
第六章:描述性统计分析--
Descriptive Statistics菜单详解
描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。
§6.1 Frequencies过程
频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。
和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并
不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。
6.1.1 界面说明
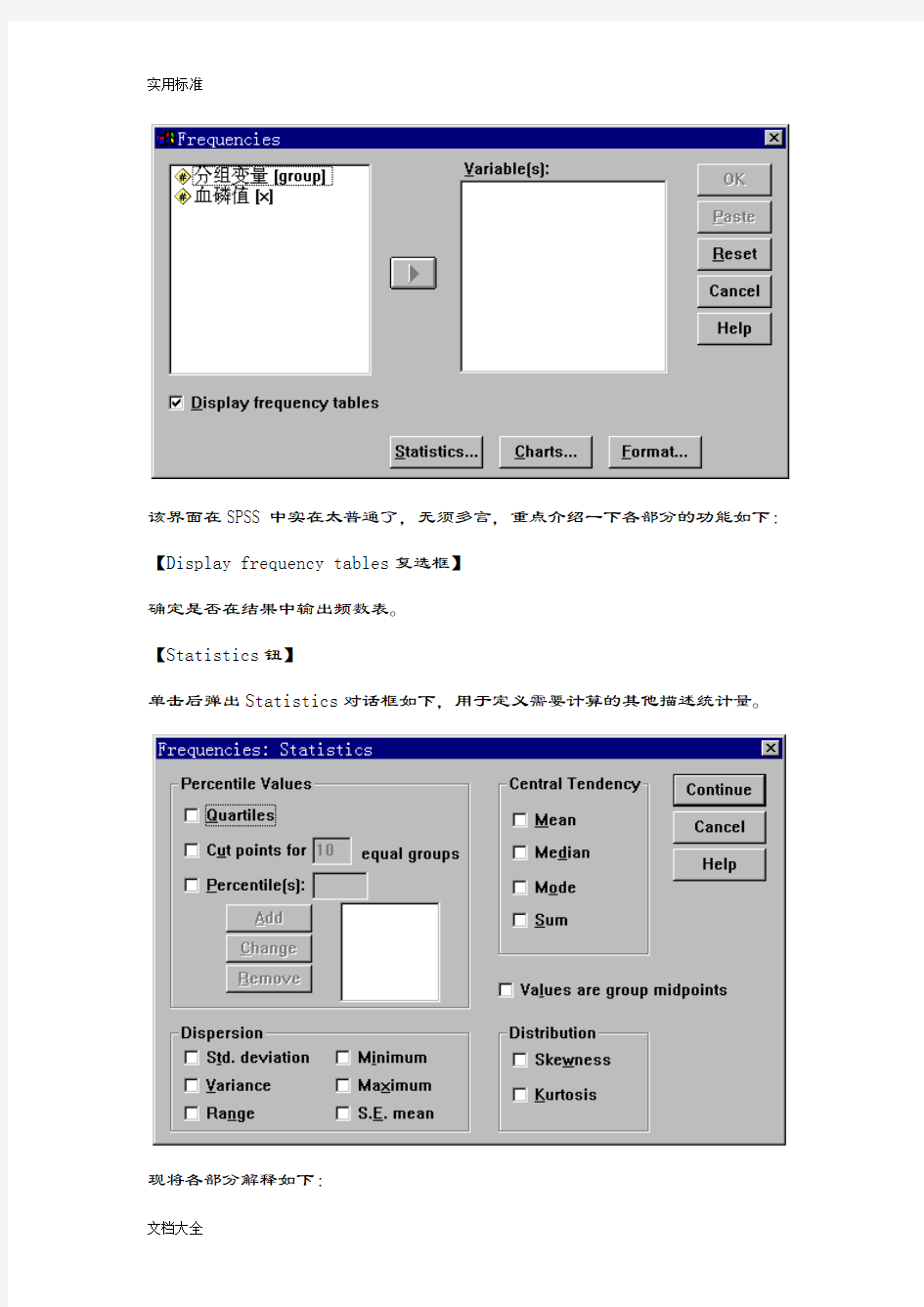
Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】
确定是否在结果中输出频数表。
【Statistics钮】
单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。
现将各部分解释如下:
o Percentile Values复选框组定义需要输出的百分位数,可计算四分位数(Quartiles)、每隔指定百分位输出当前百分位数(Cut points
for equal groups)、或直接指定某个百分位数(Percentiles),如直接指定输出P2.5和P97.5。
o Central tendency复选框组用于定义描述集中趋势的一组指标:均数(Mean)、中位数(Median)、众数(Mode)、总和(Sum)。
o Dispersion复选框组用于定义描述离散趋势的一组指标:标准差(Std.deviation)、方差(Variance)、全距 (Range)、最小值(Minimum)、最大值(Maximum)、标准误(S.E.mean)。
o Distribution复选框组用于定义描述分布特征的两个指标:偏度系数(Skewness)和峰度系数(Kurtosis)。
o Values are group midpoints复选框当你输出的数据是分组频数数据,并且具体数值是组中值时,选中该复选框以通知SPSS,免得它犯错误。
众数(Mode)指所有数值中出现频率最高的一个值,在国内用的非常少。【Charts钮】
弹出Charts对话框,用于设定所做的统计图。
o Chart type单选钮组定义统计图类型,有四种选择:无、条图(Bar chart)、圆图(Pie chart)、直方图Histogram),其中直方图还可以选择是否加上正态曲线(With normal curve)。
o Chart Values单选钮组定义是按照频数还是按百分比做图(即影响纵坐标刻度)。
【Format钮】
弹出Format对话框,用于定义输出频数表的格式,不过用处不大,一般不管。
o Order by单选钮组定义频数表的排列次序,有四个选项:Ascending values为根据数值大小按升序从小到大作频数分布;Descending values 为根据数值大小按降序从大到小作频数分布;Ascending counts为根据
频数多少按升序从少到多作频数分布;Descending counts为根据频数多少按降序从多到少作频数分布。
o Multiple Variables单选钮组如果选择了两个以上变量做频数表,则Compare variables可以将他们的结果在同一个频数表过程输出结果中显示,便于互相比较,Organize output by variables则将结果在不同的
频数表过程输出结果中显示。
o Suppress Tables more than...复选框当频数表的分组数大于下面设定数值时禁止它在结果中输出,这样可以避免产生巨型表格。
6.1.2 分析实例
例6.1 某地101例健康男子血清总胆固醇值测定结果如下,请绘制频数表、直方图,计算均数、标准差、变异系数CV、中位数M、p2.5和p97.5(卫统第三版p233 1.1题)。
4.77 3.37 6.14 3.95 3.56 4.23 4.31 4.71
5.69 4.12 4.56 4.37 5.39
6.30 5.21
7.22 5.54 3.93 5.21 4.12 5.18 5.77 4.79 5.12 5.20 5.10 4.70 4.74 3.50 4.69 4.38 4.89 6.25 5.32 4.50 4.63 3.61 4.44 4.43 4.25 4.03 5.85 4.09 3.35 4.08 4.79 5.30 4.97 3.18 3.97 5.16 5.10 5.86 4.79 5.34 4.24 4.32 4.77 6.36 6.38 4.88 5.55 3.04 4.55 3.35 4.87 4.17 5.85 5.16 5.09 4.52 4.38 4.31 4.58 5.72 6.55 4.76 4.61 4.17 4.03 4.47 3.40 3.91 2.70 4.60 4.09 5.96 5.48 4.40 4.55 5.38 3.89 4.60 4.47 3.64 4.34 5.18 6.14 3.24 4.90 3.05
解:为节省篇幅,这里只给出精确频数表的做法,假设数据已经输好,变量名为X,具体解法如下:
1.Analyze==>Descriptive Statistics==>Frequencies
2.Variables框:选入X
3.单击Statistics钮:
4.选中Mean、Std.deviation、Median复选框
5.单击Percentiles:输入2.5:单击Add:输入97.5:单击Add:
6.单击Continue钮
7.单击Charts钮:
8.选中Bar charts
9.单击Continue钮
10.单击OK
得出结果后手工计算出CV。
上面做出的直方图分组太多,需要进一步编辑。
6.1.3 结果解释
上题除直方图外的的输出结果如下:
Frequencies
最上方为表格名称,左上方为分析变量名,可见样本量N为101例,缺失值0例,均数Mean=4.69,中位数Median=4.61,标准差STD=0.8616,P2.5=3.04,P97.5=6.45。
系统对变量x作频数分布表(此处只列出了开头部分),Vaild右侧为原始值,Frequency为频数,Percent为各组频数占总例数的百分比(包括缺失记录在内),Valid percent为各组频数占总例数的有效百分比,Cum Percent为各组频数占总例数的累积百分比。
§6.2 Descriptives过程
Descriptives过程是连续资料统计描述应用最多的一个过程,他可对变量进行描述性统计分析,计算并列出一系列相应的统计指标。这和其他过程相比并无不同。但该过程还有个特殊功能就是可将原始数据转换成标准正态评分值并以变量的形式存入数据库供以后分析。
6.2.1 界面说明
【Save standardized values as variables复选框】
确定是否将原始数据的标准正态评分存为新变量。
【Options钮】
弹出Options对话框,大部分内容均在前面Frequences过程的Statistics对话框中见过,只有最下方的Display Order单选钮组是新的,可以选择为变量列表顺序、字母顺序、均数升序或均数降序。
6.2.2 结果解释
下面是一个典型的Descriptives过程结果统计表:
一望可知,这里的大部分内容都在上一节见过,因此就不再多解释了。
讲了两个过程,也许大家已经发现了:结果中的统计专业单词多数在对话框中就已经出现,因此我们以后会详细解释对话框的内容,结果中相同的单词不再重复解释。
§6.3 Explore过程
Explore过程可对变量进行更为深入详尽的描述性统计分析,主要用于对资料的性质、分布特点等完全不清楚时,故又称之为探索性分析。它在一般描述性统计指标的基础上,增加有关数据其他特征的文字与图形描述,如枝叶图、箱图等,显得更加详细、全面,有助于用户制定继续分析的方案。
6.3.1 界面说明
【Display单选钮组】
用于选择输出结果中是否包含统计描述、统计图或两者均包括。
【Dependent List框】
用于选入需要分析的变量。
【Factor List框】
如果想让所分析的变量按某种因素取值分组分析,则在这里选入分组变量。【Label cases by框】
选择一个变量,他的取值将作为每条记录的标签。最典型的情况是使用记录ID 号的变量。
【Statistics钮】
弹出Statistics对话框,用于选择所需要的描述统计量。有如下选项:o Descriptives复选框:输出均数、中位数、众数、5%修正均数、标准误、
方差、标准差、最小值、最大值、全距、四分位全距、峰度系数、峰度系数的标准误、偏度系数、偏度系数的标准误及指定的均数可信区间。
o M-estimators复选框:作中心趋势的粗略最大似然确定,输出四个不同权重的最大似然确定数。
o Outliers复选框:输出五个最大值与五个最小值。
o Percentiles复选框:输出第5%、10%、25%、50%、75%、90%、95%位数。【Plot钮】
弹出Plot对话框,用于选择所需要的统计图。有如下选项:
o Boxplots单选框组:确定箱式图的绘制方式,可以是按组别分组绘制(Factor levels together),也可以不分组一起绘制(Depentends
together),或者不绘制(None)。
o Descriptive复选框组:可以选择绘制茎叶图(Stem-and-leaf)和直方图(Histogram)。
o Normality plots with test复选框:绘制正态分布图并进行变量是否符合正态分布的检验。
o Spread vs. Level with Levene Test单选框组:当选择了分组变量时,绘制spread-versus-level图(我还没有找到他的中文名字该叫什么),设置绘图时变量的转换方式,并进行组间方差齐性检验。
【Options钮】
用于选择对缺失值的处理方式,可以是不分析有任一缺失值的记录、不分析计算某统计量时有缺失值的记录,或报告缺失值。
6.3.2 结果解释
以例6.1的数据为例,按默认方式下的选择,Explore过程的输出如下:Explore
首先是例行的处理记录缺失值情况报告,可见101例均为有效值。
上表详细列出了常用的描述统计量,如果有标准误也会列出(如偏度和峰度系数)。
X
X Stem-and-Leaf Plot
Frequency Stem & Leaf
1.00 2 . 7
8.00 3 . 00123334
9.00 3 . 556689999
24.00 4 . 000001111222333333344444
25.00 4 . 5555556666677777777788899
17.00 5 . 01111111222333334
9.00 5 . 556778889
6.00 6 . 112333
1.00 6 . 5
1.00 Extremes (>=7.2)
Stem width: 1.0000
Each leaf: 1 case(s)
以上是茎叶图,整数位为茎,小数位为叶。这样可以非常直观的看出数据的分布范围及形态,在国外非常流行。
以上是箱式图,中间的黑粗线为均数,红框为四分位间距的范围,上下两个细线为最大、最小值。
§6.4 Crosstabs过程
Crosstabs过程用于对计数资料和有序分类资料进行统计描述和简单的统计推断。在分析时可以产生二维至n维列联表,并计算相应的百分数指标。统计推断则包括了我们常用的X2检验、Kappa值,分层X2(X2
)。如果安装了相应模块,
M-H
还可计算n维列联表的确切概率(Fisher's Exact Test)值。
Crosstabs过程不能产生一维频数表(单变量频数表),该功能由Frequencies 过程实现。
6.4.1 界面说明
【Rows框】
用于选择行*列表中的行变量。
【Columns框】
用于选择行*列表中的列变量。
【Layer框】
Layer指的是层,对话框中的许多设置都可以分层设定,在同一层中的变量使用相同的设置,而不同层中的变量分别使用各自层的设置。如果要让不同的变量做不同的分析,则将其选入Layer框,并用Previous和Next钮设为不同层。Layer 在这里用的比较少,在多元回归中我们将进行详细的解释。
【Display clustered bar charts复选框】
显示重叠条图。
【Suppress table复选框】
禁止在结果中输出行*列表。
【Exact钮】
针对2*2以上的行*列表设定计算确切概率的方法,可以是不计算(Asymptotic only)、蒙特卡罗模拟(Monte Carlo)或确切计算(Exact)。蒙特卡罗模拟默认进行10000次模拟,给出99%可信区间;确切计算默认计算时间限制在5分钟内。这些默认值均可更改。
如果你在安装SPSS时没有安装EXACT模块,则此处对话框中不会出现Exact 钮。
在3*3及以上的行*列表中,确切概率的精确计算是极为漫长的过程。我曾经用SAS 6.12在P133机上计算过一个12格表的确切概率,整整跑了两个小时后,SAS告诉我说机器内存不足:(。SPSS的计算速度比SAS要慢许多倍,因此一般只需要选用蒙特卡罗模拟算出概率值的99%可信区间就行了,精度完全可以满足需要,而速度极快(10000次模拟一般耗时在10秒左右)。
【Statistics钮】
弹出Statistics对话框,用于定义所需计算的统计量。
o Chi-square复选框:计算X2值。
o Correlations复选框:计算行、列两变量的Pearson相关系数和Spearman 等级相关系数。
o Norminal复选框组:选择是否输出反映分类资料相关性的指标,很少使用。
a.Contingency coefficient复选框:即列联系数,其值界于0~1之
间;
b.Phi and Cramer's V复选框:这两者也是基于X2值的,Phi在四格表
X2检验中界于-1~1之间,在R*C表X2检验中界于0~1之间;Cramer's
V 则界于0~1之间;
https://www.doczj.com/doc/2518697409.html,mbda复选框:在自变量预测中用于反映比例缩减误差,其值为1
时表明自变量预测应变量好,为0时表明自变量预测应变量差;
d.Uncertainty coefficient复选框:不确定系数,以熵为标准的比例
缩减误差,其值接近1时表明后一变量的信息很大程度来自前一变
量,其值接近0时表明后一变量的信息与前一变量无关。
o Ordinal复选框组:选择是否输出反映有序分类资料相关性的指标,很少使用。
a.Gamma复选框:界于0~1之间,所有观察实际数集中于左上角和右
下角时,其值为1;
b.Somers'd复选框:为独立变量上不存在同分的偶对中,同序对子数
超过异序对子数的比例;
c.Kendall's tau-b复选框:界于-1~1之间;
d.Kendall's tau-c复选框:界于-1~1之间;
o Eta复选框:计算Eta值,其平方值可认为是应变量受不同因素影响所致方差的比例;
o Kappa复选框:计算Kappa值,即内部一致性系数;
o Risk复选框:计算比数比OR值;
o McNemanr复选框:进行McNemanr检验(一种非参检验);
o Cochran's and Mantel-Haenszel statistics复选框:计算X2M-H统计量
(分层X2,也有写为X2
CMH 的),可在下方输出H
假设的OR值,默认为1。
【Cells钮】
弹出Cells对话框,用于定义列联表单元格中需要计算的指标:
o Counts复选框组:是否输出实际观察数(Observed)和理论数(Expected);
o Percentages复选框组:是否输出行百分数(Row)、列百分数(Column)以及合计百分数(Total);
o Residuals复选框组:选择残差的显示方式,可以是实际数与理论数的差值(Unstandardized)、标化后的差值(Standardized,实际数与理论数
的差值除理论数),或者由标准误确立的单元格残差(Adj.
Standardized);
【Format钮】
用于选择行变量是升序还是降序排列。
6.4.2 分析实例
例6.2 某医生用国产呋喃硝胺治疗十二指肠溃疡,以甲氰咪胍作对照组,问两种方法治疗效果有无差别(医统第二版P37 例3.10)?
解:由于此处给出的直接是频数表,因此在建立数据集时可以直接输入三个变量――行变量、列变量和指示每个格子中频数的变量,然后用Weight Cases对话框指定频数变量,最后调用Crosstabs过程进行X2检验。假设三个变量分别名为R、C和W,则数据集结构和命令如下:
R C W
1.00 1.0
54.0
1.00
2.00 44.0 0
2.00
1.00 8.00
2.00
2.00 20.0 0
1.Data==>Weight Cases
2.Weight Cases by单选框:选中
3.Freqency Variable:选入W
4.单击OK钮
5.Analyze==>Descriptive Statistics==>Crosstabs
6.Rows框:选入R
7.Columns框:C
8.Statistics钮:Chi-square复选框:选中:单击Continue钮
9.单击OK钮
6.4.3 结果解释
上题的结果如下:
Crosstabs
首先是处理记录缺失值情况报告,可见126例均为有效值。
上面为列出的四格表,实际使用时可以在其中加入变量值标签,使看起来更清楚。
上表给出了一堆检验结果,从左到右为:检验统计量值(Value)、自由度(df)、双侧近似概率(Asymp.Sig.2-sided)、双侧精确概率(Exact Sig.2-sided)、单侧精确概率(Exact Sig.1-sided);从上到下为:Pearson卡方(Pearson Chi-Square 即常用的卡方检验)、连续性校正的卡方值(Continuity Correction)、对数似然比方法计算的卡方(Likelihood Ratio)、Fisher's确切概率法(Fisher's Exact Test)、线性相关的卡方值(Linear by Linear Association)、有效记录数(N of Valid Cases)。另外,Continuity Correction和Pearson卡方值处分别标注有a和b,表格下方为相应的注解:a.只为2*2表计算。b.0%个格子的期望频数小于5,最小的期望频数为13.78。因此,这里无须校正,直接采用第一行的检验结果,即X2=6.133,P=0.013。
如何选用上面众多的统计结果令许多初学者头痛,实际上我们只需要在未校正卡方、校正卡方和确切概率法三种方法之间选择即可,其余的对我们而言用处不大,可以视而不见。
应用统计学案例统计调查方案设计
统计调查方案设计案例 ▲统计调查方案的内容和撰写: 一、统计调查方案的主要内容 1、确定统计调查目的和任务 2、确定调查对象和调查单位 调查对象是指依据调查的任务和目的,确定本次调查的范围及需要调查的那些现象的总体。 调查单位是指所要调查的现象总体所组成的个体,也就是调查对象中所要调查的具体单位,即我们在调查中要进行调查研究的一个个具体的承担者。 3、确定调查内容和调查表 (1)调查课题如何转化为调查内容 调查课题转化为调查内容是把已经确定了的调查课题进行概念化和具体化。 (2)调查内容如何转化为调查表 如何把调查内容设计为调查表,这一问题会在下一章中专门介绍。 4、调查方式和调查方法 5、调查项目定价与预算 6、统计数据分析方案 7、其它内容
包括确定调查时间,安排调查进度,确定提交报告的方式,调查人员的选择、培训和组织等。 二、统计调查方案的撰写 1、统计调查方案的格式 包括摘要、前言、统计调查的目的和意义、统计调查的内容和范围、调查采用方式和方法、调查进度安排和有关经费开支预算、附件等部分。 2、撰写统计调查方案应注意的问题 (1)一份完整的统计调查方案,上述1—7部分的内容均应涉及,不能有遗漏。否则就是不完整的。 (2)统计调查方案的制订必须建立在对调查课题的背景的深刻认识上。 (3)统计调查方案要尽量做到科学性与经济性的结合。 (4)统计调查方案的格式方面能够灵活,不一定要采用固定格式。 (5)统计调查方案的书面报告是非常重要的一项工作。一般来说,统计调查方案的起草与撰写应由课题的负责人来完成。三、统计调查方案的可行性研究 (一)统计调查方案的可行性研究的方法 1、逻辑分析法 逻辑分析法是指从逻辑的层面对统计调查方案进行把关,考察其是否符合逻辑和情理。
计量经济学E v i e w s多重共线性实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
实验报告课程名称计量经济学 实验项目名称多重共线性 班级与班级代码 专业 任课教师 学号: 姓名: 实验日期: 2014 年 05 月 11日 广东商学院教务处制 姓名实验报告成绩 评语: 指导教师(签名) 年月日 说明:指导教师评分后,实验报告交院(系)办公室保存。 计量经济学实验报告 一、实验目的:掌握多元线性回归模型的估计方法、掌握多重共线性模型的识别和修正。 二、实验要求:应用教材第127页案例做多元线性回归模型,并识别和修正多重共线性。 三、实验原理:普通最小二乘法、简单相关系数检验法、综合判断法、逐步回归法。
四、预备知识:最小二乘法估计的原理、t检验、F检验、2R值。 五、实验步骤 1、选择数据 理论上认为影响能源消费需求总量的因素主要有经济发展水平、收入水平、产业发展、人民生活水平提高、能源转换技术等因素。为此,收集了中国能源消费标准煤总量、国民总收入、国内生产总值GDP、工业增加值、建筑业增加值、交通运输邮电业增加值、人均生活电力消费、能源加工转换效率等1985——2007年的统计数据。本题旨在通过建立这些经济变量的线性模型来说明影响能源消费需求总量的原因。主要数据如下: 1985~2007年统计数据
资料来源:《中国统计年鉴》,中国统计出版社2000、2008年版。 为分析Y 与X1、X2、X3、X4、X5、X6、X7之间的关系,做如下折线图: 能源消费Y 在1986到1996年间缓慢增长,在96至98年有短暂的下跌,但是98至02年开始缓慢回升,02年到06年开始快速增长。 国民总收入X1和国内生产总值X2以相同的趋势逐年缓慢增长。 工业增加值X3在1985年-1999年期间一直是缓慢增长,但在2000年出现了急剧下降的现象,2001年又急剧增长,达到下降前的水平,2001年以后开始缓慢增长。建筑业增长值x4、交通运输邮电业增加值x5、人均生活电力消费x6、能源加工转换效率x7数值较低,但都以较平缓的方式增长。 2、设定并估计多元线性回归模型 t t t t t t t u X X X X X Y ++++++=66554433221ββββββ () 录入数据,得到图。 2.2.1)采用OLS 估计参数 在主界面命令框栏中输入 ls y c x1 x2 x3 x4 x5 x6 x7回车,即可得到参数的估计结果。 由此可见,该模型的可决系数为,修正的可决系数为,模型拟和很好,F 统计量为,回归方程整体上显着。 可是其中的lnX3、lnX4、lnX6对lnY 影响不显着,不仅如此,lnX2、lnX5的参数为负值,在经济意义上不合理。所以这样的回归结果并不理想。 3、多重共线性模型的识别
精品资料 一、对我国30个省市自治区农村居民生活水平作聚类分析 1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察。因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕地面积及农村就业人数。现从2010年的调查资料中
2、将数据进行标准化变换:
3、用K-均值聚类法对样本进行分类如下:
分四类的情况下,最终分类结果如下: 第一类:北京、上海、浙江。 第二类:天津、、辽宁、、福建、甘肃、江苏、广东。 第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南。 第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、。从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平。 二、判别分析 针对以上分类结果进行判别分析。其中将新疆作作为待判样本。判别结果如下:
**. 错误分类的案例 从上可知,只有一个地区判别组和原组不同,回代率为96%。 下面对新疆进行判别: 已知判别函数系数和组质心处函数如下: 判别函数分别为:Y1=0.18x1 +0.493x2 + 0.087x3 + 1.004x4 + 0.381x5 -0.041x6 -0.631x7 Y2=0.398x1+0.687x2 + 0.362x3 + 0.094x4 -0.282x5 + 1.019x6 -0.742x7 Y3=0.394x1-0.197x2 + 0.243x3-0.817x4 + 0.565x5-0.235x6 + 0.802x7 将西藏的指标数据代入函数得:Y1=-1.08671 Y2=-0.62213 Y3=-0.84188 计算Y值与不同类别均值之间的距离分别为:D1=138.5182756 D2=12.11433124 D3=7.027544292 D4=2.869979346 经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符。 三,因子分析: 分析数据在上表的基础上去掉两个耕地面积和农村固定资产投资两个指标。经spss软件分析结果如下:
大连海事大学 实验报告 实验名称:计量经济学软件应用 专业班级:财务管理2013-1 姓名:安妮 指导教师:赵冰茹 交通运输管理学院 二○一六年十一月 一、实验目标 学会常用经济计量软件的基本功能,并将其应用在一元线性回归模型的分析中。具体包括:Eview的安装,样本数据基本统计量计算,一元线性回归模型的建立、检验及结果输出与分析,多元回归模型的建立与分析,异方差、序列相关模型的检验与处理等。二、实验环境 WINDOWSXP或2000操作系统下,基于EVIEWS5.1平台。 三、实验模型建立与分析 案例1:
我国1995-2014年的人均国民生产总值和居民消费支出的统计资料(此资料来自中华人民共和国统计局网站)如表1所示,做回归分析。 表1我国1995-2014年人均国民生产总值与居民消费水平情况
(1)做出散点图,建立居民消费水平随人均国内生产总值变化的一元线性回归方程,并解释斜率的经济意义; 利用eviews软件输出结果报告如下: Dependent Variable: CONSUMPTION Method: Least Squares Date: 06/11/16 Time: 19:02 Sample: 1995 2014 Included observations: 20
Variable Coeffici ent Std. Error t-Statisti c Prob.?? C691.0225113.3920 6.0941040.0000 AVGDP0.3527700.00490871.880540.0000 R-squared0.996528????Mean dependent var7351.300 Adjusted R-squared0.996335????S.D. dependent var4828.765 S.E. of regression292.3118????Akaike info criterion14.28816 Sum squared resid1538032.????Schwarz criterion14.38773 Log likelihood -140.881 6 ????Hannan-Quinn criter.14.30760 F-statistic5166.811????Durbin-Watson stat0.403709 Prob(F-statistic)0.000000 由上表可知财政收入随国内生产总值变化的一元线性回归方程为:
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
统计案例分析及典型例题 §抽样方法 1.为了了解所加工的一批零件的长度,抽取其中200个零件并测量了其长度,在这个问题中,总体的一个样本是 . 答案 200个零件的长度 2.某城区有农民、工人、知识分子家庭共计2 004户,其中农民家庭1 600户,工人家庭303户,现要从中抽取容量为40的样本,则在整个抽样过程中,可以用到下列抽样方法:①简单随机抽样,②系统抽样,③分层抽样中的 . 答案①②③ 3.某企业共有职工150人,其中高级职称15人,中级职称45人,初级职称90人.现采用分层抽样抽取容量为30的样本,则抽取的各职称的人数分别为 . 答案3,9,18 4.某工厂生产A、B、C三种不同型号的产品,其相应产品数量之比为2∶3∶5,现用分层抽样方法抽出一个容量为n的样本,样本中A型号产品有16件,那么此样本的容量n= . 答案80 例1某大学为了支援我国西部教育事业,决定从2007应届毕业生报名的18名志愿者中,选取6人组成志愿小组.请 用抽签法和随机数表法设计抽样方案. 解抽签法: 第一步:将18名志愿者编号,编号为1,2,3, (18) 第二步:将18个号码分别写在18张外形完全相同的纸条上,并揉成团,制成号签; 第三步:将18个号签放入一个不透明的盒子里,充分搅匀; 第四步:从盒子中逐个抽取6个号签,并记录上面的编号; 基础自测
第五步:所得号码对应的志愿者,就是志愿小组的成员. 随机数表法: 第一步:将18名志愿者编号,编号为01,02,03, (18) 第二步:在随机数表中任选一数作为开始,按任意方向读数,比如第8行第29列的数7开始,向右读; 第三步:从数7开始,向右读,每次取两位,凡不在01—18中的数,或已读过的数,都跳过去不作记录,依次可得到12,07,15,13,02,09. 第四步:找出以上号码对应的志愿者,就是志愿小组的成员. 例2 某工厂有1 003名工人,从中抽取10人参加体检,试用系统抽样进行具体实施. 解 (1)将每个人随机编一个号由0001至1003. (2)利用随机数法找到3个号将这3名工人剔除. (3)将剩余的1 000名工人重新随机编号由0001至1000. (4)分段,取间隔k= 10 0001=100将总体均分为10段,每段含100个工人. (5)从第一段即为0001号到0100号中随机抽取一个号l. (6)按编号将l ,100+l ,200+l,…,900+l 共10个号码选出,这10个号码所对应的工人组成样本. 例3 (14分)某一个地区共有5个乡镇,人口3万人,其中人口比例为3∶2∶5∶2∶3,从3万人中抽取一个300人 的样本,分析某种疾病的发病率,已知这种疾病与不同的地理位置及水土有关,问应采取什么样的方法并写出具体过程. 解 应采取分层抽样的方法. 3分 过程如下: (1)将3万人分为五层,其中一个乡镇为一层. 5分 (2)按照样本容量的比例随机抽取各乡镇应抽取的样本. 300×153=60(人);300× 15 2 =40(人); 300×155=100(人);300×15 2=40(人); 300× 15 3=60(人), 10分 因此各乡镇抽取人数分别为60人,40人,100人,40人,60人. 12分 (3)将300人组到一起即得到一个样本. 14分
统计分析报告 基于eviews软件的湖北省人均GDP时间序列模型构建与预测 姓名:刘金玉 学院:经济管理学院 学号:20121002942 指导教师:李奇明 日期:2014年12月14日
基于eviews软件的湖北省人均GDP时间序列 模型构建与预测 1、选题背景 改革开放以来,中国的经济得到飞速发展。1978年至今,中国GDP年均增长超过9%。中国的经济实力明显增强。2001年GDP超过1.1万亿美元,排名升到世界第六位。外汇储备已达2500亿美元。市场在资源配置中已经明显地发挥基础性作用。公有、私有、外资等多种所有制经济共同发展的格局基本形成。宏观调控体系初步建立。我国社会生产力、综合国力、地区发展、产业升级、所有制结构、商品供求等指标均反映出我国经济运行质量良好,为实现第三步战略。在全国的经济飞速发展的大环境下,各省GDP的增长也是最能反映其经济发展状况的指标。而人均 GDP 是最能体现一个省的经济实力、发展水平和生活水准的综合性指标,它不仅考虑了经济总量的大小,而且结合了人口多少的因素,在国际上被广泛用于评价和比较一个地区经济发展水平。尤其是我们这样的人口大国,用这一指标反映经济增长和发展情况更加准确、深刻和富有现实意义。深入分析这一指标对于反映我国经济发展历程、探讨增长规律、研究波动状况,制定相应的宏观调控政策有着十分重要的意义。 本文是以湖北省人均GDP作为研究对象。湖北省人均GDP的增长速度在上世纪90年代增长率有下滑的趋势(见表1)。进入21世纪,继东部沿海地区先发展起来,并涌现出环渤海、长三角、珠三角等城市群,以及中共中央提出“西部大开发”的战略后,中部地区成了“被遗忘的区域”,中部地区经济发展严重滞后于东部沿海地区,为此,中共中央提出了“中部崛起”的重大战略决策。自2004年提出“中部崛起”的重要战略构思后,山西、河南、安徽、湖北、湖南、江西六个省都依托自己的资源和地理优势来扩大地区竞争力,湖北省尤为突出。那么,研究湖北省人均GDP的统计规律性和变动趋势,对于了解湖北省的经济增长规律以及地方政策的制定有特别重要的意义。因此本文试图以湖北省1978-2013年人均GDP 历史数据为样本,通过ARMA 模型对样本进行统计分析,以揭示湖北省人均GDP变化的内在规律性,建立计量经济模型,并在此基础上进行短期外推预测,作为湖北未来几年经济发展的重要参考依据。
第五讲描述性统计分析评价方法——综合指标 实际上,从这一讲开始的教学内容都是介绍教育评价技术中的重要方法——教育统计分析方法,也即是分析资料的方法。其中包括描述性统计分析方法和推断性统计分析方法两大部分。 一、描述性统计分析评价方法的主要特点。对数据资料计算综合指标,然后根据综合指标值对教育客观事物给予评价。所谓综合指标指的是从数量方面综合说明事物特征的指标。常用的综合指标有绝对数、相对数、平均数和标准差。重点介绍后面两种。 二、综合指标的计算及解释 (一)绝对数(规模) (二)相对数(程度) (三)平均数(水平) 通常可用符号表示平均数 1.算术平均数(未经分类汇总的测量数据资料)计算方法见p62的(4.1)公式。 2.加权平均数(已经分类汇总的资料)
①组距数列平均数(对测量数据分组统计人数)例如P63表4-1的资料。计算方法如P63的(4.2)公式及83名教师平均年龄的计算。 * 为了减少计算的麻烦,在此介绍计算器统计功能的使用: A、操作步骤 计算器的统计功能的计算只能得到如下六个统计结果:n(数据个数)、(数据和)、(数据平方和)、(平均数)、(总体标准差)和S(样本标准差)。操作步骤如下:1)显示统计状态:2ndF STAT(或SD) 2)输入数据:每输入一个数据按DATA 3)取出统计结果:这时六个统计结果均处于待取状态,可根据需要取出其中的结果。 B、注意事项 1)若需继续进行第二组数据的统计运算时,需取消统计状态,再按上述步骤操作。按2ndF STAT即可取消统计的状态。 2)若不需要计算、、、、和S时(即进行 其他一般运算时),也应取消统计状态)。
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。
航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法顾客提出的意见是否合理请你对上面的数据进行适当的分析,回答下列问题。 (1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理为什么 (4)使用哪一个平均指标来分析上述问题比较合理 答:(1): 2:
从表中我们可以得到中位数为众数为1平均数为标准差为 (3):合理,虽然他的平均数是<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤
第4章图形和统计量分析 EViews软件提供了序列(Series)和序列组(Group)等对象的各种视图、统计分析方法和过程。当序列对象中输入数据后,就可对序列对象中输入的数据进行统计分析,并且可以通过图、表等形式进行描述。本章将介绍序列和序列组对象图形的生成和描述性统计量及其检验。 4.1 图形对象 图形(Graph)对象可以形成序列和序列组等对象的各种视图,如线图(Line)、散点图(Scatter)以及饼图(Pie)等。通过图形可以进一步观察和分析数据的变化趋势和规律。下面介绍图形对象的基本操作。 4.1.1 图形(Graph)对象的生成 图形对象也是工作文件中的基本对象之一。要生成图形对象需首先打开序列对象窗口或序列组对象窗口,选择对象窗口工具栏中的“View”|“Graph”选项。选择的对象类型不同,将弹出不同的窗口。如果在序列对象窗口下选择“View”|“Graph”选项,将弹出如图4-1所示的界面。
. . 图4-1 序列窗口下图形对象的生成 此时“Graph”弹出的菜单中有6种图形可供选择。“Line”表示生成的是折线图,如图4-2所示,其横轴表示时间或序列的顺序,纵轴表示序列对象观测值的大小。“Area”表示生成面积图,其图形的形状与“Line”(折线图)相同,不同的是“Area”(面积图)曲线下方是被填满的,而“Line”(折线图)下方是空白。 图4-2 “Line”折线图 “Bar”表示为条形图,用条状的高度表示观测值的大小。“Spike”表示尖峰图,由竖线组成,每根竖线的高度代表观测值的大小。“Seasonal Stacked Line”表示生成的是季节性堆叠图,“Seasonal Split Line”表示生成的是季节性分割线。 如果在序列组(群)对象窗口下选择“View”|“Graph”选项,将弹出如图4-3所示的界面。这里有9种图形可供选择。其前4种与上面讲述的相同。 图4-3 序列组(群)窗口下图对象的生成
统计学案例实习教学大纲(课程编号:00700397) 适用年级: 是否双语:是 否
课程类别:E:集中性实践 学时学分:课程总学时2周其中实验(上机)学时学分 2 先修课程:《统计学》《统计学案例》《市场调查与分析》 开课单位:管理学院统计系 适用专业统计学 开课学期 4 二、实践环节简介 统计学案例实习课程是统计学专业的一门技术基础课,是专业选修课程,也是统计学专业的重要实践环节课。它是在学习了统计学、市场调查与分析相关理论和方法的基础上,如何将相关理论和方法运用于实际问题的解决。拉近理论与现实的距离,使统计学专业的学生更好地掌握统计综合指标的计算和应用,抽样调查的基本理论和方法,统计预测的理论、方法及应用,并提高实践动手能力和综合分析能力。 三、实践环节教学目的与基本要求 教学目的: 1.通过课程实习,应使学生掌握统计学的基本理论,统计研究的基本方法,掌握统计综合指标的计算和应用,统计指数的编制和分析,抽样调查的基本理论和方法,掌握统计预测的理论、方法及应用。 2.通过课程实习,培养学生具备对经济运行的实际内容进行具体的计算分析,培养学生用统计方法解决实际问题的能力。 3.通过具体而全面的统计案例实习来启发学生的悟性,挖掘学生的潜能,培养学生用统计理论和统计方法解决实际问题的动手能力和创新能力,提高学生的统计素质。 基本要求: 在已学习了统计学、市场调查与分析和统计学案例等课程的前提下,要求学生既能够独立完成各项实习,又能够养成团队协作的精神,共同撰写实习报告。 四、实践环节注意事项 实习方式:学生自己动手实习。 1、以小组为单位进行实习。 2、实行开放式实习教学,增加学生选择实验项目和实验时间的自主性。 注意事项:1、实习前由教师向学生讲明课程内容、进度安排、书写实验报告要求等。 2、实习4-6人为一组, 分工、协作共同完成。 3、实习报告是本实习教学的一个重要环节, 需要学生掌握的内容可以通过实习报告反映学生对其掌握程度, 让教师了解尚存在的问题。 五、实践环节主要内容与时间安排 (一) 实习项目一大学生生活费收支状况调查 知识点:调查方案设计的基本内容,设计方法 重点:各种抽样统计调查方法的特点和应用条件 难点:大学生生活费收支状况分析 实习项目二关于逃课问题的调查 知识点:调查方案设计 重点:问卷设计 难点:对逃课问题分析。 实习项目三福州大学本科生自习情况调查 知识点:调查方案设计 重点:问卷设计
主讲人:刘莎莎 第三讲 描述性统计分析
一、 序列窗口下的描述性统计分析
知识点 1:如何以建立组对象的方式将数据导入到 Eviews 中去(第二种导入数 据的方式) 。 知识点 2:如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态 分布曲线叠加在一起,从而更直观地观察数据的分布特征。 (如何将 EViews 图形 复制粘贴到 word 中) 知识点 3:如何在序列窗口下实现描述性统计量的假设检验 知识点 4:如何实现将单序列按某一变量分类后再进行描述性统计分析(本案例 的分类变量是该天是星期几) 知识点 5:如何实现将单序列按某一变量分类后再进行假设检验 知识点 6:如何画上证综指日对数收益率的 QQ 图 知识点 7:如何估计数据的经验分布函数的参数 案例数据说明:2003 年 1 月 6 日-2009 年 6 月 26 日上证综指日对数收益率。
二、序列组窗口下的描述性统计分析
知识点 1:如何通过打开 excel 文件的方式将数据导入到 Eviews 中去。 (第三种 导入数据的方式) 。 知识点 2:如何实现多变量的描述性统计量 知识点 3:如何实现多变量描述性统计量的假设检验 案例数据说明:国家统计调查队分别在两个地区调查了 10 个家庭的收入 知识点 4:如何计算当前序列组的相关系数矩阵,协方差矩阵
主讲人:刘莎莎
案例数据说明:1983-2000 年我国粮食生产与相关投入的数据,变量包括粮食产 量(单位:万吨)、农业化肥施用量(单位:万千克)、粮食播种面积(单位: 公顷)
附注:描述性统计量的计算公式
标准差(Std.Dev.)的计算公式是:
s=
2 ( y ? y ) ∑ t t =1
T
T ?1
其中,
yt 是观测值, y 是样本平均数。
偏度(Skewness)的计算公式是:
1 T yt ? y 3 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。对
称分布的偏度是零,比如正态分布。
峰度(Kurtosis)的计算公式是:
1 T yt ? y 4 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。
正态分布的峰度值是 3。
Executive summary With the development of globalization and information technology, outsourcing has gained great popularity all over the world. On the other hand, virtual works have more chances to find freelance works with the development of outsourcing. The reasons for outsourcing includes low operational and labor costs, tax breaks, to gain more global and local market share, to reduce risks, to move to higher segments of the value added chain, to serve for innovation as well as to focus to accelerate business transformation. Now the Brammer is encountered with a problem of management that the purchasing and management of spares for the daily operations, maintenance and repair of production and manufacturing equipment is often a complex, time and resource consuming issue for most organizations. The Brammer is considering whether they will outsource the management of spares. This research will focus on identifying a management problem of the Brammer and designing an appropriate business research strategy for success in business. What is more, the essay will choose a qualitative research methodology to investigate the organizational management problem of the Brammer.
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如 何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析
案例2 美国国家健康照顾协会 美国国家健康照顾协会的主要任务是了解健康照顾人力资源的短缺情况,并为未来制定发展规划。为了掌握护理人员对所从事工作的满意程度,该协会发起了一场全国性的有关医院护理人员的调查研究。调查项目包括:工作满意度、收入、晋升机会等,填答方式采用打分制,从0~100分,分值高表示满意度高。下面是其中的一部分调查结果: 另外,按医院招募护理人员的方式,对上述资料的分组结果如下:
要求:运用描述统计方法对资料进行处理,采用的表示方法要让人能够方便地获取相应的信息,对你发现出的问题给予讨论。尤其要讨论下列内容: (1)根据给定的数据资料,指出哪些方面护理人员感到最为满意,哪些方面最不满意。有可能的话,请提出改进的措施并进行讨论。 由题目,做出如下统计分析: 列1 列2 列3
有上述分析,可知护理人员感到最为满意的是工作,收入方面最不满意。 改进措施: (2)根据变异分析的结果,为什么医护人员对工作满意度的意见差异那么大? 答:a.从列1的分析结果可知,平均数=79.8<中位数=82<众数=84,可知数据呈左偏分布,即:数据中存在极小值使得算数平均数偏向较小的一方,又因为中位数小于众数,可知数据中的较小值所占得数目较多。综上所述,列1,即工作所取得得数据中,有很多人打得分数较低,也就是说,很多人对工作都相当不满意,因此,数据的差异性较大,方差较大,医护人员对工作满意度的意见差异也很大。 b.计算各列的变异系数可得:列1变异系数=1.172125228/79.8=0.01469;列2变异系数=2.086723826/54.44=0.03833;列3变异系数=2.288884/58.36=0.03922;可知列1变异系数=0.01469>列3变异系数=0.03922>列2变异系数=0.03833;所以工作的离散系数最大,可知工作中平均数的代表性最小,说明很多分对工作并不满意,即:数据的差异性较大,方差较大,医护人员对工作满意度的意见差异也很大。 (3)从分类资料中,你能得出什么样的结论?各类医院之间,医护人员对工作满意度的差别如何,哪一类医院的情况最好? 私立医院 退伍军人
1、中国的轿车生产是否与GDP、城镇居民人均可支配收入、城镇 居民家庭恩格尔系数、私人载客汽车拥有量、公路里程等都 有密切关系?如果有关系,它们之间是种什么关系?关系强 度如何? (1)分析轿车生产量与私人载客汽车拥有量之间的关系: 首先,求的因变量轿车生产量y和自变量私人载客汽车拥有量x1的相关系数r=0.992018,说明两者间存在一定的线性相关关系且正相关程度很强。 然后以轿车生产量为因变量y,私人载客汽车拥有量x1为自变量进行一元线性回归分析,结果如下: ①由回归统计中的R=0.984101看出,所建立的回归模型对样本观测值的拟合程度很好; ②估计出的样本回归函数为:?=1.775687+0.206783 x1,说明私人载客汽车拥有量每增加1万辆,轿车生产量增加2067.83辆; ③由上表中a和β?的p值分别是0.709481543和6.60805E-15,显然a的p值大于显著性水 平α=0.05,不能拒绝原假设α=0,而β?的p值远小于显著性水平α=0.05,拒绝原假设β=0,说明私人载客汽车拥有量对轿车生产量有显著影响。
(2)分析轿车生产量与城镇居民家庭恩格尔系数之间的关系: 首先,求的因变量轿车生产量y和自变量城镇居民家庭恩格尔系数x2的相关系数r=-0.77499,说明两者间存在一定的线性相关关系但负相关程度一般。 然后以轿车生产量为因变量y,城镇居民家庭恩格尔系数x2为自变量进行一元线性回归分析,结果如下: 由回归统计中的R=0.600608看出,所建立的回归模型对样本观测值的拟合程度一般,综合其相关系数值可知此二者关系不太符合所建立的线性模型,说明二者间没有密切的线性相关关系。 (3)分析轿车生产量与公路里程之间的关系: 首先,求的因变量轿车生产量y和自变量公路里程x3的相关系数r=0.941214,说明两者间存在一定的线性相关关系且正相关程度较强。 然后以轿车生产量为因变量y,公路里程x3为自变量进行一元线性回归分析,结果如下:
统计案例分析及典型例题 §11.1 抽样方法 1.为了了解所加工的一批零件的长度,抽取其中200个零件并测量了其长度,在这个问题中,总体的一个样本是 . 答案 200个零件的长度 2.某城区有农民、工人、知识分子家庭共计2 004户,其中农民家庭1 600户,工人家庭303户,现要从中抽取容量为40的样本,则在整个抽样过程中,可以用到下列抽样方法:①简单随机抽样,②系统抽样,③分层抽样中的 . 答案 ①②③ 3.某企业共有职工150人,其中高级职称15人,中级职称45人,初级职称90人.现采用分层抽样抽取容量为30的样本,则抽取的各职称的人数分别为 . 答案 3,9,18 4.某工厂生产A 、B 、C 三种不同型号的产品,其相应产品数量之比为2∶3∶5,现用分层抽样方法抽出一个容量为n 的样本,样本中A 型号产品有16件,那么此样本的容量n = . 答案 80 例1 某大学为了支援我国西部教育事业,决定从2007应届毕业生报名的18名志愿者中,选取6人组成志愿小组.请 用抽签法和随机数表法设计抽样方案. 解 抽签法: 第一步:将18名志愿者编号,编号为1,2,3, (18) 第二步:将18个号码分别写在18张外形完全相同的纸条上,并揉成团,制成号签; 第三步:将18个号签放入一个不透明的盒子里,充分搅匀; 第四步:从盒子中逐个抽取6个号签,并记录上面的编号; 第五步:所得号码对应的志愿者,就是志愿小组的成员 . 基础自测
随机数表法: 第一步:将18名志愿者编号,编号为01,02,03, (18) 第二步:在随机数表中任选一数作为开始,按任意方向读数,比如第8行第29列的数7开始,向右读; 第三步:从数7开始,向右读,每次取两位,凡不在01—18中的数,或已读过的数,都跳过去不作记录,依次可得到12,07,15,13,02,09. 第四步:找出以上号码对应的志愿者,就是志愿小组的成员. 例2 某工厂有1 003名工人,从中抽取10人参加体检,试用系统抽样进行具体实施. 解 (1)将每个人随机编一个号由0001至1003. (2)利用随机数法找到3个号将这3名工人剔除. (3)将剩余的1 000名工人重新随机编号由0001至1000. (4)分段,取间隔k = 10 000 1=100将总体均分为10段,每段含100个工人. (5)从第一段即为0001号到0100号中随机抽取一个号l . (6)按编号将l ,100+l ,200+l ,…,900+l 共10个号码选出,这10个号码所对应的工人组成样本. 例3 (14分)某一个地区共有5个乡镇,人口3万人,其中人口比例为3∶2∶5∶2∶3,从3万人中抽取一个300人 的样本,分析某种疾病的发病率,已知这种疾病与不同的地理位置及水土有关,问应采取什么样的方法?并写出具体过程. 解 应采取分层抽样的方法. 3分 过程如下: (1)将3万人分为五层,其中一个乡镇为一层. 5分 (2)按照样本容量的比例随机抽取各乡镇应抽取的样本. 300×153=60(人);300× 15 2 =40(人); 300×155=100(人);300×15 2=40(人); 300× 15 3=60(人), 10分 因此各乡镇抽取人数分别为60人,40人,100人,40人,60人. 12分 (3)将300人组到一起即得到一个样本. 14分 练习: