高性能计算机和曙光GHPC1000集群系统.
- 格式:ppt
- 大小:7.89 MB
- 文档页数:70


世界上的超级电脑在西雅图举行的SC11大会上公布的全球超级计算机TOP500排行榜上,日本“京”(K Computer)以跨越1亿亿次每秒的计算能力继续占据榜首的位置。
同时在计算能力排在前十位的系统中,有两套超级计算机系统是来自中国的,它们分别是来自部署在天津的“天河一号”以及部署在深圳的“曙光星云“高效能计算系统。
下面就让我们来看看在这个星球上计算能力最强大的系统。
世界上超级电脑种类1.K Computer 首个跨越亿亿次运算的超级计算机世界上最快的超级计算机“京”(K Computer)是日本RIKEN高级计算科学研究院(AICS)与富士通的联合项目。
“京”(K Computer)没有使用GPU加速,而是完全基于传统处理器搭建。
“京”(K Computer)的最大性能四倍于排在第二位的“天河一号”。
现在的“京”(K Computer)配备了88128颗富士通SPARC64 VIIIfx 2.0GHz 八核心处理器,核心总量705024个,最大计算性能10.51Petaflop/s,峰值性能11.28038 Petaflop/s,同时效率高达93.2%,总功耗为12659.9千瓦。
2.天河一号曾经的王者位于中国天津国家超级计算机中心的“天河一号系统”在最新的排行榜中位列第二。
计算能力达到2.57 petaflop/s。
去年,天河一号还曾在TOP500排行榜中排名榜首。
天河一号采用了CPU+GPU的混合架构。
配有14336颗Intel Xeon X5670 2.93GHz 六核心处理器、7168块NVIDIA Tesla M2050高性能计算卡,以及2048颗我国自主研发的飞腾FT-1000八核心处理器,总计20多万颗处理器核心,同时还配有专有互联网络。
造价在6亿人民币以上。
3.JAGUAR XT5 用于民用的超级计算机“JAGUAR”超级计算机系统隶属于美国能源部,坐落于美国橡树岭国家实验室。

下一代绿色数据中心建设方案目录1 机房基础设施方案 (4)1.1 总述 (4)1.1.1 设计目标 (4)1.1.2 需求分析 (4)1.1.3 建设主要内容 (4)1.2 设计相关标准和规范 (5)1.3 机房整体规划 (6)1.3.1 机房功能分区及面积划分 (6)1.3.2 机房平面布局 (6)1.3.3 系统特点 (7)1.4 设备配置清单 (8)1.5 空调新风系统 (9)1.5.1 选型分析 (9)1.5.2 空调设备配置 (10)1.5.3 空调系统特点与优势 (11)1.5.4 空调设备性能参数 (12)1.5.5 通风系统 (13)1.6 动力配电系统 (14)1.6.1 配电结构 (14)1.6.2 UPS配置 (15)1.6.3 用电统计 (16)1.7 机柜微环境系统 (17)1.7.1 机柜 (17)1.7.2 机柜排配电 (18)1.7.3 机柜排监控 (19)1.8 装饰装修系统 (20)1.8.1 空间及布线 (20)1.8.2 装饰装修 (20)1.8.3 照明 (21)1.9 防雷接地系统 (21)1.9.1 防雷 (21)1.9.2 接地 (21)1.10 监控管理系统 (22)1.10.1 门禁 (22)1.10.2 视频监控 (22)1.10.3 集中监控 (22)1.11 消防报警系统 (23)1.11.1 消防报警 (23)1.11.2 气体灭火 (24)1.12 建筑场地条件需求 (24)1.12.1 建筑条件 (24)1.12.2 电力条件 (25)1.12.3 空调室外机场地 (25)1机房基础设施方案1.1总述1.1.1设计目标计算机机房工程是一种涉及到空调技术、配电技术、网络通信技术、净化、消防、建筑、装潢、安防等多种专业的综合性产业。
本着从满足机房建设工程项目的实际需要出发,本方案立足于建设高标准化机房的宗旨,严格遵循“投资合理、规划统一、立足现在、适度超前”的设计方向,为用户提供一个完整全面优化的解决方案。


中国成功研制千万亿次超级计算机“天河一号”新华社长沙10月29日电:随着第一台国产千万亿次超级计算机29日在湖南长沙亮相,作为算盘这一古老计算器的发明者,中国拥有了历史上计算速度最快的工具。
10月29日,国防科技大学成功研制出的峰值性能为每秒1206万亿次的“天河一号”超级计算机在湖南长沙亮相。
我国成为继美国之后世界上第二个能够研制千万亿次超级计算机的国家。
超级计算机又称高性能计算机、巨型计算机,是世界公认的高新技术制高点和21世纪最重要的科学领域之一。
这是“天河一号”千万亿次超级计算机系统。
新华社发(何书远摄)Linpack是一个用Fortran语言编写的线性代数软件包,主要用于求解线性方程和线性最小平方问题。
该软件包提供了各种线性系统中的求解方法,比如各种各样的矩阵运算。
Linpack的初衷并不是制订一个测试计算机性能的统一标准,而只是提供一些常用的计算方法的实现,但是由于该软件包的广泛使用,这样就为通过Linpack例程来比较不同计算机的性能提供了可能。
这是科研人员在对“天河一号”超级计算机进行系统性能测试。
新华社发(何书远摄)数字详解“天河一号”新华社长沙10月29日电(记者白瑞雪、王玉山、喻菲)中国首台千万亿次超级计算机“天河一号”究竟有多“超级”?以下是一组相关数字。
数字一:全系统峰值性能为每秒1206万亿次,Linpack实测性能为每秒563.1万亿次。
这意味着,“天河一号”计算一天,一台配置Intel双核CPU、主频为2.5GHz的微机需要计算160年。
数字二:共享存储总容量为1PB。
按国内数字图书馆应用软件的图片格式PDG为例计算,如果平均每册书大小约10MB的话,“天河一号”的存储量相当于4个国家图书馆(藏书量为2700万册)之和,能够为全国每人储存一张大小接近1MB的照片。
数字三:“天河一号”由103台机柜组成,每个机柜占地1.44平方米、高两米、重1.5吨,系统总重量相当于19个神舟飞船。

如何进行超级计算机集群的搭建超级计算机集群是一种将多台计算机连接在一起形成一个强大计算力的系统。
它的搭建能够为科学研究、数据分析、机器学习等领域提供高性能计算能力。
在本文中,我将介绍如何进行超级计算机集群的搭建。
1. 硬件准备超级计算机集群需要多台计算机进行连接,因此首先需要准备足够多的计算机。
这些计算机可以是台式机或者服务器,它们应该具备充足的处理能力和内存容量。
2. 网络配置搭建超级计算机集群的关键是将各个计算机连接在一起组成一个网络,以实现数据的传输和共享。
通常,可以使用交换机或者路由器来建立内部网络,确保计算机之间的通信畅通。
3. 操作系统安装与配置在每台计算机上安装相同的操作系统,如Linux操作系统。
选择合适的Linux发行版本,如Ubuntu、CentOS等,并进行基本的配置。
确保每台计算机的网络设置正确,并指定固定的IP地址。
4. 并行计算框架选择超级计算机集群可以通过并行计算框架来实现任务的分发和并行计算。
常用的并行计算框架包括MPI(Message Passing Interface)和OpenMP。
根据自己的需求和计算任务的特点选择合适的框架。
5. 软件安装与配置根据计算任务的需求,在每台计算机上安装所需的软件和库。
如若进行机器学习任务,可以安装TensorFlow、PyTorch等深度学习框架。
确保软件版本一致,并配置环境变量。
6. 分发任务通过并行计算框架将任务分发给集群中的不同计算节点,以实现任务的并行计算。
通过指定计算节点的IP地址和端口号,将任务分发给集群中的特定节点。
7. 结果收集与整合在计算完成后,将各个计算节点的结果进行收集和整合。
可以使用并行计算框架提供的API或者自行编写代码来实现结果的整合。
确保结果的正确性和完整性。
8. 系统监控与管理超级计算机集群通常包含大量的计算节点,因此需要实时监控集群的运行状态和资源使用情况。
可以使用系统监控软件来实现对计算节点的监控和管理,及时发现和解决问题。


中國超級電腦發展史在過去,超級電腦主要被用於軍事、科學、航太等高端領域。
在今天,超級電腦已大踏步進入民用時代,和人們生活密不可分。
隨著中國第一超級電腦“魔方”躋身世界前10強,中國逐漸成為超級電腦強國,超級電腦將更加頻繁地奏響平民“進行曲”,走進家庭,推動公共服務設施建設,甚至幫助人們治癒目前無法治癒的疾病……工程總投資:100億元以上工程期限:1975年——至今中國超級電腦譜系表國防科技大學電腦研究所——“銀河”系列銀河-Ⅰ1983年運算速度每秒 1 億次銀河-Ⅱ1994年運算速度每秒10 億次銀河-Ⅲ1997年運算速度每秒130 億次銀河-Ⅳ2000年運算速度每秒1萬億次銀河-Ⅴ在研運算速度每秒?億次(軍用)中科院計算技術研究所——“曙光”系列曙光一號1992年運算速度每秒 6.4 億次曙光-1000 1995年運算速度每秒25 億次曙光-1000A 1996年運算速度每秒40 億次曙光-2000Ⅰ1998年運算速度每秒200 億次曙光-2000Ⅱ1999年運算速度每秒1117 億次曙光-3000 2000年運算速度每秒4032 億次曙光-4000L 2003年運算速度每秒 4.2 萬億次曙光-4000A 2004年運算速度每秒11 萬億次曙光-5000A 2008年運算速度每秒230 萬億次曙光-6000A 在研運算速度每秒1000 萬億次國家平行電腦工程技術中心——“神威”系列神威-Ⅰ1999年運算速度每秒3840 億次神威3000A 2007年運算速度每秒18 萬億次神威-Ⅱ在研運算速度每秒300 萬億次(軍用)聯想集團——“深騰”系列深騰1800 2002年運算速度每秒 1 萬億次深騰6800 2003年運算速度每秒 5.3 萬億次深騰7000 2008年運算速度每秒106.5萬億次深騰X 在研運算速度每秒1000 萬億次。

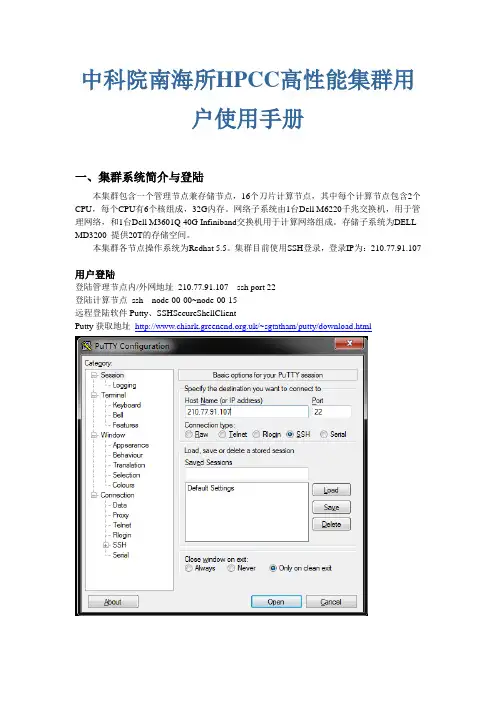
中科院南海所HPCC高性能集群用户使用手册一、集群系统简介与登陆本集群包含一个管理节点兼存储节点,16个刀片计算节点,其中每个计算节点包含2个CPU,每个CPU有6个核组成,32G内存。
网络子系统由1台Dell M6220千兆交换机,用于管理网络,和1台Dell M3601Q 40G Infiniband交换机用于计算网络组成。
存储子系统为DELL MD3200 提供20T的存储空间。
本集群各节点操作系统为Redhat 5.5。
集群目前使用SSH登录,登录IP为:210.77.91.107用户登陆登陆管理节点内/外网地址210.77.91.107 ssh port 22登陆计算节点ssh node-00-00~node-00-15远程登陆软件Putty、SSHSecureShellClientPutty获取地址/~sgtatham/putty/download.html输入登陆地址:在图”HostName(orIPaddress)”中输入IP:210.77.91.107,选中SSH协议,选择Port为22;为这个连接起一个名字,在”SavedSessions”中输入此名字”南海所集群”。
点击save按钮,这样”DefaultSettings”字样以下会出现“南海所集群”字样。
登录后的界面如下图:二、编译系统gcc v4.1.2: /usr/bingfortran v4.1.2: /usr/binperl v5.8.8 : /usr/binPGI: /opt/pgi/linux86-64/9.0-1/bin/Intel: /opt/intel/Compiler/11.1/064三、并行环境GCC编译的openmpiOpen MPI: /usr/lib64/openmpi/1.4-gcc/bin/PGI编译的openmpiOpenmpibypgi : /opt/openmpibypgi/binifort编译的openmpiopenmpibyifort : /opt/openmpibyifort/bingcc编译的mpich1MPICH1: /opt/mpich1/gnu/bingcc编译的mpich2MPICH2: /opt/mpich2/gnu/bingcc编译的mvapichMV APICH: /usr/lib64/mvapich2/1.4-gcc/binpgi编译的mvapichMV APICH2byPGI: /opt/mvapich2bypgi/binifort编译的mvapichMV APICH2byifort: /opt/mvapich2byifort/bin四、应用软件Matlab2010a :/opt/matlab/binnetcdf4 :/opt/netcdf4/binncl或ncarg :/usr/local/ncarg/binGards :/opt/grads/binncview :/opt/ncviewRIP4 :/opt/RIP4ferret :/usr/local/ferretUdunits2 :/opt/udunits/lib五、作业调度系统Platform Lava,强大的开源作业调度程序任务提交方法简介见第七节六、环境变量设置这是全局的环境变量,每个用户默认的环境变量#mvapichbypgiexport MPIHOME=/opt/mvapich2bypgiexport PA TH=/opt/mvapich2bypgi/bin:$PATHexport LD_LIBRARY_PA TH=$LD_LIBRARY_PA TH:/opt/pgi/linux86-64/9.0-1/libso#PGI PA THexport PGI=/opt/pgi/linux86-64/9.0-1export PA TH=$PGI/bin:$PA THexport MANPATH=$PGI/man:$MANPA THexport LM_LICENSE_FILE=$LM_LICENSE_FILE:/opt/pgi/license.dat#NCARGexport NCARG_ROOT=/usr/local/ncargexport PA TH=/usr/local/ncarg/bin:$PATHexport DISPLAY=:0.0export NCARG_LIB=/usr/local/ncarg/libexport NCARG_INC=/usr/local/ncarg/include#GrADSexport GADDIR=/opt/grads/datexport GASCRP=/opt/grads/libexport PA TH=/opt/grads/bin:$PA THalias grads=/opt/grads/bin/grads#NetCDFexport NETCDF=/opt/netcdf4export PA TH=$NETCDF/bin:$PA THexport NETCDF_LIBS=/opt/netcdf4/lib#RIP$export RIP_ROOT=/opt/RIP4export PA TH=$PATH:$RIP_ROOT#ferretexport FER_DIR=/usr/local/ferretexport PA TH=$FER_DIR/bin:$PA TH#udunits2export UDUNITS2_LIBS=/opt/udunits/libexport PA TH=/opt/udunits/bin:$PA TH#ncviewexport PA TH=/opt/ncview/bin:$PA THexportPATH="$PATH:/usr/lib64/openmpi/1.4-gcc/bin:/opt/intel/Compiler/11.1/064/bin:/opt/intel/Compil er/11.1/064/bin/intel64/:/opt/pgi/linux86-64/9.0-1/bin:/opt/matlab/bin:/opt/netcdf4/bin"由于每个用户可能使用的软件或者模式的环境变量不在上面的路径上,则需要每个用户修改自己的环境变量,文件为在自己的home目录下的.bashrc文件例如:假如我的用户名为lwf,则环境变量位于/home/lwf目录下修改.bashrc文件用文本编辑器打开用户目录下的.bashrc文件,例如vi命令(1)例如我新安装了JA V A程序,则在.bashrc文件末尾加入:JA V A_HOME=/home/lwf/jdk1.5.0_05export JA VA_HOMEPATH=$JA V A_HOME/bin:$PATHexport PA THCLASSPATH=.:$JA V A_HOME/lib/dt.jar:$JA V A_HOME/lib/tools.jarexport CLASSPATH(2)新加入完后保存,然后使用source命令使其生效。

1.北科院信息化服务平台对外服务简介“北科院信息化服务平台”配备了大规模计算机群;部署了许多大型、多用户计算机辅助设计和工程分析软件工具;建设了高速网络通信环境;在数据存储、信息安全等各方面提供了良好的保障措施;此外还配备了逆向工程和快速成型技术需要的设备和服务支持。
北科院信息化服务平台将成为向院内用户开放的数字化制造公共服务平台,为他们提供完整的配套资源和解决方案。
北科院信息化服务已经配备的硬件及系统资源包括:计算集群:高性能计算服务器近1,000台,计算CPU核数达到万核规模,总计算能力200万亿次/每秒,其中通用CPU计算能力150万亿次,GPU计算能力50万亿次;存储设施:基于EMC、HDS等高性能盘阵设备,采用NAS+SAN混合架构,裸容量达到1.5PB;网络带宽:250Mb/s和IPv6 1Gb/s;逆向工程和快速成型专业设备:激光三维扫描、手持式三维数字彩色扫描测量仪、三维模型快速输出设备、触觉式设计系统等。
已经配备的应用软件资源包括:工程工具软件:ANSYS、HYPERMESH、STARCCM+、ABAQUS、SIMULATIONX、LS-DYNA、Pro Engineer、Femap + NX Nastran以及CAXA服务产品群;管理工具软件:PDM、ERP等;工程渲染工具软件:3dsMax、Maya和渲染集群管理软件等。
北科院信息化服务平台对外提供5类应用服务:1. 大规模云主机部署及弹性扩展服务;支持组建虚拟私有云;提供大规模云存储测试环境;网络虚拟化支持;高可用、负载均衡测试环境以及大规模负载发生器环境。
2.高性能计算在线服务:用户远程登录计算中心的高性能计算系统,部署私有环境实施计算处理,有良好的信息安全保障环境。
3.工业计算在线服务:配备的大型工程计算软件Abaqus、Ansys、Fluent等向社会开放公共服务,用户能够通过网络远程应用这些软件工具和与之相配套的计算设备资源。
超级计算机超级计算机通常是指由数百数千甚至更多的处理器(机)组成的、能计算普通PC机和服务器不能完成的大型复杂课题的计算机。
为了帮助大家更好的理解超级计算机的运算速度我们把普通计算机的运算速度比做成人的走路速度,那么超级计算机就达到了火箭的速度。
在这样的运算速度前提下,人们可以通过数值模拟来预测和解释以前无法实验的自然现象。
超级计算机技术超级计算机技术已不再是一个新鲜的话题,美国IBM、日本NEC、中国曙光都已推出自己的超级计算机,但比较而言,以美国两院院士、“世界超级涡轮式刀片计算机之父”陈世卿博士为首的专家团队回归祖国后研发出的超级计算机仍然具有绝对的优势。
新一代的超级计算机采用涡轮式设计,每个刀片就是一个服务器,能实现协同工作,并可根据应用需要随时增减。
单个机柜的运算能力可达460.8千亿次/秒,理论上协作式高性能超级计算机的浮点运算速度为100万亿次/秒,实际高性能运算速度测试的效率高达84.35%,是名列世界最高效率的超级计算机之一。
通过先进的架构和设计,它实现了存储和运算的分开,确保用户数据、资料在软件系统更新或CPU升级时不受任何影响,保障了存储信息的安全,真正实现了保持长时、高效、可靠的运算并易于升级和维护的优势。
超级计算机的应用超级计算机是计算机中功能最强、运算速度最快、存储容量最大的一类计算机,多用于国家高科技领域和尖端技术研究,是国家科技发展水平和综合国力的重要标志。
随着超级计算机运算速度的迅猛发展,它也被越来越多的应用在工业、科研和学术等领域。
我国现阶段超级计算机拥有量为22台(中国内地19台,香港1台,台湾2台),居世界第5位,就拥有量和运算速度在世界上处于领先地位,但就超级计算机的应用领域来说我们和发达国家美国、德国等国家还有较大差距。
如何利用超级计算机来为我们的工业、科研和学术等领域服务已经成为我们今后研究发展的一个重要课题。
超级计算机是一个国家科研实力的体现,它对国家安全,经济和社会发展具有举足轻重的意义。
高性能计算集群的节点故障与错误处理方法探索在高性能计算领域,计算集群往往是处理大规模计算任务的首选。
然而,由于集群中节点数量庞大且运行负载高,节点故障和错误处理成为一个不可避免的问题。
本文将探索高性能计算集群中节点故障与错误处理的方法和策略,帮助用户在面对这些问题时能够快速、高效地解决。
一、节点故障的识别与监测在集群中,准确地识别出发生故障的节点至关重要。
常见的方法包括节点的心跳检测和日志监测。
心跳检测通过监测每个节点的状态信息,例如CPU、内存、网络等资源的使用情况,来判断节点是否正常运行。
而日志监测则是通过检测节点日志中的错误信息和异常行为,来定位可能出现故障的节点。
通过这些方法,我们能够及时地发现故障节点,为后续的处理提供基础。
二、节点故障处理的方法1. 节点故障的自动切换一旦发现故障节点,集群管理系统可以自动将任务从故障节点迁移到其他正常运行的节点上。
这种自动切换的方法可以通过备份节点的数据和状态信息来实现。
一旦故障节点宕机,备份节点会接管其上的任务,并恢复到故障节点发生故障之前的状态。
这种方法可以有效地减少任务的中断时间,并保证计算任务的连续性。
2. 节点故障的重启与恢复有时候,节点故障只是暂时性的,通过重启节点可以快速恢复其工作状态。
在集群中,可以通过基于硬件或软件的控制来实现节点的重启。
例如,基于软件的控制可以通过监测节点的负载情况和响应时间,提前判定节点故障,并触发节点的自动重启。
而基于硬件的控制则可以通过远程控制实现节点的重启操作。
通过这种方法,我们能够在短时间内解决节点故障,提高整个集群的可用性。
三、节点错误处理的方法除了节点故障外,集群中可能还存在节点错误的情况。
节点错误可以是由于硬件或软件问题引起的,例如内存错误、计算单元错误等。
在处理节点错误时,我们可以采取以下方法:1. 错误检测与纠正在高性能计算集群中,一些节点错误可以通过错误检测与纠正(EDAC)技术进行处理。
EDAC技术通过监测节点内存中的错误码,识别出错误位置,并自动纠正错误数据。
hpc 发展历程-回复HPC 发展历程在现代计算机的发展历程中,高性能计算(High-Performance Computing,HPC)起到了至关重要的作用。
HPC 是指利用并行计算或者并发计算来解决科学、工程和商业等领域中的复杂问题的能力。
它能够以更快、更高效的方式进行计算,使得诸如天气预报、药物研发和大规模数据分析等任务成为可能。
本文将一步一步回答“HPC 发展历程”的主题,并探讨其背后的重要里程碑、关键技术和前景展望。
1. 计算机的崛起和HPC初期发展(1940年代-1960年代)计算机的历史可以追溯到二战期间。
早期的计算机主要用于军事计算和密码破译等领域。
随着技术的进步,计算机逐渐开始应用于科学计算,为各种复杂的数学和物理问题提供解决方案。
然而,当时的计算机性能仍然非常有限,无法满足日益增长的计算需求。
2. 超级计算机的诞生和商业化(1970年代-1980年代)随着摩尔定律的提出和半导体技术的进步,计算机性能得到了大幅度的提升。
1976年,美国国家科学基金会(NSF)成立了一项叫做“超级计算中心”(SCC)的计划,旨在推动超级计算机的研究和开发。
1976年,世界上第一台超级计算机Cray-1问世,其速度超过了当时的任何其他计算机。
超级计算机的出现为HPC领域打开了新的大门。
随着超级计算机的商业化,人们开始意识到HPC在科学、工程和商业等领域的巨大潜力。
3. 并行计算和集群系统的兴起(1990年代)尽管超级计算机具有强大的计算能力,但其昂贵的价格和复杂的维护要求限制了其在广泛应用中的推广。
1993年,一项名为Beowulf的项目提出了一种新的超级计算机设计理念,即利用廉价的个人电脑通过联网的方式构建一个高性能计算集群系统。
这种设计方法大大降低了成本,使得HPC 能力逐渐向更广泛的用户开放。
4. 多核处理器和GPU计算(2000年代)2000年代初,摩尔定律面临着巨大的挑战,传统的单核处理器已经难以继续提升性能。