一、调查问卷
二、用SPSS Statistics软件进行描述统计分析
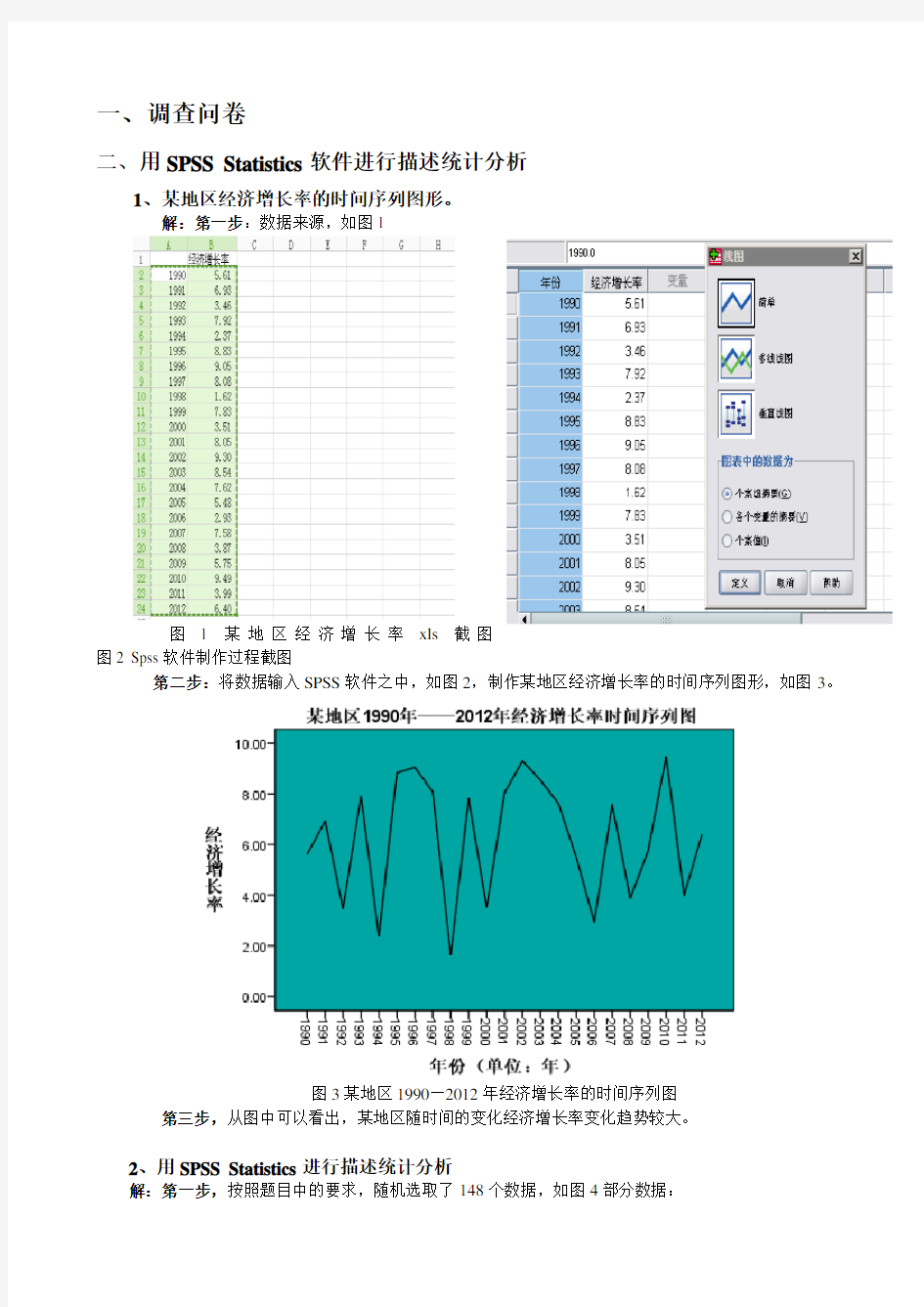
1、某地区经济增长率的时间序列图形。
解:第一步:数据来源,如图1
图 1 某地区经济增长率xls截图
图2 Spss软件制作过程截图
第二步:将数据输入SPSS软件之中,如图2,制作某地区经济增长率的时间序列图形,如图3。
图3某地区1990—2012年经济增长率的时间序列图
第三步,从图中可以看出,某地区随时间的变化经济增长率变化趋势较大。
2、用SPSS Statistics进行描述统计分析
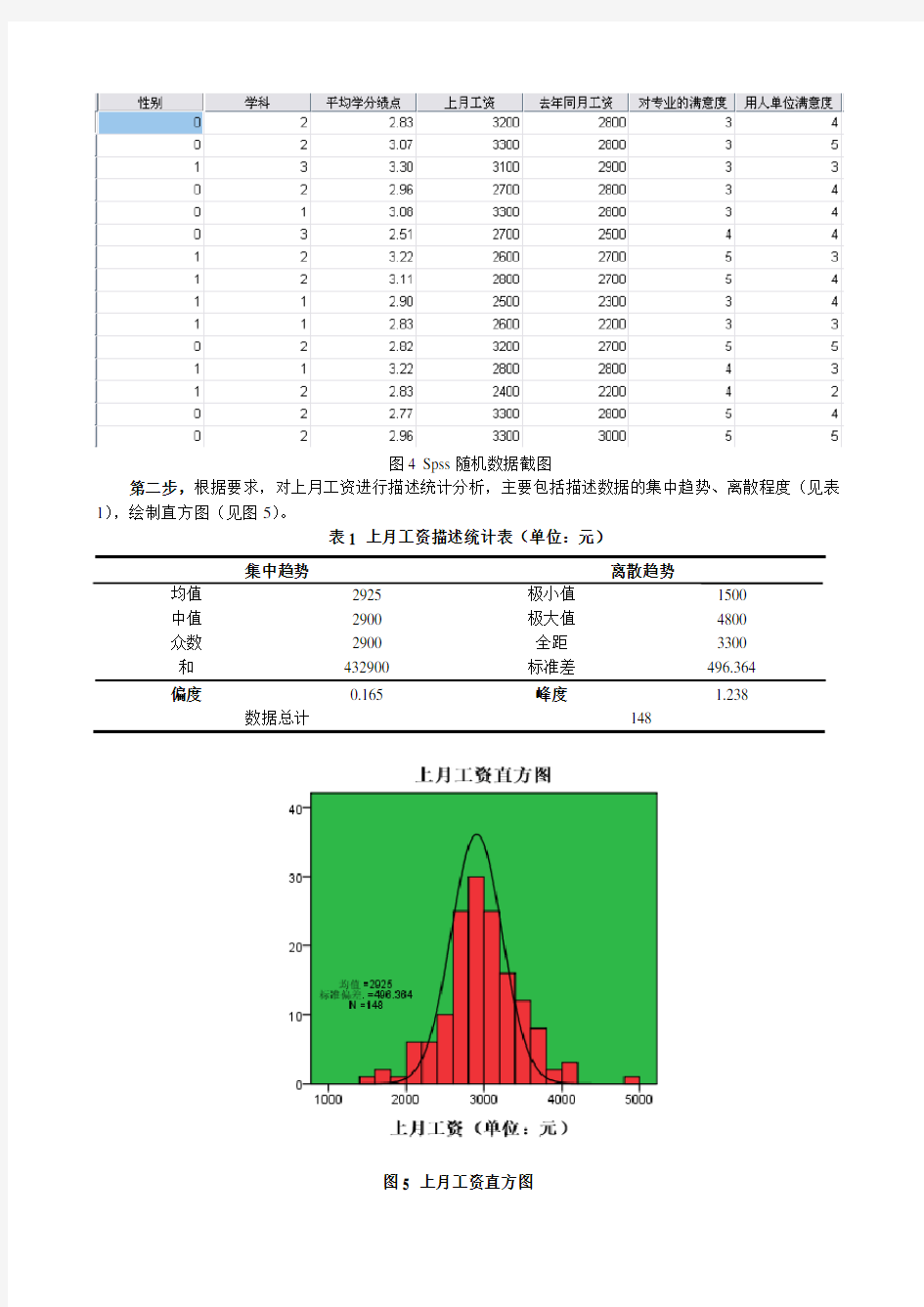
解:第一步,按照题目中的要求,随机选取了148个数据,如图4部分数据:
图4 Spss随机数据截图
第二步,根据要求,对上月工资进行描述统计分析,主要包括描述数据的集中趋势、离散程度(见表1),绘制直方图(见图5)。
表1 上月工资描述统计表(单位:元)
集中趋势离散趋势
均值2925 极小值1500
中值2900 极大值4800
众数2900 全距3300
和432900 标准差496.364
偏度0.165 峰度 1.238
数据总计148
图5 上月工资直方图
第三步,分析数据的统计分布状况。
首先,从集中趋势来,上个月平均工资2925元,其中众数和中数也都在2900元,这说明大部分工资水平在2900左右。
其次,从离散趋势来看,最高工资4800元,最低工资1500元,最高工资和最低工资相差3300元,标准差为496.364,相差较大。
最后,从直方图来看和评述统计表来看,工资在2900元以上的占多数。可以的该地区整体工资水平大于平均值的占多数,该地区工资水平相对较高。
峰度为1.238,偏度为0.165符合正态分布。
三、用SPSS Statistics 软件进行参数估计和假设检验及回归分析
1、计算总体中上月平均工资95%的置信区间(见表3)。
解:总体中上月平均工资分布未知,但是样本容量大于30,且已知标准误,所以通过SPSS 分析得出总体中上月平均工资95%的置信区间,见表3, 假设;
H0:总体中上月平均工资95%的不在此在此区间
H1:总体中上月平均工资95%的在此区间
答,总体中上月平均工资095的置信区间为[2844.37,3005.63],p=0.000<0.01,作出这样的推论正确的概率为0.95,错误的概率为0.05。
2、检验能否认为总体中上月平均工资等于2000元。
解:在本案例中,要检验样本中上月平均工资与总体中上月平均工资(为已知值:2000元)是否存在差异,即某一样本数据与某一确定均值进行比较。虽然不知道总体分布是否正态,但样本较大(N>30),可以运用单样本T 检验.通过SPSS 检验结果见(表4 、表5) 设; H o:2000=μ
H 1:2000≠μ 其中,μ表示总体中上月平均工资
表4 单个样本统计量
表5 单个样本检验
t df Sig.(双侧) 均值差值 检验值 上月工资
22.671
147
0.000
925.000
2000
答:作出结论,均值差值为925,t=22.671,p=0.000<0.01,所以拒绝原假设,接受备择假设,即否认总体中上月的平均工资等于2000元。
3、检验能否认为男生的平均工资大于女生
解:两个样本均来自于正态分布的总体且男女上月工资独立,可以进行独立样本T 检验,(见表6、表7)
假设1:H 0:2
221δδ=
H 1:2
22
1δδ≠ 其中,代表女生总体方差代表男生总体方差,2
22
1δδ
从表7中方差方程的 Levene 检验可以看出,F=0.101,P=0.751>0.05,所以不能拒绝原假设,可以认为两组数据无显著差异,所以应该选择方差相等下的T 检验。
表7独立样本检验
假设2: H 0:21μμ≤
H 1:21μμφ 其中μ1代表男生总体平均数,μ2代表女生总体平均数,下同
作出结论:从表6、表7中可以看出,男生有73人,平均工资3156.16元,女生75人,平均工资2700.00元。t=6.277,且p=0.000<0.001 所以拒绝原假设,接受备择假设,差异极显著。根据表6,可以最后得出结论,男生平均工资大于女生的结论。
4、一些学者认为,由于经济不景气,学生的平均工资今年和去年相比没有显著提高。检验这一假说。
解: 根据题意可知,需要进行相关样本T 检验,设:
H 0:μ1≤μ2 H 1;μ1>μ2 同上
表8 相关样本T 检验
均值
标准差
均值标准误 T df 相关系数 sig 上月工资 2925 496.364 40.801 去年同月工资 2721.62 447.296 36.767 上月工资&去年同月工资 203.378 183.101
15.501
13.531
147
0.93
0.000
通过表8可知,t=13.531,P=0.000<0.01,所以拒绝原假设,接受备择假设,即学生的平均工资今年和去年相比有显著提高。
方差方程的 Levene 检验 T 检验
F
Sig. t df Sig.(双侧) 均值差值 标准误差值 上月工资 假设方差相等 0.101 0.751
6.277
146
0.000
456.164
72.667
假设方差不相等
6.277 145.859 0.000 456.164 72.670
5、方差分析。
(1)使用单因素方差分析的方法检验:能否认为不同学科的上月平均工资相等。如果不能认为全相等,请做多重比较。
解:第一步,提出假设,H0:不同学科上月的平均工资是相同的
H1:至少有两门学科上个月的平局工资是相同的
经过SPSS软件计算,见表9,
第二步,决策,F=0.754,P=0.472>0.05,接受H0,拒绝H1,三者之间没有显著性差异。可以认为不同学科上月工资水平相同。
第三步,多重比较,经过Levene检验(见表10),p=0.724,方差没有显著性差异,方差齐性,经过LSD检验(见表11),P值均大于0.05,所以可以得出同样的结论,三门学科的上月工资水平没有差异。
表10 方差齐性检验
(2)在方差分析中同时考虑学科和性别因素,用双因素方差分析模型分析学科和性别对上月平均工资的影响。
解:第一步,提出假设,H0:性别和学科对上月工资水平没有影响
H1:性别和学科同时对上月工资水平有影响
第二步,经过SPSS计算,见表12,
表12主体间效应的检验
第三步,作出决策
性别因素P=0.000<0.01,在0.01水平上差异显著,所以拒绝原假设,接受备择假设,即性别因素对工资水平有显著性影响,和前面结果一致。
学科因素P=0.465>0.05,在0.05水平上差异不显著,所以接受原假设,拒绝备择假设,即学科因素对上月工资水平没有影响,和前面结果一致。
性别* 学科p=0.962>0.05,在0.05水平上差异不显著,所以接受原假设,拒绝备择假设,即学科和性别因素同时对上月工资水平没有影响。
6、非参数检验。
(1)用非参数检验方法检验能否认为男生和女生上月工资的中位数相等。
解:第一步,采用wilcoxon符号秩检验中位数,选择的原设与备择假设如下:
H0:男生与女生上月工资的中位数相等;
H1:男生与女生上月工资的中位数不相等。
第二步,通过SPSS软件计算,见表13、14
表
表14 wilcoxon秩和检验的检验统计量和p值
第三步,男生上月工资的平均秩为41.33,女生上月工资的平均秩是19.84,说明从样本看男生上月工资的中位数要高于女生。用正态分布计算时的M=1265.000,W=4115.000,Z=-5.663,p=0.000<0.01,可以拒绝原假设,认为男生与女生上月工资中位数不相等。若进行单侧检验:
H0:男生月收入中位数小于女生月收入的中位数;H1:男生月收入中位数大于于女生月收入的中位数。P值为0.000,可以拒绝原假设。
H0:男生月收入中位数大于女生月收入的中位数;H1:男生月收入中位数小于女生月收入的中位数。P值为1-0.000/2 =1,接受原假设。
因此可以认为男生上月工资中位数大于女生上月工资中位数。
(2)用非参数检验方法检验学生上月工资和去年同月工资的中位数是否有显著变化。
解:第一步,采用非参数检验中的两个相关样本样本,选择的原假设与备择假设如下:
H0:上月工资与去年同月工资差值为0
H1:上月工资与去年同月工资差值不为0
第二步,通过SPSS软件计算,结果如表15、16
第三步,作出结论,由于此样本为大样本,应该采用渐近显著性的p值(0.000),小于0.01,拒绝原
假设,接受备择假设,则可以认为上月工资与去年同月工资有显著差别。
(3)用非参数检验方法不同学科学生平均学分绩点的中位数是否相等。
解:第一步,采用Kruskal-Wallis检验不同学科学生平均学分绩点的中位数是否相等,原假设和备择假设设置如下:
H0:不同学科学生平均学分绩点的中位数相等;
H1:不同学科学生平均学分绩点的中位数不相等
第二步,通过SPSS软件计算结果如表17、18;
表17 Kruskal-Wallis检验中计算的各组平均秩
表18 Kruskal-Wallis检验的检验统计量和p值
第三步,作出结论,因为p=0.653>0.05,不可拒绝原假设,认为三个学科平均学分绩点的中位数没有显著差异.。
(4)检验学生的上月工资是否服从正态分布。
解:第一步,样本是否来自正态分布,可用单样本K-S检验,原假设和备择假设设置如下
H0:学生的上月工资服从正态分布
H1:学生的上月工资不服从正态分布
第二步,通过SPSS软件计算结果如表19
表19 单样本Kolmogorov-Smirnov 检验
第三步,作出结论,p=0.291,大于0.05,不能拒绝原假设,也就是说能认为此样本来自正态分布。(5)检验学生对专业的满意程度是否为离散的均匀分布
第一步,采用卡方分布进行检验,H0:学生对专业的满意程度服从离散的均匀分布
H1:学生对专业的满意程度不服从离散的均匀分布
第二步,通过SPSS软件计算结果表20、21
表21 卡方分布检验计算结果和相应的p 值
第三步,作出结论,因为p=0.000,小于0.01,可以拒绝原假设,接受备择假设认为学生对专业的满意程度不服从离散的均匀分布。
7、回归分析。
(1)计算上月工资与平均学分绩点的相关系数并作假设检验。 解:第一步,假设如下:H 0:0=ρ H 1:0≠ρ
第二步,通过SPSS 计算,见表22
第三步,根据计算相关系数为0.763,P=0.000<0.01,所以可以拒绝原假设,在0.01水平上二者显著相关。
(2)以上月工资为因变量,平均学分绩点为自变量做回归分析,分析模型的拟合效果和假设检验的结果。 (第一次抽样无法做回归分析,需要重新抽样)
解:第一步,假设1,H0:回归模型无意义,H1:回归模型有意义 假设2,Ho ;常量为 H1:常量不等于0
假设3,Ho :平均学分绩点的系数为0,H1:平均学分绩点的系数不等于0 第二步,通过SPSS 分析,见表23、24、25
模型平方和df 均方 F Sig.
1 回归 2.273E7 1 2.273E7 189.216 .000a
残差 1.622E7 135 120118.458
总计 3.894E7 136
模型 B t Sig.
1 (常量) -661.720 269.159 -2.458 .015
平均学分绩点1177.971 85.636 13.756 .000
图6
图7
图8
说明:
图6为残差的直方图,图中残差的分布基本均匀
图7为残差的正态P-P概率图,图中散点基本呈直线趋势,且并未发现异常点
图8残差是否有随标准化预测值增大而改变的趋势。从图中可以看出分布基本均匀,可以认为残差的方差是齐性的
第三步,作出结论,从表23中可以看出此表为拟合模型的拟合优度的情况,其中R方为0.584,Durbin-Watson统计量为2.163,比较接近2,可以认为残差之间相互独立。从表24中可以到
F=189.216 .P=0.000,可以认为这个回归模型是有统计意义的。从表25中可以得到模型的常量为-661.720,平均学分点的系数为1177.971,通过以上综合分析,最后得出的模型为:
月工资=-661.720+1177.971*平均学分绩点
(3)以上月工资为因变量,平均学分绩点和性别为自变量做回归分析,分析模型的拟合效果和假设检验的结果。
解:第一步,假设1,H0:回归模型无意义,H1:回归模型有意义
假设2,Ho;常量为H1:常量不等于0
假设3,Ho:平均学分绩点的系数为0,H1:平均学分绩点的系数不等于0 第二步,通过SPSS计算可以得出表26、27、28、29,
c
模型R R 方调整R 方标准估计的误差Durbin-Watson
1 .914b.835 .83
2 219.020 1.887
模型平方和df 均方 F Sig.
1 回归 3.252E7
2 1.626E7 338.928 .000
残差6427926.055 134 47969.597
总计 3.894E7 136
模型 B t Sig.
1 (常量) -137.317 174.010 -.789 .431
平均学分绩点1098.030 54.406 20.182 .000
性别-537.566 37.633 -14.285 .000
a
模型
维数特征值条件索引
1 1 2.616 1.000
2 .378 2.629
3 .006 21.027
第三步,作出结论,从表26中可以看出此表为拟合模型的拟合优度的情况,其中调整R方为0.835,Durbin-Watson统计量为 1.887,比较接近2,可以认为残差之间相互独立。从表24中可以到F=338.928,.P=0.000,可以认为这个回归模型是有统计意义的。从表25中可以得到模型的常量为-137.317,P=0.431>0.05,所以在统计学中,没有意义。平均学分点的系数为1098.030,性别的系数为-537.566,通过以上综合分析,最后得出的模型为:
月工资=-537.566*性别+1098.030*平均学分绩点
图9
图10
图11
说明:
图9为残差的直方图,图中残差的分布基本均匀
图10为残差的正态P-P概率图,图中散点基本呈直线趋势,且并未发现异常点
图11 残差是否有随标准化预测值增大而改变的趋势。从图中可以看出分布基本均匀,可以认为残差
的方差是齐性的
(4)在(2)和(3)模型中你会选择哪一个模型用于预测?为什么?假设一名男生的平均学分绩点为3.5,试预测他的上月工资的点估计值和区间估计。
解:(2)中模型的R方等于0.584,(3)中模型的R方等于0.835,R方越大,所以选择(3)中的模型作为预测模型。假设一名男生的平均学分绩点为3.5,根据(3)中的模型公式:
月工资=-537.566*性别+1098.030*平均学分绩点=-537.566*0+1098.030*3.5=3843.105,其置信区间为3843.105+/-219.02,结果为【3624.085,4062.125.】
数据分析方法及软件应用 (作业) 题目:4、8、13、16题 指导教师: 学院:交通运输学院 姓名: 学号:
4、在某化工生产中为了提高收率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收率数据如下面计算表所列。试在α=0.05显著性水平下分析 (1)给出SPSS数据集的格式(列举前3个样本即可); (2)分析浓度对收率有无显著影响; (3)分析浓度、温度以及它们间的交互作用对收率有无显著影响。 解答:(1)分别定义分组变量浓度、温度、收率,在变量视图与数据视图中输入表格数据,具体如下图。 (2)思路:本问是研究一个控制变量即浓度的不同水平是否对观测变量收率产生了显著影响,因而应用单因素方差分析。假设:浓度对收率无显著影响。 步骤:【分析-比较均值-单因素】,将收率选入到因变量列表中,将浓度选入到因子框中,确定。 输出: 變異數分析 收率 平方和df 平均值平方 F 顯著性 群組之間39.083 2 19.542 5.074 .016 在群組內80.875 21 3.851 總計119.958 23 显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝原假设,认为浓度对收率有显著影响。
(3)思路:本问首先是研究两个控制变量浓度及温度的不同水平对观测变量收率的独立影响,然后分析两个这控制变量的交互作用能否对收率产生显著影响,因而应该采用多因素方差分析。假设,H01:浓度对收率无显著影响;H02:温度对收率无显著影响;H03:浓度与温度的交互作用对收率无显著影响。 步骤:【分析-一般线性模型-单变量】,把收率制定到因变量中,把浓度与温度制定到固定因子框中,确定。 输出: 主旨間效果檢定 因變數: 收率 來源第 III 類平方 和df 平均值平方 F 顯著性 修正的模型70.458a11 6.405 1.553 .230 截距2667.042 1 2667.042 646.556 .000 浓度39.083 2 19.542 4.737 .030 温度13.792 3 4.597 1.114 .382 浓度 * 温度17.583 6 2.931 .710 .648 錯誤49.500 12 4.125 總計2787.000 24 校正後總數119.958 23 a. R 平方 = .587(調整的 R 平方 = .209) 第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率p值。可以看到观测变量收率的总变差为119.958,由浓度不同引起的变差是39.083,由温度不同引起的变差为13.792,由浓度和温度的交互作用引起的变差为17.583,由随机因素引起的变差为49.500。浓度,温度和浓度*温度的概率p值分别为0.030,0.382和0.648。 浓度:显著性<0.05说明拒绝原假设(浓度对收率无显著影响),证明浓度对收率有显著影响;温度:显著性>0.05说明不拒绝原假设(温度对收率无显著影响),证明温度对收率无显著影响;浓度与温度: 显著性>0.05说明不拒绝原假设(浓度与温度的交互作用对收率无显著影响),证明温浓度与温度的交互作用对收率无显著影响。 8、以高校科研研究数据为例:以课题总数X5为被解释变量,解释变量为投入人年数X2、投入科研事业费X4、专著数X6、获奖数X8;建立多元线性回归模型,
实验一S P S S简介及 统计整理
实验一SPSS简介及统计整理 一、实验目的和要求 1掌握SPSS安装、启动、主界面和退出; 2掌握SPSS的变量定义信息; 3掌握SPSS的数据录入与保存方法; 4掌握在SPSS中的实现各种统计描述参数的计算。引到学生利用正确的统计方法对数据进行适当的整理和显示,描述并探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。 5理解并掌握SPSS软件包有关数据文件创建和整理的基本操作 6学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件 7掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序8 实验类型:验证型;实验时间:2学时 二、实验主要仪器和设备 计算机一台,Windows XP操作系统,SPSS环境。 三、实验原理 SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。一个典型的SPSS数据文件如表2.1 所示。 SPSS变量的属性
SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面(如图2.1所示)即可对变量的各个属性进行设置。 四、实验内容与步骤 实验1.1数据文件管理 1.创建一个数据文件 数据文件的创建分成三个步骤: (1)选择菜单【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。窗口顶部标题为“PASW Statistics数据编辑器”。 (2)单击左下角【变量视窗】标签进入变量视图界面,根据实验的设计定义每个变量类型。 (3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。 2.读取外部数据
《SPSS统计基础》课程数据分析报告 (2016— 2017学年度第二学期) 题目:关于381名大学生学习适应情况的分析报告 班级:14小教2班 学号: 姓名: 2017年6月
381名大学生学习适应性调查数据分析报告 姓名:学号:班级: 一、数据分析目的及内容 (一)数据分析的目的 通过对师范学院学生学习适应现状及其影响因素的调查研究,了解我院学生对自己所学专业在适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应环境因素、适应总分六个维度的基本情况。本文拟在以往研究的基础上对大学生学习适应状况进行调查,并探讨影响大学生学习适应的因素,从而让大学生能更快更好地适应大学生活。 (二)数据分析的内容 1. 381名大学生在适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应 环境因素五个维度的得分及适应总分. 2.对年级、专业、生源地变量的容量等数据分布指标的描述,了解数据分布的全貌。 3.对适应学习动机、适应教学模式、使用学习能力、适应学习态度、适应环境因素五个 维度的极大值、极小值、均值和标准差的统计。 4.学习适应各因子之间的相关分析。 5.学习适应五因子及适应总分的相关性分析。 二、数据库介绍 (一)数据来源: 1被试分布:总容量为381、年级(大一156人、大二136人、大三89人)、专业(小学教育140人、学前教育本科113人、学前教育专科128人)、生源地(城镇145人、农村236人)等方面的人数分布; 2、调查工具:《大学生学习适应量表》由冯廷勇等人编制,共29 个题目,量表采 用Likert5 点计分法,即完全不符合计 1 分,比较不符合计 2 分,不确定计 3 分,较符合计4 分,完全符合计 5 分。各维度和总量表分数越高,表明适应状况越好。总分低于58分,表明学习适应状态较差需要做较大调整;总分在59到87分之间,表明学习适应状态中等,需要做适当的调整;总分在88到116分之间,表明学习适应状态良好;总分在117到145分之间,表明学习适应状态良好。量表的效度为0.85,信度为0.87。该量表由五个维度构成: (1)学习动机(8题):1、6、7、8、9、13、17、23 (2)教学模式(7题):2、3、10、14、18、22、24 (3)学习能力(6题):4、11、15、21、25、26 (4)学习态度(4题):5、12、20、27 (5)环境因素(4题):16、19、28、29 (二)变量介绍: 1、本次问卷调查有三个变量; 2、变量名称为:专业,年级,生源地; 3、变量名称的取值为:专业:1=“小学教育”,2=“学前教育本科”,3=“学前教育专 科”;年级:1=“大一”,2=“大二”,3=“大三”,4=“大四”;生源地:1=“城镇”,2=“农村”。 三、数据统计与分析
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
目录 一、SPSS界面介绍 (2) 1、如何打开文件 (2) 2、如何在SPSS中打开excel表 (3) 3、数据视图界面 (3) 4、变量视图界面 (4) 二、如何用SPSS进行频数分析 (11) 三、如何用SPSS进行多变量分析 (15) 四、如何对多选题进行数据分析 (18) 1、对多选题进行变量集定义 (18) 2、对多选题进行频数分析 (21) 3、对多选题进行多变量交互分析 (24) 五、如何就SPSS得出的表在excel中作图 (27)
一、SPSS界面介绍 提前说明:第一,我这里用的是SPSS 20.0 中文汉化版。第二,我教的是傻瓜操作,并不涉及理论讲解,具体的为什么和用什么理论公式来解释请认真去听《社会统计学》的课程。第三,因为是根据我自己的操作和理解来写的,所以可能有些地方显的不那么科学,仍然要说请大家认真去听《社会统计学》的课程,那个才是权威的。 1、如何打开文件 这个东西打开之后界面是这样的: 我们打开一个文件:
要提的一点就是,SPSS保存的数据拓展名是.sav: 2、如何在SPSS中打开excel表 在上图的下拉箭头里找到excel这个选项: 然后你就能找到你要打开的excel表了。 3、数据视图界面 我现在打开了一个数据库。 可以看到左下角这个地方有两个框,两个是可以互相切换的,跟excel切换表一样,跟excel切换表一样: 现在的页面是数据视图,也就是说这一页都是原始数据,这里的一行就是一张问卷,一列就是一个问题,白框里的1234代表的是选项。这个表当时录数据的时候为了方便看,是把ABCD都转换成了1234,所以显示的是1234,当然直接录ABCD也可以,根据具体情况看怎么录,只要能看懂。 多选题的录入全部都是细化到每个选项,比如第四题,选项A选了就是“是”,没选就是
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.00 82 34.6 34.6 34.6 2.00 76 32.1 32.1 66.7 3.00 10 4.2 4.2 70.9 4.00 22 9.3 9.3 80.2 5.00 47 19.8 19.8 100.0 合计237 100.0 100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失 0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效 131 缺失 0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效 73 缺失 0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效 32 缺失 0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
第一章 SPSS10.0 for Windows简介 SPSS软件是由美国SPSS公司研制的。SPSS的全称为Statistical Program for Social Sciences,即“社会科学统计程序”。SPSS10.0 for Windows是在Windows操作系统下运行的社会科学统计软件包,该软件是国际上公认的最优秀的统计分析软件包之一。它在经济、工业、管理、心理、教育、医学等许多领域应用广泛,在科研工作中发挥了巨大的作用。SPSS 最初的版本是建立在D0S基础上的,但在80年代末,Microsoft推出Windows后,SPSS迅速向Windows移植。并不断推出SPSS软件的新版本。SPSS for Windows版本从6.0、7.0、8.0、9.0,至1999年底,正式推出SPSS10.0 for Windows版本。该版本相对于一些早期的版本而言,不仅改写了一些模块,使运行速度大大提高,而且根据统计理论与技术的发展,增加了许多新的统计分析方法,使之功能日趋完善。近年由推出11.0和12.0 版本,这两新版本主要提高运行速度和增加了一些新统计学方法,其余与10.0 版本基本相同。本书以10.0版本介绍SPSS for Windows的使用方法。 第一节 SPSS10.0 for Windows的特点 SPSS软件风靡世界并为各个领域的广大科研工作者及其他用户所钟爱,原因在于它有以下的特点; 1、多种实用分析力法。SPSS提供了多种分析方法,包括了从基本的统计特征描述到诸如非参数检验、生存分析等各种高层次的分析。除此之外,SPSS还具有强大的绘制图形、编辑图形的能力。 2、易于学习,易于使用。对于SPSS for Windows而言,除了数据输入工作要使用键盘之外,其他的大部分操作均可以通过“菜单”、“对话框”来完成,使用户不必记忆大量的命令,操作更简单。 3、文件易于转换。与其他软件有数据转换接口。 Excel文件、文本文件等均可以转换成相应的SPSS数据文件。 4、操作方法多种多样。不仅有灵活的菜单对话框式操作,而且用户也可以自已编写SPSS 语句来进行数据统计分析工作。 第二节 SPSSl0.0 for Windows对环境的要求 一、对硬件的要求 由于SPSS主要用途是面向大型数据库的,它的运算一般涉及的数据量比较多。故而用户一般需要有较大的内存,而且如果用户还要进行多因素分析、生存分析之类的大运算量的分析,计算机至少要有16M的内存。 二、对软件的要求 SPSS for W1ndows目前没有汉化版本。一般用户可以在以下环境中运行SPSS。 1、中文Windows95、Windows98、Windows me、Windows2000 SPSS for W1ndows在此环境下运行,对话框中的按钮功能能以中文显示。可以使用中文设置变量标签和值标签。在要点表中显示中文标签。打印的时候,只能把正排汉字正常打印,图形中被旋转了的汉字打印的结果是乱码。 2、英文Windows95、Windows98、Windows me、Windows2000加中文平台,以便定义和输出中文标签。
关于某地区361个人旅游情况统计分析报告 一、数据介绍: 本次分析的数据为某地区361个人旅游情况状况统计表,其中共包含七变量,分别是:年龄,为三类变量;性别,为二类变量(0代表女,1代表男);收入,为一类变量;旅游花费,为一类变量;通道,为二类变量(0代表没走通道,1代表走通道);旅游的积极性,为三类变量(0代表积极性差,1代表积极性一般,2代表积极性比较好,3代表积极性好 4代表积极性非常好);额外收入,一类变量。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析,以了解该地区上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分地区359个人旅游基本 状况的统计数据表,在性别、旅游的积极性不同的状况下的频数分析,从而了解该地区的男女职工数量、不同积极性情况的基本分布。 统计量 积极性性别 N 有效359 359 缺失0 0 首先,对该地区的男女性别分布进行频数分析,结果如下
性别 频率百分比有效百分 比 累积百分 比 有效女198 男161 合计359 表说明,在该地区被调查的359个人中,有198名女性,161名男性,男女比例分别为%和%,该公司职工男女数量差距不大,女性略多于男性。 其次对原有数据中的旅游的积极性进行频数分析,结果如下表: 积极性 频率百分比有效百分 比 累积百分 比 有效差171 一般79 比较 好 79 好24 非常 好 6 合计359 其次对原有数据中的积极性进行频数分析,结果如下表: 其次对原有数据中的是否进通道进行频数分析,结果如下表:
一、调查问卷 二、用SPSS Statistics软件进行描述统计分析 1、某地区经济增长率的时间序列图形。 解:第一步:数据来源,如图1 图 1 某地区经济增长率xls截图 图2 Spss软件制作过程截图 第二步:将数据输入SPSS软件之中,如图2,制作某地区经济增长率的时间序列图形,如图3。 图3某地区1990—2012年经济增长率的时间序列图 第三步,从图中可以看出,某地区随时间的变化经济增长率变化趋势较大。 2、用SPSS Statistics进行描述统计分析 解:第一步,按照题目中的要求,随机选取了148个数据,如图4部分数据:
图4 Spss随机数据截图 第二步,根据要求,对上月工资进行描述统计分析,主要包括描述数据的集中趋势、离散程度(见表1),绘制直方图(见图5)。 表1 上月工资描述统计表(单位:元) 集中趋势离散趋势 均值2925 极小值1500 中值2900 极大值4800 众数2900 全距3300 和432900 标准差496.364 偏度0.165 峰度 1.238 数据总计148 图5 上月工资直方图
第三步,分析数据的统计分布状况。 首先,从集中趋势来,上个月平均工资2925元,其中众数和中数也都在2900元,这说明大部分工资水平在2900左右。 其次,从离散趋势来看,最高工资4800元,最低工资1500元,最高工资和最低工资相差3300元,标准差为496.364,相差较大。 最后,从直方图来看和评述统计表来看,工资在2900元以上的占多数。可以的该地区整体工资水平大于平均值的占多数,该地区工资水平相对较高。 峰度为1.238,偏度为0.165符合正态分布。 三、用SPSS Statistics 软件进行参数估计和假设检验及回归分析 1、计算总体中上月平均工资95%的置信区间(见表3)。 解:总体中上月平均工资分布未知,但是样本容量大于30,且已知标准误,所以通过SPSS 分析得出总体中上月平均工资95%的置信区间,见表3, 假设; H0:总体中上月平均工资95%的不在此在此区间 H1:总体中上月平均工资95%的在此区间 答,总体中上月平均工资095的置信区间为[2844.37,3005.63],p=0.000<0.01,作出这样的推论正确的概率为0.95,错误的概率为0.05。 2、检验能否认为总体中上月平均工资等于2000元。 解:在本案例中,要检验样本中上月平均工资与总体中上月平均工资(为已知值:2000元)是否存在差异,即某一样本数据与某一确定均值进行比较。虽然不知道总体分布是否正态,但样本较大(N>30),可以运用单样本T 检验.通过SPSS 检验结果见(表4 、表5) 设; H o:2000=μ H 1:2000≠μ 其中,μ表示总体中上月平均工资 表4 单个样本统计量 表5 单个样本检验 t df Sig.(双侧) 均值差值 检验值 上月工资 22.671 147 0.000 925.000 2000 答:作出结论,均值差值为925,t=22.671,p=0.000<0.01,所以拒绝原假设,接受备择假设,即否认总体中上月的平均工资等于2000元。
S P S S操作步骤汇总 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
SPSS学习 第一章数据文件的建立 数据编码 Type:Numeric:数值型 string:字符串型 Missing: Measure:scale定量变量 nominal定性变量 根据已有的变量建立新变量 1、对于数据进行重新编码 Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue 2、通过SPSS函数建立新变量 Transform—compute variable –从function group中选择公式范围下面选择具体的公式—if 中设置要改变—continue—OK(可以对变量进行各种计算) 第二章清除数据与基本统计分析 1、对不合理的数据检查并清理 检查:analysis-description statistic-frequencies—选入要检查的数据—OK 结果:频数统计表—看是否有错误—missing system 清理: 1.对系统缺失值的清理
Data—select case—if condition is satisfied—if—function group(missing)--下面选 (missing)--continue—output(delete unselected cases)--OK—对num为哪一位的进行修改 2.对sex=3的清理(直接就清除了) Data—select case—if condition is satisfied—if—sex调入再输入=3—continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 2. 对相关变量间逻辑性检查和清理 Data—select case—if condition is satisfied—if—输入表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 3.统计描述 正态分布统计描述 1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/ 2、统计描述:Analysis—descriptives--time选入—options—ok 3、按照男女统计描述:data—split file –compare group –sex调入—ok Analysis-descriptive statistic – descriptive—time 调入—options选择—OK非正态分布资料统计描述 1、正态性检验nonparametric 2、Analysis—descriptive statistics—frequencies 选入-- statistics选择—OK 第三章T检验
统计软件应用第一次作业 金融102班1005010259 于闯一.现有1992年-2006年国家财政收入和国内生产总值的数据如下表所示,请研究国家财政收入和国内生产总值之间的线性关系。 1.根据数据并作出散点图可以得知1992年-2006年国家财政收入和国内生产总值两 个变量之间具有一元线性关系。我们利用SPSS软件作出散点图,步骤如下:依次选择菜单“图形→旧对话框→散点/点状→简单分布”,具体操作如图所示: 并将“国内生产总值”作为x轴,“财政收入”作为y轴,得到如下所示图形。
图一:散点图 可以看出两变量具有较强的线性关系,可以用一元线性回归来拟合两变量。 2.为了便于数据分析所以定义三个变量,分别为“year”(年份)、“x”(国内生产总值)、“y”(财政收入)。 3.选择菜单“分析→回归→线性”,打开“线性回归”对话框,将变量“财政收入”作为因变量,“国内生产总值”作为自变量。 4.打开“统计量”对话框,选上“估计”和“模型拟合度”。单击“绘制(T)…”按钮,打开“线性回归:图”对话框,选用DEPENDENT作为y轴,*ZPRED为x轴作图。并且选择“直方图”和“正态概率图”作相应的保存选项设置,如预测值、残差和距离等。
○1变量输入和移去表
表中显示回归模型编号、进入模型的变量、移出模型的变量和变量的筛选方法。可以看出,进入模型的自变量为“国内生产总值” ○2模型综述表 R=0.989,说明自变量与因变量之间的相关性很强。R方(R2) =0.979,说明自变量“国内生产总值”可以解释因变量“财政收入”的97.9%的差异性。 ○3方差分析表 表中显示因变量的方差来源、方差平方和、自由度、均方、F检验统计量的观测值和显著性水平。方差来源有回归、残差。从表中可以看出,F统计量的观测值为592.25,显著性概率为0.000,即检验假设“H0:回归系数B = 0”成立的概率为0.000,从而应拒绝原假设,说明因变量和自变量的线性关系是非常显著的,可建立线性模型。 ○4回归系数表 表中显示回归模型的常数项、非标准化的回归系数B值及其标准误差、标准化的回归系数值、统计量t值以及显著性水平(Sig.)。从表中可看出,回归模型的常数项为-4993.281,自变量“国内生产总值”的回归系数为0.197。因此,可以得出回归方程:财政收入=-4993.281 + 0.197 ×国内生产总值。 回归系数的显著性水平为0.000,明显小于0.05,故应拒绝T检验的原假设,这也说明了回
SPSS 中主成分分析的基本操作 Xiaowenzi22与pinksss 共同制作 阐述主成分分析法的原理 主成分分析是设法将原来众多具有一定相关性(比如P 个指标),重新组合成一组新的互相无关的综合指标来代替原来的指标。通常数学上的处理就是将原来P 个指标作线性组合,作为新的综合指标。最经典的做法就是用F 1(选取的第一个线性组合,即第一个综合指标)的方差来表达,即Var(F 1)越大,表示F 1包含的信息越多。因此在所有的线性组合中选取的F 1应该是方差最打的,故称F 1为第一主成分。如果第一主成分不足以代表原来P 个指标的信息,再考虑选取F 2即选第二个线性组合,为了有效地反映原来信息,F 1已有的信息就不需要再出现再F 2中,用数学语言表达就是要求Cov(F 1, F 2)=0,则称F 2为第二主成分,依此类推可以构造出第三、第四,……,第P 个主成分。 主成分模型: F 1=a 11X 11+a 21X 21+……+a p1X p F 2=a 12X 12+a 22X 22+……+a p2X p …… F p =a 1m X 11+a 2m X 22+……+a pm X p 其中a 1i, a 2i, ……,a pi (i=1,……,m)为X 的协差阵Σ的特征值多对应的特征向量,X 1, X 2, ……, X p 是原始变量经过标准化处理的值(因为在实际应用中,往往存在指标的量纲不同,所以在计算之前先消除量纲的影响,而将原始数据标准化)。 A=(ij a )m p ×=(,1α,2α…,m α),i i i R αλα=, R 为相关系数矩阵, i i αλ、是相应的特征值和单位特征向量, 1λ≥2λ≥…≥p λ≥0 上述方程组要求: 1、a 21i +a 22i +……+a 2pi =1 (i=1,……,m) 2、m I A A =′ (A=(ij a )m p ×=(,1α,2α…,m α),A 为正交矩阵) 3、Cov(F i ,F j )=ij i δλ, =01 ij δj i j i ≠= 操作步骤: 一、 数据标准化
Spss操作要点详细版 第一章导论——SPSS介绍 学习目标:初步认识SPSS软件的内容 一、SPSS界面说明 SPSS for Windows是SPSS/PC的Windows版本,具有Windows软件的共同特点,其界面十分友好,打开SPSS程序就会出现图1-2界面。 标题栏 菜单栏 工具栏 数据栏 标签 图1-2 SPSS 11.5 for Windows 界面 该界面为SPSS 的数据编辑窗口,其组成部分及主要功能如下: 1。标题栏:功能与其它Windows软件一致。 2.菜单栏:由10个菜单项组成,每个菜单包括一系列功能。各菜单的主要功能如下。 2.1 File:文件操作菜单。单击Fil e,有图1-3下拉菜单,主要功能包括:·New:新建数据编辑窗口、语句窗口、结果输出窗口等; ·Open和Open Database:打开数据编辑窗口、语句窗口、结果输出窗口等; ·Read Text Data:读入文本文件; ·Save和Save As:保存文件; ·Display Data Info:显示数据的基本信息; ·Prin t和Print Preview:将数据管理窗口中的数据以表格的形式打印出来。
图1-3 File菜单项的下拉菜单 图1-4 Edit菜单项的下拉菜单 2.2 Edit:文件编辑菜单。主要用于数据编辑,如图1-4,主要功能包括:·UndoRedo或modify cell values:撤消或恢复刚修改过的观测值; ·cut,copy,paste:剪切、拷贝、粘贴指定的数据; ·paste variables:粘贴指定的变量; ·clear:清除所选的观测值或变量; ·find:查找数据。 2.3 View:视图编辑菜单。用于视图编辑,进行窗口外观控制。包含显示/隐藏切换、表格特有的隐藏编辑/显示功能及字体设置等功能。 2.4 Data:数据文件建立与编辑菜单。主要用于变量和观测量的编辑和整理。如图1-5,主要功能包括: ·Define Variable Properties:定义变量属性; ·Copy Data Properties:复制数据文件属性; ·Insert Variable:插入变量; ·Insert Cases:插入变量或观测值; ·Sort Cases:按照某个变量值重新排列观测值在数据文件中的顺序; ·Transpose:把数据文件的行列进行转置; ·Restructure:数据重组; ·Aggregate:对数据进行分类汇总,即按指定的变量将观测值进行汇总,以求得每组
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表:
Educational Level (years)
上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别 和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。 Descriptive Ststistics
SPSS基本操作步骤详解 本文采用SPSS21.0版本,其它版本操作步骤大体相同 一、基本步骤 (一)检查数据 在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。 例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。 1.执行次数分布表的程序 Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定) 2.执行描述统计量的程序 Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定) (二)反项计分 若是分析的预试量表中没有反向题,则此操作步骤可以省略; 量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。 例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。 Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】 (三)题项加总 量表题项加总的目的在于便于进行观察值得高低分组。 例,“XX量表”采用Likert scale五点量表式填答,题项为:a1,a2……a10,记总分为:az。 Transform(转换)→Computer Variable(计算变量)→在左边Target Variable(目标变量)中键入az,在右边Numeric Expression(数字表达式)中键入a1+a2+……+a10
数据分析方法及软件应用 课程作业 学号:13125689 姓名:柏喜红 班级:1306 北京交通大学 2013年10月
第5题:方差分析(2) 分析思路 根据所给的表定义变量,进而进行数据录入。在进行单因素和多因素对销售量的影响分析的时候,应先提出相应的零假设,进而选择检验统计量,对检验统计量进行计算,并计算出概率P值,将计算出的概率P值与给定的显著性水平进行比较,做出相应的决策。 目标一:给出SPSS数据集格式 定义变量,进行数据录入。从题意以及所给的表中可以得出,这里有四个变量,分别为销售地点、销售方式、月份和销售量。其中,销售地点和销售方式为控制变量,月份为随机变量,销售量为观测变量,结合所给的表,进行数据的录入,录入四十个观测变量值。 图1 变量视图 图2 数据视图
目标二:分析销售地点对销售量的影响 (1)操作步骤 第一步:提出零假设。零假设H0是“销售地区对销售量没有产生显著影响”。 第二步:选择检验统计量,并计算检验统计量的观测值和概率P值。 选择菜单【分析——比较均值——单因素】 将销售量指定到【因变量列表(E)】中,将销售地区指定到【因子(F)】中,点击确定按钮,出现图3所示的结果。 图3单因素方差分析 销售量 平方和df 均方 F 显著性 组间254.600 4 63.650 1.107 .369 组内2013.000 35 57.514 总数2267.600 39 第三步:给定显著性水平α=0.05,根据表1,做出决策。 (2)结果分析 从图3中可以看出,观测变量销售量的总变差(2267.600)中“销售地区”可解释的变差为254.600,抽样误差引起的变差为2013.000,他们的方差为63.650和57.514,相除所得的F统计量为1.107,对应的概率P值接近于0.369。 (3)结论 因为显著性水平α=0.05,概率P值大于α,因而应接受原假设,认为不同的销售地区度销售量不产生显著影响。 目标三:分析销售地点、销售方式和他们的交互作用对对销售量的影响 (1)操作步骤 第一步:提出零假设。零假设H0是“销售地区对销售量没有产生显著影响,销售方式对销售量没有产生显著影响,销售地区和销售方式对销售量没有产生显著的交互影响。” 第二步:选择检验统计量,并计算检验统计量的观测值和概率P值。 选择菜单【分析——一般线性模型——单变量】; 将销售量指定到【因变量(D)】中,将销售地区和销售方式指定到【固定因子(F)】