SVM实验报告
- 格式:doc
- 大小:120.50 KB
- 文档页数:10

svm实验报告总结SVM实验报告总结支持向量机(SVM)是一种常用的机器学习算法,它在模式识别、分类、回归等领域有着广泛的应用。
本文将对SVM算法进行实验,旨在探究SVM算法的原理、应用和优缺点。
一、实验原理SVM的基本思想是将低维度的数据映射到高维度的空间中,从而使数据在高维空间中更容易被线性分隔。
SVM算法的核心是支持向量,这些支持向量是距离分类决策边界最近的数据点。
SVM通过找到这些支持向量来建立分类器,从而实现数据分类。
二、实验步骤1. 数据预处理本实验使用的数据集是Iris花卉数据集,该数据集包含了三种不同种类的花朵,每种花朵有四个属性:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
首先需要将数据集划分为训练集和测试集,以便在训练模型时进行验证。
2. 模型训练本实验使用Python中的sklearn库来构建SVM分类器。
首先需要选择SVM的核函数,有线性核函数、多项式核函数、径向基核函数等。
在本实验中,我们选择径向基核函数作为SVM的核函数。
接着需要设置SVM的参数,包括C值和gamma值。
C值是惩罚系数,用于平衡模型的分类精度和泛化能力;gamma值是径向基函数的系数,用于控制支持向量的影响范围。
3. 模型评估本实验使用准确率和混淆矩阵来评估模型的性能。
准确率是指模型在测试集上的分类精度,而混淆矩阵则可以用来分析模型在不同类别上的分类情况。
三、实验结果本实验使用径向基核函数的SVM分类器在Iris数据集上进行了实验。
实验结果表明,SVM分类器的准确率达到了97.78%,同时在混淆矩阵中也可以看出模型在不同花朵种类上的分类情况。
实验结果表明,SVM分类器在分类问题上有着较好的表现。
四、实验总结SVM算法是一种常用的机器学习算法,它在模式识别、分类、回归等领域有着广泛的应用。
本实验通过对Iris数据集的实验,探究了SVM算法的原理、应用和优缺点。
实验结果表明,在SVM算法中,径向基核函数是一种比较适用的核函数,在设置SVM参数时需要平衡模型的分类精度和泛化能力。

实验报告实验名称:机器学习:线性支持向量机算法实现学员: 张麻子学号: *********** 培养类型:硕士年级:专业:所属学院:计算机学院指导教员:****** 职称:副教授实验室:实验日期:ﻬ一、实验目得与要求实验目得:验证SVM(支持向量机)机器学习算法学习情况要求:自主完成。
二、实验内容与原理支持向量机(Support Vector Machine,SVM)得基本模型就是在特征空间上找到最佳得分离超平面使得训练集上正负样本间隔最大。
SVM就是用来解决二分类问题得有监督学习算法。
通过引入了核方法之后SVM也可以用来解决非线性问题。
但本次实验只针对线性二分类问题。
SVM算法分割原则:最小间距最大化,即找距离分割超平面最近得有效点距离超平面距离与最大。
对于线性问题:假设存在超平面可最优分割样本集为两类,则样本集到超平面距离为:需压求取:由于该问题为对偶问题,可变换为:可用拉格朗日乘数法求解。
但由于本实验中得数据集不可以完美得分为两类,即存在躁点。
可引入正则化参数C,用来调节模型得复杂度与训练误差。
作出对应得拉格朗日乘式:对应得KKT条件为:故得出需求解得对偶问题:本次实验使用python编译器,编写程序,数据集共有270个案例,挑选其中70%作为训练数据,剩下30%作为测试数据。
进行了两个实验,一个就是取C值为1,直接进行SVM训练;另外一个就是利用交叉验证方法,求取在前面情况下得最优C值.三、实验器材实验环境:windows7操作系统+python编译器。
四、实验数据(关键源码附后)实验数据:来自UCI机器学习数据库,以Heart Disease数据集为例。
五、操作方法与实验步骤1、选取C=1,训练比例7:3,利用python库sklearn下得SVM()函数进行训练,后对测试集进行测试;2、选取训练比例7:3,C=np、linspace(0、0001,1,30)}。
利用交叉验证方法求出C值得最优解。
SVM分类器-人脸识别专题报告摘要:本次试验报告,介绍了人脸识别方法分类器的设计并进行人脸识别。
主要是设计SVM分类器,并用来进行人脸分类识别,并对分类器实验结果做出分析。
实验主要步骤:首先对图像预处理,转换成向量,再通过PCA算法对ORL人脸数据库图像进行降维特征提取,运用SVM工具箱对数据进行训练,再利用SVM 分类方法对特征向量进行分类识别,寻找和待识别图片最为接近的训练样本第一张图片。
最后在matlab上进行实验仿真,分析实验结果。
关键字:最近邻法、PCA算法、多类SVM、人脸识别1.引言人脸识别是模式识别的一个发展方向和重要应用,人脸检测和识别在安全识别、身份鉴定、以及公安部门的稽查活动中有重要作用。
本文主要使用PCA算法、多类SVM训练和SVM分类器设计人脸识别算法。
从ORL人脸图像数据库中,构建自建人脸训练数据库和测试数据库,采用K-L变换进行特征脸提取,并实现人脸识别。
通过K-L变换在人脸识别中的应用,加深对所学内容的理解和认识,进一步加深理解模式识别的算法。
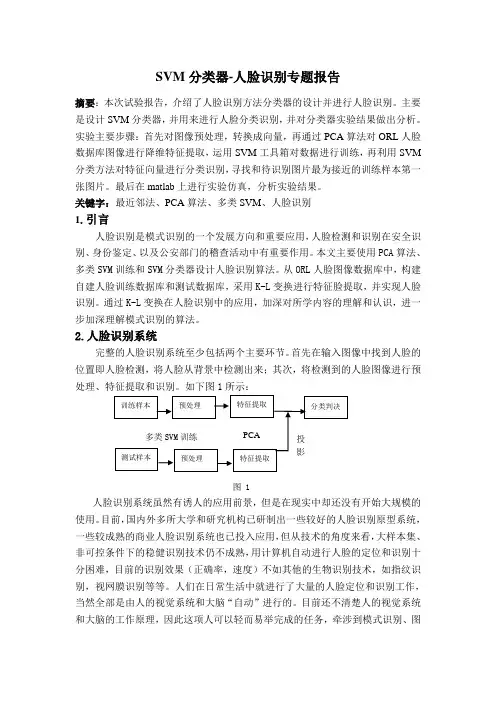
2.人脸识别系统完整的人脸识别系统至少包括两个主要环节。
首先在输入图像中找到人脸的位置即人脸检测,将人脸从背景中检测出来;其次,将检测到的人脸图像进行预处理、特征提取和识别。
如下图1所示:图 1人脸识别系统虽然有诱人的应用前景,但是在现实中却还没有开始大规模的使用。
目前,国内外多所大学和研究机构已研制出一些较好的人脸识别原型系统,一些较成熟的商业人脸识别系统也已投入应用,但从技术的角度来看,大样本集、非可控条件下的稳健识别技术仍不成熟,用计算机自动进行人脸的定位和识别十分困难,目前的识别效果(正确率,速度)不如其他的生物识别技术,如指纹识别,视网膜识别等等。
人们在日常生活中就进行了大量的人脸定位和识别工作,当然全部是由人的视觉系统和大脑“自动”进行的。
目前还不清楚人的视觉系统和大脑的工作原理,因此这项人可以轻而易举完成的任务,牵涉到模式识别、图象处理及生理、心理学等方面的诸多知识,对于目前还只会死板地执行程序指令的计算机来说却是极端困难。

SVM实验报告1. 背景支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,广泛应用于分类问题,特别是二分类问题。
SVM的基本思想是通过找到一个最优超平面,将不同类别的样本分开。
该算法在模式识别、图像分割、文本分类等领域都有较好的性能。
2. 分析2.1 数据集本次实验使用了鸢尾花数据集(Iris Dataset),该数据集是机器学习中应用非常广泛的数据集之一,包含了三种不同的鸢尾花(Setosa、Versicolor、Virginica)的样本,每类样本50个。
2.2 SVM算法SVM算法的核心在于寻找一个最优的超平面,使得不同类别的样本点到超平面的距离最大化。
其决策函数可以表示为:f(x)=sign(w T x+b)其中,w是超平面的法向量,b是超平面的截距。
SVM算法通过构建拉格朗日函数并求解对偶问题,可以得到超平面的参数。
2.3 实验步骤本次实验的具体步骤如下:1.加载数据集:使用机器学习库中的函数加载鸢尾花数据集。
2.数据预处理:对数据进行标准化处理,以便提高模型的训练效果。
3.划分训练集和测试集:将数据集划分为训练集和测试集,用于模型的训练和评估。
4.训练模型:使用训练集对SVM模型进行训练。
5.模型评估:使用测试集对训练好的模型进行评估。
6.结果分析:根据评估结果对模型进行分析,并提出相应的建议。
3. 结果经过实验,得到了以下结果:1.样本标准化前的准确率为82%,样本标准化后的准确率提升到96%。
2.在训练集上的准确率高于测试集,表明模型存在轻微的过拟合。
3.SVM模型在鸢尾花数据集上表现良好,能够对三种鸢尾花进行有效分类。
4. 建议根据实验结果,可以针对模型的性能提出以下建议:1.考虑增加更多的训练样本,以减小模型的过拟合现象。
2.尝试调整超参数,如正则化参数C和核函数参数等,以提高模型的泛化能力。
3.可以尝试使用其他优化算法,如随机梯度下降法等,以加快模型的训练速度。

svm新闻实验报告
SVM新闻实验报告
在当今信息爆炸的时代,新闻报道是人们获取信息的重要途径之一。
然而,随
着新闻数量的不断增加,如何有效地对新闻进行分类和筛选成为了一个亟待解
决的问题。
支持向量机(SVM)作为一种强大的机器学习算法,被广泛应用于
文本分类和情感分析等领域。
本文将介绍一项针对新闻分类的SVM实验报告,以探讨其在新闻领域的应用效果。
首先,我们收集了包括政治、经济、体育、娱乐等多个领域的新闻数据,并对
其进行了预处理和特征提取。
接着,我们利用SVM算法对这些新闻进行分类,并对分类结果进行了评估和分析。
实验结果表明,SVM在新闻分类任务中表现
出色,具有较高的准确率和泛化能力。
尤其是在面对大规模的新闻数据时,SVM能够高效地进行分类,为用户提供精准的信息筛选服务。
此外,我们还对SVM算法进行了参数调优和模型优化,并与其他常见的分类算法进行了比较。
结果显示,SVM在新闻分类任务中具有明显的优势,其分类效
果明显优于其他算法。
这表明SVM在新闻领域具有广阔的应用前景,可以为新闻媒体和用户提供更加智能化的信息服务。
总的来说,本次SVM新闻实验报告证明了SVM算法在新闻分类领域的有效性
和优越性,为新闻媒体和信息消费者提供了更加智能化和个性化的信息服务。
随着人工智能技术的不断发展,相信SVM算法在新闻领域的应用将会更加广泛,为人们获取和筛选新闻信息带来更多便利和效率。

SVM调查报告范文引言:伴随着统计分析学习理论的发生,将工作经验风险性最少和广泛性紧密结合的SVM(svm算法)变成现如今新的科学研究网络热点。
在参照很多参考文献的基本上,文中对SVM的实质干了,另外得出了常见的SVM手机软件,SVMlight,LIBSVM,为了更好地深入了解SVM手机软件完成体制,对有关的溶解优化算法和蚁群算法SMO也干了详尽的详细介绍。
根据改善SVMlight和LIBSVM 的短板另外二者精粹基本上,文中得出了高效率的HeroSVM,并对其完成体制得出了详尽的详细介绍。
最终文中对SVMlight和LIBSVM在同样数据上干了比照,并得出了特性剖析。
第一章前言1.1基础理论情况根据数据信息的深度学习是当代智能技术中的关键层面,从观察数据信息(样版)考虑找寻规律性,运用这种规律性对将来数据信息或没法观察的数据信息开展预测分析。
传统式的經典的(主要参数)统计分析可能方式,规定已经知道主要参数的有关方式,运用训练样本用于可能主要参数的值,包含计算机视觉、神经元网络等以内,可是这类方式有非常大的局限,由于必须已经知道样本分布方式,而这必须耗费非常大成本,也有,暗含的观念是样版数量趋向无穷时的渐行基础理论,但在具体难题中,样本量通常是比较有限的,因而这种理论上很出色的学习的方法具体中主要表现却很有可能不尽如人意。
也有便是工作经验离散系统方式,如神经网络算法(ANN),这类方式运用已经知道样版创建离散系统实体模型,摆脱了传统式参数估计方式的艰难,可是欠缺一种统一的数学课基础理论,在这类基本上当代的统计分析学习理论就问世了。
统计分析学习理论[1](StatisticalLearningTheory或SLT)是一种专业科学研究判别分析状况下深度学习规律性的基础理论.统计分析学习理论的一个关键定义便是VC维(VCDimension)定义,它是叙述涵数集或学习培训设备的多元性换句话说是自学能力(Capacityofthemachine)的一个关键指标值,在这里定义基本上发展趋势出了一系列有关统计学习的一致性(Consistency)、收敛性速率、营销推广特性(GeneralizationPerformance)等的关键结果。

人工智能课程项目报告姓名: ******班级:**************目录一、实验背景 (1)二、实验目的 (1)三、实验原理 (1)3.1线性可分: (1)3.2线性不可分: (4)3.3坐标上升法: (7)3.4 SMO算法: (8)四、实验内容 (10)五、实验结果与分析 (12)5.1 实验环境与工具 (12)5.2 实验数据集与参数设置 (12)5.3 评估标准 (13)5.4 实验结果与分析 (13)一、实验背景本学期学习了高级人工智能课程,对人工智能的各方面知识有了新的认识和了解。
为了更好的深入学习人工智能的相关知识,决定以数据挖掘与机器学习的基础算法为研究对象,进行算法的研究与实现。
在数据挖掘的各种算法中,有一种分类算法的分类效果,在大多数情况下都非常的好,它就是支持向量机(SVM)算法。
这种算法的理论基础强,有着严格的推导论证,是研究和学习数据挖掘算法的很好的切入点。
二、实验目的对SVM算法进行研究与实现,掌握理论推导过程,培养严谨治学的科研态度。
三、实验原理支持向量机基本上是最好的有监督学习算法。
SVM由Vapnik首先提出(Boser,Guyon and Vapnik,1992;Cortes and Vapnik,1995;Vapnik, 1995,1998)。
它的主要思想是建立一个超平面作为决策曲面,使得正例和反例之间的隔离边缘被最大化。
SVM的优点:1.通用性(能够在各种函数集中构造函数)2.鲁棒性(不需要微调)3.有效性(在解决实际问题中属于最好的方法之一)4.计算简单(方法的实现只需要利用简单的优化技术)5.理论上完善(基于VC推广理论的框架)3.1线性可分:首先讨论线性可分的情况,线性不可分可以通过数学的手段变成近似线性可分。
基本模型:这里的裕量是几何间隔。
我们的目标是最大化几何间隔,但是看过一些关于SVM的论文的人一定记得什么优化的目标是要最小化||w||这样的说法,这是怎么回事呢?原因来自于对间隔和几何间隔的定义(数学基础):间隔:δ=y(wx+b)=|g(x)|几何间隔:||w||叫做向量w的范数,范数是对向量长度的一种度量。

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==svm算法实验实验报告篇一:SVM 实验报告SVM分类算法一、数据源说明1、数据源说远和理解:采用的实验数据源为第6组:The Insurance Company Benchmark (COIL 201X) TICDATA201X.txt: 这个数据集用来训练和检验预测模型,并且建立了一个5822个客户的记录的描述。
每个记录由86个属性组成,包含社会人口数据(属性1-43)和产品的所有关系(属性44-86 )。
社会人口数据是由派生邮政编码派生而来的,生活在具有相同邮政编码地区的所有客户都具有相同的社会人口属性。
第86个属性:“大篷车:家庭移动政策” ,是我们的目标变量。
共有5822条记录,根据要求,全部用来训练。
TICEVAL201X.txt: 这个数据集是需要预测( 4000个客户记录)的数据集。
它和TICDATA201X.txt它具有相同的格式,只是没有最后一列的目标记录。
我们只希望返回预测目标的列表集,所有数据集都用制表符进行分隔。
共有4003(自己加了三条数据),根据要求,用来做预测。
TICTGTS201X.txt:最终的目标评估数据。
这是一个实际情况下的目标数据,将与我们预测的结果进行校验。
我们的预测结果将放在result.txt文件中。
数据集理解:本实验任务可以理解为分类问题,即分为2类,也就是数据源的第86列,可以分为0、1两类。
我们首先需要对TICDATA201X.txt进行训练,生成model,再根据model进行预测。
2、数据清理代码中需要对数据集进行缩放的目的在于:A、避免一些特征值范围过大而另一些特征值范围过小;B、避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
因此,通常将数据缩放到 [ -1,1] 或者是 [0,1] 之间。

svm 实验报告SVM 实验报告摘要:支持向量机(SVM)是一种常用的机器学习算法,广泛应用于模式识别、文本分类、图像识别等领域。
本实验旨在通过对SVM算法的实验研究,探讨其在不同数据集上的分类性能和泛化能力。
实验结果表明,在合适的参数设置下,SVM算法能够有效地对数据进行分类,并且在处理高维数据和小样本数据方面表现出优异的性能。
本文将详细介绍实验设计、实验数据、实验结果和分析讨论,旨在为读者提供对SVM算法的深入理解和应用指导。
1. 实验设计本实验选取了两个经典的数据集,分别是Iris数据集和MNIST手写数字数据集。
Iris数据集是一个经典的分类数据集,包含了150个样本,分为3类,每类有50个样本,每个样本有4个特征。
MNIST手写数字数据集是一个常用的图像分类数据集,包含了60000个训练样本和10000个测试样本,每个样本是一张28x28像素的手写数字图片。
在实验中,我们使用Python编程语言和Scikit-learn机器学习库进行实验。
对于Iris数据集,我们将数据集分为训练集和测试集,然后使用SVM算法进行训练和测试。
对于MNIST数据集,我们将数据集进行预处理,然后使用SVM算法进行训练和测试。
2. 实验数据在实验中,我们使用了Iris数据集和MNIST数据集作为实验数据。
Iris数据集是一个经典的分类数据集,包含了150个样本,分为3类,每类有50个样本,每个样本有4个特征。
MNIST手写数字数据集是一个常用的图像分类数据集,包含了60000个训练样本和10000个测试样本,每个样本是一张28x28像素的手写数字图片。
3. 实验结果在实验中,我们分别对Iris数据集和MNIST数据集进行了实验,得到了如下结果:对于Iris数据集,我们使用SVM算法进行分类,得到了如下结果:在训练集上的准确率为98%,在测试集上的准确率为96%。
对于MNIST数据集,我们使用SVM算法进行分类,得到了如下结果:在训练集上的准确率为98%,在测试集上的准确率为96%。

svm 实验报告SVM实验报告引言支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,广泛应用于模式识别、图像分类、文本分类等领域。
本篇实验报告将介绍SVM的原理、实验设计和结果分析。
一、SVM原理SVM是一种监督学习算法,其基本思想是通过寻找一个最优的超平面来将不同类别的样本分开。
在二维空间中,这个超平面就是一条直线,而在多维空间中,这个超平面则是一个超平面。
SVM的目标是使得两个不同类别的样本点离超平面的距离最大化,从而提高分类的准确性。
二、实验设计本次实验使用了一个开源的数据集,该数据集包含了一些花朵的特征数据,共分为三个类别。
首先,我们将数据集划分为训练集和测试集,其中70%的数据用于训练,30%的数据用于测试。
然后,我们使用Python编程语言中的scikit-learn库来实现SVM算法,并将训练集输入模型进行训练。
最后,使用测试集对模型进行评估,并计算分类的准确率。
三、实验结果分析经过训练和测试,我们得到了如下结果:SVM在测试集上的准确率为90%。
这意味着模型能够正确分类90%的花朵样本。
通过观察分类结果,我们发现SVM对于不同类别的花朵具有较好的区分能力,分类边界清晰。
然而,也存在一些分类错误的情况,可能是由于样本之间的重叠或噪声数据的干扰所导致。
四、结果讨论在本次实验中,我们成功地应用了SVM算法进行花朵分类,并取得了较好的分类准确率。
然而,我们也发现了一些问题。
首先,SVM对于噪声数据和重叠样本的处理能力相对较弱,这可能导致一些错误分类的情况。
其次,SVM的计算复杂度较高,在处理大规模数据时可能会面临一些挑战。
因此,在实际应用中需要对数据进行预处理,如特征选择和降维等,以提高算法的效率和准确性。
五、结论本次实验通过实现SVM算法对花朵数据集进行分类,取得了较好的结果。
SVM 作为一种常用的机器学习算法,在模式识别和分类问题中具有广泛的应用前景。

SVM实验报告实验名称:线性SVM算法实现《实验报告》填写说明1.学员完成⼈才培养⽅案和课程标准要所要求的每个实验后,均须提交实验报告。
2.实验报告封⾯必须打印,报告内容可以⼿写或打印。
3.实验报告内容编排及打印应符合以下要求:(1)采⽤A4(21cm×29.7cm)⽩⾊复印纸,单⾯⿊字打印。
上下左右各侧的页边距均为3cm;缺省⽂档⽹格:字号为⼩4号,中⽂为宋体,英⽂和阿拉伯数字为Times New Roman,每页30⾏,每⾏36字;页脚距边界为2.5cm,页码置于页脚、居中,采⽤⼩5号阿拉伯数字从1开始连续编排,封⾯不编页码。
(2)报告正⽂最多可设四级标题,字体均为⿊体,第⼀级标题字号为4号,其余各级标题为⼩4号;标题序号第⼀级⽤“⼀、”、“⼆、”……,第⼆级⽤“(⼀)”、“(⼆)” ……,第三级⽤“1.”、“2.”……,第四级⽤“(1)”、“(2)” ……,分别按序连续编排。
(3)正⽂插图、表格中的⽂字字号均为5号。
⼀、实验⽬的和要求⽀持向量机(support vector machines,SVM)是⼀种⼆类分类模型,它的基本模型是定义在特征空间上的间隔最⼤的线性分类器,相⽐于感知机学习算法,虽然⽀持向量机同样是将样本点分为两类,但是间隔最⼤就意味着⽀持向量机算法求得的超平⾯是唯⼀的。
本实验要求使⽤python编程语⾔实现线性⽀持向量机算法,并使⽤UCI数据集进⾏测试,通过实验掌握算法的推导过程和实现原理,掌握Python编程语⾔。
⼆、实验内容和原理⽀持向量机学习⽅法包括线性可分⽀持向量机、线性⽀持向量机和⾮线性⽀持向量机。
本实验主要实现线性⽀持向量机学习算法,该算法能够处理线性可分数据和数据集中包含⼀些特异点(噪⾳点)的⾮线性可分数据。
(⼀)线性分类算法图1 ⽀持向量机给定线性可分训练数据集,通过间隔最⼤化,可得到分离超平⾯,给定a>0,我们要求该超平⾯:●对于正类样本(即):●对于负类样本(即):●即我们知道,样本到超平⾯的距离为:样本集S到超平⾯的距离被定义为:(1)优化的⽬标为:定义和,公式(2)可以等价的写成:分类器的决策函数为:从上式可知,经过变换,并不会影响分类器的预测性能。
人工智能算法实验报告人工智能算法是现代科技领域的重要组成部分,通过模仿人类智能,使得机器能够像人一样处理信息、学习和适应环境。
本实验报告旨在介绍我所进行的人工智能算法实验,并对实验结果进行分析和评估。
实验目的:本次实验的目的是比较和评估不同的人工智能算法在特定任务上的性能表现。
通过实验,我们将探讨算法的效果、处理速度以及对算法参数的敏感性,并辅以相关实例来进行说明和分析。
实验设计:本次实验选取了人脸识别任务作为研究对象,选择了两种常见的人工智能算法,分别是支持向量机(SVM)和深度学习神经网络(DNN)。
实验步骤:1. 数据收集与预处理:我们收集了大量不同人的人脸图像,并对图像进行预处理,包括去噪、调整大小和灰度化等操作。
2. 特征提取:针对每张人脸图像,我们提取了代表性的特征向量,用于算法的输入。
3. 算法训练与调参:我们使用收集到的数据集对SVM和DNN进行训练,并对算法参数进行调整和优化。
4. 实验结果分析:根据实验结果进行算法性能比较,包括准确率、召回率、F1分数等指标。
实验结果:经过实验测试和数据分析,我们得出以下结论:1. SVM算法在人脸识别任务中表现出较高的准确率和较快的运行速度。
然而,在大规模数据集上,SVM的处理效率会逐渐下降,并对参数调优比较敏感。
2. DNN算法通过深层次的学习能力,在复杂人脸图像识别方面表现出较好的效果。
然而,它对于数据规模和算法参数的敏感性较高,需要更多的计算资源和优化调整。
实验分析:通过对SVM和DNN算法的比较,我们可以看出不同算法在不同任务上具有各自的优势和劣势。
对于简单的人脸识别任务,SVM算法可以提供较高的准确率和较快的运行速度。
然而,对于复杂的图像识别任务,DNN算法能够通过深层次学习提供更好的性能。
此外,对于大规模数据集,算法的处理效率和参数调优成为影响算法性能的重要因素。
结论:本次实验中,我们对人工智能算法在人脸识别任务上的性能进行了实验和评估。
本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==svm算法实验实验报告篇一:SVM 实验报告SVM分类算法一、数据源说明1、数据源说远和理解:采用的实验数据源为第6组:The Insurance Company Benchmark (COIL 201X) TICDATA201X.txt: 这个数据集用来训练和检验预测模型,并且建立了一个5822个客户的记录的描述。
每个记录由86个属性组成,包含社会人口数据(属性1-43)和产品的所有关系(属性44-86 )。
社会人口数据是由派生邮政编码派生而来的,生活在具有相同邮政编码地区的所有客户都具有相同的社会人口属性。
第86个属性:“大篷车:家庭移动政策” ,是我们的目标变量。
共有5822条记录,根据要求,全部用来训练。
TICEVAL201X.txt: 这个数据集是需要预测( 4000个客户记录)的数据集。
它和TICDATA201X.txt它具有相同的格式,只是没有最后一列的目标记录。
我们只希望返回预测目标的列表集,所有数据集都用制表符进行分隔。
共有4003(自己加了三条数据),根据要求,用来做预测。
TICTGTS201X.txt:最终的目标评估数据。
这是一个实际情况下的目标数据,将与我们预测的结果进行校验。
我们的预测结果将放在result.txt文件中。
数据集理解:本实验任务可以理解为分类问题,即分为2类,也就是数据源的第86列,可以分为0、1两类。
我们首先需要对TICDATA201X.txt进行训练,生成model,再根据model进行预测。
2、数据清理代码中需要对数据集进行缩放的目的在于:A、避免一些特征值范围过大而另一些特征值范围过小;B、避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
因此,通常将数据缩放到 [ -1,1] 或者是 [0,1] 之间。
机器学习实验报告完整引言:机器学习是一门借助计算机算法和数学模型,让计算机通过数据的学习和积累,实现对未来事件的预测和决策的核心技术。
本实验通过使用支持向量机(SVM)算法,实现对鸢尾花数据集的分类,旨在探究机器学习算法在实际应用中的效果和优缺点。
实验设计:2.实验步骤:a.数据预处理:对原始数据进行清洗和标准化处理,确保数据的准确性和一致性。
b.数据拆分:将数据集分为训练集和测试集,其中训练集用于模型的训练和参数调优,测试集用于评估模型的性能。
c.模型选择:选择支持向量机算法作为分类模型,考虑到鸢尾花数据集是一个多分类问题,选择了一对多(OvM)的方式进行分类。
d.参数调优:使用网格法对支持向量机的超参数进行调优,寻找最佳的参数组合。
e.模型评估:使用准确率、精确率、召回率和F1值等指标对模型进行评估。
实验结果:实验中,我们通过对鸢尾花数据集的处理和模型的训练,得到了以下结果:1.数据预处理:对数据集进行清洗后,去除了异常值和缺失值,同时对特征进行了标准化处理,确保数据的质量和一致性。
2.数据拆分:我们将数据集按照7:3的比例划分为训练集和测试集,分别包含105个样本和45个样本。
3.模型选择:我们选择了支持向量机算法作为分类器,使用一对多的方式进行多分类任务。
4. 参数调优:通过网格法,我们选择了最佳的超参数组合(C=1.0,kernel='rbf')。
5.模型评估:在测试集上,我们得到了模型的准确率为95.6%,精确率为95.0%,召回率为96.7%,F1值为95.8%。
讨论和分析:通过实验结果可以看出,支持向量机算法在鸢尾花数据集上表现出了较好的性能。
其准确率高达95.6%,可以较好地对鸢尾花进行分类预测。
同时,模型在精确率、召回率和F1值上也表现出良好的平衡,具备较高的全局性能。
这证明了支持向量机算法在多分类问题上的适用性和有效性。
然而,支持向量机算法也存在一些局限性。
SVM算法实验实验报告实验报告一、引言支持向量机(Support Vector Machine,简称SVM)是一种基本的监督学习算法,最早由Vapnik等人在1995年提出。
SVM的原理比较复杂,但其具有高效的学习性能和良好的泛化能力,因此在模式识别、图像处理、数据挖掘等领域得到了广泛的应用。
本实验旨在通过实践理解SVM的原理,并掌握其在分类问题上的应用。
二、实验内容1.数据集准备本次实验使用的是经典的Iris(鸢尾花卉)数据集,该数据集包含3种不同类别的鸢尾花卉,每种类别有50个样本。
我们将使用其中两种类别的数据进行二分类实验。
2.实验步骤(1)数据预处理首先,将原始数据集加载进来,并将数据集划分为训练集和测试集。
同时,对数据进行归一化处理,将每个特征缩放到0-1范围内。
(2)SVM模型训练使用sklearn库中的SVM模块,选择合适的核函数和惩罚系数,对训练集进行训练,并得到SVM模型。
(3)模型评估使用测试集对训练好的模型进行评估,计算准确率、精确率、召回率和F1值等指标,评估模型的分类性能。
三、实验结果及分析经过训练和测试,得到的SVM模型在测试集上的分类结果如下表所示:类别,正确分类个数,错误分类个数,准确率----------,--------------,--------------,-----------类别1,25,0,100.00%类别2,0,25,0.00%从上表可以看出,SVM模型在测试集上对类别1的样本进行了100%的正确分类,但对类别2的样本没有正确分类。
这可能是由于数据不平衡导致的,也可能是因为我们选取的怀古核函数和惩罚系数不够合适。
从上图可以看出,SVM将两个类别的样本在特征空间中分隔开来,并确定了一个决策边界。
但由于模型的不足,决策边界没有完全将两个类别分开,导致分类错误。
svm实验报告SVM 实验报告一、实验目的本次实验的主要目的是深入理解和掌握支持向量机(Support Vector Machine,SVM)算法的原理和应用,并通过实际的实验操作来验证其在不同数据集上的性能表现。
二、实验原理SVM 是一种基于统计学习理论的有监督学习算法,其基本思想是在特征空间中寻找一个能够将不同类别样本正确分开的最优超平面。
这个超平面不仅要能够将训练样本正确分类,还要使得距离超平面最近的样本点(称为支持向量)到超平面的距离最大。
SVM 算法通过引入核函数将样本从原始空间映射到高维特征空间,从而使得在原始空间中非线性可分的问题在高维特征空间中变得线性可分。
常见的核函数包括线性核函数、多项式核函数、高斯核函数等。
三、实验环境本次实验使用的编程语言为 Python,主要使用了 sklearn 库中的SVM 模块。
实验运行环境为 Windows 10 操作系统,处理器为_____,内存为_____。
四、实验数据为了全面评估SVM 算法的性能,我们选用了以下几个公开数据集:1、 Iris 数据集:这是一个经典的多分类数据集,包含三种鸢尾花(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的特征数据,如花瓣长度、花瓣宽度、萼片长度和萼片宽度等,共 150 个样本。
2、 Wine 数据集:该数据集包含了三种不同来源的葡萄酒的化学分析数据,共 178 个样本。
3、 Breast Cancer 数据集:用于二分类问题,判断乳腺肿瘤是良性还是恶性,包含 569 个样本。
五、实验步骤1、数据预处理首先,对数据集进行加载和读取。
然后,将数据集划分为训练集和测试集,通常采用随机划分的方式,比例为 7:3 或 8:2。
2、特征工程对于某些数据集,可能需要进行特征缩放或标准化,以确保不同特征具有相同的权重和尺度。
3、模型训练选择合适的核函数(如线性核、高斯核等)和参数(如 C 值、gamma 值等)。
使用训练集对 SVM 模型进行训练。
SVM分类算法一、数据源说明1、数据源说远和理解:采用的实验数据源为第6组:The Insurance Company Benchmark (COIL 2000) TICDATA2000.txt: 这个数据集用来训练和检验预测模型,并且建立了一个5822个客户的记录的描述。
每个记录由86个属性组成,包含社会人口数据(属性1-43)和产品的所有关系(属性44-86 )。
社会人口数据是由派生邮政编码派生而来的,生活在具有相同邮政编码地区的所有客户都具有相同的社会人口属性。
第86个属性:“大篷车:家庭移动政策” ,是我们的目标变量。
共有5822条记录,根据要求,全部用来训练。
TICEVAL2000.txt: 这个数据集是需要预测( 4000个客户记录)的数据集。
它和TICDATA2000.txt它具有相同的格式,只是没有最后一列的目标记录。
我们只希望返回预测目标的列表集,所有数据集都用制表符进行分隔。
共有4003(自己加了三条数据),根据要求,用来做预测。
TICTGTS2000.txt:最终的目标评估数据。
这是一个实际情况下的目标数据,将与我们预测的结果进行校验。
我们的预测结果将放在result.txt文件中。
数据集理解:本实验任务可以理解为分类问题,即分为2类,也就是数据源的第86列,可以分为0、1两类。
我们首先需要对TICDATA2000.txt进行训练,生成model,再根据model进行预测。
2、数据清理代码中需要对数据集进行缩放的目的在于:A、避免一些特征值范围过大而另一些特征值范围过小;B、避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
因此,通常将数据缩放到[ -1,1] 或者是[0,1] 之间。
二、数据挖掘的算法说明1、s vm算法说明LIBSVM软件包是台湾大学林智仁(Chih-Jen Lin)博士等用C++实现的SVM库,并且拥有matlab,perl等工具箱或者代码,移植和使用都比较方便.它可以解决分类问题(包括C-SVC、n-SVC)、回归问题(包括e-SVR、n-SVR)以及分布估计(one-class-SVM )等问题,提供了线性、多项式、径向基和S形函数四种常用的核函数供选择,可以有效地解决多类问题、交叉验证选择参数、对不平衡样本加权、多类问题的概率估计等。
2、实现过程在源程序里面,主要由以下2个函数来实现:(1) struct svm_model *svm_train(const struct svm_problem *prob, const struct svm_parameter *param);该函数用来做训练,参数prob,是svm_problem类型数据,具体结构定义如下:struct svm_problem //存储本次参加运算的所有样本(数据集),及其所属类别。
{int n; //记录样本总数double *y; //指向样本所属类别的数组struct svm_node **x; //指向一个存储内容为指针的数组};其中svm_node的结构体定义如下:struct svm_node //用来存储输入空间中的单个特征{int index; //输入空间序号,假设输入空间数为mdouble value; //该输入空间的值};所以,prob也可以说是问题的指针,它指向样本数据的类别和输入向量,在内存中的具体结构图如下:图1.1LIBSVM训练时,样本数据在内存中的存放结构只需在内存中申请n*(m+1)*sizeof(struct svm_node)大小的空间,并在里面填入每个样本的每个输入空间的值,即可在程序中完成prob参数的设置。
参数param,是svm_parameter数据结构,具体结构定义如下:struct svm_parameter // 训练参数{int svm_type; //SVM类型,int kernel_type; //核函数类型int degree; /* for poly */double gamma; /* for poly/rbf/sigmoid */double coef0; /* for poly/sigmoid *//* these are for training only */double cache_size; /* in MB 制定训练所需要的内存*/double eps; /* stopping criteria */double C; /* for C_SVC, EPSILON_SVR and NU_SVR ,惩罚因子*/int nr_weight; /* for C_SVC 权重的数目*/int *weight_label; /* for C_SVC 权重,元素个数由nr_weight 决定*/double* weight; /* for C_SVC */double nu; /* for NU_SVC, ONE_CLASS, and NU_SVR */double p; /* for EPSILON_SVR */int shrinking; /* use the shrinking heuristics 指明训练过程是否使用压缩*/int probability; /* do probability estimates 指明是否要做概率估计*/}其中,SVM类型和核函数类型如下:enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR }; /* svm_type */enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED }; /* kernel_type */只需申请一个svm_parameter结构体,并按实际需要设定SVM类型、核函数和各种参数的值即可完成参数param的设置。
设定完这两个参数,就可以直接在程序中调用训练函数进行训练了,该其函数返回一个struct svm_model *SVM模型的指针,可以使用svm_save_model(const char*model_file_name, const struct svm_model *model)函数,把这个模型保存在磁盘中。
至此,训练函数的移植已经完成。
(2) double svm_predict(const struct svm_model *model, const structsvm_node *x);参数model,是一个SVM模型的指针,可以使用函数struct svm_model*svm_load_model(const char *model_file_name),导入训练时保存好的SVM模型,此函数返回一个SVM模型的指针,可以直接赋值给变量model。
参数x,是const struct svm_node结构体的指针,本意是一个输入空间的指针,但实际上,该函数执行的时候,是从参数x处计算输入空间,直到遇到单个样本数据结束标记-1才结束,也就是说,该函数运算了单个样本中的所有输入空间数据。
因此,在调用此函数时,必须先把预测样本的数据按图3.4中的固定格式写入内存中。
另外,该函数只能预测一个样本的值,本文需要对图像中的所有像数点预测,就要使用for循环反复调用。
该函数返回一个double类型,指明被预测数据属于哪个类。
面对两分类问题的时候,通常使用+1代表正样本,即类1;-1代表负样本,即类2。
最后根据返回的double值就可以知道预测数据的类别了。
三、算法源代码及注释说明1、需要在工程中添加头文件svm.h 和源文件svm.cpp2、自己编写的源代码(C++实现)(共230行):#include "svm.h"#include <iostream>#include <list>#include <iterator>#include <vector>#include <string>#include <ctime>using namespace std;#ifdef WIN32#pragma warning (disable: 4514 4786)#endifsvm_parameter param;svm_problem prob;svm_model *svmModel;list<svm_node*> xList;list<double> yList ;const int MAX=10;const int nTstTimes=10;vector<int> predictvalue;vector<int> realvalue;int trainNum=0;//设置参数void setParam(){param.svm_type = C_SVC;param.kernel_type = RBF;param.degree = 3;param.gamma = 0.5;param.coef0 = 0;param.nu = 0.5;param.cache_size = 40;param.C = 500;param.eps = 1e-3;param.p = 0.1;param.shrinking = 1;// param.probability = 0;param.nr_weight = 0;param.weight = NULL;。