
SPSS操作方法:判别分析例题
实验指导之二
判别分析的SPSS软件的基本操作
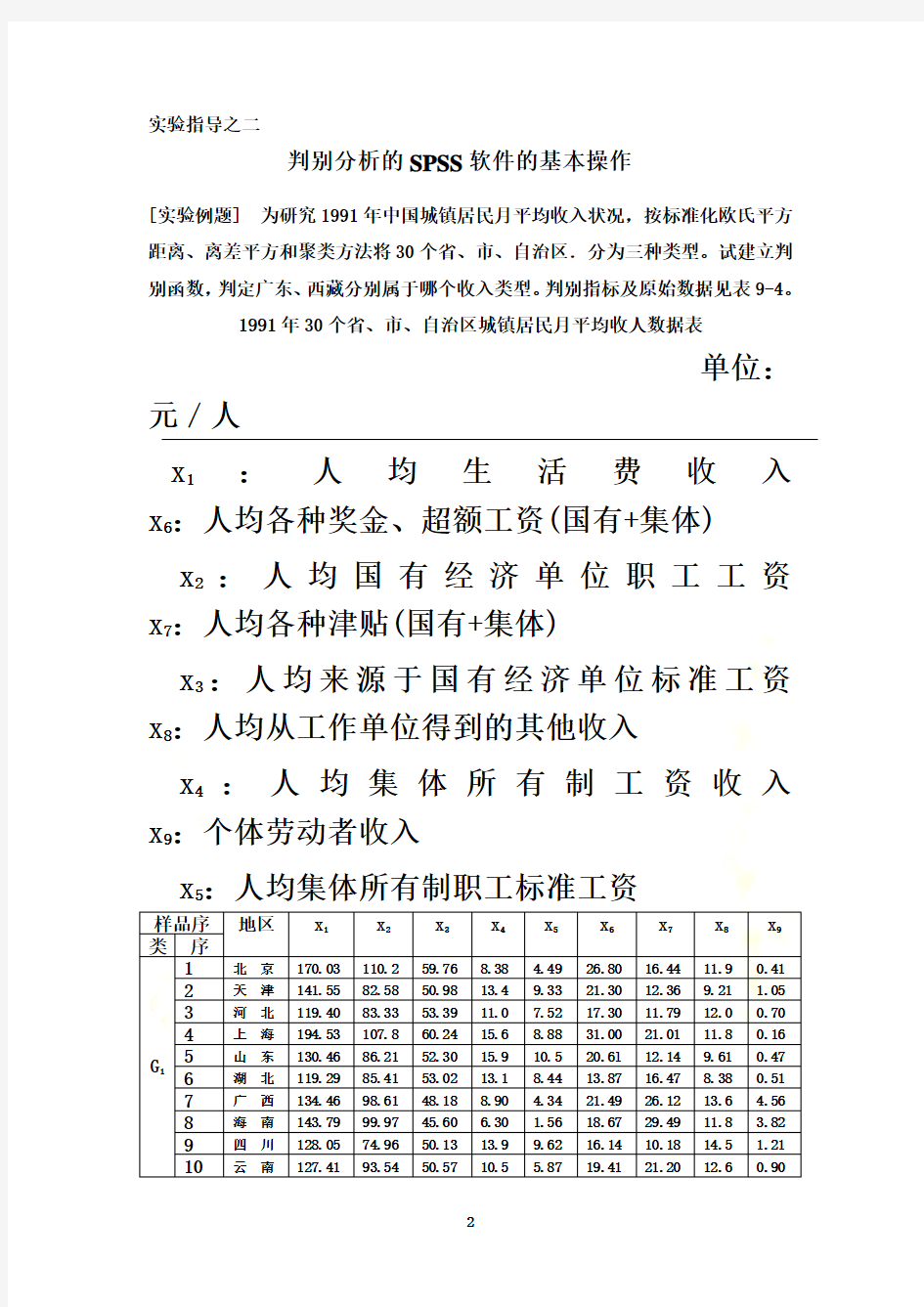
[实验例题] 为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方
距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。
1991年30个省、市、自治区城镇居民月平均收人数据表
单位:元/人
x
1
:人均生活费收入
x
6
:人均各种奖金、超额工资(国有+集体)
x
2
:人均国有经济单位职工工资
x
7
:人均各种津贴(国有+集体)
x
3
:人均来源于国有经济单位标准工资
x
8
:人均从工作单位得到的其他收入
x
4
:人均集体所有制工资收入
x
9
:个体劳动者收入
x
5
:人均集体所有制职工标准工资
样品序地区x
1x
2
x
3
x
4
x
5
x
6
x
7
x
8
x
9
类序
G
11 北京170.03110.259.768.38 4.4926.8016.4411.90.41
2 天津141.5582.5850.9813.49.3321.3012.369.21 1.05
3 河北119.4083.3353.3911.07.5217.3011.7912.00.70
4 上海194.53107.860.2415.68.8831.0021.0111.80.16
5 山东130.4686.2152.3015.910.520.6l12.149.610.47
6 湖北119.2985.4153.0213.18.4413.8716.478.380.51
7 广西134.46 98.6148.188.90 4.3421.4926.1213.6 4.56
8 海南143.79 99.97 45.60 6.30 1.56 18.67 29.49 11.8 3.82
9 四川128.05 74.96 50.13 13.9 9.62 16.14 10.18 14.5 1.21
10 云南127.41 93.54 50.57 10.5 5.87 19.41 21.20 12.6 0.90
11 新疆122.96 101.4 69.70 6.30 3.86 11.30 18.96 5.62 4.62
G
21 山西102.49 71.72 47.72 9.42 6.96 13.12 7.9 6.66 0.61
2 内蒙古106.14 76.27 46.19 9.65 6.27 9.655 20.1O 6.97 0.96
3 吉林104.93 72.99 44.60 13.7 9.01 9.435 20.61 6.65 1.68
4 黑龙江103.34 62.99 42.9
5 11.1 7.4l 8.342 10.19 6.45 2.68
5 江西98.089 69.45 43.04 11.4 7.95 10.59 16.50 7.69 1.08
6 河南104.12 72.23 47.31 9.48 6.43 13.14 10.43 8.30 1.11
7 贵州108.49 80.79 47.52 6.06 3.42 13.69 16.53 8.37 2.85
8 陕西113.99 75.6 50.88 5.21 3.86 12.94 9.492 6.77 1.27
9 甘肃114.06 84.31 52.78 7.81 5.44 10.82 16.43 3.79 1.19
10 青海108.80 80.41 50.45 7.27 4.07 8.371 18.98 5.95 0.83
11 宁夏115.96 88.2l 51.85 8.81 5.63 13.95 22.65 4.75 0.97
G
31 辽宁128.46 68.91 43.4l 22.4 15.3 13.88 12.42 9.01 1.41
2 江苏135.24 73.18 44.54 23.9 15.2 22.38 9.661 13.9 1.19
3 浙江162.53 80.11 45.99 24.3 13.9 29.5
4 10.90 13.0 3.47
4 安徽111.77 71.07 43.64 19.4 12.
5 16.68 9.698 7.02 0.63
5 福建139.09 79.09 44.19 18.5 10.5 20.23 16.47 7.67 3.08
6 湖南124.00 84.66 44.05 13.5 7.4
7 19.11 20.49 10.3 1.76
待判1 广东211.30 114.0 41.44 33.2 11.2 48.72 30.77 14.9 11.1
2 西藏175.9
3 163.8 57.89 4.22 3.37 17.81 82.32 15.7 0.00
贝叶斯判别的SPSS操作方法:
1. 建立数据文件
2.单击Analyze→Classify→Discriminant,打开Discriminant Analysis判别分析对话框如图1所示:
图1 Discriminant Analysis判别分析对话框
3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。
从对话框左侧的变量列表中选分组变量Group进入Grouping Variable框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。选择后点击Continue按钮返回Discriminant Analysis 主对话框。
图2 Define Range对话框
4、选择分析方法
?Enter independent together 所有变量全部参与判别分析(系统默认)。
本例选择此项。
?Use stepwise method 采用逐步判别法自动筛选变量。
单击该项时Method 按钮激活,打开Stepwise Method对话框如图3所示,从中可进一步选择判别分析方法。
图3 Stepwise Method对话框
?Method栏,选择变量的统计量方法
Wilks’lambda (默认)按统计量Wilks λ最小值选择变量;
Unexplained variance :按照所有组方差之和最小值选择变量;
Mahalanobis’distance:按照相邻两组的最大马氏距离选择变量;
Smallest F ratio:按组间最小F值比的最大值选择变量;
Rao’s V按照统计量Rao V最大值选择变量。
?Criteria 选择逐步回归的标准(略)选择系统默认项。
5.单击Statistics 按钮,打开Statistics对话框如图4所示,从中指定输出
的统计量。
?Descriptives描述统计量栏
Means -各类中各自变量的均值,标准差std Dev 和各自变量总样本的
均值和标准差(本例选择)。
Univariate ANOV----对各类中同一自变量均值都相等的假设进行检
验,输出单变量的方差分析结果(本例选择)。
Box’s M --对各类的协方差矩阵相等的假设进行检验(本例选择)。
图4 Statistics对话框
?Function coefficients 选择输出判别函数系数
Fisherh’s 给出贝叶斯判别函数系数(本例选择)
Unstandardized 给出未标准化的典型判别(也称典则判别)系数(费
舍尔判别函数)。
?Matrices 栏选择给出的自变量系数矩阵
Within-groups correlation 合并类内相关系数矩阵(本例选择)
Within-groups covariance 合并类内协方差矩阵(本例选择)
Separate-groups covariance 各类内协方差矩阵(本例选择)
Total covariance 总协方差矩阵(本例选择)
6.单击Classify按钮,打开Classify对话框如图5所示:
图5 Classify对话框
?Prior Probabilities栏,选择先验概率。
All groups equal 各类先验概率相等(系统默认);
Compute from groups sizes 各类的先验概率与其样本量成正比. (本例选择)
?Use Covariance Matrix 栏,选择使用的协方差矩阵
Within-groups --使用合并类内协方差矩阵进行分类(系统默认)(本例选择)
Separate-groups --使用各类协方差矩阵进行分类
?Display栏,选择生成到输出窗口中的分类结果
Casewise results 输出每个观测量包括判别分数实际类预测类(根据判别函数求得的分类结果)和后验概率等。
Summary table 输出分类的小结给出正确分类观测量数(原始类和根据判别函数计算的预测类相同)和错分观测量数和错分率(本例选择)。
Leave-one-out classification 输出交互验证结果。
?Plots栏,要求输出的统计图
Combined-groups 生成一张包括各类的散点图(本例选择);
Separate-groups 每类生成一个散点图;
Territorial map 根据生成的函数值把各观测值分到各组的区域图。(本例选择)
6.单击Save 按钮,打开Save对话框,见图6.
图6 Save对话框
?Predicted group membership 建立一个新变量,系统根据判别分数,把
观测量按后验概率最大指派所属的类;(本例选择)
?Discriminant score 建立表明判别得分的新变量,该得分是由未标准化
的典则判别函数计算。(本例选择)
?Probabilities of group membership 建立新变量表明观测量属于某一类
的概率。有m 类,对一个观测量就会给出m 个概率值,因此建立m 个新变量。(本例选择)
全部选择完成后,点击OK,得到输出结果如下:
Analysis Case Processing Summary 分类样本综述
Unweighted Cases N Percent
Valid 28 93.3 Excluded Missing or out-of-range group codes 2 6.7
At least one missing discriminating
0 .0
variable
Both missing or out-of-range group codes
and at least one missing discriminating
0 .0
variable
Total 2 6.7
Total 30 100.0
Group Statistics 各类统计分析
分类Mean Std. Valid N (listwise)
均值Deviation
有效样本数
标准差
Unweighted Weighted 1 人均生活费收入(元/人)139.2664 23.35125 11 11.000
人均国有经济单位职工工资93.0918 11.38829 11 11.000 人均来源于国有经济单位标准工资53.9882 6.80530 11 11.000 人均集体所有制工资收入11.2073 3.44937 11 11.000 人均集体所有制职工标准工资 6.7645 2.89685 11 11.000
人均各种奖金、超额工资(国有+集
19.8082 5.55600 11 11.000
体)
人均各种津贴(国有+集体) 17.8327 6.23305 11 11.000 均从工作单位得到的其他收入11.0018 2.56135 11 11.000 个体劳动者收入 1.6736 1.74528 11 11.000 2 人均生活费收入(元/人)107.3099 5.56641 11 11.000
人均国有经济单位职工工资75.9064 7.17233 11 11.000 人均来源于国有经济单位标准工资47.7536 3.42090 11 11.000 人均集体所有制工资收入9.0827 2.45900 11 11.000 人均集体所有制职工标准工资 6.0409 1.77266 11 11.000
人均各种奖金、超额工资(国有+集
11.2775 2.15323 11 11.000
体)
人均各种津贴(国有+集体) 15.4375 5.11023 11 11.000 均从工作单位得到的其他收入 6.5773 1.38350 11 11.000 个体劳动者收入 1.3845 .73428 11 11.000 3 人均生活费收入(元/人)133.5150 17.11642 6 6.000
人均国有经济单位职工工资76.1700 6.06280 6 6.000 人均来源于国有经济单位标准工资44.3033 .91825 6 6.000 人均集体所有制工资收入20.3333 4.09031 6 6.000 人均集体所有制职工标准工资12.4783 3.04592 6 6.000
人均各种奖金、超额工资(国有+集
20.3033 5.39344 6 6.000
体)
人均各种津贴(国有+集体) 13.2732 4.34722 6 6.000 均从工作单位得到的其他收入10.1500 2.80907 6 6.000 个体劳动者收入 1.9233 1.11631 6 6.000 Total 人均生活费收入(元/人)125.4796 22.22549 28 28.000
人均国有经济单位职工工资82.7143 12.09003 28 28.000 人均来源于国有经济单位标准工资49.4636 6.09033 28 28.000 人均集体所有制工资收入12.3282 5.36546 28 28.000 人均集体所有制职工标准工资7.7046 3.54143 28 28.000
人均各种奖金、超额工资(国有+集
体)
16.5630 6.10883 28 28.000
人均各种津贴(国有+集体) 15.9147 5.54104 28 28.000 均从工作单位得到的其他收入9.0811 2.98513 28 28.000 个体劳动者收入 1.6136 1.26601 28 28.000 Tests of Equality of Group Means每个变量各类均值相等的检验
Wilks' Lambda F df1 df2 Sig.
人均生活费收入(元/人).542 10.567 2 25 .000
人均国有经济单位职工工资.506 12.226 2 25 .000
人均来源于国有经济单位标准工资.583 8.923 2 25 .001
人均集体所有制工资收入.338 24.429 2 25 .000
人均集体所有制职工标准工资.478 13.672 2 25 .000
人均各种奖金、超额工资(国有+集体) .497 12.664 2 25 .000
人均各种津贴(国有+集体) .898 1.425 2 25 .259
均从工作单位得到的其他收入.516 11.715 2 25 .000
个体劳动者收入.972 .354 2 25 .705
Pooled Within-Groups Matrices(a) 合并类内协方差阵和相关矩阵
人均生活费收入(元/人)人均国
有经济
单位职
工工资
人均来
源于国
有经济
单位标
准工资
人均集
体所有
制工资
收入
人均集
体所有
制职工
标准工
资
人均各
种奖金、
超额工
资(国有
+集体)
人均各
种津贴
(国有+
集体)
人均从工作
单位得到的
其他收入
个体劳
动者收
入
Covari ance
人均生活费收入(元/
人)
289.101 92.215 24.694 9.270 -.438 64.106 15.828 9.298
-1.15
8 人均国有经济单位职92.215 79.806 23.013 -13.98-14.1018.999 31.151 -2.229 2.386
工工资 4 4
人均来源于国有经济
单位标准工资
24.694 23.013 23.374 -3.496 -2.063 1.925 -1.878 -5.027 -.052
人均集体所有制工资收入9.270
-13.98
4
-3.496 10.524 7.877 3.113 -7.158 1.660
-1.67
人均集体所有制职工标准工资-.438
-14.10
4
-2.063 7.877 6.469 .484 -7.895 .665
-1.61
1
人均各种奖金、超额工
资(国有+集体)
64.106 18.999 1.925 3.113 .484 20.020 .398 4.724 -.782 人均各种津贴(国有+
集体)
15.828 31.151 -1.878 -7.158 -7.895 .398 29.766 -.704 2.849 均从工作单位得到的
其他收入
9.298 -2.229 -5.027 1.660 .665 4.724 -.704 4.968 -.020 个体劳动者收入-1.158 2.386 -.052 -1.670 -1.611 -.782 2.849 -.020 1.683
Correla tion
人均生活费收入(元/
人)
1.000 .607 .300 .168 -.010 .843 .171 .245 -.053 人均国有经济单位职
工工资
.607 1.000 .533 -.483 -.621 .475 .639 -.112 .206 人均来源于国有经济
单位标准工资
.300 .533 1.000 -.223 -.168 .089 -.071 -.466 -.008 人均集体所有制工资
收入
.168 -.483 -.223 1.000 .955 .214 -.404 .230 -.397 人均集体所有制职工
标准工资
-.010 -.621 -.168 .955 1.000 .043 -.569 .117 -.488 人均各种奖金、超额工
资(国有+集体)
.843 .475 .089 .214 .043 1.000 .016 .474 -.135 人均各种津贴(国有+
集体)
.171 .639 -.071 -.404 -.569 .016 1.000 -.058 .402 均从工作单位得到的
其他收入
.245 -.112 -.466 .230 .117 .474 -.058 1.000 -.007 个体劳动者收入-.053 .206 -.008 -.397 -.488 -.135 .402 -.007 1.000
a The covariance matrix has 25 degrees of freedom.
Covariance Matrices(a)类内协方差矩阵和总协方差阵
分类人均生
活费收
入(元/
人)
人均国有
经济单位
职工工资
人均来
源于国
有经济
单位标
准工资
人均集
体所有
制工资
收入
人均集
体所有
制职工
标准工
资
人均各种
奖金、超额
工资(国有
+集体)
人均各种
津贴(国
有+集
体)
均从工作
单位得到
的其他收
入
个体劳
动者收
入
1 人均生活费收
入(元/人)545.28
1
179.030 37.985
13.28
6
-1.453 116.976 35.808 13.315
-10.85
9
人均国有经济单位职工工资179.03
129.693 35.643
-18.80
2
-20.620 33.023 46.461 -2.168 5.263
人均来源于国有
经济单位标准工
资
37.985 35.643 46.312 -3.559 -1.186 -.665 -6.736 -10.545 .482
人均集体所有制工资收入13.286 -18.802 -3.559
11.89
8
9.560 5.957 -12.699 1.012 -4.445
人均集体所有制
职工标准工资
-1.453 -20.620 -1.186 9.560 8.392 1.919 -14.117 -.005 -3.647
人均各种奖金、超额工资(国有+集体) 116.97
6
33.023 -.665 5.957 1.919 30.869 5.415 6.027 -3.897
人均各种津贴(国有+集体) 35.808 46.461 -6.736
-12.69
9
-14.117 5.415 38.851 1.994 6.789
均从工作单位得到的其他收入13.315 -2.168
-10.54
5
1.012 -.005 6.027 1.994 6.560 -.697
个体劳动者收入-10.859 5.263 .482 -4.445 -3.647 -3.897 6.789 -.697 3.046 2 人均生活费收
入(元/人)
30.985 32.281 16.743 -8.701 -6.425 3.911 8.151 -4.843 -.269
人均国有经济单
位职工工资
32.281 51.442 20.556 -9.294 -7.498 5.980 21.768 -5.232 -1.357
人均来源于国有
经济单位标准工
资
16.743 20.556 11.703 -6.005 -4.172 3.025 2.431 -2.925 -.978
人均集体所有制
工资收入
-8.701 -9.294 -6.005 6.047 4.231 -2.419 2.394 .261 .004 人均集体所有制
职工标准工资
-6.425 -7.498 -4.172 4.231 3.142 -1.380 .196 .155 -.106 人均各种奖金、
超额工资(国有+
集体)
3.911 5.980 3.025 -2.419 -1.380
4.636 -2.436 .506 -.145
人均各种津贴(国
有+集体)
8.151 21.768 2.431 2.394 .196 -2.436 26.114 -2.255 -.323
均从工作单位得
到的其他收入
-4.843 -5.232 -2.925 .261 .155 .506 -2.255 1.914 .307 个体劳动者收入-.269 -1.357 -.978 .004 -.106 -.145 -.323 .307 .539
3 人均生活费收
入(元/人)292.97
2
38.451 14.013
37.17
8
13.567 78.758 -8.776 29.547 16.466
人均国有经济单位职工工资38.451 36.758 2.665
-13.73
-14.286 16.990 19.297 3.658 4.120
人均来源于国有
经济单位标准工
14.013 2.665 .843 1.649 .400 4.905 -.783 1.806 .732
资
人均集体所有制工资收入37.178 -13.730 1.649
16.73
1
11.802 8.488 -15.180 5.753 .532
人均集体所有制职工标准工资13.567 -14.286 .400
11.80
2
9.278 1.340 -11.632 3.026 -.549
人均各种奖金、
超额工资(国有+
集体)
78.758 16.990 4.905 8.488 1.340 29.089 -3.967 10.556 4.171
人均各种津贴(国有+集体) -8.776 19.297 -.783
-15.18
-11.632 -3.967 18.898 -2.998 1.312
均从工作单位得
到的其他收入
29.547 3.658 1.806 5.753 3.026 10.556 -2.998 7.891 .680 个体劳动者收入16.466 4.120 .732 .532 -.549 4.171 1.312 .680 1.246
To tal
人均生活费收
入(元/人)
493.97
3
182.382 51.722
40.60
6
15.154 123.390 24.245 39.841 1.513 人均国有经济单
位职工工资
182.38
2
146.169 52.685
-20.32
8
-19.362 40.532 42.118 11.447 2.648 人均来源于国有
经济单位标准工
资
51.722 52.685 37.092
-12.22
2
-7.958 7.157 5.158 -.595 -.133 人均集体所有制
工资收入
40.606 -20.328
-12.22
2
28.78
8
18.414 15.043 -11.572 5.872 -.720 人均集体所有制
职工标准工资
15.154 -19.362 -7.958
18.41
4
12.542 6.755 -10.523 2.711 -1.031 人均各种奖金、
超额工资(国有+
集体)
123.39
40.532 7.157
15.04
3
6.755 3
7.318 1.737 13.194 .106 人均各种津贴(国
有+集体)
24.245 42.118 5.158
-11.57
2
-10.523 1.737 30.703 .708 2.548 均从工作单位得
到的其他收入
39.841 11.447 -.595 5.872 2.711 13.194 .708 8.911 .335 个体劳动者收入 1.513 2.648 -.133 -.720 -1.031 .106 2.548 .335 1.603
a The total covariance matrix has 27 degrees of freedom.
Box's Test of Equality of Covariance Matrices 协方差矩阵相等的检验
分类Rank
Log
Determinant
1 9 14.087
2 9 1.573
3 .(a) .(b)
Pooled
within-groups
9 15.603
The ranks and natural logarithms of determinants printed are those of the group covariance matrices.
a Rank < 6
b Too few cases to be non-singular
Test Results(a)检验结果
Box's M 195.630
F Approx. 2.155
df1 45
df2 1314.073
Sig. .000
a Some covariance matrices are singular and the usual procedure will not work. The
non-singular groups will be tested against their own pooled within-groups covariance matrix. The log of its determinant is 17.611.
注意,检验没有通过,即各类的协方差相等的假设在显著性水平下是不成立的。Summary of Canonical Discriminant Functions典型判别函数综述
Eigenvalues特征值
Function Eigenvalu
e
% of
Variance
Cumulative
%
Canonical
Correlation
1 5.082(a) 60.7 60.7 .914
2 3.296(a) 39.
3 100.0 .876
a First 2 canonical discriminant functions were used in the analysis.
只有两个判别函数,所以特征值只有两个。判别函数的特征值越大,说明函数越具有区别判断力。最后一列表示是典则相关系数,是组间平方和与总平方和之比的平方根,表示判别函数分数与组别间的关联程度。
Wilks' Lambda判别函数检验
Test of Function(s)
Wilks'
Lambda
Chi-squar
e d
f Sig.
1 through
2 .038 68.52
3 18 .000
2 .23
3 30.611 8 .000
上表中“1through 2”表示两个判别函数的平均数在三个类间的差异情况,P值为0.000表示差异达到显著水平。
判别函数的Wilks ′ Lambda 值可以通过特征值计算: 判别函数1和判别函数2的Wilks ′ Lambda 值为
038.0)
296.31)(082.51(1
)1)(1(121=++=++λλ
判别函数2的Wilks ′ Lambda 值为
233.0)
296.31(1
)1(12=+=+λ
“2”表示在排除了第一个判别函数后,第二个判别函数在三个组别间的差异情况,P 值=0.000表示差别函数2也达到显著水平.
Standardized Canonical Discriminant Function Coefficients 标准化典型判别函数(系统默认结果)
Function
1
2
人均生活费收入(元/人) -.515 .214 人均国有经济单位职工工资 3.381 1.050 人均来源于国有经济单位标准工资 -1.109 .244 人均集体所有制工资收入 2.446 -3.031 人均集体所有制职工标准工资 -.834 3.313 人均各种奖金、超额工资(国有+集体) -1.227 -.456 人均各种津贴(国有+集体) -1.817 .186 均从工作单位得到的其他收入 .363 1.004 个体劳动者收入 .474
.079
Structure Matrix 结构矩阵:
Function
1
2
人均集体所有制工资收入
.545(*) -.366 人均各种奖金、超额工资(国有+集体) .415(*) .204 人均集体所有制职工标准工资 .386(*) -.320 均从工作单位得到的其他收入 .360(*) .291 人均生活费收入(元/人) .344(*) .271 个体劳动者收入
.075(*)
-.004 人均国有经济单位职工工资 .128 .521(*) 人均来源于国有经济单位标准工资 -.021
.465(*)
人均各种津贴(国有+集体) -.029 .182(*)
Pooled within-groups correlations between discriminating variables and standardized canonical discriminant functions Variables ordered by absolute size of correlation within function.
* Largest absolute correlation between each variable and any discriminant function 结构矩阵是变量和标准化典型判别函数的组内相关矩阵。
Functions at Group Centroids类中心坐标(非标准化典型判别下的类中心)
分类
Function
1 2
1 .741 2.047
2 -2.418 -.870
3 3.07
4 -2.159
Classification Statistics分类分析(输出贝叶斯判别结果)
Classification Processing Summary综述表
Processed 31
Excluded Missing or out-of-range
group codes
At least one missing
discriminating variable
1
Used in Output 30
Prior Probabilities for Groups先验概率
分类Prior先验概率Cases Used in Analysis Unweighted
Weighte
d
1 .393 11 11.000
2 .39
3 11 11.000
3 .21
4 6 6.000
Total 1.000 28 28.000
Classification Function Coefficients贝叶斯判别函数的系数
分类
1 2 3
人均生活费收入(元/人).098 .157 -.026 人均国有经济单位职工工资9.355 7.816 9.743 人均来源于国有经济单位标准工资-3.303 -2.726 -4.051 人均集体所有制工资收入-5.461 -5.118 .227 人均集体所有制职工标准工资22.364 19.601 16.119 人均各种奖金、超额工资(国有+集体) -9.520 -8.357 -9.731 人均各种津贴(国有+集体) -5.260 -4.307 -6.180 均从工作单位得到的其他收入10.060 8.232 8.545 个体劳动者收入8.280 6.950 8.876 (Constant) -320.267 -228.550 -295.678
Fisher's linear discriminant functions
上表为贝叶斯判别函数的系数矩阵,可以用数学表达式表示为:
9
8
7
6
5 4
3
2
1
1
2800
.8
0598
.
10
2601
.5
5204
.9
3641
.
22 4615
.5
3032
.3
3545
.9
0978
.0
267
.
320
x
x
x
x
x x
x
x
x
y
+
+
-
-
+ -
-
+
+
-
=
9
8
7
6
5 4
3
2
1
2
950
.6
232
.8
307
.4
357
.8
601
.
19 118
.5
726
.2
816
.7
157
.0
550
.
228
x
x
x
x
x x
x
x
x
y
+
+
-
-
+ -
-
+
+
-
=
9
8
7
6
5 4
3
2
1
3
876
.8
545
.8
180
.6
731
.9
169
.
16 227
.0
051
.4
743
.9
026
.0
678
.
295
x
x
x
x
x x
x
x
x
y
+
+
-
-
+ +
-
+
-
-
=
Territorial Map分类区域图(用典型判别函数得分绘制)
Function 2
-6.0 -4.0 -2.0 .0 2.0 4.0 6.0
?????????????????????????????????????????????????????????????
6.0 ?211 ?
? 221 ?
? 211 ?
? 221 ?
? 211 ?
? 221 ?
4.0 ? 211 ?????
? 221 ?
? 211 ?
? 221 ?
? 211 ?
? 2211 ?
2.0 ?? 221 ? * ?? 111?
? 211 111333?
? 221 111333 ?
? 211 111333 ?
? 221 111333 ?
? 211 111333 ?
.0 ??? 221? 111333 ??
? 211 111333 ?
? 221 111333 ?
? * 21333 ?
? 23 ?
? 23 ?
-2.0 ????23 ? * ??
? 23 ?
? 23 ?
? 23 ?
? 23 ?
? 23 ?
-4.0 ??? 23 ???
? 23 ?
? 23 ?
? 23 ?
? 23 ?
? 23 ?
-6.0 ? 23 ?
?????????????????????????????????????????????????????????????
-6.0 -4.0 -2.0 .0 2.0 4.0 6.0
Canonical Discriminant Function 1
Symbols used in territorial map
Symbol Group Label
------ ----- --------------------
1 1
2 2
3 3
* Indicates a group centroid
典型判别函数得到的分类散布图
Canonical Discriminant Functions
Function 1
20
10
-10
F u n c t i o n 2
20
10
-10
-20分类
Group Centroids Ungrouped Cases
32
1
3
2
1
Classification Results(a)
对角线上显示的是准确预测的的个数,其余为错误预测的个数。
分类 Predicted Group Membership Total 1
2
3
Origina l Count
1
11 0 0 11 2 0 11 0 11 3
0 0 6 6 Ungrouped cases 1 0 1 2 % 1 100.0
.0 .0 100.0 2 .0 100.0
.0 100.0 3
.0 .0 100.0 100.0
Ungrouped cases
50.0
.0
50.0
100.0
a 100.0% of original grouped cases correctly classified.
由上面输出结果,可以得到贝叶斯判别的函数,并在数据编辑窗口得到一个系统根据判别分数,把观测量按后验概率最大指派所属的类变量dis_1;两个由未标准化的典则(典型)判别函数计算的判别得分新变量dis1_1和dis2_1,这个得分可以在区域图及散布图中确定每个样品的位置;三个表明观测量属于某一类的后验概率建立新变量dis1_2,dis2_2, dis3_2,概率最大的类即为样品所属的类别。
SPSS主成分分析操作步骤,详细的很啊^_^ SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。 图表 3 相关系数矩阵
图表 4 方差分解主成分提取分析表 主成分分析在SPSS中的操作应用(3) 图表 5 初始因子载荷矩阵
从图表3可知GDP与工业增加值,第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、地方财政收入这几个指标存在着极其显著的关系,与海关出口总额存在着显著关系。可见许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。 主成分个数提取原则为主成分对应的特征值大于1的前m个主成分。注:特征值在某种程度上可以被看成是表示主成分影响力度大小的指标,如果特征值小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征值大于1作为纳入标准。通过图表4(方差分解主成分提取分析)可知,提取2个主成分,即m=2,从图表5(初始因子载荷矩阵)可知GDP、工业增加值、第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、海关出口总额、地方财政收入在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;人均GDP和农业增加值指标在第二主成分上有较高载荷,说明第二主成分基本反映了人均GDP和农业增加值两个指标的信息。所以提取两个主成分是可以基本反映全部指标的信息,所以决定用两个新变量来代替原来的十个变量。但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。用图表5(主成分载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数[2]。将初始因子载荷矩阵中的两列数据输入(可用复制粘贴的方法)到数据编辑窗口(为变量B1、B2),然后利用“TransformàCompute Variable”,在Compute Variable对话框中输入“A1=B1/SQR(7.22)” [注:第二主成分SQR后的括号中填1.235],即可得到特征向量A1(见图表6)。同理,可得到特征向量A2。将得到的特征向量与标准化后的数据相乘,然后就可以得出主成分表达式[注:因本例只是为了说明如何在SPSS进行主成分分析,故在此不对提取的主成分进行命名,有兴趣的读者可自行命名]: F 1=0.353ZX 1 +0.042ZX 2 -0.041ZX 3 +0.364ZX 4 +0.367ZX 5 +0.366ZX 6 +0.352ZX 7 +0.364ZX 8+0.298ZX 9 +0.355ZX 10
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
SPSS数据案例分析
SPSS数据案例分析 目录 一.手机 APP 广告点击意愿的模型构建 (3) 1.1构建研究模型 (3) 1.2研究变量及定义 (4) 1.3研究假设 (4) 1.4变量操作化定义 (4) 1.5问卷设计 (5) 二.实证研究 (8) 2.1基础数据分析 (8) 2.2频数分布及相关统计量 (8) 2.3相关分析 (10) 2.4回归分析 (11) 2.5假设检验 (13)
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机 APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在 30 岁以下的人群占到 70%以上,因此本研究考虑性别了这一变量,同时根据手机 APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机 APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对 UTAUT 模型进行扩展,构建了手机 APP 广告点击意愿的影响因素研究模型。
1.2研究变量及定义 1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机 APP 点击意向的关系 H1:用户的广告效用期望与点击手机 APP 广告意愿正相关。 H2:用户的 APP 效用期望与点击手机 APP 广告意愿正相关 H3:社会影响与手机 APP 广告点击意愿正相关 (2)感知风险与点击手机 APP 广告意愿的关系 H4:感知风险与手机 APP 广告点击意愿负相关 H5:性别,手机流量对手机 APP 广告点击意愿没有显著影响 1.4变量操作化定义 广告效用期望:广告对我了解某品牌来说很有用 APP 效用期望:使用 APP 能够让我了解到多方面的信息 社会影响:身边的人都在使用手机 APP 广告,所以我也要使用 感知风险:在点击手机 APP 广告时,我担心我的个人隐私安全得不到保护 感知隐私安全重要性:确保点击手机 APP 广告是安全的,对我来说是很重
s p s s的数据分析案例 精选文档 TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 Tot al 474 上 表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。且接受过高于20年的教育的人数只有1人,比例很低。 2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的
SPSS皮尔逊相关分析实例操作步骤 选题: 对某地29名13岁男童的身高(cm)、体重(kg),运用相关分析法来分析其身高与体重是否相关。 实验目的: 任何事物的存在都不是孤立的,而是相互联系、相互制约的。相关分析可对变量进行相关关系的分析,计算29名13岁男童的身高(cm)、体重(kg),以判断两个变量之间相互关系的密切程度。 实验变量: 编号Number,身高height(cm),体重weight(kg) 原始数据: 实验方法: 皮 尔 逊 相 关 分 析 法 软件: 操作过程与结果分析:
第一步:导入Excel 数据文件 1.open data document ——open data ——open ; 2. Opening excel data source ——OK. 第二步:分析身高(cm )与体重(kg )是否具有相关性 1. 在最上面菜单里面选中Analyze ——correlate ——bivariate ,首先使用Pearson ,two-tailed ,勾选flag significant correlations 进入如下界面: 2. 点击右侧options ,勾选Statistics ,默认Missing Values ,点击Continue 输出结果: 图为基本的描述性统计量的输 出表格,其中身高的均值(mean ) 为、标准差(standard deviation ) 为、样本容量(number of cases ) 为29;体重的均值为、标准差为、 样本容量为29。两者的平均值和标准差值得差距不显着。 图为相关分析结果表,从表中可以看出体重和身高之间的皮尔逊相关系数为,即 |r|=,表示体重与身高呈正相关关系,且两变量是显着相关的。另外, 两者之间不相关的双侧检验值为,图中的双星号标 记的相关系数是在显着性水平为以下,认为标记的相关系数是显着的,验证了两者显着相关的关系。所以可以得出结论:学生的体重与身高存在显着的 Descriptive Statistics Mean Std. Deviation N 身高(cm ) 29 体重(kg) 29 Correlations 身高(cm ) 体重(kg) 身高(cm ) Pearson Correlation 1 .719** Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 体重(kg) Pearson Correlation .719** 1 Sig. (2-tailed) .000 Sum of Squares and Cross-products Covariance N 29 29 **. Correlation is significant at the level (2-tailed).
关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够 了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
14 6 1.3 1.3 52.5 15 116 24.5 24.5 77.0 16 59 12.4 12.4 89.5 17 11 2.3 2.3 91.8 18 9 1.9 1.9 93.7 19 27 5.7 5.7 99.4 20 2 .4 .4 99.8 21 1 .2 .2 100.0 Tot 474 100.0 100.0 al 上表及其 直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教
关于某地区361个人旅游情况统计分析报告 一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本 状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。 统计量 积极性性别 N 有效359 359 缺失0 0 首先,对该地区的男女性别分布进行频数分析,结果如下
性别 频率百分比有效百分 比 累积百分 比 有效女198 55.2 55.2 55.2 男161 44.8 44.8 100.0 合计359 100.0 100.0 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表: 积极性 频率百分比有效百分 比 累积百分 比 有效差171 47.6 47.6 47.6 一般79 22.0 22.0 69.6 比较 好 79 22.0 22.0 91.6 好24 6.7 6.7 98.3 非常 好 6 1. 7 1.7 100.0 合计359 100.0 100.0 其次对原有数据中的积极性进行频数分析,结果如下表: 其次对原有数据中的是否进通道进行频数分析,结果如下表:
为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 5
贝叶斯判别的SPSS操作方法: 1. 建立数据文件 2.单击Analyze→ Classify→ Discriminant,打开Discriminant Analysis 判别分析对话框如图1所示: 图1 Discriminant Analysis判别分析对话框 3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。 从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。 选择后点击Continue按钮返回Discriminant Analysis主对话框。 图2 Define Range对话框 4、选择分析方法 Enter independent together 所有变量全部参与判别分析(系统默 认)。本例选择此项。 Use stepwise method 采用逐步判别法自动筛选变量。
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: (
2010年中国各地区城市居民人均年消费支出和可支配收入
} 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
SPSS数据案例分析 目录 一.手机 APP 广告点击意愿的模型构建 2 1.1构建研究模型 2 1.2研究变量及定义 2 1.3研究假设 3 1.4变量操作化定义 3 1.5问卷设计 3 二.实证研究 5 2.1基础数据分析 5 2.2频数分布及相关统计量 5 2.3相关分析 7 2.4回归分析 8 2.5假设检验 10
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.2研究变量及定义 1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机 APP 广告点击意愿没有显著影响
典型相关分析 典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关, 而不是 两个变量组个别变量之间的相关。 典型相关与主成分相关有类似, 不过主成分考虑的是一组变量,而典型相关考虑的是两 组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的 成分使之与另一组的成分具有最大的线性关系。 典型相关模型的基本假设: 两组变量间是线性关系, 每对典型变量之间是线性关系,每 个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共 线性。典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因 变量。 典型相关会找出一组变量的线性组合 * *= i i j j X a x Y b y 与,称为典型变量;以 使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。 i a 和j b 称为典型系数。如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。 典型变量的性质 每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关; 原来所有 变量的总方差通过典型变量而成为几个相互独立的维度。一个典型相关系数只是两个典型变 量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关, 共同代表 两组变量间的整体相关。 典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数, 指的是一个典型变量与本组所有变量的简单相关系数,
第一章SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下:
1.将数据输入SPSS,并存盘以防断电。 2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3.按题目要求进行统计分析。 4.保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 《数据分析及其应用软件》习题 姓名__学号___成绩 习题1:出钢时所用盛钢水的钢包,因钢水对耐火材料的侵蚀,容积不断增大我们希望找出使用次数与增大的容积之间的关系,试验数据如下: 使用次数x增大容积y 2 6.42 38.20 49.58 59.50 69.70 710.00 89.93 99.99 1010.49 1110.59 1210.60 1310.80 1410.60 1510.90 1610.76 写出分析报告(内容包括以下四点) 1.用双曲线1/y = a+b/x作曲线拟合:(1)画出散点图,(2)写出回 归方程,(3)进行检验,(4)分析结果,(α= 0.05) 2.用指数曲线y = ae b/x 作曲线拟合:(1)画出散点图,(2)写出回 归方程,(3)进行检验,(4)分析结果,(α= 0.05) 3.比较两种曲线后,写出较优的曲线回归方程. 4.使用较优的曲线回归方程预测当使用次数为17次时钢包的容积增大多 少? 习题2:1.研究货运总量(万吨)与工业总值(亿元)、农业总产值(亿元)、居民非商品支出(亿元)的关系。数据见下表 编号货运总量 (万吨)工业总产值 (亿元) 农业总产值 (亿元) 居民非商品支出 (亿元) 1 2 3160 260 210 70 75 65 35 40 40 1.0 2.4 2.0 4 5 6 7 8 9 10265 240 220 275 160 275 250 74 72 68 78 66 70 65 42 38 45 42 36 44 42 3.0 1.2 1.5 4.0 2.0 3.2 3.0 (1)计算出的相关系数矩阵; (2)求关于的三元线性回归方程; (3)对所求得的回归方程作拟合优度检验; (4)对回归方程做显著性检验; (5)对每一个回归系数做显著性检验; (6)如果有的回归系数没有通过显著性检验,将其剔除。 重新建立回归方程,再作回归方程的显著性检验和回归系数显著性检验; (7)求出每一个回归系数的之置信水平为95%的置信区间; (8)求出标准化回归方程; (9)求当=75,=42,=3.1时的值,给定置信水平为99%,用SPSS软件计算精确置信区间,用手工计算近似预测区间; (10)结合回归方程对问题作一些基本分析。 习题3:为研究某地区人口死亡状况,已按某种方法将15个已知样品分为3类,指标及原始数据如下表。利用费歇线性判别函数,判定另外4个待判样品属于哪一类? 某地区人口死亡状况指标及原始数据表 组别序 号 = 0岁 组 死亡概率 =1岁 组死亡概 率 = 1 0岁 组死亡概率 =55岁 组死亡概率 =80岁 组死亡概率 =平均 预期寿命 第一 组 134.167.44 1.127.8795.1969.30 233.06 6.34 1.08 6.7794.0869.70 336.269.24 1.048.9797.3068.80 440.1713.45 1.4313.88101.2066.20 550.0623.03 2.8323.74112.5263.30 实验指导之二 判别分析的SPSS软件的基本操作 [实验例题]为研究1991年中国城镇居民月平均收入状况,按标准化欧氏平方距离、离差平方和聚类方法将30个省、市、自治区.分为三种类型。试建立判别函数,判定广东、西藏分别属于哪个收入类型。判别指标及原始数据见表9-4。 1991年30个省、市、自治区城镇居民月平均收人数据表 单位:元/人 x1:人均生活费收入 x6:人均各种奖金、超额工资(国有+集体) x2:人均国有经济单位职工工资 x7:人均各种津贴(国有+集体) x3:人均来源于国有经济单位标准工资 x8:人均从工作单位得到的其他收入 x4:人均集体所有制工资收入 x9:个体劳动者收入 x5:人均集体所有制职工标准工资 贝叶斯判别的SPSS操作方法: 1. 建立数据文件 2.单击Analyze→Classify→Discriminant,打开Discriminant Analysis判别分析对话框如图1所示: 图1 Discriminant Analysis判别分析对话框 3.从对话框左侧的变量列表中选中进行判别分析的有关变量x1~x9进入Independents 框,作为判别分析的基础数据变量。 从对话框左侧的变量列表中选分组变量Group进入Grouping Variable 框,并点击Define Range...钮,在打开的Discriminant Analysis: Define Range 对话框中,定义判别原始数据的类别数,由于原始数据分为3类,则在Minimum(最小值)处输入1,在Maximum(最大值)处输入3(见图2)。。 选择后点击Continue按钮返回Discriminant Analysis主对话框。 图2 Define Range对话框 4、选择分析方法 SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费 本次实验采用2005年东部、中部和西部各地区省份城镇居民月平均消费类型划分的数据(课本139页),将东部、中部和西部看作三个不同总体,31个数据分别来自于这三个总体。本人对这三个不同地区的城镇居民月平均消费水平进行比较,并选取人均粮食支出、副食支出、烟酒及饮料支出、其他副食支出、衣着支出、日用杂品支出、水电燃料支出和其他非商品支出八个指标来衡量城镇居民月平均消费情况。 在进行比较分析之前,首先对个数据是否服从多元正态分布进行检验,输出结果为: 表一 如表一,因为该例中样本数n=31<2000,所以此处选用Shapiro-Wilk统计量。由正态性检验结果的sig.值可以看到,人均粮食支出、烟酒及饮料支出、其他副食支出、水电燃料支出和其他非商品支出均明显不遵从正态分布(Sig.值小于,拒绝服从正态分布的原假设),因此,在下面分析中,只对人均副食支出、衣着支出和日用杂品支出三项指标进行比较,并认为这三个变量组成的向量都遵从正态分布,并对城镇居民月平均消费状况做出近似的度量。另外,正态性的检验还可以通过Q-Q图来实现,此时应判别数据点是否与已知直线拟合得好。如果数据点均落在直线附近,说明拟合得好,服从正态分布,反之,不服从。具体情况这里 不再赘述。 下面进行多因素方差分析: 一、多变量检验 表二 由地区一栏的(即第二栏)所列几个统计量的Sig.值可以看到,无论从那个统计量来看,三个地区的城镇居民月平均消费水平都是有显著差别的(Sig.值小于,拒绝地区取值不同,对Y,即城镇居民月平均消费水平的取值没有显著影响的原假设)。 二、主体间效应检验 如表三,可以看到三个指标地区一栏的(即第三栏)Sig.值分别为、、,说明三个地区在人均衣着支出指标上没有明显的差别(Sig.值大于,不拒绝地区取值不同,对指标的取值没有显著影响的原假设),反之,而在人均副食支出和日用杂品支出指标上有显著差别。 三、多重比较 实验课程名称: __多元统计分析--判别分析___ 准则判别归类,则可写成: ?? ? ??=>∈<∈) ,(),( ,),(),(,),(),(,21212211G X D G X D G X D G X D G X G X D G X D G X 当待判当当 题目:表11.5的数据包含三种鸢尾的X2=萼片宽度与X4=花瓣的宽度的观测值。对每种鸢尾有n1=n2=n3=50个观测值。 部分数据: 第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象记录,实验过程发现的问题等) 散点图:图形→旧对话框→散点图,打开简单散点图子对话框;将想X2选入X轴变量,X4选入Y轴变量,将总体选入设置标记框中,点击确定。 判别分析: 步骤: 1、选择分析→分类→判别,打开判别分析子对话框。 2、选择变量“总体”,单击→,将其加入到分组变量栏中。 3、打开定义范围子对话框,最小值输入1,最大值输入3。 4、将变量“X2萼片宽度”、“X4花瓣的宽度”选入自变量栏中。选择“一起输入自 变量”的方法。 5、打开统计变量子对话框,选择均值、单变量ANOVA、Box’M、未标准化、组内协 方差、分组协方差及总体协方差,单击继续。 6、打开分类子对话框,选择不考虑该个案时的分类,其余为默认值。 7、打开保存,选择所有的变量。 相关系数矩阵a 总体萼片宽度X2 花瓣宽度X4 合计萼片宽度X2 .190 -.122 花瓣宽度X4 -.122 .581 对数行列式 总体秩对数行列式 1 2 -6.496 2 2 -6.141 3 2 -5.189 汇聚的组内 2 -5.583 检验结果 箱的M 52.832 F 近似。8.632 df1 6 df2 538562.769 Sig. .000 Wilks 的Lambda 函数检 验Wilks 的Lambda 卡方df Sig. 1 到 2 .038 477.868 4 .000 2 .809 31.075 1 .000 典型判别式函数系数 函数 1 2 萼片宽度X2 -1.987 2.680 花瓣宽度X4 5.477 .817 (常量) -.494 -9.174 非标准化系数 SPSS与数据统计分析期末论文影响学生对学校服务满意程度的因素分析 一、数据来源 本次数据主要来源自本校同学,调查了同学们年级、性别、助学金申请情况、生源所在地、学院、毕业学校、游历情况、家庭情况、升高、体重、近视程度、学习时间、经济条件、兴趣、对学校各方面的评价、与对学校总评价以及建议等共41条信息,共收集数据样本724条。我们将运用SPSS,对变量进行频数分析、样本T检验、相关分析等手段,旨在了解同学们对学校提供的满意程度与什么因素有关。 二、频数分析 可靠性统计 克隆巴赫Alpha项数 .98562 对全体数值进行可信度分析 本次数据共计724条,首先从可靠性统计来看,alpha值为0.985,即全体数据绝大部分是可靠的,我们可以在原始数据的基础上进行分析与处理。 其中,按年级来看,绝大多数为大二学生填写(占了总人数的67.13%),之后分别依次为大二(23.76%)、大四(4.14%)、大一(4.97%)。而从专业来看,占据了数据绝大多数样本所在的学院为机械、材料、经管、计通。 三、数据预处理 拿到这份诸多同学填写的问卷之后,我们首先应对一些数据进行处理,对于数据的缺失值处理,由于我们对本份调查的分析重点方面是关于学生的经济情况的,因此对于确实的部分数据,升高、体重、近视度数、感兴趣的事等无关项我们均不需要进行缺失值的处理,而我们可能重点关注的每月家里给的钱、每月收入以及每月支出,由于其具有较强主观性,如果强行处理缺失值反而会破坏数据的完整性,因此我们筛去未填写的数据,将剩余数据当作新的样本进行分析。 而对于一些关键的数据,我们需要做一些必要的预处理,例如一些调查项,我们希望得到数值型变量,但是填写时是字符型变量,我们就应该新建一个数字型变量并将数据复制,以便后续分析。同时一些与我们分析相关的缺省值,一些明显可以看出的虚假信息,我们都需要先 关于某地区361个人旅游情况统计分析报告一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地 区359个人旅游基本状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。 统计量 积极性性别 N有效359359 缺失00 首先,对该地区的男女性别分布进行频数分析,结果如下 性别 频率百分比有效百分 比 累积百分 比 有效女19855.255.255.2 男16144.844.8100.0 合计359100.0100.0 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为44.8%和55.2%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表: 积极性 频率百分比有效百分 比 累积百分 比 有效差17147.647.647.6一般7922.022.069.6 比较 好 7922.022.091.6好24 6.7 6.798.3spss 分析案例数据
SPSS操作方法:判别分析例题
SPSS统计分析分析案例
spss相关分析案例多因素方差分析
多元统计分析--判别分析SPSS实验报告
SPSS分析报告实例
spss的数据分析报告范例
相关主题
文本预览