
哈夫曼树描述文档
一、思路
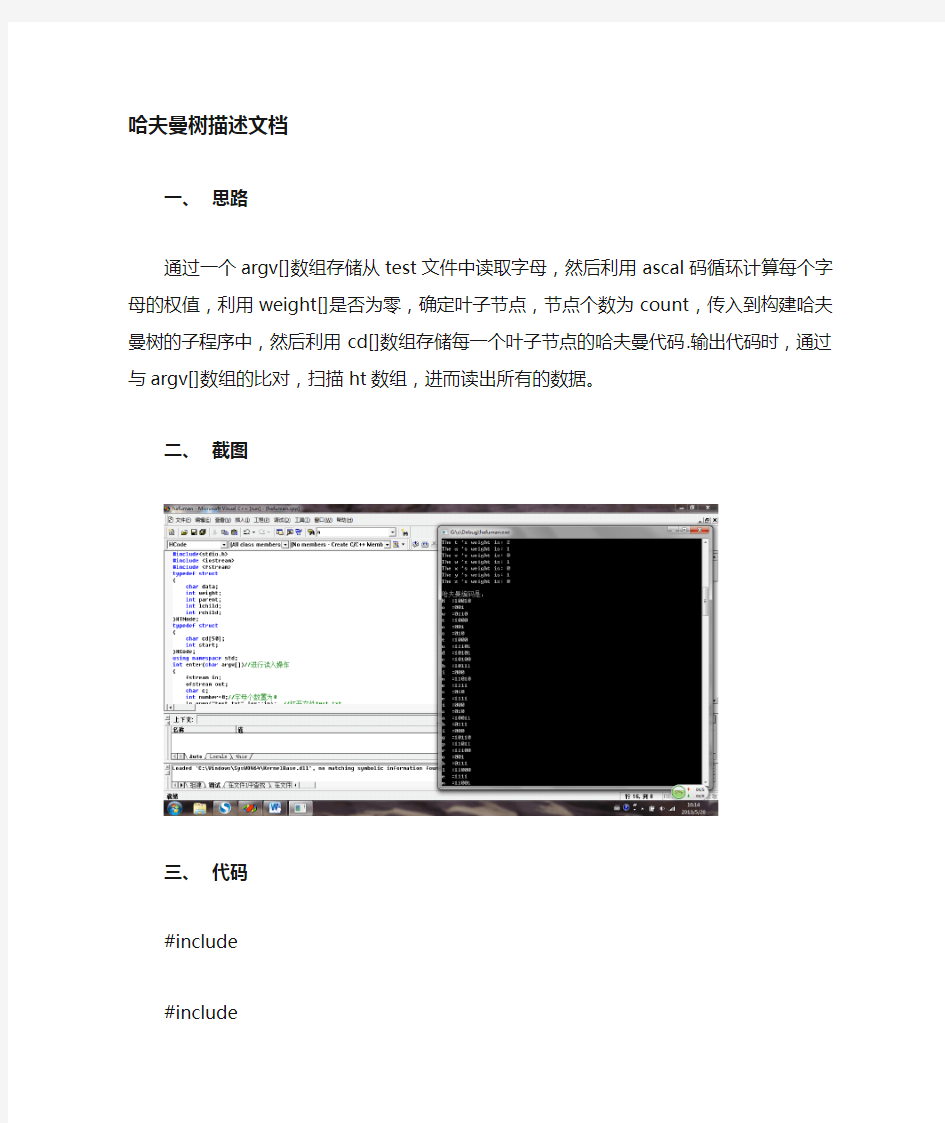
通过一个argv[]数组存储从test文件中读取字母,然后利用ascal 码循环计算每个字母的权值,利用weight[]是否为零,确定叶子节点,节点个数为count,传入到构建哈夫曼树的子程序中,然后利用cd[]数组存储每一个叶子节点的哈夫曼代码.输出代码时,通过与argv[]数组的比对,扫描ht数组,进而读出所有的数据。
二、截图
三、代码
#include
#include
#include
typedefstruct
{
char data;
int weight;
int parent;
intlchild;
intrchild;
}HTNode;
typedefstruct
{
char cd[50];
int start;
}HCode;
using namespace std;
int enter(char argv[])//进行读入操作
{
fstream in;
ofstream out;
char c;
int number=0;//字母个数置为0
in.open("test.txt",ios::in); //打开文件test.txt
out.open ("code.txt",ios::trunc); //打开文件code.txt,如果不存在就新建一个,如果存在就清空
if(!in.eof()) in>>c; //从test.txt中读取一个字符存入c
printf("原文本是:\n");
while(! in.eof()){ //文件不为空,循环读取一个字符
cout< argv[number]=c;//存储c的值到数组 number++; out< in>>c; //从test.txt中读取一个字符存入c } argv[number]='\0'; printf("\n"); in.close; out.close; //使用完关闭文件 return(number);//返回叶子节点数目 } voidCreateHT(HTNodeht[],int n) { inti,j,k,lnode,rnode; double min1,min2; for(i=0;i<2*n-1;i++) ht[i].parent=ht[i].lchild=ht[i].rchild=-1;//置初值 for(i=n;i<2*n-1;i++) { min1=min2=32167; lnode=rnode=-1; for(k=0;k<=i-1;k++) if(ht[k].parent==-1) { if(ht[k].weight { min2=min1; rnode=lnode; min1=ht[k].weight; lnode=k; } else if(ht[k].weight { min2=ht[k].weight;rnode=k; } } ht[i].weight=ht[lnode].weight+ht[rnode].weight; ht[i].lchild=lnode;ht[i].rchild=rnode;//双亲 ht[lnode].parent=i;ht[rnode].parent=i; } } voidCreateHcode(HTNodeht[],HCodehcd[],int n) { inti,f,c; HCodehc; for(i=0;i { hc.start=n;c=i; f=ht[i].parent; while(f!=-1) { if(ht[f].lchild==c) hc.cd[hc.start--]='0'; else hc.cd[hc.start--]='1'; c=f;f=ht[f].parent; } hc.start++; hcd[i]=hc; } } int main() { int enter(char argv[]); void CreateHT(HTNodeht[],int n);//创建哈夫曼树 void CreateHcode(HTNodeht[],HCodehcd[],int n);//哈夫曼编码charargv[500]; intn,i,j,k; charzimu='A'; n=enter(argv); HTNodeht[100];//创建结点 HCodehcd[200]; intweicount[58];//频度计数 int count; for(i=0;i<58;i++)//对58个字母求频度 { count=0; for(j=0;j { if(zimu==argv[j]) count++; } zimu++;//跳到第二个字母 weicount[i]=count; } zimu='A'; for(i=0;i<58;i++) { printf("The %c 's weight is: %d\n",zimu,weicount[i]); zimu++; } zimu='A'; count=0;//计算叶子个数 for(i=0;i<56;i++) { if(weicount[i]!=0) { ht[count].data=zimu; ht[count].weight=weicount[i]; count++; } zimu++; } CreateHT(ht,count); CreateHcode(ht,hcd,count); printf("\n"); printf("哈夫曼编码是:\n"); for(i=0;i for(j=0;j { if(argv[i]==ht[j].data) { printf("%c :",ht[j].data); for (k=hcd[j].start;k<=count;k++) printf("%c",hcd[j].cd[k]); printf("\n"); } } i=getchar(); return 0; } 软件02 1311611006 张松彬利用贪心算法构造哈夫曼树及输出对应的哈夫曼编码 问题简述: 两路合并最佳模式的贪心算法主要思想如下: (1)设w={w0,w1,......wn-1}是一组权值,以每个权值作为根结点值,构造n棵只有根的二叉树 (2)选择两根结点权值最小的树,作为左右子树构造一棵新二叉树,新树根的权值是两棵子树根权值之和 (3)重复(2),直到合并成一颗二叉树为 一、实验目的 (1)了解贪心算法和哈夫曼树的定义(2)掌握贪心法的设计思想并能熟练运用(3)设计贪心算法求解哈夫曼树(4)设计测试数据,写出程序文档 二、实验内容 (1)设计二叉树结点数据结构,编程实现对用户输入的一组权值构造哈夫曼树(2)设计函数,先序遍历输出哈夫曼树各结点3)设计函数,按树形输出哈夫曼树 代码: #include 数据结构课程设计设计题目:哈夫曼树及其应用 学院:计算机科学与技术 专业:网络工程 班级:网络 131 学号:1308060312 学生姓名:谢进 指导教师:叶洁 2015年7 月12 日 设计目的: 赫夫曼编码的应用很广泛,利用赫夫曼树求得的用于通信的二进制编码称为赫夫曼编码。树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和各个叶子对应的字符的编码,这就是赫夫曼编码。哈弗曼译码输入字符串可以把它编译成二进制代码,输入二进制代码时可以编译成字符串。 1、熟悉树的二叉树的存储结构及其特点。 2、掌握建立哈夫曼树和哈夫曼编码的方法。 设计内容: 欲发一封内容为AABBCAB ……(共长 100 字符,字符包括A 、B 、C 、D 、E 、F六种字符),分别输入六种字符在报文中出现的次数(次数总和为100),对这六种字符进行哈夫曼编码。 设计要求: 对输入的一串电文字符实现赫夫曼编码,再对赫夫曼编码生成的代码串进行译码,输出电文字符串。通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。电报通信是传递文字的二进制码形式的字符串。但在信息传递时,总希望总长度能尽可能短,即采用最短码。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长度为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi 恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵赫夫曼树,此构造过程称为赫夫曼编码。设计实现的功能: 1.以二叉链表存储, 2.建立哈夫曼树; 3.求每个字符的哈夫曼编码并显示。 数据结构课程设计设计题目:哈夫曼树编码译码 目录 第一章需求分析 (1) 第二章设计要求 (1) 第三章概要设计 (2) (1)其主要流程图如图1-1所示。 (3) (2)设计包含的几个方面 (4) 第四章详细设计 (4) (1)①哈夫曼树的存储结构描述为: (4) (2)哈弗曼编码 (5) (3)哈弗曼译码 (7) (4)主函数 (8) (5)显示部分源程序: (8) 第五章调试结果 (10) 第六章心得体会 (12) 第七章参考文献 (12) 附录: (12) 在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视,哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。哈夫曼编码是一种编码方式,以哈夫曼树—即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。哈弗曼编码使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和各个叶子对应的字符的编码,这就是哈夫曼编码。哈弗曼译码输入字符串可以把它编译成二进制代码,输入二进制代码时可以编译成字符串。 第二章设计要求 对输入的一串电文字符实现哈夫曼编码,再对哈夫曼编码生成的代码串进行译码,输出电文字符串。通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。电报通信是传递文字的二进制码形式的字符串。但在信息传递时,总希望总长度能尽可能短,即采用最短码。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长度为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi 恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵哈夫曼树,此构造过程称为哈夫曼编码。设计实现的功能: (1) 哈夫曼树的建立; (2) 哈夫曼编码的生成; (3) 编码文件的译码。 实验六哈夫曼树的建立与操作 一、实验要求和实验内容 1、输入哈夫曼树叶子结点(信息和权值) 2、由叶子结点生成哈夫曼树内部结点 3、生成叶子结点的哈夫曼编码 4、显示哈夫曼树结点顺序表 二、详细代码(内包含了详细的注释): #include cout<<"输入第"< 实验四 哈夫曼编码的贪心算法设计(4学时) [实验目的] 1. 根据算法设计需要,掌握哈夫曼编码的二叉树结构表示方法; 2. 编程实现哈夫曼编译码器; 3. 掌握贪心算法的一般设计方法。 实验目的和要求 (1)了解前缀编码的概念,理解数据压缩的基本方法; (2)掌握最优子结构性质的证明方法; (3)掌握贪心法的设计思想并能熟练运用 (4)证明哈夫曼树满足最优子结构性质; (5)设计贪心算法求解哈夫曼编码方案; (6)设计测试数据,写出程序文档。 实验内容 设需要编码的字符集为{d 1, d 2, …, dn },它们出现的频率为 {w 1, w 2, …, wn },应用哈夫曼树构造最短的不等长编码方案。 核心源代码 #include //选择两个parent为0,且weight最小的结点s1和s2 void Select(HuffmanTree *ht,int n,int *s1,int *s2) { int i,min; for(i=1; i<=n; i++) { if((*ht)[i].parent==0) { min=i; break; } } for(i=1; i<=n; i++) { if((*ht)[i].parent==0) { if((*ht)[i].weight<(*ht)[min].weight) min=i; } } *s1=min; for(i=1; i<=n; i++) 数据结构实验报告 实验名称:实验3——哈夫曼编码 学生姓名: 班级: 班内序号: 学号: 日期:2013年11月24日 1.实验要求 利用二叉树结构实现赫夫曼编/解码器。 基本要求: 1、初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个 字符的频度,并建立赫夫曼树 2、建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每 个字符的编码输出。 3、编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的 字符串输出。 4、译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译 码,并输出译码结果。 5、打印(Print):以直观的方式打印赫夫曼树(选作) 6、计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼 编码的压缩效果。 2. 程序分析 2.1存储结构: struct HNode { char c;//存字符内容 int weight; int lchild, rchild, parent; }; struct HCode { char data; char code[100]; }; //字符及其编码结构 class Huffman { private: HNode* huffTree; //Huffman树 HCode* HCodeTable; //Huffman编码表 public: Huffman(void); void CreateHTree(int a[], int n); //创建huffman树 void CreateCodeTable(char b[], int n); //创建编码表 void Encode(char *s, string *d); //编码 void Decode(char *s, char *d); //解码 void differ(char *,int n); char str2[100];//数组中不同的字符组成的串 int dif;//str2[]的大小 ~Huffman(void); }; 结点结构为如下所示: 三叉树的节点结构: struct HNode//哈夫曼树结点的结构体 { int weight;//结点权值 int parent;//双亲指针 int lchild;//左孩子指针 int rchild;//右孩子指针 char data;//字符 }; 示意图为: int weight int parent int lchild int rchild Char c 编码表节点结构: #include 0023算法笔记——【贪心算法】哈夫曼编码问题 1、问题描述 哈夫曼编码是广泛地用于数据文件压缩的十分有效的编码方法。其压缩率通常在20%~90%之间。哈夫曼编码算法用字符在文件中出现的频率表来建立一个用0,1串表示各字符的最优表示方式。一个包含100,000个字符的文件,各字符出现频率不同,如下表所示。 有多种方式表示文件中的信息,若用0,1码表示字符的方法,即每个字符用唯一的一个0,1串表示。若采用定长编码表示,则需要3位表示一个字符,整个文件编码需要300,000位;若采用变长编码表示,给频率高的字符较短的编码;频率低的字符较长的编码,达到整体编码减少的目的,则整个文件编码需要(45×1+13×3+12×3+16×3+9×4+5×4)×1000=224,000位,由此可见,变长码比定长码方案好,总码长减小约25%。 前缀码:对每一个字符规定一个0,1串作为其代码,并要求任一字符的代码都不是其他字符代码的前缀。这种编码称为前缀码。编码的前缀性质可以使译码方法非常简单;例如001011101可以唯一的分解为0,0,101,1101,因而其译码为aabe。 译码过程需要方便的取出编码的前缀,因此需要表示前缀码的合适的数据结构。为此,可以用二叉树作为前缀码的数据结构:树叶表示给定字符;从树根到树叶的路径当作该字符的前缀码;代码中每一位的0或1分别作为指示某节点到左儿子或右儿子的“路标”。 从上图可以看出,表示最优前缀码的二叉树总是一棵完全二叉树,即树中任意节点都有2个儿子。图a表示定长编码方案不是最优的,其编码的二叉树不是一棵完全二叉树。在一般情况下,若C是编码字符集,表示其最优前缀码的二叉树中恰有|C|个叶子。每个叶子对应于字符集中的一个字符,该二叉树有|C|-1个内部节点。 给定编码字符集C及频率分布f,即C中任一字符c以频率f(c)在数据文件中出现。C的一个前缀码编码方案对应于一棵二叉树T。字符c在树T中的深度记为d T(c)。d T(c)也是字符c的前缀码长。则平均码长定义为: #include 淮海工学院计算机工程学院实验报告书 课程名:《算法分析与设计》 题目:实验3 贪心算法 哈夫曼编码 班级:软件102班 学号:11003215 姓名:鹿迅 实验3 贪心算法 实验目的和要求 (1)了解前缀编码的概念,理解数据压缩的基本方法; (2)掌握最优子结构性质的证明方法; (3)掌握贪心法的设计思想并能熟练运用 (4)证明哈夫曼树满足最优子结构性质; (5)设计贪心算法求解哈夫曼编码方案; (6)设计测试数据,写出程序文档。 实验内容 设需要编码的字符集为{d 1, d 2, …, dn },它们出现的频率为 {w 1, w 2, …, wn },应用哈夫曼树构造最短的不等长编码方案。 实验环境 Turbo C 或VC++ 实验学时 2学时,必做实验 数据结构与算法 struct huffman { double weight; //用来存放各个结点的权值 int lchild,rchild,parent; //指向双亲、孩子结点的指针 }; 核心源代码 #include int min=11000; int min1; for(int k=0;k /******************************************/ /********* 哈夫曼树的编写与输出***********/ /******************************************/ /*用静态三叉链表实现哈夫曼树类型定义如下:*/ #define N 20 #define M 2*N-1 typedef struct { int weight; int parent; int LChild; int RChild; } HTNode,HuffmanTree[M+1]; /*select函数主体程序代码*/ void select(HuffmanTree ht,int j,& s1,& s2 ) { int i,k; int n=0; HuffmanTree rt; for(k=0;k<=j;k++) { if(ht[k].parent ==0) { rt[k]=ht[k]; n=n+1; } } for(k=0;k int m; m=2*n-1; for(i=n+1;i<=m;i++) { ht[i]={0,0,0,0}; } /*--------初始化完毕,对应算法步鄹(1)---------*/ for(i=n+1;i<=m;i++) { int s1,s2; select(ht,i-1,&s1,$s2); ht[i].weight=ht[s1].weight +ht[s2].weight ; ht[s1].parent=i;ht[s2].parent=i; ht[i].LChild=s1;ht[i].RChild=s2; } } 福建农林大学计算机与信息学院 数据结构课程设计 设计:哈夫曼编译码器 姓名:韦邦权 专业:2013级计算机科学与技术 学号:13224624 班级:13052316 完成日期:2013.12.28 1 哈夫曼编译码器 一、需求分析 在当今信息爆炸时代,如何采用有效的数据压缩技术节省数据文件的存储空间和计算机网络的传送时间已越来越引起人们的重视,哈夫曼编码正是一种应用广泛且非常有效的数据压缩技术。哈夫曼编码是一种编码方式,以哈夫曼树—即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。哈夫曼编码使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。哈夫曼编码的应用很广泛,利用哈夫曼树求得的用于通信的二进制编码称为哈夫曼编码。树中从根到每个叶子都有一条路径,对路径上的各分支约定:指向左子树的分支表示“0”码,指向右子树的分支表示“1”码,取每条路径上的“0”或“1”的序列作为和 各个叶子对应的字符的编码,这就是哈夫曼编码。哈夫曼译码输入字符串可以把它编译成二进制代码,输入二进制代码时可以编译成字符串。 二、设计要求 对输入的一串电文字符实现哈夫曼编码,再对哈夫曼编码生成的2 代码串进行译码,输出电文字符串。通常我们把数据压缩的过程称为编码,解压缩的过程称为解码。电报通信是传递文字的二进制码形式的字符串。但在信息传递时,总希望总长度能尽可能短,即采用最短码。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长度为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi 恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵哈夫曼树,此构造过程称为哈夫曼编码。设计实现的功能: (1) 哈夫曼树的建立; (2) 哈夫曼编码的生成; (3) 编码文件的译码。 三、概要设计 哈夫曼编\译码器的主要功能是先建立哈夫曼树,然后利用建好的哈夫曼树生成哈夫曼编码后进行译码。 在数据通信中,经常需要将传送的文字转换成由二进制字符0、1组成的二进制串,称之为编码。构造一棵哈夫曼树,规定哈夫曼树中的左分之代表0,右分支代表1,则从根节点到每个叶子节点所经过的 第四章作业 部分参考答案 1. 设有n 个顾客同时等待一项服务。顾客i 需要的服务时间为n i t i ≤≤1,。应该如何安排n 个顾客的服务次序才能使总的等待时间达到最小?总的等待时间是各顾客等待服务的时间的总和。试给出你的做法的理由(证明)。 策略: 对 1i t i n ≤≤进行排序,,21n i i i t t t ≤≤≤ 然后按照递增顺序依次服务12,,...,n i i i 即可。 解析:设得到服务的顾客的顺序为12,,...,n j j j ,则总等待时间为 ,2)2()1(1221--+++-+-=n n j j j j t t t n t n T 则在总等待时间T 中1j t 的权重最大,jn t 的权重最小。故让所需时间少的顾客先得到服务可以减少总等待时间。 证明:设,21n i i i t t t ≤≤≤ ,下证明当按照不减顺序依次服务时,为最优策略。 记按照n i i i 21次序服务时,等待时间为T ,下证明任意互换两者的次序,T 都不减。即假设互换j i ,)(j i <两位顾客的次序,互换后等待总时间为T ~ ,则有.~ T T ≥ 由于 ,2)2()1(1221--+++-+-=n n i i i i t t t n t n T ,2)()()2()1(1221--+++-++-++-+-=n n j i i i i i i i t t t j n t i n t n t n T ,2)()()2()1(~ 1221--+++-++-++-+-=n n i j i i i i i i t t t j n t i n t n t n T 则有 .0))((~ ≥--=-i j i i t t i j T T 同理可证其它次序,都可以由n i i i 21经过有限次两两调换顺序后得到,而每次交换,总时间不减,从而n i i i 21为最优策略。 实验三树的应用 一.实验题目: 树的应用——哈夫曼编码 二.实验内容: 利用哈夫曼编码进行通信可以大大提高信道的利用率,缩短信息传输的时间,降低传输成本。根据哈夫曼编码的原理,编写一个程序,在用户输入结点权值的基础上求哈夫曼编码。 要求:从键盘输入若干字符及每个字符出现的频率,将字符出现的频率作为结点的权值,建立哈夫曼树,然后对各个字符进行哈夫曼编码,最后打印输出字符及对应的哈夫曼编码。 三、程序源代码: #include for(int x=1;x<=j-1;x++) { if(p[x].parent==0&&p[x].weight 《用哈夫曼编码实现文件压缩》 实验报告 课程名称数据结构B 实验学期 2017 至 2018 学年第一学期学生所在院部计算机学院 年级 2016 专业班级信管B162 学生姓名学号 成绩评定: 1、工作量: A(),B(),C(),D(),F( ) 2、难易度:A(),B(),C(),D(),F( ) 3、答辩情况: 基本操作:A(),B(),C(),D(),F( ) 代码理解:A(),B(),C(),D(),F( ) 4、报告规范度:A(),B(),C(),D(),F( ) 5、学习态度:A(),B(),C(),D(),F( )总评成绩:_________________________________ 指导教师: 兰芸 用哈夫曼编码实现文件压缩 1、了解文件的概念。 2、掌握线性链表的插入、删除等算法。 3、掌握Huffman树的概念及构造方法。 4、掌握二叉树的存储结构及遍历算法。 5、利用Huffman树及Huffman编码,掌握实现文件压缩的一般原理。 微型计算机、Windows 7操作系统、Visual C++6.0软件 输入的字符创建Huffman树,并输出各字符对应的哈夫曼编码。 五.系统设计 输入字符的个数和各个字符以及权值,将每个字符的出现频率作为叶子结点构建Huffman树,规定哈夫曼树的左分支为0,右分支为1,则从根结点到每个叶子结点所经过的分支对应的0和1组成的序列便为该结点对应字符的哈夫曼编码。 流程图如下 1.输入哈夫曼字数及相应权值 相应代码 int main() { HuffmanTree HTree; HuffmanCode HCode; int *w, i; int n,wei; //编码个数及权值 printf("请输入需要哈夫曼编码的字符个数:"); scanf("%d",&n); w=(int*)malloc((n+1)*sizeof(int)); for(i=1; i<=n;i++) { printf("请输入第%d字符的权值:",i); fflush(stdin); scanf("%d",&wei); w[i]=wei; } HuffmanCoding(&HTree,&HCode,w,n); return 1; } 2.输出HT初态(每个字符的权值) 题目:哈夫曼编码器 班级:031021班姓名:李鑫学号:03102067 完成日期:2011/12 1. 问题描述 利用赫夫曼编码进行通信可以大大提高信道利用率,缩短信息传输时间,降低传输成本。这要求在发送端通过一个编码系统对待传输数据预先编码,在接收端将传来的数据进行译码(复原)。对于双工信道(即可以双向传输信息的信道),每端都需要一个完整的编/译码系统。试为这样的信息收发站编写一个赫夫曼码的编/译码系统。 2.基本要求 一个完整的系统应具有以下功能: (1) I:初始化(Initialization)。从终端读入字符集大小n,以及n个字符和n个权值,建立赫夫曼树,并将它存于文件hfmTree中。 (2) E:编码(Encoding)。利用已建好的赫夫曼树(如不在内存,则从文件hfmTree中读入),对文件ToBeTran中的正文进行编码,然后将结果存入文件CodeFile中。 (3) D:译码(Decoding)。利用已建好的赫夫曼树将文件CodeFile中的代码进行译码,结果存入文件Textfile中。 以下为选做: (4) P:印代码文件(Print)。将文件CodeFile以紧凑格式显示在终端上,每行50个代码。同时将此字符形式的编码文件写入文件CodePrin中。 (5) T:印赫夫曼树(Tree printing)。将已在内存中的赫夫曼树以直观的方式(比如树)显示在终端上,同时将此字符形式的赫夫曼树写入文件TreePrint 中。 3.测试 (1)利用教科书例6-2中的数据调试程序。 (2) 用下表给出的字符集和频度的实际统计数据建立赫夫曼树,并实现以下报文的编码和译码:“THIS PROGRAME IS MY FA VORITE”。 字符 A B C D E F G H I J K L M 频度186 64 13 22 32 103 21 15 47 57 1 5 32 20 字符N O P Q R S T U V W X Y Z 频度57 63 15 1 48 51 80 23 8 18 1 16 1 4.实现提示 (1) 编码结果以文本方式存储在文件Codefile中。 (2) 用户界面可以设计为“菜单”方式:显示上述功能符号,再加上“Q”,表示退出运行Quit。请用户键入一个选择功能符。此功能执行完毕后再显示此菜单,直至某次用户选择了“Q”为止。 (3) 在程序的一次执行过程中,第一次执行I,D或C命令之后,赫夫曼树已经在内存了,不必再读入。每次执行中不一定执行I命令,因为文件hfmTree可能早已建好。 2008级数据结构实验报告 实验名称:实验三树 学生姓名: 班级: 班内序号: 学号: 日期: 20013年11月26日 1.实验要求 实验目的 通过选择下面两个题目之一进行实现,掌握如下内容: 掌握二叉树基本操作的实现方法 了解赫夫曼树的思想和相关概念 学习使用二叉树解决实际问题的能力 实验内容 利用二叉树结构实现赫夫曼编/解码器。 基本要求: 1.初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并 建立赫夫曼树 2.建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符的编码 输出。 3.编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。 4.译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结 果。 5.打印(Print):以直观的方式打印赫夫曼树(选作) 6.计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。 2. 程序分析 哈夫曼树结点的储存结构除了二叉树所有的双亲域parents,左子树域lchild,右子树域rchild。还需要有字符域word,权重域weight,编码域code。其中由于编码是一串由0和1组成的字符串,所以code是一个字符数组。 进行哈夫曼编码首先要对用户输入的信息进行统计,将每个字符作为哈夫曼树的叶子结点。统计每个字符出现的次数(频度)作为叶子的权重,统计次数可以根据每个字符不同的ASCII 码。并根据叶子结点的权重建立一个哈夫曼树。 建立每个叶子的编码从根结点开始,规定通往左子树路径记为0,通往右子树路径记为 1.由于编码要求从根结点开始,所以需要前序遍历哈夫曼树,故编码过程是以前序遍历二叉树 电子科技大学 实验报告 课程名称:数据结构与算法 学生姓名:陈*浩 学号:************* 点名序号: *** 指导教师:钱** 实验地点:基础实验大楼 实验时间: 2014-2015-2学期 信息与软件工程学院 实验报告(二) 学生姓名:陈**浩学号:*************指导教师:钱** 实验地点:科研教学楼A508实验时间:一、实验室名称:软件实验室 二、实验项目名称:数据结构与算法—树 三、实验学时:4 四、实验原理: 霍夫曼编码(Huffman Coding)是一种编码方式,是一种用于无损数据压缩的熵编码(权编码)算法。1952年,David A. Huffman在麻省理工攻读博士时所发明的。 在计算机数据处理中,霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。 例如,在英文中,e的出现机率最高,而z的出现概率则最低。当利用霍夫曼编码对一篇英文进行压缩时,e极有可能用一个比特来表示,而z则可能花去25个比特(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个比特。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。 霍夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。 可以证明霍夫曼树的WPL是最小的。 实验报告 ( 2013 / 2014 学年第二学期) 学院贝尔学院 学生姓名任晓强 班级学号 Q12010218 指导教师季一木 指导单位计算机软件教学中心 日期 2014年3月12日 实验一:贪心算法构造哈夫曼树 问题简述: 两路合并最佳模式的贪心算法主要思想如下: (1)设w={w0,w1,......w }是一组权值,以每个权值作为根结点值,构造n棵只有根的 n-1 二叉树 (2)选择两根结点权值最小的树,作为左右子树构造一棵新二叉树,新树根的权值是两棵子树根权值之和 (3)重复(2),直到合并成一颗二叉树为止 一、实验目的 (1)了解贪心算法和哈夫曼树的定义 (2)掌握贪心法的设计思想并能熟练运用 (3)设计贪心算法求解哈夫曼树 (4)设计测试数据,写出程序文档 二、实验内容 (1)设计二叉树结点数据结构,编程实现对用户输入的一组权值构造哈夫曼树 (2)设计函数,先序遍历输出哈夫曼树各结点 (3)设计函数,按树形输出哈夫曼树 三、程序源代码 #include }Tree; typedef struct Data{ //定义字符及其对应的频率的结构int data;//字符对应的频率是随机产生的 char c; }; void Initiate(Tree **root);//初始化节点函数 int getMin(struct Data a[],int n);//得到a中数值(频率)最小的数void toLength(char s[],int k);//设置有k个空格的串s void set(struct Data a[],struct Data b[]);//初始化a,且将a备份至b char getC(int x,struct Data a[]);//得到a中频率为x对应的字符void prin(struct Data a[]);//输出初始化后的字符及对应的频率 int n; void main() { //srand((unsigned)time(NULL)); Tree *root=NULL,*left=NULL,*right=NULL,*p=NULL; int min,num; int k=30,j,m; struct Data a[100]; struct Data b[100]; int i;贪心算法构造哈夫曼树
哈夫曼树及其应用(完美版)
哈夫曼树编码译码实验报告(DOC)
哈夫曼树的建立与操作
实验三.哈夫曼编码的贪心算法设计
北邮数据结构实验3哈夫曼编码
数据结构哈夫曼树的实现
0023算法笔记——【贪心算法】哈夫曼编码问题
数据结构哈夫曼树和代码
哈夫曼编码_贪心算法
哈夫曼树的编写与输出
完整word版数据结构课程设计:电文编码译码哈夫曼编码
4+四+贪心算法+习题参考答案
哈夫曼编码算法实现完整版
哈夫曼树及编码综合实验报告
数据结构课程设计哈夫曼编码
数据结构实验三题目二_哈夫曼树
哈夫曼树及其操作-数据结构实验报告(2)
贪心法构造哈夫曼树
相关主题
文本预览