
A*算法实验报告
实验目的
1.熟悉和掌握启发式搜索的定义、估价函数和算法过程
2. 学会利用A*算法求解N数码难题
3. 理解求解流程和搜索顺序
实验原理
A*算法是一种有序搜索算法,其特点在于对估价函数的定义上。对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。因此,f是根据需要找到一条最小代价路径的观点来估算节点的,所以,可考虑每个节点n的估价函数值为两个分量:从起始节点到节点n的代价以及从节点n到达目标节点的代价。
实验条件
1.Window NT/xp/7及以上的操作系统
2.内存在512M以上
3.CPU在奔腾II以上
实验内容
1.分别以8数码和15数码为例实际求解A*算法
2.画出A*算法求解框图
3.分析估价函数对搜索算法的影响
4.分析A*算法的特点
实验分析
1. A*算法基本步骤
1)生成一个只包含开始节点n
0的搜索图G,把n
放在一个叫OPEN的列表上。
2)生成一个列表CLOSED,它的初始值为空。
3)如果OPEN表为空,则失败退出。
4)选择OPEN上的第一个节点,把它从OPEN中移入CLPSED,称该节点为n。5)如果n是目标节点,顺着G中,从n到n
的指针找到一条路径,获得解决方案,成功退出(该指针定义了一个搜索树,在第7步建立)。
6)扩展节点n,生成其后继结点集M,在G中,n的祖先不能在M中。在G中安置M的成员,使他们成为n的后继。
7)从M的每一个不在G中的成员建立一个指向n的指针(例如,既不在OPEN中,
的这些成员加到OPEN中。对M的每一个已在OPEN中或也不在CLOSED中)。把M
1
CLOSED中的成员m,如果到目前为止找到的到达m的最好路径通过n,就把它的指针指向n。对已在CLOSED中的M的每一个成员,重定向它在G中的每一个后继,以使它们顺着到目前为止发现的最好路径指向它们的祖先。
8)按递增f*值,重排OPEN(相同最小f*值可根据搜索树中的最深节点来解决)。
9)返回第3步。
在第7步中,如果搜索过程发现一条路径到达一个节点的代价比现存的路径代价低,就要重定向指向该节点的指针。已经在CLOSED中的节点子孙的重定向保存了后面的搜索结果,但是可能需要指数级的计算代价。
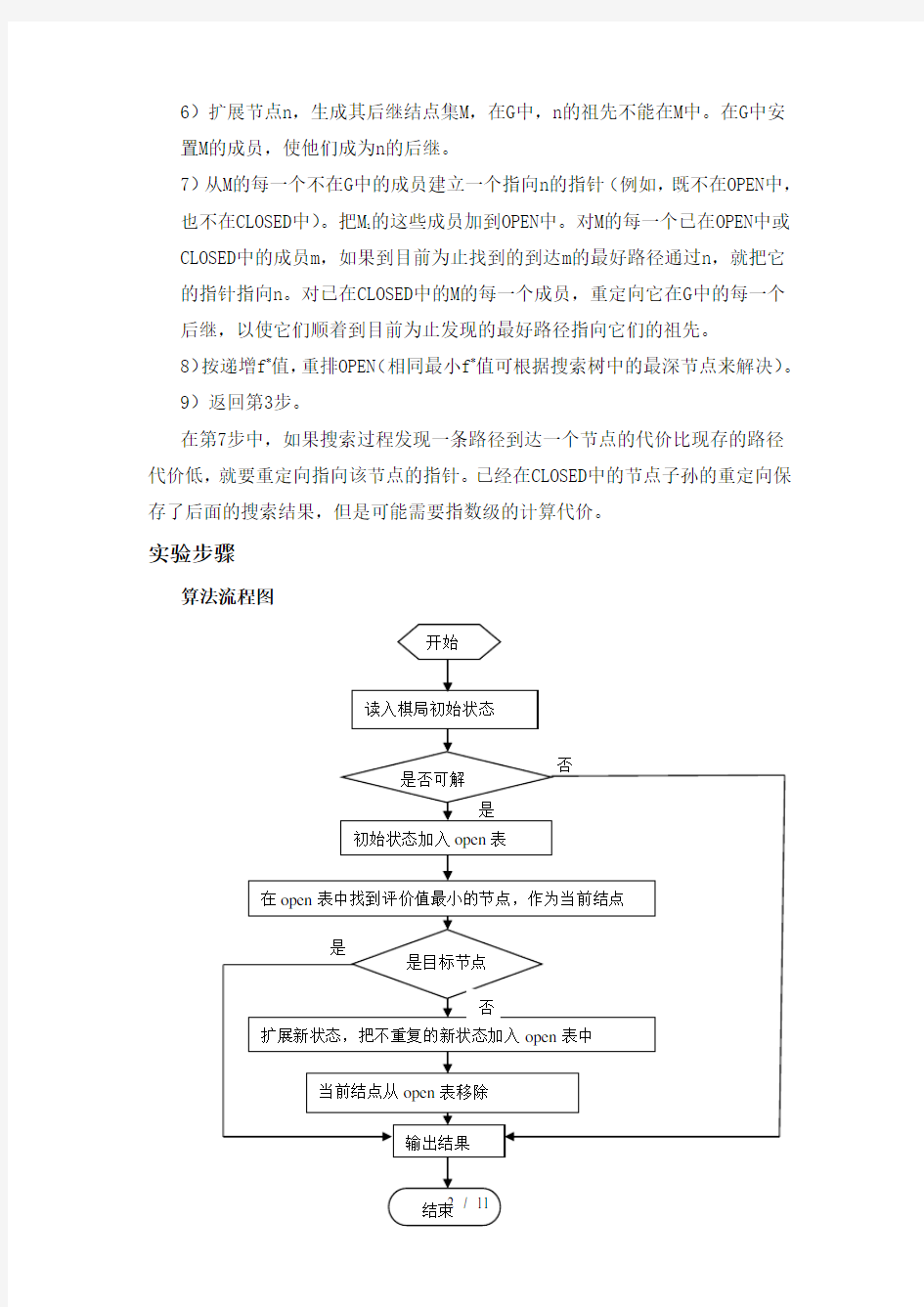
实验步骤
算法流程图
程序代码
#include
#include
#include
using namespace std;
const int ROW = 3;//行数
const int COL = 3;//列数
const int MAXDISTANCE = 10000;//最多可以有的表的数目
const int MAXNUM = 10000;
typedef struct _Node{
int digit[ROW][COL];
int dist; //一个表和目的表的距离
int dep; // t深度
int index; //节点的位置
} Node;
Node src, dest;// 父节表目的表
vector
bool isEmptyOfOPEN() //open表是否为空
{
for (int i = 0; i < node_v.size(); i++) {
if (node_v[i].dist != MAXNUM)
return false;
}
return true;
}
bool isEqual(int index, int digit[][COL]) //判断这个最优的节点是否和目的节点一样
{
for (int i = 0; i < ROW; i++)
for (int j = 0; j < COL; j++) {
if (node_v[index].digit[i][j] != digit[i][j])
return false;
}
return true;
}
ostream& operator<<(ostream& os, Node& node)
{
for (int i = 0; i < ROW; i++) {
for (int j = 0; j < COL; j++)
os << node.digit[i][j] << ' ';
os << endl;
}
return os;
}
void PrintSteps(int index, vector
{
rstep_v.push_back(node_v[index]);
index = node_v[index].index;
while (index != 0)
{
rstep_v.push_back(node_v[index]);
index = node_v[index].index;
}
for (int i = rstep_v.size() - 1; i >= 0; i--)//输出每一步的探索过程
cout << "Step " << rstep_v.size() - i
<< endl << rstep_v[i] << endl;
}
void Swap(int& a, int& b)
{
int t;
t = a;
a = b;
b = t;
}
void Assign(Node& node, int index)
{
for (int i = 0; i < ROW; i++)
for (int j = 0; j < COL; j++)
node.digit[i][j] = node_v[index].digit[i][j];
}
int GetMinNode() //找到最小的节点的位置即最优节点{
int dist = MAXNUM;
int loc; // the location of minimize node
for (int i = 0; i < node_v.size(); i++)
{
if (node_v[i].dist == MAXNUM)
continue;
else if ((node_v[i].dist + node_v[i].dep) < dist) {
loc = i;
dist = node_v[i].dist + node_v[i].dep;
}
}
return loc;
}
bool isExpandable(Node& node)
{
for (int i = 0; i < node_v.size(); i++) {
if (isEqual(i, node.digit))
return false;
}
return true;
}
int Distance(Node& node, int digit[][COL])
{
int distance = 0;
bool flag = false;
for(int i = 0; i < ROW; i++)
for (int j = 0; j < COL; j++)
for (int k = 0; k < ROW; k++) {
for (int l = 0; l < COL; l++) {
if (node.digit[i][j] == digit[k][l]) {
distance += abs(i - k) + abs(j - l);
flag = true;
break;
}
else
flag = false;
}
if (flag)
break;
}
return distance;
}
int MinDistance(int a, int b)
{
return (a < b ? a : b);
}
void ProcessNode(int index)
{
int x, y;
bool flag;
for (int i = 0; i < ROW; i++) {
for (int j = 0; j < COL; j++) {
if (node_v[index].digit[i][j] == 0)
{
x =i; y = j;
flag = true;
break;
}
else flag = false;
}
if(flag)
break;
}
Node node_up;
Assign(node_up, index);//向上扩展的节点int dist_up = MAXDISTANCE;
if (x > 0)
{
Swap(node_up.digit[x][y], node_up.digit[x - 1][y]);
if (isExpandable(node_up))
{
dist_up = Distance(node_up, dest.digit);
node_up.index = index;
node_up.dist = dist_up;
node_up.dep = node_v[index].dep + 1;
node_v.push_back(node_up);
}
}
Node node_down;
Assign(node_down, index);//向下扩展的节点
int dist_down = MAXDISTANCE;
if (x < 2)
{
Swap(node_down.digit[x][y], node_down.digit[x + 1][y]); if (isExpandable(node_down))
{
dist_down = Distance(node_down, dest.digit);
node_down.index = index;
node_down.dist = dist_down;
node_down.dep = node_v[index].dep + 1;
node_v.push_back(node_down);
}
}
Node node_left;
Assign(node_left, index);//向左扩展的节点
int dist_left = MAXDISTANCE;
if (y > 0)
{
Swap(node_left.digit[x][y], node_left.digit[x][y - 1]);
if (isExpandable(node_left))
{
dist_left = Distance(node_left, dest.digit);
node_left.index = index;
node_left.dist = dist_left;
node_left.dep = node_v[index].dep + 1;
node_v.push_back(node_left);
}
}
Node node_right;
Assign(node_right, index);//向右扩展的节点
int dist_right = MAXDISTANCE;
if (y < 2)
{
Swap(node_right.digit[x][y], node_right.digit[x][y + 1]); if (isExpandable(node_right))
{
dist_right = Distance(node_right, dest.digit);
node_right.index = index;
node_right.dist = dist_right;
node_right.dep = node_v[index].dep + 1;
node_v.push_back(node_right);
}
}
node_v[index].dist = MAXNUM;
}
int main() // 主函数
{
int number;
cout << "Input source:" << endl;
for (int i = 0; i < ROW; i++)//输入初始的表
for (int j = 0; j < COL; j++) {
cin >> number;
src.digit[i][j] = number;
}
src.index = 0;
src.dep = 1;
cout << "Input destination:" << endl;//输入目的表
for (int m = 0; m < ROW; m++)
for (int n = 0; n < COL; n++) {
cin >> number;
dest.digit[m][n] = number;
}
node_v.push_back(src);//在容器的尾部加一个数据
cout << "Search..." << endl;
clock_t start = clock();
while (1)
{
if (isEmptyOfOPEN())
{
cout << "Cann't solve this statement!" << endl;
return -1;
}
else
{
int loc; // the location of the minimize node最优节点的位置loc = GetMinNode();
if(isEqual(loc, dest.digit))
{
vector
cout << "Source:" << endl;
cout << src << endl;
PrintSteps(loc, rstep_v);
cout << "Successful!" << endl;
cout << "Using " << (clock() - start) / CLOCKS_PER_SEC
<< " seconds." << endl;
break;
}
else
ProcessNode(loc);
}
}
return 0;
}
程序运行效果图
(初始状态)
1 2 3 8 0 4 7 6 5
(结束状态)
个人实验小结
A*算法是一种有序搜索算法,其特点在于对估价函数的定义上。对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。通过本实验,我熟悉启发式搜索的定义、估价函数和算法过程,并利用A*算法求解了8数码难题,理解了求解流程和搜索顺序。实验过程中巩固了所学的知识,通过实验也提高了自己的编程和思维能力,收获很多。
A*算法实验报告 实验目的 1.熟悉和掌握启发式搜索的定义、估价函数和算法过程 2. 学会利用A*算法求解N数码难题 3. 理解求解流程和搜索顺序 实验原理 A*算法是一种有序搜索算法,其特点在于对估价函数的定义上。对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。因此,f是根据需要找到一条最小代价路径的观点来估算节点的,所以,可考虑每个节点n的估价函数值为两个分量:从起始节点到节点n的代价以及从节点n到达目标节点的代价。 实验条件 1.Window NT/xp/7及以上的操作系统 2.内存在512M以上 3.CPU在奔腾II以上 实验内容 1.分别以8数码和15数码为例实际求解A*算法 2.画出A*算法求解框图 3.分析估价函数对搜索算法的影响 4.分析A*算法的特点 实验分析 1. A*算法基本步骤 1)生成一个只包含开始节点n0的搜索图G,把n0放在一个叫OPEN的列表上。
2)生成一个列表CLOSED,它的初始值为空。 3)如果OPEN表为空,则失败退出。 4)选择OPEN上的第一个节点,把它从OPEN中移入CLPSED,称该节点为n。 5)如果n是目标节点,顺着G中,从n到n0的指针找到一条路径,获得解决方案,成功退出(该指针定义了一个搜索树,在第7步建立)。 6)扩展节点n,生成其后继结点集M,在G中,n的祖先不能在M中。在G中安置M的成员,使他们成为n的后继。 7)从M的每一个不在G中的成员建立一个指向n的指针(例如,既不在OPEN 中,也不在CLOSED中)。把M1的这些成员加到OPEN中。对M的每一个已在OPEN中或CLOSED中的成员m,如果到目前为止找到的到达m的最好路径通过n,就把它的指针指向n。对已在CLOSED中的M的每一个成员,重定向它在G中的每一个后继,以使它们顺着到目前为止发现的最好路径指向它们的祖先。 8)按递增f*值,重排OPEN(相同最小f*值可根据搜索树中的最深节点来解决)。 9)返回第3步。 在第7步中,如果搜索过程发现一条路径到达一个节点的代价比现存的路径代价低,就要重定向指向该节点的指针。已经在CLOSED中的节点子孙的重定向保存了后面的搜索结果,但是可能需要指数级的计算代价。 实验步骤 算法流程图
1.启发式搜索算法A 启发式搜索算法A,一般简称为A算法,是一种典型的启发式搜索算法。其基本思想是:定义一个评价函数f,对当前的搜索状态进行评估,找出一个最有希望的节点来扩展。 评价函数的形式如下: f(n)=g(n)+h(n) 其中n是被评价的节点。 f(n)、g(n)和h(n)各自表述什么含义呢?我们先来定义下面几个函数的含义,它们与f(n)、g(n)和h(n)的差别是都带有一个"*"号。 g*(n):表示从初始节点s到节点n的最短路径的耗散值; h*(n):表示从节点n到目标节点g的最短路径的耗散值; f*(n)=g*(n)+h*(n):表示从初始节点s经过节点n到目标节点g 的最短路径的耗散值。 而f(n)、g(n)和h(n)则分别表示是对f*(n)、g*(n)和h*(n)三个函数值的的估计值。是一种预测。A算法就是利用这种预测,来达到有效搜索的目的的。它每次按照f(n)值的大小对OPEN表中的元素进行排序,f值小的节点放在前面,而f 值大的节点则被放在OPEN表的后面,这样每次扩展节点时,都是选择当前f值最小的节点来优先扩展。
利用评价函数f(n)=g(n)+h(n)来排列OPEN表节点顺序的图搜索算法称为算法A。 过程A ①OPEN:=(s),f(s):=g(s)+h(s); ②LOOP:IF OPEN=()THEN EXIT(FAIL); ③n:=FIRST(OPEN); ④IF GOAL(n)THEN EXIT(SUCCESS); ⑤REMOVE(n,OPEN),ADD(n,CLOSED); ⑥EXPAND(n)→{mi},计算f(n,mi)=g(n,mi)+h(mi);g(n,mi)是从s通过n到mi的耗散值,f(n,mi)是从s通过n、mi到目标节点耗散值的估计。 ·ADD(mj,OPEN),标记mi到n的指针。 ·IF f(n,mk) 人工智能(A*算法) 一、 A*算法概述 A*算法是到目前为止最快的一种计算最短路径的算法,但它一种‘较优’算法,即它一般只能找到较优解,而非最优解,但由于其高效性,使其在实时系统、人工智能等方面应用极其广泛。 A*算法结合了启发式方法(这种方法通过充分利用图给出的信息来动态地作出决定而使搜索次数大大降低)和形式化方法(这种方法不利用图给出的信息,而仅通过数学的形式分析,如Dijkstra算法)。它通过一个估价函数(Heuristic Function)f(h)来估计图中的当前点p到终点的距离(带权值),并由此决定它的搜索方向,当这条路径失败时,它会尝试其它路径。 因而我们可以发现,A*算法成功与否的关键在于估价函数的正确选择,从理论上说,一个完全正确的估价函数是可以非常迅速地得到问题的正确解答,但一般完全正确的估价函数是得不到的,因而A*算法不能保证它每次都得到正确解答。一个不理想的估价函数可能会使它工作得很慢,甚至会给出错误的解答。 为了提高解答的正确性,我们可以适当地降低估价函数的值,从而使之进行更多的搜索,但这是以降低它的速度为代价的,因而我们可以根据实际对解答的速度和正确性的要求而设计出不同的方案,使之更具弹性。 二、 A*算法分析 众所周知,对图的表示可以采用数组或链表,而且这些表示法也各也优缺点,数组可以方便地实现对其中某个元素的存取,但插入和删除操作却很困难,而链表则利于插入和删除,但对某个特定元素的定位却需借助于搜索。而A*算法则需要快速插入和删除所求得的最优值以及可以对当前结点以下结点的操作,因而数组或链表都显得太通用了,用来实现A*算法会使速度有所降低。要实现这些,可以通过二分树、跳转表等数据结构来实现,我采用的是简单而高效的带优先权的堆栈,经实验表明,一个1000个结点的图,插入而且移动一个排序的链表平均需500次比较和2次移动;未排序的链表平均需1000次比较和2次移动;而堆仅需10次比较和10次移动。需要指出的是,当结点数n大于10,000时,堆将不再是正确的选择,但这足已满足我们一般的要求。 一、粒子群算法 粒子群算法,也称粒子群优化算法(Particle Swarm Optimization),缩写为PSO,是近年来发展起来的一种新的进化算法((Evolu2tionary Algorithm - EA)。PSO 算法属于进化算法的一种,和遗传算法相似,它也是从随机解出发,通过迭代寻找最优解,它也是通过适应度来评价解的品质,但它比遗传算法规则更为简单,它没有遗传算法的交叉(Crossover) 和变异(Mutation) 操作,它通过追随当前搜索到的最优值来寻找全局最优。这种算法以其实现容易、精度高、收敛快等优点引起了学术界的重视,并且在解决实际问题中展示了其优越性。 优化问题是工业设计中经常遇到的问题,许多问题最后都可以归结为优化问题.为了解决各种各样的优化问题,人们提出了许多优化算法,比较著名的有爬山法、遗传算法等.优化问题有两个主要问题:一是要求寻找全局最小点,二是要求有较高的收敛速度.爬山法精度较高,但是易于陷入局部极小.遗传算法属于进化算法(EvolutionaryAlgorithms)的一种,它通过模仿自然界的选择与遗传的机理来寻找最优解.遗传算法有三个基本算子:选择、交叉和变异.但是遗传算法的编程实现比较复杂,首先需要对问题进行编码,找到最优解之后还需要对问题进行解码,另外三个算子的实现也有许多参数,如交叉率和变异率,并且这些参数的选择严重影响解的品质,而目前这些参数的选择大部分是依靠经验.1995年Eberhart博士和kennedy博士提出了一种新的算法;粒子群优化(ParticalSwarmOptimization-PSO)算法.这种算法以其实现容易、精度高、收敛快等优点引起了学术界的重视,并且在解决实际问题中展示了其优越性. 粒子群优化(ParticalSwarmOptimization-PSO)算法是近年来发展起来的一种新的进化算法(Evolu2tionaryAlgorithm-EA).PSO算法属于进化算法的一种,和遗传算法相似,它也是从随机解出发,通过迭代寻找最优解,它也是通过适应度来评价解的品质.但是它比遗传算法规则更为简单,它没有遗传算法的交叉(Crossover)和变异(Mutation)操作.它通过追随当前搜索到的最优值来寻找全局最优 二、遗传算法 遗传算法是计算数学中用于解决最佳化的,是进化算法的一种。进化算法最初是借鉴了进化生物学中的一些现象而发展起来的,这些现象包括遗传、突变、自然选择以及杂交等。遗传算法通常实现方式为一种模拟。对于一个最优化问题,一定数量的候选解(称为个体)的抽象表示(称为染色体)的种群向更好的解进化。传统上,解用表示(即0和1的串),但也可以用其他表示方法。进化从完全随机个体的种群开始,之后一代一代发生。在每一代中,整个种群的适应度被评价,从当前种群中随机地选择多个个体(基于它们的适应度),通过自然选择和突变产生新的生命种群,该种群在算法的下一次迭代中成为当前种群。 1.在高血压诊断标准的变迁史上,()将高血压的诊断标准定为120/80mmHg以下更受益。( 2.0分) A.1949年 B.1984年 C.1993年 D.2016年 2.我国在语音语义识别领域的领军企业是()。(2.0分) A.科大讯 飞 B.图谱科 技 C.阿里巴 巴 D.华为 3.中国人工智能产业初步呈现集聚态势,人工智能企业主要集聚在经济发达的一二线城市及沿海地区,排名第一的城市是()。(2.0分) A. B.北京 C. D. 4.MIT教授Tomaso Poggio明确指出,过去15年人工智能取得的成功,主要是因为()。(2.0分) A.计算机视 觉 B.语音识别 C.博弈论 D.机器学习 5.1997年,Hochreiter&Schmidhuber提出()。(2.0分) A.反向传播算法 B.深度学习 C.博弈论 D.长短期记忆模型 6.(),中共中央政治局就人工智能发展现状和趋势举行第九次集体学习。(2.0分) A.2018年3月15日 B.2018年10月31日 C.2018年12月31日 D.2019年1月31日 7.()是指能够自己找出问题、思考问题、解决问题的人工智能。(2.0分) A.超人工智 能 B.强人工智 能 C.弱人工智 能 D.人工智能 8.据清华原副校长施一公教授研究,中国每年有265万人死于(),占死亡人数的28%。(2.0分) A.癌症 B.心脑血管疾病 C.神经退行性疾 病 D.交通事故 9.2005年,美国一份癌症统计报告表明:在所有死亡原因中,癌症占()。(2.0分) A.1/4 B.1/3 C.2/3 D.3/4 10.()是自然语言处理的重要应用,也可以说是最基础的应用。(2.0分) A.文本识别 B.机器翻译 C.文本分类 D.问答系统 11.()是人以自然语言同计算机进行交互的综合性技术,结合了语言学、心理学、工程、计算机技术等领域的知识。(2.0分) A.语音交互 B.情感交互 C.体感交互 D.脑机交互 12.下列对人工智能芯片的表述,不正确的是()。(2.0分) A.一种专门用于处理人工智能应用中大量计算任务的芯片 B.能够更好地适应人工智能中大量矩阵运算 C.目前处于成熟高速发展阶段 D.相对于传统的CPU处理器,智能芯片具有很好的并行计算性能 13.()是指能够按照人的要求,在某一个领域完成一项工作或者一类工作的人工智能。(2.0分) A.超人工智 能 B.强人工智 能 C.弱人工智 能 D.人工智能 人工智能算法实现:[1]A*算法c语言 ? 分步阅读 A*算法,A*(A-Star)算法是一种静态路网中求解最短路最有效的方法。估价值与实际值越接近,估价函数取得就越好。 A*[1](A-Star)算法是一种静态路网中求解最短路最有效的方法。 公式表示为:f(n)=g(n)+h(n), 其中f(n) 是从初始点经由节点n到目标点的估价函数, g(n) 是在状态空间中从初始节点到n节点的实际代价, h(n) 是从n到目标节点最佳路径的估计代价。 保证找到最短路径(最优解的)条件,关键在于估价函数h(n)的选取: 估价值h(n)<= n到目标节点的距离实际值,这种情况下,搜索的点数多,搜索范围大,效率低。但能得到最优解。 如果估价值>实际值,搜索的点数少,搜索范围小,效率高,但不能保证得到最优解。 工具/原料 ?DEVC++或VC 6.0 方法/步骤 1.估价值与实际值越接近,估价函数取得就越好 例如对于几何路网来说,可以取两节点间欧几理德距离(直线距离)做为估价值,即f=g(n)+sqrt((dx-nx)*(dx-nx)+(dy-ny)*(dy-ny));这样估价函数f在g值一定的情况下,会或多或少的受估价值h的制约,节点距目标点近,h值小,f 值相对就小,能保证最短路的搜索向终点的方向进行。明显优于Dijkstra算法的毫无方向的向四周搜索。 conditions of heuristic Optimistic (must be less than or equal to the real cost) As close to the real cost as possible 详细内容: 创建两个表,OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。 算起点的估价值; 将起点放入OPEN表; 2. A star算法在静态路网中的应用,以在地图中找从开始点s 到e点的最短 行走路径为例: 首先定义数据结构 #define MAPMAXSIZE 100 //地图面积最大为100x100 #define MAXINT 8192 //定义一个最大整数, 地图上任意两点距离不会超过它#define STACKSIZE 65536 //保存搜索节点的堆栈大小 #define tile_num(x,y) ((y)*map_w+(x)) //将x,y 坐标转换为地图上块的编号#define tile_x(n) ((n)%map_w) //由块编号得出x,y 坐标 #define tile_y(n) ((n)/map_w) // 树结构, 比较特殊, 是从叶节点向根节点反向链接 一单项选择题(每小题2分,共10分) 1.首次提出“人工智能”是在(D )年 A.1946 B.1960 C.1916 D.1956 2. 人工智能应用研究的两个最重要最广泛领域为:B A.专家系统、自动规划 B. 专家系统、机器学习 C. 机器学习、智能控制 D. 机器学习、自然语言理解 3. 下列不是知识表示法的是 A 。 A:计算机表示法B:“与/或”图表示法 C:状态空间表示法D:产生式规则表示法 4. 下列关于不确定性知识描述错误的是 C 。 A:不确定性知识是不可以精确表示的 B:专家知识通常属于不确定性知识 C:不确定性知识是经过处理过的知识 D:不确定性知识的事实与结论的关系不是简单的“是”或“不是”。 5. 下图是一个迷宫,S0是入口,S g是出口,把入口作为初始节点,出口作为目标节点,通道作为分支,画出从入口S0出发,寻找出口Sg的状态树。根据深度优先搜索方法搜索的路径是 C 。 A:s0-s4-s5-s6-s9-sg B:s0-s4-s1-s2-s3-s6-s9-sg C:s0-s4-s1-s2-s3-s5-s6-s8-s9-sg D:s0-s4-s7-s5-s6-s9-sg 二填空题(每空2分,共20分) 1.目前人工智能的主要学派有三家:符号主义、进化主义和连接主义。 2. 问题的状态空间包含三种说明的集合,初始状态集合S 、操作符集合F以及目标状态集合G 。 3、启发式搜索中,利用一些线索来帮助足迹选择搜索方向,这些线索称为启发式(Heuristic)信息。 4、计算智能是人工智能研究的新内容,涉及神经计算、模糊计算和进化计算等。 5、不确定性推理主要有两种不确定性,即关于结论的不确定性和关于证据的不确 定性。 #include "Stdio.h" #include "Conio.h" #include "stdlib.h" #include "math.h" void Copy_node(struct node *p1,struct node *p2); void Calculate_f(int deepth,struct node *p); void Add_to_open(struct node *p); void Add_to_closed(struct node *p); void Remove_p(struct node *name,struct node *p); int Test_A_B(struct node *p1,struct node *p2); struct node * Search_A(struct node *name,struct node *temp); void Print_result(struct node *p); struct node // 定义8数码的节点状态 { int s[3][3]; //当前8数码的状态 int i_0; //当前空格所在行号 int j_0; //当前空格所在列号 int f; //当前代价值 int d; //当前节点深度 int h; //启发信息,采用数码"不在位"距离和 struct node *father; //指向解路径上该节点的父节点 struct node *next; //指向所在open或closed表中的下一个元素 } ; struct node s_0={{2,8,3,1,6,4,7,0,5},2,1,0,0,0,NULL,NULL}; //定义初始状态 struct node s_g={{1,2,3,8,0,4,7,6,5},1,1,0,0,0,NULL,NULL}; //定义目标状态 struct node *open=NULL; //建立open表指针struct node *closed=NULL; //建立closed表指针int sum_node=0; //用于记录扩展节点总数 //*********************************************************** //********************** ********************** //********************** 主函数开始********************** //********************** ********************** //*********************************************************** void main() { 人工智能算法综述人工智能算法大概包括五大搜索技术,包括一些早期的搜索技术或用于解决比较简单问题的搜索原理和一些比较新的能够求解比较复杂问题的搜索原理,如遗传算法和模拟退火算法等。 1、盲目搜索 盲目搜索又叫做无信息搜索,一般只适用于求解比较简单的问题。包括图搜索策略,宽度优先搜索和深度优先搜素。 1、图搜索(GRAPH SERCH)策略是一种在图中寻找路径的方法。在有关图的表示方法中,节点对应于状态,而连线对应于操作符。 2、如果搜素是以接近其实节点的程度依次扩展节点的,那么这种搜素就叫做宽度优先搜素( breadth-first search。 3、深度优先搜索属于图算法的一种,英文缩写为DFS即Depth First Search其过程 简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。 二、启发式搜索 盲目搜索的不足之处是效率低,耗费过多的时间和空间。启发信息是进行搜索技术所需要的一些有关具体问题的特性的信息。利用启发信息的搜索方法叫做启发式搜索方法。 启发式搜索就是在状态空间中的搜索对每一个搜索的位置进行评估,得到最好的位置,再从这个位置进行搜索直到目标。这样可以省略大量无谓的搜索路径,提高了效率。在启发式搜索中,对位置的估价是十分重要的。采用了不同的估价可以有不同的效果。 3、博弈树搜索 诸如下棋、打牌、竞技、战争等一类竞争性智能活动称为博弈。博弈有很多种,我们讨论最简单的"二人零和、全信息、非偶然" 博弈,其特征如下: (1对垒的MAX MIN双方轮流采取行动,博弈的结果只有三种情况:MA)方胜,MIN方败;MIN方胜,MAX方败;和局。 (2 在对垒过程中,任何一方都了解当前的格局及过去的历史。 (3 任何一方在采取行动前都要根据当前的实际情况,进行得失分析,选取对自 已为最有利而对对方最为不利的对策,不存在掷骰子之类的"碰运气"因素即双方都是很理智地决定自己的行动。 在博弈过程中,任何一方都希望自己取得胜利。因此,当某一方当前有多个行 实验二 A*算法实验 一、实验目的: 熟悉和掌握启发式搜索的定义、估价函数和算法过程,并利用A*算法求解N数码难题,理解求解流程和搜索顺序。 二、实验原理: A*算法是一种有序搜索算法,其特点在于对估价函数的定义上。对于一般的有序搜索,总是选择f值最小的节点作为扩展节点。因此,f是根据需要找到一条最小代价路径的观点来估算节点的,所以,可考虑每个节点n的估价函数值为两个分量:从起始节点到节点n的代价以及从节点n到达目标节点的代价。 三、实验内容: 1分别以8数码和15数码为例实际求解A*算法。 2画出A*算法求解框图。 3分析估价函数对搜索算法的影响。 4分析A*算法的特点。 四、实验步骤: 1开始演示。进入N数码难题演示程序,可选8数码或者15数码,点击“选择数码”按钮确定。第一次启动后,点击两次“缺省”或者“随机”按钮,才会出现图片。 2点击“缺省棋局”,会产生一个固定的初始节点。点击“随机生成”,会产生任意排列的初始节点。 3算法执行。点击“连续执行”则程序自动搜索求解,并演示每一步结果;点击“单步运行”则每次执行一步求解流程。“运行速度”可自由调节。 4观察运行过程和搜索顺序,理解启发式搜索的原理。在下拉框中选择演示“15数码难题”,点击“选择数码”确定选择;运行15数码难题演示实例。 5算法流程的任一时刻的相关状态,以算法流程高亮、open表、close表、节点静态图、当前扩展节点移动图等5种形式在按钮上方同步显示,便于深入学习理解A*算法。 6根据程序运行过程画出A*算法框图。 五、实验报告要求: 1A*算法流程图和算法框图。 2试分析估价函数的值对搜索算法速度的影响。 3根据A*算法分析启发式搜索的特点。 5-1 简述机器学习十大算法的每个算法的核心思想、工作原理、适用 情况及优缺点等。 1)C4.5 算法: ID3 算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。ID3 算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。C4.5 算法核心思想是ID3 算法,是ID3 算法的改进,改进方面有: 1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足; 2)在树构造过程中进行剪枝 3)能处理非离散的数据 4)能处理不完整的数据 C4.5 算法优点:产生的分类规则易于理解,准确率较高。 缺点: 1)在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。 2)C4.5 只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。 2)K means 算法: 是一个简单的聚类算法,把n 的对象根据他们的属性分为k 个分割,k < n。算法的核心就是要优化失真函数J,使其收敛到局部最小值但不是全局最小值。 其中N 为样本数,K 是簇数,rnk b 表示n 属于第k 个簇,uk 是第k 个中心点的值。 然后求出最优的uk 优点:算法速度很快 缺点是,分组的数目k 是一个输入参数,不合适的k 可能返回较差的结果。 3)朴素贝叶斯算法: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。算法的基础是概率问题,分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。朴素贝叶斯假设是约束 性很强的假设,假设特征条件独立, 但朴素贝叶斯算法简单,快速,具有较小的出错率。在朴素贝叶斯的应用中,主要研究了电子邮件过滤以及文本分类研究。 4)K 最近邻分类算法(KNN) 分类思想比较简单,从训练样本中找出K个与其最相近的样本,然后看这k个样本中哪个类别的样本多,则待判定的值(或说抽样)就属于这个类别。缺点: 1)K 值需要预先设定,而不能自适应 2)当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K 个邻居中大容量类的样本占多数。 该算法适用于对样本容量比较大的类域进行自动分类。 5)EM 最大期望算法 EM 算法是基于模型的聚类方法,是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。E步估计隐含变量,M步估计其他参数,交替将极值推向最大。EM 算法比K-means 算法计算复杂,收敛也较慢,不适于大规模数据集和高维数据,但比K-means 算法计算结果稳定、准确。EM 经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。 6)PageRank 算法 人工智能大作业题目 1、基于A*算法求解八数码问题 (1)至少定义3种不同的启发式函数,编程实现求解八数码问题的A*算法; (2)要求用可视化界面演示算法执行过程,应能选择预定义的启发式函数,能随机初始化初始状态,能单步执行,也能连续执行,能画出搜索树,同时标出估价函数在每个节点的各项函数值,能展示OPEN表和CLOSED表的动态变化过程; (3)能统计出扩展节点数和算法执行时间,以便对采用不同启发式函数的A*算法的性能做对比研究。 2、基于A*算法的最优路径规划系统 (1)基于真实地图实现,可以是位图背景加栅格坐标数据,也可以直接使用某种格式的GIS (地理信息系统)矢量地图,地图规模不能太小; (2)用户可以设置起点和终点; (3)要求用可视化界面演示算法执行过程,能单步执行,也能连续执行,画出扩展过的所有路径,画出最优路径,能展示OPEN表和CLOSED表的动态变化过程; (4)可考虑路况信息,改进启发式函数,以求更实用。 3、A*算法的改进研究 (1)给出改进思路并编程实现改进的算法; (2)结合一个具体问题实验对比改进前后的算法性能。 4、图搜索算法对比研究 (1)编程实现广度优先、等待价、深度优先、深度受限、迭代加深、最佳优先搜索算法;(2)要求用可视化界面演示算法执行过程,能单步执行,也能连续执行,能画出搜索树,能展示OPEN表和CLOSED表的动态变化过程; (3)用户可以自定义搜索图,通过实验研究各种图搜索算法的性能。 5、基于α-β剪枝算法的五子棋游戏 (1)编写五子棋游戏程序,支持人机对战; (2)编程实现α-β剪枝算法,作为机器方的下棋算法。 6、五子棋机器博弈系统 (1)编程实现一个五子棋主控程序,要求有可视化棋盘,有裁判功能,支持通过Socket接口连接选手,有清晰简洁的通信协议,支持循环赛赛程管理; (2)每个同学编写一个五子棋下棋算法,通过Socket接口接入主控程序,与其他机器选手对战。 7、基于回溯搜索的地图着色方法 (1)对中国地图中的省级行政区进行着色,最多使用四种颜色; (2)编程实现回溯算法用于地图自动着色; (3)研究回溯的改进算法,并编程实现。 人工智能原理与方法 A*算法实现八数码搜索问题 模式识别与智能系统 SY1003113 游遵文 题目:编程实现8数码问题 初始状态: 3 8 2 1 5 7 6 4 目标状态: 1 2 3 8 4 7 6 5 要求:1、报告:给出状态表示,编码规则,搜索算法A*,简单程序说明,最优路径。 2、调通的程序(语言不限) 一、状态表示 用一个3×3的数组来表示状态,数组中的各个元素对应状态位置的数字。 其中空格用0表示。 二、编码规则 在程序实现过程中,只有移动0的位置,即可生成新的节点。 规则库 设数组中0的位置为a[i][j],其中0≤i≤2,0≤j≤2。 R1:if(i≥1) then 上移 R1:if(i≤1) then 下移 R1:if(j≥1) then 左移 R1:if(j≤1) then 右移 三、搜索算法A* 用于度量节点的“希望”的量度f(n),即用来衡量到达目标节点的路径的可能性大小。 A算法: 基本思想:定义一个评价函数,对当前的搜索状态进行评估,找出一个最有希望的节点进行扩展:f(n) = g(n) + h(n),n为被评价节点 g*(n):从s到n的最优路径的实际代价 h*(n):从n到g的最优路径的实际代价 f*(n)=g*(n)+h*(n):从s经过n到g的最优路径的实际代价 g(n)、h(n)、f(n)分别是g*(n)、h*(n)、f*(n)的估计值 g (n)通常为从S到到n这段路径的实际代价,则有g (n) ≥g*(n) h (n):是从节点n到目标节点Sg的最优路径的估计代价. 它的选择依赖于有关问题领域的启发信息,叫做启发函数 A算法:在图搜索的一般算法中,在搜索的每一步都利用估价函数f(n)=g(n)+h(n)对Open表中的节点进行排序表中的节点进行排序, 找出一个最有希望的节点作为下一次扩展的节点。 在A算法中,如果满足条件:h(n)≤h*(n),则A算法称为A*算法。 在本算法中,为实现八数码的搜索问题,定义估价函数为:f(n)=g(n)+h(n),其中g(n)表示节点n在搜索树中的深度; h(n)表示节点n的各个数码到目标位置的曼哈顿距离和。 四、程序说明 1、算法实现的步骤: (1)把初始节点S0放入Open表中,置S0的代价g(S0)=0; (2)如果Open表为空,则问题无解,失败退出; (3)把Open表的第一个节点取出放入Closed表,并记该节点为n (4)考察节点n是否为目标节点。若是,则找到了问题的解,成功退出;(5)若节点n不可扩展,则转第(2)步; (6)扩展节点n,生成其子节点ni, (其中i=1,2,3,……),将这些子节点放入Open表中,并为每一个子节点设置指向父节点的指针;按公式g(ni)=g(n)+c(n,ni)(i=1,2,…)计算Open表中的各子节点的代价,并根据各节点的代价对Open表中的全部节点按照从小到大顺序重新进行排序;然后转第(2)步。 2、思路 通过代价函数对Open表中的节点进行排序,代价小的先扩展。 2019年人工智能公需科考试多项选择题答案 二、多选择题 1.()是指能够自己找出问题、思考问题、解决问题的人工智能。( 2.0分) A.超人工智能 B.强人工智能 C.弱人工智能 D.人工智能 2.根据国际评判健康的标准,()的韩国中年人心血管呈理想状态。(2.0分) A.0.1% B.0.2% C.0.4% D.0.67% 3.中国人工智能产业初步呈现集聚态势,人工智能企业主要集聚在经济发达的一二线城市及沿海地区,排名第一的城市是()。(2.0分) A.上海 B.北京 C.深圳 D.杭州 4.癌症的治疗分为手术、放疗、化疗。据WTO统计,有()的肿瘤患者需要接受放疗。(2.0分) A.18% B.22% C.45% D.70% 5.()是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程。(2.0分) A.文本识别 B.机器翻译 C.文本分类 D.问答系统 6.我们应该正确认识统计学中概率与个体之间的关系,概率是()比较,从小到老的数据才是每个人的。(2.0分) A.横向 B.纵向 C.交叉 7.()是人工智能的核心,是使计算机具有智能的主要方法,其应用遍及人工智能的各个领域。(2.0分) A.深度学习 B.机器学习 C.人机交互 D.智能芯片 9.()是一种基于树结构进行决策的算法。(2.0分) A.轨迹跟踪 B.决策树 C.数据挖掘 D.K近邻算法 10.癌症的治疗分为手术、放疗、化疗。据WTO统计,在45%的肿瘤治愈率中,比重最高的治疗方式是()。(2.0分) A.手术 B.放疗 C.化疗 11.()是人以自然语言同计算机进行交互的综合性技术,结合了语言学、心理学、工程、计算机技术等领域的知识。(2.0分) A.语音交互 B.情感交互 C.体感交互 D.脑机交互 12.在国际评判健康的标准中,血压值低于()才是健康的。(2.0分) A.110/70mmHg B.120/80mmHg C.140/90mmHg D.160/100mmHg 13.古代把计量叫“度量衡”,其中,“量”是测量()的过程。(2.0分) A.长度 B.容积 C.温度 D.轻重 人工智能算法简介 如果你想学习人工智能算法,那么你的准备知识应该包括一些编程知识,线性代数和对概率的理解.然而今天我们的主题不在这里,我们要给大家简要介绍人工智能的能做什么事情.人工智能的范围非常广泛,从人工智能的历史,搜索算法的建立,设计游戏,解决游戏难题,到限制条件问题都值得学习.机器学习算法是人工智能里的核心.人工智能可广泛应用在自然语言处理,机器人学,机器视觉,语音分析,量化交易等等领域. 用Python 语言编程来解决人工智能问题是一个值得学习的技术.下面分别介绍一下各种常见算法. 最基本的算法就是搜索.有许多中搜索方法可以使用比如盲目搜索(uninformed search) ,提示性搜索(又叫启发性搜索), 对抗搜索(游戏)等.第二类话题就是马科夫决策过程和强化学习. 它们有一系列的应用,如自然语言处理,机器人,机器视觉等.现在我们一一讨论人工智能里的各个话题. 先来看理性智能代理机.我们研究人工智能的目的是设计智能的代理,它们可以感知其环境并且作用到环境上,从而实现其目标或者任务.一个代理可以视为一个函数F(x), 该函数从感知到的环境映射到一个作用在环境上的动作. 理性代理机,就是做正确的事情的代理.何为正确的事呢?就是代理机的表现达到最优,即所谓性能度量(performance measure)最大化.人工智能(AI)在给定的计算条件下,使得性能度量达到最大化.这就是AI 的目的.要使得性能度量最大,可以从硬件和软件两方面优化改进,我们这里只讨论软件方面. 搜索代理 search agents可以帮助我们从已知点出发找到目标点.典型的例子是走迷宫,从某个给定起点和终点,找出一条路线使得我们能从起点到达终点.代理会思考为了达到目的该如何做. 代理要做的就是定义出到达目标点的动作或动作序列(路径).一条路径会有不同的代价和深度(此处指的是通过该路径找到的解在搜索树中的深度).最常见搜索方法可分为有两大类. 盲目搜索并不用某领域的知识,它包括的技术有广度优先搜索,深度优先搜索,均匀代价搜索等.启发式搜索运用了一些如何更快地到达目标的经验法则或启发式信息,这类搜索法包括贪婪搜索法, A*搜索法, 等等.搜索算法的例子包括八皇后问题.八皇后问题是指,我们在64个格子的国际象棋棋盘上适当地放置8个皇后,使得它们横向,纵向,对角向都不"共线". 这就是要从约百万亿种可能的状态中,搜索出满足以上约束条件的状态来.另一个典型的搜索算法的例子就是路线搜索.给定包含一些城市的地图,地图可以用图结构来表示:城市用结点表示,城市之间的可能的路线用线表 实验一 A*算法实现八数码搜索问题 题目:编程实现8数码问题 初始状态: 3 8 2 1 5 7 6 4 目标状态: 1 2 3 8 4 7 6 5 要求:1、报告:给出状态表示,编码规则,搜索算法A*,简单程序说明,最优路径。 2、调通的程序(语言不限) 一、状态表示 用一个3×3的数组来表示状态,数组中的各个元素对应状态位置的数字。其中空格用0表示。 二、编码规则 在程序实现过程中,只有移动0的位置,即可生成新的节点。 规则库 设数组中0的位置为a[i][j],其中0≤i≤2,0≤j≤2。 R1:if(i≥1) then 上移 R1:if(i≤1) then 下移 R1:if(j≥1) then 左移 R1:if(j≤1) then 右移 三、搜索算法A* 用于度量节点的“希望”的量度f(n),即用来衡量到达目标节点的路径的可能性大小。 A算法: 基本思想:定义一个评价函数,对当前的搜索状态进行评估,找出一个最有希望的节点进行扩展:f(n) = g(n) + h(n),n为被评价节点 g*(n):从s到n的最优路径的实际代价 h*(n):从n到g的最优路径的实际代价 f*(n)=g*(n)+h*(n):从s经过n到g的最优路径的实际代价 g(n)、h(n)、f(n)分别是g*(n)、h*(n)、f*(n)的估计值 g (n)通常为从S到到n这段路径的实际代价,则有g (n) ≥ g*(n) h (n):是从节点n到目标节点Sg的最优路径的估计代价. 它的选择依赖于有关问题领域的启发信息,叫做启发函数 A算法:在图搜索的一般算法中,在搜索的每一步都利用估价函数f(n)=g(n)+h(n)对Open表中的节点进行排序表中的节点进行排序, 找出一个最有希望的节点作为下一次扩展的节点。 在A算法中,如果满足条件:h(n)≤h*(n),则A算法称为A*算法。 在本算法中,为实现八数码的搜索问题,定义估价函数为:f(n)=g(n)+h(n), 其中g(n)表示节点n在搜索树中的深度; h(n)表示节点n的各个数码到目标位置的曼哈顿距离和。 四、程序说明 1、算法实现的步骤: (1)把初始节点S0放入Open表中,置S0的代价g(S0)=0; (2)如果Open表为空,则问题无解,失败退出; (3)把 Open表的第一个节点取出放入 Closed表,并记该节点为n (4)考察节点n是否为目标节点。若是,则找到了问题的解,成功退出; (5)若节点n不可扩展,则转第(2)步; (6)扩展节点 n,生成其子节点 ni, (其中i=1,2,3,……),将这些子节点放入 Open表中,并为每一个子节点设置指向父节点的指针;按公式 g(ni)=g(n)+c(n,ni)(i=1,2,…)计算Open表中的各子节点的代价,并根据各节点的代价对Open表中的全部节点按照从小到大顺序重新进行排序;然后转第(2)步。 2、思路 通过代价函数对Open表中的节点进行排序,代价小的先扩展。 A*算法代码的核心部分 pnode move(pnode p,int dir) { pnode Unode=(pnode)malloc(sizeof(node)); for(int i=0;i<=2;i++) { for(int j=0;j<=2;j++) { 人工智能(A*算法) 05级计算机二班姓名: 学号:054 一、A*算法概述 A*算法是到目前为止最快的一种计算最短路径的算法,但它一种‘较优’算法,即它一般只能找到较优解,而非最优解,但由于其高效性,使其在实时系统、人工智能等方面应用极其广泛。 A*算法结合了启发式方法(这种方法通过充分利用图给出的信息来动态地作出决定而使搜索次数大大降低)和形式化方法(这种方法不利用图给出的信息,而仅通过数学的形式分析,如Dijkstra算法)。它通过一个估价函数(Heuristic Function)f(h)来估计图中的当前点p到终点的距离(带权值),并由此决定它的搜索方向,当这条路径失败时,它会尝试其它路径。 因而我们可以发现,A*算法成功与否的关键在于估价函数的正确选择,从理论上说,一个完全正确的估价函数是可以非常迅速地得到问题的正确解答,但一般完全正确的估价函数是得不到的,因而A*算法不能保证它每次都得到正确解答。一个不理想的估价函数可能会使它工作得很慢,甚至会给出错误的解答。 为了提高解答的正确性,我们可以适当地降低估价函数的值,从而使之进行更多的搜索,但这是以降低它的速度为代价的,因而我们可以根据实际对解答的速度和正确性的要求而设计出不同的方案,使之更具弹性。 二、A*算法分析 众所周知,对图的表示可以采用数组或链表,而且这些表示法也各也优缺点,数组可以方便地实现对其中某个元素的存取,但插入和删除操作却很困难,而链表则利于插入和删除,但对某个特定元素的定位却需借助于搜索。而A*算法则需要快速插入和删除所求得的最优值以及可以对当前结点以下结点的操作,因而数组或链表都显得太通用了,用来实现A*算法会使速度有所降低。要实现这些,可以通过二分树、跳转表等数据结构来实现,我采用的是简单而高效的带优先权的堆栈,经实验表明,一个1000个结点的图,插入而且移动一个排序的链表平均需500次比较和2次移动;未排序的链表平均需1000次比较和2次移动;而堆仅需10次比较和10次移动。需要指出的是,当结点数n大于10,000时,堆将不再是正确的选择,但这足已满足我们一般的要求。 求出2D的迷宫中起始点S到目标点E的最短路径? 算法: findpath() { 把S点加入树根(各点所在的树的高度表示从S点到该点所走过的步数); 把S点加入排序队列(按该点到E点的距离排序+走过的步数从 XXXX2017至2018 学年第 1 学期 《人工智能技术》 课程考试( A )卷 计科 系 级 专业 学号 姓名 一、选择题:(2分×10=20分 ) 1. 人工智能AI 的英文全称( )最早于1956年在达特茅斯会议上被提出。这是历史 上第一次人工智能研讨会,也被广泛认为是人工智能诞生的标志。 A .Automatic Intelligence B .Artifical Intelligence C .Automatice Information D .Artifical Information 2. 所谓不确定性推理是从( )的初始证据出发,通过运用( )的知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程。 A .不确定性,确定性 B .确定性,确定性 C .确定性,不确定性 D .不确定性,不确定性 3. 要想让机器具有智能,必须让机器具有知识。因此,在人工智能中有一个研究领域,主要研究计算机如何自动获取知识和技能,实现自我完善,这门研究分支学科叫( )。 A .概率推理 B .神经网络 C .机器学习 D .智能搜索 装 订 线 4. 下面几种搜索算法中,不完备的搜索算法是( )。 A .广度优先搜索 B .A*搜索 C .迭代深入深度优先搜索 D .贪婪搜索 5. 人工智能的目的是让机器能够( ),以实现某些脑力劳动的机械化。 A .模拟、延伸和扩展人的智能 B .和人一样工作 C .完全代替人的大脑 D .具有智能 6.在一个监督学习问题f:x →y 中,输出y 的值域是连续的,例如实数集R ,那么这是一个( )问题。 A .分类 B .聚类 C .回归 D .降维 7. 牙医问题中关于3 P (cavity ∨toothache )=( )。 A .0.12 B .0.28 C .0.72 D .0.36A-算法人工智能课程设计
人工智能基础算法
2019年人工智能考试题答案
人工智能算法实现
人工智能期末试题及答案完整版(最新)
人工智能A星算法解决八数码难题程序代码
人工智能算法综述
人工智能实验 实验三 A算法实验
人工智能十大算法总结
人工智能大作业题目
人工智能A算法九宫格报告
2019年人工智能考试多项选择题答案
人工智能算法简介
人工智能A算法九宫格报告
A算法人工智能课程设计
人工智能期末试卷
相关主题
文本预览