MemCache是一套高性能分布式的高速缓存系统,用于动态Web应用以减轻数据库负载,由LiveJournal的Brad Fitzpatrick开发。目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著。这是一套开放源代码软件,以BSD license授权发布。
MemCache通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。MemCache是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。
MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得MemCache能用于Java、C/C++/C#、Perl、
Python、PHP、Ruby等大部分流行的程序语言。
MemCache工作原理MemCache采用C/S架构,在服务器端启动后,以守护程序的方式,监听客户端的请求。启
动时可以指定监听的IP(服务器的内网ip/外网ip)、端口号(所以做分布式测试时,一台服务器上可以启动多个不同端口号的MemCached进程)、使用的内存大小等关键参数。一旦启动,服务就会一直处于可用状态。
为了提高性能,MemCache缓存的数据全部存储在MemCache管理的内存中,所以重启服务器之后缓存数据会清空,不支持持久化。
MemCache内存管理
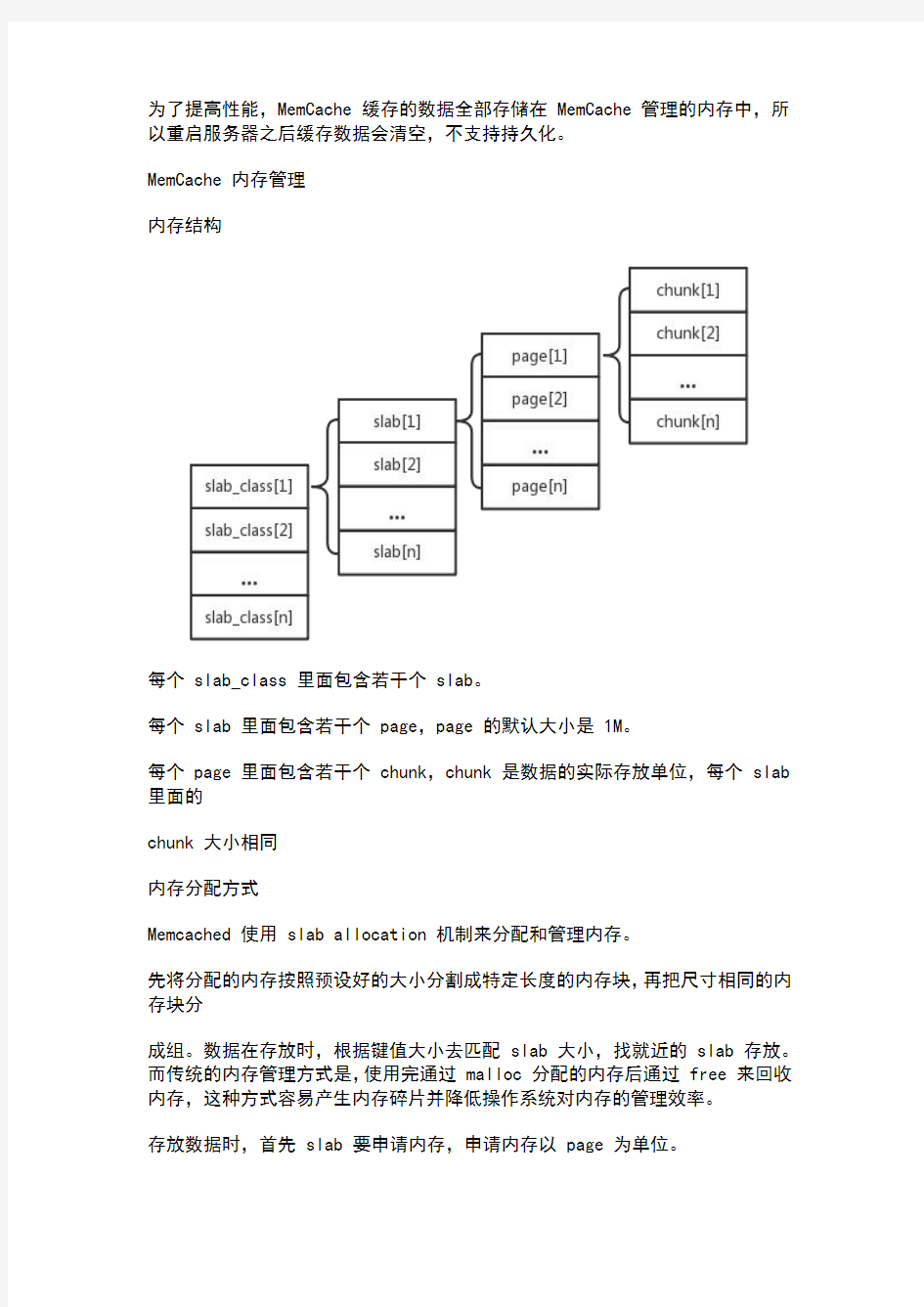
内存结构
每个slab_class里面包含若干个slab。
每个slab里面包含若干个page,page的默认大小是1M。
每个page里面包含若干个chunk,chunk是数据的实际存放单位,每个slab 里面的
chunk大小相同
内存分配方式
Memcached使用slab allocation机制来分配和管理内存。
先将分配的内存按照预设好的大小分割成特定长度的内存块,再把尺寸相同的内存块分
成组。数据在存放时,根据键值大小去匹配slab大小,找就近的slab存放。而传统的内存管理方式是,使用完通过malloc分配的内存后通过free来回收内存,这种方式容易产生内存碎片并降低操作系统对内存的管理效率。
存放数据时,首先slab要申请内存,申请内存以page为单位。
在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个
chunk数组,最后从这个chunk数组中选择一个用于存储数据。示例:
本例中,slab[1]的chunk大小为88字节、slab[2]的chunk大小为112字节、slab[3]的
chunk大小为144字节...(默认相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么一个100字节大小的value,将被放到slab[2]中。
这是由于在MemCache中,value的存放位置由其大小决定,value会被存放到与chunk
大小最接近的一个slab中,即slab allocation机制。
内存回收方式
由于slab allocator机制中,分配的chunk大小是固定的,因此可能会造成内存的浪费。对
于chunk空间的浪费问题,无法彻底解决,只能缓解该问题。
不同于FIFO(First In,First Out)删除机制,当数据容量用完MemCached分配的内存后,就会基于LRU(Least Recently Used)算法清理失效的缓存数据(放入数据时可设置失效时间),或者清理最近最少使用的缓存数据,然后放入新的数据。
在LRU中,MemCached使用的是一种Lazy Expiration策略,不会监控存入的key/value对是否过期,而是在获取key值时查看记录的时间戳,检查
key/value对空间是否过期,这样可减轻服务器的负载,即过期数据惰性删除,节省了cpu时间和检测成本。
如果MemCache启动没有追加-M,则表示禁止LRU,这种情况下内存不够时会报Out Of Memory错误。
MemCache分布式存储
为了提升MemCache的存储容量和性能,可能会有多个MemCache服务器来对客户端提供服务,这就是MemCache的分布式。
分布式实现原理
MemCache采用了单进程、单线程、异步I/O,基于事件(event_based)的服务方式,使用
libevent作为事件通知实现分布式存储。
MemCache当中的Server可以协同工作,但他们之间保存的数据各不相同,而且并不通信,每个Server只管理自己的数据。服务端并没有“分布式”功能。Client端通过IP地址和端口号指定Server端,将需要缓存的数据以
key-value的对应形式保存在Server端。key值通过hash进行转换,根据hash值把value传递到对应的具体的某个Server上。
当需要获取对象数据时,也根据key进行获取。首先对key进行hash转换,通过获得的值可以确定它被保存在了哪台Server上,然后再向该Server发出请求。Client端只需要知道保存hash(key)的值在哪台服务器上即可。
向MemCache集群存入/取出key/value时,MemCache客户端程序根据一定的算法计算存入哪台服务器,然后再把key/value值存到此服务器中。
亦即是说,存取数据分为二步:1.选择服务器;2.存/取数据。
分布式算法解析
余数算法:
根据键的整数散列值(键string的HashCODE值),除以服务器台数,根据余数确定存取服务器,这种方法计算简单,高效,但在MemCache服务器数量变化时,几乎所有的缓存都会失效。
散列算法:
先算出MemCache服务器的散列值,并将其分布到0到2^32的圆上,然后用同样的方法算出存储数据的键的散列值并映射至圆上,最后从数据映射到的位置开始顺时针查找,将数据保存到查找到的第一个服务器上,如果超过2^32,依然找不到服务器,就将数据保存到第
一台MemCache服务器上。如果添加了一台MemCache服务器,只在圆上增加服务器的逆时针方向的第一台服务器上的键会受到影响。
MemCache线程管理
MemCache网络模型是典型的单进程多线程模型。采用libevent处理网络请求,主进程负责将新来的连接分配给work线程,work线程负责处理连接,有点类似于负载均衡,通过主进程分发到对应的工作线程。
MemCache默认有7个线程,4个主要的工作线程,3个辅助线程,线程可划分为以下4种:
主线程:负责MemCache服务器初始化,监听TCP、Unix Domain连接请求;
工作线程池:MemCache默认4个工作线程,可通过启动参数修改,负责处理TCP、
UDP,Unix域套接口链路上的请求;
assoc维护线程:MemCache内存中维护一张巨大的hash表,该线程负责hash 表动态
增长;
slab维护线程:即内存管理模块维护线程,负责class中slab的平衡,MemCache启动选项中可关闭该线程。
MemCache特性与限制
MemCache中可以保存的item数据量是没有限制的,只要内存足够。
MemCache单进程在32位机中最大使用内存为2G,在64位机中则没有限制。
Key的最大长度为250个字节,超过该长度将无法存储,由常量
KEY_MAX_LENGTH250控制。
单个item最大数据是1MB,超过1MB的数据不予存储,由常量POWER_BLOCK 1048576
进行控制。
MemCache服务端是不安全的。比如已知某个MemCache节点,可以直接telnet 过去,并通过flush_all让已经存在的键值对立即失效,所以MemCache服务器最好配置到内网环境,通过防火墙制定可访问客户端。
不能够遍历MemCache中所有的item。因为这个操作的速度相对缓慢且会阻塞其他的操作。
MemCache的高性能源自于两阶段哈希结构:第一阶段在客户端,通过Hash算法根据Key值算出一个节点;第二阶段在服务端,通过一个内部的Hash算法,查找真正的item并返回给客户端。从实现的角度看,MemCache是一个非阻塞的、基于事件的服务器程序。
MemCache设置添加某一个Key值的时候,虽然传入expiry为0表示这个Key值永久有效,但是这个Key值也会在30天之后失效。由常量REALTIME_MAXDELTA60*60*24*30控制。
最大同时连接数是200,通过conn_init()中的freetotal进行控制,最大软连接数是1024,通过settings.maxconns=1024进行控制。
跟空间占用相关的参数:settings.factor=1.25,settings.chunk_size=48,影响slab的数据占用和步进方式。
MemCache是键值一一对应,key默认最大不能超过128个字节,value默认大小是1M,也就是一个slabs,如果要存2M的值(连续的),不能用两个slabs,因为两个slabs不是连续的,无法在内存中存储,故需要修改slabs的大小,多个key和value进行存储时,即使这个slabs没有利用完,那么也不会存放别的数据。
MemCache已经可以支持C/C++、Perl、PHP、Python、Ruby、Java、C#、Postgres、Chicken Scheme、Lua、MySQL和Protocol等语言客户端。
分布式缓存服务器设计原理 1.数据是如何被分布到多个服务器上的?(一致性哈希算法) 假设有n台服务器, 计算这n台服务器的IP地址的哈希值, 把这些哈希值从小到大按顺时针排列组成一个“服务器节点环”, 客户端需要存储一系列的“键值对”到这些服务器上去, 计算这些“键”的哈希值, 看看这些“键”的哈希值落在“服务器环”的哪些区间, 如下图所示: 根据上图示意,数据将被存储在“顺时针方向上的下一个服务器节点” 读取数据时,也是先根据“键”的哈希值,找到这个服务器节点, 再向这个节点索取数据。 2.数据如何均匀的分布?(虚拟服务器) 假设服务器数量较少, 很可能造成有些服务器存储的数据较多、承担的压力较大, 有些服务器就比较空闲。 这时就要把一台服务器虚拟化成多台服务器, 具体的操作办法: 在计算服务器对应的哈希值时 可以在IP地址字符串加多个“尾缀” 比如:
10.0.0.1#1 10.0.0.1#2 10.0.0.1#3 .... 这样,一台物理服务器就被虚拟化成多台服务器, 对应“服务器环”上的多个节点。 3.如何实现数据的热备份? 以顺时针方向看“服务器环” 当有客户端把数据存储在第1台服务器上后, 第1台服务器负责把该数据拷贝一份给第2台服务器 以此类推, 也就是说“服务器环”上的每一个节点,都是上一个节点的热备份节点 同时,一个服务器上存了两类数据,一类是自身的业务数据,一类是上一节点的热备数据。注意:这里所说的服务器,都是物理服务器,不是虚拟服务器。 如下图所示 4.如何让客户端发现所有服务端? 每个服务器节点都要维护一个对照表 这个对照表中包含所有服务器,(IP地址和IP地址的哈希值对照表) 配置客户端时,只要让客户端知道任意一个服务器的IP地址即可 客户端可以通过获取这个服务器的对照表从而知道所有的服务器 客户端初始化的时候,这个对照表也存储在客户端一份 客户端根据这个对照表来存取数据
第1章分布式计算概述 一、选择题 1,CD 2,ABC 3,ABCD 4,ACD 二、简答题 1,参考1.1.1和节 2,参考1.1.2节 3,分布式计算的核心技术是进程间通信,参考1.3.2节 4,单播和组播 5,超时和多线程 三、实验题 1.进程A在进程B发送receive前发起send操作 进程A进程B 发出非阻塞send操 作,进程A继续运行 发出阻塞receive操 作,进程B被阻塞进程B在进程A发起send前发出receive操作
发出非阻塞send 操作,进程A 继续运行 发出阻塞receive 操作,进程B 被阻塞 收到进程A 发送的数据,进程B 被唤醒 2. 进程A 在进程B 发送receive 前发起send 操作 进程A 进程B 发出阻塞send 操作, 进程A 被阻塞 发出阻塞receive 操作,进程B 被阻塞 进程B 在进程A 发起send 前发出receive 操作
发出阻塞send操作,进程A被阻塞 发出阻塞receive操作,进程B 被阻塞 收到进程A发送的数据,进程B 被唤醒 收到进程B返回的数 据,进程A被唤醒 3.1).在提供阻塞send操作和阻塞receive操作的通信系统中在提供非阻塞send操作和阻塞receive操作的通信系统中2).P1,P2,P3进程间通信的顺序状态图 m1 m1 m2 m2 第2章分布式计算范型概述 1.消息传递,客户-服务器,P2P,分布式对象,网络服务,移动代理等 2.分布式应用最广泛最流行的范型是客户-服务器范型,参考节
3.分布式应用最基本的范型是消息传递模型,参考节 4.参考节,P2P应用有很多,例如Napster,迅雷,PPS网络电视等 5.参考节 6.参考节 7.略 8.消息传递模式是最基本的分布式计算范型,适用于大多数应用;客户-服务器范型是最 流行的分布式计算范型,应用最为广泛;P2P范型又称为对等结构范型,使得网络以最有效率的方式运行,适用于各参与者地位平等的网络;分布式对象范型,是抽象化的远程调用,适用于复杂的分布式计算应用等。 9.略 10.中间件又称为代理,中间件为参与对象提供内容抽象,隐藏对象引用,起到中介作用。 11.略 第3章 Socket编程与客户服务器应用开发 一、填空题 1.数据包socket,流式socket 2.无连接方式,面向连接方式 3.数据层,业务层,应用层 4.迭代服务器和并发服务器 5.有状态服务器和无状态服务器 二、简答题 1.API:Application Programming Interface,应用程序编程接口,是一些预先定义 的函数,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能 力,而又无需访问源码,或理解内部工作机制的细节 Socket API:套接字应用程序编程接口,适用于进程间通信的套接字应用程序编程 接口
微信公众平台开发-PHP视频教程 课程目标 1、了解微信公众平台的原理 2、根据微信公众平台所提供的开发接口来开发一个属于自己的微信 公众平台。3、开发中常用工具的使用。 适用人群 PHP爱好者,具有PHP基础及PHP面向对象相关知识的学员。 课程简介 1、微信公众平台开发者功能启用配置 2、基于新浪SAE平台开发微信公众平台 3、微信公众平台服务器及客户端交互 4、基于VPS开发微信公众平台 5、微信公众平台关注、取消关注等事件 6、微信公众平台文字、图片等消息 7、微信公众平台简单回复 8、微信公众平台机器人API 9、微信公众平台天气API 10、微信公众平台自定义菜单开发 11、微信公众平台微站开发 12、微信公众平台后台管理平台开发 备注:此课程在线服务器为Linux操作系统,开发方式为企业真实开发方式。 第一章课程介绍 1课时5分钟 1 课程介绍 [免费观看] 5分钟 本课程课程目标、课程要求及课程内容介绍。 第二章小试牛刀 4课时29分钟 2 微信公众平台介绍 [免费观看]
5分钟 介绍什么是微信公众平台,微信公众平台的分类,如何申请微信公众平台。 3 微信公众平台开发者接入 [免费观看] 10分钟 新浪SAE平台的申请,应用创建,具体使用,上传代码并进行开发者接入验证; 4 微信公众号默认消息回复 [免费观看] 7分钟 开发者中心配置,如何进行接入,开启微信默认回复。 5 微信公众号简单消息回复 [免费观看] 5分钟 对responseMsg()方法进行修改并完成简单消息回复功能! 第三章基于VPS开发微信公众平台 34课时5小时35分钟 6 VPS介绍 7分钟 什么是VPS,VPS的优点,如何购买VPS。 7 FTP工具filezilla介绍及使用 6分钟 什么是FTP,filezilla工具介绍及使用。 8
分布式缓存的最佳实践案例分析
本文主要介绍使用分布式缓存的优秀实践和线上案例。这些案例是笔者在多家互联网公司里积累并形成的优秀实践,能够帮助大家在生产实践中避免很多不必要的生产事故。 一、缓存设计的核心要素 我们在应用中决定使用缓存时,通常需要进行详细的设计,因为设计缓存架构看似简单,实则不然,里面蕴含了很多深奥的原理,如果使用不当,则会造成很多生产事故甚至是服务雪崩之类的严重问题。 笔者在做设计评审的过程中,总结了所有与缓存设计相关的设计点,这里列出来供大家参考。 1、容量规划 ?缓存内容的大小 ?缓存内容的数量 ?淘汰策略 ?缓存的数据结构 ?每秒的读峰值 ?每秒的写峰值
2、性能优化 ?线程模型 ?预热方法 ?缓存分片 ?冷热数据的比例3、高可用 ?复制模型 ?失效转移 ?持久策略 ?缓存重建 4、缓存监控 ?缓存服务监控 ?缓存容量监控
?缓存请求监控 ?缓存响应时间监控 5、注意事项 ?是否有可能发生缓存穿透 ?是否有大对象 ?是否使用缓存实现分布式锁 ?是否使用缓存支持的脚本(Lua) ?是否避免了Race Condition 笔者在这里把这些设计点提供给读者,请读者在做缓存设计时把每一项作为一个思考的起点,思考我们在设计缓存时是否想到了这些点,以避免在设计的过程中因忽略某一项而导致严重的线上事故发生。 二、缓存设计的优秀实践 笔者在做设计评审的过程中,总结了一些开发人员在设计缓存系统时的优秀实践,如下所述:
优秀实践1 缓存系统主要消耗的是服务器的内存,因此,在使用缓存时必须先对应用需要缓存的数据大小进行评估,包括缓存的数据结构、缓存大小、缓存数量、缓存的失效时间,然后根据业务情况自行推算在未来一定时间内的容量的使用情况,根据容量评估的结果来申请和分配缓存资源,否则会造成资源浪费或者缓存空间不够。 优秀实践2 建议将使用缓存的业务进行分离,核心业务和非核心业务使用不同的缓存实例,从物理上进行隔离,如果有条件,则请对每个业务使用单独的实例或者集群,以减小应用之间互相影响的可能性。笔者就经常听说有的公司应用了共享缓存,造成缓存数据被覆盖以及缓存数据错乱的线上事故。 优秀实践3
高性能计算、分布式计算、网格计算、云计算--概念和区别 《程序员》2009-02 P34 “见证高性能计算21年” 高性能计算(High Performance Computing)HPC是计算机科学的一个分支,研究并行算法和开发相关软件,致力于开发高性能计算机(High Performance Computer)。 分布式计算是利用互联网上的计算机的中央处理器的闲置处理能力来解决大型计算问题的一种计算科学。 网格计算也是一种分布式计算。网格计算的思路是聚合分布资源,支持虚拟组织,提供高层次的服务,例如分布协同科学研究等。网格计算更多地面向科研应用,商业模型不清晰。网格计算则是聚合分散的资源,支持大型集中式应用(一个大的应用分到多处执行)。 云计算(Cloud Computing)是分布式处理(Distributed Computing)、并行处理(Parallel Computing)和网格计算(Grid Computing)的发展,或者说是这些计算机科学概念的商业实现。云计算的资源相对集中,主要以数据中心的形式提供底层资源的使用,并不强调虚拟组织(VO)的概念。云计算从诞生开始就是针对企业商业应用,商业模型比较清晰。云计算是以相对集中的资源,运行分散的应用(大量分散的应用在若干大的中心执行);
目录 高性能计算、分布式计算、网格计算、云计算--概念和区别 (1) 高性能计算 (3) 百科名片 (3) 概念 (3) 服务领域 (3) 网格 (5) 百科名片 (5) 网格的产生 (5) 网格技术的特征及其体系结构 (5) 高性能计算机的发展与应用 (17) 我国高性能计算机应用前景及发展中的问题 (17) 高性能计算机与大众生活息息相关 (17) 高性能计算机发展任重道远 (18) 分布式计算、网格计算和云计算 (21) 分布式计算 (21) 网格计算 (21) 云计算 (22) 网格计算和云计算的概念和区别 (24) 目标不同 (24) 分配资源方式的不同 (25) 殊途同归 (26) 钱德沛教授:云计算和网格计算差别何在? (27) 云计算与网格计算的概念 (27) 网格计算的特点是什么呢? (27) 云计算与网格计算区别何在 (28)
电子商务专题讲座课程论文题目:关于云 系部名称:经济管理系专业班级:营销101班 学生姓名:王丽敏学号:201004024108课程教师:王趁荣教师职称:副教授 2012年12月26日
云[1]是指停留大气层上的水滴或冰晶胶体的集合体。云是地球上庞大的水循环的有形的结果。太阳照在地球的表面,水蒸发形成水蒸气,一旦水汽过饱和,水分子就会聚集在空气中的微尘(凝结核)周围,由此产生的水滴或冰晶将阳光散射到各个方向,这就产生了云的外观。这就是在我们的生活中普遍见到的现象“云”。然而现在它却是其他的代名词,我要讲的包括阿里巴巴旗下的云计划、百度旗下的百度云以及云计算的形成和发展。 先讲一下阿里巴巴旗下的云计划,我第一次听到云计划是老师在课堂上讲阿里巴巴时提到的,当时很好奇,所以就开始慢慢了解关于云计划。我在淘宝开店时同时在阿里巴巴上注册了账号,因此可以直接进入云计划上面的生意经网站。在这之前先了解云计划的概念,发展历程以及计划。 首先,云计划的定义 云计划[2]是一个打造小企业商业智慧分享成长平台。它集合商业名家、专家学者和公众的力量,解决千万小企业的难题,助力小企业成长。由马云担任首席导师,携手由商业名家、专业机构、知名网商等组成的导师团,他们一起与小企业创业者和个人网商采取问答互动形式,进行线上交流。 第二,云计划由来 2010年5月14日,阿里巴巴店举办2010年全球股东大会。大会由阿里巴巴集团董事局主席马云及阿里巴巴公司CEO卫哲主持,吸引了包括摩根士丹利、摩根大通等国际知名投行前来。 在股东大会上,马云作为首期创业导师,启动了由他所倡导的小企业商业智慧分享平台——云计划,分享企业经营管理方面的经验和理念,帮助小企业们共同成长。 第三,“云计划”实践 2010年盛大在线推出了人才“云计划”战略。“云计划”战略由“找人计划”、“云梯计划”、“暖心计划”三大内容构成,涉及了从选人、用人到留人的管理人才三部曲。 第四,云计划的云计划 云计划是一个智慧分享的问答平台,小企业有资金、人才、管理、经营、资金等相关的问题,都可以在云计划平台上提问,云计划汇集了马云、卫哲、黄鸣、白云峰、查立等知名企业家导师,以及余庆、曾永良、柳金育、朱明、吴翔等实战经验丰富的导师,为小企业解答难题。汇聚和分享千万小企业的困
分布式系统与云计算课程教学大纲 课程名称:分布式系统与云计算 英文名称:Distributed Systems and Cloud Computing 总学时:56 总学分:2 适用对象: 物联网工程专业 先修课程:程序设计语言、计算机网络 一、课程性质、目的和任务 本课程是物联网工程专业学生的专业选修课,分布式计算提供了跨越网络透明访问各种信息资源并协同处理的能力,是大规模网络应用的基础, 云计算是海量数据处理的支撑技术。本课程旨在通过介绍分布式计算与云计算相关的理论与技术,使学生能够掌握分布式系统与云计算的概念,理解并掌握当前分布计算领域的主流技术,了解分布计算与云计算研究的方向,开阔视野,为从事分布式应用开发或云计算研究打下一定的基础。 二、教学的基本要求 了解分布式计算与云计算的基本概念。 掌握常见的几种计算模式,并明确优缺点,可以根据需要选用适当的计算模式进行开发。 了解三种典型的分布式对象技术,并能掌握其中一种进行程序开发。 掌握基于Web的应用程序开发技术。 了解当今各大公司主流的云计算技术。 了解分布式计算与云计算研究的发展趋向。 三、教学的基本内容 分布计算技术和云计算的基本概念,分布式系统的目标,云计算的优点和缺点,分布式系统层次结构,分布系统中的主要特征,客户-服务器模式的基本概念,客户-服务器端架构和体系结构。 分布式对象计算:介绍三种典型的分布式对象技术CORBA、DCOM和EJB,以CORBA 为主介绍分布式对象计算技术,包括CORBA的基本结构、ORB之间的互操作,CORBA服务和公共设施以及CORBA编程。 当今各大公司主流的云计算技术介绍:Google文件系统,Bigtable技术,MapReduce 技术,Yahoo!公司的云平台技术,Aneka云平台技术,Amazon公司的Dynamo技术,IBM 公司的云计算技术。 云计算的程序开发:基于Hadoop系统的开发,基于HBase系统的开发,基于Google App Engine系统的开发,基于Windows Azure系统的开发。
云计算数据管理平台项目实施方案
目录 1.项目实施方案 (5) 1.1.项目实施 (5) 1.1.1.实施总体要求响应和承诺 (5) 1.1.2.项目实施内容 (5) 1.2.项目组织架构 (6) 1.2.1.项目实施内部组织架构 (6) 1.2.2.甲乙方联合项目组织架构 (12) 1.3.项目人员配置和管理承诺 (18) 1.4.项目人员保障 (19) 1.4.1.实施工作配置相应资质和数量承诺 (19) 1.4.2.总体资源配置和工作量估算 (19) 1.4.3.具体人力资源配置 (20) 1.5.实施进度计划 (20) 1.6.项目实施过程 (22) 1.6.1.系统运行维护 (22) 1.6.2.系统优化完善 (26) 1.6.3.数据治理 (30) 1.7.项目交付物及质量要求响应 (31) 1.8.项目管理方案 (35) 1.8.1.项目管理方法论 (35)
1.8.3.项目进度管理 (40) 1.8.4.项目需求管理 (40) 1.8.5.项目配置管理 (41) 1.8.6.项目变更管理 (43) 1.8.7.项目质量管理 (45) 1.8.8.项目风险管理 (65) 1.8.9.项目沟通管理 (70) 1.9.测试方案 (73) 1.9.1.总体测试策略 (73) 1.9.2.总体测试方案 (74) 1.9.3.单元测试方案 (112) 1.9.4.集成测试方案 (124) 1.9.5.系统测试方案 (126) 1.9.6.测试组织 (143) 1.9.7.测试工具 (148) 1.9.8.自动化测试 (153) 1.9.9.软件测试知识库 (160) 1.9.10.实施测试 (163) 1.10.应急计划 (164) 1.10.1.本项目的关键成功因素 (164) 1.10.2.重大风险及规避措施 (166)
MemCache是一套高性能分布式的高速缓存系统,用于动态Web应用以减轻数据库负载,由LiveJournal的Brad Fitzpatrick开发。目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著。这是一套开放源代码软件,以BSD license授权发布。 MemCache通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。MemCache是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。 MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得MemCache能用于Java、C/C++/C#、Perl、 Python、PHP、Ruby等大部分流行的程序语言。 MemCache工作原理MemCache采用C/S架构,在服务器端启动后,以守护程序的方式,监听客户端的请求。启 动时可以指定监听的IP(服务器的内网ip/外网ip)、端口号(所以做分布式测试时,一台服务器上可以启动多个不同端口号的MemCached进程)、使用的内存大小等关键参数。一旦启动,服务就会一直处于可用状态。
为了提高性能,MemCache缓存的数据全部存储在MemCache管理的内存中,所以重启服务器之后缓存数据会清空,不支持持久化。 MemCache内存管理 内存结构 每个slab_class里面包含若干个slab。 每个slab里面包含若干个page,page的默认大小是1M。 每个page里面包含若干个chunk,chunk是数据的实际存放单位,每个slab 里面的 chunk大小相同 内存分配方式 Memcached使用slab allocation机制来分配和管理内存。 先将分配的内存按照预设好的大小分割成特定长度的内存块,再把尺寸相同的内存块分 成组。数据在存放时,根据键值大小去匹配slab大小,找就近的slab存放。而传统的内存管理方式是,使用完通过malloc分配的内存后通过free来回收内存,这种方式容易产生内存碎片并降低操作系统对内存的管理效率。 存放数据时,首先slab要申请内存,申请内存以page为单位。
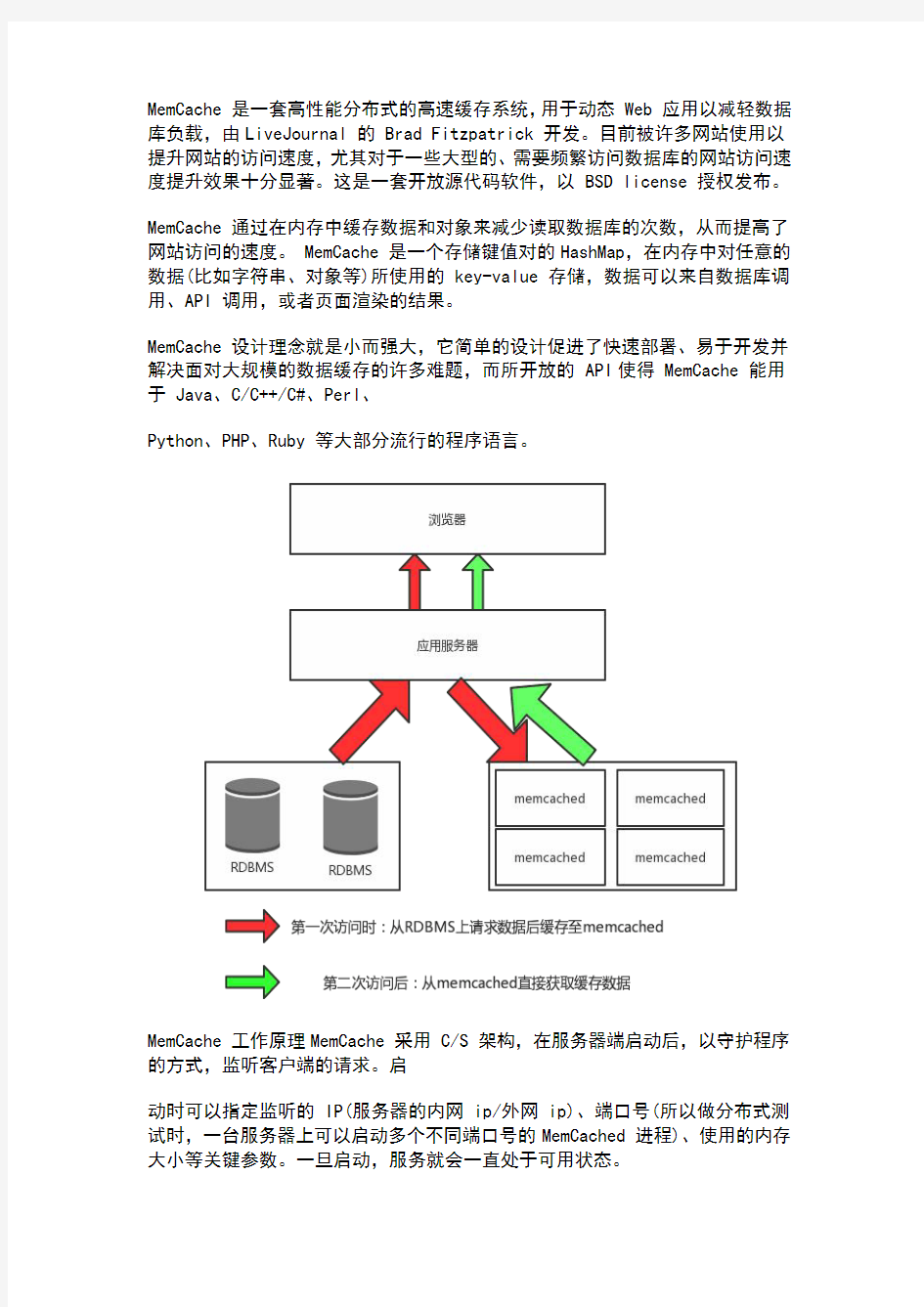
Memcached 什么是Memcached 许多Web 应用程序都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大,访问的集中,就会出现REBMS的负担加重,数据库响应恶化,网站显示延迟等重大影响。 Memcached是高性能的分布式内存缓存服务器。一般的使用目的是通过缓存数据库查询结果,减少数据库的访问次数,以提高动态Web 应用的速度、提高扩展性。如图: Memcached的特点: Memcached作为高速运行的分布式缓存服务器具有以下特点。 1.协议简单:memcached的服务器客户端通信并不使用复杂的MXL等格式, 而是使用简单的基于文本的协议。 2.基于libevent的事件处理:libevent是个程序库,他将Linux 的epoll、BSD 类操作系统的kqueue等时间处理功能封装成统一的接口。memcached使 用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高 性能。 3.内置内存存储方式:为了提高性能,memcached中保存的数据都存储在 memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重 启memcached,重启操作系统会导致全部数据消失。另外,内容容量达
到指定的值之后memcached回自动删除不适用的缓存。 4.Memcached不互通信的分布式:memcached尽管是“分布式”缓存服务器, 但服务器端并没有分布式功能。各个memcached不会互相通信以共享信 息。他的分布式主要是通过客户端实现的。 Memcached的内存管理 最近的memcached默认情况下采用了名为Slab Allocatoion的机制分配,管理内存。在改机制出现以前,内存的分配是通过对所有记录简单地进行malloc 和free来进行的。但是这中方式会导致内存碎片,加重操作系统内存管理器的负担。 Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,已完全解决内存碎片问题。Slab Allocation 的原理相当简单。将分配的内存分割成各种尺寸的块(chucnk),并把尺寸相同的块分成组(chucnk的集合)如图: 而且slab allocator 还有重复使用已分配内存的目的。也就是说,分配到的内存不会释放,而是重复利用。 Slab Allocation 的主要术语 Page :分配给Slab 的内存空间,默认是1MB。分配给Slab 之后根据slab 的大小切分成chunk. Chunk : 用于缓存记录的内存空间。 Slab Class:特定大小的chunk 的组。 在Slab 中缓存记录的原理 Memcached根据收到的数据的大小,选择最合适数据大小的Slab (图2) memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
并行计算:并行计算是相对于串行计算来说的。可分为时间上的并行和空间上的 并行。时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并 发的执行计算。并行计算的目的就是提供单处理器无法提供的性能(处理器能力 或存储器),使用多处理器求解单个问题。 分布式计算:分布式计算研究如何把一个需要非常巨大的计算能力才能解决的问 题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些 计算结果综合起来得到最终的结果。最近的分布式计算项目已经被用于使用世界 各地成千上万位志愿者的计算机的闲置计算能力,通过因特网,可以分析来自外 太空的电讯号,寻找隐蔽的黑洞,并探索可能存在的外星智慧生命等。 并行计算与分布式计算的区别:(1)简单的理解,并行计算借助并行算法和 并行编程语言能够实现进程级并行(如MPI)和线程级并行(如openMP)。而 分布式计算只是将任务分成小块到各个计算机分别计算各自执行。(2)粒度方面,并行计算中,处理器间的交互一般很频繁,往往具有细粒度和低开销的特征,并 且被认为是可靠的。而在分布式计算中,处理器间的交互不频繁,交互特征是粗 粒度,并且被认为是不可靠的。并行计算注重短的执行时间,分布式计算则注重 长的正常运行时间。(3)联系,并行计算和分布式计算两者是密切相关的。某些 特征与程度(处理器间交互频率)有关,而我们还未对这种交叉点(crossover point)进行解释。另一些特征则与侧重点有关(速度与可靠性),而且我们知道 这两个特性对并行和分布两类系统都很重要。(4)总之,这两种不同类型的计算 在一个多维空间中代表不同但又相邻的点。 集群计算:计算机集群使将一组松散集成的计算机软件和/或硬件连接起来高度 紧密地协作完成计算工作。在某种意义上,他们可以被看作是一台计算机。集群 系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连 接方式。集群计算机通常用来改进单个计算机的计算速度和/或可靠性。一般情况 下集群计算机比单个计算机,比如工作站或超级计算机性价比要高得多。根据组 成集群系统的计算机之间体系结构是否相同,集群可分为同构与异构两种。集群 计算机按功能和结构可以分为,高可用性集群(High-availability (HA) clusters)、负载均衡集群(Loadbalancing clusters)、高性能计算集群 (High-performance (HPC)clusters)、网格计算(Grid computing)。 高可用性集群,一般是指当集群中有某个节点失效的情况下,其上的任务会自动 转移到其他正常的节点上。还指可以将集群中的某节点进行离线维护再上线,该 过程并不影响整个集群的运行。
php开发主管的工作职责 php开发主管需要负责与产品需求人员沟通,完成后台架构设计、数据库设计、业务抽象、组件封装等工作。以下是小编整理的php开发主管的工作职责。 php开发主管的工作职责1 职责: 1、熟悉软件开发流程; 2、负责与需求人员接口,熟悉项目的需求规划说明; 3、负责与开发组长接口,熟悉项目的开发计划,及项目的概要设计说明数据库设计;
4、按计划完成功能模块的功能设计、代码实现, 代码编写和单元测试,并提交测试人员进行功能测试; 5、根据项目要求,判断是否需要完成《详细设计说明书》的编写; 6、严格遵守相关开发工具的编码规范; 7、参与需求和设计讨论,对项目开发各个环节进行签字确认; 8、为前端技服人员提供技术支持,解决技服过程中遇到的相关问题; 9、提交相关年、月、日计划和总结; 10、维护电子商务网站及开发工作,维护ERP系统,System Network 管理 岗位要求: 1、计算机或相关专业本科以上学历; 2、精通PHP, 编程语言,具备良好的编程风格; 3、精通网络编程,能够进行多线程开发,有实时监控系统开发经验者优先 4、具备相关行业知识或实践经验;较强的客户服务意识;
5、具备项目开发和管理经验,能良好地掌握开发速度和质量; 6、有3年以上的软件开发经验; php开发主管的工作职责2 职责: 1、负责后端各系统的架构设计、开发、重构、优化; 2、参与制定后端技术中期、短期开发计划,并带领团队完成计划; 3、解决重要项目目中的关键技术难题; 4、负责技术方案设计及关键功能的开发; 5、负责PHP开发团队的培养工作。 任职要求: 1.本科及以上学历,计算机相关专业者优先 2.有3~5年以PHP为主的中型或大型互联网产品软件的开发及维护工作经验 3.熟悉一到两种常用PHP框架(laravel、CI、Zend Framework、ThinkPHP、Yaf等)
XX分布云系统软件清单 XX自主研发16个软件模块可以按需自由组合,搭载在XX分布云平台上,提供给政府、各行各业企业、终端个人客户等使用。XX云平台上搭建以下5套软件系统,详见下表: 以下是XX五套系统 (一)云管理平台软件系统 Scaleone 是一款实现硬件虚拟化,将上层业务系统与IT 硬件设备解耦,将各种资源进行统一管理并按需分配的产品。ScaleOne 包含服务器虚拟化(SeverOne)、桌面虚拟化(DeskOne)两个子模块。 (二)云CRM客户关系管理软件系统
全面配置,随需应变,最大限度满足客户需要,以"客户高度满意"为宗旨设计的,因此,在产品的各个方面都体现了对客户需求的尊重与适应。从大的业务对象本身,到小的字段内容及展现形式都会针对客户的需要、习惯进行调整,最终保证客户可以方便高效地实现其应用目标;技术领先,产品稳定,形成平台性的CRM产品;组件结构,面向服务,充分保证产品的开放性,采用了J2EE体系架构,其基本业务功能是由一系列的组件和业务对象来提供的。这些组件对于系统的松耦合,系统开发一致性都有关至关重要的作用;应用深入,功能全面,为客户提供更多价值,产品已经包括了客户管理、市场营销管理、销售管理、售后服务管理、办公管理、财务管理、库存管理等等相关模块,可以全面管理客户的业务,为客户提供更多的价值。 (三)公共云信息(协同)管理平台系统 XX自主研发的协同管理产品系列,涵盖OA(协同办公)、EIP(企业信息门户)、KM(知识管理)、HRM(人力资源管理)、CRM(客户关系管理)、WM(工作流程管理)、PM(项目管理)、电子政务、内外网一体化管理等方面,通过大量的客户积累和丰富的实践经验,在集团管理、高新技术、生产制造、咨询顾问、医药通信、房地产、酒店餐饮、金融业等领域形成了一整套成熟的行业解决方案。 (四)云基础软件系统 云管理平台提供一站式文件安全管理服务,如文件编辑、格式转换、强大的富媒体管理、文件生命周期管理、全文搜索、版本控制、权限控制、分析、协作、多租户等功能,支持Windows、Mac 客户端,iOS 和Android 等终端之间的数据同步 (五)软件自动化部署引擎系统 iSOne软件自动化部署引擎系统提供了构建和部署云应用程序所需的全部工具和API,能让用户在基础设施上弹性部署并运行应用程序。用户可以用任何能在 JVM 内运行的语言来创建应用程序。iSOne构建在全球领先的XX科技拥有完全知识产权的分布式架构之上,主要包含云节点发现,云节点通讯和云节点路由协同等,能充分利用各个云节点的计算、存储和网络等资源的能力。iSOne内的多个组件可自动部署、管理、伸缩、容错以便执行应用程序。iSOne 完全屏蔽IaaS的具体实现以确保SaaS应用在不同IaaS上的可移植性。iSOne提供 API来访问可伸缩的抽象对象(如云数据库、云搜索引擎、云存储等),实现开发应用的云化需求。
一、背景 在高并发的分布式的系统中,缓存是必不可少的一部分。没有缓存对系统的加速和阻挡大量的请求直接落到系统的底层,系统是很难撑住高并发的冲击,分布式系统中缓存的设计是很重要的一环 使用缓存的收益: ●加速读写,缓存一般是内存操作,要比传统数据库操作要快的多 ●降低后端的负载。缓存一些复杂计算或者耗时得出的结果可以降低后端系统对CPU、 IO、线程这些资源的需求 ●本地缓存远端调用结果,减少服务间的调用,提升服务并发能力 目前问题: ●目前业务中对缓存的使用并不多,在这次直播活动中,组件性能瓶劲很多,有很大一 部分是可以通过缓存加速的 ●疫情直播活动期间,几个核心服务由于人手、改造难度问题等,最后由罗陈珑做一了 个缓存代理服务,把UC、EOMS的部分接口做了缓存代理,这些缓存本来应該由服务提供者来实现的 ●数据一致性问题,加了缓存之后,随之而来的就是数据一致性的问题,发现有数据不 能及时更新 ●目前大家对缓存使用方式不太统一,有的组件使用本地JVM缓存时封装太复杂,出现 问题不好定位,清除缓存也不好做 二、目标 ●降低分布式缓存技术使用门槛,将分布式缓存框架作为微服务开发必备的脚手架,让
开发者更易使用,避免因技术门槛而放弃使用缓存 梳理核心业务,使用分布式缓存加速服务响应速度,降低服务负载 三、分布式缓存方案 3.1 @WafCacheable 缓存 3.1.1 分布式缓存和本地jvm缓存 为了提高接口能力,需要将一些频繁访问但数据更新频率比较低的放入缓存中,不要每次从数据库或其他耗时耗资源的数据源中取。使用@WafCacheable 注解,缓存过期时间可以根据数据更新频率自由设定,不设置默认为2小时。 @WafCacheable 标记的方法被拦截后,数据获取的优先级:本地jvm缓存>redis缓存> 数据源(DB、RMI、其他耗时耗资源的操作) @WafCacheable 使用场景:高频访问低频更新的数据 注意:@WafCacheable 对同一个类里的内调方法(A调B, B上加注解不生效),如果直接用this.B(),加在B上的缓存不生效,需要使用${service}.B()调用(${service}指service实例)。 3.1.2 RMI缓存 RMI(Remote Method Invocation)是指微服务提供的SDK中FeignClient方式申请的接
1.分布式计算是一种把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,在上传运算结果够,将结果统一合并得出数据结论的科学。 2.分布式系统的关键目标:用户可以方便的访问资源;对用户隐藏资源再多台计算机上分布的情况;分布式系统是开放的;分布式系统是可扩展的3.资源可访问性:是用户可以方便的访问远程资源,并且以一种受控的方式与其他用户共享这些资源。 4.透明性;指分布系统是一个整体,而不是独立的组件的组合,系统对用户和应用程序屏蔽其组件的分离性。 5.云计算:由一系列可以动态升级和被虚拟化的资源组成,这些资源被所有云计算的用户所共享并且可以方便的通过网络访问,用户无需掌握与计算技术,只需要按照个人或者团体的需要租赁与计算的资源。 6.云计算的优缺点;优点(1.数据的可移性2.轻松维护个人应用程序和个人文件 3.对计算机的要求低4.给多人协作带来了机会5.资源整合使用率高6.节电省能,降低成本)缺点(1.对网络的高依赖性2.数据的安全问题3.数据的存活能力 7.集群运算与网格运算的区别:1在集群中,资源位于单个的管理区中由单个实体进行管理;而在网格系统中,资源分布在不同的管理区。每个管理区都有其策略和目标2应用程序的调度安排,集群系统中的调度器着眼于提高整个系统性能;而在网格系统中调度器被称为资源代理着眼于提升特定应用的表现来满足终端用户的服务质量需求。 8.分布式系统:是一组自治的计算机集合,通过通信网络和相互链接,实现资源共享和协同工作,而呈现给用户的是单个完整的计算机系统。 9.分布式与集中式区别:1.分布式各组件和进程行为是物理并发的,没有统一时钟,而集中式系统的时间是明确的,同步机制实行起来相对容易 2.分布式系统各组件必须实现可靠安全的相互作用,当一部分出现故障时,系统大部分工作仍可进行。而集中式系统出现鼓掌则不能继续工作 3.分布式系统的异构性。4与集中式系统相比,分布式系统响应时间较短。5.分布式系统具有可扩展性。 10.分布式与计算机网络区别:1.分布式系统各个计算机之间相互通信,无主从关系,网络有主从关系 2.分布式系统资源为所有用户共享,网络有限制的共享3.分布式系统中若干个计算机可相互协作共同完成一项任务,网络不行。 11.对等体系结构:在对等体系机构中,一项任务或活动涉及的所有进程扮演相同的角色,作为对等方进行协作交互,不区分客户和服务器或运行它们的计算机。 12.中间件:是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源,中间件位于客户机服务器的操作系统之上,管理计算资源和网络通信。 13.分布式系统分类:1布式计算系统2分布式信息系统3分布式普适系统 14.分布式系统中的硬件:1基于总线的多处理机2基于交换的多处理机3基于总线的多计算机4.基于交换的多计算机 15.分布式系统中的软件:1分布式操作系统,2.网络操作系统3中间件系统 16.分布式操作系统:是分布式软件系统的重要组成部分。负责管理分布式系统资源,控制分布式程序运行等,其主要目的是为了隐藏细节,管理硬件资源,提供系统接口,使得并进程能够共享系统资源。 17.网络操作系统:是传统操作系统的扩充,为用户提供各种交换信息和资源共享的服务,这是一种典型的松耦合的软件与松耦合的硬件结合形成的系统。 18.中间件系统:满足大量用户的需求;运行于多种硬件和OS平台;支持分布式计算,提供跨网络、硬件和OS平台的透明性应用或服务的交互功能;支持标准的协议;支持标准的接口。 19.分布系统中的主要特征:1.容错性是允许系统出错的,但它可以在故障后恢复,而不丢失数据分布式系统区别与单机系统的一个特征是可以容许部分失效。2.安全性指系统中的数据被有意或者无意地泄露以及数据和其他系统资源被破坏的问题。 20.客户—服务器体系结构:是一个物理上分布的逻辑整体,它是由客户机、服务器和连接支持部分组成。客户机:是一个面向最终用户的接口设备或应用程序,它是一项服务的消费者,它包含并管理数据库和通信设备,为客户请求过程提供服务;连接支持部分是用来连接客户机与服务器的部分,如网络连接、网络协议、应用接口等。 21.客户-服务器结构的优点:1.有利于实现资源共享2.有利于进程通信的同步,3.可实现管理科学化和专业化4.可快速进行信息处理5.具有更好的扩展性 22.面向连接服务与面向无连接的服务: 23.1面向连接的服务是指通信双方在通信过程中必须建立一个虚拟的通信线路 24.数据传输过程必须经过连接建立、连接维护与释放连接三个阶段; 25.在数据传输过程中,各个分组不需要携带目的节点的地址; 26.传输连接类似一个通信管道,发送者在一端放入数据,接收者在另一端取出数据,传输的分组顺序不变,因此传输的可靠性好,但是协议复杂,通信 效率不高。 27.2无连接服务的主要特点是: 28.每个分组都携带源节点与目的节点地址,各 个分组的转发过程是独立的; 29.传输过程不需要经过连接建立、连接维护与 释放连接三个阶段; 30.目的主机接收的分组可能出现乱序、重复与 丢失现象。 31.无连接服务的可靠性不是很好,但是由于省 去了很多协议处理过程,因此它的通信协议相对简 单,通信效率比较高。 32.应用程序的层次结构:1用户界面层:是用 户通过界面中的一些友好提示信息与服务器进行交 互的一个层次。2逻辑事务处理层:在客户端用户提 出请求之后,服务器对客户端提交的请求服务进行处 理,也是整个系统的核心。3数据层:是整个客户- 服务器模型的基础,一般是由服务器提供,它为逻辑 事务处理层提供处理过程所需要的数据。 33.多层体系结构的特点:安全性;稳定性;易 维护性;快速响应性;系统灵活扩展性 34.双层体系结构特点:1.缺乏有效的安全性 2.客户端负荷过重 3.服务器端工作效率低 4.容易造 成网络阻塞 35.计算机网络通信过程实质是分布在不同地 理位置的主机进程之间进行通信的过程,进程间的通 信实际就是进程之间的相互作用,客户-服务器模式 实际上就是提供呢进程间相互作用的一种方式。 36.进程通信中客户——服务器你模型的实现 方法:1并发服务器:核心是使用一个守护程序;处 于后台工作,当条件满足时被激活进行处理。2迭代 服务器:通过设置一个请求队列存储多个客户的服务 请求,服务器采用先到先服务的原则影响客户端的请 求。 37.并发与代理服务器的比较:1并发服务器: 系统资源要求高;可以处理多个用户的服务请求;从 服务器不以来主服务器而独立处理服务请求;不同的 从服务器可以分别处理不同客户的服务请求;系统的 实时性好;适应于面向连接服务类型 .2迭代服务 器:系统资源要求不高;处理客户的服务请求的数量 受到请求队列长度的限制;可以有效的控制请求处理 时间;适应于无连接的服务类型。 38.OSI七层:1物理层是OSI参考模型的最低 层,主要功能是为数据链路层屏蔽网络的底层物理传 输介质的差异。2数据链路层:OSI模型的第二层, 它控制网络层与物理层之间的通信。它的主要功能是 如何在不可靠的物理线路上进行数据的可靠传递。3. 网络层:O S I 模型的第三层,主要任务是通过路由 选择算法,为分组通过互联网选择适当的路径4.传输 层:向用户提供可靠的端到端的服务,其主要任务就 是实现分布式进程的通信,是整个协议结构的核心5. 会话层:负责在网络中的两节点之间建立、维持和终 止通信。6.表示层:主要是处理两个通信系统中交换 信息的表示方式,包括数据格式变换,数据加密和解 密,数据压缩与恢复功能7.应用层:应用层是最高层, 主要功能是为应用程序提供网络服务。 39.客户-服务器端模型的变种:1移动代码: 是指能从一台计算机下载到另一台计算机运行的代 码。2移动代理:可以从一台计算机移动到网络上的 另一台计算机,访问本地计算机得资源,完成存储信 息收集之类的任务,最后返回结果的一种应用程序。 3网络计算机:是一种专门用于网络计算机环境下的 终端设备4瘦客户:指一个软件层,它支持用户端得 计算机枪基于窗口的用户界面,而在远程的计算机上 执行的应用程序5移动设备和自主网络 40.分布式对象:将接口放在一台计算机上,对 象本身却驻留在另一台计算机上。 41.远程对象特征:它们的状态并不是分布的; 它驻留在单个计算机上,只有由该对象实现的接口可 以在其他计算机上使用。 42.分布式对象的基本模型:1.远程对象 2.分 布式共享对象。 43.远程过程调用的基本思想:是调用方通过使 用参数来把信息发送给被调用方,然后被调用方就传 回调用方想要得到的信息。 44.隐式绑定和显示绑定:隐式绑定是一种简单 机制,该机制允许客户在只使用对象引用的情况下可 以直接进行方法调用。显示绑定一般返回指向代理的 指针,该代理可以在本地使用。 45.RMI和RPC本质上的不同:RMI一般支持系 统级对象引用;RPC不需要使用通用的客户端和服务 器存根,却可以更加方便的使用针对特定对象的存 根。 46.分布式计算环境:是用来作为现有的操作系 统和分布式式应用程序之间的中抽象层 47.最常见的两种分布式对象:1分布式动态对 象,它是由服务器以客户的名义在本地创建,只能由 所代表的客户访问。2 分布式命名对象,它由服务器 创建后可以供多个客户共用 48.java远程方法调用的优点:1.安全2.可移 动属性3.设计方式4.安全5.便于编写和使用6.编写 一次7.分布式垃圾收集8.并行计算。 编程部分: 1.IDL模块 module china{ Module ruc{//no definition here} }; 映射结果 package china.ruc; 2.Idl常量 Module ConstIDL{const long myconstant=123}; 映射结果 packageConstIDL Public interface myconstant{public static final int value=(int)(123;)} 3.IDL结构体类型 Module structmodule{ Struct person{string name;short age;}; }; 生成结果 Package structmodule; Public final class persion implements org.omg.CORBA.portable.IDLEntity{ Public string name=null; Public short age=short(0); Public person(){} Public person(srting_name,short_age){name=_name;age= _age;} } 4.IDL序列和数组 Module arraymodule{ Struct somestructure{ Long longarray[15]; Sequence