
首先说一下什么是离散化以及连续变量离散化的必要性。
离散化是把无限空间中无限的个体映射到有限的空间中去,通俗点讲就是把连续型数据切分为若干“段”,也称bin,离散化在数据分析中特别是数据挖掘中被普遍采用,主要原因有:
1.算法需要。有些数据挖掘算法不能直接使用连续变量,必须要离散化之后才能纳入计算,在数据挖掘软件中,表面上看可以直接使用连续变量进行计算,实际上在软件后台已经对其进行了离散化预处理。
2.降低异常数据的敏感度,使模型更加稳定。我们知道极端值和异常值会使模型参数拟合的不准确,误差过大,影响效度,而离散化,特别是等距离散,可以有效的降低异常数据对模型的影响。道理很简单,因为离散过程也将异常数据纳入进来进行离散,最后结果使其看起来不再那么“异常”。
3.有利于对非线性关系进行诊断和描述:对连续型数据进行离散处理后,自变量和目标变量之间的关系变得清晰化。如果两者之间是非线性关系,可以重新定义离散后变量每段的取值,如采取0,1的形式,由一个变量派生为多个哑变量,分别确定每段和目标变量间的联系。这样做,虽然减少了模型的自由度,但可以大大提高模型的灵活度。即使在连续型自变量和目标变量之间的关系比较明确,例如可以用直线描述的情况下,对自变量进行离散处理也有若干优点。一是便于模型的解释和使用,二是可以增加模型的区别能力。
=======================================================
离散分为等距离散、等频离散、优化离散等
等距离散:
将连续型变量的取值范围均匀划成n等份,每份的间距相等。例如,客户订阅刊物的时间是一个连续型变量,可以从几天到几年。采取等距切分可以把1年以下的客户划分成一组,1-2年的客户为一组,2-3年为一组..,以此类分,组距都是一年
等频离散:
把观察点均匀分为n等份,每份内包含的观察点数相同。还取上面的例子,设该杂志订户共有5万人,等频分段需要先把订户按订阅时间按顺序排列,排列好后可以按5000人一组,把全部订户均匀分为十段
优化离散:
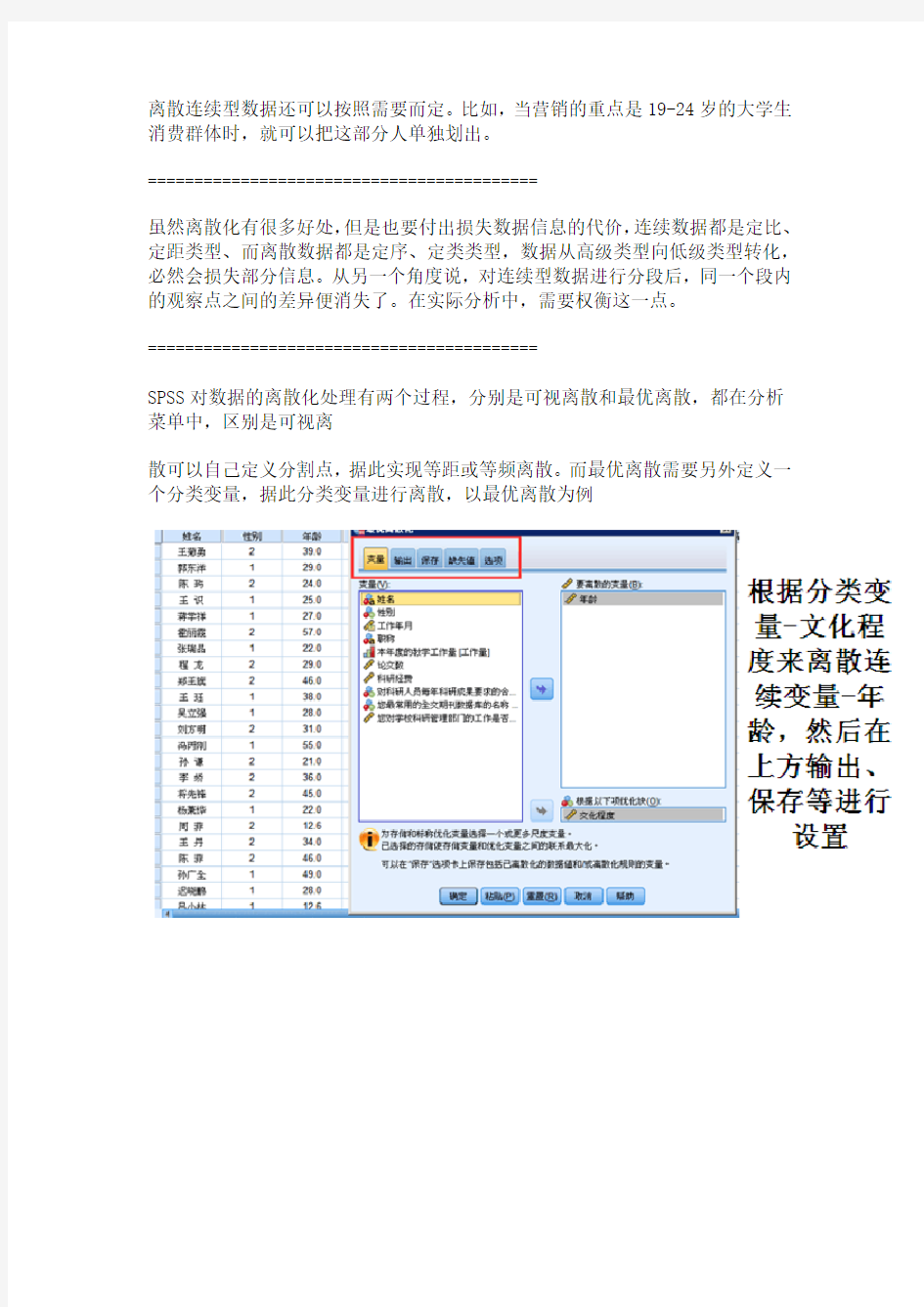
需要把自变量和目标变量联系起来考察。切分点是导致目标变量出现明显变化的折点。常用的检验指标有卡方,信息增益,基尼指数,或WOE(要求目标变量是两元变量)等距和等频在大多数情况下导致不同的结果。等距可以保持数据原有的分布,段落越多对数据原貌保持得越好。等频处理则把数据变换成均匀分布,但其各段内观察值相同这一点等距离散无法做到。
1.定义变量 (1)Name:定义变量名 变量名必须以字母或字符@开头,其它字符可以是任何字母、数字或_、@、#、$等 符号。变量名总长度不能超过8 个字符(即4 个汉字)。 (2)Type:定义变量类型 SPSS 的主要变量类型有:Numeric(标准数值型)、Comma(带逗号的数值型)、Dot (圆点作小数点的数值型)、Scientific Notation(科学记数法)、Date(日期型)、Dollar (带美元符号的数值型)、Custom Currency(自定义型)、String(字符型)。单击Type 相应单元中的按钮,选择合适的变量类型并单击OK。 (3)Width:变量长度 设置数值变量的长度,当变量为日期型时无效。 (4)Decimal:变量小数点位数 设置数值变量的小数点位数,当变量为日期型时无效。 (5)Label:变量标签 变量标签是对变量名的进一步描述,变量只能由不超过8 个字符组成,8 个字符经 常不足以表示变量的含义。而变量标签可长达120 个字符,变量标签对大小写敏感,显 示时与输入值完全一样,需要时可用变量标签对变量名的含义加以解释。 (6)Value:变量值标签 值标签是对变量的每一个可能取值的进一步描述。 (7)Missing:缺失值的定义方式 SPSS 有两类缺失值:系统缺失值和用户缺失值。在数据长方形中任何空的数字单 元都被认为系统缺失值,用点号(?)表示。SPSS 可以指定那些由于特殊原因造成的 信息缺失值,然后将它们标为用户缺失值,统计过程识别这种标识,带有缺失值的观测 被特殊处理。默认值为None。单击Value 相应单元中的按钮,可改变缺失值定义方式。(8)Column:变量的显示宽度 输入变量的显示宽度,默认为8。 (9)Align:变量显示的对齐方式 选择变量值显示时的对齐方式:Left(左对齐)、Right(右对齐)、Center(居中 对齐)。 (10)Scale:变量的测量尺度 根据变量测量精度不同,可把变量由低到高分为四种尺度:定类变量、定序变量、 定距变量和定比变量。 1)定类变量 定类变量由称为名义(nominal)变量。这是一种测量精度最低、最粗略的基于“质” 因素的变量,它的取值只代表观测对象的不同类别,例如“性别”变量、“职业”变量 等都是定类变量。定类变量的取值称为定类数据或名义数据。定类数据的共同特点是用 不多的名称来加以表达,并由被研究变量每一组出现的次数及其总计数所组成,这种数 据是枚举性的,即由计数一一而得。唯一适合于定类数据的数学关系是“等价关系”。 因而,在定类数据中,同一组内各单位是等价的,同时若更换各不同组的符号并不会改 变数据原有的基本信息。因此,最常用来综合定类数据的统计量是频数、比率或百分比等。 2)定序变量 定序变量由称为有序(ordinal)变量、顺序变量,它的取值大小能够表示观测对 象的某种顺序关系(等级、方位或大小等),也是基于“质”因素的变量。例如:“最高
一元线性回归实验指导 一、使用spss进行线性回归相关计算 题目: 为研究医药企业销售收入与广告支出的关系,随机抽取了20家医药企业,得到它们的销售收入和广告支出的数据如下表(数据在‘广告.sav’中) 1.绘制散点图描述收入与广告支出的关系 结果:(散点图粘贴在下面) 从散点图可直观看出销售收入和广告支出(存在/不存在)线性关系 2.计算两个变量的相关系数r及其检验 相关性结果表格:(粘贴在下面)
从结果中可看出,销售收入与广告支出的相关系数为(),双侧检验的P值(),r在0.01显著性水平下(),表明销售收入与广告支出之间(存在/不存在)线性关系。 3.一元线性回归分析 计算回归分析;并输出标准化残差的pp图和直方图 分析输出的结果: 模型汇总表格:(粘贴在下面) 这个表格给出相关系数R=()以及标准估计的误差() 方差分析(ANOVA)表格:(粘贴在下面) 这个表格给出回归模型的方差分析表,包括回归平方和SSR、回归均方MSR、残差平方和SSE、残差均方MSE、总平方和SST和总均方MST,F值129.762以及P值(),此处p 值(),说明回归的线性关系(显著/不显著) 系数表格:(粘贴在下面) 上面这个表格给出的是参数估计和检验的有关内容,包括回归方程的常数项、非标准化回归系数、常数项和回归系数检验的统计量t和显著性水平sig,以及回归系数的%95置信区间从此表可以得出销售收入与广告支出的估计方程为()。回归系数()表示广告支出每变动1万元,销售收入平均变动()万元。
4.残差的检验 从上面的输出结果中可得到标准化残差的标准pp图和直方图(粘贴在下面) 同时在数据表格中出现残差以及估计值和区间的上下界,其中 PRE_1为点估计值; RES_1为非标准化残差; ZRE_1为标准化残差; LMCI_1和UMCI_1表示平均值的置信区间(均值的预测区间); LICI_1和UICI_1表示个别值的预测区间的上界和下界; 下面绘制非标转化残差图:(粘贴在下面) 从残差图上可以看出,各个残差随机分布于0轴两侧,没有任何固定模式,这表明在销售收入与广告支出的一元线性回归中,线性假定以及等方差的假定成立。 下面检验残差正态性: 做出标准化残差(ZRE_1)的散点图,并在图上画出0,2,-2三条y轴参考线(粘贴在下面)
SPSS统计与分析 统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。现代的数据分析工作如果离开统计软件几乎是无法正常开展。在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。 常见的统计软件有 SAS,SPSS,MINITAB,EXCEL 等。这些统计软件的功能和作用大同小异,各自有所侧重。其中的 SAS 和 SPSS 是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。特别是 SPSS,其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操作管理和开放的数据接口以及灵活而美观的统计图表制作。SPSS 在各类院校以及科研机构中更为流行。 SPSS(Statistical Product and Service Solutions,意为统计产品与服务解决方案)。自 20 世纪 60 年代 SPSS 诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的 SPSS for Windows 大同小异,在本试验课程中我们选择 PASW Statistics 作为统计分析应用试验活动的工具。 1. SPSS 的运行模式 SPSS 主要有三种运行模式: (1)批处理模式 这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上[SPSS for Windows]→[Production Mode Facility]程序运行。 (2)完全窗口菜单运行模式 这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单易用。 (3)程序运行模式
这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。这种模式要求掌握 SPSS 的语句或脚本语言。本试验指导手册为初学者提供入门试验教程,采用“完全窗口菜单运行模式”。 2. SPSS 的启动 (1)在 windows[开始]→[程序]→[PASW],在它的次级菜单中单击“SPSS for Windows”即可启动 SPSS 软件,进入 SPSS for Windows 对话框,如图,图所示。 图 SPSS 启动
数据分析方法及软件应用 (作业) 题目:4、8、13、16题 指导教师: 学院:交通运输学院 姓名: 学号:
4、在某化工生产中为了提高收率,选了三种不同浓度,四种不同温度做试验。在同一浓度与温度组合下各做两次试验,其收率数据如下面计算表所列。试在α=0.05显著性水平下分析 (1)给出SPSS数据集的格式(列举前3个样本即可); (2)分析浓度对收率有无显著影响; (3)分析浓度、温度以及它们间的交互作用对收率有无显著影响。 解答:(1)分别定义分组变量浓度、温度、收率,在变量视图与数据视图中输入表格数据,具体如下图。 (2)思路:本问是研究一个控制变量即浓度的不同水平是否对观测变量收率产生了显著影响,因而应用单因素方差分析。假设:浓度对收率无显著影响。 步骤:【分析-比较均值-单因素】,将收率选入到因变量列表中,将浓度选入到因子框中,确定。 输出: 變異數分析 收率 平方和df 平均值平方 F 顯著性 群組之間39.083 2 19.542 5.074 .016 在群組內80.875 21 3.851 總計119.958 23 显著性水平α为0.05,由于概率p值小于显著性水平α,则应拒绝原假设,认为浓度对收率有显著影响。
(3)思路:本问首先是研究两个控制变量浓度及温度的不同水平对观测变量收率的独立影响,然后分析两个这控制变量的交互作用能否对收率产生显著影响,因而应该采用多因素方差分析。假设,H01:浓度对收率无显著影响;H02:温度对收率无显著影响;H03:浓度与温度的交互作用对收率无显著影响。 步骤:【分析-一般线性模型-单变量】,把收率制定到因变量中,把浓度与温度制定到固定因子框中,确定。 输出: 主旨間效果檢定 因變數: 收率 來源第 III 類平方 和df 平均值平方 F 顯著性 修正的模型70.458a11 6.405 1.553 .230 截距2667.042 1 2667.042 646.556 .000 浓度39.083 2 19.542 4.737 .030 温度13.792 3 4.597 1.114 .382 浓度 * 温度17.583 6 2.931 .710 .648 錯誤49.500 12 4.125 總計2787.000 24 校正後總數119.958 23 a. R 平方 = .587(調整的 R 平方 = .209) 第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率p值。可以看到观测变量收率的总变差为119.958,由浓度不同引起的变差是39.083,由温度不同引起的变差为13.792,由浓度和温度的交互作用引起的变差为17.583,由随机因素引起的变差为49.500。浓度,温度和浓度*温度的概率p值分别为0.030,0.382和0.648。 浓度:显著性<0.05说明拒绝原假设(浓度对收率无显著影响),证明浓度对收率有显著影响;温度:显著性>0.05说明不拒绝原假设(温度对收率无显著影响),证明温度对收率无显著影响;浓度与温度: 显著性>0.05说明不拒绝原假设(浓度与温度的交互作用对收率无显著影响),证明温浓度与温度的交互作用对收率无显著影响。 8、以高校科研研究数据为例:以课题总数X5为被解释变量,解释变量为投入人年数X2、投入科研事业费X4、专著数X6、获奖数X8;建立多元线性回归模型,
当代大学生对全球气候变化 认知程度的研究 摘要:随着我国经济建设的飞速发展,人们向大自然排放的有害物质与日俱增,环境问题日益严重。环境污染问题不仅影响我国人民的生存环境和生存质量,也危害人民的身体健康,在环境污染中城市环境污染已经成为制约社会发展的重要问题。本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷,采用SPSS statistics软件分析采样数据,得到频率表以及考虑性别的交叉表。本文考虑性别、城乡等差异,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究当代大学生对环境污染问题认知程度的差异。 关键字:性别;气候变化;差异;SPSS 一、研究背景 我国改革开放30多年的经济发展迅速,主要是以粗放式发展为主要模式。由此而带来的就是高增长、高能耗、高排放的三高企业,我国是发展中国家,在经济发展的过程中,政府对环境破坏的监管不力,睁一眼闭一眼,所以我国改革开放30年快速发展以牺牲能源、破坏环境为代价的,尤其我国的经济发展又极不平衡,主要是以城市主力军,这样城市的环境恶化就很严重。同样,农村人口环境保护意识淡薄,农村环境恶化也不可小觑,我国高速发展的近几十年来,环境的恶化程度逐年增加,应该引起政府环保部门的重视。 环境污染对人们的生活影响越来越严重,我们现在出门看到的最打眼的一景就是戴口罩的人越来越多,人们越来越感受到空气污染对
自己身心健康的威胁,据统计,世界儿童死亡80%是由于空气污染导致的,这个数字让人触目惊心。 环境污染很大因素是由于企业恣意排放污染物,但在日常生活中,民众的环保意识与环保行为对生活污染——尤其是随处可见的污染——有较大的影响。性别、年龄等不同,对气候变化认知程度也会存在差异。本文考虑到男女性别的差异、城乡区别,分别从基本的环保知识到主动投身环保事业等各方面加以分析,研究不同性别对环境污染问题认知程度的差异。 二、研究方法及样本描述 (一)研究方法 本研究采样方式为匿名方式随机投放网络问卷以及纸质问卷调查的方法,与2014年5月在西安交通大学进行问卷调查。调查面向西安交大本科生以及研究生,最终获得有效问卷431份。 (二)样本特征描述 431位被访者中,女性209位,占48.5%;男性222位,占51.5%。如图1所示,样本主要来自大一、大二以及大三群体,总共381位,占88.4%;大四毕业生以及研究生占11.6%。被访者所读专业性质也有较大差别,文科生178位,占41.3%;工科生人数122位,占28.3%;理科生108位,占比25.1%,如表1所示。
第二章均值比较检验与方差分析 在经济社会问题的研究过程中,常常需要比较现象之间的某些指标有无显著差异,特别当考察的样本容量n比较大时,由随机变量的中心极限定理知,样本均值近似地服从正态分布。所以,均值的比较检验主要研究关于正态总体的均值有关的假设是否成立的问题。 ◆本章主要内容: 1、单个总体均值的 t 检验(One-Sample T Test); 2、两个独立总体样本均值的 t 检验(Independent-Sample T Test); 3、两个有联系总体均值均值的 t 检验(Paired-Sample T Test); 4、单因素方差分析(One-Way ANOVA); 5、双因素方差分析(General Linear Model Univariate)。 ◆假设条件:研究的数据服从正态分布或近似地服从正态分布。 在Analyze菜单中,均值比较检验可以从菜单Compare Means,和General Linear Model得出。如图2.1所示。 图2.1 均值的比较菜单选择项 §2.1 单个总体的t 检验(One-Sample T Test)分析 单个总体的 t 检验分析也称为单一样本的 t 检验分析,也就是检验单个变量的均值是否与假定的均数之间存在差异。如将单个变量的样本均值与假定的常数相比较,通过检验得出预先的假设是否正确的结论。
例1:根据2002年我国不同行业的工资水平(数据库SY-2),检验国有企业的职工平均年工资收入是否等于10000元,假设数据近似地服从正态分布。 首先建立假设:H0:国有企业工资为10000元; H1:国有企业职工工资不等于10000元 打开数据库SY-2,检验过程的操作按照下列步骤: 1、单击Analyze →Compare Means →One-Sample T Test,打开One-Sample T Test 主对话框,如图2.2所示。 图2.2 一个样本的t检验的主对话框 2、从左边框中选中需要检验的变量(国有单位)进入检验框中。 3、在Test Value框中键入原假设的均值数10000。 4、单击Options按钮,得到Options对话框(如图2.3),选项分别是置信度(默认项是95%)和缺失值的处理方式。选择后默认值后返回主对话框。 图2.3 一个样本t检验的Options对话框 5、单击OK,得输出结果。如表2.1所示。 表2.1(a).数据的基本统计描述 One-Sample Statistics
一、作业分析 案例背景:拟分析导致急救后颅脑损伤的主要影响因素,某省医院的外科 医生收集了2003-2005年间在该科室进行过急救治疗的脑外伤病例共201例。 研究目的:差异性比较 资料类型:本例根据是否出现迟发性脑损伤将数据分为两个独立样本。 本例的数据变量有性别、年龄、入院时血循环指标、入院时症状、入院时 意识程度、是否手术急救、其它治疗、是否出现迟发性脑损伤。在这些变量中 既有连续变量又有分类变量,所以在检验时需分成两种:定量检验与定性检验。 其中定量检验为:年龄、入院时血循环指标;定性检验为:性别、入院时 症状、入院时意识程度、是否手术急救、其它治疗。 二、数据描述 1 数量变量的描述 利用SPSS软件分析→描述统计→描述,将年龄、收缩压、舒张压、血小 板拖入,得到下表: 通过表格可以发现血小板的极差为372,标准差为63.568.极差和标准差都较大,通过求自然对数来减小标准差,所以我们改用血小板的自然对数为数据。得到下表:
2.分类变量的描述 利用SPSS软件分析→表→设定表,选中性别、脑挫伤、中线移位、脑肿胀、意识程度、手术、止血药、激素、脱水剂拖入框中,得到下表: 从表中可以大致看出,脑挫伤、手术、中线移位、意识程度、激素和脱水剂几个变量和是否发生脑损伤有关。但是,这些关联是否具有统计学意义还需要进行检验。 三、差异性比较 1数量变量的差异性比较
(1)年龄与迟发性脑损伤的关系 本案例为两独立样本,我们对其进行正态性检验。 利用SPSS软件分析→统计描述→探索,得到下表: 从表中,可得出年龄成正态性分布。 利用SPSS软件分析→比较均值→独立样本T检验,检验变量为年龄,分组变量为迟发性脑损伤,单击确定得到如下结果: 发生迟发性脑损伤与未发生迟发性脑损伤组中年龄均服从正态分布,两总体方差齐。 采用两独立样本的t检验:t=-1.038,df=199,P=0.300,可以得出,以 α=0.05为检验水准,年龄与是否发生迟发性脑损伤无明显差异。 (2)收缩压、舒张压与迟发性脑损伤的关系 与上述方式相同,对数据进行正态性检验,检验结果为:
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
教案 教师姓名朱兆军课程名称统计分析与SPSS的 应用 班级10会计与统计 授课日期2012年3月1日第3周1 课时 2 课型新授课章节名称第二章SPSS数据文件的建立和管理 教学目的1. 明确SPSS数据的基本组织方式和数据行列的含义; 2. 掌握应从哪些方面描述SPSS数据文件的结构特征; 3. 熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作; 4. 熟练掌握在SPSS中读取Excel工作表数据的基本操作,了解读取文本和数据库数据的基本方法。 教学重点1.SPSS数据的录入 2.SPSS数据的保存 教学难点SPSS数据的录入 补充、删 节、更新 无教具多媒体 课外作业预习下一课 课后体会
授课主要内容 第二节SPSS数据录入和保存 一、SPSS数据的录入和编辑 1、SPSS数据的录入 2、SPSS数据的编辑 (1).SPSS数据的定位 (2)插入和删除一条个案 (3)插入和删除一个变量 (4)数据的移动、复制和删除 二、SPSS数据的保存 格式主要有:SPSS文件格式;Excel文件格式;dbf文件格式;文本文件格式 将数据保存为SPSS数据文件或其他格式的数据文件的基本操作是: File+Save,对于新的:提示文件名和类型;对于旧的,覆盖原来的,不再提问; File+Save As,另存一个数据文件,也有格式(类型)问题; Variable按钮允许用户指定保存哪些变量,不保存哪些变量,变量名前画叉的变量将被保存到磁盘中。 将数据保存为Excel文件格式时,Write variables names to spreadsheet选项呈可用状态,它的作用是指定是否将SPSS变量名写入Excel工作表的第一行上。
spss基本知识点 【篇一:spss基本知识点】 结论不同麻醉诱导方法存在组间差别;患者的收缩压在不同的诱导 方法下不同诱导时相变化的趋势不同,其中 a 组不同诱导时相收缩 压较为稳定。第八章非参数检验(nonparametrictests 菜单)参 数检验:?? 通过样本的参数来检验总体参数的方法是参数检验。如:通过样本的均值、方差来检验总体的数学期望与总体方差提出的假 设是否为真.?? 参数检验对总体的分布有一定的要求,比如正态性和 方差齐性非参数检验:?? 对总体分布情况未知时,无法用参数检验 方法?? 非参数检验通过样本的分布对总体的分布进行检验非参数检 验所要处理的问题:?? 两个总体分布未知,它们是否相同(用两组 样本来检验)?? (由一组样本)猜出总体的分布(假设),然后用 另一组样本去检验它是否正确注:两种分布是否相同,一般包含了 参数(均值、方差等)是否相同的问题。如果两个总体的分布函数 形式相同,而参数不同,也被视为概率分布不同 nonparametrictest 菜单(1) nonparametrictest 菜单(2) 卡方检验 chi‐square?? 适用于拟合优度检验,即检验单变量的分布与理论 分布是否一致?? 实例 1:贫困调查.sav 中身体状况变量的数据分 布是否符合以往的经验:?? 完全不能自理 5%?? 基本不能自理10%?? 能自理无劳动能力 20%?? 部分丧失劳动能力 25%?? 身体 健康 40% ?? 1.weightcasesby:death?? 2.analyze‐nonparametrictest‐chisquare 二项分布检验 binomial ?? 二项分布的变量将总体分为两类(如医学中的生与死),二项分布的检验是通过样本中这两类的频率来检验总体中这两类的 概率是否为给定的值 ?? binomial 过程可检验二项分类变量是个来 自概率为 p 的二项分布例 1:一般来说,新生儿染色体异常率为1%,某医院观察了 400 名新生儿,只发现一例异常,请问该地新生 儿异常率是否低于一般水平?数据文件见 6.2sav 1.weight cases by:num 2.analyze-nonparametric test-binomial 例 2:某地 某一时期内出生 40 名婴儿,其中女性 12 名(定 sex=0),男性 28名(定 sex=1)。问这个地方出生婴儿的性别比例与通常的男女 性比例(总体概率约为 0.5)是否不同? ?? 按出生顺序输入数 据, ?? 数据文件见 6.3.sav 1- sample k-s 过程 ?? 对连续性资料 的分布情况加以考察。这是一种拟合优度性检验,研究的是样本观
SPSS课后作业 第一章 1-1、spss的运行方式有几种?分别是什么? 答:SPSS的运行方式有三种,分别是批处理方式、完全窗口菜单运行方式、程序运行方式。1-2、SPSS中“DataView”所对应的表格与一般的电子处理软件有什么区别? 答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性:(1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值;(4)数据文件是一张长方形的二维表。 第二章 2-1、在SPSS中可以使用那些方法输入数据? 答:SPSS中输入数据一般有以下三种方式:(1)通过手工录入数据;(2)可以将其他电子表格软件中的数据整列(行)的复制,然后粘贴到SPSS中;(3)通过读入其他格式文件数据的方式输入数据。 2-2、对于缺失值,如何利用SPSS进行科学替代? 答:选择“Transform”菜单的Replace Missing Values命令,弹出Replace Missing Values 对话框。先在变量名列中选择1个或多个存在缺失值的变量,使之添加到“New Variable(s)”框中,这时系统自动产生用于替代缺失值的新变量。最后选择合适的替代方式即可。 2-3、在计算数据的加权平均数时,如何对变量进行加权? 答:选择“Data”菜单中的Weight Cases命令,出现如图2-22所示的Weight Cases对话框。其中, Do not weight cases项表示不做加权,这可用于取消加权;Weight cases by 项表示选择1个变量做加权。 2-4、如何对变量进行自动赋值? 答:变量的自动赋值可以将字符型、数字型数值转变成连续的整数,并将结果保存在一个新的变量中。具体操作的过程如下:选择“Transform”菜单中的Automatic Recode命令,在出现的对话框中,从左边的变量列表中选择需要自动赋值的变量,将它添加到Variable -> New Name框中,然后在下面New Name右边的文本框中输入新的变量名称,单击New Name 按钮,将新的变量名添加到上面的框中。从Recode Starting from框中有两个选项中选择一个,然后单击OK按钮,即可完成自动赋值运算。 3-1、一组数据的分布特征可以从哪几个方面进行测度? 答:一组数据的分布特征可以从平均数、中位数、众数、方差、百分位、频数、峰度、偏度等方面描述。 3-2、简述众数、中位数和均值的特点及应用场合。 答:均值是总体各单位某一数量标志的平均数。平均数可应用于任何场合,比如在简单时序预测中可用一定观察期内预测目标的时间序列的均值作为下一期的预测值。中位数是指将数据按大小顺序排列起来,形成一个数列,居于数列中间位置的那个数据。中位数的作用与算术平均数相近,也是作为所研究数据的代表值。在一个等差数列或一个正态分布数列中,中位数就等于算术平均数。在数列中出现了极端变量值的情况下,用中位数作为代表值要比用算术平均数更好,因为中位数不受极端变量值的影响。众数是指一组数据中出现次数最多的那个数据。它主要用于定类(品质标志)数据的集中趋势,当然也适用于作为定序(品质标志)数据以及定距和定比(数量标志)数据集中趋势的测度值。 3-3、
1. 定义变量 (1)Name定义变量名 变量名必须以字母或字符 @开头,其它字符可以是任何字母、数字或_、@、 #、$等 符号。变量名总长度不能超过 8 个字符(即 4 个汉字)。 (2)Type:定义变量类型 SPSS 的主要变量类型有: Numeric (标准数值型)、 Comm(a 带逗号的数值型)、 Dot (圆点作小数点的数值型)、Scientific Notation (科学记数法)、Date (日期型)、Dollar (带美元符号的数值型)、 Custom Currency (自定义型)、 String (字符型)。单击 Type 相应单元中的按钮,选择合适的变量类型并单击OK。 (3)Width :变量长度设置数值变量的长度,当变量为日期型时无效。 ( 4) Decimal :变量小数点位数设置数值变量的小数点位数,当变量为日期型时无效。 ( 5) Label :变量标签变量标签是对变量名的进一步描述,变量只能由不超过 8 个字符组成, 8 个字符经常不足以表示变量的含义。而变量标签可长达 120 个字符,变量标签对大小写敏感,显示时与输入值完全一样,需要时可用变量标签对变量名的含义加以解释。 ( 6) Value :变量值标签 值标签是对变量的每一个可能取值的进一步描述。 (7)Missing :缺失值的定义方式 SPSS 有两类缺失值:系统缺失值和用户缺失值。在数据长方形中任何空的数字单元都被认为系统缺失值,用点号(? )表示。 SPSS 可以指定那些由于特殊原因造成的信息缺失值,然后将它们标为用户缺失值,统计过程识别这种标识,带有缺失值的观测被特殊处理。默认值为 None。单击Value相 应单元中的按钮,可改变缺失值定义方式。 (8)Column:变量的显示宽度输入变量的显示宽度,默认为 8。 (9)Align :变量显示的对齐方式 选择变量值显示时的对齐方式: Left (左对齐)、 Right (右对齐)、 Center (居中对齐)。(10)Scale :变量的测量尺度根据变量测量精度不同,可把变量由低到高分为四种尺度:定类变量、定序变量、定距变量和定比变量。 1 )定类变量 定类变量由称为名义( nominal )变量。这是一种测量精度最低、最粗略的基于“质”因素的变 量,它的取值只代表观测对象的不同类别,例如“性别”变量、“职业”变量等都是定类变量。定类变量的取值称为定类数据或名义数据。定类数据的共同特点是用不多的名称来加以表达,并由被研究变量每一组出现的次数及其总计数所组成,这种数据是枚举性的,即由计数一一而得。唯一适合于定类数据的数学关系是“等价关系”。 因而,在定类数据中,同一组内各单位是等价的,同时若更换各不同组的符号并不会改变数据原有的基本信息。因此,最常用来综合定类数据的统计量是频数、比率或百分比等。 2)定序变量定序变量由称为有序( ordinal )变量、顺序变量,它的取值大小能够表示观测对象 的某种顺序关系(等级、方位或大小等),也是基于“质”因素的变量。例如:“最高 学历”变量的取值是: 1-小学及以下、 2-初中、 3-高中、中专、技校、 4-大学专科、 5-大 学本科、 6-研究生以上。由小到大的取值能够代表学历由低到高。定序变量的取值称为定序数据或有序数据。适合于定序数据的数学关系是“大于(>)”和“小于( <) 关系。在定序数据中,同一组内各单位是等价的,相邻组之间的单位是不等价的,它们存在“大于”或“小于”的关系。而且进行保序变换(或称单调变换),不改变数据原有的基本信息即等级顺序。最适合用于综合定序数据取值的集中趋势的统计量是中位数。 3)定距变量
S P S S调查报告期末作业 Document serial number【LGGKGB-LGG98YT-LGGT8CB-LGUT-
---------------------------------------------装--------------------------------- --------- 订 ---------------------------------------- -线----------------------------------- -- - --
上表表明,5中不同年级形式下共有80个样本,大一的均值最高,大二的均值次之,接着,大四的均值排第三,而大三的均值是最低的。由于在录入数据当中,选择调查问卷中选项A“是”,身边有请人带过课的同学,则录为1:;选择调查问卷中选项B“否”,身边没有请人带过课的同学,则录为2。所以,均值的结果表明,数值越大,则身边出现代课同学越少,数值越小,则表明身边出现的代课同学越多。因此,大三中的代课同学是最多的,大四次之,大二次之,大一最少。 上表表明,不同年级下代课情况的方差齐性检验值为,概率为,。如果显着性水平为,由于概率值大于显着性水平,不应拒绝零假设,认为不同年级下代课情况的总体方差无显着差异,满足方差分析的前提要求。 上表分别显示了两两不同年级下代课情况均值检验的结果。通过两两比较,最终可以得出,大一的均值>大二的均值>大三的均值,大四的均值大小情况不能确定,基本上得出的结论与实际情况相符。 五、建议 在以上对数据的分析过程当中,我们提到了逃课现象严重,收费代课行为愈发普遍的原因,这里稍微再做一下总结。原因如下: a.一些专业课程,教学内容循规蹈矩,考试题目照本宣科,无法引起学生兴趣; b.学校管理有较大漏洞,上课学生中“替身”大量潜伏而不知; c.学生自身自制力不够,容易受到外界的影响,不能静心学习; d.社会就业压力大,导致学生青睐于早点实习; 针对以上这些导致收费代课产生的原因,我想提出几点建议: (一)学校在专业设置、教师的互动性教学、知识的创新性和灵活体现、教学管理体系建设等诸多方面,都应反思,并采取一定的措施。高校则应该实行自主办学措施,在课程设置、专业方向设置上应当有自我特色。与其大张旗鼓地对“收费代课”现象进行大力批判,还不如放开手来,从根本上指导学生如何学会自主学习,如何利用有限的学习时间。倘若不加以反思,做出课程设置、教师互动性教学的改进,而是纯粹地一味加强考勤管理,必然会扼杀一部分学生的学习积极性,“人在心不在”的上课状态恐怕也难以培养出符合时代需求的大学生。 (二)学生应该分清楚学习和工作的不同意义,学习是一种能力的提高过程。大学生应当学会对自己的现在以及未来负责。大学四年,是相当宝贵的青春年华。我们年轻,我们活动,但是这些都不应该成为我们虚度时间,不学习的理由。调查结果中显示,大三的收费代课现象是最为严重的,这样的结果确实应该引起学生的重视了。我们都知道,大三是专业学习的主要一年,很多的专业课都在大三进行安排。可是大三的同学的不认真学习专业课,选择请人代课,这不是明显浪费了学习专业课的机会吗所以,这里,我想提醒本部的同学们,要合理地定位自己的身份与任务,不要在该学习的阶段去实习或娱乐。另外,也要明确自己上大学的初衷,不要因为大学生活的闲适,而慢慢丢失了自己的理想。 (三)政府要给大学生提供公平的就业环境,打击不规范的就业行为,消除掉大学生的就业焦虑。为大学生就业,提供更加全面完整的服务系统,让大学生在大学期间安心学
S P S S操作步骤汇总 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
SPSS学习 第一章数据文件的建立 数据编码 Type:Numeric:数值型 string:字符串型 Missing: Measure:scale定量变量 nominal定性变量 根据已有的变量建立新变量 1、对于数据进行重新编码 Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue 2、通过SPSS函数建立新变量 Transform—compute variable –从function group中选择公式范围下面选择具体的公式—if 中设置要改变—continue—OK(可以对变量进行各种计算) 第二章清除数据与基本统计分析 1、对不合理的数据检查并清理 检查:analysis-description statistic-frequencies—选入要检查的数据—OK 结果:频数统计表—看是否有错误—missing system 清理: 1.对系统缺失值的清理
Data—select case—if condition is satisfied—if—function group(missing)--下面选 (missing)--continue—output(delete unselected cases)--OK—对num为哪一位的进行修改 2.对sex=3的清理(直接就清除了) Data—select case—if condition is satisfied—if—sex调入再输入=3—continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 2. 对相关变量间逻辑性检查和清理 Data—select case—if condition is satisfied—if—输入表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 3.统计描述 正态分布统计描述 1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/ 2、统计描述:Analysis—descriptives--time选入—options—ok 3、按照男女统计描述:data—split file –compare group –sex调入—ok Analysis-descriptive statistic – descriptive—time 调入—options选择—OK非正态分布资料统计描述 1、正态性检验nonparametric 2、Analysis—descriptive statistics—frequencies 选入-- statistics选择—OK 第三章T检验
物流统计实验作业 <一>:试述聚类分析的基本思想以及SPSS操作的基本步骤? 系统聚类的基本思想是 聚类分析法又称集群分析法,它是研究样品或指标分类问题的一种多元统计方法。寻找一种能客观反应事物之间亲疏关系或合理评价事物性质相似程度的统计量,然后根据这种统计量和规定的分类准则把事物进行分类。 操作步骤: 1. 在SPSS窗口中选择Analyze→Classify→Hierachical Cluster,调出系统聚类分析主界面,并将变量移入Variables框中。在Cluster栏中选择Cases单选按钮,即对样品进行聚类(若选择Variables,则对变量进行聚类)。在Display栏中选择Statistics和Plots复选框,这样在结果输出窗口中可以同时得到聚类结果统计量和统计图。 2. 点击Statistics按钮,设置在结果输出窗口中给出的聚类分析统计量。这里我们选择系统默认值,点击Continue按钮,返回主界面。 3. 点击Plots,设置结果输出窗口给出的聚类分析统计图。选中Dendrogram复选框和Icicle栏中的None单选按钮,即只给出聚类树形图,而不给出冰柱图。单击Continue,返回主界面。 4. 点击Method,设置系统聚类的方法选项。Cluster Method下拉列表用于指定聚类的方法,包括组间连接法、组内连接法、最近距离法、最远距离法等;Measure栏用于选择对距离和相似性的测度方法;剩下的Transform Values和Transform Measures栏用于选择对原始数据进行标准化的方法。这里我们仍然均沿用系统默认选项。单击Continue,返回主界面。 5. 点击Save按钮,指定保存在数据文件中的用于表明聚类结果的新变量。None表示不保存任何新变量;Single solution表示生成一个分类变量,在其后的矩形框中输入要分成的类数;Range of solutions表示生成多个分类变量。这里我们选择Range of solutions,并在后面的两个矩形框中分别输入2和4,即生成三个新的分类变量,分别表明将样品分为2类、3类和4类时的聚类结果。点击Continue,返回主界面。 6. 点击OK按钮,运行系统聚类过程。 <二>:利用2001年全国31个省自治区各类小康和现代化指数的数据,利用K-均值聚类方法对地区进行聚类分析。并且对SPSS分析的结果进行分析。文件名为“小康指数.sav”。 31个省市自治区小康和现代化指数的K-Means聚类分析结果(一) 这张表展示了3类的初始类中心点的情况。由表可知第二类各指数均是最优的,第一类次之,第三类各指数最不理想。 31个省市自治区小康和现代化指数的K-Means聚类分析结果(二)
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。