
如何将SQLServer2005中的数据同步到Oracle中
有时由于项目开发的需要,必须将SQLServer2005中的某些表同步到Oracle数据库中,由其他其他系统来读取这些数据。不同数据库类型之间的数据同步我们可以使用链接服务器和SQLAgent来实现。假设我们这边(SQLServer2005)有一个合同管理系统,其中有表contract 和contract_project是需要同步到一个MIS系统中的(Oracle9i)那么,我们可以按照以下几步实现数据库的同步。
1.在Oracle中建立对应的contract 和contract_project表,需要同步哪些字段我们就建那些字段到O racle表中。
这里需要注意的是Oracle的数据类型和SQLServer的数据类型是不一样的,那么他们之间是什么样的关系拉?我们可以在SQLServer下运行:
SELECT*
FROM msdb.dbo.MSdatatype_mappings
SELECT*
FROM msdb.dbo.sysdatatypemappings
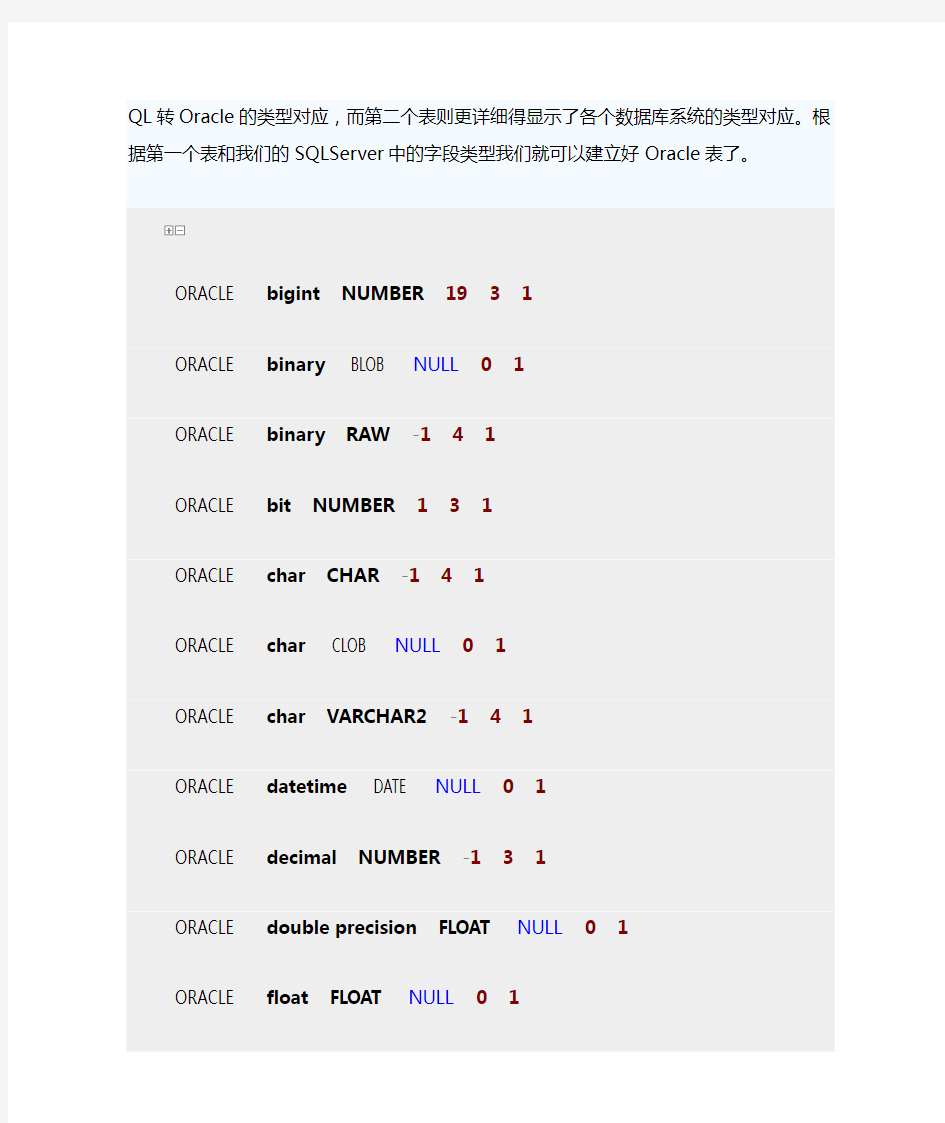
来查看SQLServer和其他数据库系统的数据类型对应关系。第一个SQL语句是看SQL转Oracle的类型对应,而第二个表则更详细得显示了各个数据库系统的类型对应。根据第一个表和我们的SQLServer中的字段类型我们就可以建立好Oracle表了。
ORACLE bigint NUMBER1931
ORACLE binary BLOB NULL01
ORACLE binary RAW-141
ORACLE bit NUMBER131
ORACLE char CHAR-141
ORACLE char CLOB NULL01
ORACLE char VARCHAR2-141
ORACLE datetime DATE NULL01
ORACLE decimal NUMBER-131
ORACLE double precision FLOAT NULL01
ORACLE float FLOAT NULL01
ORACLE image BLOB NULL01
ORACLE int NUMBER1031
ORACLE money NUMBER1931
ORACLE nchar NCHAR-141
ORACLE nchar NCLOB NULL01
ORACLE ntext NCLOB NULL01
ORACLE numeric NUMBER-131
ORACLE nvarchar NCLOB NULL01
ORACLE nvarchar NVARCHAR2 -141
ORACLE nvarchar(max) NCLOB NULL01
ORACLE real REAL NULL01
ORACLE smalldatetime DATE NULL01
ORACLE smallint NUMBER531
ORACLE smallmoney NUMBER1031
ORACLE sysname NVARCHAR2 12841
ORACLE text CLOB NULL01
ORACLE timestamp RAW841
ORACLE tinyint NUMBER331
ORACLE uniqueidentifier CHAR3841
ORACLE varbinary BLOB NULL01
ORACLE varbinary RAW-141
ORACLE varbinary(max) BLOB NULL01
ORACLE varchar CLOB NULL01
ORACLE varchar VARCHAR2-141
ORACLE varchar(max) CLOB NULL01
ORACLE xml NCLOB NULL01
ORACLE bigint NUMBER1931
ORACLE binary BLOB NULL01
ORACLE binary RAW-141
ORACLE bit NUMBER131
ORACLE char CHAR-141
ORACLE char CLOB NULL01
ORACLE char VARCHAR2-141
ORACLE datetime DATE NULL01
ORACLE decimal NUMBER-131
ORACLE double precision FLOAT NULL01
ORACLE float FLOAT NULL01
ORACLE image BLOB NULL01
ORACLE int NUMBER1031
ORACLE money NUMBER1931
ORACLE nchar CHAR-141
ORACLE nchar CLOB NULL01
ORACLE ntext CLOB NULL01
ORACLE numeric NUMBER-131
ORACLE nvarchar CLOB NULL01
ORACLE nvarchar VARCHAR2-141
ORACLE nvarchar(max) CLOB NULL01
ORACLE real REAL NULL01
ORACLE smalldatetime DATE NULL01
ORACLE smallint NUMBER531
ORACLE smallmoney NUMBER1031
ORACLE sysname VARCHAR212841
ORACLE text CLOB NULL01
ORACLE timestamp RAW841
ORACLE tinyint NUMBER331
ORACLE uniqueidentifier CHAR3841
ORACLE varbinary BLOB NULL01
ORACLE varbinary RAW-141
ORACLE varbinary(max) BLOB NULL01
ORACLE varchar CLOB NULL01
ORACLE varchar VARCHAR2-141
ORACLE varchar(max) CLOB NULL01
ORACLE xml CLOB NULL01
ORACLE bigint NUMBER1931
ORACLE binary BLOB NULL01
ORACLE binary RAW-141
ORACLE bit NUMBER131
ORACLE char CHAR-141
ORACLE char CLOB NULL01
ORACLE char VARCHAR2-141
ORACLE datetime DATE NULL01
ORACLE decimal NUMBER-131
ORACLE double precision FLOAT NULL01
ORACLE float FLOAT NULL01
ORACLE image BLOB NULL01
ORACLE int NUMBER1031
ORACLE money NUMBER1931
ORACLE nchar NCHAR-141
ORACLE nchar NCLOB NULL01
ORACLE ntext NCLOB NULL01
ORACLE numeric NUMBER-131
ORACLE nvarchar NCLOB NULL01
ORACLE nvarchar NVARCHAR2 -141
ORACLE nvarchar(max) NCLOB NULL01
ORACLE real REAL NULL01
ORACLE smalldatetime DATE NULL01
ORACLE smallint NUMBER531
ORACLE smallmoney NUMBER1031
ORACLE sysname NVARCHAR2 12841
ORACLE text CLOB NULL01
ORACLE timestamp RAW841
ORACLE tinyint NUMBER331
ORACLE uniqueidentifier CHAR3841
ORACLE varbinary BLOB NULL01
ORACLE varbinary RAW-141
ORACLE varbinary(max) BLOB NULL01
ORACLE varchar CLOB NULL01
ORACLE varchar VARCHAR2-141
ORACLE varchar(max) CLOB NULL01
ORACLE xml NCLOB NULL01
2.建立链接服务器。我们将Oracle系统作为SQLServer的链接服务器加入到SQLServer中。
具体做法参见我以前的文章https://www.doczj.com/doc/122910963.html,/studyzy/archive/2006/12/08/690307.htm l SqlServer下数据库链接的使用方法
有时候我们希望在一个sqlserver下访问另一个sqlserver数据库上的数据,或者访问其他oracle数据库上的数据,要想完成这些操作,我们首要的是创建数据库链接。
数据库链接能够让本地的一个sqlserver登录用户映射到远程的一个数据库服务器上,并且像操作本地数据库一样。那么怎么创建数据库链接呢?我现在有两种方法可以实现。
第一种:在sqlserver企业管理器中,建立,这个比较简单的,首先在"服务器对象"节点下的“数据库链接”节点上点右键,在出现的菜单中点“新建数据库链接”,然后会弹出一个界面,需要我们填写的有:链接服务器(这是一个名字,自己根据情况自行定义,以后就要通过他进行远程访问了),提供程序名称(这个就是选择数据驱动,根据数据库类型来选择,不能乱选,否则链接不上的),数据源(对于sqlserver就是远程数据库服务器的主机名或者IP,对于oracle就是在oracle net config 中配置的别名),安全上下文用户和口令(也就是远程服务器的用户和口令)。
第二种:利用系统存储过程
创建一个sqlserver对sqlserver的数据库链接:
exec sp_addlinkedserver 'link_northsnow','','SQLOLEDB','远程服务器主机名或域名或ip地址' exec sp_addlinkedsrvlogin 'link_northsnow','false',null,'用户名','用户口令' 创建一个sqlserver对Oracle的数据库链接:
exec sp_addlinkedserver 'link_ora', 'Oracle', 'MSDAORA', 'oracle数据库服务器别名'
exec sp_addlinkedsrvlogin 'link_ora', false, 'sa', '用户名', '用户口令'
有了数据库链接我们就可以使用了。对于sqlserver和oracle中的使用方法是有区别的。
对于sqlserver:
create view v_lhsy_user as select * from link_northsnow.lhsy.dbo.sys_user
select * from v_lhsy_user
其中lhsy为远程的数据库名
sys_user为表名
对于oracle:
create view vvv as select * from link_ora..NORTHSNOW.SYS_USER
select * from vvv;
其中northsnow为远程oracle数据库服务器的一个用户名,SYS_USER为该用户在该服务器上的一个表,要非常注意的是:数据库链接(link_ora)后面有两个点(..),再往后面必须全部大写,查询的对象一般为表格或者视图,不能查询同义词。
要想删除数据库链接,也有两种方法,
一种是在企业管理器中操作,这个简单。
另一种是用系统存储过程:
exec sp_dropserver 数据库链接名称,'droplogins'
3.使用SQL语句通过链接服务器将SQLServer数据写入Oracle中。
比如我们建立了链接服务器MIS,而Oracle中在MIS用户下面建立了表contract_project,那么我们的SQL语句就是:
DELETE FROM MIS..MIS.CONTRACT_PROJECT
--清空Oracle表中的数据
INSERT into MIS..MIS.CONTRACT_PROJECT--将SQLServer中的数据写到Oracle中
SELECT contract_id,project_code,actual_money
FROM contract_project
如果报告成功,那么我们的数据就已经写入到Oracle中了。用
SELECT*
FROM MIS..MIS.CONTRACT_PROJECT
查看Oracle数据库中是否已经有数据了。
4.建立SQLAgent,将以上同步SQL语句作为执行语句,每天定时同步两次。
这样我们的同步就完成了。
这里需要注意的是MIS..MIS.CONTRACT_PROJECT 这里必须要大写,如果是小写的话会造成同步失败。
Oracle Stream配置详细步骤 1 引言 Oracle Stream功能是为提高数据库的高可用性而设计的,在Oracle 9i及之前的版本这个功能被称为Advance Replication。Oracle Stream利用高级队列技术,通过解析归档日志,将归档日志解析成DDL及DML语句,从而实现 1 引言 Oracle Stream功能是为提高数据库的高可用性而设计的,在Oracle 9i及之前的版本这个功能被称为Advance Replication。Oracle Stream利用高级队列技术,通过解析归档日志,将归档日志解析成DDL及DML语句,从而实现数据库之间的同步。这种技术可以将整个数据库、数据库中的对象复制到另一数据库中,通过使用Stream的技术,对归档日志的挖掘,可以在对主系统没有任何压力的情况下,实现对数据库对象级甚至整个数据库的同步。 解析归档日志这种技术现在应用的比较广泛,Quest公司的shareplex软件及DSG公司的realsync 都是这样的产品,一些公司利用这样的产品做应用级的容灾。但shareplex或是realsync都是十分昂贵的,因此你可以尝试用Stream这个Oracle提供的不用额外花钱的功能。Oracle Stream对生产库的影响是非常小的,从库可以是与主库不同的操作系统平台,你可以利用Oracle Stream复制几个从库,从库可用于查询、报表、容灾等不同的功能。本文不谈技术细节,只是以手把手的方式一步一步的带你把Stream的环境搭建起来,细节内容可以查联机文档。 2 概述 主数据库: 操作系统:Solaris 9 IP地址:192.168.10.35 数据库:Oracle 10.2.0.2 ORACLE_SID:prod Global_name:prod 从数据库: 操作系统:AIX 5.2 IP地址:192.168.10.43
ORACLE常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:/mssql7backup/MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not nul l],..) 根据已有的表创建新表: A:select * into table_new from table_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only<仅适用于Oracle> 5、说明:删除表 drop table tablename
6、说明:增加一个列,删除一个列 A:alter table tabname add column col type B:alter table tabname drop column colname 注:DB2DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、添加主键: Alter table tabname add primary key(col) 删除主键: Alter table tabname drop primary key(col) 8、创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、创建视图:create view viewname as select statement 删除视图:drop view viewname 10、几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、几个高级查询运算词 A:UNION 运算符 UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。 B:EXCEPT 运算符 EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。 C:INTERSECT 运算符 INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。 注:使用运算词的几个查询结果行必须是一致的。 12、使用外连接
1、数据库基本语句 (1)表结构处理 创建一个表:cteate table 表名(列1 类型,列2 类型); 修改表的名字 alter table 旧表名 rename to 新表名 查看表结构 desc 表名(cmd) 添加一个字段 alter table 表名 add(列类型); 修改字段类型 alter table 表名 modify(列类型); 删除一个字段 alter table 表名 drop column列名; 删除表 drop table 表名 修改列名 alter table 表名 rename column 旧列名 to 新列名; (2)表数据处理 增加数据:insert into 表名 values(所有列的值); insert into 表名(列)values(对应的值); 更新语句:update 表 set 列=新的值,…[where 条件] 删除数据:delete from 表名 where 条件 删除所有数据,不会影响表结构,不会记录日志, 数据不能恢复--》删除很快: truncate table 表名 删除所有数据,包括表结构一并删除: drop table 表名 去除重复的显示:select distinct 列 from 表名 日期类型:to_date(字符串1,字符串2)字符串1是日期的字 符串,字符串2是格式 to_date('1990-1-1','yyyy-mm-dd')-->返回日期的 类型是1990-1-1 (3)查询语句 1)内连接 select a.*,b.* from a inner join b on a.id=b.parent_id
基于Oracle数据库的数据同步技术大体上可分为两类:Oracle自己提供的数据同步技术和第三方厂商提供的数据同步技术。Oracle自己的同步技术有DataGuard,Streams,Advanced Replication和今年 刚收购的一款叫做GoldenGate的数据同步软件。第三方厂商的数据同步技术有Quest公司的SharePlex 和DSG的RealSync。下面对这些技术逐一进行介绍。 一、DataGuard数据同步技术 DataGuard是Oracle数据库自带的数据同步功能,基本原理是将日志文件从原数据库传输到目标数据库,然后在目标数据库上应用(Apply)这些日志文件,从而使目标数据库与源数据库保持同步。DataGuard 提供了三种日志传输(Redo Transport)方式,分别是ARCH传输、LGWR同步传输和LGWR异步传输。在上述三种日志传输方式的基础上,提供了三种数据保护模式,即最大性能(Maximum Performance Mode)、最大保护(Maximum Protection Mode)和最大可用(Maximum Availability Mode),其中最大保护模式 和最大可用模式要求日志传输必须用LGWR同步传输方式,最大性能模式下可用任何一种日志传输方式。 最大性能模式:这种模式是默认的数据保护模式,在不影响源数据库性能的条件下提供尽可能高的 数据保护等级。在该种模式下,一旦日志数据写到源数据库的联机日志文件,事务即可提交,不必等待日 志写到目标数据库,如果网络带宽充足,该种模式可提供类似于最大可用模式的数据保护等级。 最大保护模式:在这种模式下,日志数据必须同时写到源数据库的联机日志文件和至少一个目标库 的备用日志文件(standby redo log),事务才能提交。这种模式可确保数据零丢失,但代价是源数据库的可用性,一旦日志数据不能写到至少一个目标库的备用日志文件(standby redo log),源数据库将会被关闭。这也是目前市场上唯一的一种可确保数据零丢失的数据同步解决方案。 最大可用模式:这种模式在不牺牲源数据库可用性的条件下提供了尽可能高的数据保护等级。与最 大保护模式一样,日志数据需同时写到源数据库的联机日志文件和至少一个目标库的备用日志文件(standby redo log),事务才能提交,与最大保护模式不同的是,如果日志数据不能写到至少一个目标库的备用日志文件(standby redo log),源数据库不会被关闭,而是运行在最大性能模式下,待故障解决并将延迟的日志成功应用在目标库上以后,源数据库将会自动回到最大可用模式下。 根据在目标库上日志应用(Log Apply)方式的不同,DataGuard可分为Physical Standby(Redo Apply)和Logical Standby(SQL Apply)两种。 Physical Standby数据库,在这种方式下,目标库通过介质恢复的方式保持与源数据库同步,这种方 式支持任何类型的数据对象和数据类型,一些对数据库物理结构的操作如数据文件的添加,删除等也可支持。如果需要,Physical Standby数据库可以只读方式打开,用于报表查询、数据校验等操作,待这些操 作完成后再将数据库置于日志应用模式下。 Logical Standby数据库,在这种方式下,目标库处于打开状态,通过LogMiner挖掘从源数据库传 输过来的日志,构造成SQL语句,然后在目标库上执行这些SQL,使之与源数据库保持同步。由于数据 库处于打开状态,因此可以在SQL Apply更新数据库的同时将原来在源数据库上执行的一些查询、报表等操作放到目标库上来执行,以减轻源数据库的压力,提高其性能。 DataGuard数据同步技术有以下优势: 1)Oracle数据库自身内置的功能,与每个Oracle新版本的新特性(如ASM)都完全兼容,且不 需要另外付费; 2)配置管理较简单,不需要熟悉其他第三方的软件产品; 3)Physical Standby数据库支持任何类型的数据对象和数据类型;
如何将SQLServer2005中的数据同步到Oracle中 有时由于项目开发的需要,必须将SQLServer2005中的某些表同步到Oracle数据库中,由其他其他系统来读取这些数据。不同数据库类型之间的数据同步我们可以使用链接服务器和SQLAgent来实现。假设我们这边(SQLServer2005)有一个合同管理系统,其中有表contract 和contract_project是需要同步到一个MIS系统中的(Oracle9i)那么,我们可以按照以下几步实现数据库的同步。 1.在Oracle中建立对应的contract 和contract_project表,需要同步哪些字段我们就建那些字段到O racle表中。 这里需要注意的是Oracle的数据类型和SQLServer的数据类型是不一样的,那么他们之间是什么样的关系拉?我们可以在SQLServer下运行: SELECT* FROM msdb.dbo.MSdatatype_mappings SELECT* FROM msdb.dbo.sysdatatypemappings 来查看SQLServer和其他数据库系统的数据类型对应关系。第一个SQL语句是看SQL转Oracle的类型对应,而第二个表则更详细得显示了各个数据库系统的类型对应。根据第一个表和我们的SQLServer中的字段类型我们就可以建立好Oracle表了。 ORACLE bigint NUMBER1931 ORACLE binary BLOB NULL01 ORACLE binary RAW-141 ORACLE bit NUMBER131 ORACLE char CHAR-141 ORACLE char CLOB NULL01 ORACLE char VARCHAR2-141 ORACLE datetime DATE NULL01 ORACLE decimal NUMBER-131 ORACLE double precision FLOAT NULL01 ORACLE float FLOAT NULL01 ORACLE image BLOB NULL01 ORACLE int NUMBER1031 ORACLE money NUMBER1931 ORACLE nchar NCHAR-141 ORACLE nchar NCLOB NULL01 ORACLE ntext NCLOB NULL01 ORACLE numeric NUMBER-131 ORACLE nvarchar NCLOB NULL01 ORACLE nvarchar NVARCHAR2 -141 ORACLE nvarchar(max) NCLOB NULL01 ORACLE real REAL NULL01 ORACLE smalldatetime DATE NULL01 ORACLE smallint NUMBER531 ORACLE smallmoney NUMBER1031
Oracle 快照及dblink使用(两台服务器数据同步)跨ORACLE实例数据同步(物化视图应用) 名词说明:源——被同步的数据库 -- 目的——要同步到的数据库 /*一、创建dblink:*/ --1、在目的数据库上,创建dblin drop public database link dblink_anson; Create public database link dblink_anson Connect to lg identified by lg using 'SDLGDB'; --源数据库的用户名、密码、服务器名k /*二、创建快照:*/ --1、在源和目的数据库上同时执行一下语句,创建要被同步的表 drop table tb_anson; create table tb_anson(c1 varchar2(12)); alter table tb_anson add constraint pk_anson primary key (C1);
--2、在目的数据库上,测试dblink select * from tb_anson@dblink_anson; select * from tb_anson; --3、在目的数据库上,创建要同步表的快照日志 Create snapshot log on tb_anson; --4、创建快照,快照(被同步(源)数据库服务必须启动) Create snapshot sn_anson as select * from tb_anson@dblink_anson; --5、设置快照刷新时间 Alter snapshot anson refresh fast Start with sysdate+1/24*60 next sysdate+10/24*60; --oracle自动在1分钟后进行第一次快速刷新,以后每隔10分钟快速刷新一次 Alter snapshot anson refresh complete Start with sysdate+30/24*60*60 next sysdate+1;
转眼,从事电信行业BI/DW已经有三年时间了,一直想写点东西,给大家共同分享,感谢ERP 100给我了一个展示的平台! 连载时间:一周一篇 连载提纲: 第一篇数据仓库建设目标、系统规模及项目面临的技术挑战 第二篇选择数据仓库平台的考虑 第三篇选择Oracle产品的原因 第四篇系统现状分析、DW数据仓库建设原则及整体规划的实现 第五篇整体规划的实现、新增应用优先级的确定及螺旋式建设方法 第六篇数据仓库的效益、成本和风险控制 第七篇数据模型设计方法 第八篇构建闭环的信息流、数据模型-分层设计、DW中的数据功能划分 第九篇数据抽取策略、数据抽取过程管理、对脏数据的管理、数据去重及元数据管理及 第十篇典型的应用流程、主题分析及应用推广方法 (第一篇)数据仓库建设目标、系统规模及项目面临的技术挑战 1 数据仓库项目建设目标: 建立统一的数据信息平台,实现客户资料和生产数据的集中存储。利用先进的数据仓库技术和决策分析技术为市场营销和客户服务工作提供有效的支撑: 2 目前系统规模: 包含12个月的话单;数据库容量为65TB,其中原始数据为25TB;最大的表包含1800亿话单
3 项目面临的技术挑战: 数据存储-系统要求存储12-18个月的详单数据; 数据装载-按小时装载详单数据,要求每天在8小时内装载5亿条详单;高峰时一个小时装载6500万条详单;在8小时内同时完成1亿7000万个汇总操作 数据访问-支持680个并发用户,支持8000个系统用户;5%的预定义查询操作在5秒钟内完成;每秒钟23个查询操作 Sina微薄互动地址:https://www.doczj.com/doc/122910963.html,/2186879022/zDx5x29Cw 感谢大家的参与和鼓励,pathwide的建议很好,下面列举出该连载的计划提纲,如下: 连载周期:一周一篇 连载提纲: 第一篇数据仓库建设目标、系统规模及项目面临的技术挑战 第二篇选择数据仓库平台的考虑 第三篇选择Oracle产品的原因 第四篇系统现状分析、DW数据仓库建设原则及整体规划的实现 第五篇整体规划的实现、新增应用优先级的确定及螺旋式建设方法 第六篇数据仓库的效益、成本和风险控制 第七篇数据模型设计方法 第八篇构建闭环的信息流、数据模型-分层设计、DW中的数据功能划分 第九篇数据抽取策略、数据抽取过程管理、对脏数据的管理、数据去重及元数据管理及 第十篇典型的应用流程、主题分析及应用推广方法 希望大家积极参与,共同分享BI/DW的项目经验,同时,有不到位的地方,还请大家多多指正,谢谢! 选择数据仓库平台时的考虑 4 选择数据仓库平台时的考虑 4.1 强大的ETL支持能力-支持按小时的数据装载 4.2 高效的数据访问-硬件的支持:多CPU 大内存并发处理 分区技术 索引技术 数据库内置分析能力 4.3 高可用性7 * 24小时不间断运行 4.4 数据访问每秒钟23到100个并发查询操作; 95%的查询在1秒内完成 4.5 数据表分区-混合分区 按地区建立列表分区; 按时间建立范围分区; 4.6 可传输的表空间 操作系统文件的直接复制;不需要数据的导入、导出
提升数据保护:Oracle数据仓库的实时数据采集在使用数据仓库软件时,最常见的约束之一是源系统数据批量提取处理时的可用时间窗口。通常,极其耗费资源的提取流程必须在非工作时间进行,而且仅限于访问关键的源系统。 低影响实时数据整合软件可以释放系统的批处理时间。当提取组件使用非侵入式方法时,如通过读取数据库事务日志,只会捕捉发生变化的数据,不会对源系统产生影响。因此,数据提取流程可以在任意时段全天候执行,即使用户在线也可以。 当以实时方式提取数据时,虽然必须改变数据采集流程中各个元素支持实时数据的方式,但是这些数据可以带来不一般的业务价值。而且,这些数据必须得到有效的保护,同时也很难针对这些不停变化的数据应用灾难恢复和备份技术。 但是,在数据仓库中应用实时数据整合的技术也可以进一步保护数据。毕竟,实时移动数据的技术也可以实时操作数据,从而形成一个数据保护技术入口。但是,变化数据的速度和效率可能会受制于数据保护流程的延迟。
这意味着,在转到整合数据仓库的主动数据采集模式时,首要考虑的问题之一是数据经过IT系统的流程和可能产生的延迟。换而言之,实时数据整合要求理解变化的数据,以及促进或妨碍这种变化的组件。 显然,企业希望保护他们的数据。然而,随着数据容量需求的增长,存储技术也成为业务持续性依赖的重要业务资产。而且,随着实时分析成为业务流程的一部分,它也归入到业务持续性的范畴之中。实现数据安全性和持续性的最基本方法是硬件或软件复制,它会自动保存第二个关键数据副本。此外,自行创建或基于开源软件创建的备份方法也不存在。 企业级数据管理应用主要涉及5个重要领域:灾难恢复、高可用性、备份、数据处理性能和更高级数据库移植。这促使IT不停地追寻先进技术,如实现数据整合及其相关基础架构元素。此外,这些战略投资能够提供符合预算的资源,在加快实时技术应用的同时,提高投资回报和修正实时数据整合项目的商业提案。
随着信息技术的飞速发展,企业信息化建设的不断深入,使得企业业务系统数量不断增加。这时,各业务系统之间数据交互,各子业务系统与核心业务系统之间数据交互,诸如此类场景的应用需求不断出现。因此,IT部门应对此类需求的压力越来越大。比较突出的问题,主要有实时性与性能的冲突,数据交互方案的安全性与健壮性等。下面浅谈下Oracle数据库之间数据同步方案,不涉及方案的好坏选择,可供参考。 Oracle 提供的数据同步方案: 1,比较原始的,触发器/Job + DBLINK的方式,可同步和定时刷新。 2,物化视图刷新的方式,有增量刷新和完全刷新两种模式,定时刷新。 3,高级复制,分为多主复制和物化视图复制两种模式。其中多主复制能进行双向同步复制和异步复制,物化视图用于单向复制,定时刷新,与2类似。 4,流复制,可实时和非实时同步。 5,GoldenGate复制,Oracle新买的复制产品,后面应该会取代流复制。它不仅能提供Oracle数据库之间的数据复制支持,还支持在不同种数据库之间的数据同步,也可设置实时和非实时同步。 6,DataGurd,此技术主要用于灾备方案,不过在最新11gR2版本中加入了备库实时应用日志,同时能open 提供read only访问的功能。因此,可以作为读写分离,或者作为report数据库,降低系统负载的一个好的方案。 其中上面1,2,3,是采用Oracle数据库内部的机制来实现,而4,5,6是采用挖掘数据库日志的方式实现的。因此,后面3中方式在性能上会更好些。 第三方提供的数据同步方案: 主要根据实现机制分为两大类: 1,采用挖掘数据库日志的方式实现 市场上用的比较多的,如Quest SharePlex, DSG RealSync 。此类软件与Oracle 新收购的GoldenGate 工具类似。 2,采用相关软件在存储级进行复制 IBM,EMC等存储厂商可以实现,使用第三方存储管理软件,如Veritas Replication也可实现。此类方式应用场景与上面6类似。
Oracle数据库之间数据同步 项目中开发库与测试数据库分离,其中某些系统表数据与基础资料数据经常需要进行同步,为方便完成指定数据表的同步操作,可以采用dblink结合dbjob方法完成,简单方便。 操作环境:此Oracle数据库服务器ip为ip1,有dbcenter与dbbranch两个库,一般需要将dbcenter的表数据同步到dbbranch,dbcenter为源库,dbbranch为目标库,具体步骤如下: 1.在源库创建到目标库的dblink create public database link dbcenter connect to username identified by userpassword using ' (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = ip1)(PORT = 1521)) ) (CONNECT_DATA = (SERVICE_NAME = orcl) ) ) ' ; 在创建dblink时,要注意,有时候可能会报用户名和密码错误,但实际上我们所输入的账户信息是正确的,此时就注意将密码的大小写按服务器上所设置的输入,并在账号密码前号加上双引号(服务器版本不同造成的)。 2.成功后验证dblink select sysdate from dual@dbcenter; 3.建立存储过程获取数据 create or replace procedure job_sync() is begin Select * from test@dbcenter; end job_sync; 4.为方便每次需要同步时自动完成同步工作,采用oraclejobs完成定时工作:
SPOOL将屏幕所有的输出输出到指定文件 -- spool 文件路径名; spool g:\mysql.sql; --业务操作 --结束输出 spool off; 执行一个SQL脚本文件 我们可以将多条sql语句保存在一个文本文件中,这样当要执行这个文件中的所有的sql语句时,用上面的任一命令即可,这类似于dos中的批处理。 --start file_name -- @ file_name start g:\mysql.sql; @ g:\mysql.sql; 对当前的输入进行编辑 edit ed 重新运行上一次运行的sql语句 / 显示一个表的结构 desc table_name ; 清屏 clear screen; 退出 exit; 置当前session是否对修改的数据进行自动提交 --SET AUTO[COMMIT] {ON|OFF|IMM[EDIATE]| n} set autocommit on; 在用start命令执行一个sql脚本时,是否显示脚本中正在执行的SQL语句 -- SET ECHO {ON|OFF}; set echo on; 是否显示当前sql语句查询或修改的行数 --SET FEED[BACK] {6|n|ON|OFF}
-- 默认只有结果大于6行时才显示结果的行数。如果set feedback 1 ,则不管查询到多少行都返回。当为off 时,一律不显示查询的行数 set feedback 1; 是否显示列标题 --当set heading off 时,在每页的上面不显示列标题,而是以空白行代替 --SET HEA[DING] {ON|OFF} set heading on; 设置一行可以容纳的字符数 -- 如果一行的输出内容大于设置的一行可容纳的字符数,则折行显示 --SET LIN[ESIZE] {80|n} set linesize 100; 设置页与页之间的分隔 -- SET NEWP[AGE] {1|n|NONE} --当set newpage 0 时,会在每页的开头有一个小的黑方框。 --当set newpage n 时,会在页和页之间隔着n个空行。 --当set newpage none 时,会在页和页之间没有任何间隔 set newpage 1; 设置一页有多少行数 --如果设为0,则所有的输出内容为一页并且不显示列标题 --SET PAGES[IZE] {24|n} set pagesize 20; 是否显示用DBMS_OUTPUT.PUT_LINE包进行输出的信息。 --SET SERVEROUT[PUT] {ON|OFF} set serveroutput on; 是否在屏幕上显示输出的内容,主要用与SPOOL结合使用。 --在用spool命令将一个大表中的内容输出到一个文件中时,将内容输出在屏幕上会耗费大量的时间,--设置set termspool off后,则输出的内容只会保存在输出文件中,不会显示在屏幕上,极大的提高了spool的速度 --SET TERM[OUT] {ON|OFF} set termout off; 在dos里连接oracle数据库 CONNECT user_name/passwd@l_jiayou
1Oracle数据仓库中的OLAP多维分析技术 在传统的数据仓库技术中,数据访问技术经常分为两部分,复杂度较低的、简单的查询应用可直接访问基于关系数据库的数据仓库服务器,而复杂度较高的联机分析处理应用(OLAP)程序则需要通过专门的多维数据库和工具实现。虽然专门的多维数据库提供一整套的分析功能,查询性能更好,但系统的维护十分困难。多维数据库需要从数据仓库复制数据,获取数据的时间延迟相当长,并需要独立的管理过程,专门的数据建模、ETL过程、安全措施和灾难恢复方案。特别是当数据仓库的容量迅速膨胀时,系统性能会急剧下降,使数据访问应用变得不可使用。 1.1OLAP的体系结构 Oracle数据库作为数据仓库的核心和引擎,它集成了OLAP,Oracle数据库的OLAP选项是一种可用的关系多维数据库。多维技术和关系技术共存在同一平台上,实现了数据可管理性和分析能力之间的平衡。通过对SQL的扩充以及在关系数据库中提供OLAP功能,支持复杂分析查询和提供卓越性能的同时,简化了数据迁移过程并降低了维护数据的费用。 1.2Oracle数据仓库中OLAP的相关特点 与传统的多维数据库相比,它集成了oracle数据库管理系统的优势。 (1)由于OLAP集成在Oracle数据库中,将所有的管理任务整合到单一的数据库中,从而简化了管理。 (2)Oracle数据库提供了基于角色的权限管理,没有授权的用户是无法访问Oracle数据库的。数据库中的所有数据,包括OLAP数据,都得到了单一安全策略的保护。所有的用户都被定义在单一的用户目录中,通过标准的Oracle安全功能,例如GRANT和PRIVILEGE来分配权限。 (3)Oracle数据库是能够对关系和多维数据同时提供SQL和OLAPAPI访问的数据库。应用程序开发者可选择使用OLAPAPI的计算和多维数据功能,或使用标准的SQL访问多维数据,任何OLAP计算都可通过SQL进行查询。 提供AnalyticWorkspaceManage(简称AVM)。 它是完全集中于分析工作区中维度模型定义和实施的管理工具。通过它可以方便地创建维表及其结构、事实表以及多维数据库与关系数据库之间的映射,并不需要编程就可实现各种运算。如最大、最小、平均、加权平均、比率和求和运算。并通过oracle提供的OLAPDML语言,这是一种过程编程语言,可用于表达各种类型的计算、设计自定义分析函数以及控制与多维数据类型相关的数据加载和计算过程。O-LAPDML集成了大量的分析函数,可用于产生任何类型的多维计算。如汇总、分配/n分摊、数据选择、财务、预测和回归、数学和统计、模型、定制维度成员等函数类型。通过SQL和PL/SQL以及OLAPWorksheet工具可以访问OLAPDML。2Oracle数据仓库中的ODM应用技术 数据挖掘可以帮助用户发现在数据中隐含的有用信息和规律。Oracle数据库中集成了数据挖掘功能,它避免了把大量数据卸载到外部专用分析服务器的复杂过程。所有的数据挖掘功能都嵌入到了Oracle数据库中,这样,数据准备、模型建立以及模型评估活动都在数据库内进行。ODM可通过Java和PL/SQL应用程序程序员接口(API)以及数据挖掘客户端访问ODM模型构建和模型计分函数,并提供了多种模型建立向导(Wizard),能够协助业务分析人员和开发人员快速地建立数据挖掘模型和对模型进行检验。Oracle数据挖掘可以为多种数据挖掘算法提供支持,这些算法包括属性重要性、分类和回归、集群、关联、特性提取、文本挖掘、序列匹配和比对—BLAST等算法。 3结语 随着数据仓库技术的广泛应用,许多数据库厂商纷纷提出数据仓库解决方案。作为全球最大的关系数据库厂商,Oracle公司也提出了自己的数据仓库解决方案。与传统的数据仓库解决方案相比,Oracle公司提出了完整的数据仓库架构与集成方案。 Oracle数据仓库中的OLAP及ODM技术分析 □李发军 (西北民族大学榆中校区计算机科学与信息工程学院甘肃?兰州730124) 摘要:本文对Oracle数据仓库中的OLAP多维分析技术,以及Oracle数据仓库中的ODM应用技术进行分析研究。 关键词:OracleOLAPODM 中图分类号:C914文献标识码:A文章编号:1007-3973(2007)10-088-1 信息化之窗 88 科协论坛?2007年第10期(下)
oracle 数据同步方案 (DBLink)
一、什么是dbLink 两台不同的数据库服务器,从一台数据库服务器(例如A数据库服务器)的一个用户读取另一台数据库服务器(例如B数据库服务器)下的某个用户的数据,这个时候可以使用dblink。其实dblink和数据库中的view差不多,建dblink的时候需要知道待读取数据库的ip地址,ssid以及数据库用户名和密码。 二、DbLink的创建步骤 说明:A数据库服务器是指-需要同步的数据库服务器,B数据库服务器是指-被同步的数据库服务器,以下文档中简称A数据库与B数据库。 1、在目的数据库上(A数据库),创建dblink drop public database link dblink_orc92_182; Create public DATABASE LINK dblink_orc92_182 CONNECT TO bst114IDENTIFIED BY password USING ''orc92_192.168.254.111''; 注释: --dblink_orc92_182 是dblink_name即创建的dblink名称 --bst114 是username即A数据库的用户 --password 是password即A数据库用户名密码 --''orc92_192.168.254.111'' 是远程数据库名即B数据库的名称,为了方便期间命名最好是“数据库名称+ip” 2、在源数据库(B数据库)和目的数据库(A数据库)上创建要同步的表 说明:不管是A数据库还是B数据库上创建的表最好有主键约束,快照才可以快速刷新 drop table test_user; create table test_user( id number(10) primary key, name varchar2(12), age number(3) );
数据仓库和Oracle-BI
一、数据仓库和Oracle BI ORACLE数据库11GR2:数据仓库- 网上课程 二、甲骨文快递/ OLAP 打不开 三、商业智能 1.Oracle商务智能11g的R1:创建分析和仪表盘 2.Oracle商务智能11g的R1:BUILD库 3.Oracle商业智能套件企业版10g第3版:BUILD库 4.Oracle商业智能套件企业版10g第3版:创建报表和仪表板 5.ORACLE BI EE10g第3版:报表/仪表板及商业智能发布加速 6.Oracle商业智能发布11G R1:基本面 7.Oracle商业智能10G:分析概述 8.Oracle BI应用7.9:对于Oracle EBS实施 9.Oracle商业智能套件企业版10g BOOTCAMP 10.Oracle BI应用7.9:开发数据仓库 11.ORACLE的实时决策(RTD)开发 12.ORACLE的实时决策3.0(RTD)开发 13.Oracle商业智能10G:分析概述– RWC 14.Oracle商业智能应用7.9.6实施
15.到Siebel商业分析7.7:第二部分- 网上课程 16.Oracle BI应用7.9:概述- 网上课程 17.到Siebel商业分析7.7:第一部分- 网上课程 18.Data WarehousingOracle商务智能11g的简介:最终用户工具- 网上课程 四、数据挖掘 打不开 五、Oracle Warehouse Builder将10g的 1.Oracle Warehouse Builder中10G:实现部分我 2.Oracle Warehouse Builder中10G:第二部分实施 3.Oracle Warehouse Builder中10G:新功能- 在线课程 4.Oracle9i的仓库构建器:脚本- 网上课程 六、Oracle商务智能 1.Oracle商务智能11g的升级和新功能 2.ORACLE BI Discoverer管理员11G:制定一个EUL 3.Oracle商务智能Discoverer Plus中11G:关系型和OLAP数据进行分析 4.Oracle商业智能发布10g第3版:基本面 5.ORACLE BI Discoverer管理员11G:制定一个EUL 6.Oracle商务智能11g的R1:系统管理- 网络课程
ORACLE 日常维护手册 查看数据库版本 SELECT*FROM V$VERSION; 查看数据库语言环境 SELECT USERENV('LANGUAGE')FROM DUAL; 查看ORACLE实例状态 SELECT INSTANCE_NAME,HOST_NAME,STARTUP_TIME,STATUS,DATABASE_STATUS FROM V$INSTANCE; 查看ORACLE监听状态 lsnrctl status 查看数据库归档模式 SELECT NAME,LOG_MODE,OPEN_MODE FROM V$DATABASE; 查看回收站中对象 SELECT OBJECT_NAME,ORIGINAL_NAME,TYPE FROM RECYCLEBIN; 清空回收站中对象 PURGE RECYCLEBIN; 还原回收站中的对象 FLASHBACK TABLE"BIN$GOZUQZ6GS222JZDCCTFLHQ==$0" TO BEFORE DROP RENAME TO TEST;
闪回误删除的表 FLASHBACK TABLE AAA TO BEFORE DROP; 闪回表中记录到某一时间点 ALTER TABLE TEST ENABLE ROW MOVEMENT; FLASHBACK TABLE TEST TO TIMESTAMP TO_TIMESTAMP('2009-10-15 21:17:47','YYYY-MM-DD HH24:MI:SS'); 查看当前会话 SELECT SID,SERIAL#,USERNAME,PROGRAM,MACHINE,STATUS FROM V$SESSION; 查看DDL锁 SELECT* FROM DBA_DDL_LOCKS WHERE OWNER ='FWYANG'; 检查等待事件 SELECT SID, https://www.doczj.com/doc/122910963.html,ERNAME, EVENT, WAIT_CLASS, T1.SQL_TEXT FROM V$SESSION A, V$SQLAREA T1 WHERE WAIT_CLASS <>'Idle' AND A.SQL_ID = T1.SQL_ID; 检查数据文件状态 SELECT FILE_NAME,STATUS FROM DBA_DATA_FILES; 检查表空间使用情况 SELECT UPPER(F.TABLESPACE_NAME) "表空间名", D.TOT_GROOTTE_MB "表空间大小(M)", D.TOT_GROOTTE_MB - F.TOTAL_BYTES "已使用空间(M)", TO_CHAR(ROUND((D.TOT_GROOTTE_MB -F.TOTAL_BYTES)/D.TOT_GROOTTE_MB *100, 2), '990.99') "使用比", F.TOTAL_BYTES "空闲空间(M)",
Oracle和IBM数据仓库方案对比 概述 成功地实施一个数据仓库项目,通常需要很长的时间。如果仅仅着眼于短期成果,缺乏整体考虑,采用一种不健全的体系结构,不仅会增加系统开发和维护成本,而且必将对发挥数据仓库的作用造成不利的影响。 Oracle公司是世界上最大的数据仓库厂家,能够提供完整的数据仓库解决方案。根据第三方专业咨询机构TDWI-Forrester所做的市场调查显示,Oracle是大多数IT主管选择数据仓库平台时的首选。 IBM数据仓库的市场占有率低于Oracle。权威市场分析机构IDC发布《全球数据仓库平台工具2006年度供应商市场份额》报告,根据2006年度软件收入,把甲骨文评为数据仓库平台工具领域的领先供应商(数据仓库平台工具包括ETL工具、数据仓库存储平台、多维数据库、前端展现工具)。IDC把甲骨文评为数据仓库管理领域的领先供应商,是因为甲骨文的市场份额已接近41%。在数据仓库管理工具市场,甲骨文排名最近的竞争对手的各项指标几乎只有甲骨文的一半,市场份额仅占22.8%。下图是另一家权威市场分析机构Gartner的数据仓库象限图: IBM同样低于Oracle。 ETL工具 IBM的ETL工具有三个:收购的DataStage(通常市场上说的IBM的ETL工具指的就是Datastage,不提供增量数据捕获功能,价格昂贵),数据联邦工具:Information Integrator(异构连接性好、提供增量数据捕获功能,但是不提供完整的数据源到目标数据库的ETL功能,尤其是数据转换功能很弱,没有ETL步骤打包、流程编排功能,没有按照事件或者时间触发ETL流程的功能,价格昂贵),包在Data Warehouse Edition中的ETL工具SQL Warehousing(功能很弱,异构连接性差,不提供增量数据捕获,是一个新工具,没有什么用户,不是IBM的主流ETL工具)。 功能点 使用场景或者益处 Oracle IBM 增量数据捕获 增量数据加载时,如果数据源系统没有时间戳,或者时间戳不可靠,需要利用读取数据源系统日志或者触发器方式获取增量数据,然后根据需要可以复制到目标数据库上或者批量同步到目标数据库上。 Oracle Data Integrator,对于Oracle数据库和DB2 400可以采用读取日志方式,其他数据库采用触发器方式