推荐系统代码结构
- 格式:pdf
- 大小:328.85 KB
- 文档页数:2

选择结构实验报告选择结构实验报告引言:选择是我们生活中不可避免的一部分。
每个人每天都要做出许多选择,无论是简单的选择还是重大的决策。
在这个实验报告中,我们将探讨选择结构的重要性以及它在日常生活和工作中的应用。
一、选择结构的定义和作用选择结构是编程中的一种控制结构,用于根据不同的条件执行不同的操作。
它基于条件的真假来决定程序的执行路径。
选择结构使得程序能够根据不同的情况做出不同的决策,从而实现更加灵活和智能的逻辑。
二、选择结构的基本形式选择结构有两种基本形式:if语句和switch语句。
if语句基于一个条件表达式的真假来决定执行的代码块,而switch语句则基于一个表达式的值来选择执行的分支。
三、选择结构的应用场景选择结构在日常生活和工作中有广泛的应用。
例如,在一个自动售货机中,根据用户选择的商品和支付的金额,系统可以通过选择结构判断是否有足够的库存和找零的硬币。
在一个电子游戏中,选择结构可以根据玩家的操作和游戏规则来判断玩家是否通过了关卡或者获得了奖励。
在一个智能家居系统中,选择结构可以根据传感器的数据和用户的设置来自动调节室内温度和照明。
四、选择结构的优化和注意事项在使用选择结构时,我们需要考虑一些优化和注意事项。
首先,我们应该尽量减少嵌套的选择结构,以提高代码的可读性和性能。
其次,我们应该合理地选择条件表达式和分支的顺序,以减少不必要的判断和计算。
最后,我们应该注意处理边界条件和异常情况,以保证程序的正确性和稳定性。
五、选择结构的局限性和未来发展选择结构虽然在许多场景下非常有用,但它也有一些局限性。
例如,当条件过多或者条件之间存在复杂的关系时,选择结构可能会变得冗长和难以维护。
此外,选择结构也无法处理连续的条件,而只能选择其中一个分支进行执行。
随着人工智能和机器学习的发展,我们可以预见选择结构在未来会有更多的应用和发展。
例如,基于大数据和深度学习的智能推荐系统可以根据用户的兴趣和行为数据来自动选择和推荐合适的内容。

使用Python实现基于内容的推荐系统基于内容的推荐系统是一种常见的推荐方法,它主要根据用户对物品的历史行为以及物品的特征来推荐相似的物品。
在这种方法中,推荐系统会分析物品之间的相似性,然后根据用户的偏好向其推荐相似的物品。
此方法通常适用于电影、音乐和图书等领域。
在Python中实现基于内容的推荐系统,可以按照以下步骤进行:1.数据收集:首先,需要收集用户对物品的历史行为数据。
这些数据可以包括用户对电影、音乐或图书的评分、浏览记录等。
可以使用已有的数据集,如MovieLens数据集或Amazon商品数据集,也可以通过爬取网页数据或调用开放API来获取数据。
2.特征提取:对于每个物品,我们需要提取一些关键特征。
比如对于电影,特征可以包括导演、演员、类型、评分等。
对于音乐,特征可以包括歌手、专辑、流派等。
对于图书,特征可以包括作者、出版日期、类别等。
这些特征应当能够描述物品的主要内容和属性。
3.特征向量化:在将特征提取为文本或数字形式后,可以使用特征向量化的方法将其转为数值向量。
常用的方法有词袋模型和TF-IDF(Term Frequency-Inverse Document Frequency)等。
词袋模型将文本信息转为向量,根据单词的频率表示特征,而TF-IDF则考虑了单词的重要性。
4.相似度计算:计算物品之间的相似度是基于内容的推荐系统的关键。
可以使用余弦相似度或欧氏距离等方法来度量物品之间的相似性。
对于每个物品,我们可以计算其与其他物品的相似度,并选择与其最相似的若干个物品作为推荐结果。
5.推荐生成:根据用户的历史行为和物品的特征,可以计算用户对未评价物品的兴趣度。
通常可以使用加权求和的方法,将用户对物品的历史评分和物品的特征相似度进行加权求和,从而得到用户对物品的兴趣度评分。
然后,根据兴趣度评分对物品进行排序,并选择评分最高的若干个物品作为推荐结果。
下面是一个基于内容的推荐系统的示例代码:```pythonimport pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarity # Step 1:数据收集data = pd.read_csv('movies.csv') #假设有一份包含电影信息的数据集,包括电影名称和特征等# Step 2:特征提取features = ['director', 'actors', 'genre'] #假设我们选取了导演、演员和类型作为电影的特征data['features'] = data[features].apply(lambda x: ''.join(x), axis=1)# Step 3:特征向量化vectorizer = TfidfVectorizer()features_matrix =vectorizer.fit_transform(data['features'])# Step 4:相似度计算similarity_matrix = cosine_similarity(features_matrix) # Step 5:推荐生成def generate_recommendations(movie_id, top_n=5):movie_index = data[data['id'] == movie_id].index[0] #根据电影id获取其在数据集中的索引similarity_scores = similarity_matrix[movie_index] #获取该电影与其他电影的相似度得分top_indices = similarity_scores.argsort()[-top_n-1:-1][::-1] #获取相似度得分最高的n个电影的索引top_movies = data.iloc[top_indices] #根据索引获取相似电影的信息return top_moviesrecommendations = generate_recommendations(movie_id=1) print(recommendations)```以上代码实现了一个简单的基于内容的电影推荐系统。

推荐系统的常⽤算法参考回答:推荐算法:基于⼈⼝学的推荐、基于内容的推荐、基于⽤户的协同过滤推荐、基于项⽬的协同过滤推荐、基于模型的协同过滤推荐、基于关联规则的推荐FM:LR:逻辑回归本质上是线性回归,只是在特征到结果的映射中加⼊了⼀层逻辑函数g(z),即先把特征线性求和,然后使⽤函数g(z)作为假设函数来预测。
g(z)可以将连续值映射到0 和1。
g(z)为sigmoid function.则sigmoid function 的导数如下:逻辑回归⽤来分类0/1 问题,也就是预测结果属于0 或者1 的⼆值分类问题。
这⾥假设了⼆值满⾜伯努利分布,也就是其也可以写成如下的形式:对于训练数据集,特征数据x={x1, x2, … , xm}和对应的分类标签y={y1, y2, … , ym},假设m个样本是相互独⽴的,那么,极⼤似然函数为:log似然为:如何使其最⼤呢?与线性回归类似,我们使⽤梯度上升的⽅法(求最⼩使⽤梯度下降),那么。
如果只⽤⼀个训练样例(x,y),采⽤随机梯度上升规则,那么随机梯度上升更新规则为:Embedding:Embedding在数学上表⽰⼀个maping:,也就是⼀个function。
其中该函数满⾜两个性质:1)injective (单射的):就是我们所说的单射函数,每个Y只有唯⼀的X对应;2)structure-preserving(结构保存):⽐如在X所属的空间上,那么映射后在Y所属空间上同理。
那么对于word embedding,就是找到⼀个映射(函数)将单词(word)映射到另外⼀个空间(其中这个映射具有injective和structure-preserving的特点),⽣成在⼀个新的空间上的表达,该表达就是word representation。
●协同过滤的itemCF,userCF区别适⽤场景参考回答:Item CF 和 User CF两个⽅法都能很好的给出推荐,并可以达到不错的效果。


---文档均为word文档,下载后可直接编辑使用亦可打印---摘要随着人们生活水平的提升,美食推荐的应用逐渐走入人们的视野,越来越多的人通过选择这些应用订餐。
但是,这些应用往往忽视了用户个性化的需求,推荐的美食千篇一律。
针对这一情况,研发了师大美食推荐移动应用系统。
本系统包括两大部分:移动应用端和云推送端。
其中,移动应用端是基于安卓平台开发,用户可以在手机应用上看到师大周边的各类美食。
云推送端可以根据用户的饮食习惯每日给用户个性化推荐美食。
通过在师大的测试表明,本系统可以有效帮助同学了解并适应学校周边的美食分布,解决学生吃饭选择困难的问题。
该论文有图20幅,表3个,参考文献18篇。
关键词:美食推荐动应用系统移动应用系统美食推荐Food Recommended Robile Application SystemDesign and ImplementationAbstractWith the improvement of people’s living standards, food recommendation applications walks into people's vision. More and more people choose to order foods by these applications on the phone. However, these applications tend to ignore the user personal requirement and the food they recommend follows the same pattern. In view of this situation, we development this mobile phone application of food recommendation. The system consists of two parts: mobile applications and cloud platform. The mobile application is based on the Android mobile phone by which users can see all kinds of food around the university. The cloud platform can recommend delicious food every day accord to user's eating habits. After rigorous testing,this application can help to adapt to the food distribution around the university and can solve the difficult problem of choosing food for the students.Key Words:Food Recommendation Mobile Application System; Mobile Application System; Food Recommendation图清单表清单1 绪论1.1 课题背景随着生活水平的提升,人们对于美食的要求也愈发多样,很多美食推荐软件也如雨后春笋般出现在应用市场。

基于JavaWeb的推荐数据后台管理系统的设计与实现1. 引言1.1 研究背景现在越来越多的网站和应用程序提供了个性化推荐功能,通过分析用户的行为和偏好来为用户推荐感兴趣的内容或产品。
推荐系统已经成为了各大互联网公司的重要组成部分,为用户提供了更加个性化和优质的服务体验。
在推荐系统中,推荐算法的设计和实现是非常重要的一环。
而推荐算法的实现又需要依托于强大的后台管理系统来支撑数据的管理和处理。
设计和实现一个基于JavaWeb的推荐数据后台管理系统变得至关重要。
本文将通过对系统架构设计、数据库设计、推荐算法实现、管理后台开发以及系统测试与调优等方面的详细介绍,来深入探讨基于JavaWeb的推荐数据后台管理系统的设计与实现。
通过本文的研究,我们可以更好地了解推荐系统的原理和实践,为推荐算法的优化和后台管理系统的开发提供参考和借鉴。
1.2 研究意义本文旨在设计与实现基于JavaWeb的推荐数据后台管理系统,旨在简化用户管理数据的操作流程,提高推荐算法的准确性和效率,解决传统数据管理系统中存在的诸多问题。
该系统将采用先进的推荐算法,为用户提供个性化的推荐服务,帮助他们更快速、更准确地找到他们感兴趣的内容。
通过实现该系统,我们可以提高公司的服务质量,提升用户体验,增加用户黏性,从而提升公司的竞争力和市场份额。
该系统还可以为公司带来更多的商业价值,为公司的发展提供有力的支持。
设计与实现基于JavaWeb的推荐数据后台管理系统具有重要的研究意义和实际价值,对于进一步推动数据管理系统的发展具有积极的推动作用。
1.3 研究目的研究目的是为了设计和实现一个基于JavaWeb的推荐数据后台管理系统,以提供个性化推荐服务。
通过研究推荐算法和开发管理后台,我们的目的是实现一个高效、准确、可靠的推荐系统,为用户提供更好的使用体验。
这个系统旨在解决传统推荐系统中存在的一些问题,如推荐精度不高、数据更新不及时、用户体验不佳等。
通过研究和实践,我们希望可以从根本上提升推荐系统的质量,使其更符合用户的需求和偏好。



个性化推荐系统代码以下是一个简单的个性化推荐系统的代码示例:```pythonimport numpy as np#用户兴趣矩阵user_interest_matrix = np.array([[1, 0, 1, 1],[0,1,0,1],[1,0,1,0],[0,0,1,1]])#物品兴趣矩阵item_interest_matrix = np.array([[0, 1, 1, 0],[1,0,1,0],[0,0,1,1],[1,1,0,0]])#用户相似度矩阵user_similarity_matrix = np.dot(user_interest_matrix, user_interest_matrix.T)#计算用户相似度def calculate_user_similarity(user_interest_matrix):user_similarity_matrix = np.dot(user_interest_matrix,user_interest_matrix.T)return user_similarity_matrix#物品相似度矩阵item_similarity_matrix = np.dot(item_interest_matrix.T,item_interest_matrix)#计算物品相似度def calculate_item_similarity(item_interest_matrix):item_similarity_matrix = np.dot(item_interest_matrix.T,item_interest_matrix)return item_similarity_matrix#基于用户的协同过滤推荐算法def user_based_collaborative_filtering(user_interest_matrix, user_similarity_matrix, user_index):user_interests = user_interest_matrix[user_index]user_similarity = user_similarity_matrix[user_index]for item_index in range(len(user_interests)):if user_interests[item_index] == 0:weighted_sum = np.dot(user_similarity,item_interest_matrix[item_index])#基于物品的协同过滤推荐算法def item_based_collaborative_filtering(item_interest_matrix, item_similarity_matrix, user_index):user_interests = user_interest_matrix[user_index]for item_index in range(len(user_interests)):if user_interests[item_index] == 0:item_similarity = item_similarity_matrix[item_index]weighted_sum = np.dot(item_similarity, user_interests)#使用示例#基于用户的协同过滤推荐user_index = 0#基于物品的协同过滤推荐item_index = 0```上述代码中,首先定义了用户兴趣矩阵和物品兴趣矩阵,分别表示用户对物品的兴趣情况。

一、实习背景随着互联网的飞速发展,信息爆炸时代已经来临。
面对海量信息,用户如何快速找到自己感兴趣的内容成为了一个亟待解决的问题。
推荐系统作为一种信息过滤和内容推荐的技术,能够根据用户的兴趣和需求,为用户推荐个性化的内容,从而提高用户体验。
为了更好地了解推荐系统的工作原理和应用,我选择在XX公司进行为期一个月的实习。
二、实习目的1. 了解推荐系统的基本概念、原理和算法。
2. 掌握推荐系统的实现流程和关键技术。
3. 熟悉推荐系统在实际项目中的应用。
4. 提高自己的编程能力和团队协作能力。
三、实习内容1. 推荐系统基础知识在实习初期,我学习了推荐系统的基本概念、原理和算法。
推荐系统主要包括协同过滤、基于内容的推荐和混合推荐等几种类型。
协同过滤通过分析用户之间的相似度,为用户推荐相似用户喜欢的商品;基于内容的推荐则根据用户的历史行为和兴趣,为用户推荐相关内容;混合推荐则是将协同过滤和基于内容的推荐相结合,提高推荐效果。
2. 推荐系统实现在了解了推荐系统的基本原理后,我开始学习推荐系统的实现流程和关键技术。
首先,需要收集用户数据,包括用户行为数据、用户兴趣数据等。
然后,对数据进行预处理,包括数据清洗、特征提取和降维等。
接下来,根据选择的推荐算法,实现推荐模型。
最后,将推荐结果展示给用户,并根据用户反馈不断优化推荐效果。
3. 推荐系统在实际项目中的应用在实习过程中,我参与了公司的一个推荐系统项目。
该项目旨在为电商平台提供个性化推荐服务,提高用户购买转化率和满意度。
在项目中,我负责了以下工作:(1)收集和整理用户数据,包括用户行为数据、用户兴趣数据等。
(2)对数据进行预处理,包括数据清洗、特征提取和降维等。
(3)选择合适的推荐算法,实现推荐模型。
(4)根据用户反馈,不断优化推荐效果。
4. 编程能力和团队协作能力的提升在实习过程中,我使用Python编程语言实现了推荐系统。
在编写代码的过程中,我遇到了很多问题,通过与同事讨论和查阅资料,最终解决了这些问题。
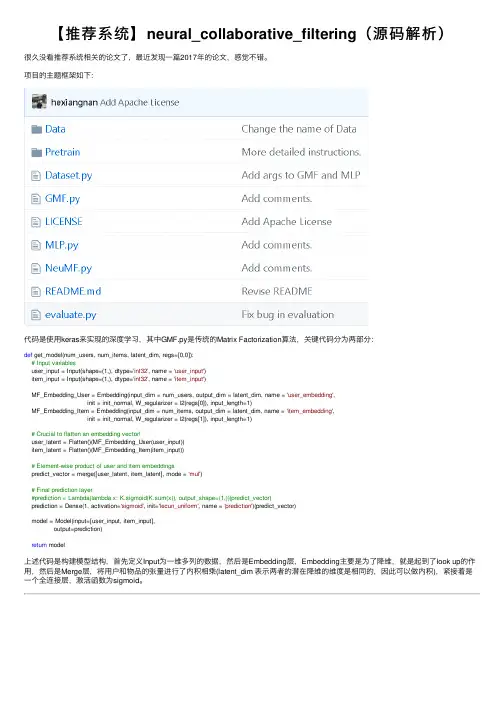
【推荐系统】neural_collaborative_filtering(源码解析)很久没看推荐系统相关的论⽂了,最近发现⼀篇2017年的论⽂,感觉不错。
项⽬的主题框架如下:代码是使⽤keras来实现的深度学习,其中GMF.py是传统的Matrix Factorization算法,关键代码分为两部分:def get_model(num_users, num_items, latent_dim, regs=[0,0]):# Input variablesuser_input = Input(shape=(1,), dtype='int32', name = 'user_input')item_input = Input(shape=(1,), dtype='int32', name = 'item_input')MF_Embedding_User = Embedding(input_dim = num_users, output_dim = latent_dim, name = 'user_embedding',init = init_normal, W_regularizer = l2(regs[0]), input_length=1)MF_Embedding_Item = Embedding(input_dim = num_items, output_dim = latent_dim, name = 'item_embedding',init = init_normal, W_regularizer = l2(regs[1]), input_length=1)# Crucial to flatten an embedding vector!user_latent = Flatten()(MF_Embedding_User(user_input))item_latent = Flatten()(MF_Embedding_Item(item_input))# Element-wise product of user and item embeddingspredict_vector = merge([user_latent, item_latent], mode = 'mul')# Final prediction layer#prediction = Lambda(lambda x: K.sigmoid(K.sum(x)), output_shape=(1,))(predict_vector)prediction = Dense(1, activation='sigmoid', init='lecun_uniform', name = 'prediction')(predict_vector)model = Model(input=[user_input, item_input],output=prediction)return model上述代码是构建模型结构,⾸先定义Input为⼀维多列的数据,然后是Embedding层,Embedding主要是为了降维,就是起到了look up的作⽤,然后是Merge层,将⽤户和物品的张量进⾏了内积相乘(latent_dim 表⽰两者的潜在降维的维度是相同的,因此可以做内积),紧接着是⼀个全连接层,激活函数为sigmoid。
推荐系统中的评价指标按照推荐任务的不同,最常⽤的推荐质量度量⽅法可以划分为三类:(1)对预测的评分进⾏评估,适⽤于评分预测任务。
(2)对预测的item集合进⾏评估,适⽤于Top-N推荐任务。
(3)按排名列表对推荐效果加权进⾏评估,既可以适⽤于评分预测任务也可以⽤于Top-N推荐任务。
对⽤户u推荐了N个物品R(u),⽤户在测试集上喜欢的物品集合为T(u)1、准确率 Precision推荐给⽤户的物品中,属于测试集的⽐例:P= \frac{R(u) \cap T(u)}{R(u)}2、召回率 Recall测试集中有多少在⽤户的推荐列表中。
描述有多少⽐例的⽤户-物品评分记录包含在最终的推荐列表中R = \frac{R(u) \cap T(u)}{T(u)}3、F1值P和R指标有时候会出现的⽭盾的情况,这样就需要综合考虑他们。
准确率和召回率的加权调和平均F1 = \frac{2PR}{P+R}4、排序分数 Ranking Score在评估推荐列表时引⽤排序指标很有⽤。
推荐系统通常预测排名列表,然⽽⽤户不太可能浏览所有的项⽬。
因此,排序指标在测量实⽤性和排名信息时可能很有趣。
排序靠前的项⽬更重要。
R=\frac{1}{|E^{U}|}\sum_{ui\epsilon E^{U}}\frac{p_{ui}}{M-k_{u}}其中,E^U表⽰测试集中所有的边的集合,如果u-i在测试集中,则E_{ui} = 1,p_{ui}表⽰商品i在⽤户u的推荐列表中的位置,分母M-k_{u}表⽰⽤户u的所有商品数组中除了该⽤户已经购买过的商品外的所有商品。
Rank Score 越⼩,说明测试集中的商品越靠前。
5、命中率 Hit ratioHR@K=\frac{Number of Hits @K}{|GT|}top-N推荐中流⾏的评价指标。
分母为所有的测试集合,分⼦表⽰每个⽤户top-k推荐列表中属于测试集合的个数的总和。
例如:三个⽤户在测试集中的商品个数分别是10,12,8,模型得到的top-10推荐列表中,分别有6个,5个,4个在测试集中,那么此时HR 的值是(6+5+4)/(10+12+8) = 0.5。
如何用Java编写一个简单的推荐系统推荐系统是一种常见的应用技术,用于根据用户的喜好和行为,向用户推荐个性化的内容或商品。
它在电子商务、社交网络、音乐、视频等领域被广泛应用。
在本文中,将介绍如何用Java编写一个简单的推荐系统。
在开始之前,首先需要了解推荐系统的基本原理。
推荐系统通常基于两种模型:基于内容的推荐和协同过滤推荐。
基于内容的推荐主要根据用户过去的历史行为和内容特征,为用户推荐相似的内容。
而协同过滤推荐则根据用户和其他用户的行为和偏好,为用户推荐与其兴趣相似的内容。
在本文中,我们将重点介绍协同过滤推荐的实现。
具体来说,我们将使用基于用户的协同过滤算法,根据用户对物品的评分,寻找与用户相似的其他用户,并基于这些相似用户的评分,为用户推荐物品。
以下是一个简单的推荐系统的实现流程:1.数据准备:首先,我们需要准备一个用户-物品-评分的数据集。
该数据集包含了用户对物品的评分信息。
2.计算相似度:接下来,我们将计算用户之间的相似度。
一个常用的相似度度量指标是余弦相似度。
我们可以使用余弦相似度公式计算用户之间的相似度。
3.找到相似用户:根据计算出的相似度,找到与目标用户最相似的K个用户。
4.生成推荐列表:对于每个相似用户,计算其评分与目标用户相似度的加权平均值。
根据这些加权平均值,生成推荐列表。
下面是一个简单的Java代码示例,实现了上述的推荐系统流程:```javaimport java.util.HashMap;import java.util.Map;public class RecommendationSystem {//用户-物品-评分的数据集private static Map<String, Map<String, Double>> ratings = new HashMap<>();public static void main(String[] args) {//初始化数据集init();//目标用户String targetUser = "User1";//寻找相似用户Map<String, Double> similarities = findSimilarUsers(targetUser);//生成推荐列表Map<String, Double> recommendations = generateRecommendations(targetUser, similarities);//打印推荐列表for (Map.Entry<String, Double> entry : recommendations.entrySet()) {System.out.println("Item: " + entry.getKey() + ", Score: " + entry.getValue());}}private static void init() {//添加用户评分信息Map<String, Double> user1Ratings = new HashMap<>();user1Ratings.put("Item1", 3.5);user1Ratings.put("Item2", 4.0);user1Ratings.put("Item3", 2.5);ratings.put("User1", user1Ratings);Map<String, Double> user2Ratings = new HashMap<>();user2Ratings.put("Item1", 4.5);user2Ratings.put("Item2", 3.0);user2Ratings.put("Item3", 5.0);ratings.put("User2", user2Ratings);Map<String, Double> user3Ratings = new HashMap<>();user3Ratings.put("Item1", 2.5);user3Ratings.put("Item2", 4.0);user3Ratings.put("Item3", 4.5);ratings.put("User3", user3Ratings);}private static Map<String, Double>findSimilarUsers(String targetUser) {Map<String, Double> similarities = new HashMap<>();//计算与目标用户的相似度for (Map.Entry<String, Map<String, Double>> entry : ratings.entrySet()) {String user = entry.getKey();if (!user.equals(targetUser)) {double similarity = computeSimilarity(targetUser, user);similarities.put(user, similarity);}}return similarities;}private static double computeSimilarity(String user1, String user2) {Map<String, Double> user1Ratings = ratings.get(user1);Map<String, Double> user2Ratings = ratings.get(user2);//计算余弦相似度//省略计算过程double similarity = 0.0;return similarity;}private static Map<String, Double> generateRecommendations(String targetUser, Map<String, Double> similarities) {Map<String, Double> recommendations = new HashMap<>();for (Map.Entry<String, Map<String, Double>> entry : ratings.entrySet()) {String user = entry.getKey();if (!user.equals(targetUser)) {Map<String, Double> userRatings = entry.getValue();for (Map.Entry<String, Double> rating :userRatings.entrySet()) {String item = rating.getKey();double score = rating.getValue();//计算加权评分double weightedScore = similarities.get(user) * score;//添加到推荐列表if (!recommendations.containsKey(item)) {recommendations.put(item, weightedScore);} else {recommendations.put(item, recommendations.get(item) + weightedScore);}}}}return recommendations;}}```需要注意的是,以上代码只是一个简单的推荐系统的实现示例,实际的推荐系统会更加复杂,可能需要考虑更多的因素,如稀疏性、冷启动问题等。
WSDM’2024Oral: LLMRec多模态推荐系统与基于大语言模型(LLMs)的数据增强文章题目: Large Language Models with Graph Augmentation for Recommendation文章代码: github LLMRec一.问题与解决方案引入side information能够帮助缓解推荐系统的数据稀疏性问题,目前主流的推荐系统(比如:亚马逊,网飞)都引入模态side information来提升推荐的结果。
但是,side information的使用不可避免地会引入一些问题,比如:噪声,低质量。
受启发于LLM的知识储备和自然语言理解能力,用LLM增强side information为上述问题提供了解决方案。
具体地,我们使用LLM增强:i) u-i交互和ii)文本模态的信息(包括user画像和item属性)。
此外,为了保证增强的数据的可靠性,我们分别针对上述i)和ii)设计了u-i交互剪枝和item feature的masked auto-encoder。
二.多模态推荐数据集(适用模型代码框架LLMRec, LATTICE, MMSSL, MICRO)该工作制作并公开了Netflix和MovieLens两个多模态数据集。
2.1 Netflix数据集Netflix是使用Kaggle网站上发布的原始Netflix Prize数据集制作的多模态数据集。
数据格式与多模态推荐的最新方法(如MMSSL、LATTICE、MICRO等)完全兼容。
对于文本模态,基础的信息包括‘title’,‘year’;视觉模态的图片则是根据电影的信息从网络爬取的海报。
2.1.1 文本模态以下三幅图片代表了(1)Kaggle网站上描述的有关Netflix的信息,(2)来自原始Netflix Prize 数据的文本信息,以及(3)由LLM增强的文本信息。
2.1.2 视觉模态视觉信息通过网络爬虫得到。
bert4rec代码复现
Bert4Rec是一种用于推荐系统的基于BERT的算法,它充分利用了BERT的文本表示能力和自然语言处理的先进技术,实现了对推荐系统的深度学习,并取得了一定的效果。
如果您想复现Bert4Rec代码,以下是一些步骤供您参考。
首先,您需要了解BERT的基本概念,如BERT的预训练和微调过程等。
同时需要掌握用于推荐系统的数据集,其中包括用户行为(如点击、
收藏、购买等)和物品信息(如电影、书籍、音乐等)等。
其次,您需要下载Bert4Rec算法的代码,该代码可在GitHub上下载。
下载完成后,您需要安装所有必要的依赖项和库,以确保代码能够顺
利运行。
接下来,您需要对从数据集中提取的用户和物品进行编码。
这可以通
过调用BERT模型的编码方法来实现,该方法将用户和物品作为文本
输入,并返回它们的向量表示。
这些向量表示将作为模型的输入。
在完成数据编码后,您需要构建Bert4Rec模型。
该模型使用了具有多层感知器(MLP)的神经网络,用于处理从BERT中提取的用户和物
品向量表示。
您可以根据需要自定义模型,并调整其超参数,以获得
最佳性能。
最后,您需要在模型上进行微调,并对其进行评估。
对于推荐系统,通常使用准确性、召回率、F1分数等来评估模型的性能。
通过调整模型参数和微调过程,您可以获得最佳的推荐结果。
总之,Bert4Rec算法是一种用于推荐系统的先进技术,可以帮助推荐引擎更好地理解用户和物品,并提供更准确、个性化的推荐结果。
通过参考以上步骤,您可以轻松地复现Bert4Rec代码,并构建自己的推荐引擎。
ncfmargin代码-概述说明以及解释1.引言1.1 概述概述部分的内容可以从以下角度来展开:概述部分旨在简要介绍文章的主题和背景,并引起读者的兴趣。
在介绍"ncfmargin代码"之前,我们需要首先解释什么是NCF(Neural Collaborative Filtering)以及NCF Margin Model。
NCF是一种基于神经网络的协同过滤算法,通过将用户和物品的特征映射到低维空间,并通过神经网络的非线性映射函数来计算用户和物品之间的相似度。
NCF模型在推荐系统领域具有重要的应用,它能够通过学习用户行为数据来进行个性化推荐。
然而,传统的NCF模型在训练过程中只关注正样本的辨别,缺乏对负样本的差异性学习。
为了解决这个问题,研究者们提出了NCF Margin Model,通过引入边际损失函数来增强对负样本的区分能力。
NCF Margin Model不仅可以提高推荐系统的准确性,还可以有效地减少推荐结果的偏差。
本文将重点介绍NCF Margin Model的代码实现,通过详细解释每个代码模块的功能和原理,帮助读者理解NCF Margin Model的具体实现过程。
在实现的过程中,我们将使用Python编程语言和相关的深度学习库,如TensorFlow或PyTorch。
文章的其余部分将分为正文和结论两个部分。
正文将详细介绍NCF Margin Model的代码实现,并提供相应的示例和实验结果。
结论将对本文的主要内容进行总结,并展望未来关于NCF Margin Model的研究方向。
通过阅读本文,读者将能够理解NCF Margin Model的原理和实现过程,掌握相关的代码技术,从而能够在推荐系统领域中应用和优化NCF Margin Model算法。
1.2文章结构文章结构部分是为了帮助读者更好地理解和组织文章内容,使文章更具逻辑性和连贯性。
以下是具体的文章结构部分内容:文章结构部分起到承上启下、串联整篇文章的作用。
似乎咱的产品七,八年前就想做个推荐系统的,就是类似根据用户的喜好,自动的找到用户喜欢的电影或者节目,给用户做推荐。
可是这么多年过去了,不知道是领导忘记了还是怎么了,连个影子还没见到。
而市场上各种产品的都有了推荐系统了。
比如常见的各种购物网站京东,亚马逊,淘宝之类的商品推荐,视频网站优酷的的类似影片推荐,豆瓣音乐的音乐推荐……一个好的推荐系统推荐的精度必然很高,能够真的发现用户的潜在需求或喜好,提高购物网詀的销量,让视频网站发现用户喜欢的收费电影…可是要实现一个高精度的推荐系统不是那么容易的,netflix曾经悬赏高额奖金寻找能给其推荐系统的精确度提高10%的人,可见各个公司对推荐系统的重视和一个好的推荐系统确实能带来经济效益。
下面咱以电影电视的推荐系统为例,一步一步的来实现一个简单的推荐系统吧,由于比较简单,整个推荐系统源码不到100行,大概70-80行吧,应该很容易掌握。
为了快速开发原型,咱采用Python代码来演示1.推荐系统的第一步,需要想办法收集信息不同的业务,不同的推荐系统需要收集的信息不一样针对咱要做的电影推荐,自然是每个用户对自己看过的电影的评价了,如下图所示:Kai Zhou对Friends打分是4分,对Bedtime Stories打分是3分,没有对RoboCop 打分Shuai Ge没有对Friends打分,对Bedtime Stories打分是3.5分……为简单,咱将此数据存成csv文件,形成一个二维的矩阵,假设存在D:\train.csv,数据如下:Name,Friends,Bedtime Stories,Dawn of the Planet of theApes,RoboCop,Fargo,Cougar TownKai Zhou,4,3,5,,1,2Shuai Ge,,3.5,3,4,2.5,4.5MeiNv,3,4,2,3,2,3xiaoxianrou,2.5,3.5,3,3.5,2.5,3fengzhi,3,4,,5,3.5,3mein v,,4.5,,4,1,mincat,3,3.5,1.5,5,3.5,3alex,2.5,3,,3.5,,4先从csv文件中加载二维矩阵,代码如下:def load_matrix():matrix={}f=open("d:\\train.csv")columns= f.readline().split(',')for line in f:scores=line.split(',')for i in range(len(scores))[1:]:matrix[(scores[0],columns[i])]=scores[i].strip("\n")return matrix matrix=load_matrix()print"matrix:",matrixload_matrix()解析csv文件,返回一个dictionary,该dictionary以(行名,列名)为索引数据有了,下面咱就正式开始干活了,推荐系统要干些什么呢?咱以电影推荐来说,推荐系统需要解决的几个主要问题:1)判断两个电影,两个观影人之间的相似度2)找到和某影片最相似的影片,或找到和某观影人有同样兴趣的人3)找到某观影人可能喜欢的电影,或找到对某影片感兴趣的人2.推荐系统的基础,判断相似度针对咱的电影推荐来说,就是判断两个电影,两个观影人之间的相似度。
代码结构
从源码来看,EasyRec纵向采用三层架构模式(展现层、业务层和持久层),横向采用模块化(核心模块,插件模块,特定领域模块及推荐模块等)。
可以清晰的了解到,EacyRec 的分层很清晰,下面是我理解的模块结构图。
Easyrec代码框架很清晰,目前项目由八个部分组成。
1 上下文组件(Content)
这一模块包含商品关联规则的生成器,随Web应用一起发布并预装的生成器。
目前,关联规则生成器是唯一预装的生成器,并作为推荐系统的离线生成器的服务组件。
2核心组件(Core)
这一模块是推荐系统Easyrec的核心包,它包含了系统所有的数据模型对象、数据访问和基本数据服务的相关的所有类。
基本的数据服务包括:ActionService、ItemAssocService、RecommenderService和RecommendationHistoryService。
在这个模块中所有的类与接口都提供了最一般的方法,对特定信息域,如动作与项目对象,能进行不同的参数化。
3域组件(Domain)
为了对特定领域的内容分离,引入这个包。
域组件包提供了为一个通用领域提供服务和数据库访问的类,如象音乐领域这样的特定领域。
同时为集成对评价动作信息,提供对第三方数据进行访问的附加接口与实用工能类。
4插件API接口包(Plugin API)
插件API接口包提供推荐系统Easyrec插件开发的基础。
它提供了实现推荐系统插件所需的所有接口。
是所有插件的父类,定义了扩展插件需要实现的接口。
5插件容器(Plugin Container)
插件容器提供插件执行的框架。
.
6插件组件(Plugins)
插件组件包本身就是一个父模块,同时也是目前easyrec支持的多个插件的集合。
7功能组件包(Utils)
功能组件包包含推荐系统Easyrec中其它模块所需要使用的功能类。
8 Web组件(Web)
Web模块是对推荐系统的各种Web服务方法的扩展,从而为各个领域提供模型对象,数据访问类和服务。
另外“idmappingservice”允许将外部的字符串IDS到内部的整数ID映射;h 此外,“authenticationservice”管理几个商户的对Web服务方法的授权访问。