数据库连接池的图解原理
- 格式:docx
- 大小:53.29 KB
- 文档页数:5

java 数据库连接池原理概述及解释说明1. 引言1.1 概述数据库连接池是在应用程序与数据库之间充当中间层的一种技术,它能够管理数据库连接的创建、分配和释放,从而提供了更高效的数据库访问方式。
在开发Java应用程序时,使用数据库连接池可以极大地提高系统性能和扩展性。
1.2 文章结构本文将首先介绍数据库连接池的基本概念和作用,并解释其相对于传统连接方式的优势。
接着,我们将深入探讨数据库连接池的原理和实现机制。
然后,我们会介绍常见的Java中的数据库连接池框架,并演示如何通过配置文件进行连接池的配置。
最后,我们还会分享一些优化技巧,帮助你进一步提升数据库连接池的性能。
1.3 目的通过阅读本文,读者将掌握以下知识:- 了解数据库连接池的基本概念和作用;- 理解数据库连接池的原理及其在Java中实现方式;- 掌握常见的Java中使用到的数据库连接池框架;- 学习如何通过配置文件进行数据库连接池配置;- 了解如何优化数据库连接池性能以及相关技巧。
通过这些内容的学习,读者将能够更好地理解和使用数据库连接池,提高应用程序的性能和可拓展性。
同时,读者也将具备一定的优化数据库连接池的能力,使其适应不同规模和并发情况下的需求。
在下一章节中,我们将详细介绍数据库连接池的原理。
2. 数据库连接池原理:2.1 数据库连接概念解释:在Java开发中,与数据库进行交互通常需要建立一个数据库连接。
每次请求都需要创建和销毁连接会导致性能上的损耗。
而数据库连接池则是一种重复利用已有连接的机制,通过预先创建一定数量的数据库连接并将其保存在池中,以供程序使用,从而提高了数据库操作的效率。
2.2 连接池的作用和优势:数据库连接池的作用是管理和维护多个数据库连接,并提供这些连接给应用程序使用。
它具有以下几点优势:- 提高系统性能: 连接池可以避免频繁地创建和销毁数据库连接,从而减少了系统资源消耗和响应延迟。
- 资源利用率高: 连接池可以实现对已有连接的重复利用,最大限度地提高了资源的利用率。

数据库连接池的原理机制1.连接池初始化:在应用程序启动时,连接池会根据配置参数预先创建一定数量的数据库连接,并存放在连接池中。
通常情况下,初始化时创建的连接数量较少,但根据实际需求会不断动态增加。
2.连接请求获取:当应用程序需要与数据库进行交互时,它会从连接池中获取一个可用的连接。
如果连接池中没有可用连接,请求线程将会等待,直到连接池中有可用连接或者超时。
这个过程是通过线程池技术实现的。
3.连接使用与归还:获取到连接后,应用程序使用这个连接进行数据库操作。
操作完成后,应用程序需要将连接归还给连接池,以便其他线程可以继续使用。
连接的归还可以通过调用连接池提供的归还方法或者将连接放入连接池管理的线程本地变量中来完成。
4.连接池维护与扩容:在连接池运行期间,连接池会监控连接的使用情况。
如果发现一些连接长时间没有被使用,连接池会关闭这个连接并删除。
同时,连接池会根据业务需求动态增加连接数量,使连接池始终保持一定数量的可用连接。
5.连接状态管理:连接池会维护每个连接的状态信息。
例如,连接的空闲状态表示连接可供使用,活动状态表示连接正在被使用。
连接池会通过时间戳等机制来检测连接的可用性和超时情况。
6.连接池参数配置:连接池提供了一系列的参数配置,用于调整连接池的大小、最大连接数、最小连接数、超时时间等。
这些参数可以根据应用的实际需求进行调优,以达到最佳的性能和稳定性。
1.提高数据库操作效率:连接池预先创建了一定数量的数据库连接,避免了每次连接数据库的开销,提高了数据库操作效率。
2.节省系统资源:连接池可以限制最大连接数,避免了频繁的连接创建和销毁过程,从而节省了系统资源。
3.提高并发处理能力:连接池可以同时为多个线程提供数据库连接,提高了系统的并发处理能力,降低了系统响应时间。
4.动态扩容与回收:连接池会动态增加和回收连接的数量,根据业务的负载情况来调整连接池的大小,以适应不同的业务需求。
5.连接状态管理:连接池能够管理连接的状态,保证连接的可用性和稳定性,提供了连接超时等机制,防止连接长时间占用而导致的资源浪费。

数据库连接池的工作机制数据库连接池是一个重要的数据库技术,它能够有效地管理数据库连接,提高数据库的性能和可靠性。
数据库连接池的工作机制是指连接池是如何管理和分配数据库连接的,下面我们来详细了解一下数据库连接池的工作机制。
首先,数据库连接池会在应用程序启动时创建一定数量的数据库连接,并将它们保存在连接池中。
这些连接可以被应用程序随时获取和释放,而不需要频繁地打开和关闭数据库连接,从而减少了连接数据库的开销。
当应用程序需要与数据库进行交互时,它会从连接池中获取一个可用的数据库连接。
如果连接池中没有可用的连接,连接池会根据预先设置的规则来创建新的连接。
这样就避免了应用程序在每次需要与数据库交互时都要建立新的连接,提高了数据库操作的效率。
在应用程序使用完数据库连接后,它会将连接释放回连接池,而不是直接关闭连接。
这样做的好处是,连接可以被重复利用,减少了连接的建立和关闭所带来的开销,提高了数据库的性能。
另外,数据库连接池还会监控数据库连接的状态,当连接出现异常或超时时,连接池会自动将这些连接从连接池中移除,并创建新的连接来替代它们,保证了连接的可靠性和稳定性。
总的来说,数据库连接池的工作机制是通过预先创建一定数量的数据库连接,并动态地管理和分配这些连接,从而提高了数据库操作的效率和可靠性。
它能够减少连接的建立和关闭开销,重复利用连接,监控连接的状态,保证了数据库的性能和稳定性。
在实际应用中,我们需要根据具体的业务需求和系统负载来合理地配置数据库连接池的参数,如最大连接数、最小连接数、连接超时时间等,以达到最佳的性能和可靠性。
总之,数据库连接池是一个非常重要的数据库技术,它的工作机制能够有效地管理和分配数据库连接,提高了数据库的性能和可靠性,对于提升系统的性能和稳定性有着重要的作用。
希望本文能够帮助大家更好地理解数据库连接池的工作机制,为实际应用中的数据库连接池的使用提供一些参考。

dbcp连接池原理
DBCP(Database Connection Pool)是Apache软件基金会的一个开源连接池实现,用于管理数据库连接。
其原理是通过预先创建一定数量的数据库连接并将其保存在连接池中,当应用程序需要连接数据库时,从连接池中获取连接,使用完毕后再将连接放回连接池中,而不是每次都建立和关闭数据库连接。
连接池的原理在于提高数据库连接的重复利用率和性能,通过减少连接的建立和关闭次数,避免了频繁创建和销毁连接所带来的开销,从而提高了系统的性能和响应速度。
DBCP连接池的工作原理包括以下几个方面:
1. 连接池初始化,在系统启动时,DBCP连接池会根据预先配置的参数(如最大连接数、最小连接数、连接超时时间等)来初始化一定数量的数据库连接,并将其保存在连接池中。
2. 连接分配,当应用程序需要连接数据库时,从连接池中获取一个可用的数据库连接,如果连接池中没有可用连接,则根据配置的最大连接数来决定是等待可用连接还是创建新的连接。
3. 连接使用,应用程序获取到连接后,可以使用该连接来进行数据库操作,操作完成后需要将连接释放回连接池,而不是关闭连接。
4. 连接回收,连接池会对连接进行管理,包括连接的有效性检测、超时连接的回收等工作,以确保连接池中的连接都是可用的。
总的来说,DBCP连接池的原理是通过提前创建一定数量的数据库连接,并对这些连接进行有效管理,以提高数据库连接的重复利用率和系统性能。
同时,连接池还可以根据系统的负载情况动态调整连接的数量,以适应不同的业务需求。

MySQL中的数据库连接和连接池原理数据库连接和连接池是每个使用MySQL数据库的开发人员都需要了解的重要概念。
数据库连接是应用程序与数据库之间建立的通路,用于执行SQL语句和数据交互。
连接池则是一种管理数据库连接的机制,通过预先创建并维护一组连接,以便在需要时可以快速获取连接并释放连接,提高数据库访问的效率和性能。
一、数据库连接数据库连接是应用程序与数据库之间的通信桥梁,用于发送SQL语句给数据库执行,并获取执行结果。
在MySQL中,通过使用JDBC(Java Database Connectivity)驱动程序可以与数据库建立连接。
1.1 JDBC连接过程JDBC连接MySQL数据库的过程主要包括以下几个步骤:1. 加载JDBC驱动程序:使用`Class.forName(driver)`方法加载MySQL的JDBC驱动程序,以便可以与数据库建立连接。
2. 创建连接:使用`DriverManager.getConnection(url, username, password)`方法创建数据库连接。
其中,url是指数据库的连接地址,可以包括协议、服务器地址、端口号、数据库名等信息。
3. 执行SQL语句:通过数据库连接对象的`createStatement()`方法创建Statement对象,并使用Statement对象的`executeQuery(sql)`方法执行SQL语句。
4. 处理结果集:通过Statement对象的`getResultSet()`方法获取结果集,并使用`ResultSet`对象的相关方法获取查询结果。
5. 关闭连接:使用数据库连接对象的`close()`方法关闭连接,释放资源。
1.2 连接参数配置在连接MySQL数据库时,还可以配置一些连接参数来设置连接的属性,例如超时时间、字符集等。
可以通过在连接URL中添加一些参数来配置连接属性。
例如,设置连接超时时间为5秒,字符集为UTF-8的连接URL可以如下所示:`jdbc:mysql://localhost:3306/test?connectTimeout=5000&characterEncoding=UTF-8`二、连接池原理连接池是一种管理数据库连接的机制,通过预先创建一组数据库连接并维护,以便在需要时可以快速获取连接,并在使用完毕后释放连接,从而提高数据库访问的效率和性能。

数据库连接池的作用及原理1. 介绍数据库连接池是数据库应用程序中常用的技术之一,它的作用是通过预先建立一定数量的数据库连接对象,将这些连接对象存放在一个池子中,然后在需要连接数据库的时候,从连接池中获取一个空闲的数据库连接对象进行使用。
使用完毕后,再将连接放回连接池,以供其他线程复用。
数据库连接池的存在可以提高数据库访问性能、降低资源消耗,使应用程序更高效稳定。
2. 作用数据库连接池的主要作用包括以下几个方面:2.1 提高数据库访问性能数据库连接的建立和释放会消耗较多的时间和系统资源。
通过使用连接池,可以避免频繁地创建和销毁连接,从而减少系统开销,并且在连接池中可复用现有的连接,减少了建立连接的时间,提高了数据库访问的响应速度。
2.2 资源控制和管理数据库连接池可以限制连接的数量,通过设置连接池的最大连接数,可以有效地控制数据库连接的使用,避免过多的连接导致系统的性能下降。
连接池还可以实现对连接的生命周期进行管理,包括连接的创建、销毁、超时等,更好地管理系统资源。
另外,连接池还可以设置连接的最小空闲数和最大空闲时间,保持连接的稳定性和可靠性。
2.3 防止数据库连接泄露在使用数据库连接时,如果没有正确释放连接,会导致连接的泄露。
数据库连接泄露会占用系统资源,最终导致系统崩溃。
连接池可以通过连接的闲置超时机制和自动回收功能,检测并关闭长时间未使用的连接,及时释放系统资源,防止连接泄露的发生。
3. 连接池的原理数据库连接池的实现原理主要包括以下几个方面:3.1 连接池的创建和初始化连接池的创建一般在系统初始化的时候进行,根据系统的需求和实际情况设置连接池的参数,例如最大连接数、最小空闲数、最大空闲时间等。
连接池也可以设置一些其他的参数,例如连接超时时间、回收机制等。
初始化连接池时,会创建一定数量的连接对象,并将这些连接对象放入连接池中。
3.2 连接的获取和释放应用程序在需要连接数据库时,可以从连接池中获取一个可用的连接对象。
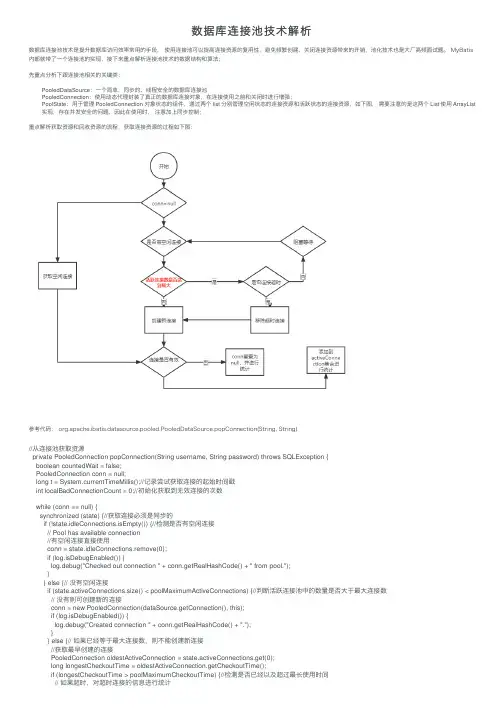
数据库连接池技术解析数据库连接池技术是提升数据库访问效率常⽤的⼿段, 使⽤连接池可以提⾼连接资源的复⽤性,避免频繁创建、关闭连接资源带来的开销,池化技术也是⼤⼚⾼频⾯试题。
MyBatis 内部就带了⼀个连接池的实现,接下来重点解析连接池技术的数据结构和算法;先重点分析下跟连接池相关的关键类:PooledDataSource:⼀个简单,同步的、线程安全的数据库连接池PooledConnection:使⽤动态代理封装了真正的数据库连接对象,在连接使⽤之前和关闭时进⾏增强;PoolState:⽤于管理 PooledConnection 对象状态的组件,通过两个 list 分别管理空闲状态的连接资源和活跃状态的连接资源,如下图,需要注意的是这两个 List 使⽤ ArrayList 实现,存在并发安全的问题,因此在使⽤时,注意加上同步控制;重点解析获取资源和回收资源的流程,获取连接资源的过程如下图:参考代码: org.apache.ibatis.datasource.pooled.PooledDataSource.popConnection(String, String)//从连接池获取资源private PooledConnection popConnection(String username, String password) throws SQLException {boolean countedWait = false;PooledConnection conn = null;long t = System.currentTimeMillis();//记录尝试获取连接的起始时间戳int localBadConnectionCount = 0;//初始化获取到⽆效连接的次数while (conn == null) {synchronized (state) {//获取连接必须是同步的if (!state.idleConnections.isEmpty()) {//检测是否有空闲连接// Pool has available connection//有空闲连接直接使⽤conn = state.idleConnections.remove(0);if (log.isDebugEnabled()) {log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");}} else {// 没有空闲连接if (state.activeConnections.size() < poolMaximumActiveConnections) {//判断活跃连接池中的数量是否⼤于最⼤连接数// 没有则可创建新的连接conn = new PooledConnection(dataSource.getConnection(), this);if (log.isDebugEnabled()) {log.debug("Created connection " + conn.getRealHashCode() + ".");}} else {// 如果已经等于最⼤连接数,则不能创建新连接//获取最早创建的连接PooledConnection oldestActiveConnection = state.activeConnections.get(0);long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();if (longestCheckoutTime > poolMaximumCheckoutTime) {//检测是否已经以及超过最长使⽤时间// 如果超时,对超时连接的信息进⾏统计state.claimedOverdueConnectionCount++;//超时连接次数+1state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;//累计超时时间增加state.accumulatedCheckoutTime += longestCheckoutTime;//累计的使⽤连接的时间增加state.activeConnections.remove(oldestActiveConnection);//从活跃队列中删除if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {//如果超时连接未提交,则⼿动回滚try {oldestActiveConnection.getRealConnection().rollback();} catch (SQLException e) {//发⽣异常仅仅记录⽇志/*Just log a message for debug and continue to execute the followingstatement like nothing happend.Wrap the bad connection with a new PooledConnection, this will helpto not intterupt current executing thread and give current thread achance to join the next competion for another valid/good databaseconnection. At the end of this loop, bad {@link @conn} will be set as null.*/log.debug("Bad connection. Could not roll back");}}//在连接池中创建新的连接,注意对于数据库来说,并没有创建新连接;conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());//让⽼连接失效oldestActiveConnection.invalidate();if (log.isDebugEnabled()) {log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");}} else {// ⽆空闲连接,最早创建的连接没有失效,⽆法创建新连接,只能阻塞try {if (!countedWait) {state.hadToWaitCount++;//连接池累计等待次数加1countedWait = true;}if (log.isDebugEnabled()) {log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");}long wt = System.currentTimeMillis();state.wait(poolTimeToWait);//阻塞等待指定时间state.accumulatedWaitTime += System.currentTimeMillis() - wt;//累计等待时间增加} catch (InterruptedException e) {break;}}}}if (conn != null) {//获取连接成功的,要测试连接是否有效,同时更新统计数据// ping to server and check the connection is valid or not//检测连接是否有效if (conn.isValid()) {//有效if (!conn.getRealConnection().getAutoCommit()) {conn.getRealConnection().rollback();//如果遗留历史的事务,回滚}//连接池相关统计信息更新conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));conn.setCheckoutTimestamp(System.currentTimeMillis());conn.setLastUsedTimestamp(System.currentTimeMillis());state.activeConnections.add(conn);state.requestCount++;state.accumulatedRequestTime += System.currentTimeMillis() - t;} else {//如果连接⽆效if (log.isDebugEnabled()) {log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection."); }state.badConnectionCount++;//累计的获取⽆效连接次数+1localBadConnectionCount++;//当前获取⽆效连接次数+1conn = null;//拿到⽆效连接,但如果没有超过重试的次数,允许再次尝试获取连接,否则抛出异常if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {if (log.isDebugEnabled()) {log.debug("PooledDataSource: Could not get a good connection to the database.");}throw new SQLException("PooledDataSource: Could not get a good connection to the database.");}}}}}if (conn == null) {if (log.isDebugEnabled()) {log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");}throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection."); }return conn;}回收连接资源的过程如下图:代码位置:org.apache.ibatis.datasource.pooled.PooledDataSource.pushConnection(PooledConnection)1//回收连接资源2protected void pushConnection(PooledConnection conn) throws SQLException {34synchronized (state) {//回收连接必须是同步的5 state.activeConnections.remove(conn);//从活跃连接池中删除此连接6if (conn.isValid()) {//先判断连接是否有效7//判断闲置连接池资源是否已经达到上限,并判断是由本连接池创建8if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) { 9//没有达到上限,进⾏回收10 state.accumulatedCheckoutTime += conn.getCheckoutTime();//增加累计使⽤时间11if (!conn.getRealConnection().getAutoCommit()) {12 conn.getRealConnection().rollback();//如果还有事务没有提交,进⾏回滚操作13 }14//基于该连接,创建⼀个新的连接资源,并刷新连接状态15 PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);16 state.idleConnections.add(newConn);17 newConn.setCreatedTimestamp(conn.getCreatedTimestamp());18 newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());19//⽼连接失效20 conn.invalidate();21if (log.isDebugEnabled()) {22 log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");23 }24//唤醒其他被阻塞的线程25 state.notifyAll();26 } else {//如果闲置连接池已经达到上限了,将连接真实关闭27 state.accumulatedCheckoutTime += conn.getCheckoutTime();28if (!conn.getRealConnection().getAutoCommit()) {29 conn.getRealConnection().rollback();30 }31//关闭真的数据库连接32 conn.getRealConnection().close();33if (log.isDebugEnabled()) {34 log.debug("Closed connection " + conn.getRealHashCode() + ".");35 }36//将连接对象设置为⽆效37 conn.invalidate();38 }39 } else {40if (log.isDebugEnabled()) {41 log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");42 }43 state.badConnectionCount++;44 }45 }46 }。

Java数据库连接池运行原理分析摘要数据库处理是应用系统业务处理中最耗时的步骤。
在应用服务器系统中,一般都采用数据库连接池(Connection Pool)的技术来解决。
本文论述了连接池的工作原理及程序实现,分析并给出了一个基本实现,以更好地理解这种模型。
关键词JDBC;数据库连接池;缓冲池1引言在使用JDBC技术开发Java和数据库有关应用的时候,随着使用人数的增加系统的性能下降非常明显,深入研究发现系统性能下降和Connection这个对象的创建有关系。
问题的根源就在于对数据库连接资源的低效管理上。
对于共享资源,有一个很闻名的设计模式:资源池。
该模式正是为了解决资源的频繁分配、释放所造成的问题。
为解决这一问题,在应用服务器系统中,比如:Tomcat、Weblogic等,一般都采用数据库连接池(Connection Pool)的技术。
本文对此项技术进行了深入分析。
2数据库连接池技术2.1概述数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。
预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
即在系统初起,或者初次使用时,完成数据库的连接,此后不再释放此连接,而是在处理后面的请求时反复使用这些已经建立的连接。
这种方式可以大大减少数据库的处理时间,有利于提高系统的整体性能,因此被广泛地应用在各种应用服务器产品中。
2.2运行原理其工作原理如图所示:1)建立数据库连接池对象—ConnectionPool,先设定Connection的数量;2)对于数据库的访问请求,直接从连接池中取得一个连接。
如果数据库连接池对象中没有空闲的连接,则等待;3)进行数据存取操作,操作完毕释放连接,回收到连接池;4)关闭数据库,释放所有数据库连接;5)系统退出时,释放数据库连接池对象。
2.3程序的实现实现程序基于MS SQL Server 2005,在MyEclipse环境下实现。

数据库连接池的原理与在MySQL中的应用一、引言数据库连接池是一种重要的连接管理工具,它能够提高数据库的访问效率和性能。
本文将从数据库连接池的原理出发,探讨其在MySQL中的应用。
二、数据库连接池的原理数据库连接池是一组数据库连接的缓存,它的存在可以避免每次请求都需要进行连接和断开操作,从而减少了数据库服务器的负担和响应时间。
1. 连接池管理数据库连接池的管理负责连接的分配和释放,同时也负责对连接的有效性进行检查。
2. 连接池参数配置连接池的参数配置是连接池管理的重要组成部分,常见的参数包括最小连接数、最大连接数、最大空闲时间等。
通过合理设置这些参数,可以根据应用的实际需求来提高连接池的性能。
3. 连接分配策略连接分配策略决定了连接从连接池中被分配的顺序。
常见的策略有:先进先出、最少使用优先等。
这些策略旨在提高连接的公平性和均衡性。
4. 连接可用性检查连接可用性检查是连接池管理的关键步骤,它通过定期对连接进行心跳检测或者执行简单的查询语句来判断连接是否可用。
如果连接不可用,则需要及时将其从连接池中移除。
三、MySQL中的连接池应用MySQL是一种常见的关系型数据库管理系统,具有高性能和可扩展性。
连接池在MySQL中的应用可以通过不同的方式实现。
1. 数据库连接池框架常见的数据库连接池框架如Apache DBCP、C3P0和HikariCP等,它们提供了完整的连接池功能,并且支持配置多种参数以适应不同的应用环境。
2. MySQL内置连接池MySQL自身也提供了内置的连接池功能,可以通过配置文件或者动态参数设置来启用连接池。
使用MySQL内置连接池可以减少依赖和配置的复杂性。
3. 连接池调优连接池在应用中的性能表现和调优是非常重要的。
通过合理设置连接池的参数,如最小连接数、最大连接数和最大空闲时间等,可以在保证可用性的前提下减少数据库连接的创建和销毁操作,从而提高数据库的访问性能。
四、连接池的优缺点数据库连接池作为一种常见的连接管理工具,在实际应用中有其优点和缺点。

数据库连接池的原理与实现数据库连接池是一种用于管理和复用数据库连接的机制,它可以有效地提高数据库访问的性能、可靠性和可扩展性。
在本文中,我们将探讨数据库连接池的原理,并介绍一个简单的实现。
数据库连接是应用程序与数据库之间的通信通道,它负责处理数据库操作和数据传输。
然而,每次从应用程序到数据库建立新的数据库连接都会产生一定的开销,包括网络通信和连接授权等。
为了减少这种开销并提高数据库的性能,使用连接池可以很好地解决这个问题。
数据库连接池的原理主要包括以下几个方面:1. 连接的初始化和销毁:连接池在启动时会提前创建一定数量的数据库连接,并将它们保存在连接池中。
应用程序在需要与数据库进行交互时,可以从连接池中获取一个可用的连接,而不是每次都重新创建一个连接。
当连接使用完毕后,应用程序将连接返回到连接池,以便下次重新使用。
当连接池不再需要时,可以销毁连接池中的所有连接。
2. 连接的复用:连接池通过复用数据库连接,可以减少连接的创建和销毁次数,提高数据库访问的效率。
当应用程序需要执行数据库操作时,它可以从连接池中获取一个可用的连接,执行完毕后将连接返回到连接池,供其他应用程序使用。
3. 连接的管理:连接池负责管理连接的状态和生命周期。
它会监控连接的可用性,当连接出现异常或超时时,连接池会自动将该连接标记为不可用,并重新创建一个新的连接来替代它。
连接池还可以限制连接的数量,以防止数据库服务器被过多的连接请求压垮。
4. 连接的配置和参数:连接池允许应用程序配置连接的参数,如最大连接数、最小连接数、连接超时时间等。
这些参数可以根据应用程序的需求进行调整,以达到最佳的数据库访问性能和资源利用率。
现在我们来介绍一个简单的数据库连接池的实现。
首先,我们使用一个线程安全的队列来保存连接池中的连接对象。
在连接池初始化时,可以创建一定数量的数据库连接,将它们添加到队列中。
当应用程序需要获取连接时,可以从队列中取出一个连接对象并返回给应用程序使用。

MySQL连接池的原理与使用指南引言在开发Web应用程序或者其他需要与数据库进行交互的项目中,数据库连接一直是一个重要的话题。
MySQL作为一种主流的关系型数据库,使用广泛,因此学习和理解MySQL连接池的原理和使用方法对于开发人员来说是非常重要的。
一、什么是连接池连接池是一种数据库连接管理的机制。
它允许应用程序从一个预先创建好的连接池中获取数据库连接,而不需要每次都重新创建和销毁连接,从而提高了应用程序的性能和效率。
二、MySQL连接池的原理1. 连接池的创建MySQL连接池的创建基于Java的数据库连接池技术。
连接池可以通过使用Java中的DataSource接口来创建。
DataSource接口定义了一些方法,用于获取和释放数据库连接。
常见的DataSource的实现类有:- c3p0:一个开源的JDBC连接池,支持JDBC3规范和JDBC4规范。
- Druid:阿里巴巴开源的JDBC连接池。
- HikariCP:一个高性能的JDBC连接池。
2. 连接池的配置在使用连接池之前,我们需要进行一些配置。
主要包括以下几个方面:- 数据库连接的URL、用户名和密码- 最大连接数和最小连接数- 连接的生命周期(超时时间、空闲时间等)- 连接的测试机制(连接是否可用等)3. 连接的获取和释放连接池创建好之后,应用程序可以通过调用DataSource接口的方法来获取和释放数据库连接。
当应用程序需要数据库连接时,它可以从连接池中获取一个连接,当使用完毕之后,将连接重新放回连接池。
4. 连接的复用连接池的一个重要特性是连接的复用。
当应用程序释放连接时,并不是直接关闭连接,而是将连接放回连接池中,以供其他应用程序使用。
这样可以避免每次获取连接时的创建和销毁连接的开销,提高了系统的性能和效率。
三、MySQL连接池的使用指南1. 导入连接池库在项目的构建文件中导入所需的连接池库。
以Maven为例,可以添加以下依赖:```<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>${mysql.version}</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>${druid.version}</version></dependency>```其中,mysql-connector-java是MySQL官方提供的JDBC驱动,druid是阿里巴巴开源的连接池库。
MySQL的连接池原理和使用方法引言:在开发和维护基于MySQL数据库的应用程序时,数据库连接管理是一个非常重要的话题。
在高并发的场景下,数据库连接的创建和销毁会消耗大量的资源和时间。
为了提高应用程序的性能和可伸缩性,使用连接池来管理数据库连接是一个常用的解决方案。
本文将介绍MySQL连接池的原理和使用方法,以帮助开发人员更好地理解和应用连接池技术。
一、连接池的原理连接池是一种重用数据库连接的机制,通过在应用程序启动时创建一定数量的数据库连接,并将这些连接缓存在连接池中。
当应用程序需要访问数据库时,从连接池中获取一个可用的连接,完成数据库操作后将连接释放回连接池。
这样可以避免频繁地创建和销毁数据库连接,提高应用程序的性能和资源利用率。
1. 连接池的创建连接池的创建一般在应用程序启动时完成。
开发人员可以通过使用MySQL提供的连接池库或第三方库,快速搭建一个可用的连接池。
在创建连接池时,需要指定连接池的一些参数,如最大连接数、最小连接数、连接超时时间等。
2. 连接的复用和归还当应用程序需要访问数据库时,先从连接池中获取一个可用的连接。
如果连接池中没有可用的连接,则根据一定的策略创建新的连接。
获取到连接后,应用程序可以执行数据库操作。
完成操作后,将连接释放回连接池,以便其他应用程序继续使用。
3. 连接的管理和监控连接池通常会提供一些管理和监控功能,用于监控连接的状态和性能。
例如,连接池可以记录连接的创建和销毁时间,连接的使用次数等统计信息。
这些信息可以帮助开发人员分析应用程序的性能瓶颈,进行优化。
二、使用MySQL连接池使用MySQL连接池可以大大简化数据库连接的管理工作,并提高应用程序的性能。
下面将介绍如何在Java应用程序中使用MySQL连接池。
1. 导入连接池库在使用MySQL连接池之前,需要将连接池相关的库文件导入到项目中。
一般情况下,连接池库文件会提供一个.jar文件,将该文件添加到项目的依赖中即可。
java数据库连接池原理Java数据库连接池原理数据库连接是应用程序与数据库之间进行通信的重要桥梁,它负责建立连接、执行SQL语句并返回结果。
然而,每次建立连接都需要经过网络传输、认证等多个步骤,这将耗费大量的时间和资源。
为了解决这个问题,数据库连接池应运而生。
数据库连接池是一个存放数据库连接的缓冲区,它维护着一定数量的数据库连接,并对外提供获取和释放连接的接口。
当应用程序需要访问数据库时,可以从连接池中获取连接,执行完操作后再将连接归还给连接池。
这样一来,就避免了频繁地创建和销毁连接,大大提高了数据库操作的效率。
那么,数据库连接池是如何工作的呢?连接池在初始化时会创建一定数量的连接,并将其放入连接池中。
连接的数量通常由最小连接数和最大连接数决定,最小连接数保证了连接池的可用性,而最大连接数限制了连接池的负载能力。
当应用程序需要获取数据库连接时,它可以通过连接池获取一个可用的连接。
连接池会先查找空闲连接,如果存在空闲连接则将其返回给应用程序;如果没有空闲连接,则根据当前连接数判断是否可以创建新的连接。
如果连接数未达到最大连接数,则连接池会创建一个新的连接并返回给应用程序;如果连接数已达到最大连接数,则应用程序需要等待,直到有连接被释放为止。
应用程序在使用完连接之后,需要将连接归还给连接池。
这样可以确保连接的重复利用,避免连接资源的浪费。
连接归还后,连接池会将连接标记为空闲状态,并重新加入到空闲连接队列中,以供其他应用程序使用。
除了上述基本功能,好的连接池还应该具备以下特点:1. 连接池应该具备连接的可重用性。
即连接池应该能够检测到连接的有效性,如果连接失效,则应该能够重新创建一个新的连接。
2. 连接池应该具备连接的可管理性。
即连接池应该能够对连接进行统计、监控和管理,包括连接的创建、销毁和状态管理等。
3. 连接池应该具备连接的可扩展性。
即连接池应该能够根据负载情况自动增加或减少连接的数量,以适应应用程序的需求。
最近我作了数据库JSP的频繁连接,在此给出数据库连接池的必要性,对于JSP来说一个
很好的J2EE服务器是很必要的,JBOOS,WebLogic都是很好的解决方案。
一般情况下,在使用开发基于数据库的WEB程序时,传统的模式基本是按以下步骤:
1. 在主程序(如Servlet、Beans)中建立数据库连接。
2. 进行SQL操作,取出数据。
3. 断开数据库连接。
使用这种模式开发,存在很多问题。首先,我们要为每一次WEB请求(例如察看
某一篇文章的内容)建立一次数据库连接,对于一次或几次操作来讲,或许你觉察不到系
统的开销,但是,对于WEB程序来讲,即使在某一较短的时间段内,其操作请求数也远
远不是一两次,而是数十上百次(想想全世界的网友都有可能在您的网页上查找资料),
在这种情况下,系统开销是相当大的。事实上,在一个基于数据库的WEB系统中,建立
数据库连接的操作将是系统中代价最大的操作之一。很多时候,可能您的网站速度瓶颈就
在于此。
其次,使用传统的模式,你必须去管理每一个连接,确保他们能被正确关闭,如
果出现程序异常而导致某些连接未能关闭,将导致数据库系统中的内存泄露,最终我们将
不得不重启数据库。
针对以上问题,我们首先想到可以采用一个全局的Connection对象,创建后就不
关闭,以后程序一直使用它,这样就不存在每次创建、关闭连接的问题了。但是,同一个
连接使用次数过多,将会导致连接的不稳定,进而会导致WEB SERVER的频频重启。故而,
这种方法也不可取。实际上,我们可以使用连接池技术来解决上述问题。首先,介绍一下
连接池技术的基本原理。顾名思义,连接池最基本的思想就是预先建立一些连接放置于内
存对象中以备使用:
如图所示,当程序中需要建立数据库连接时,只须从内存中取一个来用而不用新建。
同样,使用完毕后,只需放回内存即可。而连接的建立、断开都有连接池自身来管理。同
时,我们还可以通过设置连接池的参数来控制连接池中的连接数、每个连接的最大使用次
数等等。通过使用连接池,将大大提高程序效率,同时,我们可以通过其自身的管理机制
来监视数据库连接的数量、使用情况等。下面我们以一个名为ConnectionPool的连接池为
例来看看连接池的实现。先看看ConnectionPool的基本属性:
m_ConnectionPoolSize:连接池中连接数量下限
m_ConnectionPoolMax:连接池中连接数量上限
m_ConnectionUseCount:一个连接的最大使用次数
m_ConnectionTimeout:一个连接的最长空闲时间
m_MaxConnections = -1:同一时间的最大连接数
m_timer:定时器
这些属性定义了连接池与其中的每个连接的有效状态值。连接池的自我管理,实
际上就是通过定时的对每个连接的状态、连接的数量进行判断而进行相应操作。其管理流
程如下:
通过上图,我们可以定义出ConnectionPool要完成管理所需要的基本接口:
public class ConnectionPool implements TimerListener{
public boolean initialize() //连接池初始化
public void destroy() //连接池的销毁
public synchronized java.sql.Connection getConnection() //取一个连接
public synchronized void close() //关闭一个连接
private synchronized void removeFromPool() //把一个连接从连接池中删除
private synchronized void fillPool() //维护连接池大小
public synchronized void TimerEvent() //定时器事件处理函数
}
通过这几个接口,已经可以完成连接池的基本管理。在TimeEvent()函数中完成
连接池的状态检验工作,fillPool()时连接池至少保持最小连接数。因为我们要保存每一个
连接的状态,所以还需要一个数据库连接对象:
class ConnectionObject{
public java.sql.Connection con; public boolean inUse; //是否被使用标志
public long lastAccess; //最近一次开始使用时间
public int useCount; //被使用次数
}
加入了ConnectionObject对象后,在ConnectionPool中操作的应该只是
ConnectionObject,而其他进程需要的只是
ConnectionObject的con属性,因此我们再加入一个类,作为其他进程获得与返回连接
的接口: CLASS Conn{
GetConnection(); //从连接池中取出一个有效连接
CloseConnection(); //返回连接,此时并没有关闭连接,只是放回了连接池
DestroyPool(); //销毁连接池
}
最后我们的整个系统总的架构如下:
通过上面的介绍,我们可以看出,连接池技术的关键就是其自身的管理机制,以上的
管理流程只是本人一点见解,关键是想向大家介绍一种思路,在此基础上,您可以进一步
完善连接池技术为您所用。