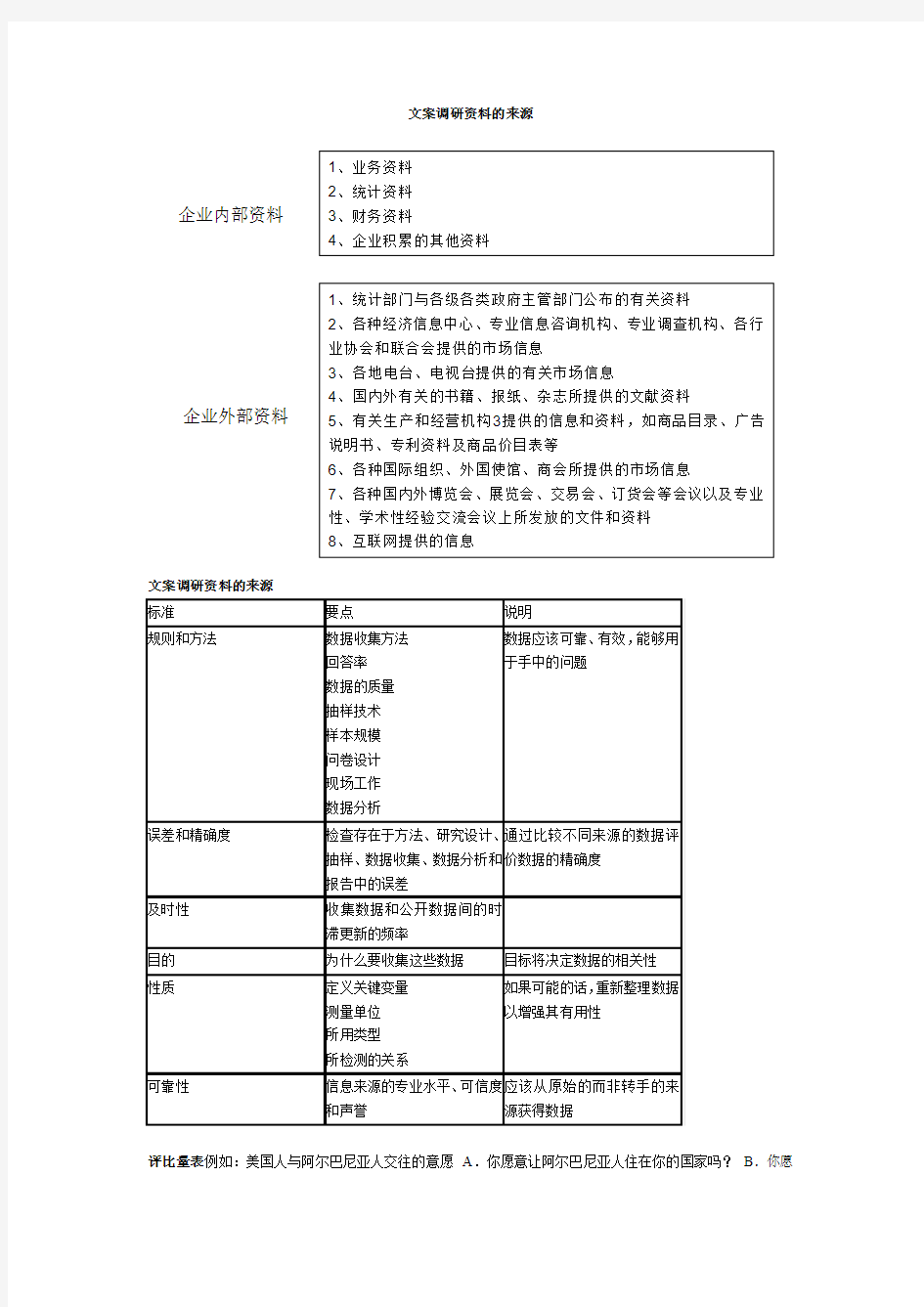

文案调研资料的来源
评比量表例如:美国人与阿尔巴尼亚人交往的意愿 A .你愿意让阿尔巴尼亚人住在你的国家吗? B .你愿
文案调研资料的来源
企业内部资料
企业外部资料
1、业务资料
2、统计资料
3、财务资料
4、企业积累的其他资料
1、统计部门与各级各类政府主管部门公布的有关资料
2、各种经济信息中心、专业信息咨询机构、专业调查机构、各行业协会和联合会提供的市场信息
3、各地电台、电视台提供的有关市场信息
4、国内外有关的书籍、报纸、杂志所提供的文献资料
5、有关生产和经营机构3提供的信息和资料,如商品目录、广告说明书、专利资料及商品价目表等
6、各种国际组织、外国使馆、商会所提供的市场信息
7、各种国内外博览会、展览会、交易会、订货会等会议以及专业性、学术性经验交流会议上所发放的文件和资料 8、互联网提供的信息
意让阿尔巴尼亚人住进你的社区吗?C .你愿意让阿尔巴尼亚人住在你家附近吗?D .你愿意让阿尔巴尼亚人住在你的隔壁吗?E .你愿意让你的孩子与阿尔巴尼亚人结婚吗?
瑟斯顿量表研究者提出若干个可能的指标项目 例如:了解人们对一周5天工作日的看法
五天工作日对于人们精神健康是绝对必要的;五天工作日是社会进步的一种表现 五天工作日是生产力提高的结果;五天工作日是对劳动者基本权利的保证;五天工作日没有必要;五天工作日会使人变得懒散 ;五天工作日有助于经济繁荣;五天工作日会减少人们的收入;…………
请您给下面的观点打分:很同意(5分) 比较同意(4分) 讲不请(3分)不太同意(2分) 很不同意(1分)1、越是有钱,越应该参加保险2、年轻人没有必要买养老保险3、只有人们的收入达到一定的水平,才会考虑 保险4、我不大爱生病,没必要参加保险公司推出的医疗保险 ……10、目前保险定价合理 语义差异量表
7 6 5 4 3 2 1
愉悦的 不悦的 简单的 复杂的 不和谐的 和谐的 传统的 现代的
配对比较量 可乐饮料在消费者心目中中的地位认为牌子i 较牌子j 为佳的人数分布
认为牌子i 较牌子j 为佳的比率
B(2.85)>C(2.15)>A(1.60)>D(1.40) 一..抽样中的误差问题
估计量方差:描述估计精度的重要指标 偏差:反映估计量的系统性误差
均方误差:更综合地反映估计误差的情况 二.抽样误差抽样中的误差可以分为抽样误差和非抽样误差两类
抽样误差:由于抽样的随机性造成的误差;定义式
; 影响因素:总体分布、样本量、
抽样方式和估计方式非抽样误差
差、调查人员误差、受访者误差 样本量的确定
一.影响样本量的因素1.调查精度
2.总体变异度3.总体规模 4.无回答情况5.调查经费情况 二.确定样本量的方法1.非概率抽样,样本量确定主要根据经验判断; 2.概率抽样,需要在计算的基础上确定
三.样本量的计算
i j A B C D A - 80 70 40 B 20 - 30 15 C 30 70 - 35 D
60
85
65
-
A B C D A 0.50 0.80 0.70 0.40 B 0.20 0.50 0.30 0.50 C 0.30 0.70 0.50 0.35 D 0.60 0.85 0.65 0.50 合计
1.60
2.85
2.15
1.40
2
???()()V E E θθθ??
=-??
??()()B ias E θθθ
=-2???()()()M SE V Bias θθθ=+?()S θ=
()S y =
=
无放回简单随机抽样
有放回简单随机抽样 绝对误差的表达式为
中t 为概率度,其数值与 a 有关由此可以解出样本量计算公
式上式中n0 为有放回条件下的样本量,既
还可以采用相对误差的要求计算样本量
若采用变异系数 若估计总体比例P ,则 若使用相对误差要求,则 设计效应Deff
利用设计效应,可以计算复杂抽样设计所需要的样本量 编码图表 某项调查的编码表格式
rY =?=001n n n N
=
+
2
0tS n rY ??
= ?
??
变
量序号
变量
名
变量 类型
变量
所占字节
取值
范围
取值对应含义
备
注
对应题
号
对应问
题
1
… 38 code … V28
数值
型 … 数值型
7
(1)
0—4 或9
1051202 …
0—3表示台数;
4表示4台或4 台以上;
问卷编
号 (28)
家中拥有电视
(S y ==
()tS y ?==001n n n N
=
+
2
20tS n ??
= ?
???
S
C Y =2
tC n r ??
= ?
??
()2
2
1t P P n -=?
()
2
02
1t P P n r P
-=
Deff =
复杂抽样估计量方差
简单随机抽样估计量方差n deff n '= 譯碼簿範例
前设计编码
前设计编码要求事先已知问题的答案类别,主要应用于结构式问卷中的封闭题和数字型开放题。
封闭题的编码设计
1 . 对单选题只需规定一个变量,取值为选项号。
Q18 请问您最近一年内买过VCD光盘吗?【】
1 买过
2 没买过
设计编码时:变量名为V18,属于数字型变量,变量所占字节数为1,变量取值范围为1,2或9,其中1表示买过,2表示没买过,9表示该题无回答。
2. 2. 对多选题的变量2. 对多选题的变量
(1) 将各个可能回答的答案选项都设为一个0—1指示变量,如被调查者选择了该答案,此变量的值为1,
否则为0。优点: 便于分析,编码的结果不用经过转换,可直接分析;缺点是不便于录入,变量随选项增多而增多.
Q17 请问您观看的DVD 光盘的主要来源是? 【 】 【 】 【 】 1 自己购买 2 租借 3 向朋友/同事/亲戚借
4 别人送的
5 单位的
6 其他
(2) 将变量定义为所选题号,变量值为选项号,变量排列顺 序即为选择答案的顺序 优点:便于录入和检查,但分析前要用程序把它们转化为各选择答案的0-1变量 Q17 请问您观看的DVD 光盘的主要来源是?(至多只选择3项 ) 【 】 【 】 【 】
1 自己购买
2 租借
3 向朋友/同事/亲戚借
4 别人送的
5 单位的
6 其他
排序题的编码设计
Q12 请您根据信任程度由大到小对下列广告排序(信任程度最高的广告前填1,其次信任的广告前填2,依次类推,最不信任的广告前填5):
【 】1 电视广告【 】2 报纸广【 】 3 广播广告【 】4 杂志广告【 】 5 路牌广告 Q12问题的编码(方法一)
变
量序
变量
名
变量类型
变量
所占字节
取值范围
取值对应含义
备
注
对
应题
对应问题
方法
一
改进
法
48
49 50 51 52
53 V171 V172 V173 V174 V175
V176 数值型
数值型 数值型 数值型 数值型
数值型 1 1 1 1 1
1
0或1
0或1 0或1 0或1 0或1
0或1 0或1
0或2 0或3 0或4 0或5
0或6
取值为1表
明该选项为主要来源,为0则不是。
全
为0表示该
题 17
观看的
VCD 盘的主要来
源
变
量变量名 变量 类型 变量所占 取值 范围 取值对应含义 (i =1,2,3,4,5,6)
备注
对应 对应 问题 48 49 50
V171 V172 V173
数值型 数值型 数值型
1 1 1
0—6 0—6 0—6
取值为i 表明第 i 选项为主要来源,为0则说明其余选项都不是主要来源
全为0表示该题无回答
17
观看的VCD 盘的主要来源
变量个数即选项个数,按照选项排列顺序,分别定义各变量为对应选项所排次序号,取值即为次序号。 Q12问题的编码(方法二)
变量个数即要求排序项数,依照次序号排列顺序,分别定义各变量为各次序号对应的选项项数,取值即为选项号。
Q12 请问下列广告中, 您最信任哪个广告? 【 】其次呢?【 】再次呢?【 】 1 电视广告2 报纸广告3 广播广告 4 杂志广告5 路牌广告
各变量为各次序号对应的选项项数,取值即为选项号。
数字型开放题的编码设计对直接回答数字的问题,变量取值即为该数字。变量所占字节数可以根据事先预计的数字最大值的位数确定。例如,直接询问被调查者的年龄,设计编码时取变量名为NL ,所占字节为2(因为调查对象要求在20~60岁之间),小数点位为0,变量取值即为年龄,单位为“岁”,取值范围为20~60或99(99表示该题缺失)。
牌子表的编码设计牌子表是记录产品品牌的统计表。它是一种编码表,在涉及产品品牌的问题时有助于被调查者回答,访问员提问和记录。牌子表中给出所有可能答案选项的代码,使访问员可直接编码。建立牌子表时应注意及时了解市场情况,加入新品牌,删除消失的品牌。另外,注意“其他”选项的设立,避免出现品牌错误、重码、漏码等错误。
后设计编码数据收集完成后再进行编码设计;实践中主要的应用对象是无结构问卷和结构式问卷中的文字开放题
开放题编码选定问卷后,仔细阅读每个被调查者对该特定问题的回答,每遇到一个新的答案类别就记录下来,同时记录各答案类别出现的频数,依次类推。这里要注意的是答案除表面含义以外,可能还有引申、隐含的含义,应注意区分。
最后结合调查分析目的对分类的要求,对各答案类别进行整理归纳,突出分析重点,尽量包含所有信息且互不交叉,将不能编码或个数较少、可不予考虑的答案归入“其他”项。此外,注意留出位置准备修改,如果后期发现较多或较重要、有新意的类别,可以增加或细化类别。
变量
序号
变量名
变量
类型
变量所
占字节
取值
范围
取值对应含义
(i =1,2,3,4,5)
备注
对应
题号
对应 问题
30
31 32 33 34
V121
V122 V123 V124 V125
数值型
数值型 数值型 数值型 数值型
1
1 1 1 1
0—5
0—5 0—5 0—5 0—5
取值为i 表明该广
告的信任程度排名为i ,为0则表明对该广告的排名缺失
全为0
表示该题无回答
12
对各类广告的排序
变量序号
变量名
变量
类型
变量所占字节
取值
范围
取值对应含义 (i =1,2,3,4,5)
备注
对应题号
对应 问题
30
31 32
V121
V122 V123
数值型 数值型 数值型
1
1 1
0—5
0—5 0—5
i 为对应信任度的广告对应的选项号。0则表明对应信任度的广告缺失
全为0
表示该题无回答
12
对各类广告的排序
后设计编码无结构问卷:首先看有无必要编码;无结构问卷编码步骤:
(1)确定变量,定义问卷变量(2)针对各变量,分别确定答案类别,定义代码 一、传播尺度测试广告效果
态度改变曲线
行为改变曲线
实施调查时机
接触广告阶段 实施购买阶段
事前态度行为
接触效果调查 信息接受效果事后态度调查
事后行为调查
A B C D E
您为什么不考虑未来两年不买该产品?
DA GMA R 理论
有意购买
有良好印象
知道品牌名
某品牌未知消费者
品牌忠诚
知名
理解 确信 行动
消费者行为研究法
广告效果指数
广告对销售额的贡献率
第六章、抽样估计 一、单项选择题(在每小题的四个备选答案中,选出一个正确答案) 1,抽样误差是指() A. 由于观察、计算等差错所引起的登记误差 B.抽样中违反随机原则出现的系统误差 C. 随机抽样而产生的代表性误差 D.认为原因所造成的误差 2.抽样误差() A.既可以避免,也可以控制 B. 既不可以避免,也不可以控制 C. 可以避免, 但不可以控制 D. 不能避免, 但可以控制 3. 抽样平均误差反映了样本估计量与总体参数之间的( ) A. 实际误差 B. 可能误差范围 C. 平均差异程度 D. 实际误差的绝对值 4.抽样平均误差是( ) A. 总体参数的标准差 B. 样本的标准差 C.样本估计量的标准差 D. 样本估计量的平均差 5.在其他条件不变的情况下, 不重复抽样的抽样误差比重复抽样的抽样误差( ) A. 大 B. 小 C. 可大可小 D. 相等 6. 反映样本估计量与总体参数之间抽样误差的可能范围的是( ) A. 抽样平均误差 B. 抽样极限误差 C. 实际抽样误差 D. 置信水平 7.简单随机抽样条件下, 当极限误差扩大一倍, 则样本容量( ) A. 只需原来的1/2 B. 只需原来的1/4 C. 需要原来的1倍 D. 需要原来的4倍 8.在其他条件不变的情况下, 总体方差越大, 所需样本容量( ) A. 越多 B. 越少 C. 可多可少 D. 不受影响 9.下列描述不正确的是( ) A.样本统计量是一种随机变量 B.样本统计量不是一种随机变量 C.每个随机变量都有其概率分布 D.样本统计量概率分布就是抽样分布 10.中心极限定理证明了:当总体期望值和方差存在、且有限时,随机抽样下的大样本均值服从下列分布() A.N(0,1) B.N() C.N() D.t(n-1)
数值计算方法 实 验 报 告 实验序号:实验一 实验名称:数值计算中误差的传播规律 实验人: 专业年级: 教学班: 学号: 实验时间:
实验一 数值计算中误差的传播规律 一、实验目的 1.观察并初步分析数值计算中误差的传播; 2.观察有效数字与误差传播的关系. 二、实验内容 1.使用MATLAB 的help 命令学习MATLAB 命令digits 和vpa 的用途和使用格式; 2.在4位浮点数下解二次方程01622=++x x ; 3.计算下列5个函数在点2=x 处的近似值 (1)60)1(-=x y , (2)61) 1(1+=x y , (3)32)23(x y -=, (4)3 3)23(1x y +=, (5)x y 70994-=. 三、实验步骤 本次实验包含三个相对独立的内容. 1.在内容1中,请解释两个命令的格式和作用; 在matlab 中采用help 语句得到:
1、digits用于规定运算精度,比如: digits(20); 这个语句就规定了运算精度是20位有效数字。但并不是规定了就可以使用,因为实际编程中,我们可能有些运算需要控制精度,而有些不需要控制。vpa就用于解决这个问题,凡是用需要控制精度的,我们都对运算表达式使用vpa函数。 例如: digits(5); a=vpa(sqrt(2)); 这样a的值就是1.4142,而不是准确的1.4142135623730950488016887242097 又如: digits(11); a=vpa(2/3+4/7+5/9); b=2/3+4/7+5/9; a的结果为1.7936507936,b的结果为1.793650793650794......也就是说,计算a的值的时候,先对2/3,4 /7,5/9这三个运算都控制了精度,又对三个数相加的运算控制了精度。而b的值是真实值,对它取11位有效数字的话,结果为1.7936507937,与a不同,就是说vpa 并不是先把表达式的值用matlab本身的精度求出来,再取有效数字,而是每运算一次都控制精度。 2.求解方程时,分别使用求根公式和韦达定理两种方法,并比较其有效数字和相对误差; 用求根公式解得:x1=-0.015,x2=-62.00 用韦达定理解得:x11=-0.016,x22=-62.00 x22=x2,x11=1/x22
《统计学》习题五参考答案 一、单项选择题: 1、抽样误差是指()。C A在调查过程中由于观察、测量等差错所引起的误差 B人为原因所造成的误差C随机抽样而产生的代表性误差 D在调查中违反随机原则出现的系统误差 2、抽样平均误差就是()。D A样本的标准差 B总体的标准差 C随机误差 D样本指标的标准差 3、抽样估计的可靠性和精确度()。B A是一致的 B是矛盾的 C成正比 D无关系 4、在简单随机重复抽样下,欲使抽样平均误差缩小为原来的三分之一,则样本容量应()。A A增加8倍 B增加9倍 C增加1.25倍 D增加2.25倍 5、当有多个参数需要估计时,可以计算出多个样品容量n,为满足共同的要求,必要的样本容量一般应是()。B A最小的n值 B最大的n值 C中间的n值 D第一个计算出来的n值 6、抽样时需要遵循随机原则的原因是()。C A可以防止一些工作中的失误 B能使样本与总体有相同的分布 C能使样本与总体有相似或相同的分布 D可使单位调查费用降低 二、多项选择题: 1、抽样推断中哪些误差是可以避免的()。A B D A工作条件造成的误差 B系统性偏差 C抽样随机误差 D人为因素形成偏差 E抽样实际误差 2、区间估计的要素是()。A C D A点估计值 B样本的分布 C估计的可靠度 D抽样极限误差 E总体的分布形式 3、影响必要样本容量的因素主要有()。A B C E A总体的标志变异程度 B允许误差的大小 C重复抽样和不重复抽样 D样本的差异程度 E估计的可靠度 三、填空题: 1、抽样推断就是根据()的信息去研究总体的特征。样本 2、样本单位选取方法可分为()和()。重复抽样不重复抽样 3、实施概率抽样的前提条件是要具备()。抽样框 4、对总体参数进行区间估计时,既要考虑极限误差的大小,即估计的()问题,又要考虑估计的()问题。准确性可靠性 四、简答题:
文案调研资料的来源 评比量表例如:美国人与阿尔巴尼亚人交往的意愿 A .你愿意让阿尔巴尼亚人住在你的国家吗? B .你愿 文案调研资料的来源 企业内部资料 企业外部资料 1、业务资料 2、统计资料 3、财务资料 4、企业积累的其他资料 1、统计部门与各级各类政府主管部门公布的有关资料 2、各种经济信息中心、专业信息咨询机构、专业调查机构、各行业协会和联合会提供的市场信息 3、各地电台、电视台提供的有关市场信息 4、国内外有关的书籍、报纸、杂志所提供的文献资料 5、有关生产和经营机构3提供的信息和资料,如商品目录、广告说明书、专利资料及商品价目表等 6、各种国际组织、外国使馆、商会所提供的市场信息 7、各种国内外博览会、展览会、交易会、订货会等会议以及专业性、学术性经验交流会议上所发放的文件和资料 8、互联网提供的信息
意让阿尔巴尼亚人住进你的社区吗?C .你愿意让阿尔巴尼亚人住在你家附近吗?D .你愿意让阿尔巴尼亚人住在你的隔壁吗?E .你愿意让你的孩子与阿尔巴尼亚人结婚吗? 瑟斯顿量表研究者提出若干个可能的指标项目 例如:了解人们对一周5天工作日的看法 五天工作日对于人们精神健康是绝对必要的;五天工作日是社会进步的一种表现 五天工作日是生产力提高的结果;五天工作日是对劳动者基本权利的保证;五天工作日没有必要;五天工作日会使人变得懒散 ;五天工作日有助于经济繁荣;五天工作日会减少人们的收入;………… 请您给下面的观点打分:很同意(5分) 比较同意(4分) 讲不请(3分)不太同意(2分) 很不同意(1分)1、越是有钱,越应该参加保险2、年轻人没有必要买养老保险3、只有人们的收入达到一定的水平,才会考虑 保险4、我不大爱生病,没必要参加保险公司推出的医疗保险 ……10、目前保险定价合理 语义差异量表 7 6 5 4 3 2 1 愉悦的 不悦的 简单的 复杂的 不和谐的 和谐的 传统的 现代的 配对比较量 可乐饮料在消费者心目中中的地位认为牌子i 较牌子j 为佳的人数分布 认为牌子i 较牌子j 为佳的比率 B(2.85)>C(2.15)>A(1.60)>D(1.40) 一..抽样中的误差问题 估计量方差:描述估计精度的重要指标 偏差:反映估计量的系统性误差 均方误差:更综合地反映估计误差的情况 二.抽样误差抽样中的误差可以分为抽样误差和非抽样误差两类 抽样误差:由于抽样的随机性造成的误差;定义式 ; 影响因素:总体分布、样本量、 抽样方式和估计方式非抽样误差 差、调查人员误差、受访者误差 样本量的确定 一.影响样本量的因素1.调查精度 2.总体变异度3.总体规模 4.无回答情况5.调查经费情况 二.确定样本量的方法1.非概率抽样,样本量确定主要根据经验判断; 2.概率抽样,需要在计算的基础上确定 三.样本量的计算 i j A B C D A - 80 70 40 B 20 - 30 15 C 30 70 - 35 D 60 85 65 - A B C D A 0.50 0.80 0.70 0.40 B 0.20 0.50 0.30 0.50 C 0.30 0.70 0.50 0.35 D 0.60 0.85 0.65 0.50 合计 1.60 2.85 2.15 1.40 2 ???()()V E E θθθ?? =-?? ??()()B ias E θθθ =-2???()()()M SE V Bias θθθ=+?()S θ= ()S y = =
第九章抽样推断 一、名词 1、抽样推断:即由样本指标来推断总体指标的统计方法。 2、抽样误差:是指抽样指标和全及指标之间的绝对离差。 3、抽样极限误差:是指样本指标与全及指标之间产生的抽样误差被允许的最大可能范围,也叫允许误差。 4、点估计:就是直接用样本指标代表总体指标的估计方法。 5、区间估计:就是把抽样指标与抽样平均误差结合起来,来推断总体指标所在的可能范围的方法。 6、假设检验:就是先对研究总体的参数做出某种假设,然后抽取样本,构造适当的统计量,利用样本提供的信息对假设的正确性进行判断的过程。 二、填空题 1.抽样推断是由(样本指标)来推断(相应的全及指标)的统计方法。 2.影响抽样误差大小的因素主要有:总体各单位标志值的差异程度、(样本的单位数目)、(抽样的具体方法)和抽样调查的组织形式。 3.抽样误差是由于抽样的(随机性)而产生的误差,这种误差不可避免,但可以控制在(所允许的范围)之内。 4.抽样平均误差是样本平均数的(标准差),是所有可能样本指标与总体指标之离差的(平均数)。 5.抽样极限误差,是指样本指标与全及指标之间产生的(抽样误差)被允许的(最大可能范围)。 6.用样本指标估计总体指标,要做到三个要求,即:(无偏性)、(一致性)、(有效性)。 7.抽样估计的方法有(点估计)和(区间估计)两种。 8.总体参数的区间估计必须同时具备(估计值)、(抽样误差范围)和(概率保证程度)三个要素。 9.总体中各单位标志值之间的变异程度越大,要求的样本单位数就(越多),即样本容量就(越大),总体各单位标志值变异程度与样本容量之间成(正比)。 10.允许误差越大,需要的样本单位数目就(越少);允许误差越小,需要的样本单位数目就(越多)。 11.对推断结果要求的可靠程度越高,必要样本单位数目就(越多);反之,可靠程度越低,必要样本单位数目就(越少)。 12.参数估计是用样本统计量估计(总体参数),而假设检验则是先对总体参数(提出假设),然后,运用样本资料验证假设(是否成立)。 三、判断 1.在抽样推断中,作为推断对象的总体和作为观察对象的样本都是确定、唯一的。(×) 2.样本容量指从一个总体中可能抽取的样本个数。(×) 3.抽样极限误差总是大于抽样平均误差。(×) 4.重复抽样误差大于不重复抽样误差。(√) 5.抽样准确度要求高,则可靠性低。(√) 6.抽样平均数的标准差或抽样成数的标准差是衡量抽样误差一般水平的尺度。(√) 7.点估计就是以样本的实际值直接作为相应总体参数的估计值。(√) 8.抽样估计的置信度就是表明抽样指标和总体指标的误差不超过一定范围的概率保证程度。(√) 四、选择 (一)单项选择 1.抽样调查所遵循的基本原则是(B)。
测量误差按其对测量结果影响的性质,可分为: 一.系统误差(system error) 1.定义:在相同观测条件下,对某量进行一系列观测,如误差出现符号和大小均相同或按一定的规律变化,这种误差称为系统误差。 2.特点:具有积累性,对测量结果的影响大,但可通过一般的改正或用一定的观测方法加以消除。 二.偶然误差(accident error) 1.定义:在相同观测条件下,对某量进行一系列观测,如误差出现符号和大小均不一定,这种误差称为偶然误差。但具有一定的统计规律。 2.特点: (1)具有一定的范围。 (2)绝对值小的误差出现概率大。 (3)绝对值相等的正、负误差出现的概率相同。 (4)数学期限望等于零。即: 误差概率分布曲线呈正态分布,偶然误差要通过的一定的数学方法(测量平差)来处理。 此外,在测量工作中还要注意避免粗差(gross error)(即:错误)的出现。 §2衡量精度的指标 测量上常见的精度指标有:中误差、相对误差、极限误差。 一.中误差 方差 ——某量的真误差,[]——求和符号。 规律:标准差估值(中误差m)绝对值愈小,观测精度愈高。 在测量中,n为有限值,计算中误差m的方法,有: 1.用真误差(true error)来确定中误差——适用于观测量真值已知时。 真误差Δ——观测值与其真值之差,有: 标准差 中误差(标准差估值),n为观测值个数。 2.用改正数来确定中误差(白塞尔公式)——适用于观测量真值未知时。 V——最或是值与观测值之差。一般为算术平均值与观测值之差,即有: 二.相对误差 1.相对中误差=
2.往返测较差率K= 三.极限误差(容许误差) 常以两倍或三倍中误差作为偶然误差的容许值。即:。§3误差传播定律 一.误差传播定律 设、…为相互独立的直接观测量,有函数 ,则有: 二.权(weight)的概念 1.定义:设非等精度观测值的中误差分别为m 1、m 2 、…m n ,则有: 权其中,为任意大小的常数。 当权等于1时,称为单位权,其对应的中误差称为单位权中误差(unit weight mean square error) m ,故有:。 2.规律:权与中误差的平方成反比,故观测值精度愈高,其权愈大。
第六章抽样 一、辨析题 1、一般来说,任意抽样技术适用于正式的实际调查。 错误。适用于非正式的探测性调查,或调查前的准备工作。 2、一般说来,总体中各单位之间标志值的变异程度越大,需要抽样的样本数目越多;反之,需要抽样的样本数目越少。 正确 3、分层最佳抽样法指的是等比例分层抽样。 错误。这是非比例分层抽样。 4、一般而言,抽样的样本占总体的比例同抽样误差成反向关系,即抽样比例越大,抽样误差相对越小。 正确 5、抽样误差是随机抽样调查中必然发生的代表性误差,所以平均误差是不可避免的。而且,这种误差一般包括了技术性误差,即调查工作中的误差。 错误。这种误差一般不包括技术性误差即调查工作中的误差。 6、总体单位之间标志变异程度越大,抽样误差越大;反之则越
小。 正确 7、样本单位数目越多,抽样误差越大,反之则越小。 错误。样本单位数目越多,抽样误差越小,反之则大。 8、一般来说,简单随机抽样比分层、分群抽样误差大,不重复抽样比重复抽样误差大。 错误。重复抽样比不重复抽样误差大。 9、点值估计是考虑了抽样误差,直接以样本指标作为总体指标的估计值,作近似的估计。 错误,不考虑抽样误差。 二、名词解释 1、抽样调查 抽样调查也称为抽查,是指从调查总体中抽选出一部分要素作为样本,对样本进行调查,并根据抽样所得的结果推断总体的一种专门性的调查活动。 2、抽样 抽样是指在抽样调查时采用一定的方法,抽选具有代表性的样本,以及各种抽样操作技巧和工作程序等的总称。 3、随机抽样 随机抽样又称为概率抽样或机率抽样,是对总体中每一个体都给予平等的抽取机会的抽样技术。在随机抽样的条件下,每个个体抽中或抽不中完全凭机遇,
抽样误差 抽样误差(Sampling error) [编辑] 什么是抽样误差 在抽样检查中,由于用样本指标代替全及指标所产生的误差可分为两种:一种是由于主观因素破坏了随机原则而产生的误差,称为系统性误差;另一种是由于抽样的随机性引起的偶然的代表性误差。抽样误差仅仅是指后一种由于抽样的随机性而带来的偶然的代表性误差,而不是指前一种因不遵循随机性原则而造成的系统性误差。 总的说来,抽样误差是指样本指标与全及总体指标之间的绝对误差。在进行抽样检查时不可避免会产生抽样误差,因为从总体中随机抽取的样本,其结构不可能和总体完全一致。例如样本 平均数与总体平均数之差,样本成数与总体成数之差| p? P | 。虽然抽样误差不可避免,但可以运用大数定律的数学公式加以精确地计算,确定它具体的数量界限,并可通过抽样设计加以控制。 抽样误差也是衡量抽样检查准确程度的指标。抽样误差越大,表明抽样总体对全及总体的代表性越小,抽样检查的结果越不可靠。反之,抽样误差越小,说明抽样总体对全及总体的代表性越大,抽样检查的结果越准确可靠。在统计学中把抽样误差分为抽样平均误差和抽样极限误差,下面就这两种误差分别进行阐释。为使推理过程简化,这里不对属性总体进行分析,而仅对变量总体进行分析计算。 [编辑] 抽样误差的计算
1、表现形式:平均数指标抽样误差;成数(比重)抽样误差。 2、平均数指标的抽样误差 1)重复抽样的条件下: 2)不重复抽样的条件下: 3、成数指标的抽样误差 1)重复抽样的条件下: 2)不重复抽样的条件下: [编辑] 影响抽样误差的因素 1.总体各单位标志值的差异程度。差异程度愈大则抽样误差愈大,差异程度愈小则则抽样误差愈小。 2.样本单位数。在其他条件相同的情况下,样本的单位数愈多,则抽样误差愈小。 3.抽样方法。抽样方法不同,抽样误差也不同。一般情况下重复抽样误差比不重复抽样误差要大一些。 4.抽样调查的组织形式。不同的抽样组织形式就有不同的抽样误差。 [编辑]
6-7 加权平均值及其中误差 一、不等精度观测和观测值的权 在测量实践中,除了等精度观测之外,还有不等精度观测。此时,求多次观测的最或然值就不能简单地用算术平均值,而是需要用“加权平均值”的方法求解。 某一观测值或观测值的函数的误差越小(精度越高),其权越大;反之,其误差越大(精度越小),其权越小。一般用“”表示中误差,用“P”表示权,并定义:“权与中误差的平方成反比”,以公式表示为 (6-26) 式中,C为任意常数。等于1的权称为“单位权“,权等于1的中误差称为“单位权中误差”,一般用表示。因此,权的另一种表达式为 (6-27) 中误差的另一种表达式为 (6-28) 在测量工作中,为了使权的概念简单明了,一般取一次观测、一个测回或单位长度(1m 或1km )等的测量误差作为单位权中误差。 二、加权平均值及其中误差 对某一未知量进行一组不等精度观测:,其中误差为,则观测值的权为。按照误差理论,此时应按下式取其加权平均值,作为该量的最或然值: 上式可以写成线性函数的形式: 根据线性函数的误差传播公式,得到 上式可化为
因此,加权平均值的中误差为 (6-29) 加权平均值的权为所有观测值的权之和: (6-30) 三、单位权中误差的计算 在处理不等精度的测量成果时,需要根据单位权中误差来计算观测值的权和加权平均值的中误差。单位权中误差一般取某一类观测值的基本精度,例如,水平角观测的一测回的中误差等。根据一组对同一量的不等精度观测,可以估算本类观测值的单位权中误差。 如对同一量的n个不等精度观测,得到 …. 取以上各式的总和,并除以n,得到 用真误差代替中误差,得到在观测量的真值已知时用真误差求单位权中误差的公式: (6-31) 在观测值的真值未知的情况下,用观测值的加权平均值代替真值;用观测值的改正值代替真误差,得到按不等精度观测值的改正值计算单位权中误差的公式; (6-32)
第四章抽样估计 一、判断题部分 1.从全部总体单位中按照随机原则抽取部分单位组成样本,只可能组成一个样本。(×) 2.在抽样推断中,全及指标值是确定的、唯一的,而样本指标值是一个随机变量。(√) 3.抽样平均误差总是小于抽样极限误差。(×) 4.在其它条件不变的情况下,提高抽样估计的可靠程度,则降低了抽样估计的精确程度。(√) 5.抽样平均误差反映抽样误差的一般水平,每次抽样的误差可能大于抽样平均误差,也可能小 于抽样平均误差。(√) 6.在抽样推断中,抽样误差的概率度越大,则抽样极限误差就越大于抽样平均误差。(√) 二、单项选择题 1.抽样平均误差是(A )。 A、抽样指标的标准差 B、总体参数的标准差 C、样本变量的函数 D、总体变量的函数 2.抽样调查所必须遵循的基本原则是(B )。 A、准确性原则 B、随机性原则 C、可靠性原则 D、灵活性原则 3.在简单随机重复抽样条件下,当抽样极限误差缩小为原来的1/2时,则样本单位数为原来的 (C )。 A、2倍 B、3倍 C、4倍 D、1/4倍 4.按随机原则直接从总体N个单位中抽取n个单位作为样本,这种抽样组织形式是( A)。 A、简单随机抽样 B、类型抽样 C、等距抽样 D、整群抽样 5.事先将总体各单位按某一标志排列,然后依排列顺序和按相同的间隔来抽选调查单位的抽样 称为(C ) A、简单随机抽样 B、类型抽样 C、等距抽样 D、整群抽样 6.在一定的抽样平均误差条件下(A )。 A、扩大极限误差范围,可以提高推断的可靠程度 B、扩大极限误差范围,会降低推断的可靠程度 C、缩小极限误差范围,可以提高推断的可靠程度 D、缩小极限误差范围,不改变推断的可靠程度 7.反映样本指标与总体指标之间的平均误差程度的指标是(C )。 A、平均数离差 B、概率度 C、抽样平均误差 D、抽样极限误差 8.以抽样指标估计总体指标要求抽样指标值的平均数等于被估计的总体指标值本身,这一标准 称为( A)。 A、无偏性 B、一致性 C、有效性 D、准确性 9.在其它条件不变的情况下,提高估计的概率保证程度,其估计的精确程度( B)。
第3章抽样误差 3.1 抽样误差的概念 医学科研中通常采用抽样研究的方法,从某总体中随机抽取一个样本来进行研究,而所得样本统计量与总体参数常不一致,这种由抽样引起的样本统计量与总体参数间的差异属于抽样误差(sampling error),这在抽样研究中是不可避免的。 例如,假设某地成年男子血红蛋白的总体均数(μ)为13.76(g/100ml),随机抽查了360名男子,算得平均血红蛋白含量X=13.45(g/100ml),若用此X作为该地区成年男子血红蛋白的总体均数(μ)的一个估计值,则(13.76-13.45)=0.31(g/100ml),此差值属于抽样误差。 抽样误差有两种表现形式,其一是:样本统计量与总体参数间的差异,如样本均数与总体均数间的差异;其二是:不同样本的统计量间的差异,如从同一总体中抽取含量相等的两样本得到的两个样本均数之间的差异。 从理论上讲,若进行K次抽样,所得的K个样本统计量(例如X)则很可能各不相同,若将这些样本统计量编制成频率分布表或绘制成频率分布图,则可看出样本统计量的抽样分布是有规律的。 3.2 抽样误差产生的条件 抽样误差产生的两个必备条件: (1) 抽样研究。抽样研究是产生抽样误差的必备条件之一。只有对总体中的部分个体进行研究,才可能导致样本指标与总体指标的不一致,而且在从同一总体进行抽样的研究中,样本含量越少的研究,理论上抽样误差必然越大。 (2) 个体变异。个体变异是产生抽样误差的另一必备条件。在医学科研领域,许多被研究对象都存在着变异现象,如血压、疗效、药物反应等。在抽样方法和样本含量不变的条件下,变异大的研究样本其抽样误差也大,反之则小。 以上是产生抽样误差的必备条件,缺一不可。若进行普查,则被研究对象的个体变异将不会产生抽样误差;若个体间无变异,当然无需作抽样研究,也无抽样误差可言。
抽样误差、抽样平均误差与抽样极限误差 一、基本概念 抽样误差是指由于随机抽样的偶然因素使样本各单位的结构不足以代表总体各单位的结构,而引起抽样指标和全及指标之间的绝对离差。因此,又称为随机误差,它不包括登记误差,也不包括系统性误差。 影响抽样误差的因素有:1、总体各单位标志值的差异程度;2、样本的单位数;3、抽样的方法;4、抽样调查的组织形式。 抽样误差又分为两种: 1、抽样平均误差。抽样平均误差是反映抽样误差一般水平的指标,它的实质含义是指抽样平均数(或成数)的标准差。即它反映了抽样指标与总体指标的平均离差程度。抽样平均误差的作用首先表现在它能够说明样本指标代表性的大小。平均误差大,说明样本指标对总体指标的代表性低;反之,则高。(记为μx 或μp ) 2、抽样极限误差。抽样极限误差指在进行抽样估计时,根据研究对象的变异程度和分析任务的要求所确定的样本指标与总体指标之间可允许的最大误差范围(记为?)。 二、计算公式 (一)抽样平均误差 1、样本平均数的平均误差 以μx 表示样本平均数的平均误差,σ表示总体的标准差。根据定义: 即n x σμ=,(若为不重复抽样,则总体方差σ要用进行修正)它说明在重复抽样的条件下,抽样平均误差与总体标准差成正比,与样本容量的平方根成反比。 例1:有5个工人的日产量分别为(单位:件):6,8,10,12,14,用重复抽样的方法,从中随机抽取2个工人的日产量,用以代表这5个工人的总体水平。则抽样平均误差为多少? 解:根据题意可得:(件) 总体标准差(件)
抽样平均误差(件) 注意:在计算抽样平均误差时,通常得不到总体标准差的数值,一般可以用样本标准差来代替总体标准差。 2、抽样成数的平均误差 总体成数P 可以表现为总体是非标志的平均数。即E(X)=P ,它的标准差 。 根据样本平均误差和总体标准差的关系,可以得到样本成数的平均误差的计算公式。 (不重复抽样时要修正) 注意:当总体成数未知时,可以用样本成数来代替。 例2:某企业生产的产品,按正常生产经验,合格率为90%,现从5000件产品中抽取50件进行检验,求合格率的抽样平均误差。 解:根据题意,在重复抽样条件下,合格率的抽样平均误差为: 在不重复抽样条件下,合格率的抽样平均误差为: (二)抽样极限误差 抽样极限误差是指用绝对值形式表示的 样本指标与总体指标偏差的可允许的最大范围。它表明被估计的总体指标有希望落在一个以样本指标为基础的可能范围。它是由抽样指标变动可允许的上限或下限与总体指标之差的绝对值求得的。 μαx Z *=?2 或μαp Z *=?2(P126,例题5-4)
第九章 抽样与抽样估计 一、单项选择题: 1.抽样极限误差是指抽样指标和总体指标之间( )。 A.抽样误差的平均数 B.抽样误差的标准差 C.抽样误差的可靠程度 D.抽样误差的最大可能范围 2.样本平均数和总体平均数( )。 A.前者是一个确定值,后者是随机变量 B.前者是随机变量,后者是一个确定值 C.两者都是随机变量 D.两者都是确定值 3.某厂要对某批产品进行抽样调查,已知以往的产品合格率分别为90%,93%,95%,要求误差范围小于5%,可靠性为95.45%,则必要样本容量为( )。 A.144 B.105 C.76 D.109 4.在总体方差不变的条件下,样本单位数量增加3倍,则抽样误差( )。 A.缩小1/2 B.为原来的33 C.为原来的1/3 D.为原来的2/3 5.在其他条件不变的前提下,若要求误差范围缩小1/3,则样本容量( )。 A.增加9倍 B.增加8倍 C.为原来的2.25倍 D.增加2.25倍 6.抽样误差是指( )。 A.在调查过程中由于观察、测量等差错所引起的误差 B.在调查中违反随机原则出现的系统误差 C.随机抽样而产生的代表性误差 D.人为原因所造成的误差 7.在一定的抽样平均误差条件下( )。 A.扩大极限误差范围,可以提高推断的可靠程度 B.扩大极限误差范围,会降低推断的可靠程度 C.缩小极限误差范围,可以提高推断的可靠程度 D.缩小极限误差范围,不改变推断的可靠程度 8.抽样平均误差是( )。 A.总体的标准差 B.样本的标准差
C.抽样指标的标准差 D.抽样误差的平均差 9.对某种连续生产的产品进行质量检验,要求每隔一小时抽出10分钟的产品进行检验,这种抽查方式是()。 A.简单随机抽样 B.类型抽样 C.等距抽样 D.整群抽样 10.先将总体各单位按主要标志分组,再从各组中随机抽取一定单位组成样本,这种抽样形式被称为()。 A.简单随机抽样 B.机械抽样 C.分层抽样 D.整群抽样 11.事先确定总体范围,并对总体的每个单位都编号,然后根据《随机数码表》或抽签的方式来抽取样本的抽样组织形式,被称为()。 A.简单随机抽样 B.机械抽样 C.分层抽样 D.整群抽样 12.在同样条件下,不重复抽样的抽样标准误差与重复抽样的抽样标准误差相比,()。 A.前者小于后者 B.前者大于后者 C.两者相等 D.无法判断 13.在重复的简单随机抽样中,当概率保证程度从68.27%提高到95.45%时(其他条件不变),必要的样本容量将会()。 A.增加一倍 B.增加两倍 C.增加三倍 D.减少一半 14.比例与比例方差的关系是()。 A.比例的数值越接近1,比例的方差越大 B.比例的数值越接近0,比例的方差越大 C.比例的数值越接近0.5,比例的方差越大 D.比例的数值越大,比例的方差越大 15.假定一个人口一亿的大国与百万人口的小国居民年龄变异程度相同,现在各自用重复抽样方法抽取本国的1%人口计算平均年龄,则平均年龄抽样误差 ()。 A.不能确定 B.两者相等 C.前者比后者大 D.前者比后者小 二、多项选择题: 1.下面说法错误的是()。 A.抽样调查中的代表性误差是可以避免的 B.抽样调查中的系统误差是可以避免的
如何合理选择抽样样本数 一、研究介绍: 研究背景:众所周知,抽样样本数的大小对调查结果的准确度有很大的影响,从统计上可以计算出每个抽样样本数所对应的抽样误差有多少。但大多数客户对抽样误差缺乏直观的感觉,无法清晰了解应该选择多大的抽样误差才能满足自己的实际需求,因此也就无从有效控制成本。另外,对于定性研究来说,也需要采用另外的指标来衡量多大的样本量才能满足定性研究的需求。 研究课题:1. 定性研究应该采用多大的样本量才能有效解决问题? 2. 定量研究中,采用不同数量的抽样样本,可达到怎样的研究效果? 研究方法:我们以过往某个调查项目的总样本数(4450样本)为母体样本,从中分别随机抽取5样本,10样本,20样本,30样本,50样本,80样本,100样本,200样本,300样本来比较其结果,为了充分了解每种样本量的抽样结果,每种样本量重复抽取30次。对比的问题指标为:不提示品牌知名度。 二、研究的主要结论:
三、详细研究分析 (一)定性样本需求分析 1、答案获得率分析 概念:答案获得率是指在调查中的答案个数与实际总体答案个数的比例。定性研究是属于探测性研究,因此不太在乎量
化的数据,而会更关注能否获得足够的答案数以供进一步的定量研究,也就是说答案获得率是否足够。 在本次研究中,采用的4450个母体样本中,果汁品牌共有17个,也就是说实际总体答案个数就是17个。因此,我们只需要对比每种抽样样本量下的平均答案个数,就可以知道该抽样样本量的答案获得率。 统计结果如下表: 从上面图表可得出,5样本的调查仅能拿到一半的答案,10样本获得七成的答案,15样本可得到80%的答案,而30样本是拐点,再得到90%的答案后,再增加样本量对答案获得率的帮助不大。
水准测量,一测站高差中误差为±3mm,若每公里观测16站,求每公里及K公里的高差中误差为多少 解:每千米的误差: ±√(16×3^2)=±4×3=±12(mm),即:±12mm/km k千米的误差:±√(k×12^2)=±(√k)12mm。 在最新版的《建筑变形测量规范》JGJ 8-2007中提到有关监测等级的定义和精度要求,其中关于沉降监测方面提到观测点测站高差中误差的概念。现我有一些疑问,特咨询大家: 1、在2007版的《建规》中提到关于变形等级为二级的精度要求,其要求观测点测站高差中误差《0.5(正负)。 问1:那么这里提到的观测点测站高差中误差如何求得,其计算公式有没有? 2、关于提到的观测点测站高差中误差,我查询了本规范中对观测点的定义,它是这样描述的: 观测点observation point:布设在建筑地基、基础、场地及上部结构的敏感位置上能反映其变形特征的测量点,亦称变形点。 问2:是不是可以认为,在判断某次沉降监测数据处理的精度是否满足相应等级的精度要求,只需要求得变形点的测站高差中误差,与之相比即可。而不用求得基准点和工作基点相应的测站高差中误差? 3.、现在回到最根本的地方,就是如何定义监测的等级,如何判定它是按二级还是按三级来监测,是否有一个公式可以计算出来。 我通过查资料,看到有这么一个推导过程: 沉降监测精度取决于监测目的、建筑物的结构和基础类型。为了监测建筑物的安全,其观测中误差应小于容许变形值的1/10~1/20;根据这一原则,通常采用“以当时可能达到的最高精度“确定变形观测精度。按照上述要求,结合该楼的实际情况,基准网采用国家一等水准测量的技术要求。沉降点的观测精度,采用以下公式进行估算m=△k/t。式中,Δ为容许变形值,t为置信区间内最大误差与中误差的比例值;K为安全系数。估算时,通常采用K=0.05,t=2。参考以上资料与方法,最后沉降观测精度确定为最弱点高程中误差m≤+1mm。由此而确定沉降监测等级。 问:不知道这么做是否科学,是否可行,或者还有其他方法来确定监测的等级。
第二节极限抽样误差 石家庄市第一职业中专学校石艳格050000 一、教学目的与要求: 1.知识目的:理解和熟练掌握极限抽样误差的概念和计算方法,让学生学会运用极限 误差对总体数据做出区间估计。 2.能力目的:从学生熟悉的实例出发,研究总体出极限误差的概念,让学生在自学的 过程中品尝获得成功的喜悦,从而激发他 们浓厚的学习兴趣。 二、教学过程 师:前面我们学习了抽样误差的概念及计算方法,明确了抽样误差是可以计算并且可以加以控制的,那如何对抽样误差进行控制呢?就是我们这节课要解决的问题。首先,请同学们想一想,如何控制抽样误差呢?(创设问题情境,让学生自主思考) 生甲:误差当然越小越好了!误差太大了,那我们用样本统计量估计的总体参数就没有意义了。(大部分同
学意见) 生乙:抽样误差是随机误差,是避不可免要产生的,我们不可能让它无限度地缩小。 师:大家说的都对,我们对抽样误差加以控制,它不能太大,这是我们很容易理解的,但它也是不可能无 限度地小。因为误差小,就意味着对总体参数估计 的精确度会很高,当我们没有50%以上的把握程度 去达到它要求的精确度时,我们也不再去做了。所 以抽样误差不能过大,也不能过小。我们把它可扩 大或缩小的倍数称为概率度,用符号t来表示。概 率度和概率(把握程度)之间有着数量对应关系。 概率越大,则概率度的值也越大,反之,概率越小,则概率度的值也越小。由此我们得到概率F(t)与 概率度t之间的对应关系。(幻灯片)我们常用的:t=1时,F(t)=68.27% t=2 时,F(t)=95.45% t=3 时,F(t)=99.73% 师:抽样误差的概念是什么?其计算公式是什么? 生:抽样误差是指样本统计量与总体参数之间的平均离
《统计学》习题五 参考答案 、单项选择题: 1、抽样误差是指( )。 C A 在调查过程中由于观察、测量等差错所引起的误差 B 人为原因所造成的误差 C 随机抽样而产生的代表性误差 D 在调查中违反随机原则出现的系统误差 2、抽样平均误差就是( )。 D A 样本的标准差 B 总体的标准差 C 随机误差 D 样本指标的标准差 3、抽样估计的可靠性和精确度( )。 B A 是一致的 B 是矛盾的 C 成正比 D 无关系 4、在简单随机重复抽样下,欲使抽样平均误差缩小为原来的三分之一,则样本容量应( )。 A A 增加 8 倍 B 增加 9 倍 C 增加 1.25 倍 D 增加 2.25 倍 5、当有多个参数需要估计时,可以计算出多个样品容量 n 为满足共同的要求,必要的样本容量 一般应是( )。 B A 总体的标志变异程度 B 允许误差的大小 C 重复抽样和不重复抽样 D 样本的差异程度 E 估计的可靠度 三、填空题: 3、 实施概率抽样的前提条件是要具备( )。抽样框 4、 对总体参数进行区间估计时,既要考虑极限误差的大小,即估计的( 虑估计的( )问题。准确性 可靠性 四、简答题: 1、抽样调查与重点调查的主要不同点。 A 最小的n 值 B 最大的n 值 6、抽样时需要遵循随机原则的原因是( C 中间的n 值 D 第一个计算出来的n 值 )。C A 可以防止一些工作中的失误 B 能使样本与总体有相同的分布 C 能使样本与总体有相似或相同的分布 D 可使单位调查费用降低 二、多项选择题: 1、抽样推断中哪些误差是可以避免的( A 工作条件造成的误差 B D 人为因素形成偏差 E 2、区间估计的要素是( A 点估计值 B D 抽样极限误差 E 3、影响必要样本容量的因素主要有( )。 A B D 系统性偏差 C 抽样随机误差 抽样实际误 差 )。 A C D 样本的分布 C 估计的可靠度 总体的分布形式 )。 A B C E 1、抽样推断就是根据( )的信息去研究总体的特征。样本 2、样本单位选取方法可分为( )和( )。重复抽样 不重复抽样 )问题,又要考
测量中误差 测量误差按其对测量结果影响的性质,可分为: 一.系统误差(system error) 1.定义:在相同观测条件下,对某量进行一系列观测,如误差出现符号和大小均相同或按一定的规律变化,这种误差称为系统误差。 2.特点:具有积累性,对测量结果的影响大,但可通过一般的改正或用一定的观测方法加以消除。 二.偶然误差(accident error) 1.定义:在相同观测条件下,对某量进行一系列观测,如误差出现符号和大小均不一定,这种误差称为偶然误差。但具有一定的统计规律。 2.特点: (1)具有一定的范围。 (2)绝对值小的误差出现概率大。 (3)绝对值相等的正、负误差出现的概率相同。 (4)数学期限望等于零。即: 误差概率分布曲线呈正态分布,偶然误差要通过的一定的数学方法(测量平差)来处理。 此外,在测量工作中还要注意避免粗差(gross error)(即:错误)的出现。
§2衡量精度的指标 测量上常见的精度指标有:中误差、相对误差、极限误差。 一.中误差 方差 ——某量的真误差,[]——求和符号。 规律:标准差估值(中误差m)绝对值愈小,观测精度愈高。 在测量中,n为有限值,计算中误差m的方法,有: 1.用真误差(true error)来确定中误差——适用于观测量真值已知时。 真误差Δ——观测值与其真值之差,有: 标准差 中误差(标准差估值), n为观测值个数。 2.用改正数来确定中误差(白塞尔公式)——适用于观测量真值未知时。 V——最或是值与观测值之差。一般为算术平均值与观测值之差,即有: 二.相对误差 1.相对中误差=
2.往返测较差率K= 三.极限误差(容许误差) 常以两倍或三倍中误差作为偶然误差的容许值。即: 。 §3误差传播定律 一.误差传播定律 设、…为相互独立的直接观测量,有函数 ,则有: 二.权(weight)的概念 1.定义:设非等精度观测值的中误差分别为m1、m2、…m n,则有: 权其中,为任意大小的常数。 当权等于1时,称为单位权,其对应的中误差称为单位权中误差 (unit weight mean square error)m0,故有:。 2.规律:权与中误差的平方成反比,故观测值精度愈高,其权愈大。
《工程测量规范》中,根据附合导线或闭合导线网闭合差计算测量中误差公式 Mβ(测)=±√([fβ*fβ/n]/N) fβ:角度闭合差 N:附合导线或闭合导线环个数 n:计算fβ时测站数 规范中规定四等导线测角中误差Mβ=2.5″,允许闭合差=2Mβ√n 现在有个问题,如果实测单个附合导线(N=1),实测闭合差为2Mβ√n, 然后代入Mβ=±√([fβ*fβ/n]/N)中求导线角度闭合差,则测角中误差为5″,超限 迷惑了,然道是单一附合导线不能用此公式计算测角闭合差还是其他的原因,为什么用规范中规定的值去反推会出现这种情况? 1、计算三角形闭合差、测角中误差(宜由20个以上三角形闭合差计算) 2、当水准网的环数超过20个时还应按环线闭合差计算MW 只有大规模作业才计算测角中误差和每公里水准测量全中误差,具体要超过20个闭合差,单个的可以并入其他测区进行计算。 首先要明白中误差的意义(按N次观测的偶然误差求得的标准差称为中误差),单次测量显然是无法计算中误差的。公式没错,只怪你你当初读书没用功。 以下是引用片段: 以下是引用魔刀火火在2007-12-15 17:17:00的发言: 《工程测量规范》中,根据附合导线或闭合导线网闭合差计算测量中误差公式 Mβ(测)=±√([fβ*fβ/n]/N) fβ:角度闭合差 N:附合导线或闭合导线环个数 n:计算fβ时测站数 规范中规定四等导线测角中误差Mβ=2.5″,允许闭合差=2Mβ√n 现在有个问题,如果实测单个附合导线(N=1),实测闭合差为2Mβ√n, 然后代入Mβ=±√([fβ*fβ/n]/N)中求导线角度闭合差,则测角中误差为5″,超限 迷惑了,然道是单一附合导线不能用此公式计算测角闭合差还是其他的原因,为什么用规范中规定的值去反推会出现这种情况?
测角中误差、测距相对中误差计算表 测站 后视 盘位 目标 半测回角值 一个测回角值 平均测回角值 半测回距值 (m ) 一个测回距值(m ) 平均测回距值(m ) 备注 JT3 JT2 左 JT4 2°09′10″ 2°09′03″ 2°09′05″ 113.574 113.576 113.576 右 2°08′55″ 113.577 左 2°09′04″ 2°09′07″ 113.575 113.575 右 2°09′09″ 113.575 JT4 JT3 左 JT2 176°35′00″ 176°34′58″ 176°34′59″ 193.465 193.467 193.465 右 176°34′56″ 193.468 左 176°35′03″ 176°34′59″ 193.460 193.463 右 176°34′55″ 193.465 JT2 JT4 左 JT3 1°15′39″ 1°15′43″ 1°15′42″ 306.922 306.923 306.923 右 1°15′46″ 306.924 左 1°15′44″ 1°15′40″ 306.922 306.922 右 1°15′35″ 306.921 计算: 1、测角中误差 (1) 测站JT3 112851290312v v v ?'"-?'"=?--==",222851290716v v v ?'"-?'"=?--==" 角度改正值 11()/214(12)2v v v =?-?=---=-∑″″″ 22()/214(16)2v v v =?-?=---=∑″″″ 观测角中误差2 22 v (2)2 2.832121 m -+=± =±±--"∑″″∈5±";