用crash调试linux kernel
- 格式:pdf
- 大小:512.53 KB
- 文档页数:14
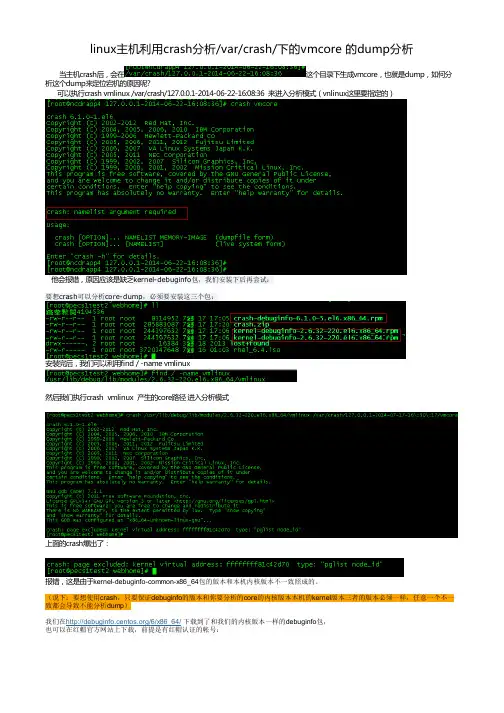
当主机crash后,会在这个目录下生成vmcore,也就是dump,如何分析这个dump来定位宕机的原因呢?可以执行crash vmlinux /var/crash/127.0.0.1-2014-06-22-16:08:36 来进入分析模式(vnlinux这里要指定的)他会报错,原因应该是缺乏kernel-debuginfo包,我们安装下后再尝试:要想crash可以分析core-dump,必须要安装这三个包:安装完后,我们可以利用find / -name vmlinux上面的crash爆出了:报错,这是由于kernel-debuginfo-common-x86_64包的版本和本机内核版本不一致照成的。
(说下:要想使用crash,只要保证debuginfo的版本和你要分析的core的内核版本本机的kernel版本三者的版本必须一样,任意一个不一致都会导致不能分析dump)##选择包和版本#再选择show debug package找到debug包 下载就可以了----------------------------------------然后安装一下:#安装包开始++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++至于我们怎么知道coredump的内核版本,可以cd /var/crash/127.0.0.1---------/然后执行strings vmcore |grep 'OSRELEASE'可以显示出vmcore的内核版本顺便附一下内核版本和系统版本的对应关系CentOS 6.0/RHEL6 Update 0 -------------------> 2.6.32-71CentOS 6.1/RHEL6 Update 1 -------------------> 2.6.32-131CentOS 6.2/RHEL6 Update 2 -------------------> 2.6.32-220CentOS 6.3/RHEL6 Update 3 -------------------> 2.6.32-279CentOS 6.4/RHEL6 Update 4 -------------------> 2.6.32-358CentOS 6.5/RHEL6 Update 5 -------------------> 2.6.32-431CentOS 6.6/RHEL6 Update 6 -------------------> 2.6.32-504++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ #后再分析下dump可以进crash模式了。

crashkernel参数(原创实用版)目录1.介绍 crashkernel 参数2.crashkernel 参数的作用3.使用 crashkernel 参数的方法4.crashkernel 参数的示例5.结论正文1.介绍 crashkernel 参数crashkernel 参数是 Linux 内核中的一个重要参数,主要用于在系统崩溃时进行内核转储,以便于对系统崩溃的原因进行分析和调试。
crashkernel 参数通常在系统启动时由内核自动设置,也可以通过手动编辑内核配置文件进行设置。
2.crashkernel 参数的作用crashkernel 参数的主要作用是在系统发生异常时,将内核的当前状态保存到一个文件中,以便于系统管理员或开发人员进行分析。
通过分析crashkernel 参数保存的内核状态,可以找到系统崩溃的原因,进而对系统进行调试和优化。
3.使用 crashkernel 参数的方法要使用 crashkernel 参数,首先需要确保系统内核已经启用了crashkernel 支持。
接下来,可以通过以下两种方法使用 crashkernel 参数:(1)使用命令行工具:可以使用“crash”命令将 crashkernel 参数保存到一个文件中。
例如:```crash /path/to/crashkernel```(2)手动编辑内核配置文件:可以手动编辑内核配置文件(通常位于 /usr/src/linux/.config 或 /usr/src/linux-xx.xx/.config),将CRASH_DUMP_ON_ZERO_PANIC设置为y,并配置一个用于存储crashkernel 文件的路径。
例如:```CONFIG_CRASH_DUMP_ON_ZERO_PANIC=yCONFIG_CRASH_DUMP_DIR=/path/to/crashdumps```4.crashkernel 参数的示例以下是一个 crashkernel 参数的示例:```$ crash /path/to/crashkernel```上述命令将把系统当前的状态保存到/path/to/crashkernel文件中。
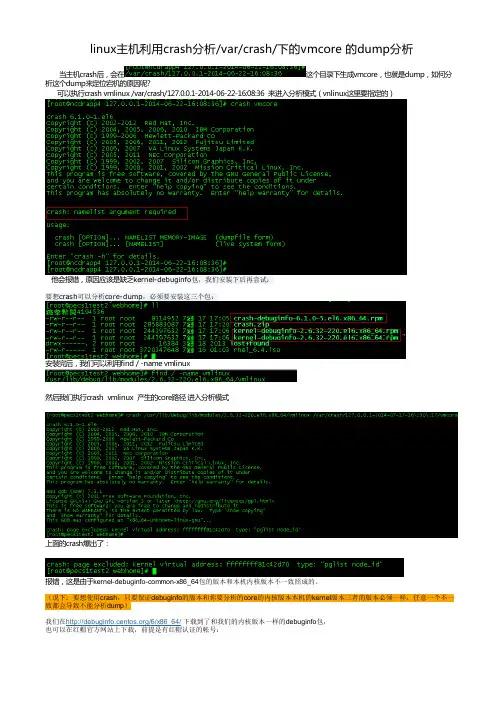
当主机crash后,会在这个目录下生成vmcore,也就是dump,如何分析这个dump来定位宕机的原因呢?可以执行crash vmlinux /var/crash/127.0.0.1-2014-06-22-16:08:36 来进入分析模式(vnlinux这里要指定的)他会报错,原因应该是缺乏kernel-debuginfo包,我们安装下后再尝试:要想crash可以分析core-dump,必须要安装这三个包:安装完后,我们可以利用find / -name vmlinux上面的crash爆出了:报错,这是由于kernel-debuginfo-common-x86_64包的版本和本机内核版本不一致照成的。
(说下:要想使用crash,只要保证debuginfo的版本和你要分析的core的内核版本本机的kernel版本三者的版本必须一样,任意一个不一致都会导致不能分析dump)##选择包和版本#再选择show debug package找到debug包 下载就可以了----------------------------------------然后安装一下:#安装包开始++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++至于我们怎么知道coredump的内核版本,可以cd /var/crash/127.0.0.1---------/然后执行strings vmcore |grep 'OSRELEASE'可以显示出vmcore的内核版本顺便附一下内核版本和系统版本的对应关系CentOS 6.0/RHEL6 Update 0 -------------------> 2.6.32-71CentOS 6.1/RHEL6 Update 1 -------------------> 2.6.32-131CentOS 6.2/RHEL6 Update 2 -------------------> 2.6.32-220CentOS 6.3/RHEL6 Update 3 -------------------> 2.6.32-279CentOS 6.4/RHEL6 Update 4 -------------------> 2.6.32-358CentOS 6.5/RHEL6 Update 5 -------------------> 2.6.32-431CentOS 6.6/RHEL6 Update 6 -------------------> 2.6.32-504++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ #后再分析下dump可以进crash模式了。

什么是 crash如前文所述,当 linux 系统内核发生崩溃的时候,可以通过 kdump 等方式收集内核崩溃之前的内存,生成一个转储文件 vmcore。
内核开发者通过分析该 vmcore 文件就可以诊断出内核崩溃的原因,从而进行操作系统的代码改进。
那么 crash 就是一个被广泛使用的内核崩溃转储文件分析工具,掌握 crash 的使用技巧,对于定位问题有着十分重要的作用。
回页首使用 crash 的先决条件由于 crash 用于调试内核崩溃的转储文件,因此使用 crash 需要依赖如下条件:1. kernel 映像文件 vmlinux 在编译的时候必须指定了 -g 参数,即带有调试信息。
2. 需要有一个内存崩溃转储文件(例如 vmcore),或者可以通过 /dev/mem 或/dev/crash 访问的实时系统内存。
如果 crash 命令行没有指定转储文件,则 crash 默认使用实时系统内存,这时需要 root 权限。
3. crash 支持的平台处理器包括:x86, x86_64, ia64, ppc64, arm, s390, s390x ( 也有部分 crash 版本支持 Alpha 和 32-bit PowerPC,但是对于这两种平台的支持不保证长期维护 )。
4. crash 支持 2.2.5-15(含)以后的 Linux 内核版本。
随着 Linux 内核的更新,crash 也在不断升级以适应新的内核。
回页首crash 安装指南要想使用 crash 调试内核转储文件,需要安装 crash 工具和内核调试信息包。
不同的发行版安装包名称略有差异,这里仅列出 RHEL 和 SLES 发行版对应的安装包名称如下:表 1. crash 工具和内核调试包系统版本crash 工具名称内核调试信息包RHEL6.2 crash kernel-debuginfo-commonkernel-debuginfoSLES11SP2 crash kernel-default-debuginfokernel-ppc64-debuginfo以 RHEL 为例,安装 crash 及内核调试信息包的步骤如下:rpm -ivh crash-5.1.8-1.el6.ppc64.rpmrpm -ivh kernel-debuginfo-common-ppc64-2.6.32-220.el6.ppc64.rpmrpm -ivh kernel-debuginfo-2.6.32-220.el6.ppc64.rpm回页首启动 crash启动参数说明使用 crash 调试转储文件,需要在命令行输入两个参数:debug kernel 和 dump file,其中 dump file 是内核转储文件的名称,debug kernel 是由内核调试信息包安装的,不同的发行版名称略有不同,以 RHEL 和 SLES 为例:RHEL6.2:/usr/lib/debug/lib/modules/2.6.32-220.el6.ppc64/vmlinuxSLES11SP2:/usr/lib/debug/boot/vmlinux-3.0.13-0.27-ppc64.debug使用 crash -h 或 man crash 可以查看 crash 支持的一系列选项,这里仅以常用的选项为例说明如下:-h:打印帮助信息-d:设置调试级别-S:使用 /boot/System.map 作为默认的映射文件-s:不显示版本、初始调试信息等,直接进入命令行-i file:启动之后自动运行 file 中的命令,再接受用户输入crash 报告分析crash 命令启动后,会产生一个转储文件的分析报告摘要,如下图所示。

crash的用法
Crash是一个开源的实时系统监控工具,可以分析和跟踪Linux内核崩溃、Oops、Panic等事件,以及收集系统运行状态信息。
使用 Crash 可以快速定位问题,如果能够成功捕捉到系统崩溃的瞬间,就可以取得最接近问题发生前后的系统状态,从而定位和解决问题。
使用 Crash 的步骤比较简单:
1. 使用“crash”命令创建 crash 调试会话,并选择要调试的内核版本;
2. 使用“bt”命令打印出堆栈回溯,以便了解系统在崩溃之前的状态;
3. 使用“info”命令查看内核变量,以便分析崩溃原因;
4. 使用“set”命令设置断点,以便在崩溃之前进行调试;
5. 退出 crash 调试会话,保存 dump 文件,以便日后分析和研究。

Crash使⽤参考整理⾃man 8 crash1、简介Crash⼯具可以⽤来分析⼀个正在运⾏的内核,也可以⽤来分析⼀个内核的crash dump⽂件,这⾥说的是内核代码异常产⽣的crash dump⽂件,不是应⽤层程序运⾏异常产⽣的core dump⽂件,它⽀持分析由netdump, diskdump, LKCD, kdump, xen‐dump 或者 kvmdump ⼯具产⽣的crash dump⽂件。
它整合了SVR4 UNIX crash的⼯具和GDB调试器,因⽽具有源码级别调试能⼒。
Crash⼯具可以⽤来分析内核的调⽤堆栈,内核源码的反汇编,内核数据结构和变量的格式化展⽰等等,另外Crash也可以传递⼀些GDB命令来执⾏。
在初始化的过程中,$HOME/.crashrc ⽂件中的命令和当前⽬录下的./.crashrc⽂件中的命令将会被执⾏。
Crash⼯具后向兼容,当内核版本变化导致Crash⼯具更新后后仍然会兼容以前的内核版本。
2、启动命令⾏crash [OPTION]... NAMELIST MEMORY-IMAGE[@ADDRESS] (⽤来分析dumpfile⽂件)crash [OPTION]... [NAMELIST] (⽤来分析正在运⾏的系统)NAMELIST:这个是未压缩的内核镜像⽂件(vmlinux)的路径,在⽤来分析dumpfile⽂件的时候也可以使⽤gzip或者bzip2压缩后的vmlinux⽂件。
MEMORY-IMAGE[@ADDRESS]:由netdump, diskdump, LKCD, kdump, xen‐dump 或者 kvmdump ⼯具产⽣的crash dump⽂件的路径,如果运⾏Crash⼯具没有输⼊这个参数的话,那么Crash⼯具将会⽤来分析正在运⾏的linux内核,分析正在运⾏的内核需要访问系统的RAM,⼀般是需要root权限的。
分析live system的时候,默认情况下/dev/crash将会被使⽤,如果这个⽂件不存在,然后会使⽤/dev/mem,但是如果kernel被配置为CONFIG_STRICT_DEVMEM,那么/proc/kcore将会被使⽤,也可以显式的指定/dev/crash、/dev/mem 、 /proc/kcore。
当主机crash后,会在这个目录下生成vmcore,也就是dump,如何分析这个dump来定位宕机的原因呢?可以执行crash vmlinux /var/crash/127.0.0.1-2014-06-22-16:08:36 来进入分析模式(vnlinux这里要指定的)他会报错,原因应该是缺乏kernel-debuginfo包,我们安装下后再尝试:要想crash可以分析core-dump,必须要安装这三个包:安装完后,我们可以利用find / -name vmlinux上面的crash爆出了:报错,这是由于kernel-debuginfo-common-x86_64包的版本和本机内核版本不一致照成的。
(说下:要想使用crash,只要保证debuginfo的版本和你要分析的core的内核版本本机的kernel版本三者的版本必须一样,任意一个不一致都会导致不能分析dump)##选择包和版本#再选择show debug package找到debug包 下载就可以了----------------------------------------然后安装一下:#安装包开始++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++至于我们怎么知道coredump的内核版本,可以cd /var/crash/127.0.0.1---------/然后执行strings vmcore |grep 'OSRELEASE'可以显示出vmcore的内核版本顺便附一下内核版本和系统版本的对应关系CentOS 6.0/RHEL6 Update 0 -------------------> 2.6.32-71CentOS 6.1/RHEL6 Update 1 -------------------> 2.6.32-131CentOS 6.2/RHEL6 Update 2 -------------------> 2.6.32-220CentOS 6.3/RHEL6 Update 3 -------------------> 2.6.32-279CentOS 6.4/RHEL6 Update 4 -------------------> 2.6.32-358CentOS 6.5/RHEL6 Update 5 -------------------> 2.6.32-431CentOS 6.6/RHEL6 Update 6 -------------------> 2.6.32-504++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ #后再分析下dump可以进crash模式了。

linux kernel assert用法在Linux内核开发中,assert(断言)是一种常见的调试工具。
它用于在程序中检查某个条件是否满足,如果不满足,则触发断言失败,中止程序的执行并显示错误消息。
本文将介绍Linux内核中assert的用法及其在开发中的重要性。
在Linux内核的源代码中,我们经常可以见到以下形式的assert语句:```c#define assert(expr) \do { \if (!(expr)) { \printk(KERN_ERR "Assertion failed: %s, file: %s, line: %d\n", #expr,__FILE__, __LINE__); \BUG(); \} \} while (0)```这里的`assert(expr)`是一个宏定义,它的作用是检查表达式`expr`是否为真。
如果`expr`为假,`assert`会输出错误消息,包括失败的表达式、所在的文件和行号,并且通过调用`BUG()`宏中止程序的执行。
使用assert语句的好处是帮助开发人员快速定位出错的地方,尤其是在调试和测试阶段。
当某个条件不满足时,断言失败会立即停止程序的执行,这样可以防止错误继续传播,并提供了一些关键信息,例如出错的表达式、文件名和行号等。
这些信息可以帮助开发人员迅速定位错误位置,加快错误修复的速度。
而在发布时,通常会使用编译选项来禁用assert语句,以提高代码的执行效率。
对C语言编译器来说,可以使用`-DNDEBUG`选项来取消定义`NDEBUG`宏,这会导致所有的assert语句在编译时被移除。
这样发布版本的代码将不会包含assert语句,从而提高代码的性能。
在Linux内核开发中,assert语句通常用于以下几种情况:1. 参数检查:在函数的开头,使用assert语句检查传入的参数是否合法。
它可以确保函数在被调用时,参数的值满足特定的条件,避免出现不可预料的错误。

Linuxkernel调试⽅法及⼯具Linux内核调试的⽅式以及⼯具集锦CSDN GitHubLinux内核调试的⽅式以及⼯具集锦 LDD-LinuxDeviceDrivers/study/debug"调试难度本来就是写代码的两倍. 因此, 如果你写代码的时候聪明⽤尽, 根据定义, 你就没有能耐去调试它了."--Brian Kernighan121 内核调试以及⼯具总结内核总是那么捉摸不透, 内核也会犯错, 但是调试却不能像⽤户空间程序那样, 为此内核开发者为我们提供了⼀系列的⼯具和系统来⽀持内核的调试.内核的调试, 其本质是内核空间与⽤户空间的数据交换, 内核开发者们提供了多样的形式来完成这⼀功能.⼯具描述debugfs等⽂件系统提供了 procfs, sysfs, debugfs以及 relayfs 来与⽤户空间进⾏数据交互, 尤其是 debugfs, 这是内核开发者们实现的专门⽤来调试的⽂件系统接⼝. 其他的⼯具或者接⼝, 多数都依赖于 debugfs.printk 强⼤的输出系统, 没有什么逻辑上的bug是⽤PRINT解决不了的ftrace以及其前端⼯具trace-cmd等内核提供了 ftrace ⼯具来实现检查点, 事件等的检测, 这⼀框架依赖于 debugfs, 他在 debugfs 中的 tracing ⼦系统中为⽤户提供了丰富的操作接⼝, 我们可以通过该系统对内核实现检测和分析. 功能虽然强⼤, 但是其操作并不是很简单, 因此使⽤者们为实现了 trace-cmd 等前端⼯具, 简化了 ftrace 的使⽤.kprobe以及更强⼤的systemtap 内核中实现的 krpobe 通过类似与代码劫持⼀样的技巧, 在内核的代码或者函数执⾏前后, 强制加上某些调试信息, 可以很巧妙的完成调试⼯作, 这是⼀项先进的调试技术, 但是仍然有觉得它不够好, 劫持代码需要⽤驱动的⽅式编译并加载, 能不能通过脚本的⽅式⾃动⽣成劫持代码并⾃动加载和收集数据, 于是systemtap 出现了. 通过 systemtap ⽤户只需要编写脚本, 就可以完成调试并动态分析内核kgdb && kgtp KGDB 是⼤名⿍⿍的内核调试⼯具, KGTP则通过驱动的⽅式强化了 gdb的功能, 诸如tracepoint, 打印内核变量等.perf erf Event是⼀款随 inux内核代码⼀同发布和维护的性能诊断⼯具, 核社区维护和发展. Perf 不仅可以⽤于应⽤程序的性能统计分析, 也可以应⽤于内核代码的性能统计和分析. 得益于其优秀的体系结构设计, 越来越多的新功能被加⼊ Perf, 使其已经成为⼀个多功能的性能统计⼯具集LTTng LTTng 是⼀个 Linux 平台开源的跟踪⼯具, 是⼀套软件组件, 可允许跟踪 Linux 内核和⽤户程序, 并控制跟踪会话(开始/停⽌跟踪、启动/停⽌事件等等).2 ⽤户空间与内核空间数据交换的⽂件系统内核中有三个常⽤的伪⽂件系统: procfs, debugfs和sysfs.⽂件系统描述procfs The proc filesystem is a pseudo-filesystem which provides an interface to kernel data structures.sysfs The filesystem for exporting kernel objects.debugfs Debugfs exists as a simple way for kernel developers to make information available to user space.relayfs A significantly streamlined version of relayfs was recently accepted into the -mm kernel tree.它们都⽤于Linux内核和⽤户空间的数据交换, 但是适⽤的场景有所差异:procfs 历史最早, 最初就是⽤来跟内核交互的唯⼀⽅式, ⽤来获取处理器、内存、设备驱动、进程等各种信息.sysfs 跟 kobject 框架紧密联系, ⽽ kobject 是为设备驱动模型⽽存在的, 所以 sysfs 是为设备驱动服务的.debugfs 从名字来看就是为 debug ⽽⽣, 所以更加灵活.relayfs 是⼀个快速的转发 (relay) 数据的⽂件系统, 它以其功能⽽得名. 它为那些需要从内核空间转发⼤量数据到⽤户空间的⼯具和应⽤提供了快速有效的转发机制.在 Linux 下⽤户空间与内核空间数据交换的⽅式, 第 2 部分: procfs、seq_file、debugfs和relayfsLinux ⽂件系统:procfs, sysfs, debugfs ⽤法简介2.1 procfs⽂件系统ProcFs 介绍`procfs 是⽐较⽼的⼀种⽤户态与内核态的数据交换⽅式, 内核的很多数据都是通过这种⽅式出⼝给⽤户的, 内核的很多参数也是通过这种⽅式来让⽤户⽅便设置的. 除了 sysctl 出⼝到 /proc 下的参数, procfs 提供的⼤部分内核参数是只读的. 实际上, 很多应⽤严重地依赖于procfs, 因此它⼏乎是必不可少的组件. 前⾯部分的⼏个例⼦实际上已经使⽤它来出⼝内核数据, 但是并没有讲解如何使⽤, 本节将讲解如何使⽤procfs.参考资料⽤户空间与内核空间数据交换的⽅式(2)——procfs2.2 sysfs⽂件系统内核⼦系统或设备驱动可以直接编译到内核, 也可以编译成模块, 编译到内核, 使⽤前⼀节介绍的⽅法通过内核启动参数来向它们传递参数, 如果编译成模块, 则可以通过命令⾏在插⼊模块时传递参数, 或者在运⾏时, 通过 sysfs 来设置或读取模块数据.Sysfs 是⼀个基于内存的⽂件系统, 实际上它基于ramfs, sysfs 提供了⼀种把内核数据结构, 它们的属性以及属性与数据结构的联系开放给⽤户态的⽅式, 它与 kobject ⼦系统紧密地结合在⼀起, 因此内核开发者不需要直接使⽤它, ⽽是内核的各个⼦系统使⽤它. ⽤户要想使⽤ sysfs 读取和设置内核参数, 仅需装载 sysfs 就可以通过⽂件操作应⽤来读取和设置内核通过 sysfs 开放给⽤户的各个参数:mkdir -p /sysfsmount -t sysfs sysfs /sysfs12注意, 不要把 sysfs 和 sysctl 混淆, sysctl 是内核的⼀些控制参数, 其⽬的是⽅便⽤户对内核的⾏为进⾏控制, ⽽ sysfs 仅仅是把内核的 kobject 对象的层次关系与属性开放给⽤户查看, 因此 sysfs 的绝⼤部分是只读的, 模块作为⼀个 kobject 也被出⼝到 sysfs, 模块参数则是作为模块属性出⼝的, 内核实现者为模块的使⽤提供了更灵活的⽅式, 允许⽤户设置模块参数在 sysfs 的可见性并允许⽤户在编写模块时设置这些参数在sysfs 下的访问权限, 然后⽤户就可以通过 sysfs 来查看和设置模块参数, 从⽽使得⽤户能在模块运⾏时控制模块⾏为.⽤户空间与内核空间数据交换的⽅式(6)——模块参数与sysfs2.3 debugfs⽂件系统内核开发者经常需要向⽤户空间应⽤输出⼀些调试信息, 在稳定的系统中可能根本不需要这些调试信息, 但是在开发过程中, 为了搞清楚内核的⾏为, 调试信息⾮常必要, printk可能是⽤的最多的, 但它并不是最好的, 调试信息只是在开发中⽤于调试, ⽽ printk 将⼀直输出, 因此开发完毕后需要清除不必要的 printk 语句, 另外如果开发者希望⽤户空间应⽤能够改变内核⾏为时, printk 就⽆法实现.因此, 需要⼀种新的机制, 那只有在需要的时候使⽤, 它在需要时通过在⼀个虚拟⽂件系统中创建⼀个或多个⽂件来向⽤户空间应⽤提供调试信息.有⼏种⽅式可以实现上述要求:使⽤ procfs, 在 /proc 创建⽂件输出调试信息, 但是 procfs 对于⼤于⼀个内存页(对于 x86 是 4K)的输出⽐较⿇烦, ⽽且速度慢, 有时回出现⼀些意想不到的问题.使⽤ sysfs( 2.6 内核引⼊的新的虚拟⽂件系统), 在很多情况下, 调试信息可以存放在那⾥, 但是sysfs主要⽤于系统管理,它希望每⼀个⽂件对应内核的⼀个变量,如果使⽤它输出复杂的数据结构或调试信息是⾮常困难的.使⽤ libfs 创建⼀个新的⽂件系统, 该⽅法极其灵活, 开发者可以为新⽂件系统设置⼀些规则, 使⽤ libfs 使得创建新⽂件系统更加简单, 但是仍然超出了⼀个开发者的想象.为了使得开发者更加容易使⽤这样的机制, Greg Kroah-Hartman 开发了 debugfs(在 2.6.11 中第⼀次引⼊), 它是⼀个虚拟⽂件系统, 专门⽤于输出调试信息, 该⽂件系统⾮常⼩, 很容易使⽤, 可以在配置内核时选择是否构件到内核中, 在不选择它的情况下, 使⽤它提供的API的内核部分不需要做任何改动.⽤户空间与内核空间数据交换的⽅式(1)——debugfsLinux内核⾥的DebugFSLinux驱动调试的Debugfs的使⽤简介Linux Debugfs⽂件系统介绍及使⽤Linux内核⾥的DebugFSDebugging the Linux Kernel with debugfsdebugfs-seq_fileLinux Debugfs⽂件系统介绍及使⽤Linux ⽂件系统:procfs, sysfs, debugfs ⽤法简介⽤户空间与内核空间数据交换的⽅式(1)——debugfsLinux 运⽤debugfs调试⽅法2.4 relayfs⽂件系统relayfs 是⼀个快速的转发(relay)数据的⽂件系统, 它以其功能⽽得名. 它为那些需要从内核空间转发⼤量数据到⽤户空间的⼯具和应⽤提供了快速有效的转发机制.Channel 是 relayfs ⽂件系统定义的⼀个主要概念, 每⼀个 channel 由⼀组内核缓存组成, 每⼀个 CPU 有⼀个对应于该 channel 的内核缓存,每⼀个内核缓存⽤⼀个在 relayfs ⽂件系统中的⽂件⽂件表⽰, 内核使⽤ relayfs 提供的写函数把需要转发给⽤户空间的数据快速地写⼊当前CPU 上的 channel 内核缓存, ⽤户空间应⽤通过标准的⽂件 I/ O函数在对应的 channel ⽂件中可以快速地取得这些被转发出的数据 mmap 来. 写⼊到 channel 中的数据的格式完全取决于内核中创建channel 的模块或⼦系统.relayfs 的⽤户空间API :relayfs 实现了四个标准的⽂件 I/O 函数, open、mmap、poll和close函数描述open 打开⼀个 channel 在某⼀个 CPU 上的缓存对应的⽂件.mmap 把打开的 channel 缓存映射到调⽤者进程的内存空间.read 读取 channel 缓存, 随后的读操作将看不到被该函数消耗的字节, 如果 channel 的操作模式为⾮覆盖写, 那么⽤户空间应⽤在有内核模块写时仍可以读取, 但是如 channel 的操作模式为覆盖式, 那么在读操作期间如果有内核模块进⾏写,结果将⽆法预知, 因此对于覆盖式写的channel, ⽤户应当在确认在 channel 的写完全结束后再进⾏读.poll ⽤于通知⽤户空间应⽤转发数据跨越了⼦缓存的边界, ⽀持的轮询标志有 POLLIN、POLLRDNORM 和 POLLERRclose 关闭 open 函数返回的⽂件描述符, 如果没有进程或内核模块打开该 channel 缓存, close 函数将释放该channel 缓存注意 : ⽤户态应⽤在使⽤上述 API 时必须保证已经挂载了 relayfs ⽂件系统, 但内核在创建和使⽤ channel时不需要relayfs 已经挂载. 下⾯命令将把 relayfs ⽂件系统挂载到 /mnt/relay.⽤户空间与内核空间数据交换的⽅式(4)——relayfsRelay:⼀种内核到⽤户空间的⾼效数据传输技术2.5 seq_file⼀般地, 内核通过在 procfs ⽂件系统下建⽴⽂件来向⽤户空间提供输出信息, ⽤户空间可以通过任何⽂本阅读应⽤查看该⽂件信息, 但是procfs 有⼀个缺陷, 如果输出内容⼤于1个内存页, 需要多次读, 因此处理起来很难, 另外, 如果输出太⼤, 速度⽐较慢, 有时会出现⼀些意想不到的情况, Alexander Viro 实现了⼀套新的功能, 使得内核输出⼤⽂件信息更容易, 该功能出现在 2.4.15(包括 2.4.15)以后的所有 2.4 内核以及2.6 内核中, 尤其是在 2.6 内核中,已经⼤量地使⽤了该功能⽤户空间与内核空间数据交换的⽅式(3)——seq_file内核proc⽂件系统与seq接⼝(4)—seq_file接⼝编程浅析Linux内核中的seq操作seq_file源码分析⽤序列⽂件(seq_file)接⼝导出常⽤数据结构seq_file机制3 printk在内核调试技术之中, 最简单的就是 printk 的使⽤了, 它的⽤法和C语⾔应⽤程序中的 printf 使⽤类似, 在应⽤程序中依靠的是 stdio.h 中的库,⽽在 linux 内核中没有这个库, 所以在 linux 内核中, 实现了⾃⼰的⼀套库函数, printk 就是标准的输出函数linux内核调试技术之printk调整内核printk的打印级别linux设备驱动学习笔记–内核调试⽅法之printk4 ftrace && trace-cmd4.1 trace && ftraceLinux当前版本中, 功能最强⼤的调试、跟踪⼿段. 其最基本的功能是提供了动态和静态探测点, ⽤于探测内核中指定位置上的相关信息.静态探测点, 是在内核代码中调⽤ ftrace 提供的相应接⼝实现, 称之为静态是因为, 是在内核代码中写死的, 静态编译到内核代码中的, 在内核编译后, 就不能再动态修改. 在开启 ftrace 相关的内核配置选项后, 内核中已经在⼀些关键的地⽅设置了静态探测点, 需要使⽤时, 即可查看到相应的信息.动态探测点, 基本原理为 : 利⽤ mcount 机制, 在内核编译时, 在每个函数⼊⼝保留数个字节, 然后在使⽤ ftrace时, 将保留的字节替换为需要的指令, ⽐如跳转到需要的执⾏探测操作的代码。

Linux内核Crash分析在工作中经常会遇到一些内核crash的情况,本文就是根据内核出现crash后的打印信息,对其进行了分析,使用的内核版本为:Linux2.6.32。
每一个进程的生命周期内,其生命周期的范围为几毫秒到几个月。
一般都是和内核有交互,例如用户空间程序使用系统调用进入内核空间。
这时使用的不再是用户空间的栈空间,使用对应的内核栈空间。
对每一个进程来说,Linux内核都会把两个不同的数据结构紧凑的存放在一个单独为进程分配的存储空间中:一个是内核态的进程堆栈,另一个是紧挨进程描述符的数据结构thread_info,叫线程描述符。
内核的堆栈大小一般为8KB,也就是8192个字节,占用两个页。
在Linux-2.6.32内核中thread_info.h文件中有对内核堆栈的定义:1.#define THREAD_SIZE 8192在Linux内核中使用下面的联合结构体表示一个进程的线程描述符和内核栈,在内核中文件include/linux/sched.h。
1.union thread_union {2.struct thread_info thread_info;3.unsigned long stack[THREAD_SIZE/sizeof(long)];4.};该结构是一个联合体,我们在C语言书上看到过关于union的解释,在在C Programming Language 一书中对于联合体是这么描述的:1) 联合体是一个结构;2) 它的所有成员相对于基地址的偏移量都为0;3) 此结构空间要大到足够容纳最"宽"的成员;4) 其对齐方式要适合其中所有的成员;通过上面的描述可知,thread_union结构体的大小为8192个字节。
也就是stack数组的大小,类型是unsigned long类型。
由于联合体中的成员变量都是占用同一块内存区域,所以,在平时写代码时总有一个概念,对一个联合体的实例只能使用其中一个成员变量,否则会把原先变量给覆盖掉,这句话如果正确的话,必须要有一个前提假设,成员占用的字节数相同,当成员所占的字节数不同时,只会覆盖相应的字节。

linux内核分析⼯具Dtrace、SystemTap、⽕焰图、crash等<< System语⾔详解 >> 关于 SystemTap 的书。
我们在分析各种系统异常和故障的时候,通常会⽤到 pstack(jstack) /pldd/ lsof/ tcpdump/ gdb(jdb)/ netstat/vmstat/mpstat/truss(strace)/iostat/sar/nmon(top)等系列⼯具,这些⼯具从某个⽅⾯为我们提供了诊断信息。
但这些⼯具常常带有各类“副作⽤”,⽐如truss(见于 AIX/Solaris) 或者 strace(见于 Linux) 能够让我们检测我们应⽤的系统调⽤情况,包括调⽤参数和返回值,但是却会导致应⽤程序的性能下降;这对于诊断毫秒级响应的计费⽣产系统来说,影响巨⼤。
有没有⼀个⼯具,能够兼得上述所有⼯具的优点,⼜没有副作⽤呢?答案是有!对于 Solaris/BSD/OS X 系统来说,那就是 DTrace ⼯具(后来,Linux 也终于有了⾃⼰类似的⼯具,stap)。
DTrace 的优势是什么呢?可以这么讲,如果你对于 OS 和应⽤熟悉,利⽤ DTrace 可以诊断所有问题;没错,是“所有”,“所有”,“所有”,重要的事情说三遍!书籍:DTrace-Dynamic-Tracing-in-Oracle-Solaris-Mac-OS-X-and-FreeBSD.pdf书籍:Solaris Dynamic Tracing Guide.pdf脚本⼯具集合:DTraceToolkit-0.99动态追踪技术(中) - Dtrace、SystemTap、⽕焰图说到动态追踪就不能不提到。
DTrace 算是现代动态追踪技术的⿐祖了,它于 21 世纪初诞⽣于 Solaris 操作系统,是由原来的 Sun Microsystems 公司的⼯程师编写的。
可能很多同学都听说过 Solaris 系统和 Sun 公司的⼤名。
crashkernel参数"crashkernel"参数通常用于Linux系统的内核启动参数中,它用于指定用于系统崩溃转储的内存大小和位置。
在Linux系统中,当系统遇到严重的错误导致崩溃时,内核会尝试将当前内存中的信息转储到预留的一块内存中,以便进行后续的分析和调试。
以下是关于"crashkernel"参数的详细解释:1. 内存大小,"crashkernel"参数中的值用于指定用于崩溃转储的内存大小。
这个值通常以MB为单位,例如"crashkernel=128M"表示预留128MB的内存用于崩溃转储。
根据系统的需求和内存大小,可以灵活地调整这个数值。
2. 内存位置,除了指定内存大小外,"crashkernel"参数还可以指定内存的位置。
例如,"crashkernel=256M@16M"表示预留256MB的内存,起始地址为物理内存的第16MB处。
这样的灵活性可以根据系统的实际情况进行调整。
3. 使用场景,"crashkernel"参数通常用于服务器环境或对系统稳定性要求较高的场景。
通过预留一部分内存用于崩溃转储,可以帮助系统管理员在系统崩溃时快速获取相关信息,有助于分析和解决问题。
4. 配置方法,在Linux系统中,可以通过boot loader(如GRUB)的配置文件(如grub.conf或grub.cfg)来设置"crashkernel"参数。
在这些配置文件中,可以添加类似"crashkernel=256M@16M"的参数来指定内存大小和位置。
总之,"crashkernel"参数在Linux系统中扮演着重要的角色,它为系统的稳定性和调试提供了重要的支持。
通过合理设置"crashkernel"参数,可以在系统崩溃时提供有效的调试信息,有助于加快故障排查和修复的速度。
crash rd命令的用法Crashrd命令是Linux系统中的一个非常有用的调试工具,它可以用来生成内核崩溃转储文件,并且可以在系统崩溃时自动执行。
在本文中,我们将介绍如何使用Crash rd命令来进行Linux系统的调试。
首先,我们需要安装Crash工具包,可以通过执行以下命令来进行安装:sudo apt-get install crash安装完成后,我们可以使用以下命令来生成内核崩溃转储文件: sudo crash /usr/lib/debug/boot/vmlinux-$(uname -r)/var/crash/$(uname -n)-$(date +%Y%m%d-%H%M).dump在上面的命令中,/usr/lib/debug/boot/vmlinux-$(uname -r)表示内核映像文件的路径,/var/crash/$(uname -n)-$(date+%Y%m%d-%H%M).dump表示崩溃转储文件的路径和文件名。
执行该命令后,我们可以在指定的路径中找到生成的崩溃转储文件。
接下来,我们使用以下命令来打开Crash rd命令行界面:sudo crash /usr/lib/debug/boot/vmlinux-$(uname -r)/var/crash/$(uname -n)-$(date +%Y%m%d-%H%M).dump在Crash rd命令行界面中,我们可以使用以下命令来进行调试: - bt:显示当前进程的函数调用栈。
- ps:显示当前系统中的所有进程。
- lsmod:显示当前系统中加载的所有模块。
- vm:显示当前系统中的虚拟内存布局。
- log:显示内核日志。
除了上述命令之外,还有许多其他的命令可以使用。
通过使用Crash rd命令,我们可以更加方便地进行Linux系统的调试和分析。
crashkernel参数一、什么是crashkernel参数在计算机系统中,crashkernel参数是用于指定内核在系统崩溃时保存内存转储信息的参数。
当系统发生严重错误导致崩溃时,crashkernel参数可以帮助开发人员分析问题,找到错误的原因并进行修复。
通过保存内存转储信息,开发人员可以还原系统崩溃时的状态,从而更好地进行故障排除和调试工作。
二、为什么需要crashkernel参数崩溃是计算机系统中常见的问题,可能是由于硬件故障、软件错误或其他原因引起。
在系统崩溃时,操作系统会停止运行,导致用户无法继续使用计算机。
为了解决这个问题,开发人员需要能够追踪系统崩溃的原因,并进行修复。
crashkernel参数的作用就是在系统崩溃时保存内存转储信息,为开发人员提供了一个还原系统状态的机会。
三、如何配置crashkernel参数配置crashkernel参数需要编辑操作系统的启动配置文件,具体的配置方法因操作系统而异。
以下是在Linux系统中配置crashkernel参数的步骤:1.打开终端,以root用户身份登录系统。
2.使用文本编辑器打开/boot/grub/grub.conf文件。
3.在文件中找到以“kernel”开头的行,该行指定了内核的启动参数。
4.在该行的末尾添加“crashkernel=128M”,其中128M表示为crashkernel分配的内存大小,可以根据需要进行调整。
5.保存文件并退出编辑器。
6.重启系统,新的crashkernel参数将生效。
四、crashkernel参数的常见问题和解决方法在配置和使用crashkernel参数时,可能会遇到一些常见的问题。
以下是一些常见问题及其解决方法:1. 操作系统无法识别crashkernel参数有时候,在编辑启动配置文件后,操作系统可能无法正确识别crashkernel参数。
这可能是由于配置文件中的语法错误或其他原因导致的。
解决方法: - 检查启动配置文件中的语法错误,确保crashkernel参数的格式正确。
int main(int argc, char **argv){char bytes[2] = {11,0}; /* 11 is the TIOCLINUX cmd number */ if (argc==2) bytes[1] = atoi(argv[1]); /* the chosen console */# Comment/uncomment the following line to disable/enable debuggingDEBUG = y# Add your debugging flag (or not) to CFLAGSifeq ($(DEBUG),y)DEBFLAGS = -O -g -DSCULL_DEBUG # "-O" is needed to expand inlineselseDEBFLAGS = -O2endifCFLAGS += $(DEBFLAGS)int scull_read_procmem(char *buf, char **start, off_t offset,int count, int *eof, void *data){int i, j, len = 0;int limit = count - 80; /* Don't print more than this */for (i = 0; i < scull_nr_devs && len <= limit; i++) {Scull_Dev *d = &scull_devices[ i];if (down_interruptible(&d->sem))return -ERESTARTSYS;len += sprintf(buf+len,"\nDevice %i: qset %i, q %i, sz %li\n",i, d->qset, d->quantum, d->size);for (; d && len <= limit; d = d->next) { /* scan the list */ len += sprintf(buf+len, " item at %p, qset at %p\n", d,d->data);if (d->data && !d->next) /* dump only the last item- save space */for (j = 0; j < d->qset; j++) {if (d->data[j])len += sprintf(buf+len," % 4i: %8p\n",j,d->data[j]);}}static int scull_get_info(char *buf, char **start, off_t offset,int len, int unused){int eof = 0;return scull_read_procmem (buf, start, offset, len, &eof, NULL);}struct proc_dir_entry scull_proc_entry = {namelen: 8,name: "scullmem",mode: S_IFREG | S_IRUGO,nlink: 1,get_info: scull_get_info,};static void scull_create_proc(){proc_register_dynamic(&proc_root, &scull_proc_entry);}static void scull_remove_proc(){[...]open("/dev", O_RDONLY|O_NONBLOCK) = 4fcntl(4, F_SETFD, FD_CLOEXEC) = 0brk(0x8055000) = 0x8055000lseek(4, 0, SEEK_CUR) = 0getdents(4, /* 70 entries */, 3933) = 1260[...]getdents(4, /* 0 entries */, 3933) = 0close(4) = 0fstat(1, {st_mode=S_IFCHR|0664, st_rdev=makedev(253, 0), ...}) = 0 ioctl(1, TCGETS, 0xbffffa5c) = -1 ENOTTY (Inappropriate ioctlfor device) write(1, "MAKEDEV\natibm\naudio\naudio1\na"..., 4096) = 4000 write(1, "d2\nsdd3\nsdd4\nsdd5\nsdd6\nsdd7"..., 96) = 96write(1, "4\nsde5\nsde6\nsde7\nsde8\nsde9\n"..., 3325) = 3325close(1) = 0_exit(0) = ?Unable to handle kernel NULL pointer dereference at virtual address 00000000printing eip:Unable to handle kernel NULL pointer dereference at virtual address \00000000printing eip:c48370c3*pde = 00000000Oops: 0002CPU: 0EIP: 0010:[faulty:faulty_write+3/576]EFLAGS: 00010286eax: ffffffea ebx: c2c55ae0 ecx: c48370c0 edx: c2c55b00esi: 0804d038 edi: 0804d038 ebp: c2337f8c esp: c2337f8cds: 0018 es: 0018 ss: 0018Process cat (pid: 23413, stackpage=c2337000)Stack: 00000001 c01356e6 c2c55ae0 0804d038 00000001 c2c55b00 c2336000 \000000010804d038 bffffbd4 00000000 00000000 bffffbd4 c010b860 00000001 \0804d03800000001 00000001 0804d038 bffffbd4 00000004 0000002b 0000002b \00000004Call Trace: [sys_write+214/256] [system_call+52/56]Code: c7 05 00 00 00 00 00 00 00 00 31 c0 89 ec 5d c3 8d b6 00 00klogd 提供了大多数必要信息用于发现问题。
crashkernel参数摘要:1.Crash Kernel概念介绍2.Crash Kernel参数的用途3.常用Crash Kernel参数解析4.如何设置Crash Kernel参数5.注意事项正文:Crash Kernel,即内核崩溃,是操作系统在遇到错误时的一种保护机制。
在这种机制下,操作系统会自动保存当前内核状态,并重新启动内核。
Crash Kernel参数则是用于配置和调整这一机制的参数,通过合理设置这些参数,可以提高操作系统的稳定性和安全性。
一、Crash Kernel概念介绍Crash Kernel,又称为内核崩溃,是指当操作系统遇到无法解决的问题时,采取的一种保护性措施。
在这种情况下,操作系统会自动保存当前内核状态,并重新启动内核,以恢复正常运行。
这种机制有助于防止系统出现更严重的故障,提高操作系统的稳定性。
二、Crash Kernel参数的用途Crash Kernel参数主要用于调整内核崩溃时的处理方式,包括以下几个方面:1.触发条件:设置何种情况下触发Crash Kernel,例如内存错误、文件系统错误等。
2.保存状态:设置内核崩溃时需要保存的状态,如进程状态、内存使用情况等。
3.恢复策略:设置内核崩溃后如何恢复,如自动重启、手动重启等。
4.日志记录:设置内核崩溃时的日志记录内容,包括日志级别、日志输出方式等。
三、常用Crash Kernel参数解析1.crashkernel_base:设置内核崩溃时的内存基地址。
2.crashkernel_size:设置内核崩溃时保存的状态信息大小。
3.panic:设置内核崩溃时的恐慌模式,例如panic=10表示在内核崩溃后10秒内重启。
4.log_buffer_size:设置内核崩溃日志缓冲区大小。
5.log_output:设置内核崩溃日志的输出方式,如syslog、console等。
四、如何设置Crash Kernel参数1.修改配置文件:通过修改操作系统配置文件,如/etc/sysctl.conf、/etc/default/grub等,来设置Crash Kernel参数。
linux crash的用法"Linux Crash"的用法引言:Linux是一种开源操作系统,它的稳定性和可靠性广受赞誉。
然而,就像任何其他操作系统一样,Linux也可能会出现崩溃的情况。
本文将详细探讨"Linux Crash"的用法,包括可能导致崩溃的因素以及如何应对和解决这些问题。
第一部分:Linux系统崩溃的原因1. 硬件故障:硬件故障是导致Linux系统崩溃的常见原因之一。
例如,内存故障、硬盘故障、电源问题等都可能导致系统无法正常运行。
2. 软件错误:软件错误也是Linux系统崩溃的常见原因之一。
例如,操作系统内核或其他关键软件的错误可能导致系统崩溃。
3. 驱动程序问题:Linux系统通常需要使用特定的驱动程序来与硬件设备进行交互。
不正确的驱动程序或驱动程序的冲突可能导致系统崩溃。
4. 内存管理问题:Linux系统使用虚拟内存管理机制来管理系统内存。
如果出现内存管理问题,例如内存泄漏或内存访问错误,系统可能会崩溃。
第二部分:应对Linux系统崩溃的步骤1. 重新启动系统:在系统崩溃后,第一步是尝试重新启动系统。
这可能是因为崩溃只是一个偶然事件,重新启动系统后问题可能会得到解决。
2. 分析错误日志:Linux系统通常会生成错误日志,记录系统崩溃时的相关信息。
通过分析错误日志,我们可以获得有关崩溃原因的线索,以便采取适当的措施。
- 使用命令"cat /var/log/syslog"来查看系统日志。
- 使用命令"dmesg"来查看内核日志。
3. 更新和修复软件:如果崩溃是由软件错误引起的,更新和修复软件可能是解决问题的方法之一。
通过使用包管理器来更新软件包,可以获得最新的错误修复和安全补丁。
- 在Debian或Ubuntu系统中,使用命令"apt-get update"和"apt-get upgrade"来更新软件包。
Kernel Debug using Crash utility
0. Crash introduction (3)
1. Filestore Specified (3)
2. Starting Point (4)
2.1 Check system basic info (4)
2.2 Check what’s latest kernel log, (5)
2.3 Check which processes are in ‘D’ state, what’s the number? (5)
2.4 Check memory status (6)
2.5 Check which process eat most memory (7)
2.6 Check which process each most of CPU (8)
2.7 Check IOWAIT for each process (only worked after 5.7) (9)
2.8 Check if “dirty page issue existed” (9)
2.9 Check the stack for “write” system call (9)
3. Common Utility (10)
4. Case Analysis (10)
4.1 Escalation 413-673-127 (10)
4.2 [PRI2][2316592] after slave node changed to primary, it reboot automatically itself . 11
5. Appendix (11)
5.1 Where to find related debug version VxFS and VxVM (11)
5.2 How to load debug info while running “crash” (11)
6. Reference (14)
0.Crash introduction
The Red Hat crash analysis utility is loosely based on the SVR4 UNIX crash command, but has been significantly enhanced by completely merging it with the GNU gdb debugger. The marriage of the two effectively combines the kernel-specific nature of the traditional UNIX crash utility with the source code level debugging capabilities of gdb.
Crash utility can be used to debug:
∙Live environment
∙Coredump triggered by some issues (such as “null pointer dereference” issue)
∙Coredump triggered by ‘sysrq-trigger’ manually (such as “system hung” issue)
1.Filestore Specified
In order to make sure crash can work well in Filestore,
∙We have to install some “kernel-kdump” related package. (It is installed in Filestore by default, Following example are from 5.6P2).
∙Make sure kernel object file existed
∙Know where is the coredump file
∙Know where is the Linux kernel source tree (in Filestore 5.6 and 5.7, kernel-source rpm package are installed by default)
∙Know the compile options for this kernel
2.Starting Point
2.3Check which processes are in ‘D’ state, what’s the number?(If
there are many process in ‘D’ statue, maybe there are some I/O
2.7Check IOWAIT for each process (only worked after 5.7)
mon Utility
∙grep (grep –A, grep –B,grep -C)
∙foreach
∙LXR server(http://10.200.100.240/lxr/http/source )
4.Case Analysis
4.1Escalation 413-673-127
Please check http://10.200.100.175/gf/download/docmanfileversion/58/1755/413-673-127_report.docx
4.2[PRI2][2316592] after slave node changed to primary, it reboot
automatically itself
Please check
http://10.200.100.175/gf/download/docmanfileversion/60/1763/2316592_report.docx
5.Appendix
5.1Where to find related debug version VxFS and VxVM
IOnce we know the VxFS /VxVM rpm version, we can find related branch and package (include debug package) easily from /engineering/file-system/scm/
For example, we got a VxFS issue in 5.5RP2HF2.
a)Check VXFS version
Cluster5_02:~ # rpm -qa|grep -i vxfs
VRTSvxfs-platform-5.0.30.332-MP3RP3HF32_SLES10
VRTSvxfs-common-5.0.30.332-MP3RP3HF32_SLES10
b)Check /engineering/file-
system/scm/linux_5_0_release_chart.html -> (search “5.0MP3RP3”) ->
/engineering/file-system/scm/5.0MP3RP3_linux.html ->
(search “HF32”) to jump to related section.
And we can found
∙Branch tag “s_Lx_5_0_MP3RP3HF32_2010-12-15”
∙RPM
location “ /build/delivery/VxFS_5.0MP3RP/5.0
MP3RP3HF32_linux/sles10_x86_64”
[notice: is a nfs server,]
How can we got debug version ko for vxfs? And how to load it
6.Reference
/anderson/crash_whitepaper/
http://10.200.100.175/gf/download/docmanfileversion/58/1755/413-673-127_report.docx
http://10.200.100.175/gf/download/docmanfileversion/60/1763/2316592_report.docx /engineering/file-system/scm/。