NumPy常用方法总结 光环大数据Python培训班
- 格式:pdf
- 大小:261.98 KB
- 文档页数:4

numpy四则运算总结numpy是Python中常用的科学计算库,提供了丰富的数学函数和数组操作功能。
其中,numpy的四则运算功能是我们经常使用的。
本文将围绕numpy的四则运算展开,探讨其用法和应用场景。
一、加法运算numpy的加法运算使用符号"+"表示。
通过numpy的ndarray数组,我们可以对数组进行逐元素的加法运算,得到新的数组。
下面是一个简单的例子:```pythonimport numpy as npa = np.array([1, 2, 3])b = np.array([4, 5, 6])c = a + bprint(c)```上述代码中,我们首先导入了numpy库,并创建了两个ndarray数组a和b,分别包含了1、2、3和4、5、6这两组数据。
然后,通过a + b的运算,将a和b的对应元素相加,得到了新的数组c。
最后,我们将c打印出来,结果为[5, 7, 9]。
加法运算在实际应用中非常常见,比如对多个向量进行求和、矩阵相加等。
numpy提供了高效的加法运算,可以方便地处理大规模数据的计算。
二、减法运算numpy的减法运算使用符号"-"表示。
与加法运算类似,减法运算也是逐元素进行的。
下面是一个简单的例子:```pythonimport numpy as npa = np.array([4, 5, 6])b = np.array([1, 2, 3])c = a - bprint(c)```上述代码中,我们创建了两个ndarray数组a和b,然后通过a - b 的运算,将a和b的对应元素相减,得到了新的数组c。
最后,我们将c打印出来,结果为[3, 3, 3]。
减法运算同样在实际应用中非常常见,比如计算向量之间的差、矩阵相减等。
numpy的减法运算可以方便地进行这些计算。
三、乘法运算numpy的乘法运算使用符号"*"表示。

python numpy用法
Numpy是Python的一个强大的科学计算包,用于数学、科学和工程计算。
它的功能强大,能够处理大量的数据,是Python科学计算的基础。
Numpy提供了灵活的数组和函数,可以用来处理数字数据。
主要有以下几种方式:一是数组,它是numpy中最常用的数据类型,其结构是多维数组,可以表示向量、矩阵、张量等数据结构。
可以用来表示向量、矩阵、张量等数据结构。
二是函数,numpy提供了大量的数学函数,可以用来做数据分析和处理,比如矩阵乘法、矩阵分解、傅立叶变换等。
三是线性代数,numpy提供了线性代数的函数,可以用来解决线性代数问题,比如矩阵分解、特征值分解等。
四是数值积分,numpy提供了大量的数值积分函数,可以用来计算复杂函数的积分,从而解决微分方程。
五是统计分析,numpy提供了大量的统计分析函数,可以用来分析数据,比如均值、方差、相关性等。
Numpy是Python科学计算的基础,具有强大的数据处理能力,可以对大量的数据进行高效的处理。
它不仅提供了灵活的数组和函数,还提供了大量的数学函数、线性代数函数、数
值积分函数和统计分析函数,可以满足各种科学计算的需求。
因此,Numpy是Python科学计算的不可缺少的工具。

python课程总结汇报在过去的一段时间里,我参加了Python课程,今天我想向大家分享一下我在这门课程中所学到的知识和经验。
首先,让我简要介绍一下Python。
Python是一种高级编程语言,其设计目标是简洁而易于阅读,使得初学者能够很快上手。
它具有丰富的库和模块,可以用于开发各种应用程序,包括网络应用、数据处理和科学计算等。
在这门课程中,我们首先学习了Python的基本语法和数据类型。
我们了解了变量、表达式、条件语句和循环结构等基本概念。
通过练习和编写简单的程序,我们逐渐熟悉了Python的语法和代码风格。
接着,我们进一步学习了函数和模块的使用。
函数是一种将一段可重用的代码封装起来的方法,通过函数可以提高代码的可读性和可维护性。
我们学习了如何定义函数、传递参数和返回值等技巧。
另外,我们还学习了如何使用Python的标准库和第三方库,利用这些库可以快速实现各种功能,而不必从头开始编写代码。
在这门课程的后半部分,我们着重学习了面向对象编程(OOP)的概念和实践。
面向对象是一种程序设计的思想,通过将数据和相关操作封装在一起,可以更好地组织和管理代码。
我们学习了如何定义类、创建对象和继承等技术。
通过实践项目,我们深入了解了面向对象编程的优点和应用场景。
除了基本的Python语法和编程技巧,这门课程还介绍了一些常用的数据分析和大数据处理技术。
我们学习了如何使用NumPy、Pandas和Matplotlib等库进行数据处理和可视化。
通过这些技术,我们可以更好地理解和分析数据,并从中获取有价值的信息。
除了理论学习外,这门课程还提供了大量的实践机会。
我们每周都有编程任务和练习,通过实际操作和调试,我们逐渐掌握了Python的应用技巧。
我们还完成了一个小型项目,通过合作解决实际问题,提高了团队合作和问题解决能力。
通过这门课程,我不仅学到了Python的基本语法和编程技巧,还深入了解了面向对象编程和数据分析等高级技术。

Python数据处理与分析教程NumPy与Pandas库使用Python数据处理与分析教程:NumPy与Pandas库使用Python是一种功能强大且易于学习的编程语言,在数据处理和分析领域中受到广泛应用。
为了更高效地处理和分析数据,Python提供了许多常用的库,其中包括NumPy和Pandas。
本教程将介绍NumPy和Pandas库的使用方法,帮助读者快速掌握数据处理和分析的基础知识。
一、NumPy库的使用NumPy是Python中用于科学计算的基础库之一。
它提供了强大的多维数组对象和对这些数组进行操作的函数。
以下是NumPy库的几个常用功能:1. 创建数组使用NumPy库,我们可以轻松地创建各种类型的数组,包括一维数组、二维数组等。
以下是创建一维数组的示例代码:```pythonimport numpy as nparr = np.array([1, 2, 3, 4, 5])print(arr)```2. 数组运算NumPy库提供了许多方便的函数来对数组进行运算,例如对数组元素进行加减乘除等。
以下是对两个数组进行相加运算的示例代码:```pythonimport numpy as nparr1 = np.array([1, 2, 3, 4, 5])arr2 = np.array([6, 7, 8, 9, 10])sum_arr = arr1 + arr2print(sum_arr)```3. 数组索引和切片NumPy库允许我们通过索引和切片操作来访问数组中的元素。
以下是对数组进行切片操作的示例代码:```pythonimport numpy as nparr = np.array([1, 2, 3, 4, 5])slice_arr = arr[2:4]print(slice_arr)```二、Pandas库的使用Pandas是Python中用于数据处理和分析的强大库。
它基于NumPy库构建,提供了更高级的数据结构和数据操作工具。

NumPy库⼊门教程:基础知识总结numpy可以说是Python运⽤于⼈⼯智能和科学计算的⼀个重要基础,近段时间恰好学习了numpy,pandas,sklearn等⼀些Python机器学习和科学计算库,因此在此总结⼀下常⽤的⽤法。
1numpy数组(array)的创建通过array⽅式创建,向array中传⼊⼀个list实现⼀维数组的创建:⼆维数组的创建:传⼊⼀个嵌套的list即可,如下例:通过arange创建数组:下例中创建⼀个0~1间隔为0.1的⾏向量,从0开始,不包括1,第⼆个例⼦通过对齐⼴播⽅式⽣成⼀个多维的数组。
通过linspace函数创建数组:下例中创建⼀个0~1间隔为1/9的⾏向量(按等差数列形式⽣成),从0开始,包括1.通过logspace函数创建数组:下例中创建⼀个1~100,有20个元素的⾏向量(按等⽐数列形式⽣成),其中0表⽰10^0=1,2表⽰10^2=100,从1开始,包括100⽣成特殊形式数组:⽣成全0数组(zeros()函数),⽣成全1数组(ones()函数),仅分配内存但不初始化的数组(empty()函数)。
注意要指定数组的规模(⽤⼀个元组指定),同时要指定元素的类型,否则会报错⽣成随机数组通过frombuffer,fromstring,fromfile和fromfunction等函数从字节序列、⽂件等创建数组,下例中⽣成⼀个9*9乘法表2显⽰、创建、改变的数组元素的属性、数组的尺⼨(shape)等3改变数组的尺⼨(shape)reshape⽅法,第⼀个例⼦是将43矩阵转为34矩阵,第⼆个例⼦是将⾏向量转为列向量。
注意在numpy中,当某个轴的指定为-1时,此时numpy会根据实际的数组元素个数⾃动替换-1为具体的⼤⼩,如第⼆例,我们指明了c仅有⼀列,⽽b数组有12个元素,因此c被⾃动指定为12⾏1列的矩阵,即⼀个12维的列向量。
4元素索引和修改简单的索引形式和切⽚:当使⽤布尔数组b作为下标存取数组x中的元素时,将收集数组x中所有在数组b中对应下标为True的元素。

numpy常用方法numpy是Python语言的重要科学计算库,它提供高效的多维数组和矩阵计算功能。
numpy中有很多重要的方法,下面介绍numpy常用方法(包含numpy的常数和随机函数)。
1. numpy的常数numpy中有一些常用的数学常数,如π 等,使用 np.pi 来调用π ,使用 np.e 来调用自然对数的底数 e 。
2. numpy的随机函数numpy中有多个随机函数,可以用于生成满足特定分布的随机序列。
numpy.random.rand(): 生成服从均匀分布的随机数,参数为维度。
np.random.rand(2,3) 会生成一个 $2\times3$ 的数组,其中的每一个数均匀分布在(0,1)的区间内。
numpy.random.randn(): 生成服从标准正态分布的随机数,参数同np.random.rand() 。
numpy.random.randint(): 生成指定范围内的整数随机数。
参数依次为 low、high(不包括)、size参数,前两个参数定义了生成随机数的范围,size为期望的随机数的形状。
numpy.random.normal(): 从正态分布中随机选择样本,参数为 loc、scale 和 size。
loc 是均值(mean),scale 是标准差(standard deviation),size 是期望得到的样本的形状。
3. 数组创建numpy支持多种方式创建数组,如生成具有固定元素的数组、从生成器中读取数据、生成随机数数组等。
以下是一些最常用的方法:numpy.array(): 从常规的Python列表或者元组中创建一个数组。
a = np.array([1, 2, 3, 4, 5]) 将以列表 [1,2,3,4,5] 为元素创造一个一维数组。
numpy.zeros(): 返回一个以0填充的数组,参数为数组的形状信息,可以使用元组作为参数。
numpy.ones(): 返回一个以1填充的数组,参数同于numpy.zeros()。
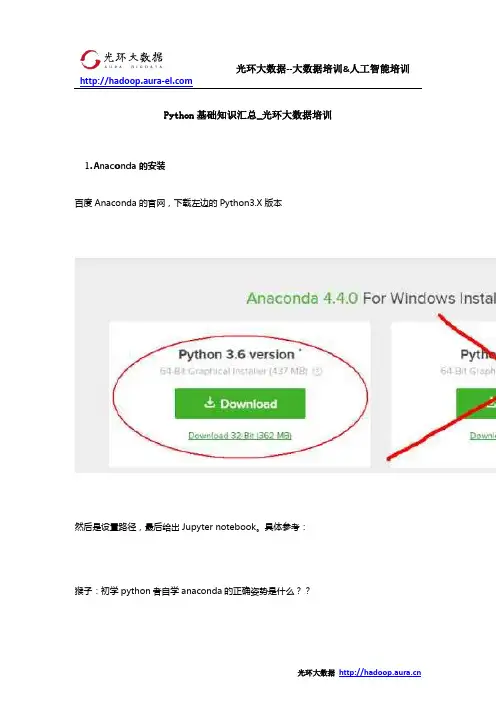
Python基础知识汇总_光环大数据培训1.Anaconda的安装百度Anaconda的官网,下载左边的Python3.X版本然后是设置路径,最后给出Jupyter notebook。
具体参考:猴子:初学python者自学anaconda的正确姿势是什么??不过平时练习的时候我个人习惯用Enthought Canopy,但比起Anaconda有些中文字符的编写不兼容。
下载链接如下:Canopy | Scientific Python Packages & Analysis Environment | Enthought2.Python的四个关键点2.1数据python常用数据类型有5类:(1)字符串(String)在python中字符串用“”或者‘’分隔(2)数字类型:整数,浮点数(3)容器:列表、集合、字典、元祖①列表(List):列表是可变的,方便增加、修改和删减数据。
列表有许多方便的函数,例如:在函数中使用列表时为防止循环的同时使列表发生改变,可以使用L1=L[:]从而复制列表,保持原列表L不变。
②元组(Tuple):元祖是不可变的,使用(),只有一个元素的元祖要加逗号:(9,)③集合(Sets):中学的知识里我们知道,集合的三个特性是:无序性,互异性,确定性。
即集合中不会存在重复元素,在python中用{}表示集合。
集合也有很多相关函数:创建空集:交集并集与做差:判断子集: 清空:删除元素:替换:增加元素:④字典(Dictionary):字典最大的特征是键值对应。
键值对用冒号(:)分割,整个字典用{}隔开。
字典是一个很好用的工具,我们可以通过字典利用增加内存来降低算法的复杂度。
(4)布尔值:True、False(注意大小写)(5)None2.2条件判断if语句可以通过判断条件是否成立来决定是否执行某个语句if-else语句就是在原有的if成立执行操作的基础上,当不成立的时候,也执行另一种操作if-elif-else语句例子:2.3循环循环有for循环while循环两种,我们常用的是for循环while True:可以用来开启循环。

python numpy库用法Python是一种功能强大的编程语言,而NumPy是Python中常用的库之一。
NumPy提供了高效的多维数组对象以及一系列用于操作数组的函数,可以帮助开发者进行快速的数值计算。
本文将以中括号内的内容为主题,详细介绍NumPy库的用法,一步一步回答。
一、什么是NumPy库及其安装NumPy是Numerical Python的简称,它是Python中用于科学计算的基础库之一。
它提供了高性能的多维数组对象(ndarray)以及丰富的函数库,用于进行数组的操作和计算。
NumPy的主要功能包括:1. 快速的数值运算:NumPy中的数组操作是以底层C语言实现的,因此非常高效。
2. 多维数组对象:NumPy的ndarray可以存储不同类型的元素,并且支持快速的元素访问和切片。
3. 广播功能:NumPy可以对不同形状的数组进行数学运算,它会自动进行维度匹配和扩展。
要安装NumPy库,可以使用pip命令,在终端中输入以下命令:pip install numpy二、创建NumPy数组在使用NumPy之前,需要先导入numpy模块。
可以使用`import numpy as np`语句来导入NumPy库,并将其命名为`np`,方便后续调用。
要创建一个NumPy数组,可以使用`np.array()`函数。
可以将Python列表、元组或其他序列类型作为参数传递给该函数,用于创建数组。
例如,可以使用以下代码创建一个一维数组:pythonimport numpy as nparr = np.array([1, 2, 3, 4, 5])print(arr)输出:[1 2 3 4 5]除了`np.array()`函数之外,NumPy还提供了一些其他函数来创建特定类型的数组,例如:- `np.zeros()`:创建一个全是0的数组。
- `np.ones()`:创建一个全是1的数组。
- `np.empty()`:创建一个未被初始化的数组。

python中numpy用法numpy是一种使用非常广泛的Python库,它可以为用户提供高效的数据处理和分析。
Numpy最初是为Python用户设计的数组计算库,它具有功能强大、编程代码简洁、效率高等优势,而且它为多种数据类型提供了统一的计算接口,可以帮助用户实现各种复杂的数据处理操作。
Numpy的基础用法可以分为两个主要部分:数据结构和算法。
首先,我们介绍一下Numpy的数据结构。
Numpy的核心数据结构是ndarray,它是一种多维数组对象,可以容纳任意大小的数据,ndarray可以按照一定的形状组织数据,有助于我们更好地处理大量数据。
例如,我们可以使用ndarray存储图像数据,ndarray可以模拟多维空间,从而帮助我们以更加快速方便的方式实现图像的平移、缩放、旋转等操作。
接下来,我们介绍一下Numpy的算法。
Numpy提供了一系列高效的数学运算算法,比如矩阵乘法和快速傅里叶变换,可以实现多种数据拟合等数据处理功能。
同时,Numpy提供了很多常见的随机函数,可以节省我们在随机采样上的大量精力,比如我们可以使用Numpy的随机函数在图像上进行噪声处理。
另外,Numpy还具有拟合和校正等统计分析方法,可以在极短的时间内完成庞大的数据分析。
此外,Numpy还具有非常高的性能。
相比于其他的编程语言,Numpy 可以更有效地调用硬件资源,通过优化代码和提供良好的优化算法,Numpy可以帮助用户提高编程效率。
Numpy是一种功能强大且实用的Python库,作为Python用户,学习Numpy的内容对于完成数据处理和分析过程至关重要。
Numpy的核心内容包括数据结构和算法,Numpy提供的算法多种多样,尤其是它提供的数据拟合和统计分析方法,可以大大减少编程的时间。
此外,Numpy的可扩展性和高性能也使其成为Python用户最重要的数据处理库之一。

numpy知识点汇总一、numpy简介numpy是Python的一个开源科学计算库,提供了高效的多维数组对象ndarray以及对多维数组进行操作的函数。
它是Python科学计算的核心库之一,被广泛应用于数据科学、机器学习、人工智能等领域。
二、安装numpy安装numpy非常简单,可以使用pip命令进行安装。
在命令行中输入"pip install numpy"即可完成安装。
安装完毕后,可以使用import numpy语句导入numpy库。
三、创建ndarrayndarray是numpy库的核心对象,它是一个多维数组对象,用于存储同类型的元素。
通过numpy库提供的函数,我们可以很方便地创建ndarray对象。
常见的创建ndarray的方法有以下几种:1. 使用array函数:可以将Python中的列表、元组等对象转换为ndarray。
2. 使用arange函数:可以创建一个等差数列的ndarray。
3. 使用linspace函数:可以创建一个指定范围内的等间隔数列的ndarray。
4. 使用zeros函数:可以创建一个全0的ndarray。
5. 使用ones函数:可以创建一个全1的ndarray。
6. 使用eye函数:可以创建一个单位矩阵的ndarray。
四、ndarray的属性和方法1. shape属性:用于获取ndarray对象的形状,即每个维度的大小。
2. dtype属性:用于获取ndarray对象的数据类型。
3. ndim属性:用于获取ndarray对象的维度数。
4. size属性:用于获取ndarray对象中元素的总个数。
5. reshape方法:用于改变ndarray对象的形状。
6. astype方法:用于改变ndarray对象的数据类型。
7. min方法和max方法:用于获取ndarray对象中的最小值和最大值。
8. sum方法、mean方法和std方法:用于计算ndarray对象中元素的和、平均值和标准差。

Numpy常⽤函数⽤法⼤全.ndim :维度.shape :各维度的尺度(2,5).size :元素的个数 10.dtype :元素的类型 dtype(‘int32’).itemsize :每个元素的⼤⼩,以字节为单位,每个元素占4个字节ndarray数组的创建np.arange(n) ; 元素从0到n-1的ndarray类型np.ones(shape): ⽣成全1np.zeros((shape), ddtype = np.int32) :⽣成int32型的全0np.full(shape, val): ⽣成全为valnp.eye(n) : ⽣成单位矩阵np.ones_like(a) : 按数组a的形状⽣成全1的数组np.zeros_like(a): 同理np.full_like (a, val) : 同理np.linspace(1,10,4):根据起⽌数据等间距地⽣成数组np.linspace(1,10,4, endpoint = False):endpoint 表⽰10是否作为⽣成的元素np.concatenate():-数组的维度变换.reshape(shape) : 不改变当前数组,依shape⽣成.resize(shape) : 改变当前数组,依shape⽣成.swapaxes(ax1, ax2) : 将两个维度调换.flatten() : 对数组进⾏降维,返回折叠后的⼀位数组-数组的类型变换数据类型的转换:a.astype(new_type) : eg, a.astype (np.float)数组向列表的转换: a.tolist()数组的索引和切⽚- ⼀维数组切⽚a = np.array ([9, 8, 7, 6, 5, ])a[1:4:2] –> array([8, 6]) : a[起始编号:终⽌编号(不含):步长]- 多维数组索引a = np.arange(24).reshape((2, 3, 4))a[1, 2, 3] 表⽰ 3个维度上的编号,各个维度的编号⽤逗号分隔- 多维数组切⽚a [:,:,::2 ] 缺省时,表⽰从第0个元素开始,到最后⼀个元素数组的运算np.abs(a) np.fabs(a) : 取各元素的绝对值np.sqrt(a) : 计算各元素的平⽅根np.square(a): 计算各元素的平⽅np.log(a) np.log10(a) np.log2(a) : 计算各元素的⾃然对数、10、2为底的对数np.ceil(a) np.floor(a) : 计算各元素的ceiling 值, floor值(ceiling向上取整,floor向下取整)np.rint(a) : 各元素四舍五⼊np.modf(a) : 将数组各元素的⼩数和整数部分以两个独⽴数组形式返回np.exp(a) : 计算各元素的指数值np.sign(a) : 计算各元素的符号值 1(+),0,-1(-).np.maximum(a, b) np.fmax() : ⽐较(或者计算)元素级的最⼤值np.minimum(a, b) np.fmin() : 取最⼩值np.mod(a, b) : 元素级的模运算np.copysign(a, b) : 将b中各元素的符号赋值给数组a的对应元素- 数据的CSV⽂件存取CSV (Comma-Separated Value,逗号分隔值) 只能存储⼀维和⼆维数组np.savetxt(frame, array, fmt=’% .18e’, delimiter = None): frame是⽂件、字符串等,可以是.gz .bz2的压缩⽂件; array 表⽰存⼊的数组; fmt 表⽰元素的格式 eg: %d % .2f % .18e ; delimiter:分割字符串,默认是空格eg: np.savetxt(‘a.csv’, a, fmt=%d, delimiter = ‘,’ )np.loadtxt(frame, dtype=np.float, delimiter = None, unpack = False) : frame是⽂件、字符串等,可以是.gz .bz2的压缩⽂件; dtype:数据类型,读取的数据以此类型存储; delimiter: 分割字符串,默认是空格; unpack: 如果为True,读⼊属性将分别写⼊不同变量。
Python基础之Numpy的基本⽤法详解⽬录⼀、数据⽣成1.1 ⼿写数组1.2 序列数组1.3 随机数组1.4 其他⽅式数组⼆、数组属性查看三、数组索引3.1 ⼀维数组的索引3.2 ⼆维数组的索引四、数组的⽅法4.1 改变数组维度4.2 数组拼接4.3 数组分隔4.4 算术运算⼀、数据⽣成1.1 ⼿写数组a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]) # ⼀维数组b = np.array([[1, 2], [3, 4]]) #⼆维数组1.2 序列数组numpy.arange(start, stop, step, dtype),start默认0,step默认1c = np.arange(0, 10, 1, dtype=int) # =np.arange(10) [0 1 2 3 4 5 6 7 8 9]d = np.array([np.arange(1, 3), np.arange(4, 6)]) # ⼆维数组# 不过为了避免⿇烦,通常序列⼆维数组都是通过reshape进⾏重新组织dd = c.reshape(2, 5) # 将⼀维数组重新组合成2⾏5列1.3 随机数组numpy.random.random(size=None) 该⽅法返回[0.0, 1.0)范围的随机⼩数。
numpy.random.randint() 该⽅法返回[low, high)范围的随机整数。
该⽅法有三个参数low、high、size 三个参数。
默认high是None,如果只有low,那范围就是[0,low)。
如果有high,范围就是[low,high)numpy.random.randn(d0,d1,…,dn) 该⽅法返回⼀个或⼀组样本,具有正态分布np.random.normal 指定期望和⽅差的正太分布e = np.random.random(size=2) # ⼀维数组,元素两个,[0.0,1.0]的随机数f = np.random.random(size=(2, 3)) # 两⾏三列数组,[0.0,1.0]的随机数h = np.random.randint(10, size=3) # [0,10]范围内的⼀⾏三列随机整数i = np.random.randint(5, 10, size=(2, 3)) # [5,10]范围内的2⾏3列随机整数1.4 其他⽅式数组numpy.zeros 创建指定⼤⼩的数组,数组元素以0 来填充numpy.ones 创建指定形状的数组,数组元素以1 来填充numpy.empty 创建⼀个指定形状(shape)、数据类型(dtype)且未初始化的数组,⾥⾯的元素的值是之前内存的值np.linspace 创建⼀个⼀维数组,数组是⼀个等差数列构成的numpy.logspace 创建⼀个于等⽐数j = np.zeros((2, 5))k = np.ones((2, 5))l = np.linspace(1, 20, 10)⼆、数组属性查看ndarray.ndimdarray.shape 数组的维度和列,对于矩阵,n ⾏m 列ndarray.size 数组元素的总个数,相当于.shape 中n*m 的值ndarray.dtype ndarray 对象的元素类型ndarray.itemsize ndarray 对象中每个元素的⼤⼩,以字节为单位ndarray.flags ndarray 对象的内存信息ndarray.real ndarray 元素的实部ndarray.imag ndarray 元素的虚部ndarray.data 包含实际数组元素的缓冲区,由于⼀般通过数组的索引获取元素,所以通常不需要使⽤这个属性。
numpy语法总结一、导入和数据转换1.安装和导入numpy:使用pip 安装numpy,然后在代码中导入numpy 模块。
```pythonimport numpy as np```2.创建数组:使用numpy 函数创建数组,如`numpy.array()`。
```pythonarr = np.array([1, 2, 3, 4, 5])```3.数据类型转换:使用`astype()` 函数转换数据类型。
```pythonarr = arr.astype(float)```二、数组和矩阵操作1.矩阵创建:使用`numpy.matrix()` 创建矩阵。
```pythonmat = np.matrix([[1, 2], [3, 4]])```2.矩阵转置:使用`T` 属性转置矩阵。
```pythonmat_trans = mat.T```3.矩阵加法:使用`+` 运算符进行矩阵加法。
```pythonmat1 = np.matrix([[1, 2], [3, 4]])mat2 = np.matrix([[5, 6], [7, 8]])mat_add = mat1 + mat2```三、数学函数和统计函数1.数学函数:使用numpy 内置的数学函数,如sin、cos、exp 等。
```pythonarr = np.array([0, 1, 2, 3, 4])sin_arr = np.sin(arr)```2.统计函数:使用numpy 内置的统计函数,如mean、std、min、max 等。
```pythonarr = np.array([1, 2, 3, 4, 5])mean = np.mean(arr)std = np.std(arr)```四、线性代数1.矩阵乘法:使用`dot()` 函数进行矩阵乘法。
```pythonmat1 = np.matrix([[1, 2], [3, 4]])mat2 = np.matrix([[5, 6], [7, 8]])mat_mul = mat1 @ mat2```2.求逆:使用`inv()` 函数求矩阵逆。
NumPy是Python中处理数组和矩阵的核心库,提供了大量的方法和函数来操作数组和矩阵。
以下是一些常见的NumPy方法汇总:1. 数组创建:- np.array(..., dtype=None, order=None, copy=True, subok=False, dtype_object=None)- np.zeros(shape, dtype=None, order=None, copy=True)- np.ones(shape, dtype=None, order=None, copy=True)- np.empty(shape, dtype=None, order=None, copy=True)2. 数组操作:- np.sum(arr, axis=None, keepdims=None, out=None, dtype=None)- np.mean(arr, axis=None, keepdims=None, out=None, dtype=None)- np.var(arr, axis=None, ddof=0, out=None, dtype=None)- np.std(arr, axis=None, ddof=0, out=None, dtype=None)- np.median(arr, axis=None, mode='median', out=None, dtype=None)3. 数组排序:- np.argsort(arr, axis=None, out=None, dtype=None)- np.sort(arr, axis=None, kind=3, out=None, dtype=None)4. 数组切片:- np.squeeze(arr, axis=None)- np.split(arr, num, axis=None)- np.concatenate(arrays, axis=0)5. 数组转置:- np.transpose(arr, axes=None, out=None)6. 数组形状和大小:- np.shape(arr)- np.size(arr)- np.reshape(arr, newshape, order='C')这些只是NumPy中的一部分方法,还有很多其他的方法和函数可以用于数组和矩阵的操作。
玩数据必备Python库之numpy使⽤详解⽬录前⾔1. ndarray介绍2. ndarray的基本操作⽣成数组数组索引、切⽚修改数组形状修改数组类型数组去重删除元素3. ndarray运算逻辑运算统计运算数组运算4. matrix 矩阵介绍5. Python中矩阵运算扩展:正态分布简介正态分布图⽅差总结前⾔numpy 库是⼀个科学计算库,使⽤⽅法:import numpy as np⽤于快速处理任意维度的数组,存储的对象是ndarray⽤于矩阵运算,存储的对象是matrix1. ndarray介绍1. ndarray的属性item = np.array([[1, 2], [3, 4], [5, 6]])# ndarray的属性print('shape 表⽰数组维度的元组', item.shape) # (3, 2)print('ndim 表⽰数组维数', item.ndim) # 2print('size 表⽰数组中元素个数', item.size) # 6print('itemsize 表⽰⼀个元素所占字节⼤⼩', item.itemsize) # 4print('dtype 表⽰数字元素的类型', item.dtype) # int322. ndarray的形状ndarray可以是任意维度的数组# ndarray的形状a1 = np.array([1, 2])a2 = np.array([[1, 2], [3, 4]])a3 = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])print('a1是{0}维数组'.format(a1.ndim))print('a2是{0}维数组'.format(a2.ndim))print('a3是{0}维数组'.format(a3.ndim))# a1是1维数组# a2是2维数组# a3是3维数组3. ndarray的类型创建ndarray对象时,可以使⽤dtype参数指定ndarray的类型# ndarray的类型item = np.array([[1, 2], [3, 4]], dtype=np.str_) # 设置类型为字符串print(item)#[['1' '2']# ['3' '4']]2. ndarray的基本操作⽣成数组1. ⽣成0和1数组# ⽣成⼀个3⾏4列的数组,元素为0。
python中numpy的知识点总结#### 数据的布尔值判断####import numpy as npx=np.array([1,2,3,4,5])xOut[1]: array([1, 2, 3, 4, 5])#判断X是否小于2x<2Out[2]: array([ True, False, False, False, False])#判断X小于2或者大于4(x<2) | (x>4)Out[4]: array([ True, False, False, False, True])mask=x<3maskOut[5]: array([ True, True, False, False, False]) x[mask]Out[6]: array([1, 2])np.sum(x<3)Out[7]: 2y=np.array([[1,2,3,4,5],[6,7,8,9,10]])yOut[8]:array([[ 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10]])x == y[0,]Out[9]: array([ True, True, True, True, True])#两个数组比较a1 = np.arange(9).reshape(3, 3)a2 = np.arange(9, 0 , -1).reshape(3, 3)a1 < a2Out[10]:array([[ True, True, True],[ True, True, False],[False, False, False]])#####数据的切片选择(开始位,结束位,步长)#位置值从0开始的x=np.arange(0,10)x[4:6]Out[11]: array([4, 5])#从0开始,步长为2的数据,::表示所有数据x[::2]Out[12]: array([0, 2, 4, 6, 8])#倒序x[::-1]Out[13]: array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])#取前6个数据x[:6]Out[14]: array([0, 1, 2, 3, 4, 5])#从第2的位置开始选x[2:]Out[15]: array([2, 3, 4, 5, 6, 7, 8, 9])#二维数据的切片处理,生成0-15的数字,4行4列y=np.arange(0,16).reshape(4,4)yOut[16]:array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11],[12, 13, 14, 15]])#y[行,列],取所有行和第二列与第三列y[:,1:3]Out[17]:array([[ 1, 2],[ 5, 6],[ 9, 10],[13, 14]])y[1:3,2:4]Out[18]:array([[ 6, 7],[10, 11]])#y[:,:]中的:表示取所有y[[1,3],:]Out[19]:array([[ 4, 5, 6, 7],[12, 13, 14, 15]])#### 数据的维度变化##### x=np.arange(0,9)y=x.reshape(3,3)yOut[20]:array([[0, 1, 2],[3, 4, 5],[6, 7, 8]])x=np.arange(0,9)y=x.reshape(3,3)yOut[21]:array([[0, 1, 2],[3, 4, 5],[6, 7, 8]])#返回一个新的数组,不是修改原来的数组y.reshape(9)Out[22]: array([0, 1, 2, 3, 4, 5, 6, 7, 8])yOut[23]:array([[0, 1, 2],[3, 4, 5],[6, 7, 8]])#修改数据reshaped = y.reshape(np.size(y)) raveled = y.ravel() #将数据展开成一维的reshaped[2] = 1000raveled[5] = 2000yOut[24]:array([[ 0, 1, 1000],[ 3, 4, 2000],[ 6, 7, 8]])y = np.arange(0, 9).reshape(3,3)flattened = y.flatten() #将数据展开成一维的flattened[0] = 1000flattenedOut[25]: array([1000, 1, 2, 3, 4, 5, 6, 7, 8])flattened.shape = (3, 3)flattenedOut[26]:array([[1000, 1, 2],[ 3, 4, 5],[ 6, 7, 8]])#数据的转置flattened.TOut[27]:array([[1000, 3, 6],[ 1, 4, 7],[ 2, 5, 8]])#### 数据的合并处理####a = np.arange(9).reshape(3, 3)b = (a + 1) * 10aOut[28]:array([[0, 1, 2],[3, 4, 5],[6, 7, 8]])bOut[29]:array([[10, 20, 30],[40, 50, 60],[70, 80, 90]])#水平方向np.hstack((a, b))Out[30]:array([[ 0, 1, 2, 10, 20, 30], [ 3, 4, 5, 40, 50, 60],[ 6, 7, 8, 70, 80, 90]])#垂直方向np.vstack((a, b))Out[31]:array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[10, 20, 30],[40, 50, 60],[70, 80, 90]])#axis = 1横轴方向,axis = 0 竖轴方向np.concatenate((a, b), axis = 1)Out[32]:array([[ 0, 1, 2, 10, 20, 30],[ 3, 4, 5, 40, 50, 60],[ 6, 7, 8, 70, 80, 90]])#每列相互拼接np.dstack((a, b))Out[33]:array([[[ 0, 10],[ 1, 20],[ 2, 30]],[[ 3, 40],[ 4, 50],[ 5, 60]],[[ 6, 70],[ 7, 80],[ 8, 90]]])#两列拼接one_d_a = np.arange(5)one_d_b = (one_d_a + 1) * 10np.column_stack((one_d_a, one_d_b)) Out[36]:array([[ 0, 10],[ 1, 20],[ 2, 30],[ 3, 40],[ 4, 50]])##行叠加np.row_stack((one_d_a, one_d_b))Out[37]:array([[ 0, 1, 2, 3, 4],[10, 20, 30, 40, 50]])#### 通用函数####m = np.arange(10, 19).reshape(3, 3)print (m)print ("{0} min of the entire matrix".format(m.min()))print ("{0} max of entire matrix".format(m.max()))##最小值、最大值的位置print ("{0} position of the min value".format(m.argmin())) print ("{0} position of the max value".format(m.argmax()))#每列、每行的最小值print ("{0} mins down each column".format(m.min(axis = 0))) print ("{0} mins across each row".format(m.min(axis = 1)))#每列、每行的最大值print ("{0} maxs down each column".format(m.max(axis = 0))) print ("{0} maxs across each row".format(m.max(axis = 1))) [[10 11 12][13 14 15][16 17 18]]10 min of the entire matrix18 max of entire matrix0 position of the min value8 position of the max value[10 11 12] mins down each column[10 13 16] mins across each row[16 17 18] maxs down each column[12 15 18] maxs across each row#平均值,标准差,方差aOut[41]: array([1, 2, 3, 4, 5, 6, 7, 8, 9])a = np.arange(1,10)a.mean(), a.std(), a.var()Out[39]: (5.0, 2.581988897471611, 6.666666666666667)#求和,乘积a.sum(), a.prod()Out[40]: (45, 362880)#累加和,累加乘a.cumsum(), a.cumprod()Out[42]:(array([ 1, 3, 6, 10, 15, 21, 28, 36, 45], dtype=int32),array([ 1, 2, 6, 24, 120, 720, 5040, 40320, 362880], dtype=int32))。
NumPy常用方法总结光环大数据Python培训班光环大数据Python培训了解到,NumPy是Python的一种开源的数值计算扩展。
这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nestedliststructure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。
NumPy(NumericPython)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。
专为进行严格的数字处理而产生。
多为很多大型金融公司使用,以及核心的科学计算组织如:LawrenceLivermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。
numpy中的数据类型,ndarray类型,和标准库中的array.array并不一样。
ndarray的创建>>>importnumpyasnp>>>a=np.array([2,3,4])>>>aarray([2,3,4])>>>a.dt ypedtype('int64')>>>b=np.array([1.2,3.5,5.1])>>>b.dtypedtype('float64 ')二维的数组>>>b=np.array([(1.5,2,3),(4,5,6)])>>>barray([[1.5,2.,3.],[4.,5.,6 .]])创建时指定类型>>>c=np.array([[1,2],[3,4]],dtype=complex)>>>carray([[1.+0.j,2.+0 .j],[3.+0.j,4.+0.j]])创建一些特殊的矩阵>>>np.zeros((3,4))array([[0.,0.,0.,0.],[0.,0.,0.,0.],[0.,0.,0.,0. ]])>>>np.ones((2,3,4),dtype=np.int16)#dtypecanalsobespecifiedarray([[ [1,1,1,1],[1,1,1,1],[1,1,1,1]],[[1,1,1,1],[1,1,1,1],[1,1,1,1]]],dtype =int16)>>>np.empty((2,3))#uninitialized,outputmayvaryarray([[3.736039 59e-262,6.02658058e-154,6.55490914e-260],[5.30498948e-313,3.14673309e -307,1.00000000e+000]])创建一些有特定规律的矩阵>>>np.arange(10,30,5)array([10,15,20,25])>>>np.arange(0,2,0.3)#it acceptsfloatargumentsarray([0.,0.3,0.6,0.9,1.2,1.5,1.8])>>>fromnumpyi mportpi>>>np.linspace(0,2,9)#9numbersfrom0to2array([0.,0.25,0.5,0.75, 1.,1.25,1.5,1.75,2.])>>>x=np.linspace(0,2*pi,100)#usefultoevaluatefun ctionatlotsofpoints>>>f=np.sin(x)一些基本的运算加减乘除三角函数逻辑运算>>>a=np.array([20,30,40,50])>>>b=np.arange(4)>>>barray([0,1,2,3]) >>>c=a-b>>>carray([20,29,38,47])>>>b**2array([0,1,4,9])>>>10*np.sin(a )array([9.12945251,-9.88031624,7.4511316,-2.62374854])>>>a<35array([T rue,True,False,False],dtype=bool)矩阵运算matlab中有.*,./等等但是在numpy中,如果使用+,-,×,/优先执行的是各个点之间的加减乘除法如果两个矩阵(方阵)可既以元素之间对于运算,又能执行矩阵运算会优先执行元素之间的运算>>>importnumpyasnp>>>A=np.arange(10,20)>>>B=np.arange(20,30)>>>A+ Barray([30,32,34,36,38,40,42,44,46,48])>>>A*Barray([200,231,264,299,3 36,375,416,459,504,551])>>>A/Barray([0,0,0,0,0,0,0,0,0,0])>>>B/Aarray ([2,1,1,1,1,1,1,1,1,1])如果需要执行矩阵运算,一般就是矩阵的乘法运算>>>A=np.array([1,1,1,1])>>>B=np.array([2,2,2,2])>>>A.reshape(2,2) array([[1,1],[1,1]])>>>B.reshape(2,2)array([[2,2],[2,2]])>>>A*Barray( [2,2,2,2])>>>np.dot(A,B)8>>>A.dot(B)8一些常用的全局函数>>>B=np.arange(3)>>>Barray([0,1,2])>>>np.exp(B)array([1.,2.71828183,7.3890561])>>>np.sqrt(B)array([0.,1.,1.41421356])>>>C=np.array([2. ,-1.,4.])>>>np.add(B,C)array([2.,0.,6.])矩阵的索引分片遍历>>>a=np.arange(10)**3>>>aarray([0,1,8,27,64,125,216,343,512,729]) >>>a[2]8>>>a[2:5]array([8,27,64])>>>a[:6:2]=-1000#equivalenttoa[0:6:2 ]=-1000;fromstarttoposition6,exclusive,setevery2ndelementto-1000>>>aa rray([-1000,1,-1000,27,-1000,125,216,343,512,729])>>>a[::-1]#reversed aarray([729,512,343,216,125,-1000,27,-1000,1,-1000])>>>foriina:...pri nt(i**(1/3.))...nan1.0nan3.0nan5.06.07.08.09.0矩阵的遍历>>>importnumpyasnp>>>b=np.arange(16).reshape(4,4)>>>forrowinb:... print(row)...[0123][4567][891011][12131415]>>>fornodeinb.flat:...prin t(node) (0123456789101112131415)矩阵的特殊运算改变矩阵形状--reshape>>>a=np.floor(10*np.random.random((3,4)))>>>aarray([[6.,5.,1.,5.] ,[5.,5.,8.,9.],[5.,5.,9.,7.]])>>>a.ravel()array([6.,5.,1.,5.,5.,5.,8. ,9.,5.,5.,9.,7.])>>>aarray([[6.,5.,1.,5.],[5.,5.,8.,9.],[5.,5.,9.,7.] ])resize和reshape的区别resize会改变原来的矩阵,reshape并不会>>>aarray([[6.,5.,1.,5.],[5.,5.,8.,9.],[5.,5.,9.,7.]])>>>a.reshap e(2,-1)array([[6.,5.,1.,5.,5.,5.],[8.,9.,5.,5.,9.,7.]])>>>aarray([[6. ,5.,1.,5.],[5.,5.,8.,9.],[5.,5.,9.,7.]])>>>a.resize(2,6)>>>aarray([[6 .,5.,1.,5.,5.,5.],[8.,9.,5.,5.,9.,7.]])矩阵的合并>>>a=np.floor(10*np.random.random((2,2)))>>>aarray([[8.,8.]为什么大家选择光环大数据!大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的大数据领域知名讲师,确保教学的整体质量与教学水准。
讲师团及时掌握时代潮流技术,将前沿技能融入教学中,确保学生所学知识顺应时代所需。
通过深入浅出、通俗易懂的教学方式,指导学生更快的掌握技能知识,成就上万个高薪就业学子。
【报名方式、详情咨询】光环大数据官方网站报名:/手机报名链接:http:// /mobile/。