实验一:语音压缩编码的实现
- 格式:doc
- 大小:56.00 KB
- 文档页数:2



实验三.语音变换和压缩编码实验通过键盘和液晶选择“菜单”中的“二. 语音变换”1.语音模数转换实验(1)在语音变换下选择“1. 语音模数变换”;(2)按下AMBE2000的复位按钮,对AMBE2000进行复位;(3)K501拨到“SIN”,将输入的模拟信号设置为2kHZ的正弦信号,通过测试点TP501可以观测到输入给AD73311的模拟信号,调节面板上的W501,可以改变输入信号的幅度;(4)通过测试点TP502观测AD73311中A/D和D/A变换的时钟输出;(5)通过测试点TP503观测AD73311中数字输出和输入的帧同步信号;(6)通过测试点TP504观测AD73311的A/D转换后的数字输出信号;(7)通过测试点TP505观测AD73311的D/A转换前的数字输入信号;(8)通过测试点TP506观测AD73311完成D/A转换后的模拟信号,并可以通过调节面板上的W502改变输出信号的幅度;(9)将K501拨到“MIC”,将输入的模拟信号设置为麦克风输入的语音信号,插入麦克风和耳机,可以从耳机中听到麦克风的声音。
测量操作与测量结果:(1)CH1连接到TP501;CH2连接到TP506;(2)按下示波器的“AUTO”键;(3)分别将CH1和CH2的电压档设为“200mV”,时间档设为“200us”;(4)将CH1向移动,CH2向下移动。
(5)调节面板上的W501和W502,分别将TP501和TP506信号的幅度调整到300 mV和500 mV左右。
(6)按“RUN/STOP”键停止波形采样。
(7)CH1为输入的模拟2KHz正弦波,CH2为输出恢复信号,可以看到恢复波形比原始波形质量变差了。
如图2-1-TP501~TP506。
2-1-TP501~TP506(8)CH1连接到TP502,CH2连接到TP503,电压档设置保持为“2.0V”,时间档设为“5us”。
可以打开测量功能,测量CH1和CH2的频率。

实验报告实验名称语音编码实验课程名称信息处理技术专业综合实验实验二 语音编码一、实验目的熟悉语音基本压缩编码的方法,观察语音压缩效果,加深对语音线性预测编码(LPC )的理解。
二、实验内容1、编写并调试语音LPC 参数提取程序。
2、编写并调试语音基音周期提取程序。
3、编写并调试语音LPC 合成程序。
三、实验原理语音信号中含有大量的冗余信息,采用各种信源编码技术减除语音信号的冗余度,并充分利用人耳的听觉掩蔽效应,就可以将其编码速率压缩很多倍,而仍能提供可懂语音。
LPC 声码器是一种比较简单实用的语音压缩方法,其基本原理是:根据语音生成模型,将语音看作激励源通过一个线性时不变系统产生的输出,利用线性预测分析对声道参数进行估值,将求得的线性预测系数,结合基音周期等少量参数进行传输,就可以在接收端利用合成滤波器重构语音信号。
线性预测系数的估计方法为:假设语音的当前样值可以用过去的M 个语音样值来进行预测()()()()()∑=-=-++-+-=Mi i M i n x a M n x a n x a n x a n x 12121~式中{}i a 即为线性预测系数。
实际值和预测值之间的均方误差可表示为()()()∑∑∑⎪⎭⎫ ⎝⎛--===n Mi i n i n x a n x n E 212ε 要求均方误差总和最小,将E 关于i a 的偏导数设置为零,可以得到()()()01=⎪⎭⎫ ⎝⎛---∑∑=Mi i n i n x a n x k n x通过采用自相关法、协方差法或格形法求解该方程,即可得到最优的{}i a 。
四、实验方法及程序1. 调用xcorr命令计算一帧语音的自相关函数。
2. 调用toeplitz命令形成该帧语音的自相关矩阵。
3. 调用durbin命令,采用杜宾递推算法计算该帧语音的线性预测系数。
4. 编写lpcauto.m函数,求取一句语音信号的线性预测系数及预测残差。
选择设当的窗函数对语音信号进行分幀。

一、实验背景与目的随着信息技术的飞速发展,语音通信已经成为人们日常生活和工作中不可或缺的一部分。
语音编码技术作为语音通信的核心技术,旨在高效地压缩语音信号,降低传输带宽,提高通信质量。
本实验旨在通过实际操作,深入理解语音编码的基本原理,掌握常用的语音编码方法,并评估其性能。
二、实验内容与步骤1. 实验内容本实验主要涉及以下内容:- 语音信号的采集与预处理;- 语音信号的时域和频域分析;- 常用语音编码方法的实现与性能评估;- 编码性能的对比分析。
2. 实验步骤(1)实验准备- 确定实验所需的软件和硬件环境,如音频采集设备、计算机等;- 下载并安装实验所需的语音信号处理软件,如MATLAB等;- 准备实验所需的语音样本,如ISDN话音、PCMU/PCMA编码的语音等。
(2)语音信号的采集与预处理- 使用音频采集设备采集一段语音信号,采样频率为16kHz;- 对采集到的语音信号进行预处理,包括去除静音、归一化、滤波等操作。
(3)语音信号的时域和频域分析- 对预处理后的语音信号进行时域分析,观察其波形、幅度谱等;- 对语音信号进行频域分析,观察其频谱图、功率谱等。
(4)语音编码方法实现与性能评估- 选择一种或多种语音编码方法,如线性预测编码(LPC)、矢量量化(VQ)等;- 根据所选编码方法,编写相应的编码程序,对预处理后的语音信号进行编码;- 对编码后的语音信号进行解码,恢复原始语音信号;- 评估编码性能,如信噪比(SNR)、均方误差(MSE)等。
(5)编码性能对比分析- 对比不同语音编码方法的性能,分析其优缺点;- 分析不同参数设置对编码性能的影响。
三、实验结果与分析1. 实验结果(1)语音信号预处理- 预处理后的语音信号波形图;- 预处理后的语音信号频谱图。
(2)语音编码方法实现- 编码后的语音信号波形图;- 编码后的语音信号频谱图。
(3)编码性能评估- 不同语音编码方法的信噪比和均方误差;- 不同参数设置对编码性能的影响。

音频信号的压缩编码技术研究音频信号的压缩编码技术在传输和存储中起到了至关重要的作用,可有效地减小数据流量,降低传输功耗和存储成本。
目前已经广泛应用于数字音频广播、互联网传输和数字音乐压缩等方面,成为音频技术发展的重要组成部分之一。
1. 音频信号的数字化与采样首先,音频信号需要进行数字化处理,使其能够通过数字媒体传输和存储。
数字化的过程包括模拟信号的采样和量化。
其中采样是以一定频率对模拟信号进行采样,产生一系列离散的样本点,量化是把这些样本点转换成数字信号,即将连续的模拟信号转换成离散的数字信号。
通常采样频率为44.1kHz或48kHz,量化位数为16bit或24bit。
2. 压缩编码技术的原理和分类压缩编码技术可以分为有损和无损两种类型。
无损压缩技术是指在压缩的过程中不会丢失任何原始数据,以保证音质的高保真度。
具体的无损压缩技术包括无损压缩编码(Lossless Compression)和正交多项式压缩(Orthogonal Polynomial Compression)等。
有损压缩技术是指在压缩的过程中会丢失部分数据,从而减小数据流量,以达到更高的压缩比。
有损压缩技术包括声学模型压缩(Acoustic Model Compression)、子带编码(Subband Coding)和小波变换(Wavelet Transform)等。
3. 压缩编码技术在音频传输和存储中的应用在音频传输和存储中,压缩编码技术可以大大减小数据流量,降低传输功耗和存储成本。
根据不同的应用场景和数据需求,可以选择合适的压缩编码技术进行音频数据压缩。
例如,在互联网音频传输中,由于网络带宽和传输速率的限制,需要使用高效的压缩技术来减小音频文件的大小。
常用的压缩编码技术包括MP3、AAC、OGG Vorbis、FLAC等。
其中,MP3是较早期的音频压缩技术,具有较好的兼容性和音质效果。
AAC是一种高效的音频编码标准,具有更好的音质和压缩效果,广泛应用于苹果产品的iTunes中。

实验一 PCM 与ADPCM 语音压缩编码学院 光电学院 专业 网络工程 姓名 陈炯烁 学号 106052011218一、 实验目的1、了解PCM 的基本原理和方法;2、了解ADPCM 的基本原理;3、了解语音压缩编码的基本原理和过程。
二、 预备知识1、PCM 的基本原理和方法;2、ADPCM 的基本原理; 三、 实验仪器1、移动通信实验箱 一台;2、台式计算机 一台; 四、 实验原理目前国际上普遍采用容易实现的A 律13折线压扩特性和μ律15折线的压扩特性。
我国规定采用A 律13折线压扩特性。
本实验中的PCM 采用的是A 律13折线PCM 。
由预备知识可知,A 率对数压缩特性定义为:⎪⎩⎪⎨⎧≤≤++≤≤+=1x 1/A ln 1ln 11/A x 0ln 1)(AAx A Axx c 在CCITT 建议中,A=87.56。
在具体实现时压缩曲线c(x)用13段折线来近似,量化电平数L=256,即编码位数R=8。
因为对语音的采样频率为8kHz ,这样,A 率13折线的PCM 输出数据流速率为64kb/s 。
下图为A 律13折线的压缩示意图:负电平部分的压扩特性和正电平部分的压扩特性是对称的 ,所以上图只画出了正电平压扩特性。
这种量化方式相比于线性量化,当信号为小信号时,其信噪比较高(尤其是语音信号)。
从图上可以看到,整个归一化电平区间被分为8个小区间,每个区间的斜率和起点电平如下表:正电平部分的第一段和第二段的斜率都是16,负电平部分的第一段和第二段的斜率也都是16,所以本来划分的16折线段实际为13折线段。
PCM 编码对一个采样值量化编码后得到的是8比特的编码,下图是这8比特的码位安排:可见,编码的第一位C 1为极性码,正电平为1,负电平为0。
C 2~C 4为段落码,表示信号绝对值处在哪个段落,3位码的8种可能状态分别代表8个段落的起点电平。
C 5~C 8为段内码,段内码共4位,并且段内采用均匀量化的方式,故共有24=16个均匀量化级。

实验一 语音压缩编码的实现——增量调制一、 实验目的(1) 会用MATLAB 语言表示基本的信号 (2) 用MA TLAB 实现语音信号的采集(3) 理解增量调制(DM )的原理并编程实现编译码二、 实验原理1、信号是随时间变化的物理量,它的本质是时间的函数。
信号可以分为时间连续信号和时间离散信号。
连续信号是指除了若干不连续的时间点外,每个时间点上都有对应的数值的信号。
离散信号则是只在某些不连续的点上有信号值,其它的时间点上信号没有定义的一类信号。
离散信号一般可以由连续信号经过模数转换而得到。
语音信号是模拟信号,经麦克风输入计算机后,就存为数字信号。
2、增量调制编码基本原理是采用一位二进制数码“1”或“0”来表示信号在抽样时刻的值相对于预测器输出的值是增大还是减小,增大则输出“1”码,减小则输出“0”码。
收端译码器每收到一个1码,译码器的输出相对于前一个时刻的值上升一个量化阶,而收到一个0码,译码器的输出相对于前一个时刻的值下降一个量化阶。
增量调制的系统结构框图如课本上图3.3-1所示。
在编码端,由前一个输入信号的编码值经解码器解码可得到下一个信号的预测值。
输入的模拟音频信号与预测值在比较器上相减,从而得到差值。
差值的极性可以是正也可以是负。
若为正,则编码输出为1;若为负,则编码输出为0。
这样,在增量调制的输出端可以得到一串1位编码的DM 码。
图3.3-1 增量调制的系统结构框图三、 实验内容与方法(一)、用windows 自带的录音机录一段自己的语音(3s 内),存为“.wav ”文件。
1、补充:语音信号的采集Wavread 函数常用的语法为:[y,fs,bite]=wavread(‘filename.wav’); 这里fs 为采样频率,bite 为采样点数。
AWGN :在某一信号中加入高斯白噪声输入信号y = awgn(x,SNR) 在信号x 中加入高斯白噪声。
信噪比SNR 以dB 为单位。

第1篇一、实验目的本次实验旨在了解和掌握语音编码技术的基本原理,通过实验加深对语音编码算法的理解,并评估不同编码算法在语音质量与编码效率之间的平衡。
二、实验内容1. 实验原理语音编码技术是数字通信领域的重要组成部分,其主要目的是将模拟语音信号转换为数字信号,以适应数字传输和处理的需要。
语音编码技术分为两大类:波形编码和参数编码。
2. 实验工具- 语音信号采集设备- 语音信号处理软件(如MATLAB)- 语音编码算法实现代码3. 实验步骤(1)信号采集使用语音信号采集设备采集一段语音信号,并保存为.wav格式。
(2)波形编码实验- 实验一:PCM编码使用PCM(脉冲编码调制)算法对采集的语音信号进行编码,设置不同的采样频率和量化位数,观察编码后的信号波形和码率。
- 实验二:波形编码改进对比分析不同预处理器(如噪声抑制、滤波等)对PCM编码的影响。
(3)参数编码实验- 实验三:线性预测编码(LPC)使用LPC算法对采集的语音信号进行编码,设置不同的预测阶数,观察编码后的信号和重建语音质量。
- 实验四:多带激励编码(MBE)使用MBE算法对采集的语音信号进行编码,观察编码后的信号和重建语音质量。
- 实验五:矢量量化编码(VQ)使用VQ算法对采集的语音信号进行编码,设置不同的码书大小和量化位数,观察编码后的信号和重建语音质量。
4. 实验结果与分析(1)PCM编码随着采样频率的提高,PCM编码后的信号质量逐渐提高,但码率也随之增加。
量化位数越多,信号质量越好,但码率也越高。
(2)波形编码改进预处理器对PCM编码的影响主要体现在降低噪声和抑制非线性失真,从而提高编码后的信号质量。
(3)线性预测编码(LPC)LPC编码后的信号质量与预测阶数密切相关。
预测阶数越高,编码后的信号质量越好,但计算复杂度也随之增加。
(4)多带激励编码(MBE)MBE编码后的信号质量较好,且在低码率下仍能保持较好的语音质量。
(5)矢量量化编码(VQ)VQ编码后的信号质量与码书大小和量化位数密切相关。
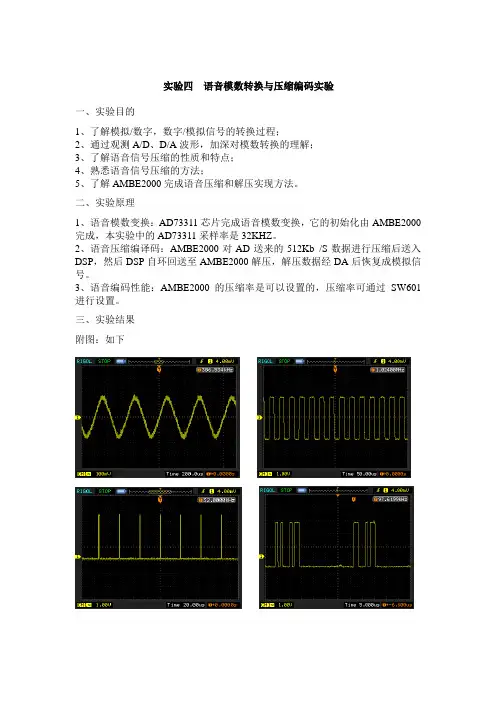
实验四语音模数转换与压缩编码实验
一、实验目的
1、了解模拟/数字,数字/模拟信号的转换过程;
2、通过观测A/D、D/A波形,加深对模数转换的理解;
3、了解语音信号压缩的性质和特点;
4、熟悉语音信号压缩的方法;
5、了解AMBE2000完成语音压缩和解压实现方法。
二、实验原理
1、语音模数变换:AD73311芯片完成语音模数变换,它的初始化由AMBE2000完成,本实验中的AD73311采样率是32KHZ。
2、语音压缩编译码:AMBE2000对AD送来的512Kb /S数据进行压缩后送入DSP,然后DSP自环回送至AMBE2000解压,解压数据经DA后恢复成模拟信号。
3、语音编码性能:AMBE2000的压缩率是可以设置的,压缩率可通过SW601进行设置。
三、实验结果
附图:如下。

语⾳压缩编码语⾳编码第⼀章⾳频1.1 ⾳频和语⾳的定义声⾳是携带信息的重要媒体,是通过空⽓传播的⼀种连续的波,叫声波。
对声⾳信号的分析表明,声⾳信号有许多频率不同的信号组成,这类信号称为复合信号。
⽽单⼀频率的信号称为分量信号。
声⾳信号的两个基本参数频率和幅度。
1.1.1声⾳信号的数字化声⾳数字化包括采样和量化。
采样频率由采样定理给出。
1.1.2声⾳质量划分根据声⾳频带,声⾳质量分5个等级,依次为:电话、调幅⼴播、调频⼴播、光盘、数字录⾳带DAT(digital audio tape)的声⾳。
第⼆章语⾳编码技术的发展和分类现有的语⾳编码器⼤体可以分三种类型:波形编码器、⾳源编码器和混合编码器。
⼀般来说,波形编码器的话⾳质量⾼,但数据率也很⾼。
⾳源编码器的数据率很低,产⽣的合成话⾳⾳质有待提⾼。
混合编码器使⽤⾳源编码器和波形编码器技术,数据率和⾳质介于⼆者之间。
语⾳编码性能指标主要有⽐特速率、时延、复杂性和还原质量。
其中语⾳编码的三种最常⽤的技术是脉冲编码调制(PCM)、差分PCM(DPCM)和增量调制(DM)。
通常,公共交换电话⽹中的数字电话都采⽤这三种技术。
第⼆类语⾳数字化⽅法主要与⽤于窄带传输系统或有限容量的数字设备的语⾳编码器有关。
采⽤该数字化技术的设备⼀般被称为声码器,声码器技术现在开始展开应⽤,特别是⽤于帧中继和IP上的语⾳。
在具体的编码实现(如VoIP)中除压缩编码技术外,⼈们还应⽤许多其它节省带宽的技术来减少语⾳所占带宽,优化⽹络资源。
静⾳抑制技术可将连接中的静⾳数据消除。
语⾳活动检测(SAD)技术可以⽤来动态跟踪噪⾳电平,并将噪⾳可听度抑制到最⼩,并确保话路两端的语⾳质量和⾃然声⾳的连接。
回声消除技术监听回声信号,并将它从听话⼈的语⾳信号中清除。
处理话⾳抖动的技术则将能导致通话⾳质下降的信道延时与信道抖动平滑掉。
2.1波形编码波形编解码器的思想是,编码前根据采样定理对模拟语⾳信号进⾏采样,然后进⾏幅度量化与⼆进制编码。
单片机能实现的语音压缩算法单片机是一种集成电路,具有微处理器、内存、输入输出接口等功能,常用于嵌入式系统中。
语音压缩算法是一种将语音信号进行压缩以减少存储空间或传输带宽的技术。
本文将介绍如何利用单片机实现一种简单的语音压缩算法。
在语音压缩中,最常用的算法之一是线性预测编码(LPC)算法。
LPC算法通过对语音信号进行预测,然后只存储预测误差,从而实现对语音信号的压缩。
在单片机中实现LPC算法,主要分为两个步骤:预测和编码。
我们需要对语音信号进行预测。
预测的目的是找到一个模型来描述语音信号的特征。
常用的预测模型是自回归模型,它假设当前的样本值可以由前面若干个样本值线性组合得到。
在单片机中,我们可以采用自相关函数的方法来估计自回归模型的参数。
自相关函数可以通过计算语音信号的样本序列与其自身的延迟序列之间的相关性来得到。
然后,我们可以利用这些参数来预测未来的样本值。
接下来,我们需要将预测误差进行编码。
编码的目的是将预测误差的信息用更少的比特数进行表示。
在单片机中,常用的编码方法是脉冲编码调制(PCM)和差分脉冲编码调制(DPCM)。
PCM将每个样本值转换为一个固定长度的比特序列,从而实现对预测误差的编码。
DPCM则是将每个样本值与前一个样本值的差值进行编码,从而利用差值的较小范围来减少编码所需的比特数。
除了LPC算法,还有其他一些语音压缩算法可以在单片机中实现。
例如,自适应差分脉冲编码调制(ADPCM)算法通过动态调整差分量化器的特征参数来适应不同的语音信号,从而提高编码效率。
另外,短时傅里叶变换(STFT)算法可以将语音信号从时域转换到频域,并利用频域的稀疏性进行压缩。
利用单片机可以实现多种语音压缩算法,其中LPC算法是最常用的一种。
通过预测和编码两个步骤,我们可以将语音信号进行有效地压缩,从而节省存储空间或传输带宽。
未来,随着单片机技术的发展,我们可以期待更多高效的语音压缩算法在单片机中实现,进一步提高语音通信的效率和质量。
语音压缩编码技术的研究及matlab的实现一.选题意义网络通信的核心部分是允许语音或语音编码的数字传输技术,而语音压缩编码是高质量、高速率语音信号传输及存储的关键技术,它一般包含语音源建模、重要感知特征提取、压缩和重新合成等过程。
语音压缩编码技术是语音识别、视频会和语音通话等技术的关键组成部分,目前这些技术正处于高速发展阶段,因此研究压缩编码技术对推动语音应用的高质量发展具有重要的现实意义。
二.国内外研究动态语音压缩编码从编码方式上分主要有波形编码、参数编码、波形及参数编码的混合编码等方式[1]。
波形编码适用于如语音识别、高质量音频等高质量应用和高速率传输环境,参数编码适用于如普通音频播放等低带宽和小存储容量的应用对象[2],下面对三种压缩编码技术的发展现状进行概述。
波形编码由于编解码质量高,因而应用较广,现有的波形压缩编码技术主要有脉冲调制编码(PCM)和其衍生的一些压缩编码方式。
PCM通过对原始语音信号进行模拟信号采样和数字量化后完成对语音信号的编码,它一般采用A率或μ率压缩算法对语音信号进行对数压缩处理[3];西安邮电大学的李鲜等[4]针对PCM编码过程中出现的语音信号频率混叠现象带来的波形重建的失真问题,设计了三阶巴特沃滋滤波器,有效抑制了高频干扰,保证了语音模拟信号到数字信号的可靠编码;Mohamed等[5]针对ITU-T G.711.1标准对语音信息进行编解码过程中产生的量化噪声问题,提出采用log-PCM估计器对信号进行后置滤波,准确估计了噪声,有效减少了语音编码噪声。
差分脉冲编码(DPCM)、自适应增量调制(ADM)、自适应差分脉冲编码调制(ADPCM)等技术都是在PCM编码的基础上改进的语音压缩编码技术,这些方法均采用记录差分信号的方式,分别从减小冗余信息、降低噪声过载、自适应量化及滤波等方面对语音压缩编码技术进行改进[6]。
刘华[7]采用ADPCM编码技术对WA V语音信号进行了仿真分析,通过编码后再解码的方式较好的还原了语音信号;Jayant[8]采用ADPCM技术,根据语音信号的截止频率范围将解码器的输出连接到N个低通滤波器中的某一个,实现编码过程中的参数自适应,有效提高了信号编码质量,获得了高质量的信号语音信号重建效果。
声音数据的压缩编码实现摘要随着信息技术的发展,语音压缩编码技术得到了快速发展和广泛应用,尤其是最近20年,语音压缩编码技术在移动通信、卫星通信、多媒体技术以及IP电话通信中得到普遍应用,起着举足轻重的作用。
为了提高通信容量和质量,对语音编码提出的要求也越来越高。
不仅要求低码率、低延迟,而且要求有很高的语音质量。
先进的语音压缩编码的目标就是要在尽可能低的比特率下,最大限度的提取语音信号的特征信息,在接收端恢复尽可能清晰自然的语音。
本文介绍了语音数据压缩编码,以及常用的编码算法,还有传感器网络的特点及传感器网络的节点数据传输的特点等,同时还重点论述了在传感器网络中数据压缩的Huffman编码和游程编码的算法原理及其实现过程,从而了解传感器网络中数据压缩的特点。
关键词:数据压缩,语音编码,传感器网络,Huffman编码,游程编码The data of speech encoding and implementationAbstractWith the development of information technology, speech compression coding technology has been rapid development and wide application. Especially in the last twenty years, speech compression technology plays a decisive role in mobile communications, satellite communications, and multimedia and IP telephony in the universal application. In order to improve communication capacity and quality, the request of the speech coding is higher and higher. Not only requires a low rate, low latency, but also has a high voice quality. The purpose of advanced speech compression coding is to distill the speech signal maximum from the characteristics of information when the bit rate is as low as possible and restore the natural clear speech as clear as possible in the receiving end. At present, The Commonly used coding method can be divided into waveform encoding, encoding parameters coding and mixed coding.This issue focuses on speech and data compression, as well as the common speech and data encoding method, the features of speech transmission in sensor networks and such as corresponding speech coding. The issue also discussed the voice data compression coding Huffman coding and run-length coding algorithm principle and its implementation process.Key words: data compression; speech encoding; sensor networks; Huffman encoding; run-length encoding目录声音数据的压缩编码实现…………………………………………………………………………………错误!未定义书签。
单片机能实现的语音压缩算法语音压缩算法是指通过对语音信号进行编码和压缩处理,以减少数据量并保持较高的音频质量。
在单片机中实现语音压缩算法,可以使嵌入式系统具备语音处理和通信的能力,从而实现语音识别、语音合成、语音通信等功能。
一、背景介绍随着嵌入式技术的发展,单片机逐渐成为各类智能设备和物联网终端的核心组成部分。
而语音作为一种重要的人机交互方式,对于嵌入式系统来说尤为重要。
然而,语音信号的数据量较大,传输和存储成本较高,因此需要对语音信号进行压缩处理,以提高传输效率和节约存储空间。
二、语音信号的特点语音信号是一种连续时间的模拟信号,具有较高的时域相关性和频域相关性。
此外,语音信号的频率范围较窄,通常在0~4kHz之间。
基于这些特点,可以利用语音信号的冗余性和感知特性进行压缩处理。
三、语音压缩算法1. 线性预测编码(LPC)算法LPC算法是一种基于线性预测模型的语音压缩算法。
它通过对语音信号进行分帧、预加重、帧内差分编码、线性预测分析等步骤,将语音信号的冗余部分去除,从而实现压缩效果。
LPC算法在单片机中的实现相对简单,可以有效地减少语音信号的数据量。
2. 离散余弦变换(DCT)算法DCT算法是一种基于频域分析的语音压缩算法。
它将语音信号从时域转换为频域,通过对频域系数进行量化和编码,实现对语音信号的压缩。
DCT算法在单片机中的实现相对复杂,但可以实现更高的压缩比和音质保真度。
3. 自适应差分脉冲编码调制(ADPCM)算法ADPCM算法是一种基于脉冲编码调制的语音压缩算法。
它通过对语音信号的差分进行编码和解码,实现对语音信号的压缩和恢复。
ADPCM算法在单片机中的实现相对简单,可以实现较高的压缩比和较好的音质。
四、单片机实现语音压缩算法的挑战与解决方案在单片机中实现语音压缩算法时,会面临计算能力有限、存储空间有限等挑战。
为了解决这些问题,可以采取以下措施:1. 优化算法:针对单片机的特点,对语音压缩算法进行优化,减少计算量和存储量的需求。
实验一 语音压缩编码的实现——增量调制
一、 实验目的
(1) 会用MATLAB 语言表示基本的信号
(2) 用MA TLAB 实现语音信号的采集
(3) 理解增量调制(DM )的原理并编程实现编译码
二、 实验原理
1、信号是随时间变化的物理量,它的本质是时间的函数。
信号可以分为时间连续信号和时间离散信号。
连续信号是指除了若干不连续的时间点外,每个时间点上都有对应的数值的信号。
离散信号则是只在某些不连续的点上有信号值,其它的时间点上信号没有定义的一类信号。
离散信号一般可以由连续信号经过模数转换而得到。
语音信号是模拟信号,经麦克风输入计算机后,就存为数字信号。
2、增量调制编码基本原理是采用一位二进制数码“1”或“0”来表示信号在抽样时刻的值相对于预测器输出的值是增大还是减小,增大则输出“1”码,减小则输出“0”码。
收端译码器每收到一个1码,译码器的输出相对于前一个时刻的值上升一个量化阶,而收到一个0码,译码器的输出相对于前一个时刻的值下降一个量化阶。
增量调制的系统结构框图如课本上图3.3-1所示。
在编码端,由前一个输入信号的编码值经解码器解码可得到下一个信号的预测值。
输入的模拟音频信号与预测值在比较器上相减,从而得到差值。
差值的极性可以是正也可以是负。
若为正,则编码输出为1;若为负,则编码输出为0。
这样,在增量调制的输出端可以得到一串1位编码的DM 码。
图3.3-1 增量调制的系统结构框图 三、 实验内容与方法
(一)、用windows 自带的录音机录一段自己的语音(3s 内),存为“.wav ”文件。
1、补充:语音信号的采集
Wavread 函数常用的语法为:[y,fs,bite]=wavread(‘filename.wav’);
这里fs 为采样频率,bite 为采样点数。
AWGN :在某一信号中加入高斯白噪声
输入信号
y = awgn(x,SNR) 在信号x 中加入高斯白噪声。
信噪比SNR 以dB 为单位。
y = awgn(x,SNR,SIGPOWER) 如果SIGPOWER 是数值,则其代表以dBW 为单位的信号强度;如果SIGPOWER 为'measured',则函数将在加入噪声之前测定信号强度。
用subplot 命令表示出原语音信号和加噪后的语音信号,用sound(y,fs,bite)回放输入的音频信号进行对比,也可用wavplay(y,fs)回放。
2、思考题(1)查看文件属性,写出音频采样大小,频道数,采样级别,并写出位速如何计算。
思考题(2)利用函数wavread 对语音信号进行采样,通过查看相应变量,写出采样点数为多少。
思考题(3)简述sound 以及wavplay 两个函数有何不同,为何直接输入wavplay(y),语音会变调?
(二)设输入信号为: ())300sin(5.0100sin t t y ππ+=,增量调制的采样频率为1000Hz ,采样时间从0到0.02s ,量化阶距δ=0.4,单位延迟器初始值为0。
思考题(1)按图3.3-1写出程序流程图,并编程实现编译码的全过程,最后用subplot 命令表示出原信号、编码输出信号以及译码输出(使用stairs(t,x)命令将译码表示为阶梯状图,在这幅图中使用hold on 命令,把原信号也一并显示出作为对比)的信号(假设理想传输,不考虑调制解调方式以及信道上的噪声)。
补充:N=length(t); 求数组长度(即行数或列数中的较大值)
D(N)=0;令数组中每个值都为0
思考题(2)由实验的结果说明什么是斜率过载,在哪些时刻发生?什么是散粒噪声,在哪些时刻发生?如何兼顾优化这两种失真?ADPCM 的主要思想是什么?
思考题(3)为什么说增量调制是PCM 的特殊形式?简述PCM 、增量调制以及DPCM 的不同。
(三)补充题:完成书本P25所示的自适应增量调制算法(控制可变因子M )
四、 实验要求
(1)编制完整的实验程序,实现对信号的模拟并得出实验结果。
(2)在实验报告中写出完整的程序,并完成上述思考题。