程中所涉及环节较多,且内容复杂,因此,在为客户所提供的数据信息上仍会有错误数据存在,使客户作出错误的判断,进而对企业造成损失。
第1章数据仓库建设 1.1数据仓库总体架构 专家系统接收增购项目车辆TCMS或其他子系统通过车地通信传输的实时或离线数据,经过一系列综合诊断分析,以各种报表图形或信息推送的形式向用户展示分析结果。针对诊断出的车辆故障将给出专家建议处理措施,为车辆的故障根因修复提供必要的支持。 根据专家系统数据仓库建设目标,结合系统数据业务规,包括数据采集频率、数据采集量等相关因素,设计专家系统数据仓库架构如下: 数据仓库架构从层次结构上分为数据采集、数据存、数据分析、数据服务等几个方面的容: 数据采集:负责从各业务自系统中汇集信息数据,系统支撑Kafka、Storm、Flume
及传统的ETL采集工具。 数据存储:本系统提供Hdfs、Hbase及RDBMS相结合的存储模式,支持海量数据的分布式存储。 数据分析:数据仓库体系支持传统的OLAP分析及基于Spark常规机器学习算法。 数据服务总线:数据系统提供数据服务总线服务,实现对数据资源的统一管理和调度,并对外提供数据服务。 1.2数据采集 专家系统数据仓库数据采集包括两个部分容:外部数据汇集、部各层数据的提取与加载。外部数据汇集是指从TCMS、车载子系统等外部信息系统汇集数据到专家数据仓库的操作型存储层(ODS);部各层数据的提取与加载是指数据仓库各存储层间的数据提取、转换与加载。 1.2.1外部数据汇集 专家数据仓库数据源包括列车监控与检测系统(TCMS)、车载子系统等相关子系统,数据采集的容分为实时数据采集和定时数据采集两大类,实时数据采集主要对于各项检测指标数据;非实时采集包括日检修数据等。 根据项目信息汇集要求,列车指标信息采集具有采集数据量大,采集频率高的特点,考虑到系统后期的扩展,因此在数据数据采集方面,要求采集体系支持高吞吐量、高频率、海量数据采集,同时系统应该灵活可配置,可根据业务的需要进行灵活配置横向扩展。 本方案在数据采集架构采用Flume+Kafka+Storm的组合架构,采用Flume和ETL 工具作为Kafka的Producer,采用Storm作为Kafka的Consumer,Storm可实现对海量数据的实时处理,及时对问题指标进行预警。具体采集系统技术结构图如下:
数据仓库与数据挖掘技术
第1章数据仓库与数据挖掘概述1.1数据仓库引论1 1.1.1为什么要建立数据仓库1 1.1.2什么是数据仓库2 1.1.3数据仓库的特点7 1.1.4数据进入数据仓库的基本过程与建立数据仓库的步骤11 1.1.5分析数据仓库的内容12 1.2数据挖掘引论13 1.2.1为什么要进行数据挖掘13 1.2.2什么是数据挖掘18 1.2.3数据挖掘的特点21 1.2.4数据挖掘的基本过程与步骤22 1.2.5分析数据挖掘的内容26 1.3数据挖掘与数据仓库的关系28 1.4数据仓库与数据挖掘的应用31 1.4.1数据挖掘在零售业的应用31 1.4.2数据挖掘技术在商业银行中的应用36 1.4.3数据挖掘在电信部门的应用40 1.4.4数据挖掘在贝斯出口公司的应用42 1.4.5数据挖掘如何预测信用卡欺诈42 1.4.6数据挖掘在证券行业的应用43 思考练习题一44
1.1.1为什么要建立数据仓库 数据仓库的作用 建立数据仓库的好处
1.1.2 什么是数据仓库 1.数据仓库的概念 W.H.Inmon在《Building the Data Warehouse》中定义数据仓库为:“数据仓库是面向主题的、集成的、随时间变化的、历史的、稳定的、支持决策制定过程的数据集合。”即数据仓库是在管理人员决策中的面向主题的、集成的、非易失的并且随时间而变化的数据集合。 “DW是作为DSS基础的分析型DB,用来存放大容量的只读数据,为制定决策提供所需的信息。” “DW是与操作型系统相分离的、基于标准企业模型集成的、带有时间属性的。即与企业定义的时间区段相关,面向主题且不可更新的数据集合。” 数据仓库是一种来源于各种渠道的单一的、完整的、稳定的数据存储。这种数据存储提供给可以允许最终用户的可以是一种他们能够在其业务范畴中理解并使用的方式。 数据仓库是大量有关公司数据的数据存储。 仓库提供公司数据以及组织数据的访问功能,其中的数据是一致的(consistent),并且可以按每种可能的商业度量方式分解和组合;数据仓库也是一套查询、分析和呈现信息的工具;数据仓库 是我们发布所用数据的场所,其中数据的质量是业务再工程的驱动器(driver of business reengineering)。 定义的共同特征:首先,数据仓库包含大量数据,其中一些数据来源于组织中的操作数据,也有一些数据可能来自于组织外部;其次,组织数据仓库是为了更加便利地使用数据进行决策;最 后,数据仓库为最终用户提供了可用来存取数据的工具。
数据库技术及其在金融行业的应用 1. 前言 数据库仓库(DW)技术从1991年开始出现,经过多年的摸索和应用,目前在一些发达国家已经建设得比较成熟,为企业综合与灵活的分析型应用提供了强大的数据支撑,为管理层的分析决策和操作层的智能营销提供了技术保证,为企业带来了多方面的收益。而在国内,数据库仓库仍处于尝试或初级建设阶段。 国内的金融行业,随着外部监管和信息披露的压力、内部管理和决策分析的需要,在建设分析类应用时,也正在逐渐从孤立的数据层向统一的数据仓库层规划和转移。建立数据仓库能够减少对数据层的重复投资和资源浪费、统一数据标准、监管和提高数据质量、消除信息孤立、支持综合分析和灵活及时的分析型应用、适应管理和发展、提高业内竞争力。 本文对数据库技术做一个概括性的介绍,并对国内外金融行业数据仓库技术的应用现状做一个简单分析。 2. 数据仓库概念 2.1. DW的提出 2.1.1. 需求 业务系统的建设与逐渐完善,巨量数据信息的积累。 分析类需求不断增加,传统分析类应用造成巨大的资源浪费和管理困难。 业务数据平台异构、数据来源口径多、标准不统一、信息孤立。 整合部门级应用,建设企业级应用,满足综合分析、复杂查询、智能营销等高级需求。 2.1.2. DW概念的提出 MIT在20世纪70年代对业务系统和分析系统的处理过程进行研究,结论是只能采用完全不同的架构和设计方法。 1988年,IBM为解决全企业数据集成问题,提出了信息仓库的概念,确立了原理、架构和规范。但没有进行实际的设计。 1991年,Bill Inmon提出了数据仓库概念,并对为什么建设数据仓库和如何建设数据仓库进行了论述。Bill Inmon被称为数据仓库之父。
数据仓库与数据挖掘 摘要 数据挖掘是一新兴的技术,近年对其研究正在蓬勃开展。本文阐述了数据仓库及数据挖掘的相关概念.做了相应的分析,同时共同探讨了两者共同发展的关系,并对数据仓库与挖掘技术结合应用的发展做了展望。用Data Miner作为对数据挖掘的工具,给出了应用于医院的数据仓库实例。指出了数据挖掘技术在医疗费用管理、医疗诊断管理、医院资源管理中具有的广泛应用性,为支持医院管理者的分析决策作出了积极探索。 Abstract The Data Mine is a burgeoning technology,the research about it is developing flourishing.In this paper,it expatiates and analyses the concepts of Data Warehouse and Data Mine Together,discussing the connections of how to expand the two technologies,and combining the two technologies with prospect.The data warehouse supports the mass data on the further handling and recycling.The paper points out the use of data mining in patient charge control,medical quality control, hospital resources allocation management. It helps the hospital to make decisions positively 关键字:数据仓库;数据挖掘;医院信息系统 Key words:Data Warehouse;Data Mine;Hospital information system
Northwind数据仓库的构建和ETL 课程设计与实验报告
课程设计与实验教学目的与基本要求 数据仓库与知识工程课程设计与实验是学习数据仓库与知识工程的重要环节,通过课程设计与实验,可以使学生全面地了解和掌握数据仓库与知识工程课程的基本概念、原理及应用技术,使学生系统科学地受到分析问题和解决问题的训练,提高运用理论知识解决实际问题的能力。 使学生在后继课的学习中,能够利用数据仓库与数据挖掘技术及实践经验,解决相应的实际问题,并能在今后的学习和工作中,结合自己的专业知识,开发相应的数据仓库与数据挖掘应用程序。培养学生将已掌握的理论与实践开发相结合的能力,以及在应用方面的思维能力和实践动手能力。 课程设计与实验一数据仓库的构建和ETL (一)目的 1.理解数据库与数据仓库之间的区别与联系; 2.掌握数据仓库建立的基本方法及其相关工具的使用。 3.掌握ETL实现的基本方法及其相关工具的使用。 (二)内容 1. 以SQL Server为系统平台,设计、建立创建数据仓库NorthwindDW(根据课程设计内容)。 2. 将业务数据库Northwind的数据经过ETL导入(或加载)到数据仓库NorthwindDW。 3. 将数据仓库NorthwindDW事实表的前100个记录导出到Excel中。 (三)数据仓库设计要求 Northwind数据库存储了一个贸易公司的订单数据、产品数据、顾客数据、员工数据、供货商数据等,假设贸易公司的经营者迫切的需要准确地把握贸易公司经营情况,跟踪市场趋势,更加合理地制定商品采购、营销和奖励政策。具体的分析需求是: ●分析某商品在某地区的销售情况 ●分析某商品在某季度的销售情况 ●分析某年销售多少金额的产品给顾客 ●分析某员工的销售业绩 任务:确定主题域、确定系统(或主题)的边界。设计数据模型(星型模型)的事实表和维表。
数据仓库技术与应用 LEKIBM standardization office【IBM5AB- LEKIBMK08- LEKIBM2C】
文章编号 :5(2004 03 收稿日期 :27 基金项目 :教育部高等学校骨干教师资助计划项目 (GG 28 作者简介 :项军 (19792 , 男 , 四川绵阳人 , 空军工程大学导弹学院计算机工程系硕士研究生 , 研究方向 :智能信息处理与人工智能 ; 雷英杰 (19562 , 男 , 陕西渭南人 , 教授 , 博士生导师 , 研究方向 :智能信息处理 , 模式识别 , 人工智能。数据仓库技术与应用 项军 , 雷英杰 (空军工程大学导弹学院 , 陕西三原 713800 摘要 :对数据仓库、联机分析处理和数据挖掘等几个概念做了详细的介绍 , 在此基础上提出适用于电信系统应用的设计思想 , 详细介绍了该系统的系统结构、关键技术的实现和各子系统功能。关键词 :数据仓库 ; 联机分析处理 ; 数据挖掘中图分类号 :文献标识码 :A The T echnique and Application of Data W arehouse XI ANGJun ,LEI Y ing 2jie (Missile Institute of Air F orce Engineering University ,Sanyuan 713800,China Abstract :This paper introduces the concepts of data warehouse ,on 2line analytical processing and data mining ,puts forward the design thought of telecommunication system and briefly introduces the system structure ,the key techniques of the system and the functions of each sub 2system. K ey w ords :data warehouse ;on 2line analytical processing ;data mining 0引言
昆明理工大学信息工程与自动化学院学生实验报告 (2015—2016学年第1学期) 课程名称:数据仓库与数据挖掘开课实验室:444 2015年10月24日年级、专业、 班 计科121 学号姓名成绩 实验项目名称数据仓库的构建指导教师 教师评语该同学是否了解实验原理: A.了解□ B.基本了解□ C.不了解□ 该同学的实验能力: A.强□ B.中等□ C.差□ 该同学的实验是否达到要求: A.达到□ B.基本达到□ C.未达到□ 实验报告是否规范: A.规范□ B.基本规范□ C.不规范□ 实验过程是否详细记录: A.详细□ B.一般□ C.没有□ 教师签名: 年月日 一、上机目的及内容 目的: 1、理解数据库与数据仓库之间的区别与联系; 2、掌握典型的关系型数据库及其数据仓库系统的工作原理以及应用方法; 3、掌握数据仓库建立的基本方法及其相关工具的使用。 内容: 以SQL Server为系统平台,设计、建立数据库,并以此为基础创建数据仓库。 要求: 利用实验室和指导教师提供的实验软件,认真完成规定的实验项目,真实地记录实验中遇到的各种问题和解决的方法与过程,并绘出模拟实验案例的数据仓库模型。实验完成后,应根据实验情况写出实验报告。 二、实验原理及基本技术路线图(方框原理图或程序流程图) 数据仓库,由数据仓库之父W.H.Inmon于1990年提出,主要功能仍是将组织透过资讯系统之联机交易处理(OLTP)经年累月所累积的大量资料,透过数据仓库理论所特有的资料储存架构,作一有系统的分析
整理,以利各种分析方法如线上分析处理(OLAP)、数据挖掘(Data Mining)之进行,并进而支持如决策支持系统(DSS)、主管资讯系统(EIS)之创建,帮助决策者能快速有效的自大量资料中,分析出有价值的资讯,以利决策拟定及快速回应外在环境变动,帮助建构商业智能(BI)。 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及Microsoft SQL Server套件 四、实验方法、步骤(或:程序代码或操作过程) --建立数据 USE master CREATE DATABASE [DW] ON PRIMARY ( NAME = N'DW', FILENAME = N'E:\DW.mdf' ) LOG ON ( NAME = N'DW_log', FILENAME = N'E:\DW_log.ldf' ) GO USE DW -------------------------------- --1、建维表 /*1.1 订单方式*/ CREATE TABLE DIM_ORDER_METHOD (ONLINEORDERFLAG INT,DSC VARCHAR(20)) /*1.2 销售人员及销售地区*/ CREATE TABLE DIM_SALEPERSON (SALESPERSONID INT, DSC VARCHAR(20), SALETERRITORY_DSC VARCHAR(50)) /*1.3 发货方式*/ CREATE TABLE DIM_SHIPMETHOD (SHIPMETHODID INT,DSC VARCHAR(20)) /*1.4 订单日期*/ CREATE TABLE DIM_DATE (TIME_CD VARCHAR(8), TIME_MONTH VARCHAR(6), TIME_YEAR VARCHAR(6), TINE_QUAUTER VARCHAR(8), TIME_WEEK VARCHAR(6), TIME_XUN VARCHAR(4)) /*1.5 客户*/ CREATE TABLE DIM_CUSTOMER (CUSTOMERID INT,
互联网大数据与传统数据仓库技术比较研究 韩路 1.Hadoop技术简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,是目前全世界最主流的大数据应用平台。以分布式文件系统(HDFS)和MapReduce为核心的Hadoop,目前已整合了其他重要组件如Hive、HBase、Spark,以及统一资源调度管理组件Yarn,形成了一个完成的Hadoop产品生态圈。 1.1.HDFS HDFS是一个分布式文件系统,可设计部署在低成本硬件上。它可以通过提供高吞吐率支持大量数据的批量处理,同时支持应用程序流式访问系统数据。 1.2.MapReduce MapReduce是一种编程模型,用于大规模数据机的并行运算。MapReduce可以将一个任务分发到Hadoop平台各个节点上并以一种可靠容错的方式并行处理大量数据集,实现Hadoop的并行任务处理功能。 1.3.Hive Hive是用于对Hadoop中文件进行数据整理、特殊查询和分析储存的工具。Hive提供了一种结构化数据的机制,支持类似传统结构化数据库中SQL元的查询语言,帮助熟悉SQL的用户查询HDFS中数据。 1.4.HBase HBase是一个分布式的、列式储存的开源数据库。HBase不同于传统关系型数据库,适合非结构化数据储存,同时可以为一个数据行定义不同的列。HBase 主要用于需要随机访问、实时读写的大数据。 1.5.Spark Spark是基于内存计算的分布式计算框架。Spark提出了RDD概念,弥补了MapReduce在并行计算各个阶段无法进行有效数据共享的缺陷。同时,Spark形成了自己的生态系统:SparkSQL、SparkStreaming、MLlib,并完全兼容Hadoop 生态系统。
数据仓库制定方案 在当下的数据仓库系统安全控制模块中,我国数据仓库安全分为不同的等级。总体来说,我国的数据仓库安全性是比较低。为更好的健全计算机数据仓库体系,进行数据仓库安全体系的研究是必要的。很多软件都是因为其比较缺乏安全性而得不到较大范围的应用,归根结底是数据仓库安全性级别比较低。为满足现阶段数据仓库安全工作的需要,有利于数据仓库保密性的控制,保证这些数据存储与调用的一致性。 当前数据仓库安全控制过程中,首先需要对这些数据进行可用性的分析,从而有利于避免数据仓库遭到破坏,更有利于进行数据仓库的损坏控制及其修复。其次为了保证数据仓库的安全性、效益性,也离不开对数据仓库整体安全性方案的应用。最后必须对数据仓库进行的一切操作进行跟踪记录,以实现对修改和访问数据仓库的用户进行追踪,从而方便追查并防止非法用户对数据仓库进行操作。 2.1数据仓库安全整体规划 本方案通过对电力行业敏感信息泄露安全威胁的分析,对数据仓库安全进行整体设计与规划,通过全系列数据仓库安全产品相互之间分工协作,共同形成整体的防护体系,覆盖了数据仓库安全防护的事前诊断、事中控制和事后分析。 制定严密可行的实施计划,整个工程严格按照计划进行;公司质量控制部利用ISO9000质量管理规范对工程的软件开发及实施全过程进行监督和控制;建立完善的软件开发和工程实施的文档体系。对程序进行测试,对各个模块之间的关联情况下可能出现的问题进行严密的测试,并不断完善在测试过程中暴露出来的问题。在这过程中质量控制小组将全程参与,确保软件质量。 需求调研是数据仓库开发的最重要的环节之一,在调研的过程中能否真实、准确地描述客户的需求,对于数据仓库的开发有着举足轻重的影响。与客户沟通不够导致对同一个事物的描述或者理解有分歧和差异,或者调研过程中流于表面文字,而没有进入实际的操作,都可能造成在需求调研的过程中造成对需求不精确的理解。失之毫厘,谬之千里,需求调研的微小差异可能会在软件的开发过程中造成较大的偏差,直接影响了工程的建设质量。为此我们为需求调研工作分配
数据仓库建设步骤 1.系统分析,确定主题 确定一下几个因素: 操作出现的频率,即业务部门每隔多长时间做一次查询分析。 在系统中需要保存多久的数据,是一年、两年还是五年、十年 用户查询数据的主要方式,如在时间维度上是按照自然年,还是财政年。 用户所能接受的响应时间是多长、是几秒钟,还是几小时。 2.选择满足数据仓库系统要求的软件平台 选择合适的软件平台,包括数据库、建模工具、分析工具等。有许多因素要考虑,如系统对数据量、响应时间、分析功能的要求等,以下是一些公认的选择标准: 厂商的背景和支持能力,能否提供全方位的技术支持和咨询服务。 数据库对大数据量(TB级)的支持能力。 数据库是否支持并行操作。 能否提供数据仓库的建模工具,是否支持对元数据的管理。 能否提供支持大数据量的数据加载、转换、传输工具(ETT)。 能否提供完整的决策支持工具集,满足数据仓库中各类用户的需要。 3.建立数据仓库的逻辑模型 具体步骤如下: 1)确定建立数据仓库逻辑模型的基本方法。 2)基于主题视图,把主题视图中的数据定义转到逻辑数据模型中。 3)识别主题之间的关系。 4)分解多对多的关系。 5)用范式理论检验逻辑数据模型。 6)由用户审核逻辑数据模型。 4.逻辑数据模型转化为数据仓库数据模型 具体步骤如下: 1)删除非战略性数据:数据仓库模型中不需要包含逻辑数据模型中的全部数据项,某些用于操作 处理的数据项要删除。 2)增加时间主键:数据仓库中的数据一定是时间的快照,因此必须增加时间主键。 3)增加派生数据:对于用户经常需要分析的数据,或者为了提高性能,可以增加派生数据。
4)加入不同级别粒度的汇总数据:数据粒度代表数据细化程度,粒度越大,数据的汇总程度越高。 粒度是数据仓库设计的一个重要因素,它直接影响到驻留在数据仓库中的数据量和可以执行的 查询类型。显然,粒度级别越低,则支持的查询越多;反之,能支持的查询就有限。 5.数据仓库数据模型优化 数据仓库设计时,性能是一项主要考虑因素。在数据仓库建成后,也需要经常对其性能进行监控,并随着需求和数据量的变更进行调整。 优化数据仓库设计的主要方法是: 合并不同的数据表。 通过增加汇总表避免数据的动态汇总。 通过冗余字段减少表连接的数量,不要超过3~5个。 用ID代码而不是描述信息作为键值。 对数据表做分区。 6.数据清洗转换和传输 由于业务系统所使用的软硬件平台不同,编码方法不同,业务系统中的数据在加载到数据仓库之前,必须进行数据的清洗和转换,保证数据仓库中数据的一致性。 在设计数据仓库的数据加载方案时,必须考虑以下几项要求: 加载方案必须能够支持访问不同的数据库和文件系统。 数据的清洗、转换和传输必须满足时间要求,能够在规定的时间范围内完成。 支持各种转换方法,各种转换方法可以构成一个工作流。 支持增量加载,只把自上一次加载以来变化的数据加载到数据仓库。 7.开发数据仓库的分析应用 建立数据仓库的最终目的是为业务部门提供决策支持能力,必须为业务部门选择合适的工具实现其对数据仓库中的数据进行分析的要求。 信息部门所选择的开发工具必须能够: 满足用户的全部分析功能要求。数据仓库中的用户包括了企业中各个业务部门,他们的业务不同,要求的分析功能也不同。如有的用户只是简单的分析报表,有些用户则要求做预 测和趋势分析。 提供灵活的表现方式。分析的结果必须能够以直观、灵活的方式表现,支持复杂的图表。 使用方式上,可以是客户机/服务器方式,也可以是浏览器方式。 事实上,没有一种工具能够满足数据仓库的全部分析功能需求,一个完整的数据仓库系统的功能可能是由多种工具来实现,因此必须考虑多个工具之间的接口和集成性问题,对于用户来说,希望看到的是一致的界面。 8.数据仓库的管理
313 二 ○一一年第三十三期 华章 Magnificent Writing 数据仓库构建技术 王萌 (南京晓庄学院,江苏南京210000) [摘要]该文从数据仓库的定义着手,结合数据仓库的通用体系结构,总结、探究了普通数据仓库和空间数据仓 库的构建方法、模型及关键要点。 [关键词]普通数据仓库;空间数据仓库;构建;数据模型随着不同的管理信息系统(MIS )在企业不同部门的大规模 应用及企业对数据管理不断提出新的要求,不仅要求能实现传统的联机事务处理,而且越来越多的要求是各种应用系统能够在企业不断积累的以及从企业外部获取的丰富信息资源的基础上,把这些分散的、不一致的、凌乱的信息资源加以利用,即更多地参与数据分析和决策支持,由此出现了一种用于数据分析处理和决策支持的数据存储和组织技术,即数据仓库技术。 1、什么是数据仓库 数据仓库是面向主题的、集成的、具有时间特征的、稳定的数据集合,用以支持经营管理中的决策制定过程。数据仓库提供用户用于决策支持的当前和历史数据,这些数据在传统的操作型数据库中很难或不能得到。 面向主题是指数据仓库中的数据是按照一定的主题域进行组织。主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。集成的是指数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。 数据仓库的体系结构分数据源、数据转换、数据仓库、数据集市和用户几部分。数据源,包括企业内部的业务数据、遗留数据、其它业务系统数据及相关WEB 数据等;数据转换是数据仓库构建的重要环节,主要是对各种复杂的数据源进行抽取、转换、装载及其他处理,同时要实现数据质量跟踪监控以及元数据抽取与创建等工作;数据仓库主要实现对各种数据的组织、存储及管理等;数据集市是为不同业务而单独设计的数据仓库系统,即开发者为企业内部的不同用户群定制特殊的数据仓库子系统。用户部分,即具体面向使用者的应用部分,主要是指数据仓库存取与检索为用户提供了访问数据仓库或数据集市的功能,其中分析与报告为用户使用数据仓库提供了一组工具,用于帮助用户对数据仓库或数据集市进行联机分析或数据挖掘等。 2、数据仓库构建方法 2.1普通数据仓库构建方法。对于普通数据仓库的构建,企业在对整个系统的建设综合各种因素的基础上,将整个项目的实施分阶段、分步骤实施,可以在每一阶段建设的基础上分阶段纳入不同的业务系统,逐步建立起一个综合的、专题较为完善的、适合部门、子单位使用的完整的数据仓库系统,从而才能使投资尽快获得收益。 在数据仓库的构建过程中,利用模糊数学可实现数据仓库内数据的语义表示,丰富数据加工的手段,提高分析处理的能力。数据仓库的构建,一般采取先构建数据集市,最后将各个数据集市整合在一起形成数据仓库的渐进模式;通过概念层、逻辑层、物理层建模,确定相关主题域的数据集市并对其进行联机分析处理。构建数据仓库模型一般采用以下几种: 2.1.1星型模型:星型模型是最常用的数据仓库设计结构的实现模式。使数据仓库形成了一个集成系统,为用户提供分析服务对象。该模型的核心是事实表,围绕事实表的是维度表。通过事实表将各种不同的维度表连接起来,各个维度表都连接到中央事实表。 2.1.2星系模型(也称雪花模型):雪花模型对星型模型的维度表进一步标准化,对星型模型中的维度表进行了规范化处理。同时也是对星型模型的扩展,每一个维度都可以向外连接到多 个详细类别表。在实际应用中,用户的需求多种多样,数据来源可能为多个事实表,故可采用多个事实表共存,之间通过公用的维表相关联的星系模型,也称为事实星座。 2.1.3原子级数据模型和汇总级数据模型并存:坚持原子级数据模型和汇总级数据模型并存,而且要尽可能地细化原子级数据。 2.1.4设立代理键:代理键是维表中一些没有业务含义的字段,只是一个由数据仓库加载程序时建立的数字。 2.2空间数据仓库构建方法。随着GIS (地理信息系统)在各行业的广泛应用,最初面向事务处理为主的空间数据库信息系统已不能满足需要,信息系统开始从管理转向决策处理,空间数据仓库就是为满足这种新的需求而提出的空间信息集成系统。尤其是地理信息决策支持系统中,空间数据仓库系统显得尤为重要。 空间数据仓库具有普通数据仓库的普遍特征,但其本身有一些特殊性。并且空间数据仓也并不是空间数据库的简单集合。与空间数据库比,空间数据仓除支持数据库外,还支持数据文件、文本文件、应用程序等众多数据源;另外空间数据仓库中的数据有时间数据、空间数据、属性数据及异构数据等多种数据;其次空间数据仓库中还包括了数据处理规则、算法等;再次空间数据仓库的数据是对原始数据进行加工、处理、集成等转换,是对数据的增值和统一;空间数据库还引入了时间纵的概念,它是以时间为基准来管理数据,可以截取不同时间尺度上的信息,从瞬态到区段时间直到全体,空间数据仓库是依赖于时间维的数据结构,它可以根据不同的需要划分不同的时间粒度等级,以便进行各种复杂的趋势分析。当然,不言而喻,它还包含了空间维的方位数据。正因为空间数据仓库与普通数据仓库的不同,并且它以空间数据仓库完全不是相同的概念,一般空间数据仓库以如下体系结构分为四大功能模块,分别是源数据、数据变换工具、空间数据仓库、客户端分析工具。源数据它不仅指那些常见的空间数据库,还包括文件、网页、知识库、遗留系统等各种数据源。数据变换工具与具有普通数据仓库数据变换相同的提取转换功能,但它还包括了特有的空间变换等。空间数据仓库以立体、多维的方式来组织和显示数据。但最基本的空间维和时间维是其反映客观世界动态变化的基础,空间数据仓库技术最关键要点也就是时间维和空间维数据组织方式。目前空间数据仓库已成为国、内外GIS (地理信息系统)研究的热点并取得了较大进展。要把空间信息融合进企业现有的数据仓库中,在原有系统不作较大改动的前提下,一般采用三种模式构建企业空间数据仓库:(1)把空间信息作为多维模型中的空间维引入;(2)把空间信息作为研究主题引入;(3)在维和度量中都包含空间信息。因此,计算并存储所有空间度量是不现实的。一般使用空间索引树(如R —tree )在最细空间粒度上构建分组层次,作为空间维的分层,每个空间维需要建立一棵空间索引树。 3、结束语总之,数据仓库构建是数据仓库技术的关键,数据仓库技术是一项基于数据管理和利用的综合性技术和解决方案,尤其是现在空间数据仓库在GIS 中的广泛应用,它成为数据库市场的新一轮增长点,同时也成为下一代信息系统的重要组成部分。
中国银行广东分行数据仓库成功应用案例 信用卡业务是商业银行业务中非常重要的一部分,中国的商业银行开展信用卡业务已多年,相关数据积累相对完备且真实,信用卡业务的经营运作也已从简单的扩大规模、以量取胜阶段进入到成熟竞争、以质取胜阶段,各商业银行不断推出新的服务品种和花样繁多的增值服务,提高市场占有率并强化品牌意识以获得利润。 中国加入WTO后,银行卡业务将在3至5年内对外资银行开放,而银行卡业务不依赖于分支机构的特点将使中国的商业银行信用卡业务面临更加严酷的竞争。信用卡业务竞争本质上就是客户的竞争,而且是优质客户的竞争。针对客户发现、客户提升、客户保持、市场细分、忠诚度、贡献度、个性化服务乃至个人信用风险等等一系列围绕客户关系的新问题,支持日常运作的信用卡生产系统是面向柜员和交易的日常营运和客户服务基础设施,无法提供众多分析、决策型用户对大量历史数据同时进行突发的、复杂的决策分析,而建立一套以客户为中心的信用卡业务分析系统则是实现上述命题的必要可行手段。 在这种情况下,中国银行广东分行引入了海波龙的Hyperion Intelligence,希望通过利用Hyperion Intelligence应用实现这样的目标:建立一套以客户为中心的信用卡业务分析系统,方便企业各级工作人员获取各类信息,实现对成本收益、风险控制、绩效评估、客户管理、营销战役等决策目标的支持,并达到风险管理和控制、客户关系管理与个性化服务、商户分析与市场策略、费用控制与利润分析四大应用目标。 成功典范 中国银行广东省分行是国内金融界最早成功实施数据仓库应用解决方案的单位,其在1996年投产的省市两级金融管理信息系统(FMIS)因首次采用并成功实施先进的数据仓库/OLAP技术而荣获“八五”国家科技攻关重大成果奖,并成为目前业界反复引用的典型成功案例。 在随后的数年中,中国银行广东省分行在决策支持/数据仓库应用研发方面的投入一直保持相当大的力度,陆续推出数项新的应用,应用领域也从最初的财务管理、资产负债指标监控等分析主题逐步延伸至目前的客户及消费行为分析、个人信用评估、授信风险监控、客户关系管理以及一对一个性化营销等分析主题。 广东华际友天信息科技有限公司和中国银行广东省分行共同实施的信用卡分析系统采用了Hyperion和IBM在业界领先的数据仓库技术和工具,专门针对信用卡业务的商业智能应用。此系统的研制目的是为与信用卡业务有关各级管理人员、统计分析人员、风险监控人员,特别是业务发展人员提供灵活有效的实时数据分析/决策支持环境,使他们能够便捷地获得并分析客户特征信息、各交易要素信息以及市场统计信息,从而支持成本收益、风险控制、绩效评估、客户管理、营销战役等决策目标的实现。
一、数据仓库 数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。 1、数据仓库是面向主题的;操作型数据库的数据组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织。主题是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。 2、数据仓库是集成的,数据仓库的数据有来自于分散的操作型数据,将所需数据从原来的数据中抽取出数据仓库的核心工具来,进行加工与集成,统一与综合之后才能进入数据仓库; 数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。 数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。 数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到当前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。 3、数据仓库是不可更新的,数据仓库主要是为决策分析提供数据,所涉及的操作主要是数据的查询; 4、数据仓库是随时间而变化的,传统的关系数据库系统比较适合处理格式化的数据,能够较好的满足商业商务处理的需求。稳定的数据以只读格式保存,且不随时间改变。 5、汇总的。操作性数据映射成决策可用的格式。 6、大容量。时间序列数据集合通常都非常大。 7、非规范化的。Dw数据可以是而且经常是冗余的。 8、元数据。将描述数据的数据保存起来。 9、数据源。数据来自内部的和外部的非集成操作系统。 二、数据仓库的特点要求 数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的,它并不是所谓的“大型数据库”。数据仓库的方案建设的目的,是为前端查询和分析作为基础,由于有较大的冗余,所以需要的存储也较大。为了更好地为前端应用服务,数据仓库往往有如下几点特点: 1. 效率足够高。 数据仓库的分析数据一般分为日、周、月、季、年等,可以看出,日为周期的数据要求的效率最高,要求24小时甚至12小时内,客户能看到昨天的数据分析。由于有的企业每日的数据量很大,设计不好的数据仓库经常会出问题,延迟1-3日才能给出数据,显然不行的。