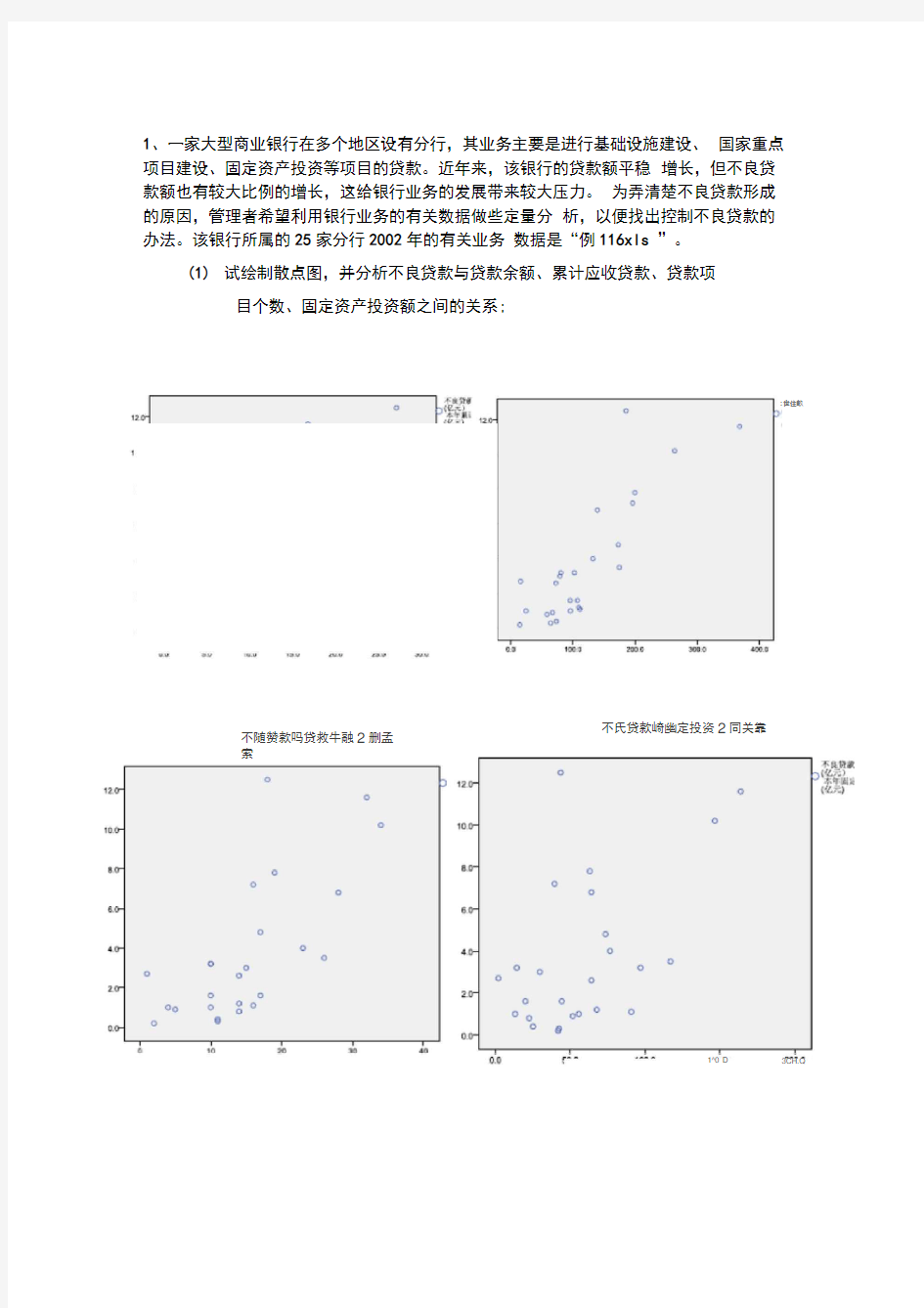
1、一家大型商业银行在多个地区设有分行,其业务主要是进行基础设施建设、国家重点项目建设、固定资产投资等项目的贷款。近年来,该银行的贷款额平稳增长,但不良贷款额也有较大比例的增长,这给银行业务的发展带来较大压力。为弄清楚不良贷款形成的原因,管理者希望利用银行业务的有关数据做些定量分析,以便找出控制不良贷款的办法。该银行所属的25家分行2002年的有关业务数据是“例116xls ”。
(1)试绘制散点图,并分析不良贷款与贷款余额、累计应收贷款、贷款项
目个数、固定资产投资额之间的关系;
:世住畝
不氏贷款崎幽定投资2同关靠
不随赞款吗贷救牛融2删孟
索
1^0 D3CH.Q
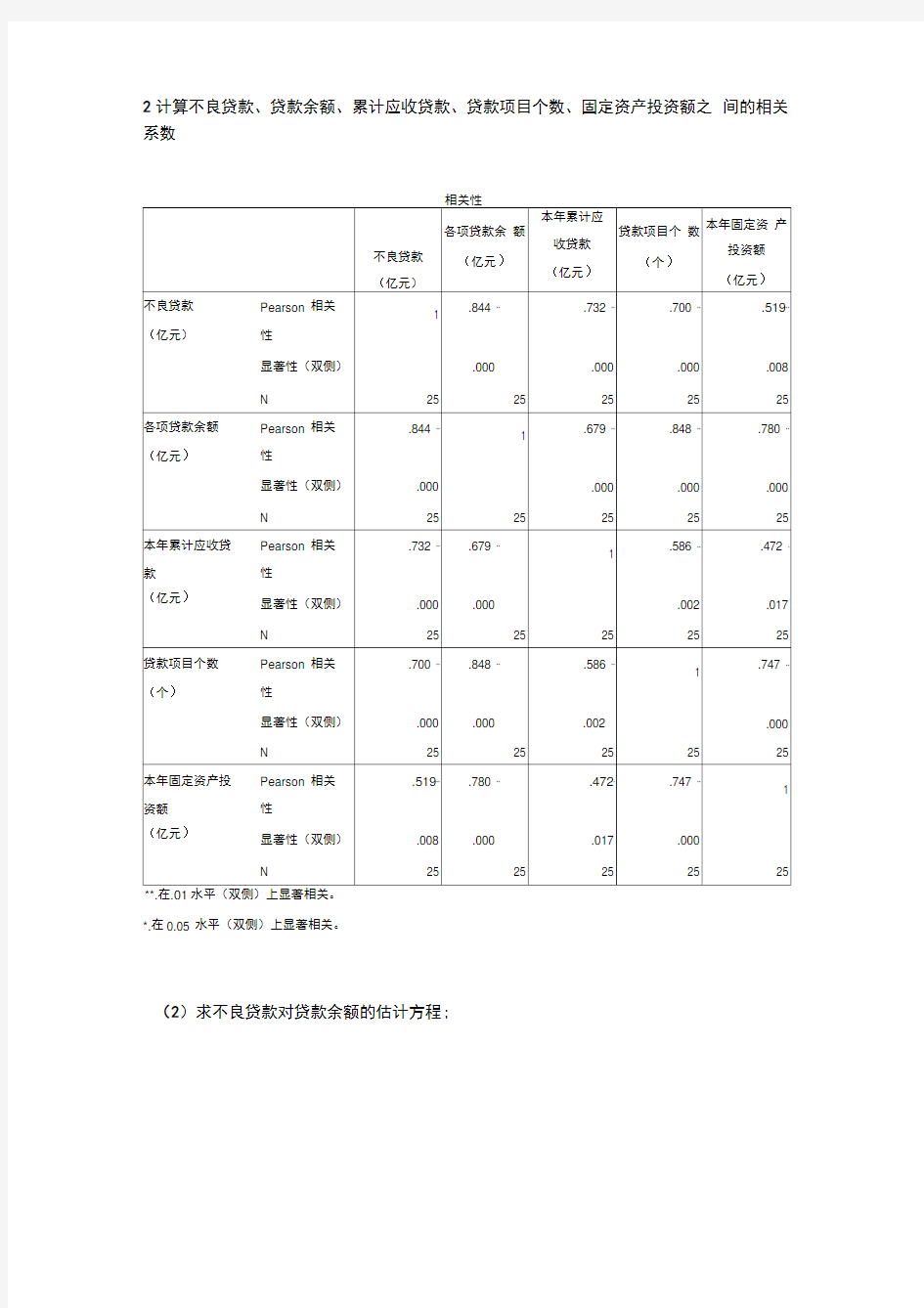
2计算不良贷款、贷款余额、累计应收贷款、贷款项目个数、固定资产投资额之间的相关系数
*.在0.05 水平(双侧)上显著相关。
(2)求不良贷款对贷款余额的估计方程;
b
a. 预测变量:(常量),本年固定资产投资额
(亿元),本年累计应收贷款
(亿元),贷款项目个数
(个),各项贷款余额
(亿元)。
b. 因变量:不良贷款
(亿元
a.预测变量常量),本年固定资产投资额
(亿元),本年累计应收贷款
(亿元),贷款项目个数
(个),各项贷款余额
(亿元)。
a.因变量不良贷款
(亿元)从表系数可以看出常量、应收贷款、项目个数、固定资产投资额,都接受原假设, 只有贷款余额拒绝原假设,所以只有贷款余额对不良贷款起作用。
a.因变量不良贷款
(亿元)
从共线性可以看出,第五个特征值对贷款余额解释87%,对应收账款解释度为12%、对贷款个数解释度为63%、对固定资产投资解释度为5%。
所以不是太共线。、
线性方程为丫=0.01X 丫为不良贷款,X为贷款余额。
4检验不良贷款与贷款余额之间线性关系的显著性(a=0.05 );回归系数的显著性(a=0.05);
模型
非标准化系数标准系数
t Sig.
共线性统计量
B 标准误差试用版容差VIF
1 (常量)-.830 .723 -1.147 .263
各项贷款余额
(亿元)
.038 .005 .844 7.534
.000 1.000 1.000
a.因变量不良贷款
(亿元)
共线性诊断a
模型维数特征值条件索引
方差比例
(常量)
各项贷款余额
(亿元)
1 1 1.837 1.000 .08 .08
2 .16
3 3.35
4 .92 .92
a.因变量不良贷款
(亿元)
通过对上表分析得出:贷款余额线性关系通过显著性检验,回归系数通过显著性检验。
5绘制不良贷款与贷款余额回归的残差图。
turn
Itt点图
2.练习《统计学》教材P330练习题11.1、11.6、11.7、11.8、11.15,对应的数据文件为“习题11.1.xls ”、“习题11.6.xls ”、“习题11.7.xls ”、“习题11.8.xls ”、“习题11.15.xls ”。(任选两题)
11.1
(1)绘制产量与生产费用之间的散点图,判断二者之间的关系形态.
产就M产费用2河的at点图
120-
100- M F-60=
40-
14
网站标稚化预计值
130 仙
正向相关
(2)计算产量与生产费用之间的线性相关系数
**.在
答:产量与生产费用之间的线性相关系数为0.92
(3)对相关系数的显著性进行检验,并说明二者间的关系强度
a.预测变量:(常量),生产费用(万元)。
答:二者的关系强度为92% P值较小拒绝原假设所以关系强
11.8
设月租金为自变量,出租率为因变量,回归并对结果进行解释和分析
进行分组,编制分配数列,计算出频率。 可用fx统计函数FREQUENCY进行统计分组 Ctrl+shift+enter 也可用“工具”菜单“数据分析”下的“直方图”进行统计分组 出现这个是经常的,最好的方法是上限-1 之后就是修饰,好这个表格弄的好看些。合计的频率42. 这个功能非常好用,反正我觉得是的,高级筛选经常会忘,而且失败率略高。在选择你要的条件就好了,之
后要你要的结果复制到一边就完成筛选了。保留下这个样子,让老师明白你是怎么做出来会 比较好。 抽样的那个,就不说了。 在细讲下,直方图 编制分配数列,计算各组次数和频率,以及累计次数和频率。 全距最大数-最小数(=max()-min()) 组数1+3.3*log(N) 组距全距/组数 上限-1依然是主要的 单击直方图,看到数据点格式直方图不是条形图,各矩形之间不应有间隔,所以需要调整。在“选项”栏中将“分类间隔”的数据设为0 再改改,弄好看些。
其他的制作也差不多,没那么难。 描述统计 把数据排一列或一行。在点击工具里面的数据分析 四分位差q1:QUARTILE(A1:A40,1) q3: =QUARTILE(A1:A40,3) (q3-q1)/2即可的7.25 移动平均法 在工具的数据分析里找咯3年移动平均 折线图是原数据来做的。最后把函数给修改一下咯yt = 74.67Ln(t) + 370.73
长期趋势值是前列两数的平均值,新数列是这一行y/T 这下面的数据是从新数列来的。
平均数是一列的平均数。总平均数就是平均数的平均数。季节指数就是平均数除以总平均数。Average(。。。。) 计算相关系数 利用函数法(统计函数) r (=CORREL(X,Y) a(=intercept(Y,X) b (=slope(Y,X)) r^2 可容易得到 利用工具里的数据分析,相关系数 可以得到 利用散点图来找函数趋势线,就可以找到a和b R^2 求回归系数在工具数据分析里找回归
统计学原理(第2版)_在线作业_4交卷时间:2017-06-0716:13:06 一、单选题 1. (5分) 当相关系数r=0时,表明变量之间()。 ? A.完全无关 ? B.无线性相关性 ? C.相关程度很小 ? D.完全相关 纠错 得分:5 知识点:8.1相关与回归分析的基本概念,统计学原理(第2版) 展开解析 答案B 解析 2. (5分)
? A.标准差系数 ? B.标准差 ? C.平均差 ? D.全距 纠错 得分:5 知识点:3.3分布离散程度的测度,统计学原理(第2版) 展开解析 答案A 解析 3. (5分) ? A.最大的变量值 ? B.最大的权数 ? C.处于分布数列中间位置的变量 ? D.最常见的数值 纠错 得分:5 知识点:3.1集中趋势指标概述,统计学原理(第2版) 在两个总体的平均数不等的情况下,比较它们的代表性大小,可以采用的标志变异指标是()。 在分布数列中,众数是()。
展开解析 答案D 解析 4. (5分) 在回归分析中,估计标准误差起着说明回归直线的代表性大小的作用:()。? A.估计标准误差大,回归直线代表性大,因而回归直线实用价值也小 ? B.估计标准误差小,回归直线代表性小,因而回归直线实用价值也小 ? C.估计标准误差大,回归直线代表性小,因而回归直线实用价值也小 ? D.估计标准误差大,回归直线代表性小,因而回归直线实用价值也大 纠错 得分:5 知识点:8.3一元线性回归分析,统计学原理(第2版) 展开解析 答案C 解析 5. (5分) 某连续型等差变量数列,其末组组限为500以上,又知其邻组组中值为480,则末组的组中值为()。
第二章统计学实验指导 实验一:统计整理与分组 实验目的: 运用excel进行常见数据类型的统计整理,能熟练运用菜单和各类函数进行数据筛选、排序,运用数据透视表绘制统计频数分布表。 实验要求: 独立完成课堂各类习题和练习,按要求完成实验内容。 实验形式: 教师演示、指导 实验内容: 1、品质数据分组:利用数据透视表直接绘制,但是需要注意排序数据 2、数值数据分组:对数据排序后,能分析选择数值数据的分组形式。 能利用数据透视表编制单项式分组统计次数数列; 熟练应用统计函数编制组距式分组统计次数分布数列。 一、统计数据的预处理 1、数据筛选:参见指导P37—39 (1)自动筛选: 将鼠标定位于数据文件的变量标题行; 点击菜单“数据”——筛选——自动筛选后,则在标题行出现下拉箭头; 在需要筛选的变量下点击下拉箭头,自行选择筛选功能(前10个,自定义),后确定。 自动筛选结果会自动从原数据区域中被选择出来显示,不符合条件的被屏蔽。 自动筛选一次只能执行一次筛选条件。 取消筛选:将数据“数据”——筛选——自动筛选再点击一次,去掉自动筛选前的“√”。(2)高级筛选: 选择空白区域创立筛选条件区域:筛选变量、筛选条件值 菜单“数据”——筛选——高级筛选后,进入高级筛选对话框;
筛选方式:通常是筛选结果另行放置,防止与原数据混淆。 列表区域:整个数据库区域,一般系统会自动选择。 条件区域:高级筛选可同时执行多个条件的综合筛选结果,选出符合条件的数据区域。 如果同时多个条件筛选,条件区域中将多个条件变量取值同行放置,表示“与”。 若至少满足多个条件之一,条件区域中将多个条件变量取值换行放置,表示“或”。 筛选文化程度为大学本科或岗位为管理员的员工则如此设置: 应用1:利用自动筛选选择男性员工; 利用高级筛选选择当前工资在3万元以上的工人; 利用高级筛选选择年龄在40岁以下或大学本科及以上的职工。 2、数据排序:参见指导P41 将鼠标定位于待分析数据区域的任意位置; 点击菜单“数据”——排序后,进入排序对话框; 排序对话框中: 主要关键字:排序变量。 次要关键字:各总体单位排序变量取值相同时,若指定次要关键字,则按此排序,否则按出现的先后顺序排。 我的数据区域:选择参与排序的数据区域。有标题行,则数据区域第一行不参与排序,一般数据区域首行为变量名时如此选择。否则,无标题行,数据从第一行第一列开始排序。 选项:指定升降序排列形式:次序、方向、方法,用于字符型数据的排序设置。 应用2:对加工零件数按照一定大小进行排序; 对售后服务质量按照一定优劣进行排序。 二、统计分组 统计整理及分析结果的编写通常在word 文档中录入和编辑,只要能用excel 生成相 对规范的统计表和统计图,然后可以复制到word 中进行美化排版即可。 管理员
首页- 我的作业列表- 《应用统计学》第一次作业答案 你的得分:100.0 完成日期:2014年02月22日16点23分 说明:每道小题括号里的答案是您最高分那次所选的答案,标准答案将在本次作业结束(即2014年03月13日)后显示在题目旁边。 一、单项选择题。本大题共20个小题,每小题 4.0 分,共80.0分。在每小题给出的选项中,只有一项是符合题目要求的。 1. 要了解某企业职工的文化水平情况,则总体单位是()。 ( B ) A.该企业的全部职工 B.该企业每一个职工的文化程度 C.该企业的每一个职工 D.该企业全部职工的平均文化程度 2.属于品质标志的是() ( C ) A.变量 B.指标 C.标志 D.变异 3.从标志角度看,变量是指() ( A ) A.可变的数量标志 B.可变的数量标志值 C.可变的品质标志 D.可变的属性标志值 4. 某工人月工资150元,则“工资”是() ( A ) A.数量标志 B.品质标志 C.质量标志 D.数量指标 5.标志与指标的区别之一是()
( A ) A.标志是说明总体特征的;指标是说明总体单位的特征 B.指标是说明总体特征的;标志是说明总体单位的特征。 C.指标是说明有限总体特征的;标志是说明无限总体特征的。 D.指标是说明无限总体特征的;标志是说明有限总体特征的。 6.乡镇企业局为总结推广先进生产管理经验,选择几个先进乡镇企业进行调查,这种 调查属于()。 ( B ) A.抽样调查 B.典型调查 C.重点调查 D.普查 7.下列各项中属于全面调查的是()。 ( D ) A.抽样调查 B.重点调查 C.典型调查 D.快速普查 8.人口普查规定统一的时间是为了()。 ( A ) A.避免登记的重复和遗漏 B.具体确定调查单位 C.确定调查对象的范围 D.为了统一调查时间,一起行动 9.调查鞍钢、武钢、宝钢等十几个大型钢铁公司就可以了解我国钢铁生产的基本情况。 这种调查方式是()。 ( B ) A.典型调查 B.重点调查 C.抽样调查 D.普查 10.全面调查与非全面调查的划分依据是()。 ( C ) A.调查的组织方式不同
统计学数学实验报告 单因素方差分析 姓名 专业 学号
单因素方差分析 摘要统计学是关于数据的科学,它所提供的是一套有关数据收集、处理、分析、解释数据并从数据中得出结论的方法,统计研究的是来自各个领域的数据。单因素方差分析也是统计学分析的一种。单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响。关键字单因素、方差、数据统计 方差分析(analysis of variance,ANOVA)就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。当方差分析中之涉及一个分类型自变量时称为单因素方差分析(one-way analysis of variance). 单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响。例如要检验汽车市场销售汽车时汽车颜色对销售数据的影响,这里只涉及汽车颜色一个因素,因而属于单因素方差分析。 为了更好的理解单因素方差分析,下面举个例子来具体说明单因素方差所要解决的问题。从3个总体中各抽取容量不同的样本数据,结果如下表1所示。检验3个总体的均值之间是否有显著差异(α=0.01)P29210.1 样本1 样本2 样本3 158 153 169 148 142 158 161 156 180 154 149 169 如果要进行单因素方差分析时,就需要得到一些相关的数据结构,从而对那些数据结构进行分析,如下表2所示: 分析步骤 1.提出假设 与通常的统计推断问题一样,方差分析的任务也是先根据实际情况提出原假设H0与备择假设H1,然后寻找适当的检验统计量进行假设检验。本节将借用上面的实例来讨论单因素试验的方差分析问题。
1、一家大型商业银行在多个地区设有分行,其业务主要是进行基础设施建设、国家重点项目建设、固定资产投资等项目的贷款。近年来,该银行的贷款额平稳增长,但不良贷款额也有较大比例的增长,这给银行业务的发展带来较大压力。为弄清楚不良贷款形成的原因,管理者希望利用银行业务的有关数据做些定量分析,以便找出控制不良贷款的办法。该银行所属的25家分行2002年的有关业务数据是“例11.6.xls”。 (1)试绘制散点图,并分析不良贷款与贷款余额、累计应收贷款、贷款项目个数、固定资产投资额之间的关系;
2计算不良贷款、贷款余额、累计应收贷款、贷款项目个数、固定资产投资额之间的相关系数 (2)求不良贷款对贷款余额的估计方程;
从表系数可以看出常量、应收贷款、项目个数、固定资产投资额,都接受原假设,只有贷款余额拒绝原假设,所以只有贷款余额对不良贷款起作用。 从共线性可以看出,第五个特征值对贷款余额解释87%,对应收账款解释度为12%、对贷款个数解释度为63%、对固定资产投资解释度为5%。 所以不是太共线。、 线性方程为Y=0.01X Y为不良贷款,X为贷款余额。
4 检验不良贷款与贷款余额之间线性关系的显著性(α=0.05);回归系数的显著性(α=0.05); 共线性诊断a 模型维数特征值条件索引 方差比例 (常量) 各项贷款余额 (亿元) 1 1 1.837 1.000 .08 .08 2 .16 3 3.35 4 .92 .92 a. 因变量: 不良贷款 (亿元) 通过对上表分析得出:贷款余额线性关系通过显著性检验,回归系数通过显著性检验。 5绘制不良贷款与贷款余 额回归的残差图。
您得得分: 100、0 完成日期:2019年07月28日14点47分 说明:每道小题选项旁得标识就是标准答案。 一、单项选择题。本大题共20个小题,每小题2、5 分,共50、0分。在每小题给出得选项中,只有一项就是符合题目要求得。 1.一个研究者应用有关车祸得统计数据估计在车祸中死亡得人数,在这个例子中使用得统计属于( )。 A.推断统计学 B.描述统计学 C.既就是描述统计学,又就是推断统计学 D.既不就是描述统计学,有不就是推断统计学 2.某研究部门准备在全市200万个家庭中抽取2000个家庭,推断该城市所有职工家庭得年人均收入。这项研 究得总体就是( )。 A.2000个家庭 B.200万个家庭 C.2000个家庭得年人均收入 D.200万个家庭得总收入 3.对某地区5000个企业得企业注册类型、产值与利润总额等调查数据进行分析,下列说法中正确得就是( )。 A.企业注册类型就是定序变量 B.利润总额就是品质标志 C.产值就是定类变量 D.产值与利润总额都就是连续变量 4.为了了解居民对小区物业服务得意见与瞧法,管理人员随机抽取了50户居民,上门通过问卷进行调查。这种 数据收集方法称为( )。 A.面访式问卷调查 B.实验调查 C.观察式调查 D.自填式问卷调查 5.对同一总体选择两个或两个以上标志重叠起来进行分组,称为( )。 A.简单分组 B.平行分组 C.一次性分组 D.复合分组 6.统计表得横行标题表明( )。 A.全部统计资料得内容 B.研究总体及其组成部分 C.总体特征得统计指标得名称 D.现象得具体数值 7.下列指标属于比例相对指标得就是( )。 A.2000年北京市失业人员再就业率为73% B.三项社会保险统筹基金收缴率95% C.北京人口性别比为103 D.北京每百户居民拥有电脑32台 8.一组数据排序后处于25%与75%得位置上得值称为( )。 A.众数 B.中位数 C.四分位数 D.算术平均数
统计学实验心得体会分享 在两天的统计学实验学习中,加深了对统计数据知识的理解和掌握,同时也对Excel操作软件的应用,统计学实验心得体会。下面是我这次实验的一些心得和体会。 统计学(statistics)一门收集,整理,显示和分析统计数据的科学,目的是探索数据内在的数量规律性。从定义中不难看出,统计学是一门针对数据而展开探求的科学。在实验中,对数据的筛选和处理就成为了比较重要的内容和要求了。同时对数据的分析也离不开相关软件的支持。因此,Eexcel软件的安装与运行则变成了首要任务。 实验过程中,对Excel软件的安装因要求具体而变的相对简单。虽然大多数计算机都已内存此软件,但在实验中通过具体的操作亦可以提高自己的计算机操作水平。接下来的重头戏就是对统计数据的输入与分析了。按Excel对输入数据的要求将数据正确输入的过程并不轻松,既要细心又要用心。不仅仅是仔细的输入一组数据就可以,还要考虑到整个数据模型的要求,合理而正确的分配和输入数据。因此,输入正确的数据也就成为了整个统计实验的基矗。 数据的输入固然重要,但如果没有分析的数据则是一点意义都没有。因此,统计数据的描述与分析也就成了关键的关键。对统计数据的众数,中位数,均值的描述可以让我们对其有一个初步的印象和大体的了解,在此基础上的概率分
析,抽样分析,方差分析,回归问题以及时间序列分析等则更具体和深刻的向我们揭示了统计数据的内在规律性。在对数据进行描述和分析的过程中,Excel软件的数据处理功能得到了极大的发挥,工具栏中的工具和数据功能对数据的处理是问题解决起来是事半功倍。 通过实验过程的进行,对统计学的有关知识点的复习也与之同步。在将课本知识与实验过程相结合的过程中,实验步骤的操作也变的得心应手。也给了我们一个启发,在实验前应该先将所涉内容梳理一遍,带着问题和知识点去做实验可以让我们的实验过程不在那么枯燥无谓。同时在实验的同步中亦可以反馈自己的知识薄弱环节,实现自己的全面提高。 本次实验是我大学生活中不可或缺的重要经历,其收获和意义可见一斑。首先,我可以将自己所学的知识应用于实践中,理论和实际是不可分的,在实践中我的知识得到了巩固,解决问题的能力也受到了锻炼;其次,本次实验开阔了我的视野,使我对统计在现实中的运作有所了解,也对统计也有了进一步的掌握。 在实验过程中还有些其它方面也让我学到了很多东西,知道统计工作是一项具有创造性的活动,要出一流成果,就必须要有专业的统计人才和认真严肃的工作态度。在实践的校对工作中,知道一丝不苟的真正内涵。 通过本次实验,不仅仅是掌握操作步骤完成实验任务而
统计学实验报告1 -标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII
实验报告
二、打开文件“数据 3.XLS”中“城市住房状况评价”工作表,完成以下操作。 1)通过函数,计算出各频率以及向上累计次数和向下累计次数;2)根据两城市频数分布数据,绘制出两城市满意度评价的环形图三、打开文件“数据 3.XLS”中“期末统计成绩”工作表,完成以下操作。 1)要求根据数据绘制出雷达图,比较两个班考试成绩的相似情况。 实验过程: 实验任务一: 1)利用函数frequency制作一张频数分布表 步骤1:打开文件“数据 3. XLS”中“某公司4个月电脑销售情况”工作表 步骤 2.在“频率(%)”的右侧加入一列“分组上限”,因统计分组采用“上限不在内”,故每组数据的上限都比真正的上限值小0.1,例如:“140-150”该组的上限实际值应为“150”,但我们为了计算接下来的频数取“149.9”. 步骤3.选定C20:C29,再选择“插入函数”按钮 3 步骤 4.选择类别“统计”—选择函数“FREQUENCY”
步骤5.在“data_array”对话框中输入“A2:I13”,在“bins_array”对话框中输入“E20:E29 该函数的第一个参数指定用于编制分布数列的原始数据,第二个参数指定每一组的上限. 步骤6.选定C20:C30区域,再按“自动求和” 按钮,即可得到频数的合计
步骤7.在D20中输入“=(C20/$C$30)*1OO” 步骤8:再将该公式复制到D21:D29中,并按“自动求和”按钮计算得出所有频率的合计。
统计学基础第一次作业 一、填空题 1、按照所采用的计量尺度不同,可以将统计数据分为_分类数据_、_顺序数据_和_数值型 数据_。 2、按照数据的收集方法的不同,可将统计数据分为_观测数据_和__实验数据_。 3、按照被描述的对象与时间的关系,可将统计数据分为_截面数据__和_时间序列数 4、体重的数据类型是:clear all。 5、民族的数据类型是:CHAR。 6、空调销量的数据类型是:电器。 7、支付方式(购买商品)的数据类型是:分类变量。 8、学生对教学改革的态度(赞同、中立、反对)的数据类型是:顺序数据。 9、从总体中抽出的一部分元素的集合,称为___样本_____。 10、参数是用来描述_总体特征_______的概括性数字度量;而用来描述样本特征的概括 性数字度量,称为___统计量_____。 11、参数是用来描述_总体特征_的概括性数字度量;而用来描述样本特征的概括性数字 度量,称为_统计量_。 12、统计数据有两种不同来源:一是_直接来源__,二是__间接来源___。 13、统计数据的误差有两种类型,即__抽样误差_和_非抽样误差。 14、统计表由_数据__、__表头__、___行标题_和__列标题__四个部分组成。 15、统计分组应遵循“不____重_____不__漏_______”、“___上限______不在组内”的 原则。 16、按取值的不同,数值型变量可分为_离散型变量__和_连续型变量_。 17、在数据分组中,_离散型变量_______可以进行单变量值分组,也可以进行组距分组, 而___连续型变量_____只能进行组距式分组。 18、组距分组中,向上累积频数是指某组_上限以下_的频数之和。 19、将某地区100个工厂按产值多少分组而编制的频数分布中,频数是_各组的工厂数 __。 20、频数分布中,靠近中间的变量值分布的频数少,靠近两端的变量值分布频数多,这
统计学原理(第2版)_在线作业_2 交卷时间:2017-10-29 19:20:33 一、单选题 1. (5分) 若商品零售价格增长2%,商品销售量增长5%,则商品零售额增长(?)。 ?A.?3% ?B.?7% ?C.?% ?D.?0% 得分:?5 知识点:? 指数体系,统计学原理(第2版) 2. (5分) 在依据概率方面,?区间估计与假设检验的关系表现在(?)。 ?A.?二者都立足于小概率 ?B.?二者都立足于大概率 ?C.?前者立足于小概率,后者立足于大概率
?D.?前者立足于大概率,后者立足于小概率 得分:?5 知识点:? 抽样估计的基本方法,统计学原理(第2版),统计学原理 3. (5分) 统计量是根据(?)计算出来的。 ?A.?分类数据 ?B.?顺序数据 ?C.?样本数据 ?D.?总体数据 得分:?5 知识点:? 数据的计量与类型,统计学原理(第2版) 4. (5分) 若销售额指数上升,销售价格指数降低,销售量指数为(?)。 ?A.?不变 ?B.?降低
?C.?增长 ?D.?零 得分:?5 知识点:? 指数体系,统计学原理(第2版) 5. (5分) 为了研究包装方式对产品销售量的影响,将包装方式定为三种,则称这种方差分析为(?)。 ?A.?单因素三水平方差分析 ?B.?双因素方差分析 ?C.?三因素方差分析 ?D.?单因素方差分析 得分:?5 知识点:? 单因素方差分析,统计学原理(第2版) 6. (5分)
用综合指数法编制总指数的关键问题之一是(?)。 ?A.?确定比较对象 ?B.?确定对比基期 ?C.?确定个体指数 ?D.?确定同度量因素及其固定时期 得分:?5 知识点:? 综合指数,统计学原理(第2版) 7. (5分) 已知总体平均数为100,变异系数为30%,则方差为(?)。 ?A.?900 ?B.?30 ?C.?300 ?D.?90 得分:?5 知识点:? 分布离散程度的测度,统计学原理(第2版)8.
统计学实验报告 一.实验步骤总结数据的搜集与整理 一.数据的搜集 ●间接数据的搜集 方法一:直接通过进入专业的数据库网站查询数据 方法二:使用搜索引擎进行数据的搜索 ●直接数据的搜集 抽样调查: 1.调查方案设计 2.调查问卷设计 3.问卷发放 4.问卷回收 二.数据的整理 ●数据编码 1.在Excel中选择三列,将三列分别命名,后两列为:编码符号、代表含义 2.数据搜集好后,按照他们的特征进行分类,并依次放入第一列 3.在“编码符号”列为每一个列别编码,并在“代表含义”列说明编码的含义 ●数据的录入 转置(行与列换位): 1.激活数据所在单元格 2.单击鼠标右键,选中“复制” 3.在空白处激活另一单元格,点击鼠标右键,选中“选择性粘贴”项。 4.在弹出的“选择性粘贴”对话框中,粘贴项选中“全部”,运算选中“无”,选中“转置” 复选框,点击确定按钮既得转置的结果。 单元格内部换行:“Alt+Enter”组合键 ●数据的导入 方法一:1.单击菜单栏“文件—打开”,在弹出的的“打开”对话框中找到要导入的文件。 2.双击鼠标左键或者单击打开按钮,所需要的文件就被导入了。 方法二:1.单击菜单栏“数据—导入外部数据—导入数据”,在弹出的“选取数据源”的对话框中找到要导入的文件。 2.双击鼠标左键或者单击打开按钮,所需要的文件就被导入了。 ●数据的筛选 自动筛选: 1.选中要筛选的数据区域 2.使用菜单栏中的“数据—筛选—自动筛选”,这时每列的第一个单元格的右边都会出现 一个下拉箭头,我们就可以通过下拉菜单中的选择实现筛选。 3.如果选择了下拉菜单中的“自定义”,就会弹出一个“自定义自动筛选方式”对话框, 在对话框中可自己选择筛选条件,然后点击确定按钮。 高级筛选: 1. 将要筛选数据区域的列标题复制粘贴在空白区域,并在他们对应下的单元格中输入所要
首页-我的作业列表- 欢迎你, 你的得分:94.0 完成日期: 2018年06月12日09点20分 说明:每道小题选项旁的标识是标准答 一、单项选择题。本大题共20个小题,每小题4.0分,共80.0分。在每小题给出的选项中,只有一项是符合题目要求的。 1. 要了解某企业职工的文化水平情况,则总体单位是() A. 该企业的全部职工 B. 该企业每一个职工的文化程度 C. 该企业的每一个职工 D. 该企业全部职工的平均文化程度 2. 属于品质标志的是() A. 变量 B. 指标 C. 标志 D.变异 3. 从标志角度看,变量是指() A. 可变的数量标志 B. 可变的数量标志值 C. 可变的品质标志 D. 可变的属性标志值 4. 某工人月工资150元,则“工资”是() A. 数量标志 B. 品质标志 C. 质量标志 《应用统计学》第一次作业答案
5. 标志与指标的区别之一是() A. 标志是说明总体特征的;指标是说明总体单位的特征 B. 指标是说明总体特征的;标志是说明总体单位的特征。 C. 指标是说明有限总体特征的;标志是说明无限总体特征 的。 D. 指标是说明无限总体特征的;标志是说明有限总体特征 的。 6. 乡镇企业局为总结推广先进生产管理经验,选择几个先进乡镇企业进行调查,这种调查属于 ()。 A. 抽样调查 B. 典型调查 C. 重点调查 D. 普查 7. 下列各项中属于全面调查的是() A. 抽样调查 B. 重点调查 C. 典型调查 D. 快速普查 8. 人口普查规定统一的时间是为了() A. 避免登记的重复和遗漏 B. 具体确定调查单位 C. 确定调查对象的范围 D. 为了统一调查时间,一起行动 9. 调查鞍钢、武钢、宝钢等十几个大型钢铁公司就可以了解我国钢铁生产的基本情况。这种调 查方式是()。 A. 典型调查 B. 重点调查 C. 抽样调查
福师《统计学》在线作业二15秋满分答案 一、单选题(共 35 道试题,共 70 分。) 1. 统计报表制度采用的是()为主要特征的调查方法。 A. 随机形式 B. 报告形式 C. 抽样形式 D. 审核形式 ——————选择:B 2. 对于经常性的人口总量及构成情况进行的调查,适宜采用()。 A. 典型调查 大众理财作业满分答案 B. 重点调查 C. 抽样调查 D. 普查 ——————选择:C 3. 抽样调查的主要目的是()。 A. 广泛运用数学的方法 B. 计算和控制抽样误差 C. 修正普查的资料 D. 用样本指标来推算总体指标 ——————选择:D 4. 若销售量增长5%,零售价格增长2%,则商品销售额增长()。 A. 7% B. 10% C. 7.1% D. 15% ——————选择:C 5. 统计分布数列()。 A. 都是变量数列 B. 都是品质数列 C. 是变量数列或品质数列 D. 是统计分组 ——————选择:C 6. 某省2000年预算内工业企业亏损面达46.3%,这是()。 A. 总量指标 B. 时点指标 C. 时期指标 D. 强度相对指标 E. 平均指标 ——————选择:D 7. 某省2000年1—3月新批94个利用外资项目,这是()。 A. 时点指标 B. 时期指标
C. 动态相对指标 D. 比较相对指标 E. 平均指标 ——————选择:B 8. 将现象按照品质标志分组时,就形成()。 A. 数量数列 B. 品质数列 C. 变量数列 D. 平均数列 ——————选择:B 9. 在是非标志总体中,具有某种标志表现的单位数所占的成数与不具有某种标志表现的单位数所占的成数关系为()。 A. 和为1 B. 差为-1 C. 差为0 D. 不确定 ——————选择:A 10. 统计认识的对象为()。 A. 个体 B. 客体 C. 总体单位 D. 总体 ——————选择:D 11. 总体与总体单位不是固定不变的,是指()。 A. 随着客观情况的发展,各个总体所包含的总体单位数也在变动 B. 随着人们对客观认识的不同,对总体与总体单位的认识也是有差异的 C. 随着统计研究目的与任务的不同,总体和总体单位可以变换位置 D. 客观上存在的不同总体和总体单位之间总是存在着差异 ——————选择:C 12. 采用两个或两个以上标志对社会经济现象总体分组的统计方法是()。 A. 品质标志分组 B. 复合标志分组 C. 混合标志分组 D. 数量标志分组 ——————选择:B 13. 在国营工业企业设备普查中,每一个国营工业企业是()。 A. 调查对象 B. 调查单位 C. 填报单位 D. 调查项目 ——————选择:B 14. 某种材料上月末库存量和本月末库存量两个指标()。 A. 都是时期指标 B. 都是时点指标
你的得分:68.0 完成日期:2013年01月10日14点52分 说明:每道小题括号里的答案是您最高分那次所选的答案,标准答案将在本次作业结束(即2013年03月14日)后显示在题目旁边。 一、单项选择题。本大题共20个小题,每小题4.0 分,共80.0分。在每小题给出的选项中,只有一项是符合题目要求的。 1. 要了解某企业职工的文化水平情况,则总体单位是()。 ( B ) A.该企业的全部职工 B.该企业每一个职工的文化程度 C.该企业的每一个职工 D.该企业全部职工的平均文化程度 2.属于品质标志的是() ( C ) A.变量 B.指标 C.标志 D.变异 3.从标志角度看,变量是指() ( A ) A.可变的数量标志 B.可变的数量标志值 C.可变的品质标志 D.可变的属性标志值 4. 某工人月工资150元,则“工资”是() ( B ) A.数量标志 B.品质标志 C.质量标志 D.数量指标 5.标志与指标的区别之一是() ( A ) A.标志是说明总体特征的;指标是说明总体单位的特征 B.指标是说明总体特征的;标志是说明总体单位的特征。 C.指标是说明有限总体特征的;标志是说明无限总体特征的。 D.指标是说明无限总体特征的;标志是说明有限总体特征的。 6.乡镇企业局为总结推广先进生产管理经验,选择几个先进乡镇企业进行调查,这种 调查属于()。 ( B ) A.抽样调查 B.典型调查 C.重点调查
D.普查 7.下列各项中属于全面调查的是()。 ( D ) A.抽样调查 B.重点调查 C.典型调查 D.快速普查 8.人口普查规定统一的时间是为了()。 ( C ) A.避免登记的重复和遗漏 B.具体确定调查单位 C.确定调查对象的范围 D.为了统一调查时间,一起行动 9.调查鞍钢、武钢、宝钢等十几个大型钢铁公司就可以了解我国钢铁生产的基本情况。 这种调查方式是()。 ( B ) A.典型调查 B.重点调查 C.抽样调查 D.普查 10.全面调查与非全面调查的划分依据是()。 ( C ) A.调查的组织方式不同 B.搜集资料的方法不同 C.调查对象包括的范围不同 D.调查时间不同 11.在国有工业企业设备普查中,每一个国有工业企业是()。 ( D ) A.调查对象 B.调查单位 C.填报单位 D.调查项目 12.将统计总体按照一定标志区分为若干个组成部分的统计方法是()。 ( D ) A.统计整理 B.统计分析 C.统计调查 D.统计分组 13.统计分配数列()。 ( C ) A.都是变量数列 B.都是品质数列 C.是变量数列或品质数列 D.是统计数列
[标签:标题] 篇一:统计学实验心得体会 统计学实验心得体会 为期半个学期的统计学实验就要结束了,这段以来我们主要通过excl软件对一些数据进行处理,比如抽样分析,方差分析等。经过这段时间的学习我学到了很多,掌握了很多应用软件方面的知识,真正地学与实践相结合,加深知识掌握的同时也锻炼了操作能力,回顾整个学习过程我也有很多体会。 统计学是比较难的一个学科,作为工商专业的一名学生,统计学对于我们又是相当的重要。因此,每次实验课我都坚持按时到实验室,试验期间认真听老师讲解,看老师操作,然后自己独立操作数遍,不懂的问题会请教老师和同学,有时也跟同学商量找到更好的解决方法。几次实验课下来,我感觉我的能力确实提高了不少。统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析、总结,并进而进行推断和预测,为相关决策提供依据和参考。它被广泛的应用在各门学科之上,从物理和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。可见统计学的重要性,认真学习显得相当必要,为以后进入社会有更好的竞争力,也为多掌握一门学科,对自己对社会都有好处。 几次的实验课,我每次都有不一样的体会。个人是理科出来的,对这种数理类的课程本来就很感兴趣,经过书本知识的学习和实验的实践操作更加加深了我的兴趣。每次做实验后回来,我还会不定时再独立操作几次为了不忘记操作方法,这样做可以加深我的记忆。根据记忆曲线的理论,学而时习之才能保证对知识和技能的真正以及掌握更久的掌握。就拿最近一次实验来说吧,我们做的是“平均发展速度”的问题,这是个比较容易的问题,但是放到软件上进行操作就会变得麻烦,书本上只是直接给我们列出了公式,但是对于其中的原理和意义我了解的还不够多,在做实验的时候难免会有很多问题。不奇怪的是这次试验好多人也都是不明白,操作不好,不像以前几次试验老师讲完我们就差不多掌握了,但是这次似乎遇到了大麻烦,因为内容比较多又是一些没接触过的东西。我个人感觉最有挑战性也最有意思的就是编辑公式,这个东西必须认真听认真看,稍微走神就会什么都不知道,很显然刚开始我是遇到了麻烦。还好在老师的再次讲解下我终于大致明白了。回到寝室立马独自专研了好久,到现在才算没什么问题了。 实验的时间是有限的,对于一个文科专业来说,能有操作的机会不是很多,而真正利用好这些难得的机会,对我们的大学生涯有很大意义。不仅是学习上,能掌握具体的应用方法,我感觉更大的意义是对以后人生路的作用。我们每天都在学习理论,久而久之就会变成书呆子,问什么都知道,但是要求做一次就傻了眼。这肯定是教育制度的问题和学校的设施问题,但是如果我们能利用好很少的机会去锻炼自己,得到的好处会大于他自身的价值很多倍。例如在实验过程中如果我们要做出好的结果,就必须要有专业的统计人才和认真严肃的工作态度。这就在我们的实践工作中,不知觉中知道一丝不苟的真正内涵。以后的工作学习我们再把这些应用于工作学习,肯定会很少被挫 折和浮躁打败,因为统计的实验已经告知我们只有专心致志方能做出好的结果,方能正确的做好一件事。 最后感谢老师的耐心指导,教会我们知识也教会我们操作,老师总是最无私最和蔼的人,我一定努力学习,用自己最大的努力去回报。 篇二:统计学实验报告与总结
应用统计学 一、单选题共 1某商场2007与2006年相比,商品销售额上涨了16%,销售量增长了18%,则销售价格增减变动的百分比为( )。 B-1.7% 2某公司所属两个分厂,今年与去年相比,由于两个分厂单位新产品成本降低而使公司的总平均成本下降了5%,由于新产品结构的变化使公司总平均成本提高了10%,该公司总平均成本增减变动的百分比为()。 D4.5% 3某企业的产品产量.产品库存量()。 D当前是时期数,后者是时点 4变量X与Y之间的负相关是指()。 C大的X值趋于同小的Y值相关联,小的X值趋于同大的Y值相关联 5物价上涨后,同样多的人民币只能购买原有商品的90%,则物价指数为( )。 B1.11% 6已知从总体中抽取一个容量为10的样本,样本均值的方差等于55,则总体方差等于()。B550 7用趋势剔除法测定季节变动时,()。 A不包括长期趋势的影响 8某企业计划规定单位成本降低8%,实际降低了5%,则成本计划完成程度为()。 C62.5% 9我国1949年末总人口为54167万人,1989年末为111191万人,计算1949-1989年人口平均增长速度开( )次方。 A40 10抽样调查与典型调查的主要区别是()。 C选取调查单位的方法不同 11对几个特大型商场进行调查,借以了解北京市商业市场商品销售的基本情况。这种调查方式属于()。 B重点调查 12设产品产量与产品单位成本之间的简单相关系数为-0.78,这说明二者之间存在着( )。 B中度相关
13下列数据属于结构相对数的是()。 B工业产值占工农业总产值的比重 14某种商品的价格今年比去年上涨了5%,销售额下降了10%,该商品销售量下降的百分比为( ) 。 B14.29% 15某百货公司今年与去年相比,商品销售量增长了10%,零售价格平均下降了10%,则商品零售额()。 C下降 16某企业产品产量比上年提高了10% ,总成本下降了5% ,则单位成本降低了()。 C13.64% 17把综合指数变为加权平均数指数形式,是为了()。 D适应实际资料的要求 18洛纶茨曲线可以用以表示()。 B累积的次数的分配 19确定连续变量的组限时,相邻组的组限是()。 B重叠的 20抽样调查抽取样本时,必须遵守的原则是()。 D随机性 21均值为20,变异系数为0.4,则标准差为()。 B8 变异系数又称标准差率,是指标准差与平均数的比值,因此,标准差为0.4*20=8 22调查对象与调查单位具有一定的对应关系。如果调查对象是全部商业企业,则调查单位是()。 A每一个商业企业 23几何平均法计算平均发展速度是()指标连乘积的N次方根。 A环比发展速度 24F检验主要是用来检验( )。 C回归方程的显著性 25已知一个时间数列的环比增长速度分别为5%、2%、3%,则该时间数列的平均增长速度为()。 A3.33%
统计学原理(第2版)_在线作业_4 交卷时间: 2017-02-19 20:33:57 一、单选题 1. (5分) A. 无线性相关性 B. 完全相关 C. 完全无关 D. 相关程度很小 纠错 得分: 5 知识点: 相关与回归分析的基本概念,统计学原理(第2版) 展开解析 答案A 解析 2. (5分) 当相关系数r=0时,表明变量之间( )。
A. 标准差系数 B. 全距 C. 平均差 D. 标准差 纠错 得分: 5 知识点: 分布离散程度的测度,统计学原理(第2版) 展开解析 答案A 解析 3. (5分) A. 最大的权数 B. 最大的变量值 C. 处于分布数列中间位置的变量 D. 最常见的数值 纠错 得分: 5 知识点: 集中趋势指标概述,统计学原理(第2版) 在两个总体的平均数不等的情况下,比较它们的代表性大小,可以采用的标志变异指标是( )。 在分布数列中,众数是( )。
展开解析 答案D 解析 4. (5分) A. 估计标准误差大,回归直线代表性小,因而回归直线实用价值也大 B. 估计标准误差大,回归直线代表性大,因而回归直线实用价值也小 C. 估计标准误差小,回归直线代表性小,因而回归直线实用价值也小 D. 估计标准误差大,回归直线代表性小,因而回归直线实用价值也小 纠错 得分: 5 知识点: 一元线性回归分析,统计学原理(第2版) 展开解析 答案D 解析 5. (5分) 在回归分析中,估计标准误差起着说明回归直线的代表性大小的作用:( )。
A. 510 B. 500 C. 520 D. 540 纠错 得分: 5 知识点: 统计数据的整理,统计学原理(第2版) 展开解析 答案C 解析 6. (5分) A. 定类尺度 B. 定比尺度 C. 定距尺度 D. 定序尺度 某连续型等差变量数列,其末组组限为500以上,又知其邻组组中值为480,则末组的组中值为( )。 计量结果不但表现为类别,而且这些类别之间可以进行顺序的比较,计量结果的顺序不能颠倒的计量尺度是( )。
一、一元回归分析 实例分析(2): 选取中国1978~2002年中国研究经费与中国GDP 之间的数量关系,建立的一元回归模型如下: i i i x y εβα++= 其中,y i 是中国GDP ,x i 是中国研究经费 线性回归分析的基本步骤及结果分析: ①绘制散点图 图1 ②简单相关分析 表1 分析:从表1中可得到两变量之间的皮尔逊相关系数为0.928,双尾检验概率p 值尾0.000<0.05,故变量之间显著相关。根据“中国研究经费”与“中国GDP ”之间的散点图与相关分析显示,“中国研究经费”与“中国GDP ”之间存在显著的正相关关系。 在此前提下进一步进行回归分析,建立一元线性回归方程。 ③线性回归分析 (1)表2给出了回归模型的拟和优度(R Square )、调整的拟和优度(Adjusted R Square )、估计标准差(Std. Error of the Estimate )以及Durbin -Watson 统计量。
从结果来看,回归的可决系数和调整的可决系数分别为0.860和0.854,即GDP的85%以上的变动都可以被该模型所解释,拟和优度较高。 表2 (2)表3给出了回归模型的方差分析表,可以看到,F统计量为141.616,对应的p值为0,所以,拒绝模型整体不显著的原假设,即该模型的整体是显著的。 表3 (3)表4给出了回归系数、回归系数的标准差、标准化的回归系数值以及各个回归系数的显著性t检验。从表中可以看到无论是常数项还是解释变量x,其t统计量对应的p值都小于显著性水平0.05,因此,在0.05的显著性水平下都通过了t 检验。变量US经费的回归系数为0.090,即US经费每增加1百万美元,USGDP
首页-我的作业列表-《应用统计学》第一次作业答案 你的得分:100.0 完成日期:2014年02月22日16点23分 说明:每道小题括号里的答案是您最高分那次所选的答案, 2014年03月13日)后显示在题目旁边。 标准答案将在本次作业结束(即 —、单项选择题。本大题共20个小题,每小题4.0 给出的选项中,只有一项是符合题目要求的。 分,共80.0分。在每小题 1 . 要了解某企业职工的文化水平情况,则总体单位是( A.该企业的全部职工 B.该企业每一个职工的文化程度 C.该企业的每一个职工 D.该企业全部职工的平均文化程度 2. 属于品质标志的是() A.变量 B.指标 C.标志 D.变异 3. 从标志角度看,变量是指( ) A.可变的数量标志 B.可变的数量标志值 C.可变的品质标志 D.可变的属性标志值 4 . 某工人月工资150元,则“工资”是() 5. A.数量标志 B.品质标志 C.质量标志 D.数量指标 标志与指标的区别之一是()
A. B. C. D. 标志是说明总体特征的;指标是说明总体单位的特征指标是说明总体特征的;标志是说明总体单位的特征。指标是说明有限总体特征的;标志是说明无限总体特征的。指标是说明无限总体特征的;标志是说明有限总体特征的。 6 . 乡镇企业局为总结推广先进生产管理经验,选择几个先进乡镇企业进行调查,这种调查属于()。 7 . A. 抽样调查 B. 典型调查 C. 重点调查 D. 普查下列各项中属于全面调查的是()。 8 . A. 抽样调查 B. 重点调查 C. 典型调查 D. 快速普查人口普查规定统一的时间是为了()。 9 . A. 避免登记的重复和遗漏 B. 具体确定调查单位 C. 确定调查对象的范围 D. 为了统一调查时间,一起行动调查鞍钢、武钢、宝钢等十几个大型钢铁公司就可以了解我国钢铁生产的基本情况。这种调查方式是()。 A. 典型调查 B. 重点调查 C. 抽样调查 D. 普查 10. 全面调查与非全面调查的划分依据是()。 A. 调查的组织方式不同