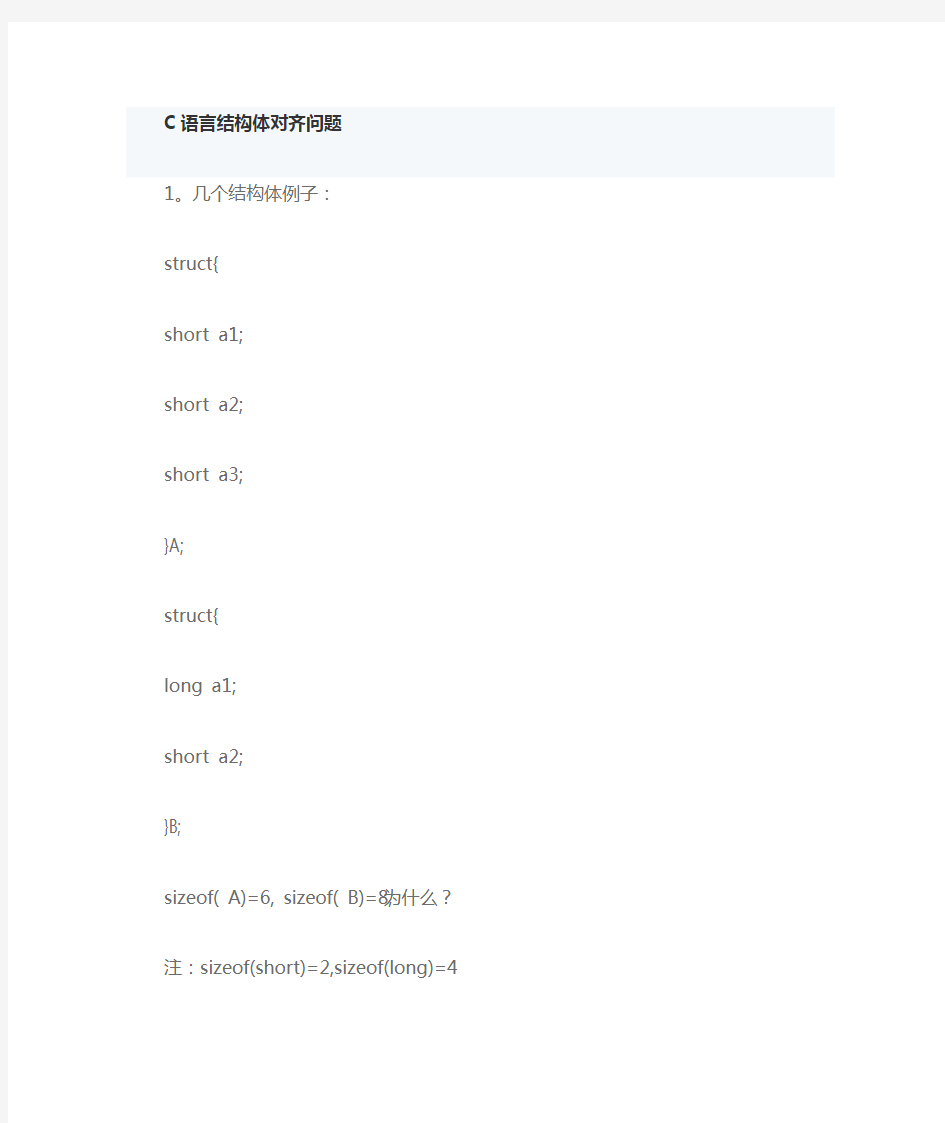

C语言结构体对齐问题
1。几个结构体例子:
struct{
short a1;
short a2;
short a3;
}A;
struct{
long a1;
short a2;
}B;
sizeof( A)=6, sizeof( B)=8,为什么?
注:sizeof(short)=2,sizeof(long)=4
因为:“成员对齐有一个重要的条件,即每个成员按自己的方式对齐。其对齐的规则是,每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数(这里默认是8字节)中较小的一个对齐。并且结构的长度必须为所用过的所有对齐参数的整数倍,不够就补空字节。”(引用)
结构体A中有3个short类型变量,各自以2字节对齐,结构体对齐参数按默认的8字节对齐,则a1,a2,a3都取2字节对齐,则sizeof(A)为6,其也是2的整数倍;
B中a1为4字节对齐,a2为2字节对齐,结构体默认对齐参数为8,则a1取4字节对齐,a2取2字节对齐,结构体大小6字节,6不为4的整数倍,补空字节,增到8时,符合所有条件,则sizeof(B)为8;
可以设置成对齐的
#pragma pack(1)
#pragma pack(push)
#pragma pack(1)
struct{
short a1;
short a2;
short a3;
}A;
struct{
long a1;
short a2;
}B;
#pragma pack(pop)
结果为sizeof( A)=6,sizeof( B)=6 ************************
#pragma pack(8)
struct S1{
char a;
long b;
};
struct S2 {
char c;
struct S1 d;
long long e;
};
#pragma pack()
sizeof(S2)结果为24.
成员对齐有一个重要的条件,即每个成员分别对齐,即每个成员按自己的方式对齐。
也就是说上面虽然指定了按8字节对齐,但并不是所有的成员都是以8字节对齐。其对齐的规则是,每个成员按其类型的对齐参数(通常是这个类型的大小)和指定对齐参数(这里是8字节)中较小的一个对齐。并且结构的长度必须为所用过的所有对齐参数的整数倍,不够就补空字节。
S1中,成员a是1字节默认按1字节对齐,指定对齐参数为8,这两个值中取1,a按1字节对齐;成员b是4个字节,默认是按4字节对齐,这时就按4字节对齐,所以sizeof(S1)应该为8;
S2 中,c和S1中的a一样,按1字节对齐,而d 是个结构,它是8个字节,它按什么对齐呢?对于结构来说,它的默认对齐方式就是它的所有成员使用的对齐参数中最大的一个,S1的就是4.所以,成员d就是按4字节对齐。成员e是8个字节,它是默认按8字节对齐,和指定的一样,所以它对到8字节的边界上,这时,已经使用了12个字节了,所以又添加了4个字节的空,从第16个字节开始放置成员e。这时,长度为24,已经可以被8(成员e按8字节对齐)整除.这样,一共使用了24个字节。
a b
S1的内存布局:1***, 1111,
c S1.a S1.b e
S2的内存布局:1***, 1***, 1111, ****11111111
这里有三点很重要:
1.每个成员分别按自己的方式对齐,并能最小化长度
2.复杂类型(如结构)的默认对齐方式是它最长的成员的对齐方式,这样在成员是复杂类型时,可以最小化长度
3.对齐后的长度必须是成员中最大的对齐参数的整数倍,这样在处理数组时可以保证每一项都边界对齐
补充一下,对于数组,比如:
char a[3];这种,它的对齐方式和分别写3个char是一样的。也就是说它还是按1个字节对齐。
如果写:typedef char Array3[3];
Array3这种类型的对齐方式还是按1个字节对齐,而不是按它的长度。
不论类型是什么,对齐的边界一定是1,2,4,8,16,32,64....中的一个。
/***********************/
字节对齐详解
为什么要对齐?
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
对齐的作用和原因:各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐。其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit 数据。显然在读取效率上下降很多。
二。字节对齐对程序的影响:
先让我们看几个例子吧(32bit,x86环境,gcc编译器):
设结构体如下定义:
struct A
{
int a;
char b;
short c;
};
struct B
{
char b;
int a;
short c;
};
现在已知32位机器上各种数据类型的长度如下:
char:1(有符号无符号同)
short:2(有符号无符号同)
int:4(有符号无符号同)
long:4(有符号无符号同)
float:4 double:8
那么上面两个结构大小如何呢?
结果是:
sizeof(strcut A)值为8
sizeof(struct B)的值却是12
结构体A中包含了4字节长度的int一个,1字节长度的char一个和2字节长度的short型数据一个,B 也一样;按理说A,B大小应该都是7字节。
之所以出现上面的结果是因为编译器要对数据成员在空间上进行对齐。上面是按照编译器的默认设置进行对齐的结果,那么我们是不是可以改变编译器的这种默认对齐设置呢,当然可以。例如:
#pragma pack (2) /*指定按2字节对齐*/
struct C
{
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
sizeof(struct C)值是8。
修改对齐值为1:
#pragma pack (1) /*指定按1字节对齐*/
struct D
{
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
sizeof(struct D)值为7。
后面我们再讲解#pragma pack()的作用。
三。编译器是按照什么样的原则进行对齐的?
先让我们看四个重要的基本概念:
1.数据类型自身的对齐值:对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double 类型,其自身对齐值为4,单位字节。
2.结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
3.指定对齐值:#pragma pack (value)时的指定对齐值value。
4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
有了这些值,我们就可以很方便的来讨论具体数据结构的成员和其自身的对齐方式。有效对齐值N是最终用来决定数据存放地址方式的值,最重要。有效对齐N,就是表示“对齐在N上”,也就是说该数据的“存放起始地址%N=0”。而数据结构中的数据变量都是按定义的先后顺序来排放的。第一个数据变量的起始地
址就是数据结构的起始地址。结构体的成员变量要对齐排放,结构体本身也要根据自身的有效对齐值圆整(就是结构体成员变量占用总长度需要是对结构体有效对齐值的整数倍,结合下面例子理解)。这样就不能理解上面的几个例子的值了。
例子分析:
分析例子B:
struct B
{
char b;
int a;
short c;
};
假设B从地址空间0x0000开始排放。该例子中没有定义指定对齐值,在笔者环境下,该值默认为4。第一个成员变量b的自身对齐值是1,比指定或者默认指定对齐值4小,所以其有效对齐值为1,所以其存放地址0x0000符合0x0000%1=0。第二个成员变量a,其自身对齐值为4,所以有效对齐值也为4,所以只能存放在起始地址为0x0004到0x0007这四个连续的字节空间中,符合0x0004%4=0,且紧靠第一个变量。第三个变量c,自身对齐值为2,所以有效对齐值也是2,可以存放在0x0008到0x0009这两个字节空间中,符合0x0008%2=0。所以从0x0000到0x0009存放的都是B内容。再看数据结构B的自身对齐值为其变量中最大对齐值(这里是b)所以就是4,所以结构体的有效对齐值也是4。根据结构体圆整的要求,0x0009到0x0000=10字节,(10+2)%4=0。所以0x0000A到0x000B也为结构体B所占用。故B从0x0000到0x000B 共有12个字节,sizeof(struct B)=12;其实如果就这一个就来说它已将满足字节对齐了,因为它的起始地址是0,因此肯定是对齐的。之所以在后面补充2个字节,是因为编译器为了实现结构数组的存取效率,试想如果我们定义了一个结构B的数组,那么第一个结构起始地址是0没有问题,但是第二个结构呢?按照数组的定义,数组中所有元素都是紧挨着的,如果我们不把结构的大小补充为4的整数倍,那么下一个结构的起始地址将是0x0000A,这显然不能满足结构的地址对齐了,因此我们要把结构补充成有效对齐大小的整数倍。其实诸如:对于char型数据,其自身对齐值为1,对于short 型为2,对于int,float,double类型,其自身对齐值为4,这些已有类型的自身对齐值也是基于数组考虑的,只是因为这些类型的长度已知了,所以他们的自身对齐值也就已知了。
同理,分析上面例子C:
#pragma pack (2) /*指定按2字节对齐*/
struct C
{
char b;
int a;
short c;
};
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
第一个变量b的自身对齐值为1,指定对齐值为2,所以,其有效对齐值为1,假设C从0x0000开始,那么b存放在0x0000,符合0x0000%1= 0;第二个变量,自身对齐值为4,指定对齐值为2,所以有效对齐值为2,所以顺序存放在0x0002、0x0003、0x0004、0x0005四个连续字节中,符合0x0002%2=0。第三个变量c的自身对齐值为2,所以有效对齐值为2,顺序存放在0x0006、0x0007中,符合0x0006%2=0。所以从0x0000到0x00007共八字节存放的是C的变量。又C的自身对齐值为4,所以C的有效对齐值为2。又8%2=0,C 只占用0x0000到0x0007的八个字节。所以sizeof(struct C)=8。
1、变量 a 所占的内存字节数是。(假设整型int 为 4 字节) structstu {charname[20]; longintn; intscore[4]; }a; A)28B)30 C)32D)46 C 2、下列程序的输出结果是 A)5B)6 C)7D)8 structabc {inta,b,c;}; main() {structabcs[2]={{1,2,3},{4,5,6}};intt; t=s[0].a+s[1].b; printf("%d\n",t); } B 3、有如下定义 structperson{charname[9];intage;}; structpersoncalss[4]={"Johu",17, "Paul",19, "Mary",18, "Adam",16,}; 根据以上定义,能输出字母M 的语句是________ 。 A)printf("%c\n",class[3].name); B)printf("%c\n",class[3].name[1]); C)printf("%c\n",class[2].name[1]); D)printf("%c\n",class[2].name[0]); D 4、以下程序的输出是________ 。 structst {intx;int*y;}*p; intdt[4]={10,20,30,40}; structstaa[4]={50,&dt[0],60,&dt[0],60,&dt[0],60,dt[0],}; main() {p=aa; printf("%d\n",++(p->x)); } A)10B)11 C)51D)60 C 6、以下程序的输出结果是________ 。 structHAR {intx,y;structHAR*p;}h[2]; main() {inth[0].x=1;h[0].y=2; h[1].x=3;h[1].y=4;
实验九参考程序 实验 9- 1 /**************************************************************** * 实验 9.1 * * ( 1 )为某商店的商品设计合适的结构体 (PRODUCT) 。每一种商品包含编号 (number) 、 * 名称 (name) 、价格 (price) 、折扣 (discount)4 项信息,根据表 9-1 ,为这些信 息选择合适的数据类型。 * (2)建立 2个函数,以实现对商品的操作。 input 函数实现商品的输入; * display 函数显示商品信息。要求这 2个函数都以商品的结构体 (PRODUCT) 指针为 参数。 * (3 )在主函数中为商品键盘定义一个结构体变量 (keyboard) ,利用 input 函数实现键 盘信息的输入; * 定义一个结构体数组 (elec_device[3]) ,利用 input 函数实现冰箱、 空调、电视 信息的输入; * 最后利用 display 函数显示 4 种商品的信息。 * * 表 9-1 #include
C语言中指针和数组名的用法,结构体与共用体的总结 2010-01-11 19:38 在C语言中,指针和数组名通常都可以混用。 例如 char *p; 访问时,*p跟p[0]是一样的,*(p+1)跟p[1]是一样的。 对于数组 char b[5]; 访问时,b[0]跟*b是一样的,b[2]跟*(b+2)是一样的。 在一般的通信中(例如串口),通常都使用字节传输。而像float,long int 之类的, 有4字节。我的方法就是取它的地址,强制转换为char型指针,然后当作数组来用。 float x; SBUF=((char*)&x)[0]; SBUF=((char*)&x)[1]; SBUF=((char*)&x)[2]; SBUF=((char*)&x)[3]; 接收时,刚好倒过来。 更有趣的是,对于数组形式,数组名和后面的偏移量可以随便换。 char buff[10]; //或者用 char *buff=&buffer; buff[3]=0xaa; 3[buff]=0xaa; //两者是一样的 因此,我认为编译器是这么做的:对于形如xxx[yyy]这样的表达式,会转化为*(xxx+yyy), 因此写成xxx[yyy]或者写成yyy[xxx]都无所谓了... c语言结构体与共用体学习笔记1 Author:yuexingtian Date:Thursday, June 12, 2008 1结构变量的赋值 测试结果:
{ struct stu { int num; char *name; char sex; float score; }boy1,boy2; boy1.num=15; https://www.doczj.com/doc/4e14172101.html,="yuexingtian"; printf("input sex and score\n"); scanf("%c %f",&boy1.sex,&boy1.score); boy2=boy1; printf("Number=%d\nName=%s\n",boy2.num,https://www.doczj.com/doc/4e14172101.html,); printf("Sex=%c\nScore=%f\n",boy2.sex,boy2.score); getch(); } 说明: 本程序中用赋值语句给num和name两个成员赋值,name是一个字符串指针变量。用scanf函数动态地输入sex和score成员值,然后把boy1的所有成员的值整体赋予boy2。最后分别输出boy2的各个成员值。本例表示了结构变量的赋值、输入和输出的方法。 2结构变量的初始化 对结构变量的初始化(还拿上例举例)
《高级语言程序设计》实验报告实验序号:8 实验项目名称:结构体
附源程序清单: 1. #include
for(i=1;i<=5;i++) stu[i].aver_score=((stu[i].score[1]+stu[i].score[2]+stu[i].score[3])/3); printf("平均成绩:"); for(i=1;i<6;i++) printf("第%d个同学的平均成绩%f:\n",i,stu[i].aver_score); printf("\n"); }; void max() { int i,k=0; float temp=stu[1].aver_score; for(i=2;i<=5;i++) if(stu[i].aver_score>temp) {temp=stu[i] .aver_score;k=i;}; printf("成绩最好的同学:\n"); printf("%d %s %s %4.2f %4.2f %4.2f %4.2f\n", stu[k].num,stu[k].name,stu[k].classname,stu[k].score[1],stu[k].score[2],stu[k].score[3],stu[k].aver _score); }; void main() { input(); averagescore(); max(); } 2.#include
C语言,结构体(struct) 用法 结构(struct) 结构是由基本数据类型构成的、并用一个标识符来命名的各种变量的组合。 结构中可以使用不同的数据类型。 1. 结构说明和结构变量定义 在T urbo C中, 结构也是一种数据类型, 可以使用结构变量, 因此, 象其它 类型的变量一样, 在使用结构变量时要先对其定义。 定义结构变量的一般格式为: struct 结构名 { 类型变量名; 类型变量名; ... } 结构变量; 结构名是结构的标识符不是变量名。 类型为第二节中所讲述的五种数据类型(整型、浮点型、字符型、指针型和 无值型)。 构成结构的每一个类型变量称为结构成员, 它象数组的元素一样, 但数组中 元素是以下标来访问的, 而结构是按变量名字来访问成员的。
下面举一个例子来说明怎样定义结构变量。 struct string { char name[8]; int age; char sex[2]; char depart[20]; float wage1, wage2, wage3, wage4, wage5; } person; 这个例子定义了一个结构名为string的结构变量person, 如果省略变量名 person, 则变成对结构的说明。用已说明的结构名也可定义结构变量。这样定义 时上例变成: struct string { char name[8]; int age; char sex[2]; char depart[20]; float wage1, wage2, wage3, wage4, wage5; }; struct string person; 如果需要定义多个具有相同形式的结构变量时用这种方法比较方便, 它先作 结构说明, 再用结构名来定义变量。 例如: struct string T ianyr, Liuqi, ...; 如果省略结构名, 则称之为无名结构, 这种情况常常出现在函数内部, 用这 种结构时前面的例子变成:
第八章结构体和共同体 一、单项选择 1. 若有以下定义: struct link { int data; struct link *next; }a,b,c,*p,*q; 且变量a和b之间已有如下图所示的链表结构,若指针p指向a,指针q指向c。 则能把c插入到a和b之间形成新的链表的语句是( C ) 2. 若有以下程序段: int a=1,b=2,c=3; struct dent { int n ; int *m ; } s[3] = {{101,&a},{102,&b},{103,&c}}; struct dent *p=s ; 则以下表达式中值为2的是( D )。 3. 下面程序的运行结果是( D )。 #iunclude
}cnum[2]={1,3,2,7} ; printf(“%d\n”,cnum[0].y/cnum[0].x*cnum[1].x) ; return 0; } 二、程序设计 1. /*学生的记录由学号和成绩组成,N名学生的数据已在主函数中放入结构体数组s 中,请编写函数fun, 它的功能是:按分数的高低排列学生的记录,高分在前。注意:部分源程序给出如下。 请勿改动main函数和其他函数中的任何内容,仅在函数fun的花括号中填入所编写的若干语句。 试题程序: */ #include C语言中不同类型的结构体的指针间可以强制转换,很自由,也很危险。只要理解了其内部机制,你会发现C是非常灵活的。 一. 结构体声明如何内存的分布, 结构体指针声明结构体的首地址, 结构体成员声明该成员在结构体中的偏移地址。 变量的值是以二进制形式存储在内存中的,每个内存字节对应一个内存地址,而内存存储的值本身是没有整型,指针,字符等的区别的,区别的存在是因为我们对它们有不同的解读,param的值就是一个32位值,并且存储在某个内存单元中,通过这个32位值就能找到param所指向的结构的起始地址,通过这个起始地址和各个结构所包含变量离起始地址的偏移对这些变量进行引用, param->bIsDisable只是这种引用更易读的写法,只要param是指向 PAINT_PARAM的指针,那么param的值就肯定存在,param存在,偏移量已知,那么param->bIsDisable就肯定存在,只是要记住,param->bIsDisable只是代表了对param一定偏移地址的值。 不是说某个地址有那个结构体你才能引用,即使没有,你也能引用,因为你已经告诉了编译器param变量就是指向一个PAINT_PARAM结构体的变量并且指明了param的值,机器码的眼中是没有数据结构一说的,它只是机械的按照 指令的要求从内存地址取值,那刚才的例子来说,peg->x,peg->y的引用无论 0x30000000是否存在一个eg结构体都是合法的,如果0x30000000开始的8 个字节存在eg结构体,那么引用的就是这个结构体的值,如果这个位置是未定义的值,那么引用的结果就是这8个字节中的未定义值,内存位置总是存在的,而对内存中值的引用就是从这些内存位置对应的内存单元取值。 举个例子: typedefstruct_eg { int x; int y; }eg; C语言结构体(struct)常见使用方法 基本定义:结构体,通俗讲就像是打包封装,把一些有共同特征(比如同属于某一类事物的属性,往往是某种业务相关属性的聚合)的变量封装在内部,通过一定方法访问修改内部变量。 结构体定义: 第一种:只有结构体定义 [cpp]view plain copy 1.struct stuff{ 2.char job[20]; 3.int age; 4.float height; 5.}; 第二种:附加该结构体类型的“结构体变量”的初始化的结构体定义 [cpp]view plain copy 1.//直接带变量名Huqinwei 2.struct stuff{ 3.char job[20]; 4.int age; 5.float height; 6.}Huqinwei; 也许初期看不习惯容易困惑,其实这就相当于: [cpp]view plain copy 1.struct stuff{ 2.char job[20]; 3.int age; 4.float height; 5.}; 6.struct stuff Huqinwei; 第三种:如果该结构体你只用一个变量Huqinwei,而不再需要用 [cpp]view plain copy 1.struct stuff yourname; 去定义第二个变量。 那么,附加变量初始化的结构体定义还可进一步简化出第三种: [cpp]view plain copy 1.struct{ 2.char job[20]; 3.int age; 4.float height; 5.}Huqinwei; 把结构体名称去掉,这样更简洁,不过也不能定义其他同结构体变量了——至少我现在没掌握这种方法。 结构体变量及其内部成员变量的定义及访问: 绕口吧?要分清结构体变量和结构体内部成员变量的概念。 就像刚才的第二种提到的,结构体变量的声明可以用: [cpp]view plain copy 1.struct stuff yourname; 其成员变量的定义可以随声明进行: [cpp]view plain copy 1.struct stuff Huqinwei = {"manager",30,185}; 也可以考虑结构体之间的赋值: [cpp]view plain copy https://www.doczj.com/doc/4e14172101.html,/2005/03/25/12365.html 所谓共用体类型是指将不同的数据项组织成一个整体,它们在内存中占用同一段存储单元。其定义形式为: union 共用体名 {成员表列}; 7.5.1 共用体的定义 union data { int a ; float b ; d o u b l e c ; c h a r d ; } obj; 该形式定义了一个共用体数据类型union data ,定义了共用体数据类型变量o b j。共用体 数据类型与结构体在形式上非常相似,但其表示的含义及存储是完全不同的。先让我们看一个小例子。 [例7 - 8 ] union data /*共用体* / { int a; float b; double c; char d; } m m ; struct stud /*结构体* / { int a; float b; double c; char d; } ; m a i n ( ) { struct stud student printf("%d,%d",sizeof(struct stud),sizeof(union data)); } 程序的输出说明结构体类型所占的内存空间为其各成员所占存储空间之和。而形同结构体的 共用体类型实际占用存储空间为其最长的成员所占的存储空间。详细说明如图7 - 6所示。 对共用体的成员的引用与结构体成员的引用相同。但由于共用体各成员共用同一段内存 空间,使用时,根据需要使用其中的某一个成员。从图中特别说明了共用体的特点,方便程序设计人员在同一内存区对不同数据类型的交替使用,增加灵活性,节省内存。 7.5.2 共用体变量的引用 可以引用共用体变量的成员,其用法与结构体完全相同。若定义共用体类型为: union data /*共用体* / { int a; float b; double c; char d; } m m ; 其成员引用为:m m . a , m m . b , m m . c , m m . d 但是要注意的是,不能同时引用四个成员,在某一时刻,只能使用其中之一的成员。 [例7-9] 对共用体变量的使用。 m a i n ( ) { union data { int a; float b; double c; char d; } m m ; m m . a = 6 ; printf("%d\n",mm.a); m m . c = 6 7 . 2 ; p r i n t f ( " % 5 . 1 l f \ n " , m m . c ) ; m m . d = ' W ' ; m m . b = 3 4 . 2 ; p r i n t f ( " % 5 . 1 f , % c \ n " , m m . b , m m . d ) ; } C语言入门教程-指向结构体的指针 2009年07月29日12:04 [导读] 指向结构体的指针 在C语言中几乎可以创建指向任何类型的指针,包括用户自定义的类型。创建结构体指针是极常见的。下面是一个例子: typedef struct{ 关键词:c语言入门 指向结构体的指针 在C语言中几乎可以创建指向任何类型的指针,包括用户自定义的类型。创建结构体指针是极常见的。下面是一个例子: typedef struct {char name[21];char city[21];char state[3];} Rec; typedef Rec *RecPointer; RecPointer r; r=(RecPointer)malloc(sizeof(Rec)); r是一个指向结构体的指针。请注意,因为r是一个指针,所以像其他指针一样占用4个字节的内存。而malloc语句会从堆上分配45字节的内存。*r是一个结构体,像任何其他Rec类型的结构体一样。下面的代码显示了这个指针变量的典型用法: strcpy((*r).city, "Raleigh"); strcpy((*r).state, "NC"); printf("%sn", (*r).city); free(r); 您可以像对待一个普通结构体变量那样对待*r,但在遇到C的操作符优先级问题时要小心。如果去掉*r两边的括号则代码将无法编译,因为“.”操作符的优先级高于“*”操作符。使用结构体指针时不断地输入括号是令人厌烦的,为此C语言引入了一种简记法达到相同的目的: r->这种写法和(*r).是完全等效的,但是省去了两个字符。 指向数组的指针 还可以创建指向数组的指针,如下所示: C语言中,头文件和源文件的关系(转) 简单的说其实要理解C文件与头文件(即.h)有什么不同之处,首先需要弄明白编译器的工作过程,一般说来编译器会做以下几个过程: 1.预处理阶段 2.词法与语法分析阶段 3.编译阶段,首先编译成纯汇编语句,再将之汇编成跟CPU相关的二进制码,生成各个目标文件(.obj文件) 4.连接阶段,将各个目标文件中的各段代码进行绝对地址定位,生成跟特定平台相关的可执行文件,当然,最后还可以用objcopy生成纯二进制码,也就是去掉了文件格式信息。(生成.exe文件) 编译器在编译时是以C文件为单位进行的,也就是说如果你的项目中一个C文件都没有,那么你的项目将无法编译,连接器是以目标文件为单位,它将一个或多个目标文件进行函数与变量的重定位,生成最终的可执行文件,在PC上的程序开发,一般都有一个main函数,这是各个编译器的约定,当然,你如果自己写连接器脚本的话,可以不用main函数作为程序入口!!!! (main .c文件目标文件可执行文件) 有了这些基础知识,再言归正传,为了生成一个最终的可执行文件,就需要一些目标文件,也就是需要C文件,而这些C文件中又需要一个main 函数作为可执行程序的入口,那么我们就从一个C文件入手,假定这个C文件内容如下: #include #include "mytest.h" int main(int argc,char **argv) { test = 25; printf("test.................%d/n",test); } 头文件内容如下: int test; 现在以这个例子来讲解编译器的工作: 1.预处理阶段:编译器以C文件作为一个单元,首先读这个C文件,发现第一句与第二句是包含一个头文件,就会在所有搜索路径中寻找这两个文件,找到之后,就会将相应头文件中再去处理宏,变量,函数声明,嵌套的头文件包含等,检测依赖关系,进行宏替换,看是否有重复定义与声明的情况发生,最后将那些文件中所有的东东全部扫描进这个当前的C文件中,形成一个中间“C文件” 2.编译阶段,在上一步中相当于将那个头文件中的test变量扫描进了一个中间C文件,那么test变量就变成了这个文件中的一个全局变量,此时就将所有这个中间C文件的所有变量,函数分配空间,将各个函数编译成二进制码,按照特定目标文件格式生成目标文件,在这种格式的目标文件中进行各个全局变量,函数的符号描述,将这些二进制码按照一定的标准组织成一个目标文件 3.连接阶段,将上一步成生的各个目标文件,根据一些参数,连接生成最终的可执行文件,主要的工作就是重定位各个目标文件的函数,变量等,相当于将个目标文件中的二进制码按一定的规范合到一个文件中再回到C文件与头文件各写什么内容的话题上:理论上来说C文件与头文件里的内容,只要是C语言所支持的,无论写什么都可以的,比如你在头文件中写函数体,只要在任何一个C文件包含此头文件就可以将这个函数编译成目标文件的一部分(编译是以C文件为单位的,如果不在任何C文件中包含此头文件的话,这段代码就形同虚设),你可以在C文件中进行函数声明,变量声明,结构体声明,这也不成问题!!!那为何一定要分成头文件与C文件呢?又为何一般都在头件中进行函数,变量声明,宏声明,结构体声明呢?而在C文件中去进行变量定义,函数实现呢??原因如下: 1.如果在头文件中实现一个函数体,那么如果在多个C文件中引用它,而且又同时编译多个C文件,将其生成的目标文件连接成一个可执行文件,在每个引用此头文件的C文件所生成的目标文件中,都有一份这个函数的代码,如果这段函数又没有定义成局部函数,那么在连接时,就会发现多个相同的函数,就会报错 2.如果在头文件中定义全局变量,并且将此全局变量赋初值,那么在多个引用此头文件的C文件中同样存在相同变量名的拷贝,关键是此变量被 c语言结构体共用体选择 题新 The pony was revised in January 2021 1、变量a所占的内存字节数是________。(假设整型i n t为4字节) struct stu { char name[20]; long int n; int score[4]; } a ; A) 28 B) 30 C) 32 D) 46 C 2、下列程序的输出结果是 A)5 B)6 C)7 D)8 struct abc {int a,b,c;}; main() {struct abc s[2]={{1,2,3},{4,5,6}};int t; t=s[0].a+s[1].b; printf("%d\n",t); } B 3、有如下定义 struct person{ char name[9]; int age;}; struct person calss[4]={ "Johu",17, "Paul",19, "Mary",18, "Adam",16,}; 根据以上定义,能输出字母M的语句是________。 A) printf("%c\n",class[3].name); B) printf("%c\n",class[3].name[1]); C) printf("%c\n",class[2].name[1]); D) printf("%c\n",class[2].name[0]); D 4、以下程序的输出是________。 struct st {int x;int *y;} *p; int dt[4]={10,20,30,40}; struct st aa[4]={50,&dt[0],60,&dt[0],60,&dt[0],60,dt[0],}; main() { p=aa; printf("%d\n",++(p->x)); } A) 10 B) 11 C) 51 D) 60 C 6、以下程序的输出结果是________。 struct HAR C语言复习题_指针&结构体 一、选择 1、若有以下定义:char s[20]="programming",*ps=s; 则不能代表字符'o'的表达式是A。 A) ps+2 B) s[2] C) ps[2] D) ps+=2,*ps 2、若有以下定义和语句: int a[10]={1,2,3,4,5,6,7,8,9,10},*p=a;则不能表示a数组元素的表达式是B。 A) *p B) a[10] C) *a D) a[p-a] 3、已知int *p,a; p=&a; 这里的运算符& 的含义D。 A) 位与运算B) 逻辑与运算C) 取指针内容D) 取变量地址 4、定义结构体如下: struct student { int num; char name[4]; int age; }; 则printf(“%d”,sizeof(struct student))的结果为: 12。 5、若有定义如下:int i=3,*p=&i; 显示i的值的正确语句是B。 A) printf(“%d”,p); B) printf(“%d”,*p); C) printf(“%p”,*p); D) printf(“%p”,p); 6、在定义结构体时,下列叙述正确的是A。 A) 系统不会分配空间 B) 系统会按成员大小分配空间 C) 系统会按最大成员大小分配空间 D) 以上说法均不正确 7、指针是一种D。 A) 标识符B) 变量C) 运算符D) 内存地址 8、定义struct s {int x; char y[6];} s1;,请问正确的赋值是C。 A) s1.y=”abc”; B) s1->y=”abc”; C) strcpy(s1.y,”abc”); D) s1.strcpy(y,”abc”); 9、已知定义“int x =1, *p”,则合法的赋值表达式是A。 A) p =&x B) p = x C) *p =&x D) *p =*x c语言结构体指针初始化 今天来讨论一下C中的内存管理。 记得上周在饭桌上和同事讨论C语言的崛起时,讲到了内存管理方面 我说所有指针使用前都必须初始化,结构体中的成员指针也是一样 有人反驳说,不是吧,以前做二叉树算法时,他的左右孩子指针使用时难道有初始化吗 那时我不知怎么的想不出理由,虽然我还是坚信要初始化的 过了几天这位同事说他试了一下,结构体中的成员指针不经过初始化是可以用(左子树和右子树指针) 那时在忙着整理文档,没在意 今天抽空调了一下,结论是,还是需要初始化的。 而且,不写代码你是不知道原因的(也许是对着电脑久了IQ和记性严重下跌吧) 测试代码如下 1.#include 2.#include 3.#include 4. 5.struct student{ 6.char *name; 7.int score; 8.struct student* next; 9.}stu,*stu1; 10. 11.int main(){ 12. https://www.doczj.com/doc/4e14172101.html, = (char*)malloc(sizeof(char)); /*1.结构体成员指针需要初始化*/ 13. strcpy(https://www.doczj.com/doc/4e14172101.html,,"Jimy"); 14. stu.score = 99; 15. 16. stu1 = (struct student*)malloc(sizeof(struct student));/*2.结构体指针需要初始化*/ 17. stu1->name = (char*)malloc(sizeof(char));/*3.结构体指针的成员指针同样需要初始化*/ 18. stu.next = stu1; 19. strcpy(stu1->name,"Lucy"); 20. stu1->score = 98; 21. stu1->next = NULL; 22. printf("name %s, score %d \n ",https://www.doczj.com/doc/4e14172101.html,, stu.score); 23. printf("name %s, score %d \n ",stu1->name, stu1->score); 24. free(stu1); 25.return 0; 26.} #include #include #include struct student{ char *name; int score; struct student* next; }stu,*stu1; int main(){ https://www.doczj.com/doc/4e14172101.html, = (char*)malloc(sizeof(char)); /*1.结构体成员指针需要初始化*/ strcpy(https://www.doczj.com/doc/4e14172101.html,,"Jimy"); stu.score = 99; stu1 = (struct student*)malloc(sizeof(struct student));/*2.结构体指针需要初始化*/ stu1->name = (char*)malloc(sizeof(char));/*3.结构体指针的成员指针同样需要初始化*/ stu.next = stu1; strcpy(stu1->name,"Lucy"); stu1->score = 98; stu1->next = NULL; printf("name %s, score %d \n ",https://www.doczj.com/doc/4e14172101.html,, stu.score); (1)有以下程序段 typedef struct NODE { int num; struct NODE *next; } OLD; 以下叙述中正确的是C A)以上的说明形式非法 B)NODE是一个结构体类型 C)OLD是一个结构体类型 D)OLD是一个结构体变量(2)若有以下说明和定义union dt { int a; char b; double c; }data; 以下叙述中错误的是 C A)data的每个成员起始地址都相同 B)变量data所占内存字节数与成员c所占字节数相等 C)程序段:data.a=5;printf("%f\n",data.c);输出结果为5.000000 D)data可以作为函数的实参(3)设有如下说明 typedef struct ST { long a; int b; char c[2]; } NEW; 则下面叙述中正确的是 C A)以上的说明形式非法 B)ST是一个结构体类型 C)NEW是一个结构体类型 D)NEW是一个结构体变量(4)以下对结构体类型变量td的定义中,错误的是 C A)typedef struct aa { int n; float m; }AA; AA td; B)struct aa { int n; float m; } td; struct aa td; C)struct { int n; float m; }aa; struct aa td; D)struct { int n; float m; }td; (5)设有以下语句 typedef struct S { int g; char h;} T; 则下面叙述中正确的是B A)可用S定义结构体变量 B)可以用T定义结构体变量 C)S是struct类型的变量 D)T是struct S类型的变量(6)设有如下说明 typedef struct { int n; char c; double x;}STD; 则以下选项中,能正确定义结构体数组并赋初值的语句是B A)STD tt[2]={{1,'A',62},{2, 'B',75}}; B) STD tt[2]={1,"A",62},2, "B",75}; C) struct tt[2]={{1,'A'},{2, 'B'}}; D)structtt[2]={{1,"A",62.5},{2, "B",75.0}}; (7)设有以下说明语句 typedef struct { int n; char ch[8]; }PER; 则下面叙述中正确的是B A) PER 是结构体变量名 B) PER是结构体类型名 C) typedef struct 是结构体类型 D)struct 是结构体类型名(8)设有以下说明语句 struct ex { int x ; float y; char z ;} example; 则下面的叙述中不正确的是B A) struct结构体类型的关键字 B)example是结构体类型名 C) x,y,z都是结构体成员名 D) struct ex是结构体类型(9)有如下定义 struct person{char name[9]; int age;}; strict person class[10]={“Johu”, 17, “Paul”, 19 “Mary”, 18, “Adam 16,}; 根据上述定义,能输出字母M的语句是D A) prinft(“%c\n”,class[ 3].mane); B) pfintf(“%c\n”,class[3].name[1]); C) prinft (“%c\n”,class[2].n ame[1]); D) printf(“%^c\n”,class[2].name[0]); (10)变量a 页眉内容 一、选择题 1、定义结构类型时,下列叙述正确的是() A、系统会按成员大小分配每个空间 B、系统会按最大成员大小分配空间 C、系统不会分配空间 D、以上说法均不正确 2、已知结构类型变量x的初始化值为{“20”,30,40,35.5},请问合适的结构定义是() A、Struct s{int no;int x,y,z}; B、Struct s{char no[2];int x,y,z}; C、Struct s{int no;float x,y,z}; D、Struct s{char no[2];float x,y,z}; 3、若程序中有定义struct abc{int x;char y;};abc s1,s2;则会发生的情况是() A、编译时会有错误 B、链接时会有错误 C、运行时会有错误 D、程序没有错误 4、已知学生记录描述为 struct student {int no; char name[20]; char set; struct {int year; int month; int day; }birth;}; struct student s; 设变量s中的“生日”应是“1984年11月11日”,下列对生日的正确赋值方式是( ). A)year=1984; B)birth.year=1984; month=11; birth.month=11; day=11; birth.day=11; C)s.year=1984; D)s.birth.year=1984; s.month=11; s.birth.month=11; s.day=11; s.birth.day=11; 5、当说明一个结构体变量时系统分配给它的内存是( ). A)各成员所需内存量的总和 B)结构中第一个成员所需内存量 C)成员中占内存量最大者所需的容量 D)结构中最后一个成员所需内存量 6、以下对结构体类型变量的定义中不正确的是( ). A)#define STUDENT struct student B)struct student STUDENT {int num; {int num; float age; float age; }std1; }std1; C)struct D)struct {int num; int num; 1、下列程序的运行结果是_B______。 void fun(int *a,int *b) { int *k: k=a;a-b;b=k; } main() { int a=3,b=6,*x=&a,*y=&b; fun(x,y); printf[”%d%d.f,a,b); } A)6 3 B)36 C)编译出错 D)0 0 PS:本题中主函数里的x、y,fun函数里的a、b、k,这些都是指针,fun函数中只是将a、b这两个指针交换了位置,而并没有改变主函数中变量a、b的值。 2、若有定义:int*p[3];,则以下叙述中正确的是____B____。 A)定义了一个基类型为int的指针变量p,该变量有三个指针 B)定义了一个指针数组p,该数组含有三个元素,每个元素都是基类型为int的指针 C)定义了一个名为+p的整型数组,该数组含有三个int类型元素 D)定义了一个可指向一维数组的指针变量p,所指一维数组应具有三个int类型元素 PS:由于运算符[]优先级比*高,int*p[3];相当于int *(p[3]);表示数组p 的三个元素都是指针变量,且每个元素都是基类型为int的指针。 3、有以下程序: void swapl(int *a,int *b) {int *c=a; a=b,b=c; } void swap2(int *a,int *b) { int c=*a: *a=*b,*b=c; } main() (int a=lO,b=15; swapl(&a,&b); printf(”%d,%d,”,a,b); a=lO,b=15; swap2(&a,&b); printf(”%d,%dt.,a,b); } 其输出结果为_10,15,15,10___。 A)15,10,10,15 B)15,10,15,10 C)10,15,10,15 D)10,15,15,10 PS:C语言规定,实参变量对形参变量的数据传递是“值传递”,只由实参传给形参,而不能由形参传回来给实参。在内函数调用结束后,形参单元被释放,实参单元仍保留并维持原值。本题中swapl()函数中,虽然改变了形参指针的值,但实参指针的值并没有改变,所以执行第一个printf后应输出10,15,;swap2()函数实现了交换两个变量a和b的值,因此执行第二个printf后输出交换后的值15,10,所以本题答案为D。 脚踏实地,心无旁骛,珍惜分分秒秒。紧跟老师,夯实基础。 什么是结构体? 简单的来说 结构体就是一个可以包含不同数据类型的一个结构 它是一种可以自己定义的数据类型 它的特点和数组主要有两点不同 首先结构体可以在一个结构中声明不同的数据类型 第二相同结构的结构体变量是可以相互赋值的 而数组是做不到的 因为数组是单一数据类型的数据集合 它本身不是数据类型(而结构体是) 数组名称是常量指针 所以不可以做为左值进行运算 所以数组之间就不能通过数组名称相互复制了 即使数据类型和数组大小完全相同 定义结构体使用struct修饰符 例如: struct test { float a; int b; }; 上面的代码就定义了一个名为test的结构体 它的数据类型就是test 它包含两个成员a和b 成员a的数据类型为浮点型 成员b的数据类型为整型 由于结构体本身就是自定义的数据类型 定义结构体变量的方法和定义普通变量的方法一样 test pn1; 这样就定义了一test结构体数据类型的结构体变量pn1 结构体成员的访问通过点操作符进行 pn1.a=10 就对结构体变量pn1的成员a进行了赋值操作 注意:结构体生命的时候本身不占用任何内存空间 只有当你用你定义的结构体类型定义结构体变量的时候计算机才会分配内存 结构体 同样是可以定义指针的 那么结构体指针就叫做结构指针 结构指针通过->符号来访问成员 下面我们就以上所说的看一个完整的例子: #include C语言中不同的结构体类型的指针间的强制转换详解
C语言结构体(struct)常见使用方法
c语言结构体与共用体之间的区别
C语言入门教程-指向结构体的指针
C语言中,头文件和源文件的关系
c语言结构体共用体选择题新
C语言复习题指针结构体
c语言结构体指针初始化===
二级C语言结构体定义及应用部分练习题(十三)(精)
C语言程序设计 结构体与共用体
c语言练习题7(指针与结构体,有答案)
C语言中结构体的使用
相关主题
文本预览