教育科研中的统计方法——Z检验和t检验
乌海市海勃湾区教研室王根运
通常我们用平均分比较两个班的成绩的优劣是不妥的。即某次考试中初二、二班数学成绩平均分低于初二、五班的平均分,不一定说明初二、二班数学真实成绩比初二、五班的差。这是因为一个班的的平均成绩具有统计意义,存在抽样误差,其平均成绩在一定范围内波动,假如再进行一次考试也许初二、二班数学成绩平均分高于初二、五班的平均分。所以比较成绩时应用平均数差异的显著性检验更科学。
统计学中平均数差异的显著性检验时规定一个显著性水平,经过检验所得差异超过这个显著性水平,表明这个差异不属于抽样误差,确实存在差异,反之属于抽样误差。这个平均数差异的显著性检验在教育科研统计中总结为Z检验或t 检验。一般地样本容量大于30时,用Z检验;样本容量小于30时,用t检验。当问题所给的条件用t检验方便时,样本容量虽然大于30,也可以用t检验。
下面是样本容量大于30时的Z检验和样本容量小于30时的t检验案例。
一、样本容量大于30时的Z检验
案例:比较初三第一学期期末实验班和对比班的化学成绩
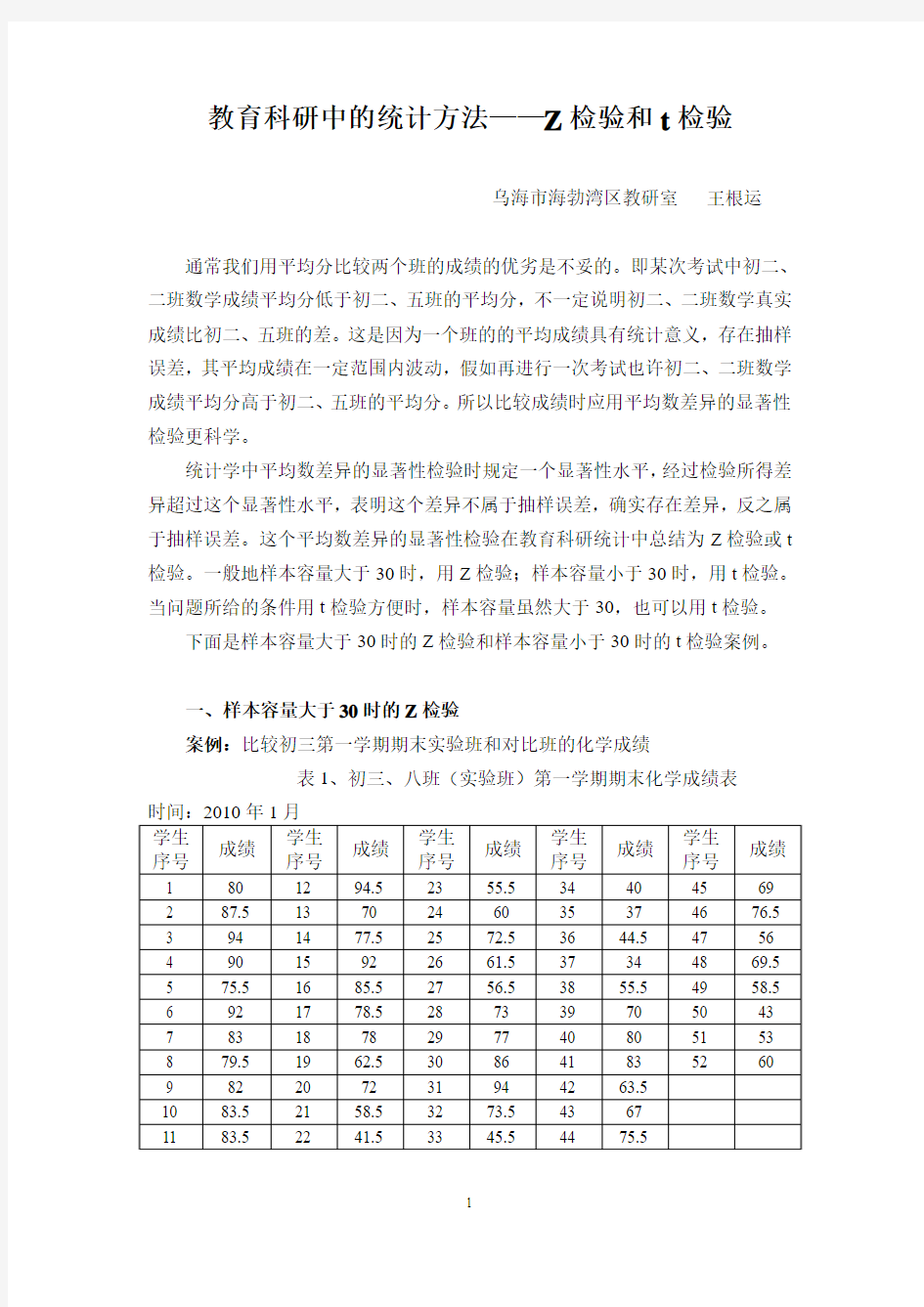
表1、初三、八班(实验班)第一学期期末化学成绩表
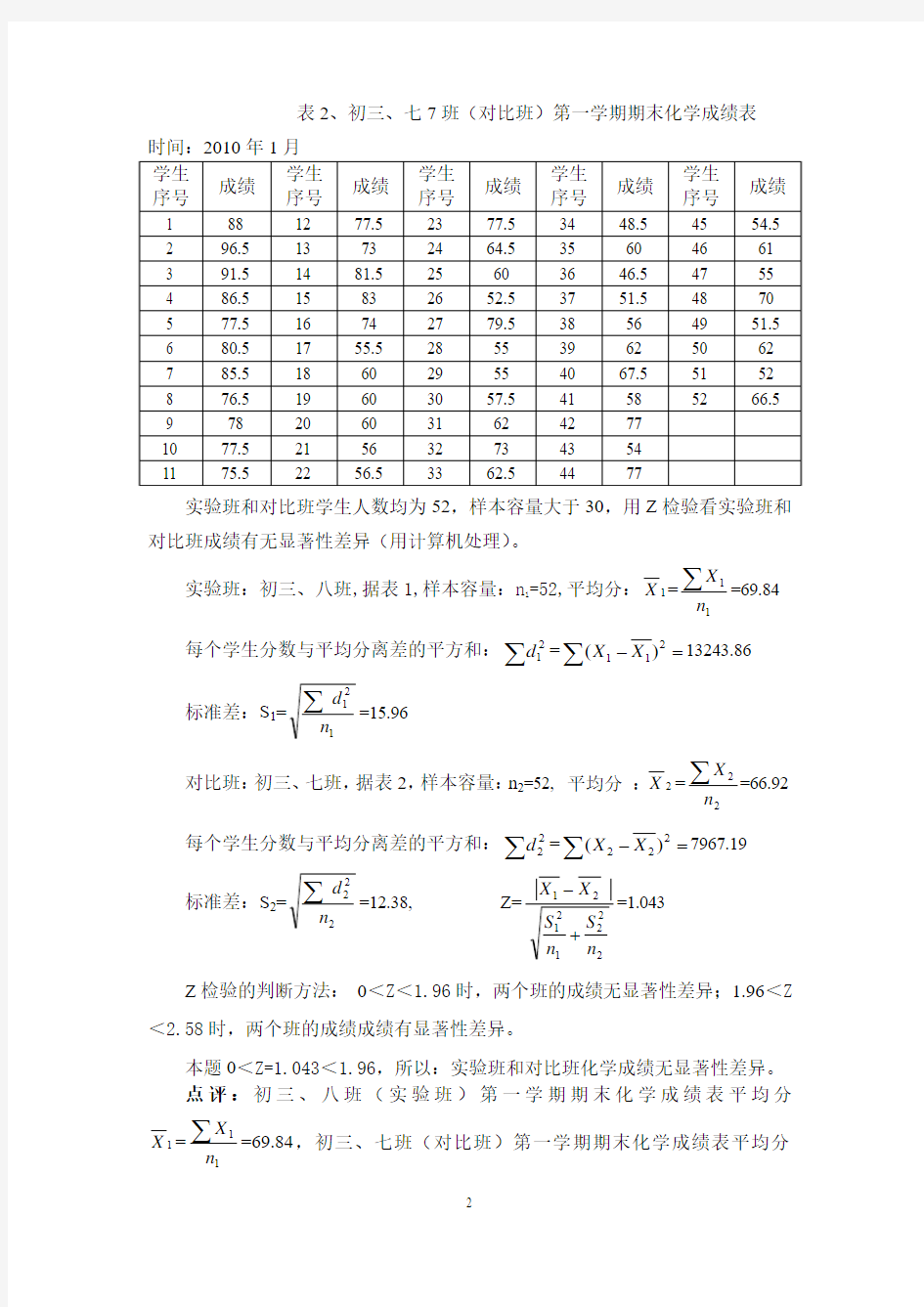
表2、初三、七7班(对比班)第一学期期末化学成绩表
时间:2010年1月
实验班和对比班学生人数均为52,样本容量大于30,用Z 检验看实验班和对比班成绩有无显著性差异(用计算机处理)。
实验班:初三、八班,据表1,样本容量:n 1=52,平均分:1X =
1
1
n X
∑=69.84
每个学生分数与平均分离差的平方和:∑21d ==-∑211)(X X 13243.86 标准差:S 1=
1
2
1n d ∑
=15.96
对比班:初三、七班,据表2,样本容量:n 2=52, 平均分 :2
X =
2
2
n X ∑=66.92
每个学生分数与平均分离差的平方和:∑2
2d ==-∑222)(X X 7967.19
标准差:S 2=
2
2
2
n d ∑
=12.38, Z=
2
22
121
21n S n S X X +-=1.043
Z 检验的判断方法: 0<Z <1.96时,两个班的成绩无显著性差异;1.96<Z <2.58时,两个班的成绩成绩有显著性差异。
本题0<Z=1.043<1.96,所以:实验班和对比班化学成绩无显著性差异。 点评:初三、八班(实验班)第一学期期末化学成绩表平均分
1
X =
1
1
n X ∑=69.84,初三、七班(对比班)第一学期期末化学成绩表平均分
2
X =
2
2
n X ∑=66.92。虽然X —1〉X —
2,但不能说明初三、八班(实验班)比初三、七
班(对比班)的化学成绩好,这是抽样误差导致的结果。事实上根据上面平均数
差异的显著性检验得出结论:两个班第一学期期末化学成绩无显著性差异。
二、相关样本,容量小于30的t 检验
同一批学生在实验前后进行两次测试得到两次成绩,若把这两次成绩看成两个样本的话,则这两个样本之间相互不是独立的,称为相关样本。
案例:王老师在初二、三班进行《语文口头作文对语文成绩影响的实验研究》,他每节课用10分钟的时间让学生进行口头小作文比赛,实验前进行一次语文成绩测试,随机抽取10名学生语文成绩(实验前成绩)记录如表,一个学期后用同样难度的试题又进行测试记录这10名学生的语文成绩(实验后成绩)记录如表。
该案例是相关样本,样本容量为10,小于30,用相关样本的t 检验看实验前和实验后初二、三班随机抽取10名学生语文成绩有无显著性差异(用计算机处理)。
样本1(实验前)成绩总和∑X 1=710 样本2(实验后)成绩总和∑X 2=795
d =∣2X -1
X ∣=∣n X X 2
1
∑∑-∣=∣10
795710-∣=8.5
样本1(实验前)和样本2(实验后)第i 个学生成绩差:d=X 2-X 1
∑d 2=∑-)(X X 122
=1267
(∑d )2=85
t=
)
1()
(0
2
2
--
-∑∑n n n d d
d =
()
110101085126705.82
---=3.456
若显著性水平α定为0.05,根据df=n-1=10-1=9查t 表:t α/2=2.262。 因为t=3.456> t α/2说明实验后学生的成绩有显著的提高。 点评:初二、三班实验前语文成绩表平均分1X =
1
1
n X
∑=71,初二、三班实
验后语文成绩表平均分2
X =
2
2
n X ∑=79.5。虽然X —1 2,但不能说明初二、三班实 验后比实验前的语文成绩好,上面平均数差异的显著性检验具有科学依据,得出的结论(两次成绩存在显著性差异)才符合事实。即初二、三班实验后比实验前的语文成绩好。 三、不同样本,容量小于30的t 检验 案例:比较初二、一班和初二、二班第二学期期末物理成绩 表1、初二、一班第二学期期末物理物理成绩表 表2、初二、二班第二学期期末物理成绩表 初二、一班和初二、二班学生人数分别为27和29,样本容量小于30,用t 检验看两个班成绩有无显著性差异(用计算机处理)。 初二、一班:均分: 1 X = 1 1 n X ∑=70.22 每个学生分数与平均分离差的平方和:∑21d ==-∑211)(X X 6620.67 初二、二班:均分:2X = 2 2 n X ∑=67.3 每个学生分数与平均分离差的平方和:∑2 2d ==-∑222)(X X 6004.21 t= )1 1( 2 d 2 12122 2 1 2 1n n n n d X X +-++-∑∑= ? ? ? ??+-++-2912712292721.600467.66203 .6722.70=0.1746 自由度df=n 1+n 2-2=27+29-2=54,若取α=0.05,查t 值表,0<t ≤2.014无显著差异,2.014<t ≤2.670有显著差异。 上面计算的0<t=0.1746≤2.014,说明初二、一班和初二、二班第二学期期末物理成绩无显著差异。 点评:初二、一班第二学期期末物理成绩平均分1X = 1 1 n X ∑=70.22,初二、 二班第二学期期末物理成绩平均分2 X = 2 2 n X ∑=67.3。虽然X — 1〉X — 2,但不能说明 初二、一班比初二、二班的物理成绩好,这是抽样误差导致的结果。事实上根据 上面平均数差异的显著性检验得出结论:两个班第二学期期末物理成绩无显著性差异。 参考书目 1、佟庆伟,教育科学中量化,中国科学技术出版社,1997。 2、王孝玲,教育测量,华东师范大学出版社,1989。 t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ σ-=。 如果样本是属于大样本(n >30)也可写成: X t μ σ-=。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数; X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为79.2分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.6317 X t μσ--=== 第三步 判断 因为,以0.05为显著性水平,119df n =-=, 查t 值表,临界值0.05(19) 2.093t =,而样本离差的t =1.63小与临界值2.093。所以,接受原假设,即进步不显著。 2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过0r =。 相关样本的t 检验公式为: X X t = 在这里,1X ,2X 分别为两样本平均数; 12X σ,2 2X σ分别为两样本方差; γ为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为79.5和72分,标准差分别为9.124,9.940。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设0H ∶1μ=2μ 第二步 计算t 值 当总体呈正态分布,如果总体标准差未知,而且样本容量n v30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈 t分布。 t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。t检验分为单总体t检验和双总体t检验。 1.单总体t检验 单总体t检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差未知且样本容量n v30,那么样本平均数与总体平均数的离差统计量呈t分布。检验统计量为: 如果样本是属于大样本(n>30)也可写成: 在这里,t为样本平均数与总体平均数的离差统计量; X为样本平均数; 为总体平均数; X为样本标准差; n为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步建立原假设H0:=73 第二步计算t值 17 厂1 .19 第三步 判断 因为,以为显著性水平,df n 1 19,查t 值表,临界值t(19)0.05 2.093 , 而样本离差的t 小与临界值。所以,接受原假设,即进步不显著。 2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显 著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用 于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据 的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性 检验。各实验处理组之间毫无相关存在, 即为独立样本。该检验用于检验两组非 相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验 完全类似,只不过r 0。 相关样本的t 检验公式为: X 1 X 2 在这里,X 1, X 2分别为两样本平均数; 为相关样本的相关系数 例:在小学三年级学生中随机抽取 10名学生,在学期初和学期末分别进行 了两次推理能力测验,成绩分别为和72分,标准差分别为,。问两次测验成绩是 否有显著地差异? 检验步骤为: 第一步 建立原假设H 。: 1= 2 1.63 X 1 X 2 2 X 1 , 2 X 2 分别为两样本方差; 2 X 2 1.T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定。 通过把所得到的统计检定值,与统计学家建立了一些随机变量的概率分布(probability distribution)进行比较,我们可以知道在多少%的机会下会得到目前的结果。倘若经比较后发现,出现这结果的机率很少,亦即是说,是在机会很少、很罕有的情况下才出现;那我们便可以有信心的说,这不是巧合,是具有统计学上的意义的(用统计学的话讲,就是能够拒绝虚无假设null hypothesis,Ho)。相反,若比较后发现,出现的机率很高,并不罕见;那我们便不能很有信心的直指这不是巧合,也许是巧合,也许不是,但我们没能确定。 F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。统计显著性(sig)就是出现目前样本这结果的机率。 2. 统计学意义(P值或sig值) 结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法。专业上,p值为结果可信程度的一个递减指标,p值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。p值是将观察结果认为有效即具有总体代表性的犯错概率。如p=0.05提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果。(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。)在许多研究领域,0.05的p值通常被认为是可接受错误的边界水平。 3. T检验和F检验 至於具体要检定的内容,须看你是在做哪一个统计程序。 举一个例子,比如,你要检验两独立样本均数差异是否能推论至总体,而行的t检验。 两样本(如某班男生和女生)某变量(如身高)的均数并不相同,但这差别是否能推论至总体,代表总体的情况也是存在著差异呢? t 检验计算公式: 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用 t 分布理论来推论差异发生的概率,从而比较两个平均数的差异 是否显著。 t 检验分为单总体 t 检验和双总体 t 检验。 1.单总体 t 检验 单总体 t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显著。当总体分布是正态分布,如总体标准差未知且样本容量 n <30,那么样本平均数与总体平均数的离差统计量呈 t 分布。检验统计量为: X t。 X n 1 如果样本是属于大样本(n >30)也可写成: X t。 X n 在这里, t 为样本平均数与总体平均数的离差统计量; X为样本平均数; 为总体平均数; X为样本标准差; n为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73 分,标准差为 17 分,期末考试后,随机抽取 20 人的英语成绩,其平均分数为 79.2 分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步建立原假设 H 0∶=73 第二步计算 t 值 X 79.2 73 t 17 1.63 X n 119 第三步判断 因为,以 0.05 为显著性水平, df n 1 19 ,查t值表,临界值 t (19)0.05 2.093 ,而样本离差的t 1.63 小与临界值 2.093 。所以,接受原假设,即进步不显著。 2.双总体 t 检验 双总体 t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显 著。双总体 t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用 于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据 的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过 r 0 。 相关样本的 t 检验公式为: t X1 X2 。 2 2 2 X1X2 X1 X 2 n 1 在这里, X1 , X 2 分别为两样本平均数; X 2 1 , X2 2 分别为两样本方差;为相关样本的相关系数。 例:在小学三年级学生中随机抽取 10 名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为 79.5 和 72 分,标准差分别为 9.124,9.940 。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步建立原假设 H0∶1= 2 第二步计算 t 值 t X1 X 2 2 2 2 X1X2 X1 X 2 n 1 = 79.571 9.12429.9402 2 0.704 9.124 9.940 10 1 =3.459 。 第三步判断 根据自由度 df n 1 9 ,查t值表 t (9)0.05 2.262 , t(9) 0.01 3.250 。由于实 际计算出来的 t =3.495>3.250= t(9) 0.01 ,则 P ,故拒绝原假设。 0.01 结论为:两次测验成绩有及其显著地差异。 由以上可以看出,对平均数差异显著性检验比较复杂,究竟使用 Z 检验还是使用 t 检验必须根据具体情况而定,为了便于掌握各种情况下的 Z 检验或 t 检验, 医学统计学试题及答案 习题 《医学统计学》第二版(五年制临床医学等本科生用) (一)单项选择题 1.观察单位为研究中的( d )。 A.样本 B. 全部对象 C.影响因素 D. 个体 2.总体是由( c )。 A.个体组成 B. 研究对象组成 C.同质个体组成 D. 研究指标组成 3.抽样的目的是(b )。 A.研究样本统计量 B. 由样本统计量推断总体参数 C.研究典型案例研究误差 D. 研究总体统计量 4.参数是指(b )。 A.参与个体数 B. 总体的统计指标 C.样本的统计指标 D. 样本的总和 5.关于随机抽样,下列那一项说法是正确的( a )。 A.抽样时应使得总体中的每一个个体都有同等的机会被抽取 B.研究者在抽样时应精心挑选个体,以使样本更能代表总体 C.随机抽样即随意抽取个体 D.为确保样本具有更好的代表性,样本量应越大越好 6.各观察值均加(或减)同一数后( b )。 A.均数不变,标准差改变 B.均数改变,标准差不变 C.两者均不变 D.两者均改变 7.比较身高和体重两组数据变异度大小宜采用( a )。 A.变异系数 B.差 C.极差 D.标准差 8.以下指标中(d)可用来描述计量资料的离散程度。 A.算术均数 B.几何均数 C.中位数 D.标准差 9.偏态分布宜用(c)描述其分布的集中趋势。 A.算术均数 B.标准差 C.中位数 D.四分位数间距 10.各观察值同乘以一个不等于0的常数后,(b)不变。 A.算术均数 B.标准差 C.几何均数 D.中位数 11.( a )分布的资料,均数等于中位数。 A.对称 B.左偏态 C.右偏态 D.偏态 12.对数正态分布是一种( c )分布。 当总体呈正态分布,如果总体标准差未知,而且样本容量n <30,那么这时一切可能的样本平均数与总体平均数的离差统计量呈t 分布。 t 检验是用t 分布理论来推论差异发生的概率,从而比较两个平均数的差异 是否显著。t 检验分为单总体t 检验和双总体t 检验。 1.单总体t 检验 单总体t 检验是检验一个样本平均数与一已知的总体平均数的差异是否显 著。当总体分布是正态分布,如总体标准差σ未知且样本容量n <30,那么样本平均数与总体平均数的离差统计量呈t 分布。检验统计量为: X t μ σ-= 。 如果样本是属于大样本(n >30)也可写成: X t μ σ-= 。 在这里,t 为样本平均数与总体平均数的离差统计量; X 为样本平均数; μ为总体平均数; X σ为样本标准差; n 为样本容量。 例:某校二年级学生期中英语考试成绩,其平均分数为73分,标准差为17分,期末考试后,随机抽取20人的英语成绩,其平均分数为分。问二年级学生的英语成绩是否有显著性进步? 检验步骤如下: 第一步 建立原假设0H ∶μ=73 第二步 计算t 值 79.273 1.6317X t μ σ--= = = 第三步 判断 因为,以为显著性水平,119df n =-=,查t 值表,临界值0.05(19) 2.093t =,而样本离差的t =小与临界值。所以,接受原假设,即进步不显著。 2.双总体t 检验 双总体t 检验是检验两个样本平均数与其各自所代表的总体的差异是否显著。双总体t 检验又分为两种情况,一是相关样本平均数差异的显著性检验,用于检验匹配而成的两组被试获得的数据或同组被试在不同条件下所获得的数据的差异性,这两种情况组成的样本即为相关样本。二是独立样本平均数的显著性检验。各实验处理组之间毫无相关存在,即为独立样本。该检验用于检验两组非相关样本被试所获得的数据的差异性。 现以相关检验为例,说明检验方法。因为独立样本平均数差异的显著性检验完全类似,只不过0r =。 相关样本的t 检验公式为: t = 在这里,1X ,2X 分别为两样本平均数; 12X σ,2 2 X σ分别为两样本方差; γ为相关样本的相关系数。 例:在小学三年级学生中随机抽取10名学生,在学期初和学期末分别进行了两次推理能力测验,成绩分别为和72分,标准差分别为,。问两次测验成绩是否有显著地差异? 检验步骤为: 第一步 建立原假设0H ∶1μ=2μ 专题八 t 检验 ⒈t 检验基础 t 检验是一种以t 分布为基础,以t 值为检验统计量资料的假设检验方法。 ⑴t 检验的基本思想: 假设在H 0成立的条件下做随机抽样,按照t 分布的规律得现有样本统计量t 值的概率为P ,将P 值与事先设定的检验水准进行比较,判断是否拒绝H 0。 ⑵t 检验的应用条件: ①样本含量较少(n <50);②样本来自正态总体(两样本均数比较时还要求两样本的总体方差相等,即方差齐性)。 【注】实际应用时,与上述条件略有偏离,只要其分布为单峰近似对称分布,对结果影响不大。 ⑶t 检验的主要应用:①单个样本均数与总体均数的比较;②配对设计资料的差值均数与总体均数0的比较;③成组设计的两样本均数差异的比较。 ⑷单样本t 检验基本公式: t= x 0s x μ-= n s x 0μ- υ=n-1 ⒉z 检验 z 分布(标准正态分布)是t 分布的特例,当样本n ≥50或者总体σ已知时用z 检验。 ⑴单样本z 检验基本公式: z= n s x 0μ- 或 z= n x 0 σμ- ⑵单样本z 检验的步骤与单样本t 检验的基本相似。 ⒊配对设计均数的比较 配对设计是为了控制某些非处理因素对实验结果的影响而采用的设计方式,应用配对设计可以减少实验误差和个体差异对结果的影响,提高统计处理的效率。 ⑴配对设计的主要四种情况: ①配对的两受试对象分别接受两种处理,如在动物实验中,常先将动物按照窝别、体重等配对成若干对,同一对的两受试对象随机分配到实验组和对照组,然后观察比较两组的实验结果。 ②同一样品用两种不同方法测量同一指标或接受不同处理。 ③自身对比,即将同一受试对象(实验或治疗)前后的结果进行比较。 ④同一对象的两个部位给予不同处理。 ⑵对配对资料的分析: 一般用配对t 检验,其检验假设为:差值的总体均数为0即μd =0。计算统计量的公式为: t= n s 0d d -,υ=n-1 式中d 为差值的均数;s d 为差值的标准差;n 为对子数。 ⑶关于自身对照(同体比较)的t 检验: ①在医学研究中,我们常常对同一批患者治疗前后的某些生理、生化指标进行测量以观察疗效,对于这些资料可以按照配对t 检验。 ②优点:节约样本含量,能够有效的控制个体自身差异对实验结果的影响;缺点:随时间变化明显的指标不宜按此类设计进行分析,此时应设立平行对照组。 【小结】 ①配对设计的t 检验统计处理的效率高于成组设计,应用配对设计可以减少实验误差和个体差异对结果的影响,提高统计处理的效率。 ②配对设计t 检验是单样本t 检验的特例,即检验差值是否来自总体均数为0的总体。 ⒋两样本均数的比较 两独立样本资料的t 检验,又称为成组t 检验,适用于完全随机设计的两样本均数的比较。 ⑴两独立样本资料的t 检验的应用条件:两组数据均服从正态分布,且两总体的方差齐。 若量总体方差不齐,可采用t '检验或进行变量变换后选择合适的方法,亦可用非参数检验如秩和检验处理。 ⑵假设检验与计算统计量: 两独立样本资料的t 检验的检验假设为μ1=μ2(相同、相等、无差别),计算统计量公式为: t= 2 1 x -x 21s x x -= ? ?? ? ??+-212 c 21n 1n 1s x x ,其中Sc (合并方差)=()()2 n n s 1n s 1n 212 2 2211-+-+-,υ=n 1+n 2-2(n 1与n 2 为两样本含量) ⑶大样本时的处理: ①当样本含量较大时(如n 1>50且n 2>50),可应用z 检验。 ②z 检验的其他应用条件与t 检验基本相似。 ③两大样本z 检验的计算公式为 卫生统计学试卷 适用范围:__________ 出题教师:__________ (本大题满分40分,每小题1分) 1. 对两样本均数作t检验,n1=20,n2=20,其自由度等于:( ) A. 19 B. 40 C. 38 D. 20 E. 39 2. 临床研究的总体一般:( ) A. 无限的 B. 有限的 C. 已知的 D. 有数量的 3. 在一项抽样研究中,当样本量逐渐增大时:( ) A. 标准误逐渐增大 B. 标准差和标准误都逐渐增大 C. 标准误逐渐减少 D. 标准差逐渐增大 E. 标准差逐渐减少 4. 12名妇女分别用两种测量肺活量的仪器测最大呼气率(l/min),比较两种方法检测结果有无差别,可进行:( ) A. X2检验 B. 配对设计t检验 C. 成组设计t检验 D. 配对设计u检验 E. 成组设计u检验 5. 对两个变量进行直线相关分析,r=0.46,P>0.05,说明两变量之间( )。 A. 有相关关系 B. 无直线相关关系 C. 无因果关系 D. 无任何关系 E. 有伴随关系 6. 对两地的结核病死亡率比较时作率的标准化,其目的是:( ) A. 为了能更好地反映人群实际死亡水平 B. 消除各年龄组死亡率不同的影响 C. 消除两地总人数不同的影响 D. 以上都不对 E. 消除两地人口年龄构成不同的影响 7. 计算相对数的目的是:( ) A. 为了进行显著性检验 B. 为了便于比较 C. 为了表示相对水平 D. 为了表示实际水平 E. 为了表示绝对水平 8. 均数与标准差适用于:( ) A. 正态分布资料 B. 负偏态分布资料 C. 不对称分布的资料 D. 频数分布类型不明的资料 E. 正偏态分布资料 9. 测量身高、体重等指标的原始资料叫:( ) A. 等级资料 B. 分类资料 C. 计数资料 D. 有序分类资料 E. 计量资料 10. 对调查表考评的三个主要方面是( )。 A. 效度,反应度,可接受性 B. 信度,效度,可接受性 C. 信度,灵敏度,特异度 D. 信度,效度,反应度 E. 效度,灵敏度,特异度 11. 相对数使用时要注意以下几点,其中哪一项是不正确的:( ) A. 分母不宜过小 B. 注意离散程度的影响 C. 不要把构成比当率分析 D. 比较时应做假设检验 E. 二者之间的可比性 1.假设检验在设计时应确定的是 A.总体参数B.检验统计量C.检验水准 D.P值E.以上均不是 2.如果t≥2,υ,,可以认为在检验水准α=处。 A.两个总体均数不同B.两个总体均数相同C.两个样本均数不同D.两个样本均数相同E.样本均数与总体均数相同 3. 计量资料配对t检验的无效假设(双侧检验)可写为。 A.μd=0 B.μd≠0 C.μ1=μ2 D.μ1≠μ2E.μ=μ0 4.两样本均数比较的t检验的适用条件是。 A.数值变量资料B.资料服从正态分布C.两总体方差相等 D.以上ABC都不对E.以上ABC都对 5.在比较两组资料的均数时,需要进行t/检验的情况是: A.两总体均数不等B.两总体均数相等C.两总体方差不等D.两总体方差相等E.以上都不是 6.有两个独立的随机样本,样本含量分别为n1和n2,在进行成组设计资料的t检验时,自由度为。 A.n1+n2 B.n1+n2-1 C.n1+n2+1 D.n1+n2-2 E.n1+n2+2 7. 已知某地正常人某定量指标的总体均值μ0=5,今随机测得该地特殊人群中的30人该指标的数值。若用t检验推断该特殊人群该指标的总体均值μ与μ0之间是否有差别,则自由度为。 A.5 B.28 C.29 D.4 E.30 8. 两大样本均数比较,推断μ1=μ2是否成立,可用。 A.t检验B.u检验C.方差分析 D.ABC均可以E.χ2检验 9.关于假设检验,下列说法中正确的是 A.单侧检验优于双侧检验 B.采用配对t检验还是成组t检验由实验设计方法决定 C.检验结果若P值大于,则接受H0犯错误的可能性很小 D.用Z检验进行两样本总体均数比较时,要求方差齐性 E.由于配对t检验的效率高于成组t检验,因此最好都用配对t检验 10. 为研究新旧两种仪器测量血生化指标的差异,分别用这两台仪器测量同一批样品,则统计检验方法应用。 A.成组设计t检验B.成组设计u检验C.配对设计t检验 D.配对设计u检验E.配对设计χ2检验 11. 阅读文献时,当P=,按α=水准作出拒绝H0,接受H1的结论时,下列说法正确的是。A.应计算检验效能,以防止假“阴性”结果 B.应计算检验效能,检查样本含量是否足够 C.不必计算检验效能D.可能犯Ⅱ型错误 E.推断正确的概率为1-β 12.两样本均数假设检验的目的是判断 A. 两样本均数是否相等B. 两样本均数的差别有多大 C.两总体均数是否相等D. 两总体均数的差别有多大 E. 两总体均数与样本均数的差别有多大 13.若总例数相同,则成组资料的t检验与配对资料的t检验相比: A.成组t检验的效率高些B.配对t检验的效率高些 C.两者效率相等D.两者效率相差不大E.两者效率不可比 15. 两个总体均数比较的t的检验,计算得t>2,n1+n2-2时,可以认为。 A.反复随机抽样时,出现这种大小差异的可能性大于 B.这种差异由随机抽样误差所致的可能性小于 C.接受H0,但判断错误的可能性小于 D.拒绝H0,但犯第一类错误的概率小于 E.拒绝H0,但判断错误的概率未知 16. 为研究两种仪器测量血生化指标的差异,分别用这两台仪器测量同一批血样,则统计检验方法应用。 A.配对设计t检验B.成组设计u检验C.成组设计t检验 D.配对设计u检验E.配对设计χ2检验 17. 在两组资料的t检验中,结果为P<,差别有统计学意义,P愈小,则: 。 第一章:单选题 (5/5 分数) 1.统计学中所说的样本是指()。 .随意抽取的总体中任意部分.有意识的选择总体中的典型部分.依照研究者要求选取总体中有意义的一部分.依照随机原则抽取总体中有代表性的一部分.依照随机原则抽取总体中有代表性的一部分 - 正确 . 有目的的选择总体中的典型部分 2.下列资料属等级资料的是()。 .白细胞计数.住院天数.门急诊就诊人数.病人的病情分级.病人的病情分级 - 正确 . ABO血型分类 3.为了估计某年华北地区家庭年医疗费用的平均支出,从华北地区的5个城市随机抽样调查了1500户家庭,他们的平均年医疗费用支出是 997元,标准差是 391 元。该研究中研究者感兴趣的总体是() .华北地区1500户家庭.华北地区的5个城市.华北地区1500户家庭的年医疗费用.华北地区所有家庭的年医疗费用.华北地区所有家庭的年医疗费用 - 正确 . 全国所有家庭的年医疗费用 4.欲了解研究人群中原发性高血压病(EH)的患病情况,某研究者调查了1043人,获得了文化程度(高中及以下、大学及以上)、高血压家族史(有、无)、月人均收入(元)、吸烟(不吸、偶尔吸、经常吸、每天)、饮酒(不饮、偶尔饮、经常饮、每天)、打鼾(不打鼾、打鼾)、脉压差(mmHg)、心率(次/分)等指标信息。则构成计数资料的指标有() .文化程度、高血压家族史吸烟、饮酒、打鼾.月人均收入、脉压差、心率.文化程度、高血压家族史、打鼾.文化程度、高血压家族史、打鼾 - 正确.吸烟、饮酒 . 高血压家族史吸烟、饮酒、打鼾 5.总体是指() .全部研究对象.全部研究对象中抽取的一部分.全部样本.全部研究指标 . 全部同质研究对象的某个变量的值-正确 第二章- 单选题 (10/10 分数) 1.描述一组偏态分布资料的变异度,以()指标较好。 . 全距 . 标准差 . 变异系数 . 四分位数间距 . 四分位数间距 - 正确.方差 2.用均数和标准差可以全面描述()资料的特征。 . 正偏态分布 . 负偏态分布 . 正态分布 . 正态分布 - 正确 . 对称分布.对数正态分布 3.各观察值均加(或减)同一数后()。 . 均数不变 . 几何均数不变 . 中位数不变 . 标准差不变 . 标准差不变 - 正确.变异系数不变 4.比较某地1~2岁和5~5.5岁儿童身高的变异程度,宜用()。 实验报告实验名称:t 检验成绩: 实验日期: 2011年10月31日实验报告日期:2011年11 月日 林虹 一、实验目的 (1)掌握单一样本t检验。 (2)掌握相关样本t检验 (3)掌握独立样本t检验 二、实验设备 (1)微机 (2)SPSS for Windows 统计软件包 三、实验内容: 1.某市统一考试的数学平均成绩为75分,某校一个班的成绩见表4-1。问该班的 成绩与全市平均成绩的差异显着吗 表4-1 学生的数学成绩 12345678910111213141516 编 号 成 96977560926483769097829887568960 绩 编17181920212223242526272829303132 号 成 68747055858656716577566092548780 绩 2.某物理教师在教学中发现,在课堂物理教学中采用“先讲规则(物理的定理或法 则),再举例题讲解规则的具体应用”与采用“先讲例题,再概括出解题规则” 这两种教学方法的教学效果似乎不同。为了验证他的这个经验性发现是否属实,他选择了两个近似相等的班级进行教学实验。进行教学实验时的教学内容、教学时间和教学地点等无关变量他都做了严格的控制,分别采用“例-规”法与“规-例”法对两个班的学生进行物理教学,然后,两个班的被试都进行同样的物理知识测验。测验成绩按“5分制”进行评定。两组被试的测验成绩见数据文件data4-02。请用SPSS,通过适当的统计分析方法,检验这两种教学方法的教学效果是否存在实质性差别。 3.某幼儿园分别在儿童入园时和入园一年后对他们进行了“比奈智力测验”,测验 结果见数据文件data4-03。请问,儿童入园一年后的智商有明显的变化吗 (例题) 4.某心理学工作者以大学生为被试,以“正性”和“负性”两种面部表情模式的照 片为实验材料,测量被试对“正性”和“负性”面部表情识别的时间,测验结果见数据文件data4-04。请用SPSS中适当的统计分析方法检验两种面部表情模式对大学生识别面部表情的时间是否存在明显的影响。 5.某小学教师分别采用“集中学习”与“分散学习”两种方式教两个小学二年级班 级的学生学习相同的汉字,两个班学生的学习成绩见data4-05。请问哪种学习方式效果更好 6.某省语文高考平均成绩为78分,某学校的成绩见data4-06。请问该校考生的平 一、单项选择题(共40 道试题,共100 分。) 1. 完全随机设计的两个大样本的样本均数比较(总体标准差 方差分析 D.三者均可 满分:2.5 分 2. 在缺乏有关历史资料,或指标难以数量化时,常用的筛选评价指标的方法是 满分:2.5 分 3. 方差分析适用条件为 满分:2.5 分 4. 在比较完全随机设计两个小样本的均数时,需用t'检验的情况是 满分:2.5 分 某假设检验,检验水准为0.05,经计算P>0.05,不拒绝H,此时若推断有错,其错误概率为 <7未知),需检验无效假设g 1=U 2是否成立,可考虑用 B. t检验 C. u检验 A.文献资料分析优选法 B.多元回归法 C.系统分析法 D.指标聚类法 A.独立性 B.正态性 C.方差齐性 D.以上都对 A.两总体方差不等 B.两样本方差不等 C.两样本均数不等 D.两总体均数不等 5. A. 0.01 B. 0.95 B = 0.01 B未知 满分:2.5 分 6. 正面的评价指标的权重估计方法中,哪一种是客观定权法 A.专家的个人判断 B.专家会议法 C. Satty 权重法 D.相关系数法 满分:2.5 分 7. 下列统计方法中属于非参数检验的是 A. u检验 方差分析 D.秩和检验 满分:2.5 分 & 抽样研究中,s为定值,若逐渐增大样本含量,则样本 A.标准误增大 B.标准误减小 C.标准误不改变 D.标准误的变化与样本含量无关 满分:2.5 分 满分:2.5 满分:2.5 治愈7人,用B 药治疗10例病人,治愈1人,比较两药疗效时,适宜的统计方法是 9. 四格表资料的卡方检验,其校正条件是 A. 总例数大于40 B. 有实际数为0 C. 有实际数小于1 D. 有一个理论数小于 5大于1,则n>40 10. 在下列何种情况, 可认为判断矩阵具有较满意的一致性 A. 当 CR<0.10 时 B. 当 CR>0.10 时 C. 当时CR<1 D. 当CR>1时 11. A. u 检验 B.直接计算概率 C. x 2检验 D.校正X 2检验 满分:2.5 12. 表示均数抽样误差大小的统计指标是 A.标准差 B. 方差 C.均数标准误 D.变异系数 某医师用A 药治疗9例病人, T检验、F检验和统计学意义(P值或sig值) 1.T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定。 通过把所得到的统计检定值,与统计学家建立了一些随机变量的概率分布(probability distribution)进行比较,我们可以知道在多少%的机会下会得到目前的结果。倘若经比较后发现,出现这结果的机率很少,亦即是说,是在机会很少、很罕有的情况下才出现;那我们便可以有信心的说,这不是巧合,是具有统计学上的意义的(用统计学的话讲,就是能够拒绝虚无假设null hypothesis,Ho)。相反,若比较后发现,出现的机率很高,并不罕见;那我们便不能很有信心的直指这不是巧合,也许是巧合,也许不是,但我们没能确定。 F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。统计显著性(sig)就是出现目前样本这结果的机率。 2. 统计学意义(P值或sig值) 结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法。专业上,p值为结果可信程度的一个递减指标,p值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。p值是将观察结果认为有效即具有总体代表性的犯错概率。如p=0.05提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果。(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。)在许多研究领域,0.05的p值通常被认为是可接受错误的边界水平。 3. T检验和F检验 至於具体要检定的内容,须看你是在做哪一个统计程序。 举一个例子,比如,你要检验两独立样本均数差异是否能推论至总体,而行的t检验。 两样本(如某班男生和女生)某变量(如身高)的均数并不相同,但这差别是否能推论至总体,代表总体的情况也是存在著差异呢? 会不会总体中男女生根本没有差别,只不过是你那麼巧抽到这2样本的数值不同? 为此,我们进行t检定,算出一个t检定值。 与统计学家建立的以「总体中没差别」作基础的随机变量t分布进行比较,看看在多少%的机会(亦即显著性sig值)下会得到目前的结果。 若显著性sig值很少,比如<0.05(少於5%机率),亦即是说,「如果」总体「真的」没有差别,那麼就只有在机会很少(5%)、很罕有的情况下,才会出现目前这样本的情况。虽然还是有5%机会出错(1-0.05=5%),但我们还是可以「比较有信心」的说:目前样本中这情况(男女生出现差异的情况)不是巧合,是具统计学意义的,「总体中男女生不存差异」的虚无假设应予拒绝,简言之,总体应该存在著差异。 每一种统计方法的检定的内容都不相同,同样是t-检定,可能是上述的检定总体中是否存在差异,也同能是检定总体中的单一值是否等於0或者等於某一个数值。 至於F-检定,方差分析(或译变异数分析,Analysis of V ariance),它的原理大致也是上面说的,但它是透过检视变量的方差而进行的。它主要用于:均数差别的显著性检验、分离各有关因素并估计其对总变异的作用、分析因素间的交互作用、方差齐性(Equality of V ariances)检验等情况。 4. T检验和F检验的关系 t检验过程,是对两样本均数(mean)差别的显著性进行检验。惟t检验须知道两个总体的方 统计学T检验的意义(P值或sig值) 1.T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定。 通过把所得到的统计检定值,与统计学家建立了一些随机变量的概率分布(probability distribution)进行比较,我们可以知道在多少%的机会下会得到目前的结果。倘若经比较后发现,出现这结果的机率很少,亦即是说,是在机会很少、很罕有的情况下才出现;那我们便可以有信心的说,这不是巧合,是具有统计学上的意义的(用统计学的话讲,就是能够拒绝虚无假设null hypothesis,Ho)。相反,若比较后发现,出现的机率很高,并不罕见;那我们便不能很有信心的直指这不是巧合,也许是巧合,也许不是,但我们没能确定。 F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。统计显著性(sig)就是出现目前样本这结果的机率。 2. 统计学意义(P值或sig值) 结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法。专业上,p值为结果可信程度的一个递减指标,p值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。p值是将观察结果认为有效即具有总体代表性的犯错概率。如p=0.05提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果。(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。)在许多研究领域,0.05的p值通常被认为是可接受错误的边界水平。 3. T检验和F检验 至於具体要检定的内容,须看你是在做哪一个统计程序。 举一个例子,比如,你要检验两独立样本均数差异是否能推论至总体,而行的t检验。 两样本(如某班男生和女生)某变量(如身高)的均数并不相同,但这差别是否能推论至总体,代表总体的情况也是存在著差异呢? 会不会总体中男女生根本没有差别,只不过是你那麼巧抽到这2样本的数值不同? 为此,我们进行t检定,算出一个t检定值。 与统计学家建立的以「总体中没差别」作基础的随机变量t分布进行比较,看看在多少%的机会(亦即显著性sig值)下会得到目前的结果。 若显著性sig值很少,比如<0.05(少於5%机率),亦即是说,「如果」总体「真的」没有差别,那麼就只有在机会很少(5%)、很罕有的情况下,才会出现目前这样本的情况。虽然还是有5%机会出错(1-0.05=5%),但我们还是可以「比较有信心」的说:目前样本中这情况(男女生出现差异的情况)不是巧合,是具统计学意义的,「总体中男女生不存差异」的虚无假设应予拒绝,简言之,总体应该存在著差异。 每一种统计方法的检定的内容都不相同,同样是t-检定,可能是上述的检定总体中是否存在差异,也同能是检定总体中的单一值是否等於0或者等於某一个数值。 至於F-检定,方差分析(或译变异数分析,Analysis of Variance),它的原理大致也是上面说的,但它是透过检视变量的方差而进行的。它主要用于:均数差别的显著性检验、分离各有关因素并估计其对总变异的作用、分析因素间的交互作用、方差齐性(Equality of Variances)检验等情况。 4. T检验和F检验的关系 t检验过程,是对两样本均数(mean)差别的显著性进行检验。惟t检验须知道两个总体的方 1.参数检验:已知总体分布类型,对未知的总体参数做推断的假设检验方法。故参数检验依赖于特定的分布类型,比较的是总体参数 2.非参数检验:不依赖于总体分布类型、不针对总体参数的检验方法。故非参数检验对总体的分布类型不做任何要求,不受总体参数的影响,比较的是分布或分布位置。适用范围广,可适用于任何类型资料 参数检验 优点:资料信息利用充分;检验效能较高 缺点:对资料的要求高;适用范围有限 2.非参数检验 优点:适用范围广,可适用于任何类型的资料 缺点:检验效能低,易犯Ⅱ型错误 凡适合参数检验的资料,应首选参数检验 对于符合参数检验条件者,采用非参数检验,其 检验效能低,易犯Ⅱ型错误 第一章绪论 1.举例说明总体和样本的概念。 研究人员通常需要了解和研究某一类个体,这个类就是总体。总体是根据研究目的所确定的所有同质观察单位某种观察值(即变量值)的集合,通常有无限总体和有限总体之分,前者指总体中的个体是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体是有限的,它是指特定时间、空间中有限个研究个体。但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。例如在一项关于2007年西藏自治区正常成年男子的红细胞平均水平的调查研究中,该地2007年全部正常成年男子的红细胞数就构成一个总体,从此总体中随即抽取2000人,分别测的其红细胞数,组成样本,其样本含量为2000人。 2.简述误差的概念。 误差泛指实测值与真实值之差,一般分为随机误差和非随机误差。随机误差是使重复观测获得的实际观测值往往无方向性地围绕着某一个数值左右波动的误差;非随机误差中最常见的为系统误差,系统误差也叫偏倚,是使实际观测值系统的偏离真实值的误差。 3.举例说明参数和统计量的概念。 某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病。统计量是研究人员能够知道的,而参数是他们想知道的。一般情况下,这些参数是难以测定的,仅能够根据样本估计。显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的。 4.简述小概率事件原理。 当某事件发生的概率小于或等于时,统计学上习惯称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓的小概率事件原理,它是进行统计推断的重要基础。 第二章调查研究设计 1.调查研究主要特点是什么 调查研究的主要特点是:①研究的对象及其相关因素(包括研究因素和非研究因素)是客观存在的,不能人为给予干预措施②不能用随机化分组来平衡混杂因素对调查结果的影响。 2.简述调查设计的基本内容。 ①明确调查目的和指标②确定调查对象和观察单位③确定调查方法④确定调查方式⑤确定调查项目和调查表⑥制定资料整理分析计划⑦制定调查的组织计划。 3.试比较常用的四种概率抽样方法的优缺点。 (1)单纯随机抽样优点是:均数(或率)及标准误的计算简便。缺点是:当总体观察单位数较多时,要对观察单位一一编号,比较麻烦,实际工作中有时难以办到。 (2)系统抽样优点是:①易于理解,简便易行②容易得到一个按比例分配的样本,由于样本相应的顺序号在总体中是均匀散布的,其抽样误差小于单纯随机抽样。缺点是:①当总体的观察单位按顺序有周期趋势或单调递增(或递减)趋势,系统抽样将产生明显的偏性。 个人总结 星期二,2017年6月20日 07:20 1、卡方检验、涉及到等级资料的需要加权 2、卡方检验列数参照标目来定 1、t检验:analyze--compare mean 2、方差分析: 完全随机设计:analyze--compare means--one-way ANOVA 随机区组、交叉设计、析因设计:Analyze--general linear model(一般线性模型)--univariate(单因素) 重复测量设计的方差分析:Analyze--general linear model(一般线性模型)--repeated measures 3、卡方检验:加权 完全随机设计、配对设计、行乘列表:analyze--descriptive statistics--crosstabs(交叉表) 4、秩和检验: 配对设计、单一样本:Analyze--nonparametric tests--legacy dialogs(旧对话 框)--2 related samples 完全随机设计两样本:Analyze--nonparametric tests--legacy dialogs(旧对话 框)--2 independent samples 完全随机设计多样本:Analyze--nonparametric tests--legacy dialogs(旧对话框)--K independent samples 随机区组设计:Analyze--nonparametric tests--legacy dialogs(旧对话框)--K related samples 完全随机(成组)设计两两比较:analyze--nonparametric tests--K independent samples 随机区组设计的两两比较:analyze--nonparametric tests--K related samples 分区个人经验的第1 页t检验计算公式89476
t检验计算公式
T检验、F检验及统计学意义
t检验计算公式.doc
2018年度医学统计学试卷及其规范标准答案
t检验计算公式
卫生统计学专题八:t检验
卫生统计学试卷(带答案)
医学统计学练习
医学统计学课后习题全
教育统计学t检验练习
卫生统计学形成性试题及答案
T检验、F检验和统计学意义(P值或sig值)
统计学T检验的意义
医学统计学课后答案
卫生统计学spss操作
相关主题
文本预览