
置信区间与置信水平、样本量的关系
置信区间与置信水平、样本量的关系(2008-10-28 08:39:39)标签:置信区间与置信水平教育分类:数学相关
置信水平Confidence level
置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。
一、置信区间的概念
置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的:
第一步:求一个样本的均值
第二步:计算出抽样误差。
人们经过实践,通常认为调查:
100个样本的抽样误差为±10%
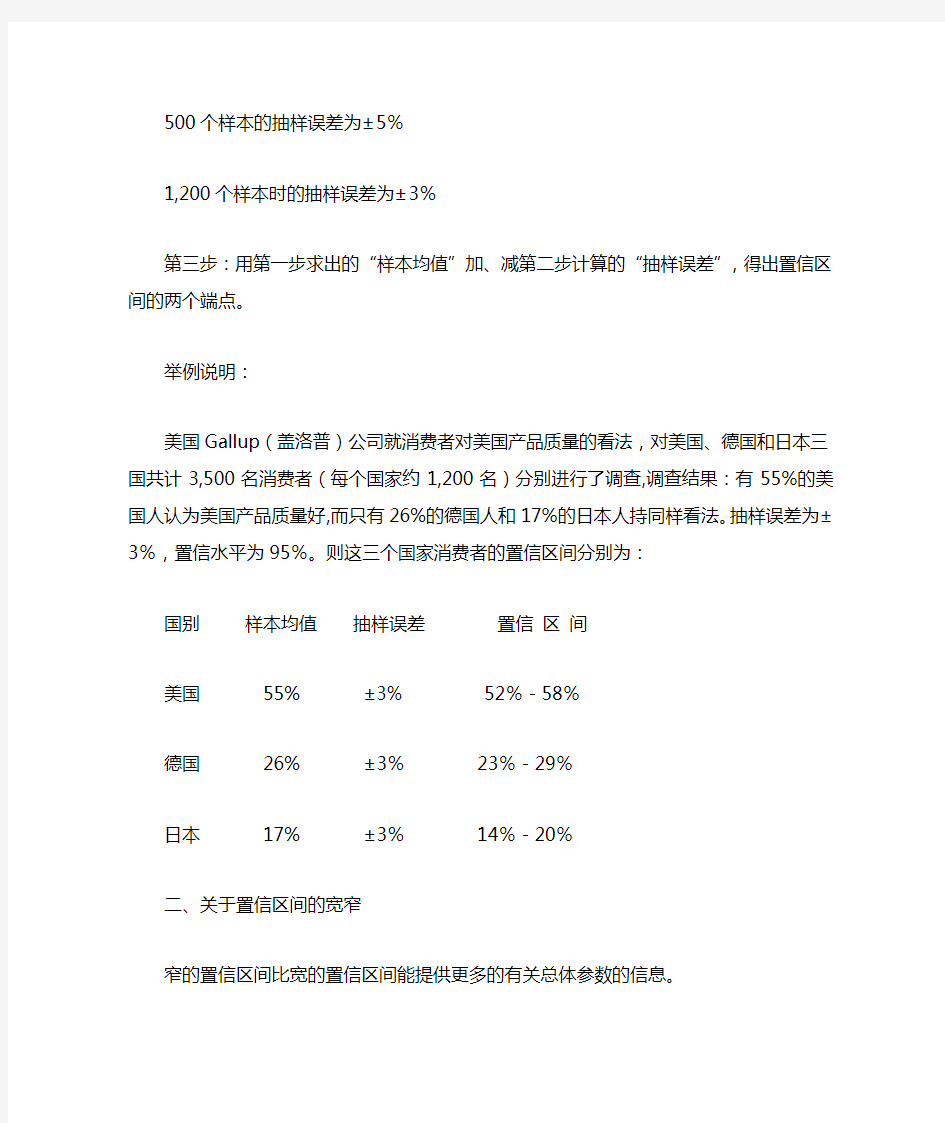
500个样本的抽样误差为±5%
1,200个样本时的抽样误差为±3%
第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。
举例说明:
美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为:
国别样本均值抽样误差置信区间
美国55% ±3% 52%-58%
德国26% ±3%23%-29%
日本17% ±3%14%-20%
二、关于置信区间的宽窄
窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。
假设全班考试的平均分数为65分,则
置信区间间隔宽窄度表达的意思
0-100分100 宽等于什么也没告诉你
30-80分50 较窄你能估出大概的平均分了(55分)
60-70分10 窄你几乎能判定全班的平均分了(65分)
三、样本量对置信区间的影响
影响:在置信水平固定的情况下,样本量越多,置信区间越窄。
下面是经过实践计算的样本量与置信区间关系的变化表(假设置信水平相同):
样本量置信区间间隔宽窄度
100 50%—70% 20 宽
800 56.2%-63.2% 7 较窄
1,600 57.5%—63% 5.5 较窄
3,200 58.5%—62% 3.5 更窄
由上表得出:
1、在置信水平相同的情况下,样本量越多,置信区间越窄。
2、置信区间变窄的速度不像样本量增加的速度那么快,也就是说并不是样本量增加一倍,置信区间也变窄一倍(实践证明,样本量要增加4倍,置信区间才能变窄一倍),所以当样本量达到一个量时
(通常是1,200,如上例三个国家各抽了1,200个消费者),就不再增加样本了。
通过置信区间的计算公式来验证置信区间与样本量的关系
置信区间=样本的推断值±(可靠程度系数×)
从上述公式中可以看出:
在其他因素不变的情况下,样本量越多(大),置信区间越窄(小)。
四、置信水平对置信区间的影响
影响:在样本量相同的情况下,置信水平越高,置信区间越宽。
举例说明:美国做了一项对总统工作满意度的调查。在调查抽取的1,200人中,有60%的人赞扬了总统的工作,抽样误差为±3%,置信水平为95%;如果将抽样误差减少为±2.3%,置信水平降到为90%。则两组数字的情况比较如下:
抽样误差置信水平置信区间间隔宽窄度
±3%95%60%±3%=57%-63% 6 宽
±2.3%90%60%±2.3%=57.7%-62.3% 4.6 窄
由上表得出:
在样本量相同的情况下(都是1,200人),置信水平越高(95%),置信区间越宽。
五、样本量对置信水平的影响
影响:在置信区间不变的情况下,样本量越多,置信水平越高。
举例说明:
置信区间样本量置信水平
52%-58%1,200 95% (前面美国盖洛普公司的例子)
第四节 正态总体的置信区间 与其他总体相比, 正态总体参数的置信区间是最完善的,应用也最广泛。在构造正态总体参数的置信区间的过程中,t 分布、2χ分布、F 分布以及标准正态分布)1,0(N 扮演了重要角色. 本节介绍正态总体的置信区间,讨论下列情形: 1. 单正态总体均值(方差已知)的置信区间; 2. 单正态总体均值(方差未知)的置信区间; 3. 单正态总体方差的置信区间; 4. 双正态总体均值差(方差已知)的置信区间; 5. 双正态总体均值差(方差未知但相等)的置信区间; 6. 双正态总体方差比的置信区间. 注: 由于正态分布具有对称性, 利用双侧分位数来计算未知参数的置信度为α-1的置信区间, 其区间长度在所有这类区间中是最短的. 分布图示 ★ 引言 ★ 单正态总体均值(方差已知)的置信区间 ★ 例1 ★ 例2 ★ 单正态总体均值(方差未知)的置信区间 ★ 例3 ★ 例4 ★ 单正态总体方差的置信区间 ★ 例5 ★ 双正态总体均值差(方差已知)的置信区间 ★ 例6 ★ 双正态总体均值差(方差未知)的置信区间 ★ 例7 ★ 例8 ★ 双正态总体方差比的置信区间 ★ 例9 ★ 内容小结 ★ 课堂练习 ★ 习题6-4 内容要点 一、单正态总体均值的置信区间(1) 设总体),,(~2σμN X 其中2σ已知, 而μ为未知参数, n X X X ,,,21 是取自总体X 的一个样本. 对给定的置信水平α-1, 由上节例1已经得到μ的置信区间 ,,2/2/???? ? ??+?-n u X n u X σσαα 二、单正态总体均值的置信区间(2) 设总体),,(~2σμN X 其中μ,2σ未知, n X X X ,,,21 是取自总体X 的一个样本. 此时可用2σ的无偏估计2S 代替2σ, 构造统计量 n S X T /μ-=, 从第五章第三节的定理知).1(~/--= n t n S X T μ 对给定的置信水平α-1, 由 αμαα-=? ?????-<-<--1)1(/)1(2/2/n t n S X n t P ,
置信区间与置信水平、样本量的关系 置信区间与置信水平、样本量的关系(2008-10-28 08:39:39)标签:置信区间与置信水平教育分类:数学相关 置信水平Confidence level 置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 一、置信区间的概念 置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的: 第一步:求一个样本的均值 第二步:计算出抽样误差。 人们经过实践,通常认为调查: 100个样本的抽样误差为±10% 500个样本的抽样误差为±5% 1,200个样本时的抽样误差为±3% 第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。 举例说明: 美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为: 国别样本均值抽样误差置信区间 美国55% ±3% 52%-58% 德国26% ±3%23%-29% 日本17% ±3%14%-20% 二、关于置信区间的宽窄 窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。 假设全班考试的平均分数为65分,则 置信区间间隔宽窄度表达的意思 0-100分100 宽等于什么也没告诉你 30-80分50 较窄你能估出大概的平均分了(55分) 60-70分10 窄你几乎能判定全班的平均分了(65分)
抽样调查样本量的确定 在贸易统计中, 对于限额以下批零餐饮企业普遍采用抽样调查方法进行解决。然而,由于当前市场经济情况的多样性,经济发展的不均衡性,以及地域宽广性,导致情况多种多样;实际情况的复杂,决定了方案的复杂性,增加了具体抽样的难度。经过多年的探讨,区域二相抽样调查比较符合当前我国的实际情况,我们在这里根据试点所掌握的情况针对采用区域二相抽样调查的贸易抽样方案中如何确定样本量进行分析。 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。
样本量的确定 北京广播学院新闻传播学院 调查统计研究所 二零零一年五月 沈浩 本讲主要内容 如何计算简单随机抽样的样本量确定 如何实现分层抽样中各层样本单位数的分配样本容量的确定 样本量=费用+精度 (函数) 确定样本容量,需要处理好预定的精度与现有经费,同时也要考虑资源和时间等限 制条件,最终的样本量确定是在上述因素之间的权衡关系。分层抽样分配样本的标准 总的样本容量事先确定 估计值要求达到的精度预先给定 影响调查样本容量的因素 调查估计值所希望达到的精度 调查估计值所能允许的误差。 估计量的抽样方差较小,估计值是精确的 估计值的精度越高,所需的样本容量就越大 影响精度的因素也同样影响着样本容量的大小 所研究指标在总体中的变异程度 总体的大小
样本设计和所使用的估计量 无回答率 客户提供的经费能支持多大容量的样本 整个调查持续的时间有多长 调查需要多少访员 能招聘到的访员有多少 除了估计值的精度以外,调查实际操作的限制条件也许是影响样本容量的最大因 素。 11>(给定精度水平下样本容量的确定样本容量的大小与调查估计值所要求的精度紧密相关 数据是通过抽样而不是普查收集的,就会产生抽样误差。 精度是由抽样方差来测量的。 随着样本容量的增加,调查估计值的精度也会不断提高。标准误差 误差界限 变异系数 抽样方差的几种计量方法 抽样调查中样本容量的确定,也经常会使用一种或多种这样的计量方法来对精度进 行说明。 非抽样误差 非抽样误差会对调查估计值的精度产生显著的影响 非抽样误差的大小与样本容量的大小却没有很大的关系 确定样本容量,就不必将这些误差作为影响因素加以考虑
如对你有帮助,请购买下载打赏,谢谢!样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。
样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。
置信水平Confidence level 置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 一、置信区间的概念 置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的:第一步:求一个样本的均值 第二步:计算出抽样误差。 人们经过实践,通常认为调查: 100个样本的抽样误差为±10% 500个样本的抽样误差为±5% 1,200个样本时的抽样误差为±3% 第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。 举例说明: 美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为: 国别样本均值抽样误差置信区间
美国55% ±3% 52%-58% 德国26% ±3%23%-29% 日本17% ±3%14%-20% 二、关于置信区间的宽窄 窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。 假设全班考试的平均分数为65分,则 置信区间间隔宽窄度表达的意思 0-100分100 宽等于什么也没告诉你 30-80分50 较窄你能估出大概的平均分了(55分) 60-70分10 窄你几乎能判定全班的平均分了(65分) 三、样本量对置信区间的影响 影响:在置信水平固定的情况下,样本量越多,置信区间越窄。 下面是经过实践计算的样本量与置信区间关系的变化表(假设置信水平相同):样本量置信区间间隔宽窄度 100 50%—70% 20 宽 800 56.2%-63.2% 7 较窄 1,600 57.5%—63% 5.5 较窄 3,200 58.5%—62% 3.5 更窄 由上表得出: 1、在置信水平相同的情况下,样本量越多,置信区间越窄。
样本量的确定方法 The pony was revised in January 2021
样本量的确定方法(2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城
2017年公卫助理:总体率的置信区间试题本卷共分为1大题50小题,作答时间为180分钟,总分100分,60分及格。 一、单项选择题(共50题,每题2分。每题的备选项中,只有一个最符合题意) 1.HOCI和OCI-的杀菌效果为( c )。 A. HOCI的杀菌效果与OCI-相同 B. HOCI的杀菌效果与OCI-低80倍 C. HOCI的杀菌效果与OCI-高80倍 D. HOCI的杀菌效果与OCI-低20倍 E. HOCI的杀菌效果与OCI-高20倍 2.高温车间是指 A.夏季车间内气温超过30℃ B.车间内气温比室外夏季设计通风计算温度高2℃及以上 C.夏季车间内气温超过35℃ D.车间内热源散热量每小时每m3大于50kcal E.未明确规定 [正确答案]:B 3.甲氧苄啶的抗菌机制是抑制细菌的 A.二氢叶酸合成酶 B.四氢叶酸合成酶
C.二氢叶酸还原酶 D.DNA回旋酶 E.RNA聚合酶 正确答案:C 4.硝酸甘油的不良反应主要是由哪种作用所致 A.心排出量减少 B.血压降低 C.耗氧量减少 D.血管扩张 E.心肌血液的重新分布 正确答案:D 5. 社会医学研究工具(问卷或量表)的效度评价不包括( B ) A 表面效度B质量效度C 结构效度D 内容效度 6. 下列何药可诱发支气管哮喘 A.甲基多巴 B.利舍平 C.呱乙啶 D.普萘洛尔 E.硝苯地平
正确答案:D 7. 环磷酰胺的不良反应不包括 A.血压升高 B.恶心、呕吐 C.脱发 D.骨髓抑制 E.出血性膀胱炎 正确答案:A 8. 粉尘对人体可有以下作用 A.致纤维化 B.刺激 C.中毒 D.致敏 E.以上全部 9. 下列哪项不是文化的基本特征( C ) A 历史性 B 现实性 C 创造性 D 渗透性 10. 问卷的一般结构包括(A ) A、封面信——指导语——问题及答案——编码
首先我们要弄清楚两个概念,置信度和置信区间 置信度:以测量值为中心,在一定范围内,真值出现在该范围内的几率。一般设定在2σ,也就是95%,95%是通常情况下置信度(置信水平)的设定值。 置信区间:在某一置信度下,以测量值为中心,真值出现的范围。 我们在论文里经常看到CI,CI是置信区间,一定概率下真值得取值范围(可靠范围)称为置信区间。其概率称为置信概率或置信度(置信水平) 真实数据往往是实际上不能获知的,我们只能进行估计,估计的结果是给出一对数据,比如从1到1.5,真实的值落在1到1.5之间的可能性是95%(也有5%的可能性在这区间之外的)。区间是由抽样的数据根据大样定律结合查表得来的。区间越小精度越高,区间越大置信度越高。打个比方,我们猜张燕燕的年龄,你给出区间是25-35,这个区间很小置信度很低但精度就很高,你说在8岁到80岁之间,那是百分百的置信度了不过精度太低毫无意义。的确99%准确度高于95%,但是它的精度(精密度)就低于95%。95%的置信度是一般通用的。
P值指的是比较的两者的差别是由机遇所致的可能性大小。P值越小,越有理由认为对比事物间存在差异。例如,P<0.05,就是说结果显示的差别是由机遇所致的可能性不足5%,或者说,别人在同样的条件下重复同样的研究,得出相反结论的可能性不足5%。P>0.05称“不显著”;P<=0.05称“显著”,P<=0.01称“非常显著”。 由于常用“显著”来表示P值大小,所以P值最常见的误用是把统计学上的显著与临床或实际中的显著差异相混淆,即混淆“差异具有显著性”和“具有显著差异”二者的意思。其实,前者指的是p<=0.05,即说明有充分的理由认为比较的二者来自同一总体的可能性不足5%,因而认为二者确实有差异,下这个结论出错的可能性<=5%。而后者的意思是二者的差别确实很大。举例来说,4和40的差别很大,因而可以说是“有显著差异”,而4和4.2差别不大,但如果计算得到的P值<=0.05,则认为二者“差别有显著性”,但是不能说“有显著差异”。
第6章总体率的区间估计和假设检验 ?掌握率的抽样误差的概念和意义 ?掌握总体率区间估计的概念意义和计算方法 ?掌握率的U检验的概念和条件,计算方法 ?第一节率的抽样误差与总体率的区间估计 一、率的抽样误差:在同一总体中按一定的样本含量n抽样,样本率和总体率或样本率之间也存在着差异,这种差异称为率的抽样误差。 例6.1 检查居民800人粪便中蛔虫阳性200人,阳性率为25%,试求阳性率的标准误。 本例:n=800,p=0.25,1-p=0.75, % 53 .1 0153 .0 800 75 .0 25 .0 = = ? = p S 二、总体率的区间估计 ㈠正态分布法 样本含量n足够大,np与n(1-p)均≥5时, 例6.2 求例6.1当地居民粪便蛔虫阳性率的95%可信区间和99%的可信区间。 95%的可信区间为:25%±1.96×1.53% 即(22.00%,28.00%) 99%的可信区间为:25%±2.58×1.53% 即(21.05%,28.95%)㈡查表法 当样本含量较小(如n≤50),np或n(1-p)<5时,样本率的分布呈二项分布,总体率的可信区间可据二项分布的理论求得。 第二节率的u检验 应用条件:样本含量n足够大,np与n(1-p)均≥5 。 此时,样本率p也是以总体率为中心呈正态分布或近似正态分布的。 一、样本率与总体率比较的u ?u值的计算公式为: 例6.5 根据以往经验,一般胃溃疡病患者有20%(总体率)发生胃出血症状。现某医生观察65岁以上胃溃疡病人152例,其中48例发生胃出血,占31.6%(样本率)。问老年胃n p ) 1(π π σ - = n p p S p ) 1(- = p S u p α ± n p p u p ) 1 ( | | | | π π π σ π - - = - =
第19讲 正态总体参数的区间估计 教学目的:理解区间估计的概念,掌握各种条件下对一个正态总体的均值和方差进行 区间估计的方法。 教学重点:置信区间的确定。 教学难点:对置信区间的理解。 教学时数: 2学时。 教学过程: 第六章 参数估计 §6.3正态总体参数的区间估计 1. 区间估计的概念 我们已经讨论了参数的点估计,但是对于一个估计量,人们在测量或计算时,常不以得到近似值为满足,还需估计误差,即要求知道近似值的精确程度。因此,对于未知参数θ,除了求出它的点估计?θ外,我们还希望估计出一个范围,并希望知道这个范围包含参数θ真值的可信程度。 设?θ为未知参数θ的估计量,其误差小于某个正数ε的概率为1(01)αα-<<,即 ?{||}1P θθεα -<=- 或 αεθθεθ-=+<<-1)??(P 这表明,随机区间)?,?(εθεθ+-包含参数θ真值的概率(可信程度)为1α-,则这个区间)?,?(εθεθ+-就称为置信区间,1α-称为置信水平。 定义 设总体X 的分布中含有一个未知参数θ。若对于给定的概率1(01)αα-<<,存在两个统计量1112(,,,)n X X X θθ= 与2212(,,,)n X X X θθ= ,使得 12{}1P θθθα <<=-
则随机区间12(,)θθ称为参数θ的置信水平为1α-的置信区间,1θ称为置信下限,2θ称为置信上限,1α-称为置信水平。 注(1)置信区间的含义:若反复抽样多次(各次的样本容量相等,均为n ),每一组样本值确定一个区间12(,)θθ,每个这样的区间要么包含θ的真值,要么不包含θ的真值。按伯努利大数定理,在这么多的区间中,包含θ真值的约占100(1)%α-,不包含θ真值的约仅占100%α。例如:若0.01α=,反复抽样1000次,则得到的1000个区间中,不包含θ真值的约为10个。 (2)置信区间的长度表示估计结果的精确性,而置信水平表示估计结果的可靠性。对于置信水平为1α-的置信区间12(,)θθ,一方面置信水平1α-越大,估计的可靠性越高;另一方面区间12(,)θθ的长度(2)ε越小,估计的精确性越好。但这两方面通常是矛盾的,提高可靠性通常会使精确性下降(区间长度变大),而提高精确性通常会使可靠性下降(1α-变小),所以要找两方面的平衡点。 在学习区间估计方法之前,我们先介绍标准正态分布的α分位点概念。 设 () ~0,1X N ,若 z α 满足条件 { },01 P X z α αα>=<<,则称点z α为标准正态分布的α分位点。例如求0.01z 。按照α分位点定义,我们有 {}0.010.01P X z >=,则{}0.010.99P X z ≤=,即0.01()0.99z φ=。查表可得0.01 2.327z =. 又 由()x ?图形的对称性知1z z αα-=-。下面列出了几个常用的z α值: 2. 正态总体均值μ的区间估计 设已给定置信水平为1α-,总体()2~,X N μσ,12,,,n X X X 为一个样本,2 ,X S 分别是样本均值和样本方差。
“置信区间与置信水平、样本量的关系 置信水平Confidence level 置信水平是指总体参数值落在样本统计值某一区内的概率;而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 一、置信区间的概念 置信区间又称估计区间,是用来估计参数的取值范围的。常见的52%-64%,或8-12,就是置信区间(估计区间)。置信区间是按下列三步计算出来的: 第一步:求一个样本的均值 第二步:计算出抽样误差。 人们经过实践,通常认为调查: 100个样本的抽样误差为±10% 500个样本的抽样误差为±5% 1,200个样本时的抽样误差为±3% 第三步:用第一步求出的“样本均值”加、减第二步计算的“抽样误差”,得出置信区间的两个端点。 举例说明: 美国Gallup(盖洛普)公司就消费者对美国产品质量的看法,对美国、德国和日本三国共计3,500名消费者(每个国家约1,200名)分别进行了调查,调查结果:有55%的美国人认为美国产品质量好,而只有26%的德国人和17%的日本人持同样看法。抽样误差为±3%,置信水平为95%。则这三个国家消费者的置信区间分别为: 国别样本均值抽样误差置信区间 美国55% ±3% 52%-58% 德国26% ±3% 23%-29% 日本17% ±3% 14%-20% 二、关于置信区间的宽窄 窄的置信区间比宽的置信区间能提供更多的有关总体参数的信息。 假设全班考试的平均分数为65分,则 置信区间间隔宽窄度表达的意思 0-100分 100 宽等于什么也没告诉你 30-80分50 较窄你能估出大概的平均分了(55分) 60-70分10 窄你几乎能判定全班的平均分了(65分) 三、样本量对置信区间的影响 影响:在置信水平固定的情况下,样本量越多,置信区间越窄。 下面是经过实践计算的样本量与置信区间关系的变化表(假设置信水平相同): 样本量置信区间间隔宽窄度 100 50%—70% 20 宽 800 56.2%-63.2% 7 较窄 1,600 57.5%—63% 5.5 较窄 3,200 58.5%—62% 3.5 更窄 由上表得出: 1、在置信水平相同的情况下,样本量越多,置信区间越窄。
抽样调查样本量确定.
抽样调查样本量的确定 在贸易统计中, 对于限额以下批零餐饮企业普遍采用抽样调查方法进行解决。然而,由于当前市场经济情况的多样性,经济发展的不均衡性,以及地域宽广性,导致情况多种多样;实际情况的复杂,决定了方案的复杂性,增加了具体抽样的难度。经过多年的探讨,区域二相抽样调查比较符合当前我国的实际情况,我们在这里根据试点所掌握的情况针对采用区域二相抽样调查的贸易抽样方案中如何确定样本量进行分析。 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1研究对象的变化程度,即变异程度; (2要求和允许的误差大小,即精度要求; (3要求推断的置信度,一般情况下,置信度取为95%; (4总体的大小; (5抽样的方法。
也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,这种说法原则上是不对的。实际上,在大城市抽样太大是浪费,在小城市抽样太少没有推断价值。 二、样本量的确定方法 如何确定样本量,基本方法很多,但是公式检验表明,当误差和置信区间一定时,不同的样 本量计算公式计算出来的样本量是十分相近的,所以,我们完全可以使用简单随机抽样计算 样本量的公式去近似估计其他抽样方法的样本量,这样可以更加快捷方便,然后将样本量根 据一定方法分配到各个子域中去。所以,区域二相抽样不能计算样本量的说法是不科学的。 1.简单随机抽样确定样本量主要有两种类型: (1对于平均数类型的变量 对于已知数据为绝对数,我们一般根据下列步骤来计算所需要的样本量。已知期望调查 结果的精度(E, 期望调查结果的置信度(L,以及总体的标准差估计值σ的具体数据,总体
样本量的确定方法 (2008-10-14 09:12:34) 一、样本单位数量的确定原则 一般情况下,确定样本量需要考虑调查的目的、性质和精度要求。以及实际操作的可行性、经费承受能力等。根据调查经验,市场潜力和推断等涉及量比较严格的调查需要的样本量比较大,而一般广告效果等人们差异不是很大或对样本量要求不是很严格的调查,样本量相对可以少一些。实际上确定样本量大小是比较复杂的问题,即要有定性的考虑,也要有定量的考虑;从定性的方面考虑,决策的重要性、调研的性质、数据分析的性质、资源、抽样方法等都决定样本量的大小。但是这只能原则上确定样本量大小。具体确定样本量还需要从定量的角度考虑。 从定量的方面考虑,有具体的统计学公式,不同的抽样方法有不同的公式。归纳起来,样本量的大小主要取决于: (1)研究对象的变化程度,即变异程度; (2)要求和允许的误差大小,即精度要求; (3)要求推断的置信度,一般情况下,置信度取为95%; (4)总体的大小; (5)抽样的方法。 也就是说,研究的问题越复杂,差异越大时,样本量要求越大;要求的精度越高,可推断性要求越高时,样本量也越大;同时,总体越大,样本量也相对要大,但是,增大呈现出一定对数特征,而不是线形关系;而抽样方法问题,决定设计效应的值,如果我们设定简单随机抽样设计效应的值是1;分层抽样由于抽样效率高于简单随机抽样,其设计效应的值小于1,合适恰当的分层,将使层内样本差异变小,层内差异越小,设计效应小于1的幅度越大;多阶抽样由于效率低于简单随机抽样,设计效应的值大于1,所以抽样调查方法的复杂程度决定其样本量大小。对于不同城市,如果总体不知道或很大,需要进行推断时,大城市多抽,小城市少抽,