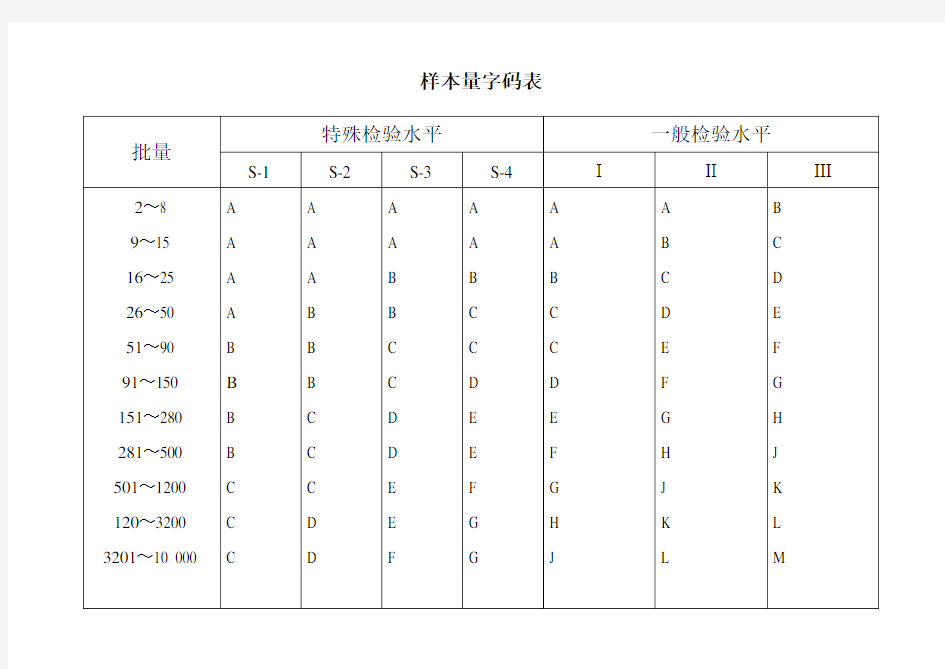
样本量字码表
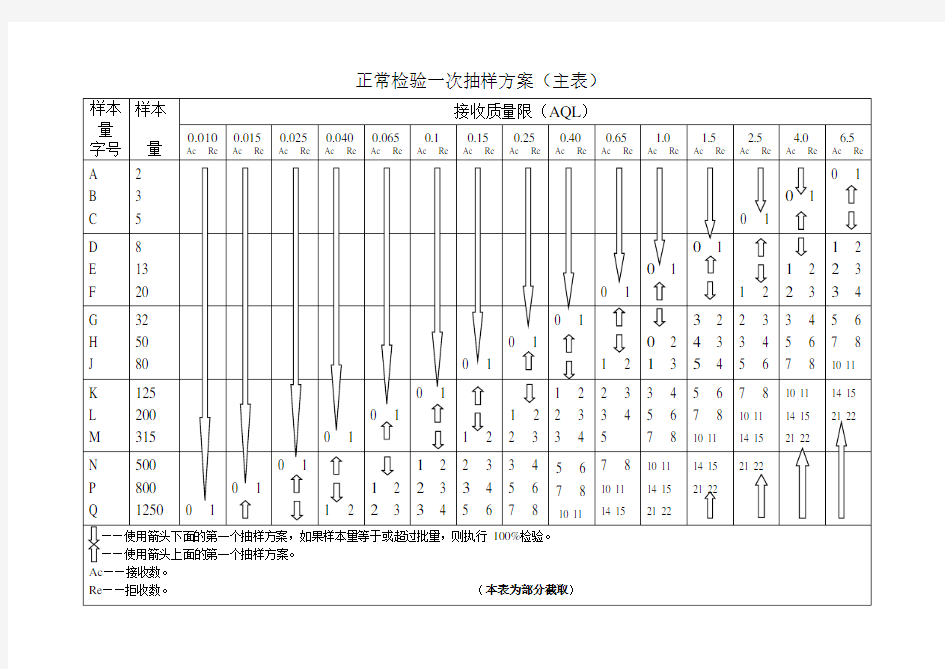
正常检验一次抽样方案(主表)
1.估计样本量的决定因素 1.1资料性质 计量资料如果设计均衡,误差控制得好,样本可以小于30例;计数资料即使误差控制严格,设计均衡,样本需要大一些,需要30-100例。 1.2研究事件的发生率 研究事件预期结局出现的结局(疾病或死亡),疾病发生率越高,所需的样本量越小,反之就要越大。 1.3 1.4 1.5 度为 1.6 1.7 1.8双侧检验与单侧检验 采用统计学检验时,当研究结果高于和低于效应指标的界限均有意义时,应该选择双侧检验,所需 样本量就大;当研究结果仅高于或低于效应指标的界限有意义时,应该选择单侧检验,所需样本量 就小。当进行双侧检验或单侧检验时,其α或β的Ua?界值通过查标准正态分布的分位数表即可得到。
2.样本量的估算 由于对变量或资料采用的检验方法不同,具体设计方案的样本量计算方法各异,只有通过查阅资料,借鉴他人的经验或进行预实验确定估计样本量决定因素的参数,便可进行估算。 护理中的量性研究可以分为3种类型:①描述性研究:如横断面调查,目的是描述疾病的分布情况或现况调查;②分析性研究:其目的是分析比较发病的相关因素或影响因素;③实验性研究:即队列研究或干预实验。研究的类型不同,则样本量也有所不同。 2.1描述性研究 例. =0.1, 2.2 2.2.1探索有关变量的影响因素研究 有关变量影响因素研究的样本量大多是根据统计学变量分析的要求,样本数至少是变量数的5-10倍。例如,如果研究肺结核患者生存质量及影响因素,首先要考虑影响因素有几个,然后通过文献回顾,可知约有12个预测影响变量,如年龄、性别、婚姻、文化程度、家庭月收入、医疗付费方式、病程、排菌、喀血、结核中毒症状、心理健康、社会支持,那么研究的变量就可以在60-120例。这是一种较为简便的估算样本量的方法,在获得相关文献支持下,最好根据公式计算,计量
研究样本大小n趋于无限时,统计量和相应的统计方法的极限性质(又称渐近性质),并据以构造具有特定极限性质的统计方法。例如,用样本均值估计总体均值θ,在n→ 时,以概率1收敛于θ(见概率论中的收敛),称为θ的强相合估计。的这个性质只有 在n→时才有意义,这叫做大样本性质,而强相合性的研究属于大样本统计的范围。根据统计量的极限性质而得出的统计方法称为大样本方法。例如:设X1,X2,…,X n是从正态总体N(μ,σ2)中抽出的样本,μ和σ未知,要作μ的区间估计。记样本方差为 当依分布收敛于标准正态分布N (0,1)。基于这个性质可知, 当n较大时,可用作为 μ的区间估计,其中是标准正态分布的上分位数(见概率分布);这个估计的置信系数当n→时趋于指定的1-α(0<α<1)。这就是一个大样本方法。 与大样本性质和大样本方法相对,小样本性质是指在样本大小n固定时统计方法的性质,小样本方法是指基于n固定时的统计量性质的统计方法。如上述第一例,当n固定时有E=θ,即为θ的无偏估计(见点估计);的这个性质在n固定时有意义,所以是小样本性质。又 如,英国统计学家W.S.戈塞特(又译哥色特,笔名“学生”)在1908年找到了 的精确分布为自由度是n-1的t分布(见统计量)。基于此事实,可知对任何固定的n,μ的区间估计具有确切的置信系数1-α。其中 是自由度为n-1的t分布上分位数。这个性质对任何固定的n都成立。因而上述区间估计是小样本方法。总之,区分大、小样本性质(或方法)的关键在于样本大小n是趋于无限还是固定,而不在于n数值的大小。 小样本方法也称为“精确方法”,因为它往往是基于有关统计量的精确分布(如前例中的t分布);与此相应,小样本方法的统计特性,如显著性水平(见假设检验)、置信系数(见区间估计)等,往往是精确而非近似的。与此相对,大样本方法也称为“渐近方法”或“近似方法”,因为它是基于统计量的渐近分布,且有关的统计特性只是近似而非精确的。在应用中,样本大小n总是一个有限数,这里就有一个近似程度如何的问题。如在对N(μ,σ2)中的μ作区间估计的例子中,指定的置信系数为0.95,按大样本理论作出区间估计 当n→时,其置信系数趋于0.95,但即使n很大,置信
1.估计样本量的决定因素 1.1 资料性质 计量资料如果设计均衡,误差控制得好,样本可以小于30例; 计数资料即使误差控制严格,设计均衡, 样本需要大一些,需要30-100例。 1.2 研究事件的发生率 研究事件预期结局出现的结局(疾病或死亡),疾病发生率越高,所需的样本量越小,反之就要越大。 1.3 研究因素的有效率 有效率越高,即实验组和对照组比较数值差异越大,样本量就可以越小,小样本就可以达到统计学的显著性,反之就要越大。 1.4 显著性水平 即假设检验第一类(α)错误出现的概率。为假阳性错误出现的概率。α越小,所需的样本量越大,反之就要越小。α水平由研究者具情决定,通常α取0.05或0.01。 1.5 检验效能 检验效能又称把握度,为1-β,即假设检验第二类错误出现的概率,为假阴性错误出现的概率。即在特定的α水准下,若总体参数之间确实存在着差别,此时该次实验能发现此差别的概率。检验效能即避免假阴性的能力,β越小,检验效能越高,所需的样本量越大,反之就要越小。β水平由研究者具情决定,通常取β为0.2,0.1或0.05。即1-β=0.8,0.1或0.95,也就是说把握度为80%,90%或95%。 1.6 容许的误差(δ) 如果调查均数时,则先确定样本的均数( )和总体均数(m)之间最大的误差为多少。容许误差越小,需要样本量越大。一般取总体均数(1-α)可信限的一半。 1.7 总体标准差(s) 一般因未知而用样本标准差s代替。 1.8 双侧检验与单侧检验 采用统计学检验时,当研究结果高于和低于效应指标的界限均有意义时,应该选择双侧检验,所需样本量就大; 当研究结果仅高于或低于效应指标的界限有意义时,应该选择单侧检验,所需样本量就小。当进行双侧检验或单侧检验时,其α或β的Ua 界值通过查标准正态分布的分位数表即可得到。
样本含量估算方法及其软件实现(一) 样本含量(sample size)即观察例数的多少,又称样本大小。在保证研究结论具有一定的可靠性(精度和检验功效)的前提下,常需要在设计阶段就人估计最少的受试对象。在医学科研中,只要是抽样研究,就要考虑样本含量的估计。 样本含量估计充分反映了科研设计中“重复”的基本原则,过小过大都有其弊端。样本含量过小,所得指标不稳定,用于推断总体的精密度和准确度差;检验的功效性低,应有的差别不能显示出来,难以获得正确的研究结果,结论也缺乏充分的证据;样本含量过大,会整加实际工作的困难,浪费人力、物力、财力和时间。由于过分追求数量,可能会引起更多的混杂因素,从而影响数据的质量。 影响假设检验时样本含量估计的因素有四个: 1.第一类错误概率的大小α也称检验水准。α越小所需样本含量越多,对于相同α,双侧检验比单侧检验所需要的样本含量更多。 2.检验功效(1-β)或第二类错误概率的大小β检验功效越大,第二类错误的概率愈小,所需要样本含量愈多。 3.容许误差δ容许误差δ愈大,所需的样本含量愈小。 4.总体标准差σ或总体概率σ愈大,所需样本含量自然愈多。总体概率越接近0.5,则所需样本含量愈多。 样本含量的估算方法有查表法和计算法两种。随着计算机的普遍使用,统计学家也开发了一些专门的样本含量估算软件。其算法都是根据上述影响因素结合统计学原理求得。 我就通过实例的样本含量的计算过程,使大家对样本含量有一个更加直观
的认识。 1 计量资料单组设计基于t检验的差异性检验 举例:已知中国50-70岁男性的平均收缩压为158 mmHg,标准差为18,用药物AAA干预,平均收缩压下降10 mmHg 则认为有临床意义,α=0.05, Power=90%,Power =1-β, 双側检验,需要多少病例数。 启动医学研究样本含量估算系统SASA1.0,在桌面上双击SASA1.0快捷方式或点击开始 \ 所有程序 \ Sample Size Adviser \ Sample Size Adviser,进入SASA1.0主窗口。在Goal栏目中选定Means(计量资料)在Group栏目中选定1,在Analysis Method栏目中选定Test(差异性检验)。
統計抽樣標準大全 AQL意义及其拟定办法 ※产品检查概念和分类 单位产品:为了实行检查需要而划分基本单元。如一辆卡车、1M棉布、1KG水泥、一双鞋等。 检查批:需要进行检查一批单位产品。简称批。构成检查批单位产品不应有本质差别,只能有随机波动。因而,一种检查批应当由在基本相似生产条件下并在大概相似时期内,所生产同类型、同级别单位产品所构成。 批量:需要检查一批产品所包括单位产品数。 致命缺陷:对使用和维护产品或对与此关于人员也许导致危害或不安全状况缺陷;或损坏产品重要、最后基本功能缺陷。 重缺陷:不同于致命缺陷,但能引起失效或明显减少产品预期性能缺陷。 轻缺陷:不会明显减少产品预期性能缺陷,或偏离原则但只轻微影响产品有效使用或操作缺陷。 产品检查可分为全数检查、抽样检查、购入检查、中间检查、成品检查、出厂检查、库存检查、监督检查、计数检查、计量检查、破坏性检查、非破坏性检查等。 抽样检查常惯用于下列状况: a) 检查是破坏性; b) 检查时,被检对象是持续体; c) 产品数量多;
d) 检查项目多; e) 但愿检查费用小; f) 作为生产过程工序控制检查。 随机抽样办法: 简朴随机抽样:随机数表法、掷骰法。 周期系统抽样:采用一定间隔进行抽样办法。 分层抽样:从一种可以分为不同子批(或称层)检查批中,按规定比例从不同层中抽取样本 ※抽样检查原则及其体系 1、计数和计量抽样检查原则 计数抽样检查原则是以计数抽样检查成果作为鉴定质量特性指标,已经制定了国标有: a) GB2828-1987《逐批检查计数抽样程序及抽样表(合用于持续批检查)》 b) GB2829-1987《周期检查计数抽样程序及抽样表(合用于生产过程稳定性检查)》 c) GB8051-1987《计数序贯抽样检查程序及表》 d) GB8052-1987《单水平和多水平计数持续抽样检查程序及表》 计量抽样检查原则是以计数抽样检查成果作为鉴定质量特性指标,已经制定了国标有:2AG
11 第三节 样本容量的确定 在区间估计中我们发现,对于某一个总体的参数进行估计时,在样本数目一定的条件下,要提高估计结果的可靠性,就需要扩大置信区间,这就要增加估计中的误差,减少了估计的实际意义。如果要减少估计的误差,就要缩短置信区间,但这样就必须要降低估计的可靠性。可见在样本数目一定的条件下,估计的精确性和估计的可靠性不能两全其美。既要提高估计的精确性,减少误差,又要提高估计可靠性的办法就是增加样本容量。但是增加样本就要同时增加抽样调查的成本,同时又可能延误时间。因此就需要研究能够满足对估计的可靠性和精确性要求的最小样本数问题。 一、均值估计问题中,样本大小的决定 在总体均值的估计问题中,要决定必要的样本大小,必须先明确如下三个问题: 1. 要规定允许的估计误差的大小,即允许的估计值与实际值之间的最大偏离值是多少,实际上也就是估计区间的大小, 2. 规定置信度,即估计所要求达到的可靠性,也就是实际的抽样误差不超过所规定的误差的可信度。 3. 要明确总体的标准差,即要求了解总体的分布情况。总体的标准差小,只要抽较少的样本就能满足对估计精确度和可靠性的要求,若总体标准差大,就必须抽取较多的样本才能达到对估计精确度和可靠性的要求。 设总体标准差为σ,样本均值的标准差为x σ。估计的置信度为1-α,于是可以 相应地得到置信系数Z α/2。于是对总体均值的估计可由下式得到: ()P X Z x -
样本大小与功效 我们在进行假设检验的时候,一般会设置显著性水平,即我们发生第一类错误的概率, α=P(第I类错误)=P(拒绝H0|H0为真) 基于显著性水平,我们可以进行拒绝域的计算,从而基于当前样本数据来推断整体数据的假设,随着计算机技术的进步,我们更能方便的通过计算的P值来判断当前样本假设检验的情况。 如果有两组样本都通过了我们的假设检验,是否说明这两组样本数据所代表的整体数据是一致的呢? 就拿我们上周的找真爱这个例子,陷入爱河的两个人,为了爱情做出了很多让人惊叹的爱情故事,这时的她觉得当前这个人就是她的白马王子,此时的她,觉得他是如此的完美,但她的闺蜜却看到了一些不好的事情,并告诉她,他是很爱他,但是他也许并不是那么的完美。我们这时候需要引入一致最大功效(UMP)准则来判断,谁的判断是更好的。 所谓的一致最大功效(UMP)准则,就是当给定检验水平α后,在所有满足的可供选择的检验样本中,哪个的样本的功效越大,那么那个假设样本则更为准确,这个就是所谓的一致最大功效检验,简称UMP检验,即: Power=1?β=P(拒绝H0|H1为真) 从上述公式来看,所谓功效,就是当原假设为假的时候,你能拒绝它的概率,它反映了这个假设能够识别错误的能力。当假设检验都能够通过显著性检验之后,我们可以假设检验具备了一定的检验正确情况的能力,此时,如果哪个假设样本的功效越大,意味着它识别错误的能力越强,那它就是更好的假设检验判定。 图:如何判断真爱
如上图所示,深陷爱海中的她,觉得他一切都是好的,把一些假爱的行为也认为是真爱;而更加冷静的闺蜜,则看出了这些行为,所以相比她,闺蜜的判断则是更为准确的。这种能够将错误行为识别出来的能力,我们称为POWER(功效),它是衡量这次通过显著性水平的假设检验中,谁更好的一个重要参数。 POWER(功效)是如此重要的参数,我们接下来看看它的大小会和那些因素有关联: 1.客观差异越大,功效越大。就是样本同检验标准之间的差异越大,此时假设检验的 功效越大,就拿我们的中国足球来说,有人说随着国内联赛的水平提升,国家队的 水平也得到了进步。是否取得了进步,我们就要拿国家队的比赛成绩来判断,例如 在世界杯十二强赛中,中国对主城战胜了韩国队,我们就认为中国队水平得到了提 升,但现在十二强赛还没有结束,中国队基本已经无缘世界杯,这说明我们之前作 出的这个判断可能是错误的。究其原因,主要是中国队同韩国队的水平差异并不是 很明显,如果中国队下次战胜巴西队,那么那时候再来说中国队水平得到了提升, 就更为准确了。 2.个体间标准差越小,功效越大。个体间标准差越小,就是样本之间的变异越小,这 时检验的功效越大。例如我们来判断一个人的成绩好不好,如果一个人每次考试的 成绩波动很小,那么我们更容易对他做出正确的判断,反之,如果一个人一次考试 90分,一次60分,波动很大,我们则很难对他做出一个正确的判断。 3.样本量越大,功效越大。就像刚才说的十二强赛一样,当中国队战胜韩国队时,我 们以此判断中国队的水平得到了提升,但对于十二强赛十场比赛的综合表现来看, 这个基于单次比赛得出的判断具有偶然性,而整个系列赛的结果则更为客观。 4.α值越大,功效越大。功效的值为1?β,所以β越小,则值Power越大;而α值越大, 则β越小,功效越大。 检验功效的意义在于,当研究的数据样本同H0的确有差异时,能够使我们知道发现它(拒绝H0)的概率是多少;此外,即使假设检验未能拒绝H0时,我们也可以通过功效来判断是否当前总体参数是否没有异常,还是当前的结果是由于样本量过小造成的,从而来降低我们做出判断带来的风险。
OCT(八进制) 最全ASCII码对应表—与键盘按键对应值 (二进)B i n(十进)D e c(十六进)H e x缩写/字符 解释 0000 0000 0 00 NUL (nul l) 空字符 0000 0001 1 01 SOH (start o f handing) 标题开始 0000 0010 2 02 STX (start o f text) 正文开始 0000 0011 3 03 ETX (end of text) 正文结束 0000 0100 4 04 EOT (end of transmission) 传输结束 0000 0101 5 05 ENQ (enquir y) 请求 0000 0110 6 06 ACK (acknowl edge) 收到通知
0000 0111 7 07 BEL (bel l) 响铃 0000 1000 8 08 BS (backspac e) 退格 0000 1001 9 09 HT (horizont al tab) 水平制表符 0000 1010 10 0A LF (NL line fee d, new line) 换行键 0000 1011 11 0B VT (vertical ta b) 垂直制表符 0000 1100 12 0C FF (NP form fee d, new page) 换页键 0000 1101 13 0D CR (carriage re turn) 回车键 0000 1110 14 0E SO (shift ou t) 不用切换0000 1111 15 0F SI (shift i n) 启用切换 0001 0000 16 10 DLE (data link escape) 数据链路转义
AQL标准 2008-08-09 18:33:12| 分类:默认分类| 标签:|字号大中小订阅 我刚才在网上逛逛,才发现所有地方连AQL标准还要卖RMB 100-500元不等,所以,我决定免费献出! 定义: AQL是英文Acceptable Quality level 即可接受质量水平的缩写 用处: AQL是用数理方法从大量抽样数据中归纳出來的一种抽样标准, 它通过对一批产品中抽取的部分样品进行检验的结果來判定整批产品的质量状況. 好处:降低质量成本, 又能及時快速了解产品质量状況. 名词解释: 抽样检验---- 是从一批交验的产品(总体)中, 对随机抽取的产品样本进行质量检验, 然后把检验结果与判定标准进行比较,从而确定该产品是否合格或是否需再进行抽检后裁決的一种质量检验方法 Ac ---- 为合格判定数: 判定批合格时, 样本中所含不合格品的最大数,称为合格判定数, 又称接收数 接受(Accepted) ---- 当抽取样品数中的不合格品数小于或等于接受数(Ac), 則表示该批量产品合格, 可以接收. Re ---- 为不合格判定数: 是判定批不合格时, 样本中所含不合格品的最小数, 又称拒收数. 拒收(Rejected) (Re), ---- 当抽取检验的样品中的不合格品数大于或等于拒收数則表示该批量产品未达到接受标准, 拒绝接收; 勉強合格(Waive) (Re), ---- 当抽取检验的样品中的不合格品数大于或等于拒收数但此类不良品的性质不会对产品的的功能/严重外观不良问题产生响, 当此类不良品作为Pass时, 调整后的不良数未超出Re数, 整批可以接受的结果。 全检(Full check) ---- 当抽样数大于或等于整批数量时, 所有数量均要检查, 即全检. 全检结果良品作为接受数, 不良品为拒收数,整批产品无需判定結果. 工作步骤 4.1 根据生产实际需要,供货情况及相关客户规定,确定合格品质水平AQL值,本公司质量允许水平规定如下: