Part2:创建本体
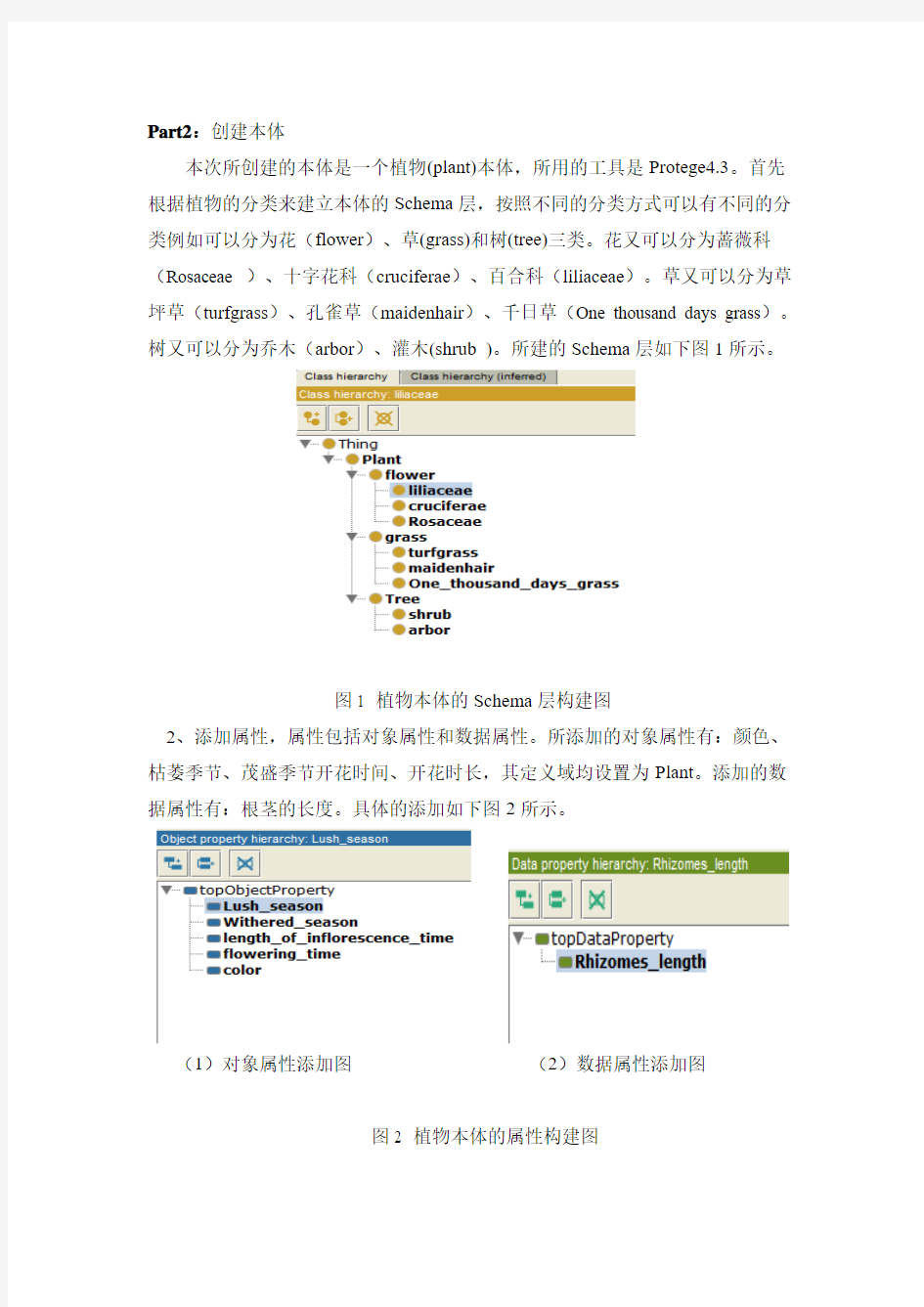
本次所创建的本体是一个植物(plant)本体,所用的工具是Protege4.3。首先根据植物的分类来建立本体的Schema层,按照不同的分类方式可以有不同的分类例如可以分为花(flower)、草(grass)和树(tree)三类。花又可以分为蔷薇科(Rosaceae )、十字花科(cruciferae)、百合科(liliaceae)。草又可以分为草坪草(turfgrass)、孔雀草(maidenhair)、千日草(One thousand days grass)。树又可以分为乔木(arbor)、灌木(shrub)。所建的Schema层如下图1所示。
图1 植物本体的Schema层构建图
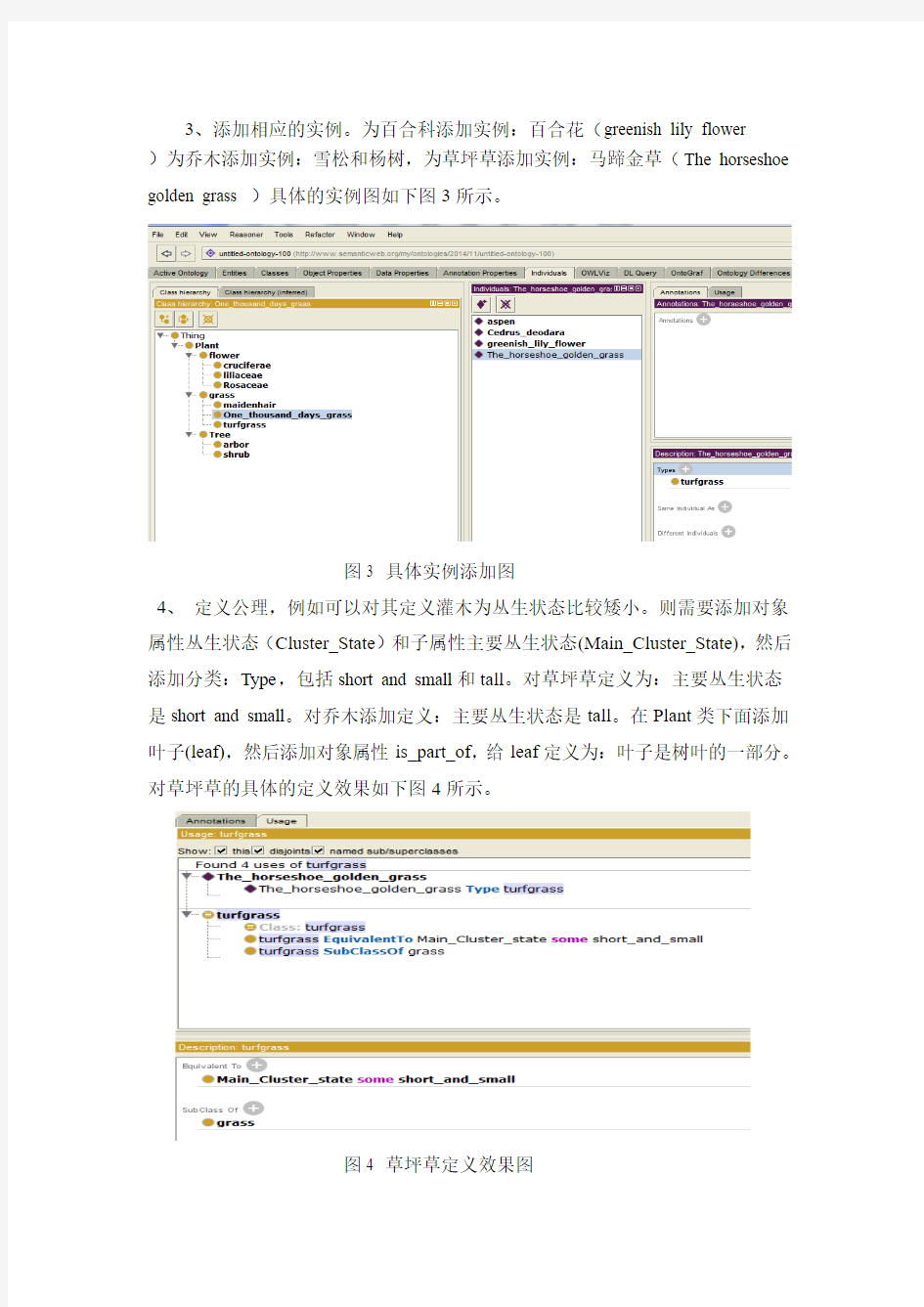
2、添加属性,属性包括对象属性和数据属性。所添加的对象属性有:颜色、枯萎季节、茂盛季节开花时间、开花时长,其定义域均设置为Plant。添加的数据属性有:根茎的长度。具体的添加如下图2所示。
(1)对象属性添加图(2)数据属性添加图
图2 植物本体的属性构建图
3、添加相应的实例。为百合科添加实例:百合花(greenish lily flower
)为乔木添加实例:雪松和杨树,为草坪草添加实例:马蹄金草(The horseshoe golden grass )具体的实例图如下图3所示。
图3 具体实例添加图
4、定义公理,例如可以对其定义灌木为丛生状态比较矮小。则需要添加对象属性丛生状态(Cluster_State)和子属性主要丛生状态(Main_Cluster_State),然后添加分类:Type,包括short and small和tall。对草坪草定义为:主要丛生状态是short and small。对乔木添加定义:主要丛生状态是tall。在Plant类下面添加叶子(leaf),然后添加对象属性is_part_of,给leaf定义为:叶子是树叶的一部分。对草坪草的具体的定义效果如下图4所示。
图4 草坪草定义效果图
5、进行推理。在Tree类下面添加松树( pine ),然后对其进行定义,定义为:松树( pine )的丛生状态是高大的(tall)。然后进行推理,通过推理可以得出松树会自动归类到乔木下面。推理效果图如下图5所示。
(1)推理前
(2)推理后
图5 推理效果图
简单的植物本体创建完成,整体效果图如下图6所示。
图6 植物本体整体效果图
Part2:创建本体 本次所创建的本体是一个植物(plant)本体,所用的工具是Protege4.3。首先根据植物的分类来建立本体的Schema层,按照不同的分类方式可以有不同的分类例如可以分为花(flower)、草(grass)和树(tree)三类。花又可以分为蔷薇科(Rosaceae )、十字花科(cruciferae)、百合科(liliaceae)。草又可以分为草坪草(turfgrass)、孔雀草(maidenhair)、千日草(One thousand days grass)。树又可以分为乔木(arbor)、灌木(shrub)。所建的Schema层如下图1所示。 图1 植物本体的Schema层构建图 2、添加属性,属性包括对象属性和数据属性。所添加的对象属性有:颜色、枯萎季节、茂盛季节开花时间、开花时长,其定义域均设置为Plant。添加的数据属性有:根茎的长度。具体的添加如下图2所示。 (1)对象属性添加图(2)数据属性添加图 图2 植物本体的属性构建图
3、添加相应的实例。为百合科添加实例:百合花(greenish lily flower )为乔木添加实例:雪松和杨树,为草坪草添加实例:马蹄金草(The horseshoe golden grass )具体的实例图如下图3所示。 图3 具体实例添加图 4、定义公理,例如可以对其定义灌木为丛生状态比较矮小。则需要添加对象属性丛生状态(Cluster_State)和子属性主要丛生状态(Main_Cluster_State),然后添加分类:Type,包括short and small和tall。对草坪草定义为:主要丛生状态是short and small。对乔木添加定义:主要丛生状态是tall。在Plant类下面添加叶子(leaf),然后添加对象属性is_part_of,给leaf定义为:叶子是树叶的一部分。对草坪草的具体的定义效果如下图4所示。 图4 草坪草定义效果图
语义网和语义网格中的本体研究综述 余一娇1,2 (1 华中师范大学语言学系,武汉,430079) (2 华中科技大学计算机学院 武汉 430074) E-mail: yjyu@https://www.doczj.com/doc/1118930973.html, 摘要:本体是语义网和语义网格研究中的一种重要方法。文中首先介绍本体的定义、本体的四元素表示法和六元组表示方法,以及本体的设计分析生命周期;然后回顾语义网研究中曾产生过巨大影响的七种本体语言。通过分析众多文献的观点,文中提出在将来我们应重点针对 DAML+OIL 和OWL两种本体语言进行深入研究。文中还列举出了本体在生物信息计算和网络管理领域应用的两个实例。最后根据语义网格和本体研究现状,提出了利用本体研究语义网格服务质量的基本思路和研究方法。 关键词:本体 本体语言 DAML+OIL OWL 语义网 语义网格 服务质量 1.前 言 Ontology在哲学领域常译为“存在论”,是指关于事物是否存在思考的学科。在计算机科学和人工智能领域则译为“本体”,其词义与哲学中的“存在论”大相径邻。1993年美国Stanford大学知识系统实验室的Gruber博士在文献[1]中定义:本体是用来帮助程序和人共享知识的概念的规范描述 (An ontology is the specification of conceptualizations, used to help programs and humans share knowledge.),后来该定义得到了进一步发展和完善[2]。文献[1]还指出:概念化是关于世界上的实体,如:事物、事物之间的关系和约束条件的知识表达。而规范一词是强调这种表达是用一种固定的形式来描述。从我们已经阅读的多篇相关文献来看,几乎所有论文都接受了上述关于本体的定义。 迅速增加的Web页面数量、丰富的页面内容和时新的消息,为知识工程领域的科学家实现面向终端用户的应用研究、开发带来了极好的机会。在Internet上实现基于语义的信息检索和情报收集,无疑是广大因特网用户的迫切需求。2001年5月,Web之父Tim Berners-Lee和合作者在《Scientific American》杂志上发表了“The Semantic Web”一文。文中正式提出了语义网的概念,鉴于Tim Berners-Lee在Web领域的巨大影响,该文后来一直被公认为是开辟语义网研究的源头文献。为了实现知识的共享和重用,语义网研究中引入本体技术是最近几年来的发展趋势,且正在被不断的实践。知识工程和人工智能学科针对本体技术进行研究已有多年历史,其中最有影响的科学研究组织是美国Stanford大学的知识系统实验室。该实验室的Gruber博士以及Deborah L. McGuiinness博士都对本体和语义网本体研究作出了巨大的贡献。 本文的结构安排如下:第二部分介绍本体的表示方法和本体开发的生命周期;第三部分介绍语义网研究中的本体语言发展过程以及多种本体语言之间的关系;第四部分介绍本体在语义网研究中的应用实例;第五部分讨论我们今后一年的研究思路和研究目标。 2. 本体的表示与本体开发 关于本体的定义如今在计算机科学领域已比较统一,但在具体的应用环境中如何规范化描述本体至今还缺乏统一的标准。目前有两种本体表示方法应用比较广泛,第一是传统的四元素表示方法、第二是较新的六元组表示法。前者源于Gruber博士的观点,后者则是2002年由新加坡南洋理工大学的Myo Myo Naing博士在一篇国际会议论文中提出。前者在世界范围内得到了比较高的认同,但
2012年第2期 Computer CD Software and Applications 信息技术应用研究 — 41 — 语义网主要应用技术与研究趋势 吴 玥 (苏州大学计算机科学与技术学院,江苏苏州 215006) 摘 要:我国企业多数已经实现了网络办公自动化,为企业的经营管理创造了优越的环境。但随着销售业务的增长,企业经营管理的范围逐渐扩大,其内部网络面临的运营难题更加明显,网络知识管理是当前企业存在的最大困难。语义网络技术的运用方便了知识管理系统的构建与操控,促进了企业知识管理效率的提升。针对这一点,本文主要分析了语义网应用的相关技术,对未来研究趋势进行总结。 关键词:语义网;应用技术;知识管理;趋势 中图分类号:TP391.1 文献标识码:A 文章编号:1007-9599(2012)02-0041-02 The Main Application Technology and Research Trends of Semantic Web Wu Yue (School of Computer Science&Technology,Soochow University,Suzhou 215006,China) Abstract:Our country enterprise majority already realize the network office automation,enterprise management to create a favorable environment.But as the sales growth,gradually expanding the scope of business management of enterprise,its internal network operator facing the problem is more apparent,network knowledge management is the current enterprise is the most difficult.Semantic network technology is convenient to use the knowledge management system's construction and operation,promote the enterprise to improve the efficiency of knowledge management.In view of this,this article mainly analyzes the semantic web technologies,the future research trends are summarized. Keywords:Semantic network;Application technology;Knowledge management;Trend 语义网是对未来计算机网络的一种假设,通过相匹配的网络 语言对文件信息详细描述,最终判断不同文档之间的内在关系。 简言之,语义网就是能参照语义完成判断的网络。企业在经营管 理中引进语义网有助于数据信息的挖掘,对数据库潜在的信息资 源充分利用,以创造更大的经济收益。 一、传统互联网知识管理的不足 互联网用于企业经营管理初期,加快了国内行业经济的改革进 步,促进了企业自动化操控模式的升级。然而,当企业经营范围不 断扩大之后,企业面临的网络管理问题也更加显著。如:业务增多、产品增多、客户增多等, 企业网络每天需要处理的文件信息不计其 数,基于传统互联网的知识管理系统也会遇到多种问题。 (一)检索问题。互联网检索是十分重要的功能,如图一。用 户在互联网上检索某一项资源时,常用的方法是通过关键词搜寻, 未能考虑到语义对资源搜索的重要性。这种检索模式下则会遇到许 多难题,如:对同义词检索会出现多余的无关资源,尽管用户在互 联网上可以查找到许多与关键词相关的信息,但多数是无用的。 图一 互联网信息检索 (二)集成问题。信息集成是网络系统按照统一的标准、编码、程序等,对整个系统存储的资源集成处理,然后实现信息资源的共享。企业互联网信息集成依旧采用人工处理,这是由于网络的自动代理软件不能处理文本代表的常识知识,信息集成问题将制约着互联网功能的持续发挥。 (三)维护问题。对于企业知识管理系统而言,其采用的文档大部分是半结构化数据,这种数据的维护管理难度较大。现有的互联网在文档维护方面缺乏先进的软件工具,对于文档信息的处理也会遇到不少错误。知识管理中的数据库资源错误会给企业经营造成误导,且带来巨大的经济损失。 二、语义网应用的相关技术 互联网研发对语义网应用研究的最终目标是“开发各种各样计算机可理解和处理的表达语义信息的语言和技术,让语义网络的功能得到最大发挥” 。因此,结合语义网络的功能特点、结构形式、信息储存等情况,用户需掌握各种语义网应用技术。就目前而言,语义网主要的应用技术包括: (一)编码技术。编码是计算机网络运行的重要元素,通过编码之后才能让程序信号及时传递。语义网编码技术就是通过编码处理将知识内容表达出来,这一过程能够把不同的知识编码为某个数据结构,从而方便了用户对数据的检索。编码技术要用到各种知识表达方法,如:一阶谓词逻辑表示法、产生式表示法、框表示法、语义网络表示法等等。 (二)框架技术。框架技术本质上就是对语义网进行层次划分,将网络结构分层不同的层面。语义网框架技术应用要借助语义 Web 模型,经过长期研究,我们把语义网体系结构分为7个层面,如图二。每个层面在语义网运行时都可发挥对应的功能,促进了语义网程序操控的稳定进行。层面框架的分析,可以掌握语义网体系中各层的功能强弱。 图二 语义网的体系结构
黄智生博士谈语义网与Web 3.0 作者徐涵发布于 2009年3月26日下午6时0分 社区 Architecture, SOA 主题 语义网 标签 Web 2.0, 采访, 元数据, 语义网 近两年来,“语义网(Semantic Web)”或“Web 3.0”越来越频繁地出现在IT 报道中,这表明语义网技术经过近10年的研究与发展,已经走出实验室进入工程实践阶段。PowerSet、Twine、 SearchMonkey、Hakia等一批语义网产品的陆续推出,预示着语义网即将在现实世界中改变人们的生活与工作方式。在Web 3.0时代即将揭开序幕之际,正确理解、掌握语义网的概念与技术,对IT人士与时俱进和增加优势是必不可少的。为此,InfoQ中文站特地邀请到来自著名语义网研究机构荷兰阿姆斯特丹自由大学的黄智生博士,请他为我们谈一谈工业界人士感兴趣的语义网话题,包括什么是语义网、语义网与Web 3.0的关系以及语义网如何给商业公司带来效益等。 InfoQ中文站:您是语义网方面的权威专家,能否先请您为我们消除概念上的困惑。现在有一个说法,即Web 3.0就是语义网。但是除了W3C定义的语义网以外,关于Web 3.0还有许多种其他说法,您认为谁才真正代表了Web 3.0?为什么? 黄智生博士(以下称黄博士):首先需要说明的是:我不认为自己是所谓的“权威”。纵观万维网的发展,总是年轻人在创造历史,他们给人类社会带来了一次又一次的惊奇。且不说万维网之父Tim Berners-Lee在1989年构想万维网的时候仅仅三十出头。Web 1.0产生的雅虎和谷歌等国际大公司的创始人大多是年轻的博士生。Web 2.0产生的Facebook等公司创始人的情况也大体如此。Web 3.0的情况也可能如此。我们甚至都不能完全指望通过现有的IT大公司的巨大投入来发展语义网。这些大公司往往受着过去成功经验的束缚,而且新技术采用的是与以往完全不同的思路,从而会加深大公司对新技术的怀疑。当然,这也为年轻人书写历史创造辉煌提供了发展空间。 由于Web 1.0和Web 2.0技术的成熟,Web 3.0的想法实际上表达了现在人们对下一代万维网技术的种种期待。从这个意义上讲,Web 3.0并不等同于语义网。网络上对Web 3.0众说纷纭,都有一定的道理。但我有一定的理由相信,语义网技术是Web 3.0的重要技术基础。我于2008年底在国内一些大学巡回讲学报告
人工智能技术导论(第三版) 第3章 1、何为状态图和与或图?图搜索与问题求解有什么关系? 解:按连接同一节点的各边间的逻辑关系划分,图可以分为状态图和与或图两大类。其中状态图是描述问题的有向图。在状态图中寻找目标或路径的基本方法就是搜索。 2、综述图搜索的方式和策略。 解:图搜索的方式有:树式搜索,线式搜索。 其策略是:盲目搜索,对树式和不回溯的线式是穷举方式,对回溯的线式是随机碰撞式。 启发式搜索,利用“启发性信息”引导的搜索。 3、什么是问题的解?什么是最优解? 解:能够解决问题的方法或具体做法成为这个问题的解。其中最好的解决方法成为最优解。 4、什么是与或树?什么是可解节点?什么是解树? 解:与或树:一棵树中的弧线表示所连树枝为“与”关系,不带弧线的树枝为或关系。这棵树中既有与关系又有或关系,因此被称为与或树。 可解节点:解树实际上是由可解节点形成的一棵子树,这棵子树的根为初始节点,叶为终止节点,且这棵子树一定是与树。 解树:满足下列条件的节点为可解节点。①终止节点是可解节点;②一个与节点可解,当且仅当其子节点全都可解;③一个或节点可解,只要其子节点至少有一个可解。 5、设有三只琴键开关一字排开,初始状态为“关、开、关”,问连接三次后是否会出现“开、开、开”或“关、关、关”的状态?要求每次必须按下一个开关,而且只能按一个开关。请画出状态空间图。 注:琴键开关有这样的特点,若第一次按下时它为“开”,则第二次按下时它就变成了“关”。 解:设0为关,1为开 6、有一农夫带一只狼、一只羊和一筐菜欲从河的左岸乘船到右岸,但受下列条件限制:1)船太小,农夫每次只能带一样东西过河。2)如果没农夫看管,则狼要吃羊,羊要吃菜。请设计一个过桥方案,使得农夫、狼、羊、菜都不受损失地过河。画出相应状态空间图。提示:(1)用四元组(农夫、狼、羊、菜)表示状态,其中每个元素都可为0或1,用0表示在左岸,用1表示在右岸。 (2)把每次过河的一次安排作为一个算符,每次过河都必须有农夫,因为只有他可以划船。解:设A=(A1,A2,A3,A4)为状态 A1:表示农夫的位置,=0:未过河、=1:已过河 A2:表示狼的位置,=0:未过河、=1:已过河 A3:表示菜的位置,=0:未过河、=1:已过河
语义网技术是当前互联网技术研究的热点之一。目前大多数页面中的使用的文字信息不便于机器自动处理,只适合人们自己阅读理解,解决可自动处理的数据和信息方面发展较慢的问题,在网络上信息量剧增、人们迫切需要计算机分担知识整理这一压力的今天,成为信息检索的一个难题。本文首先建构了一种形式化的本体描述方法,并给出了标准化的定义,主要针对在本体层定义的基础上对逻辑层展开了基础研究,对于本体概念进行逻辑推理,通过本体中关系的属性,推理出隐含在本体概念间的关系。在本文的定义中本体包含五个基本的建模元语,概念,关系,函数,公理,实例,通过本体的五个建模元语构建本体,给出本体的形式化的规范定义,本体描述中的四种特殊关系有继承关系,部分关系,实例关系和属性关系,关系的各种属性是进行本体推理的逻辑依据,有传递性属性,关系继承性,反向关系继承性,逆属性,对称性属性,反身性属性,等价性属性等等,依据这些属性的逻辑性,可以推理出所要的查找。本文利用属性的逻辑推理机制采用树搜索的查找检索方式查找出隐含在概念之间的逻辑关系是本文所要进行的主要工作,这样可以判断出概念之间是否存在一些给定判断的关系,或者一个概念和什么概念存在给定的关系,再或者两个概念间都存在什么关系等等都是我们用推理检索所要实现的判断。摘要语义网技术是当前互联网技术研究的热点之一。目前大多数页面中所使用的文字信息不便于机器自动处理,只适合人们自己阅读理解,解决可自动处理的数据和信息方面发展较慢的问题,在网络上信息量剧增、人们迫切需要计算机分担知识整理这一压力的今
天,成为信息检索的一个难题,本文中对本体层概念的推理就是为了探索计算机理解语义所做的一个尝试。语义网的体系结构向我们说明了语义网中各个层次的功能和特征,语义网的研究是阶段性的,首先解决syntax(语法)层面的问题,也就是xml,然后是解决(数据层)基本资源描述问题,也就是rdf,然后是(本体层)对资源间关系的形式化描述,就是owl,damloil,这三步已经基本告罄,当然,基于rdf 或者owl的数据挖掘和ontology管理(如合并,映射,进化)按TIMBERNERS-LEE的构想,这个工作大概到2008左右可以完成,在商业上,很快就会在知识管理,数据挖掘,数据集成方面出现一些企业。目前亟待发展的是LogicLayer(逻辑层),这方面在国内外的期刊著作中还少有提到,接下来的工作就应该是对于owlbased的数据进行推理和查询了,当前的推理方法主要是针对本体而言的,而本体的概念是在某个特定领域范围内的,而且在知识库中推理和查询是紧密的结合在一起的,相辅相成的,查询的同时必然存在着推理,而这里的推理就必须要建立在一定的逻辑模型的基础上,所以推理的方法就是基于逻辑模型的逻辑推理,可采用逻辑推理的方法。本体中推理的重点在于推理结论的正确性、完备性,若是不能保证推理的正确性,则语义网的引入就不但没有给网络资源的查询带来便利,反而阻碍了网络的发展,而且还要保证推理的完备,不遗漏应有的推理结果。本体推理的难点在于推理的高效性、资源利用率,若推理虽能达到正确性,完备性的目的而浪费了大量的时间和资源,则语义网也不能达到预期的效果,所以推理方法的使用及其效果是语义网成功的关
语义 数据的含义就是语义(semantic)。简单的说,数据就是符号。数据本身没有任何意义,只有被赋予含义的数据才能够被使用,这时候数据就转化为了信息,而数据的含义就是语义。 语义可以简单地看作是数据所对应的现实世界中的事物所代表的概念的含义,以及这些含义之间的关系,是数据在某个领域上的解释和逻辑表示。 中文名语义外文名semantic 定义数据的含义 含义对数据符号的解释 领域性特征编辑 语义具有领域性特征,不属于任何领域的语义是不存在的。而语义异构则是指对同一事物在解释上所存在差异,也就体现为同一事物在不同领域中理解的不同。对于计算机科学来说,语义一般是指用户对于那些用来描述现实世界的计算机表示(即符号)的解释,也就是用户用来联系计算机表示和现实世界的途径。 语义是对数据符号的解释,而语法则是对于这些符号之间的组织规则和结构关系的定义。对于信息集成领域来说,数据往往是通过模式(对于模式不存在或者隐含的非结构化和半结构化数据,往往需要在集成前定义出它们的模式)来组织的,数据的访问也是通过作用于模式来获得的,这时语义就是指模式元素(例如类、属性、约束等等)的含义,而语法则是模式元素的结构。 主观特征编辑 由于信息概念具有很强的主观特征,目前还没有一个统一和明确的解释。我们可以将信息简单的定义为被赋予了含义的数据,如果该含义(语义)能够被计算机所“理解”(指能够通过形式化系统解释、推理并判断),那么该信息就是能够被计算机所处理的信息。关于知识的概念目前没有明确的定义,一般来说,知识为人类提供了一种能够理解的模式用来判断事物到底表示什么或者事情将会如何发展。从知识的陈述特性上来看,知识即指用来描述信息的概念、概念之间的关系,以及概念在陈述具体事实时所必须遵守的条件。从这一点看,对于信息的语义以及信息语义之间的关联关系的描述本身就是一种知识的表达,因此在许多研究中,往往将语义的描述等同于知识的描述。
基于本体的语义检索系统的研究与应用 董涛,孟祥武 北京邮电大学计算机科学与技术学院,北京(100876) E-mail:tdong2005@https://www.doczj.com/doc/1118930973.html, 摘要:基于本体查询的语义检索是建立在Semantic Web基础之上的一种检索技术。与传统搜索引擎技术相比,它极大地提高了系统的查全率和查准率。文章首先介绍了语义网和本体的基本概念,然后通过实际举例的概念层次图详尽地阐述了本体中概念及其关系的具体意义。最后利用本体构建工具Protege并结合本体的相关标准共同构建本体,通过Jena API实现了基于OWL本体文件的语义查询系统。 关键词:本体,语义网,OWL,Jena,Protege 0. 引言 随着Internet的迅猛发展,互联网上的信息正在随指数的速度在迅速增长,出现了信息爆炸的问题。在如此浩瀚的信息海洋中,检索到有价值的信息成为当前计算机检索系统必须解决的问题。因此,信息检索技术成为当前热门的研究课题。 目前,最主要的信息检索技术有两种。一种是基于目录的检索技术,它将相关主题的页面组织起来,形成一棵目录树。因此,检索的过程,就是遍历一棵目录树的过程。另一种是基于关键字匹配的检索技术,也是最常见的检索技术[1]。 以上两种信息检索技术在查全率和查准率方面还存在着很多欠缺之处。例如:当用户查询番茄时,搜索引擎只会将包含有“番茄”一词的页面提供给用户,而不会把包含有“西红柿”一词的页面也返回给用户。因此,这就存在着查全率的问题。与此同时,搜索引擎会把包含有“番茄花园”的页面返回给用户,但这并不是用户想得到的,因此,这在查准率方面就出现了问题。 为了解决查全率和查准率的问题,就需要提高信息检索技术的精度和覆盖率。如何使搜索引擎更加智能化,使它能够充分理解用户的意图,是信息检索技术需要迫切解决的问题。近年来,语义网的提出为增强搜索引擎的智能化提供了良好的解决方案。它将网络中的各种资源结构化,使得计算机能够识别、处理。 计算机首先将检索词本体化,检索引擎通过解析、推理,然后将相关资源从本体库中提取出来,最后返回给用户。这种智能的检索技术能够提高用户的满意度,减少不相关的结果,得到更多相关的结果。 本文从构建本体及其本体库的角度出发,结合实际的应用,阐述如何建立语义检索系统进行信息检索。 1. 语义网与本体的概述 1.1 语义网 在2000年11月的XML2000会议上,Tim Berners-Lee首次提出了语义Web的概念。他将语义Web定义为:语义Web是一个网,它包含了文档或文档的一部分,描述了事物间的明显关系,且包含语义信息,以利于机器的自动处理。他于2000年提出了语义Web的体系结构[2],如下图所示:
专业导论报告 刚入大学,很多人肯定都有着既激动又迷茫的矛盾心理。激动,是因为他们通过自己的寒窗苦读12年,终于考入了大学,或许这个大学并不是他们理想中的大学,然而大学依然对他们充满着吸引力。进入大学,意味着你可以汲取更多的知识,增长更多的才干,意味着你的人生又站在了一个新的高度;迷茫,是因为很多人虽然进入了大学,可以学到更多的知识,但很多人并不知道自己学习的这些只是可以用来干什么,甚至很多人都不知道他们当初为什么会选择这个专业,大学的学习毕竟是为了将来走出大学能够更好地就业,很多大学生都并不知道自己学的专业将来走出去可以从事什么工作。因此,学校才给刚入大学的新生开设了这样一门专业导论课。 很多大学生都对专业课不重视,甚至对它不屑一顾,认为这门课学与不学,听与不听都没什么关系,因此无故逃课,课上睡觉,讲话,做其他事情等违规行为数见不鲜。其实不然,专业导论课可以说是大学最重要的一门课。通过这门课的学习,我们可以了解到我们学习的这个专业在大学里要学习哪些专业,我们学的究竟是什么,将来走出大学我们要从事哪方面的工作,了解目前的就业形势和未来的就业前景。 之所以开设这门课,目的就是为了帮助我们指明方向,让我们知道该学什么,该怎样去学以及对于以后分具体方向也有一定的把握。很多人都并不了解这些,但他们还是不愿去听,,只是懵懵懂懂地去学,老师讲什么,自己就学什么,对于自己的未来完全没有规划,结果学完大学四年都不知道自己学了些什么,自己改从事什么工作,那时的他们将感到更加迷茫,所以说认真学习这门课是非常有必要的。 说实话,当初选择计算机这个专业,纯粹只是出于对计算机有点兴趣,然而并不知道这个专业究竟要学些什么,更不知道以后还会分具体方向,不知道将来走出大学后自己能从事哪方面的工作。通过学习这门课,我对这些大概有了一个初步的了解对于计算机专业这个大类,包含了网络工程、软件工程,嵌入式等具体方向,这些方向都相互关联,却又不尽相同。目前的社会作为一个高速发展的社会,已经是一个信息化的社会,社会上的各行各业,都已离不开计算机了,各单位关于这方面的用人需求量还是挺大的,随着经济的不断增长,人民的生活不断改善,建设智慧生活、智慧城市更是少不了从事计算机方面方面的人员的参与。因此,到时无论选择哪个方向,只要认真地学好自己的专业课,并且锻炼自己各方面的能力,将来走入社会必能谋得一席之地。 当初看到老师给我的一组数据,目前计算机行业的就业形势并不是很乐观,心里难免有点失望,然而,想想老师后来说的话也确实很有道理,现代社会是一个告诉发展的社会,万物都在不断更新,时刻在变,并且计算机行业发展最为迅猛,等到我们学完大学四年之后就业形势必定还是会很乐观的。都说现在大学生就业难,就业率低,其实并不是企业或单位不需要人,而是他们也需要人,只是他们很难找到符合他们标准的人,现在中国的大学生大多在进入大学之后就成天只顾着玩,或是忙其他的事,完全荒废了学业,学完大学四年,什么也没学到,走出大学出去谋职时,自然达不到企业单位的用人要求。所以说,只要在大学期间认真的学好自己的专业课,将来走出大学才能更好地谋职。 根据近几年的就业形势来看,计算机专业的毕业生再就业方面存在着明显的两极分化现象:好的太好,坏的太坏。但是,在整个就业的过程中,更多的毕业
1.数据科学的三大支柱与五大要素是什么? 答:数据科学的三大主要支柱为: Datalogy (数据学):对应数据管理 (Data management) Analytics (分析学):对应统计方法 (Statistical method) Algorithmics (算法学):对应算法方法 (Algorithmic method) 数据科学的五大要素: A-SATA模型 分析思维 (Analytical Thinking) 统计模型 (Statistical Model) 算法计算 (Algorithmic Computing) 数据技术 (Data Technology) 综合应用 (Application) 2.如何辨证看待“大数据”中的“大”和“数据”的关系? 字面理解 Large、vast和big都可以用于形容大小 Big更强调的是相对大小的大,是抽象意义上的大 大数据是抽象的大,是思维方式上的转变 量变带来质变,思维方式,方法论都应该和以往不同 计算机并不能很好解决人工智能中的诸多问题,利用大数据突破性解决了,其核心问题变成了数据问题。 3.怎么理解科学的范式?今天如何利用这些科学范式? 科学的范式指的是常规科学所赖以运作的理论基础和实践规范,是从事某一科学的科学家群体所共同遵从的世界观和行为方式。 第一范式:经验科学 第二范式:理论科学 第三范式:计算科学 第四范式:数据密集型科学 今天,是数据科学,统一于理论、实验和模拟 4.从人类整个文明的尺度上看,IT和DT对人类的发展有些什么样的影响和冲击? 以控制为出发点的IT时代正在走向激活生产力为目的的DT(Data Technology)数据时代。大数据驱动的DT时代 由数据驱动的世界观 大数据重新定义商业新模式 大数据重新定义研发新路径 大数据重新定义企业新思维 5.大数据时代的思维方式有哪些? “大数据时代”和“智能时代”告诉我们: 数据思维:讲故事→数据说话 总体思维:样本数据→全局数据 容错思维:精确性→混杂性、不确定性 相关思维:因果关系→相关关系 智能思维:人→人机协同(人 + 人工智能) 6.请列举出六大典型思维方式; 直线思维、逆向思维、跳跃思维、归纳思维、并行思维、科学思维
语义网的发展及其可用工具 语义网的发展及其可用工具 美国阿尔法股权管理公司(Alpha Eqiuty Mangement)高级国际资产分析师Vince Fioramonti在2001年突然意识到,由于有价值的投资信息在网络上将会越来越多,今后越来越多的厂商将根据信息的重要性和关联性提供可搜集和解译这些信息的软件。语义网络将成为企业发展的利器Fioramonti称:“我曾经拥有一支专门为公司搜集和分析金融信息的分析团队。不过,他们的处理速度极为缓慢,得出的结论往往也过于主观,甚至有时会前后矛盾。”第二年,Fioramonti改用Autonomy集团的语义平台——智能数据操作层(IDOL)来自动处理各种形式的数字化信息。他们在部署中遇到了一个障碍:IDOL仅提供了常用的语义算法。Fioramonti称,阿尔法股权管理公司为此不得不组建了一个由程序员和金融分析师组成的团队,专门研发适用于金融学的算法和元数据。由于耗资过于巨大,公司最后放弃了这一项目。阿尔法股权管理公司在2008年迎来了新的契机,当时他们参加了汤森路透的机器可读新闻(Machine Readable News)服务。该服务可从3000多名路透社记者,以及网络报纸和博客等第三方资源那里收集、分析网络新闻。然后,根据影响力(如果公众对公司或产品的印象)、关联性和新颖性,对这些材料进行分析和评分。这些结果会源源不断的提供给客户,包括公共关系和营销人员、使用自动化“黑匣子交易(black
box trading)”系统的股票交易商、为长期投资决策收集整理数据的基金经理。Fioramonti称该服务每月收费并不便宜。据估计,实时数据更新的成本每月在15000至50000英镑之间。不过,对于阿尔法股权管理公司来说,该服务确实物有所值。他称,这些信息不仅帮助提升了公司的资产收益,还帮助公司击败了许多竞争对手。阿尔法股权管理公司的经历并不是唯一的案例。无论公司决定建造一个类似的内部系统,还是决定雇用服务提供商,通常都要花费巨资才能利用语义网技术。如果所搜索和分析的信息包括有针对特定商业领域的行话、概念和缩略语信息,那么同样可以实现。以下我们将为大家介绍一下那些能够帮助进行商业部署和利用语义网基础的工具,以及要想发挥这一技术的潜能还需要哪些东西。关键标准根据Tim Berners-Lee提出的概念,语义网的核心是联合搜索(Federated Search)。其可搜索引擎、代理或应用询问网络上成千上万个信息源,发现并在语义上分析相关内容,准确检索用户寻找的产品、答案或信息。尽管联合搜索正逐渐流行起来,特别是出现在了Windows7上,但是要在整个网络上广泛普及还有很长的路要走。为了有效的推动联合搜索,万维网联盟(W3C)制定了几个关键标准,定义了基本的语义基础设施。它们包括:•简单协议与RDF查询语言(SPARQL),其定义了用于查询和访问数据的标准语言。•资源描述框架(RDF)和RDF模式(RDFS),其规范了在语义本体(又称为词汇表)中如何陈述和组织信息。•网络本体语言(OWL),其对本体论和部分RDFS原理进行了详细陈述。目前这些标准的最终
绪论单元测试 1、问题: 1956年达特茅斯会议上,学者们首次提出“artificial intelligence(人工智能)”这个概念时,所确定的人工智能研究方向不包括: 选项: A:研究如何用计算机表示人类知识 B:研究智能学习的机制 C:研究人类大脑结构和智能起源 D:研究如何用计算机来模拟人类智能 答案: 【研究人类大脑结构和智能起源】 2、问题: 在现阶段,下列哪项尚未成为人工智能研究的主要方向和目标: 选项: A:研究如何用计算机模拟人类大脑的网络结构和部分功能 B:研究如何用计算机延伸和扩展人类智能 C:研究机器智能与人类智能的本质差别 D:研究如何用计算机模拟人类智能的若干功能,如会听、会看、会说 答案: 【研究机器智能与人类智能的本质差别】 3、问题: 下面哪个不是人工智能的主要研究流派? 选项: A:符号主义 B:经验主义 C:连接主义 D:模拟主义 答案: 【模拟主义】 4、问题:
从人工智能研究流派来看,西蒙和纽厄尔提出的“逻辑理论家”方法用,应当属于: 选项: A:经验主义,行为主义 B:符号主义,连接主义 C:连接主义,经验主义 D:理性主义,符号主义 答案: 【理性主义,符号主义】 5、问题: 从人工智能研究流派来看,明斯基等人所推荐的“人工神经网络”方法用计算机模拟神经元及其连接,实现自主识别、判断,应当属于: 选项: A:理性主义,符号主义 B:符号主义,连接主义 C:经验主义,行为主义 D:连接主义,经验主义 答案: 【连接主义,经验主义】 6、问题: “鸟飞派”指的是人类研究人工智能必须要完全符合智能现象的本质 选项: A:错 B:对 答案: 【错】 7、问题: 人工智能受到越来越多的关注,许多国家出台了支持人工智能发展的战略计划 选项: A:对 B:错 答案: 【对】
计算机科学与技术导论期末试卷及其答案 一、选择题(30分) 1. 用一个字节表示无符号整数,其最大值是十进制数()。 A. 256 B. 255 C. 127 D. 128 2. 一个完整的计算机系统应包括()。 A. 运算器、控制器和存储器 B. 主机和应用程序 C. 硬件系统和软件系统 D. 主机和外部设备 3. 微机中的CPU是指()。 A. 内存和运算器 B. 输入设备和输出设备 C. 存储器和控制器 D. 控制器和运算器 4. 计算机的性能主要取决于()。 A. 字长、运算速度和内存容量 B. 磁盘容量和打印机质量 C. 操作系统和外部设备 D. 机器价格和所配置的操作系统 5. 磁盘上的磁道是()。 A. 一组记录密度不同的同心圆 B. 一组记录密度相同的同心圆 C. 一组记录密度不同的阿基米德螺旋线 D. 一组记录密度相同的阿基米德螺旋线 6. 下列E–mail地址正确的是()。 A. wangfang/https://www.doczj.com/doc/1118930973.html, B. https://www.doczj.com/doc/1118930973.html, C. wangfang#https://www.doczj.com/doc/1118930973.html, D. wangfang@https://www.doczj.com/doc/1118930973.html, 7. UNIX操作系统是一种()。 A. 单用户单任务操作系统 B. 实时操作系统 C. 多用户多任务操作系统 D. 单用户多任务操作系统 8. 下列四项中,不属于计算机病毒特征的是()。 A. 潜伏性 B. 免疫性 C. 传染性 D. 激发性 9. 电子计算机主存内的ROM是指()。 A. 不能改变其内的数据 B. 只能读出数据,不能写入数据 C. 通常用来存储系统程序 D. 以上都是 10. 市场上出售的微机中,常看到CPU标注为―Pentium4/1.2G‖,其中的1.2G表示()。 A. CPU的时钟主频是1.2GMHz B. CPU的运算速度是1.2Gb/s C. 处理器的产品系列号 D. CPU与内存的数据交换率
人工智能技术导论(第三版)第3章 1、何为状态图和与或图?图搜索与问题求解有什么关系? 解:按连接同一节点的各边间的逻辑关系划分,图可以分为状态图和与或图两大类。其中状态图是描述问题的有向图。在状态图中寻找目标或路径的基本方法就是搜索。 2、综述图搜索的方式和策略。 解:图搜索的方式有:树式搜索,线式搜索。 其策略是:盲目搜索,对树式和不回溯的线式是穷举方式,对回溯的线式是随机碰撞式。 启发式搜索,利用“启发性信息”引导的搜索。 3、什么是问题的解?什么是最优解? 解:能够解决问题的方法或具体做法成为这个问题的解。其中最好的解决方法成为最优解。 4、什么是与或树?什么是可解节点?什么是解树? 解:与或树:一棵树中的弧线表示所连树枝为“与”关系,不带弧线的树枝为或关系。这棵树中既有与关系又有或关系,因此被称为与或树。 可解节点:解树实际上是由可解节点形成的一棵子树,这棵子树的根为初始节点,叶为终止节点,且这棵子树一定是与树。 解树:满足下列条件的节点为可解节点。①终止节点是可解节点;②一个与节点可解,当且仅当其子节点全都可解;③一个或节点可解,只要其子节点至少有一个可解。 5、设有三只琴键开关一字排开,初始状态为“关、开、关”,问连接三次后是否会出现“开、开、开”或“关、关、关”的状态?要求每次必须按下一个开关,而且只能按一个开关。请画出状态空间图。 注:琴键开关有这样的特点,若第一次按下时它为“开”,则第二次按下时它就变成了“关”。解:设0为关,1为开 6、有一农夫带一只狼、一只羊和一筐菜欲从河的左岸乘船到右岸,但受下列条件限制: 1)船太小,农夫每次只能带一样东西过河。2)如果没农夫看管,则狼要吃羊,羊要吃菜。 请设计一个过桥方案,使得农夫、狼、羊、菜都不受损失地过河。画出相应状态空间图。 提示:(1)用四元组(农夫、狼、羊、菜)表示状态,其中每个元素都可为0或1,用0表示在左岸,用1表示在右岸。 (2)把每次过河的一次安排作为一个算符,每次过河都必须有农夫,因为只有他可以划船。解:设A=(A1,A2,A3,A4)为状态 A1:表示农夫的位置,=0:未过河、=1:已过河 A2:表示狼的位置,=0:未过河、=1:已过河 :已过河=1:未过河、=0:表示菜的位置,A3. A4:表示羊的位置,=0:未过河、=1:已过河 具体的过河方案为: (1)农夫、羊从左岸-》右岸,留下羊-》一人回到左岸 (2)农夫、菜从左岸-》右岸,留下菜-》农夫、羊回到左岸
第一章绪论 信息技术的发展彻底的改变了人类获取/处理/传播信息的手段和方式,特别是互联网的诞生,使人们能够更加方便/迅速/多途径的获取和发送信息。全面了解现代信息技术并在实际工作中应用这些技术将有助于人们提高生活质量/工作效率以及信息素质。 1.1信息概念的定义与内涵 各学科基本概念是很重要的,信息在很多学科属于基本概念。但是,到目前为止学术界仍然没有给出一个能够被普遍接受的信息的定义,各学科对信息的定义完全不同。 1.1.1信息概念的三个层次 人们对信息的认识和解释可以分为3个层次:哲学层次/学科层次和日常生活层次。 从这三个层次认识信息并把握3个层次之间的关系,可以帮助人们正确/全面理解信息概念,这3个层次的含义具有密切的联系。 哲学层次的信息概念是从最基本/最普遍的意义上揭示信息的本质/特征和形态,是最为广义的信息概念。在众多学科层次信息概念和日常生活层次信息概念的基础上可以抽象/概括出哲学层次的信息概念。 学科层次的信息概念是哲学层次的信息概念在各学科领域的具体表现,它们具有各自学科自身的特点,具有实用性。对学科层次的信息概念的研究可以丰富和充实哲学层次的信息概念的内涵。 日常生活的信息含义是学科层次信息概念和日常生活层次信息概念的实用化和通俗化的表达。 哲学层次的信息概念揭示了信息的本质,但是它不能直接引用在各具体的学科之中,因为它已脱去了具体学科的特性和实用性。有着各自学科特性的信息概念虽然不能揭示信息的本质,但是却在特定的领域充当着重要角色。它们使得信息的表现更为具体化和多样化。生活层次的信息概念虽然是通俗化的,但是依然是信息在生活领域中的表现形式。 1.1.2生活层次的信息概念 生活层次的信息概念是直观化的/通俗化的和更为实用化的概念,它的表现形式更为丰富多样。人们日常的生活离不开信息。 1.1.3学科层次的信息概念 “负熵”:熵函数的负向变化量;负熵是物质系统有序化/组织化/复杂化状态的一种量度。 狭义信息论:1.申农:信息是减少或者消除一种情况不确定的东西; 2.信息是系统组织程度有序性的标志(负熵)。 狭义信息论的不足:1.申农的信息论并没有揭示信息是什么,而是指出信息在通讯中的作用。2.维纳只是将信息量当作信息,并没有对信息做出严格的解释,并没有说明信息是什么。3.信息传播的内容要比适用于通讯技术的客观信息要复杂的多,信息对不同的接收对象价值不同,这些狭义信息论无法解释。 国内对信息的解释大都引用狭义信息论的定义,并结合自身学科的特殊情况加以补充。 1.1.4哲学层次的信息概念 哲学层次的信息概念是从最基本最普遍的意义上来揭示信息的本质/特征和形态,是最为广义的信息概念。在众多学科层次的信息概念和日常生活层次的信息概念的基础上可以抽象/概括出哲学层次的信息概念。 通过对众多哲学信息概念的定义进行分析可以看出: 1.事物或者物质的存在方式和运动状态是信息赖以存在的基础。