
·在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。问该模式识别问题所需判别函数的最少数目是多少?
应该是252142
6
*74132
7=+=+
=++C 其中加一是分别3类 和 7类
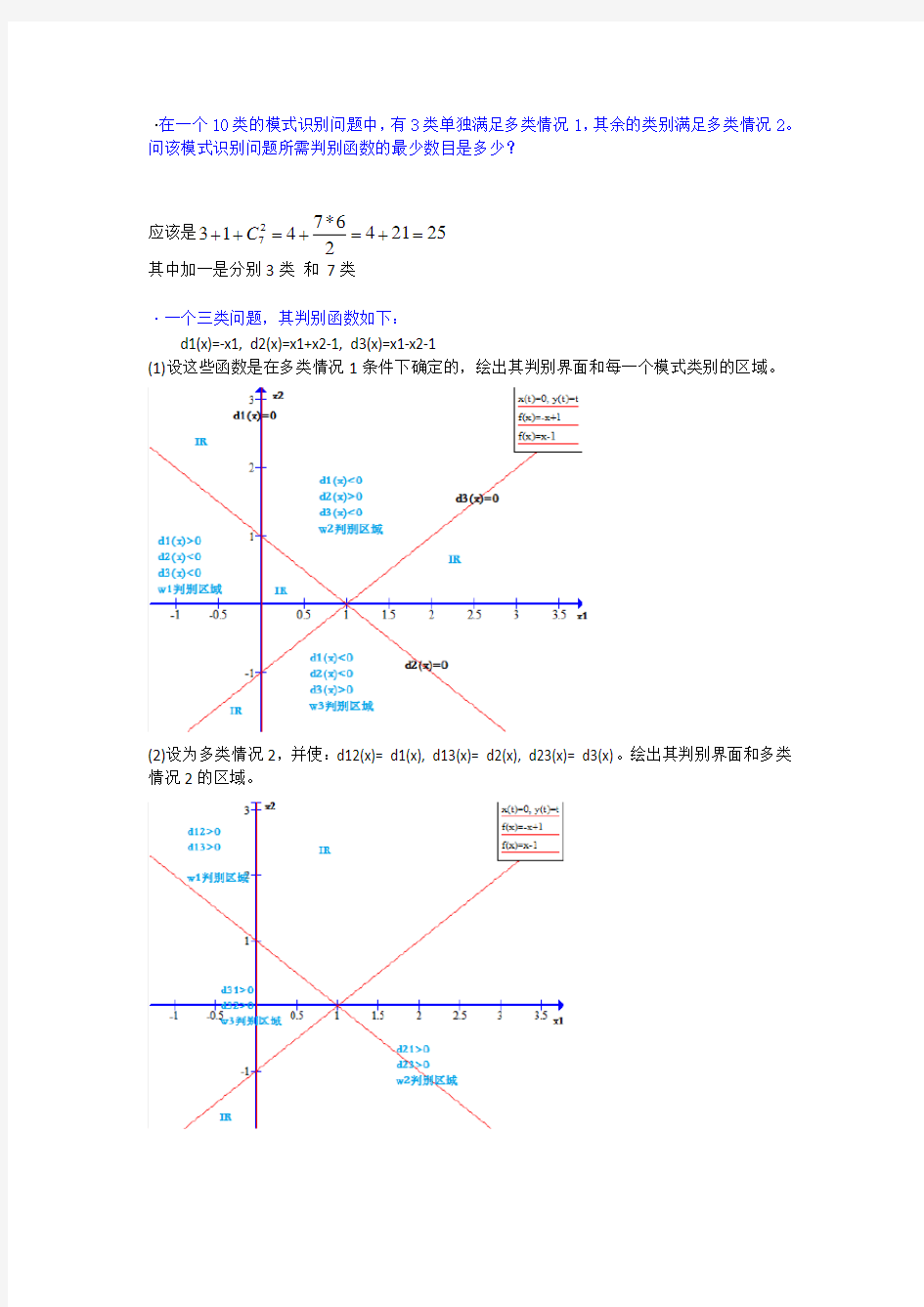
·一个三类问题,其判别函数如下: d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-1
(1)设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。
(2)设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)= d3(x)。绘出其判别界面和多类情况2的区域。
(3)设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。
·两类模式,每类包括5个3维不同的模式,且良好分布。如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。) 如果线性可分,则4个
建立二次的多项式判别函数,则102
5 C 个
·(1)用感知器算法求下列模式分类的解向量w: ω1: {(0 0 0)T , (1 0 0)T , (1 0 1)T , (1 1 0)T } ω2: {(0 0 1)T , (0 1 1)T , (0 1 0)T , (1 1 1)T }
将属于ω2的训练样本乘以(-1),并写成增广向量的形式。
x ①=(0 0 0 1)T , x ②=(1 0 0 1)T , x ③=(1 0 1 1)T , x ④=(1 1 0 1)T
x ⑤=(0 0 -1 -1)T , x ⑥=(0 -1 -1 -1)T , x ⑦=(0 -1 0 -1)T , x ⑧=(-1 -1 -1 -1)T
第一轮迭代:取C=1,w(1)=(0 0 0 0) T
因w T (1) x ① =(0 0 0 0)(0 0 0 1) T
=0 ≯0,故w(2)=w(1)+ x ① =(0 0 0 1)
因w T (2) x ② =(0 0 0 1)(1 0 0 1) T =1>0,故w(3)=w(2)=(0 0 0 1)T
因w T (3)x ③=(0 0 0 1)(1 0 1 1)T =1>0,故w(4)=w(3) =(0 0 0 1)T
因w T (4)x ④=(0 0 0 1)(1 1 0 1)T =1>0,故w(5)=w(4)=(0 0 0 1)T
因w T (5)x ⑤=(0 0 0 1)(0 0 -1 -1)T =-1≯0,故w(6)=w(5)+ x ⑤=(0 0 -1 0)T
因w T (6)x ⑥=(0 0 -1 0)(0 -1 -1 -1)T =1>0,故w(7)=w(6)=(0 0 -1 0)T
因w T (7)x ⑦=(0 0 -1 0)(0 -1 0 -1)T =0≯0,故w(8)=w(7)+ x ⑦=(0 -1 -1 -1)T
因w T (8)x ⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T =3>0,故w(9)=w(8) =(0 -1 -1 -1)T
因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。 第二轮迭代:
因w T (9)x ①=(0 -1 -1 -1)(0 0 0 1)T =-1≯0,故w(10)=w(9)+ x ① =(0 -1 -1 0)T
因w T (10)x ②=(0 -1 -1 0)( 1 0 0 1)T =0≯0,故w(11)=w(10)+ x ② =(1 -1 -1 1)T
因w T (11)x ③=(1 -1 -1 1)( 1 0 1 1)T =1>0,故w(12)=w(11) =(1 -1 -1 1)T
因w T (12)x ④=(1 -1 -1 1)( 1 1 0 1)T =1>0,故w(13)=w(12) =(1 -1 -1 1)T
因w T (13)x ⑤=(1 -1 -1 1)(0 0 -1 -1)T =0≯0,故w(14)=w(13)+ x ⑤ =(1 -1 -2 0)T
因w T (14)x ⑥=(1 -1 -2 0)( 0 -1 -1 -1)T =3>0,故w(15)=w(14) =(1 -1 -2 0)T
因w T (15)x ⑧=(1 -1 -2 0)( 0 -1 0 -1)T =1>0,故w(16)=w(15) =(1 -1 -2 0)T
因w T (16)x ⑦=(1 -1 -2 0)( -1 -1 -1 -1)T =2>0,故w(17)=w(16) =(1 -1 -2 0)T
因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第三轮迭代。 第三轮迭代:
w(25)=(2 -2 -2 0);
因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第四轮迭代。 第四轮迭代:
w(33)=(2 -2 -2 1)
因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第五轮迭代。 第五轮迭代:
w(41)=(2 -2 -2 1)
因为该轮迭代的权向量对全部模式都能正确判别。所以权向量即为(2 -2 -2 1),相应的判别函数为123()2221d x x x x =--+
(2)编写求解上述问题的感知器算法程序。 见附件
·用多类感知器算法求下列模式的判别函数: ω1: (-1 -1)T ω2: (0 0)T ω3: (1 1)T 将模式样本写成增广形式:
x ①=(-1 -1 1)T , x ②=(0 0 1)T , x ③=(1 1 1)T
取初始值w 1(1)=w 2(1)=w 3(1)=(0 0 0)T
,C=1。
第一轮迭代(k=1):以x ①=(-1 -1 1)T
作为训练样本。
d 1(1)=)1(1T
w x ①=(0 0 0)(-1 -1 1)T
=0
d 2(1)=)1(2T
w x ①=(0 0 0)(-1 -1 1)T
=0
d 3(1)=)1(3T w x ①=(0 0 0)(-1 -1 1)T
=0
因d 1(1)≯d 2(1),d 1(1)≯d 3(1),故
w 1(2)=w 1(1)+x ①=(-1 -1 1)
T
w 2(2)=w 2(1)-x ①=(1 1 -1)T
w 3(2)=w 3(1)-x ①=(1 1 -1)T
第二轮迭代(k=2):以x ②=(0 0 1)T
作为训练样本
d 1(2)=)2(1T
w x ②=(-1 -1 1)(0 0 1)T
=1
2d 3(2)=)2(3T
w x ②=(1 1 -1)(0 0 1)T
=-1
因d 2(2)≯d 1(2),d 2(2)≯d 3(2),故
w 1(3)=w 1(2)-x ②=(-1 -1 0)
T
w 2(3)=w 2(2)+x ②=(1 1 0)T
w 3(3)=w 3(2)-x ②=(1 1 -2)T
第三轮迭代(k=3):以x ③=(1 1 1)T
作为训练样本
d 1(3)=)3(1T
w x ③=(-1 -1 0)(1 1 1)T
=-2
d 2(3)=)3(2T
w x ③=(1 1 0)(1 1 1)T
=2
d 3(3)=)3(3T w x ③=(1 1 -2)(1 1 1)T
=0
因d 3(3)≯d 2(3),故
w 1(4)=w 1(3) =(-1 -1 0)
T
w 2(4)=w 2(3)-x ③=(0 0 -1)T
w 3(4)=w 3(3)+x ③=(2 2 -1)T
第四轮迭代(k=4):以x ①=(-1 -1 1)T
作为训练样本
d 1(4)=)4(1T
w x ①=(-1 -1 0)(-1 -1 1)T
=2
d 2(4)=)4(2T
w x ①=(0 0 -1)(-1 -1 1)T
=-1
d 3(4)=)4(3T w x ①=(2 2 -1)(-1 -1 1)T
=-5
因d 1(4)>d 2(4),d 1(4)>d 3(4),故
w 1(5)=w 1(4) =(-1 -1 0)
T
w 2(5)=w 2(4) =(0 0 -1)T
w 3(5)=w 3(4) =(2 2 -1)T
第五轮迭代(k=5):以x ②=(0 0 1)T
作为训练样本
d 1(5)=)5(1T
w x ②=(-1 -1 0)(0 0 1)T
=0
d 2(5)=)5(2T
w x ②=(0 0 -1)(0 0 1)T
=-1
d 3(5)=)5(3T
w x ②=(2 2 -1)(0 0 1)T
=-1
因d 2(5) ≯d 1(5),d 2(5) ≯d 3(5),故
w 1(6)=w 1(5)-x ② =(-1 -1 -1)
w 2(6)=w 2(5)+x ②=(0 0 0) w 3(6)=w 3(5)-x ②=(2 2 -2)
第六轮迭代(k=6):以x ③=(1 1 1)T
作为训练样本
d 1(6)=)6(1T
w x ③=(-1 -1 -1)(1 1 1)T
=-3
2d 3(6)=)6(3T
w x ③=(2 2 -2)(1 1 1)T
=2
因d 3(6)>d 1(6),d 3(6)>d 2(6),故
w 1(7)=w 1(6)
w 2(7)=w 2(6) w 3(7)=w 3(6)
第七轮迭代(k=7):以x ①=(-1 -1 1)T
作为训练样本
d 1(7)=)7(1T
w x ①=(-1 -1 -1)(-1 -1 1)T
=1
d 2(7)=)7(2T
w x ①=(0 0 0)(-1 -1 1)T
=0
d 3(7)=)7(3T
w x ①=(2 2 -2)(-1 -1 1)T =-6
因d 1(7)>d 2(7),d 1(7)>d 3(7),分类结果正确,故权向量不变。
由于第五、六、七次迭代中x ①、x ②、x ③均已正确分类,所以权向量的解为:
w 1=(-1 -1 -1)
T
w 2=(0 0 0)T
w 3=(2 2 -2)T
三个判别函数:
d 1(x)=- x 1 -x 2-1 d 2(x)=0
d 3(x)=2x 1+2x 2-2
·采用梯度法和准则函数
2
2
])[(81),,(b x w b x w x
b x w J T T ---=
式中实数b>0,试导出两类模式的分类算法。
[][]
)sign(*x -x *||)(|||412
b x w b x w b x w x w J T
T T ----=??|
其中,
???≤-->+=-010
-1)(b x w if b x w if b x w sign T
T T
当0>-b x w T 时,则w(k+1) = w(k),此时不对权向量进行修正;当
0≤-b x w T 时,则)(||
|)()1(2
b x w x Cx k w k w k T
k k k -+
=+|,需对权向量进行校正,
初始权向量w(1)的值可任选。即
???
??≤-->-?+=+0)(|||00)()1(2b x w if b x w x x b x w if C k w k w T k T
k k k T |
用二次埃尔米特多项式的势函数算法求解以下模式的分类问题 ω1: {(0 1)T , (0 -1)T }
ω2: {(1 0)T , (-1 0)T } (1)
11120102221201122
2
3312012224412110215512111212
2
6612112212()(,)()()1
()(,)()()2()(,)()()42()(,)()()2()(,)()()4()(,)()()2(4x x x H x H x x x x H x H x x x x x H x H x x x x x H x H x x x x x H x H x x x x x x H x H x x x ????????????=========-=========2771221021288122112212299122122122)
()(,)()()42()(,)()()2(42)
()(,)()()(42)(42)
x x x H x H x x x x x H x H x x x x x x H x H x x x ??????-===-===-===--
按第一类势函数定义,得到势函数
9
1
(,)()()k i i k i K x x x x ??==∑
其中T
x x x ),(21=,T k k k x x x ),(21=
(2)通过训练样本逐步计算累积位势K(x)
给定训练样本:ω1类为x ①=(0 1)T , x ②=(0 -1)T
ω2类为x ③=(1 0)T , x ④=(-1 0)T
累积位势K(x)的迭代算法如下
第一步:取x ①=(0 1)T
∈ω1,故
22222
12211212()152040243264K X x x x x x x x =-+++--
第二步:取x ②=(0 -1)T
∈ω1,故K 1(x ②)=5
因K 1(x ②)>0且x ②∈ω1,故K 2(x)=K 1(x)
第三步:取x ③=(1 0)T
∈ω2,故K 2(x ③)=9
因K 2(x ③)>0且x ③∈ω2,故
2
23232211()()(,)20162016K X K X K X X x x x x =-=+--
第四步:取x ④=(-1 0)T
∈ω2,故K 3(x ④)=4 因K 3(x ④)>0且x ④∈ω2,
22222
4342121212()()(,)152********K X K X K X X x x x x x x x =-=+---+
将全部训练样本重复迭代一次,得
第五步:取x ⑤=x ①=(0 1)T
∈ω1,K 4(x ⑤)=27>0
故K 5(x)=K 4(x)
第六步:取x ⑥=x ②=(0 -1)T
∈ω1,K 5(x ⑥)=-13<0
故22
65612()()(,)3232K X K X K X X x x =+=-+
第七步:取x ⑦=x ③=(1 0)T
∈ω2,K 6(x ⑦)=-32<0 故K 7(x)=K 6(x)
第八步:取x ⑧=x ④=(-1 0)T
∈ω2,K 7(x ⑧)=-32<0
故K 8(x)=K 7(x)
第九步:取x ⑨=x ①=(0 1)T
∈ω1 ,K 8(x ⑨)=32>0 故K 9(x)=K 8(x)
第十步:取x ⑩=x ② =(0 -1)T
∈ω1,K 9(x ⑩)=32>0 故K 10(x)=K 9(x)
其中第七步到第十步的迭代过程中对全部训练样本都能正确分类,因此算法收敛于判别函数
221012
()()3232d X K X x x ==-+
·用下列势函数
2
||||(,)k X X k K X X e α--=
求解以下模式的分类问题 ω1: {(0 1)T , (0 -1)T } ω2: {(1 0)T , (-1 0)T }
取α=1,在二维情况下势函数为
]
)()[(2222112
),(k k k
x x x x x x k e
e
x x K -+----==
这里:ω1类为x ①=(0 1)T
, x ②=(0 -1)T
ω2类为x ③=(1 0)T , x ④=(-1 0)T
可以看出,这两类模式是线性不可分的。算法步骤如下:
第一步:取x ①=(0 1)T
∈ω1,则22112()exp{(1)}K X x x =---
第二步:取x ②=(0 -1)T
∈ω1
因K 1(x ②)=e -(4+0)=e -4
>0,故K 2(x)=K 1(x)
第三步:取x ③=(1 0)T
∈ω2
因K 2(x ③)=e -(1+1)=e -2
>0,故
22223231212()()(,)exp{(1)}exp{(1)}
K X K X K X X x x x x =-=-------第四步:取x ④=(-1 0)T
∈ω2
因K 3(x ④)=e -(1+1) - e
-(4+0) =e -2 - e -4
>0,故
222222
434121212()()(,)exp{(1)}exp{(1)}exp{(1)}
K X K X K X X x x x x x x =-=---------+-第五步:取x ⑤=(0 1)T
∈ω1
因K 4(x ⑤)=1-e -(1+1) - e
-(1+1) =1-e -2 - e -2
>0,故K 5(x)=K 4(x) 第六步:取x ⑥=(0 -1)T
∈ω1
因K 5(x ⑥)= e -(0+4) - e
-(1+1) - e -(1+1) =e -4 - e -2- e -2
<0,故222265612122
2
2
212
12
()()(,)exp{(1)}exp{(1)} exp{(1)}exp{(1)}
K X K X K X X x x x x x x x x =+=--++---------+-
第七步:取x ⑦=(1 0)T
∈ω2
因K 6(x ⑦)= e -(1+1) + e
-(1+1)–1- e -(4+0) =e -2 +e -2-1-e -4
<0 故76()()K X K X =
第八步:取x ⑧=(-1 0)T ∈ω2
因K 7(x ⑧)= e -(1+1) + e
-(1+1) - e -(4+0) - 1=e -2 +e -2-e -4
- 1<0
故87()()K X K X =
第九步:取x ⑨=(0 1)T
∈ω1
因K 8(x ⑨)= e -(0+4) + 1- e
-(1+1) - e -(1+1)=e -4 +1-e -2-e -2
>0 故98()()K X K X =
第十步:取x ⑩=(0 -1)T
∈ω1
因K 8(x ⑨)= 1 + e -(0+4)- e -(1+1) - e -(1+1)= 1+e -4-e -2-e -2
>0 故109()()K X K X =
最后,从第七步到第十步的迭代过程中,全部模式都已正确分类,故
算法已经收敛于判别函数:
22221012122
22
212
12
()()exp{(1)}exp{(1)} exp{(1)}exp{(1)}
d X K X x x x x x x x x ==--++---------+-
·在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。问该模式识别问题所需判别函数的最少数目是多少? 应该是252142 6 *74132 7=+=+ =++C 其中加一是分别3类 和 7类 ·一个三类问题,其判别函数如下: d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-1 (1)设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类别的区域。 (2)设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)= d3(x)。绘出其判别界面和多类情况2的区域。
(3)设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和每类的区域。 ·两类模式,每类包括5个3维不同的模式,且良好分布。如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。) 如果线性可分,则4个 建立二次的多项式判别函数,则102 5 C 个 ·(1)用感知器算法求下列模式分类的解向量w: ω1: {(0 0 0)T , (1 0 0)T , (1 0 1)T , (1 1 0)T } ω2: {(0 0 1)T , (0 1 1)T , (0 1 0)T , (1 1 1)T } 将属于ω2的训练样本乘以(-1),并写成增广向量的形式。 x ①=(0 0 0 1)T , x ②=(1 0 0 1)T , x ③=(1 0 1 1)T , x ④=(1 1 0 1)T x ⑤=(0 0 -1 -1)T , x ⑥=(0 -1 -1 -1)T , x ⑦=(0 -1 0 -1)T , x ⑧=(-1 -1 -1 -1)T 第一轮迭代:取C=1,w(1)=(0 0 0 0) T 因w T (1) x ① =(0 0 0 0)(0 0 0 1) T =0 ≯0,故w(2)=w(1)+ x ① =(0 0 0 1) 因w T (2) x ② =(0 0 0 1)(1 0 0 1) T =1>0,故w(3)=w(2)=(0 0 0 1)T 因w T (3)x ③=(0 0 0 1)(1 0 1 1)T =1>0,故w(4)=w(3) =(0 0 0 1)T 因w T (4)x ④=(0 0 0 1)(1 1 0 1)T =1>0,故w(5)=w(4)=(0 0 0 1)T 因w T (5)x ⑤=(0 0 0 1)(0 0 -1 -1)T =-1≯0,故w(6)=w(5)+ x ⑤=(0 0 -1 0)T 因w T (6)x ⑥=(0 0 -1 0)(0 -1 -1 -1)T =1>0,故w(7)=w(6)=(0 0 -1 0)T 因w T (7)x ⑦=(0 0 -1 0)(0 -1 0 -1)T =0≯0,故w(8)=w(7)+ x ⑦=(0 -1 -1 -1)T 因w T (8)x ⑧=(0 -1 -1 -1)(-1 -1 -1 -1)T =3>0,故w(9)=w(8) =(0 -1 -1 -1)T 因为只有对全部模式都能正确判别的权向量才是正确的解,因此需进行第二轮迭代。 第二轮迭代: 因w T (9)x ①=(0 -1 -1 -1)(0 0 0 1)T =-1≯0,故w(10)=w(9)+ x ① =(0 -1 -1 0)T
第三章练习题 一、判断正误并解释 1.所谓商品的效用,就是指商品的功能。 分析:这种说法是错误的。商品的效用指商品满足人的欲望的能力,指消费者在消费商品时所感受到的满足程度 2.不同的消费者对同一件商品的效用的大小可以进行比较。 分析:这种说法是错误的。同一个消费者对不同商品的效用大小可以比较。但由于效用是主观价值判断,所以同一商品对不同的消费者来说,其效用的大小是不可比的。 3.效用的大小,即使是对同一件商品来说,也会因人、因时、因地而异。分析:这种说法是正确的。同一商品给消费者的主观心理感受会随环境的改变而改变。 4.边际效用递减规律是指消费者消费某种消费品时,随着消费量的增加,其最后一单位消费品的效用递减。 分析:这种说法是错误的。必须在某一特定的时间里,连续性增加。5.预算线的移动表示消费者的货币收入发生变化。 分析:这种说法是错误的。只有在收入变动,商品价格不变,预算线发生平移时,预算线的移动才表
示消费者的收入发生了变化。 6.效应可以分解为替代效应和收入效应,并且替代效应与收入效应总是反向变化。 分析:这种说法是错误的。正常物品的替代效应和收入效应是同向变化的。 二、选择 1.当总效用增加时,边际效用应该:(A ) A.为正值,但不断减少; B.为正值,且不断增加; C.为负值,且不断减少; D.以上都不对 2.当某消费者对商品X的消费达到饱合点时,则边际效用MUχ为:(C ) A.正值B.负值C.零D.不确定 3.正常物品价格上升导致需求量减少的原因在于:(C ) A.替代效应使需求量增加,收入效应使需求量减少; B.替代效应使需求量增加,收入效应使需求量增加;
1.简述模式的概念及其直观特性,模式识别的分类,有哪几种方法。(6’) 答(1):什么是模式?广义地说,存在于时间和空间中可观察的物体,如果我们可以区别它们是否相同或是否相似,都可以称之为模式。 模式所指的不是事物本身,而是从事物获得的信息,因此,模式往往表现为具有时间和空间分布的信息。 模式的直观特性:可观察性;可区分性;相似性。 答(2):模式识别的分类: 假说的两种获得方法(模式识别进行学习的两种方法): 监督学习、概念驱动或归纳假说; 非监督学习、数据驱动或演绎假说。 模式分类的主要方法: 数据聚类:用某种相似性度量的方法将原始数据组织成有意义的和有用的各种数据 集。是一种非监督学习的方法,解决方案是数据驱动的。 统计分类:基于概率统计模型得到各类别的特征向量的分布,以取得分类的方法。 特征向量分布的获得是基于一个类别已知的训练样本集。是一种监督分类的方法, 分类器是概念驱动的。 结构模式识别:该方法通过考虑识别对象的各部分之间的联系来达到识别分类的目 的。(句法模式识别) 神经网络:由一系列互相联系的、相同的单元(神经元)组成。相互间的联系可以 在不同的神经元之间传递增强或抑制信号。增强或抑制是通过调整神经元相互间联 系的权重系数来(weight)实现。神经网络可以实现监督和非监督学习条件下的分 类。 2.什么是神经网络?有什么主要特点?选择神经网络模式应该考虑什么因 素?(8’) 答(1):所谓人工神经网络就是基于模仿生物大脑的结构和功能而构成的一种信息处理系统(计算机)。由于我们建立的信息处理系统实际上是模仿生理神经网络,因此称它为人工神经网络。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。 人工神经网络的两种操作过程:训练学习、正常操作(回忆操作)。 答(2):人工神经网络的特点: 固有的并行结构和并行处理; 知识的分布存储; 有较强的容错性; 有一定的自适应性; 人工神经网络的局限性: 人工神经网络不适于高精度的计算; 人工神经网络不适于做类似顺序计数的工作; 人工神经网络的学习和训练往往是一个艰难的过程; 人工神经网络必须克服时间域顺序处理方面的困难; 硬件限制; 正确的训练数据的收集。 答(3):选取人工神经网络模型,要基于应用的要求和人工神经网络模型的能力间的匹配,主要考虑因素包括:
第三章练习题及参考答案 一、材料分析题 1.分析下列关于人民群众在历史上的作用问题的不同观点: 【材料1】 孟轲说:“民为贵,社稷次之,君为轻。”荀子认为:“君者,舟也;庶人者,水也。水则载舟,水则覆舟。” 【材料2】 梁启超说:“大人物心理之动进稍易其轨而全部历史可以改观”,“舍英雄几无历史”。胡适说:英雄人物“一言可以兴邦,一言可以丧邦”。 【材料3】 黑格尔认为,历史不是个人随意创造的,而是决定于某种“客观精神”。伟大人物是“世界精神的代理人”,拿破仑代表了“世界精神”,他“骑着马,驰骋全世界,主宰全世界”。世界历史是伟大人物和王朝的历史,“而不是一般人民的历史”。 【材料4】 AHA12GAGGAGAGGAFFFFAFAF
毛泽东说:“人民,只有人民,才是创造世界历史的动力。”马克思说:“人们自己创造自己的历史,但是他们并不是随心所欲地创造,并不是在他们自己选定的条件下创造,而是在直接碰到的,既定的,从过去承继下来的条件下创造。” 【材料5】 马克思指出:“如爱尔维修所说的,每一个社会时代都需要有自己的伟大人物,如果没有这样的人物,它就要创造出这样的人物来。”恩格斯也说:“恰巧某个伟大人物在一定时间出现于某一国家,这当然纯粹是一种偶然现象。但是,如果我们把这个人除掉,那时就会需要有另外一个人来代替它,并且这个代替者是会出现的。 AHA12GAGGAGAGGAFFFFAFAF
” 请回答: ⑴材料1思想的合理性和局限性。 ⑵分别指出材料2和材料3的思想倾向,说明材料2和材料3的共同点。 ⑶材料4是什么观点? 材料5体现了什么思想? 2.用有关历史发展规律性的原理分析下列材料: 【材料1】 人们必须认识到,人类进步能够改变的只有其速度,而不会出现任何发展顺序的颠倒或跃过任何重要的阶段。(摘自孔德:《实证哲学》) 【材料2】 一个国家应该而且可以向其他国家学习。一个社会即使探索到了本身运动的自然规律,……它还是既不能跳过也不能用法令取消自然的发展阶段。但是它能缩短和减轻分娩的痛苦。(摘自马克思:《资本论》) 【材料3】 AHA12GAGGAGAGGAFFFFAFAF
第5章:线性判别函数 第一部分:计算与证明 1. 有四个来自于两个类别的二维空间中的样本,其中第一类的两个样本为(1,4)T 和(2,3)T ,第二类的两个样本为(4,1)T 和(3,2)T 。这里,上标T 表示向量转置。假设初始的权向量a=(0,1)T ,且梯度更新步长ηk 固定为1。试利用批处理感知器算法求解线性判别函数g(y)=a T y 的权向量。 解: 首先对样本进行规范化处理。将第二类样本更改为(4,1)T 和(3,2)T .然后计算错分样本集: g(y 1)=(0,1)(1,4)T = 4 > 0 (正确) g(y 2)=(0,1)(2,3)T = 3 > 0 (正确) g(y 3)=(0,1)(-4,-1)T = -1 < 0 (错分) g(y 4)=(0,1)(-3,-2)T = -2 < 0 (错分) 所以错分样本集为Y={(-4,-1)T ,(-3,-2)T }. 接着,对错分样本集求和:(-4,-1)T +(-3,-2)T = (-7,-3)T 第一次修正权向量a ,以完成一次梯度下降更新:a=(0,1)T + (-7,-3)T =(-7,-2)T 再次计算错分样本集: g(y 1)=(-7,-2)(1,4)T = -15 <0 (错分) g(y 2)=(-7,-2)(2,3)T = -20 < 0 (错分) g(y 3)=(-7,-2)(-4,-1)T = 30 > 0 (正确) g(y 4)=(-7,-2)(-3,-2)T = 25 > 0 (正确) 所以错分样本集为Y={(1,4)T ,(2,3)T }. 接着,对错分样本集求和:(1,4)T +(2,3)T = (3,7)T 第二次修正权向量a ,以完成二次梯度下降更新:a=(-7,-2)T + (3,7)T =(-4,5)T 再次计算错分样本集: g(y 1) = (-4,5)(1,4)T = 16 > 0 (正确) g(y 2) =(-4,5)(2,3)T = 7 > 0 (正确) g(y 3) =(-4,5)(-4,-1)T = 11 > 0 (正确) g(y 4) =(-4,5)(-3,-2)T = 2 > 0 (正确) 此时,全部样本均被正确分类,算法结束,所得权向量a=(-4,5)T 。 2. 在线性感知算法中,试证明引入正余量b 以后的解区(a T y i ≥b)位于原来的解区之中(a T y i >0),且与原解区边界之间的距离为b/||y i ||。 证明:设a*满足a T y i ≥b,则它一定也满足a T y i >0,所以引入余量后的解区位于原来的解区a T y i >0之中。 注意,a T y i ≥b 的解区的边界为a T y i =b,而a T y i >0的解区边界为a T y i =0。a T y i =b 与a T y i =0两个边界之间的距离为b/||y i ||。(因为a T y i =0过坐标原点,相关于坐标原点到a T y i =b 的距离。) 3. 试证明感知器准则函数正比于被错分样本到决策面的距离之和。 证明:感知器准则函数为: ()() T Y J ∈=-∑y a a y 决策面方程为a T y=0。当y 为错分样本时,有a T y ≤0。此时,错分样本到决策面的
第三章部分习题答案 1、高级调度与低级调度的主要任务是什么?为什么要引入中级调度? 答:高级调度主要任务是根据某种算法,把外存上处于后备队列中的那些作业调入内存,也就是说高级调度的调度对象是作业。 低级调度主要任务是:决定就绪队列中的哪个进程应获得处理机,然后再由分派程序执行把处理机分配给该进程的具体操作。 中级调度的任务:使那些暂时不能运行的进程不再占用宝贵的内存资源,而将它们调至外存上去等待,把此时的进程状态称为就绪驻外存状态或挂起状态。当这些进程重又具备运行条件且内存又稍有空闲时,由中级调度来决定把外存上的那些又具备运行条件的就绪进程重新调入内存,并修改其状态为就绪状态,挂在就绪队列上等待进程调度。引入中级调度的主要目的是为了提高内存利用率和系统吞吐量。 2、何谓作业、作业步和作业流? 答:作业(Job):作业是一个比程序更为广泛的概念,它不仅包含了通常的程序和数据,而且还应配有一份作业说明书,系统根据该说明书来对程序的运行进行控制。 作业步(Job Step)。通常,在作业运行期间,每个作业都必须经过若干个相对独立,又相互关联的顺序加工步骤才能得到结果,我们把其
中的每一个加工步骤称为一个作业步,各作业步之间存在着相互联系,往往是把上一个作业步的输出作为下一个作业步的输入。 作业流:若干个作业进入系统后,被依次存放在外存上,这便形成了输入的作业流;在操作系统的控制下,逐个作业进行处理,于是便形成了处理作业流。 5、试说明低级调度的主要功能。 答:(1) 保存处理机的现场信息。 (2) 按某种算法选取进程。 (3) 把处理器分配给进程。 6、在抢占调度方式中,抢占的原则是什么? 答:(1) 优先权原则。 (2) 短作业(进程)优先原则。 (3) 时间片原则。 7、在选择调度方式和调度算法时,应遵循的准则是什么? 答:面向用户应遵循的准则是:(1) 周转时间短。(2) 响应时间快。 (3) 截止时间的保证。(4) 优先权准则。 面向系统应遵循的准则是:(1) 系统吞吐量高。(2) 处理机利用率好。(3) 各类资源的平衡利用。
{ 思考题 2.下列烯类单体适于何种机理聚合自由基聚合、阳离子聚合还是阴离子聚合并说明原因。 CH 2=CHCl CH 2 =CCl 2 CH 2 =CHCN CH 2 =C(CN) 2 CH 2 =CHCH 3 CH 2 =C(CH 3 ) 2 CH 2=CHC 6 H 5 CF 2 =CF 2 CH 2 =C(CN)COOR CH 2 =C(CH 3 )-CH=CH 2 答:CH 2 =CHCl:适合自由基聚合,Cl原子是吸电子基团,也有共轭效应,但均较弱。 CH 2=CCl 2 :自由基及阴离子聚合,两个吸电子基团。 CH 2 =CHCN:自由基及阴离子聚合,CN为吸电子基团。 CH 2=C(CN) 2 :阴离子聚合,两个吸电子基团(CN)。 CH 2=CHCH 3 :配位聚合,甲基(CH 3 )供电性弱。 / CH 2=CHC 6 H 5 :三种机理均可,共轭体系。 CF 2=CF 2 :自由基聚合,对称结构,但氟原子半径小。 CH 2 =C(CN)COOR:阴离子聚合,取代基为两个吸电子基(CN及COOR) CH 2=C(CH 3 )-CH=CH 2 :三种机理均可,共轭体系。 3. 下列单体能否进行自由基聚合,并说明原因。 CH 2=C(C 6 H 5 ) 2 ClCH=CHCl CH 2 =C(CH 3 )C 2 H 5 CH 3 CH=CHCH 3 CH 2=CHOCOCH 3 CH 2 =C(CH 3 )COOCH 3 CH 3 CH=CHCOOCH 3 CF 2 =CFCl : 答:CH 2=C(C 6 H 5 ) 2 :不能,两个苯基取代基位阻大小。 ClCH=CHCl:不能,对称结构。 CH 2=C(CH 3 )C 2 H 5 :不能,二个推电子基,只能进行阳离子聚合。 CH 3CH=CHCH 3 :不能,结构对称。 CH 2=CHOCOCH 3 :醋酸乙烯酯,能,吸电子基团。 CH 2=C(CH 3 )COOCH 3 :甲基丙烯酸甲酯,能。 CH 3CH=CHCOOCH 3 :不能,1,2双取代,位阻效应。 CF 2 =CFCl:能,结构不对称,F原子小。 ; 7.为什么说传统自由基聚合的激励特征是慢引发,快增长,速终止在聚合过程中, 聚合物的聚合度,转化率变化趋势如何 链引发反应是形成单体自由基活性种的反应。此反应为吸热反应,活化能高E = 105~150 kJ/mol,故反应速度慢。链增长反应为放热反应,聚合热约55~
作业1 用身高和/或体重数据进行性别分类(一) 基本要求: 用FAMALE.TXT和MALE.TXT的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。 具体做法: 1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。在分类器设计时可以考察采用不同先验概率(如0.5对0.5, 0.75对0.25, 0.9对0.1等)进行实验,考察对决策规则和错误率的影响。 图1-先验概率0.5:0.5分布曲线图2-先验概率0.75:0.25分布曲线 图3--先验概率0.9:0.1分布曲线图4不同先验概率的曲线 有图可以看出先验概率对决策规则和错误率有很大的影响。 程序:bayesflq1.m和bayeszcx.m
关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。比较相关假设和不相关假设下结果的差异。在分类器设计时可以考察采用不同先验概率(如0.5 vs. 0.5, 0.75 vs. 0.25, 0.9 vs. 0.1等)进行实验,考察对决策和错误率的影响。 训练样本female来测试 图1先验概率0.5 vs. 0.5 图2先验概率0.75 vs. 0.25 图3先验概率0.9 vs. 0.1 图4不同先验概率 对测试样本1进行试验得图
《马克思主义基本原理概论》第三章作业题 一、单项选择题(在每小题列出的选项中只有一个选项是正确的,请将正确选项前的字母填在题后的括号内)。 1.社会历史观的基本问题是( C ) A.生产力和生产关系的问题 B.社会规律和主观意识的关系问题 C.社会存在和社会意识的关系问题 D. 2.生产力诸要素中的主导因素是( C )ch3 A.劳动对象; B.劳动资料; C.劳动者; D.生产资料 3.划分生产关系类型的基本标志是(B ) A.产品的分配形式 B. C.人们在生产中的地位 D. 4.生产关系范畴反映的是(C )ch3 A.人与自然之间的关系 B.人与人之间的政治关系 C.人与人之间的经济关系 D.人与人之间的思想关系 5.“手推磨产生的是封建主为首的社会,蒸汽磨产生的是工业资本家为首的社会。”这句话是说(C ) A. B. C.生产力决定生产关系 D.生产力同生产关系相适应 6.人类社会发展最基本的规律是( C ) A.社会存在决定社会意识的规律 B.阶级斗争推动社会发展的规律 C.生产关系必须适合生产力的发展状况(性质)及其进一步发展的要求的规律 D.社会形态由低级到高级依次更替的规律 7.我国社会主义初级阶段实行公有制为主体,多种所有制经济共同发展的 基本经济制度的理论依据是( D A. B.唯物辩证法普遍联系的原理 C.上层建筑必须适合经济基础发展要求的规律 D.生产关系必须适合生产力发展状况及其进一步发展的要求的规律 8.在社会生活中,上层建筑对于社会发展的性质取决于( C ) A.国家政权的阶级属性 B.社会意识形态的性质 C.它所服务的经济基础的性质 D.社会生产力的性质 9. 阶级的实质是( C )。
第三章课后习题解答 1.处理机调度的主要目的是什么 【解答】处理机调度的主要目的是根据不同的系统,提供不同的处理机管理策略,以提高资源的利用率,提高系统的效率。具体地讲,处理机调度分为三个层次,即作业调度、对换和进程调度。作业调度的任务是,从外存上后备队列中,选择一些附合条件的作业调入内存,并为它创建进程、分配必要的资源。对换又称交换调度或中级调度,其主要任务是按照给定的原则和策略,将处于外存交换区中的就绪状态或等待状态的进程调入内存,或把处于内存就绪状态或内存等待状态的进程交换到外存交换区,交换调度主要涉及到内存管理与扩充。进程调度的任务是将CPU分配给一个处在就绪状态的进程。 2.高级调度与低级调度的功能是什么 【解答】高级调度即作业调度。作业调度又称为高级调度或长调度,用于选择把外存上处于后备队列中的哪些作业调入内存,并为它们创建进程、分配必要的资源。然后,再将新创建的进程排在就绪队列上,准备执行。低级调度又称为进程调度,它的功能是按照某种策略和算法,将处理机分配给一个处于就绪状态的进程。 3.处理机调度一般可分为哪三级其中哪一级调度必不可少为什么 【解答】一个作业,从进入系统并驻留在外存的后备队列上开始,直至作业运行完毕,可能要经历以下三级调度:即作业调度、对换和进程调度。 其中,进程调度是必不可少的。因为进程调度是指,系统将CPU分配给一个就绪状态的进程,即CPU是进程调度要分配的对象。如果没有进程调度,系统中的进程将无法执行。 4.作业在其存在的过程中分为哪四种状态 【解答】从进入系统到运行结束,一般要经历提交、后备、运行和完成4个阶段。相应地,作业也有提交、后备、运行和完成4种状态。只有当作业处于后备状态时,该作业才可以被调度。(1)提交状态。一个作业在其处于从输入设备进入外部存储设备的过程称为提交状态。处于提交状态的作业,因其信息尚未全部进入系统,所以不能被调度程序选中。 (2)后备状态。也称为收容状态。输入管理系统不断地将作业输入到外存中对应部分(或称输入
中国科学院自动化研究所 2014年招收攻读博士学位研究生入学统一考试试卷 科目名称:模式识别 考生须知: 1. 本试卷满分为100分,全部考试时间总计180分钟。 2. 所有答案必须写在答题纸上,写在试题纸上或草稿纸上一律无效。 1. (16分) 关于统计学习与支持向量机,请回答如下问题:(1) 给出机器学习问题的形式化表示 (4分);(2) 解释学习机器的推广能力 (4分);(3) 从几何的角度阐述线性支持向量机的原理 (4分);(4) 基于两类支持向量机,设计一个c 类(c > 2)分类训练策略 (4分)。 2. (10分) (1) 请描述径向基函数网络的结构和功能 (4分);(2) 指出径向基函数网络的参数,分析在训练一个径向基函数网络时如何调节这些参数 (6分)。 3. (10分) (1) 简述Fisher 线性判别分析的原理 (4分);(2) 针对两类分类问题,试证明在正态等方差条件下,Fisher 线性判别等价于贝叶斯判别 (6分)。 4. (10分) 假设在某个局部地区细胞识别中正常 (1ω)和异常(2ω)两类的先验分别为 1()0.85P ω=和2()0.15P ω=。现有一待识别细胞,其观察值为x ,从类条件概率密度分布曲线上查得1(|)0.2=P x ω,2(|)0.4=P x ω,请对该细胞x 进行分类,并给出计算过程。 5. (10分) 现有七个位于二维空间的样本:1(1,0)=T x ,2(0,1)=T x ,3(0,1)=-T x ,4(0,0)=T x ,5(0,2)=T x ,6(0,2)=-T x ,7(2,0)=-T x ,其中上标T 表示向量的转置。假定前三个样本属于第一类,后四个样本属于第二类,请画出最近邻法决策面。 6. (16分) 在一个模式识别问题中,有下列8个样本: 1(1,1)T =-x ,2(1,1)T =--x ,3(0,1)T =x ,4(0,1)T =-x ,5(2,1)T =x ,6(2,1)T =-x ,7(3,1)T =x ,8(3,1)T =-x ,其中上标T 表示向量的转置。请回答如下问题:(1) 如果不知道这8个样本的类别标签,请采用K-L 变换,计算其特征值和特征向量(10分);(2) 对上述8个样本,假设前4个样本属于第一类,后4个样本属于第二类,请给出一种特征选择方法,并写出相应的计算过程 (6分)。 7. (16分) (1) 给定m 维空间中的n 个样本,请给出C -均值聚类算法的计算步骤(包含算法输入和输出) (8分);(2) 针对C -均值聚类算法,指出影响聚类结果的因素,并给出相应的改进措施 (8分)。 8. (12分) 某单位有n 位职员,现从每位职员采集到m (m >10)张正面人脸图像(可能因姿态、表情、光照条件的略微不同而不同)。每张人脸图像为200(高度) ?160(宽度)像素大小的灰度图像。现在拟设计一个人脸识别系统,请回答如下问题:(1) 描述拟采用的特征提取方法及计算步骤 (4分);(2) 描述拟采用的分类器构造方法及计算步骤 (4分);(3) 请从特征提取和分类器构造两方面对你所采用的方法进行评价(即解释采用它们的原因) (4分)。 科目名称:模式识别 第1页 共1页
模式识别第三章 感知器算法 一.用感知器算法求下列模式分类的解向量w : })0,1,1(,)1,0,1(,)0,0,1(,)0,0,0{(:1T T T T ω })1,1,1(,)0,1,0(,)1,1,0(,)1,0,0{(:2T T T T ω 将属于2ω的训练样本乘以(-1),并写成增广向量的形式: T x )1,0,0,0(1 =,T x )1,0,0,1(2=,T x )1,1,0,1(3=,T x )1,0,1,1(4 = T x )1,1-,0,0(5-=,T x )1,1-,1-,0(6-=,T x )1,0,1-,0(7-=,T x )1,1-,1-,1-(8-= 第一轮迭代:取1=C ,T )0,0,0,0()1(=ω 因0)1,0,0,0)(0,0,0,0()1(1==T T x ω不大于0,故T x )1,0,0,0()1()2(1=+=ωω 因1)1,0,0,1)(1,0,0,0()2(2==T T x ω大于0,故T )1,0,0,0()2()3(==ωω 因1)1,1,0,1)(1,0,0,0()3(3==T T x ω大于0,故T )1,0,0,0()3()4(==ωω 因1)1,0,1,1)(1,0,0,0()4(4==T T x ω大于0,故T )1,0,0,0()4()5(==ωω 因1)1,1-,0,0)(1,0,0,0()5(5-=-=T T x ω不大于0,故T x )0,1-,0,0()5()6(5 =+=ωω 因1)1,1-,1-,0)(0,1-,0,0()6(6=-=T T x ω大于0,故T )0,1-,0,0()6()7(==ωω 因0)1,0,1-,0)(0,1-,0,0()7(7=-=T T x ω不大于0,故T x )1-,1-,1,0()7()8(7-=+=ωω 因3)1,1-,1-,1-)(1-,1-,1,0()8(8=--=T T x ω大于0,故T )1-,1-,1,0()8()9(-==ωω 第二轮迭代: 因1)1,0,0,0)(1-,1-,1,0()9(1-=-=T T x ω不大于0,故T x )0,1-,1,0()9()10(1-=+=ωω 因0)1,0,0,1)(0,1-,1-,0()10(2==T T x ω不大于0,故T x )1,1,1,1()10()11(2--=+=ωω 因1)1,1,0,1)(1,1,1,1()11(3=--=T T x ω大于0,故T )1,1,1,1()11()12(--==ωω 因1)1,0,1,1)(1,1,1,1()12(4=--=T T x ω大于0,故T )1,1,1,1()12()13(--==ωω
… 第三章 平面问题的直角坐标解答 【3-4】试考察应力函数3ay Φ=在图3-8所示的矩形板和坐标系中能解决什么问题(体力不计) 【解答】⑴相容条件: 不论系数a 取何值,应力函数3ay Φ=总能满足应力函数表示的相容方程,式(2-25). ⑵求应力分量 当体力不计时,将应力函数Φ代入公式(2-24),得 6,0,0x y xy yx ay σσττ==== ⑶考察边界条件 & 上下边界上应力分量均为零,故上下边界上无面力. 左右边界上; 当a>0时,考察x σ分布情况,注意到0xy τ=,故y 向无面力 左端:0()6x x x f ay σ=== ()0y h ≤≤ () 0y xy x f τ=== 右端:()6x x x l f ay σ=== (0)y h ≤≤ ()0y xy x l f τ=== 应力分布如图所示,当l h 时应用圣维南原理可以将分布的面力,等效为 主矢,主矩 y x f x f ¥ 主矢的中心在矩下边界位置。即本题情况下,可解决各种偏心拉伸问题。 偏心距e : 因为在A 点的应力为零。设板宽为b ,集中荷载p 的偏心距e :
2()0/6/6 x A p pe e h bh bh σ= -=?= 同理可知,当a <0时,可以解决偏心压缩问题。 / 【3-6】试考察应力函数22 3(34)2F xy h y h Φ= -,能满足相容方程,并求出应力分量(不计体力),画出图3-9所示矩形体边界上的面力分布(在小边界上画 出面力的主矢量和主矩),指出该应力函数能解决的问题。 【解答】(1)将应力函数代入相容方程(2-25) 444422420?Φ?Φ?Φ ++=????x x y y ,显然满足 < (2)将Φ代入式(2-24),得应力分量表达式 3 12,0,x y Fxy h σσ=-=2234(1)2==--xy yx F y h h ττ (3)由边界形状及应力分量反推边界上的面力: ①在主要边界上(上下边界)上,2h y =±,应精确满足应力边界条件式 (2-15),应力()()/2/2 0,0y yx y h y h στ=±=±== 因此,在主要边界2h y =±上,无任何面力,即0,022x y h h f y f y ??? ?=±==±= ? ???? ? ②在x=0,x=l 的次要边界上,面力分别为: 22340:0,1-2x y F y x f f h h ?? === ??? 3 221234:,12x y Fly F y x l f f h h h ?? ==- =-- ??? " 因此,各边界上的面力分布如图所示: y
第三章 作业与习题的解答 一、作业: 2、纯铁的空位形成能为105 kJ/mol 。将纯铁加热到850℃后激冷至室温(20℃),假设高温下的空位能全部保留,试求过饱和空位浓度与室温平衡空位浓度的比值。(e 31.8=6.8X1013) 6、如图2-56,某晶体的滑移面上有一柏氏矢量为b 的位错环,并受到一均匀切应力τ。 (1)分析该位错环各段位错的结构类型。 (2)求各段位错线所受的力的大小及方向。 (3)在τ的作用下,该位错环将如何运动? (4)在τ的作用下,若使此位错环在晶体中稳定 不动,其最小半径应为多大? 解: (2)位错线受力方向如图,位于位错线所在平面,且于位错垂 直。 (3)右手法则(P95):(注意:大拇指向下,P90图3.8中位错环ABCD 的箭头应是向内,即 是位错环压缩)向外扩展(环扩大)。 如果上下分切应力方向转动180度,则位错环压缩。
(4) P103-104: 2sin 2d ?τd T s b = θRd s =d ; 2/sin 2 θ?d d = ∴ τ ττkGb b kGb b T R ===2 注:k 取0.5时,为P104中式3.19得出的结果。 7、在面心立方晶体中,把两个平行且同号的单位螺型位错从相距100nm 推进到3nm 时需要用多少功(已知晶体点阵常数a=0.3nm,G=7﹡1010Pa )? (3100210032ln 22ππGb dr w r Gb == ?; 1.8X10-9J ) 8、在简单立方晶体的(100)面上有一个b=a[001]的螺位错。如果它(a)被(001)面上b=a[010]的刃位错交割。(b)被(001)面上b=a[100]的螺位错交割,试问在这两种情形下每个位错上会形成割阶还是弯折? ((a ):见P98图3.21, NN ′在(100)面内,为扭折,刃型位错;(b)图3.22,NN ′垂直(100)面,为割阶,刃型位错) 9、一个]101[2-=a b 的螺位错在(111)面上运动。若在运动过程中遇到障碍物而发生交滑移,请指出交滑移系统。 对FCC 结构:(1 1 -1)或写为(-1 -1 1) 10、面心立方晶体中,在(111)面上的单位位错]101[2-=a b ,在(111) 面上分解为两个肖克莱不全位错,请写出该位错反应,并证明所形成的扩展位错的宽度由下式给出:
题1:在一个10类的模式识别问题中,有3类单独满足多类情况1,其余的类别满足多类情况2。问该模式识别问题所需判别函数的最少数目是多少? 答:将10类问题可看作4类满足多类情况1的问题,可将3类单独满足多类情况1的类找出来,剩下的7类全部划到4类中剩下的一个子类中。再在此子类中,运用多类情况2的判别法则进行分类,此时需要7*(7-1)/2=21个判别函数。故共需要4+21=25个判别函数。 题2:一个三类问题,其判别函数如下: d1(x)=-x1, d2(x)=x1+x2-1, d3(x)=x1-x2-1 1.设这些函数是在多类情况1条件下确定的,绘出其判别界面和每一个模式类 别的区域。 2.设为多类情况2,并使:d12(x)= d1(x), d13(x)= d2(x), d23(x)= d3(x)。绘出其 判别界面和多类情况2的区域。 3.设d1(x), d2(x)和d3(x)是在多类情况3的条件下确定的,绘出其判别界面和 每类的区域。 答:三种情况分别如下图所示: 1. 2.
3. 题3:两类模式,每类包括5个3维不同的模式,且良好分布。如果它们是线性可分的,问权向量至少需要几个系数分量?假如要建立二次的多项式判别函数,又至少需要几个系数分量?(设模式的良好分布不因模式变化而改变。) 答:(1)若是线性可分的,则权向量至少需要14N n =+=个系数分量; (2)若要建立二次的多项式判别函数,则至少需要5! 102!3! N = =个系数分量。 题4:用感知器算法求下列模式分类的解向量w : ω1: {(0 0 0)T, (1 0 0)T, (1 0 1)T, (1 1 0)T} ω2: {(0 0 1)T, (0 1 1)T, (0 1 0)T, (1 1 1)T} 解:将属于2w 的训练样本乘以(1)-,并写成增广向量的形式 x1=[0 0 0 1]',x2=[1 0 0 1]',x3=[1 0 1 1]',x4=[1 1 0 1]'; x5=[0 0 -1 -1]',x6=[0 -1 -1 -1]',x7=[0 -1 0 -1]',x8=[-1 -1 -1 -1]'; 迭代选取1C =,(1)(0,0,0,0)w '=,则迭代过程中权向量w 变化如下: (2)(0 0 0 1)w '=;(3)(0 0 -1 0)w '=;(4)(0 -1 -1 -1)w '=;(5)(0 -1 -1 0)w '=;(6)(1 -1 -1 1)w '=;(7)(1 -1 -2 0)w '=;(8)(1 -1 -2 1)w '=;(9)(2 -1 -1 2)w '=; (10)(2 -1 -2 1)w '=;(11)(2 -2 -2 0)w '=;(12)(2 -2 -2 1)w '=;收敛 所以最终得到解向量(2 -2 -2 1)w '=,相应的判别函数为123()2221d x x x x =--+。 题5:用多类感知器算法求下列模式的判别函数: ω1: (-1 -1)T ,ω2: (0 0)T ,ω3: (1 1)T
第三章晶体空间格子的晶向及晶面的标定 练习题1. 以下两个平面点阵图案,画出其空间格子: 练习题2.六方点阵中布拉菲格子的先取: 练习题3. 请判断NaCl和CsCl晶体的格子类型: 氯化钠是面心立方格子、氯化铯属于简单立方格子。 练习题4. 晶向标定 (1)请在上图中标出晶向[001], [101], [110], [1-10], [1-11], [112]及[12-3]。 (2) 指出晶向族<111>包括哪几个晶向。 [111]、[-111]、[1-11]、[11-1]、[-1-1-1]、[1-1-1]、[-11-1]、[-1-11]
说明“-1”的负号应放于1的正上方,以下类同。 练习题5. 二维晶面标定 练习题6.三维晶面标定 练习题7. 请在图中画出面(001), (101), (1-11), (112)及(12-3) 练习题8. 四轴坐标系晶面标定 (1) 请把图中三个彩色晶面用三指数和四指数表示,如上图。 (2)请在右图画出(-112), (-1100), (11-20), (123), (12-33)等面。
(-112) (-1100) (11-20) (123) (12-33) 练习题9. 四轴坐标系晶向标定 (1) 请用三指数和四指数标定右图彩色晶向; 红色 绿色 蓝色 紫色 [041] [232] [210] [1-2-2] [-48-43] [14-56] [10-10] [4-51-6] (2) 请在上图中画出晶向[101], [11-1], [121], [1-11],[-2111], [-12-11]。并指出哪些属于同一晶向簇。 [101] [11-1] [121] [1-11] [-2111] [-12-11] [11-1]、[1-11]属于<111>晶向族;[-2111]、[-12-11]属于<2111>晶向族。
第一章 绪论 1.什么是模式?具体事物所具有的信息。 模式所指的不是事物本身,而是我们从事物中获得的___信息__。 2.模式识别的定义?让计算机来判断事物。 3.模式识别系统主要由哪些部分组成?数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。 第二章 贝叶斯决策理论 1.最小错误率贝叶斯决策过程? 答:已知先验概率,类条件概率。利用贝叶斯公式 得到后验概率。根据后验概率大小进行决策分析。 2.最小错误率贝叶斯分类器设计过程? 答:根据训练数据求出先验概率 类条件概率分布 利用贝叶斯公式得到后验概率 如果输入待测样本X ,计算X 的后验概率根据后验概率大小进行分类决策分析。 3.最小错误率贝叶斯决策规则有哪几种常用的表示形式? 答: 4.贝叶斯决策为什么称为最小错误率贝叶斯决策? 答:最小错误率Bayes 决策使得每个观测值下的条件错误率最小因而保证了(平均)错误率 最小。Bayes 决策是最优决策:即,能使决策错误率最小。 5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利用这个概率进行决策。 6.利用乘法法则和全概率公式证明贝叶斯公式 答:∑====m j Aj p Aj B p B p A p A B p B p B A p AB p 1) ()|()() ()|()()|()(所以推出贝叶斯公式 7.朴素贝叶斯方法的条件独立假设是(P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi)) 8.怎样利用朴素贝叶斯方法获得各个属性的类条件概率分布? 答:假设各属性独立,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi) 后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi) 类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值方差,最后得到类条件概率分布。 均值:∑==m i xi m x mean 11)( 方差:2)^(11)var(1∑=--=m i x xi m x 9.计算属性Marital Status 的类条件概率分布 给表格计算,婚姻状况几个类别和分类几个就求出多少个类条件概率。 ???∈>=<2 11221_,)(/)(_)|()|()(w w x w p w p w x p w x p x l 则如果∑==21 )()|()()|()|(j j j i i i w P w x P w P w x P x w P 2,1),(=i w P i 2,1),|(=i w x p i ∑==2 1)()|()()|()|(j j j i i i w P w x P w P w x P x w P ∑=== M j j j i i i i i A P A B P A P A B P B P A P A B P B A P 1) ()| ()()|()()()|()|(
人脸识别实验报告 ---- 基于PCA 和欧氏距离相似性测度 一、理论知识 1、PCA 原理 主成分分析(PCA) 是一种基于代数特征的人脸识别方法,是一种基于全局特征的人脸识别方法,它基于K-L 分解。基于主成分分析的人脸识别方法首次将人脸看作一个整体,特征提取由手工定义到利用统计学习自动获取是人脸识别方法的一个重要转变[1]。简单的说,它的 原理就是将一高维的向量,通过一个特殊的特征向量矩阵,投影到一个低维的向量空间中,表示为一个低维向量,并不会损失任何信息。即通过低维向量和特征向量矩阵,可以完全重构出所对应的原来高维向量。特征脸方法就是将包含人脸的图像区域看作是一种随机向量,因此,可以采用K-L 变换获得其正交K-L 基底。对应其中较大特征值的基底具有与人脸相似的形状,因此又称为特征脸。利用这些基底的线性组合可以描述、表达和逼近人脸图像,因此可以进行人脸识别与合成。识别过程就是将人脸图像映射到由特征脸张成的子空间上,比较其与己知人脸在特征空间中的位置,从而进行判别。 2、基于PCA 的人脸识别方法 2.1 计算特征脸 设人脸图像f(x,y)为二维N×M 灰度图像,用NM 维向量R 表示。人脸图像训练集为{}|1,2,...,i R i P =,其中P 为训练集中图像总数。这P 幅图像的平均向量为: _ 11P i i R R P ==∑ 对训练样本规范化,即每个人脸i R 与平均人脸_ R 的差值向量: i A =i R -_R (i= 1,2,…,P) 其中列向量i A 表示一个训练样本。 训练图像由协方差矩阵可表示为: T C AA = 其中训练样本NM ×P 维矩阵12[,,...,]P A A A A = 特征脸由协方差矩阵C 的正交特征向量组成。对于NM 人脸图像,协方差矩