2.样本描述性统计
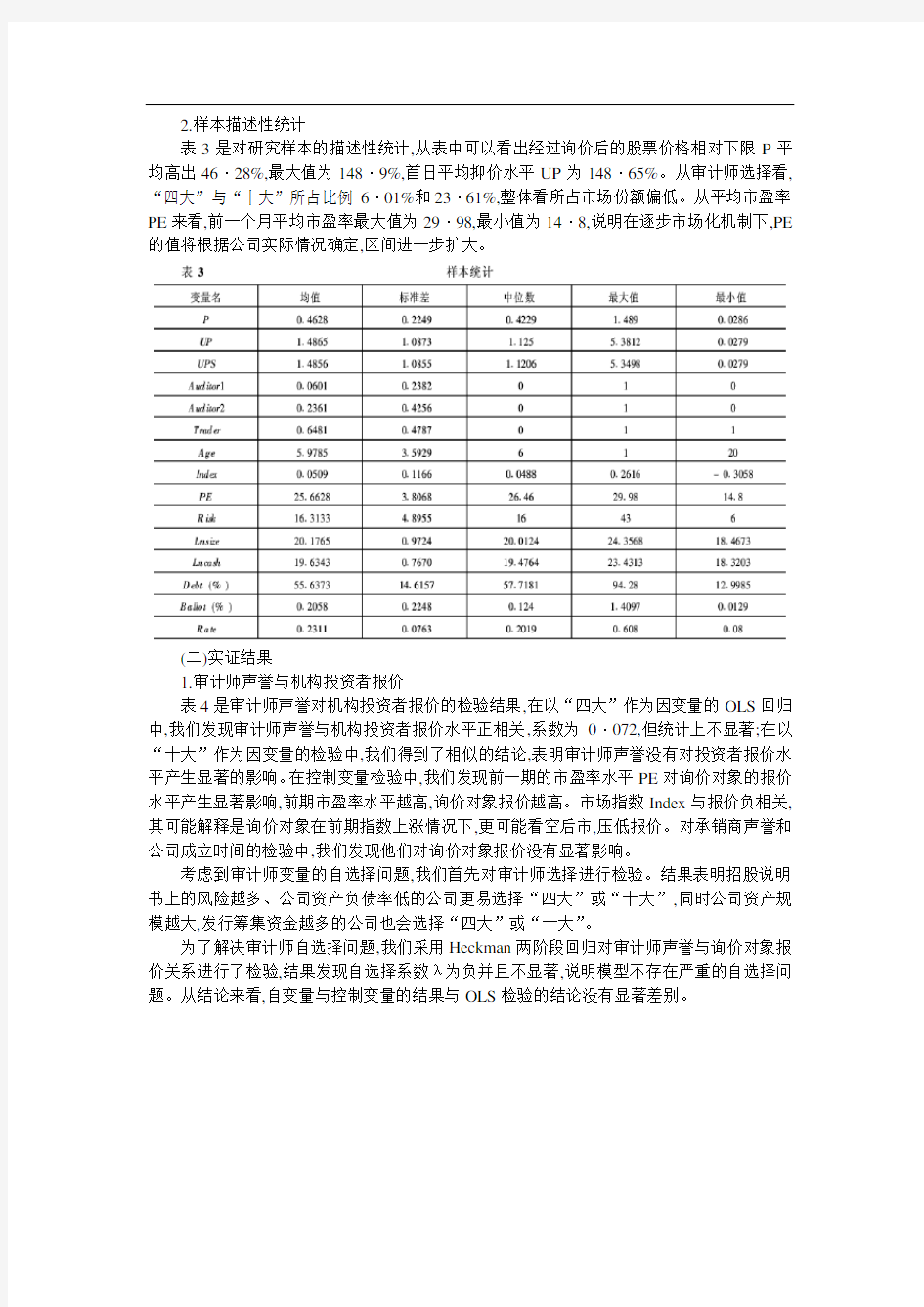
表3是对研究样本的描述性统计,从表中可以看出经过询价后的股票价格相对下限P平均高出46·28%,最大值为148·9%,首日平均抑价水平UP为148·65%。从审计师选择看,“四大”与“十大”所占比例6·01%和23·61%,整体看所占市场份额偏低。从平均市盈率PE来看,前一个月平均市盈率最大值为29·98,最小值为14·8,说明在逐步市场化机制下,PE 的值将根据公司实际情况确定,区间进一步扩大。
(二)实证结果
1.审计师声誉与机构投资者报价
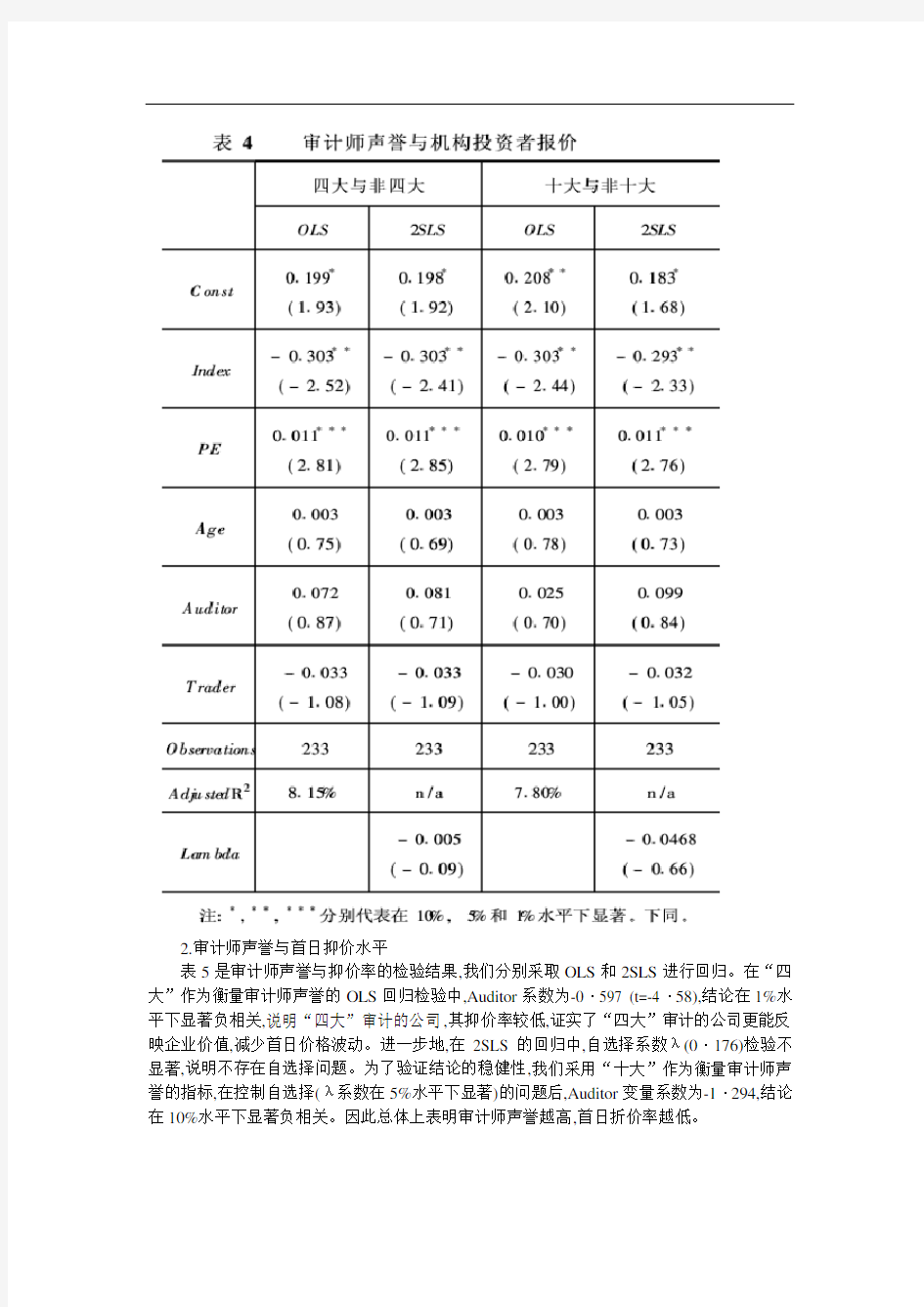
表4是审计师声誉对机构投资者报价的检验结果,在以“四大”作为因变量的OLS回归中,我们发现审计师声誉与机构投资者报价水平正相关,系数为0·072,但统计上不显著;在以“十大”作为因变量的检验中,我们得到了相似的结论,表明审计师声誉没有对投资者报价水平产生显著的影响。在控制变量检验中,我们发现前一期的市盈率水平PE对询价对象的报价水平产生显著影响,前期市盈率水平越高,询价对象报价越高。市场指数Index与报价负相关,其可能解释是询价对象在前期指数上涨情况下,更可能看空后市,压低报价。对承销商声誉和公司成立时间的检验中,我们发现他们对询价对象报价没有显著影响。
考虑到审计师变量的自选择问题,我们首先对审计师选择进行检验。结果表明招股说明书上的风险越多、公司资产负债率低的公司更易选择“四大”或“十大”,同时公司资产规模越大,发行筹集资金越多的公司也会选择“四大”或“十大”。
为了解决审计师自选择问题,我们采用Heckman两阶段回归对审计师声誉与询价对象报价关系进行了检验,结果发现自选择系数λ为负并且不显著,说明模型不存在严重的自选择问题。从结论来看,自变量与控制变量的结果与OLS检验的结论没有显著差别。
2.审计师声誉与首日抑价水平
表5是审计师声誉与抑价率的检验结果,我们分别采取OLS和2SLS进行回归。在“四大”作为衡量审计师声誉的OLS回归检验中,Auditor系数为-0·597 (t=-4·58),结论在1%水平下显著负相关,说明“四大”审计的公司,其抑价率较低,证实了“四大”审计的公司更能反映企业价值,减少首日价格波动。进一步地,在2SLS的回归中,自选择系数λ(0·176)检验不显著,说明不存在自选择问题。为了验证结论的稳健性,我们采用“十大”作为衡量审计师声誉的指标,在控制自选择(λ系数在5%水平下显著)的问题后,Auditor变量系数为-1·294,结论在10%水平下显著负相关。因此总体上表明审计师声誉越高,首日折价率越低。
你
本可以用那些和他们一起抱怨人生的时间,来读一篇有趣的小说,或者玩一个你喜欢的游戏。
渐渐的,你不再像以往那样开心快乐,曾经的梦想湮灭在每日回荡在耳边的抱怨中。你也会发现,尽管你很努力了,可就是无法让你的朋友或是闺蜜变得更开心一些。
这就不可避免地产生一个问题:你会怀疑自己的能力,怀疑自己一贯坚持的信念。
我们要有所警惕和分辨,不要让身边的人消耗了你,让你不能前进。
这些人正在消耗你。
01. 不守承诺的人
承诺了的事,就应该努力地去做到。
倘若做不到,就别轻易许诺。这类人的特点就是时常许诺,然而做到的事却是很少。于是,他的人生信用便会大大降低,到最后,也许还会成为一种欺诈。如果发现身边有这样的人,应该警惕,否则到最后吃苦的还是自己。
02. 不守时间的人
俗话说浪费别人的时间就等于谋财害命,所以不守时间也就意味着是浪费别人的时间。与这种人交往的话,不仅把自己的时间花掉了,还会带来意想不到的麻烦。
03. 时常抱怨的人
生活之事十有八九是不如意的,这些都是正常的。
我们应该看到生活前进的方向,努力前进。而不是在自怨自艾,同时还把消极的思想传递给别人。这样的人呢,一遇到困难便停滞不前,巴不得别人来帮他一把。本来你是积极向上的,可是如果受到这种人的影响,那么你也很有可能会变成这样的人,所以应该警惕。
04. 斤斤计较的人
凡事都斤斤计较的人,看不到远方的大前途,一味把精力放在小事上。比如两个人去吃饭,前提是AA制。然后饭吃好后他多付了5毛,最后他说我多付了5毛,你抽空给我吧。如此计较的人,失去了知己,也不会有很大的前途。
05. 不会感恩的人
你善心地帮助了他,可是他却不以为然,而且还想当然的认为这是应当的。多次地帮助,换来的没有一句感谢的话语,更有甚者,还在背后说别人的坏话,真是吃力不讨好。
06. 自私自利的人
以自我为中心,不会考虑别人的感受,想怎样就是怎样,也不会考虑大局,只为自己的感受。这种人,为了达到自己的私利会不择手段。
如果看完以上的描述,你的脑海里冒出一张张熟悉的脸,显然,你正在被人日复一日地消耗着。这种消耗绝对可以毁你于无形之中。
这些方法带来阳光
那么,如何给自己搭建一个严严实实的保护网,让自己始终正能量爆棚,每一分钟都是恣意的阳光呢?跟着我们下面这五步做吧!
他们继续往前走。走到了沃野,他们决定停下。
被打巴掌的那位差点淹死,幸好被朋友救过来了。
被救起后,他拿了一把小剑在石头上刻了:“今天我的好朋友救了我一命。”
一旁好奇的朋友问到:
“为什么我打了你以后你要写在沙子上,而现在要刻在石头上
呢?”
另一个笑笑回答说:“当被一个朋友伤害时,要写在易忘的地方,风会负责抹去它;
相反的如果被帮助,我们要把它刻在心灵的深处,任何风都抹不去的。”
朋友之间相处,伤害往往是无心的,帮助却是真心的。
在日常生活中,就算最要好的朋友也会有摩擦,也会因为这些摩擦产生误会,以至于成为陌路。
友情的深浅,不仅在于朋友对你的才能钦佩到什么程度,更在于他对你的弱点容忍到什么程度。
学会将伤害丢在风里,将感动铭记心底,才可以让我们的友谊历久弥新!
友谊是我们哀伤时的缓和剂,激情时的舒解剂;
是我们压力时的流泻口,是我们灾难时的庇护所;
是我们犹豫时的商议者,是我们脑子的清新剂。
但最重要的一点是,我们大家都要牢记的:
“切不可苛求朋友给你同样的回报,宽容一点,对自己也是对朋友。”
爱因斯坦说:“世间最美好的东西,莫过于有几个头脑和心地都很正直的朋友。”
统计数据的描述性分析 一、实验目的 熟悉在matlab中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf、概率分布函数df、随机数生成rnd。 二、实验内容 1 、频数表和直方图 数据输入,将你班的任意科目考试成绩输入 >> data=[91 78 90 88 76 81 77 74]; >> [N,X]=hist(data,5) N = 3 1 1 0 3 X = 75.7000 79.1000 82.5000 85.9000 89.3000 >> hist(data,5)
2、基本统计量 1) 样本均值 语法: m=mean(x) 若x 为向量,返回结果m是x 中元素的均值; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的均值。 2) 样本中位数 语法: m=median(x) 若x 为向量,返回结果m是x 中元素的中位数; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的中位数3) 样本标准差 语法:y=std(x) 若x 为向量,返回结果y 是x 中元素的标准差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的标准差
std(x)运用n-1 进行标准化处理,n是样本的个数。 4) 样本方差 语法:y=var(x); y=var(x,1) 若x 为向量,返回结果y 是x 中元素的方差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的方差 var(x)运用n-1 进行标准化处理(满足无偏估计的要求),n 是样本的个数。var(x,1)运用n 进行标准化处理,生成关于样本均值的二阶矩。 5) 样本的极差(最大之和最小值之差) 语法:z= range(x) 返回结果z是数组x 的极差。 6) 样本的偏度 语法:s=skewness(x) 说明:偏度反映分布的对称性,s>0 称为右偏态,此时数据位于均值右边的比左边的多;s<0,情况相反;s 接近0 则可认为分布是对称的。 7) 样本的峰度 语法:k= kurtosis(x) 说明:正态分布峰度是3,若k 比3 大得多,表示分布有沉重的尾巴,即样本中含有较多远离均值的数据,峰度可以作衡量偏离正态分布的尺度之一。 >> mean(data) ,
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。
航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法顾客提出的意见是否合理请你对上面的数据进行适当的分析,回答下列问题。 (1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理为什么 (4)使用哪一个平均指标来分析上述问题比较合理 答:(1): 2:
从表中我们可以得到中位数为众数为1平均数为标准差为 (3):合理,虽然他的平均数是<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤
2.样本描述性统计 表3是对研究样本的描述性统计,从表中可以看出经过询价后的股票价格相对下限P平均高出46·28%,最大值为148·9%,首日平均抑价水平UP为148·65%。从审计师选择看,“四大”与“十大”所占比例6·01%和23·61%,整体看所占市场份额偏低。从平均市盈率PE来看,前一个月平均市盈率最大值为29·98,最小值为14·8,说明在逐步市场化机制下,PE 的值将根据公司实际情况确定,区间进一步扩大。 (二)实证结果 1.审计师声誉与机构投资者报价 表4是审计师声誉对机构投资者报价的检验结果,在以“四大”作为因变量的OLS回归中,我们发现审计师声誉与机构投资者报价水平正相关,系数为0·072,但统计上不显著;在以“十大”作为因变量的检验中,我们得到了相似的结论,表明审计师声誉没有对投资者报价水平产生显著的影响。在控制变量检验中,我们发现前一期的市盈率水平PE对询价对象的报价水平产生显著影响,前期市盈率水平越高,询价对象报价越高。市场指数Index与报价负相关,其可能解释是询价对象在前期指数上涨情况下,更可能看空后市,压低报价。对承销商声誉和公司成立时间的检验中,我们发现他们对询价对象报价没有显著影响。 考虑到审计师变量的自选择问题,我们首先对审计师选择进行检验。结果表明招股说明书上的风险越多、公司资产负债率低的公司更易选择“四大”或“十大”,同时公司资产规模越大,发行筹集资金越多的公司也会选择“四大”或“十大”。 为了解决审计师自选择问题,我们采用Heckman两阶段回归对审计师声誉与询价对象报价关系进行了检验,结果发现自选择系数λ为负并且不显著,说明模型不存在严重的自选择问题。从结论来看,自变量与控制变量的结果与OLS检验的结论没有显著差别。
描述性统计
第一章描述性统计 统计分析:包括统计描述和统计推断。 步骤:数据------ 描述性统计----- 统计推断 data statistical description statistical inference 统计描述:主要是描述样本的特征。 统计推断:参数估计,假设检验。 第一节变量与数据 一、变量的类型: 1. 连续型变量(计量资料):取值范围为实数轴上的一个连续区间。 如:身高体重脉搏血细胞计数 计量资料(measurement data) : 连续型变量的观察值构成的资料。
2. 离散型变量(计数资料)只能在孤立的几个数中取值的变量。如: 二值变量(binary variable)。也称为类别变量(categorical variable) 或名义变量(nominal variable)。 如: 性别--- 男、女 职业--- 工、农、商、学、兵 计数资料(count data) : 离散型变量的频数资料。 3. 有序变量(等级资料) 如: 疗效--- 无效、有效、显效、痊愈 等级资料(ranked data):有序变量的频数资料。
二、数据的结构和特点: 1. 基本观察单位:是按研究需要确定的采集数据的基本单位。观察对象本身可以是一个基本观察单位,也可以同时具有若干个基本观察单位。 2. 记录项目:用于统计分析的记录项目通常由分组因素、反应变量和协变量三部分组成。 表1.1 100名高血压患者治疗后的临床记录 患者编号年龄(岁) 性别治疗分组收缩压(kP a) 舒张压(kP a)心电图疗效判定 1 37 男A药18.67 11.47 正常显效 2 45 女对照20.00 12.5 3 正常有效 …………………… 100 54 女B药16.80 11.73 正常有效 第二节频数表与直方图
主讲人:刘莎莎 第三讲 描述性统计分析
一、 序列窗口下的描述性统计分析
知识点 1:如何以建立组对象的方式将数据导入到 Eviews 中去(第二种导入数 据的方式) 。 知识点 2:如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态 分布曲线叠加在一起,从而更直观地观察数据的分布特征。 (如何将 EViews 图形 复制粘贴到 word 中) 知识点 3:如何在序列窗口下实现描述性统计量的假设检验 知识点 4:如何实现将单序列按某一变量分类后再进行描述性统计分析(本案例 的分类变量是该天是星期几) 知识点 5:如何实现将单序列按某一变量分类后再进行假设检验 知识点 6:如何画上证综指日对数收益率的 QQ 图 知识点 7:如何估计数据的经验分布函数的参数 案例数据说明:2003 年 1 月 6 日-2009 年 6 月 26 日上证综指日对数收益率。
二、序列组窗口下的描述性统计分析
知识点 1:如何通过打开 excel 文件的方式将数据导入到 Eviews 中去。 (第三种 导入数据的方式) 。 知识点 2:如何实现多变量的描述性统计量 知识点 3:如何实现多变量描述性统计量的假设检验 案例数据说明:国家统计调查队分别在两个地区调查了 10 个家庭的收入 知识点 4:如何计算当前序列组的相关系数矩阵,协方差矩阵
主讲人:刘莎莎
案例数据说明:1983-2000 年我国粮食生产与相关投入的数据,变量包括粮食产 量(单位:万吨)、农业化肥施用量(单位:万千克)、粮食播种面积(单位: 公顷)
附注:描述性统计量的计算公式
标准差(Std.Dev.)的计算公式是:
s=
2 ( y ? y ) ∑ t t =1
T
T ?1
其中,
yt 是观测值, y 是样本平均数。
偏度(Skewness)的计算公式是:
1 T yt ? y 3 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。对
称分布的偏度是零,比如正态分布。
峰度(Kurtosis)的计算公式是:
1 T yt ? y 4 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。
正态分布的峰度值是 3。
统计分析往往是从了解数据的基本特征开始的。描述数据分布特征的统计量可分为两类:一类表示数量的中心位置,另一类表示数量的变异程度(或称离散程度)。两者相互补充,共同反映数据的全貌。 这些内容可以通过SPSS中的“Descriptive Statistics”菜单中的过程来完成。 1 频数分析 (Descriptive Statistics - Frequencies) 频数分布分析主要通过频数分布表、条形图和直方图,以及集中趋势和离散趋势的各 种统计量来描述数据的分布特征。 下面我们通过例子来学习单变量频数分析操作。 1) 输入分析数据 在数据编辑器窗口打开“data1-2.sav”数据文件。 2)调用分析过程 在主菜单栏单击“Analyze”,在出现的下拉菜单里移动鼠标至“Descriptive Statistics”项上,在出现的次菜单里单击“Frequencies”项,打开如图3-4所示的对话框。 图3-4 “Frequencies” 对话框 3)设置分析变量 从左则的源变量框里选择一个和多个变量进入“Variable(s):”框里。在这里我们选“三化 螟蚁螟[虫口数]”变量进入“Variable(s):”框。 4)输出频数分布表
Display frequency tables,选中显示。 5)设置输出的统计量 单击“Statistics”按钮,打开图3-5所示的对话框,该对话框用于选择统计量: 图3-5 “Statistics”对话框 ①选择百分位显示“Percentiles Values”栏: Quartiles:四分位数,显示25%、50%和75%的百分位数。 Cut points for 10 equal groups:将数据平分为输入的10个等份。 Percentile(s)::用户自定义百分位数,输入值0—100之间。选中此项后,可以利用“Add”、“Change”和 “Remove”按钮设置多个百分位数。 ②选择变异程度的统计量“Dispersion”:(离散趋势) Std.deviation标准差 Minimum 最小值 Variance 方差 Maximum 最大值 Range 极差 S.E.mean均值标准误 ③选择表示数据中心位置的统计量“Central Tendency”:(集中趋势) Mean 均值 Median 中位数 Mode 众数 Sum 算术和
一、实验概述: 【目的】了解SPSS软件的安装、启动、退出以及运行管理方式;掌握SPSS软件的Analyze 菜单中的Descriptive Statistics模块进行数据的描述性统计分析。 【实施环境】SPSS—17.0统计分析软件。 二、实验内容: 用SPSS软件对实验一数据中的“熟悉程度”进行描述统计分析:描述数据的频数分布、集中趋势、离散程度和形状、并给出直方图。 三、实验步骤 步骤1:用SPSS打开已知的数据文件 选择菜单“File—>Open—>Data”,在对话框中找到需要分析的数据文件(实验一&二描述统计和假设检验.sav),然后选择“打开” 步骤2:计算所要求的描述统计量值及频数分布 1.打开文件之后,选择菜单“Analyze—>Descriptive Statistics—>Frequencies”。 2.确定所要分析的变量 要在“Frequencies 对话框”中选中左侧列表框中的“Familiarity”,之后点击列表框中间的箭头按钮,将要分析的变量加入到右侧Variable(s)列表框中。然后,选择位于小窗口下端的“Display frequency tables 复选框”,以确定要输出频数分布表。
3. 选择所要计算的统计量 在变量选择确定之后,在同一窗口上,点击“Statistics”按钮,打开统计量对话框,选择统计输出选项。 步骤3:结果输出与分析 点击Frequencies:Statistics对话框中的“Continue”按钮,再点击Frequencies 对话框中的“OK”按钮,即得到频数分布结果。 步骤4:选择菜单“Graphs—>Legacy Dialogs—>Histogram”。
关于描述性统计分析 作者:记忆de&#…文章来源:csdn blog 点击数:156 更新时间:2007-2-12 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Anal ysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。 (3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
描述性统计分析 作者:清华大学中国企业研究中心阅读次数:24704次发布日期:2005-07-04 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形。 (1)数据的频数分析:在数据的预处理部分,我们曾经提到利用频数分析和交叉频数分析来检验异常值。此外,频数分析也可以发现一些统计规律。比如说,收入低的被调查者用户满意度比收入高的被调查者高,或者女性的用户满意度比男性低等。不过这些规律只是表面的特征,在后面的分析中还要经过检验。 (2)数据的集中趋势分析:数据的集中趋势分析是用来反映数据的一般水平,常用的指标有平均值、中位数和众数等。各指标的具体意义如下: 平均值:是衡量数据的中心位置的重要指标,反映了一些数据必然性的特点,包括算术平均值、加权算术平均值、调和平均值和几何平均值。 中位数:是另外一种反映数据的中心位置的指标,其确定方法是将所有数据以由小到大的顺序排列,位于中央的数据值就是中位数。 众数:是指在数据中发生频率最高的数据值。 如果各个数据之间的差异程度较小,用平均值就有较好的代表性;而如果数据之
间的差异程度较大,特别是有个别的极端值的情况,用中位数或众数有较好的代表性。
(3)数据的离散程度分析:数据的离散程度分析主要是用来反映数据之间的差异程度,常用的指标有方差和标准差。方差是标准差的平方,根据不同的数据类型有不同的计算方法。 (4)数据的分布:在统计分析中,通常要假设样本的分布属于正态分布,因此需要用偏度和峰度两个指标来检查样本是否符合正态分布。偏度衡量的是样本分布的偏斜方向和程度;而峰度衡量的是样本分布曲线的尖峰程度。一般情况下,如果样本的偏度接近于0,而峰度接近于3,就可以判断总体的分布接近于正态分布。 (5)绘制统计图:用图形的形式来表达数据,比用文字表达更清晰、更简明。在SPSS软件里,可以很容易的绘制各个变量的统计图形,包括条形图、饼图和折线图等。 示例SIM手机描述性统计分析 为简化起见,我们只分析SIM手机用户满意调查中的两个变量:“总体感知质量”和“总体满意度”变量。 (1)数据的频数分析 用SPSS软件的频数分析可以很容易地画出两个变量的频数图:
用Excel进行数据分析:描述性统计分析 郑来轶发表于2013-04-14 22:03 来源:本站原创 在数据分析的时候,一般首先要对数据进行描述性统计分析(Descriptive Analysis),以发现其内在的规律,再选择进一步分析的方法。描述性统计分析要对调查总体所有变量的有关数据做统计性描述,主要包括数据的频数分析、数据的集中趋势分析、数据离散程度分析、数据的分布、以及一些基本的统计图形,常用的指标有均值、中位数、众数、方差、标准差等等。 接下来我们讲讲在Excel2007中完成描述性统计分析。 一、案例场景 某网站的专题活动积累了一定访问数据后,需要统计流量的的均值、区间,以及给出该专题访问量差异的量化标准,借此来作为分析每天访问量的价值、参差不齐、此起彼伏一个衡量的依据。要求得到均值、区间、众数、方差、标准差等统计数据。 二、操作步骤 1、打开数据表格,这个案例中用的数据无特殊要求,只是一列数值就可以了。 2、选择“工具”——“数据分析”——“描述统计”后,出现属性设置框
注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,可以参考上一篇文章《用Excel进行数据分析:数据分析工具在哪里?》。 3、依次选择 选项有2方面,输入和输出选项 输入区域:原始数据区域,选中多个行或列,选择相应的分组方式逐行/逐列;
如果数据有标志,勾选“标志位于第一行”;如果输入区域没有标志项,该复选框将被清除,Excel 将在输出表中生成适宜的数据标志; 输出区域可以选择本表、新工作表或是新工作簿; 汇总统计:包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。第K大(小)值:输出表的某一行中包含每个数据区域中的第k 个最大(小)值。 平均数置信度:数值95% 可用来计算在显著性水平为5% 时的平均值置信度
描述性统计结果 1、 性别结构 样本中深圳高校毕业生男性占67%,明显高于女性所占比例。但由于此次样本容量较小,故没有什么代表性。 深圳高校毕业生男女所占比例百分比图0 1020304050607080男 女 2、就业信心 样本中,只有6%的人对自己毕业后找到理想工作表示没有信心,而28%的人表示非常有信心,51%的人表示比较有信心,15%的人表示有些信心。可见大多数深圳高校毕业生对自己毕业后找到理想工作有信心。 深圳市高校毕业生对找到理想工作的信心情况百分比图 102030405060 非常有信心 比较有信心 有些信心 比较没有信心
3、接受学校或政府提供的就业辅导或培训的情况 样本中,66%的人表示没有接受过学校或政府提供的就业辅导或培训,人数比例明显高于有接受过此类培训的。 深圳市高校毕业生接受就业辅导或培训的 情况百分比图0 10203040506070接受过 没有接受过 4、薪酬要求 样本中,一半人找工作对月薪的要求不高于3000元,深圳市高校毕业生对工作月薪要求的平均水平为3653元。对月薪的要求主要集中在3000-5000元,最低要求为2000元,最高要求为10000元。 深圳市高校毕业生对工作月薪要求的情况表
变量关系检验的描述 5、不同性别的人对找到理想工作的信心情况对比 (注,因为样本容量不够,所以“非常有信心”“比较有信心”合并为“有信心”;将“有些信心”“比较没有信心”“合并为“比较没有信心”;“非常没有信心”没有人选故省去该选项。) 男女对找到工作的信心指数被分为“有信心”“比较没有信心”两项,采用两个独立样本卡方检验的统计方法,对比就业信心情况在不同性别上的凸显度。F 检验结果为0.629,在0.05水平上不显著,说明男女在这个问题上总体的方差没有显著性差异。可以推断,不同性别的人在就业信心情况上没有显著差异。(由图表也可分析出同一结果) 不同性别的人对照到理想工作的信心情况比较 0.00% 10.00%20.00%30.00%40.00%50.00%60.00%70.00%80.00%90.00%有信心 比较没有信心
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
1数据的描述性统计练习题 一、填空题 1. 一组数据向某以中心值靠拢的倾向反映了数据的(集中趋势)。 2. (众数)是一组数据中出现次数最多的变量值。 3. 一组数据排序后处于中间位置的变量值称为(中位数)。 4. 不受极端值影响的集中趋势度量指标有(四分位数)(众数)(中位数)。 5. 一组数据的最大值与最小值之差称为(极差)。 6. (离散系数)一组数据的标准差与其相应的均值之比。 7. 数据分布的不对称性是(偏度)。 8. 数据分布的尖峰程度称为(峰度)。 9. 计算比率的平均数一般用(几何平均法),它实际上是各变量值对数的(算术平均数)。 二、单项选择题 1. 对于对称分布的数据,众数、中位数和平均数的关系是(B) A. 众数>中位数>平均数 B. 众数=中位数=平均数 C. 平均数>中位数>众数 D. 中位数>众数>平均数 2. 可以计算平均数的数据类型是(C) A.分类数据 B.顺序型数据 C.数值型数据 D.所有数据 3. 顺序数据的集中趋势测度的指标(B) A.中位数 B.平均数 C.极差 D.标准差 4. 数值型数据的离散程度测度方法中,受极端变量值影响最大的是(A) A.极差 B.方差 C.均方差 D.平均差 5. 当偏态系数为正数是,说明数据的分布是(C) A.正态分布 B.左偏分布 C.右偏分布 D.U型分布 三、多项选择题 1. 数据的分布特征可以从以下哪几个方面测度和描述(ABCD) A.集中趋势 B.分布的偏态 C.分布的峰态 D.离散程度 E.长期趋势
2. 受极端变量值影响的集中趋势的度量指标是(CDE) A.众数 B.分位数 C.算数平均数 D.调和平均数 E.几何平均数 3. 加权算术平均数的大小的影响因素有(AC) A.变量值 B.样本容量 C.权数 D.分组的组数 E.数据的类型 4. 数值型数据离散程度的测度指标有(ABCDE) A.变异系数 B.极差 C.标准差 D.异众比率 E.四分位数 5. 离散系数的主要作用是(BD) A.说明数据的集中趋势 B.比较不同计量单位数据的离散程度 C.说明数据的偏态程度 D.比较不同变量值水平数据的离散程度 E.说明数据的峰态程度 四、简答题 1. 什么是数据的集中趋势?反映数据集中趋势的指标有哪些? 数据的集中趋势指一组数据向某一中心值靠拢的倾向。 反映数据集中趋势的指标主要有:众数、中位数、分位数、平均数等。 2. 什么是数据的离散程度?常用测度离散程度的指标有哪些? 离散程度反映的是各变量值远离其中心值的程度。 反映数据离散程度的指标主要有:四分位差、方差、标准差、极差、离散系数等。 3. 怎样理解平均数在统计学中的地位? 平均数在统计学中具有重要的地位,它是进行统计分析和统计推断的基础;平均数作为代表值,是误差相互抵消的结果,反映了事物必然性的数量特征。 4. 简述众数、中位数和平均数的特点和应用场合。 众数是一组数据分布的峰值,是一种位置代表值,不受极端值的影响,其缺点是不具有唯一性。虽然对数据型数据和分类数据也适用,但主要是用于分类数据的集中趋势测度值。中位数是中间位置上的代表值,也是一种位置的代表值,其特点是不受极端值的影响。顺序数据可以计算众数,但以中位数宜。 平均数是根据数据型数据计算的,而且利用了所以信息,是实际中应用最广的集中趋势测度值。虽然数据型数据可以计算众数和中位数,但以平均数为宜。平均数的主要缺点是受极端值的影响,对于偏态分布,平均数的代表性差。特别是当偏态程度较大是,可用位置平均数代替。 5. 为什么要计算离散系数?