
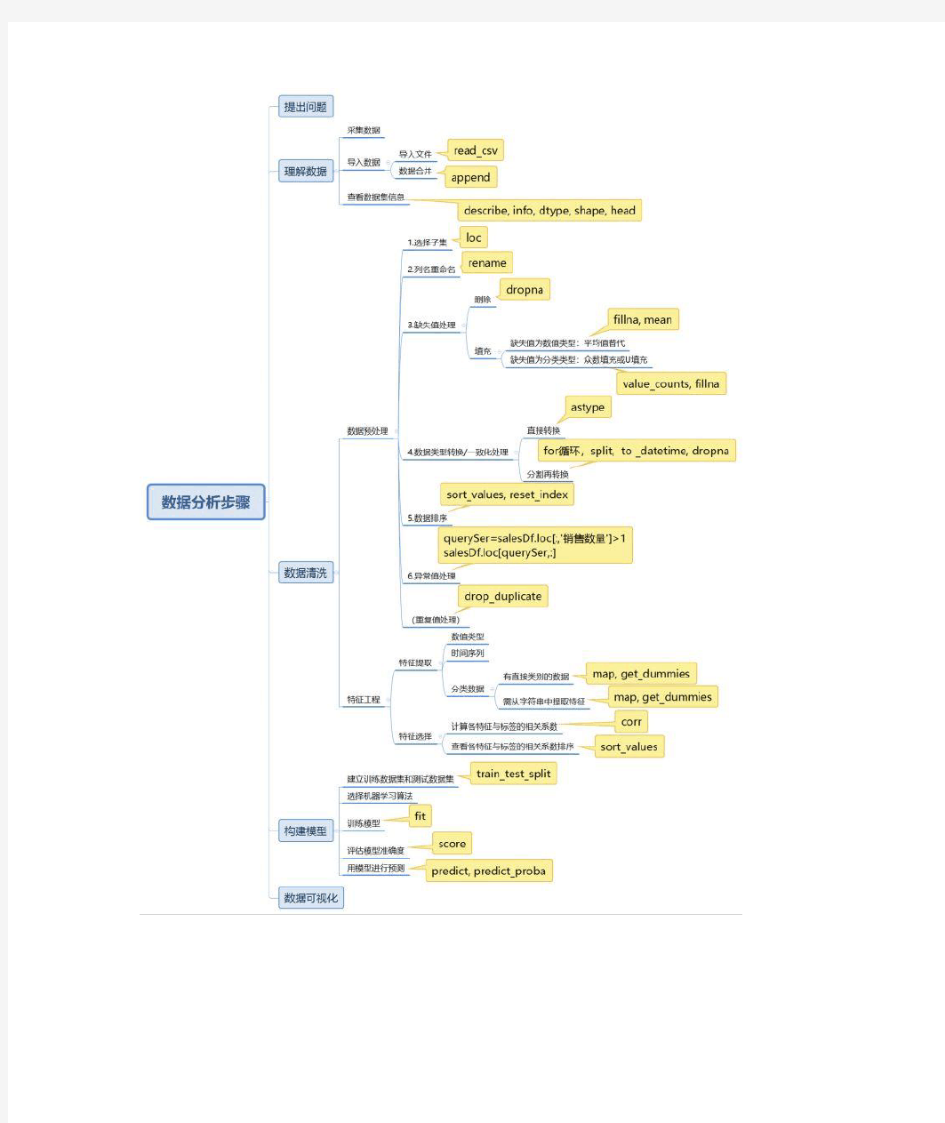
不管是用excel还是用Python,数据分析过程都遵循一样的套路。在学习完Python的基础知识之后,我把用Python进行数据分析过程中涉及的函数都标注了出来以方便后来回忆查看。
《利用python进行数据分析》读书笔记 pandas是本书后续内容的首选库。pandas可以满足以下需求:具备按轴自动或显式数据对齐功能的数据结构。这可以防止许多由于数据未对齐以及来自不同数据源(索引方式不同)的数据而导致的常见错误。. 集成时间序列功能既能处理时间序列数据也能处理非时间序列数据的数据结 构数学运算和简约(比如对某个轴求和)可以根据不同的元数据(轴编号)执行灵活处理缺失数据合并及其他出现在常见数据库(例如基于SQL的)中的关系型运算1、pandas数据结构介绍两个数据结构:Series和DataFrame。Series是一种类似于以为NumPy数组的对象,它由一组数据(各种NumPy数据类型)和与之相关的一组数据标签(即索引)组成的。可以用index和values分别规定索引和值。如果不规定索引,会自动创建0 到N-1 索引。#-*- encoding:utf-8 -*- import numpy as np import pandas as pd from pandas import Series,DataFrame #Series可以设置index,有点像字典,用index索引 obj = Series([1,2,3],index=['a','b','c'])
#print obj['a'] #也就是说,可以用字典直接创建Series dic = dict(key = ['a','b','c'],value = [1,2,3]) dic = Series(dic) #下面注意可以利用一个字符串更新键值 key1 = ['a','b','c','d'] #注意下面的语句可以将Series 对象中的值提取出来,不过要知道的字典是不能这么做提取的 dic1 = Series(obj,index = key1) #print dic #print dic1 #isnull 和notnull 是用来检测缺失数据 #print pd.isnull(dic1) #Series很重要的功能就是按照键值自动对齐功能 dic2 = Series([10,20,30,40],index = ['a','b','c','e']) #print dic1 + dic2 #name属性,可以起名字 https://www.doczj.com/doc/7610710246.html, = 's1' https://www.doczj.com/doc/7610710246.html, = 'key1' #Series 的索引可以就地修改 dic1.index = ['x','y','z','w']
用python进行数据分析 一、样本集 本样本集来源于某高中某班78位同学的一次月考的语文成绩。因为每位同学的成绩都是独立的随机变量,遂可以保证得到的观测值也是独立且随机的 样本如下: grades=[131,131,127,123,126,129,116,114,115,116,123,122,118, 121,126,121,126,121,111,119,124,124,121,116,114,116, 116,118,112,109,114,116,116,118,112,109,114,110,114, 110,113,117,113,121,105,127,110,105,111,112,104,103, 130,102,118,101,112,109,107,94,107,106,105,101,85,95, 97,99,83,87,82,79,99,90,78,86,75,66]; 二、数据分析 1.中心位置(均值、中位数、众数) 数据的中心位置是我们最容易想到的数据特征。借由中心位置,我们可以知道数据的一个平均情况,如果要对新数据进行预测,那么平均情况是非常直观地选择。数据的中心位置可分为均值(Mean),中位数(Median),众数(Mode)。其中均值和中位数用于定量的数据,众数用于定性的数据。 均值:利用python编写求平均值的函数很容易得到本次样本的平均值 得到本次样本均值为109.9 中位数:113 众数:116 2.频数分析 2.1频数分布直方图 柱状图是以柱的高度来指代某种类型的频数,使用Matplotlib对成绩这一定性变量绘制柱状图的代码如下:
引言 几年后发生了。在使用SAS工作超过5年后,我决定走出自己的舒适区。作为一个数据科学家,我寻找其他有用的工具的旅程开始了!幸运的是,没过多久我就决定,Python作为我的开胃菜。 我总是有一个编写代码的倾向。这次我做的是我真正喜欢的。代码。原来,写代码是如此容易! 我一周内学会了Python基础。并且,从那时起,我不仅深度探索了这门语言,而且也帮助了许多人学习这门语言。Python是一种通用语言。但是,多年来,具有强大的社区支持,这一语言已经有了专门的数据分析和预测模型库。 由于Python缺乏数据科学的资源,我决定写这篇教程来帮助别人更快地学习Python。在本教程中,我们将讲授一点关于如何使用Python 进行数据分析的信息,咀嚼它,直到我们觉得舒适并可以自己去实践。
目录 1. 数据分析的Python基础 o为什么学Python用来数据分析 o Python 2.7 v/s 3.4 o怎样安装Python o在Python上运行一些简单程序 2. Python的库和数据结构 o Python的数据结构 o Python的迭代和条件结构 o Python库 3. 在Python中使用Pandas进行探索性分析
o序列和数据框的简介 o分析Vidhya数据集——贷款的预测问题 4. 在Python中使用Pandas进行数据再加工 5. 使用Python中建立预测模型 o逻辑回归 o决策树 o随机森林 让我们开始吧 1.数据分析的Python基础 为什么学Python用来数据分析 很多人都有兴趣选择Python作为数据分析语言。这一段时间以来,我有比较过SAS和R。这里有一些原因来支持学习Python: ?开源——免费安装 ?极好的在线社区 ?很容易学习 ?可以成为一种通用的语言,用于基于Web的分析产品数据科学和生产中。
实训:Python数据分析 〖实训目的〗 了解Python基本编程语法,掌握Python进行数据载入、预处理、分析和可视化的方法。 〖实训内容与步骤〗 1.在Python中导入数据 (1)读取CSV文件 CSV文件是由由逗号分割字段构成的数据记录型文件。我们可以方便地把 EXCEL中的电子表格存储为CSV文件。例如,我们有一份CSV 数据是英国近些年的降雨量统计数据,可以从以下网址找https://https://www.doczj.com/doc/7610710246.html,/dataset/average-temperature-and-rainfall-england-and- source/3fea0f7b-5304-4f11-a809-159f4558e7da) 从EXCEL中看到的数据如下图2-53所示: 图2-53 读取CSV文件 如果这个文件被保存在以下位置: D:\data\uk_rain_2014.csv 我们可以在Python中利用Pandas库将它导入: >>>import pandas as pd >>>df = pd.read_csv('d:\\data\\uk_rain_2014.csv', header=0) 这里需要注意的是,因为windows下用于分割目录的“\”符号在Python中被用于转义符(转义符就是用来输入特殊符号的引导符号,例如\n是回车,\r是换行等),因此“\”本身在Python语言中需要通过“\\”来输入。 以上两行程序就将这个csv文件导入成pandas中的一种类型为Dataframe的对象中,并给这个对象起名为df。
为了验证我们确实导入了这个数据文件,我们可以把df的内容打印出来:>>>print df Water Year Rain (mm) Oct-Sep Outflow (m3/s) Oct-Sep Rain (mm) Dec-Feb \ 0 1980/81 1182 5408 292 1 1981/8 2 1098 5112 257 2 1982/8 3 1156 5701 330 3 1983/8 4 993 426 5 391 4 1984/8 5 1182 5364 217 5 1985/8 6 102 7 4991 304 6 1986/8 7 1151 5196 295 7 1987/88 1210 5572 343 8 1988/89 976 4330 309 9 1989/90 1130 4973 470 10 1990/91 1022 4418 305 11 1991/92 1151 4506 246 121992/93 1130 5246 308 (2)读取EXCEL文件 因为EXCEL文件本身可以方便地另存为CSV文件,所以把EXCEL文件导入Python的一种办法就是将EXCEL中的数据表另存为CSV文件,然后利用上一节的方法将CSV导入Python。 当然,Pandas也提供了直接读取EXCEL文件的方法。同样,如果相应的EXCEL 文件放在D:\data\uk_rain_2014.xlsx,我们同样可以在Python中利用Pandas库将它导入: >>>import pandas as pd >>>df = pd.read_excel('d:\\data\\uk_rain_2014.xlsx') 同样,我们也可以把df的内容打印出来作为验证。 将数据导入Python之后,我们就可以对数据进行分析了。但在数据量很大的时候,我们往往需要从数据中提取和筛选出一部分数据来进行针对性的分析。 2.数据提取和筛选 仍然针对上面导入的英国天气数据,由于数据有很多行,我们希望只看到数据的前5行: >>> df.head(5) Water Year Rain (mm) Oct-Sep Outflow (m3/s) Oct-Sep Rain (mm) Dec-Feb \
python数据分析过程示例
引言 几年后发生了。在使用SAS工作超过5年后,我决定走出自己的舒适区。作为一个数据科学家,我寻找其他有用的工具的旅程开始了!幸运的是,没过多久我就决定,Python作为我的开胃菜。 我总是有一个编写代码的倾向。这次我做的是我真正喜欢的。代码。原来,写代码是如此容易! 我一周内学会了Python基础。并且,从那时起,我不仅深度探索了这门语言,而且也帮助了许多人学习这门语言。Python是一种通用语言。但是,多年来,具有强大的社区支持,这一语言已经有了专门的数据分析和预测模型库。 由于Python缺乏数据科学的资源,我决定写这篇教程来帮助别人更快地学习Python。在本教程中,我们将讲授一点关于如何使用Python 进行数据分析的信息,咀嚼它,直到我们觉得舒适并可以自己去实践。
目录 1. 数据分析的Python基础 o为什么学Python用来数据分析o Python 2.7 v/s 3.4 o怎样安装Python o在Python上运行一些简单程序2. Python的库和数据结构 o Python的数据结构 o Python的迭代和条件结构
o Python库 3. 在Python中使用Pandas进行探索性分析 o序列和数据框的简介 o分析Vidhya数据集——贷款的预测问题 4. 在Python中使用Pandas进行数据再加工 5. 使用Python中建立预测模型 o逻辑回归 o决策树 o随机森林 让我们开始吧 1.数据分析的Python基础 为什么学Python用来数据分析 很多人都有兴趣选择Python作为数据分析语言。这一段时间以来,我有比较过SAS和R。这里有一些原因来支持学习Python:
python数据分析(pandas) 几年后发生了。在使用SAS工作超过5年后,我决定走出自己的舒适区。作为一个数据科学家,我寻找其他有用的工具的旅程开始了!幸运的是,没过多久我就决定,Python作为我的开胃菜。 我总是有一个编写代码的倾向。这次我做的是我真正喜欢的。代码。原来,写代码是如此容易! 我一周内学会了Python基础。并且,从那时起,我不仅深度探索了这门语言,而且也帮助了许多人学习这门语言。Python是一种通用语言。但是,多年来,具有强大的社区支持,这一语言已经有了专门的数据分析和预测模型库。 由于Python缺乏数据科学的资源,我决定写这篇教程来帮助别人更快地学习Python。在本教程中,我们将讲授一点关于如何使用Python 进行数据分析的信息,咀嚼它,直到我们觉得舒适并可以自己去实践。
目录 1. 数据分析的Python基础 o为什么学Python用来数据分析 o Python 2.7 v/s 3.4 o怎样安装Python o在Python上运行一些简单程序 2. Python的库和数据结构 o Python的数据结构 o Python的迭代和条件结构 o Python库 3. 在Python中使用Pandas进行探索性分析
o序列和数据框的简介 o分析Vidhya数据集——贷款的预测问题 4. 在Python中使用Pandas进行数据再加工 5. 使用Python中建立预测模型 o逻辑回归 o决策树 o随机森林 让我们开始吧 1.数据分析的Python基础 为什么学Python用来数据分析 很多人都有兴趣选择Python作为数据分析语言。这一段时间以来,我有比较过SAS和R。这里有一些原因来支持学习Python: ?开源——免费安装 ?极好的在线社区 ?很容易学习 ?可以成为一种通用的语言,用于基于Web的分析产品数据科学和生产中。
常用Python数据分析库详解 Python之所以这么流行,这么好用,就是因为Python提供了大量的第三方的库,开箱即用,非常方便,而且还免费哦,学Python的同学里估计有30%以上是为了做数据分析师或者数据挖掘,所以数据分析相关的库一定要熟悉,那么常用的Python数据分析库有哪些呢? 1.NumPy NumPy是Python科学计算的基础包,它提供: 1).快速高效的多维数组对象ndarray; 2).直接对数组执行数学运算及对数组执行元素级计算的函数; 3).用于读写硬盘上基于数组的数据集的工具; 4).线性代数运算、傅里叶变换,以及随机数生成。 2.Pandas 大名鼎鼎的Pandas可以说只要做数据分析的,无人不知无人不晓,因为它太重要了.Pandas库提供了我们很多函数,能够快速的方便的,处理结构化的大型数据,不夸张的说,Pandas是让Python成为强大的数据分析工具的非常重要的一个因素。 而且对于金融行业,比如基金股票的分析师来说,pandas提供了高性能的时间序列功能和一系列的工具,可以自由的灵活的处理数据,一次使用你就会爱上它。 3.Matplotlib matplotlib是最流行的用于绘制数据图表的Python库,它和下面我们要讲
的 IPython结合的很爽,绝对是好基友,提供了一种非常好用的交互式的数据绘图环境。 4.IPython IPython是Python科学计算标准工具集的组成部分,它可以把很多东西联系到一起,有点类似一个增强版的Python shell。 目的是为了提高编程,测试和调试Python代码的速度,好像很多国外的大学教授,还有Google大牛都很喜欢用IPython,确实很方便,至少我在分析数据的时候,也是用这个工具的,而且不用print,回车就能打印。
从入门到精通pandas操作 Pandas简介:Python Data Analysis Library(数据分析处理库)或pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。 pandas的数据结构: Series:一维数组,与Numpy中的一维ndarray类似。二者与Python基本的数据结构List也很相近,其区别是:List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。 Time- Series:以时间为索引的Series。 DataFrame:二维的表格型数据结构,可以理解为Series的容器。 Panel :三维的数组,可以理解为DataFrame的容器。 本文主要介绍DateFrame数据结构。 本文中用到的数据集为food_info.csv,若有需要,在留言区留言即可获得。 本文只是介绍pandas的基本使用,若要详细深入学习,请参阅pandas官方文档。 1.读取.csv格式的数据文件
food_info.csv文件的局部预览图: 每一行:代表一种食品所包含的各种营养成分#导包 import pandas #读取数据文件,并将数据赋值成一个变量 . . food_info = pandas.read_csv("food_info.csv") #将数据赋值成一个变量后,打印此变量的类型为Dataframe . . print(type(food_info)) #打印文件中数据的类型。object类型即string类型
print(food_info.dtypes) #若对pandas中的某函数不了解,可以通过help()来查看. . print(help(pandas.read_csv)) . 运行结果: 补充:DataFrame结构中的dtype类型 object————for string values int————for integer values float————for float values datetime————for time values bool————for Boolean values
https://www.doczj.com/doc/7610710246.html, 10分钟教你看懂K线图交易策略_光环大数据python培训 对于K线图,相信做交易的朋友都不陌生。本文作者用交单明了的语言解释了三日K线的交易原则,也分享了如何用python绘制K线图的方法和代码。 关于日本K线交易 据说日本人在十七世纪就已经运用技术分析的方法进行大米交易,一位名叫本间宗久的坂田大米贸易商发明了“蜡烛图”这一技术来分析每日市场上大米现货价格。现代K线图之父史蒂夫尼森认为,通过“蜡烛图”进行正式交易是自19世纪50年代开始的。 在本文,我们要重点解决以下两个问题: 我们从雅虎数据库中随机下载一些每日财经数据,用来绘制我们的K线图。在这个例子中,我们将绘制“标普500ETF”的每日K线图。你可以更改股票代码,比如“谷歌”、“苹果”、“微软”等,来绘制属于自己的K线图。 我们通常用“matplotlib.pyplot库”来进行数据可视化。Matplotlib也提供包括K线图在内的少部分特殊金融绘制工具,此类绘制工具可以在“matplotlib.finance子库”中找到。 我们还将运用通过“bokeh.plotting”绘制带有默认工具集和默认可视样式的接口。它运用了Python中用于现代浏览器Web做演示的交互式可视化库。 上述代码的输出如下所示:
https://www.doczj.com/doc/7610710246.html, 我们提供的工具将帮助你记录图表走向,并通过缩放框和变焦轮将其放大或缩小。还有一个重置按钮来显示原本的实际输出,一个保存按钮让你下载浏览器中显示的图像(即缩放的图像)。 通过“三日K线”来理解K线交易策略 让我们来看一个简单的每日交易策略,通过分析过去三天的K线来预测我们在第四天是“买进”还是“卖空”。我们将在第四天结束前关闭仓位,并提前确定盈利/亏损。 在第四天“看涨”(即买入)所对应的所对应的交易条件是: 规则1:最新烛台的面积必须大于前两支烛台的面积,而不管烛台的颜色如何。 规则2:第二支烛台必须是红色的。 规则3:最近一支烛台的收盘价必须高于第二支烛台的收盘价。 规则4:你会在第四天早上交易刚开始时买入,然后在市场收盘前卖出。 在第四天“看空”(即卖出)所对应的交易情况是: 规则1:最新K线的面积必须大于前两支烛台的面积,而不管烛台的颜色如何。 规则2:第二天的烛台必须是绿色的。
《Python数据分析与应用》教学大纲课程名称:Python数据分析与应用 课程类别:必修 适用专业:大数据技术类相关专业 总学时:64学时(其中理论36学时,实验28学时) 总学分:4.0学分 一、课程的性质 大数据时代已经到来,在商业、经济及其他领域中基于数据和分析去发现问题并做出科学、客观的决策越来越重要。数据分析技术将帮助企业用户在合理时间内获取、管理、处理以及整理海量数据,为企业经营决策提供积极的帮助。数据分析作为一门前沿技术,广泛应用于物联网、云计算、移动互联网等战略新兴产业。有实践经验的数据分析人才已经成为了各企业争夺的热门。为了推动我国大数据,云计算,人工智能行业的发展,满足日益增长的数据分析人才需求,特开设Python数据分析与应用课程。 二、课程的任务 通过本课程的学习,使学生学会使用Python进行科学计算、可视化绘图、数据处理,分析与建模,并详细拆解学习聚类、回归、分类三个企业案例,将理论与实践相结合,为将来从事数据分析挖掘研究、工作奠定基础。 三、课程学时分配
四、教学内容及学时安排 1.理论教学
2.实验教学
五、考核方式 突出学生解决实际问题的能力,加强过程性考核。课程考核的成绩构成= 平时作业(10%)+ 课堂参与(20%)+ 期末考核(70%),期末考试建议采用开卷形式,试题应包括基本概念、绘图、分组聚合、数据合并、数据清洗、数据变换、模型构建等部分,题型可采用判断题、选择、简答、应用题等方式。 六、教材与参考资料 1.教材 黄红梅,张良均.Python数据分析与应用[M].北京:人民邮电出版社.2018. 2.参考资料
《Python数据分析基础教程》课程教学大纲 课程编号: 学分:8学分 学时:128学时(最佳上课方式:理实一体化上课) 适用专业:大数据应用技术、信息管理技术及其计算机相关专业 一、课程的性质与目标 《Python数据分析基础教程》是面向大数据应用技术专业、信息管理专业及计算机相关专业的一门数据分析及应用基础课程,本课程主要介绍数据分析的概念、数据分析的流程、Python语言基础以及Python数据分析常用库,如NumPy、Matplotlib、pandas和scikit-learn库的运用等内容。通过本课程的学习,学生不仅可以更好地理解Python数据分析中的基本概念,还可以运用所学的数据分析技术,完成相关的数据分析项目的实践。 二、课程设计理念与思路 通过数据分析的案例,介绍数据分析的概念、数据分析的流程以及Python数据分析常用库的应用。同时,为便于读者能更好地理解Python的数据分析,介绍了Python 的基础语法。最后,运用所学的数据分析技术,完成相关的数据分析项目的实践。 本书各个章节中都有许多示例代码,通过示例代码帮助读者更好地理解Python数据分析中的基本概念,同时,为提高读者对数据分析技术的综合运用能力,在各个章节中还设置了项目实践的综合训练和思考练习等内容。 三、教学条件要求 操作系统:Windows 7 开发工具:Python3.6.3,PyCharm、Jupyter notebook
四、课程的主要内容及基本要求第一章数据分析概述 第二章Python与数据分析
第三章Python语言基础 第四章NumPy数组与矢量计算
Python金融投资分析实践 课程介绍 Python是什么? Python是现流行的一种多用途编程语言,广泛应用于各种非技术和技术领域。为什么选择Python进行金融数据分析?在大数据的时代,金融的数据处理也更多地借助与各种软件,而Python作为一个具有强大库的软件,在金融数据的分析上,也有非常重要的地位。美国银行、美林证券的“石英”项目、摩根大通的“雅典娜”项目,都使用了Python和其他既定技术来构建、改进和维护其核心IT系统,而很多对冲基金也开始大量地使用Python的功能,进行高效的金融应用程序开发与金融分析工作。 课程大纲 第一课Python是什么?为什么选择Python进行数据分析 Python的简介与环境部署;金融计量计算小例子——多种金融收益率的计算;蒙特卡罗模拟法的欧式期权价值计算 第二课如何灵活使用Python来分析数据? Python的基本数据类型与结构介绍;Numpy数据结构的介绍与使用; Numpy中的金融函数 第三课如何使用Python展示金融数据? Python中的二维绘图:线图、散点图、直方图、股票烛柱图等;三维曲面图 第四课如何使用Python处理时间序列? Pandas库的基本数据结构介绍;时间序列的平滑方法;高频数据的处理 第五课我们需要补充点数学基础 回归、插值、优化问题、积分与方程求解在Python中的实现 第六课我们需要补充点统计学基础 统计描述与推断统计学在金融数据上的应用 第七课如何利用Python计算投资组合?
投资组合优化的基本理论,有效边界与资本市场线的计算 第八课主成分分析(PCA)可以对金融数据做什么? 主成分分析技术介绍;利用PCA方法构造股票指数 第九课贝叶斯回归在金融学中的作用 贝叶斯回归的介绍;黄金投资公司与黄金开采公司的回归分析 第十课衍生品定价模型 资产定价基本定理;固定短期利率折现计算 第十一课金融模型的模拟计算 几何布朗模拟;跳跃扩散模拟;平方根扩散模拟 第十二课衍生品的价格是多少? 欧式期权与美式期权;期权的估值 第十三课加入衍生品的投资组合 投资组合中衍生品头寸的计算 授课讲师 何翠仪,毕业于中山大学统计学专业,炼数成金专职讲师。 在炼数成金上开设了多门关于数据分析与数据挖掘相关的课程,如《大数据的统计 学基础》、《大数据的矩阵基础》《金融时间序列分析》等,也曾到不同的公司开 展R语言与数据分析的相关培训。对数据分析有深刻认识,曾与不同领域公司合作,参与到多个数据分析的项目中,如华为、广州地铁等 课程环境 Python 2.x 授课对象 对金融投资分析有兴趣,有志从事金融行业数据分析,希望探索python在金融行业应用实践的学员; 收获预期 知道如何利用Python进行金融投资分析,并可以熟练使用Python进行金融投资分 析和数据展现
python数据分析学习方法 数据分析是大数据的重要组成部分,在越来越多的工作中都扮演着重要的角色,Python可以利用各种Python库,如NumPy、pandas、matplotlib以及IPython 等,高效的解决各式各样的数据分析问题,那么该如何学习Python数据分析呢? 大数据作为一门新兴技术,大数据系统还不完善,市场上存在的资料也很零散,只有少数大数据资深技术专家才掌握真正的大数据技术,老男孩教育徐培成老师拥有丰富的大数据实践经验,掌握大数据核心技术,大数据实战课程体系完善,能够让学员学到真本领! 老男孩教育Python与数据分析内容: 1. Python介绍、Python环境安装、Python体验 2. Python基础、语法、数据类型、分支、循环、判断、函数 3. Python oop、多线程、io、socket、模块、包、导入控制 4. Python正则表达式、Python爬虫实现 5. 行列式基础、转置、矩阵定义、矩阵运算、逆矩阵、矩阵分解、矩阵变换、矩阵的秩 6. Python对常用矩阵算法实现 7. Python常用算法库原理与使用、numpy、pandas、sklearn 8. 数据加载、存储、格式处理 9. 数据规整化、绘图与可视化 Python与数据分析是老男孩教育大数据开发课程的一部分,除此之外,老男孩教育大数据开发课程还包括:Java、Linux、Hadoop、Hive、Avro与Protobuf、
ZooKeeper、HBase、Phoenix、Flume、SSM、Kafka、Scala、Spark、azkaban等,如此全面的知识与技能,你还在等什么?赶紧报名学习吧!
常用Python数据分析工具汇总 Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性。Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的,需要安装第三方扩展库来增强分析和挖掘能力。 Python数据分析需要安装的第三方扩展库有:Numpy、Pandas、SciPy、Matplotlib、Scikit-Learn、Keras、Gensim、Scrapy等,以下是对该第三方扩展库的简要介绍: 1. Numpy Python没有提供数组功能,Numpy可以提供数组支持以及相应的高效处理函数,是Python数据分析的基础,也是SciPy、Pandas等数据处理和科学计算库最基本的函数功能库,且其数据类型对Python数据分析十分有用。 2. Pandas Pandas是Python强大、灵活的数据分析和探索工具,包含Series、DataFrame 等高级数据结构和工具,安装Pandas可使Python中处理数据非常快速和简单。 3. SciPy SciPy是一组专门解决科学计算中各种标准问题域的包的集合,包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算等,这些对数据分析和挖掘十分有用。 4. Matplotlib
Matplotlib是强大的数据可视化工具和作图库,是主要用于绘制数据图表的Python库,提供了绘制各类可视化图形的命令字库、简单的接口,可以方便用户轻松掌握图形的格式,绘制各类可视化图形。 5. Scikit-Learn Scikit-Learn是Python常用的机器学习工具包,提供了完善的机器学习工具箱,支持数据预处理、分类、回归、聚类、预测和模型分析等强大机器学习库,其依赖于Numpy、Scipy和Matplotlib等。 6. Keras Keras是深度学习库,人工神经网络和深度学习模型,基于Theano之上,依赖于Numpy和Scipy,利用它可以搭建普通的神经网络和各种深度学习模型,如语言处理、图像识别、自编码器、循环神经网络、递归审计网络、卷积神经网络等。 7. Gensim Gensim是用来做文本主题模型的库,常用于处理语言方面的任务,支持TF-IDF、LSA、LDA和Word2Vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算、信息检索等一些常用任务的API接口。 8. Scrapy Scrapy是专门为爬虫而生的工具,具有URL读取、HTML解析、存储数据等功能,可以使用Twisted异步网络库来处理网络通讯,架构清晰,且包含了各种中间件接口,可以灵活的完成各种需求。 以上是对Python数据分析常用工具的简单介绍,有兴趣的可以深入学习研究一下相关使用方法!
《python金融数据挖掘及其应用》课程教学大纲 课程代码: 学分:5 学时:80(其中:讲课学时:60 实践或实验学时:20 ) 先修课程:数学分析、高等代数、概率统计、金融基础知识、Python程序设计基础 适用专业:信息与计算科学 建议教材:黄恒秋主编.Python金融数据分析与挖掘实战[M]. 北京:人民邮电出版社.2019. 开课系部:数学与计算机科学学院 一、课程的性质与任务 课程性质:专业方向选修课。 课程任务:大数据时代,数据成为决策最为重要的参考之一,数据分析行业迈入了一个全新的阶段。通过学习本课程,使得学生在掌握Python科学计算、数据处理、数据可视化、挖掘建模等基本技能基础上,进一步地扩展应用到较为复杂金融数据处理及挖掘分析任务上,最后进行量化投资实战检验。本课程为Python在金融量化投资领域的具体应用,也是Python 在金融行业应用最为广泛的领域之一,从而使得学生具备一定的行业应用背景及就业技能。 二、课程的基本内容及要求 本课程教学时数为80学时,5学分;实验20学时,1.25学分。 第七章基础案例 1.课程教学内容: (1)股票价格指数周收益率和月收益率的计算; (2)上市公司净利润增长率的计算; (3)股票价、量走势图绘制; (4)股票价格移动平均线的绘制; (5)沪深300指数走势预测; (6)基于主成分聚类的上市公司盈利能力分析。 2.课程的重点、难点: (1)重点:案例的实现思路、算法及程序具体实现; (2)难点:案例的实现算法、程序实现过程中各类数据结构的相互转换。 3.课程教学要求: (1)了解案例实现的基本思路; (2)理解案例实现的具体算法及程序实现,各种数据结构的相互转换并实现程序计算; (3)掌握案例实现的具体过程,包括思路、算法、数据处理、程序计算及结果展现。 第八章综合案例一:上市公司综合评价
基本数据统计分析 Python 数据处理、分析、可视化与数据化运营 06
本章学习目标 了解描述性统计分析各个指标的含义 掌握交叉对比和趋势分析的基本方法与技巧 掌握结构与贡献分析的应用场景以及实现方法 重点分组与聚合分析的常用方法 掌握相关性分析的主要方法以及如何解读相关性分析结果了解漏斗、路径和归因分析基本概念
准备数据 使用Excel的DMEO数据 本节所用数据为公用数据,读取excel的demo数据。用法示例: import pandas as pd # ① import numpy as np # ② raw_data = pd.read_excel('demo.xlsx') # ③ print(raw_data.head(3)) # ④
准备数据 先将province转换为字符串 在字段中的PROVINCE 列本身是分类含义,因此将其转换为字符串类型。用法示例: raw_data['PROVINCE'] = raw_data['PROVINCE'].astype(str)
准备数据 使用describe查看描述性统计分析信息 用法示例: desc_data = raw_data.describe(include='all').T # ①获得所有字段的描述信息 desc_data['polar_distance'] = desc_data['max']- desc_data['min'] # ②得到极差(或极距)desc_data['IQR'] = (desc_data['75%']-desc_data['25%'])/2 # ③计算四分位差 desc_data['days_int'] = desc_data['last']-desc_data['first'] # ④基于last和first差值计算日期间隔desc_data['dtype'] = raw_data.dtypes # ⑤获取所有列的字段类型 desc_data['all_count'] = raw_data.shape[0] # ⑥获取所有列的总记录数量 print(desc_data.columns) # ⑦
用一张示意图表示Python变量和赋值的重点: 例如下图代码,“=”的作用就是赋值,同时Python会自动识别数据类型:整型数据 整型数据 字符串数据 字符串数据
字典使用键-值(key-value)存储,无序,具有极快的查找速度。以上面的字典为例,想要快速知道周杰伦的年龄,就可以这么写: zidian['周杰伦'] >>>'40' dict内部存放的顺序和key放入的顺序是没有关系的,也就是说,"章泽天"并非是在"刘强东"的后面。 DataFrame: DataFrame可以简单理解为Excel里的表格格式。导入pandas包后,字典和列表都可以转化为DataFrame,以上面的字典为例,转化为DataFrame是这样的: import pandas as pd df=pd.DataFrame.from_dict(zidian,orient='index',columns=['age'])#注意DataFrame的D和F是大写df=df.reset_index().rename(columns={'index':'name'})#给姓名加上字段名 和excel一样,DataFrame的任何一列或任何一行都可以单独选出进行分析。 以上三种数据类型是python数据分析中用的最多的类型,基础语法到此结束,接下来就可以着手写一些函数计算数据了。
2.从Python爬虫学循环函数 掌握了以上基本语法概念,我们就足以开始学习一些有趣的函数。我们以爬虫中绕不开的遍历url为例,讲讲大家最难理解的循环函数for的用法: A.for函数 for函数是一个常见的循环函数,先从简单代码理解for函数的用途: zidian={'刘强东':'46','章泽天':'36','周杰伦':'40','昆凌':'26'} for key in zidian: print(key) >>> 刘强东 章泽天 周杰伦 昆凌 因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不是每次都一样。默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时#迭代key和value,可以用for k, v in d.items() 可以看到,字典里的人名被一一打印出来了。for 函数的作用就是用于遍历数据。掌握for函数,可以说是真正入门了Python函数。 B.爬虫和循环 for函数在书写Python爬虫中经常被应用,因为爬虫经常需要遍历每一个网页,以获取信息,所以构建完整而正确的网页链接十分关键。以某票房数据网为例,他的网站信息长这样:
智慧树Python数据分析与数据可视化答案第一章单元测试 1、缩进对于Python程序至关重要。 A:错 B:对 正确答案:【对】 2、在Python 3.x中不能使用汉字作为变量名。 A:对 B:错 正确答案:【错】 3、下面哪些是正确的Python标准库对象导入语句? A:from math import B:import math.sin as sin C:from math import sin D:import math. 正确答案:【from math import *; from math import sin】 4、Python支持面向对象程序设计。 A:对 B:错 正确答案:【对】
5、下面属于Python编程语言特点的有? A:扩展库丰富 B:代码运行效率高 C:支持命令式编程 D:支持函数式编程 正确答案:【扩展库丰富; 支持命令式编程; 支持函数式编程】 第二章单元测试 1、已知列表x = [1, 2, 1, 2, 3, 1],那么执行x.remove(1)之后,x的值为[2, 2, 3]。A:对 B:错 正确答案:【错】 2、已知列表x = [1, 2, 3],那么执行y = x.reverse()之后,y的值为[3, 2, 1]。 A:对 B:错 正确答案:【错】 3、Python语言中同一个集合中的元素不会重复,每个元素都是唯一的。 A:错 B:对 正确答案:【对】 4、表达式3 > 5 and math.sin(0)的值为0。
B:错 正确答案:【错】 5、表达式4 < 5 == 5的值为True。 A:错 B:对 正确答案:【对】 第三章单元测试 1、生成器表达式的计算结果是一个元组。 A:错 B:对 正确答案:【错】 2、包含列表的元组可以作为字典的“键”。 A:错 B:对 正确答案:【错】 3、列表的rindex()方法返回指定元素在列表中最后一次出现的位置。A:对 B:错 正确答案:【错】 4、Python语言中同一个集合中的元素不会重复,每个元素都是唯一的。A:错
常用的Python数据分析工具 Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性。Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的,需要安装第三方扩展库来增强分析和挖掘能力。 Python数据分析需要安装的第三方扩展库有:Numpy、Pandas、SciPy、Matplotlib、Scikit-Learn、Keras、Gensim、Scrapy等,以下是对该第三方扩展库的简要介绍: 1. Numpy Python没有提供数组功能,Numpy可以提供数组支持以及相应的高效处理函数,是Python数据分析的基础,也是SciPy、Pandas等数据处理和科学计算库最基本的函数功能库,且其数据类型对Python数据分析十分有用。 2. Pandas Pandas是Python强大、灵活的数据分析和探索工具,包含Series、DataFrame 等高级数据结构和工具,安装Pandas可使Python中处理数据非常快速和简单。 3. SciPy SciPy是一组专门解决科学计算中各种标准问题域的包的集合,包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算等,这些对数据分析和挖掘十分有用。 4. Matplotlib
Matplotlib是强大的数据可视化工具和作图库,是主要用于绘制数据图表的Python库,提供了绘制各类可视化图形的命令字库、简单的接口,可以方便用户轻松掌握图形的格式,绘制各类可视化图形。 5. Scikit-Learn Scikit-Learn是Python常用的机器学习工具包,提供了完善的机器学习工具箱,支持数据预处理、分类、回归、聚类、预测和模型分析等强大机器学习库,其依赖于Numpy、Scipy和Matplotlib等。 6. Keras Keras是深度学习库,人工神经网络和深度学习模型,基于Theano之上,依赖于Numpy和Scipy,利用它可以搭建普通的神经网络和各种深度学习模型,如语言处理、图像识别、自编码器、循环神经网络、递归审计网络、卷积神经网络等。 7. Gensim Gensim是用来做文本主题模型的库,常用于处理语言方面的任务,支持TF-IDF、LSA、LDA和Word2Vec在内的多种主题模型算法,支持流式训练,并提供了诸如相似度计算、信息检索等一些常用任务的API接口。 8. Scrapy Scrapy是专门为爬虫而生的工具,具有URL读取、HTML解析、存储数据等功能,可以使用Twisted异步网络库来处理网络通讯,架构清晰,且包含了各种中间件接口,可以灵活的完成各种需求。 以上是对Python数据分析常用工具的简单介绍,有兴趣的可以深入学习研究一下相关使用方法!