
第3章居民消费预测模型建立
3.1变量的选择
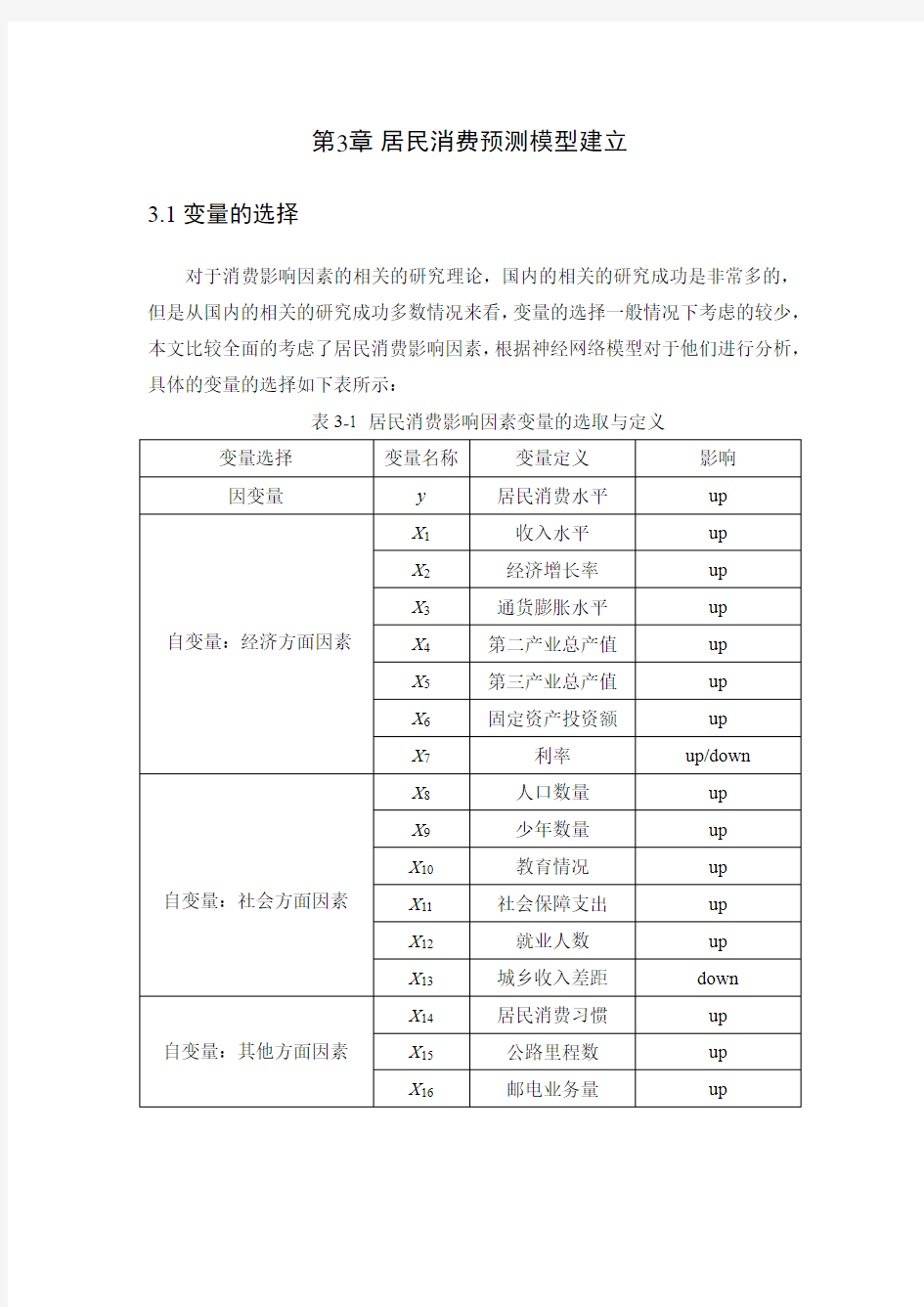
对于消费影响因素的相关的研究理论,国内的相关的研究成功是非常多的,但是从国内的相关的研究成功多数情况来看,变量的选择一般情况下考虑的较少,本文比较全面的考虑了居民消费影响因素,根据神经网络模型对于他们进行分析,具体的变量的选择如下表所示:
表3-1 居民消费影响因素变量的选取与定义
从表3-1居民消费影响因素变量的选取与定义中可以看出来,本文共选取了16个变量,考虑因素非常全面,因变量y:居民消费水平,也就是本文待研究的性能指标。
居民消费影响因素自变量:经济因素方面,本文一个选取7个,分别是X1-X7,从前面分析可以看出来迄今为止,第一产业只占有中国总体GDP的1%-3%左右,因此本文不作考虑。
居民消费影响因素自变量:社会因素方面,本文一个选取6个,分别是X8-X13,这里需要解释的是就只有一个也就是X13:城乡收入差距,X13值的确定以基尼系数来进行确定的,具体的方法可参考李权葆(2013)的阐述与其观点的研究。
居民消费影响因素自变量:其他因素方面,本文一个选取3个,分别是X14-X17。
3.2数据来源
本文选择以中国年鉴1978-2018年作为时间跨度。
上述指标的选取主要来源有《各年度中国人类发展报告》(各年份),《中国统计年鉴》(各年份),《中国知网》,《中国环境统计年鉴》(各年份),《中国教育统计年鉴》(各年份)等数据来源。
中国居民人均GDP= 中国居民总产出(GDP总额)/中国居民总人口;
中国居民平均受教育年限=(6*T小学+9*T初中+12*T高中+16*T大专以上)/(T小学+T初中+T高中+T大专以上)。
其中,T为中国居民各学历教育人口的具体数目,中国居民各学历教育人口具体的人数数据来源于《中国教育统计年鉴》。
3.3模型的建立
从表3-1居民消费影响因素变量的选取与定义以及,影响消费支出因素的分析,这里就可以进一步的建立中国居民消费支出的具体的一个数学模型:线性模型,同时,本文为了进一步的消除量纲对于计算单位的影响,需要进行归一化处理处理,本文选择的处理方式是:对于变量进行对数处理。
本文具体的需要对数处理的数据选择有:
Y :居民消费水平,具体可以表示为:lny ; X 1:收入水平,具体可以表示为:lnx1; X 3:通货膨胀水平,具体可以表示为:lnx3; X 4:第二产业总产值,具体可以表示为:lnx4; X 5:第三产业总产值,具体可以表示为:lnx5; X 6:固定资产投资额,具体可以表示为:lnx6; X 8:人口数量,具体可以表示为:lnx8; X 10:教育情况,具体可以表示为:lnx10; X 11:社会保障支出,具体可以表示为:lnx11; X 12:就业人数,具体可以表示为:lnx12; X 14:居民消费习惯,具体可以表示为:lnx14; X 15:公路里程数,具体可以表示为:lnx15; X 16:邮电业务量,具体可以表示为:lnx16;
根据以上的描述,可以建立出中国居民消费支出的具体的一个数学模型,具体表示为:
0112233441616ln ln ln ln ...ln y x x x x x ββββββε=++++++++ (3-1)
其中,0β表示居民消费支出的一个常量,1β,...,16β分别表示上述自变量:X 1,...,X 16的变量系数,ε表示的是中国居民消费支出的一个随机干扰变量。
3.4数据处理
原理:
中心化(又叫零均值化):是指变量减去它的均值。其实就是一个平移的过程,平移后所有数据的中心是(0,0)。
标准化(又叫归一化): 是指数值减去均值,再除以标准差(可以把有量纲量变为无量纲量)。
数据中心化的公式如下所示:
10n
ij
i x
==∑, (3-2)
10n
i
i y
==∑, (3-3)
21
1n
ij
i x
==∑, (3-4)
数据标准化公式如下所示:
min
max min
x x -=
- (3-5)
其中,min 表示的数据x 的最小值,max 表示的数据x 的最大值。
3.5 本章小结
本章节对于基于RBF 神经网络模型的居民消费水平走势研究的居民消费水平实际模型进行了建模研究,为后文于基于RBF 神经网络模型的研究做了必要的铺垫。
计量经济学作业 题目: 中国居民总量消费函数的实例分析 院系:数学系 专业:信息与计算科学 组成员:赵山云、陈兴耀、贾梦、冉静飞、母军 学号: 成绩: 2012年5月8日
中国居民总量消费函数的实例分析 摘要 本例旨在针对我国1978-2009年的时间序列数据,从总体上考察中国居民收入与消费的关系。首先,我们综合了几种关于收入和消费的主要理论观点,进而建立了理论模型。然后,收集了相关的信息,利用EVIEWS软件对计量模型进行了参数估计和检验,并预测。最后对我们所得的结果进行了分析,并相应提出一些政策建议。 关键词:一元回归分析,最小二乘法。EVIEWS软件,模型检验,数据收集,预测。 1、问题重述 为了从总体上考察中国居民收入的关系,附录1中给出了中国名义支出法国内生产总值GDP,名义居民总消费CONS以及表示CPI(1978=100),并由这些数据整理出实际支出法国内生产总值GPPC=GDP/CPI,居民实际消费总支出Y=CONS/CPI,以及实际可支配收入X=(GDP-TAX)/CPI等时间序列数据。建立中国居民总量消费函数模型。 2、问题分析 对于时间序列数据,也可建立类似于截面数据的计量经济模型,并进行回归分析。运用最小二乘法建立一元回归模型;用拟合优度进行模型检验;运用点预测法则,置信区间预测法则进行预测。 3、模型假设 (1)、模型选择了正确的变量; (2)、模型选择了正确的函数形式; (3)、解释变量X在所抽取的样本中具有变异性,而且随着相关容量的增加,解释变量的样本方差趋于一个非零的有限常数; (4)、解释变量X是确定性变量不是随机变量在重复抽样中取固定值。 4、符号说明 X:实际可支配收入(单位:亿元) Y:实际消费总支出(单位:亿元)
第4卷第1期2004年2月 交通运输系统工程与信息 Jo ur nal of T r anspo rt atio n Sy stems Eng ineer ing and Infor matio n T echno lo gy Vo l.4No.1Febr uar y 2004 文章编号:1009-6744(2004)01-0071-05 LOGIT 模型参数估计方法研究 金 安 (广州市规划局交通研究所,广州510030) 摘要: 离散选择模型,特别是L OG IT 模型在交通需求模型建立过程中,应用非常广泛,许多实际的交通政策问题都涉及到方式选择,然而L OG IT 模型的建立非常困难,尤其是效用函数及参数估计.本文重点就L O GIT 模型参数估计的有关问题进行讨论,特别是运用统计方法如何对效用函数的变量进行选取及比较不同形式效用函数. 关键词: L O GI T 模型;参数估计;t 检验;似然率检验中图分类号: N 945.12 On Methodology of Parameter Estimation in L OGIT Model JIN An (Instit ute o f T r aspo r tatio n,G uang zho u P la nning Bur eau,Guang zho u 510030,China ) Abstract : Disagg reg ate choice mo del ,especially L O GIT m odel ,hav e been used w idely in dev elo pment of tr avel demand mo del ,many pr actical tr anspor tation policy issues ar e concerned w ith mode choice.But pro cedure o f development of L OG IT mo del is difficult,especially mo del calibr atio n and for m of utility functio n.T his paper discuss r elat ional pr oblems o n development of L OG IT model,P articular emphasis is placed o n pr actical pr ocedur es for selection the co rr ect ex planato ry var iables and on compar ing differ ent ver sions of utility functio n using st atistical metho ds.Keywords : L OG IT mo del;par ameter est imation;t -test;likeliho od test CLC number : N 945.12 收稿日期:2003-11-24 金安:广州市规划局交通研究所工程师,工学硕士.研究方向为交通规划及交通需求模型. 1 引 言 实践过程中,LOGIT 模型效用函数不可能预先知道,模型师在建立LOGIT 模型最初阶段几乎没有效用函数任何信息,最多认为在效用函数中会有哪些可能的变量,但也不能确定所有的变量是否都需要,更不可能知道哪些变量需要进行函数变换或效用函数参数的具体数值是多少.这些问题只有通过拟合合适的观测数据,并检验这些模型来确定哪一个最能够描述观测数据.本文主要介绍拟合和测试LOGIT 模型方法. 2 数据的要求 估计和检验过程的第一步是选择合适的观测数据,用于建立LOGIT 方式选择模型所需的数据有: (1)对个体实际方式选择行为的观测.例如, 要建立工作出行方式选择模型,需要对上班出行者方式选择进行观测的数据. (2)所有被选择和没有被选择方式的相关属性值.这些属性可能作为模型中的变量.例如,假设总出行时间被认为是模型中的一个变量,则对于样本中每一个个体而言,所需数据包括每一种可能方式的总出行时间.如果属性数据仅包含被选择方式,LOGIT 模型就不能建立. (3)任何可能作为变量的个体属性值.例如,汽车拥有水平,则需要样本中每个个体家庭汽车拥有水平数. 3 模型的设定 所需数据收集后,下一步工作是设定一种或多种效用函数形式.设定步骤包括确定效用函数中变量、属性的函数变换以及效用函数的形式.这个步
预测模型 最近几年,在全国大学生数学建模竞赛常常出现预测模型或是与预测有关的题目,例如疾病的传播,雨量的预报等。什么是预测模型?如何预测?有那些方法?对此下面作些介绍。 预测作为一种探索未来的活动早在古代已经出现,但作为一门科学的预测学,是在科学技术高度发达的当今才产生的。“预测”是来自古希腊的术语。我国也有两句古语:“凡事预则立,不预则废” ,“人无远虑,必有近忧” 。卜卦、算命都是一种预测。中国古代著名著作“易经”就是一种专门研究预测的书,现在研究易经的人也不少。古代的预测主要靠预言家,即先知们的直观判断,或是借助于某些先兆,缺乏科学根据。预测技术的发展源于社会的需求和实践。20 世纪初期风行一时的巴布生图表就是早期的市场预测资料,哈佛大学的每月指数图表为商品市场、证券市场和货币市场预测提供了依据。然而这些预测都未能揭示1929-1930 年经济危期的突然暴发,使工商界深感失望。尔后,经济学家们从挫折中吸取了教训,采用趋势和循环技术对商业进行分析和预测,科学预测也因此开始萌生。20 世纪30 年代凯思斯提出政府干预和市场机制相结合的经济模型,1937 年诺依曼又提出了扩展经济模型,对近代经济模型产生重要的影响,科学的经济和商业预测也就步入发展阶段。 技术预测开始于二次世界大战后的20 世纪40 年代,直到20 世纪50 年代未才广泛应用于工农业和军事部门。由于社会、科学技术和经济的大量需求, 预测技求才成为一门真正的科学,预测未来是当 代科学的重要任务 20 世纪以来,预测技术所以得以长足进步,一方面,与社会需求有很大关
系,另一方面通过社会实践和长期历史验证,表明事物的发展是可以预测的。而且借助可靠的数据和科学的方法,以及预测技术人员的努力,预测结果的可靠性和准确性可以达到很高的程度,这也是预测技术迅速发展的另一个重要原因。 科学技术、经济和社会预测的应验率也是很高的。维聂尔曾预言20 世纪是电子时代,法国思想家迈希尔18 世纪末到19 世纪初对巴黎未来几百年的发展进行了预测。从1950 年的实际情况分析,他的预测中有36%得到证实,28%接近实现,只有36%是错误的。法国哲学家和数学家冠道塞在法国大革命时期曾采用外推法进行了一系列社会预测,其中75%得到证实。沙杰尔莱特1901 年在《二十世纪的发明》一书中的一些预测,其中64%得到证实。凯木弗尔特在1910 年和1915年公布的25项预测中,到1941年只有3 项未被证实,3 项是错误的。我国明朝开国功臣刘基就预测将来是天上铁鸟飞,地上铁马跑,那时还没有火车、飞机。 预测的目的在于认识自然和社会发展规律,以及在不同历史条件下各种规律的相互作用,揭示事物发展的方向和趋势,分析事物发展的途径和条件,使人们尽早地预知未来的状况和将要发生的事情,并能动地控制其发展,使其为人类和社会进步服务。因而预测是决策的重要的前期工作。决策是指导未来的,未来既是决策的依据,又是决策的对象,研究未来和预测未来是实现决策科学化的重要前提。预测和决策是过程的两个方面,预测为决策提供依据,而预测的目的是为决策服务,所以不能把预测模型和决策模型截然分开,有时也把预测模型称为决策模型。
三维预测模型的建立 三维预测相对于传统的矿产预测最大的进步是二维平面预测扩展到了三维空间,使研究区形态更生动形象。在创建三维预测模型之前,必须先建立三维矿床模型( 即数字矿床) ,再根据成矿有利信息分析将有利预测变量提取出来,最终形成三维预测模型。 2. 1 数字矿床的建立 数字矿床为矿床的信息模型,即一个以地理坐标为依据的、数字化的、三维显示的虚拟矿床,其核心思想是用数字化的手段整体地解决矿床及其与空间位置相关的信息的表达与知识管理。数字矿床的建立是三维定位和定量研究的重要基础。本次研究应用目前主流地质三维建模分析软件micromine,对个旧松树脚研究区地层、岩体、已知矿体、化探异常等进行三维实体建模,从而实现数字矿床的建立。数字矿床有地质体模型和工程模型。地质体模型包括地表、岩体、地层、构造、已知矿体实体模型。将收集到的等高线文件插值加密并导入micromine软件中,生成研究区地表模型,并与范围实体模型相叠加生成地表实体模型; 将收集到的岩体等深线图以同样方法生成岩体实体模型。地层实体模型与构造实体模型都是通过对勘探线剖面图进行处理,即以中段平面图为基准面,将剖面线以实际坐标投到中段平面上,再根据相应地层界线或断裂界线进行线框连接成体,得到地层实体模型及构造实体模型。同样,矿体模型是根据各剖面图上矿体面进行线框连接,本次研究区内都为层间氧化矿,因此采用平推渐灭方法生成矿体实体模型。工程模型包括钻孔模型与巷道模型。钻孔数据是钻探工程所取得的地下地质体样品的数据,是进行勘探线剖面解译各种地质现象推理和资源储量估算的重要依据。本次研究将收集到的钻孔资料按照孔口坐标表、测斜数据表、岩性分析表、样品分析表的格式进行整理后,导入micromine软件中形成钻孔数据库。通过Surpac 中数据库功能将钻孔显示出来,形成钻孔模型。
计量分析软件课程论文 论文题目:基于多元线性回归模型的影响居民消费 水平相关因素分析 姓名:学号: 学院:专业: 联系电话: 年月日 基于多元线性回归模型的影响居民消费 水平相关因素分析 一、研究背景 中国GDP总量超越日本,成为仅次于美国的第二大经济体,但我国人均GDP 依然很低,全球排名87位,这很大程度上制约了居民消费水平的提高。到2020年实现全面建成小康社会的目标,十八大明确提出提高居民人均收入和人均消费水平,共享改革开放成果。我国居民消费水平在改革开放后有了很大提高,但消费水平依然很低,消费量占GDP比重依然很小。为此,本文旨在根据全国经济宏观政策、国内生产总值、职工平均工资指数、城镇居民消费价格指数、普通中学及高等学校在校生数、卫生机构数和基本设施铁路公路货运量等因素的变化情况,来分析如何提高居民消费水平,以判断是否能使居民消费水平有很大的提高。本文通过对1978-2010年影响居民消费水平因素数据的分析,找到影响居民消费水平的主要原因,通过计量经济分析方法来建立合理的模型,探讨影响居民消费增长的长期趋势规律,并给政府提出合理的建议,以提高居民消费水平。 二、影响居民消费水平的因素 宏观经济模型) + GDP- + + =,经济发展应该紧紧抓住消费这一 I (M C X G 驾马车,而居民消费水平的高低受制于多种因素。凯恩斯消费理论认为居民消费主要受收入影响,我国居民消费一直很低,消费意愿不强,本文通过计量分析找
到影响我国居民消费水平的主要因素,从根本上改善消费不足,促进我国经济的持续稳定健康发展。 消费分为居民消费和,居民消费包括农村居民消费和城镇居民消费。本文结合居民消费水平的影响因素,列出了国内生产总值、职工平均工资指数、城镇居民消费价格指数、普通中学及高等学校在校生数、卫生机构数和基本设施铁路公路货运量等相关因素,进行计量分析,得到回归模型。 三、居民消费水平模型的总体分析框架 (1)多元线性回归法OLS 概述[1] 回归分析是计量经济分析中使用最多的方法,在现实问题研究中,因变量往往受制于多个经济变量的影响,通过统计资料,根据多个解释变量的最优组合来建立回归方程预测被解释变量的回归分析称为多元线性回归法。其模型基本形式为: 其中0β、1β、2β、3β…k β是1+k 个未知参数,称为多元回归系数。Y 称为被解释变量,t X 1、t X 2、t X 3…kt X 是k 个可以精确测量和可控的一般解释变量, t μ是随机误差项。当2≥k 时,上式为多元线性回归模型。 (2)多元回归模型的建立 定义被解释变量和解释变量,被解释变量为居民消费水平(Y 元),解释变量为国内生产总值(1X 亿元)、职工平均工资指数(2X )、城镇居民消费价格指数(3X )、普通中学及高等学校在校生数(4X 万人)、卫生机构数(5X 个)和基本设施铁路公路货运量(6X 万吨)。 (3)统计数据选取 本文所有数据均来自中国统计局和中国统计局外网中国统计年鉴。[2] 1978 184 21261 169732 195301 1979 208 175142 382929 1980 238 180553 493327 1981 264 190126 471336 1982 288 193438 492737 1983 316 196017 520197
中国居民消费水平计量经济学模型 09财政学-1班李雪 200909111008 摘要: 消费作为社会再生产的终点和起点,对于实现社会再生产的良性循环促进国民经济的持续发展具有决定性作用。要刺激消费、扩大内需,必须找出影响居民消费水平的关键因素,才能对症下药。就我国近阶段消费方面出现的一些情况,利用1985年至2009年得相关数据对我国消费的影响因素进行实证分析。先通过相关的背景理论提出问题;搜集了相关的数据,继而对计量模型进行了参数估计和检验,并加以修正。本文主要通过对影响居民消费水平的主要因素分析揭示中国居民消费水平的现状及问题,并以此提出对策。 关键词:居民消费水平居民可支配收入恩格尔系数消费物价指数 一、文献综述 宏观经济学中对居民消费行为的研究主要传统理论有凯恩斯的绝对收入假说,杜森贝利相对收入假说,莫迪里安尼的生命周期假说等。这些消费理论从不同角度论证了收入对消费的影响。我赞同收入的确是影响消费水平的最重要因素这个观点,但是其他因素(比如物价水平、收入分配的公平性、利率、人口结构等)也从不同的方面影响着居民消费水平。 陈长华(湖南,2004)对我国城镇居民消费计量模型的建立与分析,也采用了计量经济学方法来探讨决定城镇居民消费的关键因素。他的指标选择是人均消费人均国内生产总值人均可支配收入人均储蓄前期消费。他的不足之处在于没有考虑除了收入以外的其他因素对居民消费的影响。当今社会影响消费的不确定因素很多,虽然不可否认收入确实是影响消费的最重要因素,但是,仅仅用收入和储蓄作为变量,是否能够很好地拟合现实中的消费函数值得怀疑。 刘丽秋(西南大学经济管理学院,2008)在影响居民消费水平相关因素的计量分析一文中结合居民消费水平的影响因素和国务院所确定的十项措施列出了六个相关因素 (国内生产总值、职工平均工资指数、城镇居民消费价格指数、普通中学及高等学校在校生数、卫生机构数、基本设施铁路公路货运量)进行计量分析,但是她的结论中Y = 27. 12140495 + 0. 03092905302 3 X1 + 0. 001453569285 3 X5 +0. 85006329843 X3 (X1——国内生产总值 X3——城镇居民消费价格指数 X5——卫生机构数) X1——国内生产总值系数为0.
中国居民消费函数的理论与验证 中国居民消费函数的理论与验证 消费函数不论是在经济学理论还是在经济政策实践中都具有重要意义。近年来中外学者运用现代经济学理论对中国消费函数进行了大量研究。概括起来讲,这些研究可分为两类:经验归纳和理论演绎。大多数中国学者倾向于采用经验归纳法,根据经验试验性地给出决定消费需求的有关变量,然后运用计量经济学方法计算出 消费函数的各解释变量的系数,并对回归结果进行统计检验,根据检验结果,增加一些变量或减去一些变量,直至得到令人满意的结果为止。主要采用理论演绎法的学者则试图从某种理论框架出发,并把中国的制度性特点考虑进去,从而推导出相应的结果,最后再对这些结果进行统计检验。采取演绎研究法的学者所依据的理论框架最多见的是西方经济学中的生命周期与永久收入假说。 一、生命周期与永久收入假说和中国消费者的行为特征 生命周期理论与永久收入假说认为,尽管居民的收入水平具有较大的变动性(逐渐增加或经常波动),一个典型居民总是试图使其整个一生的消费处于平稳状态,因而,居民是根据他所预期的今后一生中的收入而不是根据他的现实收入来决定其消费需求的。虽然生命周期理论与永久收入假说不尽相同,但它们的基本思想是相同的。图给出了生命周期理论的基本思想(见下页)。图表明,典型居民试图在其整个一生中都使消费水平保持在常数上。为达到这个目的,当他工作时,其收入中的一部分将用于储蓄,
直到资产达到最大值[]。在时间以后,居民退休因而不再得到工资收入。此后,居民开始花费储蓄以保证消费水平仍在的水平上。 附图;图; 图.生命周期理论() 生命周期理论与永久收入假说在西方经济中得到了较好的验证。然而,在资本市场极其不完善、几乎不存在消费信贷的中国经济中,无论是生命周期理论还是永久收入假说都难以被应用于分析中国居民的消费行为。例如,按照生命周期与永久收入假说,消费者将尽量熨平一生中的消费波动,在收入低时负债,在收入高时储蓄;在盛年时期储蓄,在老年时期负储蓄。然而,在中国,不论是收入较低的年轻人还是收入较高的年长者都具有较高的储蓄倾向。对于中国居民消费行为的一系列特点,西方的传统消费理论是无法解释的,以这些理论为基础对中国居民的消费需求进行预测也难以取得令人满意的结果。因此,深入探讨适合中国国情的消费理论,并在此基础之上对中国居民消费需求的走势进行预测,从而为政府制定政策提供正确依据,不仅具有重大理论意义,而且具有重大现实意义。 要建立一个符合中国国情的消费函数,就必须首先观察中国居民消费行为的特点。中国居民消费行为的首要特点是,中国居民不是以一生为时间跨度()来寻求效用最大化,其消费支出安排具有显著的阶段性。他们的一生通常可分为几个重要的阶段,例如,一种较典型的划分是:婚前、婚后、供养子女及退休等。中国消费者一般是集中力量实现当前阶段效用的最大化,而较少考虑未来阶段的消费和效用最大化。很难想象一个未婚的年轻人会想到其退休后的消费安排。这种“短视()”行为可归因于这样的一
结直肠癌术前N分期的随机森林预测模型的建立与验证 目的:研究基于CT结肠成像(CTC)或注水法结肠CT检查并结合临床及病理资料建立的随机森林(RF)模型在预测结直肠癌术前N分期方面的价值。方法:回顾性收集并分析从2016年1月到2017年12月在吉林大学第一医院接受手术,经病理证实为结直肠癌的患者,在病理科得到每位患者的N分期,筛选出术前接受过 CT结肠平扫+增强检查的239例患者(其中N0、N1、N2期患者数目分别为119例、99例、21例),使用计算机随机分配软件以大致2:1的比例将患者分为训练集(167)测试集(72)。 分别检测病灶平扫、动脉期、静脉期的CT值,并计算动脉期、静脉期的对比强化率。病变均为单发病灶,入组患者在术前均接受CT结肠成像(CTC)或注水法结肠CT检查。 在PACS系统中收集影像学资料,在医生工作站上收集临床及病理资料(年龄、性别、糖类抗原19-9、癌胚抗原、糖类抗原72-4、肿瘤最大直径、肿瘤的位置、强化率、术后病理N分期)。使用SPSS软件分别对连续变量(性别和肿瘤位置) 进行t假设检验,对离散变量(年龄、癌胚抗原、糖类抗原19-9、糖类抗原72-4、肿瘤最大径、强化率)进行卡方检验,筛选出相关度最高的特征,进而用降维后得到的特征进行机器学习建模,通过ROC曲线和敏感度特异度等参数评价模型。 结果:结直肠癌N分期与CA199、A、V、A-P、V-P、A-P/P、V-P/P这七个特征有相关性(P值均<0.05,与年龄、最大直径、CEA、CA72-4均无相关性。随机森林模型预测的N分期与术后病理N分期具有高度一致性,训练集Kappa系数为0.78452(95%置信区间为0.69073-0.87830),测试集Kappa系数为0.58333(95%置信区间为0.39579-0.77088)。
论文题目: 居民消费价格指数与国 民经济评价分析模型学院:外国语学院 专业: 14级英语(商务)2班 姓名:XX 学号:140413212 日期:2016年12月15日
居民消费价格指数与国民经济评价分析模型 摘要 随着社会建设步伐不断加快,我国居民消费价格指数的波动幅度变大,基本 呈上升趋势,食品、烟酒、衣着、家庭设备等八大类居民消费价格指数的波动特 征也各不相同。这些不仅严重影响到我国居民的正常生活消费,而且也大大制约 着我国经济的全面健康发展。因此,有必要对我国食品、烟酒等八大类对居民消 费价格指数的影响深入研究以及居民消费指数对国民经济运作情况进行评价。 针对问题一,运用多元线性回归分析对 CPI 中的的几类因素进行分析建模及模型优化得到回归方=25.09168+0.381722+0.232533+0.134075。 可以得到居民消费价格指数主要由食品类居民消费价格指数、教育文化和娱类居民消费价格指数及居住类居民消费价格指数三大类指标影响。且食品类居民消费价格指数所占权重最大。 针对问题二,运用失业率、通货膨胀率、物价水平及宏观调控政策来衡量国 民经济运作情况,并将这四种因素与居民消费价格指数进行相关评价分析。从而 将 CPI 国民经济运行情况联系起来,并且作出评价。 关键词:居民消费价格指数、多元线性回归 目录 目录 (1) 摘要................................. 错误!未定义书签。
1. 引言.............................. 错误!未定义书签。 2. 问题重述.......................... 错误!未定义书签。 2.1问题背景....................... 错误!未定义书签。 2.2 问题提出...................... 错误!未定义书签。 3. 问题分析.......................... 错误!未定义书签。 3.1八类指标对居民消费价格指数影响研究错误!未定义书签。 3.2针对国民经济的评价............. 错误!未定义书签。 4. 问题假设.......................... 错误!未定义书签。 5. 符号说明.......................... 错误!未定义书签。 6. 建模的建立与求解.................. 错误!未定义书签。 6.1模型一:基于多组数据的线性回归模型错误!未定义书签。 6.1.1数据预处理................ 错误!未定义书签。 6.1.2样本相关系数.............. 错误!未定义书签。 6.2针对CPI对国民经济的定性分析... 错误!未定义书签。 6.2.1失业率.................... 错误!未定义书签。 6.2.2通货膨胀率................ 错误!未定义书签。 6.2.3物价水平.................. 错误!未定义书签。 7. 模型评价.......................... 错误!未定义书签。 8. 参考文献.......................... 错误!未定义书签。 引言
我国居民消费结构和消费趋势的变化 本文从网络收集而来,上传到平台为了帮到更多的人,如果您需要使用本文档,请点击下载按钮下载本文档(有偿下载),另外祝您生活愉快,工作顺利,万事如意! 内容摘要:居民消费结构的变化引起市场营销微观环境的变化。对我国居民消费结构和消费趋势做出数据和理论分析,并结合市场营销理论对其变化带来的市场营销机会从现存和未来两个方面探讨。 关键词:消费结构,消费趋势,市场营销机会 一、问题的提出 经过近三十年的高速经济增长,中国经济已由短缺经济过度为过剩经济,买方市场已经形成,企业面临日趋激烈的市场竞争。资源是稀缺的,过剩永远是相对,无限商机也蕴藏在这复杂多变、竞争激烈的市场之中。谁能独具慧眼发现机会,领先一步利用机会,谁就能在竞争中占据主动。因此,市场机会的识别和利用已成为企业发展的当务之急。其实,市场营销管理是企业竞争的重心之一,而市场营销机会分析又是市场营销管理的基础和起点。不做市场营销机会分析便没有市场营销管理;不做好市场营销机会分析便没有有效的市场营销管理。 要真正做好市场营销机会分析,就必须掌握市场
营销的核心理念。在市场营销学研究领域中,市场是以消费的需求为中心形成的市场。从生产观念到推销观念,再到营销观念,使企业经营观念发生了根本性变化。市场营销观念的诞生是现代企业经营观念的一次革命,从根本上改变了企业经营的指导思想,从原来的以产定销转变为以销定产,明确地指出企业必须以顾客的需要为最根本的出发点。这足以说明“以满足顾客需求为出发点,一切以顾客为中心”已成为市场营销的核心理念之一。一般来讲,企业的顾客市场可分为五类:消费者市场、生产者市场、经销商市场、政府市场和国际市场。消费者市场,是消费者为了个人或家庭集体消费而购买,他们为自身消费购买商品和劳务,也是我们通常所讲的居民消费,是企业顾客市场的重要组成部分。既然一切以顾客为中心,就没有理由不关注消费者市场,也即居民消费。同时,居民消费,作为市场营销的微观环境之一,作为影响企业经营活动的重要因素,在市场经济条件下总是不断的变化,已经被越来越多的企业所关注,其影响力愈加强大。因此,研究居民消费结构和消费趋势的变化,掌权居民消费特点和规律,为市场营销机会分析提供了一个重要而且有效的途径。 二、我国居民消费结构的变化
预测模型分类及优缺点分析 灰色(系统)预测模型 神经网络预测模型 趋势平均预测法 1 微分方程模型 当我们描述实际对象的某些特性随时间(或空间)而演变的过程、分析它的变化规律、预测它的未来性态、研究它的控制手段时,通常要建立对象的动态微分方程模型。微分方程大多是物理或几何方面的典型.问题,假设条件已经给出,只需用数学符号将已知规律表示出来,即可列出方程,求解的结果就是问题的答案,答案是唯一的,但是有些问题是非物理领域的实际问题,要分析具体情况或进行类比才能给出假设条件。作出不同的假设,就得到不同的方程。比较典型的有:传染病的预测模型、经济增长预测模型、正规战与游击战的预测模型、药物在体内的分布与排除预测模型、人口的预测模型、烟雾的扩散与消失预测模型以及相应的同类型的预测模型。其基本规律随着时间的增长趋势是指数的形式,根据变量的个数建立初等微分模型。微分方程模型的建立基于相关原理的因果预测法。该法的优点:短、中、长期的预测都适合,而.既能反映内部规律,反映事物的内在关系,也能分析两个因素的相关关系,精度相应的比较高,另外对初等模型的改进也比较容易理解和实现。该法的缺点:虽然反映的是内部规律,但是由于方程的建立是以局部规律:的独立性假定为基础,故做中长期预测时,偏差有点大,而且微分方程的解比较难以得到。 2 时间序列法 将预测对象按照时问顺序排列起来,构成一个所谓的时间序列,从所构成的这一组时间序列过去的变化规律,推断今后变化的可能性及变化趋势、变化规律,就是时间序列预测法。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变
化、随机性变化。考虑一组给定的随时间变化的观察值,t=1,2,3,?,n},如何选取合适模型预报,t=n+1,n+3, n+k}的值。 上面的模型统称ARMA模型,是时间序列建模中最重要和最常用的预测手段。 事实上,对实际中发生的平稳时间序列做恰当的描述,往往能够得到自回归、滑动平均或混合的模型,其阶数通常不超过2。时间序列模型其实也是一种回归模型,属于定量预测,其基于的原理是,一方面承认事物发展的延续性,运用过去时间序列的数据进行统计分析就能推测事物的发展趋势;另一方面又充分考虑到偶然因素影响而产生的随机性,为了消除随机波动的影响,利用历史数据,进行统计分析,并对数据进行适当的处理,进行趋势预测。优点是简单易行,便于掌握,能够充分运用原时间序列的各项数据,计算速度快,对模型参数有动态确定的能力,精度较好,采用组合的时间序列或者把时间序列和其他模型组合效果更好。缺点是不能反映事物的内在联系,不能分析两个因素的相关关系,常数的选择对数据修匀程度影响较大,不宜取得太小,只适用于短期预测 3 灰色预测理论模型 灰色预测的基本思路是将已知的数据序列按照某种规则构成动态或非动态的 白色模块,再按照某种变化、解法来求解未来的灰色模型。它的主要特点是模型使用的不是原始数据序列,而是生成的数据序列。其核心体系是灰色模型(GM),即对原始数据作累加生成(或其他方法生成)得到近似的指数规律再进行建模的模型方法。优点是不需要很多的数据,一般只需要4个数据就够,能解决历史数据少、序列的完整性及可靠性低的问题;能利用微分方程来充分挖掘系统的本质,精度高;能将无规律的原始数据进行生成得到规律性较强的生成数列,运算简便,易于检验,具有不考虑分布规律,不考虑变化趋势。缺点是只适用于中长期的预测,只适合指数增长的预测,对波动性不好的时间序列预测结果较差。 4 BP神经网络模型
计量经济学大作业----中国居民消费水平模型及分析 学号: 姓名: 专业: 修课时间:2014-2015学年第一学期任课教师:朱永军 成绩: 评语:
我国居民消费水平模型分析 内容摘要 消费作为社会再生产的终点和起点,对于实现社会在生产的良性循环促进国民经济的持续发展,具有决定性作用。本文运用Eviews软件对1991—2010年的历史数据进行分析,通过逐步剔除不合适的解释变量和对方程进行一系列的检验,最终找出影响我国居民消费水平的因素,并对其影响程度的大小进行定量分析,通过各种统计检验来完善模型。 【关键词】: 居民消费水平国内生产总值恩格尔系数人均可支配收入 Analysis of residents' consumption level in China Abstract As the consumption of social reproduction end point and the beginning, for the realization of society in the circulation of production and promote the sustainable development of national economy, plays a decisive role. Based on the historical data of 1994 - 2013 was analyzed by Eviews software, through gradually eliminate inappropriate explanatory variables and the equations are a series of tests, finally finds out the factors affecting the consumption level of residents in China, and the influence degree of quantitative analysis, through a variety of statistical tests to improve model.
我国居民消费水平的计量分析 摘要:改革开放以来,我国居民收入与消费水平不断提高,居民消费结构升级和消费需求扩张成为我国经济高速增长的主要动力,随着国家经济实力的增强,随着教育事业的跨越发展,国家对不同阶段、不同领域、不同地域的经济社会发展大量采用科学、定量、求实的预测、指导方法,摒弃太多的人为影响,所作出的决策越来越切合实际,而效果亦愈来愈好;而这其中,计量分析方法功不可没。所以国家制定并实施了一系列相关财政及货币政策来刺激消费,增加居民投资的作用,居民消费虽有增长却不能支撑整个国民经济的发展。不管从宏观还是微观来分析,我国居民最终消费支出都直接影响到我国的国民经济运行及整个经济的发展,所以对我国居民最终消费支出的问题进行研究是必不可少的,而且十分重要。我们可以运用研究的结果来分析现状并制定正确的应对方针。消费是经济活动的起点和归宿,也是推动经济增长的重要因素。 关键字:居民消费税收CPI 引言:居民消费水平是指居民在物质产品和劳务的消费过程中,对满足人们生存,发展和享受需要方面所达到的程度。居民消费是指花费在最终商品与服务上且能符合需要和获得满意的各项开支,是GDP中最大的组成部分。通过分析影响居民消费水平的因素,探究居民消费水平不断提高的主要原因,及时把握国民经济发展格局中居民消费需求变动趋势,制定符合我国现阶段情况的国民消费政策,对于提高我国经济增长速度和质量都有重要意义。 一、模型设定 (一)理论综述 对决定消费的主要因素,国外学术界有两种主要不同的理论观点:一种是凯恩斯主义消费函数,强调现期消费主要取决于现期收入,随着可支配收入增加,消费也增加。这种消费理论主要强调的是用收入来解释消费,也叫绝对收入假说。他指出的是消费增长与收入增长之间是一种非比例关系。另一种是面向未来的消费函数,强调消费对一生总财富的依赖,以及储蓄在稳定消费中的作用——莫迪利阿尼的生命周期理论强调为退休后的生活而储蓄的重要性;弗里德曼的持久收入假说强调储蓄在稳定高收入年份和低收入年份之间消费的作用,他强调的是持久性收入影响消费支出,而暂时性收入对消费支出的影响是通过对持久收入的影响而发生的,它的变动只会引起消费的波动,消费时持久性收入的稳定函数,而且消费的边际倾向没有递减。因此,消费不完全取决于现期收入。但是,经济学家大量经验观察说明,消费更多依赖于现期收入,主要原因,一是当居民收入下降或担心失业时,他可能会推迟或削减耐用品购买,现期消费就减少;二是当居民收入下降时,消费信贷会受到配额限制,他就不得不削减现期消费。简要的说,一种强调现期消费主要取决于现期收入。事实表明,两种因素同时对消费起着作用。 (二)变量选取 消费的决定因素包括:当期可支配收入、个人财富、物价指数、货币流通量以及永久收入等等。并且认为收入增加消费增加,收入减少消费难以减少,主要因素为实际可支配收入。 可支配收入是指国民收入减去所有家庭和公司交纳的直接税,再减去企业净储蓄,最后加上家庭从政府那里获得的转移支付。由于可支配收入计算易出现误差,且可支配收入最终仍然由国民收入决定且与国民收入值差距不大,所以我们采用国民收入代替计算。 货币流通量指货币离开金库在市场上流通的货币数量。投放货币就增加了货币流通量,反之,回笼货币就减少了货币流通量。增加或减少货币流通量主要是适应经济和社会发展需要。货币流通量过少,不能满足商品交换的需要,就会影响经济发展;货币流通量过多,超出了商品交换的需要,就会出现通货膨胀,同样会影响经济的增长。 城市居民消费价格指数是反映城市职工及其家庭所购买的生活消费品和服务项目价格
实验指导书(ARIMA模型建模与预测) 例:我国1952-2011年的进出口总额数据建模及预测 1、模型识别和定阶 (1)数据录入 打开Eviews软件,选择“File”菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Dated –regular frequency”,在“Date specification”栏中分别选择“Annual”(年数据) ,分别在起始年输入1952,终止年输入2011,文件名输入“im_ex”,点击ok,见下图,这样就建立了一个工作文件。 在workfile中新建序列im_ex,并录入数据(点击File/Import/Read Text-Lotus-Excel…, 找到相应的Excel数据集,打开数据集,出现如下图的窗口,在“Data order”选项中选择“By observation-series in columns”即按照观察值顺序录入,第一个数据是从B15开始的,所以在“Upper-left data cell”中输入B15,本例只有一列数据,在“Names for series or number if named in file”中输入序列的名字im_ex,点击ok,则录入了数据):
(2)时序图判断平稳性 双击序列im_ex,点击view/Graph/line,得到下列对话框: 显著非平稳。 IM_EX 240,000 200,000 160,000 120,000 80,000 40,000 556065707580859095000510 (3 因为数据有指数上升趋势,为了减小波动,对其对数化,在Eviews命令框中输入相应
居民消费价格指数的时间序列分析 摘要: 时间序列分析是一种根据动态数据揭示系统动态结构和规律的统计方法。本文以我国2007年1月至2011年4月居民消费价格指数为研究对象,基于居民消费价格指数存在明显的非平稳性和季节性特征,运用自回归移动平均季节模型进行建模分析,并利用SPSS建立了居民消费价格指数时间序列的相关关系模型,并对其进行预测,取得较好的效果。 关键词: 居民消费价格指数 SPSS软件时间序列分析预测 1
一、引言 (一)问题的基本情况及背景 居民消费价格指数的调查范围和内容是居民用于日常生活消费品的全部商品和服务项目价格。包括食品、烟酒及用品、衣着、家庭设备用品及维修服务、医疗保健和个人用品、交通和通讯、娱乐教育文化用品及服务、居住等八大类商品及服务项目价格。既包括居民从商店、工厂、集市所购买商品的价格,也包括从餐饮行业购买商品的价格。该指数以实际调查的综合平均单价和根据住户调查有关资料确定的权数,按加权算术平均公式计算。 全国居民消费价格指数是反映居民家庭购买生活消费品和支出服务项目费用价格变动趋势和程度的相对数。其目的在于观察居民生活消费品及服务项目价格的变动对城乡居民生活的影响,为各级党政领导掌握居民消费状况,研究和制定居民消费价格政策、工资政策以及为新国民经济核算体系中有消除价格变动因素的不变价格核算提供科学依据。居民消费价格指数还是反映通货膨胀的重要指标。当居民消费价格指数上升时,表明通货膨胀率上升,消费者的生活成本提高,货币的购买能力减弱;相反,当居民消费价格指数下降时,表明通货膨胀率下降,亦即消费者的生活成本降低,货币的购买能力增强。 居民消费价格指数的高低直接影响居民的生活水平,因此,准确的分析并及时的对居民消费价格指数做出合理的预测,对国家制定相应的经济政策,实行宏观调控,稳定物价,保证经济的增长平稳发展具有重要意义。 2
云南大学信息学院学生实验报告 课程名称:现代控制理论 实验题目:预测控制 小组成员:李博(12018000748) 金蒋彪(12018000747) 专业:2018级检测技术与自动化专业
1、实验目的 (3) 2、实验原理 (3) 2.1、预测控制特点 (3) 2.2、预测控制模型 (4) 2.3、在线滚动优化 (5) 2.4、反馈校正 (5) 2.5、预测控制分类 (6) 2.6、动态矩阵控制 (7) 3、MATLAB仿真实现 (9) 3.1、对比预测控制与PID控制效果 (9) 3.2、P的变化对控制效果的影响 (12) 3.3、M的变化对控制效果的影响 (13) 3.4、模型失配与未失配时的控制效果对比 (14) 4、总结 (15) 5、附录 (16) 5.1、预测控制与PID控制对比仿真代码 (16) 5.1.1、预测控制代码 (16) 5.1.2、PID控制代码 (17) 5.2、不同P值对比控制效果代码 (19) 5.3、不同M值对比控制效果代码 (20) 5.4、模型失配与未失配对比代码 (20)
1、实验目的 (1)、通过对预测控制原理的学习,掌握预测控制的知识点。 (2)、通过对动态矩阵控制(DMC)的MATLAB仿真,发现其对直接处理具有纯滞后、大惯性的对象,有良好的跟踪性和较强的鲁棒性,输入已 知的控制模型,通过对参数的选择,来获得较好的控制效果。 (3)、了解matlab编程。 2、实验原理 模型预测控制(Model Predictive Control,MPC)是20世纪70年代提出的一种计算机控制算法,最早应用于工业过程控制领域。预测控制的优点是对数学模型要求不高,能直接处理具有纯滞后的过程,具有良好的跟踪性能和较强的抗干扰能力,对模型误差具有较强的鲁棒性。因此,预测控制目前已在多个行业得以应用,如炼油、石化、造纸、冶金、汽车制造、航空和食品加工等,尤其是在复杂工业过程中得到了广泛的应用。在分类上,模型预测控制(MPC)属于先进过程控制,其基本出发点与传统PID控制不同。传统PID控制,是根据过程当前的和过去的输出测量值与设定值之间的偏差来确定当前的控制输入,以达到所要求的性能指标。而预测控制不但利用当前时刻的和过去时刻的偏差值,而且还利用预测模型来预估过程未来的偏差值,以滚动优化确定当前的最优输入策略。因此,从基本思想看,预测控制优于PID控制。 2.1、预测控制特点 首先,对于复杂的工业对象。由于辨识其最小化模型要花费很大的代价,往往给基于传递函数或状态方程的控制算法带来困难,多变量高维度复杂系统难以建立精确的数学模型工业过程的结构、参数以及环境具有不确定性、时变性、非线性、强耦合,最优控制难以实现。而预测控制所需要的模型只强调其预测功能,不苛求其结构形式,从而为系统建模带来了方便。在许多场合下,只需测定对象的阶跃或脉冲响应,便可直接得到预测模型,而不必进一步导出其传递函数或状