基于hadoop的分布式存储平台的搭建与验证
- 格式:doc
- 大小:1.11 MB
- 文档页数:101

一、实验背景随着信息技术的飞速发展,大数据已成为当前研究的热点。
为了更好地理解和掌握大数据技术,提高自己的实践能力,我们小组在指导老师的带领下,进行了为期一个月的大数据实验实训。
本次实训旨在通过实际操作,深入了解大数据技术的基本原理和应用,掌握大数据处理和分析的方法。
二、实验内容本次实验实训主要围绕以下几个方面展开:1. 大数据平台搭建(1)Hadoop分布式文件系统(HDFS)搭建:通过Hadoop命令行工具,完成HDFS的搭建,实现大文件的分布式存储。
(2)Hadoop分布式计算框架(MapReduce)搭建:利用Hadoop的MapReduce框架,完成数据的分布式计算。
2. 数据采集与预处理(1)数据采集:通过爬虫技术,从互联网上获取相关数据。
(2)数据预处理:对采集到的数据进行清洗、去重、去噪等操作,提高数据质量。
3. 数据存储与分析(1)数据存储:使用HBase、Hive等数据存储技术,将处理后的数据存储在分布式数据库中。
(2)数据分析:利用Spark、Flink等大数据计算框架,对存储在数据库中的数据进行实时分析。
4. 数据可视化使用ECharts、Tableau等数据可视化工具,将分析结果以图表形式展示,直观地呈现数据特征。
三、实验步骤1. 环境搭建(1)安装Java、Hadoop、HBase、Hive、Spark等软件。
(2)配置环境变量,确保各组件之间能够正常通信。
2. 数据采集与预处理(1)编写爬虫代码,从指定网站获取数据。
(2)对采集到的数据进行清洗、去重、去噪等操作。
3. 数据存储与分析(1)将预处理后的数据导入HBase、Hive等分布式数据库。
(2)利用Spark、Flink等大数据计算框架,对数据进行实时分析。
4. 数据可视化(1)使用ECharts、Tableau等数据可视化工具,将分析结果以图表形式展示。
(2)对图表进行美化,提高可视化效果。
四、实验结果与分析1. 数据采集与预处理本次实验采集了100万条电商交易数据,经过清洗、去重、去噪等操作后,得到约90万条有效数据。

使用Hadoop进行分布式数据处理的基本步骤随着大数据时代的到来,数据处理变得越来越重要。
在处理海量数据时,传统的单机处理方式已经无法满足需求。
分布式数据处理技术应运而生,而Hadoop作为目前最流行的分布式数据处理框架之一,被广泛应用于各行各业。
本文将介绍使用Hadoop进行分布式数据处理的基本步骤。
1. 数据准备在使用Hadoop进行分布式数据处理之前,首先需要准备好要处理的数据。
这些数据可以是结构化的,也可以是半结构化或非结构化的。
数据可以来自各种来源,如数据库、文本文件、日志文件等。
在准备数据时,需要考虑数据的规模和格式,以便在后续的处理过程中能够顺利进行。
2. Hadoop环境搭建在开始使用Hadoop进行分布式数据处理之前,需要先搭建Hadoop的运行环境。
Hadoop是一个开源的分布式计算框架,可以在多台机器上进行并行计算。
在搭建Hadoop环境时,需要安装Hadoop的核心组件,如Hadoop Distributed File System(HDFS)和MapReduce。
同时,还需要配置Hadoop的相关参数,以适应实际的数据处理需求。
3. 数据上传在搭建好Hadoop环境后,需要将准备好的数据上传到Hadoop集群中。
可以使用Hadoop提供的命令行工具,如Hadoop命令行界面(Hadoop CLI)或Hadoop文件系统(Hadoop File System,HDFS),将数据上传到Hadoop集群的分布式文件系统中。
上传数据时,可以选择将数据分割成多个小文件,以便在后续的并行计算中更高效地处理。
4. 数据分析与处理一旦数据上传到Hadoop集群中,就可以开始进行数据分析与处理了。
Hadoop的核心组件MapReduce提供了一种分布式计算模型,可以将数据分成多个小任务,分配给集群中的不同节点进行并行计算。
在进行数据分析与处理时,可以根据实际需求编写MapReduce程序,定义数据的输入、输出和处理逻辑。

搭建云平台实验报告一、引言云计算作为一种强大的技术,已经对现代企业和个人的IT需求产生了巨大的影响。
通过构建一个云平台,可以充分利用云计算资源,提供高效便捷的服务。
本实验旨在通过搭建一个云平台,实践云计算相关知识,并探索其内部原理和功能。
二、实验内容1. 硬件环境准备首先,我们需要准备一台具备虚拟化支持的服务器。
这里我们选择了一台配置较高的服务器,并安装最新版本的虚拟化软件。
2. 虚拟化环境搭建在准备好硬件环境后,我们开始搭建虚拟化环境。
首先,安装Hypervisor,这是一种虚拟化软件,可以创建和管理虚拟机。
我们选择了开源软件VirtualBox 作为我们的Hypervisor。
3. 虚拟机操作系统安装接下来,我们需要选择一个操作系统,并在虚拟机上安装它。
在本实验中,我们选择了一款流行的Linux发行版Ubuntu作为我们的操作系统。
在虚拟机中安装Ubuntu十分简单,只需按照提示进行即可。
4. 云平台搭建在完成虚拟机的安装后,我们开始搭建云平台。
云平台可以提供一系列云服务,如云存储、云数据库、云计算等。
在本实验中,我们将搭建一个简单的云存储服务。
首先,我们需要安装并配置一种分布式存储系统,如Ceph。
然后,配置Ceph集群,并将它们与云平台进行集成。
接着,我们需要编写相应的代码,实现文件的上传、下载和删除等功能。
最后,我们测试云存储服务的性能和可靠性。
三、实验过程1. 硬件环境准备我们选择了一台配备Intel Core i7处理器和32GB内存的服务器作为我们的云平台。
这台服务器支持虚拟化技术,可以满足我们的需求。
2. 虚拟化环境搭建我们下载并安装了VirtualBox软件,并按照官方文档进行了配置。
VirtualBox 提供了一个直观的图形界面,可以方便地管理虚拟机。
3. 虚拟机操作系统安装我们下载了Ubuntu的ISO镜像,并在VirtualBox中创建了一个新的虚拟机。
然后,我们按照安装向导的提示,完成了Ubuntu的安装。

基于Hadoop的大数据分析应用开发平台的设计与实现的开题报告一、选题背景随着时代的发展和技术的进步,数据量呈现爆发式增长。
如何高效地存储、处理和分析这些海量数据,已成为当前互联网领域的重要问题。
Hadoop是一个开源的分布式框架,可以以低成本和高效率处理大规模的数据集,具有高可扩展性、高可靠性、高可用性等优点。
与此同时,Hadoop已成为大数据分析的重要工具,广泛应用于Web搜索、社交网络、金融服务、医疗保健和政府等领域。
然而,Hadoop的学习和使用周期较长,缺乏相关开发平台的支持,导致用户难以快速上手和应用。
因此,本文旨在设计和实现一种基于Hadoop的大数据分析应用开发平台,以便于用户快速上手和应用。
二、研究内容和方法1.研究内容:(1)介绍Hadoop技术及其应用领域,剖析Hadoop的特点、优势和发展趋势;(2)分析Hadoop应用开发中的一些关键问题,如数据读取、数据处理、数据分析、数据可视化等;(3)设计和实现基于Hadoop的大数据分析应用开发平台,包括平台架构设计、应用开发模块、应用测试与优化模块等。
2.研究方法:(1)文献阅读法:对于Hadoop相关技术和应用领域的文献进行系统阅读和分析,了解Hadoop的发展历程、应用场景等方面的信息。
(2)案例分析法:通过对Hadoop应用开发项目的案例分析,掌握其中的关键问题和技术难点,对研究具有指导性和借鉴意义。
(3)实验验证法:基于实验室的数据集,开展Hadoop应用开发的实践操作,对平台进行测试和优化,确保其有效性和可用性。
三、预期研究成果(1)提出基于Hadoop的大数据分析应用开发平台,实现Hadoop 技术的快速上手和应用;(2)设计和实现平台的多个应用开发模块,包括数据读取、数据处理、数据分析、数据可视化等;(3)开展实验验证,验证平台的有效性和可用性。
四、论文结构本文拟分为五个章节:第一章为绪论,介绍研究背景、内容和方法,及预期的研究成果。
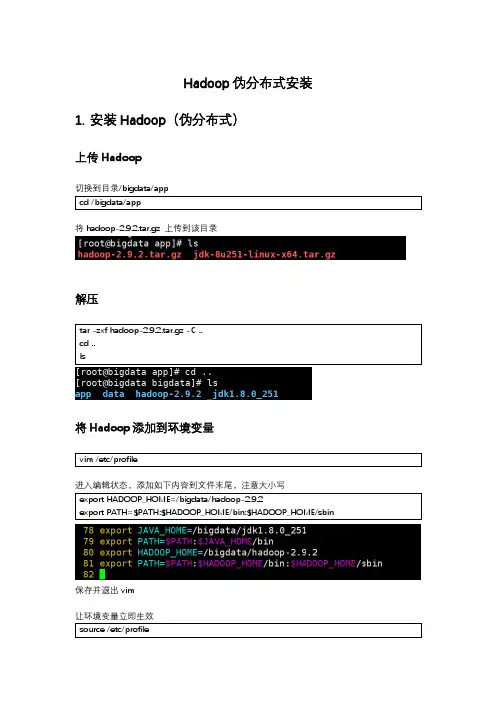
Hadoop伪分布式安装1.安装Hadoop(伪分布式)
上传Hadoop
将hadoop-2.9.2.tar.gz 上传到该目录
解压
ls
将Hadoop添加到环境变量
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并退出vim
验证环境变量是否正确hadoop version
修改配置文件hadoop-env.sh
保存并退出vim
修改配置文件core-site.xml
保存并退出vim
修改配置文件hdfs-site.xml
</property>
保存并退出vim
格式化HDFS
hdfs namenode -format
格式化成功的话,在/bigdata/data目录下可以看到dfs目录
启动NameNode
启动DataNode
查看NameNode管理界面
在windows使用浏览器访问http://bigdata:50070可以看到HDFS的管理界面
如果看不到,(1)检查windows是否配置了hosts;
位于C:\Windows\System32\drivers\etc\hosts
关闭HDFS的命令
2.配置SSH免密登录生成密钥
回车四次即可生成密钥
复制密钥,实现免密登录
根据提示需要输入“yes”和root用户的密码
新的HDFS启停命令
免密登录做好以后,可以使用start-dfs.sh和stop-dfs.sh命令启停HDFS,不再需要使用hadoop-daemon.sh脚本
stop-dfs.sh
注意:第一次用这个命令可能还是需要输入yes,按提示输入即可。

基于Hadoop 集群的日志分析系统的设计与实现作者:陈森博陈张杰来源:《电脑知识与技术》2013年第34期摘要:当前Internet上存在着海量的日志数据,他们中蕴藏着大量可用的信息。
对海量数据的存储和分析都是一个艰巨而复杂的任务,单一主机已经无法满足要求,使用分布式存储和分布式计算来分析数据已经成为了必然的趋势。
分布式计算框架Hadoop已经日趋成熟,被广泛的应用于很多领域。
该文描述了一个针对大日志分析的分布式集群的构建与实现过程。
介绍了日志分析的现状,使用vmware虚拟机搭建了Hadoop集群和日志分析系统的构建方法,并对实验结果进行了分析。
关键词:分布式计算;日志分析;Hadoop;集群;vmware中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2013)34-7647-041 概述日志文件是由系统或者应用程序产生的,用于记录系统和应用程序的操作事件如各种服务的启动、运行、关闭等信息。
通过对日志文件的分析可以获得很多有价值的数据也能实现对系统安全、性能等方面的监控。
Web日志[1]是由Web服务器产生的,随着社交网络的兴起,Web2.0时代的到来,网站的用户访问量的成级数增长,产生的日志文件大幅增多。
传统的日志文件分析方式已经无法满足大数据量日志分析的需求。
该文将以Web日志文件为例,利用Hadoop集群构建一个分布式计算平台为大数据日志文件的分析提供一个可行的解决方案,以提高了日志分析的效率,为进一步的大数据分析的提供参考。
现今日志文件分析方案是对大的日志文件先进行分割,然后对分割后的日志文件进行分析,分析方法采用文本分析及模式匹配等,最常见的是采用awk、python、perl。
这种分析方式面对大数据的日志文件分析效率低下,耗时长。
王潇博提出了基于挖掘算法的日志分析方式,并设计了TAT系统[1]。
对于Web分析除了对Web日志本身进行分析外还可以主动收集访问信息,然后将信息存于关系型数据库中。

《基于Hadoop的海量数据处理模型研究和应用》篇一一、引言随着信息化和数字化进程的深入,数据量的爆发性增长带来了海量的数据处理挑战。
面对如此庞大的数据量,传统的数据处理方法已经难以满足需求。
因此,基于Hadoop的海量数据处理模型的研究和应用显得尤为重要。
Hadoop作为一种分布式计算框架,具有高可扩展性、高容错性和低成本等特点,为海量数据处理提供了有效的解决方案。
二、Hadoop技术概述Hadoop是一个由Apache基金会开发的分布式计算平台,其核心组件包括HDFS(Hadoop Distributed File System)和MapReduce。
HDFS为海量数据提供了高可靠性的存储服务,而MapReduce则是一种编程模型,用于处理大规模数据集。
Hadoop 的优点在于其能够处理海量数据,具有高可扩展性、高容错性和低成本等特点。
三、基于Hadoop的海量数据处理模型研究1. 数据存储模型Hadoop的海量数据处理模型中,数据存储采用分布式文件系统HDFS。
HDFS将文件分割成多个块,并将这些块存储在多个节点上,从而实现了数据的分布式存储。
这种存储模型具有高可靠性和容错性,能够保证数据的完整性和安全性。
2. 数据处理模型Hadoop的数据处理模型采用MapReduce编程模型。
MapReduce将复杂的计算任务分解为多个简单的子任务,这些子任务在集群中并行执行。
Map阶段负责数据映射,将输入数据分解成键值对;Reduce阶段则对键值对进行规约操作,得出最终结果。
这种处理模型能够充分利用集群的计算能力,提高数据处理的速度和效率。
四、基于Hadoop的海量数据处理应用1. 日志数据分析日志数据是互联网公司的重要资产之一,其数量庞大且增长迅速。
基于Hadoop的海量数据处理模型可以有效地处理和分析日志数据。
通过MapReduce编程模型,将日志数据分解成多个小文件并存储在HDFS中,然后进行数据分析和挖掘,得出有价值的结论。

基于Hadoop的Nutch分布式主题主题网络爬虫的研究施磊磊,施化吉,朱玉婷(江苏大学计算机科学与通信工程学院,江苏镇江212013)摘要:针对Nutch分布式主题爬虫的爬取效率和爬取的准确度问题,本文提出了改进的主题判断和预测模型来提高下载网页的主题相关度和网页的质量,同时引入改进的PageRank 算法来计算链接主题网页的优先级,并搭建Hadoop分布式集群环境,以MapReduce分布式计算模型以达到高效率的分布式爬取,然后利用HBase、Zookeeper和Memcached来达到高效率的分布式存储,最后通过实验验证了Nutch分布式主题爬虫的高效性、准确性、扩展性和可靠性。
关键词:主题爬虫;Hadoop集群; Nutch; MapReduceResearch on Nutch distributed web crawlersubject oriented.SHI Lei-lei , SHI Hua-ji , ZHU Yu-tin(School of Computer Science and Telecommunication Engineering,Jiangsu University,Zhenjiang 212013,China)Abstract:For crawling crawling efficiency and accuracy problems Nutch crawler distributed topic, this paper proposes an improved model to predict and judge topics to improve the quality of downloaded pages and pages of the topic, while the introduction of the improved PageRank algorithm to calculate the link priorities and build Hadoop distributed cluster environment to MapReduce distributed computing model in order to achieve efficient crawling topic pages, preferably through experimental verification of the efficiency of the subject reptiles, scalability and reliability.Keywords:topic crawler;Hadoop cluster;Nutch;MapReduce1 引言Nutch是一个开源的垂直搜索引擎,它使用Java语言开发,具有跨平台应用的优点,Nutch作为主题网络爬虫和lucene的结合,功能上极其强悍,每个月数以亿计的网页爬取量,网页搜索的高速,开源的功能剖析都是我们选择研究它的关键因素。


45基于Hadoop 的高校大数据平台的设计与实现彭 航本文在对Hadoop 平台的结构及功能分析基础上,结合信息化环境下高校系统建设的现状,对基于Hadoop 的高校大数据平台的设计与实现进行研究,以供参考。
在信息化发展影响下,高校信息系统建设与运用也取得了较为显著的发展,并且在长期的运营与管理中积累了相对较多的数据,对高校信息化建设与发展有着十分积极的作用和意义。
指导注意的是,结合当前高校信息系统建设与发展现状,由于其信息系统的分阶段建设,导致在对系统运营及数据管理中是由多个不同部门分别执行,各数据之间的相互联系与有效交互明显不足。
另一方面,在大数据环境下,通过大数据平台的开发设计以实现各信息系统之间的有效对接与信息交互,形成较为统一的数据运营与管理模式,成为各领域信息建设与运营管理研究和关注重点。
1 Hadoop 平台及其结构、功能分析Hadoop 作为一个分布式系统的基础架构,在实际设计与开发运用中,是通过Hadoop 集群中的一个主控节点对整个集群的运行进行控制与管理实现,以满足该集群中多个节点的数据与计算任务协调需求。
其中,分布式文件系统HDFS 以及MapReduce 并行化计算框架是Hadoop 集群系统的核心,HDFS 是Hadoop 平台中分布式计算下数据存储管理开展基础,具有较为突出的可靠性以及扩展性和高容错性特征;而MapReduce 并行计算框架能够将分析任务分成大量并行Map 和Reduce 任务以进行Hadoop 平台运行及功能支撑;此外,HBase 是以HDFS 为基础的分布式数据库,能够实现海量数据存储,而Hive 作为数据仓库处理工具,在Hadoop 平台运行中主要用于HDFS 或者是HBase 中存储的结构化或者是半结构化的数据管理。
随着对Hadoop 研究的不断发展,当前Hadoop 平台已经成为一个包含很多子系统大数据的处理生态系统。
如下图1所示,即为Hadoop 平台的结构组成示意图。

基于Hadoop的云计算平台设计与开发摘要:随着北部湾海洋生态资源的开发和利用,海量海洋科学数据飞速涌现出来,利用云计算平台合理管理和存储这些科学数据显得极为重要。
本文提出了一种基于分布式计算技术进行管理和存储海量海洋科学数据方法,构建了海量海洋科学数据存储平台解决方案,采用linux集群技术,设计开发一个基于hadoop的云计算平台。
关键词:云计算;海洋科学数据;hadoop;分布式计算中图分类号:tp311.13文献标识码:a文章编号:1007-9599 (2011) 24-0000-02hadoop-based cloud computing platform design and developmenttang yun1,2(1.hubei university of technology school of computer science,wuhan430068,china;2. lishui city road administration detachment of the highwaybrigade,lishui323000,china)abstract:with the development and utilization of marine ecological resources in the beibu gulf,the mass of marine scientific data rapidly emerged,the use of cloud computing platform for the rational management and storage of scientific data is extremely important.in this paper,manageand store large amounts of marine science data method based on distributed computing technology to build a massive marine science data storage platform solutions,using the linux cluster technology,design and development based on a hadoop cloud computing platform.keywords:cloud computing;marine sciencedata;hadoop;distributed computing传统的对大规模数据处理是使用分布式的高性能计算、网格计算等技术,需要耗费昂贵的计算资源,而且对于如何把大规模数据有效分割和计算任务的合理分配都需要繁琐的编程才能实现,而hadoop分布式技术的发展正解决了以上的问题。
一、实验背景随着互联网的飞速发展,大数据已成为当今社会的重要资源。
为了更好地理解和应用大数据技术,我们开展了本次大数据平台实验,旨在掌握大数据平台的搭建、配置和使用方法。
二、实验目的1. 熟悉大数据平台的基本概念和架构。
2. 掌握Hadoop、HDFS、MapReduce等核心组件的搭建和配置。
3. 学会使用大数据平台进行数据处理和分析。
三、实验环境1. 操作系统:Linux2. Hadoop版本:Hadoop3.3.43. HDFS版本:HDFS 3.3.44. MapReduce版本:MapReduce 3.3.45. Java版本:Java 8四、实验内容1. Hadoop集群搭建(1)安装JDK首先,在Linux系统中安装JDK。
通过以下命令下载并安装JDK:```bashsudo apt-get install openjdk-8-jdk```(2)安装Hadoop接着,下载Hadoop安装包,解压到指定目录,并配置环境变量:sudo tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local/sudo echo "export HADOOP_HOME=/usr/local/hadoop-3.3.4" >> ~/.bashrcsudo echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >>~/.bashrcsource ~/.bashrc```(3)配置Hadoop编辑`/usr/local/hadoop-3.3.4/etc/hadoop/hadoop-env.sh`文件,配置JDK路径:```bashexport JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64```编辑`/usr/local/hadoop-3.3.4/etc/hadoop/core-site.xml`文件,配置HDFS的存储目录:```xml<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property></configuration>```编辑`/usr/local/hadoop-3.3.4/etc/hadoop/hdfs-site.xml`文件,配置HDFS的副本数量和存储目录:<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop-3.3.4/hdfs/data</value></property></configuration>```编辑`/usr/local/hadoop-3.3.4/etc/hadoop/mapred-site.xml`文件,配置MapReduce的运行模式:```xml<configuration><property><name></name><value>yarn</value></property></configuration>```(4)启动Hadoop集群```bashstart-dfs.shstart-yarn.sh```2. HDFS操作实践(1)上传文件到HDFS```bashhdfs dfs -put /local/file /hdfs/file```(2)下载文件到本地```bashhdfs dfs -get /hdfs/file /local/file```(3)查看HDFS文件目录```bashhdfs dfs -ls /hdfs```3. MapReduce编程实践(1)编写MapReduce程序创建一个名为`WordCount.java`的文件,并添加以下代码:```javaimport org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCount {public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {String[] tokens = value.toString().split("\\s+");for (String token : tokens) {word.set(token);context.write(word, one);}}}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception { Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1);}}```(2)编译MapReduce程序```bashjavac -cp /usr/local/hadoop-3.3.4/share/hadoop/common/:/usr/local/hadoop-3.3.4/share/hadoop/hdfs/:/usr/local/hadoop-3.3.4/share/hadoop/mapreduce/ WordCount.java```(3)运行MapReduce程序```bashhadoop jar WordCount.jar WordCount /hdfs/input /hdfs/output```4. HBase操作实践(1)安装HBase下载HBase安装包,解压到指定目录,并配置环境变量:```bashsudo tar -zxvf hbase-2.2.5-bin.tar.gz -C /usr/local/sudo echo "export HBASE_HOME=/usr/local/hbase-2.2.5" >> ~/.bashrcsudo echo "export PATH=\$PATH:\$HBASE_HOME/bin" >> ~/.bashrcsource ~/.bashrc```(2)配置HBase编辑`/usr/local/hbase-2.2.5/conf/hbase-site.xml`文件,配置HBase的存储目录:```xml<configuration><property><name>hbase.rootdir</name><value>file:///usr/local/hbase-2.2.5/data</value> </property></configuration>```(3)启动HBase```bashstart-hbase.sh```(4)使用HBase Shell```bashhbase shell```(5)创建表```shellcreate 'student', 'info'```(6)插入数据```shellput 'student', 'lisi', 'info:Math', '95'```(7)查询数据```shellget 'student', 'lisi', 'info:Math'```五、实验总结通过本次实验,我们掌握了大数据平台的基本概念、搭建和配置方法,以及HDFS、MapReduce和HBase等核心组件的使用。
2020年第06期49基于Hadoop 的电商数据分析系统的设计与实现李胜华湖南外贸职业学院,湖南 长沙 410000摘要:随着计算机技术的发展,“互联网+”已经被应用于各行业中,带动了行业的创新发展。
在此技术环境下, “互联网+”行业所产生的数据呈现爆炸式增长,这些数据是推动企业发展的重要因素。
对于电商行业而言,数据已经成为电商行业获得市场竞争优势的核心,提高电商数据的信息化水平是电商企业可持续发展的重中之重。
基于Hadoop 平台,展开电商数据分析系统设计,旨在为电商行业的发展提供更加精准的数据。
关键词:Hadoop 平台;电商数据;系统分析中图分类号:TP311.130 引言在信息技术的支持下,我国电子商务经济发展迅猛,电商平台已然成为国民经济的重要支柱。
而随着各大电商平台的崛起,其面临着的内部竞争越发激烈,所产生的业务数据以及日志文件也越来越多,如何存储并利用这些数据成为制约电商平台未来发展的瓶颈[1]。
如何搭建起一个强有力的大数据分析平台是当务之急。
1 基于Hadoop 的电商数据分析系统设计1.1 Hadoop 的电商数据系统功能(1)功能需求。
电商数据分析系统的根本作用就是展开对电商平台数据的分析、管理和应用[2]。
首先,该数据分析系统面向的是各大电商部门,需要设置系统登录功能,进入主操作页面中。
其次是要具有数据存储的功能,数据存储作为数据分析系统的基础,面对结构复杂的数据,要具有对这些结构化数据、非结构化数据以及半结构化数据的统一存储和查询的功能。
(2)非功能需求。
非功能需求主要是指对系统的功能性的需求。
基于Hadoop 的电商数据分析系统,具有可靠性、可扩展性以及易用性。
(3)系统业务流程。
电商数据分析系统的主要工作流程为:数据源、数据收集、HDFS 存储、数据处理、HBase/HDFS 存储、实时查询(离线运算)、输出结果或展示、数据应用。
其整个流程能够有效提高数据分析效率,确保数据分析的安全性及准确性。
大数据处理平台Hortonworks实践介绍大数据时代的到来使得数据处理变得更加复杂,传统的关系型数据库已经无法满足大规模数据存储和处理的需求。
因此,大数据处理平台应运而生,Hortonworks就是其中一款备受欢迎的平台。
Hortonworks是一款开源的大数据处理平台,基于Apache Hadoop构建。
通过Hortonworks,用户可以对海量的数据进行存储、管理和分析,进而实现数据驱动的业务应用。
今天,我们将在实践中介绍Hortonworks的使用。
准备工作在开始Hortonworks的实践之前,我们需要进行一些准备工作。
首先,我们需要准备好运行Hortonworks的服务器。
如果您还没有搭建好服务器,可以考虑使用云服务器,例如AWS EC2 或者Azure上的虚拟机。
其次,我们需要下载和安装Hortonworks的软件包。
推荐使用Ambari来管理和监控Hortonworks集群。
这里,我们将以Ambari为基础来介绍Hortonworks的使用。
搭建Hortonworks平台首先,我们需要使用Ambari来搭建Hortonworks平台。
Ambari 提供了一个网页界面,可以方便地进行集群的管理和维护。
我们可以通过以下步骤来搭建Hortonworks平台:1. 安装Ambari服务器和Ambari客户端。
2. 安装Hortonworks蓝图。
蓝图是一个包含预定义的Hadoop组件和配置的模板文件。
在Ambari上新建集群时,可以选择对应的蓝图,从而快速地搭建集群。
3. 在Ambari中创建集群。
在创建集群时,需要选择Hortonworks对应的蓝图,并进行相应的配置。
例如,选择需要安装的Hadoop组件、各个组件的配置参数、以及节点间的关系等等。
设置完成后,Ambari将自动完成Hortonworks的安装和配置。
4. 验证集群是否搭建成功。
在安装完成后,可以通过Ambari的网页界面来查看各个节点的状态,以及各个组件的运行情况。
毕业设计(论文)
中文题目:基于hadoop的分布式存储平台的搭建与验证
英文题目:Setuping and verification distributed storage platform based on hadoop
学院:计算机与信息技术
专业:信息安全
学生姓名:
学号:
指导教师:
2018 年06 月01 日
1
任务书
题目:基于hadoop的分布式文件系统的实现与验证
适合专业:信息安全
指导教师(签名):
毕业设计(论文)基本内容和要求:
本项目的目的是要在单独的一台计算机上实现Hadoop多节点分布式计算系统。
基本原理及基本要求如下:
1.实现一个NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。
它负责管理文件系统名称空间和控制外部客户机的访问。
NameNode 决定是否将文件映射到 DataNode 上的复制块上。
实际的 I/O 事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。
当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。
这个 NameNode 还会通知其他将要接收该块的副本的 DataNode。
2。
实现若干个DataNode
DataNode 也是一个通常在 HDFS 实例中的单独机器上运行的软件。
Hadoop 集群包含一个 NameNode 和大量 DataNode。
DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。
Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
DataNode 响应来自 HDFS 客户机的读写请求。
它们还响应来自NameNode 的创建、删除和复制块的命令。
NameNode 依赖来自每个DataNode 的定期心跳(heartbeat)消息。
每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。
如果DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。
具体设计模块如下:。