RX8640创建npar分区实例
- 格式:docx
- 大小:87.35 KB
- 文档页数:4
漫谈IBM pSeries的逻辑分区和动态逻辑分区(一)LPAR 既逻辑分区指的是将一个物理的服务器划分成若干个虚拟的或逻辑的服务器,每个虚拟的或逻辑的服务器运行自己独立的操作系统,有自己独享的处理器、内存和I/O资源。
动态逻辑分区允许在不中断应用操作的情况下,增加或减少分区占用的资源。
IBM将这些灵活的技术从大型机(mainframe)平台带到了基于POWER4处理器的IBM pSeries平台上从而极大的降低了该技术的价格和成本。
一、IBM pSeries 支持分区的服务器的机型:对于上面的服务器是否可以使用动态LPAR,还要看安装在服务器上的软件:可以使用动态LPAR :在动态LPAR 可用状态下,调整资源的分配可以不需要停止或重新启动相关的分区。
如果希望实现动态LPAR需要在相关的分区安装AIX 5L 5.2 版本,并且HMC recovery 软件必须至少是3.1 版本(或更高)。
如果分区运行的是AIX 5L 5.1 版本或Linux操作系统,动态逻辑分区不可用。
不可以使用动态LPAR:如果没用动态LPAR的功能, 分区的资源是静态的。
动态LPAR 对于运行AIX 5L 5.1 版本或Linux操作系统是不可用的。
当需要改变或重新配臵分区的资源时,由于没有动态LPAR, 所有相关的分区必须被停止或重新启动以使得资源的改变生效,但是不会影响其它分区的操作。
(一个服务器的分区可以同时拥有可以做动态LPAR的分区和不能做动态LPAR 的分区.)注意:Reboot一个正在运行的分区只会重新启动分区上的操作系统并不会重新启动LPAR. 如果想要重新启动LPAR,必须shut down 操作系统然后再启动操作系统,不能用reboot 方式。
二、每个LPAR至少需要一些资源,下面是每个LPAR的最小需求:1. 每个分区至少一个处理器。
2. 至少256 MB 内存。
3. 至少有一块硬盘用于安装和存储操作系统(对于AIX, 做为rootvg)。

关机:关闭分区01)telnet 129shutdown –hy 0关闭分区12)telnet 130shutdown –hy 0关闭整个主机3)telnet mp ip输入用户Admin/密码AdminMP MAIN MENU:CO: ConsolesVFP: Virtual Front PanelCM: Command MenuCL: Console LogsSL: Show Event LogsFW: Firmware UpdateHE: HelpX: Exit Connection[mp-rx8640] MP>[mp-rx8640] MP:CM> peThis command controls power enable to a hardware device.T - CabinetC - CellP - IO ChassisX - ComplexR - PartitionSelect Device: tThe power state is ON for Cabinet 0.In what state do you want the power? (ON/OFF) off [mp-rx8640] MP:CM>4)拔掉电源线开机:1)接上电源线2)整机加电3)telnet mp ip输入用户Admin/密码AdminMP MAIN MENU:CO: ConsolesVFP: Virtual Front PanelCM: Command MenuCL: Console LogsSL: Show Event LogsFW: Firmware UpdateHE: HelpX: Exit Connection[mp-rx8640] MP>[mp-rx8640] MP:CM> peThis command controls power enable to a hardware device.T - CabinetC - CellP - IO ChassisX - ComplexR - PartitionSelect Device: tThe power state is OFF for Cabinet 0.In what state do you want the power? (ON/OFF) on [mp-rx8640] MP:CM>同时启动2个分区4)启动分区0如果只启动分区0,[mp-rx8640] MP:CM> peThis command controls power enable to a hardware device.T - CabinetC - CellP - IO ChassisX - ComplexR - PartitionSelect Device: RPart# Name----- ----0) Partition 0 - UX1) Partition 1 - UXSelect a partition number:05)启动分区1[mp-rx8640] MP:CM> peThis command controls power enable to a hardware device.T - CabinetC - CellP - IO ChassisX - ComplexR - PartitionSelect Device: RPart# Name----- ----0) Partition 0 - UX1) Partition 1 - UXSelect a partition number:1。
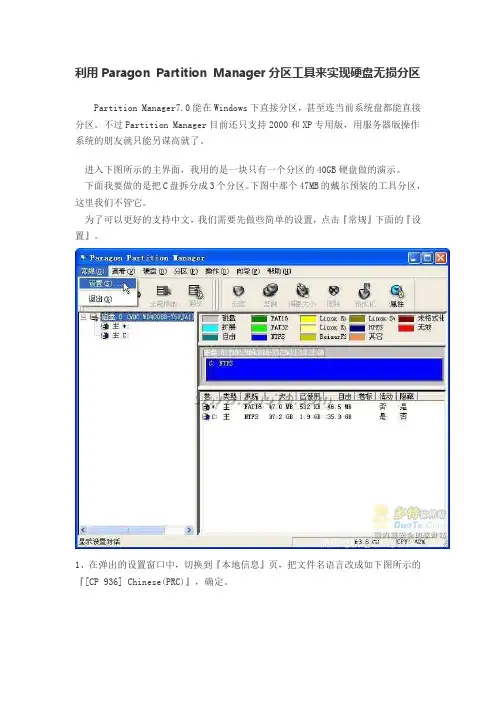
利用Paragon Partition Manager分区工具来实现硬盘无损分区Partition Manager7.0能在Windows下直接分区,甚至连当前系统盘都能直接分区。
不过Partition Manager目前还只支持2000和XP专用版,用服务器版操作系统的朋友就只能另谋高就了。
进入下图所示的主界面,我用的是一块只有一个分区的40GB硬盘做的演示。
下面我要做的是把C盘拆分成3个分区。
下图中那个47MB的戴尔预装的工具分区,这里我们不管它。
为了可以更好的支持中文,我们需要先做些简单的设置,点击『常规』下面的『设置』。
1、在弹出的设置窗口中,切换到『本地信息』页,把文件名语言改成如下图所示的『[CP 936] Chinese(PRC)』,确定。
2、回到主界面之后,在C盘的蓝色方块上点击鼠标的右键,选择『调整大小/移动』。
3、随后弹出如下图所示的窗口。
这里要把C盘改成10GB大,因此『新大小』输入10240。
确认在此之前的自由空间也是0之后,点击确定。
★注意,和用Windows自带工具分区时划分整数容量分区的规则不同,PM中想要划分多大的分区,直接在『新大小』中输入所要划分的GB数×1024即可,不要另外加5 MB的容量。
这是因为PM自动取舍分区大小的规则和Windows下不同,Wind ows是取最接近的,PM是取较大的。
4、回到主界面之后,我们发现C盘已经变成10GB了,后面多出了一块自由空间。
在自由空间的绿色块上点击右键,选择创建。
5、于是弹出了如下图所示的对话框。
我们这边当然是创建一个扩展分区了,下面的大小也当然是全部剩余容量。
★小知识。
关于各种磁盘分区的类型,主磁盘分区、扩展磁盘分区、逻辑磁盘分区。
早期的DOS和后来的Windows把磁盘分区分为了主磁盘分区和扩展磁盘分区两大类,一块硬盘上至少要有一个主磁盘分区,否则将无法引导操作系统。
除了主磁盘分区,其余的空间需要划分成一个扩展磁盘分区,然后再在扩展磁盘分区上来划分逻辑磁盘分区。

笔记本电脑隔离器用户手册第一章硬件安装一、外观示意图:二、连线:插入PC一个选择器第二章硬盘分区一、相关说明1.目前PC上所使用的硬盘,无论是IDE还是SATA借口,一个硬盘最多可以分成四个物理区(四个主分区,或者一个扩展分区+最多三个主分区,扩展分区又可分成若干个逻辑盘/分区),命名为分区0、分区1、分区2、分区3;2.单硬盘隔离方案就是将硬盘划分成上述四个区,分区0和分区1对应于内网,分区2 和分区3对应于外网,由隔离卡分别进行控制与管理,实现络网数据的逻辑隔离;3.可使用PQ等多种硬盘工具软件进行硬盘分区工作。
我们推荐使用DM这一功能强大、操作简洁的软件,使用操作前请仔细阅读《DM简介》。
随卡的启动光盘中已刻录DM,且在光盘引导后自动运行。
二、硬盘分区步骤重要提示:硬盘分区将破坏硬盘中原有的数据。
所以,若您要对使用过的硬盘进行分区,则请您务必先将该硬盘中的重要数据信息进行备份。
切切!1.安装好隔离卡,将光盘放入光驱,在PC系统加电自检、初试化后,系统进入光盘启动。
若硬盘尚未按要求进行分区,则屏幕显示以下菜单按下回车键,系统从光盘自动运行DM;2.请将硬盘按照实际使用的空间大小分为四个区:分区0、分区1、分区2、分区3,其中分区1必须为扩展分区,且可随意再分成几个逻辑盘/分区,存盘更新分区表后将分区0和分区1(含逻辑盘/分区)格式化,但不必格式化分区2和分区3,然后退出DM,请手动复位PC;3.系统重启从光盘引导后屏幕仍显示出1.中的菜单,请按下s或S键隔离卡保存已分好的分区0和分区1的相关数据,然后PC自动重启。
4.系统重启从光盘引导后,屏幕显示以下菜单按下回车键,系统从光盘自动运行DM;5.再次进入DM后,可以看到隔离卡将分区0和分区1屏蔽、分区3改为扩展分区,这时可将分区3随意再分成几个逻辑盘/分区,存盘更新分区表后将分区2和分区3(含逻辑盘/分区)格式化,然后退出DM,请手动复位PC;6.重启系统从光盘引导后屏幕仍显示出4.中的菜单,按下s或S键隔离卡保存已分好的分区2和分区3的相关数据,屏幕显示请取出光盘,按下任一键PC重启后,您可以进入外网所使用的硬盘分区,在上面安装操作系统和各种应用软件。

客户名-RX8640 NPartitions配置报告摘要:RX8640版本说明信息概要:Model:HP server rx8640S/N: SGH48158HH工作描述:HP-UX B.11.31 系统无法安装,NPartitions配置以下信息为现场操作内容:2015/6/23 17:30 客户安装系统问题2015/6/23 18:30 到达客户现场,系统安装已经完成。
检查系统状态,HP Npartitions 配置,检查硬件状态2015/6/23 10:30 工作完成一.HP Npartitions 配置过程如下:(1).Creating a Genesis Partition(没有NPar,第一次配置在MP卡)(2).客户系统有两个NPar(partition0, partition1)1)删除 Partition●使用parremove命令或 Partition Manager 删除nPartitions.●To remove the local partition issue the parremove -F -p# command, thenperform a reboot-for-reconfig (shutdown -R).2)添加cell (0/1) 到特定的partitionparmodify -p1 -a 0/3:base:y:ri (-B可选参数)●When the -B option is specified, if the partition is inactive it isbooted immediately. For active partitions, perform areboot-for-reconfig (shutdown -R) of the partition to use the cell.3)配置完成,重启主机shutdown –R4)显示partition 的信息和硬件信息parstatus# parstatusNote: No action specified. Default behavior is display all.[Complex]Complex Name : Complex 01Complex CapacityCompute Cabinet (4 cell capable) : 1Active MP Location : cabinet 0(可以添加扩展柜cabinet1,有两个IO chassis)Original Product Name : server rx8640Original Serial Number : SGH48158HHCurrent Product Order Number : AB297AOEM Manufacturer :Complex Profile Revision : 1.0The total number of partitions present : 1(partition的数量)GSM sharing : Disabled Complex-wide[Cabinet]Cabinet I/O Bulk Power BackplaneBlowers Fans Supplies Power BoardsOK/ OK/ OK/ OK/Cab Failed/ Failed/ Failed/ Failed/Num Cabinet Type N Status N Status N Status N Status MP=== ============ ========= ========= ========== ============ ======0 4 cell slot 21/0/N+ 6/0/N+ 4/0/N+ - ActiveNotes: N+ = There are one or more spare items (fans/power supplies).N = The number of items meets but does not exceed the need.N- = There are insufficient items to meet the need.= The adequacy of the cooling system/power supplies is unknown.HO = Housekeeping only; The power is in a standby state.NA = Not Applicable.[Cell]CPU Memory UseOK/ (GB) Core On Hardware Actual Deconf/ OK/ Cell Next Par Location Usage Max Deconf Connected To Capable Boot Num ========== ============ ======= ========= =================== ======= ==== === cab0,cell0 Active Core 8/0/8 32.0/0.0 cab0,bay0,chassis0 yes yes 0 cab0,cell1 Active Base 8/0/8 32.0/0.0 cab0,bay0,chassis1 yes yes 0 cab0,cell2 Absent * - - - - - - cab0,cell3 Absent * - - - - - - Cell Board 类似主板,可以安装CPU和Memory,总共可以安装4个Cell BoardNotes: * = Cell has no interleaved memory.[Chassis]Core Connected ParHardware Location Usage IO To Num=================== ============ ==== ========== ===cab0,bay0,chassis0 Active yes cab0,cell0 0cab0,bay0,chassis1 Active yes cab0,cell1 0PCI Domains (IO chassis就是PCI 的笼子)–PCI domain 0 is connected to cell 0.–As viewed from the cabinet’s rear, includes the left 8 PCI slots, numbered 1 to 8.–Slot 1 in domain 0 is for the SCSI/LAN “Procurium” PCI card.–PCI domain 1 is connected to cell 1.–As viewed from the cabinet’s rear, includes the right 8 PCI slots, numbered 1 to 8.[Partition]Par # of # of I/ONum Status Cells Chassis Core cell Partition Name (first 30 chars)=== ============ ===== ======== ========== ===============================0 Active 2 2 cab0,cell0 Partition 0Partition 0 共有2个Cell Board[Partition - HyperThread]Par Num Hyperthreading Enabled Hyperthreading Active======= ====================== =====================0 yes yes二.硬件报错信息:# ioscan -fn|grep UNCLAIMEDunknown -1 1/0/6/1/0 UNCLAIMED UNKNOWN PCI-X Ethernet (17d55832)unknown -1 1/0/14/1/0 UNCLAIMED UNKNOWN PCI-X Ethernet (17d55832)UNCLAIMED 说明硬件故障,但主机可以识别,NO_HW硬件已经无法识别到.三.帮助客户查找硬件信息查看PCI PCI card OLARUse the rad -q command to list all PCI slots and their paths.rad -q 或者olrad –q# olrad -qDriver(s)CapableSlot Path Bus Max Spd Pwr Occu Susp OLAR OLD Max Mode Num Spd Mode0-0-0-1 0/0/8/1 140 133 133 Off No N/A N/A N/A PCI-X PCI-X 0-0-0-2 0/0/10/1 169 133 133 On Yes No Yes Yes PCI-X PCI-X 0-0-0-3 0/0/12/1 198 266 133 On Yes No Yes Yes PCI-X PCI-X 0-0-0-4 0/0/14/1 227 266 266 On Yes No Yes Yes PCI-X PCI-X 0-0-0-5 0/0/6/1 112 266 266 On Yes No Yes Yes PCI-X PCI-X 0-0-0-6 0/0/4/1 84 266 133 On Yes No Yes Yes PCI-X PCI-X 0-0-0-7 0/0/2/1 56 133 133 On Yes No Yes Yes PCI-X PCI-X 0-0-0-8 0/0/1/1 28 133 133 Off No N/A N/A N/A PCI-X PCI-X 0-0-1-1 1/0/8/1 396 133 133 On Yes No Yes Yes PCI-X PCI-X 0-0-1-2 1/0/10/1 425 133 133 On Yes No Yes Yes PCI-X PCI-X 0-0-1-3 1/0/12/1 454 266 133 On Yes No Yes Yes PCI-X PCI-X 0-0-1-4 1/0/14/1 483 266 266 On Yes N/A N/A N/A PCI-X PCI-X 0-0-1-5 1/0/6/1 368 266 266 On Yes N/A N/A N/A PCI-X PCI-X 0-0-1-6 1/0/4/1 340 266 133 On Yes No Yes Yes PCI-X PCI-X 0-0-1-7 1/0/2/1 312 133 133 On Yes No Yes Yes PCI-X PCI-X 0-0-1-8 1/0/1/1 284 133 133 On Yes No Yes Yes PCI-X PCI-X slot 10 1/0/4/1 pci_slot CLAIMED SLOT PCI Slot ioscan -fn 可以看到卡的槽位信息CLAIMED设备运行正常,UNCLAIMED 设备电气连接,但设备故障。


r语言envipat包用法-回复R语言是一种用于数据分析和统计建模的流行编程语言。
在R语言中,有许多功能强大的软件包可以帮助处理和分析数据。
其中一个非常有用的包是envipat(Environmental Impact Assessment(EIA)- Pressure Assessment Tool)。
本文将一步一步地介绍envipat包的使用方法,以及它在环境影响评估中的应用。
步骤一:安装和加载envipat包首先,我们需要下载和安装envipat包。
要做到这一点,我们可以使用以下命令:rinstall.packages("envipat")安装完成后,我们需要加载envipat包以供使用。
我们可以使用以下命令加载envipat包:rlibrary(envipat)步骤二:了解envipat包的功能和使用方式envipat包是根据环境影响评估(EIA)的概念和方法开发的。
它提供了一个用于评估各种环境指标和压力源之间关系的工具。
该包提供了多个函数,可以计算和可视化环境压力指标,还可以进行环境敏感性分析和环境预测。
步骤三:数据准备和导入在使用envipat包之前,我们需要准备数据并将其导入到R环境中。
通常,数据可以是来自环境监测或调查的观测数据。
数据可以以多种格式(如CSV、Excel、SQL等)存在。
在这个例子中,我们假设我们的数据存储在一个名为"data.csv"的CSV文件中。
为了导入数据,我们可以使用以下命令:rdata <- read.csv("data.csv")现在,我们的数据已导入到一个名为data的数据框中。
步骤四:数据预处理在进行环境影响评估之前,我们需要对数据进行预处理。
这可能包括数据清洗、处理缺失值和异常值等。
envipat包提供了一些函数来帮助进行这些预处理步骤。
例如,我们可以使用以下命令删除包含缺失值的行:rdata <- na.omit(data)或者,我们可以使用以下命令移除异常值:rdata <- remove.outliers(data)步骤五:计算环境压力指标一旦数据准备和预处理完成,我们可以使用envipat包提供的函数来计算环境压力指标。

Oracle分区表 (Partition Table) 的创建及管理一、创建分区表分区表分为四类:1、范围分区表2、列表分区表3、哈希分区表4、组合分区表下面分别创建四类分区表。
1、范围分区表2、列表分区表3、哈希分区表4、组合分区表--注subpartitions 2 并不是指定subpartition的个数一定为2,实际上每个分区的子分区个数可以不同。
subpartitions 关键字的作用到底是什么?如果不指定subpartition的具体明细,则系统按照subpartitions 的值指定subpartition的个数生成子分区,名称由系统定义。
二、增加分区注:hash partitioned table 新增partition时,现有表的中所有data都有重新计算hash值,然后重新分配到分区中。
所以被重新分配的分区的indexes需要rebuild 。
三、删除分区You can drop partitions from range, list, or composite range-list partitioned tables.For hash-partitioned tables, or hash subpartitions of range-hash partitioned tables, you must perform. a coalesce operation instead.四、分区合并1. 合并父分区如果省略update indexes子句的话,必须重建受影响的分区的index 。
ALTER TABLErange_example MODIFY PARTITION part02 REBUILD UNUSABLE LOCAL INDEXES;2. 合并子分区五、分割分区hash partitions or subpartitions不能分割。
如果指定的分割分区包含任何的数据时,对应的indexes可以被标识为UNUSABLE 。
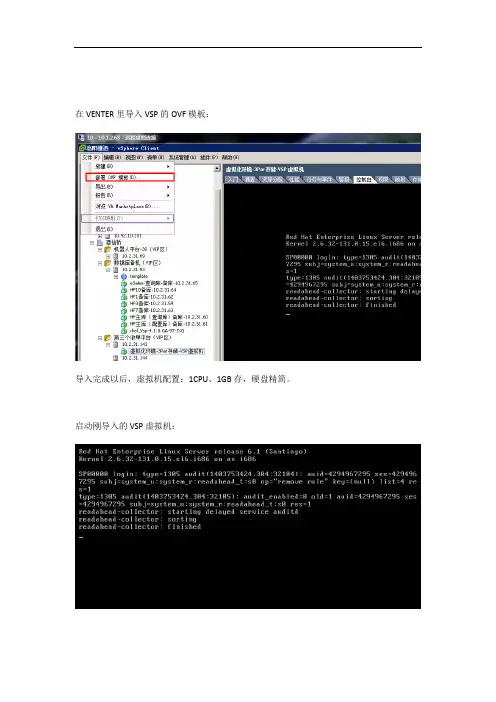
在VENTER里导入VSP的OVF模板:导入完成以后,虚拟机配置:1CPU、1GB存,硬盘精简。
启动刚导入的VSP虚拟机:一、3par存储初始化配置:1.配置VSP虚拟机在vCenter里,点击“编辑”—“部署OVF”,通过OVF文件把虚拟机导入并启动,准备配置IP地址:10.1.9.612.开机之后,询问是否进入默认配置选择NO,登陆系统时,用户名root,密码为空,通过下面这个命令配置IP地址:system-config-network –上面命令最后是空格加一个减号,只配置ETH0的IP即可,IP配置完以后,重启网络服务:service network restart3.载入Smart Start在主界面第二项里的第一部分,输入VSP的IP(10.1.9.61)、输入SN,然后等待系统初始化完成,见下图:4.然后执行Smart Start主界面里第二项里的第二部分,输入VSP的IP(10.2.31.148)【图中“1”位置】。
先执行,过程如下:5.在浏览器里,打开VSP,如下:https:// 10.2.31.148登陆权限:用户名:setupusr密码:空提前添加信任站点:再执行:输入VSP的IP地址:打开以后,配置存储的管理地址(10.2.31.149),此存储二个控制器上都有管理口(MGMT),这二个口都需要接到交换机上,这二个口共用同一个管理IP地址。
设置用户名和密码:Username:3paradmPassword:***********二、3par存储概念修改光纤PORT的角色:1.HOST在3par存储里,和其他存储一样,HOST指的是配置有HBA卡的服务器。
2.HOST SET在3par存储,HOST SET可以理解为是一个“主机组”,意思是每个HOST SET里可以包含有多台主机。
3.CPG建议策略命令名按照RAID级别_磁盘类型等信息命名,便于后期使用时快速识别各个CPG的具体配置。

如何在DOS模式下重新进行磁盘分区时间:2009-05-06 10:13最佳答案电脑自带的磁盘系统?是哪种磁盘系统?为什么失败了?八成是分区表混乱了,如果重新进行分区,可以用diskgenius(老版本叫diskman)或pm(分区魔术师),详细的操作要看情况定。
如果不要数据了(我也不确定现在这数据能不能恢复),可以用上面的软件把直接把原来的分区删了,再建立就可以了。
回答人:- 2009-03-07 12:23其他回答(共1条)硬盘分区(Fdisk)1 进入BIOS,将引导顺序设为“A: , C: , SCSI"目的:能用WIN98启动软盘引导系统。
2 进入启动菜单。
选择启动方式。
Microsoft startup Menu 中方大意:1) Start windows98 setup from CD-ROM. 1.从光驱直接安装win98 2) Start computerwith CD-ROM support 2.引导系统并加载光驱3) Start computer without CD-ROM support 3. 引导系统并不加载光驱Enter a chine 3输入选择:一,选择“3”引导进入系统二,屏幕显示DOS提示盘符“A : \ >"键入“Fdisk" 命令3,选择FAT标准执行FDISK命令Your computer has a .......... do not enable Carye drige support Do you mish to enable large disk appoint (Y\N)...[Y] 中文大意如果硬盘容量大于512mb时,将可以使用FAT32分区(突破2G限制)管理大硬盘。
警告:如果使用FAT32模式建立分区,那么DOS 6.X和Win NT系统将无法读,写所建立的逻辑盘(FAT32模式)。
你将使FAT32模式分区吗(Y\N)? [Y] (回车同意使用, 输入“N”不用)注:一般情况下应使用FAT32标准。
hp rx8640 hpux管理及安装第一部分:系统恢复过程1.将备份好的系统磁带放入磁带机中,开机。
2.工作站串口与hprx8640机器的mp口连接,运行secureCRT软件。
登录到机器后mp用户名和密码为Admin3.键入co进入到控制台,再键入0进入到分区0。
4.当系统进入到数十秒的时候,按空格键(任意键均可)终止引导进入到EFI命令菜单。
.5.进入到EFI引导操作主菜单,选择从一个文件引导。
6.在列表中选择磁带机文件设备。
7.启动到安装界面后选择Install HP-UX8.在User Interface Options里选择Advanced Installation9.在引导介质界面选择Boot from CD/DVD,Recover from Tape,从磁带机恢复10.选择系统找到的磁带设备11.修改/stand文件系统的大小为5120M12.修改/文件系统的大小为10240M13.修改/tmp文件系统的大小为8192M14.修改/home文件系统的大小为8192M15.修改opt文件系统的大小为30720M16.修改/usr文件系统的大小为10240M17.修改/var文件系统的大小为10240M18.选择Go!执行所做的修改在修改分区大小时若提示磁盘空间不够,则在“add/remove Disk”选项中添加第二块磁盘第二部分:网络绑定1.使用sam命令选择”n-networking and communications”2.选择”s-network service configuration”3.选择”a-auto port aggeregation”4.选择”c-create link aggregate”创建网卡链接聚集5.进入创建菜单后,修改”link aggregate instance”选项。
实例名按顺序选择,方便管理。
6.再修改mode选项,这里选择”MANUAL”7.在网卡列表中选择需要聚集的网卡号下例选择0号和4号网卡聚集8.选中[advanced parameters]回车,修改“load balancing algorithm”d的选项为“LB_MAC”.9.再选中“change current apa config”和“save all apa congig”两项,最后选择确认键“ok选项”。
DLPAR配置指南LPAR 即系统级的逻辑分区,它把一个物理的服务器划分成若干个虚拟的或逻辑的服务器,在每个逻辑服务器上单独运行一个私有的操作系统,有自己独享的处理器、内存和I/O 资源。
而动态逻辑分区(DLPAR) 可以使用户在不中断应用操作的情况下,增加或减少分区占用的资源。
动态逻辑分区的资源调整功能让系统管理员可以自由添加、删除或在分区之间移动系统资源,例如CPU、内存、I/O 适配器的分配,而不需要像原来修改之后重新启动分区。
系统管理员就可以根据分区系统负荷和分区业务运行特点,随时将资源动态分配到需要的地方,从而大大提供资源的利用效率和灵活性。
例如,在一个系统分区中,当它的应用处于处理峰值时,用户可以将其他分区中较为空闲的CPU移到这个分区中,在这个过程中用户不需要重新启动这两个分区的操作系统。
又如,用户可以将不常用的系统资源如CD-ROM或者磁带机在不同的分区间动态移动。
对于服务器是否可以使用动态LPAR,是要看安装在服务器上的软件是否支持。
如果希望实现动态,LPAR 需要在相关的分区安装AIX 5L 5.2 及以上版本,并且HMC recovery 软件必须至少是3.1 版本( 或更高)。
如果分区运行的是AIX 5L 5.1 以下版本,动态逻辑分区不可用。
每个LPAR 至少需要一些资源,对于P5机器下面是每个LPAR 的最小需求Power 5 系列小型机∙每个分区至少有一个处理器。
∙每个分区至少有128MB 内存。
∙每个分区至少有一块硬盘用于安装和存储操作系统, 或VIO server 上提供的1 块虚拟盘(对于AIX, 做为rootvg)。
∙每个分区至少有一块硬盘适配器或集成的适配器(含VIO server 上的虚拟适配器)用于连接硬盘。
∙每个分区至少有一块网卡(含虚拟网卡)用于每个分区与HMC 的连接。
∙每个分区必须有一个安装模式,例如NIM。
一.系统环境设备信息IBM P570 小型机(3CEC DRAW) 一台HMC IBM Xsystem3550 一台7212-103 1U式机架式磁带机一台LPAR,系统版本为AIX5.3,HMC版本为V7.3.2,系统安装完成之后,统一规划每个LPAR的ent3为DLPAR的通信端口,地址规划为与HMC控制口不同网断,建议DLPAR利用单独的hub来实施,地址分别为:HMC IP地址172.1.50.1LPAR1IP地址 172.1.50.51LPAR2 IP地址 172.1.50.52LPAR3 IP地址 172.1.50.53LPAR4 IP地址 172.1.50.54LPAR5 IP地址 172.1.50.55二.配置DLPAR要求1.建议将HMC控制台的版本升级到3.24以上,本次实验HMC版本为V7.3.2。
扫雷宝典之BCS篇1,RP44x0 and RX4640 Core IO产生的影响:系统无法启动,找不到根盘;外置IO设备无法使用;危险程度:描述:该型机器Core SCSI卡有2个独立的通道(Channel),连接硬盘背板分两种模式:Simplex vs. Duplex SCSI Mode。
默认是Simplex模式,只使用Channel A。
当使用Duplex模式时,Channel B被使用,其外接端口不能再接设备,比如外置硬盘笼子或者磁带机。
否则可能造成根盘不可访问。
解决方法:1,物理观察,是否连接Channel B的线缆2,通过操作系统察看两块物理盘的路径,判断Channel B是否被使用。
2,HPUX对USB设备的访问问题产生的影响:系统crash,业务中断;危险程度:描述:Efi中可以直接访问fat格式的U盘,但hpux不可识别,可能会造成链路reset;当安腾机器上的usb模块驱动版本较低,存在一个bug,就是当带电插拔usb设备时有可能造成系统crash,包括重启kvm。
解决方法:生产系统不要随意插U盘或者KVM,避免造成不必要的宕机,根本解决是升级USB的驱动。
3,客户设备上的IC卡问题产生的影响:业务中断;危险程度:↓↓↓描述:客户的很多设备上会使用加密设备,外观上看会有一张IC卡插在主机上,用于加密密钥使用。
解决方法:请勿拔出。
现场不要乱动设备,尤其是不负责不清楚的设备。
4,RP741x /RP7420/RP8400/RP8420/RX7620/RX8620的PCI power module问题产生的影响:系统HPMC,业务中断;危险程度:↓↓↓描述:这些机器的PCI 电源模块是一个故障单点,不是冗余供电,每个power supply和其正对的PCI backplane供电,更换时必须停机更换,否则会导致HPMC。
RP7440/RP8440及RX7640/RX8640改为冗余,不存在此问题。
目录一、创建CPG (2)二、虚拟卷创建 (3)三、创建主机 (4)四、将创建好的卷添加进主机 (6)五、手动初始化存储 (8)1、点击3PAR StoreServ > 通用配置组2、创建CPG,填写CPG名称,选中右上角高级选项,RAID类型,集大小,点击创建;1、点击3PAR StoreServ >虚拟卷>创建虚拟卷2、填写卷名称,配置,选择CGP的RAID级别,卷容量大小,点击创建;3、卷创建完成后,可以在虚拟卷下看到刚创建好的卷;三、创建主机1、点击3PAR StoreServ >主机>创建主机2、填写主机名称,主机OS,往下拉,点击添加FC3、可以看到主机的端口已经在存储系统识别,点击添加四、将创建好的卷添加进主机1、点击3PAR StoreServ >虚拟机,选择刚创建好的虚拟机,点击右上角的操作>导出;2、点击添加;3、选择需要添加的主机,点击添加;4、点击导出,配置完成就可以在主机系统扫描存储卷。
五、手动初始化存储1、串口连接,用户名/密码console/cmp43pd登入;2、登入后选择1.Out Of The Box Procedure;3、出现下图信息输入yes;按enter进行下一步;4、输入c,按enter进行下一步;5、选择5,按enter进行下一步;6、选择9,按enter进行下一步;7、选择1,按enter进行下一步;8、选择1,按enter进行下一步;9、输入存储系统名,可随意填写;10、输入yes;按enter进行下一步;11、输入c,按enter进行下一步;12、输入c,按enter进行下一步;13、输入y,按enter下一步;14、输入c;按enter下一步;15、输入1,给存储系统配置管理网络;16、输入IP地址,掩码,网关;17、输入n,按enter进行下一步;19、输入d,按enter进行下一步;21、看到已初始化完成,自动回到主菜单,此时可以登入存储进行管理配置;。
X6机器对于之前的IBM机器有了一些不同,而在阵列这个方面X6机器已经没了之前的Webios管理的界面了,只能在BIOS界面做阵列。
1.如下图,到LOGO画面按F1进到下面的图选择第二个选项System setting2.第二个选项进去之后如下图选择Storage 进去2.从第二部进去之后可以看到阵列卡的型号LST MEGARAID…,如下图4.然后继续下步,选择configuration management如下图5选第一项Enter进去如下图,选择你要做的阵列select RAID Level(此次配置要做R10阵列,共6个1T的硬盘),RAID10。
(下图是已经分好3个)6.选择要做的阵列后,要选择做阵列的硬盘,在Span1选项下面,选择Select Drives进去,进去后到大括号里按空格键打 X 选择两个硬盘。
(R10阵列,6个1T的硬盘配置是SPAN1(1+1), SPAN2(1+1), SPAN3(1+1))如下图7.选择两个硬盘[X],选择APPLY CHANGES.8.回到CREATE VIRTUAL DRIVE-ADVANCED,ADD MORE SPANS,添加SPAN2,选择Selcect drives,进去选项选择两个硬盘打X,保存;返回,添加Span3,Select Drives,进去选项选择两个硬盘打X。
此时总共是3个Span。
9.此时R10阵列,6个1T的硬盘分为3个盘组配置完毕,选择Save Configuration,Confirm打X,选Yes保存。
10.创建后阵列回去到阵列卡配置界面可以看到选项View Drives Group Properties11.进去选项后看到R10阵列,6个1T的硬盘配置是3个备份,3个使用,合计2791GB的可用空间。
RX8640创建npar分区实例
一、试验环境:
(1)设备型号:RX8640
(2)系统版本:HPUX 11.31 IA
(3)可用资源:两个CELL板,Cell0 、Cell1
二、实验过程:
1、cm>RR——重启CELL到BIB状态下
2、cm>CC——创建第一个分区
3、cm>RS
4、查看
#parstatus
#parstatus –V –p0——查看分区0状态
#parstatus –AC 查看可用的空闲CELL板
5、#parcreate –c 1:::-B –P 1 ——创建以CELL1为core cell 的分区1,下图为命令执行及成功的回显:
#parstatus 查看分区1是否曾创建成功:
CPU Memory Use
OK/ (GB) Core On Hardware Actual Deconf/ OK/ Cell Next Par Location Usage Max Deconf Connected To Capable Boot Num
========== ============ ======= ========= =================== ======= ==== ===
cab0,cell0 Active Core 4/0/8 16.0/0.0 cab0,bay0,chassis0 yes yes 0
cab0,cell1 Inactive 4/0/8 16.0/0.0 cab0,bay0,chassis1 yes yes 1
6、现在分区1是处于非激活状态,Cm>RS——重启分区1
7、重启后发现没有系统盘
8、进入分区0,删除分区1
#parremove – p 1——只能删除非激活的分区,但此时分区1为激活状态,下图为失败报错:
#Parstatus
CPU Memory Use
OK/ (GB) Core On Hardware Actual Deconf/ OK/ Cell Next Par Location Usage Max Deconf Connected To Capable Boot Num
========== ============ ======= ========= =================== ======= ==== ===
cab0,cell0 Active Core 4/0/8 16.0/0.0 cab0,bay0,chassis0 yes yes 0
cab0,cell1 Active Core4/0/8 16.0/0.0 cab0,bay0,chassis1 yes yes 1
9、所以需要cm>RR 分区1,然后执行parremove
#parstatus
[Cell]
CPU Memory Use
OK/ (GB) Core On Hardware Actual Deconf/ OK/ Cell Next Par Location Usage Max Deconf Connected To Capable Boot Num
========== ============ ======= ========= =================== ======= ==== ===
cab0,cell0 Active Core 4/0/8 16.0/0.0 cab0,bay0,chassis0 yes yes 0
cab0,cell1 Inactive 4/0/8 16.0/0.0 cab0,bay0,chassis1 yes yes 1
#parremove –p 1——删除分区1
[Cell]
CPU Memory Use
OK/ (GB) Core On
Hardware Actual Deconf/ OK/ Cell Next Par Location Usage Max Deconf Connected To Capable Boot Num ========== ============ ======= ========= =================== ======= ==== === cab0,cell0 Active Core 4/0/8 16.0/0.0 cab0,bay0,chassis0 yes yes 0
cab0,cell1 Inactive 4/0/8 16.0/0.0 cab0,bay0,chassis1 yes - -
12、#parmodify –p 0 –a 1:::——将CELL1 加入分区0
根据操作提示#shutdown –R
重启后进入系统查看:
#parstatus –V –p0——查看分区0 信息
[Cell]
CPU Memory Use
OK/ (GB) Core On Hardware Actual Deconf/ OK/ Cell Next Par Location Usage Max Deconf Connected To Capable Boot Num ========== ============ ======= ========= =================== ======= ==== === cab0,cell0 Active Core 4/0/8 16.0/0.0 cab0,bay0,chassis0 yes yes 0
cab0,cell1 Active Base4/0/8 16.0/0.0 cab0,bay0,chassis1 yes yes0。