算法之2章递归与分治
- 格式:pdf
- 大小:1.32 MB
- 文档页数:18


递归与分治算法心得
递归与分治算法都是常用的算法思想,可以很好地解决复杂问题。
递归算法是通过将问题分解为相同或相似的子问题来解决整个问题,然后再逐步合并回原问题的过程。
递归算法通常需要明确边界条件,以确保递归能够正确地停止。
分治算法是将问题分解成若干个相同或相似的子问题,递归地解决这些子问题,然后合并这些子问题的解来解决原始问题。
通常,分治算法可以高效地解决问题,但需要注意分解问题的方式和合并子问题的解的过程。
在实际应用中,递归和分治算法可以相互结合,以解决更加复杂的问题。
例如,可以使用分治算法来将问题分解成多个子问题,然后使用递归算法来解决这些子问题。
此外,还可以在递归算法中使用分治算法来对子问题进行分解和合并。
总而言之,递归与分治算法都是非常有用的算法思想,可以在许多领域中得到应用。
但是,在实际使用时,需要仔细考虑问题的性质和算法的复杂度,以确保算法的正确性和效率。
- 1 -。

递归与分治算法心得
递归与分治算法是算法设计中常见的两种方法,它们在解决问题时都采用了“分而治之”的思想,将问题分解成更小的子问题,然后通过递归调用或者合并子问题的解来得到原问题的解。
通过我的学习和实践,我深刻认识到了递归与分治算法的重要性和优势。
首先,递归算法可以使问题的描述更加简单明了。
通过将问题转化为自身的子问题,我们可以建立起更为简洁优美的数学模型。
其次,递归算法可以使问题的解决过程更加自然。
在递归过程中,我们可以利用已知的子问题解决同类问题,实现代码的复用和模块化。
此外,递归算法还可以解决一些重要的数学问题,如斐波那契数列和二分查找等。
分治算法则更加注重问题的分解和合并。
它将问题划分成若干个规模相同或相近的子问题,然后将子问题的解合并起来得到原问题的解。
这种方法在解决某些复杂问题时具有很大的优势。
例如,在排序算法中,归并排序采用了分治算法的思想,将待排序的序列分成两个长度相等的子序列,然后递归地对子序列排序,最后将子序列合并成有序序列。
这种算法具有较高的稳定性和灵活性,常常被应用于海量数据的排序任务中。
总之,递归与分治算法是算法设计中不可或缺的两种方法。
在解决问题时,我们应该根据具体情况选择合适的算法,并在实践中不断探索、总结和优化。
只有这样,我们才能更好地应对日益复杂多变的计算机科学挑战。

递归和分治法摘要:1.递归和分治法的定义2.递归和分治法的区别3.递归和分治法的应用实例4.递归和分治法的优缺点正文:递归和分治法是计算机科学中常用的两种算法设计技巧。
它们在解决问题时都采用了将问题分解成更小子问题的思路,但在具体实现上却有所不同。
下面,我们来详细了解一下递归和分治法。
1.递归和分治法的定义递归法是指在算法中调用自身来解决问题的方法。
递归函数在执行过程中,会将原问题分解成规模更小的相似子问题,然后通过调用自身的方式,解决这些子问题,最后将子问题的解合并,得到原问题的解。
分治法是指将一个大问题分解成若干个规模较小的相似子问题,然后分别解决这些子问题,最后将子问题的解合并,得到原问题的解。
分治法在解决问题时,通常需要设计一个主函数(master function)和一个子函数(subfunction)。
主函数负责将问题分解,子函数负责解决子问题。
2.递归和分治法的区别递归法和分治法在解决问题时都采用了将问题分解成更小子问题的思路,但它们在实现上存在以下区别:(1)函数调用方式不同:递归法是通过调用自身来解决问题,而分治法是通过调用不同的子函数来解决问题。
(2)递归法必须有递归出口,即必须有一个基线条件,而分治法不一定需要。
3.递归和分治法的应用实例递归法应用广泛,例如斐波那契数列、汉诺塔问题、八皇后问题等。
分治法也有很多实际应用,例如快速排序、归并排序、大整数乘法等。
4.递归和分治法的优缺点递归法的优点是代码简单易懂,但缺点是容易产生大量的重复计算,导致时间复杂度较高。
分治法的优点是时间复杂度较低,但缺点是代码实现相对复杂,需要设计主函数和子函数。
总之,递归和分治法都是解决问题的有效方法,具体应用需要根据问题的特点来选择。



算法设计与分析:递归与分治法-实验报告(总8页)实验目的:掌握递归与分治法的基本思想和应用,学会设计和实现递归算法和分治算法,能够分析和评价算法的时间复杂度和空间复杂度。
实验内容:1.递归算法的设计与实现3.算法的时间复杂度和空间复杂度分析实验步骤:1)递归定义:一个函数或过程,在其定义或实现中,直接或间接地调用自身的方法,被成为递归。
递归算法是一种控制结构,它包含了解决问题的基础情境,也包含了递归处理的情境。
2)递归特点:递归算法具有以下特点:①依赖于递归问题的部分解被划分为若干较小的部分。
②问题的规模可以通过递推式递减,最终递归终止。
③当问题的规模足够小时,可以直接求解。
3)递归实现步骤:①确定函数的定义②确定递归终止条件③确定递归调用的过程4)经典实例:斐波那契数列递推式:f(n) = f(n-1) + f(n-2)int fib(int n) {if (n <= 0)return 0;else}5)优化递归算法:避免重复计算例如,上述斐波那契数列的递归算法会重复计算一些中间结果,影响效率。
可以使用动态规划技术,将算法改为非递归形式。
int f1 = 0, f2 = 1;for (int i = 2; i <= n; i++) {f1 = f2;使用循环避免递归,重复计算可以大大减少,提高效率。
1)分治算法的定义:将原问题分解成若干个规模较小且类似的子问题,递归求解子问题,然后合并各子问题得到原问题的解。
2)分治算法流程:②将问题分解成若干个规模较小的子问题。
③递归地解决各子问题。
④将各子问题的解合并成原问题的解。
3)分治算法实例:归并排序归并排序是一种基于分治思想的经典排序算法。
排序流程:②分别对各子数组递归进行归并排序。
③将已经排序好的各子数组合并成最终的排序结果。
实现源代码:void mergeSort(int* arr, int left, int right) {if (left >= right)while (i <= mid && j <= right)temp[k++] = arr[i] < arr[j] ? arr[i++] : arr[j++];temp[k++] = arr[i++];1) 时间复杂度的概念:指完成算法所需的计算次数或操作次数。



算法分析(第二章):递归与分治法一、递归的概念知识再现:等比数列求和公式:1、定义:直接或间接地调用自身的算法称为递归算法。
用函数自身给出定义的函数称为递归函数。
2、与分治法的关系:由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。
在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。
这自然导致递归过程的产生。
分治与递归经常同时应用在算法设计之中,并由此产生许多高效算法。
3、递推方程:(1)定义:设序列01,....na a a简记为{na},把n a与某些个()ia i n<联系起来的等式叫做关于该序列的递推方程。
(2)求解:给定关于序列{n a}的递推方程和若干初值,计算n a。
4、应用:阶乘函数、Fibonacci数列、Hanoi塔问题、插入排序5、优缺点:优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。
缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。
二、递归算法改进:1、迭代法:(1)不断用递推方程的右部替代左部(2)每一次替换,随着n的降低在和式中多出一项(3)直到出现初值以后停止迭代(4)将初值代入并对和式求和(5)可用数学归纳法验证解的正确性2、举例:-----------Hanoi塔算法----------- ---------------插入排序算法----------- ()2(1)1(1)1T n T nT=−+=()(1)1W n W n nW=−+−(1)=021n-23()2(1)12[2(2)1]12(2)21...2++2 (121)n n n T n T n T n T n T −−=−+=−++=−++==++=−(1)2 ()(1)1((n-2)+11)1(2)(2)(1)...(1)12...(2)(1)(1)/2W n W n n W n n W n n n W n n n n =−+−=−−+−=−+−+−==++++−+−=−3、换元迭代:(1)将对n 的递推式换成对其他变元k 的递推式 (2)对k 进行迭代(3)将解(关于k 的函数)转换成关于n 的函数4、举例:---------------二分归并排序---------------()2(/2)1W n W n n W =+−(1)=0(1)换元:假设2kn =,递推方程如下()2(/2)1W n W n n W =+−(1)=0 → 1(2)2(2)21k k k W W W−=+−(0)=0(2)迭代求解:12122222321332133212()2(2)212(2(2)21)212(2)22212(2)2*2212(2(2)21)2212(2)222212(2)3*2221...2(0)*2(22...21)22k k k k k k k k k k k k k k k k k k k k k k k k W n W W W W W W W W k k −−−−−−−+−+−−−=+−=+−+−=+−+−=+−−=+−+−−=+−+−−=+−−−==+−++++=−1log 1n n n +=−+(3)解的正确性—归纳验证: 证明递推方程的解是()(1)/2W n n n =−()(1)1W n W n n W =−+−(1)=0,(n 1)=n +n=n(n-1)/2+n =n[(n-1)/2+1]=n(n+1)/2n W W +方法:数学归纳法证 n=1,W(1)=1*(1-1)/2=0假设对于解满足方程,则()---------------快速排序--------------------->>>平均工作量:假设首元素排好序在每个位置是等概率的112()()()(1)0n i T n T i O n n T −==+=∑ >>>对于高阶方程应该先化简,然后迭代(1)差消化简:利用两个方程相减,将右边的项尽可能消去,以达到降阶的目的。
计算机算法设计与分析第4版(王晓东著)课后答
案下载
计算机算法设计与分析第4版内容简介
第1章算法概述
1.1 算法与程序
1.2 算法复杂性分析
1.3 NP完全性理论
算法分析题1
算法实现题1
第2章递归与分治策略
2.1 递归的概念
2.2 分治法的基本思想
2.3 二分搜索技术
2.4 大整数的乘法
2.5 Strassen矩阵乘法
2.6 棋盘覆盖
2.7 合并排序
2.8 快速排序
2.9 线性时间选择
2.10 最接近点对问题
第3章动态规划
第4章贪心算法
第5章回溯法
第6章分支限界法
第7章随机化算法
第8章线性规划与网络流
附录A C++概要
参考文献
计算机算法设计与分析第4版目录
本书是普通高等教育“十一五”__规划教材和国家精品课程教材。
全书以算法设计策略为知识单元,系统介绍计算机算法的设计方法与分析技巧。
主要内容包括:算法概述、递归与分治策略、动态规划、贪心算法、回溯法、分支限界法、__化算法、线性规划与网络流等。
书中既涉及经典与实用算法及实例分析,又包括算法热点领域追踪。
为突出教材的`可读性和可用性,章首增加了学习要点提示,章末配有难易适度的算法分析题和算法实现题;配套出版了《计算机算法设计与分析习题解答(第2版)》;并免费提供电子课件和教学服务。
第一章算法概述1、算法的五个性质:有穷性、确定性、能行性、输入、输出。
2、算法的复杂性取决于:(1)求解问题的规模(N) , (2)具体的输入数据(I),( 3)算法本身的设计(A),C=F(N,I,A。
3、算法的时间复杂度的上界,下界,同阶,低阶的表示。
4、常用算法的设计技术:分治法、动态规划法、贪心法、回溯法和分支界限法。
5、常用的几种数据结构:线性表、树、图。
第二章递归与分治1、递归算法的思想:将对较大规模的对象的操作归结为对较小规模的对象实施同样的操作。
递归的时间复杂性可归结为递归方程:1 11= 1T(n) <aT(n—b) + D(n) n> 1其中,a是子问题的个数,b是递减的步长,~表示递减方式,D(n)是合成子问题的开销。
递归元的递减方式~有两种:1、减法,即n -b,的形式。
2、除法,即n / b,的形式。
2、D(n)为常数c:这时,T(n) = 0(n P)。
D(n)为线形函数cn:r O(n) 当a. < b(NT(n) = < Ofnlog^n) "n = blljI O(I1P)二"A bl吋其中.p = log b a oD(n)为幕函数n x:r O(n x) 当a< D(b)II JT{ii) = O(ni1og b n) 'ia = D(b)ll].O(nr)D(b)lHJI:中,p= log b ao考虑下列递归方程:T(1) = 1⑴ T( n) = 4T(n/2) +n⑵ T(n) = 4T(n/2)+n2⑶ T(n) = 4T(n/2)+n3解:方程中均为a = 4,b = 2,其齐次解为n2。
对⑴,T a > b (D(n) = n) /• T(n) = 0(n);对⑵,•/ a = b2 (D(n) = n2) T(n) = O(n2iog n);对⑶,•/ a < b3(D(n) = n3) - T(n) = 0(n3);证明一个算法的正确性需要证明两点:1、算法的部分正确性。
递推算法在程序编辑过程中,我们可能会遇到这样一类问题,出题者告诉你数列的前几个数,或通过计算机获取了数列的前几个数,要求编程者求出第N项数或所有的数列元素(如果可以枚举的话),或求前N项元素之和。
这种从已知数据入手,寻找规则,推导出后面的数的算法,称这递推算法。
典型的递推算法的例子有整数的阶乘,1,2,6,24,120…,a[n]=a[n-1]*n(a[1]=1);前面学过的2n,a[n]=a[n-1]*2(a[1]=1),菲波拉契数列:1,2,3,5,8,13…,a[n]=a[n-1]+a[n-2](a[1]=1,a[2]=2)等等。
在处理递推问题时,我们有时遇到的递推关系是十分明显的,简单地写出递推关系式,就可以逐项递推,即由第i项推出第i+1项,我们称其为显示递推关系。
但有的递推关系,要经过仔细观察,甚至要借助一些技巧,才能看出它们之间的关系,我们称其为隐式的递推关系。
下面我们来分析一些例题,掌握一些简单的递推关系。
例如阶梯问题:题目的意思是:有N级阶梯,人可以一步走上一级,也可以一步走两级,求人从阶梯底走到顶端可以有多少种不同的走法。
这是一个隐式的递推关系,如果编程者不能找出这个递推关系,可能就无法做出这题来。
我们来分析一下:走上第一级的方法只有一种,走上第二级的方法却有两种(两次走一级或一次走两级),走上第三级的走法,应该是走上第一级的方法和走上第二级的走法之和(因从第一级和第二级,都可以经一步走至第三级),推广到走上第i级,是走上第i-1级的走法与走上第i-2级的走法之和。
很明显,这是一个菲波拉契数列。
到这里,读者应能很熟练地写出这个程序。
在以后的程序习题中,我们可能还会遇到菲波拉契数列变形以后的结果:如f(i)=f(i-1)+2f(i-2),或f(i)=f(i-1)+f(i-2)+f(i-3)等。
我们再来分析一下尼科梅彻斯定理。
定理内容是:任何一个整数的立方都可以写成一串连续的奇数和,如:43=13+15+17+19=64。
算法分析与设计教程习题解答第1章 算法引论1. 解:算法是一组有穷的规则,它规定了解决某一特定类型问题的一系列计算方法。
频率计数是指计算机执行程序中的某一条语句的执行次数。
多项式时间算法是指可用多项式函数对某算法进行计算时间限界的算法。
指数时间算法是指某算法的计算时间只能使用指数函数限界的算法。
2. 解:算法分析的目的是使算法设计者知道为完成一项任务所设计的算法的优劣,进而促使人们想方设法地设计出一些效率更高效的算法,以便达到少花钱、多办事、办好事的经济效果。
3. 解:事前分析是指求出某个算法的一个时间限界函数(它是一些有关参数的函数);事后测试指收集计算机对于某个算法的执行时间和占用空间的统计资料。
4. 解:评价一个算法应从事前分析和事后测试这两个阶段进行,事前分析主要应从时间复杂度和空间复杂度这两个维度进行分析;事后测试主要应对所评价的算法作时空性能分布图。
5. 解:①n=11; ②n=12; ③n=982; ④n=39。
第2章 递归算法与分治算法1. 解:递归算法是将归纳法的思想应用于算法设计之中,递归算法充分地利用了计算机系统内部机能,自动实现调用过程中对于相关且必要的信息的保存与恢复;分治算法是把一个问题划分为一个或多个子问题,每个子问题与原问题具有完全相同的解决思路,进而可以按照递归的思路进行求解。
2. 解:通过分治算法的一般设计步骤进行说明。
3. 解:int fibonacci(int n) {if(n<=1) return 1;return fibonacci(n-1)+fibonacci(n-2); }4. 解:void hanoi(int n,int a,int b,int c) {if(n>0) {hanoi(n-1,a,c,b); move(a,b);hanoi(n-1,c,b,a); } } 5. 解:①22*2)(−−=n n f n② )log *()(n n n f O =6. 解:算法略。
递归和分治法摘要:一、递归与分治法的概念1.递归:函数调用自身的思想2.分治法:把一个大问题分解成若干个小问题二、递归与分治法的联系与区别1.递归通常作为分治法的实现方式2.分治法不一定要用递归实现三、递归与分治法的应用实例1.快速排序算法2.归并排序算法3.汉诺塔问题正文:递归和分治法是两种在计算机科学中经常使用的解决问题的方法。
递归是一种函数调用自身的思想,即函数在执行过程中,会调用自身来完成某些操作。
而分治法则是把一个大问题分解成若干个小问题,然后逐个解决这些小问题,最后再把它们的解合并,得到大问题的解。
这两种方法在某些情况下可以相互转化,递归通常作为分治法的实现方式,但分治法不一定要用递归实现。
递归与分治法之间的联系在于,递归通常是分治法的实现方式。
在分治法中,我们会把一个大问题分解成若干个小问题,然后通过递归的方式,逐个解决这些小问题。
最后,再把它们的解合并,得到大问题的解。
在这个过程中,递归函数的调用栈会随着问题规模的减小而减小,最终回到原点,从而完成问题的求解。
然而,分治法并不一定要用递归实现。
在一些情况下,我们可以通过迭代的方式,逐个解决小问题,然后把它们的解合并。
这种方式虽然不是通过递归函数调用自身来实现的,但它仍然符合分治法的思想,即把大问题分解成小问题,逐个解决。
递归和分治法在实际问题中有很多应用。
例如,快速排序算法和归并排序算法都是基于分治法的思想设计的。
在快速排序算法中,我们选择一个基准元素,然后把数组中小于基准的元素放在左边,大于基准的元素放在右边,再对左右两个子数组递归地执行相同的操作,直到数组有序。
而在归并排序算法中,我们同样把数组分成左右两个子数组,然后递归地对它们进行排序,最后再把排序好的子数组合并成一个有序的数组。
另一个例子是汉诺塔问题。
在这个问题中,有三个柱子和一个大小不同的圆盘。
要求把圆盘从第一个柱子移动到第三个柱子,每次只能移动一个圆盘,并且大盘不能放在小盘上。
算法分析(第二章):递归与分治法一、递归的概念知识再现:等比数列求和公式:1、定义:直接或间接地调用自身的算法称为递归算法。
用函数自身给出定义的函数称为递归函数。
2、与分治法的关系:由分治法产生的子问题往往是原问题的较小模式,这就为使用递归技术提供了方便。
在这种情况下,反复应用分治手段,可以使子问题与原问题类型一致而其规模却不断缩小,最终使子问题缩小到很容易直接求出其解。
这自然导致递归过程的产生。
分治与递归经常同时应用在算法设计之中,并由此产生许多高效算法。
3、递推方程:(1)定义:设序列01,....na a a简记为{na},把n a与某些个()ia i n<联系起来的等式叫做关于该序列的递推方程。
(2)求解:给定关于序列{n a}的递推方程和若干初值,计算n a。
4、应用:阶乘函数、Fibonacci数列、Hanoi塔问题、插入排序5、优缺点:优点:结构清晰,可读性强,而且容易用数学归纳法来证明算法的正确性,因此它为设计算法、调试程序带来很大方便。
缺点:递归算法的运行效率较低,无论是耗费的计算时间还是占用的存储空间都比非递归算法要多。
二、递归算法改进:1、迭代法:(1)不断用递推方程的右部替代左部(2)每一次替换,随着n的降低在和式中多出一项(3)直到出现初值以后停止迭代(4)将初值代入并对和式求和(5)可用数学归纳法验证解的正确性2、举例:-----------Hanoi塔算法----------- ---------------插入排序算法----------- ()2(1)1(1)1T n T nT=−+=()(1)1W n W n nW=−+−(1)=021n-23()2(1)12[2(2)1]12(2)21...2++2 (121)n n n T n T n T n T n T −−=−+=−++=−++==++=−(1)2 ()(1)1((n-2)+11)1(2)(2)(1)...(1)12...(2)(1)(1)/2W n W n n W n n W n n n W n n n n =−+−=−−+−=−+−+−==++++−+−=−3、换元迭代:(1)将对n 的递推式换成对其他变元k 的递推式 (2)对k 进行迭代(3)将解(关于k 的函数)转换成关于n 的函数4、举例:---------------二分归并排序---------------()2(/2)1W n W n n W =+−(1)=0(1)换元:假设2kn =,递推方程如下()2(/2)1W n W n n W =+−(1)=0 → 1(2)2(2)21k k k W W W−=+−(0)=0(2)迭代求解:12122222321332133212()2(2)212(2(2)21)212(2)22212(2)2*2212(2(2)21)2212(2)222212(2)3*2221...2(0)*2(22...21)22k k k k k k k k k k k k k k k k k k k k k k k k W n W W W W W W W W k k −−−−−−−+−+−−−=+−=+−+−=+−+−=+−−=+−+−−=+−+−−=+−−−==+−++++=−1log 1n n n +=−+(3)解的正确性—归纳验证: 证明递推方程的解是()(1)/2W n n n =−()(1)1W n W n n W =−+−(1)=0,(n 1)=n +n=n(n-1)/2+n =n[(n-1)/2+1]=n(n+1)/2n W W +方法:数学归纳法证 n=1,W(1)=1*(1-1)/2=0假设对于解满足方程,则()---------------快速排序--------------------->>>平均工作量:假设首元素排好序在每个位置是等概率的112()()()(1)0n i T n T i O n n T −==+=∑ >>>对于高阶方程应该先化简,然后迭代(1)差消化简:利用两个方程相减,将右边的项尽可能消去,以达到降阶的目的。
111212212()()()()2()(1)(1)2()(1)n i n i n i T n T i O n n nT n T i cn n T n T i c n −=−=−==+=+−−=+−∑∑∑ 122211()(1)(1)2()(2()(1))2(1)1()(1)(1)1()(1)111n n i i nT n n T n T i cn T i c n T n c nnT n n T n c nT n T n c n n n −−==−−−=+−+−=−+=+−+−=+++∑∑(2)迭代求解:()(1)111111(1)1(...)1321111(...)13(log )()(log )T n T n c n n n T c n n c n n n T n n n θθ−=+++=+++++=++++==三、递归树1、概念(1)递归树是迭代计算的模型(2)递归树的生成过程与迭代过程一致(3)递归树上所有项恰好是迭代之后产生和式中的项 (4)对递归树上的项求和就是迭代后方程的解 2、迭代在递归树中的表示111(()...()()...(),....()...()t t t W m W m W m f m g m m m mW m W m =+++++<++)其中称为函数项注意:每个叶结点是一个函数项3、二层子树的例子二分归并排序:(2(/2)1W n W n n =+−) →4、递归树的生成规则 ·初始:递归树只有根节点,其值为W(m) ·不断继续下述过程:将函数项叶节点的迭代式W(m)表示成二层子树 用该子树替换该叶节点·继续递归树的生成,直到树中无函数项(只有初值)为止 5、递归树生成实例(2(/2)1W n W n n =+−)>>>对递归树上的量求和:11(2(/2)1,2,(1)0()12...2(2)log 1k k k W n W n n n W W n n n n kn n n n −−=+−===−+−++−=−=−+)四、Master 定理(主定理)--------------它提供了一种通过渐近符号表示递推关系式的方法。
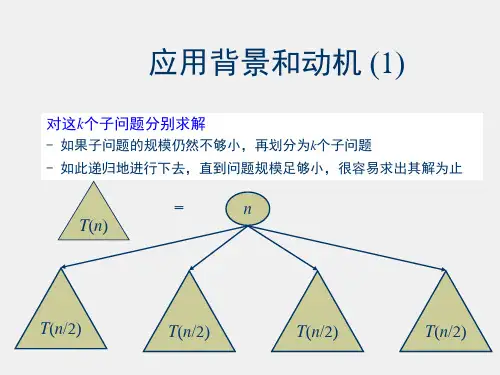
1、应用背景:T (n )=aT(n/b)+f(n)a :规约后的子问题个数 n/b :规约后子问题的规模f(n):归约过程及组合子问题的解的工作量T 二分检索:(n )=T(n/2)+1二分归并排序:T(n)=2T(n/2)+n-12、定理:1,1a b T ≥>定理:设为常数,f(n)为函数,T(n)为非负整数,且(n )=aT(n/b)+f(n),则log log log log log +1.logn .c<1n (/)(),n =a b abab abab af n b cf n T εεεθθθεθ−∃Ω∃≤若f(n)=O(n ),>0,那么T(n)=(n )2.若f(n)=(n ),那么T(n)=(n)3若f(n)=(n ),>0,且对于某个常数和充分大的有那么()(f(n))3、应用:9933log log 12a −例1:求解递推方程:T(n)=9T(n/3)+n 解 上述递推方程中的=9,b=3,f(n)=n n=n ,f(n)=O(n)2=1 T(n)=(n )εθ相当于主定理的第一种情况,其中根据定理得到13/2log 0a 例2:求解递推方程:T(n)=T(2n/3)+1解 上述递推方程中的=1,b=3/2,f(n)=1n=n =1,T(n)=(logn)θ相当于主定理的第二种情况,根据定理得到12log n =W(n/2)+1,W(1)=1a=1,b=2,n 1,()1n =logn W f n W θ==递归算法分析二分检索:()属于主定理第二种情况,()()22log n =2W(n/2)+n-1,W(1)=0a=2,b=2,n n,()n-1n =nlogn W f n W θ==二分归并排序:()属于主定理第二种情况,()()不能使用主定理的例子:22log 1n =0nlogn=()T n εε+>Ω求解()2T(n/2)+nlogn a=2,b=2,n=n,f(n)=nlogn不存在使下式成立c<1af(n/b)cf(n)≤≤不存在使对所有充分大的n 成立2(n/2)log(n/2)=n(logn-1)cnlogn五、分治法1、基本思想:将一个规模为n 的问题分解为k 个规模较小的子问题,这些子问题互相独立且与原问题相同。
递归地求解这些子问题,然后将各子问题的解合并得到原问题的解。
2、设计过程:–Divide :整个问题划分为多个子问题–Conquer :求解各子问题(递归调用正设计的算法) –Combine :合并子问题的解, 形成原始问题的解 注意:(1)子问题与原问题性质完全一样 (2)子问题之间可彼此独立的求解 (3)递归停止时子问题可直接求解 3、算法分析:设输入大小为n ,T(n)为时间复杂性 – Divide 阶段的时间复杂性 • 划分问题为a 个子问题 • 每个子问题大小为n/b • 划分时间可直接得到=D(n) – Conquer 阶段的时间复杂性 • 递归调用• 求解时间= a T(n/b)– Combine 阶段的时间复杂性 • 时间可以直接得到=C(n) T(n)=θ(1) if n<cT(n)=a T(n/b) + D(n)+C(n) otherwise 4、分治算法的特点:(1)将原问题归约为规模小的子问题(子问题与原问题具有相同的性质)(2)子问题规模足够小时可直接求解 (3)算法可以递归也可以迭代实现 (4)算法的分析方法:递推方程 5、分治法的一般描述分治算法 divide-and-conquer(P)1. if | P | <= c then S(P) //2.divide P into P1, P2, ..., Pk //3. for i←1 to k4. yi=divide-and-conquer(Pi) //5. 6、设计要点(1)原问题可以划分或者归约为规模较小的子问题 注意:子问题与原问题具有相同的性质子问题的求解彼此独立划分时子问题的规模尽可能均衡 (2)子问题的规模足够小时可直接求解 (3)子问题的解综合得到原问题的解 (4)算法的实现:递归或迭代 7、分治算法时间分析(1)时间复杂度函数的递推方程:12()(||)(||)...(||)()()k W n W P W P W P f n W c C=++++= >>>P1,P2,…P k 为划分后产生的子问题>>>f(n)为划分子问题以及将子问题综合得到原问题解的总工作量 >>>规模为c 的最小子问题的工作量为C(2)两类常见的递推方程:11()()()2()()()ki i T n a T n i f n nT n aT f n b==−+=+∑方程:方程:求解方法:方程1:迭代法,差消化简,递归树方程2:迭代法,换元法,递归树,主定理2()()()nT n aT f n b =+方程:log log ()() a 1()O(logn) a=1()() a<b ()O(nlogn) a=bO() a>b ab a bf n O n T n f n cnO n T n n ⎧≠⎪=⎨⎪⎩=⎧⎪=⎨⎪⎩为常数六、分治法的应用1、二分搜索技术问题描述:给定已按升序排好序的n 个元素a[1:n],现要在这n 个元素中找出一特定元素x 分析:✓ 该问题分解出的各个子问题是相互独立的,可以分解为若干个规模较小的相同问题;✓ 该问题的规模缩小到一定的程度就可以容易地解决; ✓ 分解出的子问题的解可以合并为原问题的解; 算法设计思想:⚫ 通过x 与中位数T(m)比较,将原问题归结为规模减半的子问题,如果x 小于中位数,则子问题由小于T(m)的数构成,否则由大于T(m)的数构成。