集群系统的概念简述
- 格式:docx
- 大小:35.18 KB
- 文档页数:2

第1篇一、Node.js 基础知识1. 什么是Node.js?请简述Node.js的特点。
Node.js是一个基于Chrome V8引擎的JavaScript运行环境,它允许开发者使用JavaScript来编写服务器端代码。
Node.js的特点包括:(1)单线程,使用事件驱动、非阻塞I/O模型,提高I/O操作效率;(2)跨平台,支持Windows、Linux、macOS等多种操作系统;(3)丰富的API,提供文件系统、网络通信、数据库连接等功能;(4)模块化,便于代码复用和维护。
2. Node.js的运行原理是什么?Node.js的运行原理主要包括以下几个方面:(1)V8引擎:Node.js使用Chrome的V8引擎来解析和执行JavaScript代码;(2)事件循环:Node.js采用单线程模型,通过事件循环机制来处理并发请求;(3)异步I/O:Node.js使用非阻塞I/O模型,通过异步API来实现高效的I/O操作;(4)模块化:Node.js采用CommonJS模块规范,便于代码复用和维护。
3. 请解释Node.js中的全局变量有哪些?Node.js中的全局变量主要包括:(1)process:表示当前正在运行的Node.js进程;(2)global:表示当前的全局对象,等同于window对象(在浏览器中);(3)console:提供控制台输出功能;(4)setTimeout、clearTimeout:用于设置和清除定时器;(5)setInterval、clearInterval:用于设置和清除周期性定时器;(6)require、module、exports:用于模块的加载、导出和导入。
二、Node.js API4. 请简述Node.js中的文件系统(fs)模块的功能。
fs模块是Node.js提供的一个文件操作API,主要功能包括:(1)文件读取:fs.readFile、fs.readFileSync;(2)文件写入:fs.writeFile、fs.writeFileSync;(3)文件追加:fs.appendFile、fs.appendFileSync;(4)文件监视:fs.watch、fs.watchFile;(5)文件删除:fs.unlink、fs.unlinkSync。

《普通生态学》“群落生态学”部分自习题一、选择题(每小题只有一个选项是符合题意的)1.生物群落特征正确的论述是[]。
A.生物群落的特征是群落内所有生物的群体表现B.一棵树木的高大挺拔代表了森林群落的外貌特征C.一棵草、一棵树各自显示着不同生物群落的外貌D.植物、动物、微生物对生物群落特征的影响大小一致2.不属于群落成员型的是[]。
A.优势种 B.建群种 C.特有种 D.亚优种3.在以下生物群落中,净第一性生产力最大的是哪种类型[]。
A.热带雨林 B.温带落叶阔叶林C.热带季雨林 D.常绿阔叶林4.海洋与陆地交界的区域是[]。
A.潮间带 B.浅海带 C.珊瑚礁 D.远洋带5.群落结构最复杂的是[]。
A.苔原 B.荒漠 C.落叶阔叶林 D.常绿阔叶林6.下述对常绿阔叶林描述正确的是[]。
A.常绿阔叶林区属于亚热带气候B.常绿阔叶林又称为夏绿林 C.乔木、灌木、草本、地被四层均具备,乔木层仅一层D.高位芽达90%以上7.下述说法不正确的是[]。
A.热带雨林是共建种群落B.阔叶林群落中出现的马尾松是罕见种C.板状根植物多属浅根植物D.湖泊中的生产者多分布在深底带11.群落交错区的特征是[]。
A.比相邻群落环境更加严酷B.种类多样性常高于相邻群落C.由于是多个群落边缘地带,相邻群落生物均不适应在此生存D.在群落交错区各物种密度均大于相邻群落12.以下有关分层现象的论述,错误的是[]。
A.动物在群落中的分层现象也很普通B.植物地下根系分层由浅入深依次是乔木、灌木、草本和地被C.水生生物也具有分层现象D.草本群落也具有分层现象13.下列关于生态型的说法,不正确的是[]。
A.生态型是一个物种对某一特定生境发生形态、生理等反应的产物B.生态型是同种生物的趋同适应C.生态型是种内的分异D.生态型根据形成主导因素的不同可有气候、土壤生态型等14.下列关于生态位的概念,错误的是[]。
A.任何物种的生态位都是一个n维的超体积B.n维超体积包含了一个物种生存和生殖所需要的全部条件C.高矮作物,深根浅根作物间作时,它们的生态位完全重叠D.热带雨林生境优越,生态位宽的广域物种十分丰富15.按丹麦植物学家C.Raunkiaer生活型分类,下列植物中属于一年生的是[]。
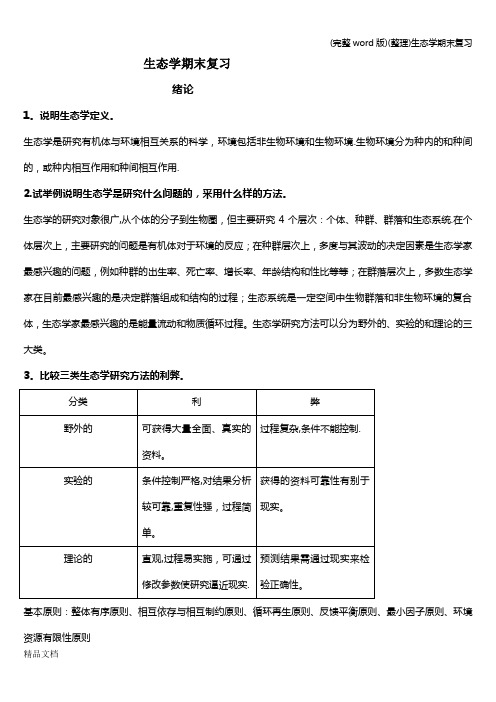
生态学期末复习绪论1。
说明生态学定义。
生态学是研究有机体与环境相互关系的科学,环境包括非生物环境和生物环境.生物环境分为种内的和种间的,或种内相互作用和种间相互作用.2.试举例说明生态学是研究什么问题的,采用什么样的方法。
生态学的研究对象很广,从个体的分子到生物圈,但主要研究4个层次:个体、种群、群落和生态系统.在个体层次上,主要研究的问题是有机体对于环境的反应;在种群层次上,多度与其波动的决定因素是生态学家最感兴趣的问题,例如种群的出生率、死亡率、增长率、年龄结构和性比等等;在群落层次上,多数生态学家在目前最感兴趣的是决定群落组成和结构的过程;生态系统是一定空间中生物群落和非生物环境的复合体,生态学家最感兴趣的是能量流动和物质循环过程。
生态学研究方法可以分为野外的、实验的和理论的三大类。
3。
比较三类生态学研究方法的利弊。
基本原则:整体有序原则、相互依存与相互制约原则、循环再生原则、反馈平衡原则、最小因子原则、环境资源有限性原则第一章生物与环境1.概念与术语a。
环境是指某一特定生物体或生物群体周围一切的总和,包括空间及直接或间接影响该生物体或生物群体生存的各种因素。
b.生态因子是指环境要素中对生物起作用的因子,如光照、温度、水分等。
c.生态福是指每一种生物对每一种生态因子,在最高点和最低点之间的范围。
d。
大环境指的是地区环境、地球环境和宇宙环境。
e。
小环境指的是对生物有直接影响的邻接环境。
f。
大环境中的气候称为大气候,是指离地面1。
5m以上的气候,由大范围因素决定。
g。
小环境中的奇虎称为小气候,是指近地面大气层中1。
5m以内的气候。
h.所有生态因子构成生物的生态环境,特定的生物体或群体的栖息地生态环境称为生境.i.对动物种群数量影响的强度随其种群密度而变化,从而调节种群数量的生态因子,称为密度制约因子。
j。
可调节种群数量,但其影响强度不随种群密度而变化的生态因子,称为非密度制约因子。
k。
任何生态因子,当接近或超过某种生物的耐受性极限而阻止其生存、生长、繁殖或扩散时,这个因素称为限制因子。

基础⽣态学问答题及答案1.什么是最⼩因⼦定律?什么是耐受性定律?利⽐希在1840年提出“植物的⽣长取决于那些处于最少量状态的营养元素”。
其基本内容是:低于某种⽣物需要的最⼩量的任何特定因⼦,是决定该种⽣物⽣存与分布的根本因素,这就是利⽐希最⼩因⼦定律。
Shelford于1913年提出了耐受性定律:任何⼀个⽣态因⼦在数量上或质量上的不⾜或过多,即当其接近或达到某种⽣物的耐受限度时会使该种⽣物衰退或不能⽣存。
2.⽣态因⼦相互联系表现在那些⽅⾯?⽣态因⼦相互联系表现在如下⽅⾯:(1)综合作⽤:环境中的每个⽣态因⼦不是孤⽴的、单独的存在,总是与其他因⼦相互联系和影响。
任何⼀个因⼦的变化,都会不同程度地引起其他因⼦的变化,导致⽣态因⼦的综合作⽤,例如⽣物能够⽣长发育,是依赖于⽓候、地形、⼟壤和⽣物等多种因素的综合作⽤。
(2)主导因⼦作⽤:对⽣物起作⽤的众多因⼦并⾮等价的,其中有⼀个是起决定性作⽤的,它的改变会引起其它⽣态因⼦发⽣改变,使⽣物的⽣长发育发⽣改变。
(3)阶段性作⽤:由于⽣态因⼦规律性变化使⽣物⽣长发育出现阶段性,在不同发育阶段,⽣物需要不同的⽣态因⼦或⽣态因⼦的不同强度。
(4)不可替代性和补偿性作⽤:对⽣物起作⽤的诸多⽣态因⼦,⼀个都不能少,不能替代,但在⼀定条件下,当某⼀因⼦数量不⾜,可依靠相近⽣态因⼦的加强得以补偿。
(5)直接作⽤和间接作⽤:⽣态因⼦对⽣物的⾏为、⽣长、⽣殖和分布的作⽤可以是直接的,也可以是间接的,有时需经历⼏个中间因⼦。
3.⽣物对极端的⾼温和低温会产⽣哪些适应?⽣物对极端⾼、低温的适应表现在形态、⽣理和⾏为等各个⽅⾯。
低温的形态适应:植物的芽和叶⽚常有油脂类物质保护,树⼲粗短,树⽪坚厚;内温动物出现贝格曼规律和阿伦规律的变化。
在⽣理⽅⾯,植物减少细胞中的⽔分,增加糖类、脂肪和⾊素等物质以降低植物冰点,增强抗旱能⼒;内温动物主要增加体内产热,此外还采⽤逆流热交换、局部异温性和适应性低体温等适应寒冷环境。

第1篇1. 请简要介绍服务器的定义、类型以及作用。
2. 请列举并解释以下术语:服务器架构、虚拟化、集群、负载均衡。
3. 请简述服务器的硬件组成部分,包括但不限于CPU、内存、硬盘、网络设备等。
4. 请说明服务器操作系统的主要类型,并举例说明它们各自的特点。
5. 请简述Linux和Windows操作系统的区别,包括安装、配置、管理等方面。
6. 请列举几种常用的服务器管理工具,并简要介绍它们的功能。
7. 请解释以下概念:IP地址、子网掩码、网关、DNS。
8. 请简述TCP/IP协议的基本原理,以及TCP和UDP协议的区别。
9. 请说明防火墙的作用,以及常见的防火墙类型。
10. 请解释以下安全术语:加密、认证、授权、审计。
二、服务器配置与优化1. 请简述服务器硬件配置的基本原则。
2. 请说明如何根据业务需求选择合适的服务器硬件。
3. 请介绍服务器内存优化方法,包括内存分配策略、内存管理工具等。
4. 请简述服务器硬盘配置原则,以及RAID技术的作用。
5. 请介绍服务器网络配置要点,包括IP地址规划、子网划分等。
6. 请说明如何优化服务器性能,包括CPU、内存、硬盘、网络等方面的优化。
7. 请介绍服务器监控的基本原理,以及常见的监控工具。
8. 请简述服务器日志分析的重要性,以及如何进行日志分析。
9. 请介绍服务器备份策略,包括全备份、增量备份、差异备份等。
10. 请说明如何进行服务器安全加固,包括操作系统、应用程序、网络等方面的安全措施。
三、服务器故障排查与处理1. 请列举服务器常见故障类型,如硬件故障、软件故障、网络故障等。
2. 请介绍如何进行服务器硬件故障排查,包括CPU、内存、硬盘、电源等。
3. 请介绍如何进行服务器软件故障排查,包括操作系统、应用程序、网络等。
4. 请说明如何进行服务器网络故障排查,包括IP地址、子网掩码、网关、DNS等。
5. 请介绍如何进行服务器性能故障排查,包括CPU、内存、硬盘、网络等。

第1篇一、缓存基础知识1. 请简要介绍缓存的作用和意义。
2. 缓存有哪些类型?请分别说明它们的特点和应用场景。
3. 什么是本地缓存和分布式缓存?它们之间有什么区别?4. 什么是缓存穿透、缓存击穿和缓存雪崩?如何避免这些问题?5. 请简述缓存一致性策略,如缓存失效、缓存更新、缓存同步等。
6. 什么是缓存命中率?如何提高缓存命中率?7. 请解释缓存失效时间(TTL)的概念及其作用。
8. 什么是缓存预热和缓存冷启动?它们分别适用于哪些场景?9. 请简要介绍缓存穿透、缓存击穿和缓存雪崩的解决方案。
10. 什么是缓存中间件?常见的缓存中间件有哪些?二、一致性哈希算法1. 请解释一致性哈希算法的原理。
2. 一致性哈希算法有哪些优点和缺点?3. 在一致性哈希算法中,如何处理服务器节点增加和减少的情况?4. 请简述一致性哈希算法在Memcached中的应用。
5. 一致性哈希算法与哈希取模算法相比,有哪些优势?三、缓存中间件1. 请介绍Redis缓存的特点和优势。
2. Redis有哪些常用数据结构?请分别说明它们的特点和应用场景。
3. Redis持久化策略有哪些?请比较它们的优缺点。
4. 请解释Redis的内存淘汰策略。
5. 请简述Redis集群的原理和配置。
6. 请介绍Memcached缓存的特点和优势。
7. Memcached的哈希算法有哪些?请比较它们的优缺点。
8. 请解释Memcached的一致性哈希算法。
9. 请简述Memcached集群的原理和配置。
10. 请介绍其他缓存中间件,如Ehcache、Caffeine等,并比较它们的优缺点。
四、缓存应用场景1. 请举例说明缓存在实际项目中的应用场景。
2. 在分布式系统中,如何使用缓存提高系统性能?3. 请分析缓存在电商、社交、金融等领域的应用。
4. 请解释缓存在数据库优化中的作用。
5. 请简述缓存在搜索引擎中的应用。
五、缓存优化策略1. 请列举一些提高缓存性能的方法。
Hadoop知识点总结Hadoop知识点总结1.什么是hadoop?hadoop是⼀个开源软件框架,⽤于存储⼤量数据,并发处理/查询在具有多个商⽤硬件(即低成本硬件)节点的集群上的那些数据。
总之Hadoop包括⼀下内容:HDFS(Hadoop分布式⽂件系统):允许以⼀种分布式和冗余的⽅式存储⼤量数据。
例如:1GB(即1024MB)⽂本⽂件可以拆分为16*128MB⽂件,并存储在Hadoop集群中的8个不同节点上。
每个分裂可以复制三次,以实现容错,以便如果⼀个节点出现错误的话,也有备份。
HDFS适⽤于顺序的"⼀次写⼊,多次读取"的类型访问。
MapReduce:⼀个计算框架。
它以分布式和并⾏的⽅式处理⼤量的数据,当你对所有年龄>18的⽤户在上述1GB⽂件上执⾏查询时,将会有"8个映射"函数并⾏运⾏,以在其128MB拆分⽂件中提取年龄>18的⽤户,然后"reduce"函数将将会运⾏以将所有单独的输出组合成单个最终结果。
YARN(⼜⼀资源定位器):⽤于作业调度和集群资源管理的框架。
Hadoop⽣态系统,拥有15多种框架和⼯具,如Sqoop,Flume,Kafka,Pig,Hive,Spark,Impala等以便将数据摄⼊HDFS,在HDFS中转移数据(即变换、丰富、聚合等),并查询来⾃HDFS的数据⽤于商业智能和分析。
某些⼯具(如Pig和Hive)是MapReduce上的抽象层,⽽Spark和Impala等其他⼯具则是来⾃MapReduce的改进架构/设计,⽤于显著提⾼延迟以⽀持近实时和实时处理2.为什么组织从传统的数据仓库⼯具转移到基于Hadoop⽣态系统的智能数据中⼼?1.现有数据基础设施:主要使⽤存储在⾼端和昂贵硬件中的"structured data,结构化数据"主要处理为ETL批处理作业,⽤于将数据提取到RDBMS和数据仓库系统中进⾏数据挖掘,分析和报告,以进⾏关键业务决策主要处理以千兆字节到兆字节为单位的数据量2.基于Hadoop的更加智能的数据基础设施,其中:结构化(例如RDBMS),⾮结构化(例如images,PDF,docs)和半结构化(例如logs,XMLs)的数据可以以可扩展和容错的⽅式存储在⽐较便宜的商⽤机器中数据可以存储诸如Spark和Impala之类的⼯具以低延迟的能⼒查询可以存储以兆兆字节到千兆字节为单位的较⼤数据量3.基于Hadoop的数据中⼼的好处是什么?随着数据量和复杂性的增加,提⾼量整体服务⽔平协议。
产业集群相关理论当前,国内外学术界掀起了对产业集群研究的高潮,出现了各种各样的观点和流派,形成了“产业集群理论丛林”的局面。
西方经济学、管理学、区位理论、经济社会学、东方管理学等学者都有丰富的产业集群方面的理论,本文简述一些在历史上或现在较主流的产业集群理论。
1.马歇尔的外部规模经济理论马歇尔(AlfredMarshall)(1890)在他的名著《经济学原理》中,提出了外部规模经济概念。
马歇尔认为,外部规模经济是指企业利用地理接近性,通过规模经济使企业生产成本处于或接近最低状态,使无法获得内部规模经济的单个企业通过外部合作获得规模经济。
他认为的外部经济有:一是地方具有专用性劳动力市场;二是生产专业化而取得的中间产品;三是可获得的技术与信息。
“企业集群正是基于外部规模经济而形成的。
集群一经形成,就会通过其优势将有直接联系的物资、技术、人力资源和各种配套服务机构等吸引过来,尤其是吸引特定性产业资源(或要素)。
随着产业链的延伸,将吸引更多的相关产业甚至不同产业,扩大地区产业规模。
而且,随着集群竞争力的增强,这种资源吸引效应还会逐步加速。
这种基于路径依赖形成的“集群—资源吸引—集群扩张—加速资源吸引”的循环累积过程,便于企业快捷获取所需资源,促进企业迅速成长。
他在论述中总结了“产业区”所具备的6个方面的特征:①与当地社区同源的价值观系统和协同的创新环境;②生产垂直联系的企业群体;③最优的人力资源配置;④产业区理想的市场—不完全竞争市场;⑤竞争与合作并存;⑥富有特色的本地金融系统。
○——企业图1 马歇尔产业集群示意图马歇尔对产业集群的研究是开创性的,他对集群理论的一个贡献就是对规模经济概念的丰富,而规模经济是产业组织学的一个重要范畴。
他把某一区域原本相互无关的经济、社会、文化等方面结合起来,造成一种企业生存、发展的产业氛围,即外部规模经济。
他发现了一种产生集群的“空气”—协同创新的环境。
2. 韦伯的集聚经济理论阿尔弗雷德·韦伯(AlfredWeber,1909)在《工业区位论》中提出集聚经济的概念来解释区位集聚。
3论述生态学的发展过程,并简述各个阶段的特点答:生态学作为一门学科的发展过程,大致可分为四个时期(过程)。
即公元十六世纪前为生态学萌发时期;公元十七世纪至十九世纪末为生态学的建立时期;二十世纪初至二十世纪五十年代,为生态学的巩固时期,二十世纪六十年代以后为现代生态学时期。
在生态学的巩固时期,以地区性特点为背景,分化为三个不同的学派,主要是欧洲学派、俄国学派和英美学派。
5 简述现代生态学的基本特点。
答:现代生态学十分重视生态学研究的尺度,尺度是某一现象和过程在时间和空间上所涉及到的范围和所发生的频率。
生态学承认的尺度有时间尺度、空间尺度和组织尺度。
6根据你对生态学学科的总体认识,谈谈生态学学科的特殊性答:生态学根据研究对象的生境划分,可划分为陆地生态学、海洋生态学、淡水生态学和岛屿生态学四个分支学科。
生态学根据研究性质可划分为理论生态学、应用生态学两类。
生态学研究的特殊性应该体现在研究对象和研究单位的特殊性。
上世纪40-50年代,动物生态学研究单位主要是种群,而植物生态学的研究单位是群落;60年代以后,生态学的研究单位是生态系统。
8 从负反馈调节入手,谈谈生态系统的自我调节功能答:负反馈控制可使系统保持稳定,由于生态系统具有负反馈的自我调节机制,所以在通常情况下,生态系统会保持自身的生态平衡。
生态平衡是一种动态平衡,当生态系统达到动态平衡的最稳定状态时,他能够自我调节和维持自己的正常功能,并能在很大程度上克服和消除外来的干扰,保持自身的稳定性。
10 简述生态系统的基本结构(组成)和基本功能答:生态系统的组成主要的由生物群落和无机环境两大部分构成。
生物群落包括生产者、消费者和分解者(还原者)三大功能类。
无机环境包括参加物质循环的无机元素和化合物、联系生物与非生物的有机物质及其它物理条件。
生态系统的基本功能是能量流动,物质循环和信息传递。
12 简述系统的概念与系统特征答:由相互作用和相互依赖的若干组成部分结合而成的具有特定功能的有机整体。
集群系统的概念简述
1.集群系统的原由
集群系统习用的单一集中式系统如大型主机(Mainframes)是庞大的,其功能也非常强,它们具有数据完整性和管理容易的优点,因为它仅是一个单一的系统,带有单个安全的领域——所有的用户都连接到同一个系统上。
这种单个的集中式系统的缺点是灵活性差——只可在一个地方使用,并且所有用户必须连接到一处。
另外,集中式系统通常非常昂贵,需要花更多的钱,然而随着时间的推移,全部系统必须用新系统替换,因而进一步需要花费。
分布式系统通常是由许多系统组成的,它们共同的能力可超过一个单一集中式系统的能力,分布式系统有一个优点就是它是局域为.所以,无论何时,无论在哪儿,只要需要,就可以使用它,用户拥有系统,并且可控制它们的使用,但是这些优点也可能成为管理上的麻烦,因为有这么多的系统要管理,通常需要更多的系统管理人员,并且可能对工作效率带来不利的影响,因为数据定位同步使数据完整性控制起来会更因难。
网络系统比分布式系统虽然又进了一步,但目前的网络计算环境存在许多缺点,如只有1/3的网络计算能力得到利用,不同厂商的网络环境不能协同工作,不同机器的数据格式(字长、字序)不能自动转换,没有通用的网络命名机制,编写分布应用程序十分繁琐等等。
从当前作用的不同层次的计算环境来看,也存在以下许多不足∶
(1)多协同工作环境,开发者之间使用Email或fp传递数据,存在正确性问题,迫使开发者在他不熟悉的机器中工作;
(2)单机环境。
计算能力受到限制;
(3)局部数据存储。
以工作站服务器作数据储备,随着系统增长,磁盘空间会出现不足;
(4)数据和程序迁移,网络计算环境无法跟踪位置和名称的变化;
(5)应用维护。
修改分布应用程序十分困难。
为了解决这些间题,研制了一种把各种分离的主机和分离的存储设备、网络连成为一个单一的逻辑系统,或称其为集群系统的体系结构.集群系统是一个高
度集成的整体,包括软件、主机、存储设备。
各种规模的计算机,从台式机到数据中心,都可包括在一个集群中。
集群系统的运作如单一虚拟系统一样。
集群中的每一个节点都是由在操作系统的一个范例控制之下的一个或多个处理机组成的。
图中分别表示了一种传统网络系统和集群系统。
由图可见,在某一CPU故障时,传统网络系统中的连在其CPU的存储外设不能使用,而在集群系统中则仍可使用。
网络操作系统和局域网(LAN),虽也提供某些集群的特性和优点,但具有很大的局限性。
孤立的LAN 与网络操作系统不能视为集群,因为对于解决当今企业范围分布式计算来说,单有LAN 与网络操作系统是不够的。