
第十二章 列联表和对应分析
我们前面介绍的相关分析可以用来分析定量变量之间的关系,但不能用于定性变量的分析。本章介绍的列联表检验和对应分析方法则可以用来分析定性变量之间的关系。
第一节 列联表与独立性检验
【例12.1】美国的一般社会调查(General Social Survey )是由美国芝加哥大学的民意调查中心进行的一项随机抽样调查,调查对象为18岁以上的成年人。调查中获得了居民的婚姻状况和幸福状况方面的数据。下面我们根据1996年的调查结果来分析两个变量之间的关系(数据文件gss96.sav )。在调查中,婚姻状况的取值为已婚、丧偶、离异、分居和未婚(分别用1-5表示);幸福状况的取值为:非常幸福、比较幸福和不太幸福(分别用1-3表示)。在SPSS 软件中打开数据文件,选择“分析”→“描述统计”→“交叉表”,把“婚姻状况”设为行变量,把“幸福状况”设为列变量,可以得到表12-1所示的列联表。从表中我们可以看出,从婚姻状况看,已婚人员的比重最高;从幸福状况看,比较幸福的人员比重最高。但从表中我们很难直观地看出两个变量之间的内在联系。
表12-1 婚姻状况和幸福状况列联表
幸福状况
合计
非常幸福 比较幸福 不太幸福
婚姻状况 已婚
574 726 82 1382 丧偶 70 149 59 278 离异 83 292 79 454 分居 14 73 30 117 未婚
136 419 99 654 合计
877
1659
349
2885
要研究二维列联表中的两个变量是否相互独立,可以使用我们在非参数检验中讲过χ2
检验。检验的零假设和备择假设为
H 0:婚姻状况和幸福状况这两个变量相互独立;H 1:婚姻状况和幸福状况不相互独立。 假定样本量为n ,列联表有r 行、s 列,表中各行的合计值分别为r i R i ,,2,1,Λ=,各列的合计值分别为s j C j ,2,1,Λ=。每个单元格中的频数为j i O ,。在零假设成立,即行变量和列变量相互独立时,每个单元格频数的期望值可以按照式(12-1)计算:
n
C R n n C n R E j i j
i ij ?=
??= (12-1) 显然,如果期望频数ij E 和观测频数ij O 相差不大,则零假设可能是正确的;如果二者差别很大,则零假设可能不成立。按照式(12-2)构造检验统计量:
∑∑
==-=r i s
j ij
ij ij E E O 11
2
2
)(χ (12-2)
在零假设成立时,该统计量近似服从自由度为)1)(1(--s r 的χ2分布。当该统计量的值很大(或p 值很小)时,就可以拒绝零假设,认为这两个变量不相互独立。
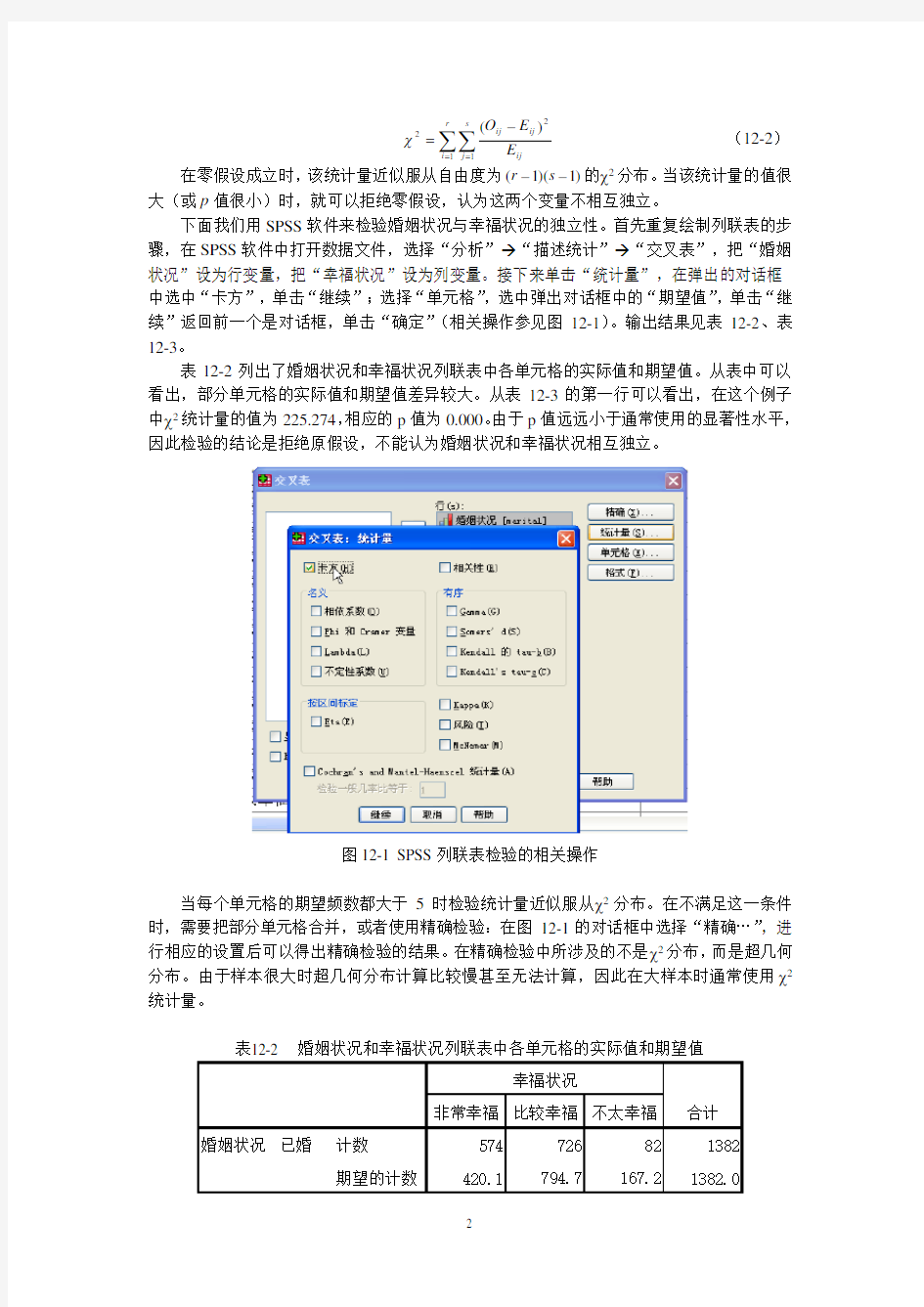
下面我们用SPSS 软件来检验婚姻状况与幸福状况的独立性。首先重复绘制列联表的步骤,在SPSS 软件中打开数据文件,选择“分析”→“描述统计”→“交叉表”,把“婚姻状况”设为行变量,把“幸福状况”设为列变量。接下来单击“统计量”,在弹出的对话框中选中“卡方”,单击“继续”;选择“单元格”,选中弹出对话框中的“期望值”,单击“继续”返回前一个是对话框,单击“确定”(相关操作参见图12-1)。输出结果见表12-2、表12-3。
表12-2列出了婚姻状况和幸福状况列联表中各单元格的实际值和期望值。从表中可以看出,部分单元格的实际值和期望值差异较大。从表12-3的第一行可以看出,在这个例子中χ2统计量的值为225.274,相应的p 值为0.000。由于p 值远远小于通常使用的显著性水平,因此检验的结论是拒绝原假设,不能认为婚姻状况和幸福状况相互独立。
图12-1 SPSS 列联表检验的相关操作
当每个单元格的期望频数都大于5时检验统计量近似服从χ2分布。在不满足这一条件时,需要把部分单元格合并,或者使用精确检验:在图12-1的对话框中选择“精确…”,进行相应的设置后可以得出精确检验的结果。在精确检验中所涉及的不是χ2分布,而是超几何分布。由于样本很大时超几何分布计算比较慢甚至无法计算,因此在大样本时通常使用χ2统计量。
表12-2 婚姻状况和幸福状况列联表中各单元格的实际值和期望值
幸福状况
合计
非常幸福 比较幸福 不太幸福
婚姻状况 已婚 计数
574 726 82 1382 期望的计数
420.1
794.7
167.2
1382.0
表12-3 婚姻状况和幸福状况间独立性的 2检验结果
值df 渐进Sig. (双侧)
Pearson 卡方225.274a8 .000
似然比230.166 8 .000
线性和线性组合137.494 1 .000
有效案例中的N 2885
a. 0单元格(.0%)的期望计数少于5。最小期望计数为14.15。
第二节对应分析
一、对应分析的基本思想
对应分析是一种描述性、探索性的数据分析方法,通常用于列联表的分析,以便用图形的方法观察行变量和列变量取值之间的对应关系。
与因子分析类似,对应分析也是一种数据降维技术。在因子分析中我们可以对变量进行降维,根据因子分析的结果分析各个变量之间的接近程度,也可以对样品(观测)进行降维,根据因子分析的结果分析样品之间的接近程度。而对应分析则可以按照相同的刻度同时对列联表中的行变量和列变量进行降维,用较少的维度(一般选用二维或三维)来代表数据表中的行变量和列变量,从而在同一个空间中用图形方法显示行变量和列变量类别之间的关系。
在表12-1的列联表中,把3个幸福状况的取值看作3维空间中的坐标,我们可以把5个幸福状况在3维空间中表示出来。如果使用因子分析的方法对3个幸福状况进行降维(同时最大限度地保留原始信息),则我们能够在2维甚至1维空间上把5个点表示出来。类似的,把表中婚姻状况的取值看作5维空间的坐标值,使用因子分析的方法进行降维,也可以把3个幸福状况在低维空间中表示出来。这样,如果能够保证两个因子分析中采用相同的刻度,则可以在同一个坐标系中把幸福状况的3个点和婚姻状况的5个点绘制出来,通过图形观察两个变量取值之间的关系。按上述方法得到的图形称为对应分析图。在对应分析图中,如果同一变量的不同类别在某个方向上靠得较近,则说明这些类别在该维度上区别不大;落在图形中大致相同区域的不同变量的分类点彼此之间有联系。
当然,为了保证对行和列进行因子分析的结果之间的对应关系,在进行对应分析时并不是根据列联表中的频数直接进行因子分析的,而是先计算相应的频率,再进行必要的变量变换,之后再用与因子分析类似的方法进行降维。
二、对应分析的软件操作和结果的解释
下面我们通过一个例子说明对应分析的软件操作和结果的解释。
【例12-2】根据美国的一般社会调查(General Social Survey)1996年的调查结果分析婚姻状况和幸福状况列两个变量之间的对应关系(数据文件gss96.sav)。
在SPSS软件中打开数据文件,选择“分析”→“降维”→“对应分析”,把“婚姻状况”设为行变量;在弹出的对话框中单击“定义范围”,最小值设为1,最大值设为5,单击“更新”、“继续”;然后把“幸福状况”设为列变量,再通过“定义范围”对话框定义其取值范围为1-3;最后单击“确定”,就可以得到相关输出结果了(相关软件操作参见图12-2)。
图12-2 SPSS对应分析的相关操作
表12-4是SPSS对应分析的摘要表。在表12-4中,“惯量”类似于因子分析中特征值对应的方差;“惯量比例”一栏中,“解释”的惯量比例类似于因子分析中的方差贡献率,“累积”的惯量比例类似于因子分析中的累积方差贡献率,这几个指标反映了每个维度的因子重要性和解释能力。表中的“卡方”是关于列联表行列独立性检验的 2统计量的值,和前面表中的相同。其后面的Sig为在行列独立的零假设下的p值,注释表明统计量对应的自由度为(5-1)×(3-1)=8。p值很小说明列联表的行与列之间有较强的相关性。
表12-4 对应分析的摘要表
维数
惯量比例置信奇异值
相关奇异值惯量卡方Sig. 解释累积标准差 2
1 .27
2 .074 .944 .944 .017 .064
2 .066 .004 .056 1.000 .021
总计.078 225.274 .000a 1.000 1.000
a. 8 自由度
在SPSS的输出中还有12-5和12-6两个表。这两个表分别给出了绘制对应分析图所需要的两套坐标。表12-5中的“质量”对应的英文为“Mass”,译为“密度”更为确切,反映的是每种婚姻状况的人数比例。表中给出了婚姻状况5个水平的坐标:已婚(-0.531, -0.016),丧偶(0.437, -0.660),离异(0.535, 0.168),丧偶(0.041, 0.979),未婚(0.389, 0.257)。表12-6给出了幸福状况三个水平的坐标:非常幸福(-0.684, -0.193),比较幸福(0.157, 0.207),不太幸福(0.975, -0.498)。
表12-6 列变量(幸福状况)的坐标
根据表12-5、12-6可以得到图12-3所示的对应分析图。这个图是在SPSS默认输出结果的基础上进行编辑得到的。从图中我们可以很直观地看出“婚姻状况”和“幸福状况”取值之间的对应关系:“已婚”和“非常幸福”最接近;“离异”、“未婚”和“比较幸福”比较接近;而“丧偶”、“分居”和“不太幸福”比较接近。两个变量取值之间的这种对应关系是单独用 2检验所无法看出的。
当然,如前所述,对应分析是一种探索性的描述统计方法,并不能保证所有的对应分析结果中两个变量的取值之间都有如此明确的对应关系。
图12-3 对于婚姻状况和幸福状况关系的对应分析图
小结
本章首先介绍了列联表中两个定性变量独立性的检验方法(χ2检验),然后介绍了对应分析方法。对应分析方法可以让我们通过图形直观地观察两个定性变量取值之间的对应关系。
在基于列联表的独立性检验中,如果行变量和列变量相互独立,则每个单元格中观测到的频数与其期望频数应该比较接近。如果二者之间悬殊较大,则说明零假设是不成立的。基于这种思想可以构造χ2检验统计量进行相应的假设检验。
对应分析是一种描述性、探索性的数据分析方法,通常用于列联表的分析,以便用图形的方法观察行变量和列变量取值之间的对应关系。与因子分析类似,对应分析也是一种数据降维技术。对应分析则可以按照相同的刻度同时对列联表中的行变量和列变量进行降维,用较少的维度(一般选用二维或三维)来代表数据表中的行变量和列变量,从而在同一个空间中用图形方法显示行变量和列变量类别之间的关系。
思考与练习
1. 表12-7的数据是592个人头发和眼睛颜色的列联表,请检验着两个变量是否相互独立。
提示:在SPSS软件中录入数据时,数据文件中应该有三个变量:头发颜色、眼睛颜色和频数,并在SPSS中选择“数据” “加权个案”,把“频数”变量指定为权数;合计值不需要录入到数
据表中。
表12-7 592个人头发和眼睛颜色的列联表
眼睛颜色
头发颜色蓝色棕色绿色淡褐色合计黑色20 68 5 15 108
金色94 7 16 10 127
棕色84 119 29 54 286
红色17 26 14 14 71
合计215 220 64 93 592
2. 用对应分析方法第1题数据中两个定性变量取值之间的关系。
2 列联表分析(Crosstabs) 列联表是指两个或多个分类变量各水平的频数分布表,又称频数交叉表。SPSS的Crosstabs过程,为二维或高维列联表分析提供了22种检验和相关性度量方法。其中卡方检验是分析列联表资料常用的假设检验方法。 例子:山东烟台地区病虫测报站预测一代玉米螟卵高峰期。预报发生期y为3级(1级为6月20日前,2级为6月21-25日,3级为6月25日后);预报因子5月份平均气温x1(℃)分为3级(1级为16.5℃以下,2级为16.6-17.8℃,3级为17.8℃以上),6月上旬平均气温x2(℃)分为3级(1级为20℃以下,2级为20.1-21.5℃,3级为21.5℃以上),6月上旬降雨量x3(mm)分为3级(1级为15mm以下,2级为15.1-30mm,3级为30mm以上),6月中旬降雨量x4(mm)分为3级(1级为29mm以下,2级为29.1-36mm,3级为36mm以上)。数据如下表。 山东烟台历年观测数据分级表() 注:摘自《农业病虫统计测报》 131页。 1) 输入分析数据 在数据编辑器窗口打开“”数据文件。 数据文件中变量格式如下: 2)调用分析过程 在菜单选中“Analyze-Descriptive- Crosstabs”命令,弹出列联表分析对话框,如下图 3)设置分析变量 选择行变量:将“五月气温[x1],六月上气温[x2],六月上降雨[x3],六月中降雨[x4]”
变量选入“Rows:”行变量框中。 选择列变量:将“玉米螟卵高峰发生期[y]”变量选入“Columns:”列变量框中。 4)输出条形图和频数分布表 Display clustered bar charts: 选中显示复式条形图。 Suppress table: 选中则不输出多维频数分布表。。 5)统计量输出 点击“Statistics”按钮,弹出统计分析对话框(如下图)。 Chi-Square: 卡方检验。选中可以输出皮尔森卡方检验(Pearson)、似然比卡方检验(Likelihood-ratio)、连续性校正卡方检验 (Continuity Correction)及Fisher精确概率检验(Fisher’s Exact test)的结果。 Correlations: 选中输出皮尔森(Pearson)和Spearman相关系数,用以说明行变量和列变量的相关程度。 Nominal: 两分类变量的关联度(Association)测量 Contingency Coefficient: 列联系数,其值越大关联性越强。 Phi and Cramer’s V:Cramer列联系数,其值越大关联性越强。 Lambda: 减少预测误差率,1表示预测效果最好,0表示预测效果最差。 Uncertainty Coefficient: 不定系数 Ordinal: 两有序分类变量(等级变量)的关联度测量 Gamma: 关联度,+1表示完全正关联,-1表示负关联,0表示无联。 Somers’d:列联度,其取值范围和意义同上。 Kendall’s tau-b: Nominal by Interval: 一个定性变量和一个定量变量的关联度
第七章列联表分析 7.1 列联表(Crosstabs)分析的过程 7.2 列联表的实例分析 7.1 列联表 (Crosstabs) 分析的过程 列联表分析的过程是对两个变量之间关系的分析方法。被分析的变量可以是定类变量也可以是定序变量。系统是通过生成列联表对两个变量进行列联表分析的。 列联表分析的功能可以通过下述操作来实现。 图7-1 列联表分析对话框 1.打开列联表分析对话框 执行下述操作: Analyze→Descriptive→Crosstabs 打开Crosstabs 对话框如图7-1 所示。 2.确定列联分析的变量 从左侧的源变量窗口中选择两个定类变量或定序变量分别进入Row(s)(行)窗口和Column(s)(列)窗口。进入Row(s)窗口的变量的取值将作为行的标志输出,而进入Column(s)窗口的变量的取值将作为列的标志输出。Display clustered bar charts 是在输出结果中显示聚类条图。Suppress table 是隐藏表格,如果选择此项,将不输出R×C 列联表。 3.选择统计分析内容 单击statistics 按钮,打开statistics 对话框,如图7-2 所示。
图7-2statistics 对话框 下面介绍该对话框中的选项和选项栏的内容: (1)Chi-square 是卡方(X2)值选项,用以检验行变量和列变量之间是否独立。适用于定类变量和定序变量。 (2)Correlations 是皮尔逊(Pearson)相关系数r 的选项。用以测量变量之间的线性相关。适用于定序或数值变量(定距以上变量)。 (3)Nominal 是定类变量选项栏。选项栏中的各项是当分析的两个变量都为定类变量时可以选择的参数。 1)Contingency coefficient:列联相关的C 系数,由卡方系数修正而得。 2) Phi and Cramer's V:列联相关的V 系数,由卡方系数修正而得。 3)Lambda:λ系数。 4)Uncertainty Coefficient:不定系数。 (4)Ordinal 是定序变量选项栏。选项栏中的各项是当分析的两个变量都为定序变量时可以选择的参数。 1)Gramma:Gramma 等级相关系数。 2)Somers’d:Somers 等级相关d 系数。 3)Kendall’s tau-b:肯得尔等级相关tau-b 系数。 4)Kendall’s tau-c:肯得尔等级相关tau-c 系数。 (5)Nominal by Interval 选项栏中的Eta 是当一个变量为定类变量,另一个变量为数值变量时,测量两个变量之间关系的相关比率。 系统默认状态是不输出上述参数。如需要可自行选择。上述选择做完以后,单击Continue 返回到Crosstabs 对话框。 4.确定列联表内单元格值的选项 单击Cells(单元格)按钮,打开Cell Display 对话框,如图7-3 所示。
应用SPSS软件进行列联表分析 在许多调查研究中,所得到的数据大多为定性数据,即名义或定序尺度测量的数据。例如在一项全球教育水平的研究中,调查了400余人的个人信息,包括性别、学历、种族等,对原始资料进行整理就可以得到频数分布表。 定义四个变量:gender(性别)、educat(学历)、minority(种族)、count(人数),其中前三个为分类变量,并且gender变量取值为0、1,标签值定义为:0表示female,1表示male;educat变量取值为1、2、3,标签值定义为:1表示学历低,2表示学历中等,3表示学历高;minority变量值为0、1,标签值定义为:0表示非少数种族,1表示为少数种族。下面做gender、educat、minority的三维列联表分析及其独立性检验。数据文件如图1所示。 图1 第一步:用“count”变量作为权重进行加权分析处理。从菜单上依次选Data--weight Cases 命令,打开对话框,如图2所示。
图2 点选Weight Cases by项,并将变量“count”移入Frequency Variable栏下,之后单击OK按钮。 第二步:从菜单上依次点选Analyze--Deseriptive Statistics--Crosstabs命令,打开列联分析对话框(Crosstabs),如图3所示。 图3 第三步:在Crosstabs对话框中,如图4将变量性别gender从左侧的列表框内移入行变量Row(s)框内,并将受教育年限编码后得到的学历变量educat移入列变量Column(s)框内(若
此时单击OK按钮,则会输出一个2*3的二维列联表)。这里要输出一个三维列联表,将变量种族minority作为分层变量移入Layer框中,并且可以勾选左下方的Display clustered bar charts项,以输出聚集的条形图,如图8图9所示。 图4 第四步:选择统计量,单击Cosstabs对话框下侧的Statistics按钮,打开其对话框,如图5 所示。 图5 在Statistics对话框内,勾选Chi-square项,以输出表2进行独立性检验。这里由于不是定距
上机练习 3 列联表分析与方差分析 本上机练习的主要目的:熟悉如何利用SPSS与Excel进行列联表分析及方差分析。本练习所使用数据文件为 和“Salary.sav”。“carown.dat”、“fastfood.sav” 1. 列联表分析 Q:如何利用列联表分析考察家庭成员数与家庭所拥有汽车数之间 的关系?(数据文件为“Carown.dat”) 在这之前,我们首先检验各变量是否存在野码(wild code)或异常值 (outlier),这可以通过频数表以及箱形图(boxplot)来判断。 在家庭成员数的频数表中,我们发现,有一个样本的家庭成员数为0,而 ,该样本取值在其范围之外,即为野码(wild 该变量的取值范围为[1, +∞] code)。对于野码的处理,一般可以采用将该样本的此变量设为缺失值或 直接去掉该样本的做法。
在家庭所拥有汽车数的频数表中,我们发现,有一个样本的家庭所拥有汽 车数为9,显然是一个极端值。我们利用boxplot也证实了该样本为一个异常值(outlier)。异常值处于该变量的正常取值范围内,但可能会对该 变量的相关统计结果产生较为严重的影响。对于异常值的处理,一般可以 采用直接去掉该样本的做法或者根据情况进行调整。而对于上述我们发现 的异常值来说,我们可以直接去掉该样本。 在上述数据清理的工作完成之后,我们可以开始进行列联表分析。因为列 联表分析只适用于分类变量,我们需要利用Transform Recode Into Different Variables…对家庭人数以及家庭所拥有汽车数进行分类,分别 定义新变量member1和cars1与之对应。具体对应关系如下: 旧变量新变量新变量类别旧变量新变量新变量类别
第十二章 列联表和对应分析 我们前面介绍的相关分析可以用来分析定量变量之间的关系,但不能用于定性变量的分析。本章介绍的列联表检验和对应分析方法则可以用来分析定性变量之间的关系。 第一节 列联表与独立性检验 【例12.1】美国的一般社会调查(General Social Survey )是由美国芝加哥大学的民意调查中心进行的一项随机抽样调查,调查对象为18岁以上的成年人。调查中获得了居民的婚姻状况和幸福状况方面的数据。下面我们根据1996年的调查结果来分析两个变量之间的关系(数据文件gss96.sav )。在调查中,婚姻状况的取值为已婚、丧偶、离异、分居和未婚(分别用1-5表示);幸福状况的取值为:非常幸福、比较幸福和不太幸福(分别用1-3表示)。在SPSS 软件中打开数据文件,选择“分析”→“描述统计”→“交叉表”,把“婚姻状况”设为行变量,把“幸福状况”设为列变量,可以得到表12-1所示的列联表。从表中我们可以看出,从婚姻状况看,已婚人员的比重最高;从幸福状况看,比较幸福的人员比重最高。但从表中我们很难直观地看出两个变量之间的内在联系。 表12-1 婚姻状况和幸福状况列联表 幸福状况 合计 非常幸福 比较幸福 不太幸福 婚姻状况 已婚 574 726 82 1382 丧偶 70 149 59 278 离异 83 292 79 454 分居 14 73 30 117 未婚 136 419 99 654 合计 877 1659 349 2885 要研究二维列联表中的两个变量是否相互独立,可以使用我们在非参数检验中讲过χ2 检验。检验的零假设和备择假设为 H 0:婚姻状况和幸福状况这两个变量相互独立;H 1:婚姻状况和幸福状况不相互独立。 假定样本量为n ,列联表有r 行、s 列,表中各行的合计值分别为r i R i ,,2,1,Λ=,各列的合计值分别为s j C j ,2,1,Λ=。每个单元格中的频数为j i O ,。在零假设成立,即行变量和列变量相互独立时,每个单元格频数的期望值可以按照式(12-1)计算: n C R n n C n R E j i j i ij ?= ??= (12-1) 显然,如果期望频数ij E 和观测频数ij O 相差不大,则零假设可能是正确的;如果二者差别很大,则零假设可能不成立。按照式(12-2)构造检验统计量:
列联表分析 【例1】性别与所喜爱颜色的调查表。 双向列联表:性别×颜色 【程序】 proc freq data=SASUSER.data9_01; tables SEX*COLOR / CHISQ NOPERCENT NOROW; weight F; run; 【例3】下面数据是某个“统计入门”课程的数据,记录了该课程中所有学生的性别和专业 (“是”为统计专业,“非”为其他专业)。对数据进行整理生成列联表并分析。 【操作:解决方案-分析-分析家调入数据统计-表分析】 【程序】 *** Table Analysis ***; proc freq data=SASUSER.data9_03; tables SEX*MAJOR; run;
【例5】雇员情况数据集Employee变量有:性别(gender)、工种(jobcat)、薪水(salary) /薪水等级(salaryrank,分高(=1)100人,中(=2)200人,低(=3)其他人)、初薪(begsalary) /薪水等级(begsalaryrank,分高(=1)100人,中(=2)200人,低(=3)其他人)和受教 育年限。试作三向、四向、五向列联表。 【程序prog9_05_1】三向表:对性别、薪水等级和工种的情况进行统计(生成2张表) *** Table Analysis ***; proc freq data=SASUSER.data9_05; tables GENDER*SALARYRANK*JOBCAT; run; 【程序prog9_05_3】五向表:对性别、薪水等级、初薪等级、受教育年限和工种的情况进 行统计(生成18张表) *** Table Analysis ***; proc freq data=SASUSER.data9_05; tables GENDER*SALARYRANK*BEGSALARYRANK*EDUCATION*JOBCAT; run; 【例6】下表是一个由220名饮酒者组成的随机样本,对饮酒者进行酒类型偏好的调查。检 验性别与饮酒偏好是否有关?(α=0.05) 【程序】 data sasuser.data9_06; input sex wine people; datalines; 1 1 60 2 1 40 1 2 50 2 2 70 ; proc freq; weight people; tables sex*wine/chisq; run;