
https://www.doczj.com/doc/1517199206.html,
图片爬虫如何使用
目标网站上有许多我们喜欢的图片,想用到自己的工作或生活中去,但苦于工作量太大,图片一张张保存太过耗时耗力,因此总是力不从心。
本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【ebay】为例,教大家如何使用八爪鱼采集软件采集ebay网站的方法。
可以将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
采集网站:
https://https://www.doczj.com/doc/1517199206.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0
使用功能点:
●分页列表信息采集
●执行前等待
●图片URL转换
https://www.doczj.com/doc/1517199206.html,
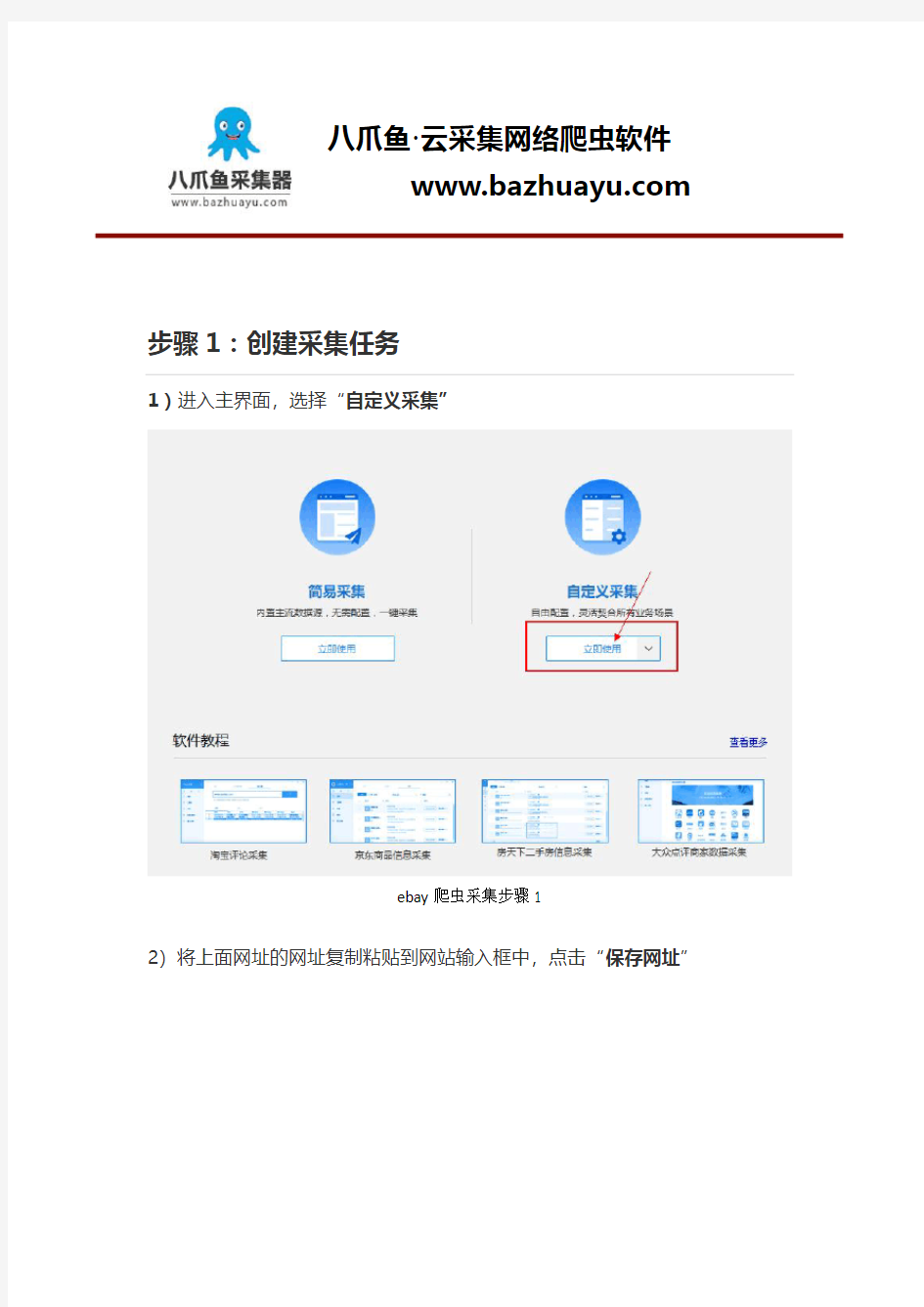
步骤1:创建采集任务
1)进入主界面,选择“自定义采集”
ebay爬虫采集步骤1
2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html,
ebay爬虫采集步骤2
3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.doczj.com/doc/1517199206.html,
ebay爬虫采集步骤3
步骤二:创建翻页循环
1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接”
ebay爬虫采集步骤4
由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
https://www.doczj.com/doc/1517199206.html,
步骤三:图片链接地址采集
1)选中页面内第一个图片,系统会自动识别同类图片。在操作提示框中,选择“选中全部”
ebay爬虫采集步骤5
2)选择“采集以下图片地址”
ebay爬虫采集步骤5
由左上角流程图中可见,八爪鱼对本页全部图片进行了循环,并在“提取数据”
https://www.doczj.com/doc/1517199206.html,
中对图片链接地址进行了提取。
此时可以用鼠标随意点击循环列表中的某一条,再点击“提取数据”,验证一下是否都有正常提取。如果有的循环项没有提取到,说明该xpath定位不准,需要修改。(多次测试,尚未发现不准情况。)
ebay爬虫采集步骤6
如还想提取其他字段,如标题,可选择“提取数据”,在下方的商品列表上点击一个商品的标题,选择“采集该链接的文本”
https://www.doczj.com/doc/1517199206.html,
ebay爬虫采集步骤7
修改下字段的名称,如网页加载较慢,可设置“执行前等待”
ebay爬虫采集步骤8
点击“开始采集,免费版用户点击“启动本地采集”,旗舰版用户可点击“启动云采集”
https://www.doczj.com/doc/1517199206.html,
ebay爬虫采集步骤9
说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
步骤四:数据采集及导出
1)采集完成后,选择导出数据
https://www.doczj.com/doc/1517199206.html,
ebay爬虫采集步骤10
2)选择合适的导出方式,将采集好的数据导出
https://www.doczj.com/doc/1517199206.html,
ebay爬虫采集步骤11
步骤五:将图片URL批量转换为图片
经过如上操作,我们已经得到了要采集的图片的URL。接下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。
图片批量下载工具:https://https://www.doczj.com/doc/1517199206.html,/s/1c2n60NI
https://www.doczj.com/doc/1517199206.html,
相关采集教程:
ebay爬虫抓取图片
https://www.doczj.com/doc/1517199206.html,/tutorial/ebaypicpc
微博图片采集
https://www.doczj.com/doc/1517199206.html,/tutorial/wbpiccj
阿里巴巴图片抓取下载
https://www.doczj.com/doc/1517199206.html,/tutorial/alibabapiccj
网站图片采集方法
https://www.doczj.com/doc/1517199206.html,/tutorial/webpiccj
京东商品图片采集详细教程
https://www.doczj.com/doc/1517199206.html,/tutorial/jdpiccj
淘宝买家秀图片采集详细教程
https://www.doczj.com/doc/1517199206.html,/tutorial/tbmjxpic
淘宝图片采集并下载到本地的方法
https://www.doczj.com/doc/1517199206.html,/tutorial/tbgoodspic
瀑布流网站图片采集方法,以百度图片采集为例
https://www.doczj.com/doc/1517199206.html,/tutorial/bdpiccj
网站图片采集
https://www.doczj.com/doc/1517199206.html,/tutorial/hottutorial/qita/tupian
https://www.doczj.com/doc/1517199206.html,
豆瓣图片采集并下载保存本地的方法
https://www.doczj.com/doc/1517199206.html,/tutorial/tpcj-7
八爪鱼——100万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。配置好采集任务后可关机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。
https://www.doczj.com/doc/1517199206.html, 美团爬虫使用方法 美团网拥有全网最全最多的商户信息,涵盖了美食攻略,外卖网上订餐,酒店预订,旅游团购,飞机票火车票,电影票,ktv团购等各种项目,吃喝玩乐都可以满足你。所以无论你是商家还是用户,都可以抓取下来上面你想要的数据,再做对比,分析,做出最有利的决策。 本次介绍八爪鱼简易采集模式下“美团数据抓取”的使用教程以及注意要点。 美团爬虫使用步骤 步骤一、下载八爪鱼软件并登陆 1、打开https://www.doczj.com/doc/1517199206.html,/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.doczj.com/doc/1517199206.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆
https://www.doczj.com/doc/1517199206.html, 步骤二、设置美团数据抓取规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.doczj.com/doc/1517199206.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集美团内容的,这里选择第四个--美团即可。
https://www.doczj.com/doc/1517199206.html, 3、找到美团-》商家信息-关键词搜索这条爬虫规则,点击即可使用。
https://www.doczj.com/doc/1517199206.html, 4、美团-商家信息-关键词搜索简易采集模式任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为美食商家列表信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组城市页面地址:输入你要在美团网上采集的城市url(可放入多个)搜索关键词:设置你要搜索的关键词,填入即可 示例数据:这个规则采集到的所有字段信息。
Python简单爬虫包Helium实现——下载百度图片 作者:头铁的小甘 怎样在网页上自动爬取数据,实行类人类行为操作?Python在爬虫这方面拥有代码简单、操作简单、意义明确。因此利用Python爬取数据做辅助手段成为各行各业的主流趋势。在这里你可能会想到urllib3库和requests库等,但对于一名小白来说,不需要详细了解这些内容,又能实行相应的操作,那么最简单就是首选Python的Helium库。该库操作最接近人行为,同样还有的就是selenium appium。但Helium库更为简单。 下面就来看看Helium库的简单包内容 主要内容如图所示 1.action:这个就是我们日常浏览网站的操作,比如说:click、write这两个是最 常用的操作,他们的意义分别是单击和在框内输入内容。(框内输入内容实现搜索内容填写,登录信息填写)。 2.predicates:这个是基本对象,就是上面操作的对象。Button、Image分别是
按钮和图像,也就是说网页是一些按钮、文本、图片等控件组成。 3. KEY :这个是定义的一些按键,模拟人类键盘操作,需要结合action 中的press 操作使用。 注意:目前这个包只支持谷歌和火狐浏览器,因此在使用前请确认计算机安装了谷歌或者火狐浏览器,而且版本尽量高,太低版本也不支持。 原理不多说,直接上例程 现在我们图片来源大多数来自于百度,那么我在这里就实现一个百度图片的批量下载。我们选择下载美女孙允珠的图片,这位美女气质非凡,穿着打扮迷人,可以借鉴打扮款式,而且很养眼。其他内容的图片流程一样,可以模拟编写代码。 主要流程如下 当你搜索百度图片时,上面就是你下载一张图片的行为。 那么计算机可以下载一张图片,怎样大规模下载?从而解放双手 相应的实际操作如下图
https://www.doczj.com/doc/1517199206.html, 淘宝店铺采集软件使用方法 淘宝上有很多店铺数据,比如销量,主营产品,宝贝数量,店铺评分等等,合理的利用好这些数据,有助于找到自己的竞争对手,了解自身与竞争对手的差别,那么应该如何去采集这些店铺数据呢。 在这里为大家推荐一款采集软件八爪鱼,只需简单配置规则,就能实现自定义采集任何网站数据,包括淘宝店铺的各种数据,下面介绍八爪鱼采集软件采集淘宝店铺的使用方法。 采集网站: https://https://www.doczj.com/doc/1517199206.html,/search?app=shopsearch&q=%E6%B1%9F%E5%B0%8F%E7%99% BD&imgfile=&commend=all&ssid=s5-e&search_type=shop&sourceId=tb.index&spm=a21bo.2017 .201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306 步骤1:创建淘宝店铺信息采集任务 1)进入主界面,选择“自定义采集”
https://www.doczj.com/doc/1517199206.html, 淘宝店铺信息采集步骤1 2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html, 淘宝店铺信息采集步骤2 步骤2:创建翻页循环 1)打开网页之后,找到页面最下方的“下一页”创建翻页循环,如下图
https://www.doczj.com/doc/1517199206.html, 淘宝店铺信息采集步骤3 点击下一页,在操作提示中选择循环点击下一页,以此生成循环翻页。注意:有时点击下一页并不会出现循环点击下一页,但若此时出现循环点击单个链接,则可以选则循环点击单个链接(或元素),其功能和循环点击下一页相同。
https://www.doczj.com/doc/1517199206.html, 网站图片抓取方法 你是否有过想将网站上看到的图片抓取保存到本地电脑?图片少量时,还可以手动一张张下载,但是图片量巨大时,这个时候手动下载既耗费时间精力,效率又极其低下。遇到这种情况怎么办呢?让八爪鱼来帮你把~只需要在八爪鱼软件中配置相应的流程,图片下载到电脑就是so easy~下面就为大家介绍最全的网站图片抓取方法。 1、图片采集 在八爪鱼中,采集图片有以下几大步 1、先采集网页图片的地址链接url 2、通过八爪鱼提供的专用图片批量下载工具将URL转化为图片 八爪鱼图片批量下载工具:https://https://www.doczj.com/doc/1517199206.html,/s/1c2n60NI 2、常见应用情景 1)非瀑布流网站纯图片采集 采集示例:豆瓣网图片采集教程https://www.doczj.com/doc/1517199206.html,/tutorial/tpcj-7 2)瀑布流网站纯图片采集 这类瀑布流网站的采集需要按下面的步骤对采集规则进行设置: ①点击采集规则打开网页步骤的高级选项; ②勾选页面加载完成后下滚动; ③填写滚动的次数及每次滚动的间隔;
https://www.doczj.com/doc/1517199206.html, ④滚动方式设置为:直接滚动到底部; 完成上面的规则设置后,再对页面中图片的url进行采集 采集示例:百度网图片采集教程https://www.doczj.com/doc/1517199206.html,/tutorial/bdpiccj 3)文章图文采集 需要将文章里的文字和图片都采集下来,一般有两种方法 方法1:判断条件,设置判断条件分别采集文字和图片 采集示例:https://www.doczj.com/doc/1517199206.html,/tutorial/txnewscj 方法2:先整体采集文字,再循环采集图片 采集示例:https://www.doczj.com/doc/1517199206.html,/tutorial/ucnewscj 3、教程目的 采集图片URL这个步骤,以上图片采集教程中都有详细说明,不再赘述。本文将重点讲解图片采集的采集技巧和注意事项。 4、采集图片URL操作步骤 以下演示一个采集图片URL的具体操作步骤,以百度图片url采集为例。不同的网站图片url会遇到不同的情况,请大家灵活处理。
https://www.doczj.com/doc/1517199206.html, 阿里巴巴数据采集器使用方法 阿里巴巴集团经过十几年的快速发展,在全球范围都有它的身影,众多的业务和关联公司形成了一个多样性的生态系统,旗下的业务有:淘宝,天猫,1688,速卖通,闲鱼,蚂蚁金服,阿里云等。如此多的关联业务,其中的数据也是很有参考价值的。学习阿里巴巴数据采集器的使用方法让获取数据的来源更广阔。本文介绍使用八爪鱼采集器采集阿里巴巴数据(以保温杯厂商为例)的方法。 采集网站: https://https://www.doczj.com/doc/1517199206.html,/selloffer/offer_search.htm?keywords=%B1%A3%CE%C2%B1%AD&n=y&spm= a260k.635.3262836.d102 本文仅以保温杯厂商搜索结果页URL作为采集示例,大家需要采集其他产品厂商可以更换链接进行采集。 采集的内容:阿里巴巴商品标题,阿里巴巴厂家名称,阿里巴巴厂家电话(其他阿里相关的数据如果要采集的话也是可以添加的) 使用功能点: ●创建循环翻页 ●商品URL采集提取
https://www.doczj.com/doc/1517199206.html, ●创建URL循环采集任务 ●修改Xpath 步骤1:创建阿里巴巴数据采集任务 1)进入主界面,选择“自定义采集”
https://www.doczj.com/doc/1517199206.html, 2)将要采集的阿里巴巴列表或搜索结果页URL复制粘贴到输入框中,点击“保存网址” 3)打开网页的时候页面需要向下滚动才会出现所有的数据,所以可以在这一步设置一个高级选项,在滚动页面这里设置页面加载完成向下滚动,滚动次数设置3秒,每次间隔3秒,滚动方式选择“直接滚动到底部”。
https://www.doczj.com/doc/1517199206.html, 4)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的商品url是这次演示采集的信息
https://www.doczj.com/doc/1517199206.html, 图片爬虫如何使用 目标网站上有许多我们喜欢的图片,想用到自己的工作或生活中去,但苦于工作量太大,图片一张张保存太过耗时耗力,因此总是力不从心。 本文向大家介绍一款网络数据采集工具【八爪鱼数据采集器】,以【ebay】为例,教大家如何使用八爪鱼采集软件采集ebay网站的方法。 可以将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。 采集网站: https://https://www.doczj.com/doc/1517199206.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换
https://www.doczj.com/doc/1517199206.html, 步骤1:创建采集任务 1)进入主界面,选择“自定义采集” ebay爬虫采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html, ebay爬虫采集步骤2 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.doczj.com/doc/1517199206.html, ebay爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接” ebay爬虫采集步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。
爬虫教案 姓名:柯--年级:三年级单元:时间:日期班级: 主题:爬虫 学习目标1知识目标:了解偏心轮及其作用。 2能力目标:探究作用力与反作用力。 3情感目标:会运用原理解释生活中的一些原理。 教学 重点 偏心轮的概念 教学 难点 领会偏心轮在实际实验中的应用 教学步骤:备注复习: 上节课我们学习了齿轮的作用是传动作用,改变物体运动速度,改变物体运动 方向和四驱带动和二驱带动。 一情境导入: 1、轮子是大家都熟悉的物品,简单说就是一根轴穿过一个圆盘的圆心。 但是你听说过偏心轮吗?这是一种结构简单却很有用的结构,今天我们就来了解一下。 2、偏心轮是指转轴不在圆心上的轮子,就是说转轴的轴线和轮子圆心的轴线是平行的,而不是在同一条线上这就是偏心轮。 偏心轮的作用主要把圆周运动改变成往复运动,在工业上主要用在机床(比如偏心式压力机、牛头刨床等),这些都是主动力为圆周运动,而实际需要的是往复直线运动的机械。在日常生活中,偏心轮也被广泛应用着。例如手机都拥有的振动提示功能是通过一个叫“振子”里面的主要构成是偏心轮。 3、作用力与反作用力 当物体A对B有力的作用时,物体B也一定同时对物体A有力的作用,这一对力互相为作用力和反作用力。两个物体之间的作用力与反作用力总是大小相等、方向相反且作用在一条直线上。人推墙壁时,这个力是作用力,墙壁也给你一个相同大小的力,就是反作用力。用手拍桌子能感觉到手痛,人站在地面上,先将两腿弯曲,再用力蹬地就能跳离地面等现象,均为作用力与反作用力 的原理。因为作用力与反作用力现象是牛顿发现并总结出来的,所以又被世人称为牛顿第三定律,牛顿(1643-1727),英国伟大的数学家、物理学家,天文复习上节课内容使学生在学习新知的同时不忘旧知,并且培养学生勤动脑多动手的好习惯。
https://www.doczj.com/doc/1517199206.html, 拼多多采集软件使用方法 在如今相对稳定的综合类电商网站中,拼多多可以说是一批黑马,越来越多的电商从业者选择在拼多多上开店,而在如今数据为王的时代,掌握拼多多数据采集是一项非常重要的技能,比如可以通过采集拼多多上的一些商品价格、销量、图片数据,可以对选品,定价起到决策作用。那么应该如何去采集呢,下面为大家详细介绍拼多多采集软件的使用方法。 步骤1:创建拼多多商品采集任务 1)进入主界面,选择“自定义采集”
https://www.doczj.com/doc/1517199206.html, 2)将要采集的网站URL复制粘贴到输入框中,点击“保存网址” 步骤2:提取拼多多数据字段 1)鼠标选中要采集的数据,比如我选的是商品标题、商品图片、商品价格,商品原价、商品销量,商品在右面的提示框中选择“选中全部” 拼多多商品采集-提取数据字段 2)随后点击“采集数据”,接下来点击“保存并开始采集”
https://www.doczj.com/doc/1517199206.html, 3)打开右上角流程按钮,观察发现图片地址是默认扫码的按钮,并不是我们想要的。
https://www.doczj.com/doc/1517199206.html, 3)选中拼多多商品图片这个字段,依次点击自定义数据字段->自定义定位元素方式,按下图进行“自定义定位元素设置图”设置。 元素匹配的xpath: //body/section[1]/div[4]/div[1]/ul[1]/li[1]/div[1]/DIV[1]/IMG[1] 相对xpath:/DIV[1]/IMG[1] 修改好后点击确定 自定义数据字段
https://www.doczj.com/doc/1517199206.html, 自定义定位元素设置图 步骤5:拼多多商品数据采集及导出 1)修改采集字段名称,点击“保存并开始采集”
https://www.doczj.com/doc/1517199206.html, 网络爬虫软件哪个好用 现在市面上的网络爬虫软件有很多,这些软件中哪个采集软件比较好呢?下面笔者简单分析一下网络爬虫软件哪个好用以及原因供大家选择。 采集软件有哪些? 1、八爪鱼 一款可视化免编程的网页采集软件,可以从不同网站中快速提取规范化数据,帮助用户实现数据的自动化采集、编辑以及规范化,降低工作成本。云采集是它的一大特色,相比其他采集软件,云采集能够做到更加精准、高效和大规模。 可视化操作,无需编写代码,制作规则采集,适用于零编程基础的用户 即将发布的7.0版本智能化,内置智能算法和既定采集规则,用户设置相应参数就能实现网站、APP的自动采集。 云采集是其主要功能,支持关机采集,并实现自动定时采集 支持多IP动态分配与验证码破解,避免IP封锁
https://www.doczj.com/doc/1517199206.html, 采集数据表格化,支持多种导出方式和导入网站 Conclusion:八爪鱼是一款适合小白用户尝试的采集软件,云功能强大,当然爬虫老手也能开拓它的高级功能。 2、火车头 作为采集界的老前辈,火车头是一款互联网数据抓取、处理、分析,挖掘软件,可以抓取网页上散乱分布的数据信息,并通过一系列的分析处理,准确挖掘出所需数据。它的用户定位主要是拥有一定代码基础的人群,适合编程老手。 采集功能完善,不限网页与内容,任意文件格式都可下载 具有智能多识别系统以及可选的验证方式保护安全 支持PHP和C#插件扩展,方便修改处理数据 具有同义,近义词替换、参数替换,伪原创必备技能 采集难度大,对没有编程基础的用户来说存在困难 Conclusion:火车头适用于编程能手,规则编写比较复杂,软件的定位比较专业而且精准化。 3、集搜客
https://www.doczj.com/doc/1517199206.html, 如何利用八爪鱼爬虫爬取图片 很多电商、运营等行业的朋友,工作中需要用到大量的图片,手动复制太麻烦,现在市面上有一款自动化爬虫工具:八爪鱼采集器,可以帮助大家用最简单的方式自动爬取大量图片,上万张图片几个小时即可轻松搞定。 八爪鱼先将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地电脑中。 下面以ebay网站为例,给大家介绍八爪鱼爬虫爬取图片的方法。 采集网站: https://https://www.doczj.com/doc/1517199206.html,/ 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换 步骤1:创建采集任务 1)进入主界面,选择“自定义采集”
https://www.doczj.com/doc/1517199206.html, 八爪鱼爬取图片步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” 八爪鱼爬取图片步骤2
https://www.doczj.com/doc/1517199206.html, 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容 八爪鱼爬取图片步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接”
https://www.doczj.com/doc/1517199206.html, 八爪鱼爬取图片步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。 步骤三:图片链接地址采集 1)选中页面内第一个图片,系统会自动识别同类图片。在操作提示框中,选择“选中全部”
https://www.doczj.com/doc/1517199206.html, ebay爬虫采集方法 本文介绍使用八爪鱼爬虫软件抓取ebay网站图片的方法:可以将网页中图片的URL采集下来,再通过八爪鱼专用的图片批量下载工具,将采集到的图片URL 中的图片,下载并保存到本地电脑中。 采集网站: https://https://www.doczj.com/doc/1517199206.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 本文仅以nike关键词搜索结果页举例说明,大家在采集ebay图片的时候,如果有其他需求,可以更换关键词搜索结果页进行采集。 采集内容:ebay商品图片url,ebay商品标题。 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换
https://www.doczj.com/doc/1517199206.html, 步骤1:创建采集任务 1)进入主界面,选择“自定义采集” ebay 爬虫采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html, ebay爬虫采集步骤2 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容
https://www.doczj.com/doc/1517199206.html, ebay 爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接” ebay 爬虫采集步骤4 由于该网页每次翻页 网址随之变化,所以不是ajax 页面,不需要设置ajax 。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax 加载。
https://www.doczj.com/doc/1517199206.html, 很多朋友都有一个疑问,就是网络爬虫到底可以爬网页上的什么数据?总的来说就是各行各业,各种网站的数据都可以通过爬虫给爬取出来,但具体怎么去爬取就需要用户自己去操作了,懂代码的用户可以自己写爬虫脚本,爬虫代码,不懂的也可以借助爬虫工具来实现。今天教大家怎么去爬虫网站上的房源数据,使用的工具是功能强大的八爪鱼采集器。 本文介绍使用八爪鱼采集58同城个人房源信息的方法。 采集网站: https://www.doczj.com/doc/1517199206.html,/chuzu/0/?PGTID=0d3090a7-0000-4f3b-684f-42220743f 441&ClickID=1 使用功能点: 分页列表及详细信息提取 https://www.doczj.com/doc/1517199206.html,/tutorial/fylbxq7.aspx?t=1 步骤1:创建采集任务
https://www.doczj.com/doc/1517199206.html, 2)将房源信息页的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html, (个人房源信息采集步骤2) 步骤2:创建翻页循环 1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。将页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
https://www.doczj.com/doc/1517199206.html, (个人房源信息采集步骤3) 步骤3:创建列表循环 1)移动鼠标,选中页面里的第一个房源信息的链接。选中后,系统会自动识别页面里的其他相似链接。在右侧操作提示框中,选择“选中全部”
https://www.doczj.com/doc/1517199206.html, (个人房源信息采集步骤4) 2)选择“循环点击每个链接”,以创建一个列表循环 (个人房源信息采集步骤5)
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 1】网络爬虫高度可配置性。
2】网络爬虫可以解析抓到的网页里的链接 3】网络爬虫有简单的存储配置 4】网络爬虫拥有智能的根据网页更新分析功能 5】网络爬虫的效率相当的高 简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。你可以简单地想象:每个爬虫都是你的“分身”。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样。你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。抢票软件,就相当于撒出去无数个分身,每一个分身都帮助你不断刷新12306 网站的火车余票。一旦发现有票,就马上拍下来,然后对你喊:土豪快来付款。大致是这样,如果想要了解爬虫的具体使用场景可以接着往下看。 像谷歌这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供大家查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是,像抢票软件这样的爬虫,对着12306 每秒钟恨不得撸几万次。铁总并不觉得很开心。这种就被定义为“恶意爬虫”。(注意,抢票的你觉得开心没用,被扫描的网站觉得不开心,它就是恶意的。) 所谓爬虫,如果从技术原理上讲,它就是一个高效的下载工具,能够批量将网页下载到本地,留作备份。如果结合一些其他工具和算法,就能够实现,收集同一类型的网页,重复执行同一动作等行为。简单讲,就是通过技术和算法模拟一个人在网络上的行为,像人一样点网页,像人一样下订单,只不过,相比起真人,他的效率高的异常。它的工作状态有些像蚁群,每个蚂蚁的工作任务都非常简单,但是,当一大群蚂蚁重复相同的工作的时候,就能产生超乎寻常的效果。比如说,如果你需要把全网关于某个关键词的网站全部收集汇总到一起(比如:三节课),这时,就是爬虫挨个查找所有关于三节课的信息,呈现到你的面前。
https://www.doczj.com/doc/1517199206.html, 网络文字抓取工具使用方法 网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务
https://www.doczj.com/doc/1517199206.html, 1)进入主界面选择,选择“自定义模式” 今日头条网络文字抓取工具使用步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html, 今日头条网络文字抓取工具使用步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
https://www.doczj.com/doc/1517199206.html, 今日头条网络文字抓取工具使用步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.doczj.com/doc/1517199206.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条网络文字抓取工具使用步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
https://www.doczj.com/doc/1517199206.html, 今日头条网络文字抓取工具使用步骤5 步骤3:采集新闻内容 创建数据提取列表 1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色
https://www.doczj.com/doc/1517199206.html, 美团数据抓取详细教程 美团数据抓取下来有很多作用,比如你可以分析每一家商铺的价格,销量,位置,人均消费,好评率等各种主要信息,帮助你做出更好的判断,分析当下主流消费用户的消费情况。 本次介绍八爪鱼简易采集模式下“美团数据抓取”的使用教程以及注意要点。 美团数据抓取使用步骤 步骤一、下载八爪鱼软件并登陆 1、打开https://www.doczj.com/doc/1517199206.html,/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.doczj.com/doc/1517199206.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆
https://www.doczj.com/doc/1517199206.html, 步骤二、设置美团数据抓取规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.doczj.com/doc/1517199206.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集美团内容的,这里选择第四个--美团即可。
https://www.doczj.com/doc/1517199206.html, 3、找到美团-》商家信息-关键词搜索这条爬虫规则,点击即可使用。
https://www.doczj.com/doc/1517199206.html, 4、美团-商家信息-关键词搜索简易采集模式任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为美食商家列表信息采集 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组城市页面地址:输入你要在美团网上采集的城市url(可放入多个)搜索关键词:设置你要搜索的关键词,填入即可 示例数据:这个规则采集到的所有字段信息。
https://www.doczj.com/doc/1517199206.html, 如何使用爬虫软件爬取数据 产品和运营在日常工作中,常常需要参考各种数据,来为决策做支持。 但实际情况是,对于日常工作中的各种小决策,内部提供的数据有时还不足给予充分支持,外部的数据大部分又往往都是机构出具的行业状况,并不能提供什么有效帮助。 于是产品和运营们往往要借助爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往需要写出一段代码,借助python去抓取出相应的内容。 说到学写代码……额,我选择放弃。 那么问题来了,有没有什么更方便的方法呢? 今天就为大家介绍1个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出98%网站的数据。 最重点是,这个软件的基础功能都是可以免费使用的 所以本次介绍八爪鱼简易采集模式下“知乎爬虫采集”的使用教程以及注意要点。步骤一、下载八爪鱼软件并登陆 1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
https://www.doczj.com/doc/1517199206.html, 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆
https://www.doczj.com/doc/1517199206.html, 步骤二、设置知乎爬虫规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.doczj.com/doc/1517199206.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集知乎关键字内容的,这里选择搜狗即可。
https://www.doczj.com/doc/1517199206.html, 3、找到知乎关键字搜索这条爬虫规则,点击即可使用。
https://www.doczj.com/doc/1517199206.html, 4、知乎关键字搜索简易采集模式任务界面介绍 查看详情:点开可以看到示例网址 任务名:自定义任务名,默认为知乎关键字搜索 任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组 搜索关键字填写注意事项:提供要采集的关键字。多关键字搜索输入多个关键字即可(回车键分隔开,即一个关键字为一行)。 示例数据:这个规则采集的所有字段信息。
https://www.doczj.com/doc/1517199206.html, Python3.x爬虫教程:爬网页、爬图片、自动登录_光环大数据培训 一、HTTP协议 HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF (Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。 HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。 HTTP的请求响应模型 HTTP协议永远都是客户端发起请求,服务器回送响应。见下图: 这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端。
https://www.doczj.com/doc/1517199206.html, 应关系。 工作流程 一次HTTP操作称为一个事务,其工作过程可分为四步: 1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。 2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。 3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。 4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。 如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了 请求报头
https://www.doczj.com/doc/1517199206.html, 万能文章采集器使用教程 作为一个小编,除了要写得一手好文章外,收集各种文章素材这也是必不可少。在茫茫网络浩如烟海的文章里,一篇篇查找手动复制黏贴过来,这显然是不现实的。如何快速通用的搞定各个平台的数据,找到一个万能的文章采集,这显然是非常有必要。 八爪鱼采集作为一款通用的网页采集器,掌握它就相当于掌握了一款万能文章采集器。下面就以某热点新闻采集为例进行讲解。 采集网站: 使用功能点: ●Ajax滚动加载设置 ●列表内容提取 步骤1:创建采集任务
https://www.doczj.com/doc/1517199206.html, 1)进入主界面选择,选择“自定义模式” 今日头条热点新闻采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”
https://www.doczj.com/doc/1517199206.html, 今日头条热点新闻采集步骤2 3)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
https://www.doczj.com/doc/1517199206.html, 今日头条热点新闻采集步骤3 步骤2:设置ajax页面加载时间 ●设置打开网页步骤的ajax滚动加载时间 ●找到翻页按钮,设置翻页循环 ●设置翻页步骤ajax下拉加载时间
https://www.doczj.com/doc/1517199206.html, 1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定 今日头条热点新闻采集步骤4 注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
基于python的网络爬虫设计【摘要】近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的利益,而网络爬虫是其中最为常用的 一种从网上爬取数据的手段。 网络爬虫,即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页) 开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一 直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛 就可以用这个原理把互联网上所有的网页都抓取下来。 那么,既然网络爬虫有着如此先进快捷的特点,我们该如何实现它呢?在众多面向对象的语言中,首选python,因为python是一种“解释型的、面向对象的、带有动态语义的”高级程序,可以使人在编程时保 持自己的风格,并且编写的程序清晰易懂,有着很广阔的应用前景。 关键词python 爬虫数据 1 前言 1.1本编程设计的目的和意义 随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(例如传统的通用搜索引擎AltaVista,Yahoo!和Google等)作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。但是,这些通用性搜索引擎也存在着一定的局限性,如: (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。 (2) 通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。 (3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频/视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。 (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。与通用爬虫(generalpurpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。 1.2编程设计目及思路 1.2.1编程设计目的 学习了解并熟练掌握python的语法规则和基本使用,对网络爬虫的基础知识进行了一定程度的理解,提高对网页源代码的认知水平,学习用正则表达式来完成匹配查找的工作,了解数据库的用途,学习mongodb数据库的安装和使用,及配合python的工作。 1.2.2设计思路
https://www.doczj.com/doc/1517199206.html, 网站数据爬取方法 网站数据主要是指网页上的文字,图像,声音,视频这几类,在告诉的信息化时代,如何去爬取这些网站数据显得至关重要。对于程序员或开发人员来说,拥有编程能力使得他们能轻松构建一个网页数据抓取程序,但是对于大多数没有任何编程知识的用户来说,一些好用的网络爬虫软件则显得非常的重要了。以下是一些使用八爪鱼采集器抓取网页数据的几种解决方案: 1、从动态网页中提取内容。 网页可以是静态的也可以是动态的。通常情况下,您想要提取的网页内容会随着访问网站的时间而改变。通常,这个网站是一个动态网站,它使用AJAX技术或其他技术来使网页内容能够及时更新。AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
https://www.doczj.com/doc/1517199206.html, 表现特征为点击网页中某个选项时,大部分网站的网址不会改变;网页不是完全加载,只是局部进行了数据加载,有所变化。这个时候你可以在八爪鱼的元素“高级选项”的“Ajax加载”中可以设置,就能抓取Ajax加载的网页数据了。 八爪鱼中的AJAX加载设置
https://www.doczj.com/doc/1517199206.html, 2.从网页中抓取隐藏的内容。 你有没有想过从网站上获取特定的数据,但是当你触发链接或鼠标悬停在某处时,内容会出现?例如,下图中的网站需要鼠标移动到选择彩票上才能显示出分类,这对这种可以设置“鼠标移动到该链接上”的功能,就能抓取网页中隐藏的内容了。 鼠标移动到该链接上的内容采集方法
https://www.doczj.com/doc/1517199206.html, 在滚动到网页底部之后,有些网站只会出现一部分你要提取的数据。例如今日头条首页,您需要不停地滚动到网页的底部以此加载更多文章内容,无限滚动的网站通常会使用AJAX或JavaScript来从网站请求额外的内容。在这种情况下,您可以设置AJAX超时设置并选择滚动方法和滚动时间以从网页中提取内容。
https://www.doczj.com/doc/1517199206.html, 如何下载网页上的图片 图片是网页内容的重要组成部分,有时候我们看到一个网页中有很多漂亮的图片,想要下载下来,只需要右键另存为即可下载下来,但是如果要下载很多的话,这样就很浪费时间了。下面以ebay商品图片为例,为大家详细介绍如何下载网页上的图片。 采集网站: https://https://www.doczj.com/doc/1517199206.html,/sch/i.html?_from=R40&_trksid=p2050601.m570.l1313.TR0.TRC0.H0.Xnik e.TRS0&_nkw=nike&_sacat=0 使用功能点: ●分页列表信息采集 ●执行前等待 ●图片URL转换 步骤1:创建采集任务 1)进入主界面,选择“自定义采集”
https://www.doczj.com/doc/1517199206.html, ebay爬虫采集步骤1 2)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址” ebay爬虫采集步骤2
https://www.doczj.com/doc/1517199206.html, 3)系统自动打开网页,红色方框中的图片是这次演示要采集的内容 ebay爬虫采集步骤3 步骤二:创建翻页循环 1)点击右上角的“流程”,即可以看到配置流程图。将页面下拉到底部,找到下一页的大于号标志按钮,鼠标点击,在右侧操作提示框中,选择“循环点击单个链接”
https://www.doczj.com/doc/1517199206.html, ebay爬虫采集步骤4 由于该网页每次翻页网址随之变化,所以不是ajax页面,不需要设置ajax。如果有网站每次翻页,网址不变,则需要在高级选项设置ajax加载。 步骤三:图片链接地址采集 1)选中页面内第一个图片,系统会自动识别同类图片。在操作提示框中,选择“选中全部”
https://www.doczj.com/doc/1517199206.html, 免费爬虫软件使用教程 增长黑客是最近很热门的个岗位,不管是大厂如BAT,还是初创企业团队,每个人都在讲增长或组建增长团队。想要增长,最关键依赖的核心是:数据。 不仅如此,互联网的产品、运营,在日常工作中,也常常需要参考各种数据,来为决策做支持。 但实际情况是,对于日常工作中的各种小决策,内部提供的数据有时还不足给予充分支持,外部的数据大部分又往往都是机构出具的行业状况,并不能提供什么有效帮助。 于是产品和运营们往往要借助爬虫来抓取自己想要的数据。比如想要获取某个电商网站的评论数据,往往需要写出一段代码,借助python去抓取出相应的内容。 说到学写代码……额,我选择放弃。 那么问题来了,有没有什么更方便的方法呢? 今天就为大家介绍1个能适应大多数场景的数据采集工具,即使不懂爬虫代码,你也能轻松爬出98%网站的数据。 最重点是,这个软件的基础功能都是可以免费使用的 所以本次介绍八爪鱼简易采集模式下“知乎爬虫采集”的使用教程以及注意要点。步骤一、下载八爪鱼软件并登陆
https://www.doczj.com/doc/1517199206.html, 1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。 2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆
https://www.doczj.com/doc/1517199206.html, 步骤二、设置知乎爬虫规则任务 1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
https://www.doczj.com/doc/1517199206.html, 2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集知乎关键字内容的,这里选择搜狗即可。
第六章:鱼虫的运动规律 ?本章节项目提要: 本章节主要是介绍鱼的基本结构、特点、运动及表现方法爬虫类的运动及表现方法昆虫类的结构、特点运动及表现方法。通过多个经典实例和典型范画,详细的分解动作的全过程,鱼虫的动作设计。掌握曲线的特点。 ?鱼虫运动规律项目的主要技能: 1.理解各种鱼类的基本运动及表现方法,鱼的基本结构、特点、运动及表 现方法能设计鱼虫类等运动轨迹线。能熟练掌握鱼虫在各种运动过程中不同风格的造型与时间、节奏的关系及绘制方法。 2.设计鱼虫类运动轨迹线,能掌握鱼虫动作规律要领及画法。 3. 掌握金鱼游动时的运动与曲线运动规律的关联。 4. 理解金鱼游动时运动规律的要点及画法。 ?建议学时:16学时 1
第一节:大鱼的运动规律 鱼是生活在水中的脊椎动物,是用鳍来行动,靠鳃来呼吸。基本形态大都呈流线形,它的运动是典型的曲线运动。鱼的基本结构与特点如图6-01,主要分为三部分头部、身部和尾部,身上有5种鳍,背鳍、胸鳍、腹鳍、臀鳍、尾鳍。 图6-01 鱼的种类繁多,为了便于学习和掌握鱼类的运动规律,可把鱼分为大鱼、小鱼和长尾鱼。 大鱼:鱼身较长较大,一般呈纺锤形。如青鱼、鲤鱼、黄鱼、鲅鱼等;鲨鱼等巨型鱼类和鲸、海豚等也可归到此类。 技能提示一: 很多我们常见的大鱼都属于“左右摆尾”型鱼类,如草鱼、鲤鱼、鲫鱼等等,游动时鳍的摆动起到相当重要的辅助作用。尾鳍随尾部肌肉的伸缩交替而形成左右上下来回摆动,起到推动身体前进和掌握游动方向的作用。 图6-02 图6-03 技能提示二: 大鱼游动时路线呈曲线运动状态,身体摆动的曲线弧度较大,缓慢而稳定。大鱼可以靠鱼鳍缓划鱼尾轻摆停在水中,也会因受惊突然用力摆尾窜逃。 图6-04 图6-05 2