
第五章出行分布预测
§5.1 概念
从出行发生预测可以得知对象区域各个分区出行产生量和出行吸引量。下面的问题是:就某个分区而言,它所产生的这些出行量究竟到那个分区去了?它所吸引的这些出行量又究竟来自哪里?也就是要预测未来规划年各个分区之间出行的交换量。我们把分区之间的出行的交换量叫做“出行分布量”,本章就来研究出行分布量的预测问题。
5.1.1 出行分布量
出行分布量是指:分区i 与分区j 之间平均单位时间内的出行量,单位时间可以是一
天、一周、一月等,也可以是专指高峰小时。就一对分区i 和j 而言,它由两部分q ij 、q ji 组成:
q ij ——以分区i 为产生点(注:不一定是出行的起点),以分区j 为吸引点(不一定是出行的终点)的出行量。
q ji ——以分区j 为产生点,分区i 为吸引点的出行量。
如同一个分区的产生量不一定等于吸引量一样,q ij 不一定等于q ji 。从下面的例子可以看出这一点。
例5-1 如图5-1所示的两分区之间的六次出行中;
q ij =4(出行1、2、5、6)
q ji =2(出行3、4)
但以i 为起点的出行数=3(出行1、4、5);
以j 为起点的出行数=3(出行2、3、6)。
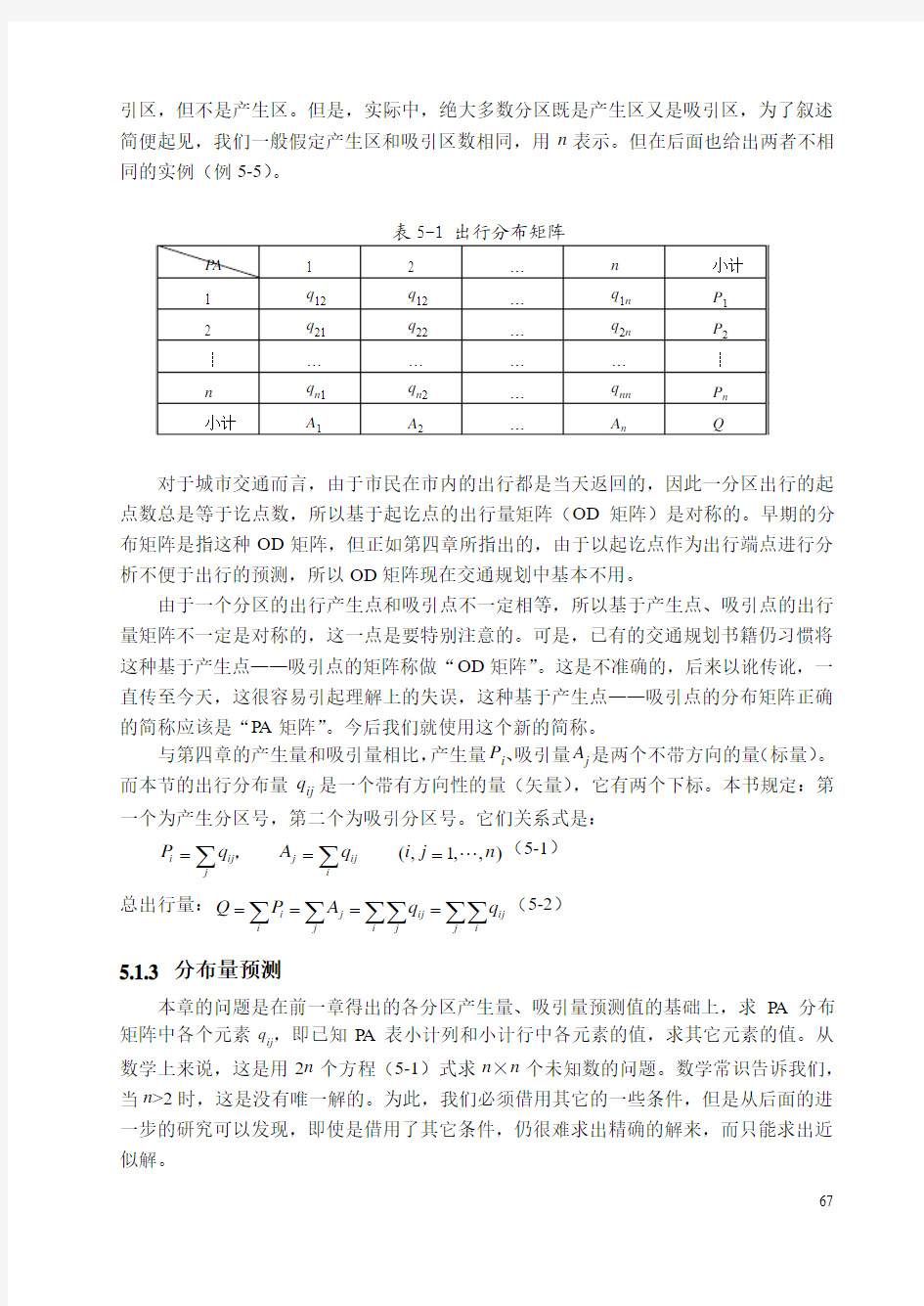
5.1.2 出行分布矩阵(PA 矩阵)
出行分布矩阵是一个二维表(矩阵),行坐标为吸引分区号(Absorbing zone ),列坐标为产生分区号(Producing zone ),元素为出行分区量。如表5-1所示,表5-1中的行数和列数相等。从理论的严格意义上讲,产生区和吸引区不一定相同,甚至某些分区只是产生区,但不吸引任何出行,因而不是吸引区,如纯住宅区,也可能有某些分区只是吸
图例:h —家庭;s —学校;f —工厂
图5-1 (例5-1)两个分区间的六次出行
引区,但不是产生区。但是,实际中,绝大多数分区既是产生区又是吸引区,为了叙述简便起见,我们一般假定产生区和吸引区数相同,用n 表示。但在后面也给出两者不相同的实例(例5-5)。
对于城市交通而言,由于市民在市内的出行都是当天返回的,因此一分区出行的起点数总是等于讫点数,所以基于起讫点的出行量矩阵(OD 矩阵)是对称的。早期的分布矩阵是指这种OD 矩阵,但正如第四章所指出的,由于以起讫点作为出行端点进行分析不便于出行的预测,所以OD 矩阵现在交通规划中基本不用。
由于一个分区的出行产生点和吸引点不一定相等,所以基于产生点、吸引点的出行量矩阵不一定是对称的,这一点是要特别注意的。可是,已有的交通规划书籍仍习惯将这种基于产生点——吸引点的矩阵称做“OD 矩阵”。这是不准确的,后来以讹传讹,一直传至今天,这很容易引起理解上的失误,这种基于产生点——吸引点的分布矩阵正确的简称应该是“PA 矩阵”。今后我们就使用这个新的简称。
与第四章的产生量和吸引量相比,产生量P i 、吸引量A j 是两个不带方向的量(标量)。而本节的出行分布量q ij 是一个带有方向性的量(矢量),它有两个下标。本书规定:第一个为产生分区号,第二个为吸引分区号。它们关系式是:
),,1,(n j i q A q P i
ij
j j
ij i ===∑∑,
(5-1)
总出行量:∑∑∑∑∑∑====i
j
j
i
ij ij j
j i
i q q A P Q (5-2)
5.1.3 分布量预测
本章的问题是在前一章得出的各分区产生量、吸引量预测值的基础上,求PA 分布矩阵中各个元素q ij ,即已知PA 表小计列和小计行中各元素的值,求其它元素的值。从数学上来说,这是用2n 个方程(5-1)式求n ×n 个未知数的问题。数学常识告诉我们,当n >2时,这是没有唯一解的。为此,我们必须借用其它的一些条件,但是从后面的进一步的研究可以发现,即使是借用了其它条件,仍很难求出精确的解来,而只能求出近似解。
我们通过对调查资料的分析和预测,可以找到和利用的数据有:现状的PA 表:]
[0
ij q (1≤i ,j ≤n );两个分区之间的交通阻抗矩阵[R ij ]。至今已开发的方法有:增长率法、引力模型法、机会模型法。我们详细介绍前两种,第三种因理论依据不足,且难于实用,不作详细介绍。
§5.2 增长率法
增长率法是一种比较简单的预测方法,包括两大类:增长函数方法和Fueness 约束条件方法。增长函数方法是指一大类方法,具体地,它又包括:常增长率法、平均增长率法、Detroit (底特律法)、Frator (弗雷德)法。
5.2.1 增长函数方法的思路
具体的增长函数方法有多种,它们的基本思路相同,不同的是各自采用不同的增长函数。首先我们给出描述共同基本思路的算法,然后就不同的增长函数讨论各个具体的增长函数方法。
增长函数的基本思路可用以下算法描述: 算法5-1:
步1:用0ij q 表现状分布量,i P 0、j A 0表现状产生量、吸引量: P i 、A j 表由第四章预
测方法得到的规划年产生量、吸引量的预测值,令k =0。
步2:计算各分区第0次产生增长率、吸引增长率:
000j
j aj i i pi A A F P P F ==
,;(5-3) 步3:设),(aj gi F F f 为增长函数,计算第(k +1)次预测值:
)
,(k
aj k pi k ij k ij F F f q q ?=+1;(5-4) 步4:检验预测结果:计算新的产生量和吸引量
∑∑++++==i
k ij k j
j
k ij k i q A q P 111
1,
,(5-5) 令1
111++++=
=k j
j k aj k i
i k pi A
A F P P F ,
(5-6)
在允许一定误差率(如3%)的前提下,对所有的i 和j 考察:11≈≈k aj k pi F F ,?若是,1
+k ij
q
为之所求,今1
+=k ij ij q q ,停止;否则进行下一步迭代,令k =k +1,转至第3步继续。
下面就各种不同的增长函数提出各种具体的增长率法。
5.2.2各种增长函数法
1 常增长率法
该方法认为,q ij 的增长仅与i 区的产生量增长率有关。增长函数为
()0,i
i pi aj pi P P
F F F f ==常(5-7)
这种方法只单方面考虑产生量增长率对增长函数的影响,忽视了吸引量增长率的影响。由于产生量与吸引量的不对称性,因此这种方法的预测精度不高,是一种最粗糙的方法,有时甚至不能保证算法5-1的迭代过程一定能收敛。
2 平均增长率法
该方法认为:q ij 的增长与i 区产生量的增长及j 分区吸引量的增长同时相关,而且相关的程度也相同。即
()()ai pi aj pi F F F F f +=2
1
,平(5-8)
此法明显比第一种方法合情理一些,这是一种最常用的方法。在实际运用时,因迭代步数较多,使计算速度稍慢,但有计算机帮忙也很好用。 3 Detroit 法
此法认为,q ij 的增长与i 分区产生量增长率pi F 成正比,而且还与j 分区吸引量增长占整个区域吸引量增长的相对比率成正比。全区域在现年和规划年的吸引总量分别为
∑j
j
A
0、∑j
j A ,因此全区域的吸引量增长率为∑∑j
j
j
j
A
A 0。于是Detroit 增长函数为
()∑∑?=?=j
j
j
j j j i i aj
pi aj pi D A A A A P P Q Q F F F F f 0
000,(5-9) 该方法是在底特律市1956年规划首次被开发利用,收敛速度较快。
4 Frator 法
1954年Frator 提出了分别从产生区和吸引区两个角度分析计算q ij ,然后平均的方法。
先从产生区考虑:
①Frator 认为,q ij 与 i 区出行量中j 分区的“相对吸引增长率” b ij 成正比。由于规
划年从i 区产生的出行量中被分区j 吸引去的出行量为aj ij F q 0
,因此,这个相对吸引增长
率为:
∑=
j
aj
ij aj
ij ij F q
F q b 0
0(5-10)
②Frator 还认为:q ij 也应与i 分区规划年的产生量)
(0
0ij ij i F P P =成正比; ③综上两点,得
∑???
?=?=j
aj
ij
aj
ij pi
i ij i ij
F
q
F q F P b P q 00
0000
1'(5-11)
再从吸引区j 分区的角度分析,同样,类似于以上三步,得
∑????=j
pi ij pi
ij aj
j
ij
F q F q F A q 0
000001"(5-12) 由于上两式的'1ij q 、"1ij
q 是表示同一个量1
ij q ,故预测值应取其平均值: ????
?????????+??=+=∑∑?i pi ij pi ij aj j j aj ij aj ij pi i ij ij ij F q F q F A F q F q F P q q q 000
00
000000011121]"'[21 22
00
0000000000
0j i aj pi ij i pi ij j
j aj ij i ij pi
aj L L F F q F q A F q P q F F +??=??????????
+????=
∑∑(5-13) 其中:∑=j
k
aj
k ij k i k pi
F q P L 、∑=
i
k pi
k
ij
k j
k aj F
q A L ——分别称为第k 轮分区i 的“产生位置系数”、分
区j 的“吸引位置系数”。
故Frator 增长函数为:
2
),(k aj
k pi k aj
k pi k aj k
pi F L L F F F F f +?
?=(5-14)
Frator 法的计算比较麻烦,但它的收敛速度快,应用还是比较广泛的。
例5-2 表5-2(1)是一个只有四个分区的现状PA 表,表5-2(2)给出了规划年的各个分区的出行产生量和吸引量。试分别用平均增长率法和Frator 法求出规划年PA 矩阵。
表5-2 例5-2的已知数据表
(1)现状PA 表 (2)规划年产生量和吸引量
解:1)平均增长率法。
用式(5-3)算得第0次的三个分区产生增长率0
pi F 分别为了:2.500,1.667,3.125;三
个分区的吸引量增长率0
aj F 分别为2.778, 1.800, 2.444。从而,算得各个平均增长率(即增
长函数),(00aj pi F F f )如表5-3(1)所示。由式
(5-5)可得第1次迭代值如表5-3(2)。从表5-3(2)可见,第1次迭代值的行和列的小计与表5-2(2)中规划年的产生量、吸引量差别较大,故须进一步进行第2次迭代运算。一直进行了6次迭代运算后,得到的结果与表5-2(2)中的值基本一致,收敛误差小于1%。结果见表5-3(3),所以此表即为所求的规划年出行分布预测结果。
表5-3 例5-2平均增长率法计算结果表
(2)平均增长率法第1次迭代结果 (3)平均增长率法第6次迭代结果
2)Frator 法。
首先求第0次位置系数,结果列在表5-4(1),在此基础上,算得第1次迭代结果如表5-4(2)所示。与平均增长率法的第1次迭代结果相比,此时的结果近似程度要高。实际上,用该法只须进行两次迭代,就可以求出满足收敛要求的结果,见表5-4(3)。
表5-4
例
5-2Frator 法计算结果表
(2)Frator 法第1次迭代结果 (3)Frator 法第2次迭代结果
可见与平均增长率法相比,Frator 的收敛速度要快得多。
5.2.3 Fueness 约束条件法
Fueness1956年提出另一种增长率法。他认为,两个分区之间出行分布量q ij 的预测值与此两个分区之间出行分布的现状值0
ij q 成正比,还与产生分区的规划年产生量预测值、吸引分区的规划年吸引量预测值有关,这种关系可用两个系数u i 、v j 表示(分别称之为产生系数、吸引系数),即
j i ij ij v u q q ?=0
(5-15)
但这两个系数不是简单地等于产生量或吸引量的增长率P i / P 0i 、A j / A 0j ,而是必须满足两个约束条件:
i
j
j ij i i
ij
P v q u q
=?=∑∑0(i =1, 2, …, n )(5-16a ) j i
i ij j j
ij
A u q v q
=?=∑∑0
( j =1, 2, …, n )(5-16b )
这个方法被称作“Furness 约束条件法”,又叫做“双约束条件增长率法”。
该法的关键是求两组系数u i 、v j (i , j =1, 2, …, n )。从数学上来说,由式(5-16)所表示的2n 个方程所组成的联立方程组可以解出这两组未知的系数(共2n 个)来。但因为这个方程组是非线性的,如果用解方程的方法,那么求解过程将是十分复杂的。为此,Furness 提出用迭代法进行求解,具体步骤如下算法。
算法5-2:
步1:初始化。令所有的u 0i =1.0,k =0。
步2:用方程组(5-16a )求解v j 。此时方程组简化为
i j
j ij P v q
=?∑0(i =1, 2, …, n )(5-17)
这其实是一个线性方程组,用线性代数的知识不难求解,设所得的解为{v k j :(j =1, 2, …, n ) }。
步3:用v k j 代入方程组(5-16b )求解{u k+1i },这仍是一个解线性方程组的问题。
步4:再用新求出的u k +1i ,代入方程组(5-16a )求解{v k +1j }。
步5:检验收敛性。对所有的i 、j ,考察u k j 与u k +1j 、v k j 与v k +1j 的相对偏差<3%?若是,{u k j }与{v k j }为之所求,停止;否则返回第3步。
Furness 法的收敛速度可与Frator 法媲美,但需要求解线性方程组,这是比较费时的,尤其是当分区数目n 较大时。如果把方程组表示成矩阵形式,如方程组(5-17)可表示为
P q V ij =?][0(5-18)
那么,它的解就是
10][-?=ij q P V (5-19)
这借用可进行矩阵运算的应用软件(如Matlab )就很容易求解了。
例5-3用Furness 法计算例5-2中的出行分布预测值。在进行了三次迭代后,就得到了表5-5所示的结果,达到了精度要求。 §5.3引力模型法
上述的增长率法的一个缺陷是没有考虑各个分区之间的交通阻抗,它对近期、或肯定至规划年整个交通网络上的交通阻抗都不会什么多大变化的出行分布预测问题是可用的。但一般对象区域的交通阻抗都会因交通设施改进或流量的增加而不断变化,这就要求在进行分布预测时,必须加入交通阻抗的因素。本节的引力模型法就是这样的预测方法。
引力模型是Casey1955年提出的,当时是受物理学中牛顿万有引力定律的启发,其形式也很象万有引力公式,故因此而得名。
5.3.1 简单模型
1、模型
最早的模型是
2ij
j i ij R
A P K q ??
=(5-20)
其中,q ij ——i 、j 分区之间的出行量(i 为产生区,j 为吸引区)预测值;
R ij ——两分区间的交通阻抗;
P i 、A j ——分别为分区i 的出行产生量、分区j 的吸引量; K ——系数。
该模型显然在形式上太拘泥于万有引力公式了,在实际应用中发现也有较大的误差。后人将它改进为
γ
βαij
j
i ij R A P K q ??
=(5-21)
其中:α、β、γ、K 是待定系数,假定它们不随时间和地点而改变。据经验,α、β取值范围0.5~1.0,多数情况下,可取α=β=1。
交通阻抗R ij 可以是出行时间、距离、油耗等因素的综和,但大多数情况下,为了简便起见,只取其中某个主要指标作为交通阻抗,在城市交通中取时间的情况较多,而在某种方式的地区交通规划取距离的情况较多。 2、参数的标定
采用线性回归方法标定模型(5-14)中的参数。两边取自然对数: ij j i ij R A P K q ln ln ln ln ln γβα-++=(5-22)
此处(P i ,A j ,R ij ,q ij )可从现状调查数中取若干个分区作为样本,待标定的参数有: ln K 、α、β、-γ,故要用多元线性回归方法。设:
Y =ln q ij , X =(1, X 1, X 2, X 3)=(1, ln P i , ln A j , ln R ij )(5-23a )
b 0=ln K , b 1=α, b 2=β, b 3= -γ(5-23b )
()()Y X X X b b b b B T T 1321
0-=??
???
???????=(5-23c ) 如果预先取α=β=1,则问题简化成了:
γij
j
i ij R A P K q ??
=(5-24)
这只须用一元线性回归方法就能标定参数K 和γ了。
例5-4 对例5-2的问题用引力模型(5-24)进行出行分布预测,假定分区之间交通阻抗(时间)如表5-6所示。
解:首先标定(5-24)中的参数γ、K 。
用一元线性回归,ij j i ij R k A P t ln ln ln ln γ-=-。令Y =ln q ij - ln(P i A j ), X =ln R ij , b 0=ln K , b 1= -γ。得:X b b Y 10+=。用一元线性回归方法求得:b 0=-5.627, b 1=0.5224从而得K =0.0036, γ=-0.5224。模型为:
52.00036.0ij
j i ij R
A P q ??
=(5-25)
再用表5-2(2)的P i 、A j 及表5-6的时间距离R ij 预测得表5-7所示的[q ij ]。
例完。 3、讨论
从表5-7的小计栏结果可见与表5-2(2)的原PA 预测值相去甚远,可见引力模型存在较大的误差。其原因不是选用公式(5-21)还是(5-24)的问题,因为取(5-24)作为引力模型也是经过实际数据证实的。其原因是这类模型本质上存在以下不足:此模型的系数无法保证:i j
ij P q =∑和j i
ij A q =∑,即对系数K 没有约束范围。解决办法是增加
约束条件,下一小节将研究这个问题。
除系数约束问题外,模型(5-21)、(5-24)还存在内内出行的阻抗值问题:对于一个分区内的出行,R ij 值不好确定。当R ij →0时,由此模型将得到q ij →∞,故对“内内出行”的出行分布量将会产生偏大的估计。解决方法有两种:一是对q ii 不用引力模型,而
改用回归分析法,以分区规模和交通服务条件作自变量;另一方法是修改“阻抗函数”。现在我们来讨论修改阻抗函数。公式(5-21)、(5-24)中的分母,其实是阻抗的函数,而阻抗的函数可以是多样的,一般地,用f (R ij )表示阻抗函数,常用的有:
1)幂型:()γ
-=ij ij R R f ;(5-26)
2)指数型:()()ij ij R b R f ?-=exp ;(5-27) 3)(幂与指数)复合型:
()γ
--?=ij
bR ij R e
R f ij
(5-28) 4)半钟型:
()γ
-+=ij ij bR a R f 1(5-29) 5)离散型:
∑=m
ij m
m ij r R f δ)((5-30) 前面(5-21)、(5-24)式就是用的幂型,其它的如指数型、复合型、半钟型均能弥补上述幂型的不足。其中指数型因只含一个参数,比较容易标定,较常使用。半钟型含两个参数,使用得少些。(幂与指数的)复合型也含两个参数,但在某些特
定的交通方式的出行分布中,有其优势。如城市交通中自行车的出行,很短的距离或很长的距离的出行数量都比较少,而中等距离的出行数量较多,这时针对这种特定交通工具的分布量用这种阻抗函数比较好,当然这属于与交通方式划分相结合的出行分布问题了,见后面第六章。
这里要特别说明一下离散型,它是一种特殊的阻抗函数。其函数表达式为
∑=m
ij m
m ij r R f δ)((5-31) 其中,r m ——第m 级费用内的阻抗平均值;
ij m
δ——狄拉克函数,当ij m δ=1表示从分区i 到分区j 的费用属于第m 级,其它情况ij
m δ=0。
该函数虽然有多个参数,但比较容易从调查资料中得到。对于与交通方式划分相结合的出行分布(见下面第六章),该类型阻抗函数有其特殊用途。如在我国的中等城市居民
图例:幂型;指数型; 复合型;半钟型
图5-2 四种阻抗函数
选择公共汽车出行时,由于一个中等城市面积规模不大,市区内公交线路都不太长,此时出行者主要关心一次出行需要换乘几次公共汽车,那么可以根据换乘公共汽车的次数确定两个分区之间的费用等级。
究竟选用哪种类型的阻抗函数要视具体情况决定。可以先用一些调查数据在坐标系上标出散点图,看它与哪类函数的曲线吻合得较好,然后决定选用哪类阻抗函数。
至于模型中的系数约束问题是一个很重要的问题,因为如例5-4所示,没有约束的系数可能导致出行分布预测的结果与预先作出的产生量和吸引量预测值明显不符。下面就专门研究系数约束问题。
5.3.2 单约束引力模型
1 模型
通过例5-4,我们发现简单引力模型无法保证:
i
j
ij
P q
=∑j i
ij
A q
=∑(5-32)
现在我们来寻找满足(5-32)式的引力模型。代(5-24)式入上面第一个式子,得
i j
ij
j i j
ij
j i j
ij P R A KP R A P K
q ===∑
∑∑γ
γ
(5-33)
从而得
∑=
j
ij
j R A K γ
/1(5-34)
对一般的阻抗函数f (R ij ),(5-34)式就可写成:
∑=
j
ij j R f A K )
(1(5-35)
此时,有
∑??=
???=j
ij j
ij j i ij j i ij R f A
R f A P R f A P K q )
()()((5-36)
从而,PA 表的第i 行元素相加,
()
()
i j
j
ij
j
ij j i j
ij P R f A R f A P q =?=∑
∑∑(5-37)
这样,使用(5-35)式的系数K 后,预测得到的PA 表每行q ij 相加,正好等于小计列的产生量P i ,也就是说,通过(5-35)式定义的系数K 就对分布量q ij 从行的角度进行
了约束,因此式(5-35)所定义的K 就叫“行约束系数”。但其结果仍不能保证j i
ij A q =∑。
如果欲从列的角度进行约束,类似地,可以定义一个“列约束系数”:
∑=
j
ij i R f P K )
(1'(5-38)
引进了行约束系数或列约束系数的引力模型叫单约束引力模型。引进行约束系数后,引力模型变成
()()
∑???=
ij j
ij j i ij R f A
R f A P q (5-39)
此模型的参数标定问题要比前面少一个参数,无须单独标定靠K ,只要标定f (R ij )中的参数,因为只要它标定了,由式(5-35)可算出K 来。 2 参数的标定
以下以()
ij
bR ij e
R f -=为例说明单约束引力模型的参数的标定步骤,用被称为“试算
法”的算法。意思是首先试探性地给参数b 取一个初值,用现状PA 表和阻抗矩阵进行检验,若不合乎精度要求,分析其原因是因为b 值太大还是太小了,据此调整b 值,进一步再作检验,直到合乎精度要求为止。
算法5-3:
步1:给b 一个初值,如b =1。 步2:从模型ij
ij R j
j
R j i ij
e
A
e
A P q --∧
???=
∑算得现状的出行量“理论值”ij q ∧
(现状PA 表中的q ij
被称为“实际值”),得现状理论分布表。
步3:计算现状实际PA 分布表的平均交通阻抗ij i j
ij R q Q R ∑∑?=1;再计算理论分布
表的平均交通阻抗:Q
R q
R
i
j
ij
ij
∑∑?=∧
?。求两者之间相对误差:
%100??
??? ?
?-=∧
R
R R δ(5-40)
当%3<δ接受关于b 值得假设,否则执行下一步。
步4:当0<δ,即R R
大的缘故,因此应该减少b 值,令b =b /2;反之增加b 值,令b =2b 。返回第2步。
算法结束。 3 补充说明
对于单约束引力模型及其参数标定方法,我们还要作以下补充说明。
1)以上标定b 的方法完全适用于取γ
-=ij ij R R f )(时关于γ的标定。
2)由(5-34)、(5-35)式我们发现,参数K 其实不是常数,它大于0且一般随时间推移不断变小。这出乎人们的预料。推导如下:
以(5-34)式为例,经大量的实际数据验证(田志立等,1995),(5-34)式中的γ不是一个常数,与出行目的有关,对于全目的的模型,γ≈0.5。由于一般地,A j 随时间的推移而变大(当分区的非住宅建筑物增多时),而R ij 随时间的推移而变小(当分区间的交通设施改善时),于是K 就随之变小。
3)正因为单约束引力模型不能同时满足行和列的约束条件,在实际中也不常使用它。下面介绍的双约束引力模型就能克服单约束引力模型的这个缺陷。
5.3.3 双约束引力模型
同时引进行约束系数和列约束系数的引力模型叫双约束引力模型。双约束引力模型的形式是:
)
('ij j i j i ij R f A P K K q ????=(5-41a ) 1
)('-???
?
????=∑j ij j j i R f A K K (i =1, …, n )(5-41b ) 1
)('-??
? ????=∑i ij i i j R f P K K (j =1, …, n )(5-41c ) 式中,K i 、K ’j 分别为行约束系数、列约束系数。
不难证明,(5-41)式的[q ij ]同时满足行、列约束条件(5-32)式。下面是以f (R ij )=R ij -r 为例的参数标定算法。
算法5-4:
步1:给参数γ取初值,可参照已建立该模型的类似城市的参数作为估计初值,此处令:γ=1。
步2:用迭代法求约束系数K i 、K ’ j :
2-1、首先令各个列约束系数K ’ j =1(j =1, …, n );
2-2、将各列约束系数K ’ j (j =1, …, n )代入(5-41b )式求各个行约束系数K i ;
2-3、再将求得的各个行约束系数K i (i =1, …, n ),代入(5-41c )式求各个列约束系数K ’j ;
2-4、比较前后两批列约束系数,考察:它们的相对误差<3%?若是,转至第3步;否则返回2-2步。
步3:将求得的约束系数K i 、K ’ j 代入(5-41a )式,用现状P i 、A j 值求现状的理论分布表[ij q ?]。
步4:计算现状实际PA 分布表的平均交通阻抗ij i j
ij R q Q ∑∑?=1;再计算理论分布
表的平均交通阻抗:Q
R q
R
i
j
ij
ij
∑∑?=∧
?。求两者之间相对误差δ(见(5-40)式)。
当∣δ∣<3%, 接受关于γ值得假设,否则执行下一步。
步5:当0<δ,即R R
算法结束。
在模型(5-41)时中,有两批参数需要标定:约束系数K i 、K ’ j ;和f (R ij )中的参数。在算法5-6中用了两层循环,第2步是内循环,任务是求K i 、K ’ j ;外循环的任务是标定f (R ij )中的参数。都是采用试算法。
下面是一个参数标定实例,在此例中,产生区吸引区是不同的,两者的数目也不同。 例5-5 有2个居住区(1、2号,作为出行产生区)和3个就业分区(3、4、5号,作为出行吸引区),它们的现状分布表和作为阻抗的出行阻抗表[R ij ],如表5-8所示,求其双约束引力模型:
γ
-????=ij
j i j i ij R A P K K q '(5-42a ) ()1
'--∑??=γ
ij
j j i R A K K (5-42b ) ()1
'--∑??=γ
ij
i i j R P K K (5-42c )
解:第一步:给参数γ取初值,令:γ=1。 第二步:用迭代法求约束系数K i 、K ’ j 。
首先令列约束系数K ’3 = K ’4= K ’5=1代入(5-42b )式求两个行约束系数:
003499
.0,003.052501220013550121
1==??
?????+?+?=-K K 再将求得的K 1、K 2带入(5-42)式中求K ’3、K ’4、K ’5:
2621.1,
0640.1',8958.0370003499.03300003.0'541
3===??
?????+?=-K K K
至此第一遍迭代完。再将新的K ’j (j =3, 4 , 5)值代入式(5-42)求第二遍迭代值K i :
003501
.0,
002996.052502621.12200064.135508958.021
1==??
?????+?+?=-K K 由新的K 1、K 2求K ’3 = K ’4= K ’5:
2618.1'0643.1'8957.0'543===K K K ,,。
第二遍迭代结束。再进行第三遍迭代,求得003501.0002996.021==K K ,。它们与第二遍的完全相同(其实只要相对误差<3%即可)迭代达到收敛,停止迭代。得:在γ=1的前提下,003501.0002996.021==K K ,;2618.1'0643.1'8957.0'543===K K K ,,。
第三步:把以上参数代入模型(5-42)式,根据现状P i 、A j 值可算得现状分布理论值:
6.1473
5003008957.0002996.0'1313113=???=???=
∧
R A P K K q j
其它结果列于表5-9。从表5-9可见ij q ∧
虽不一定等于q i j ,但j j i i A A P P ==∧
∧
,。
第四步:检验。考察ij q ∧
与q i j 的相差程度。 针对现状实际PA 表的理论分布表求各自的平均交通阻抗:
3996.3,
4.31000
4
2005100340055021003150==?+?+?+?+?+?=
∧
R
因%3<-∧
R R R ,可认为1=γ可接受。例完。
§5.4 模型的理论解释
前面两类出行分布预测方法(增长率法、引力模型法)都是来源于人们的直观经验和感性认识,并没有多少理论依据,作为一个完整的理论体系,这显然是一个缺陷,不利于它的进一步发展。本节我们要从应用数学理论出发,探讨它们的理论基础问题。主要从两个角度研究这个问题:一是从概率论的角度,一是从信息论的角度。
5.4.1 概率论的解释
作为出行分布预测的已知条件,为了规划年各个分区的产生量P i 和吸引量A j 是预先知道的,因而这个区域的出行总量Q 也是已知,∑∑==
i
j j
i A
P Q 。从调查数据中可以
统计出另外一个已知条件:现状出行分布矩阵n n ij q ?)(0,
设∑=j
i ij q Q ,0
0是现状的出行总量,那么就现状而言,Q 0个出行量中有0ij q 个是从分区i 到分区j 的出行,即分区i 到j 的出行
量占总出行量的比率是
Q
q p ij
ij =
,(5-43)
或者说任意一个出行是分区i 到j 的出行概率为p ij 。一般地,我们可以把这个概率作为规划年分区i 到j 的出行先验概率。那么,现在的问题就是,规划年有Q 个出行总量,
它将分n ×n 份,而第(i -1)n +j 份(分区i 到j )的概率是p ij ,要求各分区之间的出行量的联合分布{ p ij :i =1,2,…,n }。由概率论知,这是一个多项概率分布。联合概率函数为
∏∏=
j
i q
ij ij
ij ij p q Q P ,)(!!(5-44) 我们当然有理由认为,未来规划年真正出现的出行量联合分布{ p ij :i =1,2,…,n}应该是其中取最大概率值的那种情况。为了简化问题,令(5-44)式两边取自然对数:
[]
∑∑?+-=j
i ij ij j
i ij p q q Q P ,,)ln()!ln()!ln(ln (5-45)
再借用Stirling 近似公式:x x x x -≈ln )!ln(,上式变为
∑∑?+--≈j
i ij ij j
i ij ij ij p q q q q Q P ,,)]ln([])ln([)!ln(ln (5-46)
因此剩下的问题就是求解下面的数学规划问题:
∑∑?+--=j
i ij ij j
i ij ij ij q p q q q q Q P ij
,,)]ln([])ln([)!ln(ln :max (5-47a )
s.t.
i j
ij
P q
=∑(5-47b )
j i
ij
A q
=∑(5-47c )
使用Lagrange (拉格朗日)方法。Lagrange 函数为:
∑∑∑∑-+-+=i
j
i
ij j j j
ij i i q A q P P L ][][ln βα
∑∑∑∑∑∑-+-+?+--=i
j
i
ij j j j
ij i i j
i ij ij j
i ij ij ij q A q P p q q q q Q ][][)]ln([])ln([)!ln(,,βα(5-48)
式中,αi 、βj 是Lagrange 系数,这些系数待定。让L 对q ij 求偏导,并令这些偏导数为零,即
0)ln()ln(=--+-=??j i ij ij ij
p q q L βα(i 、j =1,2,…,n )(5-49) 解得(注意(5-43)式)
j i e e Q q p q ij j i ij ij βαβα--??
=--=0
1)exp((5-50)
令:j
i e
v e Q
u j i βα--==,
10,(5-51)
得j i ij ij v u q q ?=0
(5-52)
这正是式(5-15)所指的Fueness 约束条件模型(双约束增长率模型)。由约束条件(5-47b )、(5-47c )式可知参数是这样确定的:
∑∑=
=
i
i
ij j
j j
j
ij i
i u
q A v v q P u 00
,(5-53)
这是一个两组参数相互确定的问题,可以用解联立方程组的办法来求解,也可以用相互迭代的办法来求解,我们推荐采用后一种,见5.2.3小节的Furness 迭代方法。
我们发现,Detroit 增长率模型本质上与(5-52)式是相同的。事实上,由§5.2的迭代过程知,Detroit 模型可写成(设W =Q /Q 0):
n
aj aj k pi pi pi ij k
aj k
pi k
ij
k ij
W F F F F F q W
F F q q 1
)()(0
0100)
1(?
??==?
?=+ (5-54)
只须令:n aj aj j k pi pi pi i W
F F v F F F u 1
)(),(0
010?
== ,即得式(5-52)的形式。 上面从概率论的角度解释了两个增长率模型的理论来源,下面探讨引力模型的理论来源。
5.4.2 最大熵原理
1948年信息论创始人Shannon (香农)借用热力学中熵的概念提出了“信息熵”的概念:设A ={a 1, a 2,… , a n }是某个信息系统X 的符号表,A 中各个符号出现的概率分布为{p 1, p 2,… , p n },则信息系统X 的熵为:
∑=-=n
i i i p p X H 1
)ln()((5-55)
1957年Jaynes 提出了最大信息熵原理:在所有备选的概率分布中挑选这样的分布作为信息系统X 的分布,它在某些约束条件下,是信息熵达到最大值的分布。这是因为信息熵取最大值时对应的那组概率分布出现的可能性占绝对优势。后人又将最大信息熵原理推广到一般熵原理,作为决定系统概率分布的标准,广泛应用于气象学、交通科学等领域。一般熵原理就是:
一个确定的概率分布对应一个最大熵值;反过来,满足某些约束条件的最大熵状态必然唯一确定一个概率分布。
据此,我们可以应用这个原理解决交通的出行分布问题。在交通分布中,一共有Q 个出行,每个出行有n ×n 个选择,选择概率为{p i j =q i j /Q : i ,j =1, 2, … ,n },。其熵为
∑∑∑--=??
???????? ??-=-=j i ij ij ij ij j i i i Q q q Q Q q Q q p p H ,,]ln [ln 1
ln )ln((5-56) 如前所述,出行分布还须满足(5-47)中的两个约束条件。假定规划年的平均出行阻抗已知,设为R ,则有
R Q R
q j
i ij
ij =∑,(5-57)
这样就得到一个新的约束条件。关于交通分布的最大熵原理可用下面数学规划问题来描述(略去常数项):
∑--=j
i ij ij q Q q q h ij
,]ln )ln([:max (5-58a )
s.t.
i j
ij
P q
=∑(5-58 b )
j i
ij
A q
=∑(5-58c )
R Q R R
q j
i ij
ij ==∑,(5-58d )
这个规划问题的Lagrange 函数为:
∑∑∑∑∑∑-+-+-+=j
i j
i ij ij i
j
i
ij j j j
ij i i R q R q A q P h L ,,][][][γβα
∑∑∑∑∑∑∑-+-+-+--=i
j
ij ij i
j
i
ij j j j
ij i i j
i ij ij R q R q A q P Q q q ][][][]ln [ln ,γβα(5-59)
式中,αi 、βj 、γ是Lagrange 系数(i 、j =1,2,…,n ),这(2n +1)个系数待定。让L 对q ij 求偏导,并令这些偏导数为零,即
0ln )ln(1=---+--=??ij j i ij ij
R Q q q L γβα(i 、j =1,2,…,n )
(5-60) 解得
ij
j i R ij e e e e
Q q γβα---??=
(5-61) 令:j
j i i A e v e e P Q u j i β
α--==,
,(5-62) 得
ij
R j i j i ij e
A P v u q γ-?=(5-63)
这正是§3中的阻抗函数为指数型的双约束引力模型。
如果将上面新的约束条件(5-58d )换成
')ln(,R R q
j
i ij ij
=∑(5-58e )
那么同理可得到的数学规划问题的解就是
γ
-?=ij
j i j i ij R A P v u q (5-65) 这正是§3中的阻抗函数为幂型的引力模型。
如果将上面两个新的约束条件(5-58d )、(5-58e )同时加入,那么数学规划问题的解就是
ij
bR ij j i j i ij e
R A P v u q --???=γ
(5-66)
这正是§3中的阻抗函数为幂与指数的复合型的引力模型。
女性出行行为特征研究 出行行为分析理论研究,尤其是女性出行行为的研究目前已成为焦点。对女性出行行为针对性的分析,可以深化出行研究,从而更加有效地进行交通需求分析与预测,制定出更加有效的针对交通建设、管理与控制的政策。 随着大量女性涌入劳动力市场,女性的出行发生了巨大的改变,特别是女性的通勤出行已经成为影响交通的重要因素。本文以女性出行为研究对象,利用非集计模型,着重对比了女性和男性在出行链和交通方式方面的不同,同时指出了中西方女性出行行为的差异。 不仅有利于从根源上对女性出行行为特征和个体社会经济属性的相互影响关系进行研究,也有利于政府部门全面掌握女性交通动态,为交通政策的合理制定和城市规划提供根本依据。本文在2005年城市居民出行调查的基础上,围绕女性出行行为特征这一主题,作了以下的一些研究:(1)论文首先介绍国内、外有关出行行为研究的现状,总结了各种出行行为分析方法的特点,并指出现有研究存在的问题。 另外,本文还阐述了出行行为的数学分析方法,提出了出行行为分析的基本理论,着重介绍了随机效用理论。并在分析传统的出行研究方法上,提出了基于活动的出行研究方法。 另外,论文从出行率、出行时耗、出行目的和出行方式的角度,对比了女性和男性的出行特征和出行规律。(2)利用基于活动分析方法,引入了出行链的定义,界定了通勤者上、下班出行链开始和结束的标准,其次探讨了分类变量的独立性检验问题,为了解各个影响因素和选择行为的关系提供了统计检验方法。 利用非集计理论,构建了不同性别通勤者上班出行链类型选择模型,通过回
归系数定量分析了通勤者的社会经济等属性对其出行链选择行为的影响,比较了不同性别通勤者对出行链类型选择的差异。为全面了解不同性别通勤者整个活动和出行特征,进行了一些有益探索。 对深入研究女性通勤出行的特点提供了一定的帮助。(3)交通方式选择行为是出行行为研究的重要课题之一,本文利用非集计理论,构造了不同性别通勤者上班时刻对于步行、小汽车、公共汽车以及自行车四种交通方式的选择行为模型。 并对模型的计算结果进行了精度检验,最后利用模型回归系数的含义,解释了不同性别通勤者交通方式的选择行为,并总结了不同性别通勤者上班通勤交通方式选择的原因。(4)本文最后根据国内外调查数据,对国内外女性在出行时耗、出行链以及出行方式方面的出行特征进行了对比,阐释了国内外女性出行行为差异的原因,为今后更加全面地探索女性出行行为特征和制定相关政策提供了依据,对女性出行行为的引导和合理控制具有一定的参考价值。
居民出行调查方案设计-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN
居民出行调查方案设计 城市交通规划越来越受到重视,面对日益拥堵的交通状况,各城市采取相应的措施来解决交通拥堵这个难题,而居民出行调查数据是解决交通问题的基础,下面是居民出行调查方案设计,欢迎阅读了解。 研究背景 近几年来,随着社会经济的迅速发展,作为国民经济动脉的交通发展也非常快,城市规模也越来越大。城市交通基础设施建设步伐日益加快,快速干道、立交桥、大容量公共交通系统等大规模的交通建设项目日益增多。同时,随着城市化进程的加快,城市人口逐渐增多,城市交通需求也越来越大。所以目前国内大多数城市存在着交通供给和交通需求的矛盾日益激化的问题。交通系统作为服务系统,更要有效的满足交通需求,就需要对交通需求特征,也就是出行特征有充分的了解,从而合理引导交通的发展,科学的安排交通设施的建设,进行有效的交通需求管理。而要分析研究交通出行的特征,即交通源流的产生及其在地理空间上的流向,以及以一定的交通方式在交通网络上的分布形态,最基本也最全面的手段就是进行交通调查。对于城市交通需求,居民出行调查能全面地反映出行者的社会属性信息和出行信息,刻画城市交通出行的特征。
居民出行调查的含义 城市居民出行,是指居民为完成某一目的,使用某一种交通方式,耗用一定的时间从出发点经某一路径到达目的地的位移过程。居民出行调查,是指对居民一天内出行的详细情况进行调查,通过分析和寻找相关的变化规律,作为城市交通规划、建设的依据。对居民出行随时间、空间、目的、方式变化规律的分析,也是城市客流流量、流向分布以及交通结构方式预测的基础,可为优化现有城市公交线网以及科学制定公交线网规划提供依据。一般出行的定义是:“为完成某一目的,在可通行车辆的道路上步行超过5分钟或使用交通工具单程距离超过500米,称为一次出行”。 居民出行调查的重要性 居民出行调查是交通规划中OD调查的重要内容,是交通规划中需要收集的最基础资料之一,是进行交通需求预测和制定交通规划方案的重要依据,在城市综合和专项交通规划中扮演着极其重要的角色。国内外调查实践表明:居民出行调查可以全面地再现城市交通随即易逝、变化多的特点,能揭示城市交通结症的原因、内涵交通需求与土地利用、经济活动的规律。 通过对居民出行调查数据的整理和分析,可以把握城市交通需求与土地利用以及经济活动之间的相互关系,对
《南关区居民出行特征调查及出行预测》调查报告一、调查背景及目的 近年来,随着长春市城市交通建设的不断完善与发展,长春市的交通得到了很大的改善,居民的出行也方便了许多。另外,随着人们生活水平的不断提高,越来越多的小轿车、摩托车、助力车进入各家各户,这无形中也给城市交通带来了些许压力。居民出行调查是城市道路规划的基础性工作,为了解长春交通现状及未来发展趋势,提出合理的规划建议;也为了更好的提高我们在工程研究中进行观察、认识、思考、分析的综合能力,在老师的安排与领导下,我们组对长春市南关区居民出行情况进行了调查。 二、调查任务 (一)通过得到的数据分析居民出行特征 (二)在此基础上进行2015年、2020年长春市南关区居民出行需求预测 三、调查对象及方法 (一)调查对象:在长春市南关区以及朝阳区桂林路一带的居民。(学生、工人、服务人员、职员、公务员、教师、退休人员以及个体) 调查对象一共分为七个年龄段: 6-14 和15-19这两个年龄段一般以学生为主,出行的目的一般为上学。 20-29、30-39、40、49年龄段的人一般是上班族,出行目的一般以上班 为主;50-59、60岁以上的居民大多是退休在家,出行一般都是休闲娱 乐,购物。 (二)调查方法:现场实地问卷调查,为了确保问卷答案的真实性,准确性,调查员在调查时都是在被调查者旁边做指导,并与其交流,得到其家人 以及朋友每天的出行资料,这样大大节省了时间与人力,于此同时我们 还大量观察并且收集有关数据。 四、实施过程及结果 (一)制表以及划分交通小区 此次调查我们将南关区划分为六个交通小区以及朝阳区的一个交通小区,具体划分情况见附表1。 (二)调查内容 为了确保我们此次调查的准确性以及广泛性,我们分别对教师、学生、工人、服务人员、公务员以及一些从商人员进行了调查。并且此次调查内容我们主要侧重出发时间、出发地点、出行方式、到达地点、到达时间、出行费用几个方面。并且附带调查了出行者的性别、年龄、职业等,以便于我们分析整理数据。具体请见附表2。 (三)组内分工
3.3 交通预测及分析 3.3.1 预测的总体思路 3.3.1.1 概述 路网交通量预测分析是城市交通规划和城市道路建设规模和标准的主要依据,预测结果将直接影响到项目建设的决策。本项目交通预测可划分为以下两个部分,预测过程也相应分别进行,最后累加得到总的预测交通量。 背景交通量预测——由两部分构成,其一为背境交通量,即相关道路上的穿越交通量,起止点均在项目范围之外,主要由项目相关道路的现有交通量在研究期限内相应增长而得到;其二为研究区域内其它新建项目的交通量,由交通影响范围内其它建设项目所产生的交通量,在道路网上分配而获得。背景交通量预测采用国际通用的四步骤预测法,并利用国际上较为流行的交通规划软件(TransCAD)作为计算工具。通过对现状与规划资料(土地、人口、社会、经济、交通)的调查研究,通过进行交通小区的划分,并据此建立交通模型。通过社会经济发展预测、城市土地使用规划,得到交通生成量;采用重力模型进行收敛计算,得到小区分布交通量;通过交通方 式划分,得到机动车的出行量;采用均衡分配法进行分配,得到拟建项目的路段及交叉口流量。 拟建项目交通量预测——根据项目的建设性质及规模,预测目标年的项目交通生成量,即交通产生量与吸引量。在此基础上进一步对其进行交通分布和交通分配,将因项目而产生的交通量分配到周围道路上,得到拟建项目交通量。交通需求预测主要根据该项目的开发强度及不同用地类型出行发生和吸引率,预测该开发项目目标年内部生成的交通需求。 图3-24 交通量预测流程图 3.3.1.2 预测依据 预测的主要依据如下: 1)《珠江三角洲地区改革发展规划纲要(2008-2020)》 2)《眉山城市空间发展战略(眉山2030)》 3)《眉山市国民经济和社会发展十一五规划纲要》 3)《眉山市城市总体规划(2009-2030)》 4)《眉山市城市规划条例》 5)《眉山市城市规划技术标准与准则》 6)《眉山市城市交通规划》(1999-2020) 7)《横琴新区城市总体规划(2009-2020)》广东省城乡规划设计研究院8)《横琴新区控制性详细规划》(广东省城乡规划设计研究院) 9)《眉山市统计年鉴2009》 10)《眉山重大交通基础设施布局集疏运网络规划》
第五章出行分布预测 §5.1 概念 从出行发生预测可以得知对象区域各个分区出行产生量和出行吸引量。下面的问题是:就某个分区而言,它所产生的这些出行量究竟到那个分区去了?它所吸引的这些出行量又究竟来自哪里?也就是要预测未来规划年各个分区之间出行的交换量。我们把分区之间的出行的交换量叫做“出行分布量”,本章就来研究出行分布量的预测问题。 5.1.1 出行分布量 出行分布量是指:分区i 与分区j 之间平均单位时间内的出行量,单位时间可以是一 天、一周、一月等,也可以是专指高峰小时。就一对分区i 和j 而言,它由两部分q ij 、q ji 组成: q ij ——以分区i 为产生点(注:不一定是出行的起点),以分区j 为吸引点(不一定是出行的终点)的出行量。 q ji ——以分区j 为产生点,分区i 为吸引点的出行量。 如同一个分区的产生量不一定等于吸引量一样,q ij 不一定等于q ji 。从下面的例子可以看出这一点。 例5-1 如图5-1所示的两分区之间的六次出行中; q ij =4(出行1、2、5、6) q ji =2(出行3、4) 但以i 为起点的出行数=3(出行1、4、5); 以j 为起点的出行数=3(出行2、3、6)。 5.1.2 出行分布矩阵(PA 矩阵) 出行分布矩阵是一个二维表(矩阵),行坐标为吸引分区号(Absorbing zone ),列坐标为产生分区号(Producing zone ),元素为出行分区量。如表5-1所示,表5-1中的行数和列数相等。从理论的严格意义上讲,产生区和吸引区不一定相同,甚至某些分区只是产生区,但不吸引任何出行,因而不是吸引区,如纯住宅区,也可能有某些分区只是吸 图例:h —家庭;s —学校;f —工厂 图5-1 (例5-1)两个分区间的六次出行
精心整理城市轨道交通客流预测方法 目前, 对城市轨道交通线路客流预测尚处于探索阶段。中国城市轨道交通客流预测模式主要分为3 类:1、非基于现状OD(起点) 客流的预测模式, 将相关的公交线路客流和自行车流量向轨道交通线路转移, 得到轨道交通客流; 2、基于现状OD , ,轨 , 并 考虑到高峰小时与全日出行分布规律的差异性, 建议分别构建全日客流O D 矩阵和高峰小时客流OD 矩阵,然后通过相应的分配过程, 得到轨道交通线路的全日客流指标和高峰小时客流指标 2 全日出行的发生( 吸引) 和分布预测
2. 1 各交通小区全日出行的发生( 吸引) 预测交通小区的日发生量与人口数相关、吸引量与就业岗位数相关, 并服从指数关系。 其计算式为: i , j=1,2,…,n 式中: G i为交通小区i的发生量; A j为交通小区j的吸引量; P i为交通小区i的人口数; W j为交通小区j的就业岗位数; a i 、b i 、cj 、d j 均为模型参数, 反映了交通小区i的土地利用性质; n为交通小区数。 2. 2全日出行分布预测 全日出行分布预测可采用双约束重力模型 其中, i , j=1,2,…,n 式中: Q ij 为从交通小区i 到j 的全日出行总量; 、分别为行约束系数和列约束系数; f ( cij ) 为交通小区i 到j 的阻抗函数; cij 为交通小区i 到j 的出行阻抗。
3高峰小时的生成-分布共生模型 调查结果显示: 在高峰小时时段内, 以工作和上学为主的通勤出行所占比例很大, 一般为80% ~90% 。由于工作、上学是工作日所必须的, 且时间性强。因此, 分别建立工作和上学的出行生成分布共生模型, 并根据这 2 种出行目的, 以及在高峰小时出行中所占的比例进行调整, 从而预测得到高峰小时的出行发生( 吸引) 及分布。 工作出行模型为 i , j=1,2,…,n 上学出行模型为 i , j=1,2,…,n 式中: 为高峰小时交通小区i到j的工作出行人次数; 为高峰小时交通小区i到j的上学出行人次数; a w 、b w 、cw 、d w 均为高峰小时工作出行的生成分布共生模型参数; a s、b s 、cs 、d s均为高峰小时上学出行的生成分布共生模型参数。 其中,和有以下关系式 式中: 为高峰小时交通小区i 到j 的总出行人次数; 为高峰小时工作出行所占的比例; 为高峰小时上学出行所占的比例。 4 方式划分与分配组合模型 4.1组合出行 组合出行是指居民一次出行, 从起点到终点采用了多种出行方式联合完成。居民由起点到终点的一次组合出行如图所示。 图2组合出行
交通量分析及预测 LG GROUP system office room 【LGA16H-LGYY-LGUA8Q8-LGA162】
第三章交通量分析及预测 公路交通调查与分析 3.1.1调查综述 交通调查的目的是了解现状区域路网的交通特性,掌握路段交通量及其特征。通过交通调查来分析路段交通量及车种组成、时空分布特征等,了解区域交通发生、集中及分布状况。 本项目有关的交通调查主要是交通量调查。 交通量调查是收集沿线主要相关道路的历年交通量状况,交通量的车种构成以及有关连续式观测站点的交通量时空变化特征等资料。 相关运输方式的调查与分析 拟建项目X922荔波县翁昂至瑶山(捞村至瑶山段)公路改扩建工程路线起点位于荔波县捞村,顺接X922翁昂至捞村段,终点位于荔波县瑶山与X418平交,终点桩号K20+。路线推荐方案全长公里。 根据贵州省公路局及地方观测点提供的交通量统计资料,现有与该项目相关的公路主要有X922翁昂至捞村段(原Y101乡道),X418线。公路沿线历年的交通量观测值见表3-1。 表3-1 X922捞村至瑶山段(原Y007乡道)公路历年平均交通量单位:辆 /日
注:表中数据除混合车折算值为按小客车为标准的折算值外,其余均为自然车辆数。 预测思路与方法 3.3.1 交通量预测的总体思路 公路远景交通量的预测,是为正确制定公路修建计划提供分析基础,为项目的决策提供依据。 根据对项目所在地区社会经济和交通运输调查的资料分析,计划建设的荔波县瑶山至捞村改扩建公路工程是荔波县境内的重要公路项目。本项目的建设,将有力地促进公路沿线工业和乡镇的社会经济及交通运输发展、为精准脱贫提供交通保障。 预测远景交通量一般由趋势交通量、诱增交通量和转移交通量三部分组成。 趋势交通量是指现有公路交通量按照它固有的发展规律、自然增长的交通量。 诱增交通量是指公路的开通,使它所覆盖的影响区内经济和交通体系的深刻变化,诱使经济、产业迅猛增长,则会新产生交通量。 转移交通量是指公路建成后,由于竞争关系而从其它运输方式(铁路、水运和航空)转移过来的交通量。对本项目而言,由于没有与本项目有竞争关系的其它运输方式存在,因此本项目不考虑转移交通量。 根据分析,本项目的远景交通量主要由趋势交通量和诱增交通量组成。 3.3.2 交通量预测方法及步骤 由于该项目属于老路改造工程,大部分为改造路段,且公路沿线均设有交通观测点,因此该项目不作OD调查,采用沿线历年断面交通量与影响区社会经济的发展情况及规划,进行相关分析,预测未来特征年的远景交通量。 交通量预测 3.4.1 预测年限和特征年确定 根据交通运输部交规划发[2010]178号文件发布的《公路建设项目可行性研究报告编制办法》的规定,公路建设项目交通量的预测年限为调查年到项目建成后20年;
居民出行方式调查报告 篇一:居民日常出行方式碳排放调查报告 居民日常出行方式碳排放调查报告 一、调查背景 人类社会伴随着生物质能、风能、太阳能、水能、化石能、核能等的开发和利用,逐步从原始社会的农业文明走向现代化的工业文明。然而,随着全球人口数量的(转载于: 小龙文档网:居民出行方式调查报告)上升和经济规模的不断增长,化石能源、生物能源等常规能源的使用造成了严重的环境问题。近年来,废气污染、光化学烟雾、水污染和酸雨等的危害,以及大气中二氧化碳浓度升高所带来的全球气候变化,已被确认为人类破坏自然环境、不健康的生产生活方式和常规能源的利用所带来的严重后果。 中共十六届五中全会明确提出了“建设资源节约型、环境友好型社会”,并首次把建设资源节约型和环境友好型社会确定为国民经济与社会发展中长期规划的一项战略任务。 在此背景下,现在“低碳社会”、“低碳城市”、“低碳超市”、“低碳校园”、“低碳交通”、“低碳环保”“低碳网络”、“低碳社区”——各行各业蜂拥而上统统冠以“低碳”二字,使“低碳”成为一种时尚。其中,“低碳交通”又是热点中
的热点。在二氧化碳的排放来源中,交通运输排放的占到34%左右。交通运输以其巨大的能源消耗,给自然环境和人类生活环境造成了严重的污染。过去10 年全球二氧化碳排放总量增加了13%,而源自交通工具的碳排放增长率却达25%。因此,发展低碳交通是降低碳排放的必然要求。我们这次进行居民日常出行方式碳排放调查,就是为了解低碳交通的发展所存在的问题以及探究相关解决措施。 二、调查对象 由于调查的总体数目过大,我们采取了抽样调查的方式进行问卷调查,为了使调查样本具有代表性,不偏向某一个群体,我们选取了三个不同区位的居民小区进行调查,分别是城市中心的天荣小区,城市边缘的骏景花园小区,还有城市外围的星晖园小区。 三、调查分析 数据与分析: 你住在: [单选题] 第 1 页 1、您的性别: [单选题] 2、您的年龄: [ 单选题 ]
城市居民出行OD调查实施方案 一、调查目的: 城市居民出行是构成城市交通的主要部分通过居民出行OD调查了解某一地区居民出行规律并以此作为交通优化的数据条件之一进行城市道路交通系统分析、交通需求预测,进而改善城市交通设计、设置及规划。更大程度的方便居民出行。 二、调查组织机构: OD调查是一项涉及面广、工作量大的工作,需要许多单位、许多部门相互协作、共同完成,因此需要设立一个专门的机构,统一负责指挥、协调工作。调查前需要与当地交通局、公路局、交通设计院及各级行政管理部门等协调工作,协作完成此次调查。 三、调查方法: 等距抽样,按门牌号将各小区内全部住户每隔10户抽一户进行调查。 四、调查地点: 呼和浩特市 五、调查表设计(如下) 居民出行OD调查表 调查员:调查时间:调查区域: 1家庭基本信息 门牌号家庭住址用户姓名户主受教 育程度 联系电话家庭人数六岁以上 人数家庭年收 入 家中有何交通工具家庭常用出行方式 2家庭个人出行情况 家庭成员编号 性别 男女 年龄职业(代码)上班或上 学地址 常用出行方式 (代码) 1 2 3 4 5 6 7
填表说明:1 该表尽量由户主填,6岁以上人数统计清楚 2尽量填写真实情况 3职业代码:1学生2工人3医生4教师5公务员6服务人员 7 科研人员8个体户9退休人员10无业人员11其他 4出行方式代码:1公交车2出租车3私家车4电车5自行车 6其他 六、居民出行OD调查数据的处理技巧: 1原始数据的整理 将城市区域划分为n个交通小区,,居民出行调查回收的表格经整理可得到的OD矩阵 【t ji】生产量Pi吸引量Aj i j=1,2...n则∑=t ij=Pi ∑Pij=Aj 式中t ij---出行起点O到出行终点D的居民出行量 2数据的后期处理 从抽样数据推导出整个调查区域的OD出行特征,就要对交通小区的产生量、吸引量以及OD矩阵进行扩算
一交通量预测 1.1 交通调查现状 新开北路北延(源兴路~通沪大道)位于南通市经济技术开发区西北部,南起源兴路,北至通沪大道,全场约2.6Km,道路规划宽50m,是一条南北方向的城市主干道,是中心城区规划形成“二十一横二十二纵”的主干路布局中的一条纵向主干路,也是连通崇川区、通州区的重要道路。 新开北路北延建成后将在一定程度上缓解兴富路、东快速路等道路的交通压力,提高了开发区与崇川区的连通性,提升南通市的城市面貌,拉动城市经济的快速增长,带动沿线地区的经济发展,改变附近的交通需求,项目建成后将产生大量的旅游交通量和沿线居民的出行产生交通量。 规划道路附近用地布局及道路流量图 1.2 远期交通量需求分析 本道路建成后交通量表现为旅游交通运输产生和沿线居民出行产生的交通量等,拟建项目预测的远景交通量构成有以下三部分组成: (1)基于现状路网条件下而发展的趋势型交通量
(2)本项目建成后产生的诱增交通量 (3)本项目建成后本地出行交通量 1.3 预测思路和方法 1.3.1 预测思路 本研究预测的主要思路为:以交通调查为基础,在分析XX市路网现状状况、交通量现状和路网规划的基础上,结合XX市城市总体规划、经济产业发展的布局规划,根据研究路网的地位和交通功能,对未来交通量进行预测。 1.3.2 预测方法 交通预测方法主要有两类:一类是基于增长弹性系数直接进行预测的交通增长率预测法或基于总体发展规划的总量控制法;另一类是基于土地利用的四阶段法,即出行发生、出行分布、交通方式划分和交通量分配。本研究综合考虑两种方法,并结合TransCAD软件对目标年的交通量进行预测。 1.4 道路交通量预测 通过对现状道路交通量进行调查,通过拟建道路临近的第二条主干路或者快速路围合的范围建立道路交通网络,划分交通小区,运用Transcad软件和OD反推技术计算出该道路路段及相交道路未来年高峰小时交通量。 交通小区划分 充分考虑区域内土地使用性质,路网构成等因素,根据交通小区的划分原则,对现状道路网络进行交通小区划分。
第三章交通量分析及预测 3.1现状交通调查及分析 3.1.1项目影响区的确定 项目影响区根据对项目的影响程度,分为直接影响区和间接影响区,一般按行政区域划分。根据对各地区经济和交通的影响程度以及区域内物流和车流集散的特点,结合各地区社会经济、交通运输现状和路网状况,本项目直接影响区为彭山区,间接影响区包括眉山市、新津县等。 3.1.2交通现状分析 1、交通现状 随着城市建设用地的变化及产业结构的调整,步行和自行车出行仍然是居民的主要交通方式,但重要性有所下降,两轮电动车的出行比例已上升至10.1%,汽车出行增长较快,达到12.5%,公交车比例仅为14.7%。彭山区私家车发展势头强劲,将成为未来城市机动车增长的主要因素。 2、项目影响区交通现状及规划条件 城市交通状况的恶化和城市规模不断扩大、人口不断增加关系十分密切,当然这也是城市发展过程中必然会遇到的问题。当前我们正处在快速城市化和快速机动化交织的历史时期,城市交通压力急剧增加,过去五年彭山区机动车每年以10.8%的速度增长,而同期道路的增长速度远低于此。彭山区城范围内现状主次干道路网密度2.44公里/平方公里,城市支路路网密度更低,而城市主干道和支路的平均容积率要达到规划水平,还存在有很大差距。因此加大路网建设力度仍然是解决城市交通问题的重要途径。 3.2 交通量预测方法 交通量预测分析的目的是通过对片区路网的分析,研究项目建设给片区经济发展所带来的交通影响及其程度,判断在当前这种交通路网的承载能力下的影响,能否在可接受的范围内,并确定合理的项目出入口位置。道路断面的设置形式是否合理,满足交通功能的要求是最基本的条件。设计通行能力低于设计交通量的道路形式是不合适的,因为它容易造成片区路网的交通拥挤,甚至发生交通堵塞,要求设计通行能力必须大于设计交通量。另一方面,通行能力也不能过大,否则使道路资源不能充分利用,必然造成大量的浪费。
1.5相关规划及交通预测 1.5.2城市布局结构 城市规划区的整体空间结构为:“一心三翼、两轴四带’’。 l、“一心”:指中心城区,建设国际风景旅游城市和湘西地区的现代服务业中心。 2、“三翼”:指以武陵源风景名胜区、天门山风景名胜区和茅岩河风景名 胜区为主体的三个旅游职能片区。严格控制中湖、天子山镇发展规模,提升城镇建设水平与旅游服务品质。 3、“两轴”:指以澧水为纽带的城市发展轴和武陵源风景名胜区至天门山风景名胜区的旅游发展轴。 4、“四带”: 沙堤旅游发展带一一依托武陵山大道,发展近郊休闲度假旅游。 茅溪河旅游发展带一一依托张桑公路,发展水上休闲项目和近郊旅游度假设施。 澧水旅游发展带一一为张家界市未来旅游服务中心和度假基地建设的重点区域。 澧水城市职能拓展带一一是中心城区向东部拓展,完善城市中心地职能的空间拓展带。 1.5.3道路网规划 规划形成“两环五纵九连线’’的骨架路网结构。“两环”:快速路外环和子午路一迎宾路一大庸路构成的内环;“五纵”:茅岩路、天问路、溪西路、常德路一朝阳路、阳湖中路;“九连线”:子午路(内环以西)、荷花路、融山路、武陵山大道、沙堤大道、崇文路一永定大道、张峡路一永昌路、张联路一科技大道、官黎路一宝塔路。规划城市道路分为4级:城市快速路、主干道、次干道(包括滨河景观路)和支路。 1、快速路 城市快速路主要包括南外环、西外环、机场一南外环联络线、北外环、枫中路、武陵山大道。 2、主干路 规划城市主干路红线宽度为30-60米。主要包括子午路、迎宾路、永定大道、大桥路、大庸路、崇文路、兑泽路、西溪坪路、永昌路、科技大道、沙堤大道、桔坪路、向家岗路及李家岗路等。 3、次干路 规划城市次干路红线宽度为20-30米,主要包括回龙路、天门路、解放路、岚清路和滨江东路等。 4、滨河景观路 规划沿澧水河沿岸设置滨河景观路,滨河景观路红线宽度为20-25米。 5、支路 规划城市支路红线宽度为10-20米。 1.5.4交通量预测 1.5.4.1交通量基础资料 1、人口 1)总规分配人口 规划近期:市域人口规模172万人。 2020年张家界市中心城市人口规模按42.万人控制。其中,中心城区人口规模
简述交通量预测方法与步骤 一、交通调查与分析 1.调查综述 道路交通量与项目影响区的交通出行分布是交通量预测的基础资料。为了对公路建设项目未来年的交通量发展情况进行预测,需要调查了解项目影响区交通发展状况,相关路网交通现状,各类车辆的起讫点分布,交通组成等基础数据资料。 交通调查的内容包括两个方面,一是相关公路的道路状况和交通状况调查,另一方面是车辆出行分布调查,据此分析项目影响区的车辆出行分布状况。相关公路道路与交通状况调查主要包括相关公路历史流量发展分析,交通组成分析,用于分析项目影响区交通发展规律;车辆出行分布调查主要调查车辆出行的起讫点,即OD调查,用于分析项目影响区及相关路网车辆的空间、时间分布特征,掌握交通现状。 2、交通量OD调查及分析 OD调查和交通量观测主要是为了全面掌握项目影响区内各方向公路运输通道的交通流量、流向、车型构成等交通特性,为拟建项目所在通道的运输需求特点分析和交通量预测工作提供了可靠的基础数据。 OD调查点位置布设原则为: ⑴在能够把握交通流量分布特性和不影响调查目的及精度的前提下,尽量减少OD调查点个数,以节省人力、物力和财力; ⑵OD点应尽量远离城区(一般为10公里左右); ⑶为了和历年的交通量调查资料相互检验、补充,在不影响调查目的的前提下,调查地点尽量与历年交通量观测点一致或靠近。 以OD调查和交通量观测数据为基础,按照调查所采用的抽样率,根据主要相关公路历年交通量计算得到的月不均匀系数和周日不均匀系数将每个调查点的OD交通量进行扩大、修正,形成单点年平均日OD交通量(AADT),并得到单点OD表。交通量换算采用小客车为标准,各代表车型和车辆折算系数规定如下表所示。 各汽车代表车型与车辆折算系数
扬州市居民出行需求预测 3.1 预测思路 扬州市交通需求预测采用了城市交通需求预测的传统方法,即四阶段法,通过“四阶段”模式,从全方式出行产生预测着手,至出行分布预测,再至出行的交通方式(通过我们组调查得到的扬州市居民出行调查数据,采用类比法及优势出行距离,进行交通方式划分预测)的协调发展及其它相关因素的影响,有利于整个交通系统的内部平衡以及交通系统与外部系统的协调发展。同时,在具体进行预测工作时,在保证大前提即交通需求预测结果准确性及可靠性的条件下,对具体方法作了一定的调整,旨在突出客运需求预测的特点。 3.2 交通分区 3.2.1交通分区的原则 1、交通区的划分应根据城市规划区域的用地规模、人口规模、土地利用性质和规划布局特点来确定; 2、一般以行政分区、人工构筑物及自然疆界(如河流、铁路、森林公园、山脊等)作为交通区界; 3、尽可能以主干道作为各区的中轴线,要求区界与主干道宜有相等的距离; 4、小区不宜横穿两条公共交通主干道; 3.2.2交通分区 现状居民出行调查时,根据行政区划范围为依据,将城区分17个内部交通中区,并按道路走向、中区的位置、包含的人口数,将17个交通中区细分为27个交通小区。如表3-1、图3-1所示。 现状交通分区编码表表3-1
64 6401,6402,6403,6404,6405,6406,6407,6408,6409,6410,6411 图3-1交通小区划分图 3.2居民出行生成预测 居民出行产生预测的目的是建立中区居民出行发生量和吸引量与小区土地利用、社会经济特征等变量之间的定量关系,推算规划年各交通中区的居民出行发生量、吸引量。出行生成预测包括出行发生预测与出行吸引预测。城市土地利用是城市交通需求产生的根源。一般
第三章道路规划及交通量预测 第一节道路路网现状及道路服务水平评价 庐山区道路主要由十里大道、长江大道、外环路、学府路、学府二路,前进东路,并与周边的城市外围主干道长虹大道、庐山大道、芳兰大道、金凤路,九莲南路联系。 由于现有主要道路兼有区内交通、对外交通、以及生活性、交通性多重功能,虽在目前区域交通量并非十分巨大,但作为XX市区的规划范围,随着土地开发利用,规划道路应按城市道路“人车分离、机非分离”的原则规划设计。随着土地的开发利用,对道路运输能力也提出了更高的要求,但路网的不完善,将制约了经济的发展,现状道路的服务水平将无法满足经济发展的需要。 第二节区域路网规划 一、交通运输规划调查 道路系统历来被称为城镇的动脉和骨架,是一个城市能否规划合理的重要因素。因此道路的布局合理与否,直接关系到城镇能不能经济合理的发展。 道路规划本着“快速、顺畅、通达”的原则,合理调整布局,合理布置集镇道路网络。规划道路等级分为三级,即主干道、次干道和支路。主干道间距大于500米,红线30—60米;次干道间距为250—500米,红线宽度为20—40米;支路间距150—250米,红线宽度为9—20米以下。 二、路网规划
项目建设区域道路等级分为主干道、次干道和支路三个等级。其中主干道有十里大道、庐山大道、濂溪大道、芳兰大道、长江大道、欣荣路、外环路,道路宽度为30—50m;次干道学府路、学府二路,前进东路,道路宽度20—30 m;支路道路宽度15—20 m。 三、道路新建必要性论证 交通建设对土地利用有导向作用,土地的开发利用,必须以道路的修建为基础。濂溪大道为XX市庐山区道路骨架中最重要的一条主干道,本工程(濂溪大道延伸线)是濂溪大道的一部分。它的建设是城区土地资源使用开发的前提和必要条件。 随着城市化水平的不断提高,城市经济发展对加强人居环境的开发建设提出了更高的要求。良好的居住环境离不开道路等基础设施的建设。城市基础设施的建设也将直接服务于经济建设。为了能更好地改善XX市投资环境,改善人居生活环境,提高经济发展水平,不断加快基础设施的建设开发就成为必然。 道路建设不可避免地征集土地,拆迁房屋,造成建设区人口动迁,劳动力重新安置等社会问题。对农村居民而言,由于道路建设占用一定农田,菜地等耕地,由此会使农民的生存和生活最基本的生产资料受到影响;且对农民的劳作带来不便。但随着城镇建设发展,农民也将从务农为主转变成服务、务工、务商为主,故由此所造成的社会影响是在可承受范围内的。从长远来看,道路的建设有利于提高居民的生活质量,有利于推进XX的城市化建设进程。 本次工程沿线地势较起伏,因土地、规划部门工作到位,全线道
第四章交通需求分析 4.1前言 城市交通需求分析作为交通规划的核心工作之一,其目的是建立城市土地利用与交通的相互关系模型,进而预测不同的土地利用布局下的交通流量,为规划提供决策的依据,保证决策的科学性。 4.1.1交通需求分析的内容 运城市交通需求分析包括居民出行分析、暂住人口变动分析、对外交通枢纽交通分析、客运交通分析、货运交通分析、城市货运交通需求分析、城市客运交通需求分析、路网流量预测八部分。重点对居民出行分析、对外交通、客运交通、货运交通的未来发展趋势进行预测,并结合对外交通枢纽、客运交通、货运交通等资料分析的结论,对未来规划道路网的可能交通量分布状况进行描述和评价。 4.1.2交通需求分析遵循的原则 交通涉及到城市社会、经济各方面的因素,进行交通需求分析应遵循如下原则: ·符合经济发展规律 ·符合客运出行基本交通特征规律 ·与土地利用相互配合 ·反映政策的敏感性 4.1.3交通需求分析的基础 交通需求分析是对城市的未来状况进行定量描述,能否正确地把握城市交通发展的规律,取决于对现状交通资料的了解程度,以及对未来社会的经济发展趋势的合理结论。本次交通需求分析建立在如下基础: ·城市总体规划
·道路基础资料、交通量调查统计分析 ·有关运城市社会经济发展资料 ·相关城市的道路交通规划与道路工程专项规划资料 4.1.4交通需求分析的年限 预测分析年限保持与运城市总体规划的规划期限一致,近期为2005年,中期为2010年,远期为2020年。 4.2 居民出行分析 运城市居民分为常住人口与暂住人口,现状暂住人口比例较小,根据以往在各地进行的居民出行调查经验表明,暂住人口和常住人口出行特征虽有所差异,但差别不大,同时,考虑到暂住人口的发展,到2020年,暂住人口的交通特征将与常住人口趋于一致,尤其在对交通设施的使用上。本次需求分析中,常住人口与暂住人口按同一交通特征考虑。 在居民出行分析中,出行端点不考虑对外交通设施、旅游点等的部分流动人口,而是按本市城区居民的出行规律考虑。 4.2.1土地利用分析 城市的土地利用特征指标很多,与交通密切相关的有分类土地利用面积、土地使用性质、地形地貌、人口分布、就业岗位分布等等。 4.2.1.1分类土地利用面积 在进行交通分析时,需要将运城市区分成若干个交通小区。根据运城市总体规划确定的城市空间布局和土地利用规划,将规划用地按类别落实到各交通小区,以各小区的人口、面积、经济活动强度作为交通产生和吸引的基本因素。近期2005年人均用地指标按102m2控制,总用地面积约30km2,中期2010年人均用地指标按98m2控制,总用地面积约35km2,
武汉城市建设学院学报 J O U R N A L O F W U H A N U R B A N C O N S T R U C T I O N I S T I U T E 1999年第16卷第4期Vol.16 No.4 1999 新城区居民出行生成和分布预测模型研究 余继东吴瑞麟 摘要:对于新建城市(区),传统的四阶段交通需求预测模式难以适应城市总规阶段交通规划的需要,因为出行生成和分布预测阶段所必需的条件无法满足.在吸取国内相关城市经验的基础上,基于居民出行发生、出行吸引及出行分布的内在规律,提出一种面向新城区的简捷实用的预测模型框架. 关键词:新城区;出行发生;出行吸引系数;出行分布;OD矩阵;交通阻抗 中图分类号:TU984.141:U412.1+2 文献标识码:A Model Study of Trip Generation & Distribution Forecasting for New Urban Districts YU Ji-dong1,Wu Rui-lin1 (1.Dept.of Urban Road & Traffic Eng., Wuhan Urban Construction Ins. Wuhan 430074, China) Abstract: For new urban districts, the traditional 4-phase transportation demand forecasting model can not meet the need of the master planning due to the lack of the trip generation & distribution phase data. A feasible simplified forecasting model is proposed refering to the experiences of some new urban districts in our country and based on the inherent law of trip generation,trip attraction and trip distribution. Key words: new urban districts; trip generation; trip attraction factor; trip distribution; OD matrix; traffic friction. 我国城市化水平越来越高,涌现出大量新建城市或城市开发新区(以下简称新城区),给城市交通规划带来了新的课题,此处交通规划指总规阶段的专项性交通规划.在总规阶段编制土地利用规划时,需要编制以控制性骨干路网为目标的交通规划,以便能及时地协调土地利用与交通规划之间的互动关系.在交通供应能满足土地利用规划的同时,交通需求又能引导和刺激土地利用的下一轮规划.“先用地规划,后交通规划”是在已有的交通网络和交通设施的基础上制定城市用地发展规划,然后制定与之相适应的交通规划.但是,新城区的交通规划人员面对的只是山林荒地和少量农村居民点,现状土地交通资料几近空白,而且新城区开发速度要求交通规划的周期必须缩短,所以传统的交通规划方法在宏观指导性和现实实用性方面已不适应新城区开发建设的需要,应
基于活动的居民出行行为研究综述 丁威1,2,杨晓光2,伍速锋2 (1.西安建筑科技大学土木工程学院,西安710055;2.同济大学交通运输工程学院,上海200092) AREVIEWOFACTIVITY-BASEDTRAVELBEHAVIORRESEARCH DINGWei1,2,YANGXiao-guang2,WUSu-feng2 (1SchoolofCivilEngineering,Xi'anUniversityofArchitecture&Technology,Xi'an 710055,China;2SchoolofTrafficEngineering,TongjiUniversity,Shanghai200092,China) Abstracts:TheActivity-basedtravelbehaviortheoriesmainlystudyindividualorhouseholds'travelbehaviorlawsanddecisioncharactersintripchain.Anabundantresearchharvesthasbeengainedsincethesystematicalstudieswerecarriedthroughinwesterncountries.Thispaperfirstlyintroducestheoriginofactivity-basedtravelbehaviorresearch.Theactivity-basedapproachtotheanalysisoftravelbehaviorandtraveldemandoriginatedintheUK,theUSandGermanyin1970'stoovercomethelimitationsofthestandardfour-stageapproaches.Thestartingpointoftheapproachwastheswitchoffocusfromaggregatetripmakingtoindividualactivityparticipationandtheidentificationoftravelasaderiveddemand.Thenthedevelopmentandfruitsofactivity-basedtravelbehaviorresearchinwesterncountriesaresystematicallyillustrated,includingthefundamentaltheories,studymethods,andtheactivity-basedtraveldemandmodelsystems.Theactivity-basedtraveltheorycanbesummarizedintwobasicideas:first,thedemandfortravelisderivedfromthedemandforactivities.Secondly,humansfacetemporal-spatialconstraints.Asubstantialamountofanalysishasbeendonetorefinethetheory,testspecificbehavioralhypotheses,andexploratorymethodsofmodelingimportantaspectsofactivity-basedtravelbehavior.Boththeoreticaldevelopmentsareseenastwothreadsoriginatingfromacommonbehavioralassumption,namelythattripchainingisbasedonanr-sequentialdecisionmakingprocess.Thestudymethodofactivity-basedtravelbehaviorismainlyonthreeaspects:interspace-basedinteractionapproach,utility-basedapproachandheuristicapproach.Theseapproachesovercometheareadivisionlimitationsofthefour-stageapproachesandpresentday-to-daytravelbehaviorofindividualsandhouseholdsasbasicstudyunit.Activity-baseddemandforecastingmodelincludestwoaspects:econometricmodelandmixsimulationmodel.Thesemodelsystemsgaindevelopmentinthreesuccessivephases:MTC(MetropolitanTransportationcommission)system,Netherlands'tour-basedmodelandday-to-daytravelbehaviorchoicemodel.FinallythestatusquoandcharacteristicsoftravelbehaviorresearchinChinaareanalyzed.Theresultsindicatethattraveldemandderivingfromactivitydemand,peoplefacingtheconstraintofthetimeandspace,thelifestyleinfluencingpeople'sdecisions,andthetraveldecisionsinfluencingeachotherdynamicallyandmutuallyundervariableconditions.TheresearchisjustunderwayandChinashoulddeveloptheactivity-basedtravelbehaviorresearchbasedonanalyzingChinesetravelbehaviordeeplyinordertosupporttrafficplanninganddecision-makingoftransportmanagementpolicy. Keywords:activity-based;travelbehavior;tripchain;traveldemandmodel 文章编号:1003-2398(2008)03-0085-07 基金项目:国家自然科学基金项目(70501023);西安建筑科技大学青年科技基金项目(QN0608) 作者简介:丁威(1971—),男,河南安阳人,讲师,同济大学交通运输工程学院博士生,西安建筑科技大学讲师,研究方向为出行行为 理论。 收稿日期:2007-03-02;修订日期:2007-06-01 2008年第3期总第101期 人文地理 HUMANGEOGRAPHYVol.23.No.32008/6 85