
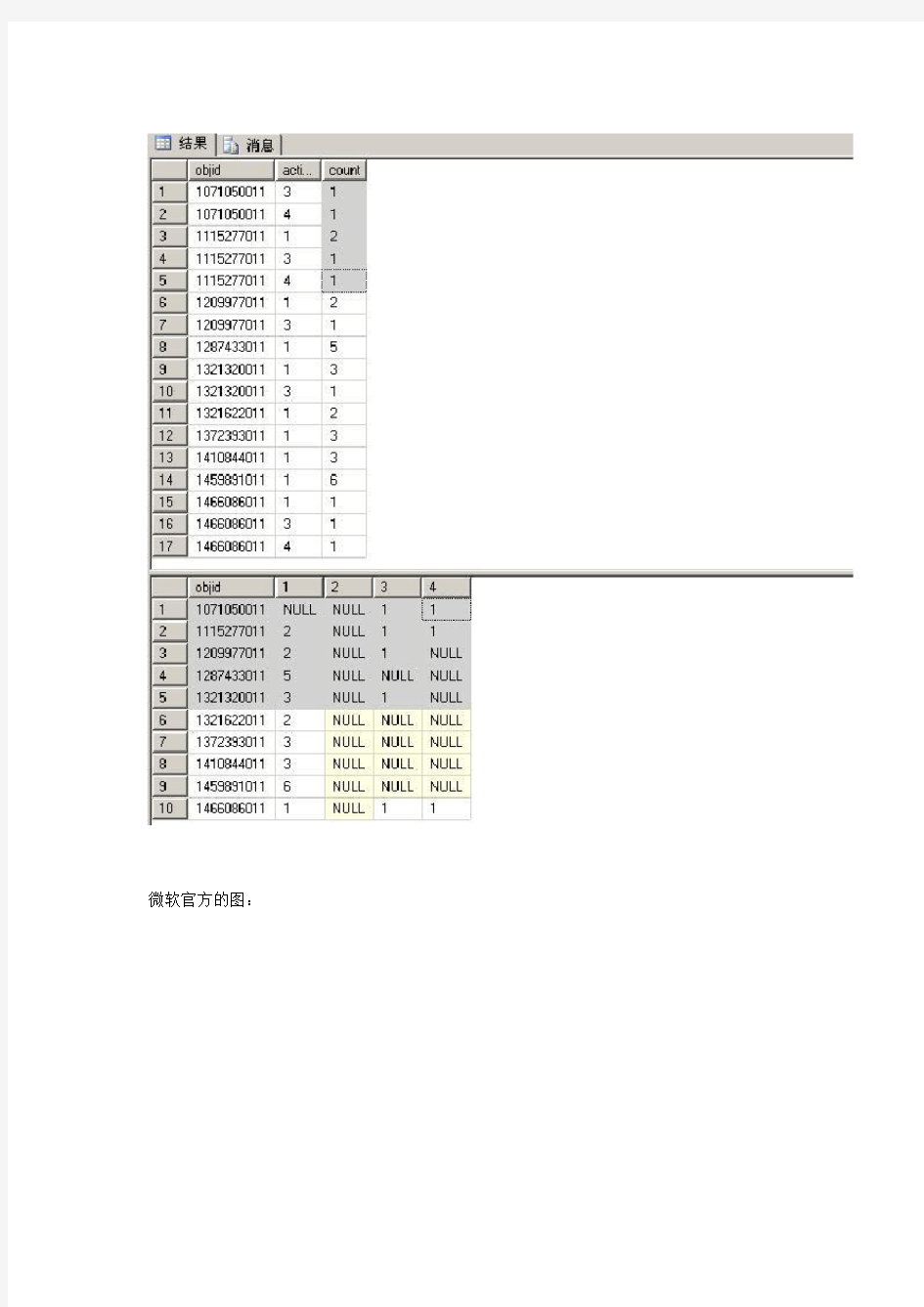
1:行转列
子查询,获取一定数据集结果
SELECT objid,action,count(1) AS [count] FROM T_MyAttention WHERE objid IN (SELECT TOP 10 objid FROM T_MyAttentiontma GROUP BY objid ORDER BY count(1) DESC)
GROUP BY objid,action
下面用行转列语法获取最终结果
select *
from
(
SELECT objid,action,count(1) AS [count] FROM T_MyAttention WHERE objid IN (SELECT TOP 10 objid FROM T_MyAttentiontma GROUP BY objid ORDER BY count(1) DESC)
GROUP BY objid,action
) t
pivot ( sum(count) for t.action in ([1],[2],[3],[4])) as ourpivot
微软官方的图:
2:列转行
怎么把一条记录拆分成几条记录?
User No. A B C
1 1 21 34 24
1 2 42 25 16 RESULT:
User No. Type Num
1 1 A 21
1 1 B 34
1 1 C 24
1 2 A 42
1 2 B 25
1 2 C 16
declare @t table(usserint ,no int ,a int,bint, c int) insert into @t select 1,1,21,34,24
union all select 1,2,42,25,16
SELECT usser,no,Type=attribute, Num=value
FROM @t
UNPIVOT
(
value FOR attribute IN([a], [b], [c])
) AS UPV
列转行备注value FOR attribute IN([a], [b], [c])这句话中,a,b,c是列的名字,但是列名不能出现在上句的select语句中。
-结果
/*
usser no Type num
---- --- -------- --------
1 1 a 21
1 1 b 34
1 1 c 24
1 2 a 42
1 2 b 25
1 2 c 16
*/
T-SQL语句中,PIVOT命令可以实现数据表的列转行,UNPIVOT则与其相反,实现数据的行转列。本文结合实例说明了这一过程,希望能对您有所帮助。
AD:WOT2015 互联网运维与开发者大会热销抢票
一、使用PIVOT和UNPIVOT命令的SQL Server版本要求
1.数据库的最低版本要求为SQL Server 2005 或更高。
2.必须将数据库的兼容级别设置为90 或更高。
3.查看我的数据库版本及兼容级别。
如果不知道怎么看数据库版本或兼容级别的话可以在SQL Server Management Studio 新建一个查询窗口输入:print @@version,运行之后在我的本机上得到:
Microsoft SQL Server 2008 R2 (RTM) - 10.50.1600.1 (Intel X86)
Apr 2 2010 15:53:02
Copyright (c) Microsoft Corporation
Express Edition with Advanced Services on Windows NT 5.2
然后我们选择一个数据库然后右键-属性选择[选项]得到下图的信息。
在确认数据库的版本和兼容级别符合1,2点的要求后你才可以接着继续往下学习。
二、使用PIVOT 实现数据表的列转行
1.在这里我们先构建一个测试数据表(这里使用的是临时表,以方便我们在退出会话的时候自动删除表及其数据)
首先我们先设计一个表架构为#Student { 学生编号[PK], 姓名, 性别, 所属班级 }的表,然后编写如下T-SQL
--创建临时表(仅演示,表结构的不合理还请包涵)
1.CREATE TABLE #Student (
2.
3.[学生编号] INT IDENTITY(1, 1) PRIMARY KEY,
4.
5.[姓名] NVARCHAR(20),
6.
7.[性别] NVARCHAR(1),
8.
9.[所属班级] NVARCHAR(20)
10.
11.);
--给临时表插入数据
1.INSERT INTO #Student (
2.
3.[姓名], [性别], [所属班级]
4.
5.)
6.
7.SELECT '李妹妹', '女', '初一 1班' UNION ALL 8.
9.SELECT '泰强', '男', '初一 1班' UNION ALL
10.
11.SELECT '泰映', '男', '初一 1班' UNION ALL
12.
13.SELECT '何谢', '男', '初一 1班' UNION ALL
14.
15.SELECT '李春', '男', '初二 1班' UNION ALL
16.
17.SELECT '吴歌', '男', '初二 1班' UNION ALL
18.
19.SELECT '林纯', '男', '初二 1班' UNION ALL
20.
21.SELECT '徐叶', '女', '初二 1班' UNION ALL
22.
23.SELECT '龙门', '男', '初三 1班' UNION ALL
24.
25.SELECT '小红', '女', '初三 1班' UNION ALL
26.
27.SELECT '小李', '男', '初三 1班' UNION ALL
28.
29.SELECT '小黄', '女', '初三 2班' UNION ALL
30.
31.SELECT '旺财', '男', '初三 2班' UNION ALL
32.
33.SELECT '强强', '男', '初二 1班';
2.查询各班级的总人数
1.SELECT
2.
3.[所属班级] AS [班级],
4.
5.COUNT(1) AS [人数]
6.
7.FROM #Student
8.
9.GROUP BY [所属班级]
10.
11.ORDER BY [人数] DESC
好了,在这里我希望把上面的表{ 班级, 人数 } 由班级[行] 的显示转换为班级[列] 的显示格式!
在此你会看到第一个PIVOT示例。是否很期待??
3.编写第一个PIVOT示例
1.SELECT
2.
3.'班级总人数:' AS [总人数],
4.
5.[初一 1班], [初一 2班],
6.
7.[初二 1班],
8.
9.[初三 1班], [初三 2班]
10.
11.FROM (
12.
13.SELECT
14.
15.[所属班级] AS [班级],
16.
17.[学生编号]
18.
19.FROM #Student
20.
21.) AS [SourceTable]
22.
23.PIVOT (
24.
25.COUNT([学生编号])
26.
27.FOR [班级] IN (
28.
29.[初一 1班], [初一 2班],
30.
31.[初二 1班],
32.
33.[初三 1班], [初三 2班]
34.
35.)
36.
37.) AS [PivotTable]
在结果表中我们看到了对于不存在的班级初一2班它的总人数为0,这符合我们预期的结果!
解释:使用POVIT首先你需要在FROM子句内定义2个表:
A.一个称为源表(SourceTable)。
B.另一个称为数据透视表(PivotTable)。
语法:
1.SELECT
2.
3.<未透视的列>,
4.
5.[第一个透视列] AS <列别名>,
6.
7.[第二个透视列] AS <列别名>,
8.
9....
10.
11.[最后一个透视列] AS <列别名>
12.
13.FROM (
14.
15.
16.
17.) AS <源表>
18.
19.PIVOT (
20.
21.<聚合函数>(<列>)
22.
23.FOR [<需要转换为行的列>] IN (
24.
25.[第一个透视列], [第二个透视列],
26.
27....
28.
29.[最后一个透视列]
30.
31.)
32.
33.) AS <数据透视表>
34.
35.<可选的ORDER BY子句>;
以上的PIVOT子句内的第1…n个透视列的值均为需要转换为行的列的常量值,需要用[]括起,支持GUID,字符串及各种数字!
4.下面演示一个较为高级的行转列的应用示例
--使用PIVOT查询班级内的男女学生人数及总人数
1.SELECT
2.
3.[所属班级] AS [班级],
4.
5.[男] AS [男生人数],
6.
7.[女] AS [女生人数],
8.
9.[男] + [女] AS [总人数]
10.
11.FROM (
12.
13.SELECT [学生编号], [所属班级], [性别] FROM #Student
14.
15.) AS [SourceTable]
16.
17.PIVOT (
18.
19.COUNT([学生编号])
20.
21.FOR [性别] IN (
22.
23.[男], [女]
24.
25.)
26.
27.) AS [PivotTable]
28.
29.ORDER BY [总人数] DESC
三、使用UNPIVOT 实现的功能其实与PIVOT恰恰相反
1.语法同PIVOT但是UNPIVOT的子句没有聚合函数
1.SELECT
2.
3.<未逆透视的列>,
4.
5.[合并后的列] AS <列别名>,
6.
7.[行值的列名] AS <列别名>
8.
9.FROM (
10.
11.
12.
13.) AS <源表>
14.
15.UNPIVOT (
16.
17.<行值的列名>
18.
19.FOR <将原来多个列合并到单个列的列名> IN (
20.
21.[第一个合并列], [第二个合并列],
22.
23....
24.
25.[最后一个合并列]
26.
27.)
28.
29.) AS <数据逆透视表>
30.
31.<可选的ORDER BY子句>;
2.看上面的语法感觉很浮云,不怕,这里带例子(继续使用II中用到的PIVOT表) --源表
1.SELECT
2.
3.'班级总人数:' AS [总人数],
4.
5.[初一 1班], [初一 2班],
6.
7.[初二 1班],
8.
9.[初三 1班], [初三 2班]
10.
11.INTO #PivotTable --为了使表达意图更清晰,我把PIVOT处理后的表放到一个临时表当
中
12.
13.FROM (
14.
15.SELECT
16.
17.[所属班级] AS [班级],
18.
19.[学生编号]
20.
21.FROM #Student
22.
23.) AS [SourceTable]
24.
25.PIVOT (
26.
27.COUNT([学生编号])
28.
29.FOR [班级] IN (
30.
31.[初一 1班], [初一 2班],
32.
33.[初二 1班],
34.
35.[初三 1班], [初三 2班]
36.
37.)
38.
39.) AS [PivotTable]
将多个列合并到单个列的转换的语句!!! --结果
1.SELECT
2.
3.[班级], [总人数]
4.
5.FROM (
6.
7.SELECT
8.
9.[初一 1班], [初一 2班],
10.
11.[初二 1班],
12.
13.[初三 1班], [初三 2班]
14.
15.FROM
16.
17.#PivotTable
18.
19.) AS [s]
20.
21.UNPIVOT (
22.
23.[总人数]
24.
25.FOR [班级] IN (
26.
27.[初一 1班], [初一 2班],
28.
29.[初二 1班],
30.
31.[初三 1班], [初三 2班]
32.
33.)
34.
35.) AS [un_p]
执行下面代码:
1.SELECT
2.
3.[所属班级] AS [班级],
4.
5.[男] AS [男生人数],
6.
7.[女] AS [女生人数],
8.
9.[男] + [女] AS [总人数]
10.
11.INTO #PivotTable2 --放到临时表方便查询
12.
13.FROM (
14.
15.SELECT [学生编号], [所属班级], [性别] FROM #Student
16.
17.) AS [SourceTable]
18.
19.PIVOT (
20.
21.COUNT([学生编号])
22.
23.FOR [性别] IN (
24.
25.[男], [女]
26.
27.)
28.
29.) AS [PivotTable]
30.
31.ORDER BY [总人数] DESC
32.
33.SELECT
34.
35.[班级],
36.
37.[男生或女生人数],
38.
39.[性别],
40.
41.[总人数]
42.
43.FROM (
44.
45.SELECT [班级], [男生人数], [女生人数], [总人数] FROM #PivotTable2
46.
47.) AS [s]
48.
49.UNPIVOT (
50.
51.[男生或女生人数]
52.
53.FOR [性别] IN (
54.
55.[男生人数],
56.
57.[女生人数]
58.
59.)
60.
61.) AS [un_p]
或者将性别和人数合并到一个列当中:
1.SELECT
2.
3.[班级],
4.
5.[性别] + ': ' + CAST([男生或女生人数] AS NVARCHAR(1)) AS [男生或女生人
数],
6.
7.[总人数]
8.
9.FROM (
10.
11.SELECT [班级], [男生人数], [女生人数], [总人数] FROM #PivotTable2
12.
13.) AS [s]
14.
15.UNPIVOT (
16.
17.[男生或女生人数]
18.
19.FOR [性别] IN (
20.
21.[男生人数],
22.
23.[女生人数]
24.
25.)
26.
27.) AS [un_p]
关于PIVOT和UNPIVOT命令的使用就介绍到这里,如果想了解更多SQL的知识可以去看看这里的文章:https://www.doczj.com/doc/343683629.html,/sqlserver/,绝对不会让您失望的哦!
SQLServer(多语句表值函数代码) 代码如下: set ANSI_NULLS ON set QUOTED_IDENTIFIER ON go CREATE FUNCTION [dbo].[ufnGetContactInformation](@ContactID int) RETURNS @retContactInformation TABLE ( -- Columns returned by the function [ContactID] int PRIMARY KEY NOT NULL, [FirstName] [nvarchar](50) NULL, [LastName] [nvarchar](50) NULL, [JobTitle] [nvarchar](50) NULL, [ContactType] [nvarchar](50) NULL ) AS -- Returns the first name, last name, job title and contact type for the specified contact. BEGIN
DECLARE @FirstName [nvarchar](50), @LastName [nvarchar](50), @JobTitle [nvarchar](50), @ContactType [nvarchar](50); -- Get common contact information SELECT @ContactID = ContactID, @FirstName = FirstName, @LastName = LastName FROM [Person].[Contact] WHERE [ContactID] = @ContactID; SET @JobTitle = CASE -- Check for employee WHEN EXISTS(SELECT * FROM [HumanResources].[Employee] e WHERE e.[ContactID] = @ContactID) THEN (SELECT [Title] FROM [HumanResources].[Employee] WHERE [ContactID] = @ContactID) -- Check for vendor
Oracle列转行和行转列的几种用法 栏到 栏主要讨论sys_connect_by_path的用法 1,具有分层关系 SQL > createtabledept(deptnononumber,deptname varchar2 (20),mgrnononumber); table created . SQL >插入deptvalues (1,“总部”,空); 1 row created . SQL >插入deptvalues (2,’浙江分公司’,1); 1 row created . SQL > insert into dept values(3,’杭州分公司’,2);已创建 1行。 SQL >提交; 提交完成。 SQL >从部门连接中选择最大值(子串(sys_connect_by_path(deptname,’,’),2))由先前部门连接= mgrno 最大值(SUBSTER(SYS _ CONNECT _ BY _ PATH(DEPTNAME),’),2) -总部,浙江分行,杭州分行 2,行-列转换 如果一个表的所有列都连接到一行,用逗号分隔:
SQL >选择最大值(SUBSTER(SYS _ CONNECT _ BY _ PATH(column _ name,’,’),2)) MAX(SUBSTRA(SYS _ CONNECT _ BY _ PATH(COLUMN _ NAME,’,’),2)) - DEPTNO,DEPTNAME,MGRNO 3,ListAgg(Oracle 11g) SQL >选择DEPTNO, 2 ListAgg(NAME,’;’) 3在组 4内(由搪瓷订购)搪瓷 5来自emp 6组由deptno 7由deptno 8 / DEPTNO搪瓷 - - 10 CLARK。国王;米勒 20亚当斯;福特。琼斯; SCOTT。史密斯 30艾伦;布莱克; JAMES;马丁; TURNER;下面的W ARD
SQLSERVER数据库操作 ******操作前,请确定SQL的服务已经开启******** 一:登录进入sql数据库 1、开始---所有程序---Microsoft SQL Server 2005---SQL Server Management Studio Express 2、此时出现“连接到服务器”的对话框, “服务器名称”设置为SQL数据库所在机器的IP地址 “身份验证”设置为SQL Server身份验证或者Windows 身份验证 填写登录名和密码后,点击“连接”按钮,即可进入到SQL数据库操作界面。 二:新建数据库 登录进去后,右击“数据库”,选择—“新建数据库” 设置数据库名称,在下面的选项卡中还可以设置数据库的初始大小,自动增长,路径。 点击确定,一个数据库就建好了。 三:如何备份的数据库文件。 登录进入后,右击相应的需要备份数据库----选择“任务” 目标下的备份到,点击“添加”按钮可以设置备份数据库保存的路径。 四:如何还原备份的数据库文件。(以本地机器为例子) 1、设置服务器名称,点击右边的下拉框的三角,选择“浏览更多…”。 此时出现查找服务器对话框,选择“本地服务器”---点开“数据库引擎”前面 的三角---选中出现的服务器名称—确定。 (注:可以在“网络服务器”选项卡中设置网络服务器) 2、设置身份验证,选择为“windows身份验证” 3、点击连接按钮,进入数据库管理页面 4、右击“数据库”,选择“还原数据库”,出现还原数据库的对话框 还原的目标----目标数据库,这里设置数据库的名字 还原的源----选择“源设备”,在弹出的对话框中点击“添加”按钮,找到所备 份的数据库文件,确定。 5、此时,在还原数据库对话框中会出现所还原的数据库的信息。在前面选中所需还 原的数据库。确定。 6、为刚刚还原的数据库设置相应的用户。 a点开“安全性”---右击“登录名”---新建登录名 b 设置登录名(假如为admin),并设置为SQL Server身份验证,输入密码,去除 “强制实施密码策略”前的勾。 C 找到导入的数据库,右击此数据库----选择“属性”,在选择页中,点击“文件” 设置所有者,点击右边的按钮,选择“浏览”,找到相应的用户(如admin)。确 定。。 7、此时重新以admin的身份进入,就可操作相应的数据库。
sqlserver到oracle数据无损迁移 编者:liuli10@https://www.doczj.com/doc/343683629.html, 版本:V1.7 最后修订日期:2015-11-21
第一章简介 1.1数据迁移 随着时代发展数据越来越被重视,而很多时候,当系统需要更新换代的时候,升级后系统所是有的数据库与当前系统的数据库并不一致,此时不仅需要数据割接,最重要的是:如何能将老系统中的数据无损的割接到新系统、新数据库中。因此,结合项目实战经验,针对从windows平台下数据库sqlserver到linux平台下oracle数据库的数据无损迁移进行总结。 1.2数据库简介 一般此处会有很多数据库以及出品公司的历史以及发展历程,在编者看来然而并没有什么大用途,百度百科都可以搜索的到,因此本章结束,直接进入实战总结环节。
第二章sqlserver数据导出 2.1sqlserver数据导出命令 当然不可否认windows为sqlserver提供了强大的图形化平台,导出数据变得只需要点一点就能完成,然而这样的数据导出对于大批量有要求的操作,是极其劳神伤财的,因此,必须要通过命令行进行格式化导出,因此,这里介绍sqlserver 本机数据库导出命令。 2.1.1bcp命令以及参数介绍 https://www.doczj.com/doc/343683629.html,/liyanmingkong/article/details/6087674 https://www.doczj.com/doc/343683629.html,/uid-25472509-id-4304562.html https://www.doczj.com/doc/343683629.html,/link?url=WV2JJM4JHxR7Qct8rr_-499zPc3aP_7E5rOt5l yEnG_Mj_tE9_-ZN1JPE2Vc2wRpkO8QkNGNLVznDfMgniCOnxXhK5jQppNpZk8 Jo1x8o23 为了将文档尽可能精简,bcp命令的参数以及介绍请自行去以上任意网址查询。或者自行baidu或者google搜索。 2.2实战语句解析 实战语句为: bcp"select*from gwbnboss.dbo.ACCOUNT_BUSINESS"queryout "C:\Users\liuli9\Desktop\sqlserverdata_mov\textfile\ACCOUNT_BUSINESS.txt"-c -r"{#$&}"-t"{@#$}"-S"127.0.0.1"-U"数据库用户名"-P"密码" 最终导出的结果存在于 C:\Users\liuli9\Desktop\sqlserverdata_mov\textfile\ACCOUNT_BUSINESS.txt 文件中,当出现“{#$&}”时表示接下来是下一行数据,出现“{@#$}”时表示接下来是下一列数据。将查询结果集完整导出,不对数据做任何格式化或者修改操作,保证数据的原生无损。
--当期时间贷款时间 SELECT DK_ID, max(substr(activeDate, 2)) activeDate FROM (SELECT DK_ID, sys_connect_by_path(activeDate, ',') activeDate FROM (SELECT DK_ID, activeDate, DK_ID || rn rchild, DK_ID || (rn - 1) rfather FROM (SELECT TEMP.DK_ID, --查询项目所在地树形结构全名 SELECT t.area_id, substr(sys_connect_by_path(t.area_name, '-'), 2) as allname , connect_by_root t.area_name as root, --是单一操作符,返回当前层的最顶层节点connect_by_isleaf as IsLeaf, --是伪列,判断当前层是否为叶子节点,1代表是,0代表否 level as lel --是伪列,显示当前节点层所处的层数 FROM dk_project_area_info t START WITH t.area_name = '项目所在地' CONNECT BY PRIOR t.area_id = t.area_pid SYS_CONNECT_BY_PATH 学习2008-09-08 10:59SELECT ename FROM scott.emp START WITH ename = 'KING' CONNECT BY PRIOR empno = mgr; 得到结果为:KING JONES SCOTT ADAMS FORD SMITH BLAKE ALLEN WARD MARTIN TURNER JAMES
表结构和数据如下(表名Test): NO V ALUE NAME 1 a 测试1 1 b 测试2 1 c 测试3 1 d 测试4 2 e 测试5 4 f 测试6 4 g 测试7 Sql语句: select No, ltrim(max(sys_connect_by_path(Value, ';')), ';') as Value, ltrim(max(sys_connect_by_path(Name, ';')), ';') as Name from (select No, Value, Name, rnFirst, lead(rnFirst) over(partition by No order by rnFirst) rnNext from (select a.No, a.Value, https://www.doczj.com/doc/343683629.html,, row_number() over(order by a.No, a.V alue desc) rnFirst from Test a) tmpTable1) tmpTable2 start with rnNext is null connect by rnNext = prior rnFirst group by No; 检索结果如下: NO V ALUE NAME 1 a;b;c;d 测试1;测试2;测试3;测试4 2 e 测试5 4 f;g 测试6;测试7 简单解释一下那个Sql吧: 1、最内层的Sql(即表tmpTable1),按No和Value排序,并列出行号:select a.No, a.Value, https://www.doczj.com/doc/343683629.html,, row_number() over(order by a.No, a.V alue desc) rnFirst
SQLSERVER数据库、表的创建及SQL语句命令 SQLSERVER数据库,安装、备份、还原等问题: 一、存在已安装了sql server 2000,或2005等数据库,再次安装2008,会出现的问题 1、卸载原来的sql server 2000、2005,然后再安装sql server 2008,否则经常sql server服务启动不了 2、sql server服务启动失败,解决方法: 进入sql server configure manager,点开Sql server 网络配置(非sql native client 配置),点sqlzhh(我sqlserver 的名字)协议,将VIA协议禁用。再启动Sql Server服务,成功 如图: 二、在第一次安装SQLSERVER2008结束后,查看安装过程明细,描述中有较多项插件或程度,显示安装失败。 解决方法:
1、重新启动安装程度setup.exe,选择进行修复安装,至完成即可。 三、先创建数据库XXX,再进行还原数据库时,选择好备份文件XXX.bak,确定后进行还原,会报如下图的错误。 解决方法: 选择好备份数据库文件后,再进入“选项”中,勾选“覆盖现在数据库”即可。
四、查看数据库版本的命令:select @@version 在数据库中,点击“新建查询”,然后输入命令,执行结果如下 五、数据库定义及操作命令: 按照数据结构来组织、存储和管理数据的仓库。由表、关系以及操作对象组成,把数据存放在数据表中。 1、修改数据库密码的命令: EXEC sp_password NULL, '你的新密码', 'sa' sp_password Null,'sa','sa'
关于动态SQL的使用-----摘录 内容摘要:在PL/SQL开发过程中,使用SQL,PL/SQL可以实现大部份的需求,但是在某些特殊的情况下,在PL/SQL中使用标准的SQL语句或DML语句不能实现自己的需求,比如需要动态建表或某个不确定的操作需要动态执行。这就需要使用动态SQL来实现。本文通过几个实例来详细的讲解动态SQL的使用。 本文适宜读者范围:Oracle初级,中级 系统环境: OS:windows2000Professional(英文版) Oracle:8.1.7.1.0 正文: 一般的PL/SQL程序设计中,在DML和事务控制的语句中可以直接使用SQL,但是DDL语句及系统控制语句却不能在PL/SQL中直接使用,要想实现在PL/SQL中使用DDL语句及系统控制语句,可以通过使用动态SQL来实现。 首先我们应该了解什么是动态SQL,在Oracle数据库开发PL/SQL块中我们使用的SQL分为:静态SQL语句和动态SQL语句。所谓静态SQL指在PL/SQL块中使用的SQL语句在编译时是明确的,执行的是确定对象。而动态SQL是指在PL/SQL块编译时SQL语句是不确定的,如根据用户输入的参数的不同而执行不同的操作。编译程序对动态语句部分不进行处理,只是在程序运行时动态地创建语句、对语句进行语法分析并执行该语句。 Oracle中动态SQL可以通过本地动态SQL来执行,也可以通过DBMS_SQL包来执行。下面就这两种情况分别进行说明: 一、本地动态SQL 本地动态SQL是使用EXECUTE IMMEDIATE语句来实现的。 1、本地动态SQL执行DDL语句: 需求:根据用户输入的表名及字段名等参数动态建表。 create or replace procedure proc_test ( table_name in varchar2,--表名 field1in varchar2,--字段名 datatype1in varchar2,--字段类型 field2in varchar2,--字段名 datatype2in varchar2--字段类型 )as str_sql varchar2(500); begin str_sql:=create table||table_name||(||field1||||datatype1||,||field2|| ||datatype2||); execute immediate str_sql;--动态执行DDL语句 exception when others then null; end; 以上是编译通过的存储过程代码。下面执行存储过程动态建表。
SQL SERVER函数大全 SQL SERVER命令大全 SQLServer和Oracle的常用函数对比 1.绝对值 S:select abs(-1) value O:select abs(-1) value from dual 2.取整(大) S:select ceiling(-1.001) value O:select ceil(-1.001) value from dual 3.取整(小) S:select floor(-1.001) value O:select floor(-1.001) value from dual 4.取整(截取) S:select cast(-1.002 as int) value O:select trunc(-1.002) value from dual 5.四舍五入 S:select round(1.23456,4) value 1.23460 O:select round(1.23456,4) value from dual 1.2346 6.e为底的幂 S:select Exp(1) value 2.7182818284590451 O:select Exp(1) value from dual 2.71828182 7.取e为底的对数 S:select log(2.7182818284590451) value 1 O:select ln(2.7182818284590451) value from dual; 1 8.取10为底对数 S:select log10(10) value 1 O:select log(10,10) value from dual; 1 9.取平方 S:select SQUARE(4) value 16 O:select power(4,2) value from dual 16
先来个简单的用法 列转行 Create table test (name char(10),km char(10),cj int) insert test values('张三','语文',80) insert test values('张三','数学',86) insert test values('张三','英语',75) insert test values('李四','语文',78) insert test values('李四','数学',85) insert test values('李四','英语',78) select name, sum(decode(km,'语文',CJ,0)) 语文, sum(decode(km,'数学',cj,0)) 数学, sum(decode(km,'英语',cj,0)) 英语 from test1 group by name 姓名语文数学英语 张三80 86 75 李四78 85 78 行转列 with x as( selectname, sum(decode(km,'语文',CJ,0)) 语文 , sum(decode(km,'数学',cj,0)) 数学, sum(decode(km,'英语',cj,0)) 英语 fromtest groupbyname) selectname,decode(rn,1, '语文', 2, '数学', 3,'英语') 课程, decode(rn, 1, 语文, 2, 数学, 3,英语) 分数 from x, (selectlevel rn from dual connectby1=1andlevel<=3) (from 后面接两个表,是笛卡尔积)
在SQL Server在线图书或者在线帮助系统中,函数的可选参数用方括号表示。在下列的CONVERT()函数例子中,数据类型的length和style参数是可选的: CONVERT (data-type [(length)], expression[,style]) 可将它简化为如下形式,因为现在不讨论如何使用数据类型: CONVERT(date_type, expression[,style]) 根据上面的定义,CONVERT()函数可接受2个或3个参数。因此,下列两个例子都是正确的: SELECT CONVERT(Varchar(20),GETDATE()) SELECT CONVERT(Varchar(20),GETDATE(), 101) 这个函数的第一个参数是数据类型Varchar(20),第2个参数是另一个函数GETDATE()。GETDATE()函数用datetime数据类型将返回当前的系统日期和时间。第2条语句中的第3个参数决定了日期的样式。这个例子中的101指以mm/dd/yyyy格式返回日期。本章后面将详细介绍GETDATE()函数。即使函数不带参数或者不需要参数,调用这个函数时也需要写上一对括号,例如GETDATE()函数。注意在书中使用函数名引用函数时,一定要包含括号,因为这是一种标准形式。 确定性函数 由于数据库引擎的内部工作机制,SQL Server必须根据所谓的确定性,将函数分成两个不同的组。这不是一种新时代的信仰,只和能否根据其输入参数或执行对函数输出结果进行预测有关。如果函数的输出只与输入参数的值相关,而与其他外部因素无关,这个函数就是确定性函数。如果函数的输出基于环境条件,或者产生随机或者依赖结果的算法,这个函数就是非确定性的。例如,GETDATE()函数是非确定性函数,因为它不会两次返回相同的值。为什么要把看起来简单的事弄得如此复杂呢?主要原因是非确定性函数与全局变量不能在一些数据库编程对象中使用(如用户自定义函数)。部分原因是SQL Server缓存与预编译可执行对象的方式。例如,即席查询可以使用任何函数,不过如果打算构建先进的、可重用的编程对象,理解这种区别很重要。 以下这些函数是确定性的: ●?AVG()(所有的聚合函数都是确定性的) ●?CAST() ●?CONVERT() ●?DATEADD() ●?DATEDIFF() ●?ASCII() ●?CHAR() ●?SUBSTRING() 以下这些函数与变量是非确定性的: ●?GETDATE()
众所周知,静态SQL的输出结构必须也是静态的。对于经典的行转列问题,如果行数不定导致输出的列数不定,标准的答案就是使用动态SQL, 到11G里面则有XML结果的PIVOT。 今天在asktom看到的一篇贴子彻底颠覆了我的看法!贴子里的链接指向另一个牛人辈出的荷兰公司: http://technology.amis.nl/2006/0 ... ing-antons-thunder/ 还记得Anton Scheffer吗?这位神人先是用10G的MODEL写了SUDOKU的一句SQL的解法,在11GR2推出之后又率先用递归WITH写了个只有短短几行的SUDOKU解法。他的作品还有EXCEL文件生成器。 早在2006年他就发明了真正动态的行转列办法,用的是一系列神秘的函数,如同自定义聚合函数STRAGG里面用的那些。这个神秘的对象代码如下: 1.CREATE OR REPLACE 2.type PivotImpl as object 3.( 4.ret_type anytype,-- The return type of the table function 5.stmt varchar2(32767), 6.fmt varchar2(32767), 7.cur integer, 8.static function ODCITableDescribe( rtype out anytype, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 ) 9.return number, 10.static function ODCITablePrepare( sctx out PivotImpl, ti in sys.ODCITabFuncInfo, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 ) 11.return number, 12.static function ODCITableStart( sctx in out PivotImpl, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number := 0 ) 13.return number, 14.member function ODCITableFetch( self in out PivotImpl, nrows in number, outset out anydataset ) 15.return number, 16.member function ODCITableClose( self in PivotImpl ) 17.return number 18.) 19./ 20. 21.create or replace type body PivotImpl as 22.static function ODCITableDescribe( rtype out anytype, p_stmt in varchar2, p_fmt in varchar2 := 'upper(@p@)', dummy in number ) 23.return number 24.is 25.atyp anytype; 26.cur integer; 27.numcols number; 28.desc_tab dbms_sql.desc_tab2; 29.rc sys_refcursor; 30.t_c2 varchar2(32767); 31.t_fmt varchar2(1000); 32.begin 33.cur := dbms_sql.open_cursor; 34.dbms_sql.parse( cur, p_stmt, dbms_sql.native ); 35.dbms_sql.describe_columns2( cur, numcols, desc_tab ); 36.dbms_sql.close_cursor( cur ); 37.-- 38.anytype.begincreate( dbms_types.typecode_object, atyp ); 39.for i in 1 .. numcols - 2
oracle列转行 1------------------------ 表结构: 1A 1B 1C 2A 2B 3C 3F 4D 转换后变成: 1A,B,C 2A,B 3C,F 4D 假设你的表结构是tb_name(id,remark),则语句如下:
SELECT a.id, wm_concat(a.remark)new_result FROM tb_name a group by a.id 2---------------------------------- 产品名称销售额季度 奶酪50第一季度 奶酪60第二季度 啤酒50第二季度 啤酒80第四季度 。。。 。。。 想转换成如下格式 产品名称第一季度销售额第二季度销售额第三季度销售额第四季度销售额 奶酪50600 0 啤酒0500
80 oracle下可以用函数decode处理: select产品名称, sum(decode(季度,'第一季度',销售额,0))第一季度销售额, sum(decode(季度,'第二季度',销售额,0))第二季度销售额, sum(decode(季度,'第三季度',销售额,0))第三季度销售额, sum(decode(季度,'第四季度',销售额,0))第四季度销售额, from表名 group by产品名称; 3------------------------------------------- oracle行转列的通用过程2010-04-0923:28经常遇到发帖求行列转换的代码,用max(decode(..))回复后,十有八九会再问一句:如果列名不固定,或者列数不固定怎么办。就要用存储过程来写,这些存储过程的代码都大同小异,我就想能不能写个通用点的过程
易语言操作SQL Server 数据库全过程 最近看到很多初学者在问在易语言中如何操作SQL Serve以外部数据库,也有人提出想要个全面的操作过程,为了让大家能够尽快上手,我给大家简单介绍一下操作SQL的过程,希望能起到抛砖引玉的作用。 由于我本身工作业比较忙,就以我目前做的一个软件的部份内容列给大家简单讲讲吧,高手就不要笑话了,只是针对初学者 第步,首先需要建立一个数据库: 以建立一个员工表为例,各字段如下 3 员工ID int 4 0 0 登陆帐号nvarchar 30 1 0 密码nvarchar 15 1 0 所属部门nvarchar 30 1 0 姓名nvarchar 10 1 0 性别nvarchar 2 1 0 年龄nvarchar 10 1 0 当前职务nvarchar 10 1 0 级别nvarchar 10 1 0 出生日期nvarchar 40 1 0 专业nvarchar 10 1 0 学历nvarchar 8 1 0 婚姻状况nvarchar 4 1 0 身份证号nvarchar 17 1 0 籍贯nvarchar 50 1 0 毕业院校nvarchar 50 1 0 兴趣爱好nvarchar 600 1 0 电话nvarchar 11 1 0 家庭成员nvarchar 20 1 0 工作经历nvarchar 600 1 0 销售行业经验nvarchar 600 1 0 离职原因nvarchar 600 1 0 升迁记录nvarchar 600 1 0 调岗记录 打+ -rd nvarchar 600 1 0 特殊贡献nvarchar 600 1 0 奖励记录nvarchar 600 1 0 处罚记录nvarchar 600 1 0 同事关系nvarchar 4 1 0 企业忠诚度nvarchar 4 1 0 入司日期nvarchar 30 1 0 在职状态nvarchar 4 1 0 上级评语nvarchar 600 1 0 最后登陆时间nvarchar 20 1 0 登陆次数nvarchar 50 1 0 照片image 16 1 一般我习惯用nvarchar,因为这是可变长的的非Unicode数据,最大长度为8000个字符,您可以根
未来社会模型中 SaaS 的位置与分量 上图是一个从连接这个透视角度抽象出来的社会模型,其中的家庭、人、组织、物都是相互连接的,它也是一个从软件架构抽象出来的社会模型。SaaS 是对软件的获得和使用方式的革命,早在 2004 年就已有端倪(当时称为 ASP,Application Service Provider)。笔者认为,可以将 SaaS 放在社会运行机制、发展趋势这样的大格局中定位其社会作用。SaaS 企业也需要这样的格局与信念,虽然在中国还没有出现非常成功的 SaaS 企业,但终究会出现的,信任、习惯、规范、与能力都需要进化,需要时间。 在没有电之前,人们就有传递信息的需求,这也是为什么微信能够存在的本质根由。同理,各种组织都离不开软件,而且软件的渗透越来越广泛与深入,因为整个世界的数字化是不可阻挡的趋势。而 SaaS 在大部分情况下是必选之路,会越来越成为标配,除非特殊原因,或者不在乎成本、或者已经拥有某种等效的软件、或者其他原因。只要这种本质性的需求存在着,社会的发展终究会以越来越先进的方式来满足它。 这里分享一个关于云的小故事,笔者曾经算过一笔账,如果在云上订购托管机房中约 500 台机器的同等算力,每年需要支出 5000 万,相当有悖于流行认知,其实对于稍微有些规模的 IT 资源诉求,云相对是更加昂贵的,但来的快、方便,两方面都是事实。
这里只想传递一个观点,长远来看,SaaS 有它存在与发展的必然性。结构上讲,它是社会运行机制中不可或缺的一部分。同样或者类似的软件,显然没有必要每个人、每个组织都各买一套或各自开发一套,这是社会资源的极大浪费,有悖于社会发展的基本规律——既然是必需的,必然选择物美价廉。而且组织支出比个人支出更理性、更注重实用价值,有利可图的需求终究会达到稳态的、某种主流服务的满足。 从架构角度看 SaaS 面临的挑战 如果说 SaaS 在大部分情况下将会成为必选之路,那么它面临的最大挑战又是什么呢?概括来讲,SaaS 面临的最大挑战是满足客户的个性化需求。从架构角度看,它体现在如下图所示的几个方面: 其中最有挑战性的又要属多变的后台逻辑与数据模型。对于 SaaS 供应商而言,这种需求显然不能通过项目的方式来定制满足,而只有通过提供灵活的自服务平台才能满足,这种灵活性就需要用 PaaS 来生产客户想要的软件。这一点笔者在2013 年做一个 SaaS 项目的架构工作时就深有体会:一开始的目标也是做 SaaS,但是后来还是走上了 PaaS 的道路,不过是专为生产 SaaS 而自用的 PaaS,而不是定位于 PaaS 供应商。 如果一个 SaaS 企业从一开始就只是聚焦某个业务,而没有着手 PaaS 的建设,那说明它在满足个性化需求的道路上一定是在某个局部、某个层面解决问题,而不是系统、全面、可复用地解决问题。同时,从中国 SaaS 市场现状来看,它的成长比较慢,环境的综合成熟度还不够高,聚焦单一业务成长的加速度不够,因此企业后续很可能会从最开始聚焦的核心业务向外扩展,到时候又要面临种种个性化需求问题。因此,一个成功的 SaaS 企业必然要去寻求 PaaS 的支撑。从这两个意义上讲,PaaS 可能也是 SaaS 企业提高生产力的必经方向。据有关数据
oracle----------行转列(动态行转不定列)----测试通过(9i) /*物料需要数量需要仓库现存量仓库现存量仓库数量批次 A1 2 C1 C1 20 123 A1 2 C1 C2 30 111 A1 2 C1 C2 20 222 A1 2 C1 C3 10 211 A2 3 C4 C1 40 321 A2 3 C4 C4 50 222 A2 3 C4 C4 60 333 A2 3 C4 C5 70 223 我需要把上面的查询结果转换为下面的。 物料需要数量需要仓库C1 C2 C3 C4 C5 A1 2 C1 20 50 10 0 0 A2 3 C4 40 0 0 110 70 */ ---------------------------------------------------------------建表 ----------------判断表是否存在 declare num number; begin select count(1) into num from user_tables where table_nam e='T EST'; if num>0 then execute immediate 'drop table TEST'; end if; end; ----------------建表 CREATE TABLE TEST( WL VARCHAR2(10), XYSL INTEGER, XYCK VARCHAR2(10),
XCLCK VARCHAR2(10), XCLCKSL INTEGER, PC INTEGER ); ----------------第一部分测试数据 INSERT INTO TEST VALUES('A1', 2, 'C1', 'C1' , 20, 123); INSERT INTO TEST VALUES('A1', 2, 'C1', 'C2' , 30, 111); INSERT INTO TEST VALUES('A1', 2, 'C1', 'C2' , 20, 222); INSERT INTO TEST VALUES('A1', 2, 'C1', 'C3' , 10, 211); INSERT INTO TEST VALUES('A2', 3, 'C4', 'C1' , 40, 321); INSERT INTO TEST VALUES('A2', 3, 'C4', 'C4' , 50, 222); INSERT INTO TEST VALUES('A2', 3, 'C4', 'C4' , 60, 333); INSERT INTO TEST VALUES('A2', 3, 'C4', 'C5' , 70, 223); COMMIT; --select * from test; ---------------------------------------------------------------行转列的存储过程CREATE OR REPLACE PROCEDURE P_TEST IS V_SQL VARCHAR2(2000); CURSOR CURSOR_1 IS SELECT DISTINCT T.XCLCK FROM TEST T ORDER BY XCLCK; BEGIN V_SQL := 'SELECT WL,XYSL,XYCK'; FOR V_XCLCK IN CURSOR_1 LOOP V_SQL := V_SQL || ',' || 'SUM(DECODE(XCLCK,''' || V_XCLCK.XCLCK || ''',XCLCKSL,0)) AS ' || V_XCLCK.XCLCK; END LOOP;
SqlServer教程:经典SQL语句集锦 SQL分类:DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据控制语言(GRANT,REVOKE,COMMIT,ROLLBACK) 首先,简要介绍基础语句:1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表:A: create table tab_new like tab_old (使用旧表创建新表) B: create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。7、说明:添加主键: [html]view plaincopyprint? 1. Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:
序号功能语句 1创建数据库(创建之前判断该数据库是否存在)if exists (select * from sysdatabases where name='databaseName') drop database databaseName go Create DATABASE databasename 2删除数据库drop database databasename 3备份数据库USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' BACKUP DATABASE pubs TO testBack 4创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 5根据已有表创建新表1、use 原数据库名 go select * into 目的数据库名.dbo.目的表名 from 原表名(使用旧表创建新表)2、create table tab_new as select col1,col2… from tab_old definition only 6创建序列create sequence SIMON_SEQUENCE minvalue 1 -- 最小值 maxvalue 999999999999999999999999999 -- 最大值start with 1 -- 开始值 increment by 1 -- 每次加几 cache 20; 7删除新表drop table tabname 8增加一个列Alter table tabname add colname coltype alter table tablename add column_b int identity(1,1) 9删除一个列Alter table tabname drop column colname 10修改一个列ALTER TABLE 表名 ALTER COLUMN 字段名 varchar(30) NOT NULL DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 11添加主键Alter table tabname add primary key(col) 12删除主键Alter table tabname drop primary key(col) 13创建索引create [unique] index idxname on tabname(col…。)14删除索引drop index idxname on tabname 15创建视图create view viewname as select statement 16删除视图drop view viewname 17选择数据记录sql="select * from 数据表 where 字段名=字段值 order by 字段名 [desc]" sql="select * from 数据表 where 字段名 like '%字段值%' order by 字段名 [desc]" sql="select top 10 * from 数据表 where 字段名=字段值 order by 字段名 [desc]" sql="select top 10 * from 数据表 order by 字段名 [desc]" sql="select * from 数据表 where 字段名 in ('值1','值2','值3')" sql="select * from 数据表 where 字段名 between 值1 and 值2" 注:like中"%"匹配0个或多个字符;like中"_"匹配一个字符 18更新数据记录sql="update 数据表 set 字段名=字段值 where 条件表达式" sql="update 数据表 set 字段1=值1,字段2=值2 ……字段n=值n where 条件表达式" 19删除数据记录sql="delete from 数据表 where 条件表达式" sql="delete from 数据表" (将数据表所有记录删除) 20添加数据记录sql="insert into 数据表 (字段1,字段2,字段3 …) values (值1,值2,值3 …)" sql="insert into 目标数据表 select * from 源数据表" (把源数据表的记录添加到目标数据表) 21数据记录统计函数AVG(字段名) 得出一个表格栏平均值 COUNT(*;字段名) 对数据行数的统计或对某一栏有值的数据行数统计MAX(字段名) 取得一个表格栏最大的值 MIN(字段名) 取得一个表格栏最小的值 SUM(字段名) 把数据栏的值相加 引用以上函数的方法: sql="select sum(字段名) as 别名 from 数据表 where 条件表达式"set rs=conn.excute(sql) 用 rs("别名") 获取统计的值,其它函数运用同上。 22查询去除重复值select distinct * from table1 23查询数据库中含有同一这字段的表select name from sysobjects where xtype = 'u' and id in(select id from syscolumns where name = 's3') 24只复制表结构select * into a from b where 1<>1 select top 0 * into b from a 25复制内容set identity_insert aa ON insert into aa(Customer_ID, ID_Type, ID_Number) select Customer_ID, ID_Type, ID_Number from TCustomer; set identity_insert aa OFF 26UNION 运算符(使用运算词的几个查询结果行必须是一致的)UNION 运算符通过组合其他两个结果表(例如TABLE1 和TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随UNION 一起使用时(即UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自TABLE1 就是来自TABLE2。 27EXCEPT 运算符EXCEPT 运算符通过包括所有在TABLE1 中但不在TABLE2 中的行并消除所有重复行而派生出一个结果表。当ALL 随EXCEPT 一起使用时(EXCEPT ALL),不消除重复行。 SQL Server语句 1/3