
嵌入式Linux之我行——u-boot-2009.08在2440上的移植
详解(六)
嵌入式Linux之我行,主要讲述和总结了本人在学习嵌入式linux中的每个步骤。一为总结经验,
二希望能给想入门嵌入式Linux的朋友提供方便。如有错误之处,谢请指正。
?共享资源,欢迎转载:https://www.doczj.com/doc/0c9374445.html,
一、移植环境
?主机:VMWare--Fedora 9
?开发板:Mini2440--64MB Nand,Kernel:2.6.30.4
?编译器:arm-linux-gcc-4.3.2.tgz
?u-boot:u-boot-2009.08.tar.bz2
二、移植步骤
上接:u-boot-2009.08在2440上的移植详解(五)
10)u-boot利用tftp服务下载内核和利用nfs服务挂载nfs文件系统。
知识点:
1.tftp服务的安装与配置及测试;
2.nfs服务的安装与配置及测试;
3.u-boot到kernel的参数传递(重点)。
我们知道使用tftp下载内核和使用nfs挂载文件系统的好处是,当我们重新编译内核或文件系
统后不用重新把这些镜像文件再烧录到flash上,而是把这些镜像文件放到开发主机的tftp或nfs
服务的主目录下,通过网络来加载他们,不用频繁的往flash上烧,这样一可以保护flash的使用
寿命,二可以方便的调试内核或文件系统,提高开发效率。可见,让u-boot实现这个功能是一件很有意义的事情。
实现这样的功能很简单,网上也有很多资料。但有很多细节的东西如果稍不注意就导致失败,这里就结合本人实现的过程进行讲述和一些问题的分析。
?tftp服务的安装与配置及测试
要使用tftp服务及测试它要安装两个软件包,一个就是tftp服务器,另外一个就是tftp客户端,这里安装客户端只是用于在主机本地测试tftp服务器是否正常运行的,来确保u-boot能够访
问tftp服务(u-boot中已有tftp客户端的功能,其实在前面几篇中都已经使用了tftp下载内核或
文件系统到开发板上,如果那里都做到了,这里就可以直接跳过)。
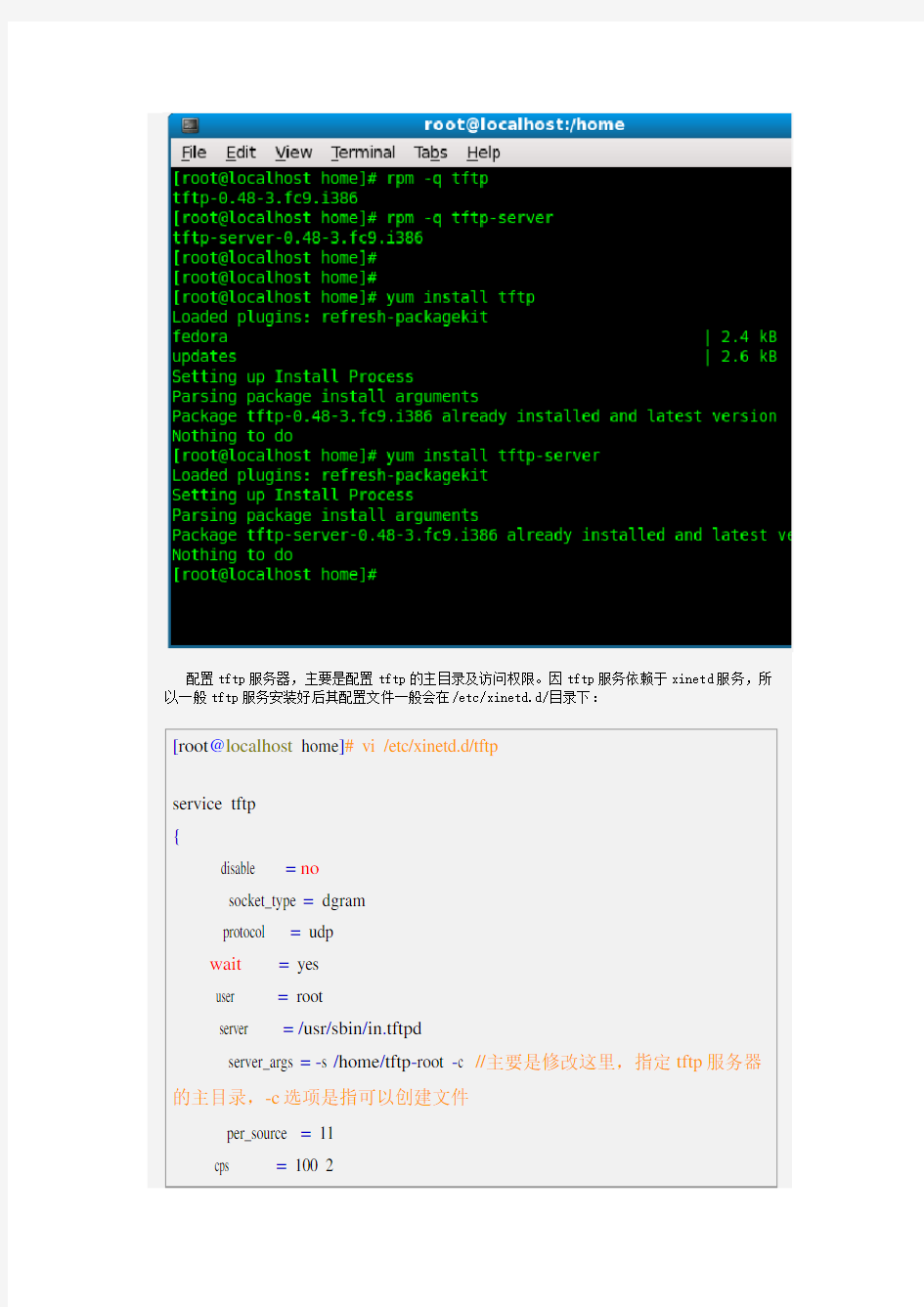
首先使用rpm命令查看你的主机上是否已经安装了tftp服务器和客户端,如果没有安装就去下
载这两个软件包进行安装或者可以使用yum命令进行在线安装,yum会自动的去搜索适合你主机平
台的最新软件包进行下载安装,如果主机已经安装了,则会提示软件包已经安装了最新的版本。如
下图所示:
配置tftp服务器,主要是配置tftp的主目录及访问权限。因tftp服务依赖于xinetd服务,所以一般tftp服务安装好后其配置文件一般会在/etc/xinetd.d/目录下:
[root@localhost home]# vi /etc/xinetd.d/tftp
service tftp
{
disable =no
socket_type = dgram
protocol = udp
wait= yes
user = root
server =/usr/sbin/in.tftpd
server_args =-s /home/tftp-root -c //主要是修改这里,指定tftp服务器的主目录,-c选项是指可以创建文件
per_source = 11
cps = 100 2
flags = IPv4
}
创建刚才指定的tftp服务器主目录,也要注意主目录的可读可写的权限:
[root@localhost home]#mkdir /home/tftp-root
[root@localhost home]#chmod 777 /home/tftp-root
启动和测试tftp服务:
[root@localhost home]#service xinetd restart //重启xinetd服务就会启动其下的所有服务,也包括tftp服务
[root@localhost home]#service iptables stop //关闭防火墙
[root@localhost home]#tftp 主机IP地址
tftp>get 要下载的文件
tftp>put 要上传的文件
tftp>q
[root@localhost home]#
?nfs服务的安装与配置及测试
以root的身份在控制台输入setup,在系统服务选项中选中nfs服务,如下图:
配置NFS服务器的共享主目录,也要注意权限问题:
[root@localhost home]# vi /etc/exports //如果没有这个文件就创建它,添加下面一行配置信息,注意格式一定要正确,否则导致服务不正常
/home/filesystem *(rw,no_root_squash,sync)
注释:“/home/filesystem”是NFS服务器的主目录,注意目录的权限
“*”表示所有的IP都可以访问NFS主目录
“rw”表示可读可写
”no_root_squash“表示登入到NFS主机的用户如果是ROOT用户,他就拥有ROOT的权限
“sync”表示同步
[root@localhost home]# service nfs restart //重新启动NFS服务,使配置文件生效
测试NFS服务是否正常。将事先准备好的文件系统放到NFS主目录下,如下:
[root@localhost home]# ls /home/filesystem/
bin dev home lib mnt root sum100 tmp var
debug etc hostname linuxrc proc sbin sys usr
[root@localhost home]#
//在主机本地测试NFS服务,将NFS主目录下的文件系统挂载到/mnt目录下,192.168.1.101是主机的IP
[root@localhost home]#mount -o nolock -t nfs 192.168.1.101:/home/filesystem /mnt
可以看到/mnt目录下的内容和NFS主目录/home/filesystem下的内容完全一致,说明NFS 服务正常:
?u-boot到kernel的参数传递
我们知道,在kernel配置选项Boot options中有一个Default kernel command string参数项,而在u-boot参数中也有一个bootargs参数项,他们都是供内核启动用的,那他们又有什么区别呢,内核启动时到底是用哪一个呢?两种参数项分别如下图所示(kernel中的参数指定是从开发板Flash分区上挂载文件系统,u-boot中的参数指定的是从NFS挂载文件系统):
实际上,内核中的参数项是内核默认提供的,在内核配置时去指定,而u-boot提供的则在u-boot启动时传递到内核中取代内核提供的参数。所以当u-boot没有提供bootargs参数时,内核启动就是用内核配置时指定的参数,当u-boot提供了bootargs参数时就使用u-boot的参数。
那么,u-boot是如果将参数信息传递到内核中的呢?而内核又是怎么接收u-boot传递过来的参数呢?这就涉及到一点点ARM寄存器的知识了。
我们知道,ARM有7种工作模式和37个寄存器(31个通用寄存器和6个状态寄存器),如下图:
ARM工作模式之间的转换就是利用这些寄存器进行,而u-boot参数的传递也利用了三个通用寄存器R0、R1和R2。关于ARM工作模式和寄存器在这里就不做讲叙了,以后再讲,这里你就理解成u-boot在启动的时候把参数存放到这三个寄存器中,到内核启动时再把寄存器中的参数取出,当然,他们并不是就这样简单的操作。下面我们看代码一一分析。
首先,我们来分析一下u-boot是怎样处理和发送要传递的参数,而u-boot要传递的参数又有哪些呢?除了我们最容易知道的bootargs(即内核commandline)参数项外,要传递的参数还有MACH_TYPE(即我们所说的机器码)、系统根设备信息(标志,页面大小)、内存信息(起始地址,大小)、RAMDISK信息(起始地址,大小)、压缩的RAMDISK根文件系统信息(起始地址,大小)。由此可见要传递的参数很多,这时候,u-boot就提供一种叫做参数链表(tagged list)的方式把这些参数组织起来,链表结构体定义在:include/asm-arm/setup.h中,而实现链表的组织在
lib_arm/bootm.c中:
我们可以看到,链表的组织是由一系列函数实现,u-boot规定,链表必须以ATAG_CORE标记开始,以ATAG_NONE标记结束,中间就是一些参数标记项,这点从代码中可以体现出来。那么在这些函数中有一个bd的参数是至关重要的,它是一个bd_info类型的结构体,定义在
include/asm-arm/u-boot.h中,而这个结构体又被一个global_data类型的结构体所引用,定义在include/asm-arm/global_data.h中,如下:
那么,那个bd参数到底是做什么用的呢?从定义中可以得知,bd记录了机器码、u-boot参数链表在内存中的地址等信息,那又问,它在什么地方进行记录的呢?它就在我们自己开发板初始化代码中记录的,如:board/samsung/my2440/my2440.c中
注意:bd_t被gd_t所引用,而在global_data.h中我们可以看到,u-boot定义了一个gd_t的全局指针变量*gd,所以在这里就可以直接使用gd来设置bd了。
好了,我们还是接着分析这个参数链表是如何被传递的,组织参数链表的系列函数在一个叫
do_bootm_linux的函数中被调用的,还是定义在lib_arm/bootm.c中
从这个函数中我们可以看到,要使参数传递生效必须需要CONFIG_SETUP_MEMORY_TAGS和CONFIG_CMDLINE_TAG这两个宏的支持,所以需要在include/configs/my2440.h中定义它们。原来我就是没定义它们,在使用NFS挂载文件系统时就出现问题。同时,theKernel这个函数指针是u-boot参数传递的至关点,我们知道,函数在内存中执行的时候其实就是一个地址,而在代码中首先将这个函数指针指向kernel的入口地址,最后还将0、机器码和u-boot参数项在内存中的地址带给这个入口地址,故执行这个入口地址的时候即kernel启动的时候可以有这三个参数进行接收。那么,这个入口地址(kernel启动地址或者说kernel入口地址)是怎么来的是谁指定的,又是多少呢?看代码,是从一个bootm_headers_t类型的结构体的成员ep取得的,而这个结构体是从调用do_bootm_linux的地方传递过来的。bootm_headers_t定义在include/image.h 中,do_bootm_linux在common/cmd_bootm.c中被调用,如下:
从代码中可以清楚的看到对bootm_headers_t的成员ep进行了赋值,但是还是不够直观这个入口地址到底是多少?只知道是使用image_get_ep函数从bootm_headers_t中的
legacy_hdr_os_copy上取得的,那它在什么地方被赋值的呢?原来在image_set_ep函数中,
定义在tools/mkimage.c中,如下:
我们再想想,这个mkimage.c是做什么用的?原来是用它来制作u-boot格式的内核——uImage,还记得怎样使用mkimage来制作uImage吧,在“u-boot-2009.08在2440上的移植详解(四)”中讲到,如下:
mkimage [-x]-A arch -O os -T type -C comp -a addr -e ep -n name -d data_file[:data_file...] image
选项:
-A:set architecture to 'arch'//用于指定CPU类型,比如ARM
-O:set operating system to 'os'//用于指定操作系统,比如Linux
-T:set image type to 'type'//用于指定image类型,比如Kernel
-C:set compression type 'comp'//指定压缩类型
-a:set load address to 'addr'(hex)//指定image的载入地址
-e:set entry point to 'ep'(hex)//内核的入口地址,一般为image的载入地址+0x40(信息头的大小)
-n:set image name to 'name'//image在头结构中的命名
-d:use image data from 'datafile'//无头信息的image文件名
-x:set XIP (execute in place)//设置执行位置
例如:
mkimage -n 'linux-2.6.30.4'-A arm -O linux -T kernel -C none -a 0x30008000 -e 0x30008000 -d zImage uImage.img
呵呵,相信此时的你拨云见日,茅塞顿开了吧!这个入口地址就是0x30008000,这也正是为什么u-boot一定要使用uImage的格式来启动内核的原因之一。注意:这里有个kernel入口地址
0x30008000,在上面还提到一个u-boot参数链表在内存中的地址0x30000100,试想如果这里指定的kernel入口地址覆盖了参数链表的地址会怎么样?
好了,把上面每个步骤从下往上看就可以知道u-boot参数项在u-boot端的传递的整个流程了,
那么,接下来再分析u-boot参数项在kernel端是怎样接收的。
kernel启动的流程如下图所示:
在文件arch/arm/boot/compressed/head.S中,start是zImage的起始点,部分代码如下:start:
......
.word 0x016f2818 @ Magic numbers to help the loader
.word start @ absolute load/run zImage address
.word _edata @ zImage end address
1:mov r7, r1 @ save architecture ID
mov r8, r2 @ save atags pointer
......
wont_overwrite: mov r0, r4
mov r3, r7
bl decompress_kernel
b call_kernel
......
call_kernel: bl cache_clean_flush
bl cache_off
mov r0, #0 @ must be zero
mov r1, r7 @ restore architecture number
mov r2, r8 @ restore atags pointer
mov pc, r4 @ call kernel
......
首先,将u-boot传递过来的r1(机器码)、r2(参数链表在内在中的物理地址)分别保存到ARM寄存器r7、r8中,再将r7作为参数传递给解压函数decompress_kernel(),在这个解压函数中再将r7传递给全局变量__machine_arch_type,然后在跳转到vmlinux入口之前再将r7、r8还原到r1、r2
中。
在arch/arm/kernel/head.S文件中,内核vmlinux入口的部分代码如下:
ENTRY(stext)
setmode PSR_F_BIT | PSR_I_BIT | SVC_MODE, r9 @ ensure svc mode @ and irqs disabled
mrc p15, 0, r9, c0, c0 @ get processor id bl __lookup_processor_type @ r5=procinfo r9=cpuid
movs r10, r5 @ invalid processor (r5=0)? beq __error_p @ yes, error 'p'
bl __lookup_machine_type @ r5=machinfo
movs r8, r5 @ invalid machine (r5=0)?
beq __error_a @ yes, error 'a'
bl __vet_atags
bl __create_page_tables
......
首先从ARM特殊寄存器(CP15)中获得ARM内核的类型,从处理器内核描述符
(proc_info_list)表(__proc_info_begin—__proc_info_end)中查询有无此ARM 内核的类型,如果无就出错退出。处理器内核描述符定义在include/asm-arm/procinfo.h 中,具体的函数实现在 arch/arm/mm/proc-xxx.S中,在编译连接过程中将各种处理器内核描述符组合成表。接着从机器描述(machine_desc)表(__mach_info_begin—
__mach_info_end)中查询有无r1寄存器指定的机器码,如果没有就出错退出,所以这也说明了为什么在u-boot中指定的机器码一定要与内核中指定的一致,否则内核就无法启动。机器编号mach_type_xxx在arch/arm/tools/mach-types文件中说明,每个机器描述符中包括一个唯一的机器编号,机器描述符的定义在 include/asm-arm/mach/arch.h中,具体实现在arch/arm/mach-xxxx文件夹中,在编译连接过程中将基于同一种处理器的不同机器描述符组合成表。例如,S3C2440处理器的机器码为1008的机器描述符如下所示:
MACHINE_START(SMDK2440,"SMDK2440")
/* Maintainer: Ben Dooks
.phys_io = S3C2410_PA_UART,
.io_pg_offst =(((u32)S3C24XX_VA_UART)>> 18)& 0xfffc,
.boot_params = S3C2410_SDRAM_PA + 0x100,//注意:这个地址就是与u-boot中参数链表在内存中的物理地址相对应
.init_irq = s3c24xx_init_irq,
.map_io = smdk2440_map_io,
.init_machine = smdk2440_machine_init,
.timer =&s3c24xx_timer,
MACHINE_END
最后就打开MMU,并跳转到 init/main.c的start_kernel()初始化系统。函数start_kernel ()的部分代码如下:
asmlinkage void __init start_kernel(void)
{
......
setup_arch(&command_line);
......
}
函数setup_arch在arch/arm/kernel/setup.c中实现,部分代码如下:
void __init setup_arch(char**cmdline_p)
{
......
setup_processor();
mdesc = setup_machine(machine_arch_type);
......
parse_tags(tags);
......
}
setup_processor()函数从处理器内核描述符表中找到匹配的描述符,并初始化一些处理器
变量。setup_machine()用机器编号(在解压函数decompress_kernel 中被赋值)作为参数返回机器描述符。从机器描述符中获得内核参数的物理地址,赋值给tags 变量。然后调用parse_tags ()函数分析内核参数链表,把各个参数值传递给全局变量。这样内核就收到了u-boot传递的参数。
?tftp下载内核和nfs挂载文件系统
好了,上面tftp服务和nfs服务都已经准备好了,u-boot到kernel的参数传递也没问题了,接下来就设置一下u-boot环境变量中的参数项和kernel的配置选项使之能使用tftp自动下载kernal 和通过网络自动挂载nfs文件系统。u-boot环境变量设置如下:
bootcmd参数项就是使用tftp把主机tftp主目录下的uImage下载到开发板SDRAM中的
0x31000000位置,接着使用bootm命令执行引导内核启动。
而bootargs参数项就是内核启动的命令行参数,u-boot就是把这个参数项传递给了内核,通过nfs挂载文件系统。这里一定要注意serverip和ipaddr的设置(即服务器IP或者开发主机IP和开发板的IP)。另外要注意,内核要能使用nfs也要配置相应的选项,如下:
File systems --->
Network File Systems --->
<*> NFS file system support ## 必选
[*] Provide NFSv3 client support ## 可选
[*] Root file system on NFS ## 必选
Networking --->
[*] Networking support
Networking options --->
[*] IP: kernel level autoconfiguration ## 必选
运行结果如下:
a. tftp下载内核,并引导内核启动:
b. u-boot传递的命令行参数被内核所接收:
c. 内核通过nfs挂载文件系统:
基于32位ARM920T内核的微处理器的嵌入式Linux系统构建详解目前,在嵌入式系统中基于ARM微核的嵌入式处理器已经成为市场主流。随着ARM技术的广泛应用,建立面向ARM构架的嵌入式操作系统成为当前研究的热点问题。 已经涌现出许多嵌入式操作系统,如VxWork,windows-CE,PalmOS,Linux等。在众多的嵌入式操作系统中,Linux以其开源代码及免费使用倍受开发人员的喜爱。本文选用的微处理器S3C2410是基于32位ARM920T内核的微处理器,基于此处理器构造一Linux 嵌入式操作系统,将其移植到基于32位的ARM920T内核的系统中,在此基础上进行应用程序开发。 l、开发环境介绍 1.1、基于S3C2410ARM920T的硬件平台 该系统的硬件平台为深圳旋极公司提供,硬件的核心部件为三星$3C2410ARM920T芯片,外围还包括:64MNANDFLASH和RAM外围存储芯片;串口、网口和USB外围接口;CSTNLCD和触摸屏外围显示设备;UDAl34lTS的外围音频设备。S3C2410处理器和外围设备共同构成了基于ARM920T的开发板。 1.2、嵌入式Limlx软件系统 该嵌入式Linux的软件系统包括以下4个部分:引导加载程序vivi;Linux2.6.14内核;YAFFS2文件系统以及用户程序。他们的可执行映像依次存放在系统存储设备上. 与通常的嵌入式系统布局有所不同,本系统在引导加载程序和内核映像之间还增加了一个启动参数区,在这个区里存放着系统启动参数。引导加载程序通过调用这些参数来决定启动模式、启动等待时间等,这些启动参数的增加加强了系统的灵活性。本系统采用64MNANDFLASH的存储设备。 2、嵌入式Linux系统设计与实现 2.1、引导加载程序vivi
探究linux内核,超详细解析子系统 Perface 前面已经写过一篇《嵌入式linux内核的五个子系统》,概括性比较强,也比较简略,现在对其进行补充说明。 仅留此笔记,待日后查看及补充!Linux内核的子系统 内核是操作系统的核心。Linux内核提供很多基本功能,如虚拟内存、多任务、共享库、需求加载、共享写时拷贝(Copy-On-Write)以及网络功能等。增加各种不同功能导致内核代码不断增加。 Linux内核把不同功能分成不同的子系统的方法,通过一种整体的结构把各种功能集合在一起,提高了工作效率。同时还提供动态加载模块的方式,为动态修改内核功能提供了灵活性。系统调用接口用户程序通过软件中断后,调用系统内核提供的功能,这个在用户空间和内核提供的服务之间的接口称为系统调用。系统调用是Linux内核提供的,用户空间无法直接使用系统调用。在用户进程使用系统调用必须跨越应用程序和内核的界限。Linux内核向用户提供了统一的系统调用接口,但是在不同处理器上系统调用的方法
各不相同。Linux内核提供了大量的系统调用,现在从系统 调用的基本原理出发探究Linux系统调用的方法。这是在一个用户进程中通过GNU C库进行的系统调用示意图,系 统调用通过同一个入口点传入内核。以i386体系结构为例,约定使用EAX寄存器标记系统调用。 当加载了系统C库调用的索引和参数时,就会调用0x80软件中断,它将执行system_call函数,这个函数按照EAX 寄存器内容的标示处理所有的系统调用。经过几个单元测试,会使用EAX寄存器的内容的索引查system_call_table表得到系统调用的入口,然后执行系统调用。从系统调用返回后,最终执行system_exit,并调用resume_userspace函数返回用户空间。 linux内核系统调用的核心是系统多路分解表。最终通过EAX寄存器的系统调用标识和索引值从对应的系统调用表 中查出对应系统调用的入口地址,然后执行系统调用。 linux系统调用并不单层的调用关系,有的系统调用会由
内核移植阶段 内核是操作系统最基本的部分。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并且内核决定一个程序在什么时候对某部分硬件操作多长时间。直接对硬件操作是非常复杂的,所以内核通常提供一种硬件抽象的方法来完成这些操作。硬件抽象隐藏了复杂性,为应用软件和硬件提供了一套简洁,统一的接口,使程序设计更为简单。 内核和用户界面共同为用户提供了操作计算机的方便方式。也就是我们在windows下看到的操作系统了。由于内核的源码提供了非常广泛的硬件支持,通用性很好,所以移植起来就方便了许多,我们需要做的就是针对我们要移植的对象,对内核源码进行相应的配置,如果出现内核源码中不支持的硬件这时就需要我们自己添加相应的驱动程序了。 一.移植准备 1. 目标板 我们还是选用之前bootloader移植选用的开发板参数请参考上文的地址: https://www.doczj.com/doc/0c9374445.html,/thread-80832-5-1.html。bootloader移植准备。 2. 内核源码 这里我们选用比较新的内核源码版本linux-2.6.25.8,他的下载地址是 ftp://https://www.doczj.com/doc/0c9374445.html,/pub/linux/kernel/v2.6/linux-2.6.25.8.tar.bz2。 3. 烧写工具 我们选用网口进行烧写这就需要内核在才裁剪的时候要对网卡进行支持 4. 知识储备 要进行内核裁剪不可缺少的是要对内核源码的目录结构有一定的了解这里进 行简单介绍。 (1)arch/: arch子目录包括了所有和体系结构相关的核心代码。它的每一个子 目录都代表一种支持的体系结构,例如i386就是关于intel cpu及与之相兼容体 系结构的子目录。PC机一般都基于此目录。 (2)block/:部分块设备驱动程序。 (3)crypto:常用加密和散列算法(如AES、SHA等),还有一些压缩和CRC校验 算法。 (4) documentation/:文档目录,没有内核代码,只是一套有用的文档。 (5) drivers/:放置系统所有的设备驱动程序;每种驱动程序又各占用一个子目 录:如,/block 下为块设备驱动程序,比如ide(ide.c)。 (6)fs/:所有的文件系统代码和各种类型的文件操作代码,它的每一个子目录支持 一个文件系统, 例如fat和ext2。
本文档的Copyleft归wwwlkk所有,使用GPL发布,可以自由拷贝、转载,转载时请保持文档的完整性,严禁用于任何商业用途。 E-mail: wwwlkk@https://www.doczj.com/doc/0c9374445.html, 来源: https://www.doczj.com/doc/0c9374445.html,/?business&aid=6&un=wwwlkk#7 linux2.6.35内核IMQ源码实现分析 (1)数据包截留并重新注入协议栈技术 (1) (2)及时处理数据包技术 (2) (3)IMQ设备数据包重新注入协议栈流程 (4) (4)IMQ截留数据包流程 (4) (5)IMQ在软中断中及时将数据包重新注入协议栈 (7) (6)结束语 (9) 前言:IMQ用于入口流量整形和全局的流量控制,IMQ的配置是很简单的,但很少人分析过IMQ的内核实现,网络上也没有IMQ的源码分析文档,为了搞清楚IMQ的性能,稳定性,以及借鉴IMQ的技术,本文分析了IMQ的内核实现机制。 首先揭示IMQ的核心技术: 1.如何从协议栈中截留数据包,并能把数据包重新注入协议栈。 2.如何做到及时的将数据包重新注入协议栈。 实际上linux的标准内核已经解决了以上2个技术难点,第1个技术可以在NF_QUEUE机制中看到,第二个技术可以在发包软中断中看到。下面先介绍这2个技术。 (1)数据包截留并重新注入协议栈技术
(2)及时处理数据包技术 QoS有个技术难点:将数据包入队,然后发送队列中合适的数据包,那么如何做到队列中的数
激活状态的队列是否能保证队列中的数据包被及时的发送吗?接下来看一下,激活状态的队列的 证了数据包会被及时的发送。 这是linux内核发送软中断的机制,IMQ就是利用了这个机制,不同点在于:正常的发送队列是将数据包发送给网卡驱动,而IMQ队列是将数据包发送给okfn函数。
参考答案 第一章 一、填空题。 1、嵌入式系统主要融合了计算机软硬件技术、通信技术和微电子技术,它是将计算机直接嵌入到应用系统中,利用计算机的高速处理能力以实现某些特定的功能。 2、目前国内对嵌入式系统普遍认同的定义是:以应用为中心、以计算机技术为基础、软硬件可裁剪、适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。 3、嵌入式系统一般由嵌入式计算机和执行部件组成,其中嵌入式计算机主要由四个部分组成,它们分别是:硬件层、中间层、系统软件层以及应用软件层。 4、嵌入式处理器目前主要有ARM、MIPS、Power PC、68K等,其中arm处理器有三大特点:体积小、低功耗、的成本和高性能,16/32位双指令集,全球合作伙伴众多。 5、常见的嵌入式操作系统有:Linux、Vxworks、WinCE、Palm、uc/OS-II和eCOS。 6、嵌入式系统开发的一般流程主要包括系统需求分析、体系结构设计、软硬件及机械系统设计、系统集成、系统测试,最后得到最终产品。 二、选择题 1、嵌入式系统中硬件层主要包含了嵌入式系统重要的硬件设备:、存储器(SDRAM、ROM等)、设备I/O接口等。(A) A、嵌入式处理器 B、嵌入式控制器 C、单片机 D、集成芯片 2、20世纪90年代以后,随着系统应用对实时性要求的提高,系统软件规模不断上升,实时核逐渐发展为,并作为一种软件平台逐步成为目前国际嵌入式系统的主流。(D) A、分时多任务操作系统 B、多任务操作系统 C、实时操作系统 D、实时多任务操作系统 3、由于其高可靠性,在美国的火星表面登陆的火星探测器上也使用的嵌入式操作系统是。(B) A、Palm B、VxWorks C、Linux D、WinCE [在此处键入]
Linux内核结构详解教程 ─────Linux内核教程 linux内核就像人的心脏,灵魂,指挥中心。 内核是一个操作系统的核心,它负责管理系统的进程,内存,设备驱动程序,文件和网络系统,决定着系统的性能和稳定性。内核以独占的方式执行最底层任务,保证系统正常运行。协调多个并发进程,管理进程使用的内存,使它们相互之间不产生冲突,满足进程访问磁盘的请求等等. 严格说Linux并不能称做一个完整的操作系统.我们安装时通常所说的Linux,是有很多集合组成的.应称为GNU/Linux. 一个Linux内核很少1.2M左右,一张软盘就能放下. 内容基础,语言简短简洁 红联Linux论坛是致力于Linux技术讨论的站点,目前网站收录的文章及教程基本能满足不同水平的朋友学习。 红联Linux门户: https://www.doczj.com/doc/0c9374445.html, 红联Linux论坛: https://www.doczj.com/doc/0c9374445.html,/bbs 红联Linux 论坛大全,所有致力点都体现在这 https://www.doczj.com/doc/0c9374445.html,/bbs/rf/linux/07.htm
目录 Linux内核结构详解 Linux内核主要五个子系统详解 各个子系统之间的依赖关系 系统数据结构 Linux的具体结构 Linux内核源代码 Linux 内核源代码的结构 从何处开始阅读源代码 海量Linux技术文章
Linux内核结构详解 发布时间:2006-11-16 19:05:29 Linux内核主要由五个子系统组成:进程调度,内存管理,虚拟文件系统,网络接口,进程间通信。
Linux内核主要五个子系统详解 发布时间:2006-11-16 19:05:54 1.进程调度(SCHED):控制进程对CPU的访问。当需要选择下一个进程运行时,由调度程序选择最值得运行的进程。可运行进程实际上是仅等待CPU资源的进程,如果某个进程在等待其它资源,则该进程是不可运行进程。Linux使用了比较简单的基于优先级的进程调度算法选择新的进程。 2.内存管理(MM)允许多个进程安全的共享主内存区域。Linux的内存管理支持虚拟内存,即在计算机中运行的程序,其代码,数据,堆栈的总量可以超过实际内存的大小,操作系统只是把当前使用的程序块保留在内存中,其余的程序块则保留在磁盘中。必要时,操作系统负责在磁盘和内存间交换程序块。内存管理从逻辑上分为硬件无关部分和硬件有关部分。硬件无关部分提供了进程的映射和逻辑内存的对换;硬件相关的部分为内存管理硬件提供了虚拟接口。 3.虚拟文件系统(VirtualFileSystem,VFS)隐藏了各种硬件的具体细节,为所有的设备提供了统一的接口,VFS提供了多达数十种不同的文件系统。虚拟文件系统可以分为逻辑文件系统和设备驱动程序。逻辑文件系统指Linux所支持的文件系统,如ext2,fat等,设备驱动程序指为每一种硬件控制器所编写的设备驱动程序模块。 4.网络接口(NET)提供了对各种网络标准的存取和各种网络硬件的支持。网络接口可分为网络协议和网络驱动程序。网络协议部分负责实现每一种可能的网络传输协议。网络设备驱动程序负责与硬件设备通讯,每一种可能的硬件设备都有相应的设备驱动程序。 5.进程间通讯(IPC) 支持进程间各种通信机制。 处于中心位置的进程调度,所有其它的子系统都依赖它,因为每个子系统都需要挂起或恢复进程。一般情况下,当一个进程等待硬件操作完成时,它被挂起;当操作真正完成时,进程被恢复执行。例如,当一个进程通过网络发送一条消息时,网络接口需要挂起发送进程,直到硬件成功地完成消息的发送,当消息被成功的发送出去以后,网络接口给进程返回一个代码,表示操作的成功或失败。其他子系统以相似的理由依赖于进程调度。
从软件工程的角度来说,嵌入式应用软件也有一定的生命周期,如要进行需求分析、系统设计、代码编写、调试和维护等工作,软件工程的许多理论对它也是适用的。 但和其他通用软件相比,它的开发有许多独特之处: ·在需求分析时,必须考虑硬件性能的影响,具体功能必须考虑由何种硬件实现。 ·在系统设计阶段,重点考虑的是任务的划分及其接口,而不是模块的划分。模块划分则放在了任务的设计阶段。 ·在调试时采用交叉调试方式。 ·软件调试完毕固化到嵌入式系统中后,它的后期维护工作较少。 下面主要介绍分析和设计阶段的步骤与原则: 1、需求分析 对需求加以分析产生需求说明,需求说明过程给出系统功能需求,它包括:·系统所有实现的功能 ·系统的输入、输出 ·系统的外部接口需求(如用户界面) ·它的性能以及诸如文件/数据库安全等其他要求 在实时系统中,常用状态变迁图来描述系统。在设计状态图时,应对系统运行过程进行详细考虑,尽量在状态图中列出所有系统状态,包括许多用户无需知道的内部状态,对许多异常也应有相应处理。 此外,应清楚地说明人机接口,即操作员与系统间地相互作用。对于比较复杂地系统,形成一本操作手册是必要的,为用户提供使用该系统的操作步骤。为使系统说明更清楚,可以将状态变迁图与操作手册脚本结合起来。
在对需求进行分析,了解系统所要实现的功能的基础上,系统开发选用何种硬件、软件平台就可以确定了。 对于硬件平台,要考虑的是微处理器的处理速度、内存空间的大小、外部扩展设备是否满足功能要求等。如微处理器对外部事件的响应速度是否满足系统的实时性要求,它的稳定性如何,内存空间是否满足操作系统及应用软件的运行要求,对于要求网络功能的系统,是否扩展有以太网接口等。 对于软件平台而言,操作系统是否支持实时性及支持的程度、对多任务的管理能力是否支持前面选中的微处理器、网络功能是否满足系统要求以及开发环境是否完善等都是必须考虑的。 当然,不管选用何种软硬件平台,成本因素都是要考虑的,嵌入式Linux 正是在这方面具有突出的优势。 2、任务和模块划分 在进行需求分析和明确系统功能后,就可以对系统进行任务划分。任务是代码运行的一个映象,是无限循环的一段代码。从系统的角度来看,任务是嵌入式系统中竞争系统资源的最小运行单元,任务可以使用或等待CPU、I/O设备和内存空间等系统资源。 在设计一个较为复杂的多任务应用系统时,进行合理的任务划分对系统的运行效率、实时性和吞吐量影响都极大。任务分解过细会不断地在各任务之间切换,而任务之间的通信量也会很大,这样将会大大地增加系统的开销,影响系统的效率。而任务分解过粗、不够彻底又会造成原本可以并行的操作只能按顺序串行执行,从而影响系统的吞吐量。为了达到系统效率和吞吐量之间的平衡折中,在划分任务时应在数据流图的基础上,遵循下列步骤和原则:
引言 Linux诞生于1991年,芬兰学生LinuSTorvaldS是Linux操作系统的缔造者,与传统的操作系统不同,Linux操作系统的开发一开始就在FSF(自由软件基金会组织)的GPL(GNU Public License)的版本控制之下,Linux内核的所有源代码都采取了开放源代码的方式。Linux具有相当多的优点。 BSP(Board Support Packet——板级支持包)是介于底层硬件和上层软件之间的底层软件开发包,其主要功能为屏蔽硬件,提供操作系统的引导及硬件驱动。Linux操作系统目前已发展为主流操作系统之一,并且还在不断的壮大和发展。 最新的2.6版内核增加了很多新特性为嵌入式应用提供广泛的支持,使得它不仅可以应用于大型系统,还可以应用于像PDA这类超小型系统中。随着Linux系统在嵌入式领域的广泛应用,对它的研究也在逐渐成为热点并且走向成熟。 在嵌入式系统开发过程中,板级支持包(BSP,BoardSuport Package)的开发已成为非常重要的环节。本文以Linux系统上的BSP技术为研究内容,讨论了BSP的基本概念和设计思想,特别针对Linux系统上BSP的层次结构、各功能模块的实现技术做了详细分析。 通过分析PC机的BIOS技术阐述了嵌入式系统中板级初始化流程和技术重点,并从源代码分析入手详细分析了PC机GURB引导程序设计技术,提出了嵌入式系统上BootLoader的程序结构和设计思想。 嵌入式操作系统对设备驱动程序的管理技术是BSP设计的重要组成部分。本文对比了Linux2.4和Linux2.6的设备驱动程序框架,同时结合大量源代码的研读,对Linux2.6内核的统一设备模型进行了深入的研究,剖析了内核对象机制的主要数据结构及驱动程序设计框架,理解了该模型对设备类的抽象机制,并在实际的项目实践中,结合所作的研究工作,圆满完成了基于ARM+Linux开发平台的BSP开发任务。 最后对本文研究工作进行了总结,并对下一步工作进行了展望。
linux内核启动+Android系统启动过程详解 第一部分:汇编部分 Linux启动之 linux-rk3288-tchip/kernel/arch/arm/boot/compressed/ head.S分析这段代码是linux boot后执行的第一个程序,完成的主要工作是解压内核,然后跳转到相关执行地址。这部分代码在做驱动开发时不需要改动,但分析其执行流程对是理解android的第一步 开头有一段宏定义这是gnu arm汇编的宏定义。关于GUN 的汇编和其他编译器,在指令语法上有很大差别,具体可查询相关GUN汇编语法了解 另外此段代码必须不能包括重定位部分。因为这时一开始必须要立即运行的。所谓重定位,比如当编译时某个文件用到外部符号是用动态链接库的方式,那么该文件生成的目标文件将包含重定位信息,在加载时需要重定位该符号,否则执行时将因找不到地址而出错 #ifdef DEBUG//开始是调试用,主要是一些打印输出函数,不用关心 #if defined(CONFIG_DEBUG_ICEDCC)
……具体代码略 #endif 宏定义结束之后定义了一个段, .section ".start", #alloc, #execinstr 这个段的段名是 .start,#alloc表示Section contains allocated data, #execinstr表示Section contains executable instructions. 生成最终映像时,这段代码会放在最开头 .align start: .type start,#function /*.type指定start这个符号是函数类型*/ .rept 8 mov r0, r0 //将此命令重复8次,相当于nop,这里是为中断向量保存空间 .endr b 1f .word 0x016f2818 @ Magic numbers to help the loader
看完了路由表,重新回到netif_receive_skb ()函数,在提交给上层协议处理前,会执行下面一句,这就是网桥的相关操作,也是这篇要讲解的容。 view plaincopy to clipboardprint? 1. s kb = handle_bridge(skb, &pt_prev, &ret, orig_dev); 网桥可以简单理解为交换机,以下图为例,一台linux机器可以看作网桥和路由的结合,网桥将物理上的两个局域网LAN1、LAN2当作一个局域网处理,路由连接了两个子网1.0和2.0。从eth0和eth1网卡收到的报文在Bridge模块中会被处理成是由Bridge收到的,因此Bridge也相当于一个虚拟网卡。 STP五种状态 DISABLED BLOCKING LISTENING LEARNING FORWARDING 创建新的网桥br_add_bridge [net\bridge\br_if.c] 当使用SIOCBRADDBR调用ioctl时,会创建新的网桥br_add_bridge。 首先是创建新的网桥: view plaincopy to clipboardprint?
1. d ev = new_bridge_dev(net, name); 然后设置dev->dev.type为br_type,而br_type是个全局变量,只初始化了一个名字变量 view plaincopy to clipboardprint? 1. S ET_NETDEV_DEVTYPE(dev, &br_type); 2. s tatic struct device_type br_type = { 3. .name = "bridge", 4. }; 然后注册新创建的设备dev,网桥就相当一个虚拟网卡设备,注册过的设备用ifconfig 就可查看到: view plaincopy to clipboardprint? 1. r et = register_netdevice(dev); 最后在sysfs文件系统中也创建相应项,便于查看和管理: view plaincopy to clipboardprint? 1. r et = br_sysfs_addbr(dev); 将端口加入网桥br_add_if() [net\bridge\br_if.c] 当使用SIOCBRADDIF调用ioctl时,会向网卡加入新的端口br_add_if。 创建新的net_bridge_port p,会从br->port_list中分配一个未用的port_no,p->br会指向br,p->state设为BR_STATE_DISABLED。这里的p实际代表的就是网卡设备。 view plaincopy to clipboardprint? 1. p = new_nbp(br, dev); 将新创建的p加入CAM表中,CAM表是用来记录mac地址与物理端口的对应关系;而刚刚创建了p,因此也要加入CAM表中,并且该表项应是local的[关系如下图],可以看到,CAM表在实现中作为net_bridge的hash表,以addr作为hash值,链入 net_bridge_fdb_entry,再由它的dst指向net_bridge_port。
对于每一个配置选项,用户可以回答"y"、"m"或"n"。其中"y"表示将相应特性的支持或设备驱动程序编译进内核;"m"表示将相应特性的支持或设备驱动程序编译成可加载模块,在需要时,可由系统或用户自行加入到内核中去;"n"表示内核不提供相应特性或驱动程序的支持。只有<>才能选择M 1. General setup(通用选项) [*]Prompt for development and/or incomplete code/drivers,设置界面中显示还在开发或者还没有完成的代码与驱动,最好选上,许多设备都需要它才能配置。 [ ]Cross-compiler tool prefix,交叉编译工具前缀,如果你要使用交叉编译工具的话输入相关前缀。默认不使用。嵌入式linux更不需要。 [ ]Local version - append to kernel release,自定义版本,也就是uname -r可以看到的版本,可以自行修改,没多大意义。 [ ]Automatically append version information to the version string,自动生成版本信息。这个选项会自动探测你的内核并且生成相应的版本,使之不会和原先的重复。这需要Perl的支持。由于在编译的命令make-kpkg 中我们会加入- –append-to-version 选项来生成自定义版本,所以这里选N。 Kernel compression mode (LZMA),选择压缩方式。 [ ]Support for paging of anonymous memory (swap),交换分区支持,也就是虚拟内存支持,嵌入式不需要。 [*]System V IPC,为进程提供通信机制,这将使系统中各进程间有交换信息与保持同步的能力。有些程序只有在选Y的情况下才能运行,所以不用考虑,这里一定要选。 [*]POSIX Message Queues,这是POSIX的消息队列,它同样是一种IPC(进程间通讯)。建议你最好将它选上。 [*]BSD Process Accounting,允许进程访问内核,将账户信息写入文件中,主要包括进程的创建时间/创建者/内存占用等信息。可以选上,无所谓。 [*]BSD Process Accounting version 3 file format,选用的话统计信息将会以新的格式(V3)写入,注意这个格式和以前的v0/v1/v2 格式不兼容,选不选无所谓。 [ ]Export task/process statistics through netlink (EXPERIMENTAL),通过通用的网络输出工作/进程的相应数据,和BSD不同的是,这些数据在进程运行的时候就可以通过相关命令访问。和BSD类似,数据将在进程结束时送入用户空间。如果不清楚,选N(实验阶段功能,下同)。 [ ]Auditing support,审计功能,某些内核模块需要它(SELINUX),如果不知道,不用选。 [ ]RCU Subsystem,一个高性能的锁机制RCU 子系统,不懂不了解,按默认就行。 [ ]Kernel .config support,将.config配置信息保存在内核中,选上它及它的子项使得其它用户能从/proc/ config.gz中得到内核的配置,选上,重新配置内核时可以利用已有配置Enable access to .config through /proc/config.gz,上一项的子项,可以通过/proc/ config.gz访问.config配置,上一个选的话,建议选上。 (16)Kernel log buffer size (16 => 64KB, 17 => 128KB) ,内核日志缓存的大小,使用默认值即可。12 => 4 KB,13 => 8 KB,14 => 16 KB单处理器,15 => 32 KB多处理器,16 => 64 KB,17 => 128 KB。 [ ]Control Group support(有子项),使用默认即可,不清楚可以不选。 Example debug cgroup subsystem,cgroup子系统调试例子 Namespace cgroup subsystem,cgroup子系统命名空间 Device controller for cgroups,cgroups设备控制器
嵌入式Linux具有稳定、可伸缩及开放源代码等特点,可兼容多 种处理器和主机,广泛适用于各种产品和应用。但是,交叉编译、 设备驱动程序开发/调试,以及更小尺寸等要求对嵌入式Linux开 发者来说都是严峻的挑战。为应对这些挑战,针对嵌入式Linux开 发的专用工具应运而生,而且发展十分迅猛。 但是,许多这类开发工具都不兼容非X86平台,而且也没有很好 地实现归档备案或集成。在其它开发环境下,组件间的高度集成并 没有完全兑现。因此,要想完全从这些免费的软件组件开始创建 一个完整的跨平台开发环境,开发者应意识到这将需要大量的调 研、实施、培训和维护方面的工作。 Linux 是少数既可以在嵌入式设备上运行也可作为开发环境的操 作系统之一。这一特性可让开发者在转向此开发系统之前于常用硬 件(比如X86桌面系统)之上开发、调试和测试应用程序和库,因 此可减少对标准参考平台和指令集仿真器的依赖。这一技术仅适用于应用程序和库,但不适用于设备驱动程序,因为后者的开发依赖于 Linux架构。 开放源代码团体及一些软件供应商可提供设备驱动程序开发工具。由于设备驱动程序比标准应用程序距离硬件更近,因此它们的开发比较困难。所幸的是,Linux 桌面系统可以利用一些Windows及其它操作系统所没有的工具。有足够经验开发设备驱动程序的开发人员可能已经习惯将Linux作为他们的桌面开发系统了。 Linux的快速发展及其桌面方案的不断涌现提出了一个重要问题:所选择的工具方案怎样在不同的Linux分布式系统上运行?它们依赖于主机平台的软件配置吗? 有些Linux工具提供独立于主机平台的开发环境,包括一系列可支持开发工具的应用软件、库和实用程序。这一方法几乎将开发环境与主机配置完全隔离开来,因此主机可以是任何Linux分布式系统,而且任何更新和修改都不会影响开发环境的功能。 这种方法的主要缺点是对存储空间的要求有所增加――约200MB,因为它自己实际上相当于一个微型Linux分布式系统。 可用的工具 一个嵌入式Linux产品的开发需要几个阶段,包括为目标板配置和构建基本Linux OS;调试应用程序、库、内核及设备驱动程序/内核模块;出货前最终方案的优化、测试和验证。 有数百种开放源代码开发工具可供选择。只要开发者原意花时间和精力去调研、实施和维护一系列各不相同的工具,总能找出一个完整的解决方案,完成几乎任何开发任务。
基于ARM的嵌入式linux内核的裁剪与 移植 0引言微处理器的产生为价格低廉、结构小巧的CPU和外设的连接提供了稳定可靠的硬件架构,这样,限制嵌入式系统发展的瓶颈就突出表现在了软件方面。尽管从八十年代末开始,已经陆续出现了一些嵌入式操作系统(比较著名的有Vxwork、pSOS、Neculeus和WindowsCE)。但这些专用操作系统都是商业化产品,其高昂的价格使许多低端产品的小公司望而却步;而且,源代码封闭性也大大限制了开发者的积极性。而Linux的开放性,使得许多人都认为Linu 0 引言 微处理器的产生为价格低廉、结构小巧的CPU和外设的连接提供了稳定可靠的硬件架构,这样,限制嵌入式系统发展的瓶颈就突出表现在了软件方面。尽管从八十年代末开始,已经陆续出现了一些嵌入式操作系统(比较著名的有Vxwork、pSOS、Nec uleus和Windows CE)。但这些专用操作系统都是商业化产品,其高昂的价格使许多低端产品的小公司望而却步;而且,源代码封闭性也大大限制了开发者的积极性。而Linux的开放性,使得许多人都认为Linux 非常适合多数Intemet设备。Linux操作系统可以支持不同的设备和不同的配置。Linux对厂商不偏不倚,而且成本极低,因而很快成为用于各种设备的操作系统。嵌入式linux是大势所趋,其巨大的市场潜力与酝酿的无限商机必然会吸引众多的厂商进入这一领域。 1 嵌入式linux操作系统 Linux为嵌入操作系统提供了一个极有吸引力的选择,它是个和Unix 相似、以核心为基础、全内存保护、多任务、多进程的操作系统。可以支持广泛的计算机硬件,包括X86、Alpha、Sparc、MIPS、PPC、ARM、NEC、MOTOROLA 等现有的大部分芯片。Linux的程序源码全部公开,任何人都可以根据自己的需要裁剪内核,以适应自己的系统。文章以将linux移植到ARM920T内核的 s3c2410处理器芯片为例,介绍了嵌入式linux内核的裁剪以及移植过程,文中介绍的基本原理与方法技巧也可用于其它芯片。 2 内核移植过程 2.1 建立交叉编译环境 交叉编译的任务主要是在一个平台上生成可以在另一个平台上执行的程序代码。不同的CPU需要有不同的编译器,交叉编译如同翻译一样,它可以把相同的程序代码翻译成不同的CPU对应语言。 交叉编译器完整的安装涉及到多个软件安装,最重要的有binutils、gcc、glibc三个。其中,binutils主要用于生成一些辅助工具;gcc则用来生成交叉编译器,主要生成arm—linux—gcc交叉编译工具;glibc主要是提供用户程序所使用的一些基本的函数库。 自行搭建交叉编译环境通常比较复杂,而且很容易出错。本文使用的是
基于嵌入式Linux的汉字输入法 An Approach to Chinese Input based on Embedded Linux Abstract: The Chinese input problem is essential to an embedded system. An approach to on-line recognition of handwritten Chinese stroke is proposed., including its realization in embedded system. Keywords: handwritten Chinese character recognition; on-line recognition; dynamic recognition; embedded system 摘要:汉字输入法是嵌入式系统输入的一项重要技术,它的功能与性能直接影响到嵌入式系统在中国的推广与应用。主要研究了联机汉字手写体输入法,以及在嵌入式系统中实现汉字手写体输入法。 关键词:手写体识别;联机识别;动态识别;嵌入式系统; .1 引言 在信息时代,嵌入式系统如个人数字助理(PDA)、JAVA手机、人工智能电器等已广泛渗入人们的日常工作和生活中。由于受到键盘大小和按键数目的限制,汉字输入是影响嵌入式系统使用的重要因素。具有强烈人性化的手写汉字输入是解决嵌入式系统汉字输入问题的最佳方法之一。随着硬件成本的降低和汉字手写体识别技术的提高,汉字手写识别在嵌入式系统的应用将会日益广泛。 嵌入式系统是硬件资源受限系统,所以汉字手写体识别应考虑到嵌入式系统这个特点。其中比较重要的是,嵌入式系统的硬件配置低,除了考虑汉字识别的识别率外,还必须考虑输入的速度。手写汉字的输入时间包括书写时间和识别时间两部分,一般以前者所耗时间较多。当前市面上融合嵌入式手写汉字输入法的产品如PDA、智能手机、智能数码相机等几乎都在整个汉字书写完毕后才出现识别结果,所以即使系统的识别速度很快,也需要把整个汉字写完,因此整体的输入速度始终没有质的提高。针对上述问题,本文提出了一种基于汉字笔顺的联机动态手写汉字识别方法,在人们书写汉字的过程中,对其已经书写的部分汉字笔划进行动态识别,预测其想要书写的汉字并输出给用户选择,并且集成弹性网格特征法,以达到在保证识别率的前提下提高整体输入速度目的。本文主要进行以下几项工作:
实例解析linux内核I2C体系结构(2) 华清远见刘洪涛四、在内核里写i2c设备驱动的两种方式 前文介绍了利用/dev/i2c-0在应用层完成对i2c设备的操作,但很多时候我们还是习惯为i2c设备在内核层编写驱动程序。目前内核支持两种编写i2c驱动程序的方式。下面分别介绍这两种方式的实现。这里分别称这两种方式为“Adapter方式(LEGACY)”和“Probe方式(new style)”。 (1)Adapter方式(LEGACY) (下面的实例代码是在2.6.27内核的pca953x.c基础上修改的,原始代码采用的是本文将要讨论的第2种方式,即Probe方式) ●构建i2c_driver static struct i2c_driver pca953x_driver = { .driver = { .name= "pca953x", //名称 }, .id= ID_PCA9555,//id号 .attach_adapter= pca953x_attach_adapter, //调用适配器连接设备 .detach_client= pca953x_detach_client,//让设备脱离适配器 }; ●注册i2c_driver static int __init pca953x_init(void) { return i2c_add_driver(&pca953x_driver); } module_init(pca953x_init); ●attach_adapter动作 执行i2c_add_driver(&pca953x_driver)后会,如果内核中已经注册了i2c适配器,则顺序调用这些适配器来连接我们的i2c设备。此过程是通过调用i2c_driver中的attach_adapter方法完成的。具体实现形式如下: static int pca953x_attach_adapter(struct i2c_adapter *adapter) { return i2c_probe(adapter, &addr_data, pca953x_detect); /* adapter:适配器 addr_data:地址信息 pca953x_detect:探测到设备后调用的函数 */ } 地址信息addr_data是由下面代码指定的。 /* Addresses to scan */ static unsigned short normal_i2c[] = {0x20,0x21,0x22,0x23,0x24,0x25,0x26,0x27,I2C_CLIENT_END}; I2C_CLIENT_INSMOD;
很久以前分析的,一直在电脑的一个角落,今天发现贴出来和大家分享下。由于是word直接粘过来的有点乱,敬请谅解! S3C2410 Linux 2.6.35.7启动分析(第一阶段) arm linux 内核生成过程 1. 依据arch/arm/kernel/vmlinux.lds 生成linux内核源码根目录下的vmlinux,这个vmlinux属于未压缩, 带调试信息、符号表的最初的内核,大小约23MB; 命令:arm-linux-gnu-ld -o vmlinux -T arch/arm/kernel/vmlinux.lds arch/arm/kernel/head.o init/built-in.o --start-group arch/arm/mach-s3c2410/built-in.o kernel/built-in.o mm/built-in.o fs/built-in.o ipc/built-in.o drivers/built-in.o net/built-in.o --end-group .tmp_kallsyms2.o 2. 将上面的vmlinux去除调试信息、注释、符号表等内容,生成arch/arm/boot/Image,这是不带多余信息的linux内核,Image的大小约 3.2MB; 命令:arm-linux-gnu-objcopy -O binary -S vmlinux arch/arm/boot/Image 3.将 arch/arm/boot/Image 用gzip -9 压缩生成arch/arm/boot/compressed/piggy.gz大小约 1.5MB;命令:gzip -f -9 < arch/arm/boot/compressed/../Image > arch/arm/boot/compressed/piggy.gz 4. 编译arch/arm/boot/compressed/piggy.S 生成arch/arm/boot/compressed/piggy.o大小约1.5MB,这里实 际上是将piggy.gz通过piggy.S编译进piggy.o文件中。而piggy.S文件仅有6行,只是包含了文件piggy.gz; 命令:arm-linux-gnu-gcc -o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/piggy.S 5. 依据arch/arm/boot/compressed/vmlinux.lds 将arch/arm/boot/compressed/目录下的文件head.o 、piggy.o 、misc.o链接生成arch/arm/boot/compressed/vmlinux,这个vmlinux是经过压缩且含有自解压代码的内核, 大小约1.5MB; 命 令:arm-linux-gnu-ld zreladdr=0x30008000 params_phys=0x30000100 -T arch/arm/boot/compressed/vmlinux.lds a rch/arm/boot/compressed/head.o arch/arm/boot/compressed/piggy.o arch/arm/boot/compressed/misc.o -o arch/arm /boot/compressed/vmlinux
[导读] 3G的接人技术已经从WCDMA/TD- SCDMA/CD-MA2000发展到HSDPA、HSUPA 以及HSPA+ ,并开始由3G 网络向4G网络过渡。 3G的接人技术已经从WCDMA/TD- SCDMA/CD-MA2000发展到HSDPA、HSUPA 以及HSPA+ ,并开始由3G 网络向4G网络过渡。目前HSDPA的接入带宽可以达到7.2 Mbps,HSPA+ 的接人带宽可以达到21 Mbps,而即将部署的LTE的网络带宽甚至达到了100 Mbps 。同时,由于接人移动互联网的智能终端的数量快速增长,人们对移动互联网的应用需求也日益增长。当人们面对几十兆带宽甚至是上百兆带宽时,必定存在带宽的过剩问题,即人们不需要在任何时刻都需要这么大的带宽,因而可以将过剩的用户带宽分配给更多的用户。 目前,WiFi技术能够支持IEEE的802.11b、802.11g和802.1ln标准,分别支持10 Mbps、54 Mbps和300 Mbps的无线传输速率。而在传输距离上,WiFi能够在几米到100m范围内实现完全覆盖。 本文正是基于3G/4G 不断增长的接入带宽以及WiFi技术的各项优点,提出了一种共享3G/4G 网络带宽的无线路由器设计方案。该方案首先利用嵌入式Linux系统,构建一个基于WiFi技术的无线局域网,智能终端等用户可以利用自带的WiFi功能接入该无线局域网,然后再将该无线局域网桥接至3G/4G网络中,从而实现各个智能终端设备对3G/4G网络带宽的共享。 1. 3G/4G路由器设计方案 本路由器的设计是基于三个模块来实现的,分别为3G模块、WiFi模块和Linux硬件平台,如图1所示。3G模块的功能是利用运营商的无线数据卡进行PPP拨号,使得路由器能通过运营商网络连接至互联网。WiFi模块的功能是使得无线网卡工作在AP(Access Point)模式,并配置动态主机配置协议的脚本文件,来建立一个2.4 GHz的WiFi无线局域网。Linux硬件平台模块的功能主要有两个方面,一方面要支持无线网卡和无线数据卡的驱动,另一方面要通过嵌入式Linux系统中的iptables数据包过滤系统将无线局域网和3G/4G网络连通。智能终端等设备通过WiFi信道接人到该路由器所提供的无线局域网中,分配到一个IP地址之后,则通过该无线局域网的网关进行数据包的接收和发送,而该网关则通过3G/4G模块上的网络拨号接口来接收和发送数据包至3G/4G 网络,从而实现了该路由器的设计方案。 图1 3G/4G路由器设计方案图 2. 3G/4G路由器硬件结构 根据3G/4G路由器设计方案,其硬件结构的三大模块分别采用深圳天谟公司生产的Devkit8500D评估板、华为公司的E392型无线上网卡和TP-Link公司的TL-WN821N型无线网卡。 Devkit8500D评估板的基本结构如图2所示。该硬件平台采用的是TI公司的DM3730微处理器。