数据库整理
- 格式:doc
- 大小:338.00 KB
- 文档页数:26

数据库中数据清洗与整理的常用方法总结数据清洗和整理是数据库管理中非常重要的步骤,它涉及到从原始数据中筛选、提取、清除错误或不相关数据的过程。
数据清洗和整理的目标是保证数据的准确性、一致性和完整性,以便进行后续的分析和应用。
本文将总结一些常用的数据清洗和整理方法。
1. 规范化数据规范化数据指的是将数据转换为统一的格式和单位。
例如,将日期统一为特定的格式(如YYYY-MM-DD),或将货币金额转换为特定的货币符号和小数位数。
这样可以解决数据中不一致的格式和单位的问题,以便于后续的计算和比较。
2. 缺失值处理在数据中常常会出现缺失值,即某些观测值缺少了某些特征值。
处理缺失值的常用方法包括删除、替换和插补。
删除是指直接删除包含缺失值的行,但这可能涉及到信息的丧失。
替换是指使用常量或统计量替换缺失值,例如用均值、中位数或众数来替代缺失的数值。
插补是利用其他相关变量的信息进行估计,来填补缺失值。
具体方法包括回归插补、最近邻插补等。
3. 异常值检测和处理异常值是指与其他观测值明显不同的数据点,它可能是由于测量误差、数据错误或统计偏差造成的。
检测和处理异常值的方法可以通过绘制箱线图、直方图等图表来识别不符合正常数据分布的值,并决定是否要删除或修正这些值。
修正方法包括替换为平均值、中位数或使用插值方法进行替代。
4. 数据类型转换在数据库中,数据的类型需要与表格、字段的定义相匹配。
当数据类型不匹配时,可能导致错误或数据丢失。
因此,数据清洗和整理的过程中,需要将数据转换为适当的数据类型,例如将字符型数据转换为数值型,确保数据的精确度和完整性。
5. 删除重复值数据库中的数据可能存在重复记录,即多个记录具有相同的特征值。
删除重复值可以提高数据的质量和准确性。
常见的方法是基于一个或多个字段检查记录是否重复,并根据需要进行删除或保留。
6. 数据分割和合并在数据库中,数据可能存储在一个字段中,需要进行分割成多个字段以便于分析和应用。

数据库系统概念知识点整理冶旭华东师范大学10计算机科学技术系Chapter 1 引言数据库管理系统(DBMS):由一个互相关联的数据的集合和一组用以访问这些数据的程序组成,数据描述某特定的企业。
DBMS的主要目标是为人们提供方便高效的环境来存储和检索数据。
数据不一致性:即同一数据的不同副本不一致。
模式分为数据库模式,物理模式和逻辑模式。
物理数据独立性:应用程序如果不依赖于物理模式,它们就被称为是具有物理数据独立性,因此即使物理模式改变了它们也无须重写。
数据模型:是数据库结构的基础,是一个用于描述数据、数据联系、数据语义和数据约束的概念工具的集合。
数据操纵语言(DML):是使得用户可以访问和操纵数据的语言。
分为过程化和非过程DML (即声明式DML)。
过程化DML:要求用户指定需要什么数据以及如何获得这些数据。
非过程化DML:只要求用户指定需要什么数据,而不指明如何获得这些数据。
事务:是数据库应用中完成单一逻辑功能的操作集合,是一个既具有原子性又具有一致性的单元。
事务管理:负责保证不管是否有故障发生,数据库都要处于一致的(正确的)状态。
事务管理器还保证并发事务的执行互不冲突。
数据库管理员(DBA):对系统进行集中控制的人。
Chapter 2 关系模型关系数据模型(relational data model): 建立在表的集合的基础上。
数据库系统的用户可以对这些表进行查询,可以插入新元组、删除元组以及更新(修改)元组。
关系代数:定义了一套在表上运算,且输出结果也是表的代数运算。
这些运算可以混合使用以得到表达所希望查询的表达式。
关系代数定义了关系查询语言中使用的基本运算。
关系代数运算可分为:基本运算(选择,投影,并,集合差,笛卡尔积,更名);附加运算(集合交,自然连接,除,赋值),扩展的运算(广义投影,聚集函数,外连接)。
码:是整个关系的性质,而不是一个个元组的性质。
关系中的任意两个元组都不允许同时在码属性上具有相同的值。

简述数据整理的步骤数据整理是指对所收集到的数据进行清洗、转换和组织,以便更好地理解和分析数据。
数据整理的过程可以分为以下几个步骤。
1. 数据收集数据整理的第一步是数据收集。
数据可以来自各种不同的来源,如调查问卷、数据库、日志文件等。
在收集数据时,需要确保数据的准确性和完整性。
2. 数据清洗数据清洗是指处理数据中的错误、缺失、重复或不一致的部分。
在数据清洗的过程中,可以使用各种方法和技术,如删除重复数据、填补缺失数据、修正错误数据等。
3. 数据转换数据转换是指将原始数据转换为适合分析的形式。
常见的数据转换操作包括数据格式转换、数据类型转换、数据合并、数据拆分等。
数据转换可以使数据更容易理解和分析。
4. 数据整合数据整合是指将来自不同来源的数据进行合并和整合。
在数据整合的过程中,需要解决数据模式不一致、数据结构不同等问题。
可以使用数据库操作或数据整合工具来进行数据整合。
5. 数据归纳数据归纳是指对数据进行总结和归纳,以便更好地理解数据的特征和规律。
在数据归纳的过程中,可以使用各种统计方法和技术,如计算平均值、中位数、标准差等。
6. 数据可视化数据可视化是指使用图表、图形、地图等方式将数据呈现出来,以便更直观地理解数据。
数据可视化可以帮助人们更好地发现数据中的模式和趋势。
7. 数据分析数据分析是指对数据进行统计和分析,以获得有关数据的洞察和结论。
数据分析可以使用各种统计方法和机器学习算法,如回归分析、聚类分析、决策树等。
8. 数据报告数据整理的最后一步是生成数据报告。
数据报告应包括数据的来源、整理过程、分析结果和结论等内容。
数据报告应具有清晰、准确、易于理解的特点。
数据整理是对收集到的数据进行清洗、转换和组织的过程。
通过数据整理,可以更好地理解和分析数据,从而得出有关数据的结论和洞察。
数据整理的步骤包括数据收集、数据清洗、数据转换、数据整合、数据归纳、数据可视化、数据分析和数据报告。
通过遵循这些步骤,可以有效地进行数据整理工作。

数据库基础知识整理与复习总结关系型数据库MySQL1、数据库底层MySQL数据库的底层是B+树。
说到B+树,先说下B树,B树也叫多路平衡查找树,所有的叶⼦节点位于同⼀层,具有以下特点:1)⼀个节点可以容纳多个值;2)除⾮数据已满,不会增加新的层,B树追求最少的层数;3)⼦节点中的值与⽗节点的值有严格的⼤⼩对应关系。
⼀般来说,如果⽗节点有a个值,那么就有a+1个⼦节点;4)关键字集合分布在整棵树中;5)任何⼀个关键字出现且只出现在⼀个节点中;6)搜索可能在叶⼦结点结束,其搜索性能等价于在关键字全集做⼀次⼆分查找。
B+树是基于B树和叶⼦节点顺序访问指针进⾏实现,它具有B树的平衡性,并且通过顺序访问指针来提⾼区间查询的性能,⼀个叶⼦节点中的key从左⾄右⾮递减排列。
特点在于:1)⾮叶⼦节点中含有n个关键字,关键字不保存数据,只作为索引,所有数据都保存在叶⼦结点;2)有的叶⼦节点中包含了全部关键字的信息及只想这些关键字记录的指针,即叶⼦节点包含链表结构,能够⽅便进⾏区间查询;3)所有的⾮叶⼦结点可以看成是索引部分,节点中仅包含其⼦树中的最⼤(或最⼩)关键字;4)同⼀个数字会在不同节点中重复出现,根节点的最⼤元素就是B+树的最⼤元素。
MySQL中的InnoDB引擎是以主键ID为索引的数据存储引擎。
InnoDB通过B+树结构对ID建⽴索引,在叶⼦节点存储数据。
若建索引的字段不是主键ID,则对该字段建索引,然后再叶⼦节点中存储的是该记录的主键,然后通过主键索引找到对应的记录。
因为不再需要全表扫描,只需要对树进⾏搜索即可,所以查找速度很快,还可以⽤于排序和分组。
InnoDB和MyISAM引擎都是基于B+树,InnoDB是聚簇索引,数据域存放的是完整的数据记录;MyISAM是⾮聚簇索引,数据域存放的是数据记录的地址。
InnoDB⽀持表锁、⾏锁、间隙锁、外键以及事务,MyISAM仅⽀持表锁,同时不⽀持外键和事务。
InnoDB注重事务,MyISAM注重性能。

生物信息学数据库分类整理汇总生物信息学数据库是存储和管理生物学领域的大量数据的重要工具和资源,对于生物信息学研究、基因组学、蛋白质组学、转录组学等领域的研究具有重要的意义。
本文将对生物信息学数据库进行分类整理和汇总,方便生物信息学研究者更好地使用和了解这些数据库。
1.基因组数据库:- GenBank:美国国家生物技术信息中心(NCBI)维护的基因序列数据库,包含已知基因的核酸序列。
- Ensembl:英国恩格斯尔基因组项目维护的一个综合性基因组数据库,包含多种物种的基因组数据。
- UCSC Genome Browser:加利福尼亚大学圣克鲁兹分校开发的一个基因组浏览器,提供多种物种的基因组序列和注释信息。
2.蛋白质数据库:- UniProt:一个综合性的蛋白质数据库,集成了多个蛋白质序列和注释信息资源。
- Protein Data Bank (PDB):存储大量已解析的蛋白质结构数据的数据库,提供原子级别的结构信息。
- Protein Information Resource (PIR):收集和整理蛋白质序列、结构和功能信息的数据库。
3.转录组数据库:- NCBI Gene Expression Omnibus (GEO):存储和共享大量的高通量基因表达数据的数据库。
- ArrayExpress:欧洲生物信息学研究所(EBI)开发的一个基因表达数据库,包含多种生物组织和疾病的表达数据。
4.疾病数据库:- Online Mendelian Inheritance in Man (OMIM):记录人类遗传疾病和相关基因的数据库。
- Orphanet:收集和整理罕见疾病和相关基因的数据库。
5.代谢组数据库:- Human Metabolome Database (HMDB):一个综合性的人类代谢物数据库,包括代谢产物的结构和功能信息。
- Kyoto Encyclopedia of Genes and Genomes (KEGG):包含多种生物体代谢途径的数据库。

数据库管理中的数据归档与清理在数据库管理中,数据归档与清理是一项至关重要的任务。
通过对数据库中的数据进行合理的归档与清理,可以提高系统的性能与效率,减少存储空间的占用,同时保护和优化数据的安全性和可用性。
本文将介绍数据归档与清理的重要性、常用的归档与清理方法以及一些注意事项。
首先,让我们来探讨数据归档与清理的重要性。
随着时间的推移和业务的增长,数据库中的数据量不断增加,而且大部分时间只有最新的数据会被频繁访问,许多旧数据可能已过时或者不再需要。
数据库中存储了大量的冗余和废弃数据会增加数据库的存储压力,并降低查询和备份的性能。
通过归档和清理过时的数据,可以释放存储空间,减少备份时间,提高系统的响应速度,从而降低数据库运维的成本。
接下来,我们将讨论几种常用的数据归档与清理方法。
1. 数据归档:数据归档是指将过时或者不再需要的数据移动到归档存储区域。
归档数据的目的是将其保留用于遵守法规、合规需求,存档数据通常不再经常访问,但仍然需要保留。
归档数据可以存储在低成本的存储设备上,如磁带库或云存储服务中,以减少数据库的存储空间占用。
通过归档,可以降低数据库的存储成本,并提高数据库的性能和效率。
2. 数据清理:数据清理是指对数据库中的冗余、重复、错误或废弃数据进行清除和整理。
一个常见的数据清理任务是删除过时的或者不再需要的记录。
定期清理无用的数据可以减少数据库的存储需求,以及提高数据库的查询效率和性能。
此外,还可以进行数据压缩来减小数据库的物理存储大小,从而减少存储成本。
3. 定期备份:数据归档与清理的另一重要方面是定期备份数据库。
通过定期备份,可以确保数据的安全性和可用性。
数据备份可以帮助恢复意外删除或损坏的数据,应对硬件故障或自然灾害等不可预见的情况。
同时,备份还可以用于数据迁移、升级以及测试和开发环境的数据恢复。
因此,定期备份是数据库管理中不可或缺的一步。
在进行数据归档与清理的过程中,还有一些需要注意的事项。

mysql数据库碎⽚整理1、drop table table_name ⽴刻释放磁盘空间,不管是 Innodb和MyISAM 。
2、truncate table table_name ⽴刻释放磁盘空间,不管是 Innodb和MyISAM 。
3、delete from table_name删除表的全部数据,对于MyISAM 会⽴刻释放磁盘空间(应该是做了特别处理,也⽐较合理),InnoDB 不会释放磁盘空间;4、对于delete from table_name where xxx带条件的删除, 不管是innodb还是MyISAM都不会释放磁盘空间,delete操作以后使⽤optimize table table_name 会⽴刻释放磁盘空间。
不管是innodb还是myisam 。
所以要想达到释放磁盘空间的⽬的,delete以后执⾏optimize table 操作。
例⼦如下:table_name 表名称。
optimize table table_name6、delete from表以后虽然未释放磁盘空间,但是下次插⼊数据的时候,仍然可以使⽤这部分空间。
总结:delete from表名;truncate table 表名;不带where参数的delete语句可以删除mysql表中所有内容,使⽤truncate table也可以清空mysql表中所有内容。
效率上truncate⽐delete快,但truncate删除后不记录mysql⽇志,不可以恢复数据。
delete的效果有点像将mysql表中所有记录⼀条⼀条删除到删完,⽽truncate相当于保留mysql表的结构,重新创建了这个表,所有的状态都相当于新表。
7、查询所有数据库占⽤磁盘空间⼤⼩的SQL语句:select TABLE_SCHEMA, concat(truncate(sum(data_length)/1024/1024,2),' MB') as data_size,concat(truncate(sum(index_length)/1024/1024,2),'MB') as index_sizefrom information_schema.tablesgroup by TABLE_SCHEMAorder by data_length desc;8、查询单个库中所有表磁盘占⽤⼤⼩的SQL语句:select TABLE_NAME, concat(truncate(data_length/1024/1024,2),' MB') as data_size,concat(truncate(index_length/1024/1024,2),' MB') as index_sizefrom information_schema.tables where TABLE_SCHEMA = 'TestDB'group by TABLE_NAMEorder by data_length desc;9:查询单个库某张表磁盘占⽤⼤⼩的SQL语句SELECT t.TABLE_SCHEMA,t.TABLE_NAME,t.TABLE_ROWS,t.DATA_LENGTH,t.INDEX_LENGTH,t.DATA_FREE,concat(round(t.DATA_FREE / 1024 / 1024, 2), 'M') AS datafreeFROM information_schema.tables tWHERE t.TABLE_SCHEMA = 'epay' and t.table_name='orders'。

数据库的数据清洗与整理说明书一、背景介绍在现代社会中,数据的重要性得到了广泛认可和应用。
数据库作为存储、管理和处理数据的重要工具,充当着数据驱动决策的基础。
然而,数据的质量问题一直是困扰数据库应用的重要挑战之一。
数据清洗和整理是保证数据库数据质量的关键步骤。
本说明书旨在介绍数据库数据清洗与整理的具体步骤和方法,以指导用户进行数据清洗和整理工作。
二、数据清洗1. 数据清洗的定义数据清洗是指通过识别、更正或删除数据库中的错误、不一致或不完整的数据,以提高数据的准确性和一致性。
2. 数据清洗步骤(1)数据审查:对数据库中的数据进行全面审查,包括数据格式、数据完整性和数据一致性等方面。
(2)数据验证:通过验证规则和逻辑,对数据的准确性进行验证,识别出可能存在的错误或异常数据。
(3)数据修复:对识别出的错误数据进行修复,可以通过手动修复、自动修复或者数据替换等方式进行。
(4)数据删除:对无效的、冗余的或重复的数据进行删除,以提高数据库的运行效率和数据的整洁性。
三、数据整理1. 数据整理的定义数据整理是指对数据库中的原始数据进行分类、排序和组织,以提高数据的可读性和可用性。
2. 数据整理步骤(1)数据分类:将数据库中的数据按照一定的规则和标准进行分类,可以根据数据的类型、属性或者业务需求进行分类。
(2)数据排序:对分类后的数据进行排序,可以按照字母、数字、时间或其他用户定义的排序规则进行排序。
(3)数据组织:将排序后的数据按照一定的结构和格式进行组织,以便用户进行查阅和利用。
(4)数据标准化:对数据库中的数据进行统一的格式和标准化处理,以提高数据的一致性和可比性。
四、附加说明1. 数据备份:在进行数据清洗和整理之前,务必进行数据库的备份,以避免数据丢失和不可逆的操作错误。
2. 数据安全:在数据清洗和整理过程中,要注意数据的安全性,避免数据泄露或被非法利用。
3. 数据更新:数据库中的数据是动态变化的,需要定期进行数据清洗和整理的更新,以保证数据的准确性和完整性。
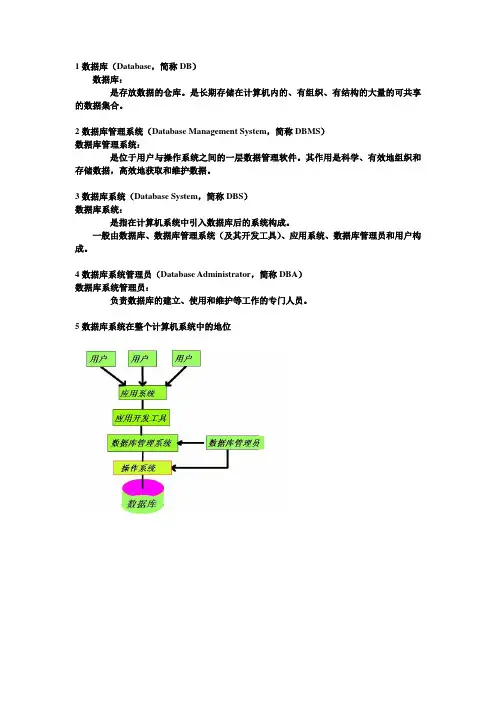
1数据库(Database,简称DB)数据库:是存放数据的仓库。
是长期存储在计算机内的、有组织、有结构的大量的可共享的数据集合。
2数据库管理系统(Database Management System,简称DBMS)数据库管理系统:是位于用户与操作系统之间的一层数据管理软件。
其作用是科学、有效地组织和存储数据,高效地获取和维护数据。
3数据库系统(Database System,简称DBS)数据库系统:是指在计算机系统中引入数据库后的系统构成。
一般由数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员和用户构成。
4数据库系统管理员(Database Administrator,简称DBA)数据库系统管理员:负责数据库的建立、使用和维护等工作的专门人员。
5数据库系统在整个计算机系统中的地位6数据管理技术的产生和发展一、人工管理阶段(1)数据不保存(2)应用程序管理数据(3)数据不共享(4)数据不具有独立性二、文件系统阶段(1)数据可以长期保存(2)由文件系统管理数据(3)数据共享性差,冗余度大(4)数据独立性差7数据库系统阶段数据库系统的特点一、数据结构化数据结构化是数据库与文件系统的根本区别。
数据库的共享性高、冗余度低、易扩充数据库系统从整体角度看待和描述数据,数据不再面向某个应用而是面向整个系统,数据可以被多个用户、多个应用共享使用。
数据独立性高数据独立性包括:数据的物理独立性和数据的逻辑独立性。
数据由DBMS统一管理(1)数据的安全性保护(2)数据的完整性检查(3)并发控制(4)数据库恢复8概念模型模型:是现实世界特征的模拟和抽象。
9数据模型分成两个不同的层次:概念模型:也称信息模型,它是按用户的观点来对数据和信息建模。
概念模型用于信息世界的建模。
概念模型不依赖于某一个DBMS支持的数据模型。
概念模型可以转换为计算机上某一DBMS支持的特定数据模型。
概念模型的特点:(1) 具有较强的语义表达能力,能够方便、直接地表达应用中的各种语义知识。

空间数据库ws整理空间数据库整理数据:指客观事物的属性、数量、位置及其相互关系等的符号描述。
空间数据:是对现实世界中空间对象(事物)的描述,其实质是指以地球表⾯空间位置为参照,⽤来描述空间实体的位置、形状、⼤⼩及其分布特征等诸多⽅⾯信息的数据。
【三⼤基本特征:空间、时间、专题属性】空间数据库概念:指以特定的信息结构(如国⼟、规划、环境、交通等)和数据模型(如关系模型、⾯向对象模型等)表达、存储和管理从地理空间中获取的某类空间信息,以满⾜不同⽤户对空间信息需求的数据库。
空间数据【⾮结构化(实体位置、⼤⼩形状和拓扑关系)】的组织和管理不同于⼀般的事务性数据【数据记录⼀般是结构化的(每⼀个记录有相同的结构和固定的长度,记录中每个字段表达的只能是原⼦数据,内部⽆结构,不允许嵌套记录)】与统计数据相⽐空间数据更复杂:数据类型多(⼏何数据、关系数据、辅助数据)数据操纵复杂⼀般数据检索、增加、删除等定位检索、拓扑关系检索等数据输出多样(数据、报表、图形)数据量⼤,空间数据种类多测量、统计数据、⽂字地图、影像等传统⽅法管理空间数据库存在问题:【eg:列出居住在离公司50英⾥以内的顾客、⽆法利⽤索引缩⼩搜索范围】违背了数据独⽴性原则——查询的实现需要了解空间对象的结构⽅法的性能——⼤量的关系元组缺乏⽤户友好性——需要⽤户对表的操纵很难定义新的空间类型不能表达⼏何计算——相邻检测;点查询;开窗查询等空间数据管理的发展过程⼈⼯管理阶段⽂件管理阶段⽂件与关系数据库系统混合管理系统全关系型空间数据库管理系统对象关系数据库管理系统关系型数据库+空间数据引擎扩展对象关系型数据库管理系统⾯向对象的数据库系统1、“关系型数据库+空间数据引擎”近年来由GIS⼚商研发的⼀种中间件解决⽅案。
⽤户将⾃⼰的空间数据交给独⽴于数据库之外的空间数据引擎,由空间数据引擎来组织空间数据在关系型数据库中的存储;⽤户需要访问数据的时候,再通知空间数据引擎,由引擎从关系型数据库中取出数据,并转化为客户可以使⽤的⽅式。

目录1.1.1 四个基本概念 (1)数据(Data) (1)数据库(Database,简称DB) (1)长期储存在计算机内、有组织的、可共享的大量数据的集合、 (1)基本特征 (1)数据库管理系统(DBMS) (1)数据定义功能 (1)数据组织、存储和管理 (1)数据操纵功能 (1)数据库的事务管理和运行管理 (1)数据库的建立和维护功能(实用程序) (2)其它功能 (2)数据库系统(DBS) (2)1.1.2 数据管理技术的产生和发展 (2)数据管理 (2)数据管理技术的发展过程 (2)人工管理特点 (3)文件系统特点 (3)1.1.3 数据库系统的特点 (3)数据结构化 (3)整体结构化 (3)数据库中实现的是数据的真正结构化 (4)数据的共享性高,冗余度低,易扩充、数据独立性高 (4)数据独立性高 (4)物理独立性 (4)逻辑独立性 (4)数据独立性是由DBMS的二级映像功能来保证的 (4)数据由DBMS统一管理和控制 (4)1.2.1 两大类数据模型:概念模型、逻辑模型和物理模型 (5)1.2.2 数据模型的组成要素:数据结构、数据操作、数据的完整性约束条件 (5)数据的完整性约束条件: (6)1.2.7 关系模型 (6)关系数据模型的优缺点 (7)1.3.1 数据库系统模式的概念 (7)型(Type):对某一类数据的结构和属性的说明 (7)值(Value):是型的一个具体赋值 (7)模式(Schema) (7)实例(Instance) (7)1.3.2 数据库系统的三级模式结构 (7)外模式[External Schema](也称子模式或用户模式), (7)模式[Schema](也称逻辑模式) (8)内模式[Internal Schema](也称存储模式) (8)1.3.3 数据库的二级映像功能和数据独立性 (8)外模式/模式映像:保证数据的逻辑独立性 (8)模式/内模式映象:保证数据的物理独立性 (8)1.4 数据库系统的组成 (9)数据库管理员(DBA)职责: (9)2.1.1 关系 (9)域(Domain):是一组具有相同数据类型的值的集合 (9)候选码(Candidate key) (9)全码(All-key) (9)主码(Primary key) (9)主属性 (9)2.2.1基本关系操作 (10)2.3.1 关系的三类完整性约束 (10)实体完整性和参照完整性: (10)用户定义的完整性: (10)2.3.2 实体完整性:主码不为空 (10)2.3.4 用户定义的完整性 (10)2.4.2 专门的关系运算:选择、投影、连接、除 (11)象集Zx:本质是一次选择运算和一次投影运算 (11)悬浮元组 (11)外连接 (11)左外连接 (11)右外连接 (11)除:查找在被除数R中能够完全覆盖除数S的部分[的剩余值] 11 3.1.2 SQL的特点 (11)1.综合统一 (12)2.高度非过程化 (12)3.面向集合的操作方式 (12)4.以同一种语法结构提供多种使用方式 (12)5. 语言简洁,易学易用 (12)3.3.1 模式的定义和删除 (12)CREATE SCHEMA <模式名> AUTHORIZATION <用户名> (12)DROP SCHEMA <模式名> <CASCADE|RESTRICT> (12)CASCADE(级联) (12)RESTRICT(限制) (13)3.3.2 基本表的定义、删除和修改 (13)CREATE TABLE <表名>(<列名> <数据类型>[ <列级完整性约束条件> ] (13)ALTER TABLE <表名> (13)DROP TABLE <表名>[RESTRICT| CASCADE]; (13)RESTRICT:删除表是有限制的。
数据的整理和分析数据是现代社会中不可或缺的重要资源,而对数据的整理和分析则能够帮助我们更好地理解和应用这些数据。
本文将探讨数据整理和分析的重要性,并介绍一些常用的方法和工具。
一、数据整理的重要性数据整理是指对原始数据进行清洗、归类、组织和转化,以便更好地进行后续的分析和应用。
数据整理的重要性主要体现在以下几个方面:1. 数据准确性提升:通过对数据进行整理,可以发现并修复数据中的错误或缺失,提升数据的准确性和可靠性。
2. 数据一致性保证:数据整理能够将不同来源、不同格式的数据进行统一和标准化处理,确保数据的一致性,方便后续的分析和比较。
3. 数据可读性增强:通过对数据进行整理和转化,可以将原始数据转化为易读易懂的格式,使数据更具可读性和可理解性。
4. 数据存储和管理:数据整理还包括对数据进行存储和管理,确保数据的安全性和可访问性。
二、数据整理的方法和工具数据整理的方法和工具多种多样,下面介绍几种常用的方法和工具:1. 数据清洗:数据清洗是数据整理的重要环节,用于发现并处理数据中的错误、缺失和异常值。
常用的数据清洗工具包括Excel、Python 等。
2. 数据归类和组织:数据归类和组织是将数据按照一定的分类标准进行组织和排序,以方便后续的分析和应用。
常用的数据归类和组织方法包括建立数据库、使用标签或标识符等。
3. 数据转化:数据转化是将原始数据转化成更适合分析和应用的格式,例如将文本数据转化为数字数据、将非结构化数据转化为结构化数据等。
常用的数据转化工具包括Excel、SQL、Python等。
4. 数据存储和管理:数据存储和管理是数据整理中必不可少的环节,常用的数据存储和管理工具包括关系型数据库(如MySQL)、非关系型数据库(如MongoDB)、云存储等。
三、数据分析的重要性数据分析是指对已经整理好的数据进行统计、计算、模型建立等方法,以从中提取有用信息、分析问题并作出决策。
数据分析的重要性主要体现在以下几个方面:1. 发现规律和趋势:通过对数据进行分析,可以发现数据背后的规律和趋势,帮助我们更好地理解现象、发现问题和机会。
数据库中数据清洗与整理的常见方法与案例分析随着互联网的发展和数据采集手段的多种多样化,工作中我们经常会面临一种问题,就是如何清洗和整理数据库中的数据。
数据清洗和整理是数据分析的重要一环,对于保证数据准确性和可信度至关重要。
本文将介绍一些常见的方法和案例,帮助读者掌握数据库中数据清洗与整理的技术。
一、常见方法1. 去除重复记录在数据库中,常常存在重复的记录,这些重复的记录会干扰我们对数据的分析和理解。
去除重复记录的方法主要有两种:使用DISTINCT关键字或利用GROUP BY子句。
DISTINCT关键字可以直接针对某一列或多列进行去重操作;而GROUP BY子句则需要结合聚合函数使用,根据需要去除重复记录。
2. 处理缺失值缺失值是指在数据库中部分字段没有值的情况。
处理缺失值的方法有多种,如插值法、删除法、替代法等。
插值法主要通过已有数据的特征,向缺失值填充预测值;删除法则是直接删除缺失值所在的记录;替代法可以使用默认值或者其他算法进行填充。
3. 格式转换数据库中的数据可能存在多种格式,比如日期格式可以是MM/DD/YYYY,也可以是YYYY-MM-DD。
在处理数据的过程中,对于格式不一致的数据会导致计算错误或混乱。
因此,格式转换是数据库中数据清洗与整理的重要步骤。
可以使用SQL中的日期函数或字符串函数来实现格式转换。
4. 异常值处理异常值是指与大部分数据明显不相符的数值,可能由于采集误差或其他原因产生。
处理异常值的方法可以是删除、替换或离群值检测。
根据具体情况,可以通过观察数据分布、采用机器学习方法或专业知识来判断并处理异常值。
5. 关联数据验证在数据库中存在多个表格的情况下,需要进行表间的关联验证,以确保数据的一致性。
关联数据验证方法主要包括外键约束和内连接或左连接等操作。
外键约束可以保证父表和子表之间的数据一致性,而连接查询操作则可以通过比较原始和关联数据的某些字段,进而验证数据的准确性。
二、案例分析1. 商品销售数据清洗假设我们有一张商品销售表格,其中包含了商品ID、销售日期、客户信息、销售量等字段。
数据库ppt整理:1.数据库(DataBase,DB)是指长期存储在计算机内、有组织的、可共享的大量数据的集合。
数据库中的数据按一定的数据模型组织、描述和存储,具有较小的冗余度、较高的数据独立性和易扩展性,并为各种用户共享。
概括而言,数据库具有永久存储和易扩展性,并为各种用户共享.2.数据(data)是承载或记录信息的按一定规律排列组合的物理符号,是形成信息的源泉,是计算机程序加工的“原料”。
简单地说,数据是对客观事物描述与记载的物理符号记录。
数据有多种表现形式,可以是文字、图形、图像、声音、语言等.3.信息(information)泛指人类社会传播的一切内容.一般而言,信息是一种被加工成为特定形式的数据,是数据的集合、含义与解释,是事物变化、相互作用、特征的反映。
当前,信息已成为人类社会活动的一种重要资源,与能源、物质并称人类社会活动的三大要素。
4.信息资源与能源、物质资源相比(1)能够重复使用,能在使用中体现自身价值并产生增值;(2)具有极强的目标导向,即使是相同的信息在不同的用户中也体现出不同的价值;(3)具有整合性,信息资源的检索和利用,不受时间、空间、语言、地域和行业的制约;(4)是社会财富,任何人无权全部或永久购买信息的使用权;同时信息资源是商品,可以被销售、贸易和交换;(5)具有流动性。
5。
信息与其它相关概念★ 信息与消息比较,消息是信息的外壳,信息是消息的内核;★ 信息与信号相比,信号是信息的载体;★ 信息与数据比较,数据是信息存在的一种形态或记录形式,数据经过解释并赋予一定意义之后,便成为信息。
★ 信息与知识相比,知识是事物运动状态和方式在人们头脑中一种有序的、规律性的表达,是信息加工的产物。
6. 数据与信息的关系◎ 数据是信息的符号表示,也称载体;◎ 信息是数据的内涵,是数据的语义解释;◎ 数据是符号化信息;◎ 信息是语义化数据。
7。
数据处理数据处理是指对各种形式的数据进行收集、存储、加工和传播的一系列活动的总和.信息处理的目的:一是从大量的、原始的数据中抽取、整理出对人们有价值的信息,以作为行动和决策的依据;二是借助计算机科学地保存和管理复杂、大量的数据,以便方便利用这些资源.8。
1.如果K是超码,则K的任意一个真子集都不是候选码。
(√)2.OLE DB的(C)是一个由COM组件构成的数据访问中介。
A.游标B.数据源C.提供者D.消费者3.SELECT语句中用来消除重复行的关键字是(DISTINCT)。
4.(D)是系统为用户开设的一个数据缓冲区,存放SQL语句产生的多条记录数据。
A.指示变量B.静态变量C.主变量D.游标5.数据库中建立索引的目的是为了(D)。
A.提高安全性B.节省存取空间C.加快建表速度D.加快查询速度6.在左外连接中,保留的是左外关系中所有的元组。
(√)7.数据库的设计完全凭经验就可以设计得比较完美,不必遵守相应原则。
(×)8.数据管理技术经历了若干阶段,其中人工管理阶段和文件系统阶段相比,文件系统的一个显著优势是(B)A.数据整体结构化B.数据可以长期保存C.数据共享性很强D.数据独立性很好9.(D)是关系数据库管理系统内部的一组系统表,它记录了数据库中所有的定义信息,包括关系模式定义、视图定义、索引定义、完整性约束定义各类用户对数据库的操作权限、统计信息等。
A.系统数据表B.模式表C.关系表D.数据字典10.实现将现实世界抽象为信息世界的是(C)A.物理模型B.逻辑模型C.概念模型D.关系模型11.下列说法正确的是(B)A.域是一组具有不同数据类型的值的集合B.数据库中不同的属性可以来自同一个域C.创建域的语句是CREATE ASSERTION(CREATE DOMAIN)D.当域上的完整性约束条件改变时必须一一修改域上的各个属性(只要修改域的定义即可)12.触发器被激活时,只有当触发条件为真时触发动作体才执行。
(√)13.定义关系的主码意味着主码属性(D)A.必须唯一B.不能为空C.唯一且部分主码属性不为空D.唯一且所有主码属性不为空14.数据库系统的三级模式结构按照从用户使用到系统存储的方向看,是指数据库系统是由外模式、模式和(内模式)三级构成。
数据库知识点整理(全)Unit 1四个基本概念1.数据(Data)是数据库中存储的基本对象。
2.数据库(Database,简称DB)是长期储存在计算机内、有组织的、可共享的大量数据集合。
3.数据库管理系统(DBMS)是位于用户与操作系统之间的一层数据管理软件(系统软件),其主要功能包括数据定义、数据操纵、数据库的运行管理以及数据库的建立和维护功能(实用程序)。
DBMS的用途是科学地组织和存储数据,高效地获取和维护数据。
4.数据库系统(Database System,简称DBS)指在计算机系统中引入数据库后的系统构成,包括数据库、数据库管理系统(及其开发工具)、应用系统、数据库管理员(DBA)和用户。
数据管理技术的发展过程人工管理阶段、文件系统阶段和数据库系统阶段。
数据库系统管理数据的特点如下:1.数据共享性高、冗余少。
2.数据结构化。
3.数据独立性高。
4.由DBMS进行统一的数据控制功能。
数据模型数据模型是用来抽象、表示和处理现实世界中的数据和信息的工具。
通俗地讲,数据模型就是现实世界数据的模拟。
数据模型的三个要素包括数据结构、数据操作和数据的约束条件。
E-R图E-R图中,实体用矩形框表示,属性用椭圆形(或圆角矩形)表示,联系用菱形表示。
组织层数据模型组织层数据模型包括层次模型、网状模型和关系模型。
其中,关系模型用“二维表”来表示数据之间的联系,基本概念包括关系、元组、属性、分量、主码和域。
关系模式的数据完整性约束关系模式的数据完整性约束包括实体完整性、参照完整性和用户定义的完整性。
DBS的三级模式结构包括外模式、概念模式和内模式(一个数据库只有一个内模式)。
Unit 2在进行数据库的操作时,可能会出现以下几个问题:Good nal models should avoid the following problems: data ndancy。
n anomalies。
n anomalies。
and update anomalies.nal ___:___ R(A1.A2.An)。
、DBS, 数据库系统:database system DBS、、DBA数据库管理器、OOP面向对象编程、数据模型、主关键字、外部关键字、元数据、数据处理、类、子类、对象、属性、事件、方法、工作区、关系模型、参照完整性E-R图参考答案:是E-R模型的图形表示法,它是直接表示概念模型的有力工具。
2.D B M S数据库管理系统(D B M S),对数据库进行管理的系统软件,是用户与数据库之间的接口。
3.S Q L结构化查询语言,是美国国家标准局AN S I确认的关系数据库语言的标准。
4.表达式参考答案:是变量、操作符、常量、函数、字段名、控件以及属性的组合。
5.基类参考答案:V F P系统提供的内部定义的类,可用作其他用户自定义类的基础。
1.D B参考答案:DATABASE,数据库,指以一定的组织形式存放在计算机存储介质上的相互关联的数据的集合。
主控索引参考答案:在复合索引的多个索引中,在某一时刻只有一个索引对表起作用,这个索引标志称为主控索引2.属性参考答案:属性(Property)定义对象的特征或某一方面的行为ODBC参考答案:开放式数据库互连,ODBC是一种用于数据库服务器的标准协议1.关系模型的基本结构是(A )。
A.二维表B.树形结构C.无向图D.有向图2.表单的背景色由属性(A )的值确定。
A.B a c k C o l o rB.P i c t u r eC.F o r e C o l o rD.C a p t i o n3.在数据库表字段的扩展属性中,通过对(B )可以限定字段的内容仅为英文字母。
A.字段格式B.输入掩码C.字段标题和注释D.字段级规则4.在向数据库添加表的操作中,下列叙述中不正确的是(B)。
A.可以将一个自由表添加到数据库中B.可以将一个数据库表直接添加到另一个数据库中C.可以在项目管理器中将自由表拖放到数据库中D.欲使一个数据库表成为另一个数据库的表,则必须先使其成为自由表5.数据库系统中,表是用来存放数据的,备注型、通用型数据存放在表的备注文件中,表的备注文件的扩展名是(C)。
命令行进入SQLCMD:sqlcmd –s machineName\instanceName使用数据库:USE db_nameGO删除数据库:(不能删除系统数据库)USE tempdbGOSELECT name,state_descFROM sys.databasesWHERE name=’db_name’GODROP DATABASE db_name1,db_name2,…GO更改数据库文件ALTER DATABASE db_name{ADD FILE<filespec>-- 指定要添加的文件|ADD LOG FILE<filespec>-- 指定要添加的日志文件| REMOVE FILE logical_file_name -- 指定要删除的数据文件名| MODIFY FILE<filespec>-- 指定要更改的文件| MODIFY NAME= new_dbname -- 重命名数据库}修改数据库属性:ALTER DATABASE db_nameSET ANSI_NULL_DEFAULT ON更名:USE tempdbGOALTER DATABASE db_nameSET SINGLE_USERALTER DATABASE db_testMODIFY NAME=db_new_nameALTER DATABASE db_new_nameSET MULTI_USER更改数据库文件组:ALTER DATABASE db_nameADD FILEGROUP filegroup_name [CONTAINS FILESTREAM]|REMOVE FILEGROUP filegroup_nam--(要先删除组中的文件)|[MODIFY FILEGROUP filegroup_name{<filegroup_option>|DEFAULT|NAME=new_filegroup_name}]注意:要更改为默认文件组,文件组中至少要包含一个文件。
分离[ , [ @skipchecks= ] 'skipchecks' ][ , [ @keepfulltextindexfile = ] 'KeepFulltextIndexFile' ]附加CREATE DATABASE db_nameON <filespec> [,..n]FOR {ATTACH|ATTACH_REBUILD_LOG}系统数据库master数据库记录了SQL SERVER的数据、端点、服务器和系统配置信息。
还有所有数据库及其数据库文件的位置,以及实例的初始化信息。
msdb数据库是SQL SERVER代理用于计划警报和作业及其它功能。
其属性主要包括msdb数据文件、日志文件的初始值。
model数据库是创建其他用户数据库的模板。
resource数据库具有只读的特性。
其中包含了SQL SERVER所用到的所有系统对象(系统视图)。
一般不要对resource 数据库进行修改。
不过,用户可以移动reource数据库。
用户可用sys.objects系统视图查看系统对象。
tempdb数据库是一个全局临时资源。
tempdb可以与所有连接共用。
表创建USE db_nameGOIF OBJECT_ID('<schema_name>.<table_name>')IS NOT NULLDROP TABLE<schema_name >.<table_name>GOCREATE TABLE table_name(<col_namel><data_type> [NULL | NOT NULL][PRIMARY | UNIQUE][FOREIGN KEY [(column_name)]]REFERENCES ref_table [(ref_column)]<col_name2><data_type>.........<constraint_definition> […n])GO也可以通过SELECT INTO创建表:SELECT col1,col2,col3 INTO tb_name1 FROM tb_name2表的修改ALTER TABLE table_nameADD [<column_name> <data_type>][PRIMARY KEY | CONSTRAINT][FOREIGN KEY (column_name) REFERENCES ref_table(ref_column)]DROP [CONSTRAINT] constraint_name |COLUMN column_nameALTER TABLEADD CONSTRAINT<contraint_name ><constraint_type>(<constraint_column_name ><logical_expression>)sys.key_constraintsDROP TABLE table_name系统表系统表在性能和安全性上都存在问题,SQL Server的后续版本中将逐步删除系统表,因此最好使用目录视图来获取系统级信息。
用户无法对系统表进行修改操作,只有通过专用的管理员连接(DAC)才能直接查询和修改系统表。
临时表存储在tempdb中本地临时表:本地且对创建者可见,其它用户不可见,当用户断开连接时,系统自动删除之。
USE db_nameGOCREATE TABLE #tb_name()全局临时表:对所有用户可见,当使用安的所有用户断开连接时,系统自动删除之。
USE db_nameGOCREATE TABLE ##tb_name()专用的管理员连接通过DAC,用户可以直接修改系统表。
DAC需要用户到服务器现场方可操作。
SQLCMD –E –S machine_name\instanceName –A其中-A表示使用DAC连接,-E建立信任连接(适用于Windows身份验证模式),-S表示连接到machine_name上的instanceName实例。
注意:在使用DAC之前,要打开SQL Server Browser服务。
数字类型,默认18;S是小数位,要:0~P.默认为0.货币型精确为4位小数。
精确与存储字节数逻辑数值型bit(可以存储整型数据1、0或NULL。
如果输入0以外的其他值时,SQL Server均将它们当作1看待)近似数字类型(浮点数据)REAL (精度7位)FLOAT(建议使用):(精度15位)FLOAT[(n)]. n是尾数(科学计数法)Unicode字符串NTEXTNCHAR[(n)]:n:1~4000,所占存储空间为2n个字节。
NVARCHAR[(n|max)]:max:2^31-1个字节,n:1~4000,占2n+2个字节。
字符串CHAR:n:1~8000,占用n字节VARCHAR:n:1~8000,占用n+2字节TEXT日期和时间DATETIME (1753.1.1-9999.12.31)SMALLDATETIME (1900.1.1-2079.6.6)格式:'yyyy-mm-dd hh:mm:ss AM/PM'转型CAST(expression AS data_type):将指定的expression的值转换为由data_type所指定的数据类型的函数。
CONVERT(data_type[(length)],expression [,style]):将指定的expression的值转换为由data_type所指定的数据类型的函数。
其它数据类型CURSOR 可用于变量或存储过程OUTPUT参数,CREATE TABLE中的列,不能使用CURSOR数据类型TIMESTAMP 自动生成的二进制数字的数据类型,存储大小为8字节。
在TIMESTAMP中只存储递增的数字,而不保留具体的日期或时间。
一个表只能有一个TIMESTAMP列。
HIERARCHYID 长度可变的层次类型,创建具有层次结构的表.最适合存储的分层数据类型是树。
UNIQUEIDENTIFIER 16字节的GUID。
NEWID()函数获得一个初始值.SQL_VARIANT 使数据库对象能够支持其他数据类型的值。
XML 可以存储XML数据的类型。
最大不能超过2GB。
XML([CONTENT | DOCUMENT] XML_schema_collection_name)TABLE 主要用于存储结果集。
TABLE变量可用于函数、存储过程和批处理的内部,也可以作为参数。
可以像SQL Server中普通的表那样使用。
GEOGRAPHY和GEOMETRY:空间类型排序规则查找所有字符排序规则select name,description from fn_helpcollations()修改数据库排序规则ALTER DATABASE db_name COLLATE France_BINGOSELECT CONVERT(VARCHAR,DATABASEPROPERTYEX(…db_name‟,‟collation‟))列级排序规则支持NVARCHAR和NCHAR等字符串类型数据。
在CREATE TABLE时,由COLLATE子句设置。
查看SELECT AS列名, AS数据类型, c.max_length AS长度,c.collation_name AS列的排序规则FROM sys.columns AS c JOIN sys.types AS tWHERE c.object_id=OBJECT_ID(…dbo.table_demo‟)修改ALTER TABLE tb_nameALTER column_name NCHAR(10)COLLATE Greek_CS_AI表达式级排序规则表达式级排序规则是SQL语句运行时,通过COLLATE设置返回的结果集的排序规则。
USE db_nameGOSELECT col1,col2FROM tb_nameORDER BY name COLLATE Latin1_General_CS_AI二进制字符串(FILESTREAM)BINARY[(n)]:固定长度二进制数据类型。
n:1~8000,占n字节。
VARBINARY[(n|max)]:可变长度二进制数据类型。
n:1~8000.max代表2^31-1个字节。
实际存储空间n+2字节。
IMAGE如果没有指定n,默认为1。