
https://www.doczj.com/doc/277672984.html,
网页链接提取方法
网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。
一、八爪鱼提取页面内的超链接
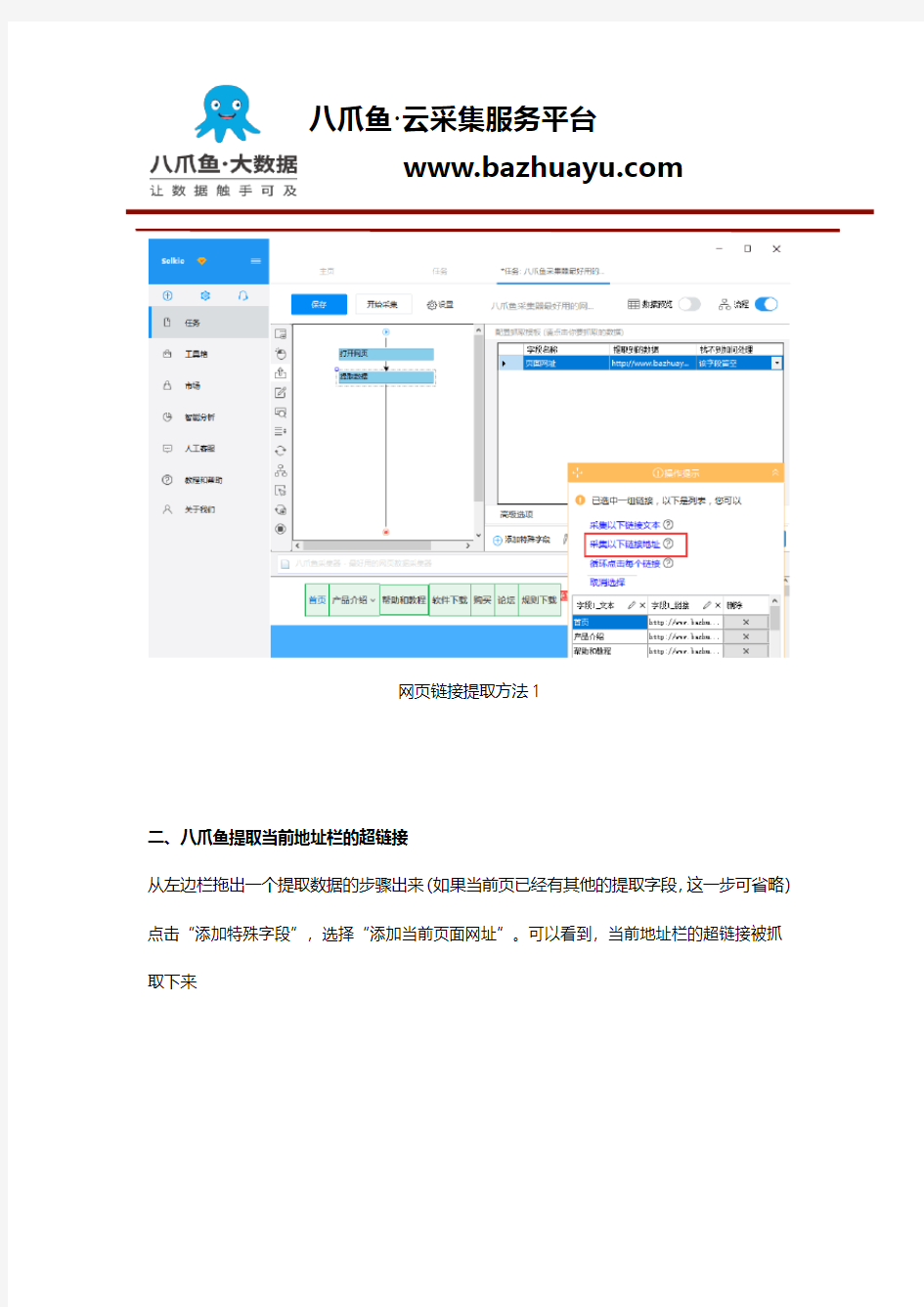
在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.doczj.com/doc/277672984.html,
网页链接提取方法1
二、八爪鱼提取当前地址栏的超链接
从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.doczj.com/doc/277672984.html,
网页链接提取方法2
而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。
采集网站:
https://https://www.doczj.com/doc/277672984.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
https://www.doczj.com/doc/277672984.html,
步骤1:创建采集任务
1)进入主界面,选择自定义模式
网页链接提取方法3
2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/277672984.html,
网页链接提取方法4
3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url
是这次演示采集的信息
网页链接提取方法5
步骤2:创建翻页循环
https://www.doczj.com/doc/277672984.html,
1)将页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,
选择“循环点击下一页”
网页链接提取方法6
步骤3:商品url采集
1)如图,移动鼠标选中列表中商品的名称,右键点击,需采集的内容会变成绿色,然后点击“选中全部”
https://www.doczj.com/doc/277672984.html,
网页链接提取方法7
2)选择“采集以下链接地址”
网页链接提取方法8
https://www.doczj.com/doc/277672984.html, 3)点击“保存并开始采集”
网页链接提取方法9
4)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”
网页链接提取方法10
https://www.doczj.com/doc/277672984.html,
步骤4:数据采集及导出
1)选择合适的导出方式,将采集好的数据导出
网页链接提取方法11
通过以上操作,目标网页内的商品超链接就被批量采集下来了。我们可以使用这些超链接,建立列表循环,来采集我们需要的其他字段数据,如下所示。
步骤5:创建url列表采集任务
1)重新创建一个采集任务,将导出后的商品链接复制,放到输入框中,点击“保存网址”
https://www.doczj.com/doc/277672984.html,
网页链接提取方法12
注意:输入框中的url列表数量不要超过2W个,超过的部分可以新建任务进行采集,url 打开的页面必须是相同网站样式相近的,否则会导致数据采集缺失。
2)在页面中点击需要采集的文本数据,点击“采集数据”
网页链接提取方法13
https://www.doczj.com/doc/277672984.html, 3)打开流程图,修改采集字段名称,点击“保存并开始采集”
网页链接提取方法14
注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
4)采集完成,点击“导出数据”
https://www.doczj.com/doc/277672984.html,
网页链接提取方法15
5)选择合适的导出方式,将采集好的数据导出
网页链接提取方法16
https://www.doczj.com/doc/277672984.html,
注:在八爪鱼中,要提取超链接,需要满足两个条件。
1、点击的字段在A标签,在网页源码中,A标签代表超链接,如果不是在A 标签内,八爪鱼无法判断
2、A标签内有href 属性,href 属性里的就是点击之后链接转向的地址,属性里显示什么,八爪鱼就提取什么。如果没有href属性,自然就没办法提取到。
这些都是八爪鱼自动判断的,其实看不懂也不影响操作。只是如果发现提取不到的时候,也许就是因为没满足这两个条件,要看当前网页源码的特点,根据特点找别的方式提取数据。
相关采集教程:
网页视频链接提取,以腾讯视频为例:
https://www.doczj.com/doc/277672984.html,/tutorial/txsp
网页数据爬取教程:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial
电商爬虫:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang
淘宝数据采集:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang/taobao
https://www.doczj.com/doc/277672984.html,
京东爬虫:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang/jd
天猫爬虫:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang/tmall
阿里巴巴数据采集:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang/alibaba
亚马逊爬虫:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang/amazon
电商爬虫教程:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/dianshang/dsqita
金融数据采集:
https://www.doczj.com/doc/277672984.html,/tutorial/hottutorial/jrzx
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
https://www.doczj.com/doc/277672984.html,
https://www.doczj.com/doc/277672984.html, 淘宝图片抓取工具使用方法 对于电商设计师来说,抓取竞品的宝贝的图片和店铺装修图片,来分析设计自己店铺的风格并做出差异化,是非常有用的方法哦。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【淘宝图片】为例,教大家如何使用八爪鱼采集软件采集淘宝图片的方法。 本文介绍使用八爪鱼7.0采集淘宝商品图片的方法:首先将淘宝商品搜索结果网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的淘宝商品图片URL,下载并保存到本地电脑中。 采集网址:淘宝商品搜索页面 比如T恤(可更换其他关键词对淘宝商品图片进行采集): https://https://www.doczj.com/doc/277672984.html,/search?q=T%E6%81%A4&imgfile=&commend=all &search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taob ao-item.1&ie=utf8&initiative_id=tbindexz_20170306 采集数据内容:淘宝商品图片地址
https://www.doczj.com/doc/277672984.html, 使用功能点: ●翻页设置 ●图片链接采集 步骤1:创建淘宝商品图片采集任务1)进入八爪鱼采集器主界面,选择自定义模式 淘宝商品图片采集步骤1
https://www.doczj.com/doc/277672984.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 淘宝商品图片采集步骤2 3)如下图红色框中的淘宝商品图片即为本次要采集的内容。
https://www.doczj.com/doc/277672984.html, 淘宝商品图片采集步骤3 步骤2:创建翻页循环 ●找到翻页按钮,设置翻页循环 ●设置ajax翻页时间 ●设置滚动页面 1)将淘宝商品搜索结果页页面下拉到底部,找到下一页按钮,鼠标点击,在右侧操作提示框中,选择“循环点击下一页”这个选项。
https://www.doczj.com/doc/277672984.html, 网页链接提取方法 网页链接的提取是数据采集中非常重要的部分,当我们要采集列表页的数据时,除了列表标题的链接还有页码的链接,数据采集只采集一页是不够,还要从首页遍历到末页直到把所有的列表标题链接采集完,然后再用这些链接采集详情页的信息。若仅仅靠手工打开网页源代码一个一个链接复制粘贴出来,太麻烦了。掌握网页链接提取方法能让我们的工作事半功倍。在进行数据采集的时候,我们可能有提取网页链接的需求。网页链接提取一般有两种情况:提取页面内的链接;提取当前页地址栏的链接。针对这两种情况,八爪鱼采集器均有相关功能实现。下面介绍一个网页链接提取方法。 一、八爪鱼提取页面内的超链接 在网页里点击需要提取的链接,选择“采集以下链接地址”
https://www.doczj.com/doc/277672984.html, 网页链接提取方法1 二、八爪鱼提取当前地址栏的超链接 从左边栏拖出一个提取数据的步骤出来(如果当前页已经有其他的提取字段,这一步可省略)点击“添加特殊字段”,选择“添加当前页面网址”。可以看到,当前地址栏的超链接被抓取下来
https://www.doczj.com/doc/277672984.html, 网页链接提取方法2 而批量提取网页链接的需求,一般是指批量提取页面内的超链接。以下是一个使用八爪鱼批量提取页面内超链接的完整示例。 采集网站: https://https://www.doczj.com/doc/277672984.html,/search?initiative_id=tbindexz_20170918&ie=utf8&spm=a21 bo.50862.201856-taobao-item.2&sourceId=tb.index&search_type=item&ssid=s5-e&commend=all&imgfile=&q=手表&suggest=history_1&_input_charset=utf-8&wq=&suggest_query=&source=sugg est
1、抓取网页数据通过指定的URL,获得页面信息,进而对页面用DOM进行 NODE分析, 处理得到原始HTML数据,这样做的优势在于,处理某段数据的灵活性高,难点在节算法 需要优化,在页面HTML信息大时,算法不好,会影响处理效率。 2、htmlparser框架,对html页面处理的数据结构,HtmlParser采用了经典的Composite 模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面 各元素。Htmlparser基本上能够满足垂直搜索引擎页面处理分析的需求,映射HTML标签,可方便获取标签内的HTML CODE。 Htmlparser官方介绍: htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件,主要用于改造或提取html。它能超高速解析html,而且不会出错。现在htmlparser最新版本为2.0。毫不夸张地说,htmlparser就是目前最好的html解析和分析 的工具。 3、nekohtml框架,nekohtml在容错性、性能等方面的口碑上比htmlparser好(包括htmlunit也用的是nekohtml),nokehtml类似XML解析原理,把html标签确析为dom, 对它们对应于DOM树中相应的元素进行处理。 NekoHTML官方介绍:NekoHTML是一个Java语言的HTML扫描器和标签补全器(tag balancer) ,使得程序能解析HTML文档并用标准的XML接口来访问其中的信息。这个解析 器能够扫描HTML文件并“修正”许多作者(人或机器)在编写HTML文档过程中常犯的错误。 NekoHTML能增补缺失的父元素、自动用结束标签关闭相应的元素,以及不匹配的内嵌元 素标签。NekoHTML的开发使用了Xerces Native Interface (XNI),后者是Xerces2的实现基础。由https://www.doczj.com/doc/277672984.html,/整理
https://www.doczj.com/doc/277672984.html, 网站爬虫如何爬取数据 大数据时代,用数据做出理性分析显然更为有力。做数据分析前,能够找到合适的的数据源是一件非常重要的事情,获取数据的方式有很多种,最简便的方法就是使用爬虫工具抓取。今天我们用八爪鱼采集器来演示如何去爬取网站数据,以今日头条网站为例。 采集网站: https://https://www.doczj.com/doc/277672984.html,/ch/news_hot/ 步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式” 网站爬虫如何爬取数据图1
https://www.doczj.com/doc/277672984.html, 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 网站爬虫如何爬取数据图2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容
https://www.doczj.com/doc/277672984.html, 网站爬虫如何爬取数据图3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定
https://www.doczj.com/doc/277672984.html, 网站爬虫如何爬取数据图4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量
https://www.doczj.com/doc/277672984.html, 网站爬虫如何爬取数据图5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 然后点击“选中子元素”
网页抓取工具如何进行http模拟请求 在使用网页抓取工具采集网页是,进行http模拟请求可以通过浏览器自动获取登录cookie、返回头信息,查看源码等。具体如何操作呢?这里分享给大家网页抓取工具火车采集器V9中的http模拟请求。许多请求工具都是仿照火车采集器中的请求工具所写,因此大家可以此为例学习一下。 http模拟请求可以设置如何发起一个http请求,包括设置请求信息,返回头信息等。并具有自动提交的功能。工具主要包含两大部分:一个MDI父窗体和请求配置窗体。 1.1请求地址:正确填写请求的链接。 1.2请求信息:常规设置和更高级设置两部分。 (1)常规设置: ①来源页:正确填写请求页来源页地址。 ②发送方式:get和post,当选择post时,请在发送数据文本框正确填写发布数据。 ③客户端:选择或粘贴浏览器类型至此处。 ④cookie值:读取本地登录信息和自定义两种选择。 高级设置:包含如图所示系列设置,当不需要以上高级设置时,点击关闭按钮即可。 ①网页压缩:选择压缩方式,可全选,对应请求头信息的Accept-Encoding。 ②网页编码:自动识别和自定义两种选择,若选中自定义,自定义后面会出现编
码选择框,在选择框选择请求的编码。 ③Keep-Alive:决定当前请求是否与internet资源建立持久性链接。 ④自动跳转:决定当前请求是否应跟随重定向响应。 ⑤基于Windows身份验证类型的表单:正确填写用户名,密码,域即可,无身份认证时不必填写。 ⑥更多发送头信息:显示发送的头信息,以列表形式显示更清晰直观的了解到请求的头信息。此处的头信息供用户选填的,若要将某一名称的头信息进行请求,勾选Header名对应的复选框即可,Header名和Header值都是可以进行编辑的。 1.3返回头信息:将详细罗列请求成功之后返回的头信息,如下图。 1.4源码:待请求完毕后,工具会自动跳转到源码选项,在此可查看请求成功之后所返回的页面源码信息。 1.5预览:可在此预览请求成功之后返回的页面。 1.6自动操作选项:可设置自动刷新/提交的时间间隔和运行次数,启用此操作后,工具会自动的按一定的时间间隔和运行次数向服务器自动请求,若想取消此操作,点击后面的停止按钮即可。 配置好上述信息后,点击“开始查看”按钮即可查看请求信息,返回头信息等,为避免填写请求信息,可以点击“粘贴外部监视HTTP请求数据”按钮粘贴请求的头信息,然后点击开始查看按钮即可。这种捷径是在粘贴的头信息格式正确的前提下,否则会弹出错误提示框。 更多有关网页抓取工具或网页采集的教程都可以从火车采集器的系列教程中学习借鉴。
// htmltotxt.cpp : 定义控制台应用程序的入口点。// //#include "stdafx.h" #include { int pos1 = src.find("href=\""); if(pos1<0) break; b = pos1; int pos2 = src.find("\"",pos1+6); if (pos2<0) break; string sub = src.substr(pos1+6,pos2-pos1-6); src.erase(src.begin()+pos1,src.begin()+pos2+1); if(sub[0] != 'h'&&sub[1] != 't'&&sub[0] != 't'&&sub[0] != 'p') { continue; } else out< https://www.doczj.com/doc/277672984.html, 如何抓取网页数据 很多用户不懂爬虫代码,但是却对网页数据有迫切的需求。那么怎么抓取网页数据呢? 本文便教大家如何通过八爪鱼采集器来采集数据,八爪鱼是一款通用的网页数据采集器,可以在很短的时间内,轻松从各种不同的网站或者网页获取大量的规范化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑,规范化,摆脱对人工搜索及收集数据的依赖,从而降低获取信息的成本,提高效率。 本文示例以京东评论网站为例 京东评价采集采集数据字段:会员ID,会员级别,评价星级,评价内容,评价时间,点赞数,评论数,追评时间,追评内容,页面网址,页面标题,采集时间。 需要采集京东内容的,在网页简易模式界面里点击京东进去之后可以看到所有关于京东的规则信息,我们直接使用就可以的。 https://www.doczj.com/doc/277672984.html, 京东评价采集步骤1 采集京东商品评论(下图所示)即打开京东主页输入关键词进行搜索,采集搜索到的内容。 1、找到京东商品评论规则然后点击立即使用 https://www.doczj.com/doc/277672984.html, 京东评价采集步骤2 2、简易模式中京东商品评论的任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为京东商品评论 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 商品评论URL列表:提供要采集的网页网址,即商品评论页的链接。每个商品的链接必须以#comment结束,这个链接可以在商品列表点评论数打开后进行复制。或者自己打开商品链接后手动添加,如果没有这个后缀可能会报错。多个商品评论输入多个商品网址即可。 将鼠标移动到?号图标可以查看详细的注释信息。 示例数据:这个规则采集的所有字段信息。 java抓取网页内容三种方式 2011-12-05 11:23 一、GetURL.java import java.io.*; import https://www.doczj.com/doc/277672984.html,.*; public class GetURL { public static void main(String[] args) { InputStream in = null; OutputStream out = null; try { // 检查命令行参数 if ((args.length != 1)&& (args.length != 2)) throw new IllegalArgumentException("Wrong number of args"); URL url = new URL(args[0]); //创建 URL in = url.openStream(); // 打开到这个URL的流 if (args.length == 2) // 创建一个适当的输出流 out = new FileOutputStream(args[1]); else out = System.out; // 复制字节到输出流 byte[] buffer = new byte[4096]; int bytes_read; while((bytes_read = in.read(buffer)) != -1) out.write(buffer, 0, bytes_read); } catch (Exception e) { System.err.println(e); System.err.println("Usage: java GetURL 国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序 https://www.doczj.com/doc/277672984.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子: https://www.doczj.com/doc/277672984.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.doczj.com/doc/277672984.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8') https://www.doczj.com/doc/277672984.html, 网络文字抓取工具使用方法 网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务 https://www.doczj.com/doc/277672984.html, 1)进入主界面选择,选择“自定义模式” 今日头条网络文字抓取工具使用步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” https://www.doczj.com/doc/277672984.html, 今日头条网络文字抓取工具使用步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。 https://www.doczj.com/doc/277672984.html, 今日头条网络文字抓取工具使用步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间 https://www.doczj.com/doc/277672984.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条网络文字抓取工具使用步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。 https://www.doczj.com/doc/277672984.html, 今日头条网络文字抓取工具使用步骤5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色 https://www.doczj.com/doc/277672984.html, 网页数据抓取方法详解 互联网时代,网络上有海量的信息,有时我们需要筛选找到我们需要的信息。很多朋友对于如何简单有效获取数据毫无头绪,今天给大家详解网页数据抓取方法,希望对大家有帮助。 八爪鱼是一款通用的网页数据采集器,可实现全网数据(网页、论坛、移动互联网、QQ空间、电话号码、邮箱、图片等信息)的自动采集。同时八爪鱼提供单机采集和云采集两种采集方式,另外针对不同的用户还有自定义采集和简易采集等主要采集模式可供选择。 https://www.doczj.com/doc/277672984.html, 如果想要自动抓取数据呢,八爪鱼的自动采集就派上用场了。 定时采集是八爪鱼采集器为需要持续更新网站信息的用户提供的精确到分钟的,可以设定采集时间段的功能。在设置好正确的采集规则后,八爪鱼会根据设置的时间在云服务器启动采集任务进行数据的采集。定时采集的功能必须使用云采集的时候,才会进行数据的采集,单机采集是无法进行定时采集的。 定时云采集的设置有两种方法: 方法一:任务字段配置完毕后,点击‘选中全部’→‘采集以下数据’→‘保存并开始采集’,进入到“运行任务”界面,点击‘设置定时云采集’,弹出‘定时云采集’配置页面。 https://www.doczj.com/doc/277672984.html, 第一、如果需要保存定时设置,在‘已保存的配置’输入框内输入名称,再保存配置,保存成功之后,下次如果其他任务需要同样的定时配置时可以选择这个配置。 第二、定时方式的设置有4种,可以根据自己的需求选择启动方式和启动时间。所有设置完成之后,如果需要启动定时云采集选择下方‘保存并启动’定时采集,然后点击确定即可。如果不需要启动只需点击下方‘保存’定时采集设置即可。 https://www.doczj.com/doc/277672984.html, 微信文章抓取工具详细使用方法 如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。 抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。 采集网站:https://www.doczj.com/doc/277672984.html,/ 步骤1:创建采集任务 1)进入主界面,选择“自定义模式” https://www.doczj.com/doc/277672984.html, 微信文章抓取工具详细使用步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” https://www.doczj.com/doc/277672984.html, 微信文章抓取工具详细使用步骤2 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字” https://www.doczj.com/doc/277672984.html, 微信文章抓取工具详细使用步骤3 2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮 微信文章抓取工具详细使用步骤4 https://www.doczj.com/doc/277672984.html, 3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5 4)页面中出现了 “八爪鱼大数据”的文章搜索结果。将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页” https://www.doczj.com/doc/277672984.html, 微信文章抓取工具详细使用步骤6 步骤3:创建列表循环并提取数据 1)移动鼠标,选中页面里第一篇文章的区块。系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素” https://www.doczj.com/doc/277672984.html, 网页内容如何批量提取 网站上有许多优质的内容或者是文章,我们想批量采集下来慢慢研究,但内容太多,分布在不同的网站,这时如何才能高效、快速地把这些有价值的内容收集到一起呢? 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集】,以【新浪博客】为例,教大家如何使用八爪鱼采集软件采集新浪博客文章内容的方法。 采集网站: https://www.doczj.com/doc/277672984.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集” https://www.doczj.com/doc/277672984.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” https://www.doczj.com/doc/277672984.html, 步骤2:创建翻页循环 https://www.doczj.com/doc/277672984.html, 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax加载数据”,超时时间设置为5秒,点击“确定”。 https://www.doczj.com/doc/277672984.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 2)鼠标点击“循环点击每个链接”,列表循环就创建完成,并进入到第一个循环项的详情页面。 https://www.doczj.com/doc/277672984.html, 网页信息抓取软件使用方法 在日常工作生活中,有时候经常需要复制网页上的文字内容,比如淘宝、天猫、京东等电商类网站的商品数据;微信公众号、今日头条、新浪博客等新闻文章数据。收集这些数据,一般都需要借助网页信息抓取软件。市面上抓取的小工具有很多,但真正好用,功能强大,操作又简单的,却屈指可数。下面就为大家介绍一款免费的网页信息抓取软件,并详细介绍其使用方法。 本文介绍使用八爪鱼采集器采集新浪博客文章的方法。 采集网站: https://www.doczj.com/doc/277672984.html,/s/articlelist_1406314195_0_1.html 采集的内容包括:博客文章正文,标题,标签,分类,日期。 步骤1:创建新浪博客文章采集任务 1)进入主界面,选择“自定义采集” https://www.doczj.com/doc/277672984.html, 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” https://www.doczj.com/doc/277672984.html, 步骤2:创建翻页循环 1)打开网页之后,打开右上角的流程按钮,使制作的流程可见状态。点击页面下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。(可在左上角流程中手动点击“循环翻页”和“点击翻页”几次,测试是否正常翻页。) https://www.doczj.com/doc/277672984.html, 2)由于进入详情页时网页加载很慢,网址一直在转圈状态,无法立即执行下一个步骤,因此在“循环翻页”的高级选项里设置“ajax 加载数据”,超时时间设置为5秒,点击“确定”。 https://www.doczj.com/doc/277672984.html, 步骤3:创建列表循环 1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。 电子设计工程 Electronic Design Engineering 第27卷Vol.27第8期No.82019年4月Apr.2019 收稿日期:2018-07-20 稿件编号:201807113 作者简介:洪鸿辉(1992—),男,广东揭阳人,硕士研究生。研究方向:大数据处理。 自互联网问世以来,经过多年的发展,互联网站点的数量在不断的增长,互联网上的信息也在不断的增加,然而,由于商业因素的问题,这些网站在为我们提供有价值的信息的同时,还会包含其他信息,例如广告或其他网站的链接。链接可能是图片,文字。这些相对于正文内容无用的信息会降低我们的阅读效率,而且这些无用的文字可能会被搜索引擎作为索引关键词,不仅降低了搜索的效率还影响了用户的体验。 很多互联网公司也发现了这一问题,所以现在越来越多的网页都会支持RSS 。若一个网页支持RSS , 我们就可以很轻易的提取网页的正文内容,但大多数网页还是不支持RSS ,所以关于正文提取这一方面的研究工作一直没有停止。网页的类型有很多种,比如新闻网站,博客网站,论坛等。新闻类网站的正文提取一直是研究的主要方向,新闻类的文章通常要提取正文内容,标题,时间,作者等。文章通常要提取正文内容,标题,时间,作者等。一方面,网页正文提取结果的好坏会影响着文本聚类,去重,语义指纹等结果。另一方面,网页正文提取在大数据时代也是一项不可或缺的环节。 1相关工作 1.1 VIPS 2003年,微软公司亚洲研究所提出了一种网页 进行视觉分块[1]算法—VIPS [2]算法。该算法的思想是 模仿人类看网页的动作,基于网页视觉内容结构信息结合Dom 树对网页进行处理。简单的说就是把页面切割不同大小的块,在每一块中又根据块网页的内容和CSS 的样式渲染成的视觉特征把其分成小块,最后建立一棵树[3]。 但是,VIPS 必须完全渲染一个页面才能对其进基于文本及符号密度的网页正文提取方法 洪鸿辉,丁世涛,黄傲,郭致远 (武汉邮电科学研究院湖北武汉430000) 摘要:大多数的网站的网页除了主要的内容,还包含导航栏,广告,版权等无关信息。这些额外的内容亦被称为噪声,通常与主题无关。由于这些噪声会妨碍搜索引擎对Web 数据的挖掘性能,所以需要过滤噪声。在本文中,我们提出基于网页文本密度与符号密度对网页进行正文内容提取,这是一种快速,准确通用的网页提取算法,而且还可以保留原始结构。通过与现有的一些算法对比,可以体现该算法的精确度,同时该算法可以较好的支持大数据量网页正文提取操作。关键词:文本密度;算法;噪音;正文提取中图分类号:TP391 文献标识码:A 文章编号:1674-6236(2019)08-0133-05 Text extraction method based on text and symbol density HONG Hong?hui ,DING Shi?tao ,HUANG Ao ,GUO Zhi?yuan (Wuhan Research Institute of Posts and Telecommunications ,Wuhan 430000,China ) Abstract:Most web pages contain not only the main content ,but also navigation bar ,advertising ,copyright and other irrelevant information.These extra contents are also referred to as noise ,usually irrelevant to the topic.Since these noises will hamper the performance of search engine for Web data mining ,noise removal is needed.In this paper ,we propose a fast ,accurate and general web content extraction algorithm based on text density and symbol density ,which can preserve the original https://www.doczj.com/doc/277672984.html,pared with some existing algorithms ,the algorithm can reflect the accuracy of the algorithm ,and the algorithm can better support the large amount of data Web page text extraction operation.Key words:text density ;algorithm ;noise ;text extract - -133 1.file_get_contents获取网页内容 2.curl获取网页内容 3.fopen->fread->fclose获取网页内容 百度贴吧内容抓取工具-让你的网站一夜之间内容丰富 [hide] var $getreplytime=1; var $showimg=1; var $showcon=1; var $showauthor=1; var $showreplytime=1; var $showsn=0; var $showhr=0; var $replylista=array(); var $pat_reply="<\/a>(.+?)如何抓取网页数据
Java抓取网页内容三种方式
国内主要信息抓取软件盘点
python抓取网页数据的常见方法
网络文字抓取工具使用方法
网页数据抓取方法详解
微信文章抓取工具详细使用方法
网页内容如何批量提取
网页信息抓取软件使用方法
基于文本及符号密度的网页正文提取方法
php获取网页内容方法
百度贴吧内容抓取工具-让你的网站一夜之间内容丰富
<\/td>\r\n<\/tr><\/table>"; var $pat_pagecount="尾页<\/font><\/a>"; var $pat_title="(.+?)<\/font>"; var $pat_replycon="<\/td>\r\n \r\n