大数据核心技术A卷精编版
- 格式:doc
- 大小:123.50 KB
- 文档页数:8

《大数据技术原理与应用》A卷复习资料一、单选题1、大数据的起源是(B)。
A.金融B.互联网C.电信D.公共管理2、大数据的最明显特点是(B)。
A.数据类型多样B.数据规模大C.数据价值密度高D.数据处理速度快3、大数据时代,数据使用的最关键是(D)。
A.数据收集B.数据存储C.数据分析D.数据再利用4、云计算分层架构不包括(D)。
A.IaasB.PaasC.SaasD.Yaas5、大数据技术是由(C)公司首先提出来的。
A.阿里巴巴B.百度C.谷歌D.微软二、多选题1、下列选项中,属于Hadoop优势的有(ABD)。
A.扩容能力强B.可靠性C.低效率D.高容错性2、下列哪项可以作为集群的管理?(ABD)A.PuppetB.PdshC.Cloudera ManagerD.Zookeeper3、下列选项中,属于Hadoop版本系列的有(BCD)。
A.HadoopB.Hadoop2C.Hadoop1D.Hadoop34、Hadoop提供的自定义配置时编辑的配置文件中,包含(ABCD)。
A.core-site.xmlB.hdfs-site.xmlC.mapred-site.xmlD.yarn-site.xml5、下列说法中,关于crontab表达式说法正确的是(AB)。
A.通过执行crontab表达式可以执行定时任务B.crontab表达式是由6个参数决定C.Crontab表达式是由5个参数决定D.以上说法均正确6、在Zookeeper选举过程中,一共有四种状态,分别是(ABCD)。
A.竞选状态B.随从状态C.观察状态D.领导者状态7、下列选项中,属于Sqoop指令的参数有(AD)。
A.imporB.outputC.inputD.export8、下列选项中,关于Hadoop集群说法正确的是(BC)。
A.Hadoop集群包含Worker节点B.Hadoop集群包含Master节点C.Hadoop集群包含Slave节点D.Hadoop集群包含HMaster节点三、判断1、一般而言,分布式数据库是指物理上分散在不同地点但在逻辑上是统一的数据库。

大数据考试题目及答案一、单选题(每题2分,共20分)1. 大数据的4V特征不包括以下哪一项?A. Volume(体量大)B. Velocity(速度快)C. Variety(种类多)D. Validity(有效性)答案:D2. Hadoop的核心组件不包括以下哪一项?A. HDFSB. MapReduceC. HiveD. Spark答案:D3. 下列哪个不是大数据技术的应用领域?A. 金融B. 医疗C. 教育D. 核能答案:D4. 在大数据存储中,以下哪个不是HDFS的特点?A. 高可靠性B. 可扩展性C. 低延迟D. 高吞吐量答案:C5. 以下哪个不是NoSQL数据库的类型?A. 文档型数据库B. 列族数据库C. 图数据库D. 关系型数据库答案:D6. 大数据的实时处理框架不包括以下哪一项?A. StormB. FlinkC. HadoopD. Kafka Streams答案:C7. 以下哪个不是大数据分析的步骤?A. 数据收集B. 数据清洗C. 数据存储D. 数据解释答案:D8. 在大数据技术中,以下哪个不是数据挖掘的算法?A. 决策树B. 聚类C. 线性回归D. 深度学习答案:D9. 以下哪个不是大数据安全和隐私保护的挑战?A. 数据泄露B. 数据篡改C. 数据滥用D. 数据共享答案:D10. 大数据技术中,以下哪个不是数据可视化工具?A. TableauB. PowerBIC. HadoopD. QlikView答案:C二、多选题(每题3分,共15分)11. 大数据技术可以应用于以下哪些领域?A. 电子商务B. 社交媒体分析C. 交通管理D. 环境监测答案:ABCD12. Hadoop生态系统中包括以下哪些组件?A. HBaseB. HiveC. PigD. MongoDB答案:ABC13. 大数据技术面临的挑战包括以下哪些?A. 数据存储B. 数据处理C. 数据安全D. 数据隐私答案:ABCD14. 以下哪些是大数据技术的优势?A. 处理大规模数据集B. 提高决策速度C. 降低成本D. 提高数据准确性答案:ABCD15. 以下哪些是大数据分析的关键步骤?A. 数据预处理B. 数据探索C. 数据建模D. 结果解释答案:ABCD三、判断题(每题2分,共10分)16. 大数据技术只能处理结构化数据。
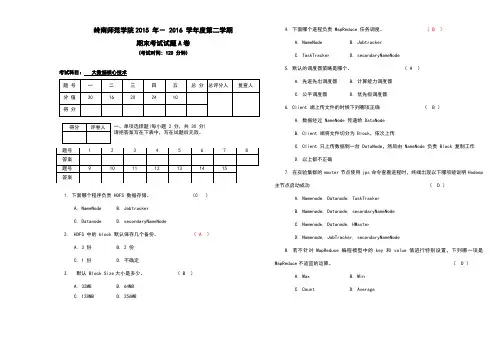
岭南师范学院2015 年- 2016 学年度第二学期期末考试试题A卷(考试时间: 120 分钟)考试科目:大数据核心技术一、单项选择题(每小题 2 分,共 30 分)请把答案写在下表中,写在试题后无效。
1. 下面哪个程序负责 HDFS 数据存储。
(C )A. NameNodeB. JobtrackerC. DatanodeD. secondaryNameNode2. HDFS 中的 block 默认保存几个备份。
( A )A. 3 份B. 2 份C. 1 份D. 不确定3. 默认 Block Size大小是多少。
( B )A. 32MBB. 64MBC. 128MBD. 256MB4. 下面哪个进程负责 MapReduce 任务调度。
( B )A. NameNodeB. JobtrackerC. TaskTrackerD. secondaryNameNode5. 默认的调度器策略是哪个。
( A )A. 先进先出调度器B. 计算能力调度器C. 公平调度器D. 优先级调度器6. Client 端上传文件的时候下列哪项正确( B )A. 数据经过 NameNode 传递给 DataNodeB. Client 端将文件切分为 Block,依次上传C. Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作D. 以上都不正确7. 在实验集群的master节点使用jps命令查看进程时,终端出现以下哪项能说明Hadoop 主节点启动成功( D )A. Namenode, Datanode, TaskTrackerB. Namenode, Datanode, secondaryNameNodeC. Namenode, Datanode, HMasterD. Namenode, JobTracker, secondaryNameNode8. 若不针对MapReduce编程模型中的key和value值进行特别设置,下列哪一项是MapReduce不适宜的运算。

大数据考试题目及答案一、单项选择题(每题2分,共20分)1. 大数据技术的核心目标是处理哪种类型的数据?A. 结构化数据B. 半结构化数据B. 非结构化数据D. 所有上述数据类型答案:D2. 在大数据分析中,以下哪个算法主要用于聚类分析?A. 决策树B. 神经网络C. K-meansD. 线性回归答案:C3. Hadoop的核心组件包括以下哪个?A. SparkB. HiveC. HBaseD. MapReduce答案:D4. 数据挖掘中的“关联规则”通常与哪位学者的名字联系在一起?A. 马斯洛B. 纳维斯C. 阿普拉姆D. 汉斯答案:B5. 大数据的“4V”特性不包括以下哪一项?A. 体量大B. 速度快C. 价值高D. 成本高答案:D6. 在大数据架构中,数据湖主要用于存储什么类型的数据?A. 仅结构化数据B. 仅非结构化数据C. 结构化和非结构化数据D. 仅半结构化数据答案:C7. 下列哪项不是大数据分析的常见应用场景?A. 市场分析B. 风险管理C. 客户细分D. 纸质文档打印答案:D8. 大数据技术可以有效地处理“数据孤岛”问题,这主要是指:A. 数据的物理隔离B. 数据的逻辑隔离C. 数据的格式不统一D. 数据的存储位置分散答案:B9. 在大数据环境下,以下哪个数据库更适合处理非关系型数据?A. MySQLB. OracleC. MongoDBD. SQL Server答案:C10. 大数据的实时分析通常依赖于哪种技术?A. 数据仓库B. 批处理C. 流处理D. 数据挖掘答案:C二、多项选择题(每题3分,共15分)11. 大数据的存储技术包括以下哪些选项?(多选)A. 云存储B. 分布式文件系统C. 关系型数据库D. NoSQL数据库答案:A B D12. 在大数据的生态系统中,以下哪些组件是常见的?(多选)A. HadoopB. SparkC. MongoDBD. Excel答案:A B C13. 大数据的分析过程通常包括哪些步骤?(多选)A. 数据采集B. 数据清洗C. 数据可视化D. 数据丢弃答案:A B C14. 以下哪些因素会影响大数据的性能?(多选)A. 数据的规模B. 数据的处理速度C. 数据的存储格式D. 数据的来源答案:A B C15. 在大数据安全领域,以下哪些措施是重要的?(多选)A. 数据加密B. 访问控制C. 数据备份D. 系统防火墙答案:A B C D三、简答题(每题10分,共20分)16. 请简述大数据的“4V”特性是什么?答案:大数据的“4V”特性指的是体量大(Volume)、速度快(Velocity)、类型多(Variety)、价值高(Value)。

现代科技概论考卷A+(新版)一、选择题(每题2分,共20分)A. 量子计算B. 虚拟现实D. 云计算2. 下列哪个国家在5G通信技术领域处于领先地位?A. 美国B. 中国C. 日本D. 德国A. 太阳能B. 风能C. 核能D. 煤炭发电A. GPSB. GLONASSC. 北斗导航系统D. 伽利略导航系统5. 下列哪个城市被誉为“世界硅谷”?A. 纽约B. 伦敦C. 北京D. 旧金山A. 嫦娥一号B. 天宫一号C. 墨子号D. 神舟一号A. 天河一号B. 神威·太湖之光C. 富士通KD. IBM蓝色基因8. 下列哪个技术是区块链技术的核心?A. 数据挖掘C. 加密算法D. 云计算A. 蚂蚁金服B. 腾讯C. 京东D. 阿里巴巴A. HTTPB. MQTTC. TCP/IPD. Bluetooth二、填空题(每题2分,共20分)1. 5G网络的主要特点是____、____、____。
3. 我国“中国制造2025”计划的主要目标是____、____、____。
4. 新能源汽车主要包括____、____、____。
5. 量子计算机的运算速度远超传统计算机,其核心原理是____。
6. 我国“天问一号”火星探测任务的主要目标是____、____、____。
7. 大数据技术的核心内容包括____、____、____。
9. 3D打印技术的应用领域包括____、____、____。
10. 无人驾驶汽车的关键技术有____、____、____。
三、简答题(每题10分,共30分)2. 请列举三种物联网技术在智能家居中的应用实例。
3. 请简要介绍我国在量子通信领域取得的成就。
四、论述题(每题15分,共30分)1. 论述大数据时代给我们的生活、工作带来的影响及挑战。
2. 结合实际,谈谈现代科技如何助力我国实现碳中和目标。
五、案例分析题(20分)材料:2021年,我国某科技企业成功研发了一款新型智能,该具备人脸识别、语音识别、自主导航等功能。

大数据试题及答案一、选择题1. 以下哪项技术不是大数据处理的核心技术?A. 分布式存储B. 分布式计算C. 数据挖掘D. 关系型数据库答案:D2. 以下哪个大数据处理框架是Apache软件基金会开发的?A. HadoopB. SparkC. FlinkD. All of the above答案:D3. 在大数据技术中,以下哪个技术用于实现数据的分布式存储?A. HDFSB. HBaseC. RedisD. Kafka答案:A4. 以下哪个大数据技术用于实现数据的分布式计算?A. MapReduceB. StormC. SparkD. Hive答案:A5. 以下哪个大数据技术用于实现实时数据处理?A. HadoopB. Spark StreamingC. FlinkD. Kafka答案:C二、填空题1. 大数据处理技术主要包括________、________、________和________。
答案:分布式存储、分布式计算、数据挖掘、数据可视化2. Hadoop框架中的________用于分布式存储,________用于分布式计算。
答案:HDFS、MapReduce3. 在大数据技术中,________是用于实现实时数据流处理的技术,________是用于实现实时计算的技术。
答案:Kafka、Flink4. 以下属于大数据应用场景的有:________、________、________。
答案:金融风控、智能推荐、物联网三、判断题1. 大数据技术仅适用于处理大规模数据集。
()答案:错误。
大数据技术不仅可以处理大规模数据集,还可以应用于中小数据集,提高数据处理和分析的效率。
2. Hadoop是一个开源的大数据处理框架,可以用于分布式存储和分布式计算。
()答案:正确。
3. Spark比Hadoop更适用于实时数据处理。
()答案:正确。
Spark具有更高的数据处理速度,可以满足实时数据处理的需求。
四、简答题1. 简述大数据技术的特点和挑战。

大数据的考试题目和答案一、单项选择题(每题2分,共20分)1. 大数据的核心特征不包括以下哪一项?A. 体量大B. 速度快C. 价值密度高D. 多样性答案:C2. Hadoop的核心组件不包括以下哪一项?A. HDFSB. MapReduceC. HiveD. Spark答案:D3. 在大数据时代,以下哪种技术不是处理数据的关键技术?A. 数据挖掘B. 机器学习C. 云计算D. 传统数据库答案:D4. 下列哪个不是大数据应用的领域?A. 金融B. 医疗C. 教育D. 农业答案:C5. 以下哪个不是大数据的存储技术?A. NoSQL数据库B. 云存储C. 传统关系型数据库D. 分布式文件系统答案:C6. 大数据的4V特性中,哪个代表数据的准确性?A. VolumeB. VelocityC. VarietyD. Veracity答案:D7. 以下哪个不是大数据分析的步骤?A. 数据收集B. 数据清洗C. 数据存储D. 数据解释答案:D8. 以下哪个不是大数据的来源?A. 社交媒体B. 传感器数据C. 传统数据库D. 纸质文档答案:D9. 在大数据技术中,以下哪个不是数据挖掘的算法?A. 决策树B. 聚类分析C. 线性回归D. 神经网络答案:C10. 大数据的实时处理技术不包括以下哪一项?A. StormB. FlinkC. HadoopD. Spark Streaming答案:C二、多项选择题(每题3分,共15分)11. 大数据技术可以应用于以下哪些行业?A. 零售B. 交通C. 教育D. 娱乐答案:ABCD12. 大数据的挑战包括以下哪些方面?A. 数据安全B. 数据隐私C. 数据存储D. 数据分析答案:ABCD13. 以下哪些是大数据的存储解决方案?A. 数据仓库B. 数据湖C. 云存储D. 传统数据库答案:ABC14. 以下哪些是大数据处理框架?A. HadoopB. SparkC. StormD. TensorFlow答案:ABC15. 大数据的分析方法包括以下哪些?A. 描述性分析B. 诊断性分析C. 预测性分析D. 规范性分析答案:ABCD三、判断题(每题2分,共10分)16. 大数据技术只能用于处理结构化数据。

1、目前大数据技术的基础是由( C )第一提出的。
(单项选择题,此题 2 分)A:微软 B :百度 C:谷歌 D:阿里巴巴2、大数据的发源是( C )。
(单项选择题,此题 2 分)A:金融 B :电信 C:互联网 D:公共管理3、依据不一样的业务需求来成立数据模型,抽取最存心义的向量,决定选用哪一种方法的数据剖析角色人员是( C )。
(单项选择题,此题 2 分)A:数据管理人员 B :数据剖析员 C:研究科学家 D:软件开发工程师4、( D )反应数据的精美化程度,越细化的数据,价值越高。
(单项选择题,此题 2 分)A:规模 B :活性 C:关系度 D:颗粒度5、数据冲洗的方法不包含(D)。
(单项选择题,此题 2 分)A:缺失值办理 B :噪声数据消除C:一致性检查 D:重复数据记录办理6、智能健康手环的应用开发,表现了( D )的数据采集技术的应用。
(单项选择题,此题 2分)A:统计报表 B :网络爬虫 C:API 接口 D :传感器7、以下对于数据重组的说法中,错误的选项是( A )。
(单项选择题,此题 2 分)A:数据重组是数据的从头生产和从头采集 B :数据重组能够使数据焕发新的光辉C:数据重组实现的要点在于多源数据交融和数据集成 D :数据重组有利于实现新奇的数据模式创新8、智慧城市的建立,不包含(C)。
(单项选择题,此题 2 分)A:数字城市 B :物联网 C :联网监控 D :云计算9、大数据的最明显特色是( A )。
(单项选择题,此题 2 分)A:数据规模大 B :数据种类多样C:数据办理速度快 D :数据价值密度高10、美国海军军官莫里经过对古人航海日记的剖析,绘制了新的航海路线图,标了然狂风与洋流可能发生的地址。
这表现了大数据剖析理念中的(B )。
(单项选择题,此题 2 分)A:在数据基础上偏向于全体数据而不是抽样数据B:在剖析方法上更着重有关剖析而不是因果剖析C:在剖析成效上更追查效率而不是绝对精确D:在数据规模上重申相对数据而不是绝对数据11、以下对于舍恩伯格对大数据特色的说法中,错误的选项是(D )。

一、单选题1、大数据的起源是(B)。
A:金融B:互联网C:电信D:公共管理2、大数据的最明显特点是(B)。
A:数据类型多样B:数据规模大C:数据价值密度高D:数据处理速度快3、大数据时代,数据使用的最关键是(D)。
A:数据收集B:数据存储C:数据分析D:数据再利用4、云计算分层架构不包括(D)。
A: Iaas B: Paas C: Saas D: Yaas5、大数据技术是由(C)公司首先提出来的。
A:阿里巴巴B:百度C:谷歌D:微软6、数据的精细化程度是指(C),越细化的数据,价值越高。
A:规模B:活性C:颗粒度D:关联性7、数据清洗的方法不包括(C)A:噪声数据清除B:一致性检查C:重复数据记录处理D:缺失值处理智能手环的应用开发,体现了(C)的数据采集技术的应用。
A:网络爬虫B:API接口C:传感器D:统计报表9、下列关于数掲重组的说法中,错误的是(A)。
A:数据的重新生产和采集B:能使数据焕发新的光芒C:关键在于多源数据的融合和集成D:有利于新的数据模式创新10、美国海军军官莫里通过对前人航海日志的分析,绘制考了新的航海路线图,标明了大风与洋流可能发生的地点。
这体现了大数据分析理念中的(B)。
A:在数据基础上倾向于全体数据而不是抽样数据B:在分析方法上更注重相关分析而不是因果分析C:在分析效果上更追究效率而不是绝对精确D:在数据规模上强调相对数据而不是绝对数据11、下列关于含思伯格对大数据特点的说法中,错误的是(D)A:数据规模大B:数据类型多C:处理速度快D:价值密度高12、当前社会中,最为突出的大数据环境是(A)A:互联网B:自然环境C:综合国力D:物联网13、在数据生命周期管理实践中,(B)是执行方法。
A:数据存储和各份规范B:数据管理和维护C:数据价值发觉和利用D:数据应用开发和管理14、下列关于网络用户行为的说法中,错误的是(C)。
A:网络公司能够捕捉到用户在其网站上的所有行为B:用户离散的交互痕迹能够为企业提升服务质量提供参C:数字轨迹用完即自动删除D:用户的隐私安全很难得以规范保护15、下列关于聚类挖报技术的说法中,错误的是(B)。

大数据考试试题题库500题[含答案]一、选择题1.大数据作为一种数据集合,它的含义包括(acd )。
(多选题3分)得分.3分A.数据很大B.很有价值C.构成复杂D.变化很快2.内存够大,所以集群的瓶颈不可能是 a 和 d3.大数据仅仅是指数据的体量大。
(判断题1分)正确错误1 得分.1分4.下列哪些国家已经将大数据上升为国家战略?abcd(多选题3分)得分.3分A.英国B.日本C.美国D.法国5.大数据的应用能够实现一场新的革命,提高综合管理水平的原因是(abcd )。
(多选题3分)得分.3分A.从被动反应走向主动预见型管理B.从粗放化管理走向精细化管理C.从单兵作战走向联合共享型管理D.从柜台式管理走向全天候管理6.建立大数据需要设计一个什么样的大型系统?abcd(多选题3分)得分.3分A.能够把应用放到合适的平台上B.能够开发出相应应用C.能够处理数据D.能够存储数据7.大数据的应用能够实现一场新的革命,提高综合管理水平的原因是abcd(多选题3分)得分.3分A.从柜台式管理走向全天候管理B.从粗放化管理走向精细化管理C.从被动反应走向主动预见型管理D.从单兵作战走向联合共享型管理8.20世纪中后期至今的媒介革命,以(acd )的出现为标志。
(多选题3分)分.得3分A.互联网B.自动化C.计算机D.数字化9.医疗领域如何利用大数据?acd(多选题3分)得分.0分A.临床决策支持B.个性化医疗C.社保资金安全D.用户行为分析10.郭永田副主任指出,物联网在大田作物生产中的应用体现在以下哪些方面?abcd(多选题3分)得分.3分A.农作物病虫害监测B.农业精准生产控制C.农田环境监测D.农作物长势苗情监测11.贵州发展大数据的“八个一”建议包括(ab;得分.3分;A.制定一个工作计划.建立一个领导机构B.培养 D.中央网络安全和信息化领导小组组长是李克强。
12.下列各项表述中正确的有哪些?ad(多选题3分)得分.0分A.我国中央网络安全和信息化领导小组宣告成立是在2013年。

一、单项选择题(每题2分共20分)
二、填空题(每空2分共20分)
1、体量,速度,多样性
2、个人信息的被识别与暴露
3、分布式文件系统,分布式并行计算,分布式数据库
4、为用户和业务部门提供决策支持
5、多元回归分析,一元回归分析
三、判断题(每个2分,共20分)
FFTFF TFFFF
四、简答题(每题10分共40分)
1 搜索引擎的产生和发展经历了哪几个阶段?试简述各阶段的特点。
答:早期出现的搜索引擎只是检索FTP网站文件的程序,随后的搜索引擎开始收录网络地址形成分类目录,后续的发展中搜索引擎开始收录标题,目前的搜索引擎,已经发展到抓取网页全文阶段。
2 大数据时代数据的存储与管理与传统数据存储方式有何区别?
答:传统数据管理方法的局限性及大数据的现实条件促使
新的数据库设计的出现,在新的数据库设计中,原本数据库模式中存在的记录和预设场域(成规数据的整齐排列)的规律被替代。
大数据为适应信息发展的需要,运用非关系型数据库作为一种新型数据库设,它不需要预先设定记录结构,同时允许处理规模庞大、结构复杂的数据。
3 常用的数据整理技术有哪些?
回退模型可视化相关性变化分析差异分析预测群集技术决策树神经网络
4 简述大数据存储的概念。
数据存储是指数据流在加工过程中产生的临时文件或需要查找的信息的存储。
数据以某种格式记录在计算机内部或外部存储介质上。
数据存储要命名,这种命名要反映信息特征的组成含义。
数据流反映了系统中流动的数据,表现出动态数据的特征;数据存储反映系统中静止的数据,表现出静态数据的特征。
2020年最新公需科目《大数据》考试题(含答案)一、填空题1.HDFS 默认 Blck Size是64MB。
(填128也正确)2.MapReduce确保每个reducer的输入都是按键排序的。
系统执行排序的过程(即将map 输出作为输入传给reducer)称为shuffle。
二、单选题3.下列关于网络用户行为的说法中,错误的是( C)。
(单选题) A.网络公司能够捕捉到用户在其网站上的所有行为B.用户离散的交互痕迹能够为企业提升服务质量提供参考C.数字轨迹用完即自动删除D.用户的隐私安全很难得以规范保护三、多选题4.下列选项中,属于贵州发展大数据的先天优势的是()。
ABCDA.空气清新B.远离地震带C.气候凉爽D.电力资源充沛5.20世纪中后期至今的媒介革命,以()的出现为标志。
ACDA.互联网B.自动化C.计算机D.数字化6.根据涂子沛先生所讲,数据就是简单的数字。
×正确错误7.大数据要求企业设置的岗位是()。
A.首席信息官和首席数据官B.首席信息官和首席工程师C.首席分析师和首席工程师D.首席分析师和首席数据官8.大数据能帮助教师改进教学。
利用大数据方法,教师通过学生反馈回来的作业,就可以发现到底是哪些学生并没有真正听懂,进而有针对性地加以辅导。
对9.大数据的思维会把原来销售的概念变成服务的概念。
对10.根据周琦老师所讲,高德交通信息服务覆盖全国主干道路及其它()以上。
DA.90%B.70%C.30%D.50%11.由于历史的原因,我国医院的信息化建设层次不齐.水平不一。
正确错误1.促进大数据发展部级联席会议在哪一年的4月13日召开了第一次会议?CA.2013年B.2014年C.2016年D.2015年12.根据涂子沛先生所讲,因为数据的内涵发生了改变,计算的内涵也发生了改变。
对13.治理理论认为,现代社会的发展必然要求公共服务多元化的供给。
对14.郭永田副主任指出,物联网在大田作物生产中的应用体现在以下哪些方面?ABCDA.农作物病虫害监测B.农业精准生产控制C.农田环境监测D.农作物长势苗情监测15.大数据的主要特征表现为()。
衡阳师范学院 2019-2020学年 第一学期 计算机科学与技术学院 软件工程专业 2017级 《云计算与大数据处理原理》期末考试试题A 卷一、单选题(每小题2分,共20分)1. 以下哪项不.是大数据的特点( ) A 、数据量大B 、数据类型多样C 、价值密度高D 、数据真实性2. 云计算的关键技术不.包括下列哪项( )A 、负载均衡B 、虚拟化C 、串行计算D 、按需部署3. 按照虚拟化的层次,Vmware 虚拟机属于( )A. 指令集架构虚拟化B. 硬件抽象层虚拟化C. 操作系统层虚拟化D. 编程语言层虚拟化 4. 平台即服务的英文缩写是( )A. PaaS B .SaaSC. IaaSD. CaaS5. h θ(x)=θT X 可作为下列哪种模型的公式()A 、逻辑回归B 、多元线性回归C 、多重线性回归D 、神经网络6. 下列哪项是MapReduce 编程模型不.能解决的问题是 ( )A .层次聚类法B .K-means 聚类C .朴素贝叶斯分类D .Top K 问题7.在MapReduce程序中,map()函数输入的数据格式是:( )A.字符串B.整型C.键值对D.数组8.下列哪项不属于聚类算法。
( )A、K-中心点B、KNNC、K-meansD、DBScan9.HDFS是基于流数据模式访问和处理超大文件的需求而开发的,适合的读写任务是____。
( )A.一次写入,少次读B.多次写入,少次读C.多次写入,多次读D.一次写入,多次读10.关于SecondaryNameNode 下面哪项是正确的:()A. 它是NameNode 的热备B. 它对内存没有要求C. 它帮助NameNod合并编辑日志,减少NameNode启动时间D. SecondaryNameNode应与NameNode部署到一个节点二、填空题(每空 2 分,共 20 分)1. 按技术路线来看,Hadoop属于云计算(填资源整合型或资源切分型)。
大数据方面核心技术有哪些(一)引言概述:大数据已经成为当前社会发展的热点领域之一,它能够以前所未有的方式对海量数据进行分析和应用。
在大数据领域中,核心技术的应用对于数据处理、存储和分析具有重要意义。
本文将介绍大数据方面的核心技术,其中包括数据采集、数据存储、数据处理、数据分析和数据可视化等五个大点。
正文内容:一、数据采集1. 传感器技术:通过传感器获取实时数据,如温度、压力和运动等。
2. 高速数据捕获技术:利用高速数据捕捉设备,对数据进行高效采集,确保数据捕获的准确性和完整性。
3. 云计算技术:通过云平台获取分布式数据,实现多方数据聚合。
二、数据存储1. 分布式存储系统:利用分布式存储系统,将海量数据分布式地存储在多台服务器上,提高数据的可靠性和存储容量。
2. 列存储技术:采用列存储结构,在处理大量数据时能够提高查询速度和压缩比率。
3. NoSQL数据库:使用非关系型数据库管理大数据,实现高性能和灵活的数据存储。
三、数据处理1. 分布式计算:利用分布式计算系统,将大规模数据进行分割,并在多台计算机上并行处理,提高数据处理速度。
2. 并行计算技术:通过将任务分解为多个子任务,并在多个处理器上同时执行,实现高效的数据计算。
3. 流式处理:采用流式处理技术,对实时数据进行快速处理和分析,以支持实时决策。
四、数据分析1. 数据挖掘:利用数据挖掘技术发现数据中的模式和趋势,从而提供决策支持和业务洞察。
2. 机器学习:应用机器学习算法对大数据进行建模和预测,从而实现智能化的数据分析和决策。
3. 文本分析:通过自然语言处理和文本挖掘技术,对大数据中的文本信息进行分析和理解。
五、数据可视化1. 图表和可视化工具:使用图表、地图和可视化工具将数据转化为可理解的图形和可视化表达形式。
2. 交互式可视化:通过交互式可视化技术,使用户能够探索和分析大数据,并从中提取有用的信息。
3. 实时可视化:实时地将数据可视化展示,以便及时发现和分析数据中的异常和趋势。
⼤数据技术-题库⼤数据技术-题库1、第⼀次信息化浪潮主要解决什么问题?A、信息传输B、信息处理C、信息爆炸D、信息转换2、下⾯哪个选项属于⼤数据技术的"数据存储和管理"技术层⾯的功能?A、利⽤分布式⽂件系统、数据仓库、关系数据库等实现对结构化、半结构化和⾮结构化海量数据的存储和管理B、利⽤分布式并⾏编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析C、构建隐私数据保护体系和数据安全体系,有效保护个⼈隐私和数据安全D、把实时采集的数据作为流计算系统的输⼊,进⾏实时处理分析3、在⼤数据的计算模式中,流计算解决的是什么问题?A、针对⼤规模数据的批量处理B、针对⼤规模图结构数据的处理C、⼤规模数据的存储管理和查询分析D、针对流数据的实时计算4、⼤数据产业指什么?A、⼀切与⽀撑⼤数据组织管理和价值发现相关的企业经济活动的集合B、提供智能交通、智慧医疗、智能物流、智能电⽹等⾏业应⽤的企业C、提供数据分享平台、数据分析平台、数据租售平台等服务的企业D、提供分布式计算、数据挖掘、统计分析等服务的各类企业5、下列哪⼀个不属于⼤数据产业的产业链环节?A、数据存储层B、数据源层C、数据分析层D、数据应⽤层6、下列哪⼀个不属于 IT 领域最新的技术发展趋势?A、互联⽹B、云计算C、⼤数据D、物联⽹7、云计算平台层(PaaS)指的是什么?A、操作系统和围绕特定应⽤的必需的服务B、将基础设施(计算资源和存储)作为服务出租C、从⼀个集中的系统部署软件,使之在⼀台本地计算机上(或从云中远程地) 运⾏的⼀个模型D、提供硬件、软件、⽹络等基础设施以及提供咨询、规划和系统集成服务 8、云计算数据中⼼是什么?A、数据中⼼是云计算的重要载体,为各种平台和应⽤提供运⾏⽀撑环境B、提供智能交通、智慧医疗、智能物流、智能电⽹等C、提供分布式计算、数据挖掘、统计分析等服务D、提供硬件、软件、⽹络等基础设施9、下列哪个不属于物联⽹的应⽤?A、智能物流B、智能安防C、环保监测D、数据采集10、下列哪项不属于⼤数据的发展历程?A、成熟期B、萌芽期C、⼤规模应⽤期D、迷茫期11、第三次信息化浪潮的标志是什么?A、个⼈计算机B、物联⽹C、云计算和⼤数据D、互联⽹12、信息科技为⼤数据时代提供哪些技术⽀撑?A、存储设备容量不断增加B、⽹络带宽不断增加C、 CPU 处理能⼒⼤幅提升D、数据量不断增⼤13、⼤数据具有哪些特点?A、数据的"⼤量化"B、数据的"快速化"C、数据的"多样化"D、数据的"价值化"14、下⾯哪个属于⼤数据的应⽤领域?A、智能医疗研发B、监控⾝体情况C、实时掌握交通状况D、⾦融交易15、⼤数据的两个核⼼技术是什么?A、分布式存储B、数据处理与分析C、分布式处理D、数据存储与管理16、云计算关键技术包括什么?A、分布式存储B、虚拟化C、分布式计算D、多租户17、云计算的服务模式和类型包括哪些?A、软件即服务(SaaS)B、平台即服务(PaaS)C、基础设施即服务(IaaS)D、数据即服务(DaaS)18、物联⽹主要由下列哪些部分组成的?A、应⽤层B、处理层C、感知层D、⽹络层19、物联⽹的关键技术包括哪些?A、识别和感知技术B、⽹络与通信技术C、数据挖掘与融合技术D、信息处理⼀体化技术20、⼤数据对社会发展的影响有哪些?A、⼤数据成为⼀种新的决策⽅式B、⼤数据应⽤促进信息技术与各⾏业的深度融合C、⼤数据开发推动新技术和新应⽤的不断涌现D、⼤数据使得数据科学家成为热门职业21、下列哪个不属于 Hadoop 的特性?A、成本⾼B、⾼可靠性C、⾼容错性D、运⾏在 Linux 平台上22、Hadoop 框架中最核⼼的设计是什么?A、为海量数据提供存储的 HDFS 和对数据进⾏计算的 MapReduceB、提供整个 HDFS ⽂件系统的 NameSpace(命名空间)管理、块管理等所有服务C、 Hadoop 不仅可以运⾏在企业内部的集群中,也可以运⾏在云计算环境中D、 Hadoop 被视为事实上的⼤数据处理标准23、在⼀个基本的 Hadoop 集群中,DataNode 主要负责什么?A、存储被拆分的数据块B、协调数据计算任务C、负责协调集群中的数据存储D、负责执⾏由 JobTracker 指派的任务 24、Hadoop 最初是由谁创建的?A、 Doug CuttingB、 LuceneC、 ApacheD、 MapReduce25、下列哪⼀个不属于 Hadoop 的⼤数据层的功能?A、数据挖掘B、离线分析C、实时查询D、 BI 分析26、在⼀个基本的 Hadoop 集群中,SecondaryNameNode 主要负责什么?A、帮助 NameNode 收集⽂件系统运⾏的状态信息B、负责执⾏由 JobTracker 指派的任务C、协调数据计算任务D、负责协调集群中的数据存储27、下⾯哪⼀项不是 Hadoop 的特性?A、只⽀持少数⼏种编程语⾔B、可扩展性⾼C、成本低D、能在 linux 上运⾏28、下列哪个不是 Hadoop 在企业中的应⽤架构?A、⽹络层B、访问层C、⼤数据层D、数据源层29、在 Hadoop 项⽬结构中,HDFS 指的是什么?A、分布式⽂件系统B、分布式并⾏编程模型C、资源管理和调度器D、 Hadoop 上的数据仓库30、在 Hadoop 项⽬结构中,MapReduce 指的是什么?A、分布式并⾏编程模型B、流计算框架C、 Hadoop 上的⼯作流管理系统D、提供分布式协调⼀致性服务 31、Hadoop 的特性包括哪些?A、⾼可扩展性B、⽀持多种编程语⾔C、成本低D、运⾏在 Linux 平台上32、Hadoop 在企业中的应⽤架构包括哪⼏层?A、访问层B、⼤数据层C、数据源层D、⽹络层33、Hadoop 中,访问层的功能是什么?A、数据分析B、数据实时查询C、数据挖掘D、数据接收34、MapReduce 的作业主要包括什么?A、从磁盘或从⽹络读取数据,即 IO 密集⼯作B、计算数据,即 CPU 密集⼯作C、针对不同的⼯作节点选择合适硬件类型D、负责协调集群中的数据存储35、⼀个基本的 Hadoop 集群中的节点主要包括什么?A、 DataNode:存储被拆分的数据块B、 JobTracker:协调数据计算任务C、 TaskTracker:负责执⾏由 JobTracker 指派的任务D、 SecondaryNameNode:帮助 NameNode 收集⽂件系统运⾏的状态信息36、下列关于 Hadoop 的描述,哪些是正确的?A、为⽤户提供了系统底层细节透明的分布式基础架构B、具有很好的跨平台特性C、可以部署在廉价的计算机集群中D、被公认为⾏业⼤数据标准开源软件37、Hadoop 主要提供哪些技术服务?A、开发⼯具B、开源软件C、商业化⼯具D、数据采集38、Hadoop 集群的整体性能主要受到什么因素影响?A、 CPU 性能B、内存C、⽹络D、存储容量39、下列关于 Hadoop 的描述,哪些是错误的?A、为⽤户提供了系统顶层分布式基础架构B、具有较差的跨平台特性C、可以部署在廉价的计算机集群中D、被公认为⾏业⼤数据标准开源软件40、下列哪⼀项不属于 Hadoop 的特性?A、较低可扩展性B、只⽀持 java 语⾔C、成本低D、运⾏在 Linux 平台上41、分布式⽂件系统指的是什么?A、把⽂件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群B、⽤于在 Hadoop 与传统数据库之间进⾏数据传递C、⼀个⾼可⽤的,⾼可靠的,分布式的海量⽇志采集、聚合和传输的系统D、⼀种⾼吞吐量的分布式发布订阅消息系统,可以处理消费者规模的⽹站中的所有动作流数据42、下⾯哪⼀项不属于计算机集群中的节点?A、源节点(SourceNode)B、主节点(Master Node)C、名称结点(NameNode)D、节点(Slave Node)43、在 HDFS 中,默认⼀个块多⼤?A、 64MBB、 32MBC、 128MBD、 16MB44、下列哪⼀项不属于 HDFS 采⽤抽象的块概念带来的好处?A、强⼤的跨平台兼容性B、⽀持⼤规模⽂件存储C、简化系统设计D、适合数据备份45、在 HDFS 中,NameNode 的主要功能是什么?A、存储元数据B、存储⽂件内容C、⽂件内存保存在磁盘中D、维护了 block id 到 datanode 本地⽂件的映射关系 46、下⾯对 FsImage 的描述,哪个是错误的?A、 FsImage ⽂件没有记录⽂件包含哪些块以及每个块存储在哪个数据节点B、 FsImage ⽂件包含⽂件系统中所有⽬录和⽂件 inode 的序列化形式C、 FsImage ⽤于维护⽂件系统树以及⽂件树中所有的⽂件和⽂件夹的元数据D、 FsImage ⽂件记录了所有针对⽂件的创建、删除、重命名等操作47、下⾯对 SecondaryNameNode 第⼆名称节点的描述,哪个是错误的?A、 SecondaryNameNode ⼀般是并⾏运⾏在多台机器上B、它是⽤来保存名称节点中对 HDFS 元数据信息的备份,并减少名称节点重启的时间C、 SecondaryNameNode 通过 HTTPGET ⽅式从 NameNode 上获取到 FsImage 和 EditLog ⽂件,并下载到本地的相应⽬录下D、 SecondaryNameNode 是 HDFS 架构中的⼀个组成部分 48、HDFS 采⽤了什么模型?A、主从结构模型B、分层模式C、管道-过滤器模式D、点对点模式49、在 Hadoop 项⽬结构中,HDFS 指的是什么?A、分布式⽂件系统B、流数据读写C、资源管理和调度器D、 Hadoop 上的数据仓库50、下列关于 HDFS 的描述,哪个不正确?A、 HDFS 采⽤具体的块概念,具有⽀持⼤规模⽂件存储、简化系统设计B、 HDFS 采⽤了主从(Master/Slave)结构模型C、 HDFS 采⽤了冗余数据存储,增强了数据可靠性D、 HDFS 还采⽤了相应的数据存放、数据读取和数据复制策略,来提升系统整体读写响应性能51、HDFS 要实现以下哪⼏个⽬标?A、兼容廉价的硬件设备B、流数据读写C、⼤数据集D、复杂的⽂件模型52、HDFS 特殊的设计,在实现上述优良特性的同时,也使得⾃⾝具有⼀些应⽤局限性,主要包括以下哪⼏个⽅⾯?A、不适合低延迟数据访问B、⽆法⾼效存储⼤量⼩⽂件C、不⽀持多⽤户写⼊及任意修改⽂件D、较差的跨平台兼容性53、HDFS 采⽤抽象的块概念可以带来以下哪⼏个明显的好处?A、⽀持⼤规模⽂件存储B、简化系统设计C、适合数据备份D、⽀持中等规模⽂件存储54、在 HDFS 中,名称节点(NameNode)主要保存了哪些核⼼的数据结构?A、 FsImageB、 EditLogC、 BlockD、 DN855、数据节点(DataNode)的主要功能包括哪些?A、负责数据的存储和读取B、根据客户端或者是名称节点的调度来进⾏数据的存储和检索C、向名称节点定期发送⾃⼰所存储的块的列表D、⽤来保存名称节点中对 HDFS 元数据信息的备份,并减少名称节点重启的时间56、HDFS 的命名空间包含什么?A、⽬录B、⽂件C、块D、磁盘57、下列对于客服端的描述,哪些是正确的?A、客户端是⽤户操作 HDFS 最常⽤的⽅式,HDFS 在部署时都提供了客户端B、 HDFS 客户端是⼀个库,暴露了 HDFS ⽂件系统接⼝C、严格来说,客户端并不算是 HDFS 的⼀部分D、客户端可以⽀持打开、读取、写⼊等常见的操作58、HDFS 只设置唯⼀⼀个名称节点,这样做虽然⼤⼤简化了系统设计,但也带来了哪些明显的局限性?A、命名空间的限制B、性能的瓶颈C、隔离问题D、集群的可⽤性59、HDFS 数据块多副本存储具备以下哪些有点?A、加快数据传输速度B、容易检查数据错误C、保证数据可靠性D、适合多平台上运⾏60、HDFS 具有较⾼的容错性,设计了哪些相应的机制检测数据错误和进⾏⾃动恢复?A、名称节点出错B、数据节点出错C、数据出错D、数据源太⼤61、下列哪个不属于 NoSQL 数据库的特点?A、灵活的可扩展性B、灵活的数据模型C、与云计算紧密融合D、⼤型的数据库62、下⾯关于 NoSQL 和关系数据库的简单⽐较,哪个是错误的?A、 RDBMS 有关系代数理论作为基础,NoSQL 没有统⼀的理论基础B、 NoSQL 很难实现横向扩展,RDBMS 可以很容易通过添加更多设备来⽀持更⼤规模的数据C、 RDBMS 需要定义数据库模式,严格遵守数据定义,NoSQL 不存在数据库模式,可以⾃由灵活定义并存储各种不同类型的数据D、 RDBMS 借助于索引机制可以实现快速查询,很多 NoSQL 数据库没有⾯向复杂查询的索引63、下列哪⼀项不属于 NoSQL 的四⼤类型?A、⽂档数据库B、图数据库C、列族数据库D、时间戳数据库64、下列关于键值数据库的描述,哪⼀项是错误的?A、扩展性好,灵活性好B、⼤量写操作时性能⾼C、⽆法存储结构化信息D、条件查询效率⾼65、下列关于列族数据库的描述,哪⼀项是错误的?A、查找速度慢,可扩展性差B、功能较少,⼤都不⽀持强事务⼀致性C、容易进⾏分布式扩展D、复杂性低66、下列哪⼀项不属于数据库事务具有 ACID 四性?A、间断性B、原⼦性C、⼀致性D、持久性67、下⾯关于 MongoDB 说法,哪⼀项是正确的?A、具有较差的⽔平可扩展性B、设置个别属性的索引来实现更快的排序C、提供了⼀个⾯向⽂档存储,操作复杂D、可以实现替换完成的⽂档(数据)或者⼀些指定的数据字段 68、下列关于 MongoDB 数据类型的说法,哪⼀项是错误的?A、 Code ⽤于存储⼆进制数据B、 Object ⽤于内嵌⽂档C、 Null ⽤于创建空值D、 String 字符串,储数据常⽤的数据类型69、下列关于 NoSQL 与关系数据库的⽐较,哪个说法是错误的?A、在⼀致性⽅⾯,RDBMS 强于 NoSQLB、在数据完整性⽅⾯,RDBMS 容易实现C、在扩展性⽅⾯,NoSQL ⽐较好D、在可⽤性⽅⾯,NoSQL 优于 RDBMS70、关于⽂档数据库的说法,下列哪⼀项是错误的?A、数据是规则的B、性能好(⾼并发)C、缺乏统⼀的查询语法D、复杂性低71、关系数据库已经⽆法满⾜ Web2.0 的需求,主要表现在以下⼏个⽅⾯?A、⽆法满⾜海量数据的管理需求B、⽆法满⾜数据⾼并发的需求C、⽆法满⾜⾼可扩展性和⾼可⽤性的需求D、使⽤难度⾼72、下列关于 MySQL 集群的描述,哪些是正确的?A、复杂性:部署、管理、配置很复杂B、数据库复制:MySQL 主备之间采⽤复制⽅式,只能是异步复制C、扩容问题:如果系统压⼒过⼤需要增加新的机器,这个过程涉及数据重新划分D、动态数据迁移问题:如果某个数据库组压⼒过⼤,需要将其中部分数据迁移出去73、关系数据库引以为傲的两个关键特性(完善的事务机制和⾼效的查询机制),到了 Web2.0 时代却成了鸡肋,主要表现在以下哪⼏个⽅⾯?A、 Web2.0 ⽹站系统通常不要求严格的数据库事务B、 Web2.0 ⽹站系统基本上不⽤数据库来存储C、 Web2.0 并不要求严格的读写实时性D、 Web2.0 通常不包含⼤量复杂的 SQL 查询74、下⾯关于 NoSQL 与关系数据库的⽐较,哪些是正确的?A、关系数据库以完善的关系代数理论作为基础,有严格的标准B、关系数据库可扩展性较差,⽆法较好⽀持海量数据存储C、 NoSQL 可以⽀持超⼤规模数据存储D、 NoSQL 数据库缺乏数学理论基础,复杂查询性能不⾼ 75、下列关于⽂档数据库的描述,哪些是正确的?A、性能好(⾼并发),灵活性⾼B、具备统⼀的查询语法C、⽂档数据库⽀持⽂档间的事务D、复杂性低,数据结构灵活76、下列关于图形数据库的描述,哪些是正确的?A、专门⽤于处理具有⾼度相互关联关系的数据B、⽐较适合于社交⽹络、模式识别、依赖分析、推荐系统以及路径寻找等问题C、灵活性⾼,⽀持复杂的图形算法D、复杂性⾼,只能⽀持⼀定的数据规模77、NoSQL 的三⼤基⽯?A、 CAPB、最终⼀致性C、 BASED、 DN878、关于 NoSQL 的三⼤基⽯之⼀的 CAP,下列哪些说法是正确的?A、⼀致性,是指任何⼀个读操作总是能够读到之前完成的写操作的结果量B、⼀个分布式系统可以同时满⾜⼀致性、可⽤性和分区容忍性这三个需求C、可⽤性,是指快速获取数据D、分区容忍性,是指当出现⽹络分区的情况时(即系统中的⼀部分节点⽆法和其他节点进⾏通信),分离的系统也能够正常运⾏79、当处理 CAP 的问题时,可以有哪⼏个明显的选择?A、 CA:也就是强调⼀致性(C)和可⽤性(A),放弃分区容忍性(P)B、 CP:也就是强调⼀致性(C)和分区容忍性(P),放弃可⽤性(A)C、 AP:也就是强调可⽤性(A)和分区容忍性(P),放弃⼀致性(C)D、 CAP:也就是同时兼顾可⽤性(A)、分区容忍性(P)和⼀致性(C),当时系统性能会下降很多80、数据库事务具有 ACID 四性,下⾯哪⼏项属于四性?A、原⼦性B、持久性C、间断性D、⼀致性81、下列哪个不属于云计算的优势?A、按需服务B、随时服务C、通⽤性D、价格不菲82、下列关于云数据库的描述,哪个是错误的?A、云数据库是部署和虚拟化在云计算环境中的数据库B、云数据库是在云计算的⼤背景下发展起来的⼀种新兴的共享基础架构的⽅法C、云数据库价格不菲,维护费⽤极其昂贵D、云数据库具有⾼可扩展性、⾼可⽤性、采⽤多租形式和⽀持资源有效分发等特点83、下列哪⼀个不属于云数据库产品?A、 MySQLB、阿⾥云 RDSC、 Oracle CloudD、百度云数据库84、UMP 系统是构建在⼀个⼤的集群之上的,下列哪⼀项不属于系统向⽤户提供的功能?A、读写分离B、分库分表C、数据安全D、资源合并85、下列关于 UMP 系统功能的说法,哪个是错误的?A、充分利⽤主从库实现⽤户读写操作的分离,实现负载均衡B、 UMP 系统实现了对于⽤户透明的读写分离功能C、 UMP 采⽤的两种资源隔离⽅式(⽤ Cgroup 限制 MySQL 进程资源和在 Proxy 服务器端限制 QPS)D、 UMP 系统只设计了⼀种机制来保证数据安全 86、下列关于阿⾥云 RDS 的说法,哪个是错误的?A、 RDS 是阿⾥云提供的关系型数据库服务B、 RDS 由专业数据库管理团队维护C、 RDS 具有安全稳定、数据可靠、⾃动备份D、 RDS 实例,是⽤户购买 RDS 服务的基本单位。
《云计算与大数据技术》期末试卷A卷一、单项选择题(共10小题,每小题2分,共计20分)1. 大数据价值密度的高低与数据总量大小成反比,这是大数据的那个特点?()(A)Volume(数据量大)(B)Variety(数据类型多)(C)Velocity(流转速度快)(D)V alue(价值密度低)2. Hadoop 2.x比1.x相比,有什么显著变化?()(A)增加DataNode (B)增加NameNode HA(C)增加了资源管理器Y ARN (D)支持Wire-compatibility3. Google GFS的Master上保存了GFS的三种元数据,以下那种元数据不能通过日志文件恢复()。
(A)命名空间(B)Chunk与文件名的映射表(C)Chunk副本的位置信息(D)以上都不能4. 关于YARN组件说法错误的是()(A)YARN采用master/slave架构(B)主节点上运行主服务ResourceMananger(C)从节点上运行从服务NodeManager(D)YARN中引入了一个逻辑概念——槽Slot,它将各类资源抽象化5. 关于Hadoop MapReduce的执行过程,以下哪个顺序正确?()(A)输入→Reduce→Shuffle→Map→输出(B)输入→Map→Shuffle→Reduce→输出(C)输入→Shuffle→Map→Reduce→输出(D)输入→Map→Reduce→Shuffle→输出6. 只启动HDFS,启动成功后,查看JPS,下面那个进程不在其中?()(A)HMaster(B)DataNode(C)Secondary NameNode(D)NameNode7. 下面选项不属于Amazon提供的云计算服务的是()。
(A)弹性计算云服务EC2 (B)简单存储服务S3(C)简单队列服务SQS (D)Net服务8. 下列关于Hive的介绍错误的是()。
(A)Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据(B)Hive是构建在Hadoop之上的一个数据仓库工具(C)数据仓库Hive不需要借助于HDFS等就可以完成数据的存储(D)Hive起源于Facebook内部信息处理平台9. ZooKeeper在集群模式下运行,那么在部署ZooKeeper集群时,至少有几个节点?()(A)4(B)3(C)2(D)110. 以下不属于Gossip协议优点的是()。
2020年最新公需科目《大数据》考试题(含答案) 一、单选题1.大数据的起源是(C )。
(单选题)A.金融B.电信C.互联网D.公共管理2.智慧城市的构建,不包含( C)。
(单选题)A.数字城市B.物联网C.联网监控D.云计算大数据的最显著特征是( A)。
(单选题)A.数据规模大B.数据类型多样C.数据处理速度快D.数据价值密度高3.万维网之父是( C)。
(单选题)A.彼得·德鲁克B.舍恩伯格C.蒂姆·伯纳斯-李D.斯科特·布朗4.支撑大数据业务的基础是( B)。
(单选题)A.数据科学B.数据应用C.数据硬件D.数据人才5.下列关于网络用户行为的说法中,错误的是( C)。
(单选题)A.网络公司能够捕捉到用户在其网站上的所有行为B.用户离散的交互痕迹能够为企业提升服务质量提供参考C.数字轨迹用完即自动删除D.用户的隐私安全很难得以规范保护二、多选题6.医疗健康数据的基本情况不包括以下哪项? CA.诊疗数据B.个人健康管理数据C.公共安全数据D.健康档案数据7.以下说法正确的有哪些?A.机器的智能方式和人是完全一样的B.机器的智能方式是结果导向的C.机器的智能方式和人的智能不同D.机器产生智能的方式是通过数据.数学模型8.宁家骏委员指出,()主导了21世纪。
A.移动支付B.大数据C.物联网D.云计算9.2015年8月31日,国务院印发了《促进大数据发展行动纲要》。
正确错误10.韩国政府利用位置信息和通话记录数据,规划出合理的公交线路,提升了政府科学决策和公共服务水平,提高了公众满意度。
正确错误11.网球比赛,与其他体育项目一样,涉及大量数据。
正确错误12.吴军博士认为未来二十年就是()为王的时代。
CA.文化B.工业C.数据D.农业13.运用大数据进行大治理要做到()。
ABCD分A.用数据决策B.用数据管理C.用数据说话D.用数据创新14.大数据时代的五个无处不在,具体指的是().服务无处不在。
岭南师范学院2015 年- 2016 学年度第二学期期末考试试题A卷(考试时间: 120 分钟)考试科目:大数据核心技术一、单项选择题(每小题 2 分,共 30 分)请把答案写在下表中,写在试题后无效。
1. 下面哪个程序负责 HDFS 数据存储。
(C )A. NameNodeB. JobtrackerC. DatanodeD. secondaryNameNode2. HDFS 中的 block 默认保存几个备份。
( A )A. 3 份B. 2 份C. 1 份D. 不确定3. HDFS1.0 默认 Block Size大小是多少。
( B )A. 32MBB. 64MBC. 128MBD. 256MB4. 下面哪个进程负责 MapReduce 任务调度。
( B )A. NameNodeB. JobtrackerC. TaskTrackerD. secondaryNameNode5. Hadoop1.0默认的调度器策略是哪个。
( A )A. 先进先出调度器B. 计算能力调度器C. 公平调度器D. 优先级调度器6. Client 端上传文件的时候下列哪项正确?( B )A. 数据经过 NameNode 传递给 DataNodeB. Client 端将文件切分为 Block,依次上传C. Client 只上传数据到一台 DataNode,然后由 NameNode 负责 Block 复制工作D. 以上都不正确7. 在实验集群的master节点使用jps命令查看进程时,终端出现以下哪项能说明Hadoop 主节点启动成功?( D )A. Namenode, Datanode, TaskTrackerB. Namenode, Datanode, secondaryNameNodeC. Namenode, Datanode, HMasterD. Namenode, JobTracker, secondaryNameNode8. 若不针对MapReduce编程模型中的key和value值进行特别设置,下列哪一项是MapReduce不适宜的运算。
( D )A. MaxB. MinC. CountD. Average9. MapReduce编程模型,键值对<key, value>的key必须实现哪个接口?( A )A. WritableComparableB. ComparableC. WritableD. LongWritable10. 以下哪一项属于非结构化数据。
(C)A. 企业ERP数据B. 财务系统数据C. 视频监控数据D. 日志数据11. HBase数据库的BlockCache缓存的数据块中,哪一项不一定能提高效率。
( D )A. –ROOT-表B. .META.表C. HFile indexD. 普通的数据块12. HBase是分布式列式存储系统,记录按什么集中存放。
( A )A. 列族B. 列C. 行D. 不确定13. HBase的Region组成中,必须要有以下哪一项。
( B )A. StoreFileB. MemStoreC. HFileD. MetaStore14. 客户端首次查询HBase数据库时,首先需要从哪个表开始查找。
( B )A. .META.B. –ROOT-C. 用户表D. 信息表15、设计分布式数据仓库hive的数据表时,为取样更高效,一般可以对表中的连续字段进行什么操作。
( A )A. 分桶B. 分区C. 索引D. 分表二、判断题(每题 2 分,共 16 分)请在下表中填写√或者×,写在试题后无效。
1.Hadoop 支持数据的随机读写。
(hbase支持,hadoop不支持)(错)2. NameNode 负责管理元数据信息metadata,client 端每次读写请求,它都会从磁盘中读取或会写入 metadata 信息并反馈给 client 端。
(内存中读取)(错)3. MapReduce 的 input split 一定是一个 block。
(默认是)(错)4. MapReduce适于PB级别以上的海量数据在线处理。
(离线)(错)5. 链式MapReduce计算中,对任意一个MapReduce作业,Map和Reduce阶段可以有无限个Mapper,但Reducer只能有一个。
(对)6. MapReduce计算过程中,相同的key默认会被发送到同一个reduce task处理。
(对)7. HBase对于空(NULL)的列,不需要占用存储空间。
(没有则空不存储)(对)8. HBase可以有列,可以没有列族(column family)。
(有列族)(错)三、简答题(每小题 5 分,共 20 分)1. 简述大数据技术的特点。
答:Volume(大体量):即可从数百TB到数十数百PB、甚至EB规模。
Variety(多样性):即大数据包括各种格式和形态的数据。
Velocity(时效性):即很多大数据需要在一定的时间限度下得到及时处理。
Veracity(准确性):即处理的结果要保证一定的准确性。
Value(大价值):即大数据包含很多深度的价值,大数据分析挖掘和利用带来巨大的商业价值。
2. 启动Hadoop系统,当使用bin/start-all.sh命令启动时,请给出集群各进程启动顺序。
答:启动顺序:namenode –> datanode -> secondarynamenode -> resourcemanager -> nodemanage r3. 简述HBase的主要技术特点。
答:(1)列式存储(2)表数据是稀疏的多维映射表(3)读写的严格一致性(4)提供很高的数据读写速度(5)良好的线性可扩展性(6)提供海量数据(7)数据会自动分片(8)对于数据故障,hbase是有自动的失效检测和恢复能力。
(9)提供了方便的与HDFS和MAPREDUCE集成的能力。
4. Hive数据仓库中,创建了以下外部表,请给出对应的HQL查询语句CREATE EXTERNAL TABLE sogou_ext (ts STRING, uid STRING, keyword STRING,rank INT, order INT, url STRING,year INT, month INT, day INT, hour INT)COMMENT 'This is the sogou search data of extend data'ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t'STORED AS TEXTFILELOCATION '/sogou_ext/20160508';(1)给出独立uid总数的HQL语句答:select count(distinct UID) from sogou_ext;(2)对于keyword,给出其频度最高的20个词的HQL语句答:select keyword from sogou_ext group by keyword order by order desc limit 20;四、设计题(每小题 8 分,共 24 分)1. 100万个字符串,其中有些是相同的(重复),需要把重复的全部去掉,保留没有重复的字符串。
请结合MapReduce编程模型给出设计思路或核心代码。
P228Public static class ProjectionMap extends Mapper<LongWritable,Text,Text,NullWritable>{Private int clo;Project void setup(Context context) throws IOException,InterruptedException{Col=context.getConfiguration().getInt(“col”,0);}Public void map(LongWritable offset,Text line,Context context){RelationA record=new RelationA (line.toString());Context.write(newText(record.getCol(col)),NullWritable.get());}}REDUCE端实现代码:Public static class ProjectionRedice extends Reducer<Text,NullWritable,Text,NullWritable>Public void reduce(Text key,Iterable<NullWritable> value,Context context)throws IOException,InterruptedException{Context.write(key,NullWritable.get());}2. 倒排索引设计。
有一个文档库,包含有大量的文档,现需要使用MapReduce编程技术对文档内容建立一个倒排索引库。
要求Reduce最后输出键值对为<单词, 文件名#偏移量>,并且前后输出的相同的key 所对应的文件名是字典序的。
如word1 doc1#200word1 doc2#10word2 doc2#10假设在map阶段已经获取了当前split分片的文件名是 String filename。
请按要求给出设计思路或核心代码。
Map(){String filename=fileSplit.getPath().getName();String temp=new String();String line=value.toString().toLowerCase();StringTokenizer iter=new StringTokenizer(line);For(;itr.hasMoreTokens();){Temp=iter.nextToken();If(!stopwords contains(temp)){Text word=new Text();Word.set(temp+”#”+fileName);Context.write(word,new IntWritable(1));}}}Reducer{Private IntWritable result=new IntWritable();Public void reduce(Text ,key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{Int sum=0;For(InWritable val:values){Sum+=val.get();}Result.set(sum);Context.write(key,result);}}3. 请在下面程序的下划线中补充完整程序(共8处)。