
《回归分析的基本思想及初步应用》课例反思
一、教材分析
1、教材的地位和作用
在《数学③(必修)》之后,学生已经学习了两个变量之间的相关关系,包括画散点图,最小二乘法求回归直线方程等内容.在人教A版选修1-2第一章第一节“回归分析的基本思想及其初步应用”这一节中进一步介绍回归分析的基本思想及其初步应用.这部分内容共计4课时,第一课时:复习必修三内容,介绍线性回归模型的数学表达式;第二课时:解释随机误差项产生的原因,使学生能正确理解回归方程的预报结果,并能从残差分析角度讨论回归模型的拟合效果;第三课时:从相关系数、相关指数角度探讨回归模型的拟合效果,以及建立回归模型的基本步骤;第四课时:介绍两个变量非线性相关关系,回归分析的应用. 本节课是第二课时的内容.
2、教学目标
知识和技能:认识随机误差,认识残差以及相关指数。
根据散点分布特点,建立线性回归模型。
了解模型拟合效果的分析工具——残差分析。
过程与方法:经历数据处理全过程,培养对数据的直观感觉,体会统计方法的应用。
通过一次函数模型和线性回归模型的比较,使学生体会函数思想。
情感、态度与价值观:
通过案例分析,了解回归分析的实际应用,感受数学“源于生活,用于
生活”,提高学习兴趣。
教学中适当地利用学生合作与交流,使学生在学习的同时,体会与他
人合作的重要性.。
3、教学重难点
重点:1、了解回归模型与函数模型的区别
2、了解任何模型只能近似描述实际问题
3、了解模型拟合效果的分析工具——残差分析
难点:参差分析
二、教法学法分析
通过创设情境——运用已有知识——发现新问题——启发引导——合作交流——得到新知识。整个活动过程,学生始终是学习活动的主体,教师是组织者、引导者、合作者。
三、学情分析
1.通过必修3的学习,学生已掌握了线性回归方程的相关知识和应用,已具有一定的对数据的直观感觉,具备了较好的数据整理和分析能力。
2.学生思维活泼,积极性高,但探究问题的能力和合作交流的能力发展还不够。
3.普高学生层次参次不齐,个体差异比较明显。
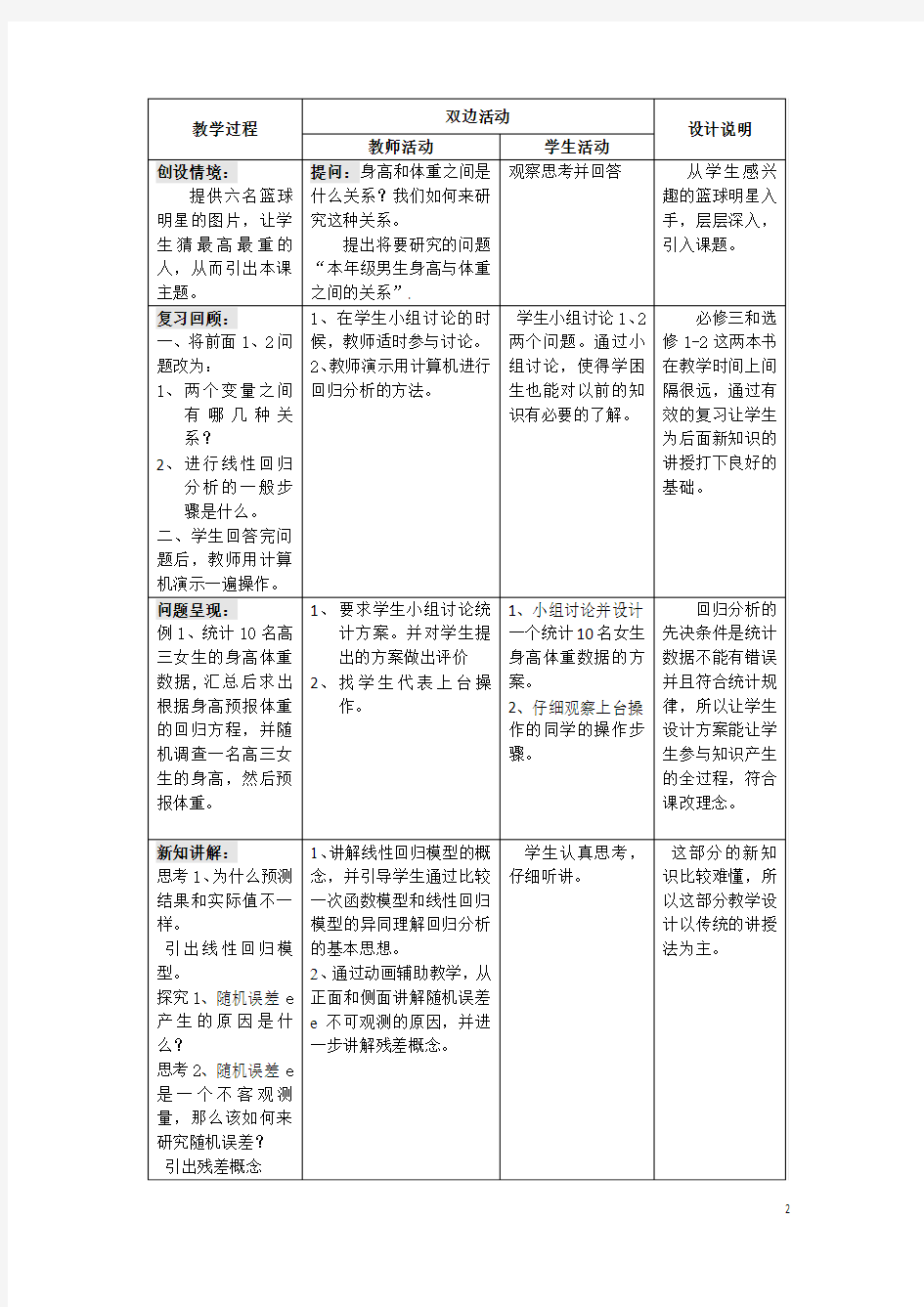
四、教学过程
五、课后反思
1、为使教学真正做到以学生为本,我对教材的知识进行了适当地重组和加工,力求给学生提供研究、探讨的时间与空间,让学生充分经历“做数学”的过程,促使学生在自主中求知,在合作中获取,在探究中发展.
2、本节课的教法特点:通过分析教材和学生认知规律,创造性地使用教材,做到既重视教材,更重视学生.具体说来有以下改造:(1)创设生活情景.利用学生的“体检经验”设置问题,既没有脱离课本例题1的相关内容,又能激发学生对数学的亲切感,引发学生看个究竟的冲动,兴趣盎然地投入学习. (2)充分体现随机观念.课本上仅仅希望利用8组数据就要学生体会到统计的思想和后继课程中回归分析的必要性,实在是为难学生了.在本课教学设计学生操作时强调“增多数据,加强比较”. 帮助学生体会“不同事件(如课本例1女大学生和高二女生)”,则统计结果不同、“同一事件(如都是高二女生),采样不同结果也不同”的基本事实.
本课教学以问题引导学习活动,通过恰时恰点地提出问题,提好问题,给学生提问的示范,使他们领悟发现和提出问题的艺术,引导他们更加主动和有兴趣地学,逐步培养学生的问题意识,孕育创新精神.例如,在“结果的分析”中预测出的体重值都不同,那么它还有参考价值吗?”目的是让学生充分认识随机误差e的来源和对预报变量的影响,而这一问题的提出,立刻吸引学生细细体会随机观念,同时激发出学生的好奇心,提升深入探求的欲望。
3 合作、探究的学习方式。本节课的合作学习体现在两个方面:除了体现在每个小组
内部成员之间,还体现在整堂课的教学结构上.小组成员内部提倡“不同的人作不同的事”,面对不同分组,学生可以自主选择的不同工作,动手带动动脑,遇到小的问题,通过探讨和帮助,能做到“学生的问题由学生自己解决”,促进对某一问题更清晰的认识,还能感受到团结合作的好处与必要.同时,每个小组的劳动成果共同构成课堂教学需要的多条回归方程,组与组之间的合作推动整节课的比较与区分得以实现. 通过本节课的教学实践,我再次体会到什么是由“关注知识”转向“关注学生”,在教学过程中,注意到了由“给出知识”转向“引起活动”,由“完成教学任务”转向“促进学生发展”,课堂上的真正主人应该是学生.一堂好课,师生一定会有共同的、积极的情感体验.本节课的教学中,知识点均是学生通过探索“发现”的,学生充分经历了探索与发现的过程.教学中没有以练习为主,而是定位在知识形成过程的探索,注重数学的思想性,如统计思想、随机观念、函数思想、数形结合的思想方法等,引导学生体验数学中的理性精神,加强数学形式下的思考和推理
案例分析报告(2014——2015学年第一学期) 课程名称:预测与决策 专业班级:电子商务1202 学号:2204120202 学生姓名:陈维维 2014 年11月
案例分析(一元线性回归模型) 我国城镇居民家庭人均消费支出预测 一、研究目的与要求 居民消费在社会经济的持续发展中有着重要的作用,居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。从理论角度讲,消费需求的具体内容主要体现在消费结构上,要增加居民消费,就要从研究居民消费结构入手,只有了解居民消费结构变化的趋势和规律,掌握消费需求的热点和发展方向,才能为消费者提供良好的政策环境,引导消费者合理扩大消费,才能促进产业结构调整与消费结构优化升级相协调,才能推动国民经济平稳、健康发展。例如,2008年全国城镇居民家庭平均每人每年消费支出为11242.85元,最低的青海省仅为人均8192.56元,最高的上海市达人均19397.89元,上海是黑龙江的2.37倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我研究的对象是各地区居民消费的差异。居民消费可分为城镇居民消费和农村居民消费,由于各地区的城镇与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城镇居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。 所以模型的被解释变量Y选定为“城镇居民每人每年的平均消费支出”。 因为研究的目的是各地区城镇居民消费的差异,并不是城镇居民消费在不同时间的变动,所以应选择同一时期各地区城镇居民的消费支出来建立模型。因此建立的是2008年截面数据模型。影响各地区城镇居民人均消费支
中国税收增长的分析 一、研究的目的要求 改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。(3)物价水平。我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。(4)税收政策因素。我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响,特别是1985年税收陡增215.42%。但是第二次税制改革对税收的增长速度的影响不是非常大。因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数” 从《中国统计年鉴》收集到以下数据 财政收入(亿元) Y 国内生产总值(亿 元) X2 财政支出(亿 元) X3 商品零售价格指 数(%) X4 1978519.283624.11122.09100.7 1979537.824038.21281.79102 1980571.74517.81228.83106
新课标数学选修1-2 1.1回归分析的基本思想及其初步应用 (教师用书独具) ●三维目标 1.知识与技能 通过典型案例的探究,了解回归分析的基本思想,会对两个变量进行回归分析,明确解决回归模型的基本步骤,并对具体问题进行回归分析以解决实际应用问题.了解最小二乘法的推导,解释残差变量的含义,了解偏差平方和分解的思想,了解判断刻画模型拟合效果的方法——相关指数和残差分析.掌握利用计算器求线性回归直线方程参数及相关系数的方法. 2.过程与方法 通过收集数据作散点图,分析散点图,求回归直线方程,分析回归效果,利用方程进行预报. 3.情感、态度与价值观 培养学生利用整体的观点和互相联系的观点来分析问题,进一步加强数学的应用意识,培养学生学好数学、用好数学的信心,加强与现实生活的联系,以科学的态度评价两个变量的相互关系. ●重点难点 重点:回归分析的基本方法、随机误差e的认识、残差图的概念、用残差及R2来刻画线性回归模型的拟合效果. 难点:回归分析的基本方法、残差概念的理解及拟合效果的判定、非线性回
归向线性回归的转化. 教学时要以残差分析为重点,突出残差表和R2的计算,通过举例说明相关关系与确定性关系的区别,说明回归分析的必要性及其方法.借助例题使学生掌握作散点图、求回归直线方程的方法,通过作残差图、计算R2让学生掌握拟合效果的判断方法.对于非线性回归问题重点在如何转换,引导学生分析总结转化方法和技巧,从而化解难点. (教师用书独具) ●教学建议 本节课建议教师采取探究式教学,把“关注知识”转向“关注学生”,在教学过程中,把“给出知识”的过程转变为“引起活动,让学生探究知识的过程”,把“完成教学任务”转向“促进学生发展”,让学生成为课堂上的真正主人.在教学中,知识点可由学生通过探索“发现”,让学生充分经历探索与发现的过程,并引导学生积极解决探索过程中发现的问题.教学中不要以练习为主,而是定位在知识形成过程的探索,例题的解答也要由学生探讨、教师点拨,共同完成.要注重数学的思想性,如统计思想、随机观念、函数思想、数形结合的思想方法等,引导学生体验数学中的理性精神,加强数学形式下的思考和推理能力. ●教学流程 创设问题情境,引出问题,引导学生探讨,从而引出回归分析、线性回归模型、刻画回归效果的有关概念及解决方法.利用填一填的形式,使学生自主学习本节基础知识,并反馈了解,对理解有困难的概念加以讲解.引导学生在学习基础知识的基础上分析回答例题1的问题,并总结规律方法,完成变式训练.引导学生分析例题2,根据图中的数据计算系数,求出回归方程,列出残差表,求出R2并判断拟合效果,完成变式训练.
回归分析的基本思想及其初步应用 1.回归分析 回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法,回归分析的基本步骤是画出两个变量的散点图,求回归直线方程,并用回归直线方程进行预报. 2.线性回归模型 (1)在线性回归直线方程y ^=a ^+b ^x 中,b ^=∑n i =1 (x i -x )(y i -y )∑n i =1 (x i -x )2 ,a ^=y --b ^x -,其中x -=1 n ∑n i =1x i ,y -=1n ∑n i =1 y i ,(x ,y )称为样本点的中心,回归直线过样本点的中心. (2)线性回归模型y =bx +a +e ,其中e 称为随机误差,自变量x 称为解释变量,因变量y 称为预报变量. [注意] (1)非确定性关系:线性回归模型y =bx +a +e 与确定性函数y =a +bx 相比,它表示y 与x 之间是统计相关关系(非确定性关系),其中的随机误差e 提供了选择模型的准则以及在模型合理的情况下探求最佳估计值a ,b 的工具. (2)线性回归方程y ^=b ^x +a ^中a ^,b ^的意义是:以a ^ 为基数,x 每增加1个单位,y 相应地平均增加b ^ 个单位. 3.刻画回归效果的方式 方式方法 计算公式 刻画效果 R 2 R 2=1-∑n i =1 (y i -y ^i )2 ∑n i =1 (y i -y )2 R 2越接近于1,表示回归的效果 越好 残差图 e ^ i 称为相应于点(x i ,y i )的残差,e ^ i =y i -y ^ i 残差点比较均匀地落在水平的 带状区域中,说明选用的模型比较合适,其中这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高 残差平方和 ∑n i =1 (y i -y ^i )2 残差平方和越小,模型的拟合效果越好 判断正误(正确的打“√”,错误的打“×”) (1)求线性回归方程前可以不进行相关性检验.( ) (2)在残差图中,纵坐标为残差,横坐标可以选为样本编号.( )
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 组样本,“N截止,代表有P个自变量,如果有x2, xp上图中的x1, 分别代表“自变量”Xp 那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 不可解释的误和其中随机误差分为:可解释的误差其中:代表随机误差, 差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) :服成正太分布,即指:随机误差1必须是服成正太分别的随机变量。0 2:无偏性假设,即指:期望值为3:同共方差性假设,即指,所有的随机误差变量方差都相等4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 多元线性回归的具体操作过程,下面以教程教程数据今天跟大家一起讨论一下,SPSS---为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
————”——“点击分析回归线性进入如下图所示的界面: 个自变10车长,车宽,耗油率,车净重等将“作为“销售量”“因变量”拖入因变量框内,将,当然,你也可以选择其它”“逐步”量拖入自变量框内,如上图所示,在“方法旁边,选择默认的方式,在分析结果中,将会得到如下图所示的结果:进入“”的方式,如果你选择(所有的自变量,都会强行进入)
统计”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F逐步如果你选择“关系最为密切,贡””自变量应该是跟“因变量“量的概率值进行筛选,最先进入回归方程的跟因变量关系最为密切,符合判断条件的概献最大的,如下图可以看出,车的价格和车轴 时将会被剔除)0.1,当概率值大于等于0.05率值必须小于 进行条件筛选,可以自变量”选择变量(E) 框内,我并没有输入数据,如果你需要对某个““内,有一个前提就是:该变量从未在另一个目标列表中”将那个自变量,移入“选择变量框即可,如下图所示:””规则设定相应的“筛选条件“出现!,再点击 弹出如下所示的框,如下所示:”统计量“点击
《回归分析的基本思想及其初步应用》 教学反思 1、设计理念 《数学课程标准》明确指出:有效的数学学习活动不能单纯地模仿与记忆,动手实践、自主探索与合作交流,可以促进学生自主、全面、可持续的发展,是学生学习数学的重要方式.为使教学真正做到以学生为本,我对教材P2—P3的知识进行了适当地重组和加工,力求给学生提供研究、探讨的时间与空间,让学生充分经历“做数学”的过程,促使学生在自主中求知,在合作中获取,在探究中发展. 2、本节课的教法特点 通过分析教材和学生认知规律,创造性地使用教材,做到既重视教材,更重视学生.具体说来有以下改造: (1)创设生活情景.利用学生的“体检经验”设置问题,既没有脱离课本例题1的相关内容,又能激发学生对数学的亲切感,引发学生看个究竟的冲动,兴趣盎然地投入学习. (2)充分体现随机观念.课本上仅仅希望利用8组数据就要学生体会到统计的思想和后继课程中回归分析的必要性,实在是为难学
生了.在本课教学设计学生操作时强调“增多数据,加强比较”. 帮助学生体会“不同事件(如课本例1女大学生和高二女生)”,则统计结果不同、“同一事件(如都是高二女生),采样不同结果也不同”的基本事实. (3)教师的作用. 在这节课里,教师在学生操作结束后,利用更多数据的操作,形成一个与学生结果的对比,这一操作与展示为学生创造了新的思维增长点,引领学生进入更深层领悟. 本课教学以问题引导学习活动,通过恰时恰点地提出问题,提好问题,给学生提问的示范,使他们领悟发现和提出问题的艺术,引导他们更加主动和有兴趣地学,逐步培养学生的问题意识,孕育创新精神.例如,在“结果的分析”中的问题4.”预测出的体重值都不同,那么它还有参考价值吗?”目的是让学生充分认识随机误差e的来源和对预报变量的影响,而这一问题的提出,立刻吸引学生细细体会随机观念,同时激发出学生的好奇心,提升深入探求的欲望. 3 合作、探究的学习方式 本节课的合作学习体现在两个方面:除了体现在每个小组内部成员之间,还体现在整堂课的教学结构上.小组成员内部提倡“不同的人作不同的事”,面对不同分组,学生可以自主选择的不同工作,
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
第二章回归分析概述 回归分析是寻求隐藏在随机现象中的统计规律的理论和方法,是经济计量学的最基本的方法论基础。讨论回归模型在经典假设条件下的参数估计、假设检验和估计量的统计性质,以及经典假设不完全满足条件下,有关问题的处理是理论经济计量学的任务。为了对回归分析理论和方法有一个全面深入的理解,本章先对回归分析的基本概念和性质予以介绍,在以后各章顺次展开以上问题的讨论。 第一节回归分析的性质 一、“回归”一词的现代含义 回归一词最早是生物统计学家高尔顿(Francis Galton)引入的。高尔顿在对人类身高之类的遗传特性的研究中,发现了他称之为“向平均回归”的现象。虽然客观上存在一种趋势,即父母高,子女也高;父母矮,子女也矮,但是给定父母的身高,子女的平均身高却有“回归”到全体人口的平均身高的倾向。也就是说,尽管父母双亲都异常高或异常矮,而子女的身高却有趋向人口总体平均身高的趋势。高尔顿的普通回归定律也被另一位统计学家皮尔逊(Karl Pearson)证实。高尔顿的兴趣在于发现人口的身高为什么有一种稳定性。这是“回归”一词的初始含义。 然而,对“回归”一词的现代解释却与初始含义有很大不同,其现代含义是回归分析研究一个被解释变量对另一个或多个解释变量的变量依存关系,其用意在于通过后者(在重复抽样中)的已知或设定值,去估计或预测前者的(总体)均值。 比如,对于父母身高与子女身高的关系研究,人们会发现,对于设定的每一个父辈的身高,都有一个儿辈的假想人口总体的身高分布与之对应,随着父辈身高的增加,儿辈的平均身高也增加。若把这种父辈身高与儿辈平均身高的一一对应关系绘制在平面坐标图上,可以得到一条直线,这条直线就叫做回归线,它表明儿辈的平均身高如何随父辈的身高变化。从现代回归的观点出发,人们关心的是给定父辈的身高情况下,如何发现儿辈平均身高的变化。也就是说,人们关心的是一旦知道了父辈的身高,如何估计预测儿辈的平均身高。 经济学家可以利用回归分析研究个人消费支出对其实际可支配收入的依从关系。通过回归分析可估计边际消费倾向(MPC),而边际消费倾向说明人们每增加一个单位的实际可支配收入而引起的消费支出的平均变化。 农业经济学家可利用回归分析研究农作物收成对施肥量,降雨量,气温等的依赖关系。这种分析能使他用给定的解释变量的信息预测或预报农作物的平均收成。 劳动经济学家利用回归分析研究货币工资变化率对失业率的依存关系,著名的菲利普斯曲线就是研究这一依存关系的成果,劳动经济学家经常利用这一曲线预测在给定的某个失业率下货币工资的平均变化。由于工资的增长会引起物价的上涨,因此通过这一曲线还可以研究通货膨胀、关于经济扩张过程方面的问题。 由货币银行学的知识可知,若其它条件不变,通货膨胀率愈高,人们愿意以货币形式保存的收入比例越低。对这种关系作回归分析,使金融学家能够预测在各种通货膨胀率下人们愿意以货币形式保存的平均收入比例。
回归分析的基本知识点及习题 本周题目:回归分析的基本思想及其初步应用 本周重点: (1)通过对实际问题的分析,了解回归分析的必要性与回归分析的一般步骤;了解线性回归模型与函数模型的区别; (2)尝试做散点图,求回归直线方程; (3)能用所学的知识对实际问题进行回归分析,体会回归分析的实际价值与基本思想;了解判断刻画回归模型拟合好坏的方法――相关指数和残差分析。 本周难点: (1)求回归直线方程,会用所学的知识对实际问题进行回归分析. (2)掌握回归分析的实际价值与基本思想. (3)能运用自己所学的知识对具体案例进行检验与说明. (4)残差变量的解释; (5)偏差平方和分解的思想; 本周内容: 一、基础知识梳理 1.回归直线: 如果散点图中点的分布从整体上看大致在一条直线附近,我们就称这两个变量之间具有线性相关关系,这条直线叫作回归直线。 求回归直线方程的一般步骤: ①作出散点图(由样本点是否呈条状分布来判断两个量是否具有线性相关关系),若存在线性相关关系→②求回归系数→ ③写出回归直线方程,并利用回归直线方程进行预测说明. 2.回归分析: 对具有相关关系的两个变量进行统计分析的一种常用方法。 建立回归模型的基本步骤是: ①确定研究对象,明确哪个变量是解释变量,哪个变量是预报变量; ②画好确定好的解释变量和预报变量的散点图,观察它们之间的关系(线性关系). ③由经验确定回归方程的类型. ④按一定规则估计回归方程中的参数(最小二乘法); ⑤得出结论后在分析残差图是否异常,若存在异常,则检验数据是否有误,后模型是否合适等. 3.利用统计方法解决实际问题的基本步骤: (1)提出问题; (2)收集数据; (3)分析整理数据; (4)进行预测或决策。 4.残差变量的主要来源: (1)用线性回归模型近似真实模型(真实模型是客观存在的,通常我们并不知道真实模型到底是什么)所引起的误差。 可能存在非线性的函数能够更好地描述与之间的关系,但是现在却用线性函数来表述这种关系,结果就会产生误差。这 种由于模型近似所引起的误差包含在中。 (2)忽略了某些因素的影响。影响变量的因素不只变量一个,可能还包含其他许多因素(例如在描述身高和体重 关系的模型中,体重不仅受身高的影响,还会受遗传基因、饮食习惯、生长环境等其他因素的影响),但通常它们每一个因素的影响可能都是比较小的,它们的影响都体现在中。 (3)观测误差。由于测量工具等原因,得到的的观测值一般是有误差的(比如一个人的体重是确定的数,不同的秤可 能会得到不同的观测值,它们与真实值之间存在误差),这样的误差也包含在中。 上面三项误差越小,说明我们的回归模型的拟合效果越好。
一般线性回归分析案例 1、案例 为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康地影响,随机抽取了30个观测数据,基于多员线性回归分析地理论方法,对儿童体内几种必需元素与血红蛋白浓度地关系进行分析研究.这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu). 表一血红蛋白与钙、铁、铜必需元素含量 (血红蛋白单位为g;钙、铁、铜元素单位为ug) case 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30y(g) 7.00 7.25 7.75 8.00 8.25 8.25 8.50 8.75 8.75 9.25 9.50 9.75 10.00 10.25 10.50 10.75 11.00 11.25 11.50 11.75 12.00 12.25 12.50 12.75 13.00 13.25 13.50 13.75 14.00 14.25 ca 76.90 73.99 66.50 55.99 65.49 50.40 53.76 60.99 50.00 52.34 52.30 49.15 63.43 70.16 55.33 72.46 69.76 60.34 61.45 55.10 61.42 87.35 55.08 45.02 73.52 63.43 55.21 54.16 65.00 65.00 fe 295.30 313.00 350.40 284.00 313.00 293.00 293.10 260.00 331.21 388.60 326.40 343.00 384.48 410.00 446.00 440.01 420.06 383.31 449.01 406.02 395.68 454.26 450.06 410.63 470.12 446.58 451.02 453.00 471.12 458.00 cu 0.840 1.154 0.700 1.400 1.034 1.044 1.322 1.197 0.900 1.023 0.823 0.926 0.869 1.190 1.192 1.210 1.361 0.915 1.380 1.300 1.142 1.771 1.012 0.899 1.652 1.230 1.018 1.220 1.218 1.000
总结:线性回归分析的基本 步骤 -标准化文件发布号:(9556-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
线性回归分析的基本步骤 步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周消费(Y )数据如下: 作出其散点图如下:
②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例 由于01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。
如将()()222777100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据: 那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: 2010年中国各地区城市居民人均年消费支出和可支配收入
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 表3 相关性 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
表4 系数a 3、结果分析 表2模型汇总:相关系数为0.965,判定系数为0.932,调整判定系数为0.930,估计值的标准误877.29128 表3是相关分析结果。消费性支出Y与可支配收入X相关系数为0.965,相关性很高。 表4是回归分析中的系数:常数项b=704.824,可支配收入X的回归系数a=0.668。a的标准误差为0.034,回归系数t的检验值为19.921,P值为0,满足95%的置信区间,可认为回归系数有显著意义。得线性回归方程Y=0.668X+704.824. 【实验结论】 (1)结果显示,变量之间具有如下关系式:Y=0.668X+704.824.也就是说消费与收入之间存在稳定的函数关系。随着收入的增加,消费将增加,但消费的增长低于收入的增长。这与凯尔斯的绝对收入消费理论刚好吻合。但为了研究方便,这里假设边际消费倾向为常数。由公式知X每增长1个单位,Y增加0.668个单位。
我国农民收入影响因素的回归分析 本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。?农民收入水平的度量常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。二是农业剩余劳动力转移水平。三是城市化、工业化水平。四是农业产业结构状况。五是农业投入水平。考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。 一、计量经济模型分析 (一)、数据搜集 根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。
资料来源《中国统计年鉴2006》。 (二)、计量经济学模型建立 我们设定模型为下面所示的形式: 利用Eviews 软件进行最小二乘估计,估计结果如下表所示: DependentVariable:Y Method:LeastSquares Sample: Includedobservations:19 Variable Coefficient t-Statistic Prob. C X1 X3 X4 X5 X6 X7 X8 R-squared Meandependentvar AdjustedR-squared 表1最小二乘估计结果 回归分析报告为: () ()()()()()()()()()()()()()()() 2345678 2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66 R Df DW F ====二、计量经济学检验 (一)、多重共线性的检验及修正 ①、检验多重共线性 (a)、直观法 从“表1最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4x6
多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据
设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024
步骤一、建立模型 知识点: 1、总体回归模型、总体回归方程、样本回归模型、样本回归方程 ①总体回归模型:研究总体之中自变量和因变量之间某种非确定依赖关系的计量模型。Y X U β=+ 特点:由于随机误差项U 的存在,使得Y 和X 不在一条直线/平面上。 例1:某镇共有60个家庭,经普查,60个家庭的每周收入(X )与每周 作出其散点图如下:
②总体回归方程(线):由于假定0EU =,因此因变量的均值与自变量总处于一条直线上,这条直线()|E Y X X β=就称为总体回归线(方程)。 总体回归方程的求法:以例1的数据为例
实用标准文案 由于()01|i i i E Y X X ββ=+,因此任意带入两个X i 和其对应的E (Y |X i )值,即可求出01ββ和,并进而得到总体回归方程。 如将()()222777100,|77200,|137X E Y X X E Y X ====和代入 ()01|i i i E Y X X ββ=+可得:0100117710017 1372000.6ββββββ=+=?????=+=?? 以上求出01ββ和反映了E (Y |X i )和X i 之间的真实关系,即所求的总体回归方程为:()|170.6i i i E Y X X =+,其图形为: ③样本回归模型:总体通常难以得到,因此只能通过抽样得到样本数据。如在例1中,通过抽样考察,我们得到了20个家庭的样本数据:
那么描述样本数据中因变量Y 和自变量X 之间非确定依赖关系的模型 ?Y X e β =+就称为样本回归模型。 ④样本回归方程(线):通过样本数据估计出?β ,得到样本观测值的拟合值与解释变量之间的关系方程??Y X β=称为样本回归方程。如下图所示: ⑤四者之间的关系: ⅰ:总体回归模型建立在总体数据之上,它描述的是因变量Y 和自变量X 之间的真实的非确定型依赖关系;样本回归模型建立在抽样数据基础之上,它描述的是因变量Y 和自变量X 之间的近似于真实的非确定型依赖关系。这种近似表现在两个方面:一是结构参数?β 是其真实值β的一种近似估计;二是残差e 是随机误差项U 的一个近似估计; ⅱ:总体回归方程是根据总体数据得到的,它描述的是因变量的条件均值
国际旅游外汇收入是国民经济发展的重要组成部分,影响一个国家或地区旅游收入的因素包括自然、文化、社会、经济、交通等多方面的因素,本例研究第三产业对旅游外汇收入的影响。《中国统计年鉴》把第三产业划分为12个组成部分,分别为x1农林牧渔服务业,x2地质勘查水利管理业,x3交通运输仓储和邮电通信业,x4批发零售贸易和餐饮业,x5金融保险业,x6房地产业,x7社会服务业,x8卫生体育和社会福利业,x9教育文化艺术和广播,x10科学研究和综合艺术,x11党政机关,x12其他行业。采用1998年我国31 个省、市、自治区的数据,以国际旅游外汇收入(百万美元)为因变量y,以如上12 个行业为自变量做多元线性回归,其中自变量单位为亿元人民币。即样本量n=31,变量p=12。 利用SPSS软件对数据进行处理,输出: 图1 输入/移除变量 图1即输入了所有模型中的变量,分别为 x1:农林牧渔服务业 x2:地质勘查水利管理业 x3:交通运输仓储和邮电通信业 x4:批发零售贸易和餐饮业 x5:金融保险业 x6:房地产业 x7:社会服务业 x8:卫生体育和社会福利业 x9:教育文化艺术和广播 x10:科学研究和综合艺术 x11:党政机关 x12:其他行业
图2 模型概述 即回归方程对样本观测值的拟合程度,复相关系数R=0.875,决定系数R 2=0.935。由决定系数接近1,得出回归拟合的效果较好,但是并不能作为严格的显著性检验。由R 2决定模型优劣时需慎重,尤其是样本量与自变量个数接近时。 图3 回归方程显著性的F 检验 F=10.482,F α(n,n-p-1)=F α(30,18)=2.11(α=0.05),P 值=0.000,表明回归方程高度显著,即12个自变量整体对因变量y 产生显著线性影响。但是并不能说明回归方程中所有自变量都对因变量y 有显著影响,因此还要对回归系数进行检验。 图4 回归系数的显著性t 检验(t 0.05(20)=1.725) y 对12个自变量的线性回归方程为: 1234 5678 9101112y 205.388 1.438 2.622 3.2970.9465.521 4.068 4.16215.40417.3389.15510.536 1.37x x x x x x x x x x x x =--++--++-++-+
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该 为: 上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切,
《回归分析的基本思想及初步应用》课例反思 一、教材分析 1、教材的地位和作用 在《数学③(必修)》之后,学生已经学习了两个变量之间的相关关系,包括画散点图,最小二乘法求回归直线方程等内容.在人教A版选修1-2第一章第一节“回归分析的基本思想及其初步应用”这一节中进一步介绍回归分析的基本思想及其初步应用.这部分内容共计4课时,第一课时:复习必修三内容,介绍线性回归模型的数学表达式;第二课时:解释随机误差项产生的原因,使学生能正确理解回归方程的预报结果,并能从残差分析角度讨论回归模型的拟合效果;第三课时:从相关系数、相关指数角度探讨回归模型的拟合效果,以及建立回归模型的基本步骤;第四课时:介绍两个变量非线性相关关系,回归分析的应用. 本节课是第二课时的内容. 2、教学目标 知识和技能:认识随机误差,认识残差以及相关指数。 根据散点分布特点,建立线性回归模型。 了解模型拟合效果的分析工具——残差分析。 过程与方法:经历数据处理全过程,培养对数据的直观感觉,体会统计方法的应用。 通过一次函数模型和线性回归模型的比较,使学生体会函数思想。 情感、态度与价值观: 通过案例分析,了解回归分析的实际应用,感受数学“源于生活,用于 生活”,提高学习兴趣。 教学中适当地利用学生合作与交流,使学生在学习的同时,体会与他 人合作的重要性.。 3、教学重难点 重点:1、了解回归模型与函数模型的区别 2、了解任何模型只能近似描述实际问题 3、了解模型拟合效果的分析工具——残差分析 难点:参差分析 二、教法学法分析 通过创设情境——运用已有知识——发现新问题——启发引导——合作交流——得到新知识。整个活动过程,学生始终是学习活动的主体,教师是组织者、引导者、合作者。 三、学情分析 1.通过必修3的学习,学生已掌握了线性回归方程的相关知识和应用,已具有一定的对数据的直观感觉,具备了较好的数据整理和分析能力。 2.学生思维活泼,积极性高,但探究问题的能力和合作交流的能力发展还不够。 3.普高学生层次参次不齐,个体差异比较明显。 四、教学过程