
C-RAN组网时的CPRI时延抖动测试
是德科技(中国)有限公司李凯
摘要:
集中基带池和分布式射频拉远技术是4G/B4G/5G无线接入网组网的发展趋势。为了节省光纤资源,会把基带池和多个射频拉远模块间的CPRI链路复用在一根光纤上进行传输,由此增加的时延抖动是否会影响系统可靠性是设计组网方案时要重点考虑的因素。本文介绍了一种利用是德公司(原安捷伦公司电子测量仪器部)的高带宽实时示波器进行C-RAN组网时的CPRI 时延抖动测试的方法,并根据实际测试结果对彩光直驱和OTN承载两种方式的时延抖动进行了分析。
关键词:
C-RAN,CPRI,时延精度,抖动
一、前言
4G移动通信技术已经进入商用阶段, 5G关键技术业已进入研发。目前及未来的更长时间,运营商需要在有限的频谱资源下提供更高的容量和数据传输速率。LTE/LTE-A中高带宽及高阶调制技术的引入,使得对于信噪比要求更高,因此单个LTE基站的覆盖范围会比采用3G技术时要小。密集组网和基站间协作的要求带来了基站站点数量扩容的巨大需求,相应地带来了选址、功耗、海量光纤资源的巨大挑战。因此,合适的组网和传输方案是推进高速数据网络应用普及的关键技术。
为此,各大运营商都在进行新的无线接入网组网方式的研究。比如中国移动的C-RAN是基于集中化处理(Centralized Processing)、协作式无线电
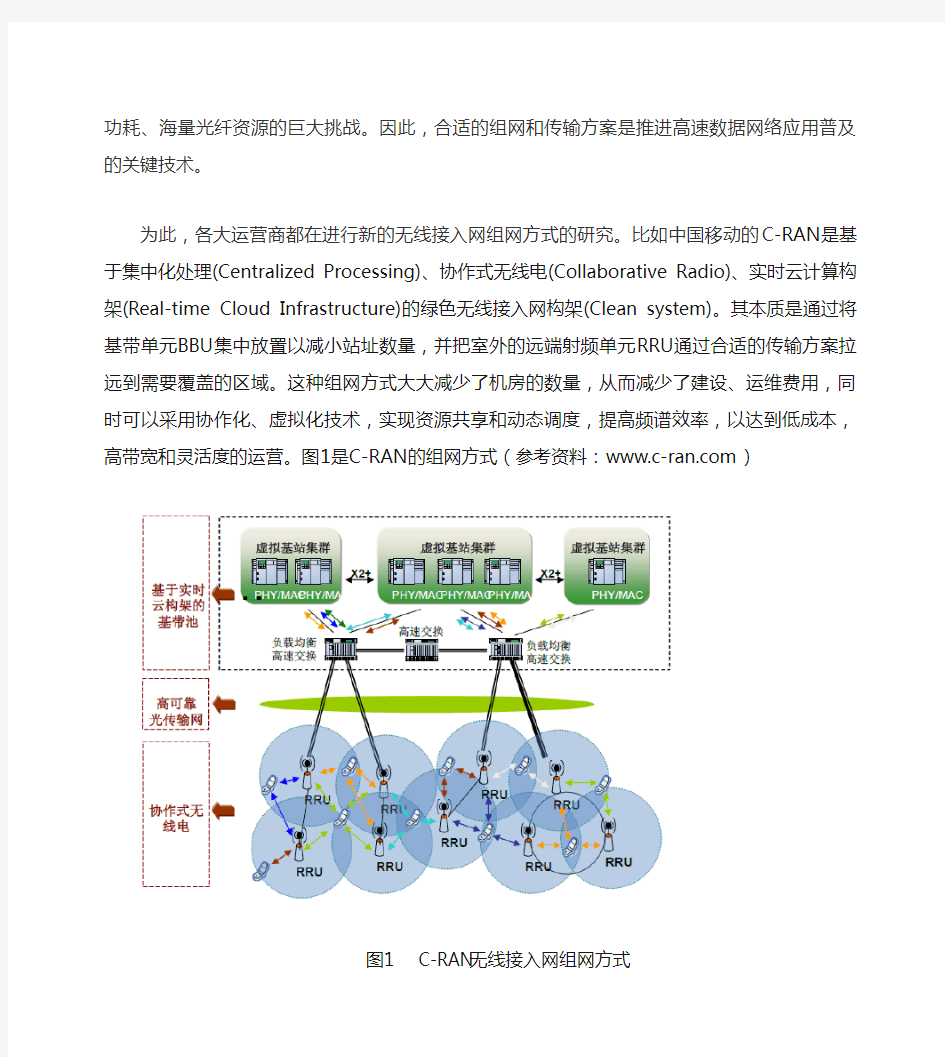
(Collaborative Radio)、实时云计算构架(Real-time Cloud Infrastructure)的绿色无线接入网构架(Clean system)。其本质是通过将基带单元BBU集中放置以减小站址数量,并把室外的远端射频单元RRU通过合适的传输方案拉远到需要覆盖的区域。这种组网方式大大减少了机房的数量,从而减少了建设、运维费用,同时可以采用协作化、虚拟化技术,实现资源共享和动态调度,提高频谱效率,以达到低成本,高带宽和灵活度的运营。图1是C-RAN的组网方式(参考资料:https://www.doczj.com/doc/573498004.html,)
图1 C-RAN无线接入网组网方式
但是这种组网方式也带来了新的挑战,其中一个要考虑的就是BBU和RRU间的CPRI信号经过传输后的时延抖动是否还满足CPRI规范的要求。
二、CPRI接口时延抖动的测试方法研究
CPRI接口传统上只是用于BBU和RRU之间的直接光纤互联,传输距离在
几百米左右,而采用C-RAN的组网方式后传输距离会加长到几十公里。为了
节省光纤资源,必须通过合适的传输方式把多条CPRI链路数据复用到一根光纤上传输,目前采用的主流技术有彩光直驱和OTN承载两种方式。彩光直驱
的方式是把多路CPRI信号通过光合分波器通过WDM方式复用在一起,具有
成本低、抖动小的优点;而OTN承载,即CPRI over OTN方式,是把CPRI
数据按照ITU-T G.709要求映射到传输网上传输,所以可靠性高、组网灵活。
无论采用哪种承载方式,都需要对CPRI信号经过传输后的定时信息的时
延和抖动情况进行测试,以确保不会影响CPRI协议本身对于时延抖动的严格要求。目前TD-LTE技术可以允许约200us的时延,因此整个传输链路(包括
光纤和传输设备)的时延不应超过这个范围。关于抖动的要求可以参考CPRI 的规范,从图2可见,CPRI要求链路时延抖动不能超过8.138ns,要求非常
严格。(参考资料:CPRI Specification V6.0)。
图2 CPRI规范对于链路时延精度的要求
随着LTE技术的采用,基带单元BBU和射频拉远单元RRU间的CPRI数据
传输速率急速攀升,目前已经逐渐从2.4576Gbps过渡到6.144Gbps甚至
9.8304Gbps。目前市面上的传输测试仪表或者支持不了9.8304Gbps的传输
速率,或者无法进行ns量级的精确时延抖动测量,因此需要寻找一种新的测
试方法,以对采用不同C-RAN组网传输方式时的时延抖动进行精确测试。
要进行两路信号间的时延和抖动的测量需要在信号中找到相应的同步标志。经过对CPRI协议的研究,发现在CPRI的帧结构中,每66.67us会有一个超帧,如图3所示。(参考资料:CPRI Specification V6.0)。而CPRI的物理层采用ANSI的8b/10b编码方式,每个超帧的帧头会有一个唯一的K28.5码型标识发送,因此可以用这个K28.5码型标识做为测试的依据。
图3 CPRI的帧结构
三、测试组网
CPRI传输时延抖动的测试组网如图4所示,测试系统采用是德公司(原安捷伦公司电子测量仪器部)的高带宽示波器和光电转换器搭建。
正常业务从BBU下发的CPRI信号经过传输设备和光纤到达RRU侧,从传输设备的入口和出口侧通过分光器各引出一路光纤信号接入测试系统。图4中所示是进行下行链路时延抖动测试的组网,也可以反过来进行上行上行链路的测试。
从被测系统引出的两路光纤信号经N1075A-S32或者81495A光电转换
器把两路光信号转成电信号,然后用高带宽的DSA90000X实时示波器进行
测量。
图4 CPRI传输时延抖动的测试组网
光电转换器有两种型号可供选择。81495A是数据速率到10Gbps的低噪
声光电转换器模块,需要插在8163B的机箱里才可工作,其内置10Gbps光信号的标准参考滤波器、光功率计及高带宽放大器。81495A的光电转换增
益高达400V/W,因此输入光信号强度可以低至-10dbm。为了节省体积和成本,一个8163B的机箱里可以同时插入2个81495A的模块。而N1075A-
S32是另一种光电转换器,其数据速率最高到32Gbps且内置分光器,但是
由于光电转换增益仅为110 V/W,为了保证最后输出的电信号进入示波器后
仍然有较好的信噪比,所以需要被测光信号的光强不能太小(建议>-5dbm)。
DSA90000X系列是非常高性能的高带宽实时示波器,最高带宽可达
33GHz,最大采样率80G/s,固有抖动小于150fs,同时可以捕获4条CPRI 接口的信号并进行物理层解码。发送端的信号经光电转换器后连接示波器通道1,接收端的信号经光电转换器后连接示波器通道3。测试中用实时示波器捕获发端和收端的信号并进行时延和抖动的测量;
下图是使用DSA90000X实时示波器配合N1075A光电转换器做CPRI
时延抖动测试的实际测试环境。
图5 实际的CPRI传输时延抖动测试环境
四、时延测试步骤
时延测试的方法是测试BBU发出信号的超帧帧头的时刻到RRU收到的
信号的超帧帧头的时间差。
1) 设置示波器对输入信号波形进进行采集,采集时间至少为200us。如
图6中黄色通道CH1波形为BBU发出的CPRI信号波形,蓝色通道
CH3波形为RRU收到的CPRI信号波形。
2) 设置示波器对通道CH1和通道CH3的波形进行解码,并分别搜索
CPRI超帧头的同步字符。
3) 记录通道CH1第一个同步字符K28.5发生的时刻,如图6中的值为: -
59.90911203us。
4) 记录通道CH3中后续的同步字符K28.5发生的时刻,如图7中的值为:
-41.52044482us。
5) 把两个测量结果相减即为光纤加上传输设备造成的时延。即传输系统
时延=-41.52044482us -(-59.90911203us)= 18.38866721us。
此时测量出的时延为光纤时延加上传输设备造成的时延,可以减去光纤
长度造成的时延得到传输设备时延。如果测试环境允许也可以直接采用0km
光纤进行测试,以得到传输设备本身的时延数据。
注意:由于CPRI协议中每66.67us会有一个超帧的帧头发送,因此同
步字符会以66.67us为周期出现,当使用长光纤时需要注意合适的同步字符
位置的选取。比如使用15km光纤时,光纤造成的时延约为75us,已经超过了超帧帧头的出现周期,所以在第4步中应选择相对于第3步的时间结果
75us之后的第一个同步字符出现的时刻作为有效数据。
图6 BBU发出的CPRI信号解码结果
图7 RRU收到的CPRI信号解码结果
五、抖动测试步骤
当进行完系统的时延测试时,下一步是进行CPRI信号经传输后抖动的测量。这需要进行一段时间内的多次连续测量并比较输入信号和输出信号间时
延的相对变化范围。测试步骤如下:
1) 根据前面时延测量结果,对两路信号间的固有时延在示波器里进行补
偿,如图8所示。可以看到进行补偿后输入和输出信号基本重合。
图8固有时延的补偿
2) 设置示波器对通道CH1的K28.5同步字符触发并进行多次波形采集,
这样通道CH1的同步字符会一直保持在时间的零点,即屏幕的正中央。
如果系统有抖动,通道CH3的K28.5同步字符的发生时刻会有左右的时间变化。图9分别是三次测量中,通道CH3的K28.5同步字符发生的时刻,可以明显看到时延的变化情况。
图9 三次测量中时延的变化情况
3) 在示波器的Trigger Action里设置自动保存测量结果,如图10所示,
可以设置自动保存测量结果的次数。随后用户可以对测量结果进行整理和统计分析。
图10 设置自动保存每次测量结果的拷屏
六、测试结果分析
采用前述的测试方法在机房环境理对市面上4家主流的设备厂商的无线接入网设备进行了CPRI时延抖动的测试。其中2家采用OTN传输方案,2家采用彩光直驱方案,测试中使用的光纤长度从0km~
15km不等,CPRI接口上承载9.8304Gbps的真实业务。每次测试都是在约3分钟的时间内进行30次测量并对结果进行统计分析。
测试结论如下:
采用OTN传输方案时,端到端由于设备造成的时延(扣除光纤时延以后)普遍在几个us左右,抖动约在2~4ns不等。
这可能由于有OTN的成帧解帧过程会造成一定的时延和抖动。
收发端进行精确的时钟同步可能有助于减小时延抖动。
采用彩光直驱方案时,端到端由于设备造成的时延(扣除光纤时延以后)普遍在几百ns左右,抖动都<300ps。这可能
由于直驱方式没有数据处理,所以时延和抖动都较小。
在机房环境下的短时间测量中,改变不同的光纤长度造成的只是绝对时延的变化,对于抖动的影响几乎很小(<100ps)。
实际运营情况下由于光纤造成的抖动还有待研究。
从测试结果来看,彩光直驱和OTN传输造成的时延抖动都没有超过CPRI规范的8ns的要求。彩光直驱时由于设备本身造成的时延和
抖动相比OTN传输时都要小一个数量级。采用 OTN方案时要重点关
注在不同时钟同步情况下的抖动情况。
以上测试结果和实际预期一致,说明测试方法是真实有效的。不过由于资源和时间所限,以上都是短时间、小样本量的测试。实际运营
情况下的长时间、大样本量的测试还有待具体的测试环境。
七、测试方案优缺点分析
这种基于实时示波器和光电转换器的CPRI接口时延抖动测试方法非常精确,测试仪表的硬件固有抖动小于150fs,考虑到解码精度带来
的误差总体测量精度小于1个数据bit周期(对于9.8304G的CPRI信
号来说相当于约100ps)。因此,这种测试方案可以在目前没有成熟
传输测试仪表的阶段有效完成精确的时延抖动测量,方便设备厂商在
研发阶段进行实际测试,也可供运营商在前期规划阶段对不同组网方案进行评估。
另外,这套测量方案的主体是高带宽的实时示波器,这款设备还可以用用于BBR和RRU内部电路如SFP+、PCIE、DDR、时钟等接口的调试。
目前这套测试方案的不足之处在于还不是全自动的参数测试。测试前还需要手动进行示波器的设置,测试后还不能自动对测试结果进行统计分析。
不过综合考虑测试精度以及可行性,这套方案基本可以满足现阶段进行CPRI时延抖动进行摸底测试的需要,以推动绿色无线接入网的商用化进程。未来随着测试需求的进一步增多,也有可能把这套测试方案开发成自动测试软件。
目录 1网络化控制系统简介 (1) 2网络化控制系统中的问题 (2) 3网络延时对PID控制系统性能影响的分析 (4) 3.1系统描述(System description) (4) 3.2 仿真分析(Simulation analysis) (6) 4网络延时为不同值的系统分析 (8) 4.1网络延时的系统阶跃响应 (8) 4.2 的系统的阶跃响应 (9) 4.3 时的系统阶跃响应 (9) 4.4 系统根轨迹分析 (10) 5实际实验(P RACTICAL EXPERIMENT) (12)
1网络化控制系统简介 网络化控制系统NCS(Networked Control Systems),又称集成通讯与控制系统ICCS (Integrated Communication and Control System)。一般认为ICCS是一种全分布式、网络化实时反馈控制系统,是将控制系统的传感器、控制器、执行器等单元通过通讯网络连接起来形成闭环的分布式控制系统。其涵盖了两方面的内容:系统节点的分布化和控制回路的网络化。这种网络化的控制模式具有信息资源能够共享、连接线数大大减少、易于扩展、易于维护等优点,但由于网络中的信息源很多,信息的传送药分时占用网络通讯资源,而网络的承载能力和通讯带宽有限,必然造成信息的冲撞、重传等现象的发生,使得数据在传输过程中不可避免地存在时延。时延由于受到网络所采用的通讯协议、负载状况、网络速率以及数据包大小等情况到影响,呈现出或固定或随机,或有界或无界的特征,从而导致控制系统性能下降甚至不稳定,也给控制系统的分析和设计带来困难。网络给NCS带来的主要问题包括:时延采样时刻和执行器响应时刻间出现了不可忽略的滞后;在某时间间隔内存在于时间相关的抖动;由于数据包在网络中传输发生丢失或冲突,导致时延增大甚至系统失稳。NCS的性能不仅依赖于控制策略及控制律器的设计,而且受到网络通讯和网路资源的限制。信息调度应尽可能避免网络中信息的冲突和拥塞现象的发生,从而大大提高网络化控制系统的服务性能。 网络化控制系统是综合自动化技术发展的必然趋势,是控制技术、计算机技术和通信技术相结合的产物。本书基于现场总线技术及自动化北京市重点实验室的科研成果,系统地介绍了网络化控制系统的组成原理、控制结构、建模方法,网络拥塞闭环控制机理,网络时延闭环控制方法,现场总线控制技术及应用,基于工业以太网的控制系统设计,基于Internet 和Web的网络远程控制系统设计。网络化控制系统软件开发技术,以及网络化控制技术在工业加热炉、工业锅炉和电厂锅炉湿法烟气脱硫中的应用。 在传统的计算机控制系统中,传感器和执行器都是与计算机实现点对点的连接,传递信号一般采用电压和电流等模拟信号。在这种结构模式下,控制系统往往布线复杂,从而增加了系统成本,降低了系统的可靠性、抗干扰性、灵活性和扩展性,特别在地域分散的情况下,传统控制系统的高成本、低可靠性等弊端更加突出。随着计算机技术和网络通信技术的不断发展,工业控制系统也发生了巨大的技术变革,网络化控制系统(NetworkedControlSystem,NCS)应运而生,其主要标志就是在控制系统中引入了计算机网络,从而使得众多的传感器、
RTP/RTCP 丢包/抖动/时延计算原理 1.RTP/RTCP的基本功能介绍 实时传输协议RTP(A Transport Protocol for Real-Time Application)提供实时的端对端传输业务(如交互的语音和图象),包括负载类型标识,序列号,时间戳,传输监视。 实时传输协议(RTP)本身并不提供任何机制保证实时传输或业务质量保证,而是让底层协议去实现。 RTP包括两个紧密相关的部分: 实时传输协议(RTP-Real Time Transport Protocol),传输有实时特性的信息; RTP控制协议(RTCP-RTP Control Protocol),监视业务质量和传输对话中成员的信息。 RTP/RTCP报文封装格式为:DL+IP+UDP+RTP/RTCP 2.RTP报文统计方法介绍 RTP报文发送统计: NTP时间标志:64比特,指示了此报告发送时的壁钟(wallclock)时刻,它可以与从其它接收者返回的接收报告块中的时间标志结合起来,测量到这些接收者的环路时延。 RTP时间标志:32比特,与以上的NTP时间标志对应同一时刻,但是与数据包中的RTP时间标志具有相同的单位和偏移量。 发送包数:32比特,从开始传输到此SR包产生时该发送者发送的RTP数据包总数。 若发送者改变SSRC识别符,该计数器重设。 发送字节数:32比特,从开始传输到此SR包产生时该发送者在RTP数据包发送的字节总数(不包括头和填充)。若发送者改变SSRC识别符,该计数器重设。 RTP报文接收统计: 丢包率:8比特,自从前一SR包或RR包发送以来,从SSRC_n传来的RTP数据包的损失比例,以固定点小数的形式表示,小数点在此域的左侧,等于将丢包率乘256后取整数部分。该值定义为损失包数被期望接收的包数除。(对应RTCP消息中的丢
VOLTE抖动时延优化专题研究
目录 摘要 (3) 背景 (4) 一、RTP简介 (5) 1.1RTP是什么 (5) 1.2RTP的应用环境 (5) 1.3RTP时延抖动公式 (6) 二、VOLTE调度概述 (7) 2.1向网侧发送BSR (7) 2.2向网侧发送SR (7) 2.3发起竞争随机接入 (8) 三、智能预调度优化 (8) 3.1优化背景 (8) 3.2预调度原理 (8) 3.3智能预调度与DRX关系 (10) 3.4预调度功能验证 (11) 3.4.1定点验证 (11) 3.4.2连片验证 (13) 3.4.3智能预调度参数组验证 (15) 四、DRX优化 (18) 4.1DRX原理 (18) 4.1.1DRX概述 (18) 4.1.2为什么要使用DRX-InactivityTimer (19) 4.1.3长周期和短周期 (19) 4.1.4DRX流程 (20) 4.2DRX功能生效验证 (21) 4.2.1测试软件观察DRX参数配置 (21) 4.2.2智能预调度与DRX关系 (22) 4.3DRX参数优化验证 (26)
4.3.1DRX长周期优化 (26) 4.3.2拉网验证 (27) 五、上行补偿调度优化 (29) 5.1优化原理 (29) 5.2测试验证 (30) 5.2.1定点验证 (30) 5.2.2连片验证 (31) 六、语音调度优先优化 (33) 6.1优化原理 (33) 6.2测试验证 (34) 6.2.1定点验证 (34) 6.2.2连片验证 (35) 七、总结 (36)
摘要 随着4G网络的快速发展,以及电信VOLTE的商用的临近,电信用户也对高清VOLTE业务充满着期待,同时VOLTE语音新业务的兴起及用户对体验的追求时时刻刻挑战着目前网络的现状。语音抖动时延是各个语音承载网络制式下的重要感知指标,本文主要以优化VOLTE调度方式为切入点,从绑定智能预调度参数组、优化DRX长周期、上行调度补偿和语音调度优先四个方面探索缩短语音抖动时延的方法,提升VOLTE用户感知。 【关键字】RTP 抖动时延智能预调度 DRX 上行补偿调度语音调度增强 背景 语音包在UM传输模式下,对端并不能完全接受,RTP Packet Loss丢包类型字段也有很多,其中RTP NETWORK LOSS 表示终端收到的RTP包序号不连续,分为二种情况,第一种是RTP空口/网络传输中被丢弃,第二种是RTP包到达乱序,序号大的包先到,此类场景出现较少。第一种会影响MOS分,第二种对MOS无影响,终端可以自己排序。QDJ UNDERFLOW表示RTP包没有丢,但是包抖动太大,终端对应时刻在buffer中取改RTP包时没有收到对应的包,该类对MOS有影响。其中在抚州前期的拉网测试中出现许多这种因为语音包时延抖动过大导致语音包溢出缓冲区,导致语音包丢失。如下图
长时延丢包网络控制系统的分析与建模 江卷,朱其新 华东交通大学电气学院,南昌(330013) E-mail:broading@https://www.doczj.com/doc/573498004.html, 摘要:本文分析了网络控制系统中的主要问题,在传感器为时间驱动,控制器和执行器为事件驱动的前提下,提出了在综合考虑网络诱导时延、时序错乱和数据包丢失时网络控制系统的建模方法,并得出了网络控制系统模型。 关键词:网络控制系统;长时延;数据包丢失;建模 1.引言 网络控制系统(networked control systems,简记为NCS)是指通过网络形成闭环的反馈控制系统,是控制科学和飞速发展的计算机网络、以及通讯技术相结合的产物。NCS与传统的点对点结构的系统相比,减少了复杂的物理连接、可以实现资源共享、实现远程操作与控制、具有高的诊断能力、安装与维护简便、能有效减少系统的重量和体积、增加了系统的灵活性和可靠性等诸多优点。正因为这些优点使得网络控制系统得到广泛的应用,网络控制问题也得到了国际控制科学界和计算机科学界的广泛关注。 网络控制系统由传感器、控制器和执行器三部分组成。传感器和控制器以及控制器和执行器之间是通过网络进行数据传输的。网络控制系统(NCS)的结构如图1所示。 图1 网络控制系统结构示意图 由于网络加入控制系统中,给控制系统带来优点的同时,也给控制系统的研究带来了新的机遇和挑战。在网络中由于不可避免地存在网络阻塞和连接中断,这又会导致网络数据包的时序错乱和数据包的丢失。NCS中的网络诱导时延会降低系统性能甚至引起系统不稳定,现在时延系统的分析和建模近年来已取得很大发展。文献【1, 2】提出了通过在系统的数据接收端设置一定长度的缓冲区的方法将ICCS的随机时延转化成一确定性时延,从而将一随机时变的系统转换成一确定性系统,并基于该确定性模型设计了ICCS的多步时延补偿器,并检验了系统模型中含有不确定参数时该补偿算法的鲁棒性。文献【3】出了一种多输入多输出ICCS的时延补偿算法,并将使用下一步预测的标准环路传递再生方法推广到多步预测的情况。由于NCS的确定性控制方法人为地扩大了网络诱导时延,从而降低了系统的性能因此很多学者研究了NCS的随机控制方法。文献【4】分析了ICCS的网络诱导时延,在时延分析中考虑了信号丢失(message rejection)和无效采样(vacant sampling),并基于控制器的离
36 0 引言 随着通信技术不断的发展,对通信技术的研究工作逐步深入。TD-LTE(Time Division Long Term Evolution)是我国研发的3G 通信技术标准TD-SCDMA(Time Division- Synchronization Code Division Multiple Access)的长期演进技术,国家在“新一代宽带无线通信网”计划中对TD-LTE 研究做出了巨大投入。 基站基带设备与射频设备之间接口称为Ir 接口。Ir 接口协议是依据通用公共无线接口CPRI (Common Public Radio Interface)协议规范制定的[1]。通用公共无线接口联盟是一个工业合作组织,致力于从事无线基站内部无线设备控制中心REC (Radio Equipment Controller )及无线设备RE(Radio Equipment)之间主要接口规范的制定工作[2]。CPRI 规范定义了OSI(Open System Interconnect)系统模型的物理层和数据链路层两层结构,物理层支持电口和光口两种接入方式,并支持时分复用。数据链路层可支持用户平台数据(IQ 数据),控制和管理平台数据,同步平台数据三种数据流。CPRI 规范系统结构图如图1所示: FPGA 以其优越的性能广泛应用于接口设计和复杂算法实现技术上。全球领先的半导体解决方案提供商Xilinx 公司和全球市场份额第二的Altera 公司均以开发出基于FPGA 的适用于工业,通信,网络等领域的专用接口解决方案,如PCI (Peripheral Component Interconnect )、PCIE(Peripheral Component Interconnect Express)、SPI(Serial Peripheral Interface)、I2C(Inter-Integrated Circuit)、Rapid IO 、CPRI 等接口。 文章基于“新一代宽带无线通信网”国家科技重大专项的子课题:TD-LTE Ir 接口一致性仿真与监测工具的开发。TD-LTE Ir 接口系统由一个基带设备和两个射频设备组成,通过光纤进行连接,采用级联的方式进行数据通信如图2所示。基带设备作为系统中的核心基带处理单元,在整个系统中起主要控制作用。 在实际的基带设备中,基带设备需要将用户数据向其上层的控制设备上报,以便完成对用户数据的处理。为验证本课题中Ir 接口对用户IQ (In-phase Quadrature )数据的处理功能。需要将基站设备中CPRI 核解析出的IQ 数据,实时高速传输至上 基于CPRI 协议的FPGA 高速数据传输模块设计与实现 王艳秋1,李旭2,高锦春1,唐碧华1,张洪光1 (1. 北京邮电大学电子工程学院,北京 100876;2. 中国电信信息化部,北京 100032) 摘 要:随着通信技术不断发展,CPRI 协议作为无线基站的接口规范逐步完善,可支持的数据速率不断提高。本课题基于“新一代宽带无线通信网”国家科技重大专项:TD-LTE 基站基带与射频模块间接口(Ir 接口)仿真与监测工具开发。本文为了测试基带设备对IQ 数据的处理能力,基于FPGA 实现对用户数据(IQ 数据)的实时高速传输至上位机进行存储。通过比较现有高速数据传输技术,提出采用分层化,模块化的设计思想,利用FPGA 实现UDP/IP 协议栈,通过千兆以太网传输至上位机。通过测试验证,本模块可实现对IQ 数据的实时高速传输,满足设计要求。 关键词:通信系统;IQ 数据;UDP/IP 协议栈;FPGA; 中图分类号:TP332 文献标识码:A DOI:10.3969/j.issn.1003-6970.2013.12.009 本文著录格式:[1]王艳秋,李旭,高锦春,等.基于CPRI 协议的FPGA 高速数据传输模块设计与实现[J].软件,2013,34(12): 36-40 CPRI Protocol Based FPGA High-speed Data Transmission Module Design and Implementation WANG Yan-qiu 1,LI Xu 2,GAO Jin-chun 1,TANG Bi-hua 1,ZHANG Hong-guang 1 1(Beijing University of Posts and Telecommunications, Beijing 100876,China)2(China Telecommunication information department, Beijing 100032,China) 【Abstract 】CPRI protocol as the communication technology unceasing development, gradually improve as a wireless base station interface specification, can support data rate continuously improve. This topic is based on "a new generation broadband wireless communication network" national science and technology major projects: the td-scdma baseband and rf module LTE base station indirect mouth interface (Ir interface) simulation and monitoring tool development. In this paper, in order to test the baseband equipment of IQ data processing capabilities, based on the FPGA implementation of user data (IQ) of real-time transmission first place machine for storage at a high speed. By comparing the existing high speed data transmission technology, put forward the method of layered and modularized design idea, using FPGA to realize the UDP/IP protocol stack, through the supremacy of gigabit Ethernet transmission machine. Through test validation, this module can realize the IQ real-time high-speed data transmission, meet the design requirement. 【Key words 】communication system; IQ data; UDP/IP stack;FPGA 作者简介:王艳秋(1987-),女,硕士研究生,计算机硬件,数字电路设计 通信联系人:高锦春,教授,主要研究方向:无线通信关键技术,通信可靠性的研究及其产品的研发工作.
数字直放站中CPRI 协议的FPGA 实现 陈岳林1,石江宏2 (1.厦门大学 福建厦门 361005;2.厦门大学无线通信实验室 福建厦门 361005) 摘 要:为了开发数字直放站连接系统,介绍CPRI 协议规范和帧结构,讨论其硬件上的实现方案,给出基于 SCAN25100的FP GA 电路模块设计,采用Verilog 语言设计开发功能模块。该方案具有便于功能扩展、成本低、使用灵活等 特点,通过实际测试表明,此方案可进行可靠的数据传输,性能稳定,从而实现了数字直放站和基站之间更有效的互通,扩大了基站的覆盖范围。 关键词:直放站;CPRI ;现场可编程逻辑阵列;SCAN25100 中图分类号:TN913 文献标识码:B 文章编号:10042373X (2009)042031204 Implementation of CPRI Protocol in Digital R epeater on FPG A CH EN Yuelin 1,SHI Jianghong 2 (1.Xiamen University ,Xiamen ,361005,China ;2.Wireless Communication Lab ,Xiamen University ,Xiamen ,361005,China ) Abstract :To develop the connection of digital repeaters ,CPRI protocol specification and f rame structure are introduced.Its implementation on hardware is discussed.The detail module design of FP GA circuit and program based on SCAN25100are elaborated.The design is easy to expand and low cost.The experimental analysis shows that the solution could accomplish the data transmission ,and the interconnection between base station and digital repeater are implemented ,the network ′s coverage is enhanced. K eywords :repeater ;CPRI ;FP GA ;SCAN25100 收稿日期:2008208221 基金项目:福建省重大专项基金资助项目(2007HZ003) 0 引 言随着移动通信的发展,通信网络覆盖范围已经成为衡量通信网络运行的重要标准,直接影响着运营商的经济效益。而直放站的发展应用,已成为提高运营商网络质量,解决网络盲区或弱区问题,增强网络覆盖的主要手段之一。一个基站可以与几个直放站相连,可以组成链状、星型、树型等灵活的拓扑结构,使基站的覆盖范围大大增加。同时,既节省空间,又降低成本,提高了组网的效率。 但由于传统模拟直放站设备间没有统一的协议规范,无法满足系统厂商与直放站厂商的兼容,无法实现基站和直放站之间更有效的互通,从而限制了两者之间控制和数据的可靠传输。2003年6年,由包括爱立信、华为、N EC 、北电网络及西门子5大集团合力制定了CPRI (Common Public Radio Interface )接口。该组织成立的主要目的是制定这个接口的标准协议,从而使该接口成为一个公共的可用的指标。开放的CPRI 接口为3G 基站产品和2G 数字直放站在增加效益,提高灵活性方面提供了便利。 1 CPRI 协议概述 CPRI 规范[1]定义了物理层和链路层两层协议,能 实现数字基带IQ 信号传输时分复用,其协议结构图如图1所示[2]。物理层用千兆以太网的标准,传输的数据采用8B/10B 编解码,通过光模块串行发送,为达到所要求的灵活度和成本效益,线路比特速率有614.4Mb/s ,1228.8Mb/s 和2457.6Mb/s 三种。链 路层定义了一个同步的帧结构。帧结构包括基本帧和超帧,每个基本帧的帧频为3.84M Hz ,包括16个时隙,根据线路比特率的不同,每个时隙的大小分别为1B ,2B ,4B 。其中第一个时隙为控制时隙,其余15个 时隙为I/O 数据时隙,用来传送I/O 数据流。超帧则由256个基本帧构成,256个基本帧的控制时隙共同构成超帧的控制结构(如图2所示),同时,定义了快速C/M 通道(以太网)和慢速C/M 通道(HDL C ),用于传送 控制类和管理类的数据,可以对直放站进行维护[3,4]。2 硬件实现方案2.1 方案对比 对于CPRI 硬件实现方案,有以下几种方案可以选择: 1 3《现代电子技术》2009年第4期总第291期 计算机应用技术
C-RAN组网时的CPRI时延抖动测试 是德科技(中国)有限公司李凯 摘要: 集中基带池和分布式射频拉远技术是4G/B4G/5G无线接入网组网的发展趋势。为了节省光纤资源,会把基带池和多个射频拉远模块间的CPRI链路复用在一根光纤上进行传输,由此增加的时延抖动是否会影响系统可靠性是设计组网方案时要重点考虑的因素。本文介绍了一种利用是德公司(原安捷伦公司电子测量仪器部)的高带宽实时示波器进行C-RAN组网时的CPRI 时延抖动测试的方法,并根据实际测试结果对彩光直驱和OTN承载两种方式的时延抖动进行了分析。 关键词: C-RAN,CPRI,时延精度,抖动 一、前言 4G移动通信技术已经进入商用阶段, 5G关键技术业已进入研发。目前及未来的更长时间,运营商需要在有限的频谱资源下提供更高的容量和数据传输速率。LTE/LTE-A中高带宽及高阶调制技术的引入,使得对于信噪比要求更高,因此单个LTE基站的覆盖范围会比采用3G技术时要小。密集组网和基站间协作的要求带来了基站站点数量扩容的巨大需求,相应地带来了选址、功耗、海量光纤资源的巨大挑战。因此,合适的组网和传输方案是推进高速数据网络应用普及的关键技术。 为此,各大运营商都在进行新的无线接入网组网方式的研究。比如中国移动的C-RAN是基于集中化处理(Centralized Processing)、协作式无线电
(Collaborative Radio)、实时云计算构架(Real-time Cloud Infrastructure)的绿色无线接入网构架(Clean system)。其本质是通过将基带单元BBU集中放置以减小站址数量,并把室外的远端射频单元RRU通过合适的传输方案拉远到需要覆盖的区域。这种组网方式大大减少了机房的数量,从而减少了建设、运维费用,同时可以采用协作化、虚拟化技术,实现资源共享和动态调度,提高频谱效率,以达到低成本,高带宽和灵活度的运营。图1是C-RAN的组网方式(参考资料:https://www.doczj.com/doc/573498004.html,) 图1 C-RAN无线接入网组网方式 但是这种组网方式也带来了新的挑战,其中一个要考虑的就是BBU和RRU间的CPRI信号经过传输后的时延抖动是否还满足CPRI规范的要求。
翻译:许江华 Adobe Systems Inc. AMF3Specification Category:ActionScript Serialization类别:AS序列化 Action Message Format--AMF3 Copyright Notice Copyright(c)Adobe Systems Inc.(2002-2006).All Rights Reserved. Abstract概览 Action Message Format(AMF)is a compact binary format that is used to serialize ActionScr ipt object graphs.Once serialized an AMF encoded object graph may be used to persist and retrieve the public state of an application across sessions or allow two endpoints to communicate through the exchange of strongly typed data. AMF(Act ion Message Format动作信息格式)是用来序列化AS(ActionScr ipt动作脚本)实例对象(object graphs)的压缩的二进制格式。序列化的AMF编码的实例对象可用来持久化,并且在不同的会话中获得应用的公共状态,或者允许在两个端点(比如客户端和服务器端--译者注)通过强类型数据交换进行通信。 AMF was introduced in Flash Player6in2001and remained unchanged with the introduction of ActionScr ipt2.0in Flash Player7and with the release of Flash Player8.This version of AMF is referred to as AMF0(See[AMF0]).In Flash Player9,Action Script3.0was introduced along with a new ActionScr ipt Virtual Machine(AVM+)-the new data types and language features made possible by these improvements prompted AMF to be updated.Given the opportunity to release a new version of AMF,several opt imiza tions were also made to the encoding format to remove redundant information from serialized data.This specif ication defines this updated version of AMF,namely AMF3. AMF引进于2001年的FlashPlayer6,并且在引入AS2.0的FlashPlayer7和FlashPlayer8中没有改变的保留了。这个版本的AMF参考于AMF0(查阅[AMF0])。在FlashPla yer9中,AS3.0同新的AS虚拟机(AVM+)一起被引进—新的数据类型和语言特性的改进致使AMF升级成为可能,给了一个发布新的AMF版本的机会,新版本的AMF在序列化数据的时候做了一些优化,使得编码格式去除了一些冗余信息。升级后的AMF版本便是AMF3。 Table of Contents目录(略) 1Introduction介绍 1.1Purpose目的 Action Message Format(AMF)is a compact binary format that is used to serialize ActionScr ipt object graphs.Once serialized an AMF encoded object graph may be used to persist and retrieve the public state of an application across sessions or allow two endpoints to communicate through the exchange of strongly typed data.(译者注:之前有翻译) The first version of AMF,referred to as AMF0,supports sending complex objects by reference which helps to avoid sending redundant instances in an object graph. 第一个版本的AMF,即AMF0,支持在避免了在对象图中发送冗余的实例的通过引用发送复杂的对象。 It also allows endpoints to restore object relationships and support circular references while avoiding problems such as infinite recursion during serialization. 他也允许端点存储对象关系,并且支持在避免问题--如在序列化时无穷的递归--的情况下的循环
实验三 一.实验名称:排队时延和丢包 二.实验目的 1.深入理解排队时延和丢包的概念 2.深入理解排队时延和丢包的关系 三.实验环境 1.运行Windows 2003 Server/XP操作系统的PC机一台。 2.每台PC机具有以太网卡两块,通过双铰线与局域网相连 3.java虚拟机,分组交换Java程序 四.实验步骤 1. 熟悉实验环境 实验之前先要设定好发送速率和传输速率 ●发送速率可选择350packet/s或500 packet/s ●传输速率可选择350 packet/s、500 packet/s或1000 packet/s。 2.设定参数:发送速率为500packet/s传输速率为500packet/s 传输速率等于发送速率时,一般不会发生丢包现象,如图3-1所示
图3-1缓存队列偶尔溢出 3.设定发送速率为500 packet/s,传输速率为350 packet/s 此时,分组一般在路由器缓存中会产生排队现象,从而导致排队时延。由于缓存器容量(队列)是有限的,当到达的分组发现排列队列已满时,将会被丢弃(参见图3-2)。 图3-2排队队列已满,到达分组被丢弃 4.设发送速率为500 packet/s,传输速率为1000 packet/s 当发送速率比传输速率小得多时,也不会产生排队时延(参见图3-3)
图3-3不会产生排队时延 五.实验现象及结果分析 1.传输速率等于发送速率时,一般不会发生丢包现象。但当实验的 时间较长时,缓存队列偶尔也会发生溢出,请分析其原因。 答:时延是指数据从网络的一端传送到另一端的所需时间。其由发送时延、传播时延、处理时延、排队时延这几个不同的部分组成的。排队时延分组在经过网络传输时,要经过许多路由器。但分组再进入路由器后要先在输入队列中排队等待处理。在路由器确定了转发接口后,还要在输出队列中排队等待转发,即产生了排队时延。排队时延的长短往往取决于网络当时的通信量。当网络的通信量很大时会发生队列溢出,使分组丢失,即发生了丢包现象。传输速率等于发送速率时,一般不会发生丢包现象。但当实验的时间较长时,缓存队列偶尔也会发生溢出,这主要是由于长时间后偶尔处理时延会比较长,队列容量有限,有可能出现堆满的情况,则数据会在缓存中等待处理。 2.你自己可以选定一系列参数组进行模拟实验,并分析其中原理和 呈现的规律性。并且,同学们可以查看程序代码分析实验的情况。 答:自己加350 1000 下面是实验图
IP电话系统语音抖动问题的分析 电话网、广播电视网、数据网三网合一是21世纪通信领域发展的必然趋势。人们已逐渐认识到,无论是传统的语音通信还是现代数据通信,最后都有可能走到统一的IP协议上来。IP 电话中的语音质量是制约其广泛应用的一个瓶颈,尤其是语音抖动现象的存在,更制约了IP电话在人们生活、工作中的应用,本文对IP电话中的语音抖动问题进行了分析,并初步提出了一个分析解决方案。 1通话过程中语音质量分析 1.1IP电话中出现的语音质量问题 在IP网络上传送话音,影响传送质量的因素主要有分组延时、分组丢失和抖动。 分组延时的定义是以秒为单位的由主机A在链路上开始向主机B发送1b信息,到主机B接收到该信息之间的时间差。换句话说,分组延时直接对应于从第一个用户开始谈话到第二个用户(听者)听到第一个音节之间的时间差。 分组丢失是指从主机A发送的,但不能到达主机B(目的地)的分组数占所发送的所有分组数的百分比。网络上分组丢失的百分比可能明显地影响IP网络上话音的质量。语音本是连续的信号,在将分组数据从主机A发送到主机B的过程中,由于分组传输路径不同,每个路径的长短和数据流量各不相同,造成了分组到达接受端的时间有所不同,这样在接受端回放的语音变得时断时连,这种现象称为话音抖动。 1.2解决技术分析 为解决IP电话中语音的质量问题,主要用以下7种技术进行提高和改善:语音压缩技术、回音消除技术、静噪抑制技术、话音抖动处理技术、话音优先技术、包分割技术和前向纠错技术。这里主要介绍语音抖动处理技术。 在语音抖动处理中主要采用的是抖动缓冲技术,即在接收方设定一个缓冲池,话音包到达时首先进入缓冲池暂存,系统以稳定平缓的速率将话音包从缓冲池中取出、解压、然后播放给受话者。这种缓冲技术可以在一定限度内有效处理话音抖动,提高音质。使用抖动缓冲技术的原理如图1所示:为了确定呼话音包的正确时间间隔,在RTP的包头上提供了一个时间戳(TimeStamp),用于记录这个呼包的产生时间。在发送端,IP网关产生的呼包①的A,B的时间间隔和B,C 的时间间隔均为20ms;经过IP网络的传输后,在接收端收到的呼包②的B,C的时间间隔变成了30ms;为了恢复原有的时间间隔,接收端呼网关根据每个呼包的RTP时间戳来确定呼包③的正确时间间隔,把他们恢复成原来的20 ms向下一级设备发送。由于消抖动缓存池不是在接收到每一个话音包的情况下就立即转发,因此还要确定适当的转发延时的大小。如果延时太长,就会使系统整体的延时变得很长;如果延时太短,IP 话音包在允许的时间范围内没有到达,话音仍会出现抖动现象,缓存池的作用不很明显。取两者平衡点的结果通常是使缓存器的网络延时保持在40 ms左右。 2解决语音抖动问题的方案
第八章因特网上的音频视频服务 音频视频数据和普通文件数据都有哪些主要区别?这些区别对音频视频数据在因特 网上传送所用的协议有哪些影响?既然现有的电信网能够传送音频视频数据,并且能够保 证质量,为什么还要用因特网来传送音频视频数据呢? 答: 区别 第一,多音频视频数据信息的信息量往往很大, 第二,在传输音频视频数据时,对时延和时延抖动均有较高的要求。 影响 如果利用协议对这些出错或丢失的分组进行重传,那么时延就会大大增加。因此 实时数据的传输在传输层就应采用用户数据报协议而不使用协议。 电信网的通信质量主要由通话双方端到端的时延和时延抖动以及通话分组的丢失率决 定。这两个因素都是不确定的,因而取决于当时网上的通信量,有网络上的通信量非常大以 至于发生了网络拥塞,那么端到端的网络时延和时延抖动以及分组丢失率都会很高,这就导
致电信网的通信质量下降。 端到端时延与时延抖动有什么区别?产生时延抖动的原因时什么?为什么说在传送音 频视频数据时对时延和时延抖动都有较高的要求? 答:端到端的时延是指按照固定长度打包进分组送入网络中进行传送;接收端再从收到 的包中恢复出语音信号,由解码器将其还原成模拟信号。时延抖动是指时延变化。数 据业务对时延抖动不敏感,所以该指标没有出现在测试中。由于上 多业务,包括语音、视频业务的出现,该指标才有测试的必要性。产生时延的原因 数据包之间由于选择路由不同,而不同路由间存在不同时延等因素,导致同一 的数据包之间会又不同的时延,由此产生了时延抖动。 把传播时延选择的越大,就可以消除更大的时延抖动,但所要分组经受的平均时延也 增大了,而对某些实时应用是很不利的。如果传播时延太小,那么消除时延抖动的效果就较 差。因此播放时延必须折中考虑。 目前有哪几种方案改造因特网使因特网能够适合于传送音频视频数据?
1、时延 时延是指数据包第一个比特进入路由器到最后一比特从路由器输出的时间间隔。在测试中通常使用测试仪表发出测试包到收到数据包的时间间隔。时延与数据包长相关,通常在路由器端口吞吐量范围内测试,超过吞吐量测试该指标没有意义。 时延的产生有多种因素,下面列出了主要的时延源: 编码的处理:模拟形式的声音信号在CODEC被采样和量化为PCM信号,DSP对PCM 信号进行压缩处理所产生的时延为编码处理时延。这种时延产生在设备侧,如果设备的编码器固定,则编码时延也固定。 包化:包化就是将编码器输出的语音净荷放置到RTP/UDP/IP包中的过程,相对于编码的时延,包化的时延很小,因为包化的过程没有复杂的运算,仅仅是增加包头和计算校验和,而编码则有大量的数学运算。 队列(Queuing):语音的净荷放置到IP包中后,要被设备转发到目的地,这些包会在设备的出接口队列中,等待被调度。转发设备不同的队列机制对IP包的处理有很大不同。可以通过合理的配置来减少语音包在队列中等待的时间,进而减少队列时延。 串行化(Serialization):接口队列中的语音IP包,被送离设备前会放置到接口的物理队列当中,如果物理队列中有一个较大分组,还在发送状态,则语音分组必须等待这个较大的分组发送完毕后才能发送,这个等待的时间就是串行化时延。比如一个时钟速率为64kbps 的链路要发送一个1600Bytes大小的FTP分组,则串行化产生的时延会达到200ms (1600×8/64000×1000)。这对于后面等待的语音包来说已经是很大的时延了。 广域网时延:对于ISP提供的广域网链路,对于用户来说只是一个黑盒子,除了上述的编码时延外,构成广域网链路的路由器交换机都会产生包化、队列、串行化的时延。而且到达同一目的的路径不同,其每个包的时延也不同,而这些时延对于用户来说是不可控的,当然我们在租用ISP的线路时,可以要求ISP提供符合时延要求的线路。 2、时延抖动 时延抖动是指时延变化。数据业务对时延抖动不敏感,所以该指标没有出现在Benchmarking测试中。由于IP上多业务,包括语音、视频业务的出现,该指标才有测试的必要性。 变化的时延被称作抖动(Jitter),抖动大多起源于网络中的队列或缓冲,尤其是在低速链路时。而且抖动的产生是随机的,比如你无法预测在语音包前的数据包的大小,既便你使用LLQ,如果大数据包正在传输过程中,当语音分组到达时,它还是要等待数据分组被发送完。而在低速的链路中,语音数据混传时,抖动是不可避免的。通常使用LFI将大包拆小,来减少大包对时延的影响。 在传统的数据测试中,抖动并不是一个被广泛重视的指标,因为对纯数据业务,抖动的影响并不是非常明显,所以过去不同的测试仪表对于抖动的定义也是各不相同。但是抖动对于视频和语音业务的质量影响非常大。城域以太网技术的驱动之一在于基于IP的视频和音频业务,所以MEF论坛和RFC 3393对抖动做了非常明确的定义:Jitter为顺序传递的相邻两个帧的转发时延之差的绝对值。Jitter值恒为正。图6是抖动计算的原理图。
计算机网络设计实验报告 09012211 孙磊 实验二:排队时延和丢包 实验目的 1.深入理解排队时延和丢包的概念 2. 深入理解排队时延和丢包的关系 实验步骤 1、熟悉实验环境 实验之前先要设定好发送速率和传输速率 发送速率可选择350packet/s或500 packet/s 传输速率可选择350 packet/s、500 packet/s或1000 packet/s。 2、设定参数:发送速率为500packet/s传输速率为500packet/s 传输速率等于发送速率时,一般不会发生丢包现象。 3、设定发送速率为500 packet/s,传输速率为350 packet/s 此时,分组一般在路由器缓存中会产生排队现象,从而导致排队时延。由于缓存器容量(队列)是有限的,当到达的分组发现排列队列已满时,将会被丢弃。
4、设发送速率为500 packet/s,传输速率为1000 packet/s 当发送速率比传输速率小得多时,也不会产生排队时延。 实验分析 1. 传输速率等于发送速率时,一般不会发生丢包现象。但当实验的时间较长时,缓存队列偶尔也会发生溢出。 2.到达先后次序不同的分组在分组丢弃和排队时延方面的表现也有所不同。如果有多个分组依次到达一个空队列,那么传输的第一个分组将不会经受任何排队时延,而最后一个分组将经受相对大的排队时延,甚至有可能被丢弃。发送速率和传输速率之间的关系对于分组的丢失和排队时延也起到重要作用,当发送速率小于传输速率时,分组不会有排队时延,更不会丢失;当发送速率等于传输速率时,分组也不会丢失;当发送速率大于传输速率时,分组产生排队时延,队列容量有限,当队列满时,到达的分组就被丢弃。在本实验中,发送方是以恒定的速率发送分组的。在实际网络环境下,发送方通常是依据某种概率分布来发送分组的,这样会导致发送速率比较快时可能发生丢包现象,发送速率慢时不会发生丢包现象。
延迟和抖动是网络性能的重要参数,对上层应用都有非常重要的影响。延迟是不可避免的,因为数据在链路中的传输必须经过一定的时间。对于一个特定的网络路径,延迟主要有传输延迟、传播延迟、处理延迟是固定延迟,排队延迟是可变延迟。排队延迟是由网络动态来决定的,网络中的拥塞状况不同,排队延迟有很大的变化。抖动是由数据包到达延迟的不同造成的。避免抖动主要基于缓冲技术。 网络延迟 数据包穿越一个或多个网段所经历的时间称为延迟。从用户的角度讲,延迟即用户发出请求到接收到远端应用系统的响应的时间。基于TCP/IP协议网络传输包括以下处理过程:路由器处理、用户数据单元在网络上传输以及服务器处理过程,相应地将产生路由延迟和用户数据单元在网络上的传输延迟。路由延迟包括域名请求延迟、TCP连接建立和释放延迟以及IP寻径延迟。从测试的角度讲,延迟分为单向延迟和双向延迟。 延迟的分类 在数据传输过程中,一般认为延迟分为如下几个部分:传输延迟,传播延迟,处理延迟和排队延迟。 打包延迟 各层的协议数据单元(PDU)都具有不同的有效负载长度,而应用层产生的响应大小的信息流需要一定的持续时间。协议层等待应用层产生满足PDU有效负载长度的字节流量,然后才能打包成协议数据单元(PDU)。这段等待时间就是打包延迟。打包延迟是实时数据流应用独有的延迟,实时流应用是指对基于时间的信息,如视频、音频和动画等进行实时传送的应用。 传输延迟 传输延迟是将所有分组的比特全部传送到线路上所需要的时间,即PDU的第一个比特从端点传送到线路上直到最后一个比特离开端点的这段时间。传输延迟与PDU大小及线路上的传送速率有关。一个存储转发机制的网络中,数据包将会产生多次的传输延迟,每次将PDU 转发下一跳都将产生一次传输延迟。 传播延迟 一个数据包中的每一个比特被推向链路后,该比特向下一跳路由器进行传播。从该链路的起点到到达下一跳路由器传输所需要的时间是传播时延。传播实验取决于比特穿过介质的速率,即该链路的传播速率,往往是等待或略小于光速的。传输时延等于两个路由器之间的距离除以传播速率,链路上的传播实验可以用PDU的第一个比特穿过链路所用的时间来定义。在局域网中,传播延迟往往不是延迟重要的组成部分,因为它往往很小。但是广域网中的传播延迟可以达到毫秒级。 排队延迟 排队延迟在分组交换网产生的延迟中占主要部分,每一次分组交换将使数据加入到缓冲队列中,每一个PDU的目的输出端可能存在着许多分组排队,这就是排队延迟。在先进先出队列中,新到达的分组的排队延迟等于所有已在该端口上排队的分组传输延迟的总和。所以说,特定分组的排队延迟取决于先期到达的正在排队等待向链路传输的分组的数量,另外也取决于输出端口的传送速度。排队延迟受网络负载的影响很大,是分组交换网中延迟变化的主要因素。排队延迟可以使毫秒级甚至是微秒级。 处理延迟 处理延迟是分组交换过程中发送端和目的端对数据进行处理所需时间的总和,如检查分组首部和决定将该分组导向哪里所需要的时间等,都是属于处理延迟。处理延迟还包括一些其他因素,如检查比特级别差错所需要的时间等。 降低网络延迟的方法: