
数据校验方法之巧用公式审核来帮忙
在用Excel录入完大量数据后,不可避免地会产生许多错误。通常多数朋友都是一手拿着原始数据,一手指着计算机屏幕,手工进行数据校验,这效率不高还累人。为此,笔者特向大家介绍两种轻松且高效的数据校验方法。
公式审核法
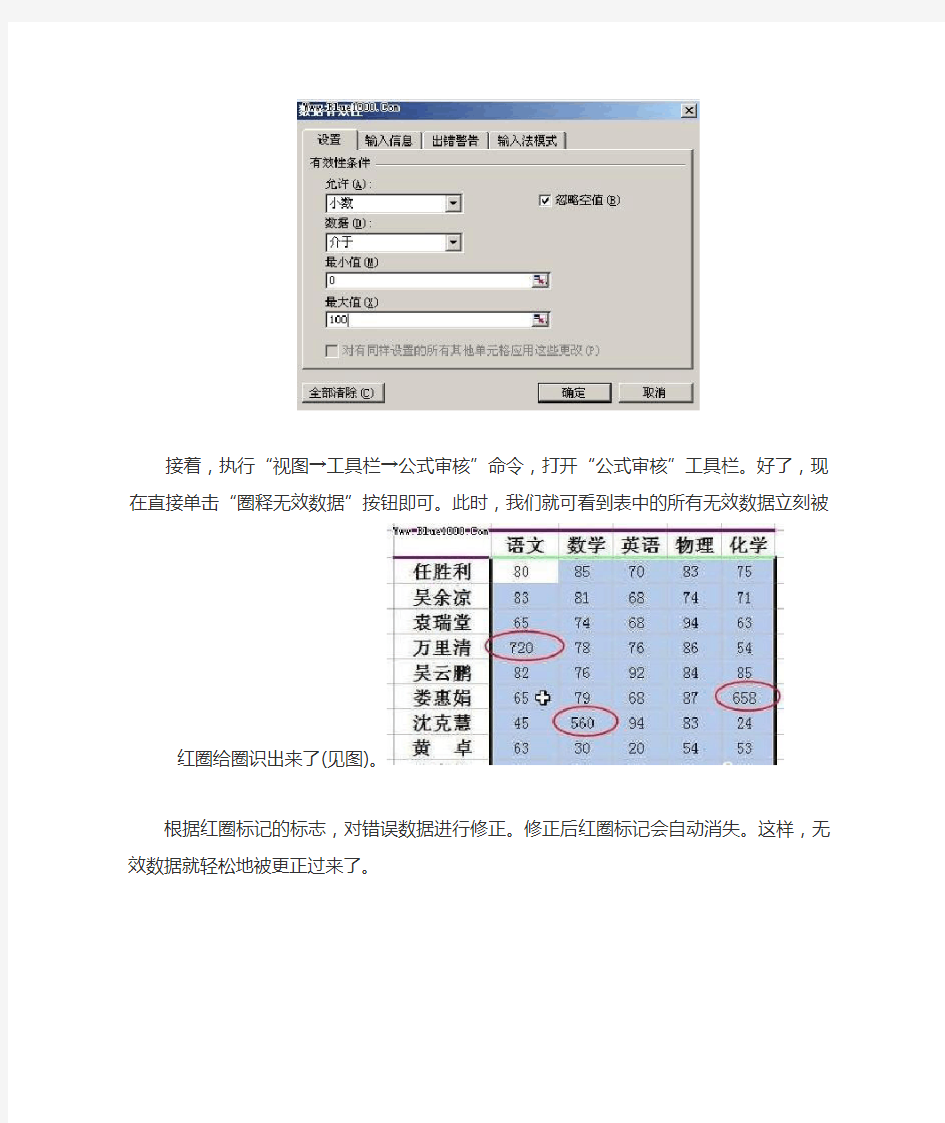
有时,我们录入的数据是要符合一定条件的,例如,对于学生成绩表而言,其中的数据通常是0~100之间的某个数值。但是,在录入时由于错误按键或重复按键等原因,我们可能会录入超出此范围的数据。那么,对于这样的无效数据,我们如何快速将它们“揪”出并予以更正呢?让我们用公式审核法来解决这类问题吧。下面笔者以一张学生成绩表为例进行介绍。
首先,打开一张学生成绩表。然后,选中数据区域(注意:这里的数据区域不包括标题行或列),单击“数据→有效性”命令,进入“数据有效性”对话框。在“设置”选项卡中,将“允许”项设为“小数”,“数据”项设为“介于”,并在“最小值”和“最大值”中分别输入“0”和“100”(见图),最后单击“确定”退出。
接着,执行“视图→工具栏→公式审核”命令,打开“公式审核”工具栏。好了,现在直接单击“圈释无效数据”按钮即可。此时,我们就可看到表中的所有无效数据立刻被红圈给圈识出来了
(见图)。
根据红圈标记的标志,对错误数据进行修正。修正后红圈标记会自动消失。这样,无效数据就轻松地被更正过来了。
IP数据包的校验和算法 IP数据包的头信息格式: +-------------------------------------------------+ | 版本 (4位) | +-------------------------------------------------+ | 首部长度(4位) | +-------------------------------------------------+ | 服务类型(TOS)8位 | +-------------------------------------------------+ | 数据包总长度(16位) | +-------------------------------------------------+ | 标识ID号(16位) | +-------------------------------------------------+ | 标志位(3位) | +-------------------------------------------------+ | 片偏移(13位) | +-------------------------------------------------+ | 生存时间(TTL)(8位) | +-------------------------------------------------+ | 协议类型 (8位) | +-------------------------------------------------+ | 首部校验和(16位) | +-------------------------------------------------+ | 源IP地址(32位) | +-------------------------------------------------+ | 目的IP地址 (32位) | +-------------------------------------------------+ * IP选项(若有) (32位) * +-------------------------------------------------+ * 数据 * +-------------------------------------------------+ 这里要说的是首部校验和字段。 在发送数据时,为了计算数IP据报的校验和。应该按如下步骤: (1)把IP数据报的校验和字段置为0。 (2)把首部看成以16位为单位的数字组成,依次进行二进制反码求和。 (3)把得到的结果存入校验和字段中。 在接收数据时,计算数据报的校验和相对简单,按如下步骤: (1)把首部看成以16位为单位的数字组成,依次进行二进制反码求和,包括校验和字段。(2)检查计算出的校验和的结果是否等于零。 (3)如果等于零,说明被整除,校验是和正确。否则,校验和就是错误的,协议栈要抛弃这个数据包。
本技术提出了一种数据验证方法,其包括服务器,服务器是用以接收第一纪录数据,服务器会根据接收时间以及第一纪录数据的种类对第一纪录数据进行编号并产生第一编号数据,服务器对第一编号数据进行加密并产生第一加密数据后服务器公告第一加密数据,当对第一纪录数据进行验证时,服务器对第一编号数据再次进行加密并产生第二加密数据,服务器判断第一加密数据以及第二加密数据是否相同,当判断结果为否,第一编号数据已被修改。 技术要求 1.一种数据验证方法,其包括服务器,所述服务器是用以接收并储存多个纪录数据,所述数据验证方法包括以下步骤: 所述服务器接收第一纪录数据; 所述服务器根据接收时间以及所述第一纪录数据的种类对所述第一纪录数据进行编号并 产生第一编号数据; 所述服务器对所述第一编号数据进行加密并产生第一加密数据; 所述服务器公告所述第一加密数据; 所述服务器对所述第一编号数据进行加密并产生第二加密数据;以及 所述服务器判断所述第一加密数据以及所述第二加密数据是否相同,当判断结果为否, 所述第一编号数据已被修改。
2.根据权利要求1所述的数据验证方法,其中所述服务器对所述第一编号数据进行加密并产生第一加密数据的步骤更包括: 所述服务器使所述第一加密数据与至少一加密数据同时加密并产生第一加密数据群组。 3.根据权利要求2所述的数据验证方法,其中所述服务器对所述第一编号数据进行加密并产生第二加密数据的步骤更包括: 所述服务器使所述第二加密数据与所述至少一加密数据同时加密并产生第二加密数据群组。 4.根据权利要求3所述的数据验证方法,其中所述服务器公告所述第一加密数据的步骤更包括: 所述服务器公告所述第一加密数据群组。 5.根据权利要求4所述的数据验证方法,其中所述服务器判断所述第一加密数据以及所述第二加密数据是否相同,当判断为否,所述第一编号数据已被修改的步骤更包括: 所述服务器判断所述第一加密数据群组以及所述第二加密数据群组是否相同,当所述判断结果为否,所述第一编号数据已被修改。 6.根据权利要求1所述的数据验证方法,其中,所述纪录数据为网页浏览纪录、档案编辑纪录、档案新增纪录或档案删除纪录。 7.根据权利要求1所述的数据验证方法,其中,所述服务器更包括储存单元,用以储存所述第一纪录数据、所述第一编号数据、所述第一加密数据、所述第二加密数据、所述第一加密数据群组以及所述第二加密数据群组。 8.根据权利要求2所述的数据验证方法,其中,所述服务器更包括网络单元,所述服务器透过所述网络单元以电子邮件、电子公布栏或网站等公开公告的方式公告所述第一加密数据或所述第一加密数据群组。 9.根据权利要求1所述的数据验证方法,其更包括:
各种校验码校验算法分析二进制数据经过传送、存取等环节会发生误码1变成0或0变成1这就有如何发现及纠正误码的问题。所有解决此类问题的方法就是在原始数据数码位基础上增加几位校验冗余位。 一、码距一个编码系统中任意两个合法编码码字之间不同的二进数位bit数叫这两个码字的码距而整个编码系统中任意两个码字的的最小距离就是该编码系统的码距。如图1 所示的一个编码系统用三个bit来表示八个不同信息中。在这个系统中两个码字之间不同的bit数从1到3不等但最小值为1故这个系统的码距为1。如果任何码字中一位或多位被颠倒了结果这个码字就不能与其它有效信息区分开。例如如果传送信息001而被误收为011因011仍是表中的合法码字接收机仍将认为011是正确的信息。然而如果用四个二进数字来编8个码字那么在码字间的最小距离可以增加到2如图2的表中所示。信息序号二进码字 a2 a1 a0 0 0 0 0 1 0 0 1 2 0 1 0 3 0 1 1 4 1 0 0 5 1 0 1 6 1 1 0 7 1 1 1 图 1 信息序号二进码字 a3 a2 a1 a0 0 0 0 0 0 1 1 0 0 1 2 1 0 1 0 3 0 0 1 1 4 1 1 0 0 5 0 1 0 1 6 0 1 1 0 7 1 1 1 1 图 2 注意图8-2的8个码字相互间最少有两bit 的差异。因此如果任何信息的一个数位被颠倒就成为一个不用的码字接收机能检查出来。例如信息是1001误收为1011接收机知道发生了一个差错因为1011不是一个码字表中没
有。然而差错不能被纠正。假定只有一个数位是错的正确码字可以是100111110011或1010。接收者不能确定原来到底是这4个码字中的那一个。也可看到在这个系统中偶数个2或4差错也无法发现。为了使一个系统能检查和纠正一个差错码间最小距离必须至少是“3”。最小距离为3时或能纠正一个错或能检二个错但不能同时纠一个错和检二个错。编码信息纠错和检错能力的进一步提高需要进一步增加码 字间的最小距离。图8-3的表概括了最小距离为1至7的码的纠错和检错能力。码距码能力检错纠错 1 2 3 4 5 6 7 0 0 1 0 2 或 1 2 加 1 2 加 2 3 加 2 3 加 3 图3 码距越大纠错能力越强但数据冗余也越大即编码效率低了。所以选择码距要取决于特定系统的参数。数字系统的设计者必须考虑信息发生差错的概率和该系统能容许的最小差错 率等因素。要有专门的研究来解决这些问题。 二、奇偶校验奇偶校验码是一种增加二进制传输系统最小距离的简单和广泛采用的方法。例如单个的奇偶校验将使码的最小距离由一增加到二。一个二进制码字如果它的码元有奇数个1就称为具有奇性。例如码字“10110101”有五个1因此这个码字具有奇性。同样偶性码字具有偶数个1。注意奇性检测等效于所有码元的模二加并能够由所有码元的 异或运算来确定。对于一个n位字奇性由下式给出奇性a0⊕a1⊕a2⊕…⊕an 奇偶校验可描述为给每一个码字加一个
输入数据校验与查错的两种方法 在数据库管理系统输入模块的开发中,如何提高输入数据的正确性是开发者应考虑的一个重要问题。为了提高输入数据的正确性,其基本的功能要求是:①输入操作简单、轻松;②输入效率高,即具有重复内容自动复制和简易代码输入替代功能;③输入格式美观大方;④具有醒目的提示等。然而,仅有这些功能要求是不够的,它们不能从根本上提高输入数据的正确性。因为,大量的原始数据的输入是件繁琐而又单调的工作,难免出错。所以,必须要有更严格、更有效的科学方法和手段来提高输入数据的正确性。在实际工作中,笔者探索了输入数据校验与查错的两种方法,供数据库管理系统的开发者参考。 1.边输入边校验法 在这种方法中,假若输入数据有错,则要求数据录入者立即更正错误。这种方法常常用于所输入的数据具有某种规律和特征,若数据录入者键入的数据违背了这个规律和特征,即立即给出输入出错警告,并强制性要求数据录入者对当前输入的数据给予修正。例如,在财务管理系统中,一张“记帐凭证”一般有借方金额和贷方金额两栏数字。会计制度要求同一张凭证中借方金额合计和贷方金额合计必须相等。根据这一特征,所以在开发“记帐凭证”数据输入程序时,程序应能自动判断,在一张“记帐凭证”的数据输入结束后,借方金额合计与贷方金额合计是否相等,若不相等,应强制要求数据输入者立即重新输入。又例如,在每年的高考中,考生的成绩数据有一部分要通过人工评分后,然后由专人输入计算机。对于考生成绩数据,它所具有的特征是:每题的最高分和最低分(零分)是确定的,并且均为数字字符。根据这个特征,在开发的考生成绩数据管理系统的输入模块中,应具有如下功能,即在每题数据输入结束后,自动判断输入的分数值是否符合上述规律,若不符合,则应立即发出警告,并强制要求录入者重新输入。 2.双工输入比较法 所谓双工输入比较法,就是将同一批数据由两个输入人员在不同的时间和不同的终端上分别录入,并且形成两个临时数据库文件,然后由第三个人在程序的作用下对两个库文件中的数据进行逐项比较并进行确认或修改。在这种方法中,尽管同一批数据被录入了两次从而造成了数据冗余和影响了录入进度,但对于被录入的数据不存在明显的规律和上述第一种方法不能查出输入出错的场合,以及对输入数据的正确性要求很高的场合,是一种不可缺少的和行之有效的方法,因为,两个数据录入者都同时在某处出错的机会极少,故这种方法可以极大地减少出错率。根据概率论原理,如果两数据录入者各自的出错率为百分之一,则双工输入法的出错率仅为万分之一。双工输入比较法在FoxPro环境下的基本算法是: ①将同一批数据由两个录入者在不同时间和不同的终端上录入,并存入两个不同名的库文件中。 ②输入“①”中产生的两个库文件名。
校验和算法 IP/ICMP/IGMP/TCP/UDP等协议的校验和算法都是相同的。今儿以IP 数据包为例来讲解一下校验和算法。 在IP数据包发送端,首先将校验和字段置为0,然后将IP数据包头按16比特分成多个单元,如果包头长度不是16比特的倍数,则用0比特填充到16 比特的倍数,其次对各个单元采用反码加法运算(即高位溢出位会加到低位,通常的补码运算是直接丢掉溢出的高位),将得到的和的反码填入校验和字段,最后发送数据。 在IP数据包接收端, 首先将IP包头按16比特分成多个单元,如果包头长度不是16比特的倍数,则用0比特填充到16比特的倍数,其次对各个单元采用反码加法运算,检查得到的和是否符合全是1(有的实现可能对得到的和取反码,然后判断最终的值是否为0),如果符合全是1(取反码后是0),则进行数据包的下一步处理,如果不符合,则丢弃该数据包。 在这里大家要注意,反码和是采用高位溢出加到低位上。 接下来以一张从网上找的一张IP数据包头图片来加以说明以上的算法。大家应该记得一个公式,即两数据的反码和等于两数据和的反码,把它推广到n个数据同样适用,公式:~[X]+~[Y]=~[X+Y] 从这张图片可以看出它的校验和是0x618D,现在我们来用它来模拟我
们的发送端和接收端。 发送端: 步骤如下: 首先,将checksum字段设为0,那么将得到IP数据包头的分段信息如下 1. 0x4500 2. 0x0029 3. 0x44F1 4. 0x4000 5. 0x8006 6. 0x0000 ------->这个为Header Checksum的值,我们前面将其 重置为0了 7. 0xC0A8 8. 0x01AE 9. 0x4A7D +10. 0x477D 结果为:0x29E70 注意要将溢出位加到低位,即0x29E70的溢出位为高位2,将它加到低位上,即0x9E70+0x2=0x9E72 0x9E72二进制为:1001 1110 0111 0010 反码为:0110 0001 1000 1101 0110 0001 1000 1101的16进制为:0x618D(这就是我们的校验和) 接收端: 当我们收到该数据包时,它的分段信息将是如下信息: 1. 0x4500 2. 0x0029 3. 0x44F1 4. 0x4000 5. 0x8006 6. 0x618D ------->这个为Header Checksum的值 7. 0xC0A8 8. 0x01AE 9. 0x4A7D +10. 0x477D 结果为:0x2FFFD 该数值的溢出位为高位2,把它加到底位D上,即0xFFFD+0x2=0xFFFF 0xFFFF二进制为:1111 1111 1111 1111 1111 1111 1111 1111反码为:0
常见校验算法 一、校验算法 奇偶校验 MD5校验 求校验和 BCC(Block Check Character/信息组校验码),好像也是常说的异或校验方法 CRC(Cyclic Redundancy Check/循环冗余校验) LRC(Longitudinal Redundancy Check/纵向冗余校验) 二、奇偶校验 内存中最小的单位是比特,也称为“位”,位有只有两种状态分别以1和0来标示,每8个连续的比特叫做一个字节(byte)。不带奇偶校验的内存每个字节只有8位,如果其某一位存储了错误的值,就会导致其存储的相应数据发生变化,进而导致应用程序发生错误。而奇偶校验就是在每一字节(8位)之外又增加了一位作为错误检测位。在某字节中存储数据之后,在其8个位上存储的数据是固定的,因为位只能有两种状态1或0,假设存储的数据用位标示为1、1、1、0、0、1、0、1,那么把每个位相加(1+1+1+0+0+1+0+1=5),结果是奇数,那么在校验位定义为1,反之为0。当CPU读取存储的数据时,它会再次把前8位中存储的数据相加,计算结果是否与校验位相一致。从而一定程度上能检测出内存错误,奇偶校验只能检测出错误而无法对其进行修正,同时虽然双位同时发生错误的概率相当低,但奇偶校验却无法检测出双位错误 三、MD5校验 MD5的全称是Message-Digest Algorithm 5,在90年代初由MIT的计算机科学实验室和RSA Data Security Inc 发明,由MD2/MD3/MD4 发展而来的。MD5的实际应用是对一段Message(字节串)产生fingerprint(指纹),可以防止被“篡改”。举个例子,天天安全网提供下载的MD5校验值软件WinMD5.zip,其MD5值是1e07ab3591d25583eff5129293dc98d2,但你下载该软件后计算MD5 发现其值却是81395f50b94bb4891a4ce4ffb6ccf64b,那说明该ZIP已经被他人修改过,那还用不用该软件那你可自己琢磨着看啦。 四、求校验和 求校验和其实是一种或运算。如下: //-------------------------------------------------------------------------------------------------- //如下是计算校验位函数 // checkdata,包括起始位在内的前九位数据的校验和 //-------------------------------------------------------------------------------------------------- unsigned char CLU_checkdata(void) { //求校验和 unsigned char checkdata=0; for(point=0;point<9,TI=1;point++) { checkdata=checkdata | buffer[point]; } return(checkdata); } 四、BCC(Block Check Character/信息组校验符号)
常用各种数据校验方法源代码Borland C++ Builder5.0 //----------------------------------------------------------------------------- //定义数据类型缩写形式 typedef unsigned char uchar; //无符号字符 typedef unsigned short ushort; //无符号短整型 typedef unsigned long ulong; //无符号长整型 typedef unsigned int uint; //无符号整型 typedef DynamicArray
目录 摘要..................................................................................................................................... I 关键词................................................................................................................................ I 1 引言 (1) 2 异常值的判别方法 (1) 2.1检验(3S)准则 (1) 2.2 狄克松(Dixon)准则 (2) 2.3 格拉布斯(Grubbs)准则 (3) 2.4 指数分布时异常值检验 (3) 2.5 莱茵达准则(PanTa) (4) 2.6 肖维勒准则(Chauvenet) (4) 3 实验异常数据的处理 (4) 4 结束语 (6) 参考文献 (7)
试验数据异常值的检验及剔除方法 摘要:在实验中不可避免会存在一些异常数据,而异常数据的存在会掩盖研究对象的变化规律和对分析结果产生重要的影响,异常值的检验与正确处理是保证原始数据可靠性、平均值与标准差计算准确性的前提.本文简述判别测量值异常的几种统计学方法,并利用DPS软件检验及剔除实验数据中异常值,此方法简单、直观、快捷,适合实验者用于实验的数据处理和分析. 关键词:异常值检验;异常值剔除;DPS;测量数据
1 引言 在实验中,由于测量产生误差,从而导致个别数据出现异常,往往导致结果产生较大的误差,即出现数据的异常.而异常数据的出现会掩盖实验数据的变化规律,以致使研究对象变化规律异常,得出错误结论.因此,正确分析并剔除异常值有助于提高实验精度. 判别实验数据中异常值的步骤是先要检验和分析原始数据的记录、操作方法、实验条件等过程,找出异常值出现的原因并予以剔除. 利用计算机剔除异常值的方法许多专家做了详细的文献[1]报告.如王鑫,吴先球,用Origin 剔除线形拟合中实验数据的异常值;严昌顺.用计算机快速剔除含粗大误差的“环值”;运用了统计学中各种判别异常值的准则,各种准则的优劣程度将体现在下文. 2 异常值的判别方法 判别异常值的准则很多,常用的有t 检验(3S )准则、狄克松(Dixon )准则、格拉布斯(Grubbs )准则等准则.下面将一一简要介绍. 2.1 检验(3S )准则 t 检验准则又称罗曼诺夫斯基准则,它是按t 分布的实际误差分布围来判别异常值,对重复测量次数较少的情况比较合理. 基本思想:首先剔除一个可疑值,然后安t 分布来检验被剔除的值是否为异常值. 设样本数据为123,,n x x x x L ,若认j x 为可疑值.计算余下1n 个数据平均值
第2章数据通信中常用的数据校验算法本章主要内容包括: 校验和算法的基本原理 奇偶校验算法的基本原理 CRC校验算法的基本原理 CRC算法的软件实现 本章介绍常用校验算法的基本原理,包括校验和、奇偶校验和CRC校验,并介绍了CRC 校验的软件实现方法。本章的数据校验算法是在数据通信中常用的检测数据错误的方法,在设计单片机的通信中可选用。 2.1 概述 数据在传输的过程中,会受到各种干扰的影响,如脉冲干扰,随机噪声干扰和人为干扰等,这会使数据产生差错,数据通信系统模型如图2.1。为了能够控制传输过程的差错,通信系统必须采用有效措施来控制差错的产生。 数据干扰数据+干扰 图2.1 数据通信系统模型 常用的差错控制方法让每个传输的数据单元带有足以使接收端发现差错的冗余信息,这种方法不能纠正错误,但可以发现数据错误,这种方法容易实现,检错速度快,可以通过重传使错误纠正,所以是非常常用的检错方案。 在种方案中常用的校验方法有奇偶校验、CRC(循环冗余校验)和校验和,下面分别介绍这三种校验算法。 2.2 奇偶校验算法 1、原理 奇偶校验算法可分为奇校验和偶校验两种,二者原理相同。在偶校验中,无论数据位有多少位,校验位只有1位,它使码组中“1”的个数为偶数,要满足如下关系式
2 0021=⊕⊕⊕⊕--a a a n n 式中,0a 为校验位,其它位为信息位,⊕表示模2加运算。在接收端,按照上式将码组中各位进行模2加,若结果为“1”,就让我传输中有错误;若为“0”,就认为无错。 奇校验算法与偶校验算法类似,只是奇校验要满足如下关系式 1021=⊕⊕⊕⊕--a a a n n 二者的校验能力相同,均能检测出奇数个错误,而对出现的偶数个错误不能检测出来。奇偶校验算法是数据通信中最常用的校验方法,在实际应用中,它分为垂直奇偶校验、水平奇偶校验和垂直水平奇偶校验。 2、垂直水平奇偶校验 垂直水平奇偶校验也称为二维奇偶校验或方阵校验,其检错能力要比普通的奇偶校验强。该校验方式把数据编码排列成矩阵,根据奇偶校验原理,在垂直和水平两个方向同时进行校验。图2.2是一个垂直水平校验的例子,最下面一行和最右一列为校验位。发送时按列序顺次传输:01110010011100100111010000110000 。 这种校验方式能检测码组中出现的全部奇数个差错和大部分偶数个差错。图2.2中△标出的差错能检测出来,但〇标出的差错同时出现时检测不出来,即所有矩形差错检测不出来。 显然,垂直水平奇偶校验编码具有良好的检错能力,同时,还能纠正一些错误,如△标出的错误可以得到纠正。这种校验方法实现容易,应用广泛。 2.3 校验和 校验和也是一种常用的校验方法,它基于冗余校验。下面介绍其原理。 发送端将数据单元分成长度为n (通常是16)的比特分段,这些分段相加,其结果仍然为n 比特长。先求和然后取反,作为校验字段附加到数据单元的末尾。带有校验和字段的数据通过网络传输,其过程如下。 发送端: ? 数据单元被分成k 段,每段n 比特; ? 将所有段相加求和; ? 对和取反得到校验和; 0 0 0 0 0 0 0 0 1 1 0 0 0 0 1 1 1 1 0 0 0 0 1 1 0 0 1 1 0 0 0 1 0 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 0 0 1 0 0 图2.2 垂直水平奇偶校验
数据采集测量结果改善的常用校正方法 改善测量结果需要进行配置、校准以及优秀的软件开发技术。本文旨在使您了解优化测量结果的软、硬件技巧,内容包括:选择并配置数据采集设备、补偿测量误差以及采用优秀的软件技术。 当您将电子信号连接到数据采集设备时,您总是希望读数能匹配输入信号的电气数值。但我们知道没有一种测量硬件是完美的,所以为了改善测量结果我们必须采用最佳的硬件配置。 根据应用需求,您必须首先要明确数据采集卡所需的模拟输入、输出通道以及数字I/O线的最少数目。其次还要考虑的重要因素有:采样率、输入范围、输入方式和精度。 第一个要考虑的问题是现场接线,根据您要采集的信号源类型,您可以使用差分、非参考单端、参考单端三种输入方式来配置数据采集卡。 总的说来,差分测量系统较为可取,因为它能消除接地环路感应误差并能在一定程度上削弱由环境引起的噪声。而另一方面,单端输入方式提供两倍数据采集通道数,可是仅适用于引入误差比数据所需精度小的情况。为选择合适的信号源模拟输入方式提供了指导选择合适的增益系数也是非常重要的。保证数据采集产品进行精确采集和转换所设定的电压范围叫做输入信号范围。为得到最佳的测量精度,使模拟信号的最大最小值尽可能占满整个ADC(+/-10V或0-10V)范围,这样就可使测量结果充分利用现有的数字位。 在数据采集系统中选择合适的增益 任何测量结果都只是您要测量的“真实值”的估计值,事实上您永远也无法完美地测量出真实值。这是因为您测量的准确性会受到物理因素的限制,而且测量的精度也取决于这种限制。 在特定的范围内,16位数据采集卡有216(65536)种数值,而12位数据采集卡有212 (4096)种数值。理想情况下,这些数值在整个测量范围内是均匀分布的,而且测量硬件会把实际测量值取整成最接近的数值并返回计算机内存。事实上有许多人认为,这种取整误差(通常称为量化误差)是决定精度的唯一因素。实际上,这种量
目录 摘要 1 课程设计目的 (1) 2 课程设计要求 (1)
1 课程设计目的 校验和是用于验证数据传输正确性的一种方法。在网络体系结构的各层协议中, 很多网络协议都利用校验和来实现差错控制功能。本课程设计主要目的是通过完 成一个简单例子,了解网络协议中的校验和计算过程。 2 课程设计要求 1 1 2 1)交换性和结合性 因为校验和主要考虑被校验数据中所包含字节的数量是奇数还是偶数,所以校验和的计算可 以以任意顺序进行,甚至可以把数据进行分组后再计算。 例如,用A,B,C,D,……,Y,Z分别表示一系列八位组,用[a,b]这样的字节来表示a*256+b的整数,那么16位校验和就可以通过以下形式给出: [A,B]+’[C,D]+’……+’[Y,Z] [1] [A,B]+’[C,D]+’……+’[Z,0] [2] 在这里+’代表1补数加法,即将前面的16位校验和和按位取反。 [1]可以以 [A,B]+’[C,D]+’……+’[J,0]+’([0,K]+’……+’[Y,Z]) [3] 的形式进行计算。
2)字节顺序的自主性 打破被校验数据中的字节顺序仍可以计算正确的16位校验和。 例如,我们交换字节组中两字节的顺序,得到 [B,A]+’[D,C]+’……+’[Z,Y] 所得到的结构与[1]式是相同的(当然结果也是要进行一次反转的)。为什么会是这样呢?我们发现两种顺序获得的进位是相同的,都是从第15位到第0位进位以及从第7位到第8位进位。这也就是说,交换字节位置只是改变高低位字节的排列顺序但并没有改变他们的内在联系。因此无论底层的硬件设置中对字节的接收顺序如何,校验和都可以被准确地校验出来。例如,假设校验和是以主机序(高位字节在前低位字节在后)计算的数据帧,但以网络序(低位字节在前高位字节在后)存放在内存中。每一个16位的字中的字节在传送过程中都交换了顺序,在计算校验和之后仍会先交换位置再存入 3 成 这些改 3 1 2 3 和,这样就可以省去一次数据移动的过程,从而提高校验和的计算速度。 4课程设计分析 校验和的计算过程主要分为三个步骤:数据文件的输入、校验和的计算和校验结果的输出。其中,
错误检测方法 标准的MOdbus串行网络采用两种错误检测方法。奇偶校验对每个字符都可用,桢检测(LRC或CRC)应用于整个消息。它们都是在消息发送前由主设备产生的,从设备在接收过程中检测每个字符和整个消息桢。 用户要给主设备配置一预先定义的超时时间要足够长,以使任何从设备都能作为正常反应。如果从设备检测到一传输错误,消息将不会接收,也不会向主设备作出回应。这样超时时间将触发设备来处理错误。发往不存在的从设备的地址也会产生超时。 1、奇偶校验 用户可以配置控制器是奇或偶校验,或无校验。这将决定了每个字符中的奇偶校验位是如何设置的。 如果指定了奇或偶校验,“1”的位数将算到每个字符的位数中(ASCII模式7个数据位,RTU中8个数据位)。例如RTU字符帧中包含以下8个数据位: 1 1 0 0 0 1 0 1 整个“1”的数目是4个。如果使用了偶校验,帧的奇偶校验位将是0,便得整个“1”的个数仍是4个。如果使用了奇校验,帧的奇偶校验位将是1,便得整个“1”的个数是5个。 如果没有指定奇偶校验位,传输时就没有校验位,也不进行校验检测。代替一附加的停止位填充至要传输的字符帧中。 2、LRC检测 使用ASCII模式,消息包括了一基于LRC方法的错误检测域。LRC域检测了消息域中除开始的冒号及结束的回车换行号外的内容。 LRC域是一个包含一个8位二进制值的字节。LRC值由传输设备来计算并放到消息帧中,接收设备在接收消息的过程中计算LRC,并将它和接收到消息中LRC域中的值比较,如果两值不等,说明有错误。 LRC方法是将消息中的8Bit的字节连续累加,丢弃了进位。 LRC简单函数如下: static unsigned char LRC(auchMsg,usDataLen) unsigned char *auchMsg ; /* 要进行计算的消息 */ unsigned short usDataLen ; /* LRC 要处理的字节的数量*/ { unsigned char uchLRC = 0 ; /* LRC 字节初始化 */ while (usDataLen--) /* 传送消息 */
方案的审核和批准
REVIEW AND APPROVAL PAGE OF PROTOCOL 1.验证目的 此验证是在风险评估RA-1610005-01的基础上为Excel公式计算表,是否能够满足数据完整性的要求
进行的验证。 2.职责 检查人是Excel公式计算表的管理员,须经过相关培训并具有完成数据完整性验证所具有的经验和技能,为QC主管指定的技术人员。 复核人具有与检查者相同的技能和培训,对检查者起监督辅助作用,并对检查者的操作过程、计算过程、及测试结果进行复核。 审核人由QC和QA担任,负责监督验证过程、审核验证方案和报告、确认验证效果、审核验证结果。 负责人由质量部经理担任,负责管理整个验证过程,对方案和报告进行批准。 3.验证的管理 3.1人员 QC主管对参加验证的检查人员进行全面的培训并记录培训过程,检查人员经过系统的培训后可以在验证过程中进行操作及记录工作。 参与验证所有人员包括方案和报告的起草、审核、批准人员及验证的执行人员都要经过资格的确认,并记录。 3.2记录和数据 该方案中必须包括来自确认和测试中的原始数据,以及其它系统相关的文件。在验证执行中产生的原始数据,包括收集的附加数据单,计算机建立和打印的数据、系统产生的数据单、色谱图等,必须作为验证记录的附件放入报告中。这些附加的数据单、图谱等必须编号、签日期和执行者的签名。 3.3文件要求 书写或打印应清晰,所有的工作只使用不退色的笔记录,修改时要求在错处划单线,签名、日期和必要时的说明,该方案相关的数据单,用于填写数据前必须由验证团队确定,所有的数据单必须用不褪色的笔手写。 3.4偏差处理 一旦验证的可接受标准不能满足,检查者需要在偏差表中登记并上报QC主管,QC主管组织人员制定纠正措施,纠正措施经QA审核有效后方可执行。任何时候,在验证结束时,每个偏差的都应给出明确的结论,所有的可接受标准是否满足要求。 3.5再验证 数据完整性中涉及的内容一经验证,批准使用后应严格执行,每次修改需要按照《变更管理规程》中规定的程序执行。系统是否需要重新验证,按照变更中风险评估的要求执行。 4.验证
我们知道,数字数据在其传输线路上会受到各种干扰的影响,有时候会产生误码,因此必须引入数据校验技术来验证数据传输的正确性和有效性。目前,最为普通的两种校验技术就是循环冗余校验和奇偶校验技术。下面将依次说明两种校验技术的原理。 奇偶校验 在发送数据时,数据位尾随的1位为奇偶校验位(1或0)。奇校验时,数据中“1”的个数与校验位“1”的个数之和应为奇数;偶校验时,数据中“1”的个数与校验位“1”的个数之和应为偶数。接收字符时,对“1”的个数进行校验,若发现不一致,则说明传输数据过程中出现了差错。注意,奇校验或偶校验由通信双方提前约定。 循环冗余校验 奇偶校验码作为一种检错码虽然简单,但是漏检率太高。在计算机网络和数据通信中用的最广泛的检错码,是一种漏检率低得多也便于实现的循环冗余码CRC (Cyclic Redundancy Code),CRC码又称为多项式码。 首先说明一个概念:生成多项式G(x),目前国际上生成多项式有下面几类标准:CRC-12码: G(x)=X12+X11+X3+X2+X+1(X后数字表示X的幂次,下同) CRC-16码: G(x)=X16+X15+X2+1 CRC-CCITT码: G(x)=X16+X12+X5+1 CRC-32码: G(x)=X32+X26+X23+X22+X16+X12+X11+X10+X8+X7+X5+X4+X2+X1+X+1 针对不同的数据传输类型(数据位不同,同步or异步传输)可选择不同的传输标准。此外,不同国家也采用不同生成多项式标准。 下面先给两个个例子(纯数学运算),大家先体会一下运算过程: 例1.已知:信息码:110011 信息多项式:K(X)=X5+X4+X+1 生成码:11001 生成多项式:G(X)=X4+X3+1(r=4,表示冗余码位数) 求:循环冗余码和码字。 解:1)(X5+X4+X+1)*X4的积是 X9+X8+X5+X4 对应的码是1100110000。 2)积/G(X)(按模二算法)。 1 00001←Q(X) (商) G(x)→1 1 0 0 1 )1 1 0 0 1 1 0 0 0 0←K(X)*Xr(“)”表示模二除号) 1 1 0 0 1 100000
错误检测与修正 二.错误检测的基本原理 发送器向所发送的数据信号祯添加错误检验码,并取该错误检测码作为该被传输数据信号的函数;接收器根据该函数的定义进行同样的计算,然后将两个结果进行比较:如果结果相同,则认为无错误位;否则认为该数据祯存在有错误位。 一般说来,错误检测可能出现三种结果: 在所传输的数据祯中未探测到,也不存在错误位; 所传输的数据祯中有一个或多个被探测到的错误位,但不存在未探测到的错误位; 被传输的数据祯中有一个或多个没有被探测到的错误位。 显然我们希望尽可能好地选择该检测函数,使检测结果可靠,即:所有的错误最好都能被检测出来;如检测出现无错结果,则应不再存在任何未被检测出来的错误。 实际采用的错误检测方法主要有两类:奇偶校验(ECC)、和校验(CheckSum)和CRC循环冗余校验。 二.奇偶校验ECC 单向奇偶校验 单向奇偶校验由于一次只采用单个校验位,因此又称为单个位奇偶校验。发送器在数据祯每个字符的信号位后添一个奇偶校验位,接收器对该奇偶校验位进行检查。典型的例子是面向ASCII码的数据信号祯的传输,由于ASCII码是七位码,因此用第八个位码作为奇偶校验位。 单向奇偶校验又分为奇校验(Odd Parity)和偶校验(Even Parity),发送器通过校验位对所传输信号值的校验方法如下:奇校验保证所传输每个字符的8个位中1的总数为奇数;偶校验则保证每个字符的8个位中1的总数为偶数。 假设某一字符的标准ASCII编码为0011000,根据奇偶校验规则,如果采用奇校验,则校验位应为1(这样字符中1的个数才能为奇数),即00110001;如果采用偶校验,校验位应为0,即00110000。 显然,如果被传输字符的7个信号位中同时有奇数个(例如1、3、5、7)位出现错误,均可以被检测出来;但如果同时有偶数个(例如2、4、6)位出现错误,单向奇偶校验是检查不出来的。 一般在同步传输方式中常采用奇校验,而在异步传输方式中常采用偶校验。 三.和校验(CheckSum) 通常用来在通信中,尤其是远距离通信中保证数据的完整性和准确性。这些数据项可以是数字或在计算检验的过程中看作数字的其它字符串。它通常是以十六进制为数制表示的形式,如: 十六进制串:0102030405060708 的校验和是:24 (十六进制) 如果效验和的数值超过十六进制的FF,也就是255,就要求其补码作为效验和。 累加和校验38H(+)44H(+)45H(+)46H(+)39H(+)45H = 185H 去除进位位1 最后两位的值85H为累加和校验值,用户在数据处理时可以按长度来作接收,然后也作累加和处理,最后计算的值与接收到的值一样,则接收到的卡号为正确卡号。 三.CRC循环冗余校验 1.CRC循环冗余校验的基本原理 发送器和接收器约定选择同一个由n+1个位组成的二进制位列P作为校验列,发送器在数据祯的K个位信号后添加n个位(n 目录摘要 1 课程设计目的 校验和是用于验证数据传输正确性的一种方法。在网络体系结构的各层协议中, 很多网络协议都利用校验和来实现差错控制功能。本课程设计主要目的是通过完 成一个简单例子,了解网络协议中的校验和计算过程。 2 课程设计要求 根据校验和的算法,编写程序为给定数据计算校验和 1)以命令行形式运行: Checksum input_file 其中Checksum为程序名,input_file为输入数据文件名 2)输出内容:数据文件的校验和 3相关知识 1校验和的概念 网络上的数据最终都是通过物理传输线路进行传输的,如果高层没有采用差错控制,那 么物理层传输的线路可能有差错。为了保证传输数据的正确性,在物理层的基础上设计 了数据链路层。设计数据链路层的主要目的就是在原始的,有差错的物理传输线路的基 础上,采用差错检测,差错控制和流量控制等方法。 目前,进行差错检测和控制的主要方法是:发送方在需要发送的数据后面增加一定的 冗余信息,这些冗余信息通常是通过对发送的数据进行某种算法计算而得到的。接收方 对接收数据进行同样的计算,然后与数据后面附加的冗余信息进行比较,如果比较结果 不同就说明在传输中出现了差错,并要求发送方重新传送该数据,以此达到确保数据准确 性的目的。在普遍使用的网络协议中,通常都设置了校验和字段以保存这些冗余信息,计算 这些校验和的算法,就是将被校验的数据按16位进行累加,然后取反码,如果数据字节长 度为奇数,则数据尾部补一个字节的0以凑成偶数。关于计算校验和算法的详细信息请参考 RFC1071. 2计算校验和 有很多数学方法可以提高校验和的速度。 1)交换性和结合性 因为校验和主要考虑被校验数据中所包含字节的数量是奇数还是偶数,所以校验和的计算可 以以任意顺序进行,甚至可以把数据进行分组后再计算。 例如,用A,B,C,D,……,Y,Z分别表示一系列八位组,用[a,b]这样的字节来表示a*256+b的整数,那么16位校验和就可以通过以下形式给出: [A,B]+’[C,D]+’……+’[Y,Z] [1] [A,B]+’[C,D]+’……+’[Z,0] [2] 在这里+’代表1补数加法,即将前面的16位校验和和按位取反。 [1]可以以 [A,B]+’[C,D]+’……+’[J,0]+’([0,K]+’……+’[Y,Z]) [3] 的形式进行计算。 1.生成多项式。 16位的CRC码产生的规则是先将要发送的二进制序列数左移16位(既乘以 )后,再除以一个多项式,最后所得到的余数既是CRC码。任意一个由二进制位串组成的代码都可以和一个系数仅为…0?和…1?取值的多项式一一对应。例如:代码1010111对应的多项式为x6+x4+x2+x+1,而多项式为x5+x3+x2+x+1对应的代码101111。 标准CRC生成多项式如下表: 名称生成多项式简记式* 标准引用 CRC-4 x4+x+1 3 ITU G.704 CRC-8 x8+x5+x4+1 0x31 CRC-8 x8+x2+x1+1 0x07 CRC-8 x8+x6+x4+x3+x2+x1 0x5E CRC-12 x12+x11+x3+x+1 80F CRC-16 x16+x15+x2+1 8005 IBM SDLC CRC16-CCITT x16+x12+x5+1 1021 ISO HDLC, ITU X.25, V.34/V.41/V.42, PPP-FCS CRC-32 x32+x26+x23+...+x2+x+1 04C11DB7 ZIP, RAR, IEEE 802 LAN/FDDI, IEEE 1394, PPP-FCS CRC-32c x32+x28+x27+...+x8+x6+1 1EDC6F41 SCTP //叶子:这里不知道问什么省略了,有些迷惑哦。要是生成多项式要是都省了,那还怎么校验?我猜想可能是中间的全为一吧。 生成多项式的最高位固定的1,故在简记式中忽略最高位1了,如0x1021实际是0x11021。 I、基本算法(人工笔算): 以CRC16-CCITT为例进行说明,CRC校验码为16位,生成多项式17位。假如数据流为4字节:BYTE[3]、BYTE[2]、BYTE[1]、BYTE[0]; 数据流左移16位,相当于扩大256×256倍,再除以生成多项式0x11021,做不借位的除法运算(相当于按位异或),所得的余数就是CRC校验码。 发送时的数据流为6字节:BYTE[3]、BYTE[2]、BYTE[1]、BYTE[0]、CRC[1]、CRC[0];II、计算机算法1(比特型算法): 1)将扩大后的数据流(6字节)高16位(BYTE[3]、BYTE[2])放入一个长度为16的寄存器; 2)如果寄存器的首位为1,将寄存器左移1位(寄存器的最低位从下一个字节获得),再与生成多项式的简记式异或; 否则仅将寄存器左移1位(寄存器的最低位从下一个字节获得); 3)重复第2步,直到数据流(6字节)全部移入寄存器; 4)寄存器中的值则为CRC校验码CRC[1]、CRC[0]。 III、计算机算法2(字节型算法):256^n表示256的n次方 把按字节排列的数据流表示成数学多项式,设数据流为BYTE[n]BYTE[n-1]BYTE[n-2]、、、BYTE[1]BYTE[0],表示成数学表达式为BYTE[n]×256^n+BYTE[n-1]×256^(n-1) +...+BYTE[1]*256+BYTE[0],在这里+表示为异或运算。设生成多项式为G17(17bit),计算机网络课设,计算校验和
CRC校验算法
相关主题
文本预览