
Oracle常用系统表
1.视图的概述 视图其实就是一条查询sql语句,用于显示一个或多个表或其他视图中的相关数据。视图将一个查询的结果作为一个表来使用,因此视图可以被看作是存储的查询或一个虚拟表。视图来源于表,所有对视图数据的修改最终都会被反映到视图的基表中,这些修改必须服从基表的完整性约束,并同样会触发定义在基表上的触发器。(Oracle支持在视图上显式的定义触发器和定义一些逻辑约束) 2.视图的存储 与表不同,视图不会要求分配存储空间,视图中也不会包含实际的数据。视图只是定义了一个查询,视图中的数据是从基表中获取,这些数据在视图被引用时动态的生成。由于视图基于数据库中的其他对象,因此一个视图只需要占用数据字典中保存其定义的空间,而无需额外的存储空间。 3.视图的作用 用户可以通过视图以不同形式来显示基表中的数据,视图的强大之处在于它能够根据不同用户的需要来对基表中的数据进行整理。视图常见的用途如下: 通过视图可以设定允许用户访问的列和数据行,从而为表提供了额外的安全控制 隐藏数据复杂性 视图中可以使用连接(join),用多个表中相关的列构成一个新的数据集。此视图就对用户隐藏了数据来源于多个表的事实。 简化用户的SQL 语句 用户使用视图就可从多个表中查询信息,而无需了解这些表是如何连接的。 以不同的角度来显示基表中的数据 视图的列名可以被任意改变,而不会影响此视图的基表 使应用程序不会受基表定义改变的影响 在一个视图的定义中查询了一个包含4 个数据列的基表中的3 列。当基表中添加了新的列后,由于视图的定义并没有被影响,因此使用此视图的应用程序也不会被影响。 保存复杂查询 一个查询可能会对表数据进行复杂的计算。用户将这个查询保存为视图之后,每次进行类似计算只需查询此视图即可。
详解ORACLE簇表、堆表、IOT表、分区表 簇和簇表 簇其实就是一组表,是一组共享相同数据块的多个表组成。将经常一起使用的表组合在一起成簇可以提高处理效率。 在一个簇中的表就叫做簇表。建立顺序是:簇→簇表→数据→簇索引 1、创建簇的格式 CREATE CLUSTER cluster_name (column date_type [,column datatype]...) [PCTUSED 40 | integer] [PCTFREE 10 | integer] [SIZE integer] [INITRANS 1 | integer] [MAXTRANS 255 | integer] [TABLESPACE tablespace] [STORAGE storage] SIZE:指定估计平均簇键,以及与其相关的行所需的字节数。 2、创建簇 create cluster my_clu (deptno number) pctused60 pctfree10 size1024 tablespace users storage( initial128k next128k minextents2 maxextents20
);
3、创建簇表 create table t1_dept( deptno number, dname varchar2(20) ) cluster my_clu(deptno); create table t1_emp( empno number, ename varchar2(20), birth_date date, deptno number ) cluster my_clu(deptno); 4、为簇创建索引 create index clu_index on cluster my_clu; 注:若不创建索引,则在插入数据时报错:ORA-02032: clustered tables cannot be used before the cluster index is built 管理簇 使用ALTER修改簇属性(必须拥有ALTER ANY CLUSTER的权限) 1、修改簇属性 可以修改的簇属性包括: * PCTFREE、PCTUSED、INITRANS、MAXTRANS、STORAGE * 为了存储簇键值所有行所需空间的平均值SIZE * 默认并行度
学习笔记:oracle数据字典详解 --- 本文为TTT学习笔记,首先介绍数据字典及查看方法,然后分类总结各类数据字典的表和视图。然后列出一些附例。 数据字典系统表,保存在system表空间中。 由表和视图组成,由服务器在安装数据库时自动创建,用户不可以直接修改数据库字典,在执行DDL 语句时,oracle会自动修改。 记录一些表和视图(只读的),新建的表不要和这空间建在一起(9i以前的版本新用户建的表默认表空间为system,注意修改) --查询数据字典: select * from dictionary --数据字典导出方法: conn / as sysdba spool on spool c:\dic.txt select * from dictionary spool off 主要四部分: 1,内部RDBMS表:x$…… 2,数据字典表:……$ 3,动态性能视图:gv$……,v$…… 4,数据字典视图:user_……,all_……,dba_……
数据库启动时,动态创建x$,在X$基础上创建GV$,在GV$基础上创建V$X$表-->GV$(视图)--->V$(视图) +++ 一,内部RDBMS表x$……,例如:x$kvit,x$bh,x$ksmsp,x$ksppi和x$ksppcv 核心部分,用于跟踪内部数据库信息,维持DB的正常运行。 是加密命名的,不允许sysdba以外的用户直接访问,显示授权不被允许。最好不要修改. x$kvit=Kernel Layer Performance Layer V Information tables Transitory Instance parameter 数据库启动时,动态创建x$…… +++ 二,数据字典表……$,如tab$,obj$,ts$…… --用来存储表、索引、约束以及其他数据库结构的信息。 --创建数据库时通过脚本sql.bsq来创建,脚本:$oracle_home/rdbms/admin/sql.bsq +++ 三,动态性能视图gv$……,v$……,如V$parameter --记录了DB运行时信息和统计数据,大部分动态性能视图被实时更新以反映DB当前状态。 --数据库创建时建立的。 --只有sysdba可以直接访问。 --查看表v$fixed_view_definition(***),可以查看GV$和V$视图的创建语句。(oracle提供一些特殊视图,用来记录其他视图的创建方式,v$fixed_view_definition就是其中之一) --select view_definition from v$fixed_view_definition where view_name='V$FIXED_TABLE'; --gv$……=Global V$,在X$……基础上创建,是为了满足OPS环境(多个实例)的需要面产生的,可以返回多个实例的信息。
ORACLE 表分区 表分区的好处和事处理 表分区描述 表分区(partition):表分区技术是在超大型数据库(VLDB)中将大表及其索引通过分区(patition)的形式分割为若干较小、可管理的小块,并且每一分区可进一步划分为更小的子分区(sub partition)。而这种分区对于应用来说是透明的。Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。每个分区都是一个独立的段(SEGMENT),可以存放到相同(不同)的表空间中。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用SQL DML 命令访问分区后的表时,无需任何修改。(对于高效率查询是有影响,主要差别是对某一分区数据时行查询时和对整体数据进行查询) 表分区的好处 通过对表进行分区,可以获得以下的好处: 1)增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 2)维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 3)均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能; 4)改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速
下载的,写的非常好,给大家分享下。 什么时候使用分区: 1、大数据量的表,比如大于2GB。一方面2GB文件对于32位os是一个上限,另外备份时间长。 2、包括历史数据的表,比如最新的数据放入到最新的分区中。典型的例子:历史表,只有当前月份的数据可以被修改,而其他月份只能read-only ORACLE只支持以下分区:tables, indexes on tables, materialized views, and indexes on materialized views 分区对SQL和DML是透明的(应用程序不必知道已经作了分区),但是DDL 可以对不同的分区进行管理。 不同的分区之间必须有相同的逻辑属性,比如共同的表名,列名,数据类型,约束; 但是可以有不同的物理属性,比如pctfree, pctused, and tablespaces. 分区独立性:即使某些分区不可用,其他分区仍然可用。 最多可以分成64000个分区,但是具有LONG or LONG RAW列的表不可以,但是有CLOB or BLOB列的表可以。 可以不用to_date函数,比如: alter session set nls_date_format='mm/dd/yyyy'; CREATE TABLE sales_range (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) ( PARTITION sales_jan2000 VALUES LESS THAN('02/01/2000'),
PO模块常用表结构 表名: PO.PO_REQUISITION_HEADERS_ALL 说明: 采购请求 REQUISITION_HEADER_ID NUMBER PR头标识码 SEGMENT1VARCHAR2(20)PR号 ENABLE_FLAG VARCHAR2(1)使能标志(Y/N) AUTHORIZATION_STATUS VARCHAR2(25)批准标志(APPROVED/) TYPE_LOOKUP_CODE VARCHAR2(25)类型(PURCHASE) REQUIST_ID NUMBER请求标识码 CANCEL_FLAG VARCHAR2(1)取消标志(Y/N) TRANSFERRED_TO_OE_FLAG VARCHAR2(1)可否转入OE标志(Y/N) PREPARER_ID NUMBER准备人ID(可与HR.PER_PEOPLE_F.PERSON_ID关联) 表名: PO.PO_REQUISITION_LINES_ALL 说明: 采购请求明细 REQUISITION_LINE_ID NUMBER PR行ID REQUISITION_HEADER_ID NUMBER PR头ID LINE_NUM NUMBER栏目 LINE_TYPE_ID NUMBER行类别 CATEGORY_ID NUMBER归类标识码 ITEM_DESCRIPTION VARCHAR2(240)项目描述 UNIT_MEAS_LOOKUP_CODE VARCHAR2(25)单位 UNIT_PRICE NUMBER单价(已折为人民币) QUANTITY NUMBER数量 DELIVER_TO_LOCATION_ID NUMBER交货位置码(与HR.HR_LOCATIONS.LOCATION_ID关联)TO_PERSON_ID NUMBER收货人代码 SOURCE_TYPE_CODE VARCHAR2(25)来源类型 ITEM_ID NUMBER项目内码 ITEM_REVISION VARCHAR2(3)项目版本 QUANTITY_DELIVERED NUMBER已交付数量 SUGGESTED_BUYER_ID NUMBER建议采购员代码 ENCUMBERED_FLAG VARCHAR2(1)分摊标志 RFQ_REQUIRED_FLAG VARCHAR2(1) NEED_BY_DATE DATE需求日期(原始) LINE_LOCATION_ID NUMBER定位行标识码(为空时表示未生成PO) MODIFIED_BY_AGENT_FLAG VARCHAR2(1)被采购员更改标志(被拆分Y/NULL)
摘要:本篇文章介绍了ORACLE数据库的新特性—分区管理,并用例子说明使用方法。 关键词:ORACLE,分区 一、分区概述: 为了简化数据库大表的管理,ORACLE8推出了分区选项。分区将表分离在若干不同的表空间上,用分而治之的方法来支撑无限膨胀的大表,给大表在物理一级的可管理性。将大表分割成较小的分区可以改善表的维护、备份、恢复、事务及查询性能。针对当前社保及电信行业的大量日常业务数据,可以推荐使用ORACLE8的该选项。 二、分区的优点: 1 、增强可用性:如果表的一个分区由于系统故障而不能使用,表的其余好的分区仍然可以使用; 2 、减少关闭时间:如果系统故障只影响表的一部分分区,那么只有这部分分区需要修复,故能比整个大表修复花的时间更少; 3 、维护轻松:如果需要重建表,独立管理每个分区比管理单个大表要轻松得多; 4 、均衡I/O:可以把表的不同分区分配到不同的磁盘来平衡I/O改善性能;
5 、改善性能:对大表的查询、增加、修改等操作可以分解到表的不同分区来并行执行,可使运行速度更快; 6 、分区对用户透明,最终用户感觉不到分区的存在。 三、分区的管理: 1 、分区表的建立: 某公司的每年产生巨大的销售记录,DBA向公司建议每季度的数据放在一个分区内,以下示范的是该公司1999年的数据(假设每月产生30M的数据),操作如下: STEP1、建立表的各个分区的表空间: CREATE TABLESPACE ts_sale1999q1 DATAFILE ‘/u1/oradata/sales/sales1999_q1.dat’ SIZE 100M DEFAULT STORAGE (INITIAL 30m NEXT 30m MINEXTENTS 3 PCTINCREASE 0) CREATE TABLESPACE ts_sale1999q2 DATAFILE ‘/u1/oradata/sales/sales1999_q2.dat’ SIZE 100M DEFAULT STORAGE (INITIAL 30m NEXT 30m MINEXTENTS 3 PCTINCREASE 0)
oracle大表分区 回答人:软界网友我来回答回答(3) STEP2、利用操作系统的工具删除以上表空间占用的文件(表空间基于裸设备无须次步),UNIX系统为例: oracle$ rm /u1/oradata/sales/sales1999_q1.dat oracle$ rm /u1/oradata/sales/sales1999_q2.dat oracle$ rm /u1/oradata/sales/sales1999_q3.dat oracle$ rm /u1/oradata/sales/sales1999_q4.dat 4 、分区的其他操作: 分区的其他操作包括截短分区(truncate),将存在的分区划分为多个分区(split),交换分区(exchange),重命名(rename),为分区建立索引等。DBA能够依照适当的情形使用。 以下仅说明分裂分区(split),例如该公司1999年第四季度销售明细数据急剧增加(因为庆国庆、迎千禧、贺回来),DBA向公司建议将第四季度的分区划分为两个分区,每个分区放两个月份的数据,操作如下: STEP1、按(1)的方法建立两个分区的表空间ts_sales1999q4p1, ts_sales1999q4p2;
STEP2、给表添加两个分区sales1999_q4_p1,sales1999_q4_p2; STEP3、分裂分区: ALTER TABLE sales SPLIT PARTITON sales1999_q4 AT TO_DATE (‘1999-11-01’,’YYYY-MM-DD’) INTO (partition sales1999_q4_p1, partition sales1999_q4_p2) 5 、查看分区信息: DBA要查看表的分区信息,可查看数据字典USER_EXTENTS,操作如下:SVRMGRL>SELECT * FROM user_extents WHERE SEGMENT_NAME=’SALES’; SEGMENT_NA PARTITION_ SEGMENT_TYPE TABLESPACE ---------- ------------ --------------- -------------- SALES SALES1999_Q1 TABLE PARTITION TS_SALES1999Q1 SALES SALES1999_Q2 TABLE PARTITION TS_SALES1999Q2 SALES SALES1999_Q3 TABLE PARTITION TS_SALES1999Q3 SALES SALES1999_Q4 TABLE PARTITION TS_SALES1999Q4 SALES SALES2000_Q1 TABLE PARTITION TS_SALES1999Q1 SALES SALES2000_Q2 TABLE PARTITION TS_SALES1999Q2 SALES SALES2000_Q3 TABLE PARTITION TS_SALES1999Q3 SALES SALES2000_Q4 TABLE PARTITION TS_SALES1999Q4
Oracle常用数据字典表(系统表或系统视图)及查询SQL 2014年12月15日?数据库?共4187字?暂无评论?阅读861 次 文章目录 ?数据字典分类 ?dba_开头 ?user_开头 ?v$开头 ?all_开头 ?session_开头 ?index_开头 ?伪表 ?数据字典常用SQL查询 数据字典是Oracle存放有关数据库信息的地方,其用途是用来描述数据的。比如一个表的创建者信息,创建时间信息,所属表空间信息,用户访问权限信息的视图等。 数据字典系统表,保存在system表空间中。查询所有数据字典可用语句“select * from dictionary;”。 数据字典分类 数据字典主要可分为四部分: 1)内部RDBMS表:x$*,用于跟踪内部数据库信息,维持DB的正常运行。是加密命名的,不允许sysdba以外的用户直接访问,显示授权不被允许。
2)数据字典表:*$,如tab$,obj$,ts$等,用来存储表、索引、约束以及其他数据库结构的信息。 3)动态性能视图:gv$*,v$*,记录了DB运行时信息和统计数据,大部分动态性能视图被实时更新以反映DB当前状态。 4)数据字典视图:user_*、all_*、dba_*,在非Sys用户下,我们访问的都是同义词,而不是V$视图或GV视图。 数据库启动时,动态创建x$,在X$基础上创建GV$,在GV$基础上创建V$X$表-->GV$(视图)--->V$(视图)。 数据字典视图可分为静态数据字典视图和动态数据字典视图。 静态数据字典是指在用户访问数据字典时内容不会发生改变。这类数据字典主要是由表和视图组成,应该注意的是,数据字典中的表是不能直接被访问的,但是可以访问数据字典中的视图。 静态数据字典中的视图分为三类,它们分别由三个前缀够成:user_*(该用户方案对象的信息)、all_*(该用户可以访问的所有对象的信息)、dba_*(全部数据库对象的信息)。 动态数据字典是Oracle包含的一些潜在的由系统管理员如SYS维护的表和视图,由于当数据库运行的时候它们会不断进行更新,所以称它们为动态数据字典。这些视图提供了关于内存和磁盘的运行情况,所以我们只能对其进行只读访问而不能修改它们。Oracle中这些动态性能视图都是以v$开头的视图,比如v$access。 dba_开头 dba_users数据库用户信息
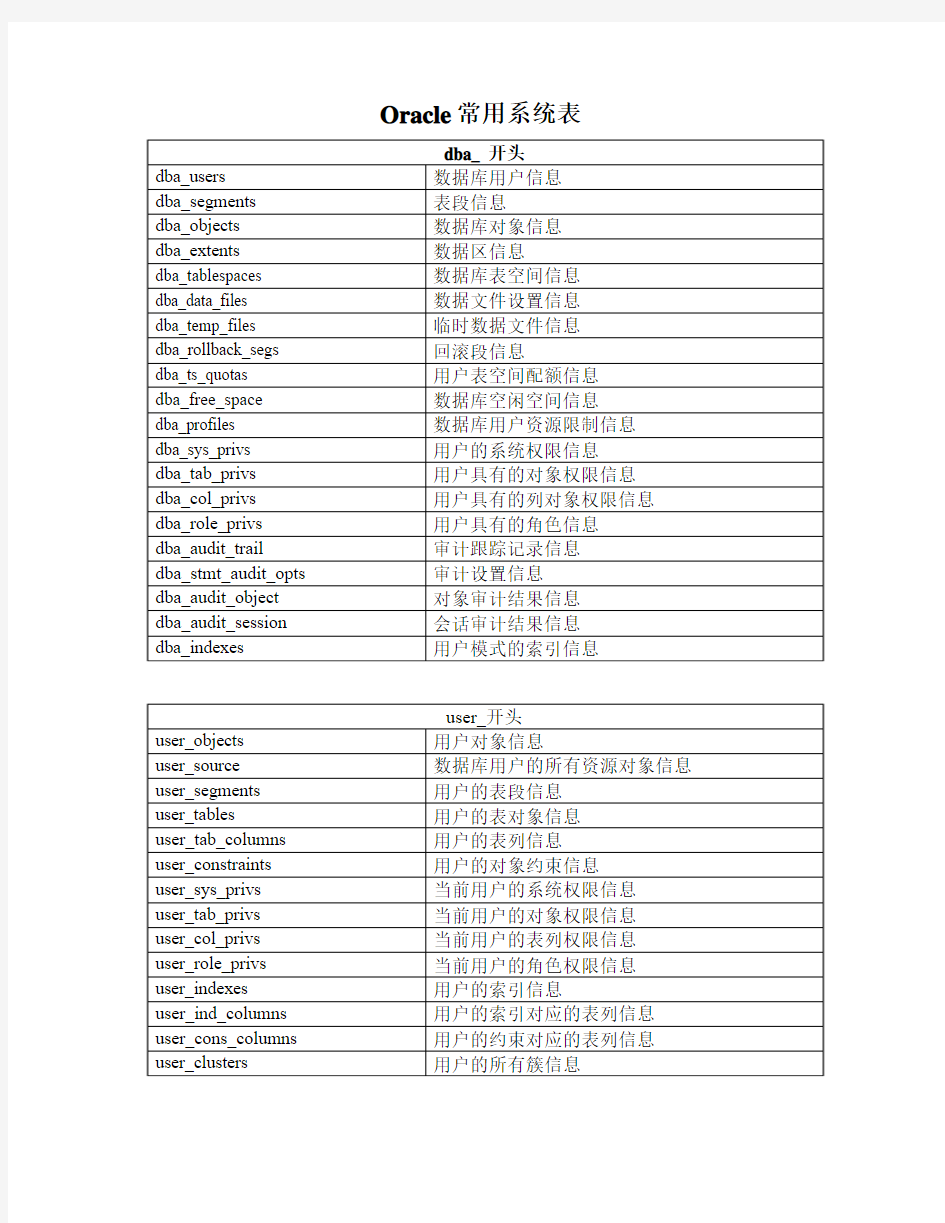
总结ORACLE系统视图及表大全: dba_开头..... dba_users 数据库用户信息 dba_segments 表段信息 dba_extents 数据区信息 dba_objects 数据库对象信息 dba_tablespaces 数据库表空间信息 dba_data_files 数据文件设置信息 dba_temp_files 临时数据文件信息 dba_rollback_segs 回滚段信息 dba_ts_quotas 用户表空间配额信息 dba_free_space数据库空闲空间信息 dba_profiles 数据库用户资源限制信息 dba_sys_privs 用户的系统权限信息 dba_tab_privs用户具有的对象权限信息dba_col_privs用户具有的列对象权限信息dba_role_privs用户具有的角色信息 dba_audit_trail审计跟踪记录信息 dba_stmt_audit_opts审计设置信息 dba_audit_object 对象审计结果信息 dba_audit_session会话审计结果信息 dba_indexes用户模式的索引信息 user_开头 user_objects 用户对象信息 user_source 数据库用户的所有资源对象信息user_segments 用户的表段信息 user_tables 用户的表对象信息 user_tab_columns 用户的表列信息 user_constraints 用户的对象约束信息 user_sys_privs 当前用户的系统权限信息
user_tab_privs 当前用户的对象权限信息 user_col_privs 当前用户的表列权限信息 user_role_privs 当前用户的角色权限信息 user_indexes 用户的索引信息 user_ind_columns用户的索引对应的表列信息 user_cons_columns 用户的约束对应的表列信息 user_clusters 用户的所有簇信息 user_clu_columns 用户的簇所包含的内容信息 user_cluster_hash_expressions 散列簇的信息 v$开头 v$database 数据库信息 v$datafile 数据文件信息 v$controlfile控制文件信息 v$logfile 重做日志信息 v$instance 数据库实例信息 v$log 日志组信息 v$loghist 日志历史信息 v$sga 数据库SGA信息 v$parameter 初始化参数信息 v$process 数据库服务器进程信息 v$bgprocess 数据库后台进程信息 v$controlfile_record_section 控制文件记载的各部分信息v$thread 线程信息 v$datafile_header 数据文件头所记载的信息 v$archived_log归档日志信息 v$archive_dest 归档日志的设置信息 v$logmnr_contents 归档日志分析的DML DDL结果信息v$logmnr_dictionary 日志分析的字典文件信息 v$logmnr_logs 日志分析的日志列表信息 v$tablespace 表空间信息
Oracle 系统包 DBMS_OUTPUT a)启用 i. dbms_output.enable(buffer_size in integer default 20000); ii. set serveroutput on; b)禁用 i. dbms_output.disable; c)PUT和PUT_LINE i. PUT:所有信息显示在同一行 ii. PUT_LINE信息显示后,自动换行 d)NEW_LINE用于在行的尾部追加行结束符,一般用PUT同时使用 e)GET_LINE和GET_LINES i. DBMS_OUTPUT.GET_LINE(li ne 0UTVARCHAR2,status OUT INTEGER)用于取缓冲区的单行 信息 ii. DBMS_OUTPUT.GET_LINES(lines OUT chararr,numlies IN OUT INTEGER) 用于取得缓冲区的多行信息 DBMS_JOB a)SUBMIT用于建立一个新作业 语法 DBMS_JOB.SUBMIT( job OUT BINARY_INTEGER, what IN VARCHAR2, next_date IN DATE DEFATULT SYSDATE, interval IN VARCHAR2 DEFAULT ' NULL' , no_parse IN BOOLEAN DEFAULT FALSE, instance IN BINARY_INTEGER DEFAULT any_instance, force IN DEFAULT FALSE); 例子 VAR jobno NUMBER; BEGIN DBMS_JOB.SUBMI( :jobno, 'pro_hrs101d0_ins_hrs101t0', sysdate, ‘sysdate+1 '); b)REMOVE!于删除作业队列中的特定作业 语法:DBMS_JOB.REMOVE(jov IN BINARY_INTEGER); 例子:DBMS_JOB.REMOVE(10);--删除JOB号为10 的JOB c)CHANGE用于改变与作业相关的所有信息
深入学习Oracle分区表及分区索引 关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类: ?Range(范围)分区 ?Hash(哈希)分区 ?List(列表)分区 ?以及组合分区:Range-Hash,Range-List。 对于表而言(常规意义上的堆组织表),上述分区形式都可以应用(甚至可以对某个分区指定compress属性),只不过分区依赖列不能是lob,long之类数据类型,每个表的分区或子分区数的总数不能超过1023个。 对于索引组织表,只能够支持普通分区方式,不支持组合分区,常规表的限制对于索引组织表同样有效,除此之外呢,还有一些其实的限制,比如要求索引组织表的分区依赖列必须是主键才可以等。 注:本篇所有示例仅针对常规表,即堆组织表! 对于索引,需要区分创建的是全局索引,或本地索引: l 全局索引(global index):即可以分区,也可以不分区。即可以建range分区,也可以建hash分区,即可建于分区表,又可创建于非分区表上,就是说,全局索引是完全独立的,因此它也需要我们更多的维护操作。 l 本地索引(local index):其分区形式与表的分区完全相同,依赖列相同,存储属性也相同。对于本地索引,其索引分区的维护自动进行,就是说你add/drop/split/truncate表的分区时,本地索引会自动维护其索引分区。 Oracle建议如果单个表超过2G就最好对其进行分区,对于大表创建分区的好处是显而易见的,这里不多论述why,而将重点放在when以及how。 ORACLE对于分区表方式其实就是将表分段存储,一般普通表格是一个段存储,而分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那几个内部,然后在分区内部去查找数据,一个分区一般保证四十多万条数据就比较正常了,但是分区表并非乱建立,而其维护性也相对较为复杂一点,而索引的创建也是有点讲究的,这些以下尽量阐述详细即可。 range分区方式,也算是最常用的分区方式,其通过某字段或几个字段的组合的值,从小到大,按照指定的范围说明进行分区,我们在INSERT数据的时候就会存储到指定的分区中。 List分区方式,一般是在range基础上做的二级分区较多,是一种列举方式进行分区,一般讲某些地区、状态或指定规则的编码等进行划分。 Hash分区方式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE 会自动去根据一套HASH算法去划分分区,只需要告诉ORACLE要分几个区即可。 WHEN 一、When使用Range分区 Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中,比如按照时间划分,2008年1季度的数据
多做知识的积累详解ORACLE数据库的分区表 此文从以下几个方面来整理关于分区表的概念及操作: 1.表空间及分区表的概念 2.表分区的具体作用 3.表分区的优缺点 4.表分区的几种类型及操作方法 5.对表分区的维护性操作. (1.) 表空间及分区表的概念 表空间: 是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表,所以称作表空间。 分区表: 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 ( 2).表分区的具体作用 Oracle的表分区功能通过改善可管理性、性能和可用性,从而为各式应用程序带来了极大的好处。通常,分区可以使某些查询以及维护操作的性能大大提高。此外,分区还可以极大简化常见的管理任务,分区是构建千兆字节数据系统或超高可用性系统的关键工具。 分区功能能够将表、索引或索引组织表进一步细分为段,这些数据库对象的段叫做分区。每个分区有自己的名称,还可以选择自己的存储特性。从数据库管理员的角度来看,一个分区后的对象具有多个段,这些段既可进行集体管理,也可单独管理,这就使数据库管理员在管理分区后的对象时有相当大的灵活性。但是,从应用程序的角度来看,分区后的表与非分区表完全相同,使用 SQL DML 命令访问分区后的表时,无需任何修改。 什么时候使用分区表: 1、表的大小超过2GB。 2、表中包含历史数据,新的数据被增加都新的分区中。 (3).表分区的优缺点 表分区有以下优点: 1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。 2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用; 3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可; 4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。 缺点:
关于oracle自带的表***********************************8 emp: empno:员工编号;ename:员工名字;job:员工工种;mgr: 上司;hiredate:入职时间;sal:基本工资;comm:补贴;deptno:所属部门编号; dept: deptno:部门编号;dname:部门名称;loc:地理位置; salgrade: grade:工资等级;losal:最低限额;hisal:最高限额; dual: 系统自带的一张空表;可用于计算数据:select 2*3 from dual; **sql_function1********************************************************** select lower(ename) from emp; 取出的名字全部变成小写。 select ename from emp where lower(ename) like '_a%';取出的名字变成小写后不含字母a select substr(ename, 2, 3) from emp;从第二个字符截,截取三个字符。 select cha(65) from dual; 将数字转化为字符(显示为a)。 select ascii('A') from dual; 将字符转化为数字。 select round(23.652) from dual; (显示24) select round(23.652, 2) from dual; (显示23.65) select round(23.652, -1) from dual; (显示20) select to_char(sal, '$99,999.9999')from emp;强制转化为指定的格式。 select to_char(sal, 'L0000.0000')from emp;同上。 select to_char(hiredate, YYYY-MM-DD HH:MI:SS) from emp; 对时间格式显示处理。 select to_char(sysdate, YYYY-MM-DD HH:MI:SS) from emp; 12进制。 select to_char(sysdate, YYYY-MM-DD HH24:MI:SS) from emp; 24进制。 *********************************************************************** **sql_function2******************************************************* select ename, hiredate from emp where hiredate > to_date('1981-2-20' 12:34:52, 'YYYY-MM-DD HH24:MI:SS'); 函数to_date 将字符转化为时间格式。 select sal from emp where sal > to_number('$1,250.00', '$9,999.99'); 函数to_number将字符转化为数字格式,以作比较。 select ename sal*12 + nvl(comm 0) from emp; 函数nvl作用为当comm为null的时候当作处理,避免了comm为null给结果带来的不便。
查看表:user_tables、all_tables、dba_tables 查看表字段:user_tab_columns、all_ tab_columns、dba_tab_columns 查看表注释:user_ tab_comments 、all_tab_comments、dba_tab_comments 查看字段注释:user_col_comments、all_col_comments、dba_col_comments 查看索引信息:user_indexes、all_indexes、dba_indexes 查看索引所在字段:user_ind_columns、all_ind_columns、dba_ind_columns 查看约束信息:user_constraints、all_constraints、dba_constraints 查看约束所在字段:user_cons_columns、all_cons_columns、dba_cons_columns 查看触发器信息:user_triggers、all_triggers、all_triggers 查看序列信息:user_sequences、all_sequences、dba_sequences 查看视图信息:user_views、all_views、dba_views 查看同义词信息:user_synonyms、all_synonyms、dba_synonyms 查看DBLINK信息:user_db_links、all_db_links、dba_db_links 查看JOB信息:user_jobs、all_jobs、dba_jobs 查看所有对象信息(过程PROCEDURE、函数FUNCTION、包和包体、JOB和LOB大字段、表、视图、索引、序列、触发器):user_objects、all_objects、dba_objects 查看过程、函数、触发器、包和包体内容:user_source、all_source、dba_source
分区表的使用 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。 一、Oracle中提供了以下几种表分区: 1、范围分区:这种类型的分区是使用列的一组值,通常将该列成为分区键。 示例1:假设有一个CUSTOMER表,表中有数据200000行,我们将此表通过CUSTOMER_ID 进行分区,每个分区存储100000行,我们将每个分区保存到单独的表空间中,这样数据文件就可以跨越多个物理磁盘。下面是创建表和分区的代码,如下: CREATE TABLE CUSTOMER ( CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY, FIRST_NAME V ARCHAR2(30) NOT NULL, LAST_NAME V ARCHAR2(30) NOT NULL, PHONE VARCHAR2(15) NOT NULL, EMAIL VARCHAR2(80), STATUS CHAR(1) ) PARTITION BY RANGE (CUSTOMER_ID) ( PARTITION CUS_PART1 V ALUES LESS THAN (100000) TABLESPACE CUS_TS01, PARTITION CUS_PART2 V ALUES LESS THAN (200000) TABLESPACE CUS_TS02 ) 注意:在创建表进行分区时,表空间必须先存在,而且建议将不同的分区放入不同的表空间中。 示例2:假设有ORDER_ACTIVITIES表,每6个月对订单进行清理,我们可以按月份对表进行分区,分区代码如下: CREATE TABLE ORDER_ACTIVITIES ( ORDER_ID NUMBER(7) NOT NULL, ORDER_DATE DA TE, TOTAL_AMOUNT NUMBER, CUSTOTMER_ID NUMBER(7), PAID CHAR(1) ) PARTITION BY RANGE (ORDER_DA TE) ( PARTITION ORD_ACT_PART01 V ALUES LESS THAN
竭诚为您提供优质文档/双击可除 oracle表格格式 篇一:oracle数据库表的创建 实验一oracle数据库表的创建 一、实验目的: 1.熟悉oRacle服务器产品、能够查看oRacle服务器安装结果,掌握服务器上的文件结构。 2.熟悉及掌握oRacle三种实用工具:sql-plus、 sql-pluswoRksheet、企业管理控制台。 3.了解库、表的结构特点。 4.了解oracle9i的基本数据类型。 5.学会使用t-sql语句创建和管理表。 二、实验器材: 计算机:p42.4、80g硬盘、512m内存、winodwsxp操作系统、oRacle9iFoRwindows 三、实验说明: 本次实验的计算机上已经安装了oRacle9iFoRwindows 数据库,其登录名为:sys或system;用户的密码:manager。 四、实验内容和步骤:
(一)oracle9i工具的熟悉与使用 1.查看数据库服务器上的安装结果 (1)查看服务器上安装的产品 在操作系统界面上选择【开始】/【程序】/【oracleinstallationproducts】/【universalinstaller】选项,调出oracle通用安装器,单击【已安装产品】按钮将看到已经成功安装在服务器上的oracle9i产品组件,如图所示。 (2)查看服务器的程序组 在操作系统界面上选择【开始】/【程序】可以看到安装完oracle9i系统后的程序组有两类,一类是“oracleinstallationproducts”,另一类是“orahome92”。前者是通用安装工具,后者包括了八类程序组,如图所示。 (3)查看服务器的服务 安装完毕后,数据库服务器必须以后台服务的方式运行起来,才能保证给客户端(或用户)提供各种对数据的管理和操作功能。 当完成数据库服务器的安装后,基本的服务已经自动运行起来了,但还有些服务需要手工启动。 对后台服务的管理操作为:双击【我的电脑】/【控制面板】/【管理工具】/【服务】选项,将出现该计算机上的所有服务列表,启动方式如果为“自动”表示该服务随数据
oracle分区表的建立方法 Oracle的分区表能够包括多个分区,每个分区差不多上一个独立的段(SEGMENT),能够存放到不同的表空间中。查询时能够通过查询表来访咨询各个分区中的数据,也能够通过在查询时直截了当指定分区的方法来进行查询。 分区提供以下优点: 由于将数据分散到各个分区中,减少了数据损坏的可能性; 能够对单独的分区进行备份和复原; 能够将分区映射到不同的物理磁盘上,来分散IO; 提高可治理性、可用性和性能。 Oracle提供了以下几种分区类型: 范畴分区(range); 哈希分区(hash); 列表分区(list); 范畴-哈希复合分区(range-hash); 范畴-列表复合分区(range-list)。 Oracle的一般表没有方法通过修改属性的方式直截了当转化为分区表,必须通过重建的方式进行转变,下面介绍三种效率比较高的方法,并讲明它们各自的特点。
方法一:利用原表重建分区表。 步骤: SQL> CREATE TABLE T (ID NUMBER PRIMARY KEY, TIME DATE); 表已创建。 SQL> INSERT INTO T SELECT ROWNUM, CREATED FROM DBA_OBJECTS; 已创建6264行。 SQL> COMMIT; 提交完成。 SQL> CREATE TABLE T_NEW (ID, TIME) PARTITION BY RANGE (TIME) 2 (PARTITION P1 V ALUES LESS THAN (TO_DATE('2004-7-1', 'YYYY-MM-DD')), 3 PARTITION P2 V ALUES LESS THAN (TO_DA TE('2005-1-1', 'YYYY-MM-DD')), 4 PARTITION P3 V ALUES LESS THAN (TO_DA TE('2005-7-1', 'YYYY-MM-DD')), 5 PARTITION P4 V ALUES LESS THAN (MAXV ALUE)) 6 AS SELECT ID, TIME FROM T; 表已创建。 SQL> RENAME T TO T_OLD;