
统计分析与SPSS的应用
摘要:为对统计分析与spss应用分析所学知识进行巩固和检验,特运用所学知识进行简单的统计分析应用,下文以某校学生学期成绩进行模拟分析。
一:原始数据:10级市场营销2班成绩
分析一:综测成绩四分位数
上表表明:综测成绩的最小值为68.61分,最大值为89.15分。其中25%的学生综测成绩为74.4100分,50%的学生综测成绩为80.3740分,75%的学生综测成绩为85.2200分。四分位数差从侧面证实了学生综测成绩呈一定左偏分布。
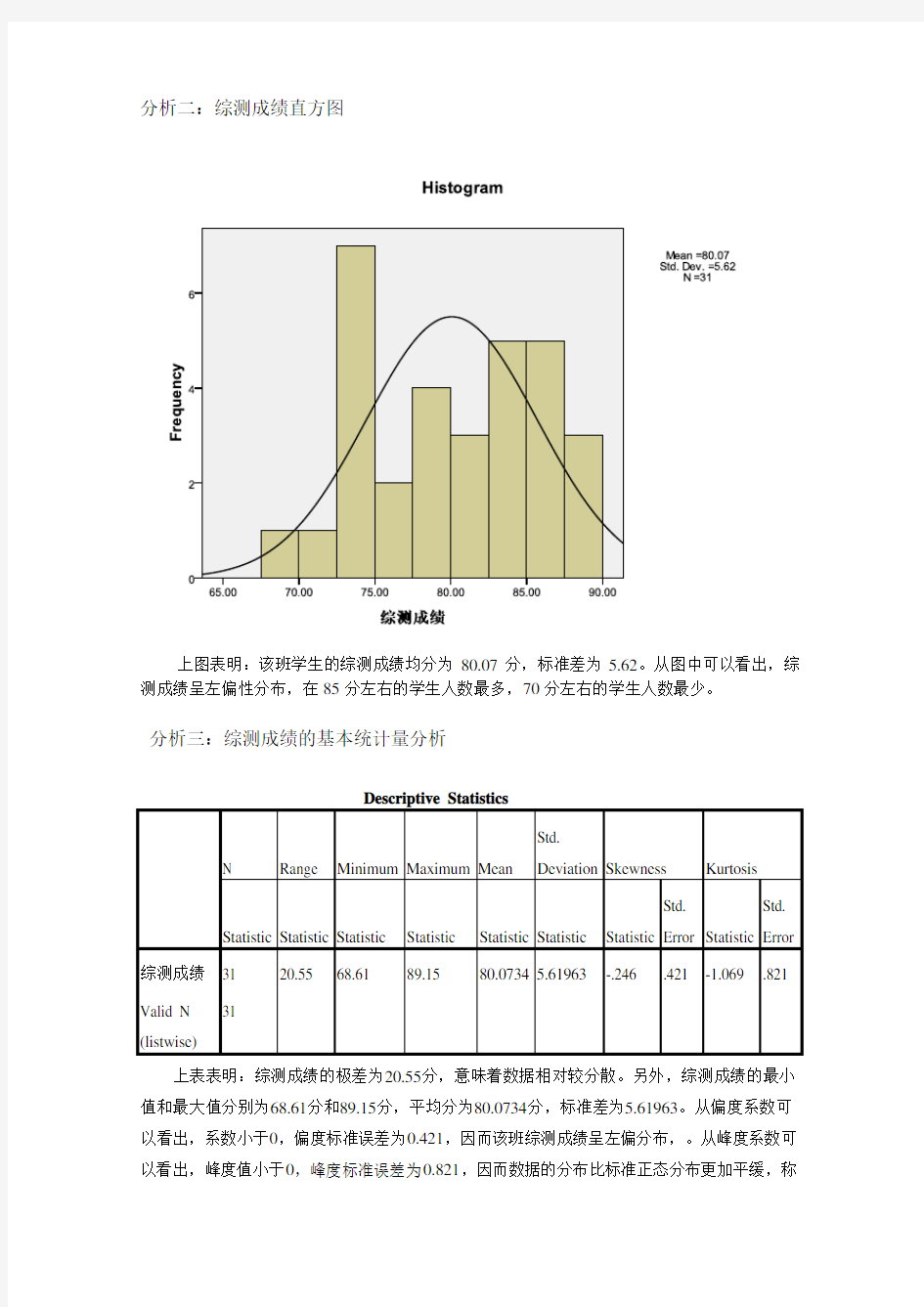
分析二:综测成绩直方图
上图表明:该班学生的综测成绩均分为80.07分,标准差为5.62。从图中可以看出,综测成绩呈左偏性分布,在85分左右的学生人数最多,70分左右的学生人数最少。
分析三:综测成绩的基本统计量分析
上表表明:综测成绩的极差为20.55分,意味着数据相对较分散。另外,综测成绩的最小值和最大值分别为68.61分和89.15分,平均分为80.0734分,标准差为5.61963。从偏度系数可以看出,系数小于0,偏度标准误差为0.421,因而该班综测成绩呈左偏分布,。从峰度系数可以看出,峰度值小于0,峰度标准误差为0.821,因而数据的分布比标准正态分布更加平缓,称
为平峰分布。
分析四:各科成绩的统计量分析比较
各科成绩统计量结果分析表
由上表可知:宏观经济学的全距最大,而生产与运作管理的全距最小,表明宏观经济学的成绩离散程度最高,而生产与运作管理的成绩离散程度最低;同时,对于标准差而言,也是宏观经济学的标准差最大而生产与运作管理的标准差最小。各科成绩平均分最高的为体育成绩,平均分最低的为英语成绩。各科成绩中只有人力资源管理的成绩是呈右偏分布,其他各科成绩均呈左偏分布。另外,各科成绩中,只有宏观经济学的成绩呈尖峰分布,其他各科呈平峰分布。
分析五:各科成绩的Q-Q图分析
由上图可得出结论:各科成绩均符合正态分布,只有几个高分和低分点略偏离正态分布线。分析六:对体育成绩的t检验
由上面两个表的内容可知:本班31人的体育成绩中,平均分为87.2903分,标准差为
8.29535。原假设为:本班体育成绩的平均分不低于88分。单样本t检验中t统计量的双尾概率P-值为0.637,比例总体均值的95%置信区间为(-3.7524,2.3331)。如果显著性水平为0.05,由于应进行单尾检验且0.637/2大于显著性水平,因此不应拒绝原假设,不能认为本班体育成绩的平均分不显著高于88分,同时88分大于95%的置信区间的下限值也证实了这个结论。
分析七:性别对大学英语成绩的单因素方差分析结果
上表是性别对大学英语成绩的单因素方差分析结果。可以看到:观测变量大学英语成绩的离差平方总和为1629.097;如果仅考虑性别单个因素的影响,则大学英语成绩总变差中,性别
可解释的变差为585.265,抽样误差引起的变差为1043.832,它们的方差分别为585.265和
35.994,相除所得的F统计量观测值为16.260,对应的概率P-值近似为0。如果显著性水平为0.05,由于概率P-值小于显著性水平,因此应拒绝原假设,认为性别对大学英语成绩产生了显著性影响,性别对大学英语成绩的影响效应不全为0。
分析八:会计学成绩及格率二项分布检验
为0.9。检验及格率为0.9。由于是小样本,检验值和观察值恰好一致,可认为本班的会计学及格率达到了90%。
分析九:均学成绩与综测成绩的相关系数分析
由表可知,均学成绩与综测成绩间的简单相关系数为0.952,说明两者之间存在正的强相关性,其相关系数检验的概率P-值近似为1,两者存在强的相关性。该表中相关系数上角的两个星号(**)表示显著性水平为0.01时拒绝原假设。一个星号(*)表示显著性为0.05时拒绝原假设。因此,两个星号比一个星号拒绝原假设犯错误的可能性更
由表可知,当聚成3类时,1类的有15人,2类的有7人,3类的有9人;当聚成2类时,1类有15人,2类有16人。
学习心得:通过这次作业的完成,我了解到,统计分析必须完善基础,不断提高统计分析能力。将课本所学的方法与知识灵活运用,多加练习才能熟练的对一份数据做好正确的分析。
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
广东海洋大学 统计分析与spss 的应用实习报告 姓名: 班级: 学号: 学院(系)职业技术学院专业名称会计电算化使用班级102实习地点软件七室起止时间2012.12.3—2012.12.14路敷设各类管资料腐跨接线槽口不盒处,调试全部高料试卷验;工作;设备与验方设备于调试试卷技在最大障高行自动绝动作资料试于差
统计分析与s p s s的应用实习报告 学院(系)职业技术学院专业会计电算化班级102 学生姓名学号实习地点软件七室201 实习要求: 1、掌握spss软件的使用基础和数据文件的建立和管理操作; 2、掌握spss数据的排序、变量计算、数据选取、计数、分类汇总、数据分组等预处理功能操作; 3、掌握spss的频数分析、计算基本描述统计量、多选项分析、比率分析等基本统计分析操作及解读; 4、掌握spss的参数检验操作及解读; 5、掌握spss的方差分析操作及解读; 6、了解spss的非参数检验操作及解读; 7、掌握spss的相关分析操作及解读; 8、掌握spss的一元线性回归分析操作及解读,了解其它回归分析。 实习目的: 本实习是《统计学原理》课程的实习环节。统计学是社会科学与管理学各专业的基础课程,重点介绍定量研究社会经济现象的基本方法。本课程是为具备一定统计学基础知识的高年级本科生和专科生开设的。通过实习掌握spss软件的统计分析功能和操作技能,把统计分析的基本原理和方法通过spss软件来实现,并能对结果进行解读,主要包括如下内容:SPSS 软件使用基础、用SPSS 进行描述统计、频数分析、交叉列联表分析、多选项分析、参数检验、方差分析、非参数检验、相关回归分析等。 实习时间: 2012.12.3—2012.12.14 实习地点:软件七室 实习内容: 本次实习中老师主要对以下六个方面的内容进行较为详细地讲解和我们进行了相应内容的操作。 1、数据文件的建立和管理 建立SPSS数据文件首先应了解SPSS数据文件的特点、数据的组织形式的基本方式和相关概念,这样才能建立一个完整且全面的数据环境,服务于以后的数据分析工作。数据
学生姓名:肖浩鑫学号:31407371 一、实验项目名称:实验报告(三) 二、实验目的和要求 (一)变量间关系的度量:包括绘制散点图,相关系数计算及显著性检验; (二)一元线性回归:包括一元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验,利用回归方程进行估计和预测; (三)多元线性回归:包括多元线性回归模型及参数的最小二乘估计,回归方程的评价及显著性检验等,多重共线性问题与自变量选择,哑变量回归; 三、实验内容 企业编号产量(台)生产费用(万元)企业编号产量(台)生产费用(万元) 1 40 130 7 84 165 2 42 150 8 100 170 3 50 155 9 116 167 4 5 5 140 10 125 180 5 65 150 11 130 175 6 78 154 12 140 185 (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数,并对相关系数的显著性进行检验(),并说明二者之间的关系强度。 地区人均GDP(元)人均消费水平(元) 北京22460 7326 辽宁11226 4490 上海34547 11546 江西4851 2396 河南5444 2208 贵州2662 1608 陕西4549 2035
(1)绘制散点图,并计算相关系数,说明二者之间的关系。 (2)人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (3)计算判定系数和估计标准误差,并解释其意义。 (4)检验回归方程线性关系的显著性() (5)如果某地区的人均GDP为5000元,预测其人均消费水平。 (6)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 航空公司编号航班正点率(%)投诉次数(次) 1 81.8 21 2 76.6 58 3 76.6 85 4 75.7 68 5 73.8 74 6 72.2 93 7 71.2 72 8 70.8 122 9 91.4 18 10 68.5 125 (1)用航班正点率作自变量,顾客投诉次数作因变量,估计回归方程,并解释回归系数的意义。(2)检验回归系数的显著性()。 (3)如果航班正点率为80%,估计顾客的投诉次数。 4. 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果: 方差分析表 变差来源df SS MS F Significance F 回归 2.17E-09 残差40158.07 —— 总计11 1642866.67 ——— 参数估计表 Coefficients 标准误差t Stat P-value Intercept 363.6891 62.45529 5.823191 0.000168 X Variable 1 1.420211 0.071091 19.97749 2.17E-09 (1)完成上面的方差分析表。 (2)汽车销售量的变差中有多少是由于广告费用的变动引起的?
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第4章SPSS基本统计分析 1、利用第 2 章第7 题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。 分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。 Statistics 户口所在职业年龄 地 N Valid 282 282 282 Missing 0 0 0 户口所在地 Frequency Percent Valid Cumulative Percent Percent 中心城市200 70.9 70.9 70.9 Valid 边远郊区82 29.1 29.1 100.0 Total 282 100.0 100.0 职业 Frequency Percent Valid Cumulative Percent Percent 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0 公交建筑业15 5.3 5.3 39.4 Valid 经营性公司18 6.4 6.4 45.7 学校15 5.3 5.3 51.1 一般农户35 12.4 12.4 63.5 种粮棉专业 户 4 1.4 1.4 64.9
种果菜专业 10 3.5 3.5 68.4 户 工商运专业 34 12.1 12.1 80.5 户 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9 现役军人 3 1.1 1.1 100.0 Total 282 100.0 100.0 年龄 Frequency Percent Valid Cumulative Percent Percent 20 岁以下 4 1.4 1.4 1.4 20~35 岁146 51.8 51.8 53.2 Valid 35~50 岁91 32.3 32.3 85.5 50 岁以上41 14.5 14.5 100.0 Total 282 100.0 100.0
CHAPTER 15 西北研究院蔡嘉驰131246 15.4 (i) What we choose is part of u t. Then gMIN t and u t are correlated, which causes OLS to be biased and inconsistent. (ii) I think it is uncorrelate because gGDP t controls for the overall performance of the U.S. economy. (iii) The change of U.S. minimum may someway change the state minimum and vice versa. If the state minimum is always the U.S. minimum, then gMIN t is exogenous in this equation and we would just use OLS. 15.7 (i) Because students that would do better anyway are also more likely to attend a choice school. (ii) Since u1 does not contain income, random assignment of grants within income class means that grant designation is not correlated with unobservables such as student ability, motivation, and family support. (iii) The reduced form is choice= π0 + π1faminc + π2grant + v2, and we need π2≠ 0. (iv) The reduced form for score is just a linear function of the exogenous variables: score= α0 + α1faminc + α2grant + v1. This equation allows us to directly estimate the effect of increasing the grant amount on the test score, holding family income fixed.So it is useful. C15.1 (i) The regression of log(wage) on sibs gives
《统计分析软件》试(题)卷 班级姓名学号 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.”
(2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。 男生数学的均值为82.25高于女生的均值78.5。女生的的标准差7.09930高于男生的标准差3.77492。 2.
3.
优共有4人,良具有12人中有4人。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:<1> (1) (2)
Gender Educational Level (years)N Valid 474474Missing 00关于某公司474名职工综合状况的统计分析报告 1、 数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu (受教育水平程度),jobcat (职务等级),salbegin (起始工 资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss 统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、。。。以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。2、 数据分析 1、 频数分析。基本的统计分析往往从频数分析开始。通过频数分析 能够了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女 性别分布进行频数分析,结果如下: Gender FrequencyPercent Valid Percent Cumulative Percent Valid Female 21645.645.645.6 Male 258 54.4 54.4 100.0 Total 474100.0100.0 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表 : Educational Level (years) Valid Cumulative
计算机与信息技术学院专业实习报告 学校:商丘师范学院 专业:信息管理与信息系统年级:2012 姓名:亚慧 学号:121112015 时间:2015.09
《统计分析与SPSS的应用》 实习报告 专业实习题目:数据处理与分析 一.实习目的 1.初步了解探索数据分析的基本方法和思路 2.掌握问题的研究思路及方法 3.掌握统计分析软件实现这些方法的步骤和原理 4.熟悉SPSS操作系统,掌握数据管理界面的简单的操作; 5.熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。 6.掌握常用统计图(线图、条形图、饼图、散点、直方图等)的绘制方法;熟悉描述性统计图的绘制方法; 7.熟悉描述性统计图的一般编辑方法。掌握相关分析的操作,对显著性水平的基本简单判断。二.实习要求 1.遵守学校实习纪律和学校的各项规章制度 2.服从领导和指导老师的实习安排、虚心接受指导老师的安排 3.不得冒名顶替,否则严肃处理 4.按时上下课,不得缺席 5.掌握SPSS软件的基本操作、数据分析的基本功能和基本步骤 6.掌握对SPSS所分析的各项数据的理解、数据分析的基本方法和思路 7.掌握工作中如何进行数据的收集、整理以及统计分析报告的撰写的方法。 8.掌握相关关系的含义,并准确应用,熟练掌握绘制散点图的具体操作 9.掌握线性回归分析的主要目标、及具体操作。 三.实习任务 (一)下列表为数据处理所有表格和数据 信管12-1成绩表 学号性别计算机 网络 管理信 息系统 统计 学 市场营 销学 现代管 理学 运筹学 信息资 源管理 英语上 学期 英语 下学 期 大三 综合 成绩 121112001 女82.00 90.00 79.00 82.00 84.00 85.30 81.00 74 75 89.5
SPSS操作实验 (作业1) 作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。然而,当代大学生对华夏文明究竟知道多少呢 某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。请利用这些资料,分析以下问题。 问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。 问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。 要求: 直接导出查看器文件为.doc后打印(导出后不得修改) 对分析结果进行说明,另附(手写、打印均可)。 于作业布置后,1周内上交 本次作业计入期末成绩
答案 问题一 操作过程 1.打开数据文件作业。同时单击数据浏览窗口的【变量视图】按钮,检查各个 变量的数据结构定义是否合理,是否需要修改调整。 2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对 话框。在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。 3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字 “5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。再单击【继续】按钮,返回【频率】对话框。
应用统计s p s s分析报 告 TYYGROUP system office room 【TYYUA16H-TYY-TYYYUA8Q8-
学生姓名:肖浩鑫学号: 一、实验项目名称:实验报告(三) 二、实验目的和要求 (一)变量间关系的度量:包括绘制散点图,相关系数计算及显着性检验; (二)一元线性回归:包括一元线性回归模型及参数的最小二乘估计,回归方程的评价及显着性检验,利用回归方程进行估计和预测; (三)多元线性回归:包括多元线性回归模型及参数的最小二乘估计,回归方程的评价及显着性检验等,多重共线性问题与自变量选择,哑变量回归; 三、实验内容 企业编号产量(台)生产费用(万 元)企业编号产量(台)生产费用(万 元) 1 40 130 7 84 165 2 42 150 8 100 170 3 50 155 9 116 167 4 5 5 140 10 125 180 5 65 150 11 130 175 6 78 154 12 140 185 (2)计算产量与生产费用之间的线性相关系数,并对相关系数的显着性进行检验(),并说明二者之间的关系强度。 2. 下面是7个地区2000年的人均国内生产总值(GDP)和人均消费水平的统计数 地区人均GDP(元)人均消费水平(元) 北京22460 7326 辽宁11226 4490 上海34547 11546 江西4851 2396 河南5444 2208 贵州2662 1608 陕西4549 2035 (2)人均GDP作自变量,人均消费水平作因变量,利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。
(3)计算判定系数和估计标准误差,并解释其意义。 (4)检验回归方程线性关系的显着性() (5)如果某地区的人均GDP为5000元,预测其人均消费水平。 (6)求人均GDP为5000元时,人均消费水平95%的置信区间和预测区间。 3. 随机抽取10家航空公司,对其最近一年的航班正点率和顾客投诉次数进行调查, 航空公司编号航班正点率(%)投诉次数(次) 1 21 2 58 3 85 4 68 5 74 6 93 7 72 8 122 9 18 10 125 系数的意义。 (2)检验回归系数的显着性()。 (3)如果航班正点率为80%,估计顾客的投诉次数。 4. 某汽车生产商欲了解广告费用(x)对销售量(y)的影响,收集了过去12年的有关数据。通过计算得到下面的有关结果: 变差来源df SS MS F Significance F 回归 残差—— 总计11——— Coefficients标准误差t Stat P-value Intercept X Variable 1 (2)汽车销售量的变差中有多少是由于广告费用的变动引起的? (3)销售量与广告费用之间的相关系数是多少? (4)写出估计的回归方程并解释回归系数的实际意义。 (5)检验线性关系的显着性(a=)。 5. 随机抽取7家超市,得到其广告费支出和销售额数据如下
吉林财经大学 《SPSS统计软件分析》作业(2010——2011学年第一学期) 学院信息学院 专业班级电子商务0806班 学生姓名王瑞霞 学号1403080616
1、对未分组资料频数分析 从中国统计局中获得从11月21日至30日国内50个城市主要食品平均价格变动情况,以该数据为例为例,进行频数分析。 首先输入数据: 选择Analyze中Descriptive Statistics——Frequencies,打开Frequencies对话框;将需处理的变量键入变量框中
单击Statistics…按钮统计量子对话框12指标,选中所需要计算的指标: 单击Charts …按钮,选择需绘制的统计图: 单击OK按钮开始运行,运行结果为:
从上图中可以看出数据中缺失值为0,花生油的平均价格104.84是最高的,而巴氏牛奶的平均价格1.81最低,全部食品平均价格的平均数为16.5327,标准差为22.4668,各种食品的平均价格差距较大。
条形图、饼形图以及直方图是用不同的图形表示方法来说明数据的指标,其实质是一样的,从图中可以看出平均价格在0—22元之间的食品是最多的,20—40元之间的食品数次之,接下来是40—60元之间的食品,不存在平均价格在60—100之间的食品。 2、以食品平均价格为依据对数据进行分组并对分组后的数据进行频数分析: Transform —Recode—Into same V ariables ,将要分组的变量放入Numeric 栏中,单击Old and new V alues分组:
分组结果如下图所示: 回到数据编辑窗,定义变量的V alue labels : 再对食品平均价格进行频数分析,分析结果如下截图所示
目录 一、研究背景及其意义 (3) 二、研究方案 (3) 研究目标 (3) 研究内容 (4) 研究方法 (4) 三、科学技术与经济发展的关系分析 (4) 科技投入 (4) 科技产出 (5) 经济发展 (7) 小结 (7) 四、科学技术与经济发展的模型分析 (8) 模型假设 (8) 符号说明 (8) 信度与相关性分析 (8) 因子分析 (9)
回归分析 (10) 五、结论 (13) 附录: (14) 科学技术与经济发展的关系 一、研究背景及其意义 十九大报告指出:创新是引领发展的第一动力,是建设现代化经济体系的战略支撑。要瞄准世界科技前沿,强化基础研究,实现前瞻性基础研究、引领性原创成果重大突破。加强应用基础研究,拓展实施国家重大科技项目,突出关键共性技术、前沿引领技术、现代工程技术、颠覆性技术创新,为建设科技强国、质量强国、航天强国、网络强国、交通强国、数字中国、智慧社会提供有力支撑。加强国家创新体系建设,强化战略科技力量。深化科技体制改革,建立以企业为主体、市场为导向、产学研深度融合的技术创新体系,加强对中小企业创新的支持,促进科技成果转化。倡导创新文化,强化知识产权创造、保护、运用。培养造就一大批具有国际水平的战略科技人才、科技领军人才、青年科技人才和高水平创新团队。 而科技作为创新的重要引领者和实践者,对于建设创新型国家起着重要作用。科技进步是经济发展与社会发展的强大推动力。邓小平同志曾指出;"科学技术是第一生产力";江泽民同志也曾指出:"科学技术是第一生产力,而且是先进生产力的集中体现和主要标志。科学技术的突飞猛进,给世界生产力和人类经济发展带来了极大的推动,未来的科学发展还将产生新的重大飞跃"。在当今这个信息化和全球化加速的时代,科技进步对经济社会发展的促进作用越来越显着,科技进步成为生产力水平的首要决定因素,是国家或区域竞争力的重要源泉。近年来,随着我国经济增长方式的转变,科技支撑和引领经济社会发展的作用越来越强,无论是国家还是区域都需要通过依靠科技进步来促进经济社会发展。科技进步考核有效地促进了科教兴国、可持续发展和人才强国战略的落实,使科技促进经济杜会发展的能力逐步提升。
---------------------------------------------装--------------------------------- --------- 订 -----------------------------------------线---------------------------------------- 班级 姓名 学号 - 广 东 财 经 大 学 答 题 纸(格式二) 课程 数据处理技术与SPSS 20 15 -20 16 学年第 1 学期 成绩 评阅人 评语: ========================================== (题目)关于本部学生对收费代课现象支持度的调查报告 (正文) 一、调查背景 如今,大学生逃课现象屡见不鲜,随之衍生了“收费代课”的现象。据了解,在全国近百所高校中,存在“收费代课”现象的高校居然有一半之多。当“收费代课”现象衍变成了一种行业,成为有领导、有组织、有规模、有纪律的机构,不仅仅应当引起社会的关注,更应引起校方对教育方式的深刻反思。“有偿代课”作为一种不正常的校园现象,有其存在的社会土壤,其原因有多方面,值得让人对当前大学教育深思。在“收费代课”现象蔚然成风之时,我们学校的学生们也加入了这支大队伍。对于这样的一种收费代课的行为,同学们褒贬不一,每个人都有自己的看法。然而,这种行为经常在我们的身边发生着,无疑应该引起我们的关注,并引发我们的深思,形成一定的判别能力与认知能力。
二、调查目的 我们希望通过本次调查了解广东财经大学本部学生选择收费代课的原因,以及对本专业学习、实习实践的认知程度,是否支持放弃学习去实习或者做自己的事情,是否支持收费代课。同时,我们也希望通过这份调查报告揭露出的一些情况,一方面,帮助学生更好地权衡学习与实习的利弊,更加理性地对待收费代课的行为,做出对自己正确合适的选择;另一方面,引起学校对这种收费代课现象的重视,给学校提一些建议,希望学校采取一些措施改善这种不良校风。 三、调查方法 从可行性角度出发,本次调查采用非概率随机抽样的街头拦截法,集中对象为本部大三大四的同学,以自愿形式对本部同学分发调查问卷,总共发出80份问卷,回收80份,有效问卷80份。收集问卷之后,利用spss软件进行数据整理与分析,最后把结论整理成调查报告。调查报告中采用的数据分析方法主要有:频数分析、多选项分析、交叉列联表行列变量间关系的分析、单因素方差分析等。 四、描述统计 1、对样本性别作频数分析 从上表可以看出,这次填写问卷的女生较多,占了样本的66.3%,这与我们学校男女比例不均衡有很大的关系,样本的男女比例不相等,也可以较好地接近学校的实际情况,有利于我们得到更为准确的结论。 2、对样本年级作频数分析 从上表可知,参加问卷调查的大三大四学生比例明显比较高,这与一开始我们预期相符,样本中大三大四学生所占比例较多,有利于我们得到更为有针对性的结论。
SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医
疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费质量和消费结构都发生了明显的变化。城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势,其中食品类支出比重降幅最大;衣着类有所下降;家庭设备用品类下降幅度不是很大。与此同时,医疗保健、交通通讯、文化娱乐教育服务、居住及杂项商品支出在消费支出中的比例均有上升,富裕阶段的消费特征开始显现。 四、我国城镇居民消费结构及趋势的统计分析
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.00 82 34.6 34.6 34.6 2.00 76 32.1 32.1 66.7 3.00 10 4.2 4.2 70.9 4.00 22 9.3 9.3 80.2 5.00 47 19.8 19.8 100.0 合计237 100.0 100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失 0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效 131 缺失 0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效 73 缺失 0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效 32 缺失 0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
精选范文、公文、论文、和其他应用文档,希望能帮助到你们! SPSS简单数据分析报告
目录 一、数据样本描述 (4) 二、要解决的问题描述 (4) 1 数据管理与软件入门部分 (4) 1.1 分类汇总 (4) 1.2 个案排秩 (5) 1.3 连续变量变分组变量 (5) 2 统计描述与统计图表部分 (5) 2.1 频数分析 (5) 2.2 描述统计分析 (5) 3 假设检验方法部分 (5)
3.1 分布类型检验 (5) 3.1.1 正态分布 (5) 3.1.2 二项分布 (6) 3.1.3 游程检验 (6) 3.2 单因素方差分析 (6) 3.3 卡方检验 (6) 3.4 相关与线性回归的分析方法 (6) 3.4.1 相关分析(双变量相关分析&偏相关分析) (6) 3.4.2 线性回归模型 (6) 4 高级阶段方法部分 (6) 三、具体步骤描述 (7) 1 数据管理与软件入门部分 (7) 1.1 分类汇总 (7) 1.2 个案排秩 (8) 1.3 连续变量变分组变量 (10) 2 统计描述与统计图表部分 (11) 2.1 频数分析 (11) 2.2 描述统计分析 (14) 3 假设检验方法部分 (16) 3.1 分布类型检验 (16) 3.1.1 正态分布 (16) 3.1.2 二项分布 (17)
3.1.3 游程检验 (18) 3.2 单因素方差分析 (22) 3.3 卡方检验 (24) 3.4 相关与线性回归的分析方法 (26) 3.4.1 相关分析 (26) 3.4.2 线性回归模型 (28) 4 高级阶段方法部分 (32) 4.1 信度 (32) 一、数据样本描述 本次分析的数据为某公司474名职工状况统计表,其中共包含11个变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用SPSS统计软件,对变量进行统计分析,以了解该公司职工总体状况,并分析职工受教育程度、起始工资、现工资的分布特点及相互间的关系。 二、要解决的问题描述 1 数据管理与软件入门部分 1.1 分类汇总 以受教育水平程度为分组依据,对职工的起始工资和现工资进行数据
《SPSS统计软件》课程作业 要求:数据计算题要求注明选用的统计分析模块和输出结果;并解释结果的意义。完成后将作业电子稿发送至 1. 某单位对100名女生测定血清总蛋白含量,数据如下: 计算样本均值、中位数、方差、标准差、最大值、最小值、极差、偏度和峰度,并给出均值的置信水平为95%的置信区间。 解: 描述 统计量标准误 血清总蛋白含量均值.39389 均值的95% 置信区间下限 上限 5% 修整均值 中值 方差
标准差 极小值 极大值 范围 四分位距 偏度.054.241 峰度.037.478 样本均值为:;中位数为:;方差为:;标准差为:;最大值为:;最小值为:;极差为:;偏度为:;峰度为:;均值的置信水平为95%的置信区间为:【,】。 2. 绘出习题1所给数据的直方图、盒形图和QQ图,并判断该数据是否服从正态分布。解:
正态性检验 Kolmogorov-Smirnov a Shapiro-Wilk 统计量 df Sig. 统计量 df Sig. 血清总蛋白含量 .073 100 .200* .990 100 .671 a. Lilliefors 显着水平修正 *. 这是真实显着水平的下限。 表中显示了正态性检验结果,包括统计量、自由度及显着性水平,以K-S 方法的自由度sig.=,明显大于,故应接受原假设,认为数据服从正态分布。 3. 正常男子血小板计数均值为9 22510/L , 今测得20名男性油漆工作者的血小板计数值(单位:9 10/L )如下: 220 188 162 230 145 160 238 188 247 113 126 245 164 231 256 183 190 158 224 175 问油漆工人的血小板计数与正常成年男子有无异常
统计分析与SPSS的应用 摘要:为对统计分析与spss应用分析所学知识进行巩固和检验,特运用所学知识进行简单的统计分析应用,下文以某校学生学期成绩进行模拟分析。 一:原始数据:10级市场营销2班成绩 分析一:综测成绩四分位数 上表表明:综测成绩的最小值为68.61分,最大值为89.15分。其中25%的学生综测成绩为74.4100分,50%的学生综测成绩为80.3740分,75%的学生综测成绩为85.2200分。四分位数差从侧面证实了学生综测成绩呈一定左偏分布。
分析二:综测成绩直方图 上图表明:该班学生的综测成绩均分为80.07分,标准差为5.62。从图中可以看出,综测成绩呈左偏性分布,在85分左右的学生人数最多,70分左右的学生人数最少。 分析三:综测成绩的基本统计量分析 上表表明:综测成绩的极差为20.55分,意味着数据相对较分散。另外,综测成绩的最小值和最大值分别为68.61分和89.15分,平均分为80.0734分,标准差为5.61963。从偏度系数可以看出,系数小于0,偏度标准误差为0.421,因而该班综测成绩呈左偏分布,。从峰度系数可以看出,峰度值小于0,峰度标准误差为0.821,因而数据的分布比标准正态分布更加平缓,称
为平峰分布。 分析四:各科成绩的统计量分析比较 各科成绩统计量结果分析表 由上表可知:宏观经济学的全距最大,而生产与运作管理的全距最小,表明宏观经济学的成绩离散程度最高,而生产与运作管理的成绩离散程度最低;同时,对于标准差而言,也是宏观经济学的标准差最大而生产与运作管理的标准差最小。各科成绩平均分最高的为体育成绩,平均分最低的为英语成绩。各科成绩中只有人力资源管理的成绩是呈右偏分布,其他各科成绩均呈左偏分布。另外,各科成绩中,只有宏观经济学的成绩呈尖峰分布,其他各科呈平峰分布。
SPSS统计分析结课报告 居民收入水平与经济发展的关系 姓名: 学号: 班级: 学院: 日期:
目录 一、研究背景及其意义 (3) 二、研究方案 (3) 2.1 研究目标 (3) 2.2 研究内容 (3) 2.3 研究方法 (3) 2.4 数据来源 (3) 三、居民收入水平与经济发展的关系分析 (3) 3.1 居民收入水平 (3) 3.2 经济发展 (5) 3.3 小结 (6) 四、科学技术与经济发展的模型分析 (6) 五、结论 (10)
一、研究背景及其意义 居民收入是指一个国家物质生产部门的劳动者在一定时期内创造的价值总和。人均国民收入这一指标能大体反映一国的经济发展水平。党的十九大报告指出,必须始终把人民利益摆在至高无上的地位,让改革发展成果更多更公平惠及全体人民,朝着实现全体人民共同富裕不断迈进。报告在论述提高保障和改善民生水平,加强和创新社会治理部分中,特别强调要提高就业质量和人民收入水平。 二、研究方案 2.1研究目标 党的十九大报告把2020年实现全面建成小康社会目标之后的第二个百年奋斗目标,按照2035年基本实现社会主义现代化和本世纪中叶建成社会主义现代化强国,分两步或两个阶段进行安排。在描述第一步目标时,报告指出,“人民生活更为宽裕,中等收入群体比例明显提高,城乡区域发展差距和居民生活水平差距显著缩小,基本公共服务均等化基本实现,全体人民共同富裕迈出坚实步伐”。报告描述的第二步目标,是到本世纪中叶,富强民主文明和谐美丽的社会主义现代化强国建成时,“全体人民共同富裕基本实现,我国人民将享有更加幸福安康的生活”。 本文利用相关的数据,力争较全面地反映居民收入与经济发展之间的关系,为相关政策制定的提供借鉴,为我国相关工作的有效开展提供支持。 2.2研究内容 由于区域数据相对而言比较残缺、难收集,因此报告从国民居民收入水平数据分析方面与我国经济发展之间的关系进行理论分析。 2.3研究方法 本文在采用了一元线性回归的知识,对居民收入水平和区域经济发展进行研究分析。 2.4数据来源 本研究所采用的数据主要来源于国家统计局、各大信息网站等,数据权威性较高,其中2017-2018年部分数据有缺失,通过各数据网站进行了部分补充,但真实性和准确性有待考证。 三、居民收入水平与经济发展的关系分析 3.1居民收入水平