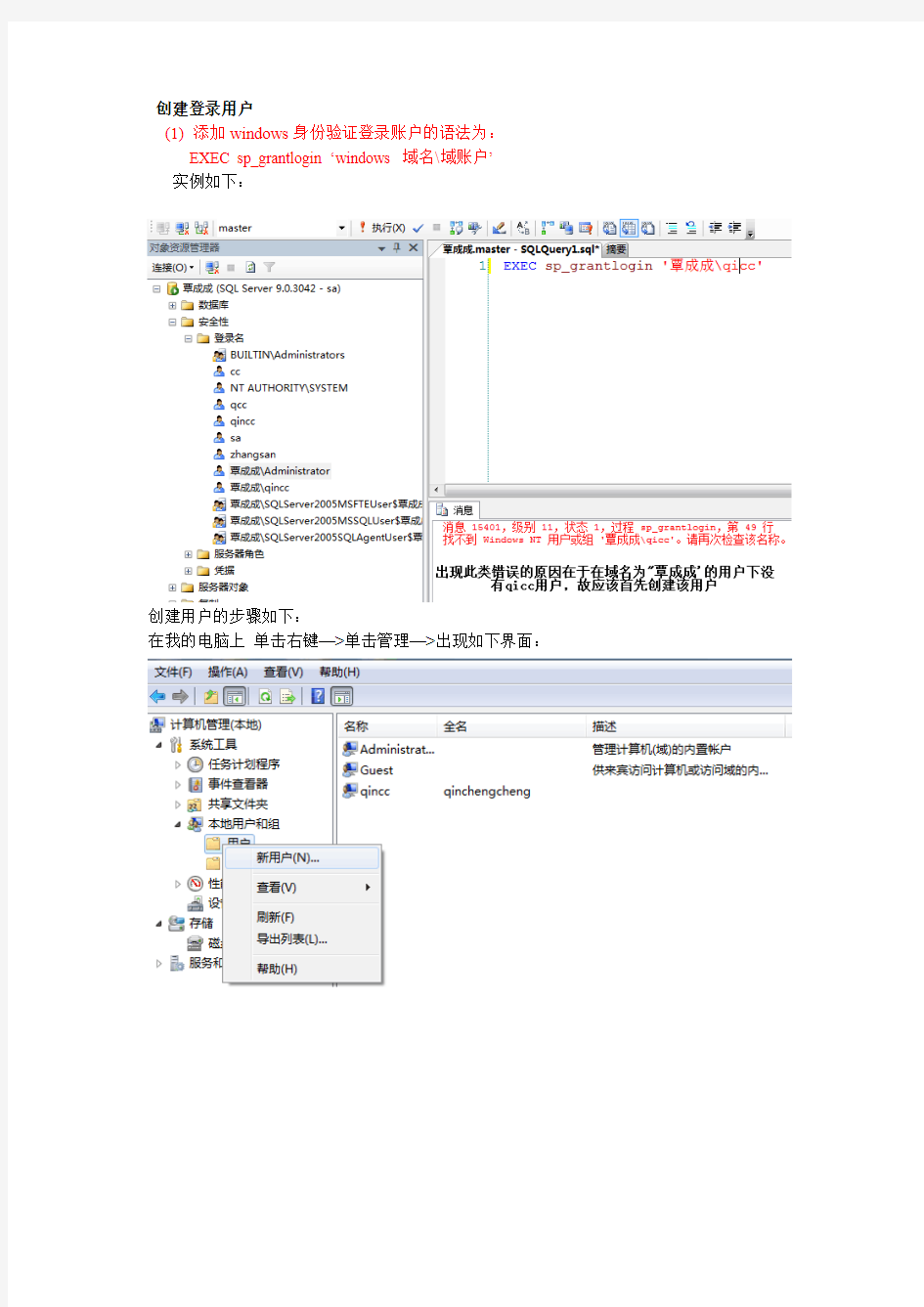
创建登录用户
(1)添加windows身份验证登录账户的语法为:
EXEC sp_grantlogin ‘windows 域名\域账户’
实例如下:
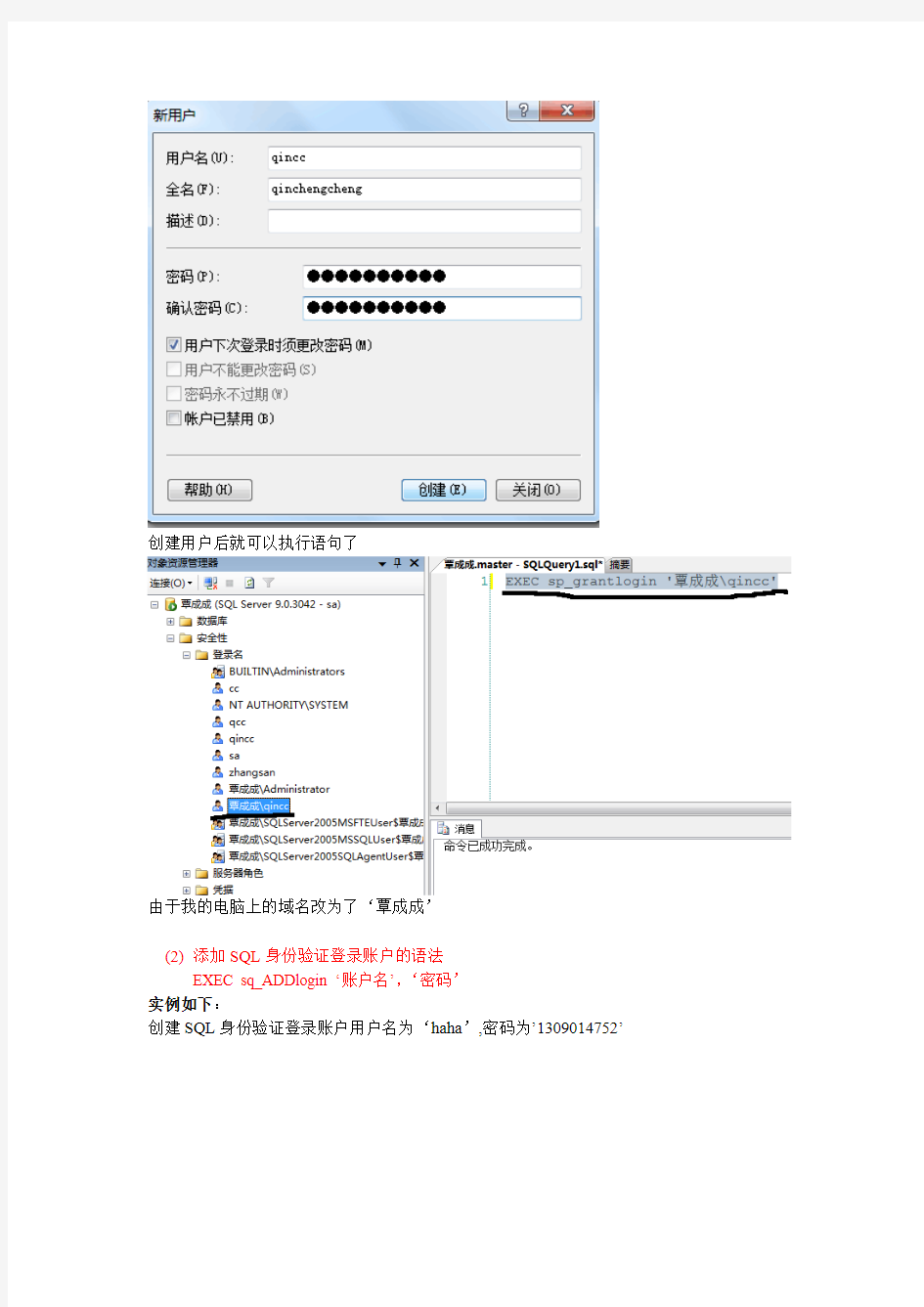
创建用户的步骤如下:
在我的电脑上单击右键—>单击管理—>出现如下界面:
创建用户后就可以执行语句了
由于我的电脑上的域名改为了‘覃成成’
(2)添加SQL身份验证登录账户的语法
EXEC sq_ADDlogin ‘账户名’,‘密码’
实例如下:
创建SQL身份验证登录账户用户名为‘haha’,密码为’1309014752’
(3)删除SQL身份验证登录账户的语法为:
EXEC sq_droplogin’账户名’
删除SQL身份验证登录账户‘haha’
EXEC sp_droplogin'haha'
使用扩展存储过程:xp_cmdshell中启用xp_cmdshell的方法如果为启用xp_cmdshell则会出现如下错误:
启用xp_cmdshell的方法如下:
如果不使用事务则会出现以下错误:
由于转账过程中,出现了张三余额为0,违反了余额约束在>=1,正确的应该是转账不成功,张三和李四的余额仍为以前的余额,张三:1000元,李四1元使用事务:
begin transaction --开始事务
declare @errorsum int
set @errorsum=0
--转账:张三的账户少元,李四的账户多元
update bank set currentMoeny=currentMoeny-1000
where customerName='张三'
set @errorsum=@errorsum+@@error--错误进行累计,如果@errorsu=0就表示没有错误update bank set currentMoeny=currentMoeny+1000
where customerName='李四'
set @errorsum=@errorsum+@@error
if @errorsum<>0
begin
print'交易失败,回滚事务'
rollback transaction--当出现错误时,就回滚到开始事务时,数据都恢复到开始事务时
end
else
begin
print'交易成功,提交事务'
commit transaction--当没有错误时,就提交事务,执行SQL语句end
go
print'查看转账事务后的余额'
select*from bank
go
执行的结果如下:
如果出现以下错误表示当执行多条语句时,未加上go进行批处理
1.使用语句创建数据库,创建主数据文件和日志文件的属性为5个
--主数据(日志)名(逻辑名)
--主数据文件存储的位置(物理名)
--主数据文件的初始大小
--主数据文件的最大大小
--主数据文件的增长率
2.在数据库中打印文字
if exists(select * from sysdatabases where name='xp9') --该语句的含义为如果在数据库中已经存在xp9的话,则删除数据库xp9
begin
drop database xp9
print '删除数据库xp9成功'
end
go
--其中begin的含义相当于if语句中的‘{’,而其中的end的含义相当于if语句中的‘}’--要想在数据库中打印出文字则只需要使用print关键字即可
3.数据库文件的组成
主数据文件:*.mdf
次要数据文件:*.ndf
日志文件:*.ldf
4.数据库其他的属性:
文件存放位置,分配的初始空间,属于哪个文件组
文件增长:可以按百分比或实际大小指定增长速度
文件容量设置:可以指定文件增长的最大值或不受限制
5.使用语句创建数据库代码如下:
create database xp9
on primary
(
name='stuDB_data',--主数据文件名(逻辑名)
filename='D:\project\stuDB_data.mdf', --主数据文件存储的位置(物理名)
size=5mb,--主数据文件的初始大小
maxsize=100, --主数据文件的最大的大小
filegrowth=15% --主数据文件的增长率
)
log on
(
name='stuDB_log', --主日志文件名(逻辑名)
filename='D:\project\stuDB_log.ldf',--主日志文件存储的位置(物理名)
size=1mb, --主日志文件的初始大小
maxsize=10mb, --主日志文件的最大的大小
filegrowth=10% --主日志文件的增长率
)
go
6.删除数据库
--drop database 数据库名
--实例如下
use master --设置当前数据库为master,以便访问sysdatabases表
go
if exists(select * from sysdatabases where name='xp9') --该语句的含义为如果在数据库中已经存在xp9的话,则删除数据库xp9
begin
drop database xp9
print '删除数据库xp9成功' --要想在数据库中打印文本,则只需要使用print关键字即可
end
go
7.创建多日志和多主文件的数据库
create database xp9
on primary
(
name='stuDB_data',
filename='D:\project\stuDB_data.mdf',
size=3mb,
maxsize=100mb,
filegrowth=15%
),
(
name='stuDB_data1',
filename='D:\project\stuDB_data1.mdf',
size=3mb,
maxsize=100mb,
filegrowth=15%
)
log on
(
name='stuDB_log',
filename='D:\project\stuDB_log.ldf',
size=1mb,
maxsize=10mb,
filegrowth=10%
),
(
name='stuDB_log1',
filename='D:\project\stuDB_log1.ldf',
size=1mb,
maxsize=10mb,
filegrowth=10%
)
--注意点:创建多主文件的方法就是在主文件的后面加上一个逗号
8.char(6),varchar(10),nchar(10)三则之间的区别
char(6)固定长度即长度为6个字符,不管该数据是否有6个字符,都是占6个字符,如一个汉字实际占2个字符,但是使用char(6)类型修饰后,则该汉字占6个字符
varchar(10)可变长度,即最大长度为10个字符,如一个汉字则占2个字符,并且数据长度不能超过10字符长度
nchar(10)
8.创建表的基本步骤:
确定表中有哪些列
确定每列的数据类型
给表添加各种约束
创建各表之间的关系
具体代码如下:
格式如下:
create table 表名
(
列名1 列的数据类型是否允许为空,
列名2 列的数据类型是否允许为空,
列名3 列的数据类型是否允许为空,
)
go
create table stuInfo
(
stuid int identity(1000,1) not null, --种子标识,从1000开始,增长量为1 stuname varchar(20) not null,
stusex nchar(1) not null,
stuage int not null,
stuemail varchar(50),
stutel varchar(20),
stuaddress varchar(100)
)
go
9.为表添加约束
(1)添加约束的语法为:
alter table 表名
add constraint 约束名约束类型具体的约束说明
(2)具体的实例如下:
alter table stuinfo --主键约束
add constraint PK_stuinfo_stuid primary key(stuid)
alter table stuinfo --检查约束
add constraint CH_stuinfo_stusex check(stusex='男' or stusex='女')
alter table stuinfo --检查约束
add constraint CH_stuinfo_stuage check(stuage between 18 and 60)
alter table stuinfo --默认约束
add constraint DF_stuinfo_stusex default('男') for stusex
alter table stuinfo --唯一约束
add constraint UQ_stuinfo_stuname unique(stuname)
alter table stuinfo
add constraint CH_stuinfo_stuemail check(stuemail like '%@%')
alter table stymarks
add constraint CH_stymarks_labexam check (labexam between 0 and 100)
添加外键约束:
`alter table stymarks --外键约束
add constraint FK_stuinfo_stymarks_stuid foreign key(stuid) references stuinfo(stuid)
10.删除约束:
(1)删除约束的语法为:
alter table 表名
drop constraint 约束名
(2)实例如下:
alter table stuinfo --删除学生的唯一约束
drop constraint UQ_stuinfo_stuname --使用创建唯一约束时的约束名来删除约束11.删除表
(1)语法为:drop table 表名
创建表时首先要判断表是否存在,如果不存在则如果执行创建表语句,
使用实例如下:
use stuDB
go
if exists(select * from sysobjects where name='stuinfo')
drop table stuinfo --判断表是否已经存在,如果存在则删除,不存在则创建
create table stuinfo
(
)go
12.新建一个SQL账户(三道权限)
--1.新建登录用户,可以打开SQL数据库,但是不能打开数据库
exec sp_addlogin 'hxh','12323'
--2.新建数据库用户,可以打开指定的数据库
--在数据库xp9中新建数据库xp9用户,xunpo_db_aaa,可以打开xp9数据库,但是不能打开xp9数据库中的表
第三章
1.使用语句创建数据库,创建主数据文件和日志文件的属性为5个
--主数据(日志)名(逻辑名)
--主数据文件存储的位置(物理名)
--主数据文件的初始大小
--主数据文件的最大大小
--主数据文件的增长率
2.在数据库中打印文字
if exists(select * from sysdatabases where name='xp9') --该语句的含义为如果在数据库中已经存在xp9的话,则删除数据库xp9
begin
drop database xp9
print '删除数据库xp9成功'
end
go
--其中begin的含义相当于if语句中的‘{’,而其中的end的含义相当于if语句中的‘}’--要想在数据库中打印出文字则只需要使用print关键字即可
3.局部变量
--局部变量的名称必须以标记@作为前缀
--声明局部变量的语句为:declare @变量名变量类型
如:
declare @num1 int
--局部变量赋值有两种方法:
使用set语句或select语句
如:
set @varible_name=value 或select @variable_name=value
综合实例:根据座位号查找李文才的左右同桌
/*--查找李文才的信息--*/
declare @name varchar(8) --学员姓名
set @name='李文才' --使用set赋值
set * from stuinfo where stuname=@name
/*--查找李文才的左右同桌--*/
declare @seat int --座位号
select @seat=stuseat from stuinfo where stuname=@name --使用select赋值
select * from stuinfo where(stuseat=@seat+1)or(stuseat=@seat-1)
go
4.全局变量
SQL Server中的所有全局变量都使用两个@标志作为前缀
常用的全局变量
@@error 最后一个T-SQL错误的错误号
@@identity 最后一次插入的标识值
@@language 当前使用的语言的名称
@@max_connections 可以创建的同时连接的最大数目
@@rowcount 受上一个SQL语句影响的行数
@@servername 本地服务器的名称
@@servicename 该计算机上的SQL服务的名称
@@timeticks 当前计算机上每刻度的微秒数
@@transcount 当前连接打开的事务数
@@version SQL Server 的版本信息
5.输出语句有两种:
print 局部变量或字符串
select 局部变量as自定义列名
实例:
print '服务器的名称'+ @@servername
select @@servername as '服务器名称'
注意print和select的区别
用print方法输出结果将在消息窗口以文本的方式显示,用select方法结果将在网格窗口以表格方式显示
6.if-else 条件语句
语法:
if(条件)
语句或语句块
else
语句或语句块
语句块使用begin...end表示
if(条件)
begin
语句1
语句2
end
else
使用实例如下:
declare @avg float
select @avg=avg(writexam) from stymarks --为声明的变量赋值
if(@avg>70)
begin
print '成绩优秀'
select top 3 * from stymarks order by writexam desc
end
else
begin
print '本班成绩较差'
select top 3 * from stymarks order by writexam asc
end
7.while 循环语句
语法:
while(条件)
语句或语句块
break
或
while(条件)
begin
语句1
语句2
break
end
break表示退出循环,如果有多条语句,才需要begin-end语句块
使用实例如下:
--本次考试成绩较差,如果有一个人的笔试没有通过,则所有人的笔试都加2分
--方法一:
declare @minWritExam int
select @minWritExam=min(writexam) from stymarks
while(@minWritExam<60)
begin
update stymarks set writexam=writexam+2 --这里必须使用更新
set @minWritExam=@minWritExam+2 --注意要想对局部变量赋值,只能有两种方法set或select
end
select * from stymarks
--方法二:
--1.找出没有通过的人数
declare @sum int
select @sum=count(writexam) from stumarks where writexam<60
--2.如果存在没有通过的人,那么就要提分
declare @sum int
while(1=1)
begin
select @sum=count(*) from stymarks where writexam<60
if(@sum>0)
update stymarks set writexam=writexam+2
else
break
end
8.case多分支语句
语法:
case
when 条件1 then 结果1
when 条件2 then 结果2
else 其他结果
end
实例如下:
--case...end 分支语句
--使用ABCDE来给机试成绩分等级
select *,平均成绩=(writexam+labexam)/2,等级评定=
case
when (writexam+labexam)/2>90 then 'A'
when (writexam+labexam)/2>80 then 'B'
when (writexam+labexam)/2>70 then 'C'
when (writexam+labexam)/2>60 then 'D'
else 'E'
end
from stymarks
9.批处理语句
--go批处理语句
SQLServer 规定:如果是建库,建表语句,以及存储过程和视图等,必须在语句末尾添加‘GO'
批处理标志
--goto跳转
if(2>1)
begin
print '第一条语句'
lab: --标记
print '第二条语句'
goto lab
print '第三条语句'
end
10.retrun :可以在任意位置使用return从语句块或过程中退出,系统将不会执行return语句之后的语句
语法:
return [值为整数的表达式]
11.GOTO语句
GOTO语句可以是程序直接跳到指定的标有标识符的位置处继续执行,而位于GOTO语句和标识符之间的程序将不会被执行。
注意点:GOTO语句和标识符可以用在语句块,批处理和存储过程中,标识符可以为数字与字符的组合,但必须以':'结尾,如:‘al:’在GOTO语句行,标识符后面不用跟‘:’12.waitfor语句
--指定触发语句块,存储过程或事务执行时间,时间间隔或事件
--用来暂时停止程序执行,直到所设定的等待时间过后才继续往下去执行
语法:
waitfor {delay 'time'|time 'time'}
其中,delay 用于指定时间间隔,time用于指定某一时刻,其数据类型为datetime,格式为:‘hh:mm:ss’
具体实例:
例3-58 使用WAITFOR TIME语句,以便在晚上10:20执行存储过程update_all_stats。
程序清单如下:
begin
waitfor time '22:20'
execute update_all_stats
end
第四章
一、子查询
--找出比李四大的学员信息
--1>用变量得到结果
use xp9
--找出李四的年龄用变量存起来
declare @age int
select @age=stuAge from student where stuName='李斯文'
--使用变量值来查找信息
select * from student where stuAge>@age
--2>使用子查询
select * from student where stuAge>(select stuAge from student where stuName='李斯文')
--查询笔试成绩刚好通过60分的学员
select * from student
--1.使用表连接
select student.*,stumarks.* from student inner join stumarks
on student.stuNo=stumarks.stuNo
where https://www.doczj.com/doc/0111009990.html,bExam>60
--2.子查询
--在成绩表中根据成绩查询出学员的学号--子查询也是内部查询
select stuNo from stumarks where LabExam>60
--在学员表中根据查出来的学号查询学员信息--父查询也是外部查询
select * from student where stuNo
in (select stuNo from stumarks where LabExam>60)
--in 在定值的范围中
-- in (定值1,定值2,...)值要完全匹配
--查询没有参加考试的学员信息
--1>表连接
select student.* from student left outer join stumarks
on student.stuNo=stumarks.stuNo
where ExamNo is null
--2>子查询
select student.* from student where student.stuNo
not in(select stuNo from stumarks)
--exists子查询
--例如数据库的存在检测
if exists (select * from sysDatbases where name='stuDB')
drop database stuDB
--检测数据库是否存在如果存在则删除,不存在则创建
if exists(子查询)
语句
--如果子查询的结果非空,即记录条数1条以上,则exists(子查询)将返回真(true),否则返回假(false)
--exists也可以作为where语句的子查询,但一般都能用in子查询替换
--如果笔试有80分以上的,就每人提2分,否则提5分
use xp9
go
--1>结合聚合函数实现
if(select count(*) from stumarks where writtenExam>80)>0
begin
print '每人提2分'
update stumarks set writtenExam=writtenExam+2
end
else
begin
print '每人提5分'
update stumarks set writtenExam=writtenExam+5
end
--2>exists 关键字实现
if eixsts(select * from stumarks where writtenExam>80)
begin
print '每人提2分'
update stumarks set writtenExam=writtenExam+2
end
else
begin
print '每人提5分'
update stumarks set writtenExam=writtenExam+5
end
--如果没有人笔试成绩和机试成绩都大于60,那么试题偏难,每人加3分,否则每人加1分if not exists(select * from stumarks where writtenExam>60 and LabExam>60) print '试题偏难,每人加3分'
else
print '每人加1分'
--1.应到人数,实到人数,缺考人数
--声明变量
declare @yd int
declare @sd int
declare @qk int
select @yd=count(*) from student
select @sd=count(*) from stumarks
select 应到人数=@yd,实到人数=@sd,缺考人数=@yd-@sd
select stu.stuName 姓名,stu.stuNo 学号,笔试成绩=
case
when writtenExam is null then '缺考'
else convert(varchar(5),writtenExam)
end
,机试成绩=
case
when https://www.doczj.com/doc/0111009990.html,bExam is null then '缺考'
else convert(varchar(5),https://www.doczj.com/doc/0111009990.html,bExam)
end,是否通过=
case
when writtenExam>=60 and LabExam>=60 then '是'
else '否'
end
from student stu left outer join stumarks sm
on stu.stuNo=sm.stuNo
--数据库第五章事务,索引,视图
--1.事务
--事务必须具备的属性:
--原子性:事务是一个完整的操作,事务的各步操作是不可分的(原子的):要么都执行,要么都不执行
--一致性:当事务完成时,数据必须处于一致状态
--隔离性:对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,他不应以任何方式依赖于或影响其他事务
--永久性:事务完成后,它对数据库的修改被永久保持,事务日志能够保持一致
--如何创建事务:
开始事务:begin transaction
提交事务:commit transaction
回滚(撤销)事务:rollback transaction
注意:一旦事务提交或回滚,则事务结束
--判断某条语句执行是否出错
--使用全局变量@@error
--@@error只能判断当前一条T-SQL语句执行是否有错,为了判断事务中所有T-SQL语句是否有错,我们需要对错误进行累计
create table bank
(
customerName char(10),--顾客姓名
currentMoeny money --当前余额
)
go
alter table bank
add constraint CH_bank_currentMoney check(currentMoeny>=1)
go
insert into bank values('张三',1000)
insert into bank values ('李四',1)
select * from bank
--转账从张三这转1000元钱给李四
update bank set currentMoeny=currentMoeny-1000 where customerName='张三'
update bank set currentMoeny=currentMoeny+1000 where customerName='李四'
select * from bank
--使用事务进行转账
begin transaction --开始事务(指定事务从此处开始,后续的T-SQL语句都是一个整体)declare @errnum int
update bank set currentMoney=currentMoney-1000 where customerName='张三'
set @errnum=@@error
update bank set currentMoeny=currentMoeny+1000 where customerName='李四'
set @errnum=@errnum+@@error --累计是否有错误
if(@errnum<>0) --表示有错
begin
print '转账过程出错了,事务要回滚到开始事务之前的状态,也就是begin tran'
rollback tran --回滚事务
end
else
begin
print '转账过程成功了,数据已提交,并永久保存'
commit tran --提交事务
end
go
--索引
--1.创建索引
创建索引的语法为:
create [unique][clustered|nonclustered]index index_name
on table_name(column_name[,column_name]...)
[with fillfactor=x]
--其中unique 指定唯一索引,可选
clustered,nonclustered 指定是聚集索引还是非聚集索引,可选
HUNAN CITY UNIVERSITY 数据库系统课程设计设计题目:宿舍管理信息系统 姓名: 学号: 专业:信息与计算科学 指导教师: 20年 12月1日 目录 引言 3 一、人员分配 4 二、课程设计目的和要求 4 三、课程设计过程 1.需求分析阶段 1.1应用背景 5 1.2需求分析目标5 1.3系统设计概要 5 1.4软件处理对象 6 1.5系统可行性分析 6 1.6系统设计目标及意义7
1.7系统业务流程及具体功能 7 8 2.系统的数据字典11 3.概念结构设计阶段 13 4.逻辑结构设计阶段 15 5.物理结构设计阶段 18 6.数据库实施 18 7.数据库的运行和维护 18 7.1 解决问题方法 19 7.2 系统维护 19 7.3 数据库性能评价 19 四、课程设计心得. 20 参考文献 20 引言 学生宿舍管理系统对于一个学校来说是必不可少的组成部分。目前好多学校还停留在宿舍管理人员手工记录数据的最初阶段,手工记录对于规模小的学校来说还勉强可以接受,但对于学生信息量比较庞大,需要记录存档的数据比较多的高校来说,人工记录是相当麻烦的。而且当查找某条记录时,由于数据量庞大,还只能靠人工去一条一条的查找,这样不但麻烦还浪费了许多时间,效率也比较低。当今社会是飞速进步的世界,原始的记录方式已经被社会所淘汰了,计算机化管理正是适应时代的产物。信息世界永远不会是一个平静的世界,当一种技术不能满足需求时,就会有新的技术诞生并取代旧技术。21世纪的今天,信息社会占着主流地位,计算机在各行各业中的运用已经得到普及,自动化、信息化的管理越来越广泛应用于各个领域。我们针对如此,设计了一套学生宿舍管理系统。学生宿舍管理系统采用的是计算机化管理,系统做的尽量人性化,使用者会感到操作非常方便,管理人员需要做的就是将数据输入到系统的数据库中去。由于数据库存储容量相当大,而且比较稳定,适合较长时间的保存,也不容易丢失。这无疑是为信息存储量比较大的学校提供了
校园基础地理空间数据库建设设计方案 遥感1503班第10组 (杨森泉张晨欣杨剑钢熊倩倩) 测绘地理信息技术专业 昆明冶金高等专科学校测绘学院 2017年5月
一.数据来源 二. 目的 三 .任务 四. 任务范围 五 .任务分配与计划六.小组任务分配七. E-R模型设计八.关系模式九.属性结构表十.编码方案
一.数据来源 原始数据为大二上学期期末实训数字测图成果(即DWG格式的校园地形图) 导入GIS 软件数据则为修改过的校园地形图 二.目的 把现实世界中有一定范围内存在着的应用数据抽象成一个数据库的具体结构的过程。空间数据库设计要满足用户需求,具有良好的数据库性能,准确模拟现实世界,能够被某个数据库管理系统接受。
三.任务 任务包括三个方面:数据结构、数据操作、完整性约束 具体为: ①静态特征设计——结构特性,包括概念结构设计和逻辑结构设计; ②动态特性设计——数据库的行为特性,设计查询、静态事务处理等应用程序; ③物理设计,设计数据库的存储模式和存储方式。 主要步骤:需求分析→概念设计→逻辑设计→物理设计 原则:①尽量减少空间数据存储冗余;②提供稳定的空间数据结构,在用户的需要改变时,数据结构能够做出相应的变化;③满足用户对空间数据及时访问的需求,高校提供用户所需的空间数据查询结果;④在空间元素间为耻复杂的联系,反应空间数据的复杂性;⑤支持多种决策需要,具有较强的应用适应性。 四、任务范围 空间数据库实现的步骤、建库的前期准备工作内容、建库流程 步骤:①建立实际的空间数据库结构;②装入试验性数据测试应用程序;③装入实际空间数据,建立实际运行的空间数据库。 前期准备工作内容:①数据源的选择;②数据采集存储原则;③建库的数据准备;④数据库入库的组织管理。 建库流程:①首先必须确定数字化的方法及工具;②准备数字化原图,并掌握该图的投影、比例尺、网格等空间信息;③按照分层要求进行
实验1 SQL SERVER 2008环境 一、实验目的 1.掌握服务管理器的启动和停止方法; 2.掌握SQL Server Management Studio对象资源管理器的使用方法; 3.掌握注册服务器的步骤。 4.掌握E-R图在计算机中的画法。 二、实验学时 2学时 三、实验要求 1.了解SQL Server 2008的安装过程。 2.熟练掌握SQL Server2008数据库服务器的启动方法。 3.熟练掌握SQL Server2008数据库服务器的登录方法和注册方法。 4.掌握E-R图的画法,学会使用Visio画出标准的E-R图。 5.独立完成实验内容,并提交书面实验报告。 四、实验内容 1.了解并熟悉SQL Server 2008的安装方法。 2.登录SQL Server 2008服务器,主要包括启动、暂停、停止和重新启动服务器,登录SQL Server Management Studio等操作; 3. 掌握SQL Server Management Studio对象资源管理器的使用方法; 4.注册SQL Server 2008服务器。 5. 有一个图书管理系统需要构建E-R图,要求如下: (1)可随时查询书库中现有书籍的品种、数量与存放位置。所有各类书籍均可由书号唯一标识。 (2)可随时查询书籍借还情况,包括借书人单位、姓名、借书证号、借书日期和还书日期。约定:任何人可借多种书,任何一种书可为多个人所借,借书证号具有唯一性。 (3)当需要时,可通过数据库中保存的出版社的电报编号、电话、邮编及地址等信息向相应出版社增购有关书籍。约定,一个出版社可出版多种书籍,同一本书仅为一个出版社出版,出版社名具有唯一性。 将有关实体型及其联系画出E-R模型图画在实验报告册中。
1 实验目的与要求 (1)掌握数据库的建立、删除和修改操作。 (2)理解基本表之间的关系,掌握表结构的建立、修改和删除操作,创建模式导航图。 2 实验内容与结果 实验内容: (1) 创建一个BookDB数据库,要求至少一个数据文件和一个日志文件。 (2) 创建图书管理相关4张关系表,表结构如图3-1至图3-4所示。 图3-1图书分类表BookClass 图3-2 图书表Book 图3-3读者表Reader 图3-4 借阅表Borrow
(3) 表结构的修改,要求: ①修改图书表结构,要求出版社名称和入库时间不允许为空。 ②修改读者表结构,要求读者身份证号不允许为空。 实验结果如下: 创建数据库: CREATE DATABASE BookDB48 ON PRIMARY (NAME='BookDB', FILENAME='C:\数据库文件\', SIZE=3, MAXSIZE=20, FILEGROWTH=1 ) LOG ON ( NAME='BookDB_LOG', FILENAME='C:\数据库文件\', SIZE=3, MAXSIZE=20, FILEGROWTH=1) 脚本如下:(创建的四个表) CREATE TABLE BookClass48( classNo char(3)NOT NULL,--图书分类号 className varchar(20)NOT NULL,--图书分类名称 CONSTRAINT BookClass48PK PRIMARY KEY(classNo) ) CREATE TABLE Book48( bookNo char(10)NOT NULL,--图书编号 classNo char(3)NOT NULL,--图书分类号 bookName varchar(40)NOT NULL,--图书名称 authorName varchar(8)NOT NULL,--作者名字 publishingName varchar(20)NULL,--出版社名称 publishingNo char(17)NULL,--出版社编号 publishingDate datetime NULL,--出版社日期 price numeric(7,2)NULL,--单价 shopDate datetime NULL,--入库时间 shopNum datetime NULL,--入库数量 CONSTRAINT Book48PK PRIMARY KEY(bookNo), CONSTRAINT Book48FK FOREIGN KEY(classNo)REFERENCES BookClass48(classNo) )
数据库学习笔记 图形化界(Navicate Premium)面操作数据库 1、工具---->命令行操作 2、选中某个表对象--->右击---->逆向表到模型---生成各表的关系模型 3、选中某个表对象-->右击-->对象信息--->DDL查看创建表的信息 Sql语言集数据定义语言,数据操纵语言,数据查询语言,数据控制语言于一体,可以完成数据库生命周期中的全部工作。 数据定义语言:完成创建,修改或删除数据库中的各种对象有create,drop,alter的命令。 数据查询语言:按各种条件查询数据库中的数据有select及其相关命令。 数据操纵语言:对已经从在的数据库对其进行数据的插入,删除和修改有insert,update,delete命令。 数据库控制语言:用于授权或收回访问数据库的某种特权,控制数据操纵事物的发生时间及效果,对数据库进行监视。有grant,revoke,commit,rollback等命令。 一、数据库操作 1、启动数据库:net start mysql 2、关闭数据库:net stop mysql 3、打开数据库:mysql -u root -p123 4、显示所有数据库:show databases;
5、创建数据库:create database mydb1; 6、删除数据库:drop database mydb1; 二、单表操作: 1、选择并使用数据库:use mydb1 2、创建表:(宠物表) 宠物表:id名字、主人、种类,性别、出生和死亡日期。create table pet( id int primary key, name varchar(20), owner varchar(20), species varchar(20), sex char(1), birth date, death date ); 3、插入数据: insert into pet values(1,’ergou’,’zx’,’dog’,’f’,’2013-09-06’ null); 4、查询所有内容 select * from pet; 5、删除一条数据: delete from pet where id=1;
——货存控制系统 6、1数据库设计概述 ㈠数据库设计的概念:数据库设计就是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,使之能够有效地存储数据,满足各种用户的应用需求(信息要求与处理要求)。在数据库领域内,常常把使用数据库的各类系统统称为数据库应用系统。 ㈡数据库设计的特点 1、数据库建设就是硬件、软件与干件的结合:三分技术、七分管理、十二分基础数据,技术与管理的界面称之为干件。 2、数据库设计过程就是结构设计与行为设计的密切结合:结构设计就是设计数据库结构,行为设计就是设计应用程序、事务处理等。 ㈢数据库设计的方法 1、手工试凑法:设计质量与设计人员的经验与水平有直接关系,缺乏科学理论与工程方法的支持,工程质量难保证。 2、规范设计法:基本思想就是过程迭代与逐步求精。 ㈣数据库设计的基本步骤 准备工作:选定参加设计的人员。 ⑴分析员:数据库设计的核心人员,自始至终参与数据库设计,其水平决定了数据库系统的质量。 ⑵用户:主要参加需求分析与数据库的运行维护,用户的积极参与将加速数据库设计,提高数据库设计的质量。 ⑶程序员:在系统实施阶段参与进来,负责编制程序。 ⑷操作员:在系统实施阶段参与进来,准备软硬件环境。 ㈤数据库设计的过程(六个阶段) 1、需求分析阶段: 准确了解与分析用户需求(包括数据与处理),就是整个设计过程的基础,就是最困难、最耗费时间的一步。 2、概念结构设计阶段: 整个数据库设计的关键,通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型 3、逻辑结构设计阶段: 将概念结构转换为某个DBMS所支持的数据模型,并对其进行优化。 4、数据库物理设计阶段: 为逻辑数据模型选取一个最适合应用环境的物理结构(包括存储结构与存取方法)。 5、数据库实施阶段: 运用DBMS提供的数据语言、工具及宿主语言,根据逻辑设计与物理设计的结果建立数据库、编制与调试应用程序、组织数据入库并进行试运行。 6、数据库运行与维护阶段: 数据库应用系统经过试运行后即可投入正式运行,在运行过程中不断对其进行评价、调整与修改。 设计一个数据库应用系统往往就是上述六个阶段的不断反复。 ㈥数据库设计各阶段的模式形成: 1、需求分析阶段:综合各个用户的应用需求。 2、概念设计阶段:形成独立于机器特点,独立于各个DBMS产品的概念模式(E-R图)。
无锡市基础空间数据SHP格式设计方案 (大比例尺) 1、综述 1.1目的 为无锡市规划局基础空间数据建库提供标准。 1.2适用范围 1:500、1:1000、1:2000基础地形图数据 1.3制定原则 ●保证按本方案生产的数据可以实现同SHP数据的高效互转; ●保证按本方案生产的数据在转入数据库后可以实现标准图的输出; ●操作方便。 1.4类型约定 ● ●
1.5引用标准 《GB/T 14804-93 1:500 1:1000 1:2000 地形图要素分类与代码》(1994-08-01)《GB/T 7929-1995 1:500 1:1000 1:2000 地形图图式》(1996-05-01) 《GB 1:500 1:1000 1:2000 地形图数字化规范》(1998-08-01) 《GB/T14804-93 1:500 1:1000 1:2000 地形图要素分类与代码》(1994-08-01)《GT地籍数据库标准》 《GB/T 13923-92 国土基础信息数据分类与代码》(1993-07-01) 2、实体的划分 数据在SDE的服务器里是按照点、线、面和注记划分的,每一个SDE图层(FEATURECLASS)只能存储上述的一种空间对象。由于这种存储模型的限制,势必造成很多国标中的复杂地物被拆分到不同的SDE图层。为了在编码中体现设计的合理性、对实体的物理存储进行统一的管理,特在数据库的设计中在对空间实体做逻辑的划分。 2.1简单点 ●简单点实体只记录插入点的位置和相关属性,所有的简单点实体都必须以插入符号 的形式采集。 ●简单点状实体对应ARCOBJECT体系的IPOINT对象。 ●采集单位在使用点符号的时候要保证简单点的符号要和本方案提供的符号描述一 致,符号的插入点一致。 2.2简单无向线 ●简单线需要作业单位针对每一种实体制作线符号,这里所指的线符号必须是采集系 统提供的线符号库,不能用程序绘制。
《数据库系统概论》实验报告 题目:实验一 数据库和表的基本操作和约束条件姓名班级学号日期 刘凯10031201 2012302606 2014.10 一、实验内容、步骤以及结果 1.利用图形用户界面创建,备份,删除和还原数据库和数据表 创建初始数据库信息如下 备份数据库
删除表 2.利用SQL语言创建和删除数据库和数据表创建数据库 CREATE DATABASE studentdata ( FILENAME = 'D:\studentdata.mdf' , SIZE = 20480KB , MAXSIZE = 102400KB , FILEGROWTH = 10240KB ) LOG ON ( FILENAME = 'D:\studentdata_1.ldf' , SIZE = 2048KB , MAXSIZE = 5120KB , FILEGROWTH = 1024KB ) GO 创建三张表
CREATE TABLE dbo.C( Cno char(4)PRIMARY KEY , Cname char(40) , Cpno int , Ccredit int,) GO CREATE TABLE dbo.S( Sno char(4)PRIMARY KEY , Sname char(40) , Ssex char(4) , Sbirth] char(40) , Sdept char(4) , ) CREATE TABLE [dbo].[SC]( Sno char(4) , Cno char(4) , Grade int ) GO 备份数据库 Backup database studentdata to disk = ‘D:\studentdata.db.bak’ 删除数据库 Deleta database studentdata.db 还原数据库 Restore database studentdata from disk = ‘D:\studentdata.db.bak’ 3.利用图形用户界面对上题中创建的Student库的S表中,增加以下的约束和索引 主键 Sname唯一键
SQL是英文Structured Query Language的缩写,意思为结构化查询语言。SQL被作为关系型数据库管理系统的标准语言。一个典型的关系型数据库通常由一个或多个被称作表格的对象组成。数据库中的所有数据或信息都被保存在这些数据库表格中。数据库中的每一个表格都具有自己唯一的表格名称,都是由行和列组成,其中每一列包括了该列名称,数据类型,以及列的其它属性等信息,而行则具体包含某一列的记录或数据。 SQL 语句可以用来执行各种各样的操作,例如更新数据库中的数据,从数据库中提取数据等。SQL语句可以分为以下几组: DML(Data Manipulation Language,数据操作语言):用于检索或者修改数据; DDL(Data Definition Language,数据定义语言):用于定义数据的结构,比如创建、修改或者删除数据库对象; DCL(Data Control Language,数据控制语言):用于定义数据库用户的权限。 DML 组可以细分为以下的几个语句: SELECT:用于检索数据; INSERT:用于增加数据到数据库; UPDATE:用于从数据库中修改现存的数据 DELETE:用于从数据库中删除数据。 DDL 语句可以用于创建用户和重建数据库对象。下面是DDL 命令: CREATE TABLE ALTER TABLE DROP TABLE CREATE INDEX DROP INDEX DCL 命令用于创建关系用户访问以及授权的对象。下面是几个DCL 命令: ALTER PASSWORD GRANT REVOKE CREATE SYNONYM 下面主要介绍几个常用的数据库操作语句的格式: 数据查询:select 语句主要被用来对数 据库进行查询并返回符合用户查询标准的结果数据。Select 语句的语法格式如下:select column1 [, column2,etc] from tablename [where condition]; ([] 表示可选项) select 语句中位于select 关键词之后的列名用来决定那些列将作为查询结果返回。用户可以按照自己的需要选择任意列,还可以使用通配符“*”来设定返回表格中的所有列。select 语句中位于from 关键词之后的表格名称用来决定将要进行查询操作的目标表格。Select 语句中的where 可选从句用来规定哪些数据值或哪些行将被作为查询结果返回或显示。 向表格中添加、更新、删除记录 添加新记录 SQL 语言使用insert 语句向数据库表格中插入或添加新的数据行。Insert 语句的使用格式如下: insert into tablename (first_column,https://www.doczj.com/doc/0111009990.html,st_column)
摘要 数据库技术是计算机科学技术发展最快,应用最为广泛的技术之一。其在计算机设计,人工智能,电子商务,企业管理,科学计算等诸多领域均得到了广泛的应用,已经成为计算机信息系统和应用的核心技术和重要基础。 随着信息技术的飞速发展,信息化的大环境给各成人高校提出了实现校际互联,国际互联,实现静态资源共享,动态信息发布的要求; 信息化对学生个人提出了驾驭和掌握最新信息技术的素质要求;信息技术提供了对教学进行重大革新的新手段;信息化也为提高教学质量,提高管理水平,工作效率创造了有效途径. 校园网信息系统建设的重要性越来越为成人高校所重视. 利用计算机支持教学高效率,完成教学管理的日常事务,是适应现代教学制度要求、推动教学管理走向科学化、规范化的必要条件;而教学管理是一项琐碎、复杂而又十分细致的工作,工资计算、发放、核算的工作量很大,不允许出错,如果实行手工操作,每月须手工填制大量的表格,这就会耗费工作人员大量的时间和精力,计算机进行教学管理工作,不仅能够保证各项准确无误、快速输出,而且还可以利用计算机对有关教学的各种信息进行统计,同时计算机具有手工管理所无法比拟的优点.例如:检索迅速、查找方便、可靠性高、存储量大、保密性好、寿命长、成本低等。这些优点能够极大地提高员工工资管理的效率,也是教学的科学化、正规化管理,与世界接轨的件。在软件开发的过程中,随着面向对象程序设计和数据库系统的成熟,数据设计成为软件开发的核心,程序的设计要服从数据,因此教学管理系统的数据库设计尤其重要。 本文主要介绍教学管理系统的数据库方面的设计,从需求分析到数据库的运行与维护都进行详细的叙述。本系统利用IBM DB2企业版本开发出来的。DB2是IBM公司开发的关系关系数据库管理系统,它把SQL语言作为查询语言。 本文的分为5章。其中第1章主要是课题简介及设计的内容与目的。第2章是需求分析,此阶段是数据库设计的起点。第3章是概念设计,它是将需求分析的用户需求抽象为信息结构,这是整个数据库设计最困难的阶段。第4章是逻辑结构设计,它将概念模型转换为某个DBMS所支持的数据模型。第5章是数据库的实施与运行,它包括数据的载入及数据库的运行。 关键词:SQL语言;IBM DB2;数据库设计;教学管理系统 I
沈阳工程学院 学生实验报告 (课程名称:数据库原理及应用) 实验题目:数据库模式设计 班级软件本111学号2011417104姓名吴月芬 日期2012.10.16 地点F座606 指导教师孙宪丽祝世东
一、实验目的 熟练掌握采用SQL命令建立数据库表、索引和视图的方法。 二、实验环境 Oracle10g数据库系统。 三、实验内容与要求 (一)实验内容 1.建立学生数据库模式 学生表:student (sno学号,sname姓名,ssex性别,sage年龄,sdept所在系) 其中: sno 长度为4的字符串,为主码; sname 长度为8的字符串; ssex 长度为2的字符串,其值只取男、女; sage 短整数,其值在0-150之间; sdept 长度为10的字符串。 2.建立课程数据库模式 课程表:course ( cno课程号,cname课程名,ccredit学分) 其中: cno 长度为4的字符串,为主码 cname 长度为10的字符串,不能为空,且不能有重复课程名; ccredit 短整数。 3.建立选课数据库模式。 选课表:sc (sno学号,cno课程号,grade成绩) 其中: sno 长度为4的字符串,和student表sno外键关联,且级联删除 cno 长度为4的字符串,course表cno外键关联,
grade 短整数,值或空或为0—100之间, (sno,cno) 联合作主码。 (二)实验要求 在Oracle10g的iSQLPlus中完成下列操作: (1)创建上述三个表。 (2)向Student 表增加"入学时间"列(列名为Scome,日期型)。 (3)将年龄的数据类型改为半字长整数。 (4)为Student中sname添加列级完整性约束,不能为空。 (5)删除Student中sname列级完整性约束。 (6)为SC建立按学号升序和课程号降序建立唯一索引. (7)在表student的sname字段建立一个升序索引。 (8)删除在表student的sname字段建立的索引。 (9)给student表增加一个地址(address)属性。 (10)给student表删除地址(address)属性。 (11)建立视图view1,要求有sno,sname,cname,grade四个字段。 (12)建立视图view2,要求有sno,ssex,sage三个字段。 四、实验过程及结果分析 (1)1)创建学生数据库模式,代码如下: create table student ( sno char(11) primary key, sname char(8), ssex char(2) check ssex in (‘男’,’女’), sage number check between 0 and 150, sdept char(10) );
集成电路的发展到目前为止,依次经历了SSI,MSI,LSI,VLSI四个阶段。 微型计算机可采用不同的主振频率的CPU芯片。叵现有芯片的主振频率为8MHZ,也就是说它的主振周期为0.125US,(主振周期=1/主振频率)若已知每个机器周期平均含有4个主振周期,该机的平均指令执行速度为0.8MI/S,那么该机的平均指令周期为 1.25US,(平均指令周期=1/平均指令执行速度)平均每个指令周期含有 2.5个机器周期(平均机器周期数=平均指令周期/平均机器周期)。若改用主振周期为0.4US的CPU芯片,则计算机的平均指令执行速度为0.25MI/S(平均指令执行速度=1/平均指令周期=1/主振周期*平均机器周期含主振周期数*机器周期数)。若要得到平均每秒40万次的指令执行速度,则应采用主振频率为4MHZ的CPU 芯片。(平均指令执行速度=1/{(1/主振频率)*主振周期数*机器周期数}) 单个磁头在向盘片的磁性涂层上写入数据时,是以串行方式写入的。 虚拟存储管理系统的基础是程序的局部性理论。此理论的基本含义是程序执行时对主存的访问是不均匀的。局部性有两种表现形式:时间局部性和空间局部性。它们的意义分别为最近被访问的单元,很可能在不久的将来还要被访问和最近被访问的单位,很可能在它附近的单元还要被访问。根据局部性理论,DENNING提出了工作集的理论。 设有四级流水线,分别完成取指、译码、运算、存数四步操作,各步时间依次为30ns\50ns,80ns和100ns。则流水线的操作周期应为100ns。(取平均时间取决于流水线最慢的一步)每步操作时间依次为60、100、50、70 ns。该流水线的操作周期应为100 ns。若有一小段程序需要用20条基本指令完成则得到第一条指令结果400ns,结果完成该段程序需2300 ns。在流水线结构的计算机中,频繁执行条件转移指令时会严重影响机器的效率。当有中断请求发生时,若采用不精确断点法,则将不仅影响中断响应时间,还影响程序的正确执行。内存按字节编址,地址从A4000H到CBFFFH,共有160K 字节(CBFFFH-A4000H=27FFFH=160K)。若用存储容量为32K*8BIT的存储器芯片构成该内存,至少需要5片。(160K/32K=5) 若指令流水线把一条指令分为取指、分析和执行三部分,且三部分的时间分别是T取指=T分析=2NS,T执行=1NS,则100条指令全部执行完毕需203NS (T=100*2+3=203) 在单指令流多数据流计算机SIMD中,各处理单元必须以同步方式,在同一时间内执行同一条指令。 容量为64场面的CACHE采用组相联方式映像,字块大小为128个字,每4块为一组。若主存容量为4096块, 且以字编址,那么主存地址应为19位(4096*128=219 字),主存区号应为6位。(4096/64=32) 甲通过计算机网络给乙发消息,表示甲同意与乙签订合 同,不久后甲不承认发过该消息。为了防止这种情况的 出现,应该在计算机网络中采取数字签名技术 硬磁盘存储器的道存储密度是指沿磁盘半径方向上单 位长度毫米或英寸上的磁道数,而不同磁道上的位密度 是靠近圆心的密度大。 中央处理器CPU中的控制器是由基本的硬件部件构成 的。外设接口部件不是构成控制器的部件。中央处理 CPU主要由运算器和控制器组成,控制器中程序计数器 保存了程序的地址。中央处理CPU的主要功能不包括传 输数据。 使CACHE命中率最高的替换算法是替换最近最少使用 的块算法LRU。一般来说CACHE的功能全部由硬件实现。 某32位计算机的CACHE容量为16KB,CACHE块的大小 为16B,若主存与CACHE的地址映射采用直接映射方式, 则主存在地址为1234E8F8的单元装入的CACHE地址为 10 1000 1111 1000平均命中率最高的是近期最少使用 LRU算法。设某流水线计算机主存的读/写时间为100ns, 有一个指令和数据合一的CACHE已知该CACHE的读/写 时间为10 ns,取指令的命中率为98%,取数的命中率 为95%。在执行某类程序时,约有1/5指令需要存/取 一个操作数。假设指令流水线在任何时间都不阻塞,则 设置CACHE后,每条指令的平均访存时间约为12 ns。 (4/5*{10*98%+100*2%}+1/5*{1095%+100*5%}=12 ns) 相联存储器的访问方式是按内容访问。 利用并行处理技术可以缩短计算机的处理时间,所谓并 行性是指在同一时间完成两种或两种以上工作。可以采 用多种措施来提高计算机系统的并行性,它们可分成三 类即资源重复,资源共享和时间重叠。提供专门用途的 一类并行处理机亦称阵列处理机以SIMD方式工作,它 适用于矩阵运算。多处理机是目前性能较高计算机的基 本结构,它的并行任务的派生是需要专门的指令来表示 程序中并发关系和控制并发执行。 中断响应时间是指从发出中断请求到进入中断处理所 用的时间。 虚拟存储器对应用程序员透明而对系统程序员不透明. 虚拟存储器一定是多级存储器,而多级存储器不一定是 虚拟存储器. 程序中10%的指令占用了90%的执行时间,这一规则被 称为局部性原理。建立存储层次体系依据的原理是局部 性原理。 可随机读写且只要不断电则基本存储信息就可一直保 存的称为SRAM可随机读写但即便在不断电的情况下其 存储的信息也要定时刷新才不致丢失的称为DRAM所存 信息由生产厂家用掩膜技术写好后就无法再改变的称 为ROM通过紫外线照射后可擦除所有信息然后重新写 入新的信息并可多次进行的称为EPROM通过电信号可 在数秒钟内快速删除全部信息但不能进行字节级别删 除操作的称为Flash Memory 存储器读写速率越高每位的成本也越高,存储容量也越 大,解决这一问题的方法是采用多级存储体系. 为了大幅度提高处理器的速度,当前处理器都采用了指 令级并行处理技术如超级标量Superscaler它是指采 用多个处理部件多条流水线并行执行.流水线组织是实 现指令并行的基本技术影响流水线连续流动的因素除 数据相关性、转移相关性能、功能部件冲突和中断系统. 要发挥流水线的效率还必须重点改进编译系统在RISC 设计中对转移相关性一般采用延迟转移方法解决 计算机执行程序所需时间P,可用P=I·CPI·T来估计, 其中I是程序经编译后的机器指令数,CPI是执行每条 指令所需的平均机器周期数,T为每个机器周期的时间。 RISC计算机是采用虽增加I,但更减少CPI来提高机器 的速度。它的指令系统具有指令种类少的特点。指令控 制部件的构建,CISC更适于采用微程序控制,而RISC 更知于采用硬布线控制逻辑。RISC机器又通过采用大 量的寄存器加快处理器的数据处理速度。RISC的指令 集使编译优化工作更简单。访问内存需要的机器周期比 较少不是RISC的特点。 计算机总线在机内各部件之间传输信息.在同一时刻只 可以有一个设备发数据,一个或多个设备收数据.系统 总线由三总分构成.它们是地址总线、控制总线、数据 总线。早期的微机,普遍采用ISA总线,它适合16位 字长的数据处理为了适应增加字长和扩大寻址空间的 需要,出现了EISA总线它与ISA总线兼容。目前在奔 腾机上普遍使用,数据吞吐量可达2Gbit/s的局部总线 是PCI总线。 在流水线操作时,每个阶段的执行时间应取3个阶段执 行时间中的最大值。 SCSI是一种通用的系统级标准输入/输出接口,其中 FASTSCSI-II标准的数据宽度为16位,数据传送率达 20MB/S。大容量的辅助存储器采用RAID磁盘阵列。RAID 是工业标准共有6级。其中RAIDI是镜像磁盘阵列,具 有最高的安全性;RAID5是无独立校验盘的奇偶校验码 磁盘阵列;RAID2是采用纠错海明码的磁盘阵列;RAID0 则是既无冗余也无校验的磁盘阵列,它采用了数据分块 技术,具有专长最高的I/O性能和磁盘空间利用率,比 较容易管理,但没有容错能力。RAID是一种经济的磁 盘冗余阵列,它采用智能控制器和多磁盘驱动器以提高 数据传输率。RAID与主机连接较普遍使用工业标准接 1页
HUNAN CITY UNIVERSITY 数据库系统课程设计 设计题目:宿舍管理信息系统 姓名: 学号: 专业:信息与计算科学 指导教师: 20年 12月1日
目录 引言 3 一、人员分配 4 二、课程设计目的和要求 4 三、课程设计过程 1.需求分析阶段 1.1应用背景 5 1.2需求分析目标5 1.3系统设计概要 5 1.4软件处理对象 6 1.5系统可行性分析 6 1.6系统设计目标及意义7 1.7系统业务流程及具体功能 7 1.8.1数据流程图8 2.系统的数据字典11 3.概念结构设计阶段 13 4.逻辑结构设计阶段 15 5.物理结构设计阶段 18 6.数据库实施 18 7.数据库的运行和维护 18 7.1 解决问题方法 19 7.2 系统维护 19 7.3 数据库性能评价 19 四、课程设计心得. 20参考文献 20
引言 学生宿舍管理系统对于一个学校来说是必不可少的组成部分。目前好多学校还停留在宿舍管理人员手工记录数据的最初阶段,手工记录对于规模小的学校来说还勉强可以接受,但对于学生信息量比较庞大,需要记录存档的数据比较多的高校来说,人工记录是相当麻烦的。而且当查找某条记录时,由于数据量庞大,还只能靠人工去一条一条的查找,这样不但麻烦还浪费了许多时间,效率也比较低。当今社会是飞速进步的世界,原始的记录方式已经被社会所淘汰了,计算机化管理正是适应时代的产物。信息世界永远不会是一个平静的世界,当一种技术不能满足需求时,就会有新的技术诞生并取代旧技术。21世纪的今天,信息社会占着主流地位,计算机在各行各业中的运用已经得到普及,自动化、信息化的管理越来越广泛应用于各个领域。我们针对如此,设计了一套学生宿舍管理系统。学生宿舍管理系统采用的是计算机化管理,系统做的尽量人性化,使用者会感到操作非常方便,管理人员需要做的就是将数据输入到系统的数据库中去。由于数据库存储容量相当大,而且比较稳定,适合较长时间的保存,也不容易丢失。这无疑是为信息存储量比较大的学校提供了一个方便、快捷的操作方式。本系统具有运行速度快、安全性高、稳定性好的优点,并且具备修改功能,能够快速的查询学校所需的住宿信息。 面对目前学校发展的实际状况,我们通过实地调研之后,对宿舍管理系统的设计开发做了一个详细的概述。
西安邮电大学 (计算机学院) 课内实验报告 实验:数据库及数据库中表的建立实验 课程:数据库系统原理与应用 班级:经济学1601班 学号: 学生姓名:冯丹娜 任课教师:樊珊
SQL Server 2000管理工具的使用和创建数据库 一、实验目的 1.熟悉SQL Server 2000的环境。 2.掌握企业管理器的基本使用方法,对数据库及其对象有基本了解,了解对 SQL Server 2000进行配置的方法。 3.掌握查询分析器的基本使用方法以及在查询分析器中执行T-SQL 语句的方 法。 4.了解SQL Server 2000数据库的逻辑结构和物理结构。 5.学会在企业管理器中创建数据库及查看数据库属性。 6.学会使用T-SQL语句创建数据库。 二、实验内容 1.学会使用企业管理器和查询分析器管理工具。 2.使用企业管理器创建数据库。 创建一个教务管理数据库,名称为JWGL,数据文件的初始大小为20MB,文件增长方式为自动增长,文件增长增量设为5MB,文件的增长上限为500MB。日志文件的初始大小为10MB,文件增长增量设为1MB,文件的增长限制设为100MB。数据文件的逻辑文件名和物理文件名均采用默认值,分别为JWGL_data 和d:\Microsoft SQL Server\MSSQL\data\JWGL_data.mdf;事务日志文件的逻辑文件名和物理文件名也采用默认值,分别为JWGL_log和d:\Microsoft SQL Server\MSSQL\data\JWGL_log.ldf。 3.在查询分析器中使用T-SQL语句创建数据库。 创建一个名为Market的数据库(注意e盘下应存在sql_data目录)。CREATE DATABASE Market ON (NAME=Market_Data, FILENAME='e:\sql_data\Matket_Data.mdf', SIZE=10, MAAXSIZE=50, FILEGROWTH=10%) LOG ON (NAME=Market_Log, FILENAME='e:\sql_data\Market_Log.ldf', SIZE=5, MAXSIZE=15, FILEGROWTH=10%); 4.使用T_SQL语句或企业管理器创建一个图书借阅管理数据库,数据库名为 TSGL,数据文件和日志文件的初始大小、增长方式、文件的增长上限等均可采用默认值。 5.使用T-SQL语句或企业管理器创建第二章习题10的SPJ数据库,可以自行 定义文件大小、增长方式。 6.查看物理磁盘目录,理解并分析SQL Server 2000数据库的存储结构。 7.使用企业管理器查看数据库属性。 8.使用T-SQL语句或企业管理器对于(2)~(5)中建立的数据库进行修改和 删除操作,并进一步查看物理磁盘目录。
数据库读书笔记 导语:读书笔记是指读书时为了把自己的读书心得记录下来或为了把文中的精彩部分整理出来而做的笔记。以下是数据库读书笔记的内容,希望你们喜欢! 数据库读书笔记n 物化视图——物化视图是包括一个查询结果的数据库对象,物化视图不是在使用时才读取,而是预先计算并保存表连接或聚集等耗时较多的操作结果,这样在查询时大大提高读取速度,特别适用于多个数据量较大的表进行连接操作及分布式数据库中需要进行分布在多个站点的表进行连接操作时使用。 物化视图可以进行远程数据的本地复制,此时物化视图的存储也可以成为快照。主要用于实施数据库间的同步。 物化视图对于数据库客户端的使用者来说如同一个实际表,具有和表相同的一般select操作,而其实际上是一个视图,一个定期刷新的数据视图。物化视图的刷新可采用自动刷新和人工刷新两种方式,具体刷新方式和刷新时间在定义物化视图的时候可以定义。使用物化视图可以实现视图的所有功能,因物化视图不是在使用时才读取,而大大提高了读取速度,特别使用抽取大量数据表中某些信息以及分布式环境中跨节点进行多表数据连接的场合。 n 聚集 在数据库运行初期,数据库对SQL语句各种写法的性能
优劣还不敏感,但是随着数据库正式使用,数据库中的数据不断增加,劣质SQL语句和好的SQL语句之间的速度差异就逐渐显示出来。 n 合理使用索引 n 避免和简化排序:通常在运行order by和group by 的SQL语句值,会涉及到排序操作,应当简化成避免对大型表进行重复排序,因为磁盘排序的开销是很大的。与内存排序相比,磁盘排序操作很慢,从而会花费很长时间,降低数据库性能,而且磁盘排序会消耗临时表空间中的资源。 当能够利用索引自动以适当的次序产生输出时,优化器就可以避免不必要的排序步骤,以下是一些影响因素由于现有索引的不足,导致排序时索引中不包括一个或几个待排序的列;group by或order by 子句中列的次序与索引的次序不一样;排序的列来源于不同的表。 为了避免不必要的排序,就要正确建立索引,合理地合并数据表。如果排序不可避免,那么应当试图简化它,如缩小排序的范围等。 n 消除对大型表数据的顺序存取:嵌套查询中,对表的顺序存取对查询效率可能产生致命的影响。避免这种情况的主要方法就是对连接的列进行索引。还可以使用并集来避免顺序存取,尽管在所有的检查列上都有索引,但某些形式的where子句强迫优化器使用顺序存取。
《数据库技术》课程设计 设计目的: 数据库技术课程设计是在学生系统的学习数据库技术课程后,按照关系型数据库的基本原理,综合运用所学的知识,以个人或小组为单位,设计开发一个小型的数据库管理系统。通过对一个实际问题的分析、设计与实现,将数据库技术、原理与应用相结合,使学生学会如何把书本上学到的知识用于解决实际问题,培养学生的动手能力;另一方面,使学生能深入理解和灵活掌握教学内容。 总体要求: 1)2到3人为一个小组,每个小组设组长一人,小组成员既要有相互合作的 精神,又要分工明确。 2)每个学生都必须充分了解整个设计的全过程。 3)从开始的系统需求分析到最后的软件测试,都要有详细的计划,设计文档 应按照软件工程的要求书写。 4)系统中的数据表设计应合理、高效,尽量减少数据冗余。 5)软件界面要友好、安全性高。 6)软件要易于维护、方便升级。 7)后台数据库(DBMS)用SQL Server2008. 8)前台开发工具自选,但一般情况下应该是小组的每个成员都对该语言较熟 悉,避免把学习语言的时间放在设计期间。 9)每组提交一个课程设计报告和可行的应用软件。 具体设计要求: 结合一个具体任务(课程设计参考题目),完成一个基于C/S模式或者B/S 模式的数据库系统的设计与开发。 正文要包括系统总体设计、需求分析、概念设计、逻辑设计(在逻辑设计中,需要检测是否满足3NF,如果设计为不满足3NF的,要说明原因)、物理设计(物理设计中,要设置表的索引、完整性、联系等)、测试、安装说明、用户使用说明书,参考文献等。 主要应包括如下内容: 1.完成课题任务的需求分析、完成系统总体结构设计方案。(主控功能模块、数据处理模块、统计报表模块等) 2.数据库结构的设计与实现。 3.数据库安全的设计 4.客户端数据库应用程序的开发。 5.综合调试方法的掌握。
数据库基础知识试题 部门____________ __________ 日期_________ 得分__________ 一、不定项选择题(每题1.5分,共30分) 1.DELETE语句用来删除表中的数据,一次可以删除( )。D A .一行 B.多行 C.一行和多行 D.多行 2.数据库文件中主数据文件扩展名和次数据库文件扩展名分别为( )。C A. .mdf .ldf B. .ldf .mdf C. .mdf .ndf D. .ndf .mdf 3.视图是从一个或多个表中或视图中导出的()。A A 表 B 查询 C 报表 D 数据 4.下列运算符中表示任意字符的是( )。B A. * B. % C. LIKE D._ 5.()是SQL Server中最重要的管理工具。A A.企业管理器 B.查询分析器 C.服务管理器 D.事件探察器 6.()不是用来查询、添加、修改和删除数据库中数据的语句。D A、SELECT B、INSERT C、UPDATE D、DROP 7.在oracle中下列哪个表名是不允许的()。D A、abc$ B、abc C、abc_ D、_abc 8.使用SQL命令将教师表teacher中工资salary字段的值增加500,应该使用的命令 是()。D A、Replace salary with salary+500 B、Update teacher salary with salary+500 C、Update set salary with salary+500 D、Update teacher set salary=salary+500 9.表的两种相关约束是()。C