
Db2 存储过程学习总结
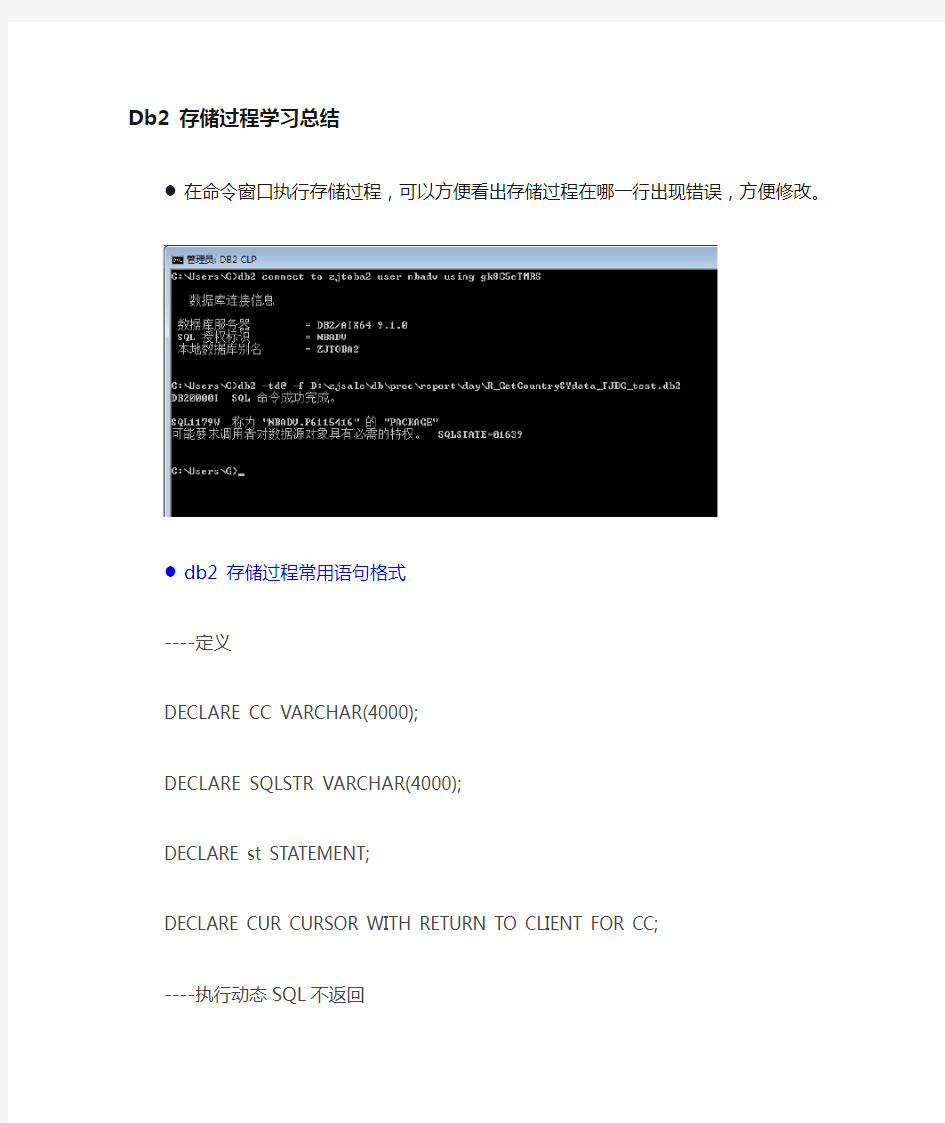
●在命令窗口执行存储过程,可以方便看出存储过程在哪一行出现错误,方便修改。
●db2 存储过程常用语句格式
----定义
DECLARE CC VARCHAR(4000);
DECLARE SQLSTR VARCHAR(4000);
DECLARE st STATEMENT;
DECLARE CUR CURSOR WITH RETURN TO CLIENT FOR CC;
----执行动态SQL不返回
PREPARE st FROM SQLSTR;
EXECUTE st;
----执行动态SQL返回
PREPARE CC FROM SQLSTR;
OPEN CUR;
----判断是否为空,使用值替代
COALESCE(判断对象,替代值)
----定义临时表
DECLARE GLOBAL TEMPORARY TABLE SESSION.TempResultTable
(
Organization int,
OrganizationName varchar(100),
AnimalTypeName varchar(20),
ProcessType int,
OperatorName varchar(100),
OperateCount int
)
WITH REPLACE -- 如果存在此临时表,则替换
NOT LOGGED;
DB2 9.x临时表使用总结
1). DB2的临时表需要用命令Declare Temporary Table来创建,并且需要创建在用户临时表空间上;
2). DB2在数据库创建时,缺省并不创建用户临时表空间,如果需要使用临时表,则需要用户在创建临时表之前创建用户临时表空间;
3). 临时表的模式为SESSION,SESSION即基于会话的,且在会话之间是隔离的。当会话结束时,临时表的数据被删除,临时表被隐式卸下。对临时表的定义不会在SYSCAT.TABLES中出现 .;
4). 缺省情况下,在Commit命令执行时,DB2临时表中的所有记录将被删除; 这可以通过创建临时表时指定不同的参数来控制;
5). 运行ROLLBACK命令时,用户临时表将被删除;
下面是DB2临时表定义的一个示例:
DECLARE GLOBAL TEMPORARY TABLE results
(
RECID VARCHAR(32) , --id
XXLY VARCHAR(100), --信息来源
LXDH VARCHAR(32 ), --信息来源联系电话
FKRQ DATE --反馈时间
) ON COMMIT PRESERVE ROWS WITH REPLACE NOT LOGGED;
----字符串函数
Substr
----隐形游标迭代
for 游标名as select....... do
使用游标名.字段名
内容区块
end for;
----直接返回值或变量
declare rs1 cursor with return to caller for select 0 from sysibm.sysdummy1;
----判断表是否存在
select count(*) into @exists from syscat.tables where tabschema = current schema and tabname='ZY_PROCESSLOG';
----取前面N条记录
select * from 表名FETCH FIRST N ROWS ONLY
----定义返回值
declare rs0 cursor with return to caller for select 0 from sysibm.sysdummy1;
declare rs1 cursor with return to caller for select 1 from sysibm.sysdummy1;
----得到插入的自增长列最大值
VALUES IDENTITY_VAL_LOCAL() INTO 变量
Merge into [A] using [B] on 条件when ***
通过这个merge你能够在一个SQL语句中对一个表同时执行inserts和updates操作. 当然是update还是insert是依据于你的指定的条件判断的,Merge into可以实现用B表来更新A表数据,如果A表中没有,则把B表的数据插入A表. MERGE命令从一个或多个数据源中选择行来updating或inserting到一个或多个表
语法如下
MERGE INTO [your table-name] [rename your table here]
USING ( [write your query here] )[rename your query-sql and using just like a table]
ON ([conditional expression here] AND [...]...)
WHEN MATHED THEN [here you can execute some update sql or something else ] WHEN NOT MATHED THEN [execute something else here ! ]
我们先看看一个简单的例子,来介绍一个merge into的用法
merge into products p using newproducts np on (p.product_id = np.product_id)
when matched then
update set p.product_name = np.product_name
when not matched then
insert values(np.product_id, np.product_name, np.category)
在这个例子里。前面的merger into products using newproducts 表示的用newproducts表来merge到products表,merge的匹配关系就是on后面的条件子句的内容,这里根据两个表的product_id来进行匹配,那么匹配上了我们的操作是就是when matched then的子句里的动作了,这里的动作是update set p.product_name = np.product_name, 很显然就是把newproduct里的内容,赋值到product的product_name里。如果没有匹配上则insert 这样的一条语句进去。大家看看这个merget inot的用法是不是一目了然了呀。这里merger 的功能,好比比较,然后选择更新或者是插入,是一系列的组合拳,在做merge的时候,这样同样的情况下,merge的性能是优于同等功能的update/insert语句的。
Oracle的substr函数简单用法
substr(字符串,截取开始位置,截取长度) //返回截取的字
substr('Hello World',0,1) //返回结果为'H' *从字符串第一个字符开始截取长度为1的字符串substr('Hello World',1,1) //返回结果为'H' *0和1都是表示截取的开始位置为第一个字符
substr('Hello World',2,4) //返回结果为'ello'
substr('Hello World',-3,3)//返回结果为'rld' *负数(-i)表示截取的开始位置为字符串右端向左数第i 个字符
测试:
select substr('Hello World',-3,3) value from dual;
附:java中substring(index1,index2)的简单用法
作用:从字符串索引(下标)为index1的字符开始截取长度为index2-index1 的字符串。
String str="Hello World";
System.out.println(str.substring(0,5));
打印结果为:Hello
●LOCATE(substr,str), LOCATE(substr,str,pos)
第一个语法返回字符串str第一次出现的子串substr的位置。第二个语法返回第一次出现在字符串str的子串substr的位置,从位置pos开始。substr不在str中,则返回0。
SQL> SELECT LOCATE('bar', 'foobarbar');
+---------------------------------------------------------+
| LOCATE('bar', 'foobarbar') |
+---------------------------------------------------------+
| 4 |
+---------------------------------------------------------+
1 row in set (0.00 sec)
●
●
●REPLACE函数的使用
REPLACE
用第三个表达式替换第一个字符串表达式中出现的所有第二个给定字符串表达式。
语法
REPLACE ( ''string_replace1'' , ''string_replace2'' , ''string_replace3'' )
参数
''string_replace1''
待搜索的字符串表达式。string_replace1 可以是字符数据或二进制数据。
''string_replace2''
待查找的字符串表达式。string_replace2 可以是字符数据或二进制数据。
''string_replace3''
替换用的字符串表达式。string_replace3 可以是字符数据或二进制数据。
返回类型
如果string_replace(1、2 或3)是支持的字符数据类型之一,则返回字符数据。如果string_replace(1、2 或3)是支持的binary 数据类型之一,则返回二进制数据。
示例
下例用xxx 替换abcdefghi 中的字符串cde。
SELECT REPLACE(''abcdefghicde'',''cde'',''xxx'')GO
下面是结果集:
------------abxxxfghixxx(1 row(s) affected)
SQL的partition by 字段(可实现自动分配组号跟归组合并)先看例子:
if object_id('TESTDB') is not null drop table TESTDB
create table TESTDB(A varchar(8), B varchar(8))
insert into TESTDB
select 'A1', 'B1' union all
select 'A1', 'B2' union all
select 'A1', 'B3' union all
select 'A2', 'B4' union all
select 'A2', 'B5' union all
select 'A2', 'B6' union all
select 'A3', 'B7' union all
select 'A3', 'B3' union all
select 'A3', 'B4'
-- 所有的信息
SELECT * FROM TESTDB
A B
-------
A1 B1
A1 B2
A1 B3
A2 B4
A2 B5
A2 B6
A3 B7
A3 B3
A3 B4
-- 使用PARTITION BY 函数后
SELECT *,ROW_NUMBER() OVER(PARTITION BY A ORDER BY A DESC) NUM FROM TESTDB
A B NUM
-------------
A1 B1 1
A1 B2 2
A1 B3 3
A2 B4 1
A2 B5 2
A2 B6 3
A3 B7 1
A3 B3 2
A3 B4 3
可以看到结果中多出一列NUM 这个NUM就是说明了相同行的个数,比如A1有3个,他就给每个A1标上是第几个。
-- 仅仅使用ROW_NUMBER() OVER的结果
SELECT *,ROW_NUMBER() OVER(ORDER BY A DESC)NUM FROM TESTDB
A B NUM
------------------------
A3 B7 1
A3 B3 2
A3 B4 3
A2 B4 4
A2 B5 5
A2 B6 6
A1 B1 7
A1 B2 8
A1 B3 9
可以看到它只是单纯标出了行号。
db2 循环示例
--首先是for 循环
begin atomic
declare v_id int;
declare v_name varchar(30);
for v_c as select id,name from J1
do
set v_name=v_c.id||v_https://www.doczj.com/doc/2e11708991.html,;
insert into j1 values(v_c.id+10,v_name); end for;
end
--然后是while 循环
begin atomic
declare v_cnt int;
set v_cnt=100;
while (v_cnt<1000) do
insert into j1 values (v_cnt+1000,'nixiaozi');
set v_cnt=v_cnt+1;
end while;
end
--repeat 循环
create procedure p10
language sql
modifies sql data
BEGIN atomic
DECLARE v_id INTEGER ;
DECLARE v_name varchar(20);
set v_id=1;
set v_name='n';
REPEAT
SET v_id = v_id + 2;
SET v_name = cast(v_id as varchar(3))||v_name;
insert into j6 values(v_id,v_name);
UNTIL (v_id > 100)
END REPEAT;
END
SQL中使用WITH AS提高性能-使用公用表表达式(CTE)简化嵌套SQL
一.WITH AS的含义
WITH AS短语,也叫做子查询部分(subquery factoring),可以让你做很多事情,定义一个SQL片断,该SQL片断会被整个SQL语句所用到。有的时候,是为了让SQL语句的可读性更高些,也有可能是在UNION ALL的不同部分,作为提供数据的部分。
特别对于UNION ALL比较有用。因为UNION ALL的每个部分可能相同,但是如果每个部分都去执行一遍的话,则成本太高,所以可以使用WITH AS短语,则只要执行一遍即可。如果WITH AS短语所定义的表名被调用两次以上,则优化器会自动将WITH AS短语所获取的数据放入一个TEMP表里,如果只是被调用一次,则不会。而提示materialize则是强制将WITH AS短语里的数据放入一个全局临时表里。很多查询通过这种方法都可以提高速度。
二.使用方法
先看下面一个嵌套的查询语句:
select * from person.StateProvince where CountryRegionCode in
(select CountryRegionCode from person.CountryRegion where Name like 'C%') 上面的查询语句使用了一个子查询。虽然这条SQL语句并不复杂,但如果嵌套的层次过多,会使SQL语句非常难以阅读和维护。因此,也可以使用表变量的方式来解决这个问题,SQL语句如下:
declare @t table(CountryRegionCode nvarchar(3))
insert into @t(CountryRegionCode) (select CountryRegionCode from person.CountryRegion where Name like 'C%')
select * from person.StateProvince where CountryRegionCode
in (select * from @t)
虽然上面的SQL语句要比第一种方式更复杂,但却将子查询放在了表变量@t中,这样做将使SQL语句更容易维护,但又会带来另一个问题,就是性能的损失。由于表变量实际
上使用了临时表,从而增加了额外的I/O开销,因此,表变量的方式并不太适合数据量大且频繁查询的情况。为此,在SQL Server 2005中提供了另外一种解决方案,这就是公用表表达式(CTE),使用CTE,可以使SQL语句的可维护性,同时,CTE要比表变量的效率高得多。
下面是CTE的语法:
[ WITH
expression_name [ ( column_name [ ,n ] ) ]
AS
( CTE_query_definition )
现在使用CTE来解决上面的问题,SQL语句如下:
with
cr as
(
select CountryRegionCode from person.CountryRegion where Name like 'C%'
)
select * from person.StateProvince where CountryRegionCode in (select * from cr) 其中cr是一个公用表表达式,该表达式在使用上与表变量类似,只是SQL Server 2005在处理公用表表达式的方式上有所不同。
在使用CTE时应注意如下几点:
1. CTE后面必须直接跟使用CTE的SQL语句(如select、insert、update等),否则,CTE 将失效。如下面的SQL语句将无法正常使用CTE:
with
cr as
(
select CountryRegionCode from person.CountryRegion where Name like 'C%'
)
select * from person.CountryRegion -- 应将这条SQL语句去掉
-- 使用CTE的SQL语句应紧跟在相关的CTE后面--
select * from person.StateProvince where CountryRegionCode in (select * from cr)
2. CTE后面也可以跟其他的CTE,但只能使用一个with,多个CTE中间用逗号(,)分隔,如下面的SQL语句所示:
with
cte1 as
(
select * from table1 where name like 'abc%'
),
cte2 as
(
select * from table2 where id > 20
),
cte3 as
(
select * from table3 where price < 100
)
select a.* from cte1 a, cte2 b, cte3 c where a.id = b.id and a.id = c.id
3. 如果CTE的表达式名称与某个数据表或视图重名,则紧跟在该CTE后面的SQL语句使用的仍然是CTE,当然,后面的SQL语句使用的就是数据表或视图了,如下面的SQL语句所示:
-- table1是一个实际存在的表
with
table1 as
(
select * from persons where age < 30
)
select * from table1 -- 使用了名为table1的公共表表达式
select * from table1 -- 使用了名为table1的数据表
4. CTE 可以引用自身,也可以引用在同一WITH 子句中预先定义的CTE。不允许前向引用。
5. 不能在CTE_query_definition 中使用以下子句:
(1)COMPUTE 或COMPUTE BY
(2)ORDER BY(除非指定了TOP 子句)
(3)INTO
(4)带有查询提示的OPTION 子句
(5)FOR XML
(6)FOR BROWSE
6. 如果将CTE 用在属于批处理的一部分的语句中,那么在它之前的语句必须以分号结尾,如下面的SQL所示:
declare @s nvarchar(3)
set @s = 'C%'
; -- 必须加分号
with
t_tree as
(
select CountryRegionCode from person.CountryRegion where Name like @s
)
select * from person.StateProvince where CountryRegionCode in (select * from t_tree)
CTE除了可以简化嵌套SQL语句外,还可以进行递归调用,关于这一部分的内容将在下一篇文章中介绍。
●sql中COALESCE()函数的功能
返回其参数中的第一个非空表达式
●sql trim()函数
去掉两头空格
sql语法中没有直接去除两头空格的函数,但有ltrim()去除左空格rtrim()去除右空格。
合起来用就是sql的trim()函数,即select ltrim(rtrim(UsrName))
NULLIF
如果两个指定的表达式相等,则返回空值。
语法NULLIF ( expression1 ,expression2 )
参数expression1,expression2
常量、列名、函数、子查询或算术运算符、按位运算符以及字符串运算符的任意组合。
返回类型返回类型与第一个expression1 相同。
输出结果:
如果两个表达式不相等,NULLIF 返回第一个expression1 的值。
如果两个表达式相等,NULLIF 返回空值NULL。
SQLServer函数是一样的功能
例子:PRINT NULLIF('222','') --返回222
PRINT ISNULL(NULLIF('222','222'),'23') --返回23 证明返回的是null
可能有不少朋友使用SQL SERVER做开发也已经有段日子,但还没有或者很少在项目中使用存储过程,或许有些朋友认为根本没有必要使用存储过程等等。其实当你一个项目做完到了维护阶段时,就会发现存储过程给我们带来了好处了,修改方便,不能去改我们的应用程序,只需要改存储过程的内容,而且还可以使我们的程序速度得到提高。 QUOTE: SQL SERVER 联机丛书中的定义: 存储过程是保存起来的可以接受和返回用户提供的参数的 Transact-SQL 语句的集合。 可以创建一个过程供永久使用,或在一个会话中临时使用(局部临时过程),或在所有会话中临时使用(全局临时过程)。 也可以创建在 Microsoft SQL Server 启动时自动运行的存储过程。 要使用存储过程,首先我们必需熟悉一些基本的T-SQL语句,因为存储过程是由于一组T-SQL语句构成的,并且,我们需要了解一些关于函数、过程的概念,因为我们需要在应用程序中调用存储过程,就像我们调用应用程序的函数一样,不过调用的方法有些不同。 下面我们来看一下存储过程的建立和使用方法。 一、创建存储过程 和数据表一样,在使用之前我们需要创建存储过程,它的简明语法是: QUOTE: CREATE PROC 存储过程名称 [参数列表(多个以“,”分隔)] AS SQL 语句 例: QUOTE: CREATE PROC upGetUserName @intUserId INT, @ostrUserName NVARCHAR(20) OUTPUT -- 要输出的参数 AS BEGIN -- 将uName的值赋给 @ostrUserName 变量,即要输出的参数 SELECT @ostrUserName=uName FROM uUser WHERE uId=@intUserId END 其中 CREATE PROC 语句(完整语句为CREATE PROCEDURE)的意思就是告诉SQL SERVER,
DB2 SQLJ 存储过程开发宝典,第 2 部分 简介: 在第 1 部分,我们已经介绍了 SQLJ 存储过程的基本知识,如何逐步完成开发和调试。现在,我们将总结说明在运行 SQLJ 存储过程时,经常遇到的错误,并对这些错误产生的原因进行分析,并给出相应的修正方法。此外,在开发过程中,有一些值得考虑或者需要进一步说明的问题,我们也将他们罗列出来,予以探讨。 引言 在第 1 部分,我们已经介绍了 SQLJ 存储过程的基本知识,如何逐步完成开发和调试。现在,我们将总结说明在运行 SQLJ 存储过程时,经常遇到的错误,并对这些错误产生的原因进行分析,并给出相应的修正方法。此外,在开发过程中,有一些值得考虑或者需要进一步说明的问题,我们也将他们罗列出来,予以探讨。 常见错误总结 由于程序代码本身、运行环境、参数配置等原因,SQLJ 存储过程在被调用时,可能会发生各种错误。对这些错误进行分析,明确其产生的原因,找到相应的应对措施,并加以归纳总结,对我们提高开发水平、保证产品质量和提高工作效率等方面具有重要的意义。这些信息对于 SQLJ 应用开发的初学者尤为重要,能够直接的帮助他们解决开发实际工作中遇到的问题,表 1 列出了常见的 SQLJ 存储过程运行错误,原因以及相应措施。 表 1. 常见错误 错误 原因 措施 SQL4306N Java 存储过程或用户定义的函数 名称(特定名称 特定名称)不能调用 Java 方法 方法,特征符为 字符串 DB2 通过 JAR 包名、类名、方法名和签名(Signature )无法找到创建存储过程时指定的被调用的方法。可能是引用的类不存在、jar 包没有安装、方法声明的参数列表与数据库期望的参数列表不匹配或者不是“public”实例方法 1.查看 Java 代码中的方法名和类名,检查存储过程 DDL 中 Java 方法名、类名和 jar 包名是否有误; 2.检查 jar/calss 文件是否在指定位置,如 sqllib/function 目录下; 3.检查存储过程 DDL 中的方法参数列表是否与 Java 代码匹配(使用 javap – s class_id 可以查看类中方法的签名),并且 Java 代码中该方法是 public 的。 SQL4304N Java 存储过程或用户定义的函数 名称(特定名称 特定名称)不能装入 Java 类 类,原因码为 原因码。 1. RC=1:在 CLASSPATH 上找不到该类。往往可能是我们在 DDL 发生了拼写错误; 2. RC=2:该类未实现必需的接口 COM.ibm.db2.app.StoredProc 或缺少 public 访问权标志。如果是 PARAMETER STYLE DB2GENERAL 的存储过程,那么要求被调用 Java 类是 public 的并继承了接口 COM.ibm.db2.app.StoredProc 。 1.检查 Java 代码中的类 / 方法名和存储过程 DDL 中 Java 类 / 方法名是否一致; 2.检查 jar/calss 文件是否在 CLASSPATH 中,如 sqllib/function 目录下; 3.检查是否 DDL 指定了 PARAMETER STYLE DB2GENERAL 而 Java 代码类是否是 public 并继承 接口 COM.ibm.db2.app.StoredProc 。 SQL4302N 过程或用户定义的函数 名称(特定名称 特定名称)由于异常 字符串 而 存储过程由于异常而异常终止。通常可能是查询返回是空的 数据集,或是 SQL 中使用“select into :hostvar”但是实际查 询返回多条数据,或 Java 运行中出现空指针异常等。 检查 db2diag.log 诊断日志,找到错误,修正 Java 代码。
C#调用存储过程简单完整例子https://www.doczj.com/doc/2e11708991.html,/itblog/article/details/752869 创建存储过程 Create Proc dbo.存储过程名 存储过程参数 AS 执行语句 RETURN 执行存储过程 GO DECLARE @iRet INT, @PKDisp VARCHAR(20) SET @iRet = '1' Select @iRet = CASE WHEN @PKDisp = '一' THEN 1 WHEN @PKDisp = '二' THEN 2 WHEN @PKDisp = '三' THEN 3 WHEN @PKDisp = '四' THEN 4 WHEN @PKDisp = '五' THEN 5 ELSE 100 END DECLARE @i INT SET @i = 1 WHILE @i<10 BEGIN set @i=@i+1 PRINT @i END DECLARE @d INT set @d = 1 IF @d = 1 BEGIN -- 打印 PRINT '正确' END ELSE BEGIN PRINT '错误' END
CREATE PROC P_TEST @Name VARCHAR(20), @Rowcount INT OUTPUT AS BEGIN SELECT * FROM T_Customer WHERE NAME=@Name SET @Rowcount=@@ROWCOUNT END GO ---------------------------------------------------------------------------------------- --存储过程调用如下: ---------------------------------------------------------------------------------------- DECLARE @i INT EXEC P_TEST 'A',@i OUTPUT SELECT @i --结果 /* Name Address Tel ---------- ---------- -------------------- A Address Telphone (所影响的行数为 1 行) ----------- 1 (所影响的行数为 1 行) */ ---------------------------------------------------------------------------------------- --DotNet 部分(C#) --WebConfig 文件: ---------------------------------------------------------------------------------------- ......
1.1 SQL过程的结构 命名规则: 1、清洗过程名称命名: PROC_业务主题_目标表(PROC_JY_KJYRLJB 交易主题的卡交易日类聚表) 2、函数名称命名: PROC_业务主题_函数名(PROC_JY_GETYWZL 交易主题取得卡业务种类函数) 3、变量命名: VAR_变量描述(VAR_YWZL 业务种类变量) 4、游标命名: CUR_游标描述(CUR_KJYB 对卡交易表进行游标处理) 语法: CREATE PROCEDURE 过程名称 (参数列表 DYNAMIC RESULT SETS 结果集数量 是否允许SQL LANGUAGE SQL BEGIN SQL 过程体
END 范例“资产负债.sql ”中 第1行:Create Procedure admin.BalanceSheetDayly定义了过程名称 参数列表为Out ProcState varchar(100 其定义SQL 过程从客户应用获取,或返回客户应用的0个或多个参数,参数列表使用逗号侵害各个参数 参数类型有三种: l IN 从客户应用检索值。其不能够在SQL 过程体中修改 l OUT 向客户应用返回值 l INOUT 从客户应用检索值,并返回值 省略了结果集数量的定义,default 为0。即表示不返回结果集。 省略了是否允许SQL 的说明。其值指出了存储过程是否会使用SQL 语句,如果使用,其类型如何: l NO SQL 不能够执行任何SQL 语句 l COTAINS SQL 可以执行不会读取SQL 数据,也不会修改SQL 数据的SQL 语句 l READS SQL DATA 可以包含不会修改SQL 数据的SQL 语句 l MODIFIES SQL DATA 可以执行任何SQL 语句,除了不能够在存储过程中支持的语句以外。
本文将为您介绍一个DB2存储过程使用动态游标的例子,如果您对动态游标的使用感兴趣的话,不妨一看,对您学习DB2的使用会有所帮助。 CREATE PROCEDURE data_wtptest( IN in_taskid_timestamp varchar(30), OUT o_err_no int, OUT o_err_msg varchar(1024)) LANGUAGE SQL P1: BEGIN ATOMIC --声明开始 --临时变量出错变量 DECLARE SQLCODE integer default 0; DECLARE SQLStmt varchar(1024) default ''; DECLARE r_code integer default 0; DECLARE state varchar(1024) default 'AAA';--记录程序当前所作工作 DECLARE at_end int DEFAULT 0; DECLARE t_destnetid int default 0; DECLARE t_recvid varchar(30) default ''; DECLARE SP_Name varchar(50) default 'data_wtptest'; --声明放游标的值 --声明动态游标存储变量 DECLARE stmt1 STATEMENT; DECLARE c1 CURSOR FOR stmt1; --声明出错处理 DECLARE EXIT HANDLER FOR SQLEXCEPTION begin set r_code=SQLCODE; set o_err_no=1; set o_err_msg='处理['||state||']出错,'||'错误代码SQLCODE:['||CHAR(r_code) || '].'; insert into fcc_sp_log(object,name,value) values(SP_Name,in_taskid_timestamp,o_err_msg); end; DECLARE continue HANDLER for not found begin
存储过程 1 CREATE OR REPLACE PROCEDURE 存储过程名 2 IS 3 BEGIN 4 NULL; 5 END; 行1: CREATE OR REPLACE PROCEDURE 是一个SQL语句通知Oracle数据库去创建一个叫做skeleton存储过程, 如果存在就覆盖它; 行2: IS关键词表明后面将跟随一个PL/SQL体。 行3: BEGIN关键词表明PL/SQL体的开始。 行4: NULL PL/SQL语句表明什么事都不做,这句不能删去,因为PL/SQL体中至少需要有一句; 行5: END关键词表明PL/SQL体的结束
存储过程创建语法: create or replace procedure 存储过程名(param1 in type,param2 out type) as 变量1 类型(值范围); --vs_msg VARCHAR2(4000); 变量2 类型(值范围); Begin Select count(*) into 变量1 from 表A where列名 =param1; If (判断条件) then Select 列名into 变量2 from 表A where列名 =param1; Dbms_output。Put_line(‘打印信息’); Elsif (判断条件) then Dbms_output。Put_line(‘打印信息’); Else Raise 异常名(NO_DATA_FOUND); End if; Exception When others then Rollback;
End; 注意事项: 1,存储过程参数不带取值范围,in表示传入,out表示输出 类型可以使用任意Oracle中的合法类型。 2,变量带取值范围,后面接分号 3,在判断语句前最好先用count(*)函数判断是否存在该条操作记录 4,用select 。。。into。。。给变量赋值 5,在代码中抛异常用 raise+异常名 CREATE OR REPLACE PROCEDURE存储过程名 ( --定义参数 is_ym IN CHAR(6) ,
论文写作中MathType应用技巧 1. 快捷键 首先是一些需要熟练掌握的常用快捷键,比如, (1) 插入常用符号 上标:Ctrl+H 下标:Ctrl+L 积分号:Ctrl+I 根式:Ctrl+R 上横线:Ctrl+Shift+连字符 矢量箭头:Ctrl+Alt+连字符 单撇:Ctrl+Alt+' 双撇:Ctrl+Alt+" 小括号:Ctrl+9或Ctrl+0 中括号:Ctrl+[ 或Ctrl+] 大括号:Ctrl+{ 或Ctrl+} 分式:Ctrl+F 斜杠分式:Ctrl+/ 先按“Ctrl+T”放开后,再按N(n次根式)、S(求和符号)、P(乘积符号)等。 (2) 微调符号的位置 先选取要移动的符号; 再用“Ctrl+箭头键”配合操作即可实现上、下、左、右的平移; 用“Ctrl+Alt+空格”键可适当增加空格。 (3) 符号大小缩放 100%:Ctrl+1 200%:Ctrl+2
400%:Ctrl+4 800%:Ctrl+8 2. 批量修改公式的字号和大小 论文投稿之后,一不小心被拒稿了,这时只能重新找个期刊再投。然而,这个期刊对格式的要求可能和前面一个期刊的要求不一样。这样的话,排版需要修改公式的大小,一个一个手动修改不仅费时费力,而且容易漏掉。 有没有批量修改的办法?按照下面几步操作就能实现: (1)双击一个公式,打开MathType,进入编辑状态; (2)点击size菜单——define——字号对应的pt值,一般五号对应10pt,小四对应12pt; (3)点击preference->equation preference -> save to file ->存一个与默认配置文件不同的名字; (4)关闭MathType回到word文档; (5)点击word界面上的MathType——format equation——load equation preferrence选项下面的browse按钮,选中刚才存的配置文件,点选whole document 选项,点确定,搞定。 3. 公式的自动编号 第二次的投稿,终于没有被拒稿,但是需要大修。大修的时候,需要添加一些公式,也要删掉一些公式。如果手动编号,需要一个个重新编号,修改工作量变得巨大。这时,采用自动编号和自动引用会方便很多。 MathType提供四种类型的公式输入: inline(文本中的公式) display style 没有编号的单行公式
db2回滚处理问题 DB2处理器对于存储过程来说,有着不可替代的作用。在DB2中,SQL存储过程可以利用DB2处理器(Condition Handler)来处理存储过程运行过程中的SQL错误(SQLERROR)、SQL警告(SQLWARNING)和没有数据(NOT FOUND)三种常见情况以及你自己定义的触发,你可以使用包括退出(EXIT)、继续(CONTINUE)和撤销(UNDO)在内的三种处理器。 在SQL存储过程运行过程中,如果出现了SQLERROR、SQLWARNING和NOT FOUND 三种情况,SQL存储过程将会自动将执行SQL语句后的SQLCODE和SQLSTATE存储在你事先定义好的变量SQLCODE和SQLSTATE中,并触发你在存储过程中定义的处理器。 在SQL存储过程处理错误,您需要做如下两步:声明SQLCODE和SQLSTATE 变量、定义处理器。在SQL存储过程中,您通过下列语句声明SQLCODE和SQLSTATE 变量: DECLARE SQLCODE INTEGER DEFAULT 0; DECLARE SQLSTATE CHAR(5) DEFAULT ‘00000’; 当存储过程执行时,DB2会自动将该SQL语句的返回码付给这两个变量,你可以在调试程序的时候,将这两个值插入到调试表中,或者利用处理器将这两个值返回给调用者。这样可以方便SQL存储过程的调试。注意:当你在SQL存储过程中存取SQLCODE和SQLSTATE时,DB2会自动将SQLCODE和SQLSTATE置为零。 可以通过下列语句定义DB2处理器: DECLARE handler-type HANDLER FOR condition SQL-procedure-statement 其中handler-type可以是如下几种: CONTINUE:SQL存储过程在执行完处理器中的SQL语句后,继续执行出错SQL 语句后边的SQL语句。 EXIT: SQL存储过程在执行完处理器中的SQL语句后,退出存储过程的执行。 UNDO:这种处理器仅限于原子动作(ATOMIC)复合SQL语句,SQL存储过程将会回滚包含该处理器的复合SQL语句,并在执行完该处理器中的SQL语句后,继续执行原子动作(ATOMIC)复合SQL语句后面的SQL语句。 包括如下三种常见情况: SQLEXCEPTION:在SQL执行过程中返回任何负值。 SQLWARNING:在SQL执行过程中出现警告(SQLWARN0为‘W’),或者是任何不是+100的正的SQL返回值,相应的SQLSTATE以‘01’开始。 NOT FOUND:SQL返回值为+100或者SQLSTATE以‘02’开始。 当然你也可以使用DECLARE语句为特定的SQLSATE定义你自己的。
题目1 1、学校图书馆借书信息管理系统建立三个表: 学生信息表:student 图书表:book 借书信息表:borrow 请编写SQL语句完成以下的功能: 1)查询“计算机”专业学生在“2007-12-15”至“2008-1-8”时间段内借书的学生编号、 学生名称、图书编号、图书名称、借出日期;参考查询结果如下图所示: 2)查询所有借过图书的学生编号、学生名称、专业;参考查询结果如下图所示:
3)查询借过作者为“安意如”的图书的学生姓名、图书名称、借出日期、归还日期; 参考查询结果如下图所示: 4)查询目前借书但未归还图书的学生名称及未还图书数量;参考查询结果如下图所 示: 附加:建表语句:
标准答案:
题目2 程序员工资表:ProWage 创建一个存储过程,对程序员的工资进行分析,月薪1500到10000不等,如果有百分之五十的人薪水不到2000元,给所有人加薪,每次加100,再进行分析,直到有一半以上的人大于2000元为止,存储过程执行完后,最终加了多少钱? 例如:如果有百分之五十的人薪水不到2000,给所有人加薪,每次加100元,直到有一半以上的人工资大于2000元,调用存储过程后的结果如图:
请编写T-SQL来实现如下功能: 1)创建存储过程,查询是否有一半程序员的工资在2200、3000、3500、4000、5000或6000 元之上,如果不到分别每次给每个程序员加薪100元,至之一半程序员的工资达到2200,3000,3500,4000,5000或6000元。 2)创建存储过程,查询程序员平均工资在4500元,如果不到则每个程序员每次加200元, 至到所有程序员平均工资达到4500元。 建表语句
Word中MathType公式调整的一些技巧 一、批量修改公式的字号和大小 数学试卷编辑中,由于排版等要求往往需要修改公式的大小,一个一个的修改不仅费时费力,还容易产生各种错误。如果采用下面介绍的方法,就可以达到批量修改公式大小的效果。 (1)双击一个公式,打开MathType,进入编辑状态; (2)点击size(尺寸)菜单→define(自定义)→字号对应的pt(磅)值,一般五号对应10pt(磅),小四对应12pt(磅); (3)根据具体要求调节pt(磅)值,然后点击OK(确定)按钮; (4)然后点击preference(选项)→equation preference (公式选项)→save to file(保存到文档),保存一个与默认配置文件不同的名字,然后关闭MathType 回到Word文档; (5)点击Word界面上的菜单MathType→format equations(公式格式)→load equation preferrence(加载公式选项),点击选项下面的browse(浏览)按钮,选中刚才保存的配置文件,并点选whole document(整个文档)选项,最后单击OK(确定)按钮。 到此,就安心等着公式一个个自动改过来吧…… 但这样处理后,下次使用Word文档进行MathType公式编辑时,将以上述选定的格式作为默认设置。如果需要恢复初始状态,可以按以下步骤操作:(1)双击一个公式,打开MathType,进入编辑状态; (2)然后点击preference(选项)→equation preference (公式选项)→Load factory settings(加载出厂设置),然后关闭MathType回到Word文档。 二、调整被公式撑大的Word行距 点击“文件”菜单下的“页面设置”项。在“文档网格”标签页中的“网格”一栏,勾选“无网格”项。 但此时也存在一个问题,就是此时的行间距一般比预期的行间距要小。这时
一些常用快捷键掌握一些快捷键对提高工作效率帮助很大,下面是我总结的一些快捷键(括号内为实现的功能)。1.放大或缩小尺寸 Ctrl+1(100%);Ctrl+2(200%);Ctrl+4(400%);Ctrl+8(800%)。 2.在数学公式中插入一些符号 Ctrl+9或Ctrl+0(小括号);Ctrl+[ 或Ctrl+](中括号);Ctrl+{ 或Ctrl+}(大括号); Ctrl+F(分式);Ctrl+/(斜杠分式);Ctrl+H(上标);Ctrl+L(下标);Ctrl+I(积分号); Ctrl+R(根式);Ctrl+Shift+连字符(上横线);Ctrl+Alt+连字符(矢量箭头); Ctrl+Alt+'(单撇);Ctrl+Alt+"(双撇);先按“Ctrl+T”放开后,再按N(n次根式)、S(求和符号)、P(乘积符号)等。 3.微移间隔 先选取要移动的公式(选取办法是用“Shift+箭头键”),再用“Ctrl+箭头键”配合操作即可实现上、下、左、右的平移;用“Ctrl+Alt+空格”键可适当增加空格。 4.元素间的跳转 每一步完成后转向下一步(如输入分子后转向分母的输入等)可用Tab键,换行用Enter键。 添加常用公式 MathType的一大特色就是可以自己添加或删除一些常用公式,添加的办法是:先输入我们要添加的公式,然后选中该公式,用鼠标左键拖到工具栏中适当位置即可。删除的方式是右击工具图标,选择“删除”命令即可。 在编辑word文档时,如果需要录入公式将是一件非常痛苦的事情。利用Mathtype作为辅助工具,会为文档的公式编辑和修改提供很多方便。 下面介绍几种mathtype中比较重要的技巧 一、批量修改公式的字号和大小 论文中,由于排版要求往往需要修改公式的大小,一个一个修改不仅费时费力还容易使word产生非法操作。 解决办法,批量修改:双击一个公式,打开mathtype,进入编辑状态, 点击size菜单-》define->字号对应的pt值,一般五号对应10pt,小四对应12pt 其他可以自己按照具体要求自行调节。其他默认大小设置不推荐改动。 然后点击preference->equation preference -> save to file ->存一个与默认配置文件不同的名字,然后关闭mathtype回到word文档。 点击word界面上的mathtype ->format equation -> load equation preferrence选项下面的browse按钮,选中刚才存的配置文件,点选whole document选项,确定,就安心等着公式一个个改过来。 二、公式的自动编号和引用功能 mathtype提供四种类型的公式输入inline(文本中的公式) display style 没有编号的单行公式, left numbered display style 编号在左边 right ... 编号在右边 在编辑公式时,如果出现删除公式的情况,采用手动编号会使得修改量变得很大,采用自动编号和自动引用会方便很多,这些功能都已经在安装mathtype后集成在word的按钮上了,将鼠标悬停在相应的按钮上就可以看到具体的功能描述,由于应用十分简单,就不再此赘述了。 三、与latex代码之间的转换 mathtype编辑器中的translator 里面提供了向latex,amslatex等格式的方便转换。选择相应的翻译目标后,将下面的两个inculde 选项去掉,你的mathtype就可以直接将公式翻译称为latex代码了,这对于latex的初学者和记不住latex 代码的人非常重要。 四、 书写数学符号时,请参考下面的给定数学符号,需要时直接复制即可. 另外还有几个表示思路: (强调:平时考试不可乱用下面两行的符号,这些写法只适合在论坛发帖)
Db2 存储过程学习总结 ●在命令窗口执行存储过程,可以方便看出存储过程在哪一行出现错误,方便修改。 ●db2 存储过程常用语句格式 ----定义 DECLARE CC VARCHAR(4000); DECLARE SQLSTR VARCHAR(4000); DECLARE st STATEMENT; DECLARE CUR CURSOR WITH RETURN TO CLIENT FOR CC; ----执行动态SQL不返回 PREPARE st FROM SQLSTR; EXECUTE st; ----执行动态SQL返回 PREPARE CC FROM SQLSTR; OPEN CUR; ----判断是否为空,使用值替代 COALESCE(判断对象,替代值)
----定义临时表 DECLARE GLOBAL TEMPORARY TABLE SESSION.TempResultTable ( Organization int, OrganizationName varchar(100), AnimalTypeName varchar(20), ProcessType int, OperatorName varchar(100), OperateCount int ) WITH REPLACE -- 如果存在此临时表,则替换 NOT LOGGED; DB2 9.x临时表使用总结 1). DB2的临时表需要用命令Declare Temporary Table来创建,并且需要创建在用户临时表空间上; 2). DB2在数据库创建时,缺省并不创建用户临时表空间,如果需要使用临时表,则需要用户在创建临时表之前创建用户临时表空间; 3). 临时表的模式为SESSION,SESSION即基于会话的,且在会话之间是隔离的。当会话结束时,临时表的数据被删除,临时表被隐式卸下。对临时表的定义不会在SYSCAT.TABLES中出现 .; 4). 缺省情况下,在Commit命令执行时,DB2临时表中的所有记录将被删除; 这可以通过创建临时表时指定不同的参数来控制; 5). 运行ROLLBACK命令时,用户临时表将被删除; 下面是DB2临时表定义的一个示例: DECLARE GLOBAL TEMPORARY TABLE results ( RECID VARCHAR(32) , --id XXLY VARCHAR(100), --信息来源 LXDH VARCHAR(32 ), --信息来源联系电话 FKRQ DATE --反馈时间 ) ON COMMIT PRESERVE ROWS WITH REPLACE NOT LOGGED; ----字符串函数
DB2存储过程简单例子 客户在进行短信服务这个业务申请时,需要填写一些基本信息,然后根据这些信息判断这个用户是否已经存在于业务系统中。因为网上服务和业务系统两个项目物理隔离,而且网上数据库保存的客户信息不全,所以判断需要把数据交换到业务系统,在业务系统中判断。 解决方式是通过存储过程,以前也了解过存储过程,但没使用到项目中。不过经过一番努力最后还是完成了,期间遇到了一些困难,特写此文让对DB2存储过程还不熟悉的童鞋避免一些无谓的错误。 DROP PROCEDURE "PLName" @ CREATE PROCEDURE "PLName"(--存储过程名字 IN IN_ID BIGINT , --以下全是输入参数 IN IN_ENTNAME VARCHAR(200) , IN IN_REGNO VARCHAR(50), IN IN_PASSWORD VARCHAR(20), IN IN_LEREP VARCHAR(300), IN IN_CERTYPE CHARACTER(1), IN IN_CERNO VARCHAR(50), IN IN_LINKMAN VARCHAR(50), IN IN_SEX CHARACTER(1), IN IN_MOBTEL VARCHAR(30), IN IN_REQDATE TIMESTAMP, IN IN_REMITEM VARCHAR(300), IN IN_STATE CHARACTER(1), IN IN_TIMESTAMP TIMESTAMP ) BEGIN declare V_RESULT BIGINT; --声明变量 DELETE FROM TableNameA WHERE ID = IN_ID;
目录 1 详解MathType中如何批量修改公式字体和大小 (2) 2 如何在等号上插入容 (3) 3 详解MathType快捷键使用技巧 (3) 4 数学上的恒不等于符号怎么打 (3) 5 MathType表示分类的大括号怎么打 (3) 6 编辑公式时如何让括号的容居中 (3) 7 MathType怎么编辑叉符号 (3) 8 怎样用MathType编辑竖式加减法 (3) 9 如何用MathType编辑除法竖式 (3) 10 如何用MathType编辑短除法 (3) 如何调整MathType矩阵行列间距 (3) 12在MathType中怎样表示将公式叉掉 (3) 13 MathType怎么输入字母上方的黑点 (3) 14 MathType如何编辑大于或约等于符号 (3)
1 详解MathType中如何批量修改公式字体和大小 MathType应用在论文中时,有时会因为排版问题批量修改公式字体和大小,一个一个的修改不仅费时费力,还容易出现错误,本教程将详解如何在MathType公式编辑器中批量修改公式字体和大小。批量修改公式字体和大小的操作步骤: 步骤一双击论文中的任意一个公式,打开MathType公式编辑器软件。 步骤二单击菜单栏中的大小——定义命令,打开“定义尺寸”对话框。如果使用的是英文版MathType,点击size——define即可。 步骤三在“定义尺寸”对话框中,通过更改pt值的大小可以达到修改MathType字体的效果。英文版下为“Full”。
一般情况下,五号字对应的pt值为10,小四号字对应的pt值为12。因为“磅”是大家比较熟悉的单位,用户也可以将pt值换成“磅”来衡量。 步骤四菜单栏中的选项——公式选项——保存到文件,选择保存路径。英文版的MathType点击preference——equation preference —— save to file 步骤六关闭MathType软件后,点击word文档中的MathType——Insert Number——format equation,打开format equation对话框。
MySQL存储过程详解 1.存储过程简介 我们常用的操作数据库语言SQL语句在执行的时候需要要先编译,然后执行,而存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它。 一个存储过程是一个可编程的函数,它在数据库中创建并保存。它可以有SQL语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。 存储过程通常有以下优点: (1).存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。 (2).存储过程允许标准组件是编程。存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。 (3).存储过程能实现较快的执行速度。如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。 (4).存储过程能过减少网络流量。针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。 (5).存储过程可被作为一种安全机制来充分利用。系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。 2.关于MySQL的存储过程 存储过程是数据库存储的一个重要的功能,但是MySQL在5.0以前并不支持存储过程,这使得MySQL在应用上大打折扣。好在MySQL 5.0终于开始已经支持存储过程,这样即可以大大提高数据库的处理速度,同时也可以提高数据库编程的灵活性。 3.MySQL存储过程的创建 (1). 格式
整理者为我 实例1:只返回单一记录集的存储过程。 银行存款表(bankMoney)的内容如下 要求1:查询表bankMoney的内容的存储过程 create procedure sp_query_bankMoney as select * from bankMoney go exec sp_query_bankMoney 注* 在使用过程中只需要把中的SQL语句替换为存储过程名,就可以了很方便吧! 实例2(向存储过程中传递参数): 加入一笔记录到表bankMoney,并查询此表中userID= Zhangsan的所有存款的总金额。 Create proc insert_bank @param1 char(10),@param2 varchar(20),@param3 varchar(20),@param4 int,@param5 int output with encryption ---------加密 as insert bankMoney (id,userID,sex,Money)
Values(@param1,@param2,@param3, @param4) select @param5=sum(Money) from bankMoney where userID='Zhangsan' go 在SQL Server查询分析器中执行该存储过程的方法是: declare @total_price int exec insert_bank '004','Zhangsan','男',100,@total_price output print '总余额为'+convert(varchar,@total_price) go 在这里再啰嗦一下存储过程的3种传回值(方便正在看这个例子的朋友不用再去查看语法内容): 1.以Return传回整数 2.以output格式传回参数 3.Recordset 传回值的区别: output和return都可在批次程式中用变量接收,而recordset则传回到执行批次的客户端中。 实例3:使用带有复杂 SELECT 语句的简单过程 下面的存储过程从四个表的联接中返回所有作者(提供了姓名)、出版的书籍以及出版社。该存储过程不使用任何参数。 USE pubs IF EXISTS (SELECT name FROM sysobjects WHERE name = 'au_info_all' AND type = 'P') DROP PROCEDURE au_info_all GO
文档编号:ETL-11-T-2008 DB2 SQL及存储过程编写规范 当前版本:V1.0 版本日期:2009年08月15日
文件信息 修订记录 文件审核/审批 此文件需如下审核 文档分发 此文档将分发至如下个人或机构
1引言 1.1 目的 本标准是针对IBM DB2数据库SQL编写设计而起草的开发规范;同时,也作为各项目ETL组评审ETL任务开发质量的标准之一。 本标准将作为项目规范开发系列之一,并且需要在项目实施工作中不断改进和完善,保障规范能够真正的提高质量和效率。 引言 1.2 总则 整个系统中ETL开发的编码,包括基于封装的程序包中的代码,在对象的命名和使用、程序的注释和排版,都应当注重规范 在编码的过程中,应时刻牢记优化的重要性,对重要程序块或程序包需要注明其逻辑结构。在必要的时候,还应进行代码评审 本规范适用各IBM DB2数据库和项目ETL开发的程序包 应用于系统基于数据库的ETL模块开发并对应用集市相关开发提供参考与指导1.3 预期读者 项目管理人员 软件设计人员 软件编程人员 质量控制人员 软件维护人员
1.4 术语和定义 描述术语 本文档采用以下的术语描述: 规范:编程时强制必须遵守的原则标准:量化的规范。 说明:对此规则或建议进行必要的说明和解释。 示例:对此规则或建议给出适当的例子。 编码术语 编码(Coding) 关键字(Keyword) 函数(Function) 存储过程(Procedure) 变量(Variable) 游标(Cursor) ETL(Extraction、Translation、Loading) 2编码规范 2.1 命名规范 对象命名不能超过30个英文字母,前缀和单词之间用下划线分隔,尽量不采用汉语拼音,使用英文单词或公认单词缩写,单词缩写可通过去掉“元音” 形成。 所有数据库对象(表、视图、存储过程)、关键字和系统函数、数据类型大写;自定义变量、游标小写。 命名的组成只能使用26个英文字母、下划线或阿拉伯数字,不能使用汉字。 名称具有复数意义时,使用名词的正确的复数形式 当一个SQL 语句中涉及到多个表时,始终使用表名别名来限定字段名。这使其他人阅读起来更清楚,避免了含义模糊的引用。 一般情况下,列名称不应包含表名或者表名的任何形式,列名不允许使用统
存储过程如同一门程序设计语言,同样包含了数据类型、流程控制、输入和输出和它自己的函数库。 --------------------基本语法-------------------- 一.创建存储过程 create procedure sp_name() begin ......... end 二.调用存储过程 1.基本语法:call sp_name() 注意:存储过程名称后面必须加括号,哪怕该存储过程没有参数传递 三.删除存储过程 1.基本语法: drop procedure sp_name// 2.注意事项 (1)不能在一个存储过程中删除另一个存储过程,只能调用另一个存储过程 四.其他常用命令 1.show procedure status 显示数据库中所有存储的存储过程基本信息,包括所属数据库,存储过程名称,创建时间等2.show create procedure sp_name 显示某一个mysql存储过程的详细信息 --------------------数据类型及运算符-------------------- 一、基本数据类型: 略 二、变量: 自定义变量:DECLARE a INT ; SET a=100; 可用以下语句代替:DECLARE a INT DEFAULT 100; 变量分为用户变量和系统变量,系统变量又分为会话和全局级变量 用户变量:用户变量名一般以@开头,滥用用户变量会导致程序难以理解及管理 1、在mysql客户端使用用户变量 mysql> SELECT 'Hello World' into @x; mysql> SELECT @x; mysql> SET @y='Goodbye Cruel World'; mysql> select @y; mysql> SET @z=1+2+3; mysql> select @z; 2、在存储过程中使用用户变量 mysql> CREATE PROCEDURE GreetWorld( ) SELECT CONCAT(@greeting,' World'); mysql> SET @greeting='Hello'; mysql> CALL GreetWorld( );